Análisis de tecnologías de bases de datos en el World Wide Web
84
0
0
Texto completo
(2) 3. CONTENIDO l. INTRODUCCIÓN .............................................................................................................................. 5 2. JAVA DATABASE CONNECTIVITY (JDBC) ........................................................................................... 9 2.1 INTRODUCCIÓN ......................................................................................................................... 9 2.2 JDBC y ODBC ........................................................................................................................... 10 2.3 MODELOS lWO-TIER Y THREE-TIER ............... .......................................................................... 11 2. 4 SQL ......................................................................................................................................... 13 2.5 COMPONENTES JDBC................................................................................................................ 14 2.6 TIPOS DE CONTROLADORES ..................................................................................................... 14 2.7 CONEXIÓN CON LA BASE DE DATOS ......................................................................................... 16 2.8 EJECUCIÓN DE SENTENCIAS SQL ................................................... .... ....................................... 17 2.9 EL OBJETO RESULTSET ....................................................................................... ....... ......... ...... 19 2.10 USO DE SENTENCIAS PREPARADAS ......................................................................................... 20 2.11 USO DE TRANSACCIONES ....................................................................................................... 22 2.12 PROCEDIMIENTOS ALMACENADOS .......................................................................................... 23 3. OPEN DATABASE CONNECTIVITY (ODBC) ....................................................................................... 26 3.1 INTRODUCCIÓN ....................................................................................................................... 26 3.2 ARQUITECTURA DE ODBC ..... .. ................................... .............................. ................................. 28 4. OLE DB / ADO ............................................................................. ...... ......... ................................... 32 4.1 INTRODUCCIÓN ....................................................................................................................... 32 4.2 COMPONENT OBJECT MODEL (COM) ......................................................................................... 34 4.3 OLE DB .................................................................................................................................... 36 4.4 ACTIVEX DATA OBJECTS (ADO) ................................................................................................ 37 4.5 MODELO DE OBJETOS ADO ........ .... .. .... ........................... .......................................................... 38 4.6 EL PROVEEDOR DE OLE DB PARA ODBC ....................................... .. .......................... ......... ........ 44 4.7 ACTIVE SERVER PAGES (ASP) ...................................................... ............................................. 46 S. LIVEWIRE DATABASE SERVICE ....................................................................................................... 50 5.1 INTRODUCCIÓN ....................................................................................................................... 50 5.2 JAVASCRIPT SERVER-SIDE ........................................................................................................ 51 5.3 CONEXIONES ........................................................................................................................... 54 5.4 POOLS DE CONEXIONES ........................................................................................ .. ........ .. ....... 55 5.5 BASES DE DATOS MULTIHILOS ................................................................................................. 56 5.6 MANEJO DE POOLS DE CONEXIONES ................................................... ............................. .. ...... 57 S. 7 CONEXIONES INDIVIDUALES .................................................................................................... 58 5.8 CONEXIONES ACTIVAS A TRAVES DE PETICIONES ..................................................................... 59 5. 9 SENTENCIAS SQL ..................................................................................................................... 60 5.10 CURSORES ............................................................................................................................. 61 5.11 MANEJO DE TRANSACCIONES .............. ........................... ............................... ..... ........... ... ...... 66 5.12 DATOS BINARIOS ........................ ........................................................................................... 68 5.13 PROCEDIMIENTOS ALMACENADOS .......................................................................................... 69 6. CONCLUSIÓN .............................................................. .................................................................. 72 ANEXO A. LA ESPECIFICACIÓN CGI .................................................................................................... 76 A.1 INTRODUCCIÓN ....................................................................................................................... 76 A.2 FUNCIONAMIENTO DE CGI ....................................................................................................... 77 A.3 PASO DE INFORMACIÓN DEL SERVIDOR ................................................................................... 77 A.4 ENVIO DE INFORMACIÓN AL CLIENTE ....................................................................................... 79 A.5 WINDOWS CGI. ............................................................................................................. ........... 79 A.6 FASTCGI .................................................................................................................................. 80 GLOSARIO ........................................................................................................................................ 82 BIBLIOGRAFÍA ................................................................................................................................... 84.
(3) 4. LISTA DE FIGURAS FIG. 3.1. ARQUITECTURA DE ODBC ................................................................................................... 29 FIG. 4.1. ARQUITECTURA DEUDA ..................................................................................................... 33 FIG. 4.2. MODELO DE OBJETOS DE ADO ............................................................................................ 38.
(4) 5. 1. INTRODUCCIÓN El World Wide Web o Web, propuesto por Tim Berniers-Lee del European Laboratory for Particle Physics, fué diseñado como un sistema distribuido basado en hipertexto. El proyecto definió la comunicación utilizada por los clientes y servidores, denominada HyperText Transfer Protocol (HTTP) así como el formato en el cual los documentos serían transferidos, denominado HyperText Markup Language (HTML). Otro aspecto clave del Web fué su capacidad de especificar direcciones de objetos particulares dentro del sistema, conocidas como Uniform Resource Locators (URL).. Aunque el HTML es una forma poderosa de presentar información tiene severas limitaciones, entre ellas su naturaleza estática. Debido a que los documentos HTML son archivos de texto, estos necesitan ser continuamente actualizados para incorporar nueva información. Además, la mayor cantidad de información en las organizaciones se encuentra en bases de datos y no en documentos. La necesidad de un método para mantener esta información cambiando dinámicamente dió nacimiento al concepto de Common Gateway Interface (CGI). En la especificación CGI [1 ], un programa redirige su salida a un cliente HTTP generando código HTML en forma dinámica. El servidor de HTTP está diseñado para interpretar esta salida y enviarla al cliente.. Los primeros métodos para llevar la información de base de datos relacionales al Web utilizaban programas CGI. Estos métodos se basaban en la ejecución de un programa que se conectaba a la base de datos, realizaba una operación específica y enviaba sus resultados al cliente. Este proceso consistía en los siguientes pasos:.
(5) 6. •. El cliente Web requería la información al servidor Web.. •. Cuando el servidor de Web recibía la petición del cliente ejecutaba el programa CGI el cual se conectaba a la base de datos.. •. El servidor de la base de datos ejecutaba el correspondiente código SOL.. •. El programa CGI recuperaba la salida enviada por el manejador de base de datos agregándole código HTML adicional que el visualizador requería para desplegar los datos.. •. Finalmente el servidor de Web enviaba al cliente el código HTML generado dinámicamente por el programa CGI, donde era desplegado.. Sin embargo, realizar la conectividad con la base de datos desde los programas CGI no era fácil. Ciertos programas, denominados gateways, fueron diseñados para recibir datos del cliente Web y usarlos para comunicarse con la base de datos [2] . Desafortunadamente, estos gateways, implementados sobre todo en sistemas UNIX, tenían que ser diseñados para bases de datos específicas. Para construir tales. gateways un programador necesitaba accesar las interfaces de programación de la base de datos, normalmente proporcionadas por el vendedor de la misma. Estas interfaces consistían de un conjunto de llamadas a bibliotecas para ser utilizadas por programas en operaciones sobre bases de datos. Estos programas eran escritos generalmente en el lenguaje C. Algunos ejemplos de estas interfaces utilizadas eran Pro*C de Oracle y ESQL/C de lnformix.. Además, CGI presentaba otras desventajas, entre ellas su desempeño. Debido a que cada petición iniciaba una nueva instancia de la aplicación, CGI utilizaba muchos de los recursos del sistema y el desempeño bajaba drásticamente en servidores procesando múltiples accesos a la bases de datos..
(6) 7. Más recientemente el lenguaje Java se está convirtiendo en uno de los lenguajes favoritos de los desarrolladores de aplicaciones de bases de datos debido a sus características multihilos, a que es altamente portable y a que incluye manejo de sockets para la programación cliente/servidor. Los programas Java pueden ser. ejecutados como applets, servlets o aplicaciones. Los applets son programas Java normalmente obtenidos a través de una red y ejecutados por un cliente Web. Los servlets proporcionan una solución basada en Java para solucionar los problemas. relacionados con la programación lado servidor de APls específicos a una plataforma o CGI. Son la contraparte lado servidor de lo que los applets son en el lado cliente y a diferencia de estos no presentan componentes GUI.. Java Database Connectivity (JDBC) es un API SQL que incluye clases Java, un administrador de controladores y controladores de bases de datos. El controlador contiene la lógica necesaria para accesar tanto bases de datos de escritorio como servidores SQL. JDBC, al igual que ODBC, esta basada en el estándar Call Level Interface (CU) de X/Open. La lista de compañías desarrollando tecnologías JDBC incluye a Oracle, Sybase, lnformix, IBM, Visigenic e lntersolv entre otros.. La conectividad con bases de datos ha sido también agregada a los servidores Web, lo que permite a los administradores de sitios Web agregar sentencias SQL en sus documentos HTML y scripts haciendo el desarrollo de aplicaciones más fácil. Entre estos servidores destaca el Netscape Enterprise Server que por medio de JavaScript y su LiveWire Database Service, puede accesar bases de datos en servidores de Oracle, Sybase, lnformix y 082, además de servidores utilizando ODBC.. Por otra parte, Microsoft con una visión más amplia, promueve su estrategia Universal Data Access (UDA), por medio de la cual cualquier cliente será capaz de utilizar cualquier dato independientemente de donde esté localizado y como se encuentre almacenado. UDA incluye OLE DB como una interface de bajo nivel a cualquier tipo de datos, sin importar su tipo, formato o ubicación; ActiveX Data Objects (ADO) como un modelo de programación a nivel aplicación que permite al programador.
(7) 8. escribir aplicaciones sobre datos OLE DB; y Open Database Connectivity (ODBC) la API para acceso a bases de datos SQL más ampliamente utilizada.. El negocio del Web y las bases de datos también ha incluido a los mismos vendedores de bases de datos. Estas compañías han comprendido que muchos clientes necesitan la habilidad de enlazar la información de sus bases de datos al Web. Entre estas compañías destaca Oracle Corporation con su Oracle WebServer. El Oracle WebServer es un servidor Web con un servidor Oracle estrechamente integrado que permite la creación de documentos HTML dinámicos a partir de datos almacenados en una base de datos Oracle. Cuando los datos de esta base de datos cambian, los documentos HTML son actualizados automáticamente sin ningún esfuerzo adicional por parte del administrador del sitio Web [3].. Este trabajo analiza las principales tecnologías de bases de datos utilizadas en el desarrollo de aplicaciones en el Web, lo cual es de gran utilidad para webmasters buscando integración con bases de datos así como para desarrolladores que desean implementar aplicaciones con bases de datos en Internet o en una intranet. En particular se enfoca a las tecnologías JDBC, ODBC, ADO / OLE DB y LiveWire. El trabajo asume que el lector tiene conocimientos básicos tanto de la tecnología Web así como de bases de datos relacionales [4]. En particular se requieren conocimientos básicos de HTML [5], Java [6], JavaScript [7][8] y SQL [9]..
(8) 9. 2. JAVA DATABASE CONNECTIVITY (JDBC). 2.1 INTRODUCCIÓN JDBC es un API para la ejecución de sentencias SQL. Consiste en un conjunto de clases e interfaces escritas en el lenguaje de programación Java. JDBC proporciona un API estándar para desarrolladores de herramientas y aplicaciones para bases de datos [1 O].. Utilizando JDBC es posible enviar sentencias SQL a diversas bases de datos. En otras palabras, usando JDBC, no es necesario escribir un programa para accesar una base de datos Oracle, otro para accesar una base de datos Sybase y otro para accesar una base de datos lnformix. Con JDBC solo será necesario la escritura de un programa el cual enviará las sentencias SQL a la base de datos apropiada. Además, con una aplicación escrita en el lenguaje Java tampoco hay que preocuparse por escribir aplicaciones para correr en diferentes plataformas [11].. En resumen, JDBC hace posible tres cosas: establece una conexión con la base de datos, envía sentencias SQL y procesa los resultados de estas sentencias. El siguiente fragmento de código da un ejemplo básico de estos pasos:. Con n e ction con e xion = Driv e rManager . g e t Co nn ec ti o n( "ora c le. j dbc. driver. Ora c l eDr i ver", Statement sentencia. " scot t",. "ti ge r"). conexion.createStatement();. Re s ultSet re s ult ado= sentenc ia. executeQuery (" SELECT titul o , precio FROM al bum") ;.
(9) 10 while (resultado.next()). {. String titulo= getString ("titulo"); int precio= getFl o at("precio");. JDBC es una interface de bajo nivel, lo que significa que es utilizada para llamar sentencias SQL directamente. Puede utilizarse de esta forma o puede usarse también como una base sobre la cual construir interfaces y herramientas de más alto nivel. Una interface de alto nivel es amigable al usuario ya que utiliza un API más comprensible y conveniente el cual es trasladado a una interface de más bajo nivel como JDBC.. 2.2 JDBC y ODBC Actualmente ODBC es la interface de programación más ampliamente utilizada para el acceso a bases de datos relacionales. ODBC ofrece la habilidad de conectarse con una gran cantidad de bases de datos en varias plataformas.. Aunque es posible utilizar ODBC directamente desde el lenguaje Java esto es realizado en forma más eficiente a través de JDBC por medio del JDBC-ODBC bridge [11].. Existen varias razones por las cuales utilizar JDBC en lugar de usar ODBC . ODBC no es apropiado para usarse directamente desde Java debido a que usa una interface C. Las llamadas desde Java a código nativo C tienen varias deficiencias en seguridad, implementación y portabilidad de aplicaciones. Por otra parte, una traducción literal del API en C de ODBC a un API Java no sería una opción adecuada. Por ejemplo, Java no utiliza apuntadores y ODBC hace un extenso uso de ellos. Podría pensarse que JDBC es una traducción de ODBC con una interface orientada a objetos para el lenguaje Java.. ODBC es también difícil de aprender ya que combina características sencillas y avanzadas y presenta opciones complejas aún para consultas sencillas. Finalmente, un.
(10) 11. API Java como JDBC es necesario para lograr una solución completamente Java. Cuando se utiliza ODBC, el administrador de controladores ODBC y sus controladores deben ser instalados manualmente en cada computadora cliente. Cuando el controlador JDBC está escrito completamente en Java el código es automáticamente instalable, portable y seguro en todas las plataformas Java desde microcomputadoras hasta mainframes.. Recientemente, Microsoft ha introducido nuevos APls más allá de ODBC : RDO. DAO, ADO y OLE DB. Estos diseños van en la misma dirección que JDBC en cierta forma, por ejemplo, al ser interfaces orientadas a objetos basadas en clases que pueden ser implementadas en ODBC.. 2.3 MODELOS TWO-TIER Y THREE-TIER La arquitectura cliente/servidor divide el procesamiento entre dos o más procesos, normalmente, en dos o más computadoras. Cualquier aplicación de bases de datos es una aplicación cliente/servidor que maneja el almacenamiento de datos en el proceso de la base de datos y la manipulación y presentación de los datos en algún otro lado. El servidor es el motor de bases de datos que almacena los datos y el cliente es el proceso que obtiene o crea los datos. La forma más simple de una arquitectura cliente/servidor es llamada arquitectura two-tier [12].. La arquitectura de un sistema depende de la aplicación. Por ejemplo, para situaciones como el despliegue de simples páginas Web un diseño two-tier es suficiente. Esto se debe a que el despliegue de páginas HTML estáticas requiere poca manipulación de datos. Aún cuando la aplicación fuera ligeramente más compleja, como una aplicación de entrada de datos utilizando formas HTML, una arquitectura two-tier podría aún ser buena opción.. Idealmente la arquitectura cliente/servidor deja a cada computadora realizar el procesamiento relevante a su especialización. Las estaciones de trabajo están.
(11) 12. diseñadas para proporcionar al usuario una interface gráfica de tal forma que ellas realizan la presentación de los datos. Los servidores están diseñados para manejar datos complejos de tal forma que ellos sirven como almacenamiento de datos. Pero conforme los sistemas se vuelven más complejos aparecen nuevas necesidades las cuales no tienen un lugar claro en el modelo two-tier. Además, los sistemas two-tier son notorios por su falta de capacidad para adaptarse a ambientes nuevos y a un crecimiento en el número de usuarios y volumen de datos.. El reuso de objetos es un concepto central en el desarrollo orientado a objetos. En cierta forma el reuso de objetos es simplemente el reuso de código. Pero en otro sentido, el reuso de objetos significa usar exactamente las mismas instancias de objetos en una aplicación que las que se utilizan en otra aplicación. Implementar el reuso de objetos en un sistema two-tier es casi imposible ya que cada cliente termina con sus propias copias de los datos.. Se pueden evitar estos problemas extendiendo los sistemas two-tier a three-tier. Una arquitectura three-tier agrega al modelo two-tier una tercera capa que aísla el procesamiento de datos en una ubicación central y maximiza el reuso de objetos.. En un modelo three-tier las sentencias SQL son enviadas a una capa intermedia de servicios la cual envía estas sentencias a la base de datos. La base de datos procesa las sentencias y envía los resultados de regreso a la capa intermedia la cual a su vez los envía al usuario. Entre las ventajas del modelo three-tier están que la capa intermedia hace posible el mantener un control sobre los accesos y los tipos de actualizaciones que pueden realizarse a los datos. Otra ventaja es que el usuario puede utilizar un API de más alto nivel el cual es trasladado por la capa intermedia a las llamadas de bajo nivel necesarias.. Hasta ahora la capa intermedia ha sido típicamente escrita en lenguajes como C o C++ los cuales ofrecen el más alto desempeño. Sin embargo, con la introducción de compiladores optimizadores que trasladan bytecode Java a eficiente código máquina, esta siendo cada vez más práctico implementar estas capas intermedias en Java..
