Construcción y entrenamiento de redes neuronales multicapa mediante el uso de algoritmos genéticos celulares
77
0
0
Texto completo
(2) A mis padres.
(3) Crió, pues, Dios al hombre a imagen suya: a imagen de Dios le crió, criólos varón y hembra. Y echóles Dios su bendición, y dijo: Creced, y multiplicaos, y henchid la tierra, y enseñoreaos de ella, y dominad a los peces del mar, y a las aves del cielo, y a todos los animales, que se mueven sobre la tierra. Génesis 1, 27ss..
(4) Agradezco a todas las personas que han contribuido al desarrollo de este trabajo, especialmente: A mis familiares y amigos. A mis colegas del CEETI, CEI y Departamento de Matemática de la Universidad Central de Las Villas..
(5) RESUMEN En el presente trabajo se presenta una técnica para la construcción y entrenamiento de topologías óptimas para redes neuronales multicapa haciendo uso de algoritmos genéticos celulares con codificación jerárquica. Para el desarrollo de la misma se diseñó el cromosoma con codificación jerárquica.. La construcción y entrenamiento de las redes se formuló como un problema de. optimización multiobjetivo, que incorpora criterios de optimización a partir de las medidas estadísticas recomendadas por la Asociación para el Desarrollo de la Instrumentación Médica (AAMI, en inglés). La construcción y entrenamiento de las redes neuronales multicapa se realiza usando un algoritmo genético celular, como la evolución de un autómata celular estocástico. Para el proceso de evaluación se usaron las bases de casos para cáncer de mamas de la Universidad de Wisconsin. Los resultados obtenidos son presentados, observándose superioridad en cuanto a desempeño a los reportados en la literatura sobre las bases de casos referidas..
(6) ABSTRACT In this work, it is presented a technique for the construction and training of optimal topologies for Multilayer Perceptron Neural Networks, using Cellular Genetic Algorithms with Hierarchical Coding. The construction and training of the Neural Networks was formulated as a multiobjetive optimization problem using the statistical measures recommended by the Association for Advancement of Medical Instrumentation (AAMI). The construction and training of the Multilayer Perceptron Neural Networks uses a Cellular Genetic Algorithm, as the evolution of a stochastic cellular automaton. The evaluation process was carried out with two well-known classification problems in breast cancer diagnosis, by using databases provided by the University of Wisconsin.. The obtained. results are presented, being observed superiority on some reported in the literature using the referred databases..
(7) 1. Índice. INTRODUCCIÓN...........................................................................................................................3 ASPECTOS TEÓRICOS Y MODELOS ELEMENTALES DE LAS REDES NEURONALES MULTICAPA, LOS ALGORITMOS GENÉTICOS Y LOS AUTÓMATAS CELULARES ..............8 1.1. Redes Neuronales ............................................................................................................................ 8. 1.2. Redes Neuronales Multicapa.......................................................................................................... 9. 1.3. Algoritmos Genéticos Convencionales......................................................................................... 10. 1.4. Algoritmos Genéticos con Codificación Jerárquica ................................................................... 18. 1.5. Autómatas Celulares ..................................................................................................................... 20. CONSTRUCCIÓN Y ENTRENAMIENTO DE TOPOLOGÍAS PARA REDES NEURONALES MULTICAPA USANDO ALGORITMOS GENÉTICOS CELULARES ........................................28 2.1. Esquema General de entrenamiento usando Algoritmos Genéticos con Codificación. Jerárquica .................................................................................................................................................. 28 2.2. Codificación Jerárquica de una Red Neuronal Multicapa ........................................................ 29. 2.3. D2REA ........................................................................................................................................... 30. 2.4. Operadores Genéticos ................................................................................................................... 33. 2.5. Formulación Multiobjetivo de la Construcción de RNM usando Algoritmos Genéticos ....... 35. 2.6. Algoritmos Genéticos Celulares ................................................................................................... 36. 2.7. Lenguaje Unificado de Modelación (UML) ................................................................................ 38. 2.8. Diagrama de Casos de Uso y Actores .......................................................................................... 39. 2.9. Diagramas de Clases ..................................................................................................................... 40. ANÁLISIS DE LOS RESULTADOS............................................................................................44 3.1. Construcción de Clasificadores para el Diagnóstico de Células Cancerosas ........................... 44.
(8) 2. Índice. 3.2 Resultados para Base de Casos del Cáncer de Mamas (Mediciones Subjetivas) del Hospital de la Universidad de Wisconsin, EE.UU. ......................................................................................................... 46 3.3 Resultados para Base de Casos de Diagnóstico del Cáncer de Mamas (Mediciones Geométricas) del Hospital de la Universidad de Wisconsin, EE.UU............................................................................ 50 CONCLUSIONES........................................................................................................................54 RECOMENDACIONES ...............................................................................................................55 BIBLIOGRAFÍA...........................................................................................................................56 ANEXO 1. AUTÓMATAS CELULARES LINEALES ..................................................................63 ANEXO 2. DESCRIPCIÓN DEL “JUEGO DE LA VIDA” ..........................................................65 ANEXO 3 IMPLEMENTACIÓN DE D2REA EN MATLAB 7.0....................................................67 ANEXO 4 REFINAMIENTO DE LOS CASOS DE USOS DEL CGANN-TRAINER 1.0..............70 ANEXO 5 DIAGRAMA DE CLASES...........................................................................................71.
(9) 3. Introducción INTRODUCCIÓN. Planteamiento y definición del problema El algoritmo de retropropagación del error es el más difundido en la comunidad científica para el entrenamiento de redes neuronales multicapa (multilayer perceptrom, MLP, en inglés), sin embargo, este algoritmo presenta limitaciones que motivan la exploración de otros métodos para el entrenamiento de las redes [DEM98], [HAY99], [LEC98], [ORR98], [PRI00], [RUM86a], [RUM86b]. Varios trabajos han mostrado la posibilidad del planteamiento de la construcción y entrenamiento de las redes neuronales multicapa mediante un problema de optimización multiobjetivo [MAN99], [ANG94], [MIL89], [MAN94], donde las funciones a optimizar controlan el desempeño de las mismas y, en algunos casos, la construcción dinámica de sus topologías. Por otra parte, los algoritmos evolutivos presentan grandes ventajas en la solución de problemas complicados, con restricciones y múltiples funciones objetivo. Una extensión de los mismos son los algoritmos genéticos con codificación jerárquica, los cuales proporcionan grandes ventajas en la búsqueda de soluciones a problemas donde la determinación de la estructura (desconocida a priori) es de vital importancia y los algoritmos genéticos celulares donde la evolución de la población no solo ocurre en el tiempo sino también en el espacio [WHI93]. A todos estos hechos se suman, el aumento de la capacidad de cómputo de las máquinas modernas y sus bajos costos, así como el hecho de que soluciones necesarias para problemas específicos puedan ser obtenidas automáticamente, aún cuando estas sean alcanzadas a partir de un esquema de cálculo de alto costo computacional. A partir de lo antes expuesto el problema científico a resolver será la construcción y el entrenamiento de redes neuronales multicapa óptimas para usar en problemas de clasificación. La hipótesis de investigación queda como sigue: Con el uso de algoritmos genéticos celulares es posible la construcción y el entrenamiento de redes neuronales multicapa óptimas para usar en problemas de clasificación. La hipótesis de investigación quedará validada si se comprueba que: •. Mediante la construcción y entrenamiento de redes neuronales multicapa usando algoritmos genéticos celulares se obtienen clasificadores que igualan o sobrepasan las.
(10) 4. Introducción prestaciones de otros clasificadores para las bases de casos de cáncer de mamas del Hospital de la Universidad de Wisconsin. Estas prestaciones serían la superación del 95 % de clasificación para las bases de casos de observaciones subjetivas y de mediciones geométricas.. Objetivos del trabajo Objetivo general Desarrollar una técnica para la construcción y entrenamiento de redes neuronales multicapa óptimas mediante el uso de algoritmos genéticos celulares con codificación jerárquica. Objetivos específicos •. Formular el entrenamiento de redes neuronales multicapa como la evolución de un autómata celular probabilístico, que incluye: •. Formulación de la población como un autómata celular probabilístico.. •. Definición de los criterios de selección y reemplazo.. •. Definición de los operadores genéticos.. •. Formulación de la construcción y entrenamiento de las redes neuronales multicapa mediante un problema de optimización multiobjetivo.. •. •. Poner a punto el sistema CGANN-Trainer 1.0, que incluye: •. Diseño e implementación de la interfaz visual del software.. •. Elaboración del manual de usuario del software.. Validar los resultados mediante la construcción y evaluación de clasificadores para los siguientes problemas reales: •. Clasificación de células cancerosas (diagnóstico), en Cancerosa y No Cancerosa, para base de casos del Hospital de la Universidad de Wisconsin para el diagnóstico del cáncer de mamas a partir de observaciones subjetivas [WOL91]..
