Integración de técnicas de deep learning y algoritmos de aprendizaje multi etiqueta para la Clasificación de Textos
96
0
0
Texto completo
(2)
(3) A GRADECIMIENTOS. Para empezar, quiero agradecer a mi orientador Profesor Mg. Alexander Victor Ocsa Mamani, por estar siempre presente e incentivarme a entrar en el mundo de la investigación. Quien me guío en el desarrollo de este trabajo con sus valiosos aportes y consejos, en el área de aprendizaje de máquina. Por los desafíos que me proporcionó, y principalmente por su confianza. A los compañeros del Círculo de Investigación de la UNSA y compañeros del proyecto de Vigilancia Tecnológica de la UNSA por el apoyo y compañerismo en todo momento. A mi familia quienes por ellos soy lo que soy. A mis padres que, gracias a su apoyo, consejos, comprensión y ayuda en los momentos más difíciles de mi vida, han inculcado en mi valores, principios y enseñanzas para ser perseverante y empeñoso hasta conseguir mis metas. A CONCYTEC y CIENCIACTIVA por el apoyo y financiamiento de esta investigación. A todos los profesores de la maestría que nos proporcionaron los conocimientos necesarios para realizar investigación. Al “Centro de Investigación, Transferencia de Tecnologías y Desarrollo de Software I + D + i” - CiTeSoft-UNSA por su colaboración en el uso de sus equipos e instalaciones, para el desarrollo de este trabajo de investigación. Y finalmente a todas las personas que directa o indirectamente contribuyeron finalizar este trabajo de investigación.. II.
(4) R ESUMEN. n el campo del aprendizaje automático se realizan muchas aplicaciones, como la clasificación y agrupación de datos. La clasificación de datos puede ser de dos tipos: binaria cuando se tienen una clase y multi-clase cuando se tienen más de una clase. Ambos restringen a que una instancia a clasificar pertenezca a una sola clase. Pero en la clasificación de textos es lógico pensar que un texto puede pertenecer a una o más clases. A este tipo de clasificación se le denomina clasificación multi-etiqueta y se encuentra dentro del aprendizaje multi-etiqueta. Sobre este tipo de clasificación los clasificadores binarios o multi-clase tienen dificultades para resolver esto, debido a que restrigen la clasificación a una sola etiqueta. Para afrontar este tipo de clasificación se han propuesto algunas maneras de resolver esto. Algunos autores proponen transformar la clasificación multi-etiqueta en clasificación binaria como el método Binary Relevance (BR). Con este método se pierde la correlación de las etiquetas y a su vez aumenta el tamaño del conjunto de datos de entrenamiento. Otras propuestas que se han realizado son adaptar algoritmos de clasificación binaria o multi-clase como las Máquinas de Soporte Vectorial o Redes Neuronales. Por otro lado, investigaciones recientes utilizan técnicas de deep learning (Aprendizaje Profundo) como son: la Redes Neuronales Convolucionales y Redes Neuronales Recurrentes para la clasificación de textos y oraciones. Por ahora estos solo trabajan con clasificación binaria y multi-clase. Analizando el modelo propuesto por Zhang, el cual es un modelo de clasificación que utiliza una representación de textos a nivel de caracteres y redes neuronales convolucionales como clasificador, se encontró que este modelo tiende a perder información, con lo cual, la precisