Sistema para el análisis de técnicas descriptivas y regresión borrosa Aplicaciones
101
0
0
Texto completo
(2) El que suscribe, Lisset Denoda Pérez, hago constar que el trabajo titulado “Sistema para el análisis de técnicas descriptivas y regresión borrosa. Aplicaciones” fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del Laboratorio. Fecha. II.
(3) “Sólo tengo por seguro lo que es incierto” François Villon. “Es imposible aprender sobre lo que se cree saber” Epicteto. III.
(4) Dedicatoria Al rey de reyes, al único y fiel, al Salvador, a mi Dios. A mi gran amiga y madre. A mis abuelos que no han dejado de existir. A mi novio y futuro esposo, Osvaldo. A mi sobrinita Brendi por ser mi inspiración y felicidad.. IV.
(5) Agradecimientos A Dios por su inmenso amor y fidelidad. A mi mamá, por su amor intenso, y todo el sacrificio en pos de mi formación profesional. A Osvaldo, mi novio, por su amor, su entrega diaria y sus esfuerzos para poder tener la computadora para realizar este trabajo. A Pablo, mi padrasto, por su amor, por todo el apoyo logístico y la ayuda constante en los años de la carrera. A toda mi familia por confiar en mí, por estar siempre al tanto de lo que acontece en mi vida y por el cariño y afecto que siempre me han tenido. A Gladita, mi tutora, por su paciencia y amor constante, por el tiempo dedicado, por sus valiosas ideas, por aceptar ser mi tutora teniendo más tesiantes. A Jorge Luis, mi otro tutor, primeramente por su gran amistad desde el comienzo de mi carrera, por su ayuda excepcional, por ser un ejemplo de tenacidad y esfuerzo. A todos los profesores que a lo largo de estos años han influido en mi formación y madurez profesional. A Inti, Sandro y Moreira por brindarme su ayuda ante cualquier interrogante. A todos mis compañeros de estudio con los que he compartido estos cinco años. Lisset Denoda Pérez. V.
(6) RESUMEN En esta tesis se presentan los conceptos fundamentales de la teoría de conjuntos borrosos. Se definen los números borrosos triangulares, trapezoidales, así como sus operaciones fundamentales. Se muestran variantes para realizar el cálculo de medidas descriptivas borrosas como la media, moda, mediana y varianza. Se exponen los elementos fundamentales de la regresión borrosa haciendo énfasis en dos medidas de bondad de ajuste. Se presentan los aspectos principales del análisis, diseño e implementación del software “efuzzy 1.0”. Se explica el mecanismo que posee el Mathematica para intercambiar información con otros programas externos. Se presentan los pasos para conectar un programa en Java con el kernel del Mathematica mediante la biblioteca JLink. Finalmente se muestra la funcionalidad del Mathematica usada en el software “efuzzy 1.0”. Se mostraron dos aplicaciones con datos reales. En el primer caso de estudio se realizó un tratamiento borroso para valorar el nivel de satisfacción de los clientes que asisten al área de cajeros en dos sucursales de BANDEC en Santa Clara. La modelación con números borrosos es buena ya que se reduce el grado de subjetividad del evaluador. En el segundo caso de estudio, se obtuvieron tres modelos de regresión borrosa aplicados a un problema de finanzas.. VI.
(7) ABSTRACT This thesis shows the principal concepts of the fuzzy set theory. Triangular fuzzy numbers and trapezoidal fuzzy numbers and their operations are defined. Several ways to calculated fuzzy descriptive statistics like mean, median, mode and variance, are shown. The fundamental elements of the fuzzy regression and two goodness of fit measures are also shown. The principal aspects related with the analysis, design and implementation of the software efuzzy 1.0 are presented. The Mathematica's algorithms to interchange information with external software are explained. Steps to connect a Java program with the kernel of Mathematica using JLink library are shown. Finally, the functions of Mathematica needed by effuzy were exposed. Two real data applications were presented. In the first study case, the satisfaction level of the clients of two banks of Santa Clara, was studied. The fuzzy number modelation is good because it reduces the subjectivity of the evaluator. In the second study case, three fuzzy regression models of the finances problem were obtained.. VII.
(8) ÍNDICE INTRODUCCION ............................................................................................................ 1 1.. TEORÍA DE LOS CONJUNTOS BORROSOS ...................................................... 6 1.1. Subconjunto borroso ......................................................................................... 6. 1.1.1 Definiciones básicas sobre conjuntos borrosos ................................................ 7 1.2. Intervalos de confianza y números borrosos .................................................. 11. 1.2.1 Intervalos de confianza .................................................................................. 11 1.2.2 Números borrosos ......................................................................................... 12 1.2.3 Distancia entre números borrosos .................................................................. 14 1.2.4 Clasificación de los números borrosos en un orden total ................................ 16 1.3. Operaciones con números borrosos................................................................ 17. 1.3.1 Aritmética de Intervalo .................................................................................. 17 1.3.2 Aritmética borrosa......................................................................................... 19 1.4. Algunos tipos especiales de números borrosos ............................................... 22. 1.4.1 Números borrosos triangulares ...................................................................... 22 1.4.2 Números borrosos trapezoidales .................................................................... 23 1.5. Análisis descriptivo borroso ........................................................................... 25. 1.5.1 Media borrosa ............................................................................................... 25 1.5.2 Moda borrosa ................................................................................................ 26 1.5.3 Mediana borrosa............................................................................................ 27 1.5.4 Varianza borrosa ........................................................................................... 29 1.5.5 Métodos de defuzzificación ........................................................................... 30 1.6. Análisis de regresión ....................................................................................... 31 VIII.
(9) 1.6.1 Regresión Probabilística ................................................................................ 31 1.6.2 Regresión Borrosa ......................................................................................... 33 1.6.3 Regresión borrosa posibilística ...................................................................... 34 1.6.4. 2.. Indices de Bondad de Ajuste ......................................................................... 36. 1.7. Aplicaciones del análisis estadístico borroso .................................................. 38. 1.8. Consideraciones finales ................................................................................... 39. ANÁLISIS, DISEÑO E IMPLEMENTACIÓN DEL SOFTWARE “EFUZZY. 1.0”. ................................................................................................................................. 40 2.1. Patrones de diseño........................................................................................... 40. 2.1.1 Patrón Visitor ................................................................................................ 41 2.2. Análisis, Diseño e Implementación de la Herramienta .................................. 42. 2.2.1 Diagrama de casos de uso.............................................................................. 43 2.2.2 Diagrama de clases........................................................................................ 44 2.2.3 Diagramas de actividad ................................................................................. 49 2.2.4 Artefactos del sistema ................................................................................... 52 2.2.5 Implementación del software ......................................................................... 53 2.3. Enlace entre el Mathematica 6.0 y el Java. .................................................... 54. 2.3.1 Comunicación entre Mathematica y MathLink .............................................. 54 2.3.2 Integración del Mathematica y el Java mediante JLink. ................................. 54 2.3.3 Metodología para conectar un programa en Java con el kernel del Mathematica ………………………………………………………………………………...55 2.3.4 Funcionalidad del Mathematica usada en la biblioteca fuzzy ......................... 59 2.4 3.. Consideraciones finales ................................................................................... 59. MANUAL DE USUARIO Y APLICACIONES..................................................... 61 IX.
(10) 3.1. Manual de usuario .......................................................................................... 61. 3.1.1 Requerimientos ............................................................................................. 61 3.1.2 Ficheros de entrada ....................................................................................... 61 3.1.3 Ventana inicial del software .......................................................................... 62 3.1.4 Interfaz principal de la aplicación .................................................................. 62 3.1.5 Opciones de Menú ........................................................................................ 65 3.2. Tratamiento borroso para valorar el nivel de satisfacción de los clientes que. asisten al área de cajeros en dos sucursales de BANDEC en Santa Clara ............... 72 3.3. Aplicación de la regresión lineal borrosa posibilística a problemas de pocas. observaciones .............................................................................................................. 76 3.4. Aplicación a la tasa de cambio del Euro ........................................................ 77. 3.5. Consideraciones finales ................................................................................... 81. CONCLUSIONES .......................................................................................................... 83 RECOMENDACIONES ................................................................................................ 84 REFERENCIAS BIBLIOGRÁFICAS .......................................................................... 85 ANEXOS ......................................................................................................................... 87. X.
(11) Introducción. INTRODUCCION “El mundo es un lugar borroso” (Aranguren y Muzachiodi, 2003). La mayoría de los fenómenos que ocurren a diario son imprecisos en la descripción de su naturaleza. Esta imprecisión puede estar asociada con su forma, posición, momento, color o textura entre otros elementos. En muchos casos el mismo concepto puede tener diferentes grados de imprecisión en diferentes contextos o en el tiempo. Un día cálido en invierno no es lo mismo que un día cálido en primavera. La definición exacta de cuando la temperatura pasa de fría a caliente es imprecisa, pues resulta imposible identificar un punto de corte tal que al realizar una variación de sólo un grado, la temperatura del ambiente pase de ser considerada fría a caliente. Este tipo de imprecisión o borrosidad asociado continuamente a los fenómenos, es común en casi todos los campos de estudio: sociología, física, biología, finanzas, ingeniería, y psicología entre muchos otros (Aranguren y Muzachiodi, 2003). Por ejemplo, considérense las siguientes sentencias: . La temperatura del ambiente está caliente.. . La inflación actual aumenta rápidamente.. . Los grandes proyectos generalmente tardan mucho.. . Alejandro es alto pero Ana no es bajita.. Todas estas proposiciones describen ''la forma de las cosas en el mundo'' (Aranguren y Muzachiodi, 2003) sin embargo, son incompatibles con el modelado tradicional de la lógica de Aristóteles, enunciada por primera vez 300 años A.C. La lógica aristotélica ha sido estudiada por miles de científicos y filósofos. Está basada en una idea sencilla comprendida por todos: una proposición es verdadera o falsa. No existen posiciones intermedias entre esos dos extremos. La lógica borrosa estudia elementos de la lógica tradicional aplicados a valores borrosos. Los elementos de un conjunto borroso son pares ordenados que indican el valor del elemento y su grado de pertenencia a dicho conjunto. De esta manera, la lógica borrosa maneja la incertidumbre presente en la estructura de un conjunto de datos. Los conjuntos 1.
(12) Introducción. borrosos fueron introducidos por primera vez en 1965, por Zadeh (Zadeh, 1965), pero sus orígenes se remontan hasta 2,500 años. La Regresión Borrosa aparece en la historia de los análisis de regresión en 1982 (Tanaka et al., 1982), gracias a Hideo Tanaka y sus colaboradores (aunque) existe una exposición previa de 1980 (Tanaka et al., 1980), pasando a constituir una nueva alternativa de regresión frente a las muchas metodologías de regresión que existían para trabajar con números precisos. El análisis de regresión borrosa se fundamenta en el análisis de regresión tradicional de la estadística e intenta extender su aplicación a datos que pueden modelarse a través de subconjuntos borrosos. El análisis de regresión borrosa ha sido estudiado y aplicado en diferentes áreas tal como la modelación de datos económicos o financieros (Aguilera Cuevas y Rodríguez Betancourt, 1999), la ingeniería de software (Conte et al., 1986), el reconocimiento de un patrón de estimación humana (Romero Cortés y Aguilar Vázquez, 1999). La “estadística borrosa” persigue aplicar métodos estadísticos a datos borrosos y de esta forma aumentar el dominio de aplicabilidad del campo de la estadística. (Nguyen y Wu, 2006) En el prólogo del libro Matheron (Matheron, 1975), el cual contiene las bases matemáticas para el estudio de las observaciones de valores establecidos (como nuevos tipos de datos), G. Watson escribió “La estadística moderna podría definirse como la aplicación de la computación y la matemática al análisis de datos. Esta debe crecer a medida que se consideren nuevos tipos de datos y avance la tecnología de la computación”. Debido a la forma general del cúmulo de datos y las tecnologías artificiales inteligentes, es que estamos lidiando con la estadística borrosa como una nueva forma de estadística. Esta investigación presenta un tema actual y general: el análisis estadístico de datos borrosos (datos en donde su categorización no es de forma dura sino de manera borrosa más precisamente este tipo de datos se categoriza en posibles clases diferentes con cierto grado de pertenencia en cada una). Por su naturaleza, estos números son más complejos y generales que las observaciones numéricas clásicas sobre las que se aplican las técnicas 2.
(13) Introducción. descriptivas y los análisis multivariante estadístico, entre los que se encuentran los análisis clásicos de regresión (Nguyen y Wu, 2006). Los paquetes estadísticos profesionales no incluyen el trabajo con datos borrosos por lo que no se maneja la incertidumbre presente en la estructura de un conjunto de datos. Este constituye en esencia el problema científico que le da origen a la presente tesis. Como objetivo general se propone: “desarrollar un sistema que permita realizar análisis descriptivos con datos borrosos y regresión borrosa en un software libre para dar solución a diferentes problemas”. Para lograr dicho objetivo general, se proponen los objetivos específicos: 1. Diseñar un sistema que permita: . Realizar análisis descriptivos con datos borrosos.. . Realizar análisis de regresión borrosa.. 2. Implementar el sistema que incluya los aspectos anteriores. 3. Mostrar aplicaciones con datos reales. Se formularon además las siguientes Preguntas de Investigación: 1. ¿Cuáles son los procedimientos para obtener medidas de tendencia central y de variabilidad borrosas? 2. ¿Cómo se obtiene una ecuación de regresión borrosa? ¿Cómo se interpreta? Justificación Los paquetes estadísticos profesionales, como el SPSS (Statistics Package for the Social Sciences) no incluyen aún métodos borrosos. El sistema que se propone elaborar incluirá técnicas de estadística descriptiva borrosas y realizará análisis de regresión borrosa, por lo que será una valiosa herramienta en manos de los investigadores. La regresión borrosa permite el manejo de cantidades afectadas por imprecisión e incertidumbre que no son manejables usando la regresión probabilística. Existen muchas 3.
(14) Introducción. magnitudes cuantitativas que pueden representarse adecuadamente mediante números borrosos: mediciones con márgenes de error, valor de las monedas frente a otras monedas referenciales en los mercados financieros, precio de las materias primas (oro, plata, cobre, etc.) y de los combustibles fósiles (petróleo, gas, carbón, etc.). Cuando se dispone de pocas observaciones para hacer una regresión probabilística se añade a este problema la dificultad de poder verificar los supuestos. En esta situación una alternativa de modelación ventajosa es un modelo borroso que pueda incorporar un nivel de confianza posibilístico (Kim et al., 1996). En los modelos en donde los datos sean insuficientes o imperfectos, originados por la imprecisión o vaguedad, se ha demostrado que es útil el uso de un tratamiento difuso o borroso (Izyumov et al., 2001, Tsaur y Wang, 1999, Sugeno, 1985, Klir y Folger, 1988, Chang y Ayyub, 2001, Nadipuram, 1999, Boris). Viabilidad de la investigación El estado actual de la lógica borrosa ofrece una amplia gama de ideas a desarrollar en este trabajo. Para el desarrollo de esta investigación se cuenta con los recursos necesarios para acometer las tareas propuestas. Se cuenta con la investigación desarrollada por uno de los tutores: Jorge Luis Morales en su tesis de maestría relativo al tema de regresión borrosa, así como un poderoso lenguaje de programación: Java. El primer paso para la realización de este trabajo fue la confección del marco teórico. Para ello se realizó una amplia revisión de la literatura consultando libros, artículos y páginas de internet, entre otras fuentes. Sus elementos esenciales se encuentran expuestos de manera resumida en el primer capítulo de la presente tesis. Como conclusión de la elaboración del marco teórico se enuncian las siguientes hipótesis de investigación: H1: “Utilizando el Java como lenguaje de programación, se implementa un sistema computacional para calcular estadígrafos descriptivos borrosos y realizar análisis de regresión borrosa”. H2: “El software implementado permite resolver problemas reales de varios campos de aplicación”. 4.
(15) Introducción. La tesis se estructura en tres capítulos. El primero de ellos contiene una presentación detallada de las formulaciones matemáticas más importantes relacionadas con la lógica borrosa. Se definen los números borrosos triangulares, trapezoidales, así como sus operaciones fundamentales. Se muestran variantes para realizar el cálculo de medidas descriptivas borrosas como la media, moda, mediana y varianza. Se exponen los elementos fundamentales de la regresión borrosa haciendo énfasis en dos medidas de bondad de ajuste. En el capítulo dos se expone la plataforma de desarrollo y los diagramas creados para las fases de análisis y diseño de la herramienta. Se propone una metodología para conectar un programa en Java con el kernel del Mathematica mediante la biblioteca JLink. En el capítulo tres se muestra el manual de usuario del software y dos aplicaciones con datos reales. En el primer caso de estudio se realizó un tratamiento borroso para valorar el nivel de satisfacción de los clientes que asisten al área de cajeros en dos sucursales de BANDEC en Santa Clara. En el segundo caso de estudio, se obtuvieron tres modelos de regresión borrosa aplicados a un problema de finanzas. Todos los capítulos terminan con un epígrafe de consideraciones finales en el que se resumen los aspectos más importantes que se trataron. Finalmente se enuncian las conclusiones y recomendaciones, se relaciona la bibliografía y se muestran algunos anexos.. 5.
(16) Capítulo 1. 1. TEORÍA DE LOS CONJUNTOS BORROSOS En este capítulo se expone la teoría de los conjuntos borrosos y se formaliza en las principales definiciones del análisis estadístico borroso.. 1.1. Subconjunto borroso. La matemática de conjuntos borrosos que podría denominarse como clásica, se basa en la lógica aristotélica fundamentada en el principio que muestra que una proposición únicamente puede ser verdadera o falsa (1,0 respectivamente), pero no ambas cosas a la vez, es decir no existiendo ningún grado de verdad intermedio. Como consecuencia de dicho principio, en la teoría de conjuntos, para un subconjunto A definido sobre un conjunto universo o referencial X, un elemento del universo pertenece o no pertenece a dicho conjunto A, es decir, no existe ningún tipo de ambigüedad sobre su pertenencia. Matemáticamente la pertenencia a un conjunto se expresa a través de una función característica A (x) que asigna valores a todos los elementos de A en el conjunto discreto {0,1}. Dicho valor es 0 cuando el elemento no pertenece al conjunto y 1 cuando el elemento pertenece totalmente. Es decir, matemáticamente la función característica viene dada por:. A : X {0,1} 1 x A x X A ( x) 0 x A. (1.1). Del principio del tercero excluido se deriva el principio de exclusión. Este indica que si un elemento x del universo X pertenece a un conjunto A, no pertenece a su complemento, A c y viceversa. Matemáticamente podemos expresar el principio de exclusión como:. x X , si A ( x) 1 Ac ( x) 0. (1.2). Un conjunto borroso es un conjunto para el cual la pertenencia de un elemento está definida de forma borrosa. Así, si se denomina X como al universo o conjunto referencial, un 6.
(17) Capítulo 1. subconjunto borroso, que se denotará de la siguiente manera A , es aquel en el que la pertenencia de un elemento x X tiene asignado un nivel de verdad que puede tomar valores en el conjunto continuo [0,1]. El nivel de pertenencia de un elemento x vendrá dado por su función de pertenencia o función característica A (x) . Así, se puede definir a un subconjunto borroso como A {( x, A ( x)) | x X } siendo la función de pertenencia:. A : X [0,1]. (1.3). x X A ( x) [0,1] Donde 0 indica la no pertenencia al conjunto A. y 1 la pertenencia absoluta.. Evidentemente, existe una degradación del nivel de pertenencia de forma que si. A ( x) 0.9 , el nivel de pertenencia del elemento x es muy elevado, y si A ( x) 0.1 el nivel de pertenencia de x es muy bajo. Así puede interpretarse como el grado en que un elemento particular que se considera cumple con las especificaciones que definen a los elementos del conjunto en cuestión y no debe interpretarse como la probabilidad de pertenencia. Si la probabilidad de que un elemento x pertenece al conjunto A es de 0.9 y se afirma que x pertenece al conjunto A , tenemos un 90 % de probabilidad de acertar, pero el elemento intrínsecamente pertenece o no pertenece a A . Cuando se dice que la función de pertenencia de x es 0.9 se quiere decir que cumple en nuestro criterio con el 90% de las características que definen los elementos del conjunto A . En resumen, la probabilidad indica incertidumbre estadística mientras que la función de pertenencia indica vaguedad y subjetividad. Además, se puede observar que un conjunto ordinario o “crisp” es un caso particular de un conjunto borroso, para el cual únicamente se diferencian dos niveles de pertenencia: la pertenencia absoluta y la no pertenencia. 1.1.1 Definiciones básicas sobre conjuntos borrosos. En esta sección se presentan las definiciones y resultados básicos relacionados con los conjuntos borrosos. Para un estudio más profundo se pueden consultar (Buckley y Eslami, 2002, Hanss, 2005) 7.
(18) Capítulo 1. Definición 1.1 (Conjunto Vacío) El Subconjunto borroso A es vacío si y solo si A ( x) 0 x X y se escribe A . Definición 1.2 (Igualdad) Si A y B son dos subconjuntos borrosos de un conjunto X, se dice que A B sí y solo si. A ( x) B ( x) x X . Definición 1.3 (Cardinalidad escalar) La cardinalidad escalar de un conjunto borroso A en el conjunto finito X, se define como (Luca y Termini, 1972, Lee, 2005):. | A | A ( x). (1.4). xX. Cuando X es finito, ( {x1 ,....., xn } ), el conjunto borroso A se puede expresar como: n. A A ( x1 ) / x1 ..... A ( xn ) / xn A ( xi ) / xi. (1.5). i 1. donde el + y la. . deben entenderse en el sentido de la teoría de conjuntos. Por convenio,. los pares A ( x) / x con A ( x) 0 se omiten. En el caso de que X no sea finito, la notación es:. A A ( x) / x X. (1.6). Definición 1.4 (Inclusión) Si A y B son dos subconjuntos borrosos de un conjunto X, se dice que A es subconjunto de B si y solo si A ( x) B ( x) x X , esta relación se expresa como A B . Si el conjunto universo es finito, se pueden relajar la condición anterior para medir el grado en el que un conjunto borroso está incluido en otro (Galindo Gómez, 2008). 8.
(19) Capítulo 1. S ( A, B ) . 1 {| A | max{ 0, A ( x), B ( x)}} |A| xX. (1.7). Definición 1.5 (Subconjunto propio) Si A y B son dos subconjuntos borrosos de un conjunto X, se dice que A es subconjunto. B. propio. de. si. AB. si y solo si. y. sólo. AB y. si. A ( x) B ( x) x X ,. y. se. escribe. como. AB. El concepto de cardinalidad de un conjunto borroso no tiene nada que ver con el similar en el caso de conjuntos comunes (número de elementos), sino que se refiere más bien a su tamaño. Definición 1.6 (Soporte) El soporte de un subconjunto borroso A , dentro de un conjunto universal X, es el conjunto convencional (crisp) que contiene todos los elementos de X que tienen un grado de pertenencia mayor que 0 en A .. sop( A ) {x X | A ( x) 0}. (1.8). Un concepto muy útil es el conjunto de nivel (umbral) α, grado de presunción, o α-corte, como se conoce en la bibliografía sobre conjuntos borrosos. Este concepto permite un enfoque muy interesante de la teoría de conjuntos borrosos, ya que la familia formada por los α-cortes contiene toda la información sobre el conjunto borroso. Definición 1.7 (Conjunto de nivel α o α-corte) Dado un número [0,1] y un conjunto borroso A , se define el conjunto de nivel α o αcorte de A como el conjunto A cuya función característica se define: 1 si A ( x) . A ( x) . 0 en cualquier otro caso. (1.9). En conclusión, el α-corte se compone de aquellos elementos cuyo grado de pertenencia supera o iguala el umbral α. 9.
(20) Capítulo 1. Hablamos de α-cortes estrictos si: 1 si A ( x) . A ( x) . 0 en cualquier otro caso. (1.10). Cualquier conjunto borroso A se puede representar mediante la unión de sus α-cortes de la siguiente manera:. A ( x) max [ A ( x)] [ 0,1]. (1.11). Definición 1.8 (Altura) La altura de un conjunto borroso A es el supremo (o el máximo, cuando el conjunto universo X es finito) de la función de pertenencia A (x) :. alt ( A ) Sup A ( x). (1.12). xX. Definición 1.9 (Núcleo) Se define el núcleo de un subconjunto borroso como al α-corte que presenta un grado de verdad 1:. nucl ( A ) {x X | A ( x) 1} .. (1.13). Las propiedades fundamentales de conjuntos borrosos y relaciones, tales como altura, núcleo, soporte y α-corte, se ilustran en la figura 1.1.. Figura 1.1 Altura, núcleo, conjunto soporte y α-corte de un conjunto borroso A 10.
(21) Capítulo 1. Definición 1.10 (Normalidad) El subconjunto borroso A es normal si: sup A ( x) 1 o sea si alt ( A ) 1 .. (1.14). xX. En este caso, muchos autores consideran que A (x) es una “medida” de posibilidad y A es una distribución de posibilidad. El concepto de convexidad también juega un papel importante en la teoría de conjuntos borrosos. Las condiciones de convexidad se definen en referencia a la función de pertenencia. Definición 1.11 (Convexidad) El subconjunto borroso A es convexo si: x1 , x2 X , [0,1], A [x1 (1 ) x2 ] Min( A ( x1 ), A ( x2 )) x X. (1.15). Alternativamente, también se puede decir que el subconjunto borroso A es convexo si sus α-cortes, A son conjuntos convexos: , [0,1], A A. 1.2. Intervalos de confianza y números borrosos. En esta sección se dará la definición de números borrosos los cuales son un caso particular y de gran interés de los subconjuntos borrosos. Para ello se muestra en primer lugar el concepto de intervalo, que es fundamental dentro de los números borrosos. 1.2.1 Intervalos de confianza Un número ordinario a , puede interpretarse utilizando el concepto de función de pertenencia como:. 1 si x a 0 si x a. a ( x) . (1.16). De manera similar podemos definir un intervalo de confianza para un número ordinario. Tal intervalo será un conjunto binario clásico A, que representa cierto tipo de incertidumbre 11.
(22) Capítulo 1. acerca del valor auténtico de dicho número. Por ejemplo, si el intervalo se denota por. A [a1 , a3 ], a1 , a3 , a1 a3 , este se puede considerar como una clase de conjuntos. En la figura 1.2 se expresa el intervalo como función de pertenencia: 0 si x a1 A ( x) 1 si a1 x a3 0 si x a 3 . (1.17). Si a1 a3 este intervalo indica un punto que es [a1 , a1 ] a1. Figura 1.2 Número ordinario A [a1 , a3 ] dado por un intervalo de confianza 1.2.2 Números borrosos Un número borroso es expresado como un conjunto borroso definiendo un intervalo borroso en los números reales . Como la frontera de este intervalo es ambigua, el intervalo es además un conjunto borroso. Generalmente un intervalo borroso se representa por dos puntos extremos a1 y a 3 y un punto central a 2 que es el punto en donde se alcanza el valor máximo como [a1 , a2 , a3 ] . (Figura 1.3). Figura 1.3. Número borroso A [a1 , a2 , a3 ] 12.
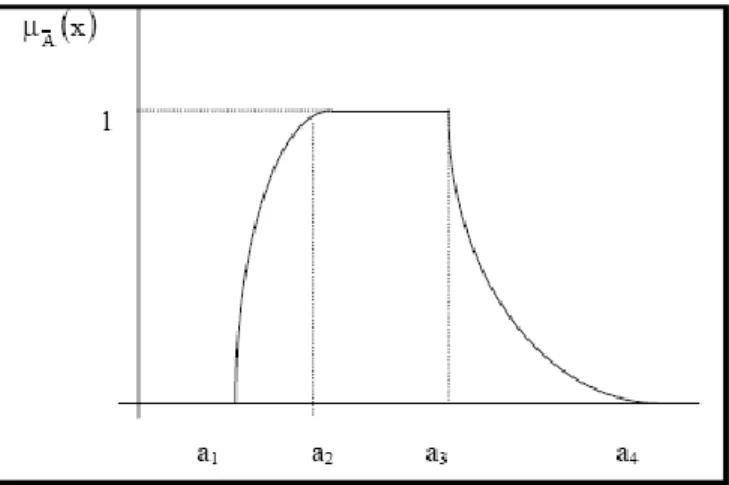
(23) Capítulo 1. Un número borroso es un subconjunto borroso N definido sobre la recta real y que cumple además las siguientes propiedades. 1. Es normal, es decir, que el núcleo de N es no vacío o lo que es lo mismo, existe al menos un elemento x de tal que N ( x) 1 2. Es convexo, geométricamente quiere decir que los α-cortes de N son intervalos cerrados y acotados. 3. El soporte de N está acotado. 4. La función de pertenencia es seccionalmente continua. Los números borrosos constituyen una herramienta valiosa para representar cantidades estimadas u observadas en el contexto de la lógica borrosa. Varios autores diferencian dentro del concepto de número borroso de acuerdo a si su núcleo es un valor real o si el núcleo es un intervalo de confianza. En nuestro caso no distinguimos a los números borrosos por la forma que se utilice para representar su núcleo. Son muchos los ejemplos prácticos en los que el grado de pertenencia de un determinado elemento del universo X se puede expresar como una función de una característica medible del mismo. El valor que toma un elemento x en la función de pertenencia de. N , N (x) , es interpretado por muchos autores como una “medida” de la posibilidad de ocurrencia de x, así el número borroso N es interpretado como una distribución de posibilidad. De forma general la función de pertenencia de un número borroso N puede escribirse como: f ( x) a1 x a 2 1 a 2 x a3 N ( x) g ( x) a 3 x a 4 en otro caso 0. (1.18). 13.
(24) Capítulo 1. El intervalo de confianza [a1 , a4 ] es el soporte del número borroso y [a2 , a3 ] es el núcleo del número borroso. Asimismo f(x) es creciente en el intervalo [a1 , a2 ] y g(x) es decreciente en el intervalo [a3 , a 4 ] (ver figura 1.4). Figura 1.4 Forma general de un número borroso Sin embargo, en muchas ocasiones será más práctico operar con su representación a través de sus conjuntos de nivel o α-cortes. Estos son intervalos de confianza que se pueden representar como:. N {x | N ( x) } [ f 1 ( ), g 1 ( )] [n1 ( ), n2 ( )]. (1.19). donde n1 ( ) (n2 ( )) serán funciones crecientes (decrecientes de ) con n1 ( ) n2 ( ) 1.2.3 Distancia entre números borrosos Existen numerosas situaciones en las cuales parte de la información disponible aportada por diferentes expertos, está expresada por estimaciones inciertas. El conocimiento de distancia sirve para calcular el grado de separación entre dos elementos, dos conjuntos, etc. Según (Kaufmann y Gil Aluja, 1992) y (Kaufmann et al., 1994) acentúan la importancia de conocer las distancias que separan dichas previsiones para poder agruparlas convenientemente a los efectos de poder adoptar decisiones.. 14.
(25) Capítulo 1. Sea X un conjunto no vacío. Una función d de valores reales no negativos definida en el producto cartesiano X X se llama una métrica o distancia en X, tal que para todo elemento a, b, c X se verifica los siguientes axiomas. i.. d (a, b) 0. y d (a, a) 0. ii.. d (a, b) d (b, a) (Simetría ). iii.. a b d (a, b) 0. iv.. d (a, b) d (b, c) d (a, c) (desigualda d triangular ). donde según (Kaufmann y Gupta, 1985) es un operador asociado con la noción de distancia. Si se satisface ii, iii, iv pero no necesariamente i, entonces la función d es una pseudométrica. Se pueden utilizar muchas variantes para determinar la distancia. Las más utilizadas entre esta gran variedad son la distancia de Hamming, la distancia de Euclides y la distancia de Minkowski, por lo que para un mismo problema se obtendrían resultados no idénticos. En esta investigación se utiliza la distancia de Hamming. Distancia de Hamming para intervalos de confianza Dados dos números borrosos A y B de R expresados por intervalos A [a1 , a2 ] y. B [b1 , b2 ] , se puede definir una distancia de Hamming a la izquierda y otra a la derecha: Distancia izquierda: d I ( A , B ) a1 b1. (1.20). Distancia derecha: d D ( A , B ) a2 b2. (1.21). Distancia total: d ( A, B ) d I d D a1 b1 a2 b2. (1.22). 15.
(26) Capítulo 1. Distancia de Hamming para números borrosos continuos La distancia entre dos números borrosos continuos A y B de R expresados por sus. cortes A [a1 ( ), a2 ( )] y B [b1 ( ), b2 ( )] , se obtiene generalizando la distancia izquierda y derecha respectivamente de los intervalos para todo valor de [0,1] . 1. d I ( A , B ) a1 ( ) b1 ( ) d. (1.23). 0. 1. d D ( A , B ) a 2 ( ) b2 ( ) d. (1.24). 0. 1. 1. d ( A , B ) a1 ( ) b1 ( ) d a 2 ( ) b2 ( ) d 0. (1.25). 0. Si se desea una distancia normalizada, es decir cuyo valor se encuentre entre 0 y 1, se deben escoger dos números reales 1 y 2 , tales que dichos números vengan dados de forma conveniente para que contengan a A 0 y B 0 . Y se obtiene una distancia relativa mediante la expresión (Kaufmann y Gupta, 1985).. ( A, B ) . d ( A, B ) 2( 2 1 ). (1.26). Esta ecuación da la distancia entre dos números borrosos; es también llamada índice de desemejanza (disimilitud) entre A y B (Kaufmann y Gupta, 1985). 1.2.4 Clasificación de los números borrosos en un orden total Se debe señalar que existen varias formas de establecer un orden a partir de la noción de distancia, nosotros seguiremos el procedimiento descrito en (Merigó Lindahl, 2008). Para establecer un orden total entre n números borrosos A1 , A2 ,..., An a partir del uso de la noción de distancia se sigue el siguiente proceso: 16.
(27) Capítulo 1. Se calcula el máximo de A1 , A2 ,..., An : AM A1 () A2 ()...() An. 1. Se obtienen las distancias de cada número borroso al máximo: i 1,..., n : d ( Ai , AM ). 2. El número Ai más cercano a AM , es decir aquel cuya distancia sea menor se considera que es el mayor de los n números borrosos. Pero en el paso 2 pueden haber varios números borrosos con el mismo desplazamiento y entonces se utiliza un procedimiento propuesto en (Kaufmann y Gupta, 1985). En estos casos (clases de números borrosos con el mismo desplazamiento) se aplica un segundo criterio que se basa en la moda o valor central del número borroso. Si no tiene una moda única (cuestión que no ocurre si hablamos de números borrosos triangulares), se toma la media de los valores modales. Es posible que las modas generen subclases de equivalencia que nos obliguen, todavía a utilizar un tercer criterio que se basa en la divergencia y consiste en seleccionar de cada subclase la divergencia (a3-a1) como criterio para la ordenación lineal de números borrosos.. 1.3. Operaciones con números borrosos. Las operaciones aritméticas entre números borrosos pueden establecerse a partir de la aritmética entre intervalos de confianza. 1.3.1 Aritmética de Intervalo Supongamos que tenemos dos intervalos cerrados y acotados cualesquiera, tales como,. A [a1 , a2 ] y B [b1 , b2 ] , con a1 , a2 , b1 , b2 . En general cuando se aplica una función a un conjunto de intervalos, el límite inferior (superior) del intervalo resultante será el valor mínimo (máximo) calculado aplicando esa función a todas las posibles combinaciones de valores pertenecientes a los intervalos considerados. 17.
(28) Capítulo 1. Si * denota suma, resta, multiplicación, o división, entonces [a1 , a2 ] * [b1 , b2 ] [c, d ] donde:. [c, d ] {a * b | a1 a a2 , b1 b b2 }. (1.27). Si * es división se asumirá que el cero no pertenece al intervalo [b1 , b2 ] . La ecuación anterior se puede especializar en cada caso de acuerdo a: Suma:. [a1 , a2 ] [b1 , b2 ] [a1 b1 , a2 b2 ]. (1.28). Resta:. [a1 , a2 ] [b1 , b2 ] [a1 b2 , a2 b1 ]. (1.29). Multiplicación:. [a1 , a2 ] [b1 , b2 ] [c, d ]. (1.30). donde:. c Min{a1b1 , a1b2 , a2 b1 , a2 b2 } d Max{a1b1 , a1b2 , a2 b1 , a2 b2 } Si el conjunto borroso está definido sobre , entonces [a1 , a2 ] [b1 , b2 ] [a1b1 , a2 b2 ] Se define ahora la operación de inverso para una mejor comprensión de la operación de división. Inverso:. [a1 , a2 ]1 [c, d ]. (1.31). donde:. 1 1 c Min , a1 a 2 . 18.
(29) Capítulo 1. 1 1 d Max , excepto para a1 0 a2 a1 a 2 1 1 Si el conjunto borroso está definido sobre , sería [a1 , a 2 ]1 , a 2 a1 División:. 1 1 [a1 , a 2 ] [a1 , a 2 ] [b1 , b2 ]1 [a1 , a 2 ] , [b1 , b2 ] b2 b1 . (1.32). Multiplicación por un número real: Un número real puede interpretarse como a [a, a], a , por tanto:. a[b1 , b2 ] [c, d ]. (1.33). donde c Min [ab1 , ab2 ] y d Max[ab1 , ab2 ] 1.3.2 Aritmética borrosa A continuación se estudiarán las operaciones más usuales entre números borrosos. Si los -cortes y la función de pertenencia de los números borrosos sobre los que se realizan estas operaciones A y B vienen dados por:. A {x | A ( x)} {A [a1 ( ), a2 ( )] | 0 1} B {x | B ( x)} {B [b1 ( ), b2 ( )] | 0 1}. Para hallar la función de pertenencia de C A * B debemos aplicar el principio de extensión generalizado teniendo en cuenta que se está evaluando una aplicación. f : . De forma general, y si suponemos que: 0 Sop( A ) y 0 Sop( B ) :. C ( x) Max [Min( A ( x1 ), B ( x2 ))] x x1 *x2. (1.34). siendo los -cortes de C , C : 19.
(30) Capítulo 1. Min{a1 ( ) * b1 ( ), a1 ( ) * b2 ( ), a 2 ( ) * b1 ( ), a 2 ( ) * b2 ( )}, C [c1 ( ), c2 ( )] Max{a1 ( ) * b1 ( ), a1 ( ) * b2 ( ), a 2 ( ) * b1 ( ), a 2 ( ) * b2 ( )} . (1.35). Suma de números borrosos: Sea C A B , la función de pertenencia de C se halla como:. C ( x) Max [Min( A ( x1 ), B ( x2 ))] x x1 x2. (1.36). y sus -cortes: C [c1 ( ), c2 ( )] [a1 ( ) b1 ( ), a2 ( ) b2 ( )]. (1.37). Resta de números borrosos: Sea C A B , la función de pertenencia de C se halla como:. C ( x) Max [Min( A ( x1 ), B ( x2 ))] x x1 x2. (1.38). y sus -cortes: C [c1 ( ), c2 ( )] [a1 ( ) b2 ( ), a2 ( ) b1 ( )] ya que C A ( B ). (1.39). Multiplicación de números borrosos: Sea C A B , la función de pertenencia de C se halla como:. C ( x) Max[ Min( A ( x1 ), B ( x2 ))] x x1 x2. (1.40). siendo sus -cortes Min{a1 ( ) b1 ( ), a1 ( ) b2 ( ), a 2 ( ) b1 ( ), a 2 ( ) b2 ( )}, C [c1 ( ), c2 ( )] Max{a1 ( ) b1 ( ), a1 ( ) b2 ( ), a 2 ( ) b1 ( ), a 2 ( ) b2 ( )} . (1.41). Si el Sop(A ) y el Sop(B ) respectivamente se obtiene entonces que: C [c1 ( ), c2 ( )] [a1 ( ) b1 ( ), a2 ( ) b2 ( )]. 20.
(31) Capítulo 1. Inverso: Sea A un número borroso tal que Sop(A ) . Su inverso C A 1 tiene como función de pertenencia:. 1 x. C ( x) A ( ) 1 1 con -cortes C [c1 ( ), c2 ( )] , a 2 ( ) a1 ( ) . (1.42). (1.43). División de números borrosos: Sea C A B , en los cuales 0 Sop( A ) y 0 Sop( B ) : La función de pertenencia de C se halla como:. C ( x) Max [ Min ( A ( x1 ), B ( x2 ))] x x. (1.44). 1. x2. siendo sus -cortes a1 ( ) a1 ( ) a 2 ( ) a 2 ( ) Min{ b ( ) , b ( ) , b ( ) , b ( )}, 1 2 1 2 C [c1 ( ), c 2 ( )] a1 ( ) a1 ( ) a 2 ( ) a 2 ( ) Max{ b ( ) , b ( ) , b ( ) , b ( )} 1 2 1 2 . (1.45). Si el Sop(A ) y el Sop(B ) respectivamente se obtiene entonces que:. a ( ) a 2 ( ) C [c1 ( ), c2 ( )] 1 , b2 ( ) b1 ( ) . Multiplicación por un escalar: Sea A un número borroso y k un escalar. El producto C kA tiene función de pertenencia:. 21.
(32) Capítulo 1. x A ( k ) si k 0 C ( x) 1 si x 0 si k 0 0 si x 0. 1.4. (1.46). Algunos tipos especiales de números borrosos. A continuación se presentan algunos números borrosos particulares y sus propiedades más importantes. 1.4.1 Números borrosos triangulares Los números borrosos triangulares son los más usados en la práctica por su relativa comodidad de manipulación. Sin embargo muchos autores han cuestionado su utilización indiscriminada. Como es evidente estos son la versión más sencilla del concepto general de número borroso L-R. Un número borroso triangular (NBT) tiene, como su nombre lo indica, la forma triangular mostrada en la figura 1.5.. Figura 1.5 Número borroso triangular A [a1 , a2 , a3 ] . La función de pertenencia para este número borroso triangular viene dada por: x a1 a a si a1 x a 2 1 2 a3 x A ( x) si a 2 x a3 a3 a 2 0 en otro caso . (1.47). 22.
