Mercado de datos para el proceso de formación de másteres y especialistas de postgrado en la UCLV
83
0
0
Texto completo
(2) Declaración Jurada. El que suscribe, Luis Izquierdo Rivero, hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Licenciatura en Ciencias de la Computación, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicado sin autorización de la Universidad.. ______________________________ Luis Izquierdo Rivero Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. ___________________________________ Firma del Tutor. __________________________________ Firma del Jefe del Laboratorio. I.
(3) Exergo. "El verdadero progreso es el que pone la tecnología al alcance de todos." Henry Ford. II.
(4) Dedicatoria A mi mamá Y mi Papá: Por su apoyo incondicional. Por su educación y enseñanza en la vida. Por su lucha incansable para lograr todo lo que he alcanzado. A mi hermano y A Lary: Por sus consejos, por su amistad, por darme todo lo necesario para poder realizar mis sueños. A mi pequeña Princesa: Por su amor, apoyo y entrega Por luchar junto a mí y no rendirse nunca, aún en los años más difíciles de mi carrera. Por ser única e inigualable. A mis abuelos: Por ser especiales para mí. Por entregarme su cariño y dedicación. A mi tío Vicente: Por ser como un padre para mí.. III.
(5) Agradecimientos A mi tutor Rosendo: Por ser de gran ayuda para la realización de este trabajo. Por sus consejos y profesionalidad durante mi investigación. A mi familia: Por ser gran parte de mi vida. A Leidys Laura: Por ser mi princesa de cuentos de hadas. A Mabel, Noel, teresa y Laura: Por acogerme en su seno familiar. A Michel: Por explicarme lo necesario de la BD. A mis Compañeros: Que. juntos compartimos las alegrías y preocupaciones que esta. tarea implica. A todos, Muchas Gracias!!!. IV.
(6) Resumen En la UCLV existe en la actualidad un Sistema de Control de Postgrado, cuya base de datos está implementada en PostgrSQL, y donde se almacenan múltiples datos históricos para el control de este Proceso, incluyendo la parte relacionada al Procedimiento de Formación de Másteres y Especialistas. Dicha información es suministrada a través de la Red universitaria por las diferentes áreas autorizadas a impartir postgrados. La Dirección de Postgrado del propio centro necesita analizar con frecuencia la información de manera no tradicional a través de informes ad-hoc, para entregar a los directivos resultados tabulados y gráficos que permitan producir nuevos conocimientos sobre dicho procedimiento. Este trabajo se centra entonces en el análisis de los datos históricos referentes a Maestrías y Especialidades basado en el uso del Pentaho, como herramienta fundamental para los procesos de extracción, transformación, limpieza y carga (ETL) obteniendo una vista unificada con la mayor calidad posible en forma de Mercado de Datos. Dichos datos por solicitud del tutor se almacenan en el SGBD Access donde se implementó el Modelo Estrella del Mercado de Datos específico. A partir de esa base de datos es posible crear con facilidad varios informes ad-hoc, de los cuales se muestran algunos ejemplos en esta investigación.. V.
(7) Abstract In UCLV there is currently a Postgraduate Control System, whose database is implemented in PostgrSQL, and where multiple historical data are stored for the control of this Process, including the part related to the Training Procedure for Masters and Specialists. This information is provided through the University Network for the different areas authorized to teach postgraduate courses. The postgraduate department of the center itself needs to frequently analyze information in a non-traditional way through ad-hoc reports, to deliver to manager’s tabulated results and graphs that allow producing new knowledge about such procedure. This work focuses on the analysis of the historical data concerning Masters and Specialties based on the use of Pentaho, as a fundamental tool for extraction, transformation, cleaning and loading (ETL) processes, obtaining a unified view with the highest possible quality In the form of a Data Market. These data by request of the tutor are stored in the Access DBMS where the specific Data Market Star Model was implemented. From this database it is possible to easily create several ad-hoc reports, of which some examples are shown in this research.. V.
(8) Índice Capítulo 1 Estado del arte de los Mercados de Datos. ................................................... 9 1.1 Información ............................................................................................................ 9 1.2 Inteligencia de negocio .......................................................................................... 9 1.2.1 Niveles organizacionales en los que colabora la inteligencia de negocio ........ 9 1.2.2 Beneficios de la inteligencia de negocio ........................................................ 10 1.3 Almacén de datos ................................................................................................ 13 1.3.1 Modelo de datos apropiado ........................................................................... 14 1.3.2 Características distintivas de un almacén de datos ....................................... 15 1.3.3 Ventajas e inconvenientes de los DW ........................................................... 15 1.4 Mercado de datos ................................................................................................ 16 1.4.1 Tipos de mercados de datos.......................................................................... 16 1.4.2 Ventajas e inconvenientes de los mercados de datos ................................... 17 1.5 Modelado de datos en el DM ............................................................................... 18 1.5.1 Tablas de dimensiones .................................................................................. 18 1.5.2 Tablas de hechos .......................................................................................... 19 1.5.3 Esquemas multidimensionales ...................................................................... 20 1.6 Funciones ETL ..................................................................................................... 22 1.6.1 Obtención de los datos .................................................................................. 22 1.6.2 Calidad de los datos ...................................................................................... 22 1.6.3 Integración de datos ...................................................................................... 23 1.6.4 Proceso de extracción de datos..................................................................... 24 1.6.5 Limpieza ........................................................................................................ 26 VI.
(9) 1.6.6 Transformación .............................................................................................. 28 1.6.7 Carga ............................................................................................................. 28 1.7 Aspectos sobre la metodología de Kimball .......................................................... 29 1.7.1 Planificación del proyecto .............................................................................. 29 1.7.2 Definición de los requerimientos del negocio................................................. 30 1.7.3 Modelo dimensional ....................................................................................... 30 1.7.4 Diseño Físico ................................................................................................. 31 1.7.5 Diseño e implementación del subsistema de ETL ......................................... 31 1.7.6 Diseño de la arquitectura técnica ................................................................... 31 1.7.7 Selección del producto e implementación ..................................................... 32 1.7.8 Especificación de aplicaciones de BI ............................................................. 32 1.7.9 Desarrollo de aplicaciones de BI ................................................................... 32 1.7.10 Implementación ........................................................................................... 32 1.7.11 Mantenimiento y crecimiento ....................................................................... 33 1.7.12 Administración del proyecto ......................................................................... 33 1.8 Herramientas que se utilizan para realizar los procesos de ETL ......................... 33 1.8.1 Apatar ............................................................................................................ 33 1.8.2 CloverETL ...................................................................................................... 34 1.8.3 Pentaho Data Integration ............................................................................... 34 1.9 PostgreSQL como sistema actual ........................................................................ 35 1.10 Access como SGBD destino .............................................................................. 36 Conclusiones Parciales .............................................................................................. 37 Capítulo 2 Descripción del desarrollo del Mercado de Datos. ....................................... 38 2.1 Planificación del proyecto .................................................................................... 38 VII.
