UNIVERSIDAD POLITÉCNICA DE MADRID
ESCUELA TÉCNICA SUPERIOR DE
INGENIEROS DE MONTES
T E S I S D O C T O R A L
Análisis estadístico comparativo
de
series cronológicas de parámetros decalidad del
agua;
valoración
de
diferentes modelos de predicción.
UNIVERSIDAD POLITÉCNICA DE MADRID
ESCUELA TÉCNICA SUPERIOR DE
INGENIEROS DE MONTES
ñnálisís estadístico comparativo de serles cronológicas de parámetros de calidad del agua: valoración de diferentes modelos de predicción.
Trabajo que se presenta en la Escuela Técnica Superior de Ingenieros de Montes para la obtención del grado de Doctor.
Autor; Concepción González Garcia Ingeniero de Montes
ÜNISHBIDAD POLITECNIA DE MADRID
ESCUELA TÉCNICA SUPERIOR DE
INGENIEROS DE MONTES
Análisis estadístico comparativo de series cronológicas de parámetros de calidad del agua: valoración de diferentes modelos de predicción.
Trabajo que se presenta en la Escuela Técnica Superior de Ingenieros de Montes para la obtención del grado de Doctor.
Autor: Concepción González García Ingeniero de Montes
I N D I C E
AGRADECIMIENTOS RESUMEN
SUMMARY INTRODUCCIÓN
0.1 • Planteamiento del trabajo 0.2 - Obj et i vos
0.3 • Organización del trabajo
CAPITULO 1 ANÁLISIS DE SERIES DE TIEMPO:
REVISIÓN DE MÉTODOS Y CLASIFICACIÓN 1.0 - Introducción
1.2 - Objetivos
1.3 - Métodos de Análisis
1.4 • Método empleado en este trabajo: J u s t i f i c a d o
CAPITULO 2 METODOLOGÍA BOX - J E N K I N S J ETAPAS Y APLICACIÓN 2.0 - Introducción
2.1 • Ti pos de series
2.2 - Series cronológicas y procesos estocásticos 2.3 • Procesos estacionarios
2.4 - Procesos no estacionarios 2.5 - Metodología Box-Jenkins
5.1.- Estudio descriptivo
5.2.- Identificación del modelo 5.3.- Estimación de parámetros 5.4.- Diagnosis del modelo 5 . 5 . - P r e d i c c i ó n
6.2.- Tratamiento de serles incompletas: Referenci as
6.3.- Método empleado en esta trabajo 6.4.- Datos anómalos
APÉNDICE AL CAPITULO 2
CAPITULO 3 CALIDAD DEL AGUA EH LA CUENCA DEL GUADIANA: CURSOS ALTO T MEDIO EN LA PROVINCIA DE CIUDAD REAL
3.0 - Antecedentes
3.1 - Estaciones de control del HOPU: Situación y características
3.2 - Parámetros de calidad del agua 3.3 - índices de calidad del agua
50 53 55 58
76
80 39
92
CAPITULO 4 SERIES DE CAUDALES 4.1 - Generalidades
4.2 - Modelos para series de Caudales: Referencias 2.1.- Series anuales
2.2.- Series mensuales 2.3.- Series semanales 2.4.- Series diarias
4.3 - Series de Caudal en la cuenca del Guadiana: obtención de modelos
3.1.- Estudio descriptivo
3.2.- Análisis de correlogramas
3.3.- Estimación y predicción: Resultados 4.4. - C o n c l u s i o n e s
96 97 97 101 107 108
109 109 113 116 129
CAPITULO 5 SERIES DE TEMPERATURA DEL AGUA
3 .1 . • Estudio d e s c r i p t i v o 168 3.2.- Análisis de cor retogramaa : identificación de
modelos 170 3.3.- Estimación y p r e d i c c i ó n : R e s u l t a d o s 172
5.4 - C o n c l u s i o n e s 194 CAPITULO 6 SERIES DE OXIGENO DISUELTO
6.1 - Generalidades 2 1 7 6.2 - Modelos para seríes de Oxígeno d i s u e l t o :
R eferene i as 218 ó.3 - Series de oxigeno disuelto en la cuenca de l
Guadiana: Obtención de modelos 221 3.1.- Estudio d e s c r i p t i v o 221 3.2.- Análisis de c o r r e l o g r a m a s : identificación de
mode l os 223 3.3.- Estimación y p r e d i c c i ó n : R e s u l t a d o s 224
6.4 - C o n c l u s i o n e s 250 CAPITULO 7 ANÁLISIS DE SERIES DE MATERIAS EN SUSPENSIÓN
7 . 1 - G e n e r a L i d a d e s 275
7.2 - Series de materias en s u s p e n s i ó n en la cuenca del
G u a d i a n a : obtención de modelos 277 2.1.- Estudio descriptivo 277 2.2.- Análisis de c o r r e l o g r a m a s : identificación de
modelos 280 2.3.- Estimación y p r e d i c c i ó n : R e s u l t a d o s 281
7 . 3 - C o n c l u s i o n e s 2 8 7 C A P I T U L O 8 A N Á L I S I S DE S E R I E S DE C O N D U C T I V I D A D
8 . 1 - G e n e r a l i d a d e s 3 1 8 8.2 - Series de conductividad en La cuenca del
2.3.- Estimación y predicción: Resultados 323
8.3 • Conclusiones 344
CAPITULO 9 ANÁLISIS DE SERIES DE DEMANDA QUÍMICA. DE OXIGENO
9.1 - Generalidades 371 9.2 - Series de D.O.O. en la cuenca del Guadiana:
obtención de modelos 373 2.1.- Estudio descriptivo 373 2.2.- Análisis de correlogramas: identificación de 375
modelos
2.3.- Estimación y predicción: Resultados 376
9.3 - Conc lusi ones 382
CAPITULO 1 ANÁLISIS DE SERIES DE DEMANDA BIOQUÍMICA DE OXIGENO
10.1 - Genera l i dades 41 1
10.2 - Series de D.B.O. en la cuenca del Guadiana: 413 obtención de modelos
2.1.- Estudio descriptivo 413 2.2.- Análisis de correlogramas: identificación de
model os 416 2.3.- Estimación y predicción: Resultados 417
10.3 - C o n c l u s i o n e s 421 CAPITULO 11 ANÁLISIS COMPARATIVO DE RESULTADOS
11.0 - Introducción 452 11.1 - Clasificación de parámetros según los modelos
ajustados 453 1.1.- Tipos de modelos identificados 454
1.2.- Evaluación de las series según su estructura
de c o n t i n g e n c i a
1 T . 3 - D e t e r m i n a c i ó n de la s i m i l i t u d e n t r e las d o s c l a s i f i c a c i o n e s de p a r á m e t r o s
3 . 1 . - í n d i c e de s i m i l i t u d e n t r e c l a s i f i c a c i o n e s
4 6 9 4 6 9 3 . 2 , - O b t e n c i ó n del v a l o r de I „ p a r a las d o s
m r
c l a s i f i c a c i o n e s de p a r á m e t r o s de c a l i d a d d e
a g u a 470
1 1 . 4 - A p l i c a c i ó n de la c l a s i f i c a c i ó n por m o d e l o s d e las s e r i e s de d a t o s a la a g r u p a c i ó n de
e s t a c i o n e s 473
A G R A D E C I M I E N T O S
Deseo expresar mi agradecimiento a mis d i r e c t o r e s D.
Manuel Díaz y D. J o s é Manuel Moral por s u s ánimos y
consejos.
Al personal de l a Comisaría General de Aguas del MOPU
en Madrid que t a n amablemente me f a c i l i t a r o n e l acceso a l a s
s e r i e s d e d a t o s e x i s t e n t e s , i n d i s p e n s a b l e s p a r a l a
r e a l i z a c i ó n de e s t e t r a b a j o .
A todos l o s amigos y compañeros de l a Escuela, siempre
d i s p u e s t o s a c o l a b o r a r , muy especialmente a Eugenio Martínez
Falero por su inestimable ayuda.
R E S U M E N
Este t r a b a j o t i e n e por objeto c o n t r a s t a r l a v a l i d e z de
l a s t é c n i c a s de A n á l i s i s de S e r i e s Temporales de modelos
ARIMA en e l t r a t a m i e n t o de un extenso grupo de medidas de
p a r á m e t r o s de c a l i d a d d e l agua de l a cuenca d e l r í o
Guadiana.
La e l e c c i ó n de l a metodología Box-Jenkins para dicho
a n á l i s i s ha s i d o c o n s e c u e n c i a de una amplia r e v i s i ó n y
s u b s i g u i e n t e c l a s i f i c a c i ó n de l a s d i f e r e n t e s t é c n i c a s de
t r a t a m i e n t o de s e r i e s de t i e m p o , y en p a r t i c u l a r l a s
r e l a c i o n a d a s con l a c a l i d a d del agua.
Se h a c e é n f a s i s e s p e c i a l en l o s c o n t r a s t e s y
h e r r a m i e n t a s empleadas en cada una de l a s e t a p a s de
c o n s t r u c c i ó n de l o s modelos y en l o s t r a b a j o s s o b r e
a p l i c a c i ó n a s e r i e s incompletas de d a t o s .
A c o n t i n u a c i ó n , s e a n a l i z a n más de c i e n s e r i e s ,
o b t e n i é n d o s e modelos de p r e d i c c i ó n que r e p r e s e n t a n y
c a r a c t e r i z a n e l comportamiento de l a s mismas.
Se comparan y evalúan l o s d i s t i n t o s t i p o s de modelos
o b t e n i d o s c l a s i f i c a n d o l o s p a r á m e t r o s : (1) s e g ú n e l
comportamiento de sus s e r i e s y (2) mediante o t r o s métodos
e s t a d í s t i c o s . La obtención de un í n d i c e de s i m i l i t u d e n t r e
ambas c l a s i f i c a c i o n e s permite agrupar l a s e s t a c i o n e s en base
a l a e s t r u c t u r a e s t o c á s t i c a de sus s e r i e s , mediante t é c n i c a s
de " c l u s t e r " , r e s u l t a n d o g r u p o s de e s t a c i o n e s con
S ü M M A R Y
The aim of this work is to test the validity of ARIMA models as Time Series Analysis method on a wide number of water guality data parameters from the basin of Guadiana river.
Box-Jenkins methodology has been selected after a large revisión and subsequent classification of different time series methods concerned with water quality parameters.
Special emphasis is made on test and tools used in each of the building model steps and on works concerning applications to data series with missing valúes.
More than one hundred time series are analysed. The estimated models represent and characterize the behaviour of the data series.
INTRODUCCIÓN
0.1 - Planteamiento del trabajo 0.2 - Objetivos
INTRODUCCIÓN
0,1 - PLANTEAHIENTG DEL TRABAJO
El estudio de variables que evolucionan a lo largo del tiempo (fenómenos temporales) presenta, desde el punto de vista estadistico, peculiaridades que invalidan los métodos más frecuentes de tratamiento de fenómenos aleatorios, estudiados mediante muestras de valores procedentes de experimentación o de muestreo. Estos caracteres particulares se resumen en dos aspectos: entorno variable y dependencia entre observaciones.
condiciones en que se obtuvo la primera, por lo que de cada "t" sólo se tendrán muestras unitarias de variables aleatorias dependientes.
El seguimiento y control de procesos temporales en que intervienen variables medio-ambientales y la recogida de datos a intervalos regulares corre a cargo de organismos públicos. Datos de este tipo son abundantes por su interés y observación tradicional en Meteorología e Hidrología.
El tratamiento de series de datos hidrometeorológicos con base en la metodología Box-Jenkins ha sido ampliamente recogido en diversas publicaciones de esta década (Salas et al., 1980; Hipel, 1985; MacNeil, 1987).
Otro tipo de datos de seguimiento más reciente, son los relativos al control de calidad de aguas.
0.2 - OBJETIVOS
Un p r i m e r o b j e t i v o e s e l a n á l i s i s de l a s s e r í e s de
d a t o s p a r a l a o b t e n c i ó n d e m o d e l o s u n i v a r i a n t e s d e
p r e d i c c i ó n . Con e s t e f i n s e h a n e m p l e a d o s e r i e s d e 7
p a r á m e t r o s de d i s t i n t a s e s t a c i o n e s de c o n t r o l de l a cuenca
d e l Guadiana. E s t o s s e r á n i n d i c a t i v o s d e l comportamiento
e s t o c á s t i c o de cada s e r i e .
Un segundo o b j e t i v o e s l a u t i l i z a c i ó n de l o s t i p o s de
modelos o b t e n i d o s p a r a una c l a s i f i c a c i ó n de e s t a c i o n e s , de
forma que p e r m i t a c o n f i r m a r l a r e p r e s e n t a c i ó n de l a s mismas
p o r l a s c a r a c t e r í s t i c a s e s t o c á s t i c a s de s u s s e r i e s .
P a r a e l l o , s e c o m p a r a n d o s c l a s i f i c a c i o n e s d e
p a r á m e t r o s : (1) según e l t i p o de e s t r u c t u r a e s t o c á s t i c a más
f r e c u e n t e en c a d a p a r á m e t r o a n a l i z a d o ; y (2) s e g ú n e l
c o e f i c i e n t e d e c o n t i n g e n c i a d e c a d a p o s i b l e p a r e j a d e
p a r á m e t r o s .
E l a l t o í n d i c e d e s i m i l i t u d e n t r e l a s d o s
c l a s i f i c a c i o n e s p e r m i t e l a a p l i c a c i ó n d e l c r i t e r i o d e
c l a s i f i c a c i ó n en b a s e a l o s m o d e l o s o b t e n i d o s a l a
0.3 - ORGANIZACIÓN DEL TRABAJO
En el Capitulo 1 se revisan los distintos métodos de análisis de series de tiempo, desde los más sencillos, únicamente descriptivos, hasta los más complejos cuya finalidad es la obtención de modelos del fenómeno para su utilización en predicción y control. De menor a mayor complejidad se obtiene una clasificación de tales métodos, justificando el elegido para este estudio.
En el Capitulo 2 se tratan las distintas etapas de construcción del modelo en la metodología Box-Jenkins, con los análisis empleados posteriormente en las series analizadas. También se comentan, en este capitulo, distintos trabajos sotare series de datos incompletas y su tratamiento con esta metodología, ya que en este tipo de datos, es frecuente encontrar períodos sin valores a lo largo de una serie observada, ocasionados por diferentes causas (bajas entre el personal encargado, variaciones en los métodos de medición, épocas de imposibilidad de toma de datos, etc.).
En el Capítulo 3. se citan los antecedentes en España de los estudios de calidad de aguas, con especial referencia a trabajos anteriores sobre datos de la cuenca elegida para el estudio y sus características en la zona de situación de las estaciones tratadas.
Se enumeran y sitúan los puntos de muestreo con datos de fechas y longitud de las series analizadas.
para una mejor verificación de los resultados.
Se señalan los parámetros de calidad del agua recogidos por el MOPU y la selección de 7 de ellos para este estudio, por su importancia en los Índices de calidad del agua.
En los Capítulos 4 a 10. se tratan las series correspondientes a cada una de las variables analizadas.
Cada uno de estos capitulos comienza con un apartado de generalidades sobre el parámetro estudiado, con referencia a las características y medición de valores. La mayor o menor dificultad en la medida de cada parámetro dará idea de la aproximación de los datos y de las posibles anomalías que se encuentren en el comportamiento de sus series.
En los Capítulos 4, 5 y 6 correspondientes a las series de Caudal, Temperatura del agua y Oxígeno disuelto se
incluye un apartado donde se hace referencia a trabajos sobre tratamiento de series de estos mismos parámetros y de otros relacionados como la Demanda Bioquímica de Oxígeno.
A continuación, para cada parámetro, se analizan las series y se obtiene modelos de predicción, finalmente se incluye un cuadro resumen de resultados y un apartado de conclusiones.
Al final de cada uno de estos capítulos se presentan los gráficos necesarios en las etapas descriptiva y de identificación de los modelos, así como algunas series residuales.
Anexo.
En el Capitulo 11, se realiza un análisis comparativo de las series tratadas de cada variable en cada punto de control para la obtención de una clasificación de los parámetros de calidad tratados, en base a los modelos estimados. Su comparación con una segunda clasificación de los mismos, con base en contrastes de independencia clásicos para cada pareja de variables y el cálculo de un índice de similitud entre ambas agrupaciones, permite la aplicación a las estaciones de control, de la clasificación por el comportamiento estocástico de sus series de parámetros.
En el Capitulo 12, se exponen las conclusiones finales y las líneas de trabajo.
CAPITULO 1
ANÁLISIS DE SERIES DE TIEMPO: REVISIÓN DE MÉTODOS Y CLASIFICACIÓN 1.0 - Introducción
1.2 - Objetivos
1.3 - Métodos de Análisis
CAPITULO 1
ANÁLISIS DE SERIES DE TIEMPO:
REVISIÓN DE MÉTODOS Y CLASIFICACIÓN
1.0 - INTRODUCCIÓN
La búsqueda de un modelo matemático representativo de un proceso observado a lo largo del tiempo, en principio, puede conducir a dos soluciones: (a) la obtención de un modelo basado en leyes físicas que permita calcular el valor de dicha variable en función del tiempo, de forma exacta en cualquier instante "t"; (b) la obtención de un modelo que permita calcular la probabilidad de que un valor
futuro quede entre dos valores determinados.
