Tratamiento del perfil de la función glotal mediante técnicas de simulación numérica
60
0
0
Texto completo
(2) Agradecimientos En primer lugar me gustaría dar las gracias a mi profesor Fadragas, que me ofreció la oportunidad de llevar a cabo este proyecto y me ha dado todas las pautas necesarias para sacarlo adelante. A Carlos Ferrer y a Lucia por estar siempre pendientes de mis avances. A todos mis demás profesores por haberme convertido en una persona mas responsable. A todo el grupo de mis amigos de beca, los cuales, más que amigos son hermanos. Al Pikin por haber estado a mi lado y ser mi mejor amigo Y por último, y sí por ello más importante, gracias a mi familia, que ha logrado soportarme en mis días malos y de estrés, yo personalmente no hubiera sido capaz. En especial, quiero agradecer a mi madre, mi padre, mis abuelos, tíos, hermanos y mi novia Lilian por la paciencia y el apoyo mostrado en los momentos más duros.. 1.
(3) Resumen El campo de la síntesis de voz ha tenido importantes avances, sin embargo, la naturalidad aún se puede mejorar. Actualmente se conoce que para obtener mayor naturalidad de la voz, lo mejor es que la fuente de excitación empleada en el sintetizador produzca una señal lo más parecida posible al que se produce en la glotis. En esta investigación se establecen algunas precisiones cuantitativas sobre la posible influencia del perfil de la función glotal sobre la producción del sonido de la voz y se realiza una simulación, mediante el software MATLAB, de la eficiencia de recuperación de señales de las mismas.. 2.
(4) Abstract The field of speech synthesis has had important advances, however, the naturalness can still be improved. It is now known that in order to obtain greater naturalness of the voice, it is best that the excitation source used in the synthesizer produces a signal as close as possible to that produced in the glottis. In this research some quantitative precisions are established on the possible influence of the profile of the glottal function on the production of the sound of the voice and a simulation is realized, through the MATLAB software, of the efficiency of recovery of the same ones.. 3.
(5) Índice INTRODUCCIÓN................................................................................................................................. 5 CAPÍTULO 1: FUNDAMENTOS TEÓRICOS PARA EL ANÁLISIS DE SEÑALES DE VOZ .............. 8 PROCESOS AUTORREGRESIVOS DE ORDEN P, AR (P) .......................................................................... 8 Definición (Proceso AR (p)): ........................................................................................................ 8 Condición Suficiente para que un AR (p) sea Estacionario ........................................................ 9 Propiedades de los Procesos AR (p) Estacionarios ................................................................... 9 La Función de Autocovarianza de los Procesos AR (p) ............................................................ 10 La Varianza de los Procesos 𝐴𝑅(𝑝) .......................................................................................... 10 Estimación de la Función de Autocorrelación (FAC) de un 𝐴𝑅(𝑝) ........................................... 11 TRANSFORMADA DISCRETA DE FOURIER ........................................................................................... 12 Definición ................................................................................................................................... 12 Propiedades de la DFT ............................................................................................................. 13 Transformada Rápida de Fourier .............................................................................................. 14 TRANSFORMADA Z ........................................................................................................................... 15 Definición ................................................................................................................................... 15 Transformada Z bilateral ........................................................................................................... 16 Transformada Z unilateral ......................................................................................................... 16 Transformada Z inversa ............................................................................................................ 17 Región de convergencia (ROC) ................................................................................................ 16 Propiedades de la transformada Z ............................................................................................ 17 SEÑALES ......................................................................................................................................... 18 Definición de señal .................................................................................................................... 18 Tipos de señales: ...................................................................................................................... 18 Objetivo del procesamiento de señal: ....................................................................................... 18 Señales en tiempo discreto ....................................................................................................... 19 Diseño de filtros en tiempo discreto .......................................................................................... 20 Modelado todo polos de señales ............................................................................................... 22 CAPÍTULO 2: MODELOS DE FILTRADO INVERSO DE LA VOZ ................................................... 24 LA VOZ ............................................................................................................................................ 24 HISTORIA DE PRODUCCIÓN DE VOZ ................................................................................................... 27 FILTRADO INVERSO DE SEÑALES DE VOZ ........................................................................................... 29 MODELO ‘‘FUENTE-FILTRO’’.............................................................................................................. 30 MODELO DE LILJENCRANTS-FANT ..................................................................................................... 33 MODELO DE ROSENBERG ................................................................................................................. 35 CAPÍTULO 3: SIMULACIÓN NUMÉRICA DEL GRUPO DE FUNCIONES PROPUESTAS POR ROSENBERG.................................................................................................................................... 37 OBTENCIÓN Y GRABACIÓN DE SEÑALES ............................................................................................. 37 ANÁLISIS DE SEÑALES NO VOCALIZADAS ............................................................................................ 37 ANÁLISIS DE SEÑALES VOCALIZADAS ................................................................................................. 39 MODELACIÓN DEL TRACTO VOCAL .................................................................................................... 40 SIMULACIÓN NUMÉRICA DEL PROCESO DE ESTIMACIÓN DE UNA SEÑAL DE VOZ A PARTIR DE LAS FUNCIONES PROPUESTAS POR ROSENBERG ...................................................................................... 42 SIMULACIÓN NUMÉRICA DE LA FUNCIÓN DE TIPO TRAPEZOIDAL VARIANDO LA PENDIENTE DEL ÚLTIMO TRAMO. ........................................................................................................................................... 44 CONCLUSIONES .............................................................................................................................. 46 REFERENCIAS BIBLIOGRÁFICAS .................................................................................................. 48. 4.
(6) Introducción El habla es de gran importancia para el hombre, puesto que es reconocida como la principal vía de comunicación entre los seres humanos. Sin embargo, lo que muchos desconocen es que constituye un proceso sumamente complejo, donde intervienen varios órganos y sistemas. El análisis de la señal de voz y su posterior reconocimiento deben superar algunos problemas que en principio parecen triviales ya que son superados de forma sencilla por los seres humanos, algunos de ellos son, la correcta elección y extracción de las características de la señal de voz, tratar con corrección las variaciones inherentes a género, velocidad de emisión, pronunciación y acentos, tamaños de los vocabularios a reconocer, ruido y distorsión de los entornos donde se utilizan, inclusive hasta el estado de ánimo del locutor. Pese a las dificultades, se ha logrado gracias a múltiples corrientes independientes de investigación y desarrollo, sistemas de uso real, en los cuales la exactitud es superior al 90%, siempre considerando tareas acotadas de una u otra manera. El campo de las aplicaciones del procesamiento de voz constituye, aún, un sitio poco explorado por lo que existe hacia la temática, gran interés por parte de la comunidad científica internacional. Puede decirse que, resultan variados los campos desde los cuales es abordada la información contenida en la señal de voz, pueden mencionarse: los sistemas de comunicación con transmisión, análisis, síntesis y reconocimiento de voz; en los estudios de fonética acústica y en la lingüística, centralizados en la entonación; de vital importancia es su aplicación en la enseñanza de sordos, entre otras. Como antecedente directo del presente estudio se encuentra la investigación sobre la modelación matemática del tracto vocal en presencia de jitter, la cual evalúa el modelo de predicción lineal para recuperar la fuente de información y con ella los instantes de cierre glotal en presencia de jitter por duración y por posición. Adicionalmente se evalúa el comportamiento del modelo propuesto utilizando una base de datos de señales reales. Los resultados de este trabajo apuntan que, el modelo presenta mejor desempeño en presencia de jitter por posición que en. 5.
(7) presencia de jitter por duración, para lo cual se utilizó como medida de calidad la diferencia entre los instantes glotales de la señal glotal recuperada por el modelo y la señal que se utilizó para generar una vocal sintética. Aun cuando parezca que existen puntos en común entre la investigación antes citada y la que se expone, puede decirse que presentan grandes puntos divergentes en cuanto a los modelos de realización. Lo planteado anteriormente ha permitido trazar el siguiente tema de investigación: Extracción de datos de señales de voz y la simulación numérica de los pulsos glotales a partir del modelo planteado por Rosenberg. La investigación en cuestión posee gran importancia. Este estudio propiciará conocimientos en el área de procesamiento de señales. Los resultados obtenidos son de aplicación para el desarrollo de investigaciones en el campo de la calidad vocal, la logopedia y la foniatría. También los resultados obtenidos servirán de material de estudio para estudiantes y profesores. Para complementar el tema propuesto se planteó el siguiente problema científico: ¿Cómo contribuir a la creación de un modelo matemático para comprender, con mayor claridad, el comportamiento de la función glotal? Para dar solución al problema antes mencionado se traza los siguientes objetivos: Objetivo General: Establecer algunas precisiones cuantitativas sobre la posible influencia del perfil de la función glotal sobre la producción del sonido de la voz, en particular, considerando los efectos del grado de inclinación de la porción derecha de la curva de la función glotal en el momento del cierre brusco de la glotis. Objetivos Específicos: 1. Conceptualizar. los. principales. fundamentos. teóricos. de. la. investigación. 2. Analizar los Modelos de Producción y Filtrado de señales de voz propuestos por Liljencrants-Fant y Rosenberg. 3. Procesar utilizando el software MATLAB los modelos matemáticos representativos de los pulsos glotales referidos por Rosenberg (1971). 6.
(8) 4. Obtener una representación empírica de la función transferencia del tracto vocal mediante filtrado inverso, utilizando como referencia la mejor función glotal propuesta por Rosenberg. 5. Simular comparativamente los efectos de los perfiles de la función glotal del grupo de Rosenberg. 6. Analizar el comportamiento de la señal de voz estimada para distintas pendientes del último tramo de la función glotal de tipo trapezoidal.. Para dar cumplimiento a los objetivos trazados, la tesis se encuentra estructurada de la siguiente forma: Capítulo 1: Se exponen una serie de contenidos, como Procesos Autorregresivos, Transformadas Integrales y Señales, con el objetivo de lograr una primera aproximación al procesamiento y filtrado inverso de señales de voz. Capítulo 2: Se analizan modelos de producción y filtrado inverso de señales de voz los cuales constituyen una referencia obligatoria en el desarrollo de este trabajo. Capítulo 3: Se realiza un análisis del comportamiento de las señales de voz y una simulación numérica de la recuperación de las señales, a partir de distintas aproximaciones de la forma de onda de la glotis según las funciones propuestas por Rosenberg (Rosenberg, 1971). Se determina cuantitativamente, aplicando un concepto de distancia entre series de tiempo, cuál de las funciones referidas es la más adecuada, o sea, la que introduce menos error en la recuperación. Similarmente se realiza una simulación numérica, utilizando la función tipo trapezoidal, donde se ha variado la pendiente del último tramo y obteniéndose un valor mínimo de la distancia entre las series de tiempo para un valor intermedio de la pendiente.. 7.