(12) 13. 2.4 SQL. Un área de dificultad con el uso de SQL es que aunque la mayoría de las bases de datos utilizan SQL para una funcionalidad básica estas no se adaptan a la sintaxis del estándar SQL más recientemente definido o a su funcionalidad más avanzada. Por ejemplo, no todas las bases de datos soportan procedimientos almacenados y aquellas que lo hacen utilizan sintaxis no consistente una con otra. Se espera que la porción de SQL que es realmente estándar se extienda para incluir más funcionalidad.. Una forma por medio de la cual JDBC trata este problema es permitiendo que cualquier cadena de consulta sea pasada a través del controlador de la base de datos. Esto significa que la aplicación puede usar la funcionalidad SQL que desee pero corre el riesgo de recibir errores en algunas bases de datos. De hecho, una consulta de una aplicación no necesariamente tiene que ser SQL sino que puede ser un derivado especializado de SQL diseñado para bases de datos específicas.. Para aplicaciones más complejas JDBC trata la compatibilidad SQL en forma diferente. JDBC proporciona información descriptiva acerca de la base de datos por medio de su interface DatabaseMetaData de tal forma que las aplicaciones se puedan adaptar a los requerimientos y capacidades de cada base de datos.. Debido a que JDBC será utilizado como un API base para el desarrollo de herramientas de acceso a bases de datos y APls de más alto nivel, enfrenta también el problema de compatibilidad SQL de cualquier software construido con él. La designación "JDBC Compliant" fué creada para establecer un nivel estándar de funcionalidad JDBC. Para utilizar esta designación un controlador debe soportar al menos el ANSI SQL-2 Entry Level. ANSI SQL-2 se refiere al estándar adoptado por el American National Standards lnstitute en 1992. Entry Level se refiere a una lista específica de capacidades SQL. Los desarrolladores de controladores se deben asegurar que sus controladores cumplen con estos estándares utilizando el software de prueba disponible con el API JDBC..
(13) 14. La designación "JDBC Compliant" indica que la implementación JDBC de algún vendedor ha pasado las pruebas de compatibilidad proporcionadas por JavaSoft. Estas pruebas verifican la existencia de todas las clases y métodos definidos en el API JDBC así como también que la funcionalidad SQL Entry Level esté disponible. Aunque estas pruebas no son exhaustivas proporcionan cierto grado de confiabilidad en la implementación JDBC.. 2.5 COMPONENTES JDBC JavaSoft proporciona tres componentes de JDBC: el administrador de controladores JDBC, la suite de prueba de controladores JDBC y el JDBC-ODBC bridge.. El administrador de controladores JDBC es la parte principal de la arquitectura JDBC y forma parte del Java Development Kit. Su función principal es conectar las aplicaciones Java con el controlador JDBC adecuado. La suite de prueba de controladores JDBC, disponible desde el sitio Web de JDBC, proporciona cierta confiabilidad acerca de la funcionalidad de los controladores JDBC. El JDBC-ODBC bridge permite que los controladores ODBC puedan ser utilizados como controladores JDBC.. 2.6 TIPOS DE CONTROLADORES. Los controladores JDBC disponibles actualmente caen en alguna de las siguientes categorías:. Tipo 1. JDBC-ODBC bridge. El JDBC-ODBC bridge, desarrollado en forma conjunta por JavaSoft e lntersolv, proporciona acceso JDBC a bases de datos mediante el uso de controladores ODBC. Para lograr esto las llamadas a funciones JDBC son convertidas a llamadas a funciones ODBC. El JDBC-ODBC bridge es especialmente atractivo como una solución inmediata con clientes que actualmente usan ODBC asi.
(14) 15. como para el uso con bases de datos para las cuales no existen aún productos JDBC pero sí controladores ODBC.. El JDBC-ODBC bridge fué escrito en C++ e implementado como una biblioteca de enlance dinámico (Dynamic Link Library o DLL) o como una biblioteca compartida. Los controladores ODBC son tambien escritos en C o C++ e implementados como DLLs o bibliotecas compartidas. El hecho de que tanto el JDBC-ODBC bridge como los controladores ODBC no sean componentes Java significa que no pueden ser cargados desde Internet e interpretados por un visualizador. Ademas, tanto el JDBC-ODBC bridge como los controladores JDBC deben ser previamente instalados en cada máquina cliente. Por otra parte, al estar escritos en C o C++, son dependientes de la plataforma por lo que se deben desarrollar implementaciones por separado para cada arquitectura y sistema operativo. Por tanto, este tipo de controlador es más adecuado en redes en las cuales la instalación del cliente no sea un problema mayor o en servidores de aplicaciones escritos en Java en una arquitectura three-tier.. Tipo 2. Controlador parcialmente Java con API nativa. Este tipo de controlador convierte llamadas JDBC a llamadas en el API cliente para Oracle, Sybase, lnformix u otras bases de datos. Especificamente aprovecha tecnologías de transporte de red como SQL*Net, 1-Connect y OpenClient de Oracle, lnformix y Sybase respectivamente. Debido a que el software de transporte de red (SQL *Net, 1-Connect o OpenClient) está implementado como DLLs o bibliotecas compartidas y escritas en C o C++ no puede ser cargado desde Internet o interpretado en tiempo de ejecución por algún visualizador. Por el contrario, el software de transporte de red cliente debe ser instalado previamente en todas las máquinas cliente.. Tipo 3. Controlador Java puro JDBC-red. Este controlador traslada llamadas JDBC a un protocolo de red independiente de la base de datos el cual es después trasladado a un protocolo de la base de datos por un servidor. Este servidor esta habilitado para conectar sus clientes Java a muchas diferentes bases de datos. En general, esta es la alternativa JDBC más flexible..
(15) 16. Tipo 4. Controlador Java puro con protocolo nativo. Este tipo de controlador convierte llamadas JDBC directamente a un protocolo de red utilizado por la base de datos. Esto permite una llamada directa de una máquina cliente a la base de datos y es una excelente solución para acceso en una intranet. Esencialmente, estos controladores remplazan el software de transporte de red (SQL*Net, 1-Connect o OpenClient) con un cliente Java puro. La principal ventaja de este tipo de controlador es que no es necesaria la instalación de algún software en las máquinas cliente por lo que son una solución ideal para el desarrollo de applets. La fuente principal de estos controladores son los vendedores de bases de datos debido a que el software de transporte de red es típicamente propietario. Una desventaja de este tipo de controladores es que están diseñados para una base de datos particular en lugar de ser controladores universales que puedan conectarse a una gran variedad de bases de datos. Por tanto, un applet que requiera conexiones a múltiples bases de datos necesitara cargar varias versiones de este tipo de controlador, uno por cada base de datos.. JavaSoft espera que eventualmente las categorías de controladores 3 y 4 sean las formas preferidas para acceso a bases de datos con JDBC. Las categorías de controladores 1 y 2 son soluciones temporales en los casos donde no existe aún soluciones totalmente Java.. 2. 7 CONEXIÓN CON LA BASE DE DATOS. Establecer una conexión con una base de datos involucra dos pasos: cargar el controlador y realizar la conexión.. Cargar los controladores implica únicamente una línea de código. Por ejemplo, para cargar el JDBC-ODBC bridge se debe utilizar una línea de código como la siguiente:. Cla ss .forN a rne( "sun.j dbc.odbc .JdbcOdbcDr iver");.
(16) 17. La documentación del controlador proporcionará el nombre de la clase a utilizar. Por ejemplo, si el nombre de la clase es oracle . jdb c.driver. OracleDriver se deberá utilizar la siguiente línea de código:. Class.forName("orac le.jdbc.dri ve r.OracleDri veru);. No es necesario crear una instancia del controlador y registrarlo con el DriverManager ya que Class. forName hace esto automáticamente. Cuando se ha. cargado un controlador, está disponible para realizar una conexión con la base de datos. Un ejemplo de lo anterior se muestra en la siguiente línea de código:. Connec tion conex ion. DriverMa n a ger.getConnec ti o n(url, " scot t u ,. "tigeru);. La cadena a proporcionar en el parámetro url dependerá de varios factores . Si se esta utilizando el controlador del JDBC-ODBC bridge, el URL iniciará con j dbc: odbc. El resto del URL es generalmente la fuente de datos o el sistema de. bases de datos. Para el caso de un controlador JDBC la documentación del controlador indicará que subprotocolo utilizar. Por ejemplo, Oracle ha registrado el nombre ora c l e como subprotocolo por lo que la primera y segunda parte del URL será j dbc: oracle. La documentación del controlador indicará como formar el resto del URL.. Si alguno de los controladores que han sido cargados reconoce el URL proporcionado al método Dri verManager. getConnection el controlador establecerá una conexión con la base de datos especificada en el URL. La clase Dr i verMa na ger maneja todos los detalles respecto al establecimiento de la conexión.. La conexión regresada por el método Dr i ve rManag e r. g e t Co nnec ti o n es una conexión que puede ser utilizada para enviar sentencias SQL a la base de datos.. 2.8 EJECUCIÓN DE SENTENCIAS SQL La siguiente sentencia SQL crea la tabla a/bum:.
(17) 18 CREATE TABLE album ( catalogo. INTEGER. PRIMARY KEY,. artista. CHARACTER(60). NOT NULL,. titulo. CHARACTER(80). NOT NULL,. empresa. CHARACTER ( 4 O) ,. ano. INTEGER,. precio. FLOAT). Este código no termina con un terminador de sentencias ya que este puede variar de una base de datos a otra. Por ejemplo, Oracle usa punto y coma (;) y Sybase la palabra go para indicar el fin de una sentencia. El controlador a utilizar proporcionará el terminador de sentencia adecuado por lo que no será necesario incluirlo en el código JDBC.. Un objeto Statement es lo que envía las sentencias SOL a la base de datos. Para enviar sentencias SOL solo es necesario crear un objeto Statement y ejecutarlo proporcionando el método de ejecución apropiado. El método executeUpda te es utilizado para sentencias DDL (Data Definition Language) así como para sentencias que actualizan tablas. El método executeQuery es utilizado para ejecutar sentencias SELECT. Para crear un objeto Statement es necesario una instancia de una conexión. activa. En el siguiente ejemplo se muestra la creación del objeto Statement sentencia mediante el uso del objeto Connection conexion:. Statement sentencia. conexion.createStatement();. En este punto sentencia existe, pero aún no tiene una sentencia SOL para enviar a la base de datos. Es necesario proporcionar esta sentencia al método usado para ejecutar sentencia como se muestra a continuación:. sentencia . executeUpdate("CREATE TABLE album" + "(catalogo. INTEGER. PRIMAR Y KEY, ". " art i sta. CHARACTER(60 ). NOT NULL, ". "titulo. CHARACTER ( 80). NOT NULL, " +. "empresa. CHARACTER ( 4 O) , " +. "ano. INTEGER , " +. +. +.
(18) 19 "precio. FLOAT)");. También es posible asignar una sentencia SQL a una variable y utilizar esta variable con executeUpdate: String crearTabla = "CREATE TABLE alburn" + " ( catalogo. INTEGER. PRIMAR Y KE Y, " +. "artista. CHARACTER ( 60). NOT NULL, " +. "titulo. CHARACTER(BO). NOT NULL, " +. "empresa. CHARACTER ( 4 O) , " +. "ano. INTEGER, " +. "prec io. FLOAT)";. s e nt e ncia.e xecuteUpdate(crearTabla);. El siguiente código inserta una fila de datos en la tabla a/bum:. Staternent sente n cia = conexion . crea teStat e rnen t (); sentencia.executeUpdate("INSERT INTO alburn" + "VALUES (3427756, "1973,. 'Jethro Tull',. 'Aqualung',. 'Chr ysa lis', " +. 9.99)");. 2.9 EL OBJETO RESUL TSET. JDBC regresa los resultados de sentencias SELECT en un objeto Resul t s et por lo que es necesario declarar una instancia de esta clase. El siguiente código demuestra la declaración del objeto Resul tSet resultado y la asignación de las filas resultantes de una consulta al mismo:. Res ultSet resultado. sente n cia.executeQuery{"SELECT titulo , prec i o. FROM album") ;. La variable resultado, la cual es una instancia de Resul tSet, contiene las filas resultantes de la consulta anterior. Para accesar estos datos es necesario ir a cada fila. y recuperar los datos de acuerdo a su tipo. El método next mueve lo que es llamado un cursor a la siguiente fila y hace esa fila, llamada la fila actual, la fila en la cual se.
(19) 20. puede operar. JDBC no proporciona un método previous de tal forma que no es posible moverse de regreso en un objeto Resul tSet.. Es necesario utilizar el método getxxx del tipo apropiado para recuperar el valor de cada columna. Por ejemplo para recuperar un dato SQL VARCHAR se usará getString y para un tipo SQL FLOAT getFloat. El siguiente código accesa e. imprime los valores almacenados en la fila actual de resultado.. St r ing consulta= "SELECT titul o , precio FROM album"; ResultSet re s ultado= sentencia . executeQuer y( consulta); whi le (r esult ado . n e x t () ) { String tit u lo= resultado . getString("titulo"); Float preci o = resulta do . ge tfloat("pr ec i o" ); Sys tem. o ut.println(titul o +". ". + pre c i o) ;. JDBC ofrece dos formas de identificar la columna de la cual el método g et XXX obtendrá algún valor. Una forma es indicando el nombre de la columna, como en el ejemplo anterior. La segunda forma es indicando el índice o número de columna como en:. String ti t ul o = r e s ultado .getString( l) ; Fl o at prec i o = r es ul t ado . g e t Fl o at (2 );. en donde el número se refiere al número de columna en el conjunto de resultados y no en la tabla original.. 2.10 USO DE SENTENCIAS PREPARADAS En algunas ocasiones es más conveniente o más eficiente utilizar un objeto Pr epa r edS t at e rne n t para enviar sentencias SQL a la base de datos. Este tipo. especial de sentencia es derivado de la clase más general Staternent utilizada anteriormente.. q.JS5 'j.
(20) 21. Si es necesario utilizar un objeto Statement muchas veces, el uso del objeto PreparedStatement normalmente reducirá el tiempo de ejecución. La característica. princípal de un objeto PreparedStatemen t a diferencia de un objeto Stateme n t, es que este recibe una sentencia SOL cuando es creado. La ventaja de esto es que en la mayoría de los casos la sentencia SOL será enviada a la base de datos inmediatamente, en donde es compilada. Como resultado, un objeto PreparedStatement contiene no solo una sentencia SOL sino también una sentencia. SOL que ha sido compilada.. Los objetos Prepare dSt atement pueden ser utilizados para sentencias SOL con parámetros a las cuales se les proporcionaran valores diferentes cada vez que sean ejecutadas. Al igual que con los objetos Stat e ment, los objetos PreparedStatement son creados con un método Connecti o n. Un ejemplo del uso. de PreparedSt at e me nt con dos parámetros de entrada se muestra a continuación:. Pr eparedStatement s e ntencia= c o nexion.prepar eS tatement( "U PDATE alburn SET p re c i o =? WHERE c atalo go=?" ) ;. Será necesario proporcionar valores antes de poder ejecutar una sentencia PreparedStatement. Esto se realiza por medio de los métodos SetXXX de la clase Prepar e d Statement. Utilizando el objeto Pr e paredSt a t eme nt del ejemplo anterior. se podría utilizar:. s ent e n c ia.setfl o at(l, 11. 9 9); se nt enc ia . set int( 2 , 3 427756 ) ;. El primer argumento dado a set XXX indica cual signo de interrogación en la sentencia original será reemplazado, y el segundo argumento indicara el valor que este tomará. Después de que los dos valores de la sentencia Prepa r edStateme n t han sido establecidos esta se ejecutará utilizando el método exec u teU p da te :. sen te n c ia.exe c ut e Up date( ) ;.
(21) 22. Mientras que el método e x e c uteQuery regresa un objeto Resul tSet conteniendo los resultados de la consulta enviada a la base de datos, el valor regresado por executeUpdate es un entero que índíca cuantas filas de una tabla fueron actualizadas. Cuando el método executeUpdate es utilizado con una sentencia DDL esta retornará el entero O.. 2.11 USO DE TRANSACCIONES. Una transacción es un conjunto de una o más sentencias que son ejecutadas juntas como una unidad de tal forma que o todas o ninguna de ellas son ejecutadas. Cuando una conexión es creada esta se encuentra en modo auto-commit. Esto sígnifíca que cada sentencia SQL índívidual es tratada como una transaccíón y será automáticamente completada (commit) después de ser ejecutada con éxíto. Para permitir que dos o más sentencias sean agrupadas en una transacción es necesario deshabilitar el modo auto-commit como en la siguiente línea de código:. c o n e x ion. setAutoCommit( f alse) ;. Una vez que el modo auto-commit es deshabilitado ninguna sentencia SQL será completada hasta que se llame al método comrni t explícitamente. Todas las sentencías ejecutadas después de la llamada previa al método comrni t serán incluidas en la transacción actual y serán completadas juntas como una unidad. Cada vez que el método comrni t es llamado, ya sea automática o explícitamente, todos los cambios resultantes de las sentencias en la transacción se hacen permanentes.. Para evitar conflictos durante una transacción, un manejador de bases de datos utiliza candados, los cuales son mecanismos para bloquear el acceso a otros a los datos que están siendo accesados por la transacción. En el modo auto-commit, donde cada sentencia es una transacción , los candados son establecidos solo por una transacción. Una vez que un candado es establecido este permanecerá hasta que la transacción sea completada o cancelada (rollback). El efecto de este candado podría.
(22) 23. ser prevenir a un usuario de una lectura errónea (dirty read). Accesar un dato actualizado que no ha sido completado es considerado una lectura errónea ya que es posible que esta transacción sea cancelada y el dato regresado a su valor previo.. La forma en que los candados son establecidos es determinado por el nivel de transacción. Un ejemplo del nivel de transacción es TRANSACTI ON_READ_COMMITED el cual no permite que algún valor sea accesado hasta que la transacción sea completada. La interface Connect ion incluye cinco valores que representan los niveles de transacciones que se pueden usar en JDBC.. Normalmente no es necesario establecer un nivel de transacción y es preferible utilizar el nivel por defecto definido en la base de datos. JDBC permite consultar que nivel de transacción esta utilizando la base de datos mediante el método ge tT ra n sactionisol atio n y también permite establecer un nuevo nivel a través del. método setTransactionisolation.. Una llamada al método rollba c k cancela una transacción y regresa cualquier dato que haya sido modificado a su valor previo. Si al tratar de ejecutar una o más sentencias en una transacción se obtiene un SQLException se deberá llamar al método r o llback e iniciar la transacción de nuevo.. 2.12 PROCEDIMIENTOS ALMACENADOS Un procedimiento almacenado es un grupo de sentencias SQL que forman una unidad lógica y realizan una tarea particular. Los procedimientos almacenados son utilizados para encapsular un conjunto de operaciones o consultas para ejecutarse en la base de datos. Estos procedimientos pueden ser compilados y ejecutados con diferentes parámetros y resultados y pueden tener cualquier combinación de parámetros de entrada y salida.. Los procedimientos almacenados son soportados por la mayoría de las bases de.
(23) 24. datos aunque existen una gran variación en su sintaxis y capacidades. Por ejemplo, la siguiente sentencia SQL crea un procedimiento almacenado en Oracle:. CREATE PROCEDURE altas (catal o g o IN INTEGER, artista IN CHARACTER, titulo in CHARACTER, emp re sa IN CHARACTER, ano IN I NTEGER, precio IN FLOAT) AS BEGIN INSERT INTO a lbum VALUES (cata l ogo , a r tista , t i t ul o , e mp resa , ano , precio); END ;. El primer paso para llamar a un procedimiento almacenado es crear un objeto CallableStatement. Al igual que con los objetos Statement y PreparedStatement esto es llevado a cabo utilizando el objeto Connecti o n . Un. objeto CallableStatement contiene una llamada a un procedimiento almacenado y no contiene el procedimiento en sí. El siguiente código es un ejemplo de la ejecución de procedimientos almacenados en JDBC:. Cal l ableStateme nt se n tencia = co ne xion . prep areCall( "{ ca l l altas(? , ? ,. ? , ? , ?,?) }" ) ;. sent e ncia.setint(l, catalogo ); sent e n c ia.setString(2 , artista ); sentencia . setString(3, titulo ) ; sentencia . setStr ing ( 4 , e mp r esa ); se nte n cia . se tin t( S , a n o) ; se n te n c ia.se t Fl o at( 6 , preci o) ; senten c ia.exe c ut e Up d a te();. La primer línea de código crea una llamada al procedimiento almacenado altas. Si el procedimiento contiene una consulta se deberá ejecutar utilizando el método executeQuery. Por otra parte si el procedimiento contiene una actualización a datos. o una sentencia DDL el método a utilizar será e xecu t eUpda t e . Cuando un procedimiento almacenado contiene más de una sentencia SQL que pueda producir más de un conjunto de resultados o más de una actualización se deberá utilizar el método execute . La clase Call ab l eSt at e me nt es una subclase de.
(24) 25. PreparedStatement, por lo tanto un objeto CallableStatement puede tomar. parámetros de entrada al igual que un objeto PreparedStatement. Además, un objeto CallableStatement puede tomar tanto parámetros de entrada como de salida..
(25) 26. 3. OPEN DATABASE CONNECTIVITY (ODBC). 3.1 INTRODUCCIÓN ODBC es un API para acceso a bases de datos ampliamente utilizado. Esta basado en las especificaciones Call-Level Interface (CLI) de X/Open e ISO/IEC y utiliza SQL como su lenguaje de acceso a bases de datos. ODBC esta diseñado para permitir a una aplicación accesar diferentes bases de datos utilizando el mismo código fuente. Estas aplicaciones para bases de datos llaman funciones de ODBC, las cuales están implementadas en controladores específicos a una base de datos. Debido a que los controladores son cargados en tiempo de ejecución un usuario solo tiene que agregar un nuevo controlador para accesar una nueva base de datos sin necesidad de recompilar o reenlazar la aplicación [13] .. Las funciones del API de ODBC son implementadas por los desarrolladores de los controladores específicos para cada base de datos. Las aplicaciones llaman las funciones en estos controladores para accesar las bases de datos en forma independiente. El Driver Manager de ODBC administra la comunicación entre las aplicaciones y los controladores.. Aunque Microsoft proporciona un Driver Manager para computadoras corriendo Windows NT Server, Windows NT Workstation y Windows 95 y ha escrito varios controladores ODBC, cualquiera puede escribir aplicaciones y controladores ODBC. De hecho la mayoría de las aplicaciones y controladores ODBC son producidos por otras.
(26) 27. compañías. Además estas aplicaciones y controladores están también disponibles para la plataforma Macintosh y varios sistemas UNIX.. Para ayudar a los desarrolladores de aplicaciones y controladores Microsoft ofrece el ODBC Software Development Kit (SDK) en las plataformas Windows actuales. Además, Microsoft en conjunto con Visigenic Software ha portado este SDK tanto a la plataforma Macintosh y como a varios sistemas UNIX. Salvo pequeñas excepciones, ODBC esta diseñado para obtener las capacidades de la base de datos y no para complementarlas por lo que utilizar ODBC en una base de datos sencilla no la convertiría en una más sofisticada.. ODBC utiliza dos requerimientos en su arquitectura para estandarizar el acceso a bases de datos:. •. Las aplicaciones deben ser capaces de accesar múltiples bases de datos utilizando el mismo código sin necesidad de recompilación o reenlace del mismo.. •. Las aplicaciones deben ser capaces de accesar múltiples bases de datos simultáneamente.. Las aplicaciones pueden enviar sentencias utilizando la gramática de ODBC o una gramática específica a la base de datos. Si una sentencia utiliza una gramática ODBC que es diferente a la gramática de la base de datos el controlador la convierte a esta ultima antes de enviarla a la fuente de datos. Sin embargo, tales conversiones son poco comunes y la mayoría de las bases de datos utilizan una gramática SQL estándar.. ODBC proporciona un número significativo de características de las bases de datos pero no requiere que los controladores soporten todas estas características. Por otra parte, si ODBC proporcionara solo características que sean comunes a todas las bases de datos su utilidad seria muy limitada. En lugar de eso, ODBC requiere que los controladores implementen solo un subconjunto de estas características. Estos controladores implementaran las características restantes solo si están soportadas por.
(27) 28. su base de datos o si estos pueden emularlas. Para que una aplicación pueda determinar que características son proporcionadas por el controlador y la base de datos, ODBC proporciona las funciones SQLGetinfo y SQLGetFunctions que regresan información general acerca de las capacidades del controlador y de la base de datos además de una lista de las funciones soportadas.. 3.2 ARQUITECTURA DE ODBC La arquitectura de ODBC tiene cuatro componentes:. •. Aplicación. Es el componente que ejecuta llamadas a funciones ODBC para enviar sentencias SQL y recuperar resultados.. •. Driver Manager. El Driver Manager carga y elimina controladores para la aplicación. Procesa las llamadas a las funciones ODBC o pasa estas al controlador.. •. Controlador. El controlador procesa las llamadas a funciones ODBC, envía la petición SQL a una fuente específica de datos y regresa los resultados a la aplicación. Si es necesario, el controlador modifica la petición de la aplicación de tal forma que esta cumple con la sintaxis soportada por la base de datos asociada.. •. Fuente de datos. La fuente de datos consiste de los datos que el usuario desea accesar además del manejador de base de datos, sistema operativo y, en algunos casos, red necesarios para accesar los datos.. La figura 3.1 muestra la relación entre estos cuatro componentes. La figura muestra como pueden existir múltiples controladores y fuentes de datos, lo cual permite a la aplicación el acceso simultáneo a datos de más de una fuente de datos. Por otra parte, muestra como el API ODBC es utilizado tanto entre la aplicación y el Driver Manager como entre el Driver Manager y el controlador. La interface entre Driver Manager y el controlador es llamada Service Provider Interface o SPI..
(28) 29 Aplicación 1. D. PAPldeODBC. Driver Manager 1. D Controlador. D Controlador. D. PAPldeODBC. Controlador. D. D. D. Fuente de Datos. Fuente de Datos. Fuente de Datos. Fig. 3.1. Arquitectura de ODBC.. Algunas tareas son comunes a todas las aplicaciones independientemente de como utilicen ODBC . Estas tareas definen el flujo de cualquier aplicación ODBC :. •. Seleccionar una fuente de datos y conectarse a ella.. •. Enviar una sentencia SQL para su ejecución.. •. Recuperar resultados, si existen.. •. Procesar errores.. •. Completar o cancelar la transacción.. •. Desconectarse de la fuente de datos..
(29) 30. El Driver Manager es una biblioteca que administra la comunicación entre la aplicación y los controladores. Por ejemplo, en las plataformas Windows, el Driver Manager es una biblioteca de enlace dinámico (DLL) escrita por Microsoft. El Driver Manager resuelve algunos problemas comunes a todas las aplicaciones. Estos incluyen determinar que controlador utilizar basado en el nombre de la fuente de datos, cargar y descargar estos controladores y llamar funciones en estos controladores.. La aplicación es enlazada al Driver Manager y llama las funciones ODBC en el Driver Manager no en el controlador. La aplicación identifica el controlador destino y la fuente de datos. Cuando el Driver Manager carga el controlador construye una tabla de apuntadores a las funciones de este controlador.. Los controladores son bibliotecas que implementan las funciones de ODBC. Cada controlador es específico a una base de datos; por ejemplo, un controlador para Oracle no podrá accesar directamente datos en una base de datos lnformix. Entre las tareas realizadas por un controlador se incluyen:. •. Conectarse y desconectarse de la fuente de datos.. •. Encontrar errores de funciones no revisados por el Driver Manager.. •. Iniciar Transacciones.. •. Enviar sentencias SQL a la fuente de datos para su ejecución .. •. Enviar y recuperar datos de una fuente de datos incluyendo la conversión de tipos de datos especificados por la aplicación.. La arquitectura del controlador cae en dos categorías dependiendo del software que procesa las sentencias SQL:.
(30) 31. •. Controladores basados en archivos. En este caso el controlador accesa los datos físicos directamente. El controlador actúa tanto como controlador como fuente de datos, es decir, procesa llamadas ODBC y sentencias SQL. Por ejemplo, los controladores dBASE son controladores basados en archivos ya que dBASE no proporciona un motor de bases de datos que el controlador pueda utilizar. Es importante notar que los desarrolladores de controladores basados en archivos necesitan escribir sus propios motores de bases de datos.. •. Controladores basados en manejadores de bases de datos relacionales. En este caso el controlador accesa los datos físicos a través de un motor de bases de datos separado. El controlador únicamente procesa llamadas ODBC. Pasa las sentencias SQL al motor de bases de datos para su procesamiento. Por ejemplo, los controladores de Oracle son controladores basados en manejadores de bases de datos relacionales ya que Oracle tiene un motor de bases de datos que el controlador utiliza..
(31) 32. 4. OLE DB I ADO. 4.1 INTRODUCCIÓN Las aplicaciones actuales requieren la integración de información almacenada no solamente en los tradicionales sistemas de bases de datos sino también en sistemas de archivos, hojas electrónicas, bases de datos de escritorio, herramientas administradoras de proyectos, correo electrónico, servicios de directorios y datos multimedia entre otros. Varias compañías de bases de datos están promoviendo un método basado en la base de datos tradicional. En este método, el vendedor de bases de datos extiende la base de datos e interfaces de programación para soportar nuevos tipos de datos, incluyendo texto, video y audio. Este método requiere mover todos los datos requeridos por la aplicación, los cuales pueden estar distribuidos en diversas fuentes a través de la empresa, al sistema de base de datos del vendedor.. UDA (Universal Data Access) es una alternativa al método anterior. Sin embargo, también puede implementarse como un método complementario y utilizarse en conjunto con este. La premisa de UDA es permitir a las aplicaciones el acceso eficiente a los datos donde estos residan sin replicación, transformación o conversión.. UDA es una plataforma para el desarrollo de aplicaciones que requieren acceso a diversos datos relacionales y no relacionales a través de una intranet o de Internet. UDA consiste de una colección de componentes software que interactúan unos con.
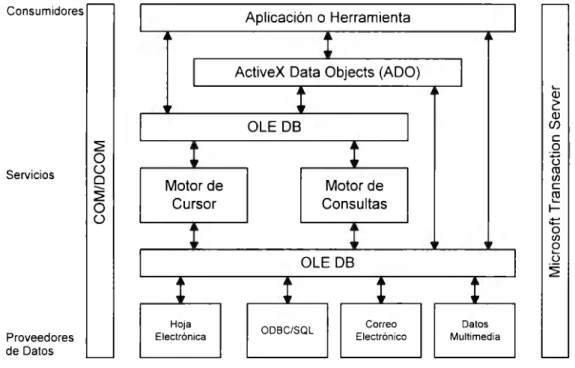
(32) 33. otros utilizando un conjunto común de interfaces a nivel sistema definidas por OLE DB [14].. OLE DB es la interface de programación a nivel sistema de Microsoft diseñada para proporcionar acceso a cualquier tipo de dato sin importar su tipo, formato o ubicación. OLE DB especifica un conjunto de interfaces COM que encapsulan u ocultan varios servicios de administración de bases de datos. Mientras OLE DB es una interface de programación a nivel sistema, ADO es una interface de programación a nivel aplicación. ADO es un modelo de programación de bases de datos que permite al programador escribir aplicaciones sobre datos OLE DB desde cualquier lenguaje incluyendo Visual Basic, Java, VBScript, JavaScript y C/C++.. Consumidores. Aplicación o Herramienta. ActiveX Data Objects (ADO) L... (].). 2::. (].). (/). OLE DB. e:. o. ~. u. o. Servicios. ü. o ~. o. (I] (/). e:. Motor de Consultas. Motor de Cursor. ~ 1-. .:= o. ü. (/). o. L... ü. OLE DB. Proveedores de Datos. Hoja Electrónica. ODBC/SQL. ~. Correo Electrónico. Datos Multimedia. Fig. 4 .1. Arquitectura de UDA.. La figura 4 .1 muestra la arquitectura de UDA. En esta arquitectura existen tres tipos generales de componentes de bases de datos:. •. Proveedores de datos. Los proveedores de datos son componentes que representan las fuentes de datos como pueden ser bases de datos relacionales,.