(11) 5. Introducción •. Clasificación de células cancerosas (diagnóstico), en Cancerosa y No Cancerosa, para base de casos del Hospital de la Universidad de Wisconsin para el diagnóstico del cáncer de mamas a partir de mediciones geométricas [WOL95].. Aportes del Trabajo •. Uso de algoritmos genéticos celulares, con cromosoma codificado jerárquicamente, para construir y entrenar topologías óptimas para redes neuronales multicapa.. Campos de aplicación El amplio uso actual de las redes neuronales multicapa en la Inteligencia Artificial, para la solución de problemas en las más disímiles ramas, hace del software construido una herramienta muy general. Además de los problemas reales utilizados para la validación de este trabajo, a continuación se relacionan otras aplicaciones relacionadas con investigaciones del Centro de Estudios de Electrónica y Tecnologías de la Información (CEETI), de la Universidad Central de Las Villas (UCLV), donde también pudiera ser útil el CGANN-Trainer 1.0: •. Clasificación de Complejos QRS. Uno de los factores fundamentales en la detección de arritmias cardíacas es la correcta clasificación de los complejos QRS. La gran variedad de formas que los mismos pueden tener en una misma persona, provoca que la mayoría de los clasificadores desarrollados sólo reporten un porciento de efectividad limitado en dicho problema. En la literatura se reporta el uso de diferentes tipos de redes para su clasificación, entre ellas las más utilizadas son las de tipo MLP. Sin embargo, muchas de ellas son de elevada complejidad topológica (gran cantidad de conexiones) y, por tanto, requieren de un elevado número de operaciones para la clasificación de dichas morfologías. Esto está dado, fundamentalmente, por la cantidad de rasgos de entrada, que está determinado por la descomposición que se utilice para caracterizar la misma. Numerosas descomposiciones y parametrizaciones se reportan en la literatura, sin embargo no se han reportado estudios sobre cuales de ellas determinan topologías poco complejas, que serían de gran utilidad para sistemas de supervisión en tiempo real. Las potencialidades del CGANN- Trainer 1.0, lo convierten en un fuerte candidato para la exploración de dichas descomposiciones y la obtención de redes neuronales de reducida complejidad. Para ello, sólo sería necesario construir bases de casos estudiados para cada una de las descomposiciones que se deseen estudiar, y utilizarlas en el CGANN-Trainer 1.0..
(12) 6 •. Introducción Clasificación y diagnóstico de disartrias. Las disartrias están asociadas a diferentes patologías neurológicas como son: Parkinsonismo, esclerosis lateral amiotrópica, lesiones cerebelares, distonía, mal de Corea, entre otras. Se presenta la problemática de reconocer, mediante las voces de los pacientes, el tipo de disartria que padecen. Este diagnóstico es de gran utilidad para el médico a la hora de emitir un diagnóstico preciso, pues existen pacientes que su único síntoma, o el más sobresaliente es su voz. Este trabajo forma parte de una investigación que se lleva a cabo en el CEETI, específicamente, en el área de procesamiento digital de señales de voz, que consiste en realizar un sistema automático que permita hacer una clasificación de las disartrias. Se está realizando, colateralmente, la medición de una serie de parámetros de voces, para que, finalmente, los datos que se introduzcan a la red neuronal sean los vectores como resultado de dichas mediciones. Las técnicas actuales de procesamiento digital de voz, específicamente en el área de diagnóstico y de reconocimiento de patrones del habla, ven en las redes neuronales una opción más para estos fines. A partir de una base de casos con valoraciones subjetivas de pacientes, donde se analizan sus voces patológicas, se plantea la problemática de determinar una red neuronal, con la complejidad mínima, para su utilización en sistemas de tiempo real para el diagnóstico de las disartrias. El costo computacional del clasificador empleado es de vital importancia para acometer esta tarea. Nuevamente el CGANNTrainer 1.0 se presenta como una opción viable.. •. Compresión de señales e imágenes. Quizás uno de los enfoques más interesantes que se pueden dar a la utilización de este software, está en el campo de la compresión de señales e imágenes. Muchas son las aplicaciones que tienen las redes neuronales, la compresión de datos no escapa a ellas. En la literatura se han reportado numerosos trabajos donde se muestra la posibilidad de utilizar redes neuronales de tipo MLP para la compresión de señales e imágenes. El principio básico establece la construcción de una red multicapa con un número impar de capas intermedias; la capa del centro se define con menos neuronas que la capa de entrada, el número de neuronas de la capa de salida debe coincidir con el de la capa de entrada y, como principio de funcionamiento, la entrada debe ser igual a la salida. La idea es que una vez entrenada, la red se divide en dos partes por dicha capa, la parte izquierda se utiliza como compresor y la derecha como descompresor. La tasa de compresión está determinada por la razón entre la cantidad de neuronas de la capa de entrada y la cantidad de neuronas de la capa central. Para el entrenamiento de la red se utiliza un aprendizaje no adaptativo, se calculan los pesos mediante sistemas de ecuaciones.
(13) 7. Introducción y otros métodos. Si bien este enfoque no ha obtenido resultados superiores a otros métodos utilizados para la compresión de señales e imágenes, sí constituye una variante más en dicha esfera. Los métodos utilizados para el entrenamiento de las redes presentan varias limitaciones, y realmente las tasas de compresión no llegan a ser elevadas. Un problema visible en muchas publicaciones es que fijan la topología de la red y, en cierta medida, fuerzan la estructura de la misma, lo cual pudiese ir en detrimento de las prestaciones del compresor. Las características del CGANN-Trainer 1.0, lo convierten en una opción viable para la compresión de señales e imágenes. El principio a seguir sería el mismo que en trabajos anteriores, es decir, la misma cantidad de neuronas de entrada que de salida, y como principio de funcionamiento, salida igual a entrada; sólo que ahora las topologías tendrían más flexibilidad y el espacio de búsqueda sería mucho más amplio. Luego de realizada la construcción de la topología, sólo restaría determinar que capa oculta tiene la menor cantidad de neuronas activas y la tasa de compresión sería la razón entre la cantidad de neuronas de entrada y la menor cantidad de neuronas activa en una capa oculta.. Para la presentación de esta investigación, esta tesis de Maestría se estructuró de la forma siguiente: introducción, tres capítulos, conclusiones y recomendaciones, bibliografía y anexos. En la Introducción, se caracteriza la situación problémica y se fundamenta el problema científico a resolver, así como la estrategia general seguida para su solución como problema científico. El Capítulo 1 contiene el marco teórico-referencial que sustentó la investigación originaria. El Capítulo 2 resume y explica todo el modelo desarrollado: el uso de los algoritmos genéticos y los autómatas celulares para la construcción y entrenamiento de redes neuronales multicapa. El Capítulo 3 describe el software que soporta el modelo y su evaluación, donde se muestran los casos de aplicación que evidencian la factibilidad y utilidad del procedimiento desarrollado como vía para demostrar la hipótesis de investigación planteada. Completan la tesis, un cuerpo de Conclusiones y Recomendaciones derivadas de la investigación realizada, la Bibliografía consultada y un grupo de Anexos como complemento de los resultados expuestos..
(14) 8. Introducción. ASPECTOS TEÓRICOS Y MODELOS ELEMENTALES DE LAS REDES NEURONALES MULTICAPA, LOS ALGORITMOS GENÉTICOS Y LOS AUTÓMATAS CELULARES En el presente capítulo se presenta una panorámica de los elementos teóricos fundamentales sobre los que se sostiene este trabajo.. 1.1 Redes Neuronales El uso de redes neuronales (RN) para sistemas de control y procesamiento de señales ha sido gratamente aceptado por la comunidad científica. La mayoría de sus aplicaciones se reportan en el campo de las telecomunicaciones, reconocimiento de patrones, análisis financiero y de predicciones, control de procesos, reconocimiento del lenguaje y bioinformática [HAG96]. La tendencia al uso de las RN en la solución de problemas de clasificación, es comprensible, debido fundamentalmente a su capacidad de imitar la naturaleza del cerebro humano (capacidad de aprendizaje), y el hecho de que su estructura puede ser formulada matemáticamente. Una correcta selección de la topología de la RN es capaz de aumentar el rendimiento del sistema en términos de velocidad de aprendizaje, exactitud, resistencia a ruidos y capacidad de generalización. De aquí que una RN puede ser considerada como una unidad de procesamiento paralelo y distribuido que consta de múltiples elementos de procesamiento. Su estructura es compleja, desconocida y tiene que ser preconcebida inicialmente. La técnica para obtener una topología óptima de RN puede ser generalizada en los siguientes puntos: 1. Un análisis a priori de las potencialidades de la RN..
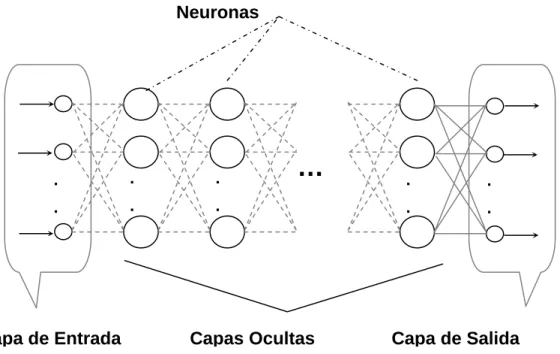
(15) 9. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. 2. La elección de un tamaño óptimo de la RN que reduzca el espacio de búsqueda en el proceso de aprendizaje. 3. El uso de un método matemático para determinar la arquitectura y parámetros de la RN.. 1.2 Redes Neuronales Multicapa Una de las topologías de redes neuronales más usadas en la inteligencia artificial son las llamadas redes neuronales multicapa (RNM). La figura 1.1 muestra la topología asociada a una RNM.. Neuronas. .. .. .. .. .. .. Capa de Entrada. …. Capas Ocultas. .. .. .. .. Capa de Salida. Figura 1.1 Topología de una red multicapa feedforward En la RNM, el elemento básico de procesamiento es llamado neurona (figura 1.2). Una neurona consta de un nivel de activación τ (bias), un conjunto de conexiones de entrada (x1,..., xn), con. τ x1 w1 w2. x2. y. f. … xn B. wn B. B. Figura 1.2 Esquema de una neurona simple.
(16) 10. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. un peso asociado a cada una de ellas (w1,..., wn), y una salida (y).. ⎛. n. ∑w x ⎝. La salida de una neurona es determinada como: y = f ⎜. i =1. i. i. ⎞ + τ ⎟ , donde x1 , x 2 ,..., x n son ⎠. las señales de entrada, w1 , w2 ,..., wn son los pesos de las conexiones de entrada, τ es el valor del bias y f es una función de salida definida, que puede ser una tangente hiperbólica, paso unitario, etc. La correcta funcionalidad de la topología de la red está determinada por un algoritmo de aprendizaje, capaz de modificar los parámetros de la red (connections weights). El algoritmo de retropropagación del error (Backpropagation, BP, en inglés), que utiliza el método del gradiente en su proceso de actualización de los pesos, es el más utilizado por la comunidad científica [SAR00]. Sin embargo, el BP presenta algunas limitaciones y desventajas como las que se dan a continuación: 1. Necesita que la topología esté predeterminada, ignorando así la existencia de topologías menos complejas. 2. Mientras mayor sea la complejidad de la topología, el desempeño del BP es mucho menor. 3. Generalmente, la convergencia del método es lenta, pero una incorrecta selección de los pesos iniciales (solución inicial), puede hacerla aún más lenta. 4. El algoritmo puede estancarse en mínimos locales y nunca alcanzar el óptimo. 5. Una incorrecta selección de la tasa de aprendizaje, puede provocar que el algoritmo diverja en el proceso de búsqueda del mínimo.. 1.3 Algoritmos Genéticos Convencionales Los principios básicos de los algoritmos genéticos convencionales (AG) fueron inicialmente propuestos por Holland [HOL75]. Más tarde, varios autores han desarrollado diferentes trabajos en esta temática [GOL89], [DAV91], [MIC96]. Los AG están inspirados en el mecanismo de selección natural, en el cual los individuos con mejores características son los más propensos a ser seleccionados en un ambiente de competencia. En este último, los AG utilizan una analogía directa de la evolución natural. Mediante un método de evolución genético, puede ser alcanzada una solución óptima, representada por el individuo ganador de esta competencia genética..
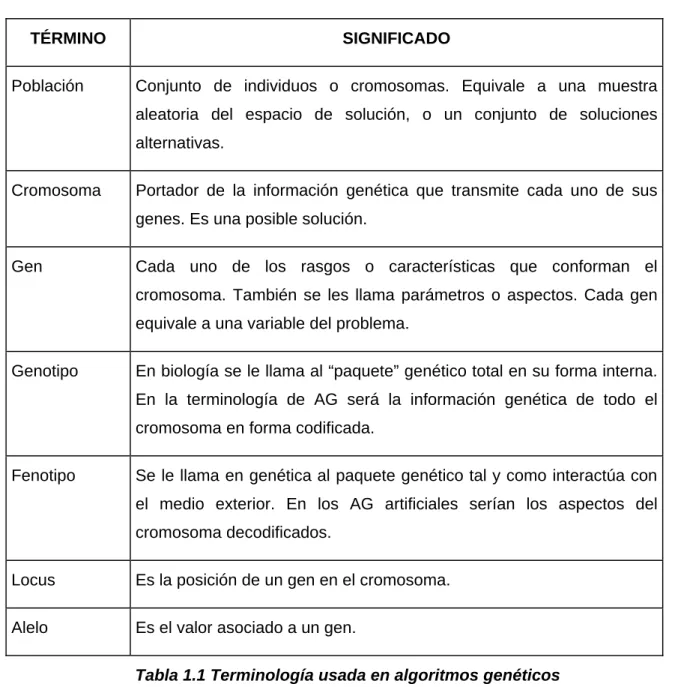
(17) 11. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. Los AG codifican en un individuo, representado por un conjunto de parámetros, una solución potencial de un problema dado. Estos parámetros son estimados como los genes de un cromosoma y pueden ser estructurados en forma lineal, como una cadena de valores consecutivos (la codificación binaria es la más utilizada). Un valor positivo, conocido como aptitud (fitness value), es asociado a cada cromosoma, y es utilizado como indicador del grado de aptitud del cromosoma para el problema en cuestión (valor objetivo). La tabla 1.1 presenta los términos más comúnmente usados en los AG. TÉRMINO Población. SIGNIFICADO Conjunto de individuos o cromosomas. Equivale a una muestra aleatoria del espacio de solución, o un conjunto de soluciones alternativas.. Cromosoma. Portador de la información genética que transmite cada uno de sus genes. Es una posible solución.. Gen. Cada uno de los rasgos o características que conforman el cromosoma. También se les llama parámetros o aspectos. Cada gen equivale a una variable del problema.. Genotipo. En biología se le llama al “paquete” genético total en su forma interna. En la terminología de AG será la información genética de todo el cromosoma en forma codificada.. Fenotipo. Se le llama en genética al paquete genético tal y como interactúa con el medio exterior. En los AG artificiales serían los aspectos del cromosoma decodificados.. Locus. Es la posición de un gen en el cromosoma.. Alelo. Es el valor asociado a un gen. Tabla 1.1 Terminología usada en algoritmos genéticos. Durante el proceso de evolución, los cromosomas con mayor grado de aptitud tiene la tendencia a producir descendientes de mejor calidad, lo que se traduce como individuos que.
(18) 12. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. codifican una mejor solución para cualquier problema. En aplicaciones prácticas de los AG, una población inicial de individuos es construida con valores aleatorios. El tamaño de la misma varía de un problema a otro, aunque se han reportado algunas publicaciones referentes a la selección de este tamaño [MAH94]. En cada ciclo genético del proceso evolutivo, una nueva generación es creada a partir de la actual. Esto se realiza cuando un grupo de individuos, usualmente llamados parents, o matting pool cuando nos referimos a una colección de ellos, es seleccionado por un mecanismo de selección específico. Los genes correspondientes a los parents son combinados para la producción de sus descendientes utilizando operadores genéticos específicos. Como resultado de este proceso, se espera que el mejor cromosoma dé lugar a un mayor número de descendientes, emulando el mecanismo de la naturaleza de supervivencia del más fuerte. El esquema de selección de ruleta (Roulette Wheel Selection) [DAV91] es uno de los más frecuentemente utilizados. El ciclo de evolución se repite hasta que se cumpla un criterio de parada especificado. Este criterio está determinado por un número de ciclos predeterminado, la detección de una variación de individuos entre generaciones menor que un umbral, o cuando se alcance o supere un fitness específico. El siguiente pseudocódigo muestra el esquema de un AG convencional. t = 0 {inicializar aleatoriamente la población} InicializarPoblacion P (t); {evaluar todos los individuos de la población} Evaluar P (t); MIENTRAS no se cumpla Condición de Parada HACER t = t + 1; P' = SeleccionarPadres(t); {seleccionar padres} Recombinar P'(t); Mutar P'(t);. {alterar el material genético aleatoriamente}. Evaluar P'(t); P = sobrevivientes P,P'(t);. {seleccionar los sobrevivientes}. FIN DEL CICLO El diagrama de bloques de la figura 1.3 muestra el funcionamiento de un AG que es como sigue: 1. El AG genera aleatoriamente una población de n estructuras (cadenas, cromosomas o.
(19) 13. Capítulo I. Aspectos teóricos y modelos elementales de las redes… individuos).. 2. Sobre la población actúan los operadores transformando la población. Una vez completada la acción de los tres operadores, se dice que ha transcurrido un ciclo generacional. 3. Luego se repite el paso anterior mientras no se garantice el criterio de parada del AG. En el ciclo de evolución de los AG, se utilizan fundamentalmente dos operadores [MAN99], cruce y mutación, aunque el mecanismo de selección que se emplee también puede ser considerado como otro operador. El porciento de operaciones de cruce y mutación que se realicen en una población dada, está determinado por dos valores Pc y Pb, los cuales son las probabilidades de ocurrencia respectiva para los operadores anteriores. La selección de los parámetros de control Pc y Pb puede ser un complejo problema de optimización no lineal. Además, sus valores dependen críticamente de las características de la función objetivo. Algunas sugerencias al respecto han sido introducidas en [DEJ90], [GRE92]..
(20) 14. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. Generación aleatoria de la Población Inicial. Evaluación de los cromosomas de acuerdo a Función Objetivo. Criterio de Parada para la Optimización Objetivo. SI Sí. TERMINAR. No Proceso de Reproducción (selección). Cruzamiento. Mutación. Actualización de los individuos de la próxima generación y evaluación de la población. Figura 1.3 Diagrama de bloques representativo de un AG En [MAN99] se señalan algunas características intrínsecas de los AG necesarias a considerar a la hora de su uso. Estas son: 1. AG en paralelo. 2. Capacidad para enfrentar problemas multiobjetivo. 3. Robustez. 4. Capacidad para enfrentar restricciones. ¿Por qué utilizar AG y no otros métodos conocidos? Las razones que se pueden argumentar son varias. Los métodos conocidos son buenos mientras el problema no es muy complejo. Los AG permiten la solución eficiente de funciones extremadamente complejas..
(21) 15. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. Las potencialidades de los AG se pueden resumir por sus habilidades para resolver una variedad de problemas muy difíciles: 1. Trabajar sin conocimiento previo de la función a optimizar. 2. Optimizar funciones “ruidosas”. 3. Trabajar sin información secundaria como pudieran ser los gradientes de funciones. La mayoría de los especialistas en este tema coinciden en que los AG pueden resolver las dificultades representadas en los problemas de la vida real que a veces son insolubles por otros métodos. Para Goldberg el tema central de la investigación en AG consiste en la robustez: el balance entre la eficacia y la eficiencia necesaria para sobrevivir en muchos ambientes diferentes [GOL89]. Goldberg destaca las formas en que difieren los AG de los sistemas tradicionales: 1. Los AG trabajan con una codificación del conjunto de parámetros, no con los parámetros en sí. 2. Los AG realizan la búsqueda a partir de una población de puntos, no de un punto simple. 3. Los AG sólo utilizan la información de la función objetivo, sin derivadas u otro conocimiento auxiliar. 4. Los AG utilizan reglas de transición probabilísticas, no determinísticas. Goldberg, además, expone algunos motivos por los que los AG pueden ser atractivos para el desarrollo de aplicaciones: 1. Pueden resolver problemas difíciles de forma rápida y confiable. 2. Son fáciles de enlazar a simulaciones y modelos existentes. 3. Son extensibles. 4. Son fáciles de hibridizar. Los AG han sido utilizados tradicionalmente en problemas de búsqueda y optimización. Éste es el campo en que más aplicaciones se reportan, habiéndose realizado incluso trabajos con funciones muy complejas como en los trabajos de De Jong en 1975 [GOL89]. También se ha trabajado en la obtención de soluciones a ecuaciones no lineales. Además de esto, los AG han sido ampliamente usados en aplicaciones de aprendizaje automatizado. Los sistemas genéticos de aprendizaje automático, según se refiere en [GOL89], han tenido un desarrollo sostenido desde inicios de los años 60, reportándose variedad de trabajos, entre los más importantes se.
(22) 16. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. encuentran los relativos a los sistemas clasificadores [GOL89], que son sistemas que aprenden reglas de inferencia simples que guían el comportamiento del sistema. A pesar de todo esto, los AG presentan algunas desventajas considerables. Éstos no ofrecen garantía de convergencia en problemas arbitrarios; ordenan rápidamente áreas interesantes de un espacio, pero son un método débil, sin las garantías de procedimientos más convergentes. En este caso, si para el problema que se está resolviendo, se conocen métodos locales pero convergentes, la solución es aplicar un esquema híbrido. De forma que cuando el AG encierre las mejores regiones, se apliquen los métodos locales. Por tanto se combina la globalidad y el paralelismo de los AG con un comportamiento convergente. En los AG puede haber lo que se llama convergencia prematura; o sea, en un momento dado todos los individuos de la población tienen un valor de adaptación o ajuste muy cercano y la mejoría de una generación a otra es muy poca. Si, al principio de una corrida, se toma por el operador de selección, una proporción significativa de la población en una generación, puede conducir a convergencia prematura. Al final de una corrida, el ajuste promedio de la población puede estar cercano al mejor ajuste de la población, lo que puede conducir a moverse aleatoriamente entre los mediocres. Otras dificultades detectadas en el trabajo con AG han llevado a los investigadores a profundizar en aspectos teóricos aún por demostrar, entre los que se encuentran: 1. Elección adecuada de los parámetros de control. 2. El papel exacto del cruce y la mutación. 3. Propiedades de convergencia. La experiencia empírica indica que AG distribuidos y paralelos son eficientes para determinar los parámetros de control. No obstante, se necesita más evidencia experimental.. 1.3.1 Elementos a tener en cuenta a la hora de aplicar un AG Tamaño de la población: Muchos trabajos se han escrito relativos a la influencia del tamaño de la población en la convergencia del AG [MAH94]. En principio, es lógico pensar que el trabajo con poblaciones pequeñas corren el riesgo de representar pobremente el espacio de soluciones. Por otro lado, las poblaciones de gran tamaño consumen mayor tiempo.
(23) 17. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. computacional. Sobre esta disyuntiva, se obtuvo que el tamaño óptimo de una población de cadenas binarias crece exponencialmente con la longitud de la cadena [GOL89a]. Generación de la población inicial: Se describen fundamentalmente dos vías para obtener la población inicial con que el AG comienza su trabajo: •. Generación aleatoria de los individuos: Usualmente la población inicial es generada aleatoriamente.. •. Sembrado de individuos: La población inicial tiene individuos de alta calidad obtenidas mediante otra heurística pudiera ayudar al AG a encontrar mejores soluciones más rápido que con un comienzo aleatorio.. Reemplazo: Cada iteración de un AG simple crea una subpoblación totalmente nueva de una población existente. Este es llamado AG generacional. El AG que reemplaza sólo una fracción pequeña de cromosomas a la vez, es llamado AG de estado fijo o "steady-state". Selección: Existen varias técnicas de selección que han sido ampliamente abordadas en la literatura [MAN99]. Algunas de estas son: 1. Muestreo estocástico con remplazamiento (el mecanismo de ruleta se incluye dentro de esta técnica). 2. Muestreo estocástico con remplazamiento parcial. 3. Muestreo estocástico universal. Cruzamiento: Para el operador de cruzamiento en los AG, diferentes técnicas han sido propuestas y analizadas: 1. Cruzamiento de uno, dos y múltiples puntos: El cruzamiento de un punto de cruce es el que utiliza el AG simple. Ocurre seleccionando aleatoriamente un punto de cruzamiento y los segmentos que se forman a partir de este punto en los cromosomas padres son intercambiados. En el esquema de cruzamiento de dos puntos, dos puntos son seleccionados aleatoriamente y los segmentos de las cadenas entre ellos, intercambiados. El cruzamiento de múltiples puntos trata cada cadena como un anillo de bits dividido por k puntos de cruce en k segmentos. Los segmentos alternados son intercambiados entre el par de cadenas a entrecruzar..
(24) 18. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. 2. Cruzamiento uniforme: Es el intercambio de bits entre las cadenas, en vez de segmentos como los casos anteriores. En cada posición de la cadena, los bits son probabilísticamente intercambiados con una probabilidad fija. Mutación: Este proceso es muy importante ya que puede ser que un individuo malo tuviera alguna característica muy buena. Cuando este individuo pasa por el proceso de reproducción existe una alta probabilidad de que sea eliminado y por lo tanto se pierda esa característica deseable. La recuperación de esta característica puede ser prácticamente imposible a través de los otros mecanismos genéticos. La mutación de bits se realiza simplemente cambiando el valor de bit que se desea mutar. La mutación de otros valores depende de las características del problema.. 1.4 Algoritmos Genéticos con Codificación Jerárquica Un detallado análisis de la estructura biológica de los cromosomas se expone en [MAN99]. Aquí, se describe según la comunidad médica y biológica, que la estructura de un cromosoma está formada por un número de variaciones de genes, que están organizadas de manera jerárquica. Este fenómeno es una analogía directa, de muchos problemas de la práctica, especialmente de corte ingenieril. En [MAN99], se presenta un nuevo método que imita la formulación de la estructura biológica del ADN, de manera que se forma una estructura genética jerárquica precisa para formular soluciones de problemas ingenieriles, en la cual los cómputos genéticos básicos permanecen invariables. A partir de estas características, proponen una nueva formulación jerárquica de los cromosomas, estableciendo una analogía que consiste en: 1. Genes paramétricos (genes estructurales). 2. Genes de control (secuencias reguladoras). La generalización de esta estructura, se realiza mediante la introducción de múltiples niveles de genes de control en una forma jerárquica, como se indica en la Figura 1.4..
(25) 19. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. Cada nivel asociado a los genes de control, está conformado por una cadena de bits, la activación de los cuales determina la influencia de estos sobre los niveles inferiores, sucesivamente hasta llegar a los genes paramétricos. El uso de esta estructura jerárquica, permite que los cromosomas contengan mucha más información que los de los AG convencionales; además los genes inactivos siempre están presentes en la misma. Las operaciones genéticas entre los cromosomas jerárquicos se realiza similarmente que en los AG convencionales. Las operaciones de cruzamiento y mutación pueden ser aplicadas similarmente a lo que ocurre en los AG convencionales, solo que estas deben ser realizadas por nivel. Las probabilidades de cruzamiento y mutación en cada nivel no tienen que ser. Gen de Control. Gen de Control. Gen de. Figura 1.4 Estructura Jerárquica del Cromosoma necesariamente iguales, inclusive en la mayoría de los problemas reales estas difieren debido a que el nivel de importancia de cada nivel es diferente. El uso de AG con Codificación Jerárquica (CJ), cobra particular importancia tanto en la optimización paramétrica como en la determinación de la estructura de la solución, en problemas donde la estructura de la solución es desconocida. A partir del hecho de que la estructura de los cromosomas en los AG con CJ es fija (genes de control y genes paramétricos), y que pueden aparecer parámetros de diferentes tamaños, las modificaciones a los operadores convencionales no son de gran complejidad. En efecto, los métodos estándares pueden ser aplicados independientes a cada nivel de genes. Debe notarse que los cambios realizados a los niveles de orden superior, pueden determinar cambios en los de orden inferior. Esta última es la razón principal por la que los AG jerárquicos son buenos no solamente para obtener los parámetros de la solución, sino también su estructura..
(26) 20. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. 1.5 Autómatas Celulares Un autómata celular (AC) es un modelo formal que está compuesto por un conjunto de entes elementales, cada uno de ellos susceptible de encontrarse en un cierto estado y de alterarlo de un instante al siguiente, asumiendo que el tiempo transcurre de forma discreta. La regla que gobierna la transición de estados en los entes es sensible a los estados de los demás elementos en su vecindad, siendo por tanto una regla de transición local. El aspecto que más caracteriza a los ACs es su capacidad para dotar al conjunto del sistema, visto como un todo, una serie de propiedades emergentes inducidas por la propia dinámica local. En general, no es fácil obtener las propiedades globales de un sistema definido como el anterior, complejo por naturaleza, a no ser por vía de la simulación, partiendo de un estado inicial de la población de objetos y cambiando en cada instante los estados de todos ellos de forma síncrona. La definición de un AC requiere fijar los términos especificados en la tabla 1.2. TÉRMINO Conjunto de entes. SIGNIFICADO Se necesita saber cuántos objetos elementales van a formar la población del sistema. En principio no hay restricción a su número, pudiendo ser desde unos pocos hasta una infinidad. En ocasiones es importante situarlos sobre una región geográfica, identificándose entonces los entes con sus respectivas coordenadas geográficas.. Vecindades. Para cada elemento del sistema es necesario establecer su vecindad, esto es, aquellos otros elementos que serán considerados como sus vecinos. En caso de asociar objetos con coordenadas de un sistema de referencia, el criterio suele ser construir la vecindad de un elemento dado con todos aquellos otros elementos que se encuentran a menos de una cierta distancia o radio, de forma que los más alejados no ejerzan influencia directa sobre él..
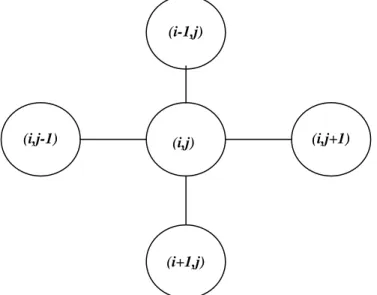
(27) 21. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. TÉRMINO. SIGNIFICADO. Conjunto de estados. En cada instante, cada elemento deberá encontrarse en un cierto estado. El caso más sencillo corresponde a los elementos biestables, los cuales se pueden encontrar en sólo uno de dos estados posibles, 0 y 1, por ejemplo. Pero también el estado puede venir representado por un vector de componentes reales o por una cadena de un lenguaje formal.. Regla de transición La regla de transición define la dinámica del sistema. Dado un local. elemento y un instante determinados, la regla devuelve el siguiente estado del elemento, para ello necesita como argumentos los estados actuales, tanto del elemento considerado como de aquellos que conforman su vecindad. Las reglas de transición pueden ser deterministas o probabilistas, además, no todos los elementos necesitan obedecer a la misma regla. Tabla 1.2 Terminología usada en los autómatas celulares. El primer AC formalmente establecido se debe a John von Neumann (1903-1957) y Stanislaw Ulam (1909-1984). Los elementos o células de un AC están dispuestos sobre los nodos de una malla rectangular, cada uno de ellos susceptible de encontrarse en cualquiera de un número. (i-1,j). (i,j-1). (i,j). (i,j+1). (i+1,j). Figura 1.5 Vecindad de von Neumann.
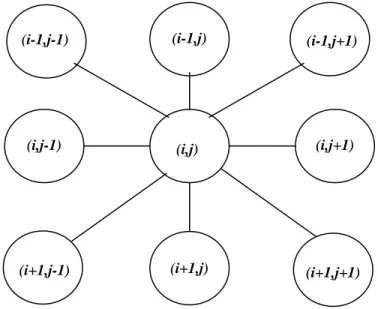
(28) 22. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. finito de estados posibles. La vecindad de cada célula suele estar formada por las cuatro vecinas más próximas (Norte, Sur, Este y Oeste), como en la Figura 1.5, las ocho más próximas (N, NE, E, SE, S, SO, O, NO), como en la Figura 1.6, u otras vecindades más amplias.. (i-1,j-1). (i-1,j). (i-1,j+1). (i,j-1). (i,j). (i,j+1). (i+1,j-1). (i+1,j). (i+1,j+1). Figura 1.6 Vecindad de Moore. Las vecindades en los bordes de la malla dependen de las condiciones que se impongan en los límites. Se suelen considerar dos casos: Bordes periódicos. Células opuestas se consideran vecinas..
(29) 23. Capítulo I. Aspectos teóricos y modelos elementales de las redes… Bordes absorbentes. Las células de los bordes no tienen vecinos más allá de los límites del retículo (Figura 1.7).. 1. 2. 3. 4. 5. 6. 1. 2. 3. 4. Figura 1.7. Autómata Celular Bidimensional con vecindad de von Neumann y bordes absorbentes. La regla de transición de muchos ACs es igual para todas las células, de ahí que también se les llame sistemas homogéneos a los ACs. Si esta regla de transición tuviera alguna componente aleatoria entonces estaríamos hablando de autómata celular probabilístico. Esta propiedad hace que una misma célula con la misma vecindad en dos momentos diferentes no tiene por que evolucionar de la misma manera. Dentro de los trabajos más exhaustivos sobre autómatas celulares están los de Stephen Wolfram realizados en la década de 1980 [WOL83], [WOL84] y [WOL85]. Los ACs son usados en las más disímiles ramas de la ciencia y la tecnología [GAN04]: •. Modelación de Sistemas Biológicos y Físicos [DEU03], [MOR02], [SCH02], [MOO01], [SAN01].. •. Reconocimiento de Patrones [GAN01], [GAN02], [GAN03a], [GAN03b], [SIK01]..
(30) 24. Capítulo I. Aspectos teóricos y modelos elementales de las redes… •. Procesamiento Paralelo [SCH01], [BAG02].. •. Procesamiento de Señales e Imágenes [LAF00].. •. Ciencias Sociales [MUH02], [RAB02]. De especial interés son los autómatas celulares lineales.. Estos han sido ampliamente. estudiados. En el anexo 1 aparece una descripción de este tipo de autómata celular.. 1.5.1 Autómatas Celulares y Teoría de la Computabilidad Sin duda, el formalismo más popular y menos abstracto es el ideado por Alan Turing y que se conoce precisamente con el nombre de máquina de Turing (MT). Aquí sólo se darán algunos esbozos sobre las MT, centrando el interés en los resultados, más que en cómo llegar a ellos. Para profundizar en los aspectos formales es mejor acudir a [HAM80], [ARB64] y muchos otros. La MT es un dispositivo formal, no físico, que consta de una cabeza de lectura/escritura susceptible de encontrarse en un estado q de Q, siendo Q un conjunto finito, y una cinta de memoria con infinitas casillas, cada una de ellas marcadas con 0 ó 1. Cuando la cabeza lee un símbolo de la cinta, dependiendo de su estado actual, cambiará a un nuevo estado de Q; además, la propia cabeza escribirá un símbolo de {0,1} sobre la cinta en su posición actual y hará un movimiento, bien a la izquierda (I), bien a la derecha (D) o permanecerá en reposo (R), dispuesta a otro proceso elemental de cómputo. Todo este ciclo de lectura/escritura/cambio de estado/movimiento está gobernado por cierta función T cuyo dominio es un subconjunto de Qx{0,1} y recorrido en Qx{0,1}x{I,D,R}. La aplicación reiterada de T, partiendo de una grabación inicial dada sobre la cinta determina su evolución hasta que la cabeza de lectura/escritura se encuentre en un estado y leyendo un símbolo para los que T no está definida. Llegado este caso, la MT se para y la información que ha quedado sobre la cinta es el resultado del proceso. Tanto el estado inicial de la cinta como el estado de ésta tras la parada de la máquina pueden ser representados por sendos números enteros siguiendo algún tipo de codificación. De esta forma se podrá establecer un primer criterio de computabilidad: Definición: Una función natural f de variable natural es computable por la máquina Z si siendo n el estado inicial de la cinta, la información de ésta tras la parada de Z coincide con m=f(n)..
(31) 25. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. Existe una cantidad infinitamente numerable de MT que pueden calcular una infinidad numerable de funciones computables. Aquí entra en escena el concepto de máquina de Turing universal (MTU), definida de una vez y para siempre, que es capaz de simular el comportamiento de cualquier otra MT. Así, el estado inicial de una MTU consiste en información relativa a la definición de la MT a ser simulada (el programa) junto con la información a procesar (los datos). Esto nos lleva a la siguiente definición. Definición: Una función natural f de variable natural es Turing-computable si es computable por la MTU mediante una codificación apropiada. Pese al aspecto artificioso del modelo, la MT permite formalizar el resbaladizo concepto de cómputo. De hecho, el resultado más importante es una proposición no demostrable matemáticamente que se conoce con el nombre de Tesis de Church-Turing: cualquier cálculo que se pueda realizar de forma mecánica puede ser procesado por una Máquina de Turing. Cuando se da como entrada de una MTU la codificación de una MT (la función f) y una entrada n (el argumento de f), pueden suceder diferentes cosas: •. La MTU no parará nunca, en cuyo caso f(n) se dice que no es Turing-computable. El hecho de que existan problemas que se puedan plantear en términos finitos pero que no son resolubles en tiempo finito viene a ser una versión más del conocido Teorema de Gödel (Wolfram, 1984).. •. La MTU evolucionará y alcanzará el estado de parada. En tal caso, f(n) será Turingcomputable, pudiendo ocurrir: o. Que el tiempo transcurrido hasta la parada sea función polinómica de n: T(n) = a0 + a1n + a2n2 +...+ aknk. Se dice de estos problemas que pertenecen a la clase P.. o. Que el tiempo necesario para la parada sea mayor que el polinómico, por ejemplo exponencial. Dentro de este grupo hay una clase de problemas que tienen especial interés, son aquellos para los que existe un procedimiento (una MT) que permite decidir si un cierto valor de ensayo m es realmente la solución f(n) que se busca. Estos problemas forman la clase NP. La clase P es subconjunto de NP, pero todavía se desconoce si la igualdad P=NP es cierta..
(32) 26. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. A veces, las cosas son más complicadas y no existe forma de saber si el problema del cómputo de f llevará o no a la parada de la MTU. Este es el conocido como problema de la parada, en el que se demuestra que no existe un método general para decidir si la máquina se parará para un cálculo dado. El estudio de si una función f puede ser evaluada por una MT o por cualquier otro dispositivo formal corresponde a la teoría de la computabilidad, mientras que los recursos en tiempo de cómputo y en espacio de memoria necesarios para la realización de la tarea los estudia la teoría de la complejidad computacional. La teoría de la computabilidad y de la complejidad va mucho más allá de lo esbozado más arriba. Otros modelos formales se han diseñado para ampliar la potencia de las MT, de forma que problemas no computables o de cálculo difícil se vuelvan más manejables. La existencia de funciones imposibles de evaluar por métodos algorítmicos, o bien que siendo evaluables el tiempo necesario para ello va más allá de lo razonablemente factible, tiene una consecuencia importante para lo que se llama método científico; algunos problemas sólo pueden ser abordados por técnicas de simulación, de forma que los ordenadores además de servir para hacer operaciones numéricas, también sirven como laboratorios de experimentación [WAG85]. Esta consecuencia es especialmente cierta en lo que se refiere al estudio de los sistemas emergentes, muchas de cuyas propiedades no será posible deducirlas de forma exacta, con lo que únicamente queda el recurso de la simulación. El juego de la vida (JV) descubierto por John Conway y hecho público por Martin Gardner [GAR70], [GAR71] [GAR72], comenzó como una curiosidad matemática recreativa y terminó siendo una referencia teórica en el problema del procesamiento distribuido de la información. El anexo 2 muestra una descripción de este modelo. El JV es un computador universal [BER82]. La demostración se basa en el artificio de probar que se puede configurar el espacio celular de forma que algunos de sus objetos actúen como puertas lógicas o memorias, codificándose los bits de información que se trasladan de una puerta a otra mediante objetos móviles. Así, cualquier problema que se pueda resolver, proceso que se pueda simular o cálculo que se pueda realizar con un circuito digital se puede llevar a cabo también en el JV. Todo esto tiene sin embargo un aspecto negativo, y es que según el problema se complica, el número de.