(9) Capítulo 1: Fundamentos Teóricos para el Análisis de Señales de Voz Procesos Autorregresivos de Orden p, AR (p) Definición (El Operador de Rezago): Se denota por L (Lag, en inglés) y es tal que 𝐿(𝑌𝑡 ) = 𝑌𝑡−1 . Es decir, L opera sobre una serie rezagándola un período hacia atrás. De igual manera𝐿(𝑌𝑡−1 ) = 𝑌𝑡−2 , luego 𝐿(𝐿(𝑌𝑡 )) = 𝐿2 (𝑌𝑡 ) = 𝑌𝑡−2 y en general𝐿𝑝 (𝑌𝑡 ) = 𝑌𝑡−𝑝 . Se define también 𝐿0 = 1, el operador identidad. Un polinomio de grado p en el operador 𝐿 se define como el operador formado por una combinación lineal de potencias de 𝐿 𝐵𝑝 (𝐿) = 𝛽0 + 𝛽1 𝐿 + 𝛽2 𝐿 2 + ··· + 𝛽𝑝 𝐿𝑝 , tal que: 𝑝. 𝐵𝑝 (𝐿)(𝑌𝑡 ) = (𝛽0 + 𝛽1 𝐿 + 𝛽2 𝐿 2 + ··· + 𝛽𝑝 𝐿𝑝 )𝑌𝑡 = ∑ 𝛽𝑗 𝐿𝑗 𝑌𝑗 , 𝑗=0 𝑝. = ∑ 𝛽𝑗 𝑌𝑡−𝑗 , 𝑗=0. = 𝛽0 𝑌𝑡 + 𝛽1 𝑌𝑡−1 + 𝛽2 𝑌𝑡−2 +··· + 𝛽𝑝 𝑌𝑡−𝑝 .. (1.1). Definición (Proceso AR (p)): Se dice que 𝑌𝑛 , 𝑛 ∈ 𝑍 sigue un proceso AR (p) si: 𝑌𝑛 = 𝜑1 𝑌𝑛−1 + 𝜑2 𝑌𝑛−2 +··· + 𝜑𝑝 𝑌𝑛−𝑝 + 𝜀𝑛 , donde 𝜀𝑛 ∼ 𝑅𝐵(0, 𝜎2). Usando el operador de rezago L se puede escribir como 𝜑𝑝 (𝐿)(𝑌𝑛 ) = 𝜀𝑛 con 𝜑𝑝 (𝑧) = 1 − 𝜑1 𝑧 + 𝜑2 𝑧 2 +··· + 𝜑𝑝 𝑧 𝑝 , 𝑧 ∈ 𝐶, el polinomio autorregresivo.. 8.
(10) Condición Suficiente para que un AR (p) sea Estacionario La condición suficiente para que 𝑌𝑡 ∼ 𝐴𝑅(𝑝) sea estacionario en covarianza es que las p raíces del la ecuación 𝜑𝑝 (𝑧) = 0, 𝑧1 , 𝑧2 , . . . , 𝑧𝑝 cumplan |𝑧𝑖 | > 1 , donde 𝜑𝑝 (𝑧) es el polinomio característico del AR (p) definido por 𝜑𝑝 (𝑧) = 1 − 𝜑1 𝑧 + 𝜑2 𝑧 2 +··· + 𝜑𝑝 𝑧 𝑝 , 𝑧 ∈ 𝐶. (1.2). La condición se describe como: “Para que un proceso autorregresivo de orden p sea estacionario en covarianza, es suficiente que las raíces del polinomio autorregresivo estén por fuera del círculo unitario”. Propiedades de los Procesos AR (p) Estacionarios Para un proceso 𝑌𝑡 ∼ 𝐴𝑅(𝑝), se tiene que 𝐸(𝑌𝑡 ) = 0. Demostración: Si 𝑌𝑡 es estacionario en covarianza entonces 𝐸(𝑌𝑡 ) = µ Además, 𝐸(𝑌𝑡 ) = 𝜑1 𝐸(𝑌𝑡−1 ) + 𝜑2 𝐸(𝑌𝑡−2 ) +··· + 𝜑𝑝 𝐸(𝑌𝑡−𝑝 ) + 0 Pero todas las esperanzas son µ. Luego µ = 𝜑1 µ + 𝜑2 µ +··· + 𝜑𝑝 µ. Si µ ≠ 0 entonces 1 = 𝜑 1 +··· + 𝜑𝑝 Por tanto 𝜑𝑝 (1) = 0 Esto es una contradicción (→←), ya que ∀𝑧 ∈ 𝐶, |𝑧| ≤ 1 entonces 𝜑𝑝 (𝑧) ≠ 0 Luego debe tenerse que µ = 0, es decir, el proceso es de media cero. ∎ Un proceso 𝑌𝑡 ∼ 𝐴𝑅(𝑝) con 𝐸(𝑌𝑡 ) = µ ≠ 0 se define como 𝜑(𝐿)(𝑌𝑡 ) = 𝜑0 + 𝜀𝑡. 9. (1.3).
(11) Donde 𝜑0 = 𝜑𝑝 (𝐿)(µ) = (1 − 𝜑1 − 𝜑2 −··· −𝜑𝑝 )µ Nótese que también se puede escribir 𝑌𝑡 = (1 − 𝜑1 −··· −𝜑𝑝 )µ + 𝜑1 𝑌𝑡−1 +··· +𝜑𝑝 𝑌𝑡−𝑝 + 𝜀𝑡 De donde 𝑌𝑡 − µ = 𝜑1 (𝑌𝑡−1 − µ) +··· + 𝜑𝑝 (𝑌𝑡−𝑝 − µ) + 𝜀𝑡 Es decir, el proceso (𝑌𝑡 − µ) es 𝐴𝑅(𝑝) de media cero. La Función de Autocovarianza de los Procesos AR (p) La función de autocovarianza de un proceso 𝑌𝑡 ∼ 𝐴𝑅(𝑝) estacionario en covarianza, 𝑅(𝑘) se puede calcular resolviendo una ecuación recursiva lineal denominada, en plural, las ecuaciones de Yule–Walker. Un proceso 𝐴𝑅(𝑝), 𝑌𝑛 = ∑𝑝𝑗=1 𝜑𝑗𝑌 𝑛−𝑗 + 𝜀𝑡. que satisface la condición de. estacionario en covarianza. Su función fac 𝑅(𝑘) satisface la ecuación recursiva 𝑅(𝑘) = ∑𝑝𝑗=1 𝜑𝑗 𝑅(𝑘 − 𝑗), 𝑘 = 1, 2, … … … ( 𝑒𝑐𝑢𝑎𝑐𝑖𝑜𝑛𝑒𝑠 𝑑𝑒 𝑌𝑢𝑙𝑒 − 𝑊𝑎𝑙𝑘𝑒𝑟).. (1.4). La Varianza de los Procesos 𝐀𝐑(𝐩) Si 𝑌 𝑡 ∼ 𝐴𝑅(𝑝) de media cero, estacionario en covarianza entonces: 𝜑𝑝 (𝐿)(𝑌𝑛 ) = 𝜀𝑛 , 𝑝𝑎𝑟𝑎 𝜀𝑛 ∼ 𝑅𝐵(0, 𝜎 2 ) Además, se cumple que ∀𝑧, |𝑧| ≤ 1 𝜑𝑝 (𝑧) ≠ 0 entonces el cociente 1 ⁄𝜑𝑝 (𝑧) se puede desarrollar en serie de potencias de 𝑧, y colocar ∞. 1 ⁄𝜑𝑝 (𝑧) = ∑ 𝜓𝑗 𝑧 𝑗 𝑗=0. para ciertos coeficientes (𝜓𝑗 , 𝑗 = 0,1, . . . ), 𝑐𝑜𝑛 𝜓0 = 1. Por tanto, se puede colocar. 𝑌𝑛 =. 1 (𝜀 ) = 𝜀𝑛 + 𝜓1 𝜀𝑛−1 + 𝜓2 𝜀𝑛−2 + . .. 𝜑𝑝 (𝐿) 𝑛. Tomando varianza en ambos miembros, se obtiene:. 10.
(12) 𝑉𝑎𝑟(𝑌𝑛 ) = 𝜎 2 ∑∞ 𝑗=0 𝜓𝑗 .. (1.5). Estimación de la Función de Autocorrelación (FAC) de un 𝐀𝐑(𝐩) 𝜌(𝑘) = 𝐶𝑜𝑟𝑟(𝑌𝑡 , 𝑌𝑡+𝑘 ), 𝑘 = 1,2, . . . , 𝑝, 𝑝 + 1, . ... (1.6). Cumple que: 1. Se tiene un sistema lineal 𝑝 × 𝑝 que cumple: 1 𝜌(1) 𝜌(1) 𝜌(2) ⋯ 𝐴= 𝜌(2) 𝜌(3) ⋮ ⋱ (𝜌(𝜌 − 1) 𝜌(𝜌 − 2) ⋯. 𝜌(𝜌 − 1) 𝜑1 𝜌(1) 𝜌(𝜌 − 2) 𝜑2 𝜌(2) ] 𝜌(𝜌 − 3) , 𝜑 = [ ⋮ ] , 𝜌 = [ ⋮ ⋮ 𝜑𝑝 𝜌(𝑝) 1 ). Entonces 𝐴𝜑 = 𝜌 Luego dada 𝜌̂(1), . . . , 𝜌̂(𝑝) se puede resolver tomando 𝜑̂ = 𝐴̂−1 𝜌̂, los estimadores de Yule-Walker de 𝜑.. 2. 𝜌(𝑘) = 𝜑1 𝜌(𝑘 − 1) + 𝜑2 𝜌(𝑘 − 2) +··· + 𝜑𝑝 𝜌(𝑘 − 𝑝),. 𝑘 = 𝑝, 𝑝 + 1, ... Forma una ecuación en diferencias finitas con condiciones iniciales 𝜌(1), . . . , 𝜌(𝑝), para 𝜌(𝑘), 𝑘 ≥ 𝑝 + 1, con solución 𝜌(𝑘) = 𝑠1 𝑔1𝑘 + 𝑠2 𝑔22 +··· + 𝑠𝑝 𝑔2𝑝 Donde 𝑔𝑖 = 1/𝑧𝑖 y 𝑧𝑖 es la i-ésima raíz de la ecuación característica 1 − 𝜑1 𝑧 − 𝜑2 𝑧 2 −··· −𝜑𝑝 𝑧 𝑝 = 0 Con |𝑧𝑖 | > 1 ⇔ |𝑔𝑖 | < 1, luego se debe cumplir que 𝜌(𝑘) → 0, 𝑘 → ∞.. 11.
(13) Transformada Discreta de Fourier La Transformada Discreta de Fourier o DFT (del inglés, Discrete Fourier Transform) es un tipo de transformada discreta utilizada en el análisis de Fourier. Transforma una función matemática en otra, obteniendo una representación en el dominio de la frecuencia, siendo la función original una función en el dominio del tiempo. Pero la DFT requiere que la función de entrada sea una secuencia discreta y de duración finita. Dichas secuencias se suelen generar a partir del muestreo de una función continua, como puede ser la voz humana. Al contrario que la transformada de Fourier en tiempo discreto (DTFT), esta transformación únicamente evalúa suficientes componentes frecuenciales para reconstruir el segmento finito que se analiza. Utilizar la DFT implica que el segmento que se analiza es un único período de una señal periódica que se extiende de forma infinita; si esto no se cumple, se debe utilizar una ventana para reducir los espurios del espectro. Por la misma razón, la DFT inversa (IDFT) no puede reproducir el dominio del tiempo completo, a no ser que la entrada sea periódica indefinidamente. Por estas razones, se dice que la DFT es una transformada de Fourier para análisis de señales de tiempo discreto y dominio finito. Las funciones sinusoidales base que surgen de la descomposición tienen las mismas propiedades. La entrada de la DFT es una secuencia finita de números reales o complejos, de modo que es ideal para procesar información almacenada en soportes digitales. En particular, la DFT se utiliza comúnmente en procesado digital de señales y otros campos relacionados dedicados a analizar las frecuencias que contiene una señal muestreada, también para resolver ecuaciones diferenciales parciales, y para llevar a cabo operaciones como convoluciones o multiplicaciones de enteros largos. [Matias, 2011] [Oppenheim, 2011] Definición La secuencia de N números complejos 𝑥0 , … , 𝑥𝑁−1 se transforma en la secuencia de N números complejos 𝑋0 , … , 𝑋𝑁−1 mediante la DFT con la fórmula:. 12.
(14) 𝑋𝑘 = ∑𝑁−1 𝑛=0 𝑥𝑛 𝑒. −2𝜋𝑖 𝑘𝑛 𝑁. 𝑘 = 0, … , 𝑁 − 1. (1.7). 2𝜋𝑖. donde i es la unidad imaginaria y 𝑒 𝑁 es la N-ésima raíz de la unidad. La transformada se denota a veces por el símbolo ℱ. La transformada inversa de Fourier discreta (IDFT) viene dada por 1. 𝑥𝑛 = 𝑁 ∑𝑁−1 𝑘=0 𝑋𝑘 𝑒. −2𝜋𝑖 𝑘𝑛 𝑁. 𝑛 = 0, … , 𝑁 − 1. (1.8). Propiedades de la DFT Completitud: La transformada discreta de Fourier es una transformación lineal e invertible. ℱ: ℂ𝑁 → ℂ𝑁 Donde ℂ denota el cuerpo de los números complejos. En otras palabras, para cada N > 0, cualquier vector complejo N-dimensional tiene una DFT y una IDFT que consisten también en vectores complejos N-dimensionales. 2𝜋𝑖. Ortogonalidad: Los vectores 𝑒 𝑁 𝑘𝑛 forman una base ortogonal sobre el cuerpo de los vectores complejos N-dimensionales: 2𝜋𝑖. 𝑘𝑛 𝑁 ∑𝑁−1 ) (𝑒 𝑘=0 (𝑒. −2𝜋𝑖 𝑘′𝑛 𝑁. ) = 𝑁𝛿𝑘𝑘′. (1.9). Donde 𝛿𝑘𝑘 ′ es la delta de Kronecker. Esta condición de ortogonalidad puede ser utilizada para obtener la fórmula de la IDFT a partir de la definición de la DFT, y es equivalente a la propiedad de unicidad. Si la expresión que define la DFT se evalúa para todos los enteros k en lugar de únicamente para 𝑘 = 0, … , 𝑁 − 1, la secuencia infinita resultante es una extensión periódica de la DFT, de período N. Esta periodicidad puede demostrarse directamente a partir de la definición:. 13.
(15) 𝑥𝑛+𝑁 = ∑𝑁−1 𝑛=0 𝑥𝑛 𝑒. −2𝜋𝑖 (𝑘+𝑁)𝑛 𝑁. = ∑𝑁−1 𝑛=0 𝑥𝑛 𝑒. −2𝜋𝑖 𝑘𝑛 𝑁. 𝑒 −2𝜋𝑖𝑛 = ∑𝑁−1 𝑛=0 𝑥𝑛 𝑒. −2𝜋𝑖 𝑘𝑛 𝑁. = 𝑋𝑘. (1.10). De forma similar, se puede demostrar que la fórmula de la IDFT lleva a una extensión periódica. 2𝜋𝑖. Teorema del desplazamiento: Multiplicando 𝑥𝑛 por una fase lineal 𝑒 𝑁 𝑛𝑚 para cualquier entero m equivale a un desplazamiento circular de la salida 𝑋𝑘 : 𝑋𝑘 se reemplaza por 𝑋𝑘−𝑚 donde el subíndice se repite periódicamente (período N). De forma similar, un desplazamiento circular de la entrada 𝑥𝑛 equivale a multiplicar la salida 𝑋𝑘 por una fase lineal. Matemáticamente, si {𝑥𝑛 } representa el vector 𝑥 entonces: 2𝜋𝑖. 2𝜋𝑖. Si 𝐹({𝑋𝑛 })𝑘 = 𝑋𝑘 entonces 𝐹 ({𝑥𝑛 ∗ 𝑒 𝑁 𝑛𝑚 }) = 𝑋𝑘−𝑚 y 𝐹({𝑥𝑛−𝑚 })𝑘 = 𝑋𝑘 𝑒 − 𝑁 𝑛𝑚 𝑘. Transformada Rápida de Fourier FFT es la abreviatura usual (del inglés Fast Fourier Transform) de un eficiente algoritmo que permite calcular la transformada de Fourier discreta (DFT) y su inversa. La FFT es de gran importancia en una amplia variedad de aplicaciones, desde el tratamiento digital de señales y filtrado digital en general a la resolución de ecuaciones en derivadas parciales o los algoritmos de multiplicación rápida de grandes enteros. El algoritmo pone algunas limitaciones en la señal y en el espectro resultante. La aparición de un algoritmo eficaz para esta operación fue una piedra angular en la historia de la informática. [Matias, 2011] [Oppenheim, 2011] Definición Sean 𝑥0 , … , 𝑥𝑛−1 números complejos. La transformada discreta de Fourier se define como:. 14.
(16) 2𝜋𝑖. − 𝑗𝑘 𝑓𝑗 = ∑𝑛−1 𝑗 = 0, … , 𝑛 − 1 𝑘=0 𝑥𝑘 𝑒 𝑛. (1.11). La evaluación directa de esa fórmula requiere 𝑂(𝑛²) operaciones aritméticas. Mediante un algoritmo FFT se puede obtener el mismo resultado con sólo 𝑂(𝑛 𝑙𝑜𝑔 𝑛) operaciones. En general, dichos algoritmos dependen de la factorización de n pero, al contrario de lo que frecuentemente se cree, existen FFTs para cualquier n, incluso con n primo. La idea que permite esta optimización es la descomposición de la transformada a tratar en otras más simples y éstas a su vez hasta llegar a transformadas de 2 elementos donde k puede tomar los valores 0 y 1. Una vez resueltas las transformadas más simples hay que agruparlas en otras de nivel superior que deben resolverse de nuevo y así sucesivamente hasta llegar al nivel más alto. Al final de este proceso, los resultados obtenidos deben reordenarse.. Transformada Z En procesamiento de señales, la Transformada Z convierte una señal real o compleja definida en el dominio del tiempo discreto en una representación en el dominio de la frecuencia compleja. El nombre de Transformada Z (TZ) procede de la variable del dominio, al igual que se podría llamar "Transformada S" a la Transformada de Laplace. Un nombre más adecuado para la TZ podría haber sido "Transformada de Laurent", ya que está basada en la serie de Laurent. La TZ es a las señales de tiempo discreto lo mismo que Laplace a las señales de tiempo continuo. [Garibay, 1997] Definición La Transformada Z, al igual que otras transformaciones integrales, puede ser definida como una transformada unilateral o bilateral.. 15.
(17) Transformada Z bilateral La TZ bilateral de una señal definida, en el dominio del tiempo discreto x[n] es una función X(z) que se define −𝑛 𝑋(𝑧) = 𝑍{𝑥[𝑛]} = ∑∞ 𝑛=−∞ 𝑥[𝑛]𝑧. (1.12). donde n es un entero y z es, en general, un número complejo de la forma 𝑧 = 𝐴𝑒 𝑗𝑤. (1.13). donde A es el módulo de z, y ω es la frecuencia angular en radianes por segundo (rad/s). Transformada Z unilateral De forma alternativa, en los casos en que x[n] está definida únicamente para n ≥ 0, la transformada Z unilateral se define como −𝑛 𝑋 + (𝑧) = 𝑍 + {𝑥[𝑛]} = ∑∞ 𝑛=0 𝑥[𝑛]𝑧. (1.14). Región de convergencia (ROC) La región de convergencia, también conocida como ROC, define la región donde la transformada-z existe. La ROC es una región del plano complejo donde la TZ de una señal tiene una suma finita. La ROC para una x[n] es definida como el rango de z para la cual la transformada-z converge. Ya que la transformada–z es una serie de potencia, converge cuando 𝑥[𝑛]𝑧 −𝑛 es absolutamente sumable. −𝑛 𝑅𝑂𝐶 = {𝑧: ∑∞ < ∞} 𝑛=−∞ 𝑥[𝑛]𝑧. Propiedades de la Región de Convergencia:. 16. (1.16).
