Paralelización de la meta heurística ¨Optimización en Mallas Variables¨ utilizando la Arquitectura CUDA
74
0
0
Texto completo
(2) Declaración Jurada. El que suscribe, Adrian Martínez Prieto, hago constar que el trabajo titulado Paralelización de la meta-heurística ¨Optimización en Mallas Variables¨ utilizando la Arquitectura CUDA fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Licenciatura en Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ________________ Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. _____________________________ Firma del Tutor(es). ____________________________ Firma del Jefe del Laboratorio. 24 de junio de 2015.
(3) Dedicatoria. A mis padres, por todo su apoyo. A toda mi familia… i.
(4) Agradecimientos. Un agradecimiento especial a mi tutor Ernesto Díaz López, por guiarme durante todo el proceso de investigación que dio como resultado este trabajo. Un agradecimiento especial al Dr. Daniel Gálvez Lio, por su apoyo y ayuda incondicional. A mis padres por toda su ayuda, confianza y compresión, a mi hermano y familia por estar conmigo en todo. A mi novia por su dedicación y apoyo, a sus padres por acogerme como uno más de la familia. A los amigos de la carrera por ayudarme en todo momento. A mis profesores de clases que con tanta sabiduría me prepararon para ser un buen profesional. Es imposible mencionar a todas las personas que me ayudaron en todo este caminar, en estos momentos pasan todos por mi mente, sus enseñanzas, juegos, risas, tristezas, en fin… Tengo la certeza de que al mencionarlos nunca terminaría, todos y cada uno están en mí.. ii.
(5) Resumen. RESUMEN En el campo de la optimización, tanto académico como industrial los problemas que se presentan a diario son a menudo complicados y NP-difícil. La solución computacional de los mismos no puede llevarse a cabo de una manera exacta en un plazo de tiempo razonable, y el uso de recursos de hardware de cómputo para esta solución aumenta considerablemente. Para lidiar con tal asunto, el diseño de los métodos de solución debe estar basado en el uso conjunto de los enfoques avanzados de la optimización combinatoria, los métodos de paralelismo e ingeniería a gran escala. Por lo que existen diferentes ramas de la investigación dedicadas al desarrollo constante de estas técnicas. En las últimas décadas, en la rama de la Inteligencia Artificial las meta-heurísticas poblacionales representan una poderosa herramienta para la solución de problemas complejos. El objetivo de este trabajo es exponer los resultados obtenidos a partir de la aplicación de técnicas paralelas utilizando la arquitectura CUDA a la meta-heurística poblacional “Optimización en Mallas Variables” (VMO), con el propósito de lograr una mejora en el costo computacional en la misma. En el trabajo se implementan en paralelo las etapas más costosas del algoritmo en el proceso de expansión y contracción de la malla para la obtención de la nueva población inicial. Los resultados obtenidos fueron validados utilizando una versión secuencial de la metaheurística. Los tiempos de ejecución de ambos algoritmos se comparan, mostrándose mejoras sustanciales en la versión paralela con el uso de CUDA. Palabras Clave: Meta-heurística, VMO, GPGPU, CUDA.. iii.
(6) Abstract. ABSTRACT In the field of optimization, both academic and industrial problems that occur daily are often complicated and NP-hard. The computational solution of such problems cannot be carried out in a precise manner in a reasonable period of time, and the use of hardware resources of computation for this solution greatly increases. To address this issue, the design of the solution methods should be based on the set of the advanced approaches of combinatorial optimization using the methods of parallelism and engineering scale. So there are different branches of research dedicated to the ongoing development of these techniques. In recent decades, in the field of Artificial Intelligence, population based meta-heuristics represent a powerful tool for solving complex problems. The objective of this paper is to present the results obtained from the application of parallel techniques using the CUDA architecture to the meta-heuristic "Variable Mesh Optimization" (VMO), with the purpose of achieving an improvement in the computational cost. In the work are implemented in parallel the more expensive stages of the algorithm in the process of expansion and contraction of the mesh for obtaining the new initial population. The results obtained were validated using a sequential version of the meta-heuristics. The runtimes of both algorithms are compared, showing substantial improvements in the parallel version with the use of CUDA. Key Words: Meta-heuristic, VMO, GPGPU, CUDA.. iv.
(7) Tabla de contenido. TABLA DE CONTENIDO INTRODUCCIÓN ............................................................................................................. - 1 CAPÍTULO 1. META-HEURÍSTICAS, MODELO DE PROGRAMACIÓN EN CUDA. ELEMENTOS FUNDAMENTALES ............................................................................... - 4 1.1.. Meta-heurística .......................................................................................................... - 4 -. 1.2.. Meta-heurística poblacional ....................................................................................... - 6 -. 1.2.1.. Algoritmos Evolutivos ......................................................................................... - 7 -. 1.2.2.. Inteligencia Colectiva .......................................................................................... - 8 -. 1.3.. Meta-heurísticas paralelas .......................................................................................... - 9 -. 1.4.. Meta-heurística y GPU .............................................................................................. - 12 -. 1.5.. Modelo de Programación en CUDA........................................................................... - 15 -. 1.6.. Conclusiones parciales del capítulo ........................................................................... - 20 -. CAPÍTULO 2. 2.1.. PARALELIZACIÓN DE LA META-HEURÍSTICA VMO ............. - 22 -. Caracterización general de la meta-heurística VMO .................................................. - 22 -. 2.1.1.. Fomento de la diversidad .................................................................................. - 27 -. 2.1.2.. Características específicas para dominios continuos.......................................... - 27 -. 2.1.3.. Tamaño de la malla ........................................................................................... - 31 -. 2.2.. Paralelización de la meta-heurística VMO utilizando CUDA ....................................... - 32 -. 2.3.. Conclusiones parciales del capítulo ........................................................................... - 40 -. CAPÍTULO 3. 3.1.. VALIDACIÓN DE LOS RESULTADOS ......................................... - 41 -. Definición de las funciones de referencia .................................................................. - 41 -. 3.1.1.. Funciones bases ................................................................................................ - 42 -. 3.1.2.. Funciones totalmente separables...................................................................... - 43 -. 3.1.3.. Funciones aditivas o parcialmente separables I: ................................................ - 44 -. 3.1.4.. Funciones aditivas o parcialmente separables II: ............................................... - 46 -. 3.1.5.. Funciones traslapadas ....................................................................................... - 48 -. 3.1.6.. Funciones no separables ................................................................................... - 49 -. 3.2.. Análisis estadístico de los resultados ........................................................................ - 50 -. 3.3.. Análisis temporal de los algoritmos .......................................................................... - 53 -. 3.4.. Conclusiones parciales del capítulo ........................................................................... - 54 -. CONCLUSIONES ........................................................................................................... - 55 v.
(8) Tabla de contenido. RECOMENDACIONES ................................................................................................. - 56 BIBLIOGRAFÍA ............................................................................................................. - 57 ANEXOS ......................................................................................................................... - 59 Anexo A.. Técnicas estadísticas utilizadas.......................................................................... - 59 -. Anexo B.. Kernels utilizados .............................................................................................. - 62 -. Anexo B.1. Kernel randomNumbers ............................................................................ - 62 -. Anexo B.2. Kernel calculate_EuclidiaDistance.............................................................. - 62 -. Anexo B.3. Kernel f_Function ...................................................................................... - 62 -. Anexo B.4. Kernel g_Function ..................................................................................... - 63 -. Anexo B.5. Kernel under_overExtremeNode_Generate............................................... - 63 -. vi.
(9) Lista de figuras. LISTA DE FIGURAS FIGURA 1.1: TAXONOMÍA DE LOS MÉTODOS DE OPTIMIZACIÓN. ....................................................................................- 6 FIGURA 1.2: MEJORES CODIFICACIONES PARA PROBLEMAS DE OPTIMIZACIÓN. ...............................................................- 10 FIGURA 1.3: MODELOS PARALELOS DE META-HEURÍSTICA. .........................................................................................- 12 FIGURA 1.4: DISTRIBUCIÓN DE LAS UNIDADES DE PROCESAMIENTO EN LA CPU Y GPU.....................................................- 12 FIGURA 1.5: OPERACIONES DE PUNTO FLOTANTE POR SEGUNDO PARA LA CPU Y GPU ....................................................- 16 FIGURA 1.6: ANCHO DE BANDA DE MEMORIA PARA LA CPU Y GPU .............................................................................- 17 FIGURA 1.7: JERARQUÍA DE HILOS .........................................................................................................................- 18 FIGURA 1.8: MAYA DE BLOQUES DE HILOS...............................................................................................................- 18 FIGURA 1.9: ESQUEMA GENERAL DE PROGRAMACIÓN EN CUDA .................................................................................- 20 FIGURA 2.1: ALGORITMO GENERAL VMO ...............................................................................................................- 25 FIGURA 2.2: EJEMPLO DE API DEL HOST PARA GENERAR NÚMEROS ALEATORIOS .............................................................- 34 FIGURA 2.3: DIAGRAMA DE ACTIVIDAD DEL KERNEL RANDOMNUMBERS........................................................................- 35 FIGURA 2.4: DIAGRAMA DE ACTIVIDAD DEL KERNEL CALCULATE_EUCLIDIADISTANCE .......................................................- 36 FIGURA 2.5: DIAGRAMA DE ACTIVIDAD DEL KERNEL F_FUNCTION ................................................................................- 37 FIGURA 2.6: DIAGRAMA DE ACTIVIDAD DEL KERNEL G_FUNCTION ................................................................................- 38 FIGURA 2.7: DIAGRAMA DE ACTIVIDAD DEL KERNEL UNDER_OVEREXTREMENODE_GENERATE ..........................................- 39 -. vii.
(10) Lista de tablas. LISTA DE TABLAS TABLA 1.1: TIPOS DE MEMORIA EN LA GPU ............................................................................................................- 19 TABLA 3.1: EVALUACIÓN DE LA FO (SECUENCIAL) ....................................................................................................- 51 TABLA 3.2: EVALUACIÓN DE LA FO (PARALELA) ........................................................................................................- 51 TABLA 3.3: RESULTADOS DEL TEST DE WILCOXON (1) ...............................................................................................- 52 TABLA 3.4: RESULTADOS DEL TEST DE WILCOXON (2) ...............................................................................................- 52 TABLA 3.5: TIEMPO DE EJECUCIÓN VMO (SECUENCIAL) ............................................................................................- 53 TABLA 3.6: TIEMPO DE EJECUCIÓN VMO (PARALELA) ...............................................................................................- 53 -. viii.
(11) Introducción. INTRODUCCIÓN En la sociedad actual los problemas de optimización están presentes prácticamente en todos los lugares. Muchos de estos problemas poseen una solución con un alto grado de complejidad o se hace muy difícil encontrar una solución exacta, por lo que se suele recurrir a métodos de solución aproximados. Las meta-heurísticas denotan un tipo general de los métodos de aproximación sobre la base de las heurísticas. Están basadas en estrategias para diversificar el esfuerzo de búsqueda y evitar caer en extremos locales. Durante las últimas décadas han demostrado un rendimiento extraordinario en la solución a problemas de optimización discreta y continua. Teniendo en cuenta la complejidad computacional de los problemas, no debe sorprendernos que la computación paralela sea objetivo de investigaciones para mejorar el rendimiento de las meta-heurísticas, tanto en el caso discreto como continuo. En las últimas décadas la computación paralela ha sido revelada como una poderosa herramienta para dar solución a problemas de optimización de gran complejidad. El diseño y la puesta en práctica de las meta-heurísticas paralelas han sido fuertemente influenciados por las diferentes plataformas computacionales. Muchas contribuciones han sido propuestas para el diseño y la puesta en funcionamiento de las meta-heurísticas paralelas, usar procesadores paralelos masivos, redes o clústeres de estaciones de trabajo, y computadoras de memoria compartidas. Los enfoques propuestos están basados en tres modelos paralelos: evaluación paralela de una sola solución, evaluación paralela de las soluciones y la ejecución paralela (cooperativa o independiente) de algunas meta-heurísticas. Actualmente, el uso de las Unidades de Procesamiento Gráfico (Graphics Processing Unit; GPU) ha aumentado extraordinariamente, en principio por el acelerado desarrollo que ha alcanzado la industria de los videos juegos y al inmenso número de jugadores de todo el mundo, arrastrando consigo la necesidad de desarrollar nuevas GPU capaces de aumentar sus prestaciones y los recursos disponibles que den soporte a las nuevas creaciones de esta industria. Estas unidades están disponibles en muchos equipos: computadoras portátiles, -1-.
(12) Introducción. máquinas de escritorio, e incluso hasta en los teléfonos móviles. Pero no solo eso, estas unidades además de ser utilizadas en aplicaciones gráficas y de video, también su utilización se ha extendido a otros dominios de aplicación, como el procesamiento paralelo en la computación científica gracias a la aparición de la Arquitectura Unificada de Dispositivos de Cómputo (Compute Unified Device Architecture; CUDA), el nuevo conjunto de herramientas de desarrollo de propósito general de NVIDIA sobre la GPU, también conocido este concepto como Computación de Propósito General sobre Unidades de Procesamiento Gráfico (General Purpose Graphics Processing Unit; GPGPU). La programación en CUDA se ha convertido en un nuevo paradigma de programación paralela, aunque se mantienen los principios generales, incluye características especiales como nuevos tipos de memoria y un modelo de ejecución de hilos diferente. CUDA intenta explotar las ventajas de la GPU frente a la Unidad Central de Procesamiento (Central Processing Unit; CPU) de propósito general utilizando el paralelismo que ofrecen sus múltiples núcleos, la cual permite la ejecución de un gran número de hilos de manera simultánea, procesando la misma secuencia de instrucciones de forma secuencial por cada hilo ejecutado de manera paralela. En algunas áreas como la computación numérica, se está presenciando una proliferación de bibliotecas de software como CUBLAS para el trabajo con Álgebra Lineal Básica en la GPU, sin embargo, en otras áreas como la optimización combinatoria, especialmente en metaheurística, la utilización de la GPU no crece al mismo paso. Debido a la importancia de esta área dentro de la investigación científica y en el campo de la Inteligencia Artificial se ha generado un interés cada vez mayor por el desarrollo de la misma. Por todo lo antes expuesto resulta imprescindible encontrar nuevas alternativas de búsqueda en el ámbito de las meta-heurísticas poblacionales que mejoren el costo computacional de los algoritmos, aprovechando los avances tecnológicos actuales, de lo que se deriva el siguiente problema científico: ¿Cómo mejorar el costo computacional de los algoritmos poblacionales en la meta-heurística VMO, aprovechando los avances tecnológicos en la arquitectura CUDA? Para resolver este problema se plantearon las siguientes preguntas de investigación: -2-.
(13) Introducción. 1. ¿Qué elementos se deben tener en cuenta dentro del modelo de programación en CUDA para la implementación de VMO? 2. ¿Qué estrategias de programación paralela serán factibles a implementar para lograr la optimización del algoritmo poblacional VMO? Para darle solución al problema científico se planteó el siguiente objetivo general de investigación que consiste en: Implementar un algoritmo paralelo utilizando técnicas paralelas en la arquitectura CUDA para lograr una mejora en el costo computacional sobre la meta-heurística VMO, desarrollada en el Centro de Estudios de Informática de la Universidad Central ¨Marta Abreu¨ de las Villas. Para cumplir este objetivo general el mismo fue desglosado en los objetivos específicos siguientes: 1. Describir el modelo de programación en CUDA. 2. Implementar en C++ una versión secuencial del algoritmo VMO. 3. Desarrollar una versión paralela sobre CUDA del algoritmo VMO. 4. Analizar estadísticamente la versión paralela respecto a su versión secuencial. La paralelización de la meta-heurística poblacional VMO que se pretende implementar sería de gran utilidad para el Centro de Estudios de Informática de la UCLV. La tesis está estructurada en tres capítulos. En el Capítulo 1 se trata de manera general, los conceptos esenciales de meta-heurística, haciendo énfasis en las meta-heurísticas poblacionales, se tratan temas relacionados con las meta-heurísticas paralelas y su vinculación con la GPU, así como el modelo de programación en CUDA. Seguidamente, en el Capítulo 2 se presenta una descripción de la meta-heurística poblacional VMO, las características específicas para dominios continuos, así como los elementos esenciales en la implementación de la versión paralela del algoritmo. Finalmente en el Capítulo 3 se expondrán los resultados obtenidos de ambas versiones y sus respectivas comparaciones estadísticas. Este documento culmina con las conclusiones, recomendaciones, referencias bibliográficas y los anexos. -3-.