(33) Capítulo 1. donde el soporte viene dado por [a1 , a3 ] , su radio izquierdo es l a a2 a1 y su radio derecho es ra a3 a2 . Por tanto sus - cortes vienen dados por: A [a1 (a2 a1 ) , a3 (a3 a2 ) ] [a1 ( ), a2 ( )]. (1.48). donde en este caso se sabe que A es un intervalo cerrado y acotado para 0 1donde: 1. a1 ( ) será una función monótona creciente de en el intervalo [0,1] 2.. a 2 ( ) será una función monótona decreciente de para 0 1. 3.. a1 (1) a2 (1). La monotonía creciente (decreciente) se demuestra, como es usual, probando que se cumple la relación. da1 ( ) da ( ) 0( 2 0) d d. Un número borroso triangular se denota mediante su centro y sus radios en la forma A [an , l a , ra ] , o alternativamente mediante una terna de confianza donde los valores que. la componen son el valor más pequeño posible, el valor de mayor pertenencia o el valor central y el valor más elevado posible, es decir A [a1 , a2 , a3 ] . Como se puede observar la función de pertenencia de un número borroso triangular es lineal. La extensión izquierda es la recta que pasa por (a1 ,0) y (a 2 ,1) y la extensión derecha es la recta que toma valores en (a 2 ,1) y (a3 ,0) . 1.4.2 Números borrosos trapezoidales Otra de las formas de números borrosos son los números borrosos trapezoidales. Estas formas trapezoidales surgen como consecuencia de que ellas tienen varios puntos con máximo grado de pertenencia de valor 1. Para un número borroso trapezoidal no se obtiene un solo punto cuando =1, sino una línea horizontal sobre un intervalo [a2 , a3 ] tal como muestra la figura 1.6.. 23.
(34) Capítulo 1. Figura 1.6. Número borroso trapezoidal A [a1 , a2 , a3 , a4 ] . La función de pertenencia para este número borroso trapezoidal viene dada por:. x a1 a a si a1 x a 2 1 2 1 si a 2 x a3 A ( x) a 4 x si a x a 3 4 a 4 a3 en otro caso 0. (1.49). donde el soporte viene dado por [a1 , a4 ] , el núcleo viene dado por el intervalo [a2 , a3 ] como ya se vio anteriormente, su radio izquierdo es l a a2 a1 y su radio derecho es. ra a4 a3 . Por tanto sus - cortes vienen dados por: A [a1 (a2 a1 ) , a4 (a4 a3 ) ]. (1.50). Un número borroso trapezoidal A se denota mediante su núcleo y sus radios en la forma A [a1n , a2 n , l a , ra ] , o alternativamente mediante una cuarteta de confianza donde los. valores que la componen son el valor más pequeño posible, el valor inferior y el valor superior que conforman el núcleo y el valor más elevado posible, es decir A [a1 , a2 , a3 , a4 ] .. Como se puede observar la función de pertenencia de un número borroso trapezoidal también es lineal. La función que delimita el nivel de pertenencia de los valores inferiores f(x), es la recta que pasa por los puntos (a1 ,0) y (a 2 ,1) y la que delimita el grado de 24.
(35) Capítulo 1. pertenencia de valores superiores al núcleo, g(x) es la recta que pasa por los puntos (a3 ,1) y. (a 4 ,0) .. 1.5. Análisis descriptivo borroso. Cuando se quiere investigar las opiniones de las personas o el consenso en algunos temas determinados, el uso de la moda o la mediana será más adecuado que el de la media. Sin embargo las estadísticas tradicionales ofrecen una sola respuesta o cierto rango de la respuesta, incapaz de reflejar suficientemente el pensamiento complejo de un individuo. Si las personas pueden utilizar la función de pertenencia para expresar el grado de sus sentimientos sobre la base de sus propias decisiones, la respuesta presentada estará más cerca al pensamiento humano real. El análisis estadístico borroso crece como una nueva disciplina debido a la necesidad de hacer frente a la información imprecisa causada por el pensamiento humano en ciertos ambientes experimentales. En este epígrafe se formalizan las definiciones de media borrosa, moda borrosa, mediana borrosa y varianza borrosa. Para un estudio más profundo se puede consultar (Nguyen y Wu, 2006). 1.5.1 Media borrosa En esta sección se muestra la definición de media borrosa para datos con múltiples valores y datos con valores intervalares (Nguyen y Wu, 2006). Definición 1.12 (Media muestral borrosa: datos con múltiples valores) Sea U el conjunto universo y L L1 , L2 ,..., Lk un conjunto de k variables lingüísticas en. m m m U, y FX i i1 i 2 ... ik , j 1,2,..., n , sea una sucesión de muestras aleatorias L1 L2 Lk k. borrosas en U, mij ( mij 1) es la pertenencia con respecto a L j . j 1. Entonces la media muestral borrosa se define como: 25.
(36) Capítulo 1. 1 n 1 n 1 n m m i1 n mik i2 n i 1 n i 1 i 1 FX ... L1 L2 Lk. (1.51). Definición 1.13 (Media muestral borrosa: datos con valores intervalares) Sea U el conjunto universo, y Fxi ai , bi , ai , bi R, i 1,..., n una sucesión de muestras borrosas aleatoria en U. Entonces la media muestral borrosa se define como:. 1 n 1 n F x ai , bi n i 1 n i 1 . (1.52). 1.5.2 Moda borrosa En esta sección se formaliza la definición de moda borrosa para datos con múltiples valores y datos con valores intervalares (Nguyen y Wu, 2006). Definición 1.14 (Moda muestral borrosa: datos con múltiples valores) Sea U el conjunto universo y L L1 , L2 ,..., Lk un conjunto de k variables lingüísticas en U, y FS i , i 1,2..., n, una sucesión de muestras aleatorias borrosas en U, para cada muestra FS i , asignamos a una variable lingüística L j una pertenencia normalizada k. n. j 1. i 1. mij ( mij 1) . Sea S j mij , j 1,2..., k . Entonces el máximo valor de S j (con respecto a L j ) se llama moda borrosa (MB) de la muestra, es decir es la pertenencia con respecto a L j . Entonces la moda muestral borrosa se define como:. . MB L j S j max Si 1i k. . (1.53). Nota: Un nivel de significación α para la moda borrosa puede ser definida de la siguiente forma: Sea U el conjunto universo y L L1 , L2 ,..., Lk un conjunto de k variables lingüísticas en U, y FS i , i 1,2..., n, una sucesión de muestras aleatorias borrosas en U. Para cada 26.
(37) Capítulo 1. muestra FS i , asignamos a una variable lingüística L j una pertenencia normalizada k. n. j 1. i 1. mij ( mij 1) . Sea S j I ij , j 1,2..., k , I ij 1 si mij , I ij 0 si mij . Por lo que el máximo valor de S j (con respecto a L j ) se llama moda borrosa (MB) muestral, es. . . decir, MB L j S j max Si . Si hay más de dos conjuntos de L j que satisfacen las 1i k. mismas condiciones, se dice que la muestra borrosa tiene un acuerdo múltiple común.. Definición 1.15 (Moda muestral borrosa: datos con valores intervalares) Sea U el conjunto universo, L L1 , L2 ,..., Lk un conjunto de k variables lingüísticas en U, y. FS a ,b , a ,b R ,i 1,..., n i. i. i. i. i. una sucesión de muestras borrosas aleatorias en U.. Para cada muestra FSi , si existe un intervalo. c, d . que está respaldado por ciertas. muestras, entonces llamamos a estas muestras un conglomerado. Sea MS un conjunto de conglomerados que contiene el máximo número de muestras, entonces, la moda borrosa (MB) se define como: MB a, b ai , bi | ai , bi MS. (1.54). Si a, b no existe (por ejemplo a, b es un conjunto vacío) se dice que esta muestra borrosa no tiene moda borrosa. 1.5.3 Mediana borrosa En esta sección se formaliza la definición de mediana borrosa para datos con múltiples valores y datos con valores intervalares (Nguyen y Wu, 2006).. 27.