(18) La región de convergencia tiene propiedades que dependen de las características de la señal, x[n]. . La ROC no tiene que contener algún polo. Por definición un polo es donde x[z] es infinito. Ya que x[z] tiene que ser finita para todas las ‘z’ para tener convergencia, no puede existir ningún polo para ROC.. . Si x[n] es una secuencia de duración finita, entonces la ROC es todo el planoz, excepto en |𝑧| = 0 𝑜 |𝑧| = ∞.. . Si x[n] es una secuencia del lado derecho entonces la ROC se extiende hacia fuera en el último polo desde x[z].. . Si x[n] es una secuencia del lado izquierdo, entonces la ROC se extiende hacia dentro desde el polo más cercano en x[z].. . Si x[n] es una secuencia con dos lados, la ROC va ser un anillo en el planoz que está restringida en su interior y exterior por un polo.. Transformada Z inversa La Transformada Z inversa se define 1. 𝑋[𝑛] = 𝑍 −1 {(𝑋(𝑧))} = 2𝜋𝑗 ∮𝐶 𝑋(𝑧)𝑧 𝑛−1 𝑑𝑧. (1.15). Donde ¨C¨ es un círculo cerrado que envuelve el origen y la región de convergencia (ROC). El contorno, ¨C¨ debe contener todos los polos de X (z). Propiedades de la transformada Z 𝑍. Linealidad: 𝑎1 𝑥1 (𝑛) + 𝑎2 𝑥2 → 𝑎1 𝑋1 (𝑧) + 𝑎2 𝑋2 (𝑧). 17.
(19) 𝑍. Desplazamiento con respecto al tiempo: 𝑥(𝑛 − 𝑘) → 𝑧 −𝑘 𝑋(𝑧) 𝑍. Inversión en el tiempo: 𝑥(−𝑛) → 𝑋(𝑧 −1 ) 𝑍. Convolución: 𝑥1 (𝑛) ∗ 𝑥2 (𝑛) → 𝑋1 (𝑧)𝑋2 (𝑧) Multiplicación: 𝑥1 (𝑛)𝑥2 (𝑛) →. 𝑧. 1 𝑧 ∮ 𝑋 (𝑣)𝑋2 (𝑣)𝑣 −1 𝑑𝑣 2𝜋𝑗 𝑐 1. Señales. Figura 1.1 Señal de ruido ambiental Definición de señal Una señal es una variación de una magnitud que transmite una información. Tipos de señales: De una variable, de varias variables. Unidimensional, multidimensional. De variable discreta, de variable continua. Objetivo del procesamiento de señal: Codificación, transmisión, recepción, almacenamiento y representación de señales en sistemas de comunicación de forma eficiente y fiable.. 18.
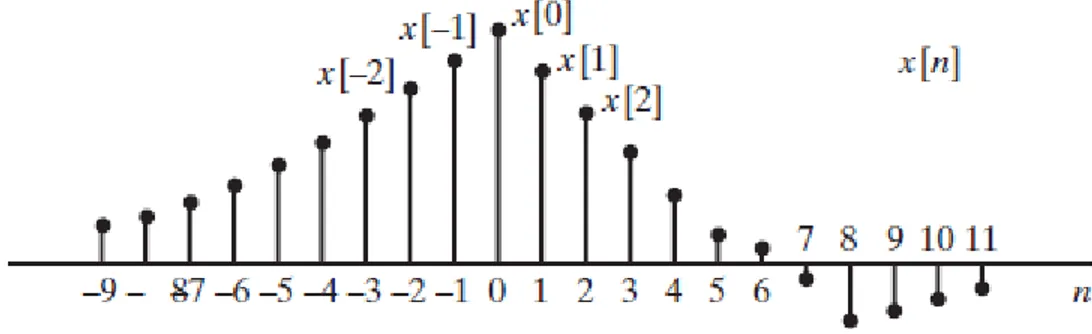
(20) Extracción de información de señales ruidosas. Señales en tiempo discreto El tratamiento de señales en tiempo discreto se basa en el procesamiento de secuencias numéricas indexadas con variables enteras en vez de utilizar funciones de variable independiente continua. En el tratamiento digital de señales (TDS) las señales se representan mediante secuencias de números de precisión finita y el proceso se realiza mediante cómputo digital. El término más general tratamiento de señales en tiempo discreto incluye el tratamiento digital de señales como un caso especial, pero incluye también la posibilidad de que las secuencias de muestras (datos muestreados) sean procesados con otras tecnologías en tiempo discreto. A menudo la distinción entre los términos tratamiento de señales en tiempo discreto y tratamiento digital de señales es de poca importancia, ya que ambos tratan con señales en tiempo discreto. Esto es particularmente cierto cuando se emplea cómputo de alta precisión. Aunque hay muchos ejemplos en los que las señales que se van a procesar son ya de por sí secuencias en tiempo discreto, la mayoría de las aplicaciones requieren el uso de la tecnología de tiempo discreto para procesar señales originadas en tiempo continuo. En este caso, las señales en tiempo continuo se convierten en una secuencia de muestras, es decir, en señales en tiempo discreto. [Gómez, 2001][Oppenheim, 2011] Las señales en tiempo discreto se representan matemáticamente como secuencias de números. Una secuencia de números x, en los que el n-ésimo número se indica como 𝑥[𝑛], se escribe formalmente así: 𝑥 = {𝑥[𝑛]}, −∞ < 𝑛 < ∞,. (1.17). siendo n un entero. En casos prácticos, estas secuencias surgen frecuentemente de muestrear una señal analógica (es decir, en tiempo continuo) 𝑥𝑎 (𝑡). En este caso, el valor numérico del n-ésimo número de la secuencia es igual al valor de la señal analógica,𝑥𝑎 (𝑡) en el instante temporal 𝑛𝑇, es decir, 𝑥[𝑛] = 𝑥𝑎 (𝑛𝑇), −∞ < 𝑛 < ∞.. 19. (1.18).
(21) La cantidad T se denomina periodo de muestreo, y su inversa es la frecuencia de muestreo. Aunque las secuencias no surgen siempre del muestreo de señales analógicas, es conveniente referirse a 𝑥[𝑛] como la “n-ésima muestra” de la secuencia. Además, aunque estrictamente hablando, 𝑥[𝑛] indica el n-ésimo número de la secuencia, la notación de la Ecuación (2.1) es innecesariamente compleja, por lo que resulta conveniente y exento de ambigüedad hablar de “la secuencia x[n]” con lo que queremos indicar la secuencia completa, lo mismo que cuando decimos “la señal analógica 𝑥𝑎(𝑡)”. Las señales en tiempo discreto (es decir, las secuencias), se representan frecuentemente en forma gráfica como se indica en la Figura 1.2.. Figura 1.2 Representación gráfica de una señal en tiempo discreto.. Aunque la abscisa se dibuja como una línea continua, es importante tener en cuenta que 𝑥[𝑛] está definida sólo para valores enteros de n. No es correcto pensar que 𝑥[𝑛] es cero en valores de n no enteros. Simplemente, 𝑥[𝑛] no está definida para valores no enteros de n. [Alvarado, 2011][O’Leidhin, 2011] Diseño de filtros en tiempo discreto Los filtros son una clase particularmente importante de sistemas lineales e invariantes con el tiempo. El término filtro selectivo en frecuencia sugiere un sistema que deja pasar ciertas componentes de frecuencia y rechaza completamente otras, pero en un contexto. 20.
(22) más amplio cualquier sistema que modifique ciertas frecuencias con respecto a otras se denomina también filtro. El diseño de filtros en tiempo discreto se refiere a la determinación de los parámetros de una función de transferencia o de una ecuación en diferencias que se aproxime a una respuesta al impulso o a una respuesta en frecuencia deseadas, dentro de unas tolerancias especificadas. Los sistemas en tiempo discreto implementados mediante ecuaciones en diferencias se puede clasificar en dos categorías básicas: sistemas con respuesta al impulso infinita (IIR) y sistemas con respuesta al impulso finita (FIR). El diseño de filtros IIR requiere la obtención de una función de transferencia aproximada con la forma de una función racional de z. Por otra parte, el diseño de filtros FIR requiere la aproximación de polinomios. Las técnicas de diseño comúnmente utilizadas para esas dos clases toman diferentes formas. Cuando los filtros en tiempo discreto comenzaron a ser de uso común, sus diseños se basaban en la correspondencia de diseños de filtros, en tiempo continuo, bien conocidos y formulados mediante técnicas como la invarianza al impulso y la transformación bilineal. [O’Leidhin, 2011] El diseño de filtros requiere realizar las siguientes etapas: especificación de las propiedades deseadas del sistema, aproximación de las especificaciones mediante un sistema causal en tiempo discreto y realización del Sistema. El primero es altamente dependiente de la aplicación y el tercero de la tecnología utilizada para la realización. En términos prácticos, el filtro deseado se realiza utilizando hardware digital y se emplea a menudo para filtrar una señal que proviene de una señal en tiempo continuo mediante muestreo periódico seguido por una conversión analógico-digital. Por este motivo se suelen denominar filtros digitales a los filtros en tiempo discreto, incluso aunque las técnicas de diseño que se utilizan se relacionan en la mayoría de los casos únicamente con la naturaleza de tiempo discreto de las señales y los sistemas que intervienen. 1993,1995][Milenkovic, 1986]. 21. [Fant, 1981,.