(14) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. CAPÍTULO 1. META-HEURÍSTICAS, MODELO DE PROGRAMACIÓN EN CUDA. ELEMENTOS FUNDAMENTALES En este capítulo se realizará una descripción general de los elementos fundamentales y las bases teóricas que dan sustento al presente trabajo, permitiendo formular una idea general de los temas que se tratarán en el mismo. 1.1. Meta-heurística En muchas ocasiones nos enfrentamos a problemas en los que encontrar la mejor solución trae consigo un alto grado de complejidad computacional o en algunos casos no se cuenta con un algoritmo para encontrar esta solución. Para resolver este tipo de problemas se pueden emplear los métodos de búsqueda heurísticos los cuales son capaces de encontrar una aproximación a una posible solución del problema, estos métodos están orientados a reducir la cantidad de búsqueda requerida para encontrar una solución. De lo que se desprende la siguiente definición: (Hooker, 1995) Un método heurístico es un procedimiento para resolver un problema complejo de optimización mediante una aproximación intuitiva, en la que la estructura del problema se utiliza de forma inteligente para obtener una buena solución de manera eficiente. En los últimos años se ha presenciado un aumento en el desarrollo de procedimientos heurísticos para resolver problemas de optimización. Este hecho queda claramente reflejado en la creación de revistas especializadas para la difusión de este tipo de procedimientos; como es el caso de la revista “Journal of Heuristics”1 editada por primera vez en el año 1995 (Cáceres, 2009). Al realizar un estudio de los algoritmos heurísticos se puede constatar que éstos dependen en gran medida del problema en concreto para el que se han diseñado. De manera que se puede asegurar que no existe el método heurístico que sea capaz de obtener los mejores resultados. 1. url: http://www.springer.com/math/applications/journal/10732. -4-.
(15) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. para cualquier problema complejo, resultado conocido como Teorema “No Free Lunch” (Wolpert and Macready, 1997). Con el desarrollo de la ciencia a través de los años se han desarrollado un conjunto de métodos bajo el nombre de meta-heurístico con el propósito de obtener mejores resultados que los alcanzados por los heurísticos tradicionales. (Osman and Kelly, 1996) Los procedimientos meta-heurísticos son una clase de métodos aproximados los cuales han sido diseñados para resolver problemas complejos de optimización. Los meta-heurísticos proporcionan un marco general para crear nuevos algoritmos híbridos combinando diferentes conceptos derivados de la inteligencia artificial, la evolución biológica y los mecanismos estadísticos (Glover and Kochenberger, 2003). Debido al gran desarrollo que han alcanzado los procedimientos meta-heurísticos, se han realizado diversas propuestas de clasificación de los mismos, dentro de las que se encuentran las siguientes: (Blum and Roli, 2003) Meta-heurísticas de trayectoria simple: se utiliza el término de trayectoria simple porque el proceso de búsqueda que desarrollan estos métodos se caracteriza por una trayectoria en el espacio de soluciones; es decir, que partiendo de una solución inicial, son capaces de generar un camino o trayectoria en el espacio de búsqueda a través de operaciones de movimiento. Algunas de estas meta-heurísticas son las siguientes: la Búsqueda Tabú (Taboo Search), Recocido Simulado (Simulated Annealing), Búsqueda de Vecindades Variables (Variable Neighborhood Search), Búsqueda Local Guiada (Guided Local Search), Búsqueda Local Iterativa (Iterated Local Search), entre otras. Meta-heurísticas poblacionales: Las meta-heurísticas basadas en población o metaheurísticas poblacionales, son aquellas que emplean un conjunto de soluciones (población) en cada iteración del algoritmo, en lugar de utilizar una única solución como las metaheurísticas del grupo anterior. Estas proporcionan de forma intrínseca un mecanismo de exploración paralelo del espacio de soluciones, y su eficacia depende en gran medida de cómo se manipule dicha población. Dentro de esta clasificación se destacan los Algoritmos Evolutivos (Evolutionary Algorithms; EA) y los algoritmos basados en Inteligencia Colectiva (Swarm Intelligence; SI). -5-.
(16) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. Estas meta-heurísticas poblacionales son de las más estudiadas y comparten como característica fundamental que han sido inspiradas en algún proceso natural. En la Figura 1.1 se muestra una taxonomía de los principales métodos de optimización.. Figura 1.1: Taxonomía de los métodos de optimización.. Los algoritmos exactos: óptimos para la explotación del espacio de búsqueda en instancias de problemas de tamaño pequeño. Las meta-heurísticas: obtienen una aproximación al óptimo de una función en problemas de grandes instancias. 1.2. Meta-heurística poblacional En el diseño de los algoritmos meta-heurísticos es importante tener en cuenta la definición de los operadores que se encargan de dirigir la búsqueda hacia zonas promisorias del espacio de solución. Para ello, se tienen que tener en cuenta dos factores importantes: (Yagiura and Ibaraki, 2001) La exploración: también llamada diversificación en la literatura, es el proceso de guiar la búsqueda hacia regiones no exploradas. Un algoritmo que realice una insuficiente exploración podría obviar regiones enteras, por lo que si el óptimo se encontrase en una de esas regiones no tendría ninguna posibilidad de ser encontrado, generalmente las metaheurísticas poblacionales (P meta-heurística) están más orientadas a la exploración, ya que estas proveen de una mejor diversificación en todo el espacio de búsqueda (Luong, 2011). La explotación: también llamada intensificación en la literatura, es el proceso de realizar una búsqueda minuciosa e intensa de mejores soluciones en un entorno cercano a buenas soluciones ya encontradas. Este proceso es fundamental para obtener una mayor precisión en -6-.
(17) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. las soluciones encontradas; aunque, cuando caen en un óptimo local, suelen quedarse estancados en este, generalmente las meta-heurísticas de trayectoria simple (S metaheurística) están más orientadas a la explotación, ya que estas poseen la habilidad de intensificar la búsqueda en la región local (Luong, 2011). En muchos casos, en las meta-heurísticas poblacionales, el factor de poseer una mayor exploración en la búsqueda es regulado por parámetros introducidos a los métodos o decisiones tomadas en presencia de números aleatorios. Para incrementar la explotación en estos algoritmos, los mismos se combinan con métodos de trayectoria simple, los cuales presentan un alto nivel de explotación de la zona del espacio de búsqueda que ha sido explorada (Cáceres, 2009). 1.2.1. Algoritmos Evolutivos Los Algoritmos Evolutivos se caracterizan por tres conceptos fundamentales: replicación, variación y selección natural. La población en este tipo de algoritmos representa un conjunto de individuos2, los cuales se mantienen mediante replicación. La variación es la encargada de introducir diversidad en la población, mediante una serie de diferencias entre los descendientes y sus progenitores y el proceso de selección se encarga de obtener de la nueva población los mejores individuos, de acuerdo a determinado criterio. Todos los EA se caracterizan por estar formados de una población inicial (usualmente generada aleatoriamente) sobre la cual se realiza un proceso iterativo que conduce a la evolución de dicha población, mediante los siguientes procesos: 1. Se aplica un operador de selección para determinar la probabilidad de cada individuo de la población de perdurar en la siguiente generación, formándose así una población temporal. 2. Se aplican operadores evolutivos (recombinación, mutación), a parte o la totalidad de la población temporal, con lo que se produce un conjunto de nuevas soluciones. 3. Se calcula el valor de la función a optimizar en las nuevas soluciones generadas.. 2. En los Algoritmos Evolutivos esta estructura representa una solución al problema, también conocido como cromosoma en Algoritmos Genéticos.. -7-.