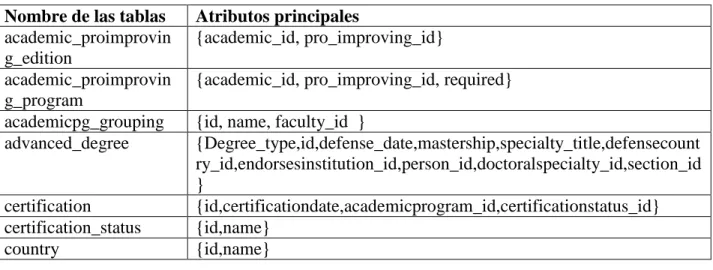
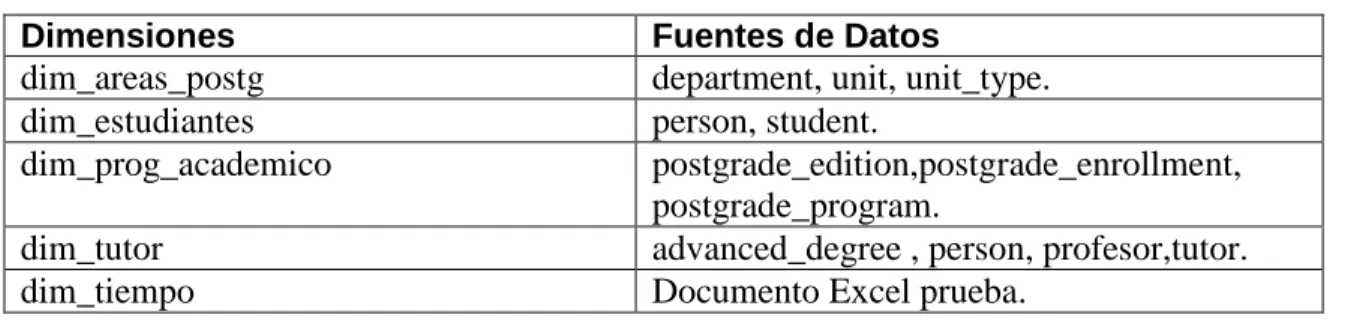
(10) 2.1.1 Objetivos ........................................................................................................ 38 2.1.2 Alcance .......................................................................................................... 38 2.1.3 Beneficios ...................................................................................................... 38 2.2 BD del Sistema de control de postgrado de la UCLV .......................................... 38 2.2.1 Tablas y atributos .......................................................................................... 40 2.2.2 Principales errores encontrados .................................................................... 42 2.3 Modelado dimensional ......................................................................................... 43 2.3.1 Elección de las dimensiones.......................................................................... 43 2.3.2 Medidas encontradas .................................................................................... 43 2.3.3 Tabla de hechos ............................................................................................ 44 2.4 Diseño de la arquitectura técnica ......................................................................... 44 2.4.1 Datos ............................................................................................................. 45 2.4.2 Back room...................................................................................................... 48 2.4.3 Front room ..................................................................................................... 49 2.5 Diseño físico ........................................................................................................ 50 2.5.1 dim_areas_postg ........................................................................................... 50 2.5.2 dim_estudiantes ............................................................................................. 51 2.5.3 dim_prog_academico .................................................................................... 51 2.5.4 dim_tutor ........................................................................................................ 51 2.5.5 dim_tiempo .................................................................................................... 52 Conclusiones Parciales .............................................................................................. 52 Capítulo 3 Implementación y Prueba. ........................................................................... 53 3.1 Implementación de las ETL para poblar el DM Análisis de maestrías de la UCLV ................................................................................................................................... 53 3.1.1 Llenado del DSA ............................................................................................ 53 VIII.
(11) 3.1.2 Carga inicial hacia el DM Análisis de maestrías de la UCLV ......................... 55 3.1.3 Carga incremental hacia el DM Análisis de maestrías de la UCLV ............... 58 3.2 Script para ejecutar los trabajos........................................................................... 61 3.3 Informes prototípicos ........................................................................................... 62 3.3.1 Consulta N°1.................................................................................................. 62 3.3.2 Consulta N°2.................................................................................................. 63 3.3.3 Consulta N°3.................................................................................................. 63 3.4 Mejora del proceso de toma de decisiones del área de maestrías y especialidades. .......................................................................................................... 66 Conclusiones Parciales .............................................................................................. 66 Conclusiones ................................................................................................................. 67 Recomendaciones......................................................................................................... 68 Referencias Bibliográficas ............................................................................................. 69. IX.
(12) Lista de Figuras Figura N° 1: Fases de la metodología Ralph Kimball. Fuentes: The Microsoft Data Warehouse Toolkit (Mundy et al. 2006); The Data Warehouse Lifecycle Toolkit (Kimball et al. 1998). ................................................................................................................... 30 Figura N° 2: Diseño lógico del DM. Fuente: Elaboración propia. .................................. 44 Figura N° 3: Diseño físico del DM. Fuente: Elaboración propia. ................................... 50 Figura N° 4: dsa_prog_acad. Fuente: Elaboración propia............................................. 54 Figura N° 5: dsa_areas_postg. Fuente: Elaboración propia. ......................................... 54 Figura N° 7: dsa_tutor. Fuente: Elaboración propia. ..................................................... 55 Figura N° 9: Esquema del subsistema ETL. Fuente: Elaboración propia. ..................... 56 Figura N° 10: inicial_areas_postg. Fuente: Elaboración propia..................................... 56 Figura N° 11: inicial_estudiantes. Fuente: Elaboración propia. ..................................... 57 Figura N° 12: inicial_prog_acad. Fuente: Elaboración propia. ...................................... 57 Figura N° 13: inicial_tutor. Fuente: Elaboración propia. ................................................ 57 Figura N° 14: inicial_tiempo. Fuente: Elaboración propia.............................................. 58 Figura N° 15: transf_iniciales. Fuente: Elaboración propia............................................ 58 Figura N° 16: incremental_estud. Fuente: Elaboración propia. ..................................... 59 Figura N° 17: incremental_tutor. Fuente: Elaboración propia........................................ 59 Figura N° 18: incremental_areas_postg. Fuente: Elaboración propia. .......................... 60 Figura N° 19: incremental_prog_acad. Fuente: Elaboración propia. ............................. 60 Figura N° 20: incremental_tiempo. Fuente: Elaboración propia. ................................... 60 Figura N° 21: transf_incrementales. Fuente: Elaboración propia. ................................. 61 Figura N° 22: llenado_th. Fuente: Elaboración propia. .................................................. 61. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 1.
(13) Lista de Tablas Tabla N° 1: Tablas y atributos de la fuente de datos. .................................................... 40 Tabla N° 2: Tablas de maestrías y especialidades. ...................................................... 42 Tabla N° 3: Tabla de mapeo de datos para el modelo dimensional. ............................. 45 Tabla N° 4: Atributos de la dimensión dim_areas_postg. .............................................. 50 Tabla N° 5: Atributos de la dimensión dim_estudiantes. ............................................... 51 Tabla N° 6: Atributos de la dimensión dim_prog_academico. ....................................... 51 Tabla N° 7: Atributos de la dimensión dim_tutor. .......................................................... 51 Tabla N° 8: Atributos de la dimensión dim_tiempo. ....................................................... 52 Tabla N° 9: Consulta 1. ................................................................................................. 62 Tabla N° 10: Consulta 2. ............................................................................................... 63 Tabla N° 11: Consulta 3 inciso a). ................................................................................. 64 Tabla N° 12: Consulta 3 inciso b). ................................................................................. 65. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 2.