Si es posible conseguir una ecuación del primer tipo se habrá obtenido un modelo determinista. En el segundo caso se tendrá un modelo de probabilidad o modelo estocástico. En la mayoría de los fenómenos dependientes del tiempo, observados en la Naturaleza, intervienen multitud de factores desconocidos que van a hacer prácticamente imposible llegar a una representación de tipo determinista, pero sí será posible conseguir aproximaciones al conocimiento de la evolución del proceso en estudio representadas con un modelo estocástico.
de t i e m p o . V a r i a b l e s o b s e r v a d a s en l a N a t u r a l e z a en forma
d e s e r i e s d e t i e m p o : m e t e o r o l ó g i c a s , h i d r o l ó g i c a s ,
p o b l a c i o n e s a n i m a l e s , e t c . , p u e d e n s e r r e p r e s e n t a d a s
m e d i a n t e modelos de t i p o e s t o c á s t i c o .
P a r a e l l o , a c o n t i n u a c i ó n , s e c i t a n l o s o b j e t i v o s
p e r s e g u i d o s en e l a n á l i s i s de e s t e t i p o de o b s e r v a c i o n e s y
s e r e v i s a n , m e d i a n t e u n a c l a s i f i c a c i ó n , l o s m é t o d o s
empleados p a r a t a l e s o b j e t i v o s .
1.1 - OBJETIVOS
El análisis de las series de tiempo va a tener por objeto, de forma amplia, y de menor a mayor profundidad,
(Kendall,1976) , los siguientes tipos de estudios:
a) Construir para una serie, un modelo sencillo que describa el comportamiento del proceso de manera concisa.
b) Explicar el comportamiento de una serie en relación con otras variables observadas, también en forma de series de tiempo, y obtener un modelo que relacione las distintas variables consideradas.
c) Prever el comportamiento futuro de la serie, a partir de los modelos obtenidos en (a) o en (b).
Los apartados anteriores se pueden resumir en dos objetivos principales: obtención del modelo y predicción, constituyendo, así, las dos fases de un sistema de predicción.
1.2 - MÉTODOS DE AN&LISIS
De menor a mayor complejidad se distinguen:
1. Cualitativos o subjetivos: dependen de la intuición y del conocimiento que se tenga del proceso. Pueden depender o no de las observaciones pasadas. A pesar de su falta de rigor, en algunos casos pueden ser bastante apropiados e incluso el único método razonable de previsión, (Abraham y Ledolter, 1983). En este apartado se encuentra, entre otros, el conocido método Delphi, (Wheelwright y Makridakis, 1985).
2 . C u a n t i t a t i v o s : b a s a d o s en m o d e l o s m a t e m á t i c o s deterministas o estocásticos (también probabilistas o estadísticos), tienen en cuenta los factores que intervienen en el proceso generador de la serie.
Las técnicas de análisis de series de tiempo son de tipo cuantitativo y, dentro de ellas, se pueden diferenciar por el número de variables tratadas cada vez.
datos se encuentran los siguientes métodos:
2.1. Métodos de series de tiempo
2.1.1.- Métodos univariantes
2.1.1.1.- Métodos simples o de alisado fsmoothínef) i
Se basan en separar el patrón de comportamiento de la serie, de la parte aleatoria, mediante técnicas de alisado (promedios móviles, alisado exponencial). Empleados por investigadores operativos.
2.1.1.2.- Métodos de descomposición:
Tratan de identificar las componentes del patrón básico de la serie, normalmente tres, tendencia (Tt),
estacionalidad (s^) y ciclos (Ct), de manera que una serie histórica de observaciones (X-p X2, •••/ Xn) , en forma resumida (X*.) t se puede expresar como
*t = f(Tf sf ct> + Et
El e r r o r (E^.) r e p r e s e n t a l a p a r t e a l e a t o r i a de l a
2 . 1 . 1 . 3 . . - Métodos avanzados
2 . 1 . 1 . 3 . 1 . . - En e l dominio de l a frecuencia: A n á l i s i s
e s p e c t r a l , a n á l i s i s de f r e c u e n c i a s o a n á l i s i s de
F o u r i e r .
Se b a s a en l a u t i l i z a c i ó n d e f u n c i o n e s
s i n u s o i d a l e s p a r a d e s c r i b i r y r e p r e s e n t a r p a u t a s
p e r i ó d i c a s de v a r i a c i ó n en una s e r i e t e m p o r a l . La
h e r r a m i e n t a p r i n c i p a l de t r a b a j o e s l a d e n s i d a d
e s p e c t r a l . En e s t r e c h a c o r r e s p o n d e n c i a con l a
n a t u r a l e z a f í s i c a d e l fenómeno s e han empleado en
e l e c t r i c i d a d , f i s i c a , meteorología, (Jenkins y Watts,
1968; Bloomfield, 1976).
2 . 1 . 1 . 3 . 2 . - En e l dominio del tiempo.
2 . 1 . 1 . 3 . 2 . 1 . - Modelos en e l espacio de l o s e s t a d o s :
F i l t r o de Kalman, predicción Bayesiana.
Basados en l a propiedad de Markov de independencia
del futuro de un proceso de su pasado, dado e l estado
p r e s e n t e en e l i n s t a n t e " t " .
Un modelo de espacio de e s t a d o s e s t á formado por
dos ecuaciones: una "ecuación de medida" que d e s c r i b e
e l e s t a d o d e l p r o c e s o en e l momento " t " y una
"ecuación de t r a n s i c i ó n " que r e p r e s e n t a e l v e c t o r de
"t-1". La formulación de estos modelos se debe a Kalman (1960 a, 1960 b, 1963), y Kalman y Buey (1961). Una versión simplificada para el caso de modelización de series univariantes puede encontrarse en Harvey
(1984) . Harrison y Stevens (1971, 1976) dan una interpretación Bayesiana al filtro de Kalman aplicado para predicción, cuando emplean información "a priori" sobre el vector de estado para inicializar parámetros de la ecuación de estado.
Se ha aplicado, principalmente, en el control de sistemas físicos en los que las ecuaciones de estado tienen una interpretación directa en el sistema objeto de estudio.
2 . 1 . 1 . 3 . 2 . 2 . - Modelos paramétricos basados en ecuaciones en diferencias estocásticas (Modelos ARIMA y metodología Box- Jenkins).
Una serie temporal (Xt) es formulada como salida de un filtro lineal excitado mediante un ruido (a^.) :
Filtro
xt
La m e t o d o l o g í a e s t a d í s t i c a o p e r a t i v a p a r a l a
c o n s t r u c c i ó n de modelos de p r e v i s i ó n de s e r i e s de
tiempo g e n e r a l e s , basada en l a t e o r í a matemática de
Jenkins en 1970. Desde entonces han ido apareciendo multitud de trabajos tanto en el campo teórico como en el aplicado, sobre este tipo de modelos.
Casos especiales de esta metodología, son los modelos que relacionan una variable salida con una o más variables entrada (Box y Jenkins, 1976), conocidos por modelos de función de transferencia o de regresión dinámica y, como caso particular, el análisis de intervención. Se suelen citar dentro de los métodos univariantes, como modelos de regresión dinámica
(Peña, 1987), por haber una sola variable de salida.
Modelos de función de transferencia
Expresan la relación dinámica determinista entre una serie entrada (Xt) y una serie salida (Yt) , de un sistema linear, perturbada por un ruido N^., que, a su vez, puede ser la salida de otro sistema,
X4
Filtro
Filtro
N4
->-Y't Yt
Análisis de intervención
(impulsos o escalones). Propuesto por Box y Tiao (1975).
En estos dos últimos tipos de modelos se considera que no existe realimentación entre la entrada y la salida.
2.1.2.- Métodos multivariantes
Los métodos avanzados de análisis de series de tiempo tienen una ampliación inmediata al caso multivariante.
2.1.2.1..- Dominio de la frecuencia: Análisis espectral
Brillinger (1975).
2.1.2.2.- Dominio del tiempo.
2.1.2.2.1.- Modelos de espacio de estados: Luenberg
(1967) y Buey (1968).
2.1.2.2.2.- Modelos ARIMA vectoriales: Hannan (1970).
N
xlt" x2t" x3t~
Función de transferencia multivariante
l t
N 2 t N 3 t
y i t
*2t
Y3t
Donde N
l t ' N 2 t 'Nj,^., s o n p r o c e s o s
e s t o c á s t i c o s que r e p r e s e n t a n e l e f e c t o de l a s
v a r i a b l e s no i n c l u i d a s o e l "ruido" del s i s t e m a .
Casos p a r t i c u l a r e s de e s t e esquema g e n e r a l , que
c o n s t i t u y e n l o s n i v e l e s i n f e r i o r e s del a n á l i s i s , en
e s t a metodología, son:
N i v e l I I I : No e x i s t e n l o s p r o c e s o s {N
k t} , e l
proceso e s t o c á s t i c o v e c t o r i a l {Xj^} e s t á compuesto
por procesos e s t o c á s t i c o s { a ^
t} , donde cada a ^ es un
p r o c e s o d e v a r i a b l e s a l e a t o r i a s n o r m a l e s
i n d e p e n d i e n t e s . El diagrama se reduce a:
alt" a2t" a3t"
Modelo estocástico multivariante
vlt v2t *3t
(Los n i v e l e s I y I I se corresponden con l o s modelos de
u n a s e r i e y d e f u n c i ó n d e t r a n s f e r e n c i a ,
respectivamente, del apartado 2 . 1 . 1 . 3 . 2 . 2 . ) .
