Análisis visual de datos biofarmacéuticos
93
0
0
Texto completo
(2) Hago constar que el presente trabajo fue realizado en la Universidad Central Marta Abreu de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ______________________ Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. ___________________ Firma del tutor. ____________________ Firma del jefe del Laboratorio.
(3) A mis hermanos, por mucho que me vuelvan loco..
(4) Quisiera agradecer a mis tutores, por su guía y por compartir su experiencia, y a mi familia, por ser mi principal apoyo y aliento, aunque algunos no tengan la menor idea de lo que hablo la mayor parte del tiempo..
(5) RESUMEN La sobrecarga de información causada por el exceso de datos biofarmacéuticos plantea un reto para el análisis de propiedades relacionadas con el proceso de absorción oral de fármacos y la determinación de su biodisponibilidad, cuyas características hacen que sea poco apropiado el uso de técnicas completamente automatizadas y cuyo volumen impide a los especialistas examinarlos directamente. Este trabajo permitió identificar relaciones y patrones interesantes dentro de las variables vinculadas a este proceso, empleando métodos y herramientas del análisis visual de datos como alternativa a otros enfoques más tradicionales. Para ello, se concibió un modelo de análisis basado en los principios del análisis visual y ajustado a las características propias de los datos biofarmacéuticos, centrándose en el empleo de herramientas analíticas como el agrupamiento y técnicas de visualización destinadas al trabajo con datos multivariados como formas de análisis e interacción fundamentales. Como validación del modelo se realizó la implementación de una herramienta informática basada en este, con énfasis en la extensibilidad de sus funcionalidades y la flexibilidad en su uso. La aplicación de esta a un caso de estudio relacionado con la extracción de información referente a una de las propiedades objetivo de optimización en el proceso de desarrollo de fármacos, permitió confirmar la efectividad del modelo desarrollado y del análisis visual de datos en general, para dar solución a este problema de análisis.. Palabras Clave: Análisis visual, biodisponibilidad, clasificación BCS, agrupamiento, sobrecarga de información, datos multivariados..
(6) ABSTRACT The information overload caused by the excess of biopharmaceutical data poses a challenge for the analysis of properties related to oral absorption process of drugs and the assessment of their bioavailability, whose characteristics make it inappropriate to apply fully automated techniques as well as their volume impede the specialists from directly examining the data. This work allowed to identify interesting relations and patterns within the variables related to this process, employing Visual Analytics methods and tools as an alternative to more traditional approaches. In order to achieve this, an analysis model was conceived based on the principles of Visual Analytics and adjusted to the characteristics of biopharmaceutical data, focusing in the use of analytical tools such as clustering and visualization techniques meant for working with multivariate data as its main analysis and interaction forms respectively. As validation for the model, an informatics tool based on it was implemented, paying special attention to the extensibility of its functions and the flexibility of its use. The application of said tool to a case of study related to extracting information related to one of the optimization target properties in the drug development process, allowed to confirm the effectiveness of the developed model and Visual Analytics in general, to provide a solution to this analysis problem.. Keywords: overload.. Visual Analytics, bioavailability, BCS classification, clustering, information.
(7) TABLA DE CONTENIDOS INTRODUCCIÓN .................................................................................................................. 1 CAPÍTULO 1. VISUAL ANALYTICS ................................................................................. 7 1.1 Aspecto Biofarmacéutico ............................................................................................. 7 1.2 Perspectiva general de Visual Analytics ..................................................................... 11 1.3 El proceso de Visual Analytics ................................................................................... 15 1.4 Técnicas y aplicaciones de Visual Analytics .............................................................. 18 Datos espacio-temporales ............................................................................................. 18 Datos multivariados ...................................................................................................... 19 Datos textuales.............................................................................................................. 22 Grafos y redes ............................................................................................................... 23 1.5 Alternativas para desarrollar soluciones de Visual Analytics ..................................... 25 Processing ..................................................................................................................... 26 D3.js.............................................................................................................................. 28 matplotlib ...................................................................................................................... 30 1.6 Herramientas seleccionadas ........................................................................................ 33 Conclusiones parciales ..................................................................................................... 35 CAPÍTULO 2. MODELO PARA EL ANÁLISIS VISUAL DE DATOS BIOFARMACÉUTICOS ..................................................................................................... 36 2.1 Consideraciones en torno a los datos biofarmacéuticos ............................................. 36 2.2 Requerimientos de análisis ......................................................................................... 38 2.3 Propuesta de modelo ................................................................................................... 40 Estructura general ......................................................................................................... 41 Ejecución del flujo de análisis ...................................................................................... 43 Formas de interacción ................................................................................................... 47 2.4 Consideraciones de diseño para componentes del modelo ......................................... 51 Componentes de entrada ............................................................................................... 52 i.
(8) Componentes de análisis .............................................................................................. 54 Componentes de visualización ..................................................................................... 56 Conclusiones parciales ..................................................................................................... 58 CAPÍTULO 3. IMPLEMENTACIÓN DEL MODELO: BCSMAP .................................... 60 3.1 Análisis de actores y casos de uso .............................................................................. 60 3.2 Diseño y comportamiento de la interfaz de usuario ................................................... 62 3.3 Diseño de la implementación ..................................................................................... 66 Módulo view ............................................................................................................... 68 Módulo execution ................................................................................................... 69 Paquete extensions ................................................................................................ 72 Módulo mpl ................................................................................................................. 73 Módulo mainui .......................................................................................................... 74 Módulo helpers ........................................................................................................ 75 3.4 Caso de estudio: propiedades que influyen sobre la permeabilidad ........................... 75 CONCLUSIONES ................................................................................................................ 80 RECOMENDACIONES ...................................................................................................... 81 BIBLIOGRAFÍA .................................................................................................................. 82. ii.
(9) LISTA DE FIGURAS Figura 1.1 El proceso de búsqueda de sentido en Visual Analytics ...................................... 16 Figura 1.2 El proceso de Visual Analytics ............................................................................ 17 Figura 2.1 Estructura general de un flujo de análisis de acuerdo al modelo ........................ 43 Figura 2.2 Comportamiento de la ejecución de un componente .......................................... 45 Figura 2.3 Influencia del estado de activación en la ejecución: conexión ........................... 47 Figura 2.4 Influencia del estado de activación en la ejecución: componente....................... 47 Figura 3.1 Vista general de la interfaz de usuario de la aplicación ...................................... 63 Figura 3.2 Ventana de edición de esquemas de entrada e inspector de vistas de datos ....... 65 Figura 3.3 Estructura de paquetes y módulos de la aplicación ............................................. 67 Figura 3.4 Diagrama de clases: módulo view ..................................................................... 70 Figura 3.5 Diagrama de clases: módulo execution ......................................................... 72 Figura 3.6 Ejemplo de una extensión ................................................................................... 74 Figura 3.7 Configuración inicial del flujo de análisis para el caso de estudio ..................... 77 Figura 3.8 Distribución de las clases en la vista III/I y en los datos originales .................... 78 Figura 3.9 Comparación de la distribución de clases para el nuevo agrupamiento.............. 79. iii.
(10) INTRODUCCIÓN El descubrimiento y desarrollo de nuevos agentes terapéuticos es un proceso sumamente complejo y representa una inversión significativa de recursos materiales y humanos, así como de tiempo. La mayoría de los estimados indican que puede tomar entre 10-15 años y más de 1200 millones de dólares desarrollar un fármaco exitoso. Está bien establecido que las propiedades biofarmacéuticas y farmacocinéticas desfavorables son una de las principales causas que conducen a fallos en las etapas preclínicas y clínicas del desarrollo del fármaco, limitando su disponibilidad sistémica y con ello su utilidad terapéutica. El Sistema de Clasificación Biofarmacéutica (BCS) surge como un marco para la clasificación experimental de la absorción de los fármacos, propiedad vital para la efectividad de los fármacos administrados por vía oral. Dicha clasificación se realiza de acuerdo a la solubilidad acuosa y la permeabilidad intestinal de los compuestos, dividiéndolos en cuatro clases: Clase I (elevada solubilidad y permeabilidad), Clase II (baja solubilidad y elevada permeabilidad), Clase III (elevada solubilidad y baja permeabilidad), y clase IV (baja solubilidad y permeabilidad). El BCS provee una base para el establecimiento de correlaciones in vitro-in vivo y realizar estimaciones de la absorción (Amidon et al., 1995), así como predecir su disposición (interacciones metabólicas y de transporte) y potenciales efectos de su interacción con los alimentos. Además, se contempla la posibilidad de exonerar de estudios de bioequivalencia e interacción fármaco-fármaco a aquellos fármacos que fuesen clasificados dentro de la Clase I y III. La aplicación de la clasificación BCS, trae aparejada una serie de beneficios que abarcan desde una considerable reducción en costes y tiempo de desarrollo hasta evitar la realización innecesaria de pruebas en seres humanos. El beneficio económico para la industria farmacéutica mundial con tan solo una implementación más extendida de la 1.