(14) Introducción Múltiples trabajos se han dedicado a disertar sobre el término información y su importancia como recurso indispensable para la sociedad, cuyo desarrollo ha rebasado cualquier pronóstico realizado años atrás. El sector de la información y su industria se han convertido en un factor esencial para el accionar humano en la sociedad moderna. La información es el significado que otorgan las personas a las cosas. Los datos se perciben mediante los sentidos, estos integran y generan la información necesaria para el conocimiento con el cual es posible tomar decisiones para realizar las acciones cotidianas que aseguran la existencia social (Go 2000). La mayoría de las decisiones de empresas, organizaciones e instituciones se basan en información de experiencias pasadas. Generalmente, la información que es necesaria para investigar sobre un cierto dominio de la organización se encuentra en sistemas operacionales de bases de datos, tanto internas como externas, y otras fuentes muy diversas, no necesariamente bases de datos (Gómez 2015). Desde hace varias décadas las organizaciones empresariales han buscado en el almacenamiento de datos de sus sistemas operacionales soluciones que les ayuden a atender sus necesidades a la hora de tomar decisiones de negocio (Sanz 2010). Los usuarios que toman estas decisiones y planifican día a día, a mediano o a largo plazo, la calidad, disponibilidad y presentación de la información juegan un papel categórico, pues este tipo de usuarios necesitan disponer de información tanto consolidada y detallada de cómo marchan las actividades ya cumplidas, predecir tendencias y comportamientos para tomar decisiones proactivas (Marroquín & Tejada 2007). Actualmente, las bases de datos operacionales son útiles en un entorno muy concreto que responde a las necesidades para las que se crearon. Estas necesidades suelen involucrar entornos de gestión puros en los que las características principales de las operaciones suelen ser las de la simplicidad en las consultas y tipos de los datos (Sanz 2010). Con estos sistemas tradicionales se preparan reportes ad-hoc para encontrar respuestas a algunas de las preguntas del negocio, pero se necesita dedicar mucho del tiempo asignado en el análisis de localización y presentación de los datos, como también asignación de recursos humanos y de procesamiento del departamento de sistemas para poder responderlas, sin tener en cuenta la degradación de los sistemas Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 3.
(15) transaccionales. Esta problemática se debe a que dichos sistemas transaccionales no fueron construidos con el fin de brindar síntesis, análisis, consolidación, búsquedas y proyecciones (Marroquín & Tejada 2007). Por otra parte, las necesidades de información hoy en día han variado. La disponibilidad de gran cantidad de información es de vital importancia para los negocios, ya que las decisiones de futuro se suelen tomar sobre la base de dicha información. Este tipo de necesidades para reflejar tendencias, evoluciones, hechos históricos en el negocio y posibilidades futuras son temas que la alta dirección de las instituciones y empresas deben manejar y manejan de una forma habitual y son las causantes de que hayan aparecido en el mercado herramientas denominadas "ayudas a la toma de decisiones" (Sanz 2010). Existen diversos tipos de sistemas informacionales de soporte para la toma de decisiones, pero el que ha tenido más auge a escala mundial en las grandes instituciones ha sido sin duda los Almacenes de Datos [acrónimo del inglés DataWarehouse (DW)], convirtiéndose en el centro de atención de las organizaciones, puesto que provee un ambiente para hacer un mejor uso de la información administrada por diversas aplicaciones operacionales (Gómez 2015). Los DW surgen por la necesidad de resolver problemas de análisis de grandes masas de información, estos se subdividen en unidades lógicas más pequeñas dependiendo del subsistema de la entidad del que procedan o para el que sea necesario; dichas unidades lógicas se denominan Mercado de Datos [acrónimo del inglés Data Mart (DM)], los cuales resuelven estudios a nivel de departamento. Un DM es una versión del almacén de datos, la diferencia principal es que la creación de un DM es específica para una necesidad de datos seleccionados, enfatizando el fácil acceso a una información relevante y el análisis de datos estadísticos que apoyan la toma de decisiones (Rodríguez et al. 2013). El desarrollo sostenido de la informatización en empresas de Cuba ha implicado la necesidad de que se realicen estudios referidos a los sistemas informacionales. La implementación y explotación de almacenes y mercados de datos son los objetivos principales de diferentes organismos e instituciones dedicadas al desarrollo de sistemas de información con el fin de mejorar la calidad de los datos en búsqueda de información no revelada tradicionalmente para detectar tendencias industriales, comerciales y de servicio. En la Universidad Central “Marta Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 4.
(16) Abreu” de las Villas (UCLV) se han realizado trabajos aplicados a diferentes esferas, en calidad de tesis de diploma en pregrado y tesis de maestrías y doctorados en postgrado, los cuales abordan la creación de almacenes y mercado de datos.. Situación Problemática: Actualmente, en la Dirección de Postgrado de la UCLV se explota una base de datos implementada en PostgreSQL donde se almacena un amplio volumen de información histórica sobre el control de postgrado. El actual sistema contiene información de los procesos de superación profesional: formación de másteres, especialistas y doctores; es operado por la secretaría de postgrado de cada facultad y centros universitarios municipales. Los informes que brinda este sistema son listas tradicionales y cálculos estadísticos generales que no responden totalmente a las necesidades de la dirección de postgrado ante las solicitudes de la rectoría universitaria. Por lo que es necesario desarrollar un DM específico para el proceso de maestrías y especialidades en un ambiente que permita después crear con facilidad los informes ad-hoc necesarios, escogiendo el Sistema Gestor de Base de Datos (SGBD) Access como sistema destino para implementar el DM, por solicitud expresa del tutor. Además de crear la estructura informativa del mercado con la herramienta Pentaho que posibilita fácilmente la carga, transformación y limpieza de los datos a partir de la Base de Datos del Sistema de Control de Postgrado. Por tanto, la idea principal del presente trabajo es desarrollar un DM en el sistema gestor de base de datos (SGBD) Access utilizando la herramienta Pentaho para que la dirección de Postgrado de la UCLV con gran disponibilidad obtenga información sólida y confiable, que satisfagan sus necesidades.. Objetivo General: Desarrollar un Mercado de Datos para el análisis estadístico por solicitudes del proceso de maestrías y especialidades de la UCLV a partir de los datos históricos del SIGENU-PG.. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 5.
(17) Objetivos Específicos: 1. Realizar un análisis de la estructura relacional del actual Sistema de Control de Postgrado de la UCLV, específicamente lo relacionado con el proceso de maestrías y especialidades. 2. Implementar el modelo estrella del mercado de datos en el SGBD Access. 3. Describir el mapeo de los datos del mercado de datos con respecto al SIGENU-PG. 4. Establecer los procesos ETL para lograr la carga y transformación de los datos desde el SIGENU-PG al mercado de datos con ayuda de Pentaho. 5. Crear varios informes prototípicos de resultados estadísticos calculados necesarios a la Dirección de Postgrado (DPG) sobre el gestor destino, como muestra de uso del mercado de datos.. Justificación: El Sistema de Control de Postgrado actualmente en funcionamiento en la UCLV permite controlar aspectos como la planificación, las matrículas, la asignación de evaluaciones, el control de las tesis de los diferentes programas de postgrados (cursos, entrenamientos, diplomados, maestrías, especialidades y doctorados) y ayuda a las áreas universitarias autorizadas a emitir actas, listas de matrículas, sábanas de crédito, informes finales de cursos, certificados de aprobación o de impartición de cursos, entre otras cosas. Sin embargo, el análisis estadístico que permite la toma de decisiones sobre el proceso de postgrado se logra a través de otros estudios que reflejan la eficiencia del proceso en sí, basado en los resultados históricos allí almacenados. Este tipo de análisis es engorroso lograrlo sobre el propio sistema y por ello se justifica el desarrollo de este trabajo que permitiría lograr diferentes análisis específicamente sobre el subproceso de Formación de Másteres y Especialistas (uno de los frentes que se controlan en la Dirección de Postgrado).. Viabilidad: La existencia del SIGENU-PG con ya más de 3 años de uso en todas las áreas universitarias, que incluye además datos de años previos, brinda la posibilidad de usar esos datos históricos para análisis más complejos.. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 6.