(33) 34. hojas electrónicas y datos multimedia.. •. Servicios. Los servicios son componentes que consumen y producen datos OLE DB.. •. Consumidores de datos. Los consumidores de datos son componentes que consumen datos OLE DB. Estos pueden ser modelos de acceso a datos de alto nivel como ADO o aplicaciones escritas en lenguajes como C++ o Java.. Todas las interacciones entre los componentes de la figura 4.1, indicadas por flechas bidireccionales, pueden ocurrir en procesos a través de protocolos de red como COM Distribuido (DCOM) o HTTP.. 4.2 COMPONENT OBJECT MODEL (COM} Tradicionalmente diferentes tipos de software han proporcionado sus servicios en diferentes formas. Por ejemplo, una aplicación puede enlazarse a una biblioteca y luego accesar sus servicios por medio de llamadas a funciones de esta biblioteca. O una aplicación puede utilizar los servicios proporcionados por otra, la cual corre en un proceso separado, requiriendo la definición de un protocolo entre las dos aplicaciones. O quizás otra aplicación utilice los servicios del sistema operativo a través de llamadas al sistema. O quizás aún, una aplicación necesite los servicios de otra aplicación corriendo en una máquina diferente accesible a través de una red. COM define una forma estándar por medio de la cual un software pueda proporcionar sus servicios a otro software.. Con COM cada software implementa sus servicios como uno o más objetos COM. Cada objeto COM soporta una o más interfaces cada una de las cuales incluye cierto número de métodos. Un método es típicamente una función o procedimiento que realiza una función específica y puede ser llamado por el software que utiliza el objeto COM (el cliente de este objeto). Cada cliente accesa los servicios proporcionados por.
(34) 35. un objeto COM únicamente al invocar los métodos de las interfaces del objeto y no pueden accesar directamente cualquiera de los datos del objeto.. Para llamar los métodos de una interface COM el cliente debe adquirir un apuntador a esta interface. Un objeto COM típicamente proporciona sus servicios a través de varias interfaces por lo que un cliente deberá tener un apuntador separado por cada interface cuyos métodos necesite utilizar. Una vez que un cliente tiene un apuntador a la interface deseada de un objeto en ejecución puede empezar a utilizar los servicios de dicho objeto llamando los métodos de la interface.. El uso de objetos es una idea central en COM aunque la forma en que COM define y usa objetos difiere de la forma en que los objetos son utilizados en otras tecnologías populares orientadas a objetos. Por otra parte, COM proporciona un mecanismo efectivo para el reuso de software permitiendo la creación de componentes. En los últimos 35 años los diseñadores de hardware han pasado de construir computadoras del tamaño de un cuarto a lap-tops basadas en pequeños y poderosos microprocesadores. Por otra parte en este mismo periodo de tiempo los desarrolladores de software han pasado de construir grandes sistemas basados en ensamblador y Cobol a construir aún grandes sistemas en C y C++. La razón por la cual el diseño de software no ha avanzado a la misma velocidad que el diseño de hardware se debe a que el diseño de hardware ha sido enormemente apoyado por el reuso de componentes existentes. El reuso de componentes es también una forma de crear mejor software. El crear nuevas aplicaciones a partir de componentes existentes permite producir código más confiable además de que puede efectuarse en un proceso más rápido y en una forma más económica [15].. Al igual que las bibliotecas tradicionales los objetos que resuelven problemas específicos pueden ser creados una vez y reutilizados muchas veces. Pero los objetos tienen aún más que ofrecer que las bibliotecas. A través de la herencia un objeto puede reutilizar la definición de interfaces de otro objeto. Además el polimorfismo simplifica el reuso escondiendo diferencias irrelevantes..
(35) 36. A pesar de sus ventajas, la tecnología de objetos no ha alcanzado su máximo potencial de permitir el reuso de software, no existiendo un mercado de objetos reusables actualmente. El principal problema es que no existen estándares para enlazar objetos binarios. Aunque es posible compilar un objeto y después utilizar este objeto binario a través de una biblioteca, su funcionamiento solo está garantizado cuando el mismo compilador es utilizado tanto en la biblioteca como en la aplicación que está utilizando la biblioteca. Otro problema es el reuso de objetos a través de diferentes lenguajes.. COM pretende solucionar estos problemas. Los objetos COM son empacados en bibliotecas o archivos ejecutables y luego distribuidos en un formato binario. Debido a que COM define una forma estándar de accesar estos objetos binarios, los objetos COM pueden ser escritos en algún lenguaje y usados en cualquier otro. Además, debido a que los objetos COM son instanciados conforme son utilizados, cuando una nueva versión es instalada en el sistema todos los clientes automáticamente obtendrán la nueva versión la siguiente vez que utilicen el objeto.. 4.3 OLE DB Al revisar una base de datos relacional típica se puede ver que está compuesta internamente de una serie de funciones separadas. Un motor de bases de datos relacionales incluye un catálogo de metadatos, un motor SQL y analizador para el procesamiento de peticiones, un administrador de transacciones, probablemente un motor de cursores y los datos almacenados en tablas. El concepto de OLE DB es explotar la base de datos en sus partes básicas [16]. OLE DB proporciona componentes externos a la base de datos que proporcionan esta funcionalidad típica de bases de datos en una arquitectura de componentes reusables. Y debido a que estos componentes no están directamente enlazados a la base de datos pueden ser compartidos a través de múltiples aplicaciones.. OLE DB define una jerarquía de cuatro objetos principales [17]. El objeto Da ta.
(36) 37. Source encapsula funciones que identifican un proveedor de datos particular, verifica. que el usuario tenga los permisos apropiados para conectarse al proveedor e inicializa la conexión a una fuente de datos específica.. El objeto Session encapsula las funciones para conectarse a una fuente de datos particular.. El objeto Corrunand encapsula las funciones que permiten a un consumidor invocar la ejecución de comandos de definición o de manipulación de datos.. Los objetos Rowset son creados ya sea directamente de una sesión o como el resultado de la ejecución de algún comando.. 4.4 ACTIVEX DATA OBJECTS (ADO) ADO es un conjunto de interfaces de alto nivel que actúan sobre datos OLE DB. Aunque OLE DB es una poderosa interface para manipular datos, la mayoría de los desarrolladores de aplicaciones no necesitan el bajo nivel de control que OLE DB proporciona sobre el acceso a los datos [18].. ADO soporta características clave para el desarrollo de aplicaciones cliente/servidor así como aplicaciones basadas en el Web como las siguientes:. •. Objetos independientes. A diferencia de Data Access Objects (DAO) o Remate Data Objects (ROO) con ADO no es necesario navegar a través de una jerarquía para crear objetos debido a que la mayoría de los objetos pueden ser creados en forma independiente.. •. Procedimientos almacenados. ADO soporta procedimientos almacenados con parámetros de entrada y salida así como valores de regreso..
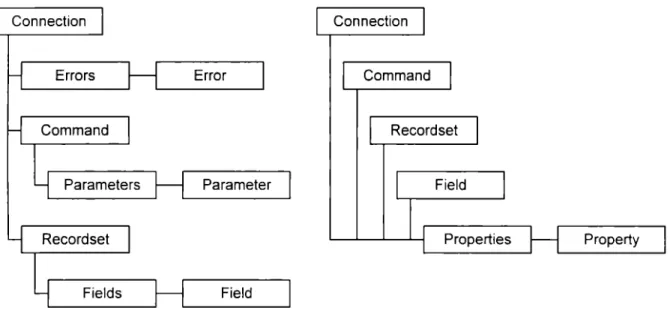
(37) 38. •. Cursores. ADO soporta diferentes tipos de cursores.. •. Conjuntos de resultados. ADO soporta múltiples conjuntos de resultados a partir de procedimientos almacenados u otras sentencias.. El Remate Data Service (ROS) de ADO permite el manejo de datos en forma remota. Por medio de ROS es posible mover datos de un servidor a una aplicación cliente o página Web, manipular los datos en el cliente y regresar los datos actualizados al servidor en un solo paso. Previamente liberado como Advanced Data Connector, ROS ha sido combinado con el modelo de programación de ADO para simplificar el manejo de datos en el lado cliente.. Connection. Errors. Connection. Error. Command. Record set. Parameters. Para meter. Record set. Fields. Field. Properties. Property. Field. Fig. 4.2. Modelo de objetos de ADO.. 4.5 MODELO DE OBJETOS ADO Aunque los objetos ADO pueden crearse fuera del ámbito de una jerarquía estos objetos muestran una relación jerárquica según en el modelo de objetos ADO mostrado en la figura 4.2 . Los siete objetos de este modelo son: Conne c ti o n, Command , Recordse t , Error, Pa rame t er, Field y Prop er t y [19]..