(11) _______________________________________________________________________________________________INTRODUCCIÓN. clasificación BCS se estima en cerca de 128 millones de dólares (Cook, Davit and Polli, 2010), en su mayor parte debido a la posibilidad de desestimar formulaciones poco prometedoras en etapas tempranas del desarrollo y de realizar los estudios de solubilidad requeridos en paralelo al proceso de formulación. Por supuesto, la aplicación de técnicas computacionales a la predicción y estudio de estas y otras propiedades no queda fuera del espectro de intereses de la investigación en este campo. Actualmente, el desarrollo de técnicas y modelos computacionales para la estimación de las propiedades de nuevos compuestos, de conjunto con resultados experimentales, brindan a los especialistas una cantidad sin precedentes de datos referentes a propiedades biofarmacéuticas. Entre ellas se han identificado algunas con una influencia constatable en los parámetros de clasificación BCS y la efectividad de un fármaco de forma general, dando pie a la posibilidad de que existan otras con un comportamiento similar. Esta situación aparentemente deseable ha llevado sin embargo a la aparición de un nuevo problema: la búsqueda de relaciones y patrones dentro de un elevado número de variables, con interacciones por lo general muy complejas dado que representan o se hallan influenciadas por factores químicos y biológicos, y donde en la mayoría de los casos no se tienen hipótesis previas sobre la naturaleza de dichas relaciones, está lejos de ser una tarea trivial aún para un especialista, sobre todo al considerar el volumen de datos de este tipo con que se trabaja. El empleo de técnicas de minería de datos como medio para extraer información interesante a partir de estos datos es una idea casi inmediata. Sin embargo, aproximaciones de este tipo u otras formas de análisis automatizado todavía enfrentan desafíos significativos en cuanto a la escalabilidad de los algoritmos, el incremento en el número de dimensiones y la heterogeneidad e incertidumbre en los datos, pudiendo no resultar apropiadas en todos los escenarios de análisis (Sun et al., 2013). También se pone de manifiesto el problema de la limitada interactividad, la dificultad del usuario de incorporar su conocimiento del problema para refinar los métodos interactivamente e interpretar de forma intuitiva los resultados obtenidos a partir del análisis (Kohlhammer et al., 2011).. 2.
(12) _______________________________________________________________________________________________INTRODUCCIÓN. La aplicación de técnicas y herramientas de Visual Analytics y de minería de datos visual, definida como “el proceso de interacción y razonamiento analítico sobre una o más representaciones visuales de datos abstractos que conduce al descubrimiento visual de patrones robustos contenidos en esos datos y que conforman la información y conocimiento utilizado en el proceso de toma de decisiones” (Simoff, Böhlen and Mazeika, 2008), presenta una alternativa viable para enfrentar estos retos. Bajo la premisa de hacer uso efectivo de la capacidad humana de abstracción, razonamiento analítico e interpretación de información visual (Simoff, Böhlen and Mazeika, 2008), se enfocan en convertir al usuario en parte central y activa del proceso de análisis mediante una mayor interactividad y el uso de metáforas visuales, supliendo la dificultad de los seres humanos para procesar grandes volúmenes de datos con la capacidad de las computadoras modernas para realizar eficientemente este tipo de tareas. Esta aproximación se distingue de la visualización tradicional, ya sea científica o de información, en su empleo indistinto tanto de los datos en crudo como del resultado de aplicar algún algoritmo o técnica de análisis automatizado sobre estos, así como en el empleo de herramientas estadísticas para garantizar que las representaciones visuales generadas representen los datos tan fielmente como sea posible. Por otro lado, difiere de la minería de datos en su mayor enfoque en la interacción con el usuario y el empleo de la visualización como herramienta para analizar y transmitir información. Subjetivamente, la posibilidad del usuario de dirigir de forma efectiva y activa el proceso de análisis en la dirección que le resulte de mayor interés, con una consecuente reducción del tamaño del espacio de búsqueda, permite suponer una mayor eficiencia del proceso de análisis en su conjunto y una mejor integración de su conocimiento del problema, aunque no resulte sencillo comprobarlo de forma concreta. Por otro lado, el empleo de metáforas visuales para transmitir resultados y permitir la generación y comprobación de hipótesis es un medio que está más cercano a las representaciones mentales que los seres humanos emplean para enfrentar un problema, conllevando un menor esfuerzo cognitivo en la interpretación y permitiendo identificar patrones interesantes que de otra forma pasarían desapercibidos (Simoff, Böhlen and Mazeika, 2008).. 3.
(13) _______________________________________________________________________________________________INTRODUCCIÓN. Es válido aclarar que la transformación de los datos en representaciones visuales con sentido para el problema sobre el que se trabaja no es un asunto trivial (Keim et al., 2008), ni la aplicación de un enfoque visual es mejor por definición (van Wijk, 2005): para un problema bien definido y estudiado, donde una solución óptima o un buen estimado de esta pueda ser obtenida mediante métodos de análisis completamente automatizados, la aplicación de Visual Analytics carece de sentido. Dadas las características de Visual Analytics como enfoque integrador que combina la visualización, factores humanos y el análisis de datos, y teniendo en cuenta la consideración anterior, sus aplicaciones fundamentales se verían a la hora de enfrentar grandes espacios de datos, con posibles conflictos o que debe ser integrada a partir de diferentes fuentes, especialmente cuando el sistema no cuenta con conocimiento que aún se encuentra oculto en la mente del experto (Keim et al., 2008), lo cual describe de forma bastante acertada la situación presente en el proceso de desarrollo de fármacos. La Unidad de Modelación y Experimentación Biofarmacéutica (UMEB) del Centro de Bioactivos Químicos (CBQ) de la Universidad Central “Marta Abreu” de las Villas (UCLV), es un grupo de investigación centrado principalmente en el área biofarmacéutica, tanto desde el punto de vista teórico como experimental, relacionada con la etapa preclínica del desarrollo de medicamentos. De aquí que este grupo tenga particular interés en la investigación relativa a la aplicación de la clasificación BCS y la influencia de las propiedades de los compuestos sobre dicha clasificación. Las alternativas computacionales y el uso de herramientas informáticas para asistir a su investigación son también de gran interés, evidenciado en iniciativas para el desarrollo de bases de datos para la consulta y análisis de propiedades biofarmacéuticas como soporte al proceso de desarrollo de fármacos. Este es sin duda un escenario ideal para la aplicación de las técnicas discutidas, lo que lleva al planteamiento del siguiente problema de investigación: La determinación del grado de relación entre las diferentes variables que influyen en el proceso de absorción de fármacos, así como la posibilidad de identificar agrupamientos y tendencias dentro de las mismas o descubrir nuevas relaciones entre variables, resulta en la práctica difícil de aplicar para grandes volúmenes de datos de propiedades donde no se han definido correlaciones previas entre sus variables; además la utilización de técnicas 4.