(38) Capítulo 1. Definición 1.16 (Mediana muestral borrosa: datos con múltiples valores) Sea U el conjunto universo y L L1 , L2 ,..., Lk un conjunto de k variables lingüísticas en. m m m U, y X i i1 i 2 ... ik , i 1,2,..., n , sea una sucesión de muestras aleatorias L1 L2 Lk n. borrosas en U, Sea S j mij , j 1,2..., k , T 1 i 1. j. mínima L j tal que. S i 1. j. S S1 S 2 2 ... k k . Entonces, la n n n. T T T { es el mínimo entero que sea } se llama mediana 2 2 2. muestral borrosa de xi , es decir. medianaBorrosa( xi ) L j : mínimo j . n. S i 1. j. T 2 . (1.55). Mediana muestral borrosa: datos con valores intervalares Para calcular la mediana muestral borrosa en datos con valores intervalares existen dos procedimientos. El primer procedimiento viene dado por la definición 1.17 que aparece como ha sido mencionado anteriormente en Fundamentals of Statistics with Fuzzy Data (Nguyen y Wu, 2006). Definición 1.17 Sea U el conjunto universo, y Fxi ai , bi , ai , bi R, i 1,..., n una sucesión de muestras borrosas aleatorias en U. Sea c j el centro de cada intervalo ai , bi y l j la longitud de cada intervalo ai , bi . Entonces la mediana muestral borrosa se define como:. FMediana (c; r ), c mediana c j , r . mediana l j 2. (1.56). 28.
(39) Capítulo 1. El segundo procedimiento fue seleccionado para la implementación del software ya que ofrece menor incertidumbre en los resultados, además que se aplica el procedimiento clásico para obtener la mediana. Pasos para obtener la mediana muestral borrosa en datos con valores intervalares: 1. Ordenar los números borrosos siguiendo el procedimiento mostrado en el subepígrafe 1.2.4. 2. Aplicar el procedimiento para obtener la mediana clásica. Si el número de intervalos es impar la mediana es el número borroso que se encuentra en la posición del medio y si es par entonces la mediana es el número borroso que se corresponde con la semisuma de cada componente de los números borrosos centrales. 1.5.4 Varianza borrosa A continuación se define la varianza relativa borrosa siguiendo el mismo razonamiento de las definiciones anteriores. Definición 1.18 (Varianza relativa borrosa: datos con múltiples valores) Sea U el conjunto universo y L L1 , L2 ,..., Lk un conjunto de k variables lingüísticas en. m m m U, y FX i i1 i 2 ... ik , i 1,2,..., n , sea una sucesión de muestras aleatorias L1 L2 Lk k. borrosas en U, mij ( mij 1) es la pertenencia con respecto a L j . Entonces la varianza j 1. muestral borrosa (VB) se define como: n. 1 n ( m mi1 ) i1 n i 1 i 1 k. VB . n. 1 n ( m mi 2 ) i2 n i 1 i 1. n. (n 1) mij j 1 i 1. L1. 2. k. . n. 1 n ( m mik ) i1 n i 1 i 1. n. (n 1) mij j 1 i 1. L2. 2. k. ... . 2. n. (n 1) mij j 1 i 1. Lk. (1.57). 29.
(40) Capítulo 1. 1.5.5 Métodos de defuzzificación En muchos problemas, aunque estimemos las variables que lo describen mediante números borrosos, será necesario cuantificar las magnitudes que pretendemos estimar finalmente mediante un valor cierto, es decir, debemos asignarles un valor crisp. Esto es lo que en la literatura borrosa se conoce como “defuzzificar” números borrosos, o lo que los profesores Kaufmann y Gil Aluja denominan como “hacer caer la entropía”. La literatura borrosa da diversas alternativas para la defuzzificación de números borrosos, a continuación se enuncian siete métodos y se describen los dos utilizados. Métodos de defuzzificación: 1. Principio de Máxima Pertenencia (Max-membership principle). 2. Centroide (Centroid method). 3. Promedio ponderado (Weighted average method). 4. Media de la Máxima Pertenencia (Mean–max membership). 5. Centro de suma (Centre of sums). 6. Centro de mayor área (Centre of largest area). 7. Primero de los máximos o último de los máximos (First of maxima or last of maxima). Método Centroide: Es el método más ampliamente utilizado. Puede ser llamado como método de centro de gravedad o método de centro de área. Según este método el valor cierto representativo A de un número borroso , se halla como:. A. . x  ( x)dx. sop (  ). .  ( x)dx. (1.58). sop (  ). 30.
(41) Capítulo 1. Método Media de Máxima Pertenencia: Para un número borroso , su número equivalente cierto A es un valor crisp que pertenece al núcleo de , es decir: A= x| x Nucl( A). (1.59). En el caso en que el núcleo del número borroso se componga únicamente de un valor, la determinación de A es inmediata. Sin embargo, si el núcleo es un intervalo de confianza se utilizará la siguiente expresión: A. 1.6. ab 2. (1.60). Análisis de regresión. El uso de las técnicas de regresión sobre las observaciones experimentales ha permitido el estudio de numerosos fenómenos en diversos campos de la ciencia como la Agricultura, Química, Medicina, Medio Ambiente, Psicología, Biología y Economía lo que ha supuesto un gran avance, no solo por los desarrollos matemáticos alcanzados sino también por su aplicación en situaciones reales. Dichas técnicas requieren de un número suficiente de observaciones “precisas” y “fiables”. Sin embargo no siempre es posible obtener el conjunto de observaciones requerido, o éstas contienen algún tipo de imperfección a consecuencia de la imprecisión o vaguedad de los datos. En cualquier caso, los modelos obtenidos a partir de datos reales (suficientes o no, con imperfecciones o no) deberían proveer de capacidades predictivas y descriptivas (Crespo, 2002). 1.6.1 Regresión Probabilística El objetivo del análisis de regresión es determinar la relación de una variable dependiente (respuesta, predicha o endógena) con un conjunto de variables independientes (predictoras, explicativas exógenas). Formalmente dado un conjunto de datos ( xi , yi ) , para i 1,..., n , donde xi m e y i es el valor correspondiente al vector x i , y dada una función f ( x, A) , se quiere encontrar el vector de parámetros A, tal que: 31.
(42) Capítulo 1. yi f ( xi , A) para i 1,..., n. (1.61). En general no suele haber una solución exacta para la ecuación anterior debido a la variabilidad de los datos en el mundo real, a la infinidad de factores que se reflejan de cada dato y a la incertidumbre de muchas mediciones. Por este motivo debe buscarse una manera de relajar el cumplimiento estricto de la igualdad. La regresión probabilística, la más conocida y utilizada entre las técnicas de regresión, flexibiliza la relación (1.61) definiendo una función de pérdida L, que mide como los errores de predicción entre y i y f ( xi , A) debieran penalizarse, con la idea de encontrar una solución lo más aproximada posible al cumplimiento de la igualdad. Una elección habitual de función de pérdida es la norma L p :. L p ( y f ( x, A), x) | y f ( x, A) | p. (1.62). Para algún número positivo p. La función de pérdida más utilizada es el ajuste de los mínimos cuadrados donde p=2, que presenta ventajas analíticas, ya que L1 tiene el inconveniente de presentar discontinuidades en sus derivadas. Lo más frecuente es que f sea una función lineal pero no siempre esta función es la más adecuada y por ello son importantes también los casos en que, por ejemplo, las funciones. f son cuadráticas, más generalmente polinomios, o incluso, expresiones más complejas en que aparezcan funciones trascendentes. Sin embargo por lo general los modelos no lineales se pueden reducir a lineales mediante transformaciones de las variables. Cuando es posible realizar dicha transformación, se dice que se trata de un modelo intrínsecamente lineal. El modelo clásico de regresión lineal basado en la teoría de las probabilidades, asume que se dispone de n observaciones independientes para las variables y, x1 , x2 ,..., xm . Para cada observación se asume el modelo lineal siguiente:. yi 0 1 xi 1 ,... m xim i. (1.63). 32.