(38) 39. Un objeto Connection representa una conexión abierta con una fuente de datos. En el caso de un sistema de base de datos cliente/servidor puede ser el equivalente a una conexión de red con el servidor. Con las colecciones, métodos y propiedades del objeto Connection se pueden realizar operaciones como:. •. Configurar la conexión antes de abrirla con las propiedades Mode, ConnectionString y ConnectionTimeout.. •. Establecer la base de datos por defecto con la propiedad Defaul tDatabase.. •. Establecer el nivel de aislamiento para las transacciones abiertas por medio de la propiedad IsolationLevel.. •. Especificar un proveedor OLE DB con la propiedad Provider.. •. Establecer e interrumpir las conexiones físicas a la fuente de datos mediante los métodos Open y Close.. •. Ejecutar una sentencia en una conexión con el método Exec u te y configurar la ejecución con la propiedad CommandTimeout.. •. Administrar transacciones sobre la conexión abierta, incluyendo transacciones anidadas cuando el proveedor las soporte, con los métodos BeginTrans, CommitTrans y RollbackTrans y con la propiedad Attribu tes.. •. Examinar errores regresados de la fuente de datos con la colección Errors.. •. Obtener información acerca del esquema de la base de datos con el método OpenSchema..
(39) 40. El objeto Comrnand es una definición de una sentencia específica que se desea ejecutar contra una fuente de datos. Este objeto se utiliza para consultar una base de datos y regresar resultados en un objeto Recordset o para manipular la estructura de la base de datos. Con las colecciones, métodos y propiedades del objeto Comrna n d se pueden realizar operaciones como:. •. Definir el texto ejecutable de una sentencia (por ejemplo, una sentencia SOL) mediante el uso de la propiedad ComrnandTe x t.. •. Definir consultas parametrizadas o argumentos de procedimientos almacenados con objetos Parameter y la colección Parameters.. •. Ejecutar una sentencia y regresar un objeto Recordset utilizando el método Ex ecu t e .. •. Especificar el tipo de sentencia con la propiedad ComrnandType antes de la ejecución para optimizar el desempeño.. •. Controlar si el proveedor salva o no una versión preparada o compilada de la sentencia antes de su ejecución mediante la propiedad Prepar ed.. •. Establecer el número de segundos que un proveedor esperara para la ejecución de una sentencia mediante la propiedad ComrnandTimeout.. •. Asociar una conexión abierta con un objeto Comrna n d por medio de su propiedad ActiveConne c ti o n.. Un objeto Re co r dse t representa el conjunto completo de registros resultantes de una consulta. En un momento dado el objeto Records e t hace referencia únicamente a un registro denominado el registro actual..
(40) 41. En ADO existen cuatro tipos de cursores:. •. Cursor dinámico. Este tipo de cursor permite ver registros agregados, modificados y eliminados por otros usuarios.. •. Cursor de clave. Este cursor se comporta como un cursor dinámico excepto que impide visualizar registros que otros usuarios agregan así como registros que otros usuarios eliminan. Los datos cambiados por otros usuarios permanece visibles.. •. Cursor estático. Proporciona una copia estática de un conjunto de registros para localizar datos o generar reportes. Registros agregados, modificados o eliminados por otros usuarios no serán visibles.. •. Cursor solo hacia adelante. Este cursor se comporta en forma idéntica a un cursor dinámico excepto que solo proporciona una navegación hacia adelante a través de los registros. Esto mejora el desempeño en situaciones en donde solo es necesario hacer un recorrido hacia adelante en el conjunto de registros.. Para escoger el tipo de cursor se deberá especificar la propiedad Curso rType antes de abrir el objeto Recordset o pasar un argumento CursorType con el método. Open. Algunos proveedores no soportan todos los tipos de cursores. Si no se especifica el tipo de cursor, ADO utilizara un cursor solo hacia adelante por defecto. Se pueden crear tantos objetos Recordset como sean necesarios.. Cuando se abre un objeto Recordset el apuntador de registro actual es posicionado en el primer registro, si existe, y las propiedades BOF y EOF son puestas en. False. Si no existen registros ambas propiedades son puestas en True. Se pueden utilizar los métodos MoveFirst, MoveLast, MoveNext, MovePrevious y Move así como las propiedades Ab so lu tePosi tion, AbsolutePage y Fil ter para reposicionar el registro actual. Los objetos Recordset solo hacia adelante únicamente soportan el método MoveNext..
(41) 42. El objeto Error contiene los detalles acerca de errores en acceso a datos pertenecientes a una determinada operación. Cada operación involucrando objetos ADO puede generar uno o más errores del proveedor. Cuando ocurre un error, uno o más objetos Error son colocados en la colección Errors del objeto Connecti o n. Cuando otra operación ADO genera un error, la colección Errors es inicializada y un nuevo conjunto de objetos Error son colocados en esta colección. Cada objeto Error representa un error especifico del proveedor no un error de ADO. Los errores ADO son expuestos en el mecanismo de manejo de errores en tiempo de ejecución.. Para obtener detalles específicos acerca de cada error se pueden leer las propiedades del objeto Error, entre ellas las siguientes:. •. La propiedad De ser ipt ion contiene el texto del error.. •. La propiedad Number contiene el valor entero del error.. •. La propiedad Source identifica al objeto que generó el error.. •. Las propiedades SQLState y Nati veError proporcionan información acerca de las fuentes de datos SQL.. El objeto Parameter representa un parámetro o argumento asociado con un objeto Command basado en una consulta parametrizada o un procedimiento almacenado. Muchos proveedores soportan sentencias parametrizadas. En estas sentencias la acción a realizar es definida una vez aunque los parámetros son utilizados para alterar algunos detalles de la sentencia.. Un objeto Fie ld representa una columna de datos con un tipo de datos común . Un objeto Reco rdset contiene una colección Fie l ds construida de objetos Field. Cada objeto Field corresponde a una columna en el objeto Rec o rdset. La propiedad Val u e de los objetos Field se utiliza para establecer o regresar datos para el registro.
(42) 43. actual. Algunas de las funciones que se pueden realizar con las propiedades de un objeto Field son:. •. Regresar el nombre de un campo con la propiedad Name.. •. Visualizar o modificar los datos en el campo con la propiedad Value.. •. Regresar las características básicas de un campo son las propiedades Type, Precision y NumericScale.. El objeto Property representa una característica dinámica de un objeto ADO definida por el proveedor. Los objetos ADO tienen dos tipos de propiedades: construidas y dinámicas. Las propiedades construidas son aquellas implementadas en ADO e inmediatamente disponibles a cualquier nuevo objeto. Las propiedades construidas no aparecen como objetos Property en una colección Properties de algún objeto.. Las propiedades dinámicas son definidas por el proveedor de datos y aparecen en la colección Properties del objeto ADO apropiado.. Un objeto Property tiene definidas cuatro propiedades construidas:. •. La propiedad Name, la cual es una cadena que identifica la propiedad.. •. La propiedad Type, la cual es un entero que especifica el tipo de datos de la propiedad.. •. La propiedad Value, que contiene el valor de la propiedad.. •. La propiedad At tributes, la cual es un valor que indica características de la propiedad específicas al proveedor..
Figure

Documento similar
[r]
[r]
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
Abstract: This paper reviews the dialogue and controversies between the paratexts of a corpus of collections of short novels –and romances– publi- shed from 1624 to 1637:
U-Ranking cuenta con la colaboración del Ministe- rio de Universidades, al permitirnos el acceso al Sistema Integrado de Información Universitaria (SIIU). El SIIU es
El valor agregado 6 del indicador por universidad se pre- senta en una escala de 0 (mínimo valor obtenido por una universidad del sistema en ese indicador) a 100 (correspondiente
El segundo paso es elegir la comunidad autónoma o comunidades que se contemplan como lugares en los que cursar los estudios. Para ello, el usuario debe marcar las elegidas
El segundo paso es elegir la comunidad autónoma o comunidades que se contemplan como lugares en los que cursar los estudios. Para ello, el usuario debe marcar las elegidas