(33) 27. Capítulo I. Aspectos teóricos y modelos elementales de las redes…. células necesarias crecerá exponencialmente y hacerse impracticable su codificación y resolución en el JV; es el precio a pagar por un modelo tan sencillo. Si bien el Juego de la Vida es inútil a efectos prácticos, su importancia teórica no es despreciable, pues permite demostrar que un dispositivo de cómputo paralelo puede ejecutar cualquier algoritmo. Esta es una variante de la Tesis de Turing. Si se amplía el número de posibles estados por célula y se definen reglas de transición más sofisticadas, será posible obtener autómatas celulares más potentes, también con capacidades de computación universales, pero que resulten más prácticos. Tal es el caso de los autómatas celulares no uniformes [SIP97]..
(34) 28. Capítulo II. Construcción y Entrenamiento de topologías…. CONSTRUCCIÓN Y ENTRENAMIENTO DE TOPOLOGÍAS PARA REDES NEURONALES MULTICAPA USANDO ALGORITMOS GENÉTICOS CELULARES 2.1 Esquema General de entrenamiento usando Algoritmos Genéticos con Codificación Jerárquica La figura 2.1 muestra la interrelación entre las principales etapas involucradas en el proceso de solución del problema de construcción de clasificadores basados en redes neuronales, multicapa utilizando algoritmos genéticos con codificación jerárquica.. Evaluación y puntuación de cromosomas. Asignación de fitness. Población Inicial Evaluación y fitness Ranking. Generador de RN. Población Casos de Entrenamiento. Reemplazo. Cromosomas Codificados Jerárquicamente. Selección. Mutación Sub-población descendientes. Reproductores Cruce. Figura 2.1 Esquema general para la construcción de clasificadores basados en RNM utilizando D2REA. Primeramente se crea una población de cromosomas jerárquicos, donde cada cromosoma codifica a una red neuronal multicapa (topología y pesos asignados aleatoriamente), que constituye una solución potencial del problema de optimización multiobjetivo a resolver. El epígrafe 2.2 presenta los detalles asociados a la codificación de un cromosoma jerárquico..
(35) 29. Capítulo II. Construcción y Entrenamiento de topologías…. Cada cromosoma es evaluado, según los criterios definidos, a partir de la respuesta de la red neuronal multicapa para un conjunto de entrenamiento dado. La asignación de fitness se realiza utilizando el esquema propuesto D2REA [TOR02]. Este esquema de puntuación, D2REA, es descrito en el epígrafe 2.3. Para el proceso de selección se utiliza un esquema de selección estocástico, el cual permite que los individuos con mayor fitness tengan mayor probabilidad de ser seleccionados. Este hecho posibilita, como resultado, que los mejores individuos puedan dar lugar a un mayor número de descendientes. Los operadores de mutación y cruce son utilizados a partir de la descripción realizada en el epígrafe 2.4. Seguidamente son seleccionados aquellos descendientes que participarán en el proceso de reemplazo, a partir de sus grados de aptitud. Finalmente, son seleccionados todos aquellos pertenecientes a los Pareto fronts que conforman un porciento específico del tamaño de la población actual. Para el proceso de reemplazo se utiliza una estrategia de reemplazo elitista, donde en cada iteración se mantiene un porciento de la población actual. El restante porciento es reemplazado por los mejores individuos, en términos del esquema de asignación de fitness empleado, de la subpoblación de descendientes. Estos individuos son incorporados a la población e intervendrán en el próximo ciclo de iteración del algoritmo. El proceso de optimización finaliza cuando se haya alcanzado un número de iteraciones específico, o se haya alcanzado algún criterio de parada especificado previamente.. 2.2 Codificación Jerárquica de una Red Neuronal Multicapa En la figura 2.2 se muestra la representación jerárquica de un cromosoma que codifica una red neuronal multicapa, según el esquema propuesto en [MAN99]. Cada cromosoma está conformado por dos tipos de genes, genes de control y genes de conexión. Para los genes de control se utiliza una cadena de bits que indica la presencia o no de las capas (genes de control de capas) y a su vez, estos controlan otra cadena de bits que se usa para chequear la presencia o no de neuronas por capa (genes de control de neuronas). En el caso de los genes utilizados para las conexiones de la red, se utilizan en su representación valores reales para la codificación de los pesos asociados a cada conexión y a los biases respectivos. A partir de esta estructura, se define que para que un cromosoma resulte válido, es decir, que codifique a una red neuronal multicapa válida, debe existir al menos un gen de control de capas activo; y a su vez, al menos un gen de control de neuronas asociado, activo también. La presencia de genes que activan y desactivan capas y neuronas permite la exploración dinámica de otras topologías de redes menos complejas..
(36) 30. Capítulo II. Construcción y Entrenamiento de topologías…. Gen de Control Capas Gen de Control para Neuronas Ocultas. 1. 0. …. 1. 1 1 0. 1 1 1. …. 0 1 0. w 1 w2 w3 b1. Gen de Parámetros de Conexión. …. 3-Input w1. 1-Output. w2 w3. … Figura 2.2 Codificación Jerárquica de la topología de una RNM. Debe resaltarse, que dentro del tratamiento específico que se le realiza a la estructura de los cromosomas, siempre están presentes genes activos e inactivos dentro de los genes de control y paramétricos. En el caso de los genes inactivos, estos son mantenidos para futuras generaciones; esto evita, en gran medida, la caída en mínimos locales que a la larga se traducen en una convergencia prematura. O sea, de generación en generación se mantiene un balance entre el conocimiento acumulado y la exploración de nuevas áreas en el espacio de búsqueda. Esta estructura permite grandes variaciones en los cromosomas, manteniendo simultáneos cambios genéticos múltiples. Como resultado, un simple cambio en un nivel de control alto, provoca múltiples cambios en niveles inferiores (activación o desactivación en el nivel completo).. 2.3 D2REA El uso de algoritmos genéticos para abordar problemas de optimización multiobjetivo ha sido ampliamente abordado por la literatura científica [SHA85], [BOO87], [HOR92], [HOR93], [FON93], [MEN99] y [DEB00]. D2REA (Domination Ranking Refinement based Evolutionary Algorithm) [TOR02] es un método de asignación de fitness basado en los criterios de dominación de Pareto [FON93] y en el esquema de puntuación (ranking) propuesto por Fonseca.
(37) 31. Capítulo II. Construcción y Entrenamiento de topologías…. en [FON93]. En el anexo 3 se presenta la implementación en MATLAB 6.0 del método. La complejidad computacional del mismo es O (k 2 n 2 ) , para el peor de los casos (hasta un nivel de dos funciones objetivos), donde. k : Cantidad de funciones objetivos del problema a solucionar n : Tamaño de la población del AG para un ciclo específico En [FON93] el ranking correspondiente a un individuo, se calcula como el número de individuos en la población actual, por los cuales dicho individuo es dominado; mientras los individuos no dominados son penalizados de acuerdo con la densidad de población de su correspondiente región de compromiso. En D2REA, el ranking de un individuo, se calcula como la suma pesada de las dominaciones de un individuo en cada uno de los correspondientes esquemas de Pareto, obtenidos mediante la supresión de hasta dos de las funciones objetivo correspondientes al problema. Esta estrategia se presenta como una generalización del algoritmo VEGA [SHA85], utilizando el esquema de puntuación propuesto por Fonseca e incorporando grados de dominación correspondientes a subproblemas de optimización, obtenidos mediante la supresión de subconjuntos de funciones objetivo bajo optimización. Como resultado, este método de asignación de fitness, reduce el efecto introducido por soluciones no dominadas de manera local, el fenómeno de especiación, y es capaz, además, de muestrear uniformemente regiones de la superficie de soluciones de compromiso [TOR02], i.e. Pareto fronts. El resultado de la conformación de los Pareto fronts, a diferencia del esquema de Fonseca, produce un cubrimiento de las regiones no dominadas por una cantidad mayor de Pareto fronts de menor dimensión. Esto se produce como consecuencia de la disminución de la puntuación asignada a los individuos que tienen un buen desempeño en un subconjunto pequeño de conjunto total de funciones objetivo del problema en cuestión.. 2.3.1 Atenuación del fenómeno de deriva genética durante la selección Para atenuar el fenómeno de deriva genética se utiliza la técnica de formación de nichos (Niche Formation en inglés) propuesta en [DEB00], aplicada en el espacio objetivo. Para calcular un estimado de la densidad de soluciones alrededor de un individuo en la población se toma la distancia promedio de los dos puntos a ambos lados del punto en cuestión para cada uno de los valores objetivos. Esta densidad estima el tamaño del cuboide que encierra al punto sin tener.