(18) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. 4. Se obtiene una nueva población a partir de la población temporal y los nuevos individuos generados. Dichos pasos son realizados hasta que se cumple un criterio de parada (generalmente se establece un número máximo de evaluaciones de la función objetivo o se alcanza un límite máximo temporal). En los EA existen varios criterios para realizar la selección de los nuevos individuos que servirán de base para la generación de la población temporal de la próxima iteración. Entre los más utilizados están: Selección elitista: la población temporal está compuesta por los mejores individuos de la población actual, es decir, los individuos que tienen mejor evaluación de la función objetivo a optimizar. Este tipo de selección puede llevar al algoritmo a un estancamiento de la población en óptimos locales. Selección aleatoria: es la encargada de obtener una población temporal de forma totalmente aleatoria. Este criterio reduce la explotación del espacio de búsqueda, ya que se pueden omitir buenas soluciones de la población temporal que podrían arrojar mejores resultados en la generación de la nueva población. Selección probabilística: donde a cada solución se le asigna una probabilidad en dependencia de su calidad y mediante las generaciones aleatorias se puede determinar qué solución formará parte de la población temporal (Cáceres, 2009). Dentro de los principales EA se encuentran; los Algoritmos Genéticos (Genetic Algorithms), la Búsqueda Dispersa (Scatter Search), la Evolución Diferencial (Differential Evolution), entre otros. 1.2.2. Inteligencia Colectiva Las meta-heurísticas basadas en Inteligencia Colectiva son técnicas inspiradas en el estudio de comportamientos colectivos presentes en sistemas de la naturaleza. La expresión “Inteligencia Colectiva” fue introducida por Gerardo Beni, Suzanne Hackwood y Jing Wang en 1989, en el contexto de sistemas robóticos celulares (Martinoli, 2001). -8-.
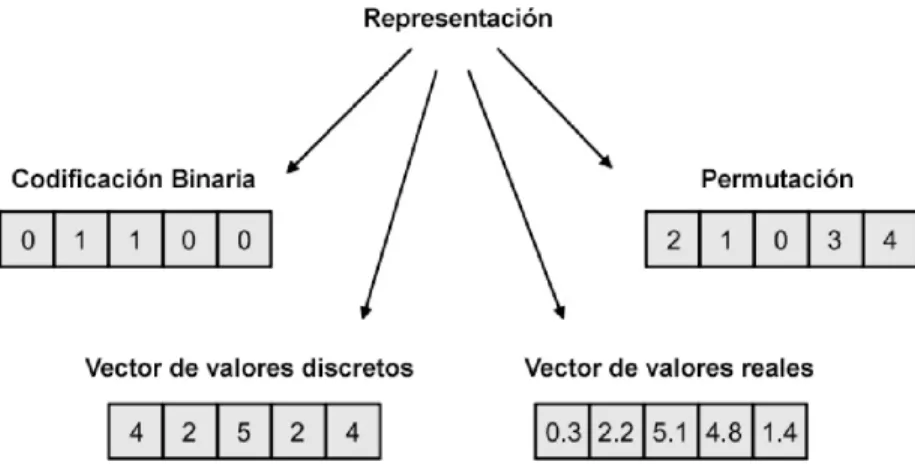
(19) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. La principal característica de los algoritmos basados en la SI está determinada por la estrecha colaboración social que presentan a través del sistema de comunicación que surge entre los individuos del colectivo (Engelbrecht, 2005). Dicha comunicación, puede presentarse de forma directa o indirecta. La comunicación indirecta ocurre cuando un individuo altera el medio en que se desarrollan y los otros son capaces de reaccionar a estos cambios. La comunicación directa es aquella que ocurre a través de la obtención de la ubicación de otros individuos mediante sonido, visibilidad u otra forma directa de interacción. Dentro de los principales métodos basados en SI se encuentran; la Optimización basada en Enjambre de Partículas (Particle Swarm Optimization; PSO) (Kennedy and Eberhart, 1995), Optimización basada en Colonia de Hormigas (Ant Colony Optimization; ACO) (Botee and Bonabeau, 1998). Dentro de los problemas de optimización combinatoria fundamentados en ACO se encuentran; el Sistema de Hormigas (Ant System; AS) (Dorigo et al., 1996), el Sistema de Colonia de Hormigas (Ant Colony System; ACS) (Dorigo and Gambardella, 1997), el Sistema de Hormigas Máximo-Mínimo (Max-Min Ant System; MMAS) (Stützle and Hoos, 2000), el Sistema de Hormigas con Ordenación Jerárquica (Rank-Based Ant System) (Bullnheimer et al., 1997), el Sistema de Hormigas Mejor-Peor (BestWorst Ant System) (Cordon et al., 2000), entre otros. 1.3. Meta-heurísticas paralelas Un elemento fundamental en el diseño de las meta-heurísticas es la representación de la solución. La codificación tiene un papel muy importante en la eficiencia y la eficacia de cualquier meta-heurística así que constituye un paso esencial en su diseño, por lo que debe ser apropiada y relevante al problema de optimización en cuestión. Además, la calidad de una representación tiene una influencia considerable sobre la eficiencia de los operadores de búsqueda aplicados en esta representación. En la literatura se resaltan cuatro codificaciones importantes: codificación binaria (ej. problema de la mochila), vector de valores discretos (ej. problema de asignación), permutación (ej. problemas de planificación) y vector de valores reales (ej. funciones continuas). La Figura 1.2 ilustra un ejemplo de cada representación (Luong, 2011). -9-.
(20) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. Figura 1.2: Mejores codificaciones para problemas de optimización.. El uso de meta-heurísticas permite reducir la complejidad computacional del proceso de búsqueda considerablemente, en particular, cuando la función objetivo y las restricciones relacionadas con el problema de optimización necesitan grandes recursos de cómputo y el tamaño del espacio de búsqueda es enorme. Para lograr un mejor rendimiento en su implementación se deben tener en cuenta consideraciones importantes, como es el caso, de los métodos de trayectoria simple en el que ejecutar el proceso iterativo de búsqueda sobre grandes vecindades requiere una cantidad considerable de recursos computacionales, lo mismo ocurre en las meta-heurísticas poblacionales, cuando el proceso de generación de nuevos individuos se realiza sobre un conjunto grande de la población. En general, evaluar una función para cada solución es frecuentemente la operación más costosa de la meta-heurística. Como consecuencia, se ha comenzado un fuerte estudio para diseñar meta-heurísticas eficientes. Generalmente ese esfuerzo se traduce en introducir nuevos operadores de movimiento, algoritmos híbridos, modelos paralelos, entre otros. El paralelismo aparece naturalmente cuando en una población de soluciones (o un vecindario), cada una de las soluciones que pertenecen a la misma es una unidad independiente. Debido a esto, el rendimiento de las meta-heurísticas mejora significativamente cuando se ejecuta en paralelo (Luong, 2011). La computación paralela y distribuida puede ser usada en el diseño e implementación de meta-heurísticas por las razones siguientes:. - 10 -.
(21) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. Acelerar la búsqueda: uno de los objetivos principales de paralelizar una meta-heurística es reducir el tiempo de búsqueda. Esto es un aspecto crucial para algunas clases de problemas donde tenemos requisitos en los tiempos de búsqueda. Mejorar la robustez: una meta-heurística paralela podría ser más robusta en correspondencia con solucionar problemas de optimización diferentes y ejemplos diferentes de un problema en particular de una manera eficaz. La robustez también puede ser medida en relación con la sensibilidad de la meta-heurística hacia sus parámetros. Mejorar la calidad de las soluciones obtenidas: algunos modelos de meta-heurísticas paralelas permiten mejorar la calidad de la búsqueda. Ciertamente, intercambiar información entre meta-heurísticas cooperativas modificará su comportamiento en términos de búsqueda en el ámbito asociado al problema. El objetivo principal de una cooperación paralela entre las meta-heurísticas es mejorar la calidad de las soluciones. Solucionar problemas a gran escala: las meta-heurísticas paralelas permiten solucionar ejemplos complicados de problemas de optimización a gran escala. Un ejemplo de ello es solucionar más modelos matemáticos exactos relacionados con problemas de optimización diferentes. Con este propósito, en (Luong, 2011) se describen tres modelos paralelos muy importantes para las meta-heurísticas: el nivel de solución, el nivel de iteración y el nivel algorítmico (ver Figura 1.3): Modelo paralelo del nivel de solución: El enfoque está en la evaluación paralela de una única solución. Las operaciones pueden llevarse a cabo sobre una solución de manera paralela. Modelo paralelo del nivel de iteración: Este modelo no modifica el comportamiento de la heurística. La evaluación de las soluciones se realiza de manera paralela. Una ejecución eficiente para este modelo es cuando la evaluación de cada solución es costosa. Modelo paralelo del nivel algorítmico: Algunas meta-heurísticas son iniciadas simultáneamente para evaluar las mejores soluciones. Estas pueden ser heterogéneas u. - 11 -.