(18) La existencia de herramientas de software y hardware adecuadas, así como el conocimiento táctico adquirido para la realización de esta tarea permite afirmar que es viable desarrollarla.. Preguntas de Investigación: 1. ¿Por qué construir un Mercado de Datos y no un Almacén de Datos? 2. ¿Por qué el modelo estrella y no el de copo de nieve? 3. ¿Qué tablas y atributos específicos que aparecen en el SIGENU-PG son necesarios para el Mercado de Datos? 4. ¿Qué procedimientos de ETL se pueden establecer con ayuda del Pentaho que sirva para transformar y cargar los datos desde PostgreSQL a Access? 5. ¿Cómo el SGBD Access brindará las funcionalidades necesarias para la creación de consultas Ad-Hoc que respondan a los intereses de la DPG y la Rectoría de la UCLV?. Hipótesis: La existencia de un Mercado de Datos correspondiente al proceso de Formación de Másteres y Especialistas, a partir de la información histórica almacenada en el Sistema de Control de Postgrado de la UCLV, que pueda ser actualizado con una frecuencia mensual, posibilitará crear a través de informes ad-hoc, tablas y gráficos que apoyen la toma de decisiones a nivel universitario referente a la determinación de la eficiencia, calidad, pertinencia y otras características de este proceso, de una manera más ágil y fácil para la Dirección de Postgrado de este centro de altos estudios.. Estructura de la tesis: El presente documento está estructurado en tres capítulos. Cada capítulo constituye una mejor comprensión para obtener un entendimiento global del trabajo, la estructura del contenido queda conformada de la siguiente manera: Capítulo 1. Estado del arte de los Mercados de Datos En este capítulo se abordan los conceptos esenciales de Almacén de Datos y Mercado de Datos, sobre todo lo que abarca la metodología de Ralph Kimball. También se detallan las ventajas de. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 7.
(19) las herramientas a utilizar: Pentaho para desarrollar las ETL y Access como SGBD destino del DM propuesto. Capítulo 2. Descripción del desarrollo del Mercado de Datos En este capítulo se realiza un análisis de la estructura del modelo relacional del Sistema de Control de Postgrado de la UCLV, haciendo énfasis en la parte referente al control del proceso de maestrías y especialidades. También se argumenta cada paso de la metodología de desarrollo de Kimball para la implementación del DM. Además se definirá el modelo estrella necesario como estructura multidimensional del DM y se describirán los procesos ETL necesarios. Capítulo 3. Implementación y Prueba En este capítulo se muestra la implementación del DM acorde con el modelo estrella definido previamente. Además se aborda la realización de las transformaciones necesarias en la herramienta Pentaho para el llenado del DM; también se describe la implementación del script para la ejecución del trabajo orquestado por las transformaciones descritas anteriormente, se muestra la realización de una carga inicial de datos del Sistema Actual al DM en Access y se desarrollarán varias consultas ad-hoc como prueba sobre el gestor destino.. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 8.
(20) Capítulo 1 Capítulo 1 Estado del arte de los Mercados de Datos. 1.1 Información En cualquier actividad productiva en la que estemos inmersos, día a día debemos tomar decisiones que indicarán el rumbo de nuestra empresa, ya sea hacia el éxito o al fracaso, pero para tomar una decisión lo más acertada posible es necesario basarnos en información de calidad. Para que la información sea considerada de calidad debe ser: Exacta: estar libre de errores, Oportuna: estar en el momento que se le requiere Relevante: dando respuesta a las preguntas del ¿qué?, ¿por qué?, ¿cuándo?, ¿dónde?, ¿quién?, y ¿cómo?. Disponer de datos no es lo mismo que disponer de información. Los datos se convierten en información cuando se pueden utilizar para responder a cuestiones del negocio, de tal manera que se pueda comprender mejor el funcionamiento del mismo. La inteligencia de negocio permite responder a tales cuestiones, por lo que los tomadores de decisiones de todos los niveles pueden responder rápidamente ante los cambios en el entorno de los negocios (Marroquín & Tejada 2007).. 1.2 Inteligencia de negocio La Inteligencia de negocio [acrónimo del inglés Business Intelligence (BI)] es el proceso a través del cual es posible agrupar, resumir e interpretar la información para medir el desempeño de la empresa contra sus metas y la industria donde compite. En la era de la información, las organizaciones tienen a su disposición vastas cantidades de datos, recolectadas en sistemas transaccionales. Dichos sistemas son esenciales para la operación del negocio (Marroquín & Tejada 2007). 1.2.1 Niveles organizacionales en los que colabora la inteligencia de negocio Las soluciones de inteligencia de negocio están orientadas a apoyar a las organizaciones para resolver sus necesidades de información en los tres niveles básicos: operativo, táctico y Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 9.
(21) Capítulo 1 estratégico. De esta forma se logra crear un ambiente de trabajo en el que las decisiones de cualquier nivel son tomadas en base a información y conocimiento de la realidad que vive el negocio. El nivel operativo consiste en operaciones tradicionales que son efectuadas de modo rutinario en las empresas mediante la captura masiva de datos y sistemas de procesamiento transaccional. Las tareas son cotidianas y soportan la actividad diaria de la empresa (contabilidad,. facturación,. almacén,. presupuesto. y. otros. sistemas. administrativos).. Tradicionalmente se asocian a las Jefaturas o Coordinaciones operativas o de tercer nivel. En el nivel táctico se plantean opciones y caminos posibles para alcanzar la estrategia indicada por la dirección de la empresa. Se facilita la gestión independiente de la información por parte de los niveles intermedios de la organización. Este tipo de información es extraída específicamente de un área o departamento de la organización, por lo que su alcance es local y se asocia a gerencias o subdirecciones. Mientras que el nivel estratégico está orientado principalmente a soportar la Toma de Decisiones de las áreas directivas para alcanzar la misión empresarial. Se caracteriza por sistemas sin carga periódica de trabajo y sin gran cantidad de datos, sin embargo, la información que almacenan está relacionada a un aspecto cualitativo más que cuantitativo, que puede indicar como operará la empresa ahora y en el futuro, el enfoque es distinto, pero sobre todo es diferente su alcance (Marroquín & Tejada 2007). 1.2.2 Beneficios de la inteligencia de negocio Los principales beneficios que se pueden obtener al implementar una solución de inteligencia de negocio según (Marroquín & Tejada 2007) en una organización son: . Respuestas inmediatas a preguntas del negocio, que son básicas para la toma de decisiones.. . Integración de datos entre los diferentes sistemas de información existentes en la organización.. . Permite lograr una visión del futuro a través del análisis de datos históricos.. . Dar la libertad al tomador de decisiones para crear diferentes escenarios de análisis, sin la dependencia del área de tecnología.. . Lograr medir el desempeño de la organización en función de sus metas y la industria en donde compite.. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 10.