(14) _______________________________________________________________________________________________INTRODUCCIÓN. novedosas de visualización para facilitar el análisis intuitivo de datos no han sido aplicadas al análisis de relaciones de datos multidimensionales del proceso de absorción. Por tanto, el objetivo general de la investigación es: Identificar posibles relaciones entre las variables vinculadas al proceso de absorción de fármacos mediante el empleo de métodos y herramientas del análisis visual de datos. En base a ello se definen los siguientes objetivos específicos: 1. Analizar, dentro de la base de datos, las principales variables relacionadas con la fracción de fármaco absorbido y su biodisponibilidad. 2. Identificar posibles técnicas y herramientas de visualización a utilizar en base a las variables seleccionadas. 3. Proponer un marco de trabajo y una metodología para el análisis visual de datos biofarmacéuticos. 4. Desarrollar una herramienta informática que soporte la metodología propuesta e incluya las técnicas de visualización identificadas en el trabajo. Las preguntas de investigación planteadas en base a estos objetivos son: • ¿Cómo determinar las variables con mayor influencia en las propiedades fracción de fármaco absorbido y biodisponibilidad? • ¿Cuáles son las técnicas y herramientas de visualización más apropiadas para el conjunto de datos disponible? • ¿Cuáles son las aplicaciones y sistemas computacionales existentes que podrían servir como base para desarrollar una solución a la problemática planteada? • ¿Cómo organizar el proceso de análisis visual de datos biofarmacéuticos? • ¿Qué tecnologías emplear para el desarrollo y adaptación de las técnicas de visualización seleccionadas sobre el marco de trabajo establecido? Esta investigación se encuentra fundamentada desde su valor práctico y económico en el interés derivado de la importancia que revisten las propiedades biofarmacéuticas en su vinculación el desarrollo y formulación de ingredientes activos y en la obtención de 5.
(15) _______________________________________________________________________________________________INTRODUCCIÓN. adecuados perfiles de absorción y valores de biodisponibilidad, con la consiguiente disminución en costes y tiempo de desarrollo si se logra la exoneración de los ensayos clínicos. Desde el aspecto del valor teórico, no se cuenta actualmente con métodos y herramientas de análisis visual diseñados o ajustados específicamente al trabajo con datos biofarmacéuticos y la identificación de relaciones que tributen al proceso de absorción de fármacos, por lo cual se pretende iniciar este tipo de estudios y evaluar su impacto en el desarrollo de medicamentos para su administración oral. Este documento se encuentra estructurado en 3 capítulos. El Capítulo 1 aborda brevemente el aspecto biofarmacéutico a modo de introducción, haciendo hincapié en las variables disponibles y el trabajo realizado en base a ellas.. Posteriormente se introducen los. conceptos fundamentales relacionados con Visual Analytics y se abordan algunas de las alternativas disponibles para implementar soluciones de este tipo y aplicaciones basadas en ellas. En el Capítulo 2 se discuten el marco de trabajo y la propuesta de metodología desarrollados para realizar el análisis de datos biofarmacéuticos, haciendo énfasis en las consideraciones referentes a interactividad y extensibilidad. En el Capítulo 3 se presentan los resultados obtenidos a partir de la implementación de la propuesta y su validación. Finalmente se exponen las conclusiones obtenidas, recomendaciones para la continuación de este trabajo en el futuro y las referencias bibliográficas que fueron empleadas.. 6.
(16) CAPÍTULO 1. VISUAL ANALYTICS El análisis automatizado de grandes volúmenes de datos para extraer información, identificar patrones interesantes, realizar clasificación, etc., es un problema desafiante desde el punto de vista computacional. Visual Analytics propone un enfoque centrado en el analista como parte fundamental del proceso de análisis, integrando la capacidad humana de reconocimiento de patrones y regularidades a técnicas automatizadas para el procesamiento de datos. A continuación, se discuten las características del problema particular que se aborda en este trabajo: el análisis de datos biofarmacéuticos. Posteriormente se pasa a tratar Visual Analytics: su definición, aplicaciones y alcance, mencionando brevemente algunas aplicaciones desarrolladas para cada uno de sus campos de aplicación. Finalmente se presentan y discuten las ventajas y desventajas de algunas de las opciones disponibles para la creación e implementación de soluciones de Visual Analytics. 1.1 Aspecto Biofarmacéutico Los procesos involucrados en el descubrimiento y desarrollo de fármacos han cambiado considerablemente en años recientes: el acceso a información genómica tanto de bacterias como de los seres humanos ofrece una rica fuente de blancos moleculares para tratar enfermedades (Mannhold et al., 2009). La química se ha adaptado a este proceso desarrollando métodos tales como la síntesis combinatoria y paralela, permitiendo la síntesis rápida de cientos o incluso cientos de miles de moléculas en cantidades, purezas y marcos de tiempo razonables. Los datos históricos acerca de potenciales medicamentos en desarrollo indican que las principales razones para su fallo se basan en la toxicidad, eficacia y su farmacocinética y metabolismo. Por tanto, actualmente la evaluación de propiedades como absorción, distribución, metabolismo y excreción (ADME) de los posibles candidatos se realiza en 7.
(17) CAPÍTULO 1. VISUAL ANALYTICS. etapas tempranas del proceso. Sin embargo, dados los costes asociados, el interés se ha movido hacia la predicción y simulación de las propiedades moleculares, con el consiguiente desarrollo de herramientas computacionales que permitan incluir las propiedades ADME en el diseño de bibliotecas de compuestos, la evaluación de bibliotecas virtuales y la selección de los compuestos más prometedores para enfrentar una batería de pruebas in vitro (Mannhold et al., 2009). Por razones de conveniencia para el paciente y la terapia, la mayor parte de medicamentos son administrados por vía oral. Para mantener la dosis al nivel más bajo posible, unos valores elevados de absorción oral y biodisponibilidad son fundamentales, y por tanto propiedades fundamentales a ser optimizadas en un nuevo medicamento. Las razones principales para la optimización de la biodisponibilidad se basan en que un bajo nivel de esta (<30%) resulta en propiedades farmacocinéticas erráticas, haciendo difícil dosificar el medicamento. Además, elevados valores de biodisponibilidad implican una reducción en la dosis necesaria y por tanto menores efectos tóxicos y menor coste del medicamento. La biodisponibilidad, que caracteriza magnitud y la velocidad a la cual un medicamento se vuelve disponible en la circulación general dentro del organismo, es resultado de una larga cadena de eventos, y es influenciada, entre otras propiedades, por la solubilidad y permeabilidad del compuesto. Los valores de esta propiedad son normalmente estudiados mediante ensayos in vivo en ratas y perros, sin embargo, una predicción in silico confiable de esta puede permitir tomar mejores decisiones en guiar proyectos de desarrollo a llevar los mejores candidatos a ensayos clínicos (Mannhold et al., 2009). En el caso de la permeabilidad, esta se halla determinada por la capacidad del compuesto de atravesar la membrana biológica. Cualquier correlación de la permeabilidad con la absorción oral permite observar una tendencia de que, a mayor permeabilidad, mejor es la absorción del fármaco. Esto la convierte en un blanco fundamental a ser optimizado para los fármacos a ser administrados por vía oral, sin embargo, obtener o predecir sus valores de forma confiable resulta difícil dada la complejidad de los procesos que intervienen. Especialmente en el caso de los modelos desarrollados para predecir su comportamiento en humanos, sus resultados se vuelven menos confiables a medida que se vuelven más desligados de los procesos biológicos presentes. 8.
(18) CAPÍTULO 1. VISUAL ANALYTICS. La solubilidad, por otro lado, ha sido reconocida como un factor limitante en la absorción de los compuestos, ya que solamente el fármaco completamente disuelto es capaz de atravesar la membrana gastrointestinal y por tanto ser administrados efectivamente por la vía oral. Los estimados del grado de solubilidad ideal para una buena absorción oral dependen de la permeabilidad del compuesto y de la dosis requerida. Aquí se pone de manifiesto que tanto permeabilidad como solubilidad no se encuentran aisladas la una de la otra, sino que se encuentran estrechamente vinculadas, y que la obtención de un buen valor de biodisponibilidad depende en buena medida, aunque no de forma absoluta, de los valores de estas propiedades. Teniendo en cuenta lo anterior, los estudios de disolución han sido empleados como una herramienta para el pronóstico de la absorción oral de fármacos, con el resultado de la proposición del Sistema de Clasificación Biofarmacéutica (BCS). Este plantea la clasificación de los fármacos en cuatro grupos o clases atendiendo a sus valores de solubilidad y permeabilidad, contemplando la posibilidad de exonerar de una serie de ensayos clínicos a aquellos fármacos que sean clasificados como Clase I (correspondiente a elevada solubilidad y permeabilidad). Sin embargo, la aplicabilidad del sistema se halla limitada por la dificultad de encontrar datos fiables para estas propiedades. Para solventar esta dificultad, un esfuerzo considerable ha sido realizado en función de la construcción de modelos y métodos a partir de los cuales estimar estas propiedades. En el caso de la solubilidad, han sido especialmente notables los trabajos orientados a lograr su predicción computacional. Sin embargo, en buena medida debido a la carencia de conjuntos de datos experimentales lo suficientemente grandes medidos bajo condiciones idénticas y a la propia variabilidad de estas propiedades, los métodos disponibles no son lo suficientemente robustos como para producir predicciones confiables en todos los casos. Una perspectiva interesante es la de que, de la misma forma en que la solubilidad y la permeabilidad, y por tanto indirectamente también la biodisponibilidad, se encuentran interrelacionadas y existe un cierto nivel de dependencia entre ambas, estas a su vez dependen de una larga serie de propiedades más básicas. Estas otras propiedades, al depender fundamentalmente de la estructura del compuesto y solo de esta, pueden ser. 9.
(19) CAPÍTULO 1. VISUAL ANALYTICS. medidas y estimadas con relativamente mayor facilidad que la solubilidad, permeabilidad y biodisponibilidad de un compuesto. Aunque no pueden dejarse de lado los factores biológicos que intervienen en todo el proceso, la posibilidad de mapear valores o patrones dentro de los valores de alguna combinación de estas propiedades a un comportamiento particular de los valores de las propiedades objetivo no deja de ser interesante. Desde este punto de vista, ya se han realizado trabajos tratando de encontrar este tipo de regularidades o relaciones, como es el caso de la predicción de la ionización (𝑝𝐾𝑎 ) y su posible relación con la solubilidad y permeabilidad al influenciar en los mecanismos de transporte a nivel celular, dando buenos resultados para estructuras con grupos funcionales conocidos y bien medidos, aunque deja mucho que desear todavía en el caso de estructuras innovadoras. Otras propiedades que han resultado blanco de este interés han sido el área superficial polar1, y los coeficientes de distribución y partición (𝑙𝑜𝑔𝐷 y 𝑙𝑜𝑔𝑃, respectivamente), empleados para lograr estimaciones de la permeabilidad y solubilidad de un compuesto. Sin embargo, estas investigaciones se hallan dirigidas a los efectos de una propiedad determinada, más que a conjuntos de ellas y su interrelación, principalmente debido a la dificultad que supone la búsqueda de estas relaciones. La aplicación de técnicas de Visual Analytics podría ser el medio con el cual viabilizar la realización de este tipo de estudio más general, permitiendo la generación y comprobación de hipótesis más complejas al proveer una visión más general e interpretable de las regularidades dentro de los datos disponibles. Sería especialmente deseable su implementación para la etapa de identificación y optimización de fármacos candidatos, al poder en alguna medida discriminar aquellas formulaciones que resulten menos prometedoras y dar prioridad a las que muestren indicios, en base al análisis realizado, de buenas condiciones para su administración por vía oral. Esto podría redundar en una implementación más efectiva de la clasificación BCS, con los consecuentes beneficios en cuanto a la reducción de costes y tiempo de desarrollo.. 1. PSA, Polar Surface Area. 10.
(20) CAPÍTULO 1. VISUAL ANALYTICS. 1.2 Perspectiva general de Visual Analytics El rápido avance de las tecnologías ha traído aparejado un incremento sustancial y constante en las capacidades computacionales disponibles para aplicar a cualquier tipo de tarea. Una de las consecuencias más evidentes de este proceso es el significativo aumento de la capacidad de generar y almacenar volúmenes de datos cada vez mayores. Sin embargo, la capacidad de analizar efectivamente y extraer información relevante a partir de este cúmulo de datos no parece crecer con la misma rapidez (Keim and Thomas, 2008). Tal desbalance resulta preocupante cuando se considera que tales acciones son cruciales para muchos dominios de aplicación, especialmente los que involucran alguna forma de toma de decisiones. La mayor parte de aplicaciones de la vida real no precisan del empleo de los datos en bruto, que generalmente carecen de valor por sí mismos, sino que es la información contenida en ellos la que resulta de interés (Kerren et al., 2008). Este fenómeno donde la capacidad de generación excede a la de procesamiento de los datos se conoce comúnmente como sobrecarga de información (Eppler and Mengis, 2004; Fry, 2007), y constituye un reto en la actualidad, donde la obtención de datos ha dejado de ser un problema para ceder su lugar a cómo lidiar efectivamente con estos. En (Kerren et al., 2008) se definen una serie de preguntas que deberían ser respondidas por cualquier tecnología que afirme haber dado una solución satisfactoria a este problema: - ¿Quién o qué define la relevancia de la información para una tarea dada? - ¿Cómo pueden ser identificados los procedimientos apropiados en un proceso de toma de decisiones complejo? - ¿Cómo puede presentarse la información resultante de forma orientada a la toma de decisiones o a la resolución de la tarea? - ¿Qué tipos de interacción pueden facilitar la solución de problemas y la toma de decisiones? La idoneidad de muchas de las herramientas existentes para enfrentar este tipo de tareas es cuando menos cuestionable cuando se enfoca con estas preguntas en mente. La existencia de softwares de uso comercial ampliamente utilizados, basados en metáforas de interacción con más de una década de existencia (Keim and Thomas, 2008) y que fueron pensadas para 11.
(21) CAPÍTULO 1. VISUAL ANALYTICS. volúmenes de datos mucho menos considerables, es una muestra de ello. Además, en la mayoría de las ocasiones carecen de herramientas de análisis automatizado que puedan asistir al usuario en su proceso de búsqueda de conocimiento. Esto implica que a menudo fallen en proveer la información oportuna en tiempo real, algo indispensable para hacer frente a un escenario donde es necesario lidiar con el fenómeno de sobrecarga de información. En el otro extremo del espectro, las aproximaciones basadas puramente en la aplicación de técnicas automatizadas acarrean la desventaja de volverse menos interpretables a medida que se vuelven más sofisticadas. Esto afecta el grado de confianza sobre los resultados obtenidos y se convierte en un obstáculo cuando la confiabilidad es vital: la búsqueda, filtrado y cualquier forma de análisis completamente automatizado funcionan de forma confiable y previsible generalmente solo para problemas bien definidos y conocidos (Kerren et al., 2008). Por otro lado, el carácter cerrado de muchas de estas técnicas dificulta la interacción con el usuario, que en la mayoría de los casos no puede contribuir con su conocimiento del dominio del problema al proceso de análisis, ni comprender por qué ni cómo se arribó a una determinada conclusión. Este es un ejemplo de cómo este enfoque falla en responder la primera de las interrogantes planteadas: la responsabilidad de definir qué información es relevante debería recaer sobre el usuario o especialista y no sobre el método de análisis empleado. Visual Analytics plantea un enfoque que pretende llenar el vacío existente entre los métodos de análisis automatizado y el analista mediante el empleo de métodos más inteligentes a la hora de analizar los datos (Keim and Thomas, 2008), convirtiendo la sobrecarga de información en una oportunidad al hacer transparente al proceso analítico la forma de procesar los datos (Kerren and Schreiber, 2012). Este objetivo se pretende lograr principalmente mediante el empleo de la representación visual de la información y la interacción directa del analista o usuario, mediante técnicas de visualización, para apoyar el uso de técnicas estadísticas y de análisis automatizado. Ello está sustentado en que el empleo de metáforas visuales bien diseñadas para representar la información reduce el trabajo cognitivo requerido para actividades como la interpretación y 12.