2.1.2.2.3.- Modelos espacio-tiempo
2.2. Métodos Causales — — — — — . — _ — . — • - — ^ . _ t —
El análisis de regresión se puede considerar como un método más para realizar predicciones de la variable dependiente en función de las independientes. En el caso de las series de tiempo, puede servir como método auxiliar para la construcción de los modelos propios de tales datos.
2.2.1. Análisis de regresión simple
En los métodos univariantes, regresiones de la serie (X-j.) en función del índice "t" pueden servir para modelizar sus componentes, en el caso de descomposición. Los modelos ARIMA pueden considerarse como casos especiales de
regresión de una variable consigo misma en instantes anteriores.
2.2.2. Regresión múltiple
Y
t =
ál
Yt - l "
52
Yt - 2 " - - - ~
5r
Yt - r
+ ao
xt - b " - - - - « s
xt - b - s
++ ^ O
zt - c - ^ i
zt - c - l - " - - 0 u
zt - c - u
+ et
La v a r i a b l e d e p e n d i e n t e Y
ty v a r i a s v a r i a b l e s
i n d e p e n d i e n t e s ( e n t r e e l l a s l a Y) son e x p r e s a d a s como
1.3 - MÉTODO EMPLEADO EN ESTE TRABAJO: JUSTIFICACIÓN
En primer lugar, y con referencia al caso univariante, se comentan los métodos anteriores y las relaciones entre ellos.
Operativamente, todo método de previsión univariante efectúa una descomposición de una serie temporal en dos componentes: (1) la parte sistemática de la serie que puede explicarse por su propio pasado; (2) el componente aleatorio o perturbación que engloba la parte impredecible de variación de la serie. Todos los métodos univariantes realizan, implícita o explícitamente esta descomposición.
El método de descomposición es el método más clásico de análisis de series. Se empleó a principios de siglo y es en Los años 20 cuando se establecen las bases de su metodología. Muy utilizado en Economía, tiene ciertas insuficiencias teóricas desde un punto de vista estadístico pero, en la práctica, se han obtenido buenos resultados en las previsiones.
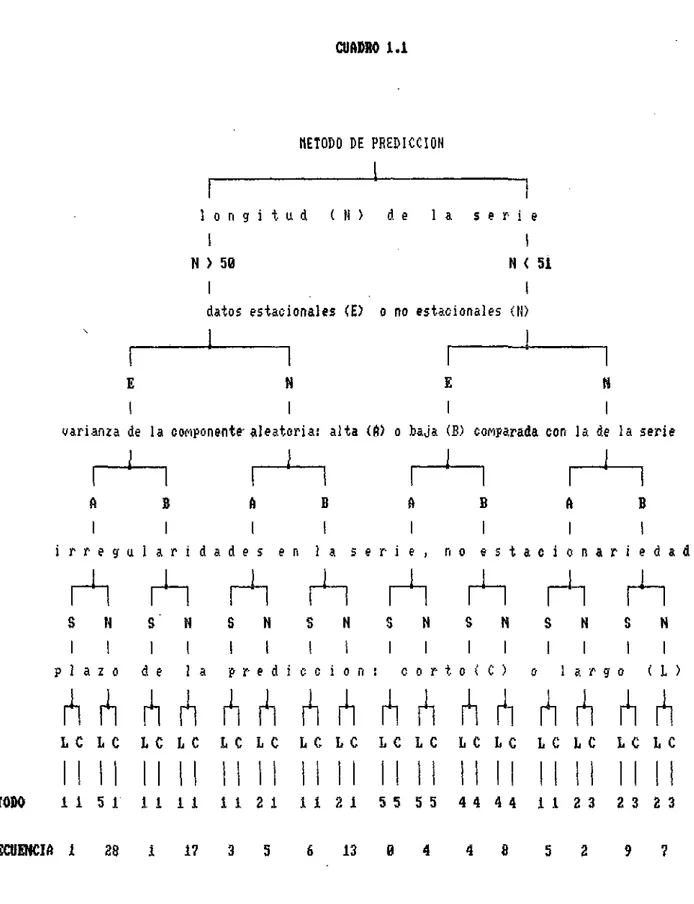
previsión más adecuado según las características de la serie a analizar (número de observaciones, estacionalidad, variabilidad, periodo de predicción) (ver Cuadro - 1.1).
Los tres enfoques básicos dentro del apartado de "métodos avanzados", tienen objetivos y, por lo tanto, dominios de aplicación originalmente distintos.
El análisis espectral cuando el dominio frecuencial se corresponde estrechamente con la naturaleza fisica del fenómeno.
El modelado en el espacio de los estados cuando la estructura dinámica del sistema es conocida y el objetivo básico es el control del mismo.
El enfoque paramétrico ARIMA en el resto de los casos en los cuales el objetivo básico es la construcción de modelos estocásticos a partir de la evidencia empirica disponible.
La separación entre los distintos métodos no es tan clara como aparece expuesta en la clasificación anterior, ya que existen relaciones entre ellos.
Comparando los modelos ARIMA con el análisis espectral, que es también un procedimiento general de análisis de procesos estocásticos, y desde un punto de vista estrictamente matemático, ambos procedimientos son duales,
CUADRO 1.1
HETODÜ DE PREDICCIÓN
l o n g i t u d , ( H ) d e l a s e r i e
I I N > 50 N < 51
I I datos e s t a c i o n a l e s (E) o no estacionales ÍH)
variafua de la eoeiponentr a l e a t o r i a s a l t a íft) o baja (B) comparada con l a de la s e r i e
i-H
H i
i-H r-H
ft 8 fl B 8 B A B
I I I I I I I I
i r r e g u l a r i d a d e s e n l a s e r i e , n o e s t a c i o n a r ! e d a dS N S í ) S N S N 5 N S N S N S N
I I I I I I 1 i I I I I I I I I p l a z o d e l a p r e d i c c i ó n : c o r t o í C ) o l a r g o ( l )
L C L C L C L C L C L C L C L C L C L C L C L C L C L C L C L C
HEIOW 1 1 5 1 1 1 1 1 1 1 2 1 I Í 2 1 5 5 5 5 4 4 4 4 1 1 2 3 2 3 2 3
FRECUENCIA í 38 í 17 3 5 6 13 6 4 4 8 5 2 9 ?
MÉTODOS: <i) Box-Jenkinsj <2) Broun; (3) Srown Modificado; (4) Holt-Hintera; (5> Harcison
La diferencia entre ambos métodos es principalmente práctica: cuando el obj etivo es identificar el orden de un proceso ARMA (p,d,q) resulta más operativo trabajar con la
función de autocorrelación simple (f.a.s.) y la función de autocorrelación parcial (f.a.p.) que con el espectro.
Por otra parte, dentro de las técnicas en el dominio del tiempo, el método de "espacio de estados" es un procedimiento de predicción más general, que incluye como casos especiales la regresión tradicional y los modelos ARIMA, además de la predicción bayesiana y los modelos con coeficientes variables en el tiempo (Abraham y Ledolter, 1983) .
Box y Jenkins (1970) organizaron la metodología de modelizar series de tiempo. Establecieron claramente las fases de construcción del modelo, dificultad que plantean los métodos de alisado exponencial, en cuanto a identificación y validación del modelo, dependiendo la elección del método de alisado, de la experiencia, habilidad y conocimiento de las características de los datos cuyos valores futuros se desea pronosticar (Gardner, 1985).
La característica más acusada de la metodología Box-Jenkins para la modelización univariante es su generalidad. De hecho, puede demostrarse que los procedimientos clásicos de previsión (descomposición y alisado exponencial) son casos especiales de estos modelos (Peña, 1978).
apareciendo modelos optimizados para cada caso en los que se han estudiado. Entre las aplicaciones hay que citar el caso de series hidrológicas y de calidad de aguas, (Hlpel et al., 1986).
Uno de los factores que han influido en ese desarrollo es la proliferación de programas de ordenador que facilitan el trabajo de construcción del modelo en cada una de sus etapas. Sin embargo, el método de Box-Jenkins, no llega a ser un sistema de predicción automático para el cual se pueda construir un programa de ordenador y confiar ciegamente en el resultado final. Es un sistema iterativo donde la experiencia del analista para la adecuada contrastacion crítica de los resultados en cada etapa juega el papel principal (Peña, 1978).
De todo lo anterior se desprende que la elección del método de análisis de una serie de tiempo va a depender:
1.- Del conocimiento que se tenga del proceso generador de las observaciones que forman la serie en estudio;
2.- Del número de observaciones;
3.- Del periodo de predicción (a corto, a medio o a largo plazo).