(22) Capítulo 1 La creación de sistemas que ayuden a guardar información para después utilizarla en la esfera de la inteligencia de negocio es muy importante para las organizaciones que manejan grandes volúmenes de datos. Los sistemas transaccionales surgen con las primeras aplicaciones empresariales de los equipos informáticos, para realizar de forma automatizada tareas administrativas repetitivas e intensivas en mano de obra: la gestión de nóminas, la facturación a clientes, el control de inventarios, la contabilidad, etc. Sistemas transaccionales OLTP Los OLTP (Online Transaction Processing) son sistemas transaccionales que están altamente afinados para realizar su trabajo rápidamente, usualmente en tiempo real, y a menudo con el uso de mainframes y otros servidores grandes. Capturan las transacciones de un negocio y las persisten en estructuras relacionales llamadas base de datos (Zaldívar 2014). Las características principales de los sistemas OLTP son: (Zaldívar 2014) . Realizan transacciones en tiempo real del proceso de un negocio, con lo cual los datos almacenados cambian continuamente, y conducen procesos esenciales del negocio.. . Los sistemas OLTP son los responsables del mantenimiento de los datos, ya sea agregando datos, realizando actualizaciones o bien eliminándolos.. . Las estructuras de datos deben estar optimizadas para validar la entrada de los mismos, y rechazarlos si no cumplen con determinadas reglas de negocio.. . Para la toma de decisiones, proporciona capacidades limitadas ya que no es su objetivo, por lo tanto no es prioridad en su diseño. Al requerir información histórica relativa al negocio con un sistema OLTP, se produciría un impacto negativo en el funcionamiento del sistema.. OLAP- OnLine Anlytical Processing La tecnología OLAP es una forma específica para representar datos financieros, operacionales, comerciales y estadísticos orientados a los ejecutivos, especialistas y analistas. Está diseñada para ayudar a la toma de decisiones y una mejor comprensión de la información. La idea central es poder contestar las preguntas de los usuarios, de una forma fácil, poderosa e intuitiva. Un sistema OLAP permite a los usuarios entrar en detalles y generalizar, filtrar, ordenar, clasificar y reagrupar datos, calculándose totales intermediarios y finales en forma instantánea (Zaldívar 2014). Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 11.
(23) Capítulo 1 Las siguientes son características que la tecnología OLAP posee: (Zaldívar 2014) . Las bases de datos de OLAP tienen un esquema que está optimizado para que las preguntas realizadas por los usuarios sean respondidas rápidamente.. . Las preguntas que se le hacen a un OLAP, deben permitir un uso interactivo con los usuarios.. . Los cubos de OLAP almacenan varios niveles de datos conformados por estructuras altamente optimizadas que responden a las expectativas de negocio de la empresa.. . Un sistema OLAP está preparado para realizar informes complejos de una manera simple.. . OLAP proporciona una vista de datos multidimensional que se extiende más allá del análisis de dos dimensiones que puede proporcionar una simple planilla de cálculo utilizada como tal.. . Se pueden cambiar fácilmente las filas, las columnas, y las páginas en informes de OLAP, pudiendo leer la información de la manera que se crea más conveniente para el análisis.. Sistema de soporte de decisiones (DSS) El sistema de soporte de decisiones es un sistema interactivo provisto de programas y herramientas, para ayudar a los responsables de la toma de decisiones a utilizar tecnologías de comunicaciones, datos, documentos, conocimiento y/o modelos para identificar y resolver problemas, para completar tareas del proceso de decisión, y para tomar decisiones (Zaldívar 2014). Minería de Datos La minería de datos se emplea para el descubrimiento de conocimiento: es un proceso de búsqueda, a partir de los datos, de conocimientos nuevos y no anticipados (Villanueva 2008). Las bases de datos están diseñadas para el trabajo transaccional y no para el análisis de los datos, por lo que el análisis es lento y que los costes de almacenamiento masivo y conectividad se han reducido en los últimos años; una forma eficiente de operar consiste en copiar los datos necesarios para OLAP en un sistema unificado. Este es el origen de los DW y toda la tecnología asociada (data warehousing). Estos facilitan el análisis de los datos en tiempo real (OLAP) y no disturban el OLTP de las bases de datos originales (Gómez 2015).. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 12.
(24) Capítulo 1 1.3 Almacén de datos El concepto de DW, cuya traducción literal sería almacén o repositorio de datos, surge alrededor del año 1990 con la necesidad de recopilar información de datos acumulados durante años por los sistemas de gestión. Este concepto nace como producto de la evolución de los sistemas para dar soporte a la toma de decisiones. Los sistemas de DW apuntan a la creación y mantenimiento de estructuras destinadas al análisis de datos, transformando éstos en información y la información en conocimiento. La definición más tradicional del término DW según (Inmon 1992) es: “Un almacén de datos es una colección de datos: . Orientados a Temas o Materias: Los datos almacenados brindan información sobre un sujeto o asunto en particular en lugar de concentrarse en la dinámica de las transacciones de la organización.. . Integrado: Los datos cargados en el DW pueden provenir de diferentes fuentes y son integrados para dar una visión global coherente.. . Variables en el Tiempo: El DW se carga con los distintos valores que toma una variable en el tiempo para permitir comparaciones, lo que implica que todos los datos deben estar asociados con un período de tiempo específico.. . No volátiles: Los datos son estables en el DW, se agregan y modifican datos, pero los datos existentes no son removidos.. que será utilizada fundamentalmente en el proceso de toma de decisiones”. Mientras que Ralph Kimball otro conocido autor en el tema de los DW, define un almacén de datos como: "una copia de las transacciones de datos específicamente estructurada para la consulta y el análisis" (Kimball 1998), nos indica que el Almacén de Datos es un conglomerado de todos los Data Marts dentro de una organización, siendo una copia de los datos transaccionales estructurados de una forma especial para el análisis, de acuerdo, al modelo dimensional (no normalizado) que incluyen las dimensiones de análisis y sus atributos, su organización jerárquica, así como los diferentes hechos de negocio que se quieren analizar. Por un lado, tenemos tablas para representar las dimensiones y por otro lado, tablas para los hechos.. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 13.
(25) Capítulo 1 También fue Kimball quien estableció que un DW no era más que: “la unión de todos los Data Marts de una entidad” (Kimball & Ross 2002). Los DW prestan acceso a datos para análisis complejos, información de conocimientos y toma de decisiones. Proporcionan respuesta a las demandas de alto rendimiento de datos e información de una organización. Soportan varios tipos de aplicaciones, como OLAP, DSS y aplicaciones de minería de datos (Villanueva 2008). 1.3.1 Modelo de datos apropiado Un almacén de datos posee con frecuencia datos integrados provenientes de diversas fuentes procesadas para su almacenamiento, para examinar los DW y distinguirlos de las bases de datos transaccionales es necesario contar con un modelo de datos que sea apropiado, estos DW se estructuran por un modelo multidimensional que es una buena opción para las tecnologías OLAP y de soporte a la toma de decisión. También los DW suelen mantener series de tiempo y análisis de tendencia, que necesitan más datos históricos de los que contienen generalmente las bases de datos transaccionales y la información contenida en el DW cambia con menos frecuencia y puede considerarse como tiempo no real con actualización periódica es decir son no volátiles. Además la información del DW es menos precisa (de grano grueso) y se actualiza de acuerdo a una política de actualización que realiza el componente de adquisición del almacén, elegida con cuidado, y que es generalmente incremental (Villanueva 2008). Existen varias razones que justifican la creación del DW para obtener la información necesaria en los procesos de gestión comercial, en lugar de obtener esa información directamente de las bases de datos de las aplicaciones operacionales: (Marroquín & Tejada 2007) . Rendimiento: se tarda menos en acceder a los datos del repositorio del DW que en hacer una consulta a varias BD distintas. Además hacer consultas complicadas a las BD de los sistemas operacionales puede empeorar el tiempo de respuesta de estos sistemas para otros usuarios.. . Múltiples orígenes de datos: combinar los datos de distintas fuentes suele ser una tarea bastante complicada para las personas encargadas de tomar decisiones con esa información. Normalmente hay que homogenizar los datos de una forma u otra durante el proceso de carga (ETL) para obtener datos específicos y poder realizar un adecuado análisis.. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 14.
(26) Capítulo 1 En general el DW es una herramienta útil para el análisis específico de datos y anudado a reglas de análisis pueden ofrecer apoyo a la toma de decisiones al implementarle dichas reglas. 1.3.2 Características distintivas de un almacén de datos Las características distintivas de un almacén de datos según (Villanueva 2008) son: Visión conceptual multidimensional. Dimensionalidad genérica. Dimensiones ilimitadas y niveles de agregación. Operaciones de dimensiones cruzadas sin restricciones. Tratamiento de matriz “esparcida” (sparse) y dinámica. Arquitectura cliente-servidor. Soporte multiusuario. Accesibilidad. Transparencia. Manipulación de datos intuitiva. Buen rendimiento al crear informes consistentes. Creación de informes flexibles. 1.3.3 Ventajas e inconvenientes de los DW Las ventajas por las que es recomendable usar un Almacén de Datos son: . Hacen más fácil el acceso a una gran variedad de datos a los usuarios finales.. . Facilitan el funcionamiento de las aplicaciones de los sistemas de apoyo a la decisión tales como informes de tendencia, informes de excepción, informes que muestran los resultados reales frente a los objetivos planteados a priori, etc.. . Los DW pueden trabajar en conjunto, por lo tanto puede aumentar el valor operacional de las aplicaciones empresariales, en especial la gestión de relaciones con clientes.. Utilizar DW también plantea algunos inconvenientes, algunos de ellos son: . A lo largo de su vida los almacenes de datos pueden suponer altos costos. El almacén de datos no suele ser estático. Los costos de mantenimiento son elevados.. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 15.
(27) Capítulo 1 . A veces, ante una petición de información estos devuelven una información subóptima, que también supone una pérdida para la organización.. . Los almacenes de datos se pueden quedar obsoletos relativamente pronto.. . A menudo existe una delgada línea entre los almacenes de datos y los sistemas operacionales. Hay que determinar qué funcionalidades de estos se pueden aprovechar y cuáles se deben implementar en el almacén de datos, resultaría costoso implementar operaciones no necesarias o dejar de implementar alguna que sí vaya a necesitarse.. 1.4 Mercado de datos Los DM son pequeños DW centrados en un tema o un área de negocio específico (departamental) dentro de una organización. Se caracteriza por disponer la estructura óptima de datos para analizar la información al detalle desde todas las perspectivas que afecten a los procesos de dicho departamento. Un DM presenta las mismas características de integración, variabilidad en el tiempo, orientación temática y no volatilidad que los DW y puede ser alimentado por los datos de un DW, o integrar por sí mismo un compendio de distintas fuentes de información. 1.4.1 Tipos de mercados de datos Se definen dos tipos de DM, los dependientes y los independientes:(Naranjo & Shinin 2006) Dependientes: Son los que se construyen a partir de un almacén de datos central, es decir reciben sus datos de un repositorio empresarial central. Según la tendencia marcada por (Inmon 2005) sobre los DW, un DM dependiente es un subconjunto lógico (vista) o un subconjunto físico (extracto) de un almacén de datos más grande, que se ha aislado por alguna de las siguientes razones: . Se necesita para un esquema o modelo de datos espacial (por ejemplo, para reestructurar los datos para alguna herramienta OLAP).. . Prestaciones: Al descargar el DM a un ordenador independiente para mejorar la eficiencia o para obviar las necesidades de gestionar todo el volumen del DW centralizado.. . Seguridad: Para separar un subconjunto de datos de forma selectiva a los que queremos permitir o restringir el acceso. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 16.
(28) Capítulo 1 . Conveniencia: La de poder pasar por alto las autorizaciones y requerimientos necesarios para poder incorporar una nueva aplicación en el Almacén de Datos principal de la Empresa.. . Demostración sobre el terreno: Para demostrar la viabilidad y el potencial de una aplicación antes de migrarla al Almacén de Datos de la Empresa.. . Política: Razones internas de la organización para hacer esta división o separación de los datos del almacén de datos, por ejemplo: o Cuando se decide una estrategia para las TIC (Tecnologías de la información) en situaciones en las que un grupo de usuarios tiene más influencia, para determinar si se financia dicha estrategia o descubrir si ésta no sería buena para el Almacén de Datos centralizado. o Estrategia para los consumidores de los datos en situaciones en las que un equipo de Almacén de Datos no está en condiciones de crear un Almacén de Datos utilizable.. Independientes: Son aquellos DM que no dependen de un almacén de datos central, ya que pueden recibir datos directamente del ambiente operacional, ya sea mediante procesos internos de las fuentes de datos o almacenes de datos operacionales (ODS). 1.4.2 Ventajas e inconvenientes de los mercados de datos Los DM presentan varias ventajas que permiten a pequeñas empresas con poco fondo monetario su realización entre estas se encuentra: . Poco volumen de datos en comparación con los DW.. . Consultas SQL y/o DMX sencillas.. . Validación directa de la información.. . Facilidad para la historización de los datos.. La realización de los DM trae consigo también inconvenientes que pueden afectar la toma de decisiones de las empresas como son: . Crecen conforme el tiempo avanza.. . Se centra en un área de negocio en específico.. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 17.
(29) Capítulo 1 1.5 Modelado de datos en el DM Un Data Mart es una solución que permite dar soporte a una empresa pequeña, un departamento o área de negocio de una empresa grande por lo que el volumen de datos es más limitado con contenidos específicos y presenta un alcance histórico menor, pero cubre de manera óptima las necesidades de informes. El primer paso fundamental y decisivo para comenzar con el desarrollo de un DM es realizar el modelado de datos, en el cual se determinan cuáles son las tablas que serán denominadas Dimensiones y cuál será la tabla que almacenará todas las combinaciones posibles de dichas dimensiones, esta tabla es denominada Tabla de Hecho. 1.5.1 Tablas de dimensiones Las Tablas de dimensiones describen el contexto para analizar los hechos y están conformadas por datos textuales (alfanuméricos), datos desnormalizados donde cada fila contiene su clave primaria y los atributos descriptores de todos los niveles de jerarquía y son tablas más pequeñas que las tablas de hechos (Modéjar 2005). Las dimensiones contienen los diversos atributos que queremos analizar, además se estructuran en forma jerárquica, conforme a diferentes niveles de detalle. Las tablas de dimensiones se construyen con todos los atributos que incluyen de una forma desnormalizada y con una clave que identifica el mínimo nivel de detalle. Los tipos de dimensiones según (Zaldívar 2014) son: . Dimensiones normales: aquellas que agrupan diferentes atributos que están relacionados por el ámbito al que se refieren (todas las características de un cliente, los diferentes componentes de la dimensión tiempo, etc.).. . Dimensiones causales: son en las que los atributos pueden causar cambios en los procesos de negocio (por ejemplo, la dimensión promoción en el proceso de negocio de ventas).. . Dimensiones heterogéneas: agrupan conjuntos heterogéneos de atributos, que no están relacionados entre sí.. . Dimensiones roll-up: es un subconjunto de otra, necesarias para el caso en que tenemos tablas de hechos con diferente granularidad.. . Dimensiones Junk: agrupan indicadores de baja cardinalidad.. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 18.
(30) Capítulo 1 . Dimensiones role-playing: cuando una misma dimensión interviene en una tabla de hechos varias veces (por ejemplo, la fecha en una tabla de hechos donde se registran varias fechas referidas a conceptos diferentes), es necesario reutilizar la misma dimensión, pues no tiene sentido crear tantas dimensiones como usos se hagan de ella. Podemos crear vistas sobre la tabla de la dimensión completa que nos permiten usarla varias veces o jugar con los alias de tabla. La misma dimensión juega un rol diferente según el sitio donde se utiliza.. . Dimensiones degeneradas: no tienen ningún atributo y por tanto, no tienen una tabla específica de dimensión. Incluyen para ellas un identificador en la tabla de hechos, que identifica completamente a la dimensión (por ejemplo, un pedido de ventas). Nos interesa tener determinada la transacción (minería de datos, por ejemplo), pero los datos interesantes de este elemento los tenemos repartidos en las diferentes dimensiones (cliente, producto, etc.).. . Mini dimensiones o dimensiones Outrigger: conjunto de atributos de una dimensión que se extraen de la tabla de dimensión principal, pues se suelen analizar de forma diferente. El típico ejemplo son los datos socio demográficos asociados a un cliente (que se utilizan, por ejemplo, para la minería de datos).. 1.5.2 Tablas de hechos Las tablas de hechos describen las actividades básicas de una empresa, cada fila se compone por varias claves primarias (compuestas por claves ajenas de las dimensiones) y medidas (datos numéricos). Generalmente las relaciones son muchos-muchos (m-n) con dimensiones y unomuchos (m-1) en particular con cada dimensión (Modéjar 2005). Los hechos son los indicadores de negocio que dan sentido al análisis de las dimensiones. Las tablas de hechos incluyen los indicadores asociados a un proceso de negocio en concreto y las claves de las dimensiones que intervienen en dicho proceso, en el mínimo nivel de granularidad o detalle. Existen varios tipos de tablas de hechos (Zaldívar 2014): . De Transacciones: representan eventos que suceden en un determinado espacio-tiempo. Se caracterizan por analizar los datos con el máximo detalle. Reflejan las transacciones relacionadas con nuestros procesos de negocio (ventas, compras, inventario, etc.).. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 19.
(31) Capítulo 1 . Sin Hechos: no tienen medidas y representan la ocurrencia de un evento determinado. Por ejemplo, la asistencia a un curso puede ser una tabla de hechos sin métricas asociadas.. . Instantáneas periódicas: son tablas de hecho usadas para recoger información de forma periódica a intervalos de tiempo regulares sobre un hecho. Nos permiten tomar una foto de la situación en un momento establecido (por ejemplo, al final del día, de una semana o de un mes). Un ejemplo puede ser la foto del surtido de materiales en existencia, al final de cada día.. . Instantáneas Acumulativas: representan el ciclo de vida completo de una actividad o proceso, que tiene un principio y final. Suelen representar valores acumulados.. . Consolidadas: tablas de hechos construidas como la acumulación, en un nivel de granularidad o detalle diferente, de las tablas de hechos de transacciones.. 1.5.3 Esquemas multidimensionales Los esquemas multidimensionales más comunes para modelar DW son el esquema copos de nieve, constelación de hechos y el esquema estrella. 1.5.3.1 Esquema copos de nieve. Los esquemas de copos de nieve contienen una tabla de hechos central y numerosas tablas de dimensiones para la información descriptiva sobre el tema. Suele aplicarse cuando diversos atributos caracterizan a los niveles más altos de jerarquía. Se puede elegir el normalizar solo algunas dimensiones y otras no, aumentado así, la complejidad del diseño y metadatos (Zaldívar 2014). Según (Modéjar 2005) sus ventajas y desventajas son: Ventajas . Fácil para definir jerarquías.. . Podría salvar espacio en disco, pero no demasiado.. . Mejora considerablemente cuando un gran número de requerimientos solicitan datos agregados o de niveles superiores de jerarquías porque escanean un reducido números de filas.. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 20.
(32) Capítulo 1 Inconvenientes . Aumenta el número de tablas (aumenta el número de uniones) demorándose en exceso algunos requerimientos.. . Aumenta la complejidad de diseño y mantenimiento.. . Requiere una clave primaria más por cada nivel de jerarquía normalizado.. . No es soportado por todas las herramientas del mercado.. 1.5.3.2 Constelación de hechos. La constelación de hechos es un conjunto de tablas de hechos que comparten algunas tablas de dimensiones. Según (Modéjar 2005) sus ventajas y desventajas son: Ventajas . Rapidez de respuestas a consultas de datos agregados.. Inconvenientes . Un gran número de tablas de agregados.. . Cada tabla de agregados se usa para calcular su nivel y al navegar por jerarquías requiere escanear distintas tablas.. . Aumenta el tamaño de los metadatos.. . Dificulta su gestión y mantenimiento ya que para cada carga nueva de datos se ha de recalcular todas las tablas de hechos.. . Puede haber requerimientos que necesiten varias tablas.. El esquema multidimensional más usado para la construcción de los DM es el Esquema Estrella. El modelo de esquema en estrella puede verse como una simple estrella en la cual existe una tabla central que contiene los hechos del negocio que se desean modelar, y múltiples tablas radiantes, llamadas dimensiones, conectadas a la tabla central a través de las respectivas llaves primarias y foráneas. A diferencia de la estructura de otros esquemas de base de datos, un esquema estrella contiene dimensiones desnormalizadas (Marroquín & Tejada 2007).. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 21.
(33) Capítulo 1 1.5.3.3 Esquema estrella. Según (Modéjar 2005) las ventajas y desventajas del esquema estrella son: Ventajas . Fácil de entender por los usuarios.. . Reduce el número de uniones físicas implicando respuestas rápidas para la mayoría de las consultas.. . Metadatos sencillos.. . Soportado por la inmensa mayoría de las aplicaciones.. Inconvenientes . El aumento del tamaño de la tabla de hechos con datos agregados puede empeorar el rendimiento general, por ello se recomienda tablas de hechos agregados al margen.. . Las dimensiones tienen un tamaño enorme, alrededor de 50 atributos (Kimball & Caserta 2004a).. . Es poco robusto o susceptible a cambios.. 1.6 Funciones ETL 1.6.1 Obtención de los datos La extracción, transformación y carga, no son más que procedimientos destinados a obtener los datos de las fuentes operacionales, limpiarlos, convertirlos a los formatos de utilización y cargarlos en el repositorio final, lo cual constituye un proceso decisivo en la construcción del DW. Generalmente un equipo de desarrolladores enfrentan el trabajo de construir un Sistema ETL para el DW, que como todo sistema pasa por una fase de análisis de los requerimientos, desde su planeación constituye un desafío para los integrantes del equipo quienes deben establecer esos requerimientos que debe cumplir el sistema. Un proceso ETL es extremadamente complejo, propenso a errores y consume mucho tiempo (Sitmitsis & Vassiliadis 2005) . 1.6.2 Calidad de los datos La calidad de los datos es un término que abarca tanto el estado de los datos, así como el conjunto de procesos para lograr dicho estado. El objetivo es disponer de datos libre de errores,. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 22.
(34) Capítulo 1 duplicados, omisiones, variaciones y datos innecesarios. Según (Díaz de la Paz 2012) los datos deben ser correctos, inequívocos, coherentes y completos: . Datos correctos: Son los que los valores y las descripciones de los datos deben describir su verídica definición.. . Datos inequívocos: Son los que los valores y las descripciones de los datos sólo pueden tener un único significado.. . Datos coherentes: Son los que los valores y las descripciones de datos deben usar una notación constante para transmitir su verdadero significado. Ejemplo: para mantener la coherencia de los datos se debe utilizar solo una nomenclatura.. . Datos completos: Se debe garantizar que los valores individuales y las descripciones de los datos se definan para cada caso, permitiendo identificar que valores posibles puede tomar cada dato y se debe asegurar que el número total de registros completados después que se realice el proceso de integración debe ser del 100% completo asegurando que no se pierde información en alguna parte del flujo de datos.. 1.6.3 Integración de datos La integración de datos proporciona un mecanismo para unir datos de diferentes fuentes en un esquema único. La integración se lleva a cabo en dos etapas (Préstamo 2004): . Homogenización: es la transformación de la información del formato original de las fuentes naturales al formato y modelo de datos del DW.. . Integración: es la información recuperada, agregada y organizada al esquema del DW.. La integración de datos de expresión como lo define (Casters et al. 2010) se refiere al proceso de combinación de datos desde fuentes diferentes para proporcionar una única vista comprensible sobre todo de los datos combinados. Un proceso ETL bien diseñado extrae datos de las fuentes, hace cumplir estándares de calidad de datos, a fin de que los datos puedan ser utilizados por los desarrolladores para las aplicaciones y los usuarios finales puedan tomar decisiones estratégicas. Es decir, los datos son extraídos de los sistemas fuentes, los cuales pasan por una secuencia de transformaciones antes de que se carguen en el DW. El repositorio de los sistemas que contienen las fuentes de datos para un DW puede variar desde hojas de cálculo hasta sistemas mainframe. Las transformaciones complejas son Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 23.