(22) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. homogéneas, independientes o cooperativas, empezar en la misma o en diferentes soluciones, configurado con los mismos o diferentes parámetros.. Figura 1.3: Modelos paralelos de meta-heurística.. 1.4. Meta-heurística y GPU Durante años, el uso de procesadores gráficos se ha dedicado a aplicaciones gráficas. Conducido por la demanda de gráficos 3D de alta definición sobre computadoras personales, la GPU ha evolucionado hacia un alto paralelismo, un ambiente multi hilos y muchos procesadores. Realmente, esta arquitectura posee un alto poder de procesamiento computacional y un gran ancho de banda de memoria comparado con la CPU tradicional. En la Figura 1.4 tomada de (Corporation, 2014a) se muestran las arquitecturas de la CPU y la GPU respectivamente.. Figura 1.4: Distribución de las unidades de procesamiento en la CPU y GPU.. - 12 -.
(23) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. Como se puede apreciar la CPU no tiene una gran número de Unidades Aritmético Lógicas (ALU), pero si posee una caché grande y una unidad de control importante. Como resultado, la CPU está especializada para manejar las múltiples y diferentes tareas en paralelo que requieren muchos datos. Así, los datos son almacenados dentro de la caché para acelerar sus accesos. La unidad de control manejará el flujo de instrucciones para maximizar la ocupación en las ALU, y optimizar la gestión de la caché. Contrario a esto, se puede observar como en la GPU se tiene un gran número de ALU, con un caché limitado y pocas unidades de control. Esto permite que la GPU se especialice más en calcular de forma masiva y paralela un conjunto de elementos pequeños e independientes, mientras se tiene un gran flujo de datos a procesar. Debido a que más transistores están dedicados al procesamiento de datos, en vez de al almacenamiento de los mismos y al control del flujo de instrucciones (Corporation, 2014a). La optimización combinatoria paralela sobre GPU requiere un esfuerzo enorme en el diseño. Algunas de las consideraciones más importantes son: la distribución eficiente del procesamiento de datos entre CPU y GPU, la sincronización de los hilos, la optimización de la transferencia de datos entre las diferentes memorias, las restricciones de capacidad de estas memorias, entre otras. Tales asuntos deben ser tenidos en cuenta para el diseño de modelos meta-heurísticos paralelos con el objetivo de solucionar problemas de optimización a gran escala sobre arquitecturas de GPU (Luong, 2011). Cooperación entre la CPU y la GPU: requiere definir la repartición de tareas en la metaheurística. Para lograr este asunto, la optimización de la transferencia de datos entre los dos componentes se hace necesaria para obtener el mejor rendimiento. Control del paralelismo: En la GPU se ejecutan de forma paralela un conjunto enorme de hilos, estos hilos son ejecutados en cualquier orden. Por lo que un control eficiente de los hilos es fundamental para cumplir con las restricciones de memoria. A cada hilo se le asigna un identificador único asignado en tiempo de ejecución en la GPU. Gestión de la memoria: Optimizar el rendimiento de aplicaciones de GPU a menudo supone optimizar los accesos a los datos que incluyen el uso apropiado de varios espacios de. - 13 -.
(24) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. memoria de la GPU. Para ello se debe tener en cuenta el uso adecuado de las diferentes memorias, sus tamaños y su latencia de acceso. En la computación de propósito general sobre unidades de procesamiento de gráficos, la CPU es considerada como un anfitrión (host) y la GPU es usada como un coprocesador. De esta manera, cada GPU tiene su propia memoria y elementos de procesamiento que están separados de la computadora anfitriona. Los datos deben ser transferidos entre el espacio de memoria del anfitrión y la memoria de GPU durante la ejecución del programa. Cada GPU soporta el modelo Programa Simple-Múltiples Datos (Single Program Multiple Data; SPMD), los múltiples procesadores autónomos ejecutan el mismo programa simultáneamente sobre datos diferentes. Para conseguir esto, se definió el concepto de kernel. El kernel es una función llamada desde el anfitrión y ejecutado simultáneamente sobre el dispositivo especificado por algunos procesadores en paralelo. El trabajo con kernel es dependiente del lenguaje de programación que se esté usando. Por ejemplo, CUDA u OpenCL son ambientes de computación paralelos que están provistos de una interfaz de programación de aplicaciones para las arquitecturas de la GPU. Estos juegos de herramientas presentan un modelo de hilos que suministra un concepto abstracto para las arquitecturas Instrucción Simple-Múltiples Datos (Single Instruction Multiple Data; SIMD). La transferencia de memoria de la CPU para la memoria del dispositivo GPU es una operación síncrona que necesita cierto tiempo. Efectivamente, el ancho de banda del bus PCIe y la latencia entre CPU y GPU pueden reducir el rendimiento de la búsqueda significativamente. Como resultado, un objetivo cuando se programan aplicaciones sobre la GPU es establecer eficientemente una repartición de las tareas (Luong, 2011). En general, para las arquitecturas distribuidas, el rendimiento global en meta-heurísticas se ve limitado por los retrasos de comunicación y el rendimiento alcanzado en los accesos a la memoria en las arquitecturas GPU. Efectivamente, cuando se realiza un estudio de las soluciones paralelas, se puede apreciar que el principal obstáculo en las arquitecturas distribuidas es la eficiencia de comunicación.. - 14 -.
(25) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. 1.5. Modelo de Programación en CUDA Durante 30 años, una de las principales estrategias de los productores de procesadores para mejorar el rendimiento de las computadoras personales ha sido incrementar la velocidad de reloj del micro procesador. Empezando con las primeras computadoras personales a comienzos del 1980, las cuales tenían una CPU que trabajaban a una velocidad de alrededor de 1 MHz. Aproximadamente 30 años después, la mayoría de los procesadores de escritorio tienen velocidades de reloj entre 1GHz y 4GHz. Aunque incrementar la velocidad de reloj de la CPU no es el único método para aumentar el rendimiento. En 2005, confrontado con un mercado cada vez más competitivo y pocas opciones los fabricantes de CPU comenzaron a producir procesadores con dos núcleos en lugar de uno. Durante los siguientes años, continuó este desarrollo con el lanzamiento de tres, cuatro, seis y hasta ocho núcleos en las CPU. Comenzando la revolución de los multi procesadores. Junto a todo esto, el estado del procesamiento de gráficos pasó por una revolución algo más dramática. A fines de 1980 y a comienzos de 1990, con el aumento de la popularidad de sistemas operativos con una interfaz gráfica impulsados por la ambición de la gigante industria Microsoft Windows se creó en el mercado un nuevo tipo de procesador. Ya por esos años usuarios comenzaron a adquirir las primeras tarjetas aceleradoras de gráficos 2D para sus computadoras personales. Por esos años, en el mundo de la computación profesional, la compañía Silicon Graphics apostó por popularizar el uso de gráficos en 3D en una variedad de mercados, incluyendo aplicaciones gubernamentales, aplicaciones de defensa y visualización científica y técnica, así como proveer un conjunto de herramientas para crear unos efectos cinemáticos increíbles. En 1992, Silicon Graphics lanzó al mercado la interfaz de programación para su hardware liberando la biblioteca OpenGL, una API para el desarrollo de aplicaciones gráficas en 3D (Sanders and Kandrot, 2010). Al mismo tiempo, compañías como NVIDIA, ATI Technologies, entre otras, comenzaron a liberar aceleradores de gráficos. Esto permitió la consolidación de los gráficos 3D como una tecnología que alcanzaría en los próximos años un desarrollo inigualable.. - 15 -.