CAPITULO 2
METODOLOGÍA BOX-JEMKINS: ETAPAS ¥ APLICACIÓN 2 . 0 - Introducción
2.1 - Tipos de series
2.2 - Series cronológicas y procesos ©stoeásteicos 2.3 - Procesos estacionarios
2.4 - Procesos no estacionarios 2.5 - Metodología Box-Jenkins
5.1.- Estudio descriptivo
5.2.- Identificación del modelo 5.3.- Estimación de parámetros 5.4.- Diagnosis del modelo 5.5.- Predicción
2.6 - Aplicación
6.1.- Series de datos empleadas
6.2.- Tratamiento de series incompletas i Referencias
CAPITULO 2
METODOLOGÍA BOX-JENKINS: ETAPAS Y APLICACIÓN
2 . 0 - INTRODUCCIÓN
La m e t o d o l o g í a d e Box y J e n k i n s c o n s t i t u y e u n
p r o c e d i m i e n t o e s t a d í s t i c o muy p o t e n t e p a r a e l t r a t a m i e n t o y
m o d e l i z a c i ó n d e v a r i a b l e s d i n á m i c a s , ( P e ñ a , 1 9 7 8 ) . Su
d e s a r r o l l o en e l campo p r á c t i c o ha e s t a d o c o n d i c i o n a d o a l a
e v o l u c i ó n de l o s p a q u e t e s e s t a d í s t i c o s de o r d e n a d o r , dada l a
complej i d a d de c á l c u l o s que r e q u i e r e y e l volumen de d a t o s
que s e s u e l e n m a n e j a r .
Las p r i n c i p a l e s c a r a c t e r í s t i c a s de e s t a m e t o d o l o g í a son
su g e n e r a l i d a d (puede manejar p r á c t i c a m e n t e c u a l q u i e r s e r i e
de tiempo) y s u s ó l i d a b a s e t e ó r i c a .
El l i b r o de Box y J e n k i n s ( 1 9 7 6 ) , r e f e r e n c i a p r i n c i p a l
p a r a e l e s t u d i o y o b t e n c i ó n de modelos ARIMA con s u s c a s o s
p a r t i c u l a r e s d e a n á l i s i s d e i n t e r v e n c i ó n y f u n c i ó n d e
t r a n s f e r e n c i a , t i e n e como o b j e t i v o p r i n c i p a l e l
e s t a b l e c i m i e n t o d e e t a p a s , b i e n d i f e r e n c i a d a s , p a r a
de procesos estocásticos y, en concreto, de análisis de series de tiempo.
En este capítulo se señalan las etapas de análisis y construcción de modelos, con indicación en cada una de los procedimientos empleados en los capitulos siguientes.
Los fundamentos teóricos se encuentran dispersos en la bibliografía anterior sobre procesos estocásticos y series de tiempo (Wiener, 1949; Wilks, 1962; Bartlett, 1 9 5 5 , — ) y posterior (Fuller, 1976; Priestley, 1981; Chatfield, 1984). Por ello, se incluye, al final del capítulo, un apéndice de conceptos teóricos y notación de los tipos de modelos considerados.
2.1 - TIPOS DE SERIES
Una serie cronológica es una secuencia de observaciones ordenadas de forma natural. Normalmente, cada observación está asociada a un instante en el tiempo, a un punto determinado de una trayectoria, etc. Las variables tiempo y espacio suelen dar el orden de las observaciones. En general, en los casos en que las observaciones están ordenadas por una sola variable, cualquiera que sea ésta, se le va a llamar "tiempo".
Una serie cronológica puede ser continua si las observaciones se generan de forma continua: una señal eléctrica, por ejemplo, o discreta si el conjunto de observaciones es discreto: temperatura máxima diaria, precipitación mensual, caudal diario en un punto de un rio.
Una serie cronológica de tipo discreto se puede obtener,
a) por muestreo de una serie continua a intervalos regulares de tiempo (concentración de un residuo tóxico en el agua de un rio medida cada hora).
b) por acumulación de una variable durante un periodo de tiempo (precipitaciones mensuales en una zona). En el presente estudio se van a emplear series de tipo discreto, obtenidas por muestreo a intervalos mensuales. Una serie de N observaciones se va a representar por Xlf X2, -•. / XN, y, en general, Xfc/ va a ser la observación en el instante "t".
si mediante una función matemática, se puede conocer con certeza el resultado de la serie a partir del valor que toma
la variable tiempo, por ejemplo, X^. = sen (27rat) , con "a" constante conocida; y no deterministas o estadísticas, si los valores tienen una componente aleatoria. Estas últimas quedan descritas mediante su distribución de probabilidad. Las series que trataremos van a ser estadísticas.
2.2 - SERIES CRONOLÓGICAS Y PROCESOS ESTOCASTICOS
En la práctica, una serie cronológica va a ser una secuencia finita de valores: x1 ( x2, ••-, xN. En el aspecto probabilístico, la observación x^. es un valor de la variable aleatoria X^., y la serie Xlf X2, -••» XN es la
secuencia de las variables aleatorias correspondientes a cada instante t = 1, 2, ..., N. Una serie de tiempo [X^. o X(t)] expresará bien una secuencia de valores (cuando se analice una serie real), bien una secuencia de variables aleatorias (cuando se trate de las propiedades
estadísticas de las series cronológicas, en general).
consultarse el Apéndice a este capitulo donde aparecen ampliadas).
Una clase de procesos, particularmente importante en el análisis de series cronológicas es la de los procesos estacionarios.
En los procesos estrictamente estacionarios (e.e.), la función de distribución de la variable aleatoria es la misma en cada instante t¿. Más aún, la distribución
conjunta depende sólo del intervalo entre los t^, tj y no de los valores de la variable en cada momento.
Por tanto, si (X^ : t e Z } es un proceso e.e., entonces las variables X^ siguen una misma ley de probabilidad de función de densidad f(x), de media M y de varianza <r(x), independientes de t.
Si la estacionariedad se cumple para cualquier conjunto {X(t1), ..., X(tn)} con n < p, (p entero positivo), se dice que hay estacionariedad de orden p.
En muchos procesos { X^. } , la estacionariedad se entiende como una distribución de equilibrio, que no depende de las condiciones iniciales, a la cual tiende el proceso cuando t -> «°. Esto significa que cuando un proceso ha sido observado durante un periodo largo, la distribución de X^. cambiará muy poco. Si las condiciones iniciales se mantienen en toda la evolución del proceso y son las mismas que las especificadas para la distribución de equilibrio, el proceso es estacionario en el tiempo y dicha distribución es la estacionaria.
definida, en un sentido probabilístico, si se conoce la función de distribución conjunta para cualquier (Xft^,
..., X(tn)} finito de variables aleatorias. En la práctica, dicha función suele ser desconocida, por lo que, se define u n a e s t a c i o n a r i e d a d m e n o s r e s t r i c t i v a l l a m a d a estacionariedad en sentido amplio, débil o de segundo orden.
Un proceso se llama débilmente estacionario (d.e.) si satisface las dos condiciones:
M (t) •
ii
y cov(x
t, x
r) = R(r-t)
Para un proceso gaussiano, definido por la propiedad de que la función de densidad conjunta de probabilidad asociada a las X(t), es normal multivariante, estacionariedad de orden 2 implica estacionariedad estricta.
Para los procesos estacionarios se definen en el Apéndice al final del capítulo, un conjunto de funciones y sus estimadores, que constituyen las herramientas básicas de la fase de identificación del modelo.
Por su posterior utilización en la metodología Box-Jenkins, a continuación, se consideran las propiedades de
la autocorrelación muestral, r(k), en el caso de un proceso puramente aleatorio, cuando las f(k) teóricas son nulas salvo para k=0. El interés de su estudio reside en que permite decidir si los valores r(k) de una serie dada son
significativamente distintos de cero o no.
puede demostrar (Kendall y S t u a r t , 1966) que
E [ r ( k ) ] —> 1/N y Var [ r ( k ) ] —> 1/N
y que l o s r ( 0 ) , r ( l ) , . . . , r (k) s e d i s t r i b u y e n ,
a s i n t ó t i c a m e n t e , de forma normal b a j o c o n d i c i o n e s de
e s t a c i o n a r i e d a d d é b i l . De e s t a manera se pueden dar a l 95%
de confianza, l o s l i m i t e s aproximados ± 2/JN. Los v a l o r e s
m u é s t r a l e s d e r ( k ) f u e r a d e e s o s l í m i t e s s e r á n
" s i g n i f i c a t i v a m e n t e " d i s t i n t o s de cero a un 5% de n i v e l de
s i g n i f i c a c i ó n . La magnitud y e l r e t a r d o k en e l que
a p a r e z c a n c o e f i c i e n t e s s i g n i f i c a t i v o s van a a y u d a r a l a
i n t e r p r e t a c i ó n f í s i c a del proceso, especialmente k = 1 y l o s
k que indiquen v a r i a c i ó n e s t a c i o n a l .