(23) Modelado todo polos de señales 𝑞. 𝐻(𝑧) =. ∑𝑘=0 𝑏𝑘 𝑧 −𝑘. (1.19). −𝑘 1−∑𝑃 𝑘=1 𝑎𝑘 𝑧. El modelo que representa la Ecuación (2.19) tiene en general polos y ceros. Aunque existen diversas técnicas para determinar el juego completo de coeficientes del numerador y del denominador de la Ecuación (2.19), los más útiles y más ampliamente utilizados se han concentrado en restringir el valor de q a cero y, en ese caso, H (z) en la Ecuación (2.19) tiene la forma: 𝐻(𝑧) = 1−∑𝑃. 𝐺. −𝑘 𝑘=1 𝑎𝑘 𝑧. 𝐺. = 𝐴(𝑧). (1.20). Se ha sustituido el parámetro b0 por el parámetro G para resaltar su papel como factor de ganancia global. Estos modelos se denominan acertadamente modelos “todo polos”. Dada su naturaleza, podría esperarse que un modelo todo polos sólo sirviera para modelar señales de duración infinita. Aunque esto puede ser cierto en sentido teórico, seleccionar esta forma de función de transferencia del modelo funciona bien en señales que aparecen en muchas aplicaciones, y los parámetros se pueden calcular de forma directa partiendo de segmentos de duración finita de la señal dada. La entrada y salida del sistema todo polos satisfacen la ecuación en diferencias de coeficientes constantes 𝑠̂ [𝑛] = ∑𝑃𝑘=1 𝑎𝑘 𝑠̂ [𝑛 − 𝑘] + 𝐺𝑣 [𝑛],. (1.21). lo que indica que la salida del modelo en el instante n está formada por una combinación lineal de las muestras anteriores más una muestra de entrada escalada. Esta estructura sugiere que el modelo todo polos es equivalente al supuesto de que la señal se puede aproximar mediante una combinación lineal sus valores anteriores. En consecuencia, este método de modelado de señales se denomina a menudo análisis predictivo lineal o predicción lineal. [Pericas, 1993] [Shina, 2010]. 22.
(24) Los filtros, la respuesta impulsional y la función de transferencia que tienen determinan los conceptos siguientes: . La ganancia (G (f)) se define como la amplificación de la señal de salida respecto a la entrada. Si esta amplificación es negativa, se habla de atenuación.. . La respuesta en amplitud de un filtro se define como el módulo de la respuesta frecuencial del filtro.. Las razones fundamentales por las que se utiliza un modelado todo-polos en procesamiento de voz son: a) Si se ignoran los sonidos nasales y algunos fricativos, la función de transferencia del tracto vocal es una función todo-polos y el efecto de la glotis y la radiación de los labios puede caracterizarse mediantes algunos polos adicionales. b) Los parámetros de un modelo todo-polos pueden obtenerse eficientemente aplicando técnicas de predicción. Sin embargo, la utilización de modelos con ceros finitos conlleva la resolución de sistemas de ecuaciones no lineales, lo cual incrementa considerablemente el coste de cálculo. c) Un modelo todo-polos permite aproximar cualquier modelo racional utilizando un número suficientemente elevado de polos. [O’Leidhin, 2011]. 23.
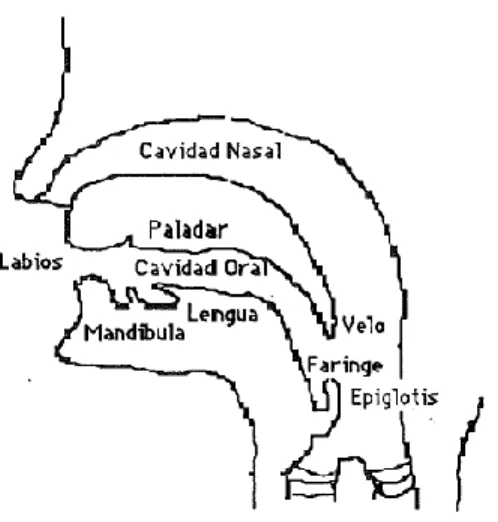
(25) Capítulo 2: Modelos de Filtrado Inverso de la Voz La voz La voz es una onda acústica de presión que se origina a partir de los movimientos fisiológicos voluntarios de los órganos del aparato fonador humano. En todo tipo de sonidos, el aire es expelido desde los pulmones a la tráquea y forzado a pasar entre las cuerdas vocales. A partir de este momento, el estado de relajación o tensión de las cuerdas vocales y el movimiento relativo de los órganos articulatorios define los diferentes sonidos. Durante la generación de los sonidos sonoros, el aire expelido hacia los labios por los pulmones provoca la vibración de las cuerdas vocales a un ritmo que depende de la presión del aire en la tráquea y del ajuste fisiológico de las mismas. Este ajuste incluye cambios en la longitud, grosor y tensión de las cuerdas vocales. El ritmo a que se abre y cierra la glotis, orificio que queda entre las cuerdas vocales, se corresponde con la frecuencia fundamental de la voz, inversa del período en una señal acústica, y con el tono percibido (pitch, en la literatura inglesa). La presión del aire subglótica y las variaciones temporales del área glotal determinan la velocidad volumétrica del flujo de aire glotal expelida al tracto vocal. Esta velocidad volumétrica glotal define la entrada de energía acústica o función de excitación al tracto vocal. El tracto vocal, que se extiende desde la glotis hasta los labios, actúa como un tubo acústico de sección no uniforme y variante con el tiempo. Esta variación temporal de la forma del tracto vocal es debida a los movimientos de los labios, la mandíbula, la lengua y el velo. Durante la generación de los sonidos no nasales, el velo separa el tracto vocal de la cavidad nasal. La cavidad nasal constituye un tubo acústico adicional para la transmisión del sonido usado en la generación de los sonidos nasales.. 24.
(26) Figura 2.1 Esquema del aparato fonador humano. Los sonidos sordos se generan manteniendo abiertas las cuerdas vocales voluntariamente, haciendo pasar el aire a través de ellas y usando los órganos articulatorios para crear una constricción. En la generación de los sonidos sonoros fricativos se produce a la vez vibración de las cuerdas vocales y constricción. Por último, los sonidos oclusivos son generados provocando presión en la boca y liberando luego el aire abruptamente.. Como la forma del tracto vocal cambia de forma más bien lenta en el habla continua, es razonable suponer que el sistema en tiempo discreto del modelo tiene propiedades fijas en un intervalo de tiempo del orden de 10 ms. Por tanto, el sistema en tiempo discreto se puede caracterizar en cada uno de esos intervalos de tiempo por una respuesta al impulso, una respuesta en frecuencia o un conjunto de coeficientes de un sistema IIR (Infinite Impulse Response). Concretamente, un modelo de la función de transferencia del tracto vocal tiene la forma ∑𝐾. 𝑏 𝑧 −𝑘. 𝑉(𝑧) = ∑𝑃𝑘=0 𝑎𝑘𝑧 −𝑘. (2.1). 𝑘=0 𝑘. O, de forma equivalente 𝐾. 𝑉(𝑧) =. 𝐾. 𝑖 (1−𝛼 𝑧 −1 ) ∏ 0 (1−𝛽 𝑧) 𝐴𝑧 −𝐾0 ∏𝑘=1 𝑘 𝑘 𝑘=1. 𝑃 [ ] 2 (1−𝑟 𝑒 𝑗𝜃𝑘 𝑧 −1 )(1−𝑟 𝑒 −𝑗𝜃𝑘 𝑧 −1 ) ∏𝑘=1 𝑘 𝑘. 25. ,. (2.2).
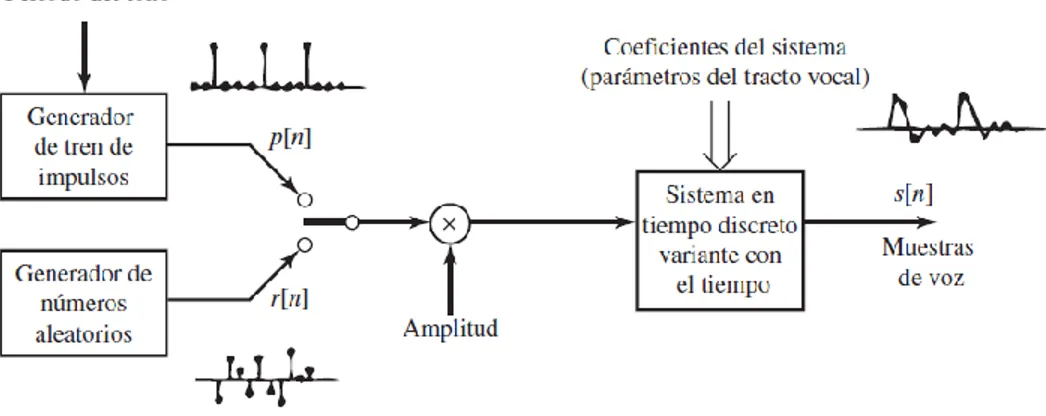
(27) donde las cantidades 𝑟𝑘 𝑒 −𝑗𝜃𝑘 𝑐𝑜𝑛| 𝑟𝑘 | < 1 son las frecuencias naturales complejas del tracto vocal que, por supuesto, dependen de la forma de dicho tracto vocal y en consecuencia varían con el tiempo. Los ceros de 𝑉(𝑧) dan cuenta de la duración finita de la forma de onda del pulso glótico y de los ceros de transmisión causados por el estrechamiento del tracto vocal en la creación de sonidos sonoros nasales y sonidos fricativos. Estos ceros a menudo no se incluyen, ya que resulta muy difícil estimar sus posiciones a partir sólo de la señal de voz. Además, se ha demostrado (Atal y Hanauer, 1971) que la forma espectral de la señal de voz se puede modelar de forma precisa sin utilizar ceros, si se incluyen polos extra para modelar las resonancias del tracto vocal. El sistema del tracto vocal es excitado por la secuencia de excitación p[n], que es un tren de impulsos que modelo los sonidos de voz sonoros y por r[n], que es una secuencia de ruido pseudoaleatorio cuando se modelan sonidos de voz sordos, como los fricativos y los oclusivos. Muchos de los problemas fundamentales del tratamiento de voz se reducen a la estimación de los parámetros del modelo de la Figura 13.22. Estos parámetros son los siguientes: . Los coeficientes de V(z) o las posiciones de los polos y los ceros.. . El modo de excitación del sistema del tracto vocal, es decir, un tren de impulsos periódicos o ruido aleatorio.. . La amplitud de la señal de excitación.. . El periodo del tono de la excitación vocal para sonidos sonoros.. Figura 2.2 Modelo en tiempo discreto de la producción de voz.. 26.