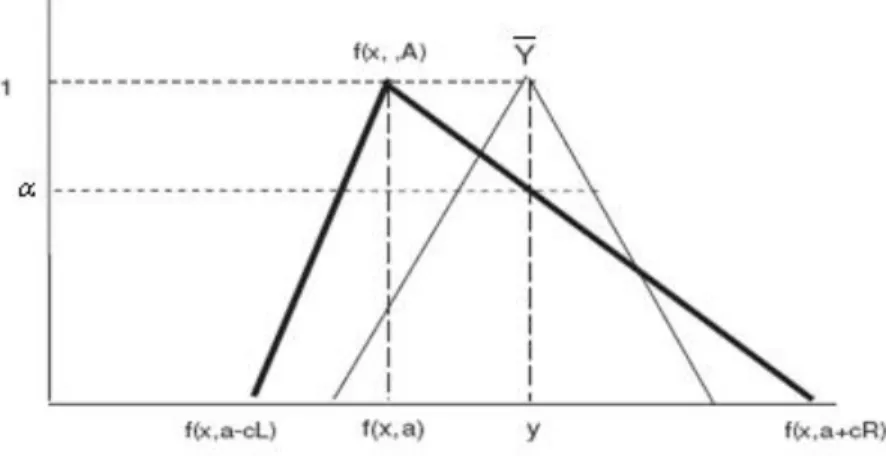
(43) Capítulo 1. _____. Donde los valores i , i 1, m son parámetros desconocidos, i es el término de perturbación estocástica de la i-ésima observación. Es importante destacar que el análisis de regresión lineal múltiple parte de las hipótesis de independencia de las observaciones. y i , normalidad de los residuos o errores y. homogeneidad de sus varianzas. 1.6.2 Regresión Borrosa En el análisis de regresión borrosa, las desviaciones entre los valores de pertenencia observados y los valores de pertenencia estimados se asume que dependen de la incertidumbre de la estructura del modelo. En cambio en el análisis de regresión lineal clásica, las desviaciones se suponen causadas por errores, de origen aleatorio, en las observaciones. La relación (1.61) no se cumple, por lo general, para los números reales. Sin embargo considerando números borrosos, siempre es posible encontrar coeficientes, que con un cierto nivel de pertenencia, cumplan la relación (ver figura 1.7).. Figura 1.7: Estimación posibilística de Regresión Borrosa. En la figura 1.7 se aprecia que, en un sentido más tradicional, la igualdad entre el dato original y el valor estimado, se cumple para su valor central, con un nivel de pertenencia α.. 33.
(44) Capítulo 1. Por otra parte, Y 0 f ( x, A) 0 , con lo que cualquier valor que está incluido en el número borroso Y , también está incluido en el número borroso estimado. En la regresión borrosa se asume que la relación entre la variable explicada y las explicativas. es. lineal,. pero. en. este. caso. si. se. dispone. de. una. muestra. {( X 1 , Y1 ), ( X 2 , Y2 ),..., ( X j , Y j ),...., ( X n , Yn )} , las posibles divergencias que pudieran surgir. entre la j-ésima observación de la variable dependiente Y j y su estimación Yˆ j , se expresa mediante una relación borrosa del tipo: Y A0 A1 x1 A2 x2 ... Am xm. (1.64). En (1.64), los coeficientes A0 , A1 , A2 ,..., Am , son números borrosos, por lo que el i-ésimo queda caracterizado por. Ai {x, Ai ( x)} {Ai [ A1i ( ), A2i ( )] | 0 1}. (1.65). Es decir, las divergencias que se producen respecto a la teórica relación lineal no tiene naturaleza aleatoria, sino borrosa. Así mismo se puede comprobar que el término de error no queda introducido como sumando en el hiperplano, sino que es incorporado en los coeficientes Ai , i 0,1,2,..., m , al asumirse que son números borrosos. De forma análoga a la técnica de mínimos cuadrados, una vez que se disponga de la muestra, nuestro objetivo debe ser ajustar los coeficientes Ai . 1.6.3 Regresión borrosa posibilística A continuación se presentará la regresión borrosa posibilística que dio origen de la regresión borrosa. Nos ajustaremos a la formulación de Hideo Tanaka (Tanaka y Ishibuchi, 1992, Tanaka, 1987). En la relación (1.61) se define el problema de regresión general. A partir de dicha formulación se puede introducir un modelo de regresión borrosa sustituyendo el número yi por el número borroso: 34.
(45) Capítulo 1. (1.66) Se supone que se tiene un conjunto inicial de n observaciones, donde los valores de entrada son. precisos. X ij con i 1,. y. están. , n y j 1,. representados. en. la. matriz. de. valores. reales. , m y la variable de salida Yi es imprecisa siendo sus valores. sujetos a funciones de pertenencia triangulares con parámetros ( yi , li , ri ) . El objetivo principal de la regresión borrosa es encontrar el o los coeficientes representados por A que tengan la menor incertidumbre posible. Para obtener una solución, se considera que Yi tiene una función de pertenencia de tipo LR, y que los coeficientes Aj (a j , cl j , crj ) también tienen una función de pertenencia L j R j . En este estudio la función objetivo f será una función lineal definida por: m. f ( x, A ) A0 A j x j .. (1.67). j 1. Yi tendrá. una función de pertenencia no simétrica ( yi , li , ri ) LR .. Las restricciones. posibilísticas en el caso general son: m. a j 0. m. X i j L ( ) cl j X i j yi L1 ( )li 1. j. para i 1,..., n. (1.68). j 0. m. m. j 0. j 0. a j X i j R1 ( ) crj X i j yi R 1 ( )ri para i 1,..., n cl j 0 ; cr j 0 para j 0,..., m. (1.69) (1.70). Si se consideran funciones de pertenencia triangulares (no necesariamente simétricas), por ejemplo, funciones LR, las restricciones posibilísticas (1.68)-(1.69) se reducen a: m. m. j 0. j 0. a j X i j (1 )) cl j X i j yi (1 )li. para i 1,..., n. (1.71). 35.
(46) Capítulo 1. m. a X j 0. j. m. i j. (1 )) crj X i j yi (1 )ri para i 1,..., n. (1.72). j 0. Esta última forma es la más habitual de plantear las restricciones posibilísticas de la regresión borrosa. 1.6.4 Índices de Bondad de Ajuste Un aspecto fundamental dentro del campo de la regresión borrosa es el estudio de la bondad del ajuste obtenido. En esta sección se analizan diferentes índices de bondad que se pueden utilizar para determinar la calidad de la estimación obtenida a través del proceso de regresión. No son muchos los estudios de regresión borrosa que incorporan un estudio de bondad y ajuste de los métodos propuestos. En (Donoso Salgado, 2006) se pueden encontrar seis medidas de bondad y ajuste normalizadas (varían entre 0 y 1) que controlan diversos aspectos de la similitud entre dos números borrosos y que evalúan la calidad de una estimación de regresión borrosa. Además se realiza una calificación para saber hasta qué punto cumplen con su objetivo: . SIM1 pondera las diferencias entre las distribuciones de posibilidad de Yi e Yˆi incluyendo la totalidad de las funciones de pertenencia.. . SIM2 mide las diferencias en el soporte, tanto del punto central como sus dos extensiones, entre los valores de salida y sus respectivas estimaciones.. . SIM3 mide las diferencias tanto de las extensiones como de la tendencia central.. . SIM4 mide la diferencia máxima de las extensiones de los datos de entrada con sus respectivas estimaciones.. . SIM5 mide la proximidad de las funciones de pertenencia con un solo punto, el supremo de la intersección.. . R 2 borroso mide las diferencias cuadráticas del valor central observado con el valor. central estimado. A continuación se explicarán estos dos índices: el SIM3 y el R 2 borroso. 36.
(47) Capítulo 1. Índice de Bondad del ajuste SIM3 Este índice mide las diferencias tanto de las extensiones como de la tendencia central. Por lo tanto de esta manera se define: (1.73) Donde (1.74) (1.75). Con esta definición de 1:. se construye el índice de bondad y ajuste Sim3 que varía entre 0 y. n. SIM 3 . (1 Ri ) i 1. (1.76). n. Medida de ajuste de la tendencia central Para medir la calidad del ajuste de la tendencia central, se conoce de la regresión probabilística el coeficiente de determinación, llamado también R-cuadrado, que varía entre 0 y 1. Esta medida parte del concepto de que la varianza total de las observaciones de la variable dependiente se puede descomponer en la suma de la varianza explicada más la no explicada, interpretándose el coeficiente de determinación como la proporción de la varianza total que es explicada por la regresión. Formalmente se tiene que: n. R2 . Varianza ex plicada Varianza total. ( yˆ i 1 n. (y i 1. i. y)2. i. y). (1.77) 2. 37.
Figure

![Figura 1.2 Número ordinario A [ a 1 , a 3 ] dado por un intervalo de confianza 1.2.2 Números borrosos](https://thumb-us.123doks.com/thumbv2/123dok_es/7406319.469647/22.918.201.508.805.1006/figura-número-ordinario-dado-intervalo-confianza-números-borrosos.webp)
![Figura 1.5 Número borroso triangular A [ a 1 , a 2 , a 3 ] .](https://thumb-us.123doks.com/thumbv2/123dok_es/7406319.469647/32.918.149.558.592.813/figura-número-borroso-triangular-a-a-a-a.webp)
+7



Documento similar