Un método a l t e r n a t i v o para juzgar cuándo un c o e f i c i e n t e
r ( k ) e s d i s t i n t o de c e r o e s e l s i g u i e n t e : " s i podemos
suponer que l a s primeras h a u t o c o r r e l a c i o n e s t e ó r i c a s son
d i s t i n t a s de cero pero l a s s i g u i e n t e s son c e r o , entonces:
h
V a r [ r ( k ) ] = ( 1 + 2 2 f(j))/N , k > h
j = l '
2.3 - PROCESOS ESTACIONARIOS
La metodología empleada se basa, para la obtención de modelos, en la expresión de la serie de tiempo observada como "output" de un filtro lineal cuyo "input" es una serie { at : t e Z } conocida por proceso ruido blanco (o puramente aleatorio) , en el que las variables at son independientes, r(a^., as) = 0 , t f s , con la misma distribución (se suele suponer distribución normal) de media cero y varianza cr(a).
C u a d r o 2 , 1
Representación en términos de un ruido blanco
Representación en términos de los valores pasados
Coeficientes $ -Í
Coeficientes TTJ.
Condición de estacionariedad
Condición de invertibilidad
Fas j>k
Fap ak k
PROCESOS AR
Xt = 0(B)_1at
<í.(B)Xt » at
Infinitos
Número finito
Las raices de <p(z) están fuera del círculo unidad
Siempre invertible
Infinitas: mezcla de exponenciales y/o sinusoides que — > 0
Húmero finito
PROCESOS MA
xt = e(B)at
e c B ) - ^ = at
Número finito
Infinitos
S iempre estacionario
Las raices de e(z) están fuera del círculo unidad
Número finito
Los procesos mixtos, ARMA, son una mezcla de los dos anteriores, por lo que sus propiedades, especialmente de fas y fap, son el resultado de la superposición de las correspondientes a los correlogramas de AR y MA. Su compleja estructura hace que el orden, (p,q) , de este tipo de procesos sea dificil de identificar en la práctica.
Un resumen de sus propiedades se recoge en el cuadro 2.2.
Cuadro 2.2
PROCESOS MIXTOS ARMA (p,q)
Representación en términos de a^ Representación en forma de un modelo de regresión
Coeficientes f A
Coeficientes ITJ.
Condición de estacionariedad
Condición de invertibi1idad
Fas pk
Fap akk
Xt = *(B) 1 8(B)at
e ( B )- 1 0(B)Xt = at
Infinitos
Infinitos
Las raices de <p(z) están fuera del círculo unidad.
Las raices de ©(z) están fuera del circulo unidad.
Infinitas: para k > q-p+l, están dadas por una mezcla de exponenciales y/o sinusoides que tienden a cero.
2.4 - PROCESOS NO ESTACIONARIOS
En general, las series de tiempo observadas en la realidad no van a ser estacionarias, aunque en periodos largos de observación, el comportamiento de la serie sea similar. Para ajustar alguno de los modelos estacionarios anteriores a dichas series es necesario eliminar las fuentes de variación causantes de la no estacionariedad y que se manifiesta por variaciones en la media, en la varianza o en ambas.
La definición de estos procesos y su notación se da en el Apéndice.
La forma general de estos procesos viene dada por los modelos multiplicativos ARIMA (p,d,q)x(P,D,Q)e:
*p(Be)<£p(B)(l-B)d(l-Be)D Xt = eq(B)eQ(Bé)at
Estos modelos son los más generales de la metodología de Box y Jenkins para series univariantes y representan de forma simple muchos fenómenos reales.
00
rj + . 2 Rei(rei+j + rei-j>
i=l
f j .
1 + 2 2 re iRe i
i=l
Hamilton y Watts (1978) demuestran que la fap de un proceso estacional tiene la estructura siguiente:
(a) En los primeros retardos aparecerá la fap de la estructura regular y en los estacionales la fap de la estacional.
(b) A la derecha de cada coeficiente estacional (retardos je+1, je+2, ...) aparecerá la fap de la parte regular. Si el coeficiente estacional es positivo la fap regular aparece invertida, mientras que si es negativo la fap aparece con su signo.
(c) A la izquierda de los coeficientes estacionales (retardos je-1, je-2, ...) se observará la fas de la parte regular.
2.5 - METODOLOGÍA DE BOX-JENKINS
Las etapas básicas de construcción del modelo y los
métodos empleados en este trabajo para cada una de ellas se describen a continuación.
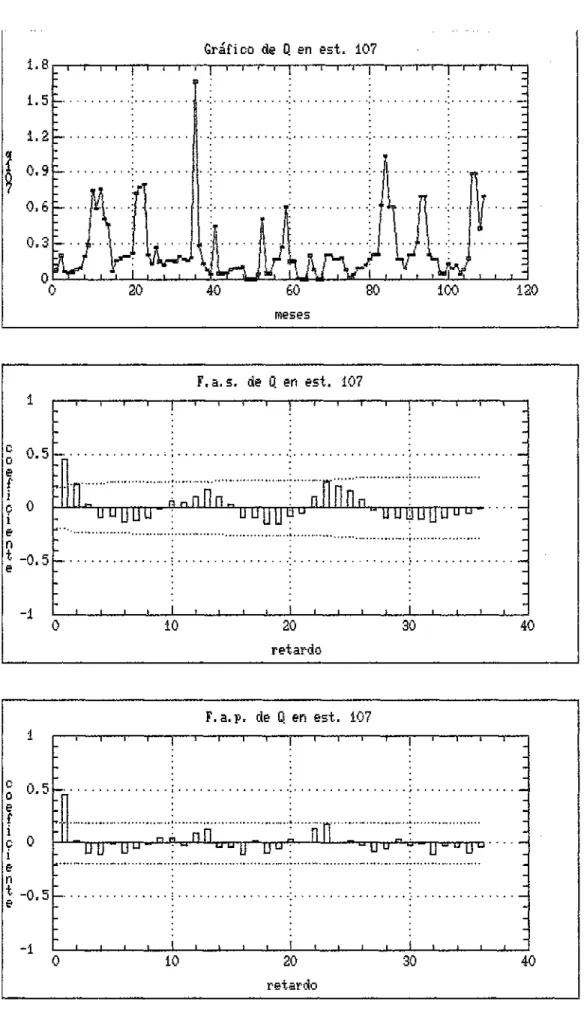
El primer paso en el análisis de una serie observada X^. es el examen de su gráfico con respecto del tiempo. Esto proporciona una primera estimación visual de su media, varianza, valores anómalos, tendencia, periodicidades y posible distribución. La metodología Box-Jenkins no supone, en principio, normalidad en los datos, por lo que no se requieren contrastes de normalidad en este análisis previo, el cual se completa en la siguiente etapa de identificación con ayuda de los correlogramas muéstrales.
5.2.- Identificación del modelo
En esta etapa se sugiere un tipo de modelo para los datos dentro de la clase general ARIMA. Para ello, se consideran tres pasos:
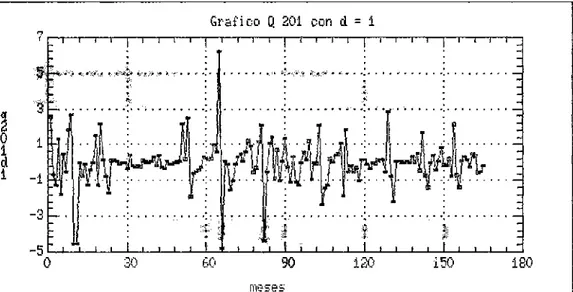
(a) Comprobar si la serie es estacionaria o no, mediante gráficos de los datos y de los correlogramas. Si no lo e s , se diferencia la serie hasta c o n s e g u i r estacionariedad.
en función del tiempo, se ha probado una transformación logarítmica de la serie inicial sin buenos resultados, bastando para estabilizar la serie con d = 1. En el resto de las series tratadas no estacionarias es suficiente una diferencia regular o estacional.
(b) Identificar el modelo adecuado y los órdenes p y q de los polinomios AR y MA, respectivamente, de la estructura regular de los datos con el análisis de los gráficos de fas y fap de la serie estacionaria, teniendo en cuenta las características vistas para las fas y fap de los distintos procesos (Cuadros 2.1 y 2.2) y con la ayuda de gráficos de procesos simulados de los tipos citados.
(c) Lo mismo que en (b) para determinar los órdenes P y Q de los polinomios AR y MA estacionales, en el caso de que los datos presenten estacionalidad.
5.3.- Estimación de parámetros
Mediante algoritmos de optimización no lineal se obtienen estimadores máximo verosímiles que minimizan la
suma de cuadrados de los residuos at. El más frecuente y el
5.4.- Diagnosis del modelo
En esta etapa se emplean distintos contrastes y técnicas para detectar irregularidades que indiquen discrepancias entre el modelo y la serie observada. En este caso se introducirán modificaciones y se repetirá el proceso a partir del paso 5.2.