(28) Historia de Producción de voz Uno de los problemas más atractivos y complejos en la investigación del habla es cómo analizar y modelar la fuente de voz humana. Hay una necesidad para un conocimiento general más profundo de la voz, características de la fuente y mecanismos de producción, no menos importante para propósitos de síntesis del habla. Este es uno de los muchos campos en los que Hiroya Fujisaki ha hecho contribuciones significativas (Fujisaki y Ljungqvist, 1986, 1987). Una herramienta importante para los estudios de la fuente de voz es filtración inversa de la onda de voz, que es un proceso de cancelación de la estructura formante regenerando así una réplica del volumen glótico, función del tiempo, de velocidad o su derivada. Por objetivos descriptivos, se necesitan modelos adecuados para aproximar estas funciones de tiempo con unos pocos parámetros. Los primeros experimentos sobre filtrado inverso fueron informados por Fant (1959). Principales puntos de referencia fueron la demostración de excitaciones dobles en una voz ronca (Briess y Fant, 1962) y glotografía fotoeléctrica combinada con filtrado inverso (Fant y Sonesson, 1962). Lindqvist-Gauffin (1964, 1965, 1970) estudió formas de onda dentro de un marco fonatorio del flujo glotal y que fue seguido por estudios más extensos de Sundberg y Gauffin (1979). Experimentos en filtrado inverso continuo y Teoría del modelado de la fuente de la voz se han divulgado en una serie de artículos de Fant (1979a, 1979b, 1980, 1982a, 1982b, 1986). Un informe de Mártony (1965) sobre el espectro de la fuente de voz contribuyó al desarrollo de las técnicas de análisis de dominio de frecuencia (Fant y Lin, 1988, 1991). Otras contribuciones importantes a las técnicas de filtrado inverso y estudios de fuentes de voz son de Rothenberg (1973, 1983). Aspectos más complejos de la interacción acústico-aerodinámica fueron por primera vez tratado por Ananthapadmanabha y Fant (1982), y seguido por Fant et al. (1985b), Fant (1986), Fant y Lin (1987, 1988) y Lin (1990).. 27.
(29) Fant (1979a, 1979b, 1980) introdujo un modelo de tres parámetros del flujo vocal que permite una variación del cociente abierto y la simetría del pulso. Se aplicó a los estudios de las características del filtro fuente de la voz con variaciones temporales incluyendo la abducción glotal en la aspiración sonora. Un avance importante fue el modelo LF (Fant et al., 1985a), que ahora se utiliza ampliamente. La novedad fue la introducción de una fase de retorno gradual después de la discontinuidad del flujo al cierre. Esta extensión resultó ser de mayor importancia perceptual que cualquiera de los parámetros tradicionales de la forma del pulso del flujo glotal. Una variante del LF-model es la de Ananthapadmanabha (1984) que sugirió una parabólica en lugar de una exponencial fase de retorno. Una revisión de los modelos de fuentes de voz aparece en (Fujisaki y Ljungqvist, 1986). El trabajo descriptivo aplicado con el modelo LF se ha descrito en (Gobl, 1988, Karlsson, 1990, 1991, Gobl y Karlsson, 1989). Los problemas más generales del modelado de la fuente de la voz se han tratado adentro (Gobl y Ni Chasaide, 1988; Fant y Lin, 1988). Las reglas de fuente de voz para la síntesis del habla se han discutido en (Carlson et al., 1989, 1991). (Fant, 1993) En el 2009 Fant y Johan Liljencrants proponen un esquema de reducción de datos para estudios de fuente de voz característica en el habla conectada. El objetivo, según Fant es concentrarse en un número limitado de parámetros capaces de definir lo esencial de la forma de onda de fuente, y las características de magnitud de excitación. Se muestra que la amplitud oscilatoria máxima del flujo glotal y la derivada de flujo en la discontinuidad de cierre juntas cumplen con estos requisitos y que pueden ser continuamente extraídas y mostradas en sincronía con un espectrograma. En el artículo Optimizations and Fitting Procedures for the Liljencrants-Fant model for Statistical Parametric Speech Synthesis, se describen los esfuerzos para construir el sintetizador de voz ClusterGen utilizando el modelo Liljencrants-Fant (LF). Se utiliza la técnica de filtrado inverso adaptativo iterativo para derivar una estimación inicial de la derivada del flujo glotal (GFD). Posteriormente se localizan los períodos de tono de candidatos en el GFD estimado y se estiman los parámetros. 28.
(30) del modelo de LF usando un algoritmo de optimización de pendientes de gradiente. La energía residual en el GFD, después de restar la señal LF ajustada, fue modelada por un modelo LPC de 4 términos más el término de energía para extender el modelo de excitación y tener en cuenta la información de origen no capturada por el modelo LF.. Filtrado inverso de señales de voz El habla vocal se puede considerar como una onda glotal determinista que es entrada a un sistema lineal, caracterizado por las resonancias del tracto vocal. Un problema interesante es analizar la forma de onda del habla para separarla en el tracto vocal y los componentes de la onda glotal. El filtrado inverso glotal es el proceso de hacer esta separación. La señal del habla se analiza para determinar la respuesta de salida acústica del tracto vocal a una entrada de flujo glotal. Esta respuesta se utiliza para especificar los coeficientes de un filtro inverso que, aplicado a la onda de voz acústica, da una estimación de la onda de flujo glotal como su salida. El filtro inverso sirve para cancelar el efecto de la de la señal de voz para revelar la fuente de voz subyacente. El filtrado inverso glotal es importante porque la capacidad de determinar la onda de flujo glotal tiene una serie de aplicaciones principales. Una aplicación es la mejora en la calidad de voz codificada como se utiliza en la síntesis del habla y la transmisión de habla codificada. Se ha establecido que la forma de onda de fuente utilizada para impulsar un vocodificador tiene una influencia significativa en la calidad del habla, y el uso de forma de pulso derivado del análisis teórico de la onda de flujo glotal da como resultado una mejora en la calidad de síntesis sobre impulsos simples. Otra aplicación del filtrado inverso es el diagnóstico no invasivo de los trastornos de la voz. Puede ser posible extraer características de la estimación de la onda glotal del filtro inverso que indican diferentes tipos de anomalías con los pliegues vocales. La cantidad limitada de datos de filtro inverso en voz anormal indica que las formas de onda de flujo son difíciles de interpretar en el caso desordenado. La dificultad puede provenir de artefactos de análisis, un problema que puede ser aliviado por. 29.
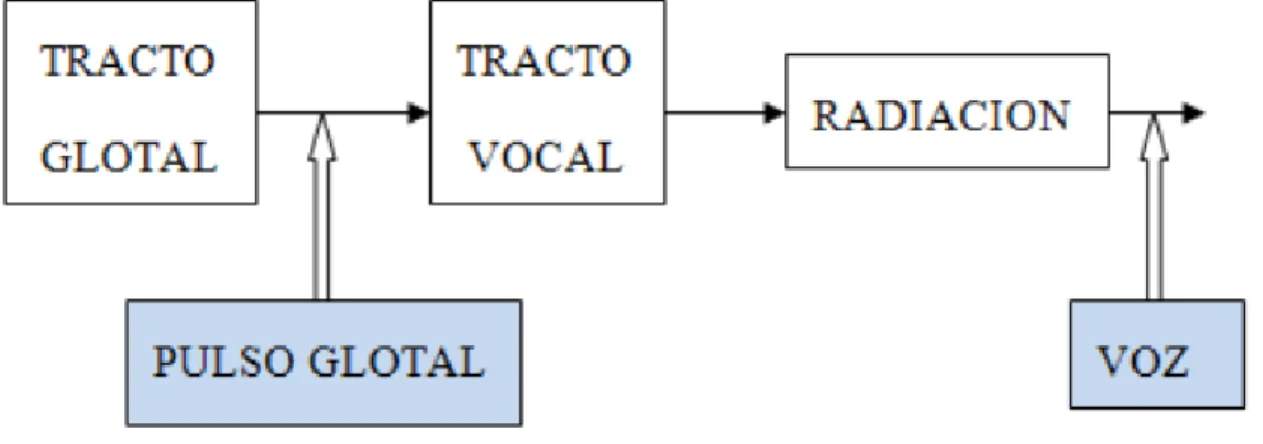
(31) algoritmos de análisis de filtro inverso mejorados. Un trabajo más reciente, sin embargo, indica que aunque la forma de onda de flujo en el caso desordenado puede ser difícil de interpretar, la aparición de una forma de onda de filtro inverso más normal se puede observar en el curso de la terapia de voz. El tipo de información que se busca extraer sobre la fuente glotal a través del filtrado inverso es la forma del pulso glotal junto con la variación ciclo a ciclo en la forma del pulso. Una descripción paramétrica del ciclo de trabajo de la forma del impulso, las pendientes relativas de la apertura y el cierre glotales, la asimetría de impulsos, podrían formar un código parsimonioso para la fuente de voz en un vocodificador. La descripción también podría formar un conjunto de características a partir de las cuales se puede realizar un diagnóstico de trastorno de voz. Hasta ahora no se ha abordado la cuestión de cómo determinar el filtro inverso correcto. [Milenkovic, 1986]. Modelo ‘‘Fuente-Filtro’’ La forma de onda glotal es la convolución entre el pulso glotal y la función del tracto vocal, que es fijo para cada modelo y como resultado se obtienen las señales sintéticas. Esto se conoce como el modelo “Fuente – Filtro” de producción de la voz. En la Figura 2.3 se muestra un esquema del modelo Fuente –Filtro.. Figura 2.3 Modelo Fuente –Filtro.. 30.
(32) Si g(t) representa los pulsos de aire generados en la glotis, en la figura denotado como pulso glotal, que son conformados espectralmente por la función de transferencia del tracto vocal H(f) y por la radiación de los labios R(f), la señal de voz se puede expresar como: 𝑠 (𝑡) = 𝑔 (𝑡) ∗ ℎ(𝑡) ∗ 𝑟(𝑡),. (2.3). donde (*) denota la operación de convolución. O aplicando la transformada de Fourier: 𝑆(𝑓) = 𝐺(𝑓) 𝐻(𝑓) 𝑅(𝑓).. (2.4). En general, para simplificar este modelo se supone que el tracto glotal está formado por dos polos de los cuales uno se compensa con los efectos de radiación de los labios (𝑅 (𝑧) = 1 − 𝛼𝑧 −1) y el otro mediante un preénfasis que se hace a la señal de la voz antes de ser analizada, por lo que se funden las características de frecuencia de la fuente y el radiador en una señal de espectro en la glotis (fuente), de manera que toda la conformación de la señal acústica pueda atribuirse al tracto vocal. Otra alternativa es considerar el radiador como una operación de derivación, que convierte una señal de velocidad de flujo g (t) en una señal de presión s (t). En la Figura 2.4 se muestra el modelo Fuente-Filtro simplificado.. Figura 2.4 Modelo Fuente-Filtro simplificado.. Las cuerdas vocales en vibración constituyen una fuente periódica (sonidos sonoros), ya que producen una onda sonora periódica, si, al contrario, la fuente se encuentra en la cavidad bucal, la señal producida será de tipo aperiódico (sonidos sordos), pues tendrá como base una fricción producida por un estrechamiento del canal por el cual pasa el aire (sonidos fricativos) o bien una oclusión como consecuencia del cierre total de dicho canal (sonidos oclusivos), el resultado acústico de una fuente aperiódica se conoce como ruido. Debido a que el habla es. 31.