(22) CAPÍTULO 1. VISUAL ANALYTICS. síntesis (Kerren et al., 2008). De esta forma el analista gana mayor confianza en los resultados obtenidos al ser parte central del proceso, pudiendo concentrar sus capacidades completamente en el aspecto analítico al tiempo que es capaz de aplicar capacidades computacionales avanzadas para aumentar la efectividad de su búsqueda y descubrimiento de información interesante. En base a estos criterios, Visual Analytics puede definirse como “la ciencia del razonamiento analítico asistido mediante interfaces visuales interactivas” (Keim et al., 2008). Trabajos más recientes en esta área han ampliado esta definición y dejan bien planteadas sus metas al considerarlo “la combinación del análisis automatizado y visualizaciones interactivas para aumentar la efectividad del entendimiento, razonamiento y toma de decisiones sobre la base de un conjunto de datos muy grande y complejo” (Kohlhammer et al., 2011). Esta última definición pone de manifiesto su naturaleza de proceso fundamentalmente iterativo que incluye aspectos diversos correspondientes a campos como la recolección de información, el pre procesamiento de datos, la representación del conocimiento, la interacción y la toma de decisiones; todo ello asistido mediante el empleo de la visualización. Fundamentalmente, se trata de la combinación de métodos de descubrimiento de conocimiento y técnicas estadísticas con la capacidad humana de percibir patrones, buscar relaciones y arribar a conclusiones a partir de información visual. Esta combinación y enfoque centrado en la interacción es uno de los puntos fuertes de Visual Analytics como herramienta de análisis (Sun et al., 2013). Desde el punto de vista de los objetivos que se persiguen con su aplicación, se puede decir que se encuentra orientado a la creación de herramientas y técnicas que permitan sintetizar información y derivar conocimiento a partir de datos masivos (en volumen o dimensión), dinámicos, ambiguos y a menudo en conflicto; detectar lo esperado y descubrir lo inesperado; proveer análisis oportunos, defendibles y comprensibles; así como comunicar dichos análisis efectivamente para realizar acciones apropiadas (Kerren et al., 2008; Kohlhammer et al., 2011).. 13.
(23) CAPÍTULO 1. VISUAL ANALYTICS. Es evidente la estrecha relación existente entre Visual Analytics y los campos de la visualización científica y la visualización de información. Esto se debe principalmente a que el primero ha evolucionado y se ha nutrido a partir de los avances en las dos últimas. Sin embargo, existen diferencias fundamentales que los distinguen y convierten a Visual Analytics en una disciplina separada por derecho propio, y que es conveniente señalar. El trabajo de visualización tradicional, ya sea en la visualización científica o de información, no tiene que lidiar necesariamente con tareas de análisis, ni emplear algoritmos de análisis de datos avanzados. También desde el punto de vista del área de investigación pueden apreciarse diferencias claves: la visualización científica se concentra en formas más eficientes de representación y la visualización de información se dirige hacia la producción de metáforas visuales y métodos de interacción valiosos para clases particulares de datos. Mientras tanto, Visual Analytics se enfoca en cómo convertir dichas interacciones en inteligencia mediante la cual ajustar los parámetros del sistema a fin de mostrar la información más relevante para el usuario (Kerren et al., 2008; Kerren and Schreiber, 2012). De esta forma se pretende que los intereses de análisis del usuario se reflejen de forma consistente en los componentes del sistema, tanto en los algoritmos de análisis automatizado como en las visualizaciones empleadas para transmitir la información. Esta última es una idea fundamental para Visual Analytics y que ha sido abordada de diversas maneras: un ejemplo se presenta en (Yang, Rundensteiner and Ward, 2007), donde se discute una metodología para el análisis de datos multivariados basada en el concepto de “nuggets” o fragmentos interesantes de información, determinados y refinados de forma automática por el sistema mediante el análisis de las interacciones del usuario (según el tiempo empleado visitando un subconjunto específico de datos, o la cantidad de veces que se haya visitado, por ejemplo). El resultado final puede ser etiquetado, comentado y compartido, dando pie a la realización de un análisis eficiente y colaborativo, otra de las aspiraciones de Visual Analytics.. 14.
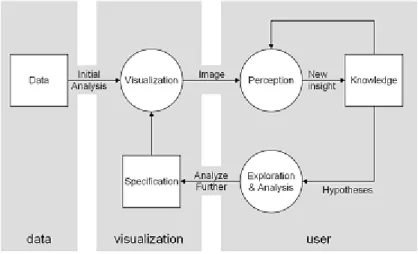
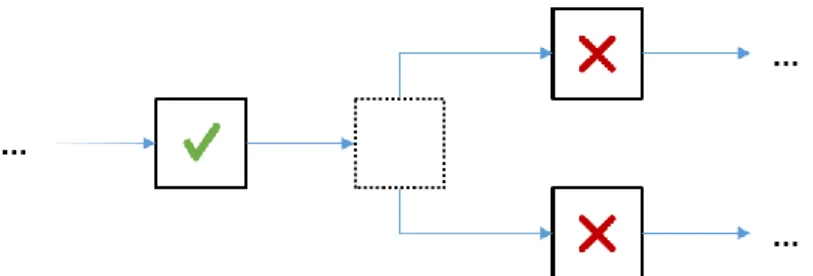
(24) CAPÍTULO 1. VISUAL ANALYTICS. 1.3 El proceso de Visual Analytics Un número importante de sistemas destinados a la visualización de información, así como algunas técnicas de visualización específicas, derivan su enfoque directamente del mantra propuesto en (Shneiderman, 1996): “dar una visión general primero, zoom/filtrar, detalles según se demanden”. Para ajustarlo al enfoque de Visual Analytics, este requiere de la extensión realizada en (Sacha et al., 2014): “analizar primero, mostrar lo importante, zoom/filtrar, analizar en mayor profundidad, detalles según se demanden”. La creación de cualquier tipo de representación visual de un conjunto de datos grande y complejo requiere de la realización de algún proceso de análisis. Este debe responder al desafío de encontrar una representación tan fiel como sea posible a los datos que la produjeron, al mismo tiempo que evita la introducción de incertidumbre o ambigüedad en la interpretación.. Sería ingenuo suponer. que una. representación seleccionada. arbitrariamente ofrece una visión imparcial de los datos subyacentes: cualquiera que sea esta, favorecerá alguna de las posibles interpretaciones por encima de las demás (Kerren et al., 2008). Visual Analytics aspira a ofrecer una solución al introducir al usuario en un ciclo de búsqueda de sentido, en el que los datos pueden ser manipulados interactivamente para alcanzar un mejor entendimiento tanto de estos como de su representación. Intuitivamente, se puede pensar que se parte de una representación inicial e interacciones adecuadas obtenidas tras la aplicación de diferentes técnicas matemáticas y estadísticas (Kerren et al., 2008; Sacha et al., 2014), en correspondencia con el primer paso del mantra extendido de Visual Analytics: “analizar primero”. El proceso entra entonces en un bucle en donde el usuario puede ganar entendimiento sobre los datos, idealmente guiando al sistema hacia técnicas analíticas más concentradas y adecuadas para sus objetivos. Al mismo tiempo, al interactuar con la representación visual, el usuario alcanza una mejor comprensión de esta, empleando diferentes vistas que le asistan en la confirmación o generación de hipótesis a partir de iteraciones anteriores. La Error! Reference source not found. muestra el ciclo de búsqueda de sentido tal como se desarrolla dentro de Visual Analytics. 15.