Con los resultados de la estimación se analizan los siguientes puntos para decidir la validez del modelo identificado:
(a) Ana1i s i s de res iduos: Sobre los residuos a^, se comprueba si tienen media nula, varianza constante y son incorrelados para cualquier retardo. La observación del gráfico de los residuos va a ser el primer paso para detectar anomalías. El segundo paso es la obtención de la fas r^(k). Si los residuos son independientes y normales, los r^(k) serán, aproximadamente, para k altos variables aleatorias con media cero, varlanzas asintóticas 1/n (si n es el número de residuos) y distribución normal. La varianza asintótica es válida para k grande pero no para los primeros retardos, por lo que el valor 1/n sobreestima la desviación típica de las autocorrelaciones residuales en esos retardos.
h
Q(h) = n (n + 2) S ra{j)/(n - h) j=l
se distribuye según una X1 con grados de libertad igual al número de coeficientes en la suma (h) , menos el número de parámetros estimados (p+q para modelos no estacionales y P+P+Q+q para los estacionales).
Si los residuos presentan coeficientes significativos en fas y fap, su observación se empleará para modificar el modelo.
Después de comprobar que los residuos son incorrelados, se aplica el contraste para ver si E[a^.] = 0. Se aceptará que los residuos tienen media nula si
^a s(a)/n
no es significativamente grande con relación a la distribución N(0,1).
La varianza residual aa estimada (ETR = error tipico
residual) proporciona una medida del ajuste global del modelo y es, también, el error de predicción a un periodo.
En caso de datos estacionales el contraste del "periodograma acumulado" para los residuos es útil para detectar periodicidades no absorbidas por el modelo ajustado
(Box & Jenkins, 1976).
serie de at
a(B)at = /3(B)ut
e incorporar al modelo final
a(B)0(B)wt = 6(B)ÍI(B)ut
A los ut se les aplicarán los contrastes de (b).
(c) Parámetros estimados: Sus errores tipicos aproximados o los intervalos de confianza de las estimas de los coeficientes, van a indicar si las mismas son significativas o no. La matriz de correlaciones entre los parámetros servirá para ver si hay parámetros redundantes. Si hubiera que eliminar algún parámetro se volverá a estimar el modelo con los coeficientes restantes. En este punto se ha seguido el principio de elegir el menor número posible de parámetros (principio de "parsimonia": Box & Jenkins, 1976; Ledolter & Abraham, 1981). Este apartado se complementa con
(¿> y (e).
(d) Sobreaiuste: Consiste en estimar un modelo con mayor número de parámetros que el inicial y comprobar si los coeficientes adicionales son significativos.
(e) Cancelación de operadores: Si se expresa el modelo de forma que los polinomios AR y MA estén factorizados, pueden aparecer términos a uno y otro lado de la igualdad que se simplifiquen por tener coeficientes semejantes.
modelo ajustado a la serie completa de datos se mantiene cuando ésta se divide en dos mitades y se estudian cada una por separado. Si el modelo ajustado a cada una de esas series sigue siendo el obtenido en un principio se dará como válido.
(g) Una variante del apartado (f) consiste en predecir con el modelo ajustado la última parte de la serie y comparar la evolución de las predicciones con la de los datos reales; o bien ajustar el modelo a la primera parte
(3/4) de la serie observada y predecir el último 1/4.
(h) Decisión entre modelos candidatos: Bien con la ayuda de los pasos (f) y (g) comparando las predicciones con los valores observados, bien por el ETR. En este último caso, si la diferencia entre los ETR es pequeña, y la elección están un modelo estacionario (sin diferencias) y otro que no lo es, se preferirá el no estacionario, aunque ETR(est.) < ETR(no est.). Esto se reflejará en las predicciones pues, las del modelo no estacionario seguirán las oscilaciones de la media, mientras que las del estacionario acabarán estabilizándose alrededor de un valor medio constante. En las series reales es más lógico que la media sea más o menos fluctuante.
5.5,- Predicción
de las predicciones de valores futuros X^.+.i, j = 1, 2, ..., a partir del modelo adoptado, se puede encontrar en Abraham y Ledolter, 1983 y 1986, además del clásico Box-Jenkins
(1976). No obstante se citan algunas características por su aparición en los capítulos posteriores.
A partir del modelo aceptado como válido se obtiene un valor X.£+1, 1 > 1, como la predicción de origen " t " a período 1.
Los valores futuros de la serie, obtenidos con el modelo aceptado, tienen error cuadrático medio mínimo, es decir, que son las predicciones óptimas y vienen dadas, para cualquier 1, por la esperanza condicionada
EE&t+l / X^, X2, ..., X^.]
La predicción estimada del valor en "t+1", se suele expresar como Xt(l) = Xt + 1.
Es conveniente adaptar las predicciones a medida que se obtienen nuevas observaciones,
X]_/ i Xrji , Xrp+^, ... , Xip+j o b s e r v . ' ' — v a l o r e s f u t u r o s — '
L a p r e d i c c i ó n e s t i m a d a p a r a e l v a l o r XT +.: e n f o r m a ele proceso general es
oo
Xrp( j ) = S y J+JC arp.-^ = Y -¡aqi + y-i+x3'!'-! + * * * k=0
^T+l(J ^ ~ j+laT+l + jaT + •**
y la predicción adaptada será: XT+1(j-l) = xT(j) + ^ J + I ^ T + I
El periodo 1 (o j) adecuado de predicción depende del tipo de modelo pero, en general, por su escaso número de coeficientes suelen dar predicciones a corto plazo (uno o dos periodos) o hasta "e" períodos en caso de existir estacionalidad.
En los capítulos correspondientes a las variables cuyas series se han analizado mediante la metodología expuesta, no se han incluido los gráficos de los residuos, en la mayoría de los casos, por no considerar necesaria, salvo en casos especiales, su inclusión dado el número de gráficos
indispensables en la fase descriptiva y de identificación de los modelos.
Por otra parte, el análisis de resultados de la estimación de modelos, con los correlogramas y contrastes para los residuos, se incluyen si en la fase de verificación resulta necesario volver a estimar uno o más modelos para la misma serie de datos.
2.6 ^ APLICACIÓN
6.1.- series de datos empleadas
año 1973.
Por l a n a t u r a l e z a de l o s d a t o s , - gran número de
v a r i a b l e s , p r o c e d e n t e s , a l g u n a s de e l l a s , de a n á l i s i s
cuidadosos en l a b o r a t o r i o s d i s t a n t e s del l u g a r de muestreo
-l a s s e r i e s s u e -l e n e s t a r i n c o m p -l e t a s , o no e x i s t e n
o b s e r v a c i o n e s en número s u f i c i e n t e p a r a a p l i c a r l a
metodología.
El primer problema que se p l a n t e a es l a a p l i c a c i ó n de
una metodología para a n a l i z a r s e r i e s completas de v a l o r e s
X ( t ^ ) , (con i = 1, . . . , N, y l o s t ^ meses) a s e r i e s en l o s
que f a l t a n l o s d a t o s en v a r i o s momentos t í . En una misma
s e r i e , pueden f a l t a r v a r i o s d a t o s c o n s e c u t i v o s , y datos
intermedios X(t^) en l o s que e x i s t e n l o s v a l o r e s a n t e r i o r y
p o s t e r i o r , X f t . ^ ) y X ( t
i + 1) .
6 . 2 . - Tratamiento de s e r i e s incompletas: Referencias
La mayoría de l o s métodos de a n á l i s i s de s e r i e s de
t i e m p o e s t á n r e s t r i n g i d o s a s e r i e s c o m p l e t a s de d a t o s
tomados a i n t e r v a l o s r e g u l a r e s . P e r o , en l a p r á c t i c a ,
aparecen s i t u a c i o n e s con lagunas en l a toma s e c u e n c i a l de
l o s d a t o s , como o c u r r e con l o s h i d r o m e t e o r o l ó g i c o s y de
c a l i d a d ambiental. En e l caso de l o s d a t o s de c a l i d a d de
aguas en d i s t i n t o s r i o s de una cuenca, por v a r i a c i o n e s en
l o s métodos de a n á l i s i s , imposibilidad de medición por f a l t a
de agua en c i e r t o s meses del año, e t c . , l a s s e r i e s no e s t á n
completas. Para a p l i c a r la metodología Box-Jenkins con e l
estudio, es necesario completarla.
Los trabajos revisados sobre el tratamiento de series con falta de datos (missing observations) van desde los más sencillos derivados de los métodos de alisado exponencial
(Wright, 1985, 1986a, 1986b) a los más sofisticados empleando modelos ARIMA y filtro de Kalman (Jones, 1980 , Harvey & Pierse, 1984). Nos referiremos a los distintos estudios que tratan sobre el análisis de series incompletas mediante la metodología Box-Jenkins.