(38) 32. Capítulo II. Construcción y Entrenamiento de topologías…. en cuenta ningún otro punto en la población, que no sean sus vecinos en cada valor objetivo. A esta densidad la llamamos densidad de población (crowding distance en inglés) y será mayor en la medida que esté más aislado el individuo.. En la figura 2.3, la densidad de población del i-ésimo punto en su front (marcado con puntos negros) es el promedio de los lados del cuboide representado con líneas discontinuas. El siguiente pseudocódigo representa el cálculo de la densidad de población. L = Cardinal(I);. {número de elementos en I}. {FO = Cantidad de Funciones Objetivos;} Para cada i desde 1 hasta L hacer I[i].DP = 0; {inicializar densidad de poblacion} Para cada objetivo m hacer I = Ordenar(I,m); {Ordenamos I usando el objetivo m} I[1].DP = I[1].DP + (I[2].m – I[1].m); I[L].DP = I[L].DP + (I[L].m - I[L-1].m); Para i = 2 hasta L-1 hacer I[i].DP = I[i].DP + (I[i+1].m – I[i-1].m); Para cada i desde 1 hasta L hacer I[i].DP = I[i].DP/FO; En el pseudocódigo anterior I representa al conjunto de individuos y I[i].m representa el valor del m-ésimo objetivo en el i-ésimo elemento de la población. La complejidad de dicho algoritmo esta determinada por el algoritmo de ordenamiento que se implementa..
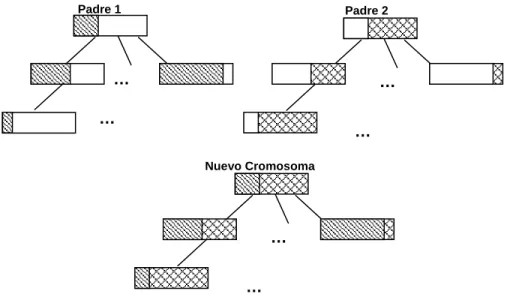
(39) 33. Capítulo II. Construcción y Entrenamiento de topologías…. El peor caso que puede presentarse el cuando en el conjunto optimal de Pareto está compuesto por toda la población. En este caso, si se indica por n ese tamaño y se utiliza el algoritmo de ordenamiento QuickSort [AHO83], con complejidad O( n log n) , la complejidad computacional del algoritmo de cálculo de la densidad poblacional es de O(mn log n ) , donde m es la cantidad de funciones objetivo del problema en cuestión. Una vez calculado la densidad de población de cada elemento de la población, respecto al front de Pareto a que pertenezca, se aplica dentro de cada front una penalización mayor, a aquellos elementos que tengan menor densidad de población. Esta penalización se establece aplicando dos mecanismos de ruleta a la hora de seleccionar, uno para seleccionar el front, que se hace de acuerdo al ranking de éste y otro para seleccionar el individuo dentro del front, que se hace de acuerdo a la densidad de población. A partir de este esquema, dentro de un mismo front, aquellos elementos más aislados tienen mayor probabilidad de ser seleccionados. El proceso de selección se realiza de acuerdo al ranking establecido anteriormente. A partir de las puntuaciones calculadas, se realiza un muestreo estocástico con reemplazo utilizando una ruleta simple [DAV91]. Los individuos seleccionados, son los futuros padres del proceso de reproducción que se realiza posteriormente.. 2.4 Operadores Genéticos Las características de la estructura empleada en la codificación jerárquica de los cromosomas, presupone el empleo de operaciones genéticas específicas: Cruzamiento en los genes de control: La estructura del cromosoma, está conformada por genes para el control de la activación de las capas ocultas y genes para el control de la activación de neuronas por capa oculta. Para ambos niveles se definieron probabilidades de cruce Pch, Pcn respectivamente. La operación de cruzamiento se realiza por niveles, utilizando en cada uno cualquier variante de los métodos tradicionales [MAN99]: cruce por un punto y uniforme. Cruzamiento en los genes de conexión: A igual que en los genes de control en el caso de los genes paramétricos, las operaciones de cruce se realizan por un punto o uniforme. Para el caso de los genes de las conexiones se utiliza una probabilidad de cruce Pcc..
(40) 34. Capítulo II. Construcción y Entrenamiento de topologías…. La característica fundamental de este esquema, es la utilización de diferentes probabilidades para cada nivel, a partir de la influencia de los niveles superiores sobre los inferiores. La Figura 2.4 muestra el esquema general para la operación de cruzamiento por un punto. Mutación en los genes de control: Una mutación de bits es aplicada a los genes de control, a partir de probabilidades definidas para cada nivel: Pmh, Pmn . Esta se realiza alterando el bit especificado en caso que se realice una mutación.. Padre 1. Padre 2. …. …. …. … Nuevo Cromosoma. … … Figura 2.4 Operación de cruzamiento multinivel para los genes de control y paramétricos. Mutación en los genes de conexión: Una mutación para valores reales [MAN99] es aplicada a los genes de conexión. La misma se realiza adicionando a cada gen de conexión un determinado. valor. de. una. variable. aleatoria. con. distribución. normal,. con. una. probabilidad Pmc de que esto ocurra.. m( x ) = x + Z En la fórmula x es el gen de conexión que se mutará y Z → N ( μ , σ 2 ) es una variable aleatoria con distribución normal de media μ y varianza σ 2 . Los valores de μ y σ 2 se eligen de acuerdo al problema que se esté resolviendo. Generalmente μ y σ 2 se usan los valores de 0 y 1..
(41) 35. Capítulo II. Construcción y Entrenamiento de topologías…. 2.5 Formulación Multiobjetivo de la Construcción de RNM usando Algoritmos Genéticos El planteamiento del problema de construcción de red neuronal multicapa, como un problema de optimización multiobjetivo, tiene la siguiente formulación: Para el caso de construcción de red neuronal multicapa para la clasificación entre dos clases se precisa minimizar cinco funciones objetivo, cuatro de las cuales son definidas a partir de cuatro medidas estadísticas básicas, recomendadas por la AAMI [WOL91]: Verdaderos Positivos (TP), Falsos Positivos (FP), Verdaderos Negativos (TN) y Falsos Negativos (FN). En este contexto, TP significa la clasificación correcta de un valor positivo. FP indica la cantidad de valores negativos dados como positivos, TN es la cantidad de negativos detectados correctamente y FN es definido como la cantidad de valores positivos dados como negativos. Los criterios de desempeño utilizados son:. Sensibilidad:. Sens =. TP ; corresponde a la fracción de positivos detectadas TP + FN. correctamente con relación a la cantidad de positivos verdaderos de la base de casos. Especificidad: Spec =. TN ; es la fracción de negativos detectados correctamente con TN + FP. relación a la cantidad de negativos de la base de casos. Predictividad Positiva: PP =. TP ; es la fracción de positivos detectados correctamente TP + FP. con relación a las clasificaciones positivas. Predictividad Negativa: PN =. TN ; es la fracción de negativos detectados correctamente TN + FN. con relación a las clasificaciones negativas. Razón de Clasificación: C _ Rate =. TP + TN ; es la razón de las clasificaciones TP + TN + FP + FN. correctas con relación a todas las clasificaciones..
Figure


+7



Documento similar