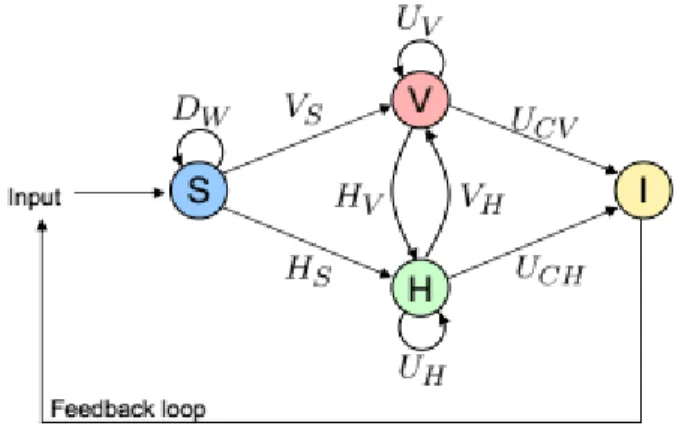
(25) CAPÍTULO 1. VISUAL ANALYTICS. Tanto el ciclo de búsqueda de sentido como el proceso iterativo responden a los pasos fundamentales discutidos en (Kohlhammer et al., 2011): transformación de los datos, mapeo visual, análisis basado en modelos e interacción del usuario. Formalmente, el proceso iterativo de Visual Analytics puede definirse de la siguiente manera: a partir de un conjunto de fuentes de datos (mayormente heterogéneas), se escogen los conjuntos de datos 𝑆 = 𝑆1 , 𝑆2 , … , 𝑆𝑚 , donde cada 𝑆𝑖 , 𝑖 ∈ (1, … , 𝑛) consiste de los atributos 𝐴𝑖1 , 𝐴𝑖2 , … , 𝐴𝑖𝑘 .. Figura 1.1 El proceso de búsqueda de sentido en Visual Analytics (Keim and Thomas, 2008). El objetivo o salida del proceso es el conocimiento o conclusión 𝐼, el cual se obtiene ya sea a partir del conjunto 𝑉 de visualizaciones creadas o mediante la confirmación de las hipótesis 𝐻 como resultado de los medios de análisis automatizado. En más detalle, se considera este proceso como una transformación 𝐹: 𝑆 → 𝐼, donde se define a 𝐹 como una concatenación de funciones 𝑓 ∈ {𝐷𝑊 , 𝑉𝑋 , 𝐻𝑌 , 𝑈𝑍 }, que se definen a continuación: - 𝐷𝑊 describe las funcionalidades básicas de pre procesamiento de datos, con 𝐷𝑊 : 𝑆 → 𝑆 y 𝑊 ∈ {𝑇, 𝐶, 𝑆𝐿, 𝐼}, incluyendo las funciones de transformación de datos (𝑇), limpieza de datos (𝐶), selección de datos (𝑆𝐿) e integración de datos (𝐼), respectivamente. - 𝑉𝑋 , 𝑋 ∈ {𝑆, 𝐻} simboliza las funciones de visualización, las cuales son tanto funciones de visualización de datos 𝑉𝑆 : 𝑆 → 𝑉 o funciones que visualizan hipótesis 𝑉𝐻 : 𝐻 → 𝑉. 16.
(26) CAPÍTULO 1. VISUAL ANALYTICS. - 𝐻𝑌 , 𝑌 ∈ {𝑆, 𝑉} representa el proceso de generación de hipótesis. Se distingue en este caso entre las funciones que generan hipótesis a partir de los datos 𝐻𝑆 : 𝑆 → 𝐻 y funciones que generan hipótesis a partir de visualizaciones 𝐻𝑉 : 𝑉 → 𝐻. - Finalmente, se definen las funciones que representan la interacción con el usuario, de la forma 𝑈𝑍 , 𝑍 ∈ {𝑉, 𝐻, 𝐶𝑉, 𝐶𝐻}. Estas pueden afectar solamente a las visualizaciones a mano (𝑈𝑉 : 𝑉 → 𝑉, selección o zoom), o afectar únicamente a las hipótesis (𝑈𝐻 : 𝐻 → 𝐻, generación de nuevas hipótesis a partir de las existentes). Por último, pueden extraerse conclusiones a partir de las visualizaciones o de las hipótesis (𝑈𝐶𝑉 : 𝑉 → 𝐼, 𝑈𝐶𝐻 : 𝐻 → 𝐼). Típicamente, el paso de transformación de datos que se considera en el modelo, y que en la práctica incluye las operaciones de limpieza, integración y transformación de estos, se define mediante una función de pre procesamiento 𝐷𝑃 = 𝐷𝑇 (𝐷𝐼 (𝐷𝐶 (𝑆1 , 𝑆2 , … , 𝑆𝑛 ))). Tras la aplicación de este se puede proceder a emplear métodos de análisis automatizado (𝐻𝑆 = {𝑓𝑠1 , 𝑓𝑠2 , … , 𝑓𝑠𝑞 }) o técnicas de visualización (𝑉𝑆 : 𝑆 → 𝑉, 𝑉𝑆 = {𝑓𝑣1 , 𝑓𝑣2 , … , 𝑓𝑣𝑠 }) para descubrir patrones que puedan encontrarse dentro de los datos. Estos se corresponden con los aspectos de mapeo visual y de análisis basado en modelos. La naturaleza iterativa del proceso se ilustra en la Error! Reference source not found... Figura 1.2 El proceso de Visual Analytics (Keim Daniel and Mansmann, 2010). En la mayoría de los casos, las aplicaciones de la vida real requieren la interacción del usuario para refinar los parámetros de los métodos de análisis automatizados y manipular las visualizaciones generadas. Esto se traduce en que, tras la obtención de un primer conjunto de resultados, el usuario puede refinar los resultados mediante la aplicación de 17.
(27) CAPÍTULO 1. VISUAL ANALYTICS. subsecuentes pasos de análisis de datos, ya sea repitiendo el análisis precedente con criterios o umbrales más finos, o empleando un diseño completamente nuevo del proceso de análisis. Los resultados obtenidos a partir de los métodos automatizados pueden ser procesados mediante las funciones de visualización para obtener una representación de una hipótesis, o los hallazgos obtenidos a partir del análisis de las visualizaciones pueden ser confirmados mediante la aplicación de métodos automatizados (Sun et al., 2013). 1.4 Técnicas y aplicaciones de Visual Analytics A pesar de ser una disciplina relativamente nueva, las potencialidades de Visual Analytics para dar respuesta a los retos de análisis de datos actuales han dado pie a un vigoroso desarrollo de diferentes técnicas y aplicaciones basadas en sus premisas. Estas se pueden distribuir de acuerdo a los dominios de aplicación principales y la naturaleza de los datos con los que trabajan, pudiendo determinarse cinco categorías fundamentales (Sun et al., 2013). Datos espacio-temporales La primera de estas se encuentra enfocada al análisis y el trabajo con datos espacio temporales, los cuales se han convertido en algunos de los más prominentes dentro del campo de Visual Analytics (Keim et al., 2008), puesto que encontrar relaciones espaciales y temporales dentro de los datos es imprescindible para un gran número de tareas de análisis (Keim Daniel and Mansmann, 2010), entre las que se pueden contar la búsqueda de relaciones causa-efecto o tendencias en el tiempo. El análisis de datos geoespaciales es una de las principales vertientes desarrolladas dentro de este campo. En (Slingsby, Dykes and Wood, 2011) se presenta un sistema de análisis visual interactivo para explorar y analizar los resultados producidos por un clasificador geo demográfico llamado OAC2. Ese trabajo emplea OAC para clasificar la población del Reino Unido mediante 41 variables en conjuntos de áreas geográficas organizadas en una. 2. Output Area Classification. 18.