Entre los primeros trabajos se encuentra el de Brubacher y Wilson (1976). Estos autores emplean el término de "interpolación" para el proceso de estimar valores intermedios de una serie, con gran número de datos
(observaciones horarias de 7 años), mediante un modelo Box-JenJcins , el cual es identificado y ajustado con observaciones consecutivas, en número suficiente (datos horarios de 4 ó 5 semanas), de la misma serie. Describen un método iterativo, de forma que, cada vez se utilizan los valores de los parámetros obtenidos en la iteracción precedente. Las mejores estimas de los datos que faltan se obtienen resolviendo un sistema de ecuaciones lineales donde tienen en cuenta la observación anterior y posterior al dato perdido. El inconveniente de este método, para aplicar a nuestro caso, es que no hay suficientes observaciones consecutivas para poder identificar el modelo a estimar.
a considerar en caso de series con falta de datos, con buenos resultados esperables, siempre que las observaciones que faltan sean menos del 10% y no se encuentren demasiado próximas al primer valor de la serie, ya que sólo se tienen en cuenta los valores precedentes al perdido. Las series que se van a analizar en este trabajo, tienen porcentajes variados de falta de datos, dependiendo de la estación de control de que se trate, en general, sobrepasan el 10%.
Posteriormente, Lettenmaier (1980) con base en lo propuesto por Brubacher & Wilson y extendiendo la técnica de predicción de Box-Jenkins, emplea el análisis de
intervención con series en que faltan datos, de forma que estima, simultáneamente, los parámetros del modelo y los datos perdidos. Como dichos autores, supone conocido el modelo (número de parámetros) a estimar.
Peña (1987) revisa trabajos anteriores sobre análisis de series con falta de datos y propone dos procedimientos para obtener valores suavizados de los datos que faltan (o que se han suprimido por considerarse anómalos): (l) mediante análisis de intervención; (2) mediante la representación en el espacio de estados del modelo ARIMA que sigue la serie, empleando el filtro de Kalman para estimar los valores perdidos. Lo mismo que en los casos anteriores se supone conocido el modelo ARIMA de la serie en estudio y, ciñéndonos al procedimiento (1), no resulta operativo si las observaciones que faltan son muchas ya que por cada dato perdido se introduce un nuevo parámetro a estimar.
pequeña parte de su libro sobre análisis estadístico con falta de datos, a la estimación de los mismos en series de tiempo. Señalan como técnica general para encontrar estimas máximo verosímiles de datos incompletos el "algoritmo EM
(Estimation - Maximization)" . En el caso concreto de series, los modelos AR(p) requieren modificaciones especiales del algoritmo, que estos autores indican como
"fáciles de implementar aunque no triviales de describir" por lo que se limitan a presentar un AR(1), y surgen dificultades en presencia de términos MA. Peña (1988) , en una publicación reciente, señala que "el algoritmo EM es relativamente complejo y requiere el uso de rutinas de programación no lineal y de filtro de Kalman, que no son fáciles de encontrar y manejar. De hecho, no existe ningún programa de uso general para la estimación de las observaciones que faltan en series incompletas".
En todos los casos anteriores, con referencia especial a la estimación de modelos ARIMA para series incompletas, es necesario identificar o conocer, de alguna manera, el modelo que sigue la serie. Vo-Day permite ese paso calculando la fas y la fap teniendo en cuenta sólo los datos observados realmente y cuando faltan pocos datos (< 10%).
6.3.- Método empleado en este trabajo
Por las características de los datos empleados se ha procedido de la siguiente manera para completar las series:
s u a v i z a d o p o r i n t e r p o l a c i ó n l i n e a l s i m p l e e n t r e la observación anterior y la posterior (Velleman & Hoaglin, 1 9 8 1 ) , salvo en el caso de que alguno de tales datos se considere como anómalo con respecto al resto de los valores de la serie;
(2) si son varios datos consecutivos los que faltan, se ha obtenido la media del mes correspondiente.
Las r a z o n e s que han l l e v a d o a u t i l i z a r d i c h o procedimiento, a nuestro caso, además de los inconvenientes citados en las referencias de otros métodos, han sido:
1) Se trata de obtener un modelo aproximado que represente cada serie de cada uno de los parámetros seleccionados (20 puntos de control y 7 parámetros por p u n t o ) , es decir, gran número de series a estudiar, con observaciones tomadas como datos orientativos del estado del agua en determinado momento.
2) La obtención de cada modelo no se puede automatizar totalmente, ya que, es preciso analizar cada serie por separado, así como los resultados procedentes de cada etapa de construcción del modelo.
4) En el citado trabajo de Peña (1988) , demuestra que "el estimador óptimo de una observación ausente en una serie temporal que sigue un modelo ARIMA es una media ponderada de las observaciones disponibles", por lo que, los valores interpolados son un buen punto de partida para tratar de identificar el modelo que sigue la serie. Por otra parte, cuando las observaciones que faltan se encuentran próximas al final de la serie, Peña (1988) comienza la obtención de estimadores óptimos "rellenando los agujeros en la serie con valores escogidos arbitrariamente", y un valor arbitrario puede ser el valor medio del mes a que corresponde el
"hueco".
5) Para cada serie se ha tenido en cuenta el porcentaje de observaciones que faltan, no considerando aquellas con porcentajes mayores del 40%.
6.4.- Datos anómalos (outliers)
Las series, a veces, presentan valores aislados demasiado altos o demasiado bajos, de forma que no parecen pertenecer al conjunto general de datos.
Las causas que los producen pueden ser variadas: errores de medida, de recogida de datos, de transcripción o de introducción al ordenador para su procesado. Si no se pueden corregir con el valor adecuado, se excluirán y se tratarán como si el dato correspondiente faltara.
investigar la causa puede aportar información valiosa para análisis posteriores (análisis de intervención) .
Cualquiera que sea su origen, dichos valores van a requerir atención especial, unas veces para sustituirlos y otras para analizar los efectos de la situación que les originó.
Si los valores son muy extremos, se detectarán fácilmente con la observación del gráfico inicial de la serie. Si no, se podrán localizar posteriormente al estudiar los correlograrnas o los residuos resultantes del modelo ajustado.
APÉNDICE AL CAPITULO 2
1.- procesos estocastieos
En Fuller (1976) se encuentra la siguiente definición: "Si (íí,A,P) es un espacio probabilístico, con sucesos elementales y Z un conjunto de índices "t", una serie de tiempo de valores reales (o proceso estocástico) es una
función real X(t,w) definida sobre Z x íl, tal que para cada t, X(t,to) es una variable aleatoria sobre (íl,A,P). Dicha
función se suele expresar por X^ o X^.(w) , y una serie de tiempo puede considerarse como un conjunto (X-j. : t e Z) de variables aleatorias.". Para fijo, X(t,u) es una función real de t, que define una trayectoria del proceso.
2.- Procesos estacionarios
"Un proceso {X^.: t e Z} es estrictamente estacionario (e.e.) si la distribución de probabilidad conjunta de Xít.j+k), X(t2+k), ..., X(tn+k), sólo depende de k, para todo n > 1 y todo tl f ..., tn e Z. Es decir,
(1) FCxíti), x(t2), x(tn)] =F[x(t1+k), ..., x(tn+k)]«
2.1.- Función de autocovarianza
Se define la autocovarianza de X^. a retardo k e Z, como Cov(Xt, xt + k) = r(k)
La función de autocovarianza del proceso X^. viene dada por T(k) y k es el argumento, k = 0, 1, .., N-l (N = n5 de valores de la serie) .
La magnitud de los T(k) depende de las unidades de medida de X^.. Con el fin de interpretar mejor esos
coeficientes, se estandariza r(k) dividiendo por r(0).
2.2.- Función de autocorrelación simple
La autocorrelación de retardo k e z, viene dada por
j>(k) = T (k) / T (0)
Y J0(0) = l.
La función de autocorrelación simple (en adelante fas) o correlograma está dada por P(k), y k es el argumento.
estudio de las propiedades de un proceso estocástico estacionario. Entre sus características es interesante citar la de « "no unicidad" en caso de procesos no gaussianos, ya que éstos quedan completamente determinados por su media, varianza y fas. Sin embargo, es posible encontrar varios procesos no normales con la misma fas, dificultando la
interpretación de la fas muestral», (Chatfield, 1984).
2.3.- Función de autocorrelación parcial
La correlación parcial entre Xt y X^.+jc es el parámetro que mide la correlación entre las dos variables una vez eliminada la influencia sobre ellas de las variables intermedias Xt + 1, ..., xt+k-l*
x
t = « í A + i
+ ei
Xt = a21Xt+l + a22Xt+2 + e2
Xt = aklXt+l + ak2Xt+2 + ••• + akkXt+k + et
los coeficientes a¿^ proporcionan las autocorrelaciones
parciales a retardo i = 1, 2, ..., k, (Peña, 1987).
La función de autocorre1ación parcial (fap) es a(k) y k el argumento.
3.- Estimación de los parámetros de un proceso
estacionario
Dada una serie estacionaria X ^ X2, . . ., XN, a partir
de ella se estiman la media p,, las autocovarianzas i (k) y
las autocorrelaciones.
La media \i se estima con la media muestral
H
XN = ( S Xt) / N
t=l
Para la estimación de r(k), suponiendo \i conocida y,
para simplificar, igual a cero, se suele emplear
l N-k
c (k) = S (X
t- x
N) ( x
t + k- x
N)
H t-1