(33) un fenómeno continuo, su función de transferencia varía a lo largo del tiempo. Partiendo de esta idea básica, es posible esquematizar la producción de los sonidos del habla, teniendo en cuenta que existe también la posibilidad de combinar la fuente periódica (sonidos sonoros) y la aperiódica (sonidos sordos). En la Figura 2.5 se representa este esquema.. Figura 2.5 Esquema de producción de los sonidos del habla. Para generar la señal de excitación glotal, se puede utilizar una gran variedad de métodos, que se han orientado al modelado físico del sistema vibratorio de la glotis. Sin embargo; no existe consenso en cuanto a la cantidad de elementos a considerar en los modelos, y los resultados son limitados en cuanto a la variedad de modos de vibración que permiten explicar. [Tabares, 2013][Sundararaja,2008] Pero lo más frecuente ha sido la búsqueda de alternativas con mayor abstracción matemática aún a costo de un menor fundamento físico, como es el caso del empleo de la señal residual del filtrado inverso para estimar la forma de onda de excitación. Las formas de onda obtenidas se han representado mediante modelos paramétricos que le asignan determinadas funciones matemáticas a las fases de apertura y cierre de la glotis, entre estos modelos se destacan los poligonales y trigonométricos descritos por Rosenberg en 1971, y el modelo de Liljencrants-Fant. Algunos autores plantean que hasta el momento no existen razones para preferir uno u otro modelo de excitación.. 32.
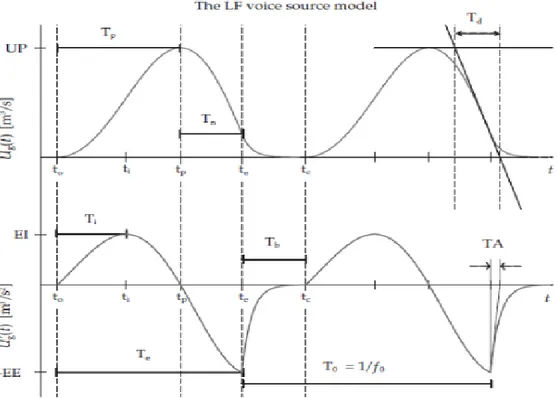
(34) Modelo de Liljencrants-Fant Para hacer una explicación más precisa de los diferentes parámetros de este modelo, se recurre a la Figura 2.6. En la parte superior se muestran dos pulsos glotales de este modelo, mientras que la figura inferior se corresponde con su derivada. Las expresiones matemáticas que permiten obtener estas señales, y que se muestran en la misma figura, proporcionan los valores de la derivada, y mediante integración podemos obtener los pulsos glotales. El modelo está formado por dos segmentos determinados por las ecuaciones presentes en la figura. El primero de ellos es sinusoidal con amplitud creciente desde el instante de la apertura de la glotis 𝑡0 , hasta el instante de la excitación principal 𝑡𝑒 . La forma de este segmento viene dada por 3 parámetros: wg=2πF, siendo F la frecuencia del seno; α, que determina la tasa de aumento de la amplitud; y E0, que es un factor de escala. El segundo segmento es una función exponencial que modela el flujo desde el instante de máxima excitación hasta el momento que se produce el cierre glotal 𝑡𝑐 . Esta parte del periodo glotal es denominada fase de retorno, y determina un flujo residual tras la máxima excitación. En el modelo LF se controla esta fase mediante el parámetro 𝑇𝑎 , una medida de la duración efectiva de la fase de retorno. Con este modelo se asume que los instantes de cierre y de apertura son el mismo: 𝑡0 = 𝑡𝑐 por lo que se perdería la fase en la que la glotis permanece cerrada. Además de los 4 parámetros de variación mencionados, se establece que el área negativa de la derivada del pulso glotal debe ser igual a la positiva, lo que implicaría conservar las características principales entre dos pulsos consecutivos. Con este modelo de la excitación, es posible tomar medidas específicas sobre las formas de ondas glóticas. Algunos de estos parámetros son los siguientes: Frecuencia fundamental. Se define como 1/T0, siendo T0 la duración del periodo glotal, definido por el tiempo entre los instantes de máxima excitación de dos pulsos consecutivos. Excitation strength, EE. Amplitud negativa de la excitación principal, que ocurre en el instante de máxima discontinuidad del pulso glotal. Suele calcularse como el mínimo valor negativo de la derivada del pulso glotal en cada ciclo.. 33.
(35) Dynamic leakage, RA. Es el flujo residual durante la fase de retorno, que tiene lugar desde el instante de la excitación hasta el cierre glotal. Mide la duración efectiva de la fase de retorno, TA, normalizada al periodo fundamental.. Open quotient, OQ. Es la proporción de tiempo en la que la glotis permanece abierta. Otro parámetro relacionado con éste, es UP, el pico del pulso glotal como se ve en la Figura 2.7.. Figura 2.6 Modelo de la Forma de onda glotal de Liljencrants-Fant.. 𝑈𝑔′ (𝑡) = 𝐸0 𝑒 𝑎𝑖 𝑠𝑒𝑛 𝜔𝑔 𝑡, 𝑡0 ≤ 𝑡 < 𝑡𝑒 −𝐸𝐸 −𝑔(𝑡−𝑡 ) { ′ 𝑒 − 𝑒 −𝑔𝑇𝑏 ), 𝑡 ≤ 𝑡 < 𝑡 𝑈𝑔 (𝑡) = (𝑒 𝑒 𝑐 𝜀𝑇𝑎. Además de estos y otros parámetros, también es importante la estabilidad pulso a pulso para determinar la cualidad vocal. Todas las características mencionadas hasta ahora, eran relativas al dominio temporal del pulso glotal, pero también es. 34.
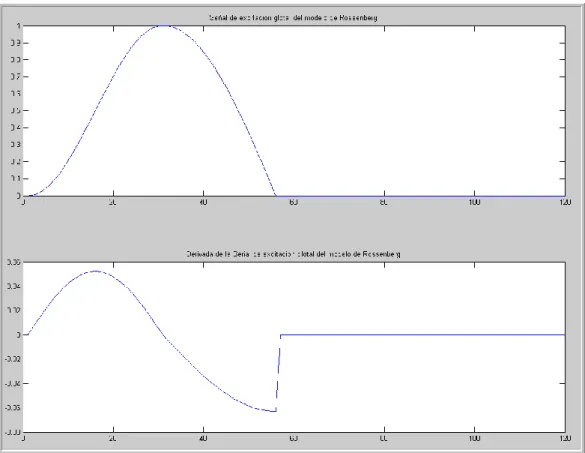
(36) posible extraer características a partir de su espectro. Una de las más comunes es el cálculo de la pendiente de este espectro. También se pueden llevar a cabo medidas sobre el espectro de la señal de voz. Una característica comúnmente usada es la comparación de la amplitud del primer armónico con el nivel de otra componente frecuencial. Estas técnicas son fácilmente aplicables, pero hay que tener en cuenta que en este espectro también se verán reflejados factores ajenos a la excitación. (Díaz, 2007)(Fant, 1995)(García, 2015). Modelo de Rosenberg El modelo de Rosenberg (Díaz, 2007) permite modificar dos parámetros: fase de apertura (N1) y la fase de cierre (N2). Rosenberg utilizó una técnica de filtrado inverso para extraer la forma de onda glotal de la voz. A partir de sus experimentos obtuvo las ecuaciones que modelan la forma de onda, las cuales son:. Las derivadas de estas ecuaciones son:. 35.
(37) Figura 2.6 Modelo de la Forma de onda glotal de Rosenberg.. 36.
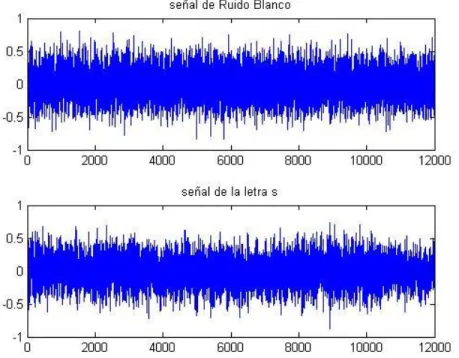
(38) Capítulo 3: Simulación numérica del grupo de funciones propuestas por Rosenberg Obtención y grabación de señales Se realizan una serie de grabaciones a través de un micrófono en un área con ruido ambiental para la obtención de datos de señales de voz. Se utiliza el código (en MATLAB v 7.10.0) siguiente: . wavrecord (n, Fs): graba sonidos mediante el micrófono.. Análisis de señales no vocalizadas Se realiza un análisis de la letra ¨s¨ y se compara con una señal de ruido blanco gaussiano generada. En las Figuras 3.1 y 3.2 se comparan ambas señales. Como se aprecia las señales presentan gráficos muy similares lo que corrobora la generación de señales no vocalizadas mediante un ruido blanco, sin embargo, la señal de ruido blanco presenta una energía uniforme en todo el periodograma mientras que la mayor energía de la letra ¨s¨ se concentra en la zona de alta frecuencia.. 37.
(39) Figura 3.1 Gráficos de una señal de ruido blanco y una señal no vocalizada. Figura 3.2 Periodogramas de una señal de ruido blanco y una señal no vocalizada. 38.