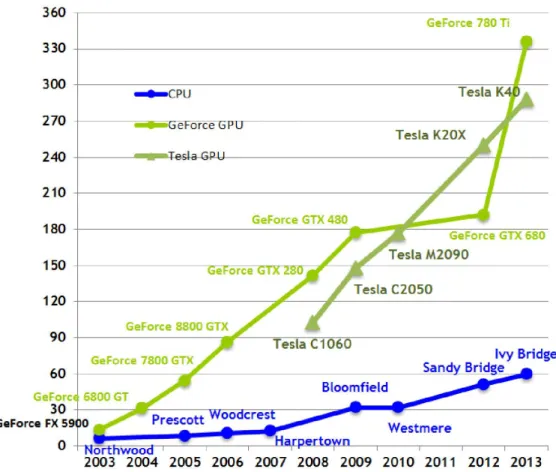
(26) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. Para la compañía NVIDIA el desarrollo de la GPU era más que procesamiento gráfico. Conducido por la demanda insaciable del mercado de los gráficos 3D en tiempo real de alta definición, la GPU ha evolucionado hacia un procesador con un alto nivel de paralelismo, múltiple hilos con un poder computacional tremendo y un gran ancho de banda de memoria (ver Figura 1.5 y Figura 1.6). Así fue como después del lanzamiento de sus tarjetas de la serie GeForce 3 el desarrollo de sus dispositivos tomaría un nuevo camino. En noviembre de 2006, NVIDIA reveló el primer GPU con DirectX 10 de la industria, el GeForce 8800 GTX, este era también el primer GPU construido con la arquitectura CUDA de NVIDIA (Corporation, 2014a). Esta arquitectura incluía algunos nuevos componentes diseñados estrictamente para la computación de GPU y aliviar muchas de las limitaciones que impidieron que procesadores gráficos previos permitieran su uso en computación de propósito general.. Figura 1.5: Operaciones de punto flotante por segundo para la CPU y GPU. - 16 -.
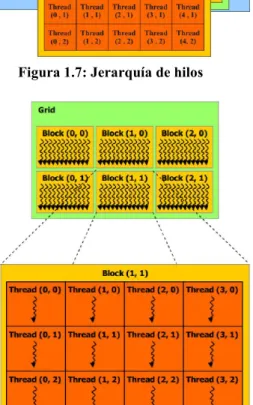
(27) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. Figura 1.6: Ancho de banda de memoria para la CPU y GPU. El diseño del modelo de programación en CUDA está pensado para que las aplicaciones puedan escalar su paralelismo para así incrementar el número de núcleos computacionales. La programación en CUDA está basada en tres abstracciones básicas; una jerarquía de grupos de hilos, de tipos de memoria, y barreras de sincronización. A su vez la estructura que conforma la jerarquía de hilos en este modelo está formada por tres componentes básicos: mallas, bloques e hilos. Un conjunto de bloques conforman las mallas; un bloque está formado por un grupo de hilos, los mismos son la unidad constituyente más elemental (la Figura 1.7 y Figura 1.8 ilustran esta organización). Una malla puede ser definida como un grupo de bloques que ejecuta cierta función llamada kernel (González, 2014).. - 17 -.
(28) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. Figura 1.7: Jerarquía de hilos. Figura 1.8: Maya de bloques de hilos. Los hilos dentro de un bloque son ejecutados concurrentemente en un Multiprocesador de flujo (Streaming Multiprocessors; SM), el cual está formado por ocho procesadores de flujo (Streaming Processor, SP). A su vez los bloques dentro de las mallas son distribuidos entre los diferentes multiprocesadores, lo que establece otro grado de paralelismo. Los SM son las unidades de cálculo por la cuales está constituido una moderna GPGPU típica, a los cuales le son asignados bloques de hilos para su ejecución paralela. Cada SM tiene una o más unidades de recolección de instrucciones, múltiples ALU, cierta cantidad de memoria compartida accesible por todos los hilos del bloque, y un grupo de registros compartidos - 18 -.
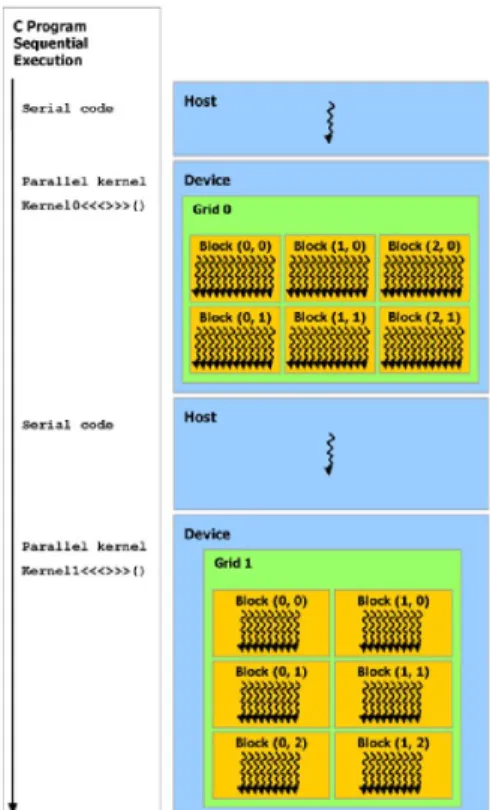
(29) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. entre los hilos. Como las diferentes ALU comparten una misma secuencia de instrucciones, los hilos asignados a estas ejecutan la misma instrucción utilizando una arquitectura llamada Instrucciones Simples Múltiples Hilos (Single Instruction Multiple Thread; SIMT). El lenguaje CUDA-C de NVIDIA es una extensión para C que permite el desarrollo de rutinas de GPU llamadas kernel, actualmente se han desarrollado nuevas herramientas que permiten hacer uso de CUDA en otros lenguajes de programación, como son: C++, Fortran, Java, Python, entre otros. Cada kernel define instrucciones que son ejecutadas sobre el GPU por muchos hilos al mismo tiempo siguiendo el modelo SIMD. Al conjunto de hilos requeridos para ejecutar un kernel es llamado cuadrícula o malla (grid) en la terminología CUDA (Kromer et al., 2011). Los hilos que se ejecutan en un dispositivo CUDA tienen acceso a múltiples espacios de memoria: global, local, compartida, constante, textura y registros (ver Tabla 1.1). Cada hilo tiene un espacio de memoria local privado; a su vez, cada bloque de hilos posee memoria compartida visible solo a todos los hilos del bloque y con la misma duración de vida que el bloque. Además, todos los hilos ejecutando cierto kernel tienen acceso a la misma memoria global (Kromer et al., 2011). La información almacenada en la memoria global, constante y de textura, es persistente a través de diferentes ejecuciones de funciones kernel en la misma aplicación (Corporation, 2014a). Estas dos últimas solo pueden ser modificadas desde el host. Tipos de memoria Global Registros Local Compartida Constante Textura. Velocidad. Tamaño. Accesos. Alcance. Tiempo de vida. Lenta Muy rápida Lenta Rápida Rápida (caché) Rápida (caché). Grande Muy pequeña Grande Pequeña Mediana Mediana. R/W R/W R/W R/W R R. Malla + host 1 Hilo 1 Hilo Bloque Malla + host Malla + host. Liberada x Host Hilo Hilo Bloque Liberada x Host Liberada x Host. Tabla 1.1: Tipos de memoria en la GPU. El modelo de programación en CUDA asume que los hilos de CUDA se ejecutaran sobre un dispositivo físico que funciona como un coprocesador al anfitrión en la corrida de un programa en C. Esto es el caso, por ejemplo, cuando los kernels son ejecutados sobre la GPU y el resto del programa se ejecuta sobre la CPU (Ver Figura 1.9).. - 19 -.
(30) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. El modelo de programación en CUDA también supone que tanto el anfitrión como el dispositivo mantienen sus propios espacios de memoria distintos en el DRAM, refiriéndose a la memoria del anfitrión y la memoria de dispositivo, respectivamente. Por lo tanto, un programa maneja los espacios de memoria global, constante y textura visibles a los kernels a través de las llamadas en tiempo de ejecución a CUDA. Esto incluye la asignación y liberación de memoria en el dispositivo, tanto como la transferencia de datos entre el anfitrión y la memoria de dispositivo (Corporation, 2014a).. Figura 1.9: Esquema general de programación en CUDA. 1.6. Conclusiones parciales del capítulo Para obtener un diseño eficiente en la implementación de las meta-heurísticas paralelas se debe tener en cuenta entre otros aspectos: la distribución eficiente del procesamiento de datos entre CPU y GPU, un control eficiente del paralelismo y la optimización en la gestión de información entre las diferentes memorias. En el modelo de programación en CUDA, se establece que tanto el anfitrión como el dispositivo poseen sus propios espacios de memoria, refiriéndose a la memoria del anfitrión - 20 -.
(31) Capítulo 1: Meta-heurísticas, Modelo de Programación en CUDA. Elementos fundamentales. y la memoria del dispositivo, respectivamente. Para poder hacer uso de la GPU, es necesario realizar la asignación y liberación de memoria en el dispositivo, tanto como la transferencia de datos entre el anfitrión y la memoria de dispositivo. Las funciones que son ejecutadas sobre la GPU son llamadas funciones kernel.. - 21 -.
(32) Capítulo 2: Paralelización de la meta-heurística VMO. CAPÍTULO 2. PARALELIZACIÓN DE LA META-HEURÍSTICA VMO La Optimización Basada en Mallas Variables (Variable Mesh Optimization; VMO) es una meta-heurística poblacional con características evolutivas donde un conjunto de nodos que representan soluciones potenciales a un problema de optimización, forman una malla (población) que se expande y contrae dinámicamente, desplazándose por el espacio de búsqueda. Esta meta-heurística consta esencialmente de cuatro etapas, en las tres primeras se realiza un proceso de expansión en cada ciclo, donde se generan nuevos nodos en dirección a los extremos locales (nodos de la malla con mejor calidad en distintas vecindades) y el extremo global (nodo obtenido de mejor calidad en todo el proceso desarrollado), así como a partir de los nodos fronteras de la malla (nodos de mayor y menor norma). Luego en la última etapa se realiza un proceso de contracción de la malla, donde los mejores nodos resultantes en cada iteración son seleccionados como malla inicial para la iteración siguiente. La formulación general de esta meta-heurística abarca tanto los problemas de optimización continuos como los discretos (Cáceres, 2009). 2.1. Caracterización general de la meta-heurística VMO La esencia del método VMO es crear una malla de puntos en el espacio m dimensional, sobre la cual se realiza el proceso de optimización de una función FO(x1, x2,…, xm); la cual se mueve mediante un proceso de expansión hacia otras regiones del espacio de búsqueda. Esta malla se hace más “fina” en aquellas zonas que parecen ser más promisorias. Se dice que es una malla dinámica en el sentido que la malla cambia su tamaño (cantidad de nodos) y configuración durante el proceso de búsqueda. Los nodos se representan como vectores de la forma n(x1, x2,…, xm). El proceso de generación de la nueva población en cada iteración comprende los siguientes pasos: 1. Generación de la malla inicial. 2. Generación de nodos en dirección a los extremos locales (nl). 3. Generación de nodos en dirección al extremo global (ng). - 22 -.
(33) Capítulo 2: Paralelización de la meta-heurística VMO. 4. Generación de nodos a partir de las fronteras de la malla (nf). El método incluye los siguientes parámetros de configuración: Cantidad de nodos de la malla inicial (Ni). Cantidad máxima de nodos de la malla en cada ciclo (N), donde 3 · Ni < N. Tamaño de la vecindad (k). Condición de parada (M), generalmente se establece una cantidad de evaluaciones de la FO. A continuación se presenta una descripción más detallada de cada una de las etapas de la meta-heurística VMO en el proceso de generación de nuevos nodos (expansión): Generación de la malla inicial en cada iteración: la malla inicial consta de Ni nodos, los cuales en la primera iteración son generados de forma aleatoria (o por otro método que garantice tener soluciones dispersas). En las restantes iteraciones del método para obtener esta malla inicial se realiza un proceso de contracción, que se basa en una selección de los nodos con mejor calidad (mejor evaluación de la FO) entre los N nodos existentes al final de cada iteración, si al realizar esta contracción obtenemos una cantidad de nodos menor que Ni se generan nuevos nodos de manera aleatoria hasta alcanzar los Ni nodos de la malla inicial. Generación de nodos en dirección a los extremos locales: esta primera etapa del proceso de expansión en VMO se caracteriza por realizar una exploración hacia las vecindades de cada uno de los nodos de la malla inicial. Para lo cual, se buscan los vecinos más cercanos de cada nodo n a través de una función de distancia o semejanza. Luego, se selecciona cuál de los nodos de esa vecindad tiene mejor calidad (evaluación de la FO) que el nodo actual (denotándose ese mejor nodo por nl). Si ninguno de los vecinos es mejor, entonces este se considera un extremo local y no se generan nodos a partir de él en este paso. En otro caso, se genera un nuevo nodo (n*) teniendo como progenitores el nodo (n) y el extremo local (nl). La cercanía del nuevo nodo al actual o al extremo local depende de un factor (r), calculado en base a los valores que alcanza la FO en cada uno de los nodos involucrados.. - 23 -.
(34) Capítulo 2: Paralelización de la meta-heurística VMO. Para calcular los valores de las componentes de este nuevo nodo se usa la ecuación: n*(i) = f(n(i), nl(i), r). (2.1). Donde i representa el i-ésimo componente de cada nodo. La función f depende totalmente del dominio de cada una de las dimensiones del problema, por lo que se puede presentar como una función de selección de valores para casos discretos o como una aproximación para casos continuos. Mientras mayor sea la diferencia entre los valores de FO en los nodos involucrados, mayor será la cercanía o semejanza de n* a nl, esto lo garantiza el factor r. Generación de nodos en dirección al extremo global: Este paso tiene como propósito realizar una exploración hacia el nodo que mejor calidad ha tenido en todo el proceso de búsqueda (extremo global, ng); en esencia, se generan nuevos nodos a partir de cada nodo de la malla inicial en dirección a este, utilizando la ecuación (2.2): n*(i) = g(n(i), ng(i), r). (2.2). Al igual que en el paso anterior, g es una función que está totalmente relacionada con el dominio de cada dimensión, se garantiza que mientras mayor sea la diferencia entre la calidad de cada nodo involucrado (determinado por r) mayor será la cercanía del nuevo nodo al extremo global. Este paso se encargada de acelerar la convergencia del método. Generación de nodos a partir de los nodos más externos de la malla: este proceso de generación de nuevos nodos tiene lugar con el objetivo de explorar el espacio de búsqueda en dirección a las fronteras de cada dimensión. Para ello, se seleccionan los nodos cuyas posiciones se encuentran en los extremos de la malla inicial (nodos fronteras, nf). El proceso de detección de este tipo de nodo se realiza siguiendo algún criterio en dependencia del espacio solución, en este caso se seleccionarán los nodos de menor y mayor norma. La generación de los nuevos nodos se obtiene a través de la ecuación: n*(i) = h(nf(i),w). (2.3). Donde w se conoce como desplazamiento y tiene como objetivo desplazar los nodos fronteras en dirección a los puntos más y menos externos del espacio de soluciones (depende de la definición de las fronteras del problema).. - 24 -.
(35) Capítulo 2: Paralelización de la meta-heurística VMO. En este paso se seleccionan tantos nodos externos como sean necesarios para completar el tamaño total de la malla en el ciclo; en principio, recuerden que se debe cumplir la restricción (3 · Ni < N) para garantizar que se generen algunos nodos en este paso. A continuación se presenta la estructura general del algoritmo VMO (ver Figura 2.1), como se puede apreciar la condición de parada está descrita por un número máximo de evaluaciones de la función objetivo. Generación de la malla inicial (Ni) de forma aleatoria. Evaluar los nodos de la malla inicial, seleccionar el mejor (ng). Repetir: Para cada nodo en la malla inicial del ciclo hacer Encontrar sus (k) nodos más cercanos. Determinar el mejor de los vecinos (ne). Si (ne) es mejor que el nodo actual, entonces Generar nuevo nodo usando ecuación (2.1). Fin Si Fin Para Para cada nodo en la malla inicial del ciclo hacer Generar un nuevo nodo usando la ecuación (2.2). Fin Para Seleccionar los nodos más externos de la malla. Generar nuevo nodo usando la ecuación (2.3). Mientras los N nodos de la malla en el ciclo actual no se hayan generado Generar nuevo nodo aleatoriamente. Construir la malla inicial actual de manera elitista. Ordenar los nodos de la malla inicial según su calidad. Aplicar operador de limpieza adaptativo. Hasta M evaluaciones Figura 2.1: Algoritmo general VMO. Esta meta-heurística tiene características muy similares con otros métodos existentes como por ejemplo: El considerar solamente los vecinos más cercanos en la etapa de expansión hacia los extremos locales fue introducido en el método PSO (Parsopoulos and Vrahatis, 2002), donde - 25 -.