(28) CAPÍTULO 1. VISUAL ANALYTICS. jerarquía de tres niveles. Otra aplicación relacionada es la llamada BallotMaps (Wood et al., 2011). Esta es una herramienta interactiva que se basa en el uso de gráficas organizadas jerárquicamente para facilitar el análisis de datos tanto espaciales como no espaciales. Esta fue empleada para estudiar la relación entre el número de votos recibidos por un candidato y su posición en la boleta electoral para examinar los patrones geográficos asociados. Esta está limitada, sin embargo, en que no considera los patrones de inclinación del voto a lo largo del tiempo. Por otro lado, el análisis de datos que varían en el tiempo es un área que reúne un interés creciente. El trabajo con series de tiempo ambientales es una de las aplicaciones que se le ha dado a la aplicación de Visual Analytics al tratamiento de datos temporales. Aplicaciones como CloudLines (Krstajic, Bertini and Keim, 2011) y ChronoLenses (Zhao et al., 2011) muestran algunas de las aproximaciones que se toman: la primera emplea una metáfora visual compacta y novedosa para visualizar series temporales en un espacio limitado, mientras que la segunda provee diferentes tipos de lentes para explorar regiones de interés en datos pertenecientes a series temporales, permitiendo a los usuarios interactuar con las lentes para crear flujos de trabajo analítico que faciliten el análisis exploratorio. La combinación de ambos aspectos en datos espacio-temporales, puede probar ser un campo aún más desafiante que cada uno por separado y continúa siendo un tópico difícil dentro de Visual Analytics (Sun et al., 2013). La ocurrencia natural de este tipo de datos, que reflejan situaciones muy comunes como patrones de movimiento y transportación, es un aliciente para el trabajo investigativo en esta dirección. Datos multivariados El trabajo con datos multivariados es un área de investigación muy activa actualmente, orientado a explorar y entender las correlaciones y distribuciones entre diferentes dimensiones de los datos. Para lograr este propósito, los métodos pertenecientes a esta área se dividen en dos clases principales: los métodos basados en proyección que emplean reducción de dimensiones, y los métodos que emplean la generación de patrones visuales (Sun et al., 2013).. 19.
(29) CAPÍTULO 1. VISUAL ANALYTICS. Los métodos basados en la proyección o reducción de dimensiones tratan de encontrar proyecciones de datos con un elevado número de dimensiones en un espacio más con un subconjunto de estas, al tiempo que se preserva algún conjunto de características interesantes de los datos originales. Una de las técnicas más empleadas para la reducción del número de dimensiones es el escalado multidimensional3. Este tradicionalmente emplea la distancia euclidiana como medida para computar la similitud de los datos, aunque existen trabajos como el de (Lee et al., 2013) que plantean que esta no es buena para caracterizar las distancias entre clústeres y proponen una distancia alternativa basada en la estructura, produciendo una mejor calidad de la proyección obtenida. Las relaciones heterogéneas entre dimensiones en espacios de alta dimensión son ignoradas en casi todos los métodos de análisis (Sun et al., 2013). Una excepción interesante es el trabajo presentado en (Turkay, Filzmoser and Hauser, 2011), donde se propone el uso de factores representativos extraídos mediante una combinación de métodos que incluyen MDS, análisis de componentes principales4 y factores basados en modelos de distribución, para capturar las relaciones de agrupación entre dimensiones. Este enfoque fue empleado exitosamente para descubrir subconjuntos de individuos en un estudio del proceso de envejecimiento de un cerebro sano, empleando datos con 315 dimensiones. LAMP5 (Joia et al., 2011) es un nuevo método de proyección basado en una teoría de mapeo ortogonal para lidiar con datos con elevado número de dimensiones, centrado en la eficiencia y que permite a los usuarios refinar los resultados de forma progresiva a través de la inclusión de su conocimiento (Sun et al., 2013). LAMP se basa en una formulación matemática derivada de la teoría de mapeo ortogonal que le otorga robustez y precisión al proceso al tiempo que permite que este sea un método local que requiere un reducido número de muestras para trabajar. Ello se traduce en mayores facilidades para la interacción del usuario, que requiere menos trabajo para integrar su conocimiento del problema. Estas características de LAMP hacen que sea idóneo para la exploración y organización dinámica de los datos, una posibilidad altamente. 3. MDS, Multidimensional Scaling PCA, Principal Component Analysis 5 LAMP, Local Affine Multidimensional Projection 4. 20.
(30) CAPÍTULO 1. VISUAL ANALYTICS. atractiva en muchos dominios de aplicación, especialmente para la correlación de datos (Joia et al., 2011). Los métodos que toman una aproximación visual intentan mapear directamente los datos multivariados para visualizarlos, incluyendo el empleo de las técnicas orientadas a píxeles o el uso de sistemas de coordenadas paralelas para representar todas las dimensiones simultáneamente. Es interesante considerar que este último caso también puede clasificarse como una técnica de proyección, pues se pretende visualizar datos n-dimensionales en un espacio bidimensional. Aún más, en muchos casos la reducción, al menos hasta cierto punto, del número total de dimensiones puede ser un requerimiento para la aplicación efectiva de algunas de estas técnicas, sobre todo en el caso de las coordenadas paralelas. iVisClassifier (Choo et al., 2010) es un sistema de Visual Analytics para realizar clasificación basado en reducción de dimensiones supervisada mediante la aplicación de análisis de discriminante lineal6. Dado un conjunto de etiquetas y de datos multivariados, LDA obtiene una representación con un número reducido de dimensiones, proveyendo una buena visión general de la estructura de clústeres presentes en los datos. Un aspecto interesante es que permite interactuar con el conjunto completo de dimensiones reducidas mediante el empleo de sistemas de coordenadas paralelas y gráficos de dispersión, aumentando la interactividad y la facilidad de interpretación de los resultados de LDA: los usuarios pueden entender cada una de las dimensiones reducidas y cómo estas influencian los datos. El análisis de clústeres es una estrategia poderosa y ampliamente empleada para el tratamiento de datos multivariados ante la ausencia de conocimiento o hipótesis previas sobre los modelos de clasificación de los datos, permitiendo conformar dichos modelos a partir de los resultados obtenidos. Sin embargo, la ausencia de modelos formales y reglas de clasificación en un escenario de exploración particular, no implica que los especialistas del campo no cuenten con una vasta cantidad de conocimiento no compilado e intuición que puedan aportar. De hecho, los resultados obtenidos mediante la aplicación de técnicas. 6. LDA, Linear discriminant analysis. 21.
(31) CAPÍTULO 1. VISUAL ANALYTICS. no supervisadas, que se basan en elecciones puramente algorítmicas a la hora de conformar los clústeres, rara vez están completamente de acuerdo con la opinión de los expertos. ClusterSculptor (Nam et al., 2007), es una propuesta de marco de trabajo y una herramienta que permite al especialista del dominio inyectar su conocimiento en el proceso de agrupamiento, representando el espacio n-dimensional mediante la aplicación de mapas de píxeles y dendrogramas para representar los datos y la estructura de clústeres actual. En (Castellanos-Garzón et al., 2013), se presenta un marco de trabajo destinado al análisis de clústeres en datos de micro arreglos de ADN desde una perspectiva de Visual Analytics. Otra aplicación que hace uso de Visual Analytics y técnicas de agrupamiento se encuentra propuesta en (Uemura et al., 2016). En este se emplea una técnica de agrupamiento llamada doble agrupamiento asimétrico7, que ha sido desarrollada recientemente para realizar búsquedas en sub espacios de datos multivariados, para enfrentar un problema de clasificación relativo a la identificación de supernovas de un tipo particular. La técnica empleada agrupa las dimensiones altamente correlacionadas de forma automática, formando sub espacios de características de forma interactiva y progresiva. Esto se logra mediante la combinación de k-medias esférico para agrupar las dimensiones altamente correlacionadas y luego k-medias estándar para identificar subconjuntos en las muestras de datos. Lograr una integración natural de los métodos basados en proyección con los que se basan en representaciones visuales es una dirección de investigación interesante (Sun et al., 2013), pues promete la combinación de la capacidad de los primeros de lidiar con datos con un muy elevado número de dimensiones con la interpretación intuitiva de los segundos. Datos textuales El análisis de información textual es uno de los principales retos para la minería de datos, principalmente debido a que la mayor parte esta corresponde a corpus textuales libre y sin estructura y a la ambigüedad inherente al lenguaje natural. Por otro lado, la masiva cantidad de datos hace impracticable que los especialistas lean toda esta información. 7. ABC, Asymmetric bi-clustering. 22.