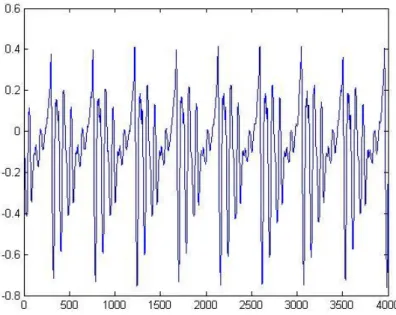
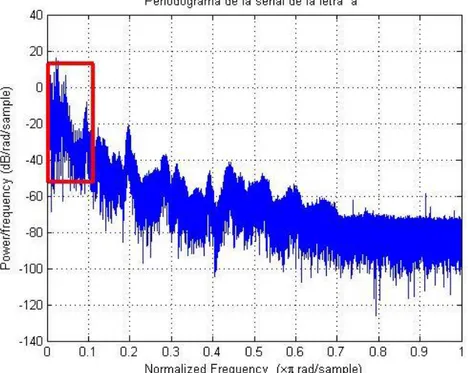
(40) Análisis de señales vocalizadas Se realiza un análisis de una grabación de la letra “a” que se obtuvo en un Estudio de Grabación en Alemania. Esta señal fue grabada con buena calidad y carece de ruidos.. Figura 3.3 Gráfico de la señal de la letra “a” A diferencia de la “s”, la señal “a” presenta cierta periodicidad como muestra la Figura 3.3. En el periodograma (Figura 3.4) se observa que la concentración de la energía de esta vocal se ubica en la zona de baja frecuencia.. 39.
(41) Figura 3.5 Periodograma de la señal de la letra “a”. Modelación del Tracto Vocal A partir de la señal de la letra “a”, mostrada anteriormente, y el modelo de Rosenberg se obtiene el tracto vocal utilizando la deconvolución.. Figura 3.6 Modelo del Tracto Vocal.. 40.
(42) A partir del modelo del tracto vocal se realizan una serie de simulaciones donde se altera la forma de onda glotal para comparar el grado de eficiencia en que recupera la señal. Las funciones que describen la forma de onda glotal que se utilizan en las simulaciones están referidas en (Rosenberg, 1971). En la Figura 3.7 se muestra un esquema de estas funciones.. Figura 3.7 Gráfico de las formas de onda glotal utilizadas (Rosenberg, 1971).. Las ecuaciones son las siguientes: 3𝛼 𝑡. Función Trapezoidal: 𝐹𝑇 (𝑡) = {3𝛼 2. [1 − ( 𝑡. Función B:. 2 𝑇𝑝 𝑡−𝑇𝑝 𝑇𝑁. , 0 ≤ 𝑡 ≤ 𝑇𝑝 (3.1) )] , 𝑇𝑝 ≤ 𝑡 ≤ 𝑇𝑝 + 𝑇𝑁. 2. 𝑡. 3. 𝛼[3 (𝑇 ) − 2 (𝑇 ) ], 0 ≤ 𝑡 ≤ 𝑇𝑝. 𝑝 𝑝 𝐹𝐵 (𝑡) = { 𝑡−𝑇𝑝 2 𝛼 [1 − ( 𝑇 ) ] , 𝑇𝑝 ≤ 𝑡 ≤ 𝑇𝑝 + 𝑇𝑁. (3.2). 𝑁. 𝛼. Función C:. 𝐹𝐶 (𝑡) = {. 2. 𝑡. [1 − cos(𝜋 𝑇 )], 0 ≤ 𝑡 ≤ 𝑇𝑝 𝑝. 𝜋 𝑡−𝑇𝑝. 𝛼 cos( 2. 𝑇𝑁. 41. ), 𝑇𝑝 ≤ 𝑡 ≤ 𝑇𝑝 + 𝑇𝑁. (3.3).
(43) 𝛼. Función D:. 𝐹𝐷 (𝑡) = {𝛼. 2. 𝑡. [1 − cos(𝜋 𝑇 )], 0 ≤ 𝑡 ≤ 𝑇𝑝 𝑝. [1 + cos(𝜋 2. 𝑡−𝑇𝑝 𝑇𝑁. (3.4). )], 𝑇𝑝 ≤ 𝑡 ≤ 𝑇𝑝 + 𝑇𝑁. 𝜋 𝑡. Función E:. 𝛼 𝑠𝑒𝑛( 2 𝑇 )], 0 ≤ 𝑡 ≤ 𝑇𝑝 𝑝. 𝐹𝐸 (𝑡) = { 𝜋 𝑡−𝑇𝑝 𝛼 cos( 2 𝑇 ), 𝑇𝑝 ≤ 𝑡 ≤ 𝑇𝑝 + 𝑇𝑁. (3.5). 𝑁. Donde 𝑇𝑝 𝑦 𝑇𝑁 representan el tiempo de crecimiento y el tiempo de decrecimiento de la función glotal respectivamente.. Simulación numérica del proceso de estimación de una señal de voz a partir de las funciones propuestas por Rosenberg La simulación (ver Anexo 1) se realizó con 𝑇𝑝 = 40 y 𝑇𝑁 = 16 según lo indicado en (Rosenberg, 1971). A continuación se muestra la recuperación de la señal de la letra “a” a partir de las funciones anteriores.. Figura 3.9 Señal de la letra “a” recuperada a partir de las ecuaciones (3.1) (3.2) (3.4) (3.5) respectivamente.. 42.
(44) Figura 3.10 Señal de la letra “a” recuperada por la ecuación (3.3) (Rosenberg).. Se define el error de estimación como: 1. 𝑒 = 𝑀 ∑𝑀 ̂(𝑖)]2 𝑖=1[𝑦(𝑖) − 𝑦. (3.6). Siendo 𝑦 la señal original y 𝑦̂ la estimada.. Figura 3.10 Error de la señal estimada a partir las ecuaciones (3.1) (3.2) (3.3) (3.4) y (3.5). 43.
(45) Resultado 1. Los errores de las señales estimadas (Figura 3.11) indican que no existe una función, de las propuestas por Rosenberg, que produzca mejor recuperación que la indicada con la letra C, o sea, la seleccionada por dicho autor como la de mejor resultado. Este criterio se ratifica en esta investigación de manera cuantitativa.. Simulación. numérica. de. la. función. de. tipo. trapezoidal variando la pendiente del último tramo. La simulación (ver Anexo 2) se realiza tomando la función de tipo trapezoidal (3.1) y se varía la pendiente del último tramo como se muestra en la Figura 3.11.. Figura 3.11 Gráfico de las funciones trapezoidales con diferentes pendientes en el último tramo. Se realiza la simulación numérica de la misma forma que la anterior y se calcula el error de estimación correspondiente a cada función (Figura 3.12).. 44.
(46) Figura 3.12 Error de la señal estimada a partir de las funciones de tipo trapezoidal.. Resultado 2: El error de la señal estimada por la función de tipo trapezoidal disminuye gradualmente mientras la pendiente aumenta de forma modular, pero a partir de la función 5 el error comienza a aumentar lo que indica que existe un punto de error mínimo de la función trapezoidal.. 45.
(47) Conclusiones En esta investigación se conceptualizaron los principales fundamentos teóricos para una mejor comprensión del procesamiento y el filtrado inverso de señales de voz. Se describieron los Modelos de producción y filtrado inverso de señales de voz propuestos por Liljencrants-Fant y Rosenberg y se obtuvo una representación empírica de la función transferencia del tracto vocal mediante filtrado inverso, utilizando como referencia la mejor función glotal propuesta por Rosenberg. Se compararon los efectos de los perfiles de la función glotal propuestas en (Rosenberg, 1971), mediante la simulación numérica, obteniendo el mejor perfil de la función del tracto glotal, la cual coincide con la propuesta por Rosenberg. También se analizó el comportamiento de la señal de voz estimada para distintas pendientes del último tramo de la función glotal de tipo trapezoidal obteniendo como resultado que el error mínimo de la señal estimada no se encuentra en la pendiente más abrupta.. 46.
(48) Recomendaciones -. Realizar las simulaciones para la variación de las pendientes de los demás perfiles de formas de onda de la glotis.. -. Analizar la relación que existe entre la pendiente de error mínimo de la forma de onda glotal de tipo trapezoidal y la de Rosenberg.. 47.
(49) Referencias Bibliográficas 1. Alvarado Moya, José Pablo. 2011. Procesamiento Digital de Señales. http://creativecommons.org/licenses/by-nc-sa/3.0/ 2. Antón, J. 2015. Desarrollo de un sistema de reconocimiento de habla natural independiente del locutor 3. Cabrer, Bernardí. 2004. Modelos lineales sin estacionalidad I. http://www.uv.es/~cabrer/Espanyol/material/Tema8/Tema8.pdf 4. Díaz, I. Suárez, S. 2007. Modelos de Excitación Glotal 5. Fant, G 1981. The Source Filter Concept in Voice Production. Journal: STLQPSR vol. 22 número 1 pag: 021-037. http://www.speech.kth.se/qpsr 6. Fant, G 1993 . Some problems in voice source analysis. Speech Communication 13 (1993) 7-22. http://www.speech.kth.se/qpsr 7. Fant, G 1995. The LF-model revisited. Transformations and frequency domain analysis. http://www.speech.kth.se/qpsr 8. Fant, G, Liljencrants, J , 2009. Data reduction of LF voice source parameters. http://www.speech.kth.se/qpsr 9. Fant G, Liljencrants,J, Lin, Q, 1985. A four-parameter model of glottal flow. http://www.speech.kth.se/qpsr 10. García Cantalapiedra, Adrián. 2015. Caracterización de hablantes mediante extracción de información de cualidad vocal. 11. Garibay Jiménez, Ricardo. 1997. Análisis de Sistemas y Señales Control Digital http://www.uv.es/~cabrer/Espanyol/material/Tema8/Tema8.pdf 12. Gómez, Juan Carlos. 2001. Procesamiento Digital de Señales de Voz. Modelos de Producción de Voz. http://www.fceia.unr.edu.ar/prodivoz/modelo_prodvoz.pdf 13. Gonzalo, Ríos. 2008. Series de Tiempo. http://www.saber.cic.ipn.mx/cake/SABERsvn/trunk/Repositorios/webVerArchivo /5331/2. 48.
Figure
+7
Documento similar
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
You may wish to take a note of your Organisation ID, which, in addition to the organisation name, can be used to search for an organisation you will need to affiliate with when you
Where possible, the EU IG and more specifically the data fields and associated business rules present in Chapter 2 –Data elements for the electronic submission of information
The 'On-boarding of users to Substance, Product, Organisation and Referentials (SPOR) data services' document must be considered the reference guidance, as this document includes the
In medicinal products containing more than one manufactured item (e.g., contraceptive having different strengths and fixed dose combination as part of the same medicinal
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
Fuente de emisión secundaria que afecta a la estación: Combustión en sector residencial y comercial Distancia a la primera vía de tráfico: 3 metros (15 m de ancho)..