(36) Capítulo 2: Paralelización de la meta-heurística VMO. al determinar la mejor partícula global se toman en cuenta dos enfoques: considerar el mejor de toda la población o la mejor partícula entre los vecinos más cercanos. La atracción a zonas más promisorias del espacio de búsqueda con la expansión en dirección al extremo global fue introducido también en PSO; donde en su versión original (Kennedy and Eberhart, 1995), cada partícula es atraída por la mejor posición global del enjambre. La concepción de expansión y contracción de la malla inicial es una forma de evolucionar la población inicial con la incorporación de nuevas soluciones para luego reducirla a través de un proceso de selección. Este elemento es una característica fundamental en los Algoritmos Evolutivos Generacionales. La selección de la malla inicial de manera elitista también fue introducido en los Algoritmos Genéticos como estrategia para acelerar la convergencia. A pesar de poseer algunas características similares con otros métodos existentes, VMO incorpora otros elementos propios, como son: Realizar en una misma iteración del algoritmo la generación de nuevos individuos en dirección hacia los extremos locales de cada vecindad y al extremo global de la población. Esto representa una nueva forma de realizar intensificación y diversificación manteniendo la dirección de la búsqueda. Realizar una selección elitista incorporándole un operador de limpieza adaptativo para mantener cierta diversidad, en la que se tiene en cuenta tanto la calidad como la separabilidad entre soluciones al mismo tiempo. Este elemento garantiza que el método realice una profunda exploración del espacio solución, disminuyendo en gran medida el estancamiento de soluciones en óptimos locales. En el proceso de limpieza adaptativo, la distancia que garantiza la separabilidad de las soluciones es un valor que decrece en función del estado del método. Permitiendo al inicio del algoritmo soluciones más distantes que al final de la ejecución. Se incorpora una forma para guiar la exploración hacia los extremos del espacio de búsqueda, a través de la generación de nuevos individuos a partir de los nodos fronteras de - 26 -.
(37) Capítulo 2: Paralelización de la meta-heurística VMO. la malla. De esta manera se aprovecha la posición que ocupan estos nodos, explorando fuera de los entornos donde se está realizando la búsqueda. 2.1.1. Fomento de la diversidad Se conoce que la diversidad en los métodos poblacionales es un elemento esencial para lograr una buena exploración del espacio de búsqueda. En tal sentido los investigadores han planteado diversas estrategias. Para este caso particular se presenta un mecanismo para fomentar la diversidad, que se basa en mantener una cierta separabilidad entre los nodos de la malla inicial, sin dejar de lado la calidad de las soluciones encontradas. Para ello, se propone un operador de limpieza adaptativo, que funciona de la siguiente manera: 1. Se ordenan todos los nodos de la malla en función de su calidad. 2. Se compara cada nodo de la malla con el resto, eliminando aquellos cuya distancia euclidiana sea menor que una cota calculada dinámicamente. Este valor de la distancia debe permitir que el proceso sea decreciente; de forma que se logre mayor separabilidad entre los nodos al inicio que al final de la ejecución del algoritmo. 3. Luego, si la malla resultante quedara con menos nodos que la cantidad de Ni, la misma se completa con nodos generados de forma aleatoria. Este mecanismo mezcla dos elementos importantes, tales como: la calidad de los nodos seleccionados con la posición que ocupan en el espacio de solución. Provocando que los nodos con mejor calidad tengan mayor probabilidad de formar parte de la malla en la próxima iteración. 2.1.2. Características específicas para dominios continuos En este epígrafe se definen con mayor precisión cada uno de los operadores de VMO para funciones continuas. Generación aleatoria de la malla inicial: a cada uno de los nodos de la malla inicial se le asignan vectores reales generados aleatoriamente, donde cada uno de sus componentes son valores aleatorios definidos en el intervalo definido para cada caso. - 27 -.
(38) Capítulo 2: Paralelización de la meta-heurística VMO. Generación de nodos en dirección a los extremos locales: para calcular los vecinos más cercanos de cada nodo de la malla se utiliza como función de distancia la euclidiana, definida como sigue:. (2.4) El factor (r), que determina la cercanía del nuevo nodo al nodo actual o al extremo local, se calcula usando la ecuación siguiente:. (2.5) Esta forma de calcular el factor (r) se puede utilizar lo mismo en problemas de optimización de minimización o maximización, ya que solo mide la razón de separabilidad entre dos valores, no interesa el caso de estudio. La función f para la generación de nuevos nodos a partir de cada nodo de la malla inicial en dirección a los extremos locales, se define por la ecuación:. (2.6). Donde vm(i) representa el valor medio entre el nodo actual y el extremo local para la i-ésima dimensión y se calcula como:. (2.7) Además, va[a, b] denota un valor aleatorio en el intervalo [a, b] y cd es una cota de distancia adaptativa y se calcula según la ecuación: - 28 -.
(39) Capítulo 2: Paralelización de la meta-heurística VMO. (2.8) En la que M denota el número máximo de evaluaciones de FO y j la evaluación actual. En dependencia del por ciento del total que represente la evaluación actual, se definen valores de distancia que representan partes del intervalo permitido. De forma general, la función f se define de tal forma que en el primer caso se obtiene para la i-ésima componente el valor medio entre el nodo actual y el extremo local; en el segundo caso, se explora la vecindad del extremo local utilizando un valor en función de la distancia mínima permitida y, en el último caso, se genera un número aleatorio entre el valor medio y el extremo local. Generación de nodos en dirección al extremo global: en esta etapa de la generación se crean nuevos nodos a partir de cada nodo de la malla inicial en dirección al extremo global. Para esto, se utiliza el valor del factor r calculado por la ecuación (2.5), sustituyendo ne por ng, donde el valor medio (vm) entre el nodo actual y el extremo global se calcula utilizando la ecuación (2.7). La función de generación g se define de la siguiente manera:. (2.9) Según la función g, si existe una gran diferencia entre la evaluación de la función objetivo del extremo global y el nodo actual, hay mayor probabilidad de que la i-ésima componente tome valores más cercanos a ng, en caso contrario se le asigna el valor medio. Generación de nodos a partir de los más externos de la malla: En este paso se completa la cantidad total de nodos que debe tener la malla, generando nuevos individuos a partir de los nodos más extremos en el espacio de búsqueda. Para seleccionar este tipo de nodos se realiza - 29 -.
(40) Capítulo 2: Paralelización de la meta-heurística VMO. un ordenamiento de la malla inicial utilizando el valor de la norma de cada uno, definida por la ecuación:. (2.10) Los nodos de mayor norma son los que están situados en el contorno (puntos más externos) de la malla inicial y los de menor norma serán entonces los puntos más internos de la misma. La función h permite generar nuevos nodos en dirección a las fronteras definidas para este caso de estudio, mediante las expresiones: Para los nodos más externos:. (2.11) Para los nodos más internos:. (2.12) Donde el desplazamiento w se calcula como:. (2.13) El parámetro M y la variable j, están estrechamente relacionados y provocan las variaciones en el valor de w; el primero representa el número total de evaluaciones de la función objetivo y la j la evaluación actual. La variable w0 representa el desplazamiento inicial y wf el valor final de este (si w0 > wf efecto decreciente). Para obtener desplazamientos decrecientes relacionados con las amplitudes de cada función, se desarrolló una propuesta adaptativa, donde w0 = am / 10 y wf = am / 100. Por su parte am - 30 -.
Figure



+7



Documento similar