(32) CAPÍTULO 1. VISUAL ANALYTICS. Una de las aproximaciones son los métodos basados en temas, los cuales extraen temas y eventos a partir de los corpus textuales para luego proceder a su análisis mediante la aplicación de técnicas de visualización. Recientemente se ha puesto de manifiesto la relevancia de la información temporal asociada a los textos, dando pie al surgimiento de aplicaciones y líneas de investigación como EventRiver, Visual Backchannel y TextFlow, las cuales analizan y rastrean principalmente la evolución temporal y difusión de eventos, temas o actividades (Sun et al., 2013). Los métodos basados en características usan partes del texto, tales como características a nivel de palabra y a nivel de documento, para visualizar el texto. Un ejemplo muy empleado son las nubes de palabras, debido principalmente a su capacidad de ofrecer una visión general muy intuitiva de colecciones textuales mediante la visualización de las palabras claves de forma compacta: las palabras más representativas son mostradas en una fuente de mayor tamaño. Varios algoritmos han sido propuestos para la generación de tales representaciones, entre los que se incluyen Wordle y ManiWordle (Sun et al., 2013). Una de las direcciones de desarrollo en estos métodos es la creación y empleo de métodos que preserven las relaciones semánticas que se encuentran en el texto: palabras clave que coocurren frecuentemente en los documentos aparecerán más cercanas en la representación visual. Se han desarrollado técnicas para visualizar no solamente el contenido de colecciones textuales, sino también las relaciones entre los diversos documentos que las componen, reconocer y recomendar características de legibilidad, y analizar propiedades lingüísticas. Grafos y redes El análisis visual de grafos y estructuras de redes es un importante campo de aplicación para las técnicas de Visual Analytics, sobre todo en una situación donde cobran cada vez mayor importancia entidades tales como las redes sociales y el Internet de forma general, cuya representación más natural es precisamente en forma de componentes interconectados. Los métodos empleados para tratar este tipo de dominio caen dentro de dos tipos principales: aquellos que crean representaciones mediante el empleo de visualizaciones de 23.
(33) CAPÍTULO 1. VISUAL ANALYTICS. matrices o diagramas de nodos y enlaces, y los que trabajan mediante la reducción de confusión o desorden. Las matrices comprimidas son una alternativa que explora las características de una red y redistribuye la visualización matricial para una presentación compacta. Estas han sido empleadas para el descubrimiento de subredes en redes de gran tamaño. Los diagramas de nodos y enlaces son una de las representaciones más populares y prevalentes para los grafos, dado lo intuitivo que resulta analizar las relaciones entre los elementos que representan los nodos mediante el sencillo expediente de referirse a las aristas que los conectan. Su aplicación ha resultado exitosa en tareas como la extracción de información a partir de redes sociales y referencias en artículos científicos. TreeNetViz es una aplicación representativa de este enfoque, al emplear un diagrama de este tipo con una configuración radial para visualizar simultáneamente la estructura jerárquica y las relaciones dentro de una red social. Otra de las aplicaciones para estas técnicas es el análisis de elementos de conjuntos y sus relaciones. LineSets es una técnica destinada al análisis visual de datos en forma de conjuntos, empleando curvas para enlazar los elementos relacionados entre estos, ofreciendo como ventaja frente a métodos tradicionales una reducción en la confusión de la representación resultante y que resulta apropiada para situaciones complejas donde muchos subconjuntos se solapan. La confusión causada por un exceso de información o elementos de presentación es un problema común y desafiante dentro de la visualización. Este se halla especialmente presente en cualquier intento de representar una red compleja, donde las relaciones entre elementos pueden llegar a saturar la pantalla, limitando seriamente la interpretación de los resultados. El agrupamiento de aristas es una técnica ideada para dar una solución a este inconveniente. La idea consiste en agrupar las aristas que recorren caminos adyacentes en una representación de nodos y enlaces. Un desarrollo posterior sobre esta es el agrupamiento jerárquico de aristas, el cual hace uso de la información jerárquica contenida dentro de los grafos compuestos para realizar el mismo procedimiento. 24.
(34) CAPÍTULO 1. VISUAL ANALYTICS. Las investigaciones recientes han presentado otros métodos para realizar agrupamiento de aristas, como técnicas basadas en geometría, donde una malla es empleada para atraer las aristas a ciertos puntos de control dentro de esta generando los grupos de aristas; y técnicas basadas en esqueletos, donde se extrae el esqueleto de un grafo y se fuerza a las aristas a estar tan próximas a la estructura de este como sea posible. La variedad de enfoques y aplicaciones que se pueden beneficiar de la aplicación de soluciones basadas en Visual Analytics es sorprendente, sin embargo, todavía existen una gran variedad de retos que enfrentar para aprovechar de forma óptima sus potencialidades. En particular, la identificación y elección del mejor (o más apropiado) algoritmo automatizado en función del problema que se enfrenta, la determinación de los límites más allá de los cuales no puede ser automatizado y proceder a desarrollar una solución que integre de forma apropiada a este con técnicas de visualización e interacción apropiadas (Kerren et al., 2008), continúa siendo una tarea imponente. 1.5 Alternativas para desarrollar soluciones de Visual Analytics Evidentemente, la implementación real y posterior efectividad de cualquier diseño o solución basada en Visual Analytics depende fuertemente de una buena elección de los mecanismos de interacción, herramientas de análisis y metáforas visuales que se emplearán para la representación de la información, de acuerdo a la naturaleza del problema. Sin embargo, la selección de un marco de trabajo o conjunto de herramientas puede probar ser crucial en términos del esfuerzo empleado en llevar a término cualquier esfuerzo de implementación. Existe una amplia gama de bibliotecas y conjuntos de herramientas destinados a la creación de visualizaciones, cada una con un mayor o menor grado de especialización, que pueden ser empleadas para la creación de soluciones basadas en Visual Analytics. Cada una de ellas puede proveer facilidades o crear dificultades en dependencia de los criterios en base a los cuales fueron creadas, por lo que es necesario tener en cuenta este detalle a la hora de realizar una elección de este tipo. No se pretende en este trabajo realizar una discusión exhaustiva de todas las alternativas disponibles, sino de una pequeña muestra que fue considerada a la hora de llevar a una 25.
(35) CAPÍTULO 1. VISUAL ANALYTICS. implementación concreta las propuestas que se tratarán más adelante, y que se considera que dan una buena perspectiva de los diferentes enfoques existentes a la hora de crear una solución basada en Visual Analytics. Processing Processing es un proyecto originalmente creado en 2001 como una extensión de dominio específico para el lenguaje Java, orientada a su uso por artistas y diseñadores (Fry, 2007). Actualmente, gracias a una amplia comunidad y la extensión de su uso, se ha convertido en una herramienta de diseño y creación de prototipos empleada en áreas diversas como gráficos de movimiento, trabajo artístico y visualización de datos complejos. Processing es un ambiente de programación simple, pensado para hacer más sencilla la creación de aplicaciones orientadas a la visualidad, con un énfasis manifiesto en la animación y en proveer a los usuarios con retroalimentación instantánea mediante la interacción (Fry, 2007). A medida que esta herramienta ha ido madurando, se ha dado el caso de su empleo en trabajo a nivel de producción además de su rol como herramienta de bocetado. Dado que se apunta a llevar este tipo de programación a ser accesible para una audiencia más amplia, Processing es un software de código abierto, con descargas gratuitas y sin necesidad de pagar por su uso. Además, dado el propósito con el que fue creado, a pesar de estar basado en Java, su modelo conceptual, específicamente el flujo de ejecución de los programas, cómo se construyen las interfaces, etc., es notablemente diferente de Java. Los componentes fundamentales de Processing son: - El ambiente de desarrollo de Processing (PDE, Processing Development Environment), un IDE8 con un conjunto mínimo de capacidades diseñado para ser una introducción básica a un ambiente de programación o para probar ideas rápidamente. - Una colección de comandos que conforman el núcleo de la interfaz de programación de Processing, además de un conjunto de bibliotecas que brindan soporte para operaciones más avanzadas, como dibujar usando OpenGL, leer archivos XML y guardar imágenes complejas en formato PDF. 8. Integrated Development Environment. 26.
Figure
+7


Documento similar