(35) Capítulo 1 usualmente implementadas en programas procedimentales, ya sea fuera de bases de datos como por ejemplo (en C, Java, PASCAL) o dentro de base de datos (Mufioz & Trujillo 2011). Según (Vassiliadis 2009) define la funcionalidad de los procesos ETL como: 1. Extracción de los datos apropiados de las fuentes de datos. 2. Transporte para un área de preparación de los datos donde serán procesados. 3. Transformación de los datos fuentes y el cálculo de los valores nuevos con el propósito de obedecer la estructura de relación del DW destino. 4. Aislamiento y limpieza de registros problemáticos, para garantizar que las reglas de negocio y las restricciones de la BD sean respetadas. 5. Carga de los datos limpios y transformados para la relación apropiada en el DW. Después que se tiene toda la información necesaria de los atributos de las fuentes de datos se procede con la extracción de los datos para realizar la carga a las tablas de dimensiones y seguidamente con el llenado de la tabla de hechos teniendo en cuenta el control donde se almacenan todas las combinaciones posibles de todas las dimensiones. Esta tabla de hechos debe hacer integridad referencial a las dimensiones que la componen. 1.6.4 Proceso de extracción de datos El proceso de extracción trae consigo la acción de obtener la información deseada a partir de los datos almacenados en fuentes externas. La extracción está dividida en dos fases: la inicial y la incremental (Kimball et al. 1998; El-Sappagh, S, H et al. 2011; Yuan et al. 2011) y durante la misma, los datos son extraídos de sus fuentes y propagados para el DSA (Kimball et al. 1998; Castellanos et al. 2009). 1.6.4.1 Extracción inicial. En la extracción inicial, se obtienen por primera vez los datos de sus diferentes fuentes para ser cargados dentro del DW. Este proceso se hace solo una vez después de construir el DW para poblarlo con un gran volumen de datos (Kimball et al. 1998; El-Sappagh, S, H et al. 2011). La captura de cambios en los datos en sus fuentes no tiene importancia porque en la mayoría de los casos se extrae la fuente de datos entera (Kimball & Caserta 2004b).. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 24.
(36) Capítulo 1 1.6.4.2 Extracción incremental. La extracción incremental es más compleja que la inicial porque se debe tener en cuenta la estructura de las fuentes de datos y en concordancia con estas, aplicar una de las técnicas de existentes para la captura de cambios en los datos [Change Data Capture (CDC)] (García 2014). La aproximación más sencilla para la actualización del DW es llamada “recarga completa” cuya idea es simplemente volver a correr el proceso ETL de carga inicial (Jörg & Dessloch 2009; Jörg & Dessloch 2010) pero en la actualidad es la menos utilizada por su ineficiencia porque no es práctico eliminar y volver a cargar los datos del DW puesto que los datos históricos tienen que ser preservados. Los procesos ETL utilizan diversas técnicas de CDC para capturar los datos modificados, añadidos y eliminados en las fuentes de datos desde la última extracción, con el propósito de actualizar el DW (Casters et al. 2010; El-Sappagh, S, H et al. 2011).Estos procesos son periódicos coincidiendo con el ciclo de actualización del DW y las necesidades del negocio (ElSappagh, S, H et al. 2011). Existen varias técnicas que se pueden utilizar para capturar los cambios en los datos (Eccles 2013). Cada una de ellas sigue una de las siguientes maneras en el subsistema CDC: . Pull CDC, donde una técnica de CDC captura los cambios de los datos en las fuentes.. . Push CDC, donde una técnica de CDC detecta los cambios en los datos en su ruta para las fuentes de datos.. Las técnicas de CDC con arquitectura Pull existen en abundancia, debido a la relativa facilidad con la cual pueden ser implementadas. Las técnicas Push son rara vez implementadas, pero tienen la ventaja de estar en mejor posición para permitir la captura de los cambios en los datos en tiempo real (García 2014). En este trabajo solo se analiza la arquitectura Pull CDC. Según la clasificación dada por (Bouman & Van Dongen 2009; Casters et al. 2010) existen dos categorías principales de técnicas de CDC: intrusivas y poco intrusivas. Estos autores además de conceptualizar estas técnicas ofrecen soluciones en la herramienta PDI por lo que se estará trabajando en base de sus conceptos. Las técnicas intrusivas más utilizadas son: la técnica basada en fuentes de datos donde existen dos alternativas de esta (la lectura directa basada en marcas temporales (timestamps) y Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 25.
(37) Capítulo 1 secuencias de la base de datos). También se encuentran la técnica basada en disparadores y en instantáneas (snapshot). Todas estas técnicas tienen un posible impacto en el desempeño de la fuente donde los datos son recuperados, y por tanto, cualquier operación que requiera ejecuta declaraciones SQL. Dentro de la técnica poco intrusiva está la basada en archivos log. La técnica intrusiva CDC que se utiliza en este trabajo es la basada en instantáneas. Esta técnica es la más confiable de todas las técnicas incrementales de carga para capturar cambios en los datos porque el proceso hace una comparación fila por fila en busca de cambios y es casi imposible la pérdida de datos, además puede ser aplicada a cualquier fuente de datos como el SGBD PostgreSQL que es donde se encuentran almacenados los datos fuente de este trabajo. La herramienta Pentaho Data Integration (PDI) contiene el paso Merge rows (diff) que utiliza un algoritmo para realizar uno de los pasos fundamentales de la técnica basada en instantáneas. Este paso toma dos conjuntos de entrada ordenados por clave y realiza una comparación por fila de cada atributo, devolviendo un campo que contiene una bandera de salida la cual toma uno de los siguientes cuatro valores: identical, new, changed y deleted (Casters et al. 2010) . 1.6.5 Limpieza La limpieza de los datos “sucios” es un proceso multifacético y complejo que consiste en analizar los datos corporativos para descubrir inexactitudes, anomalías y transformar los datos para asegurar que sean precisos y coherentes. Asegurar la integridad referencial, le proporciona al DW la capacidad de identificar correctamente al instante, cada objeto del negocio, tales como un producto, un cliente o un empleado. Según (Sánchez 2000) la limpieza de datos se divide en: . Limpieza pre-integración: La limpieza pre-integración consiste en limpiar los datos de las fuentes de datos individuales antes de combinarlas en forma de almacén. En esta etapa, el mecanismo de limpieza en cada fuente de datos suele estar consciente con el metadato de otra fuente de datos y del metadato del resultado del almacén. Un ejemplo de limpieza preintegración puede ser que un campo en particular que es resultado de combinar diferentes fuentes sea acotado dentro del mismo dominio.. . Limpieza post-integración: después de la limpieza pre-integración el dato es integrado para formar un sencillo DW. Los datos combinados pueden no tener integridad a pesar del hecho que las fuentes de datos individuales son íntegros. Esto puede ser debido a varias razones. Mercado de Datos para el Proceso de Formación de Másteres y Especialistas de Postgrado en la UCLV. 26.
Figure


+7






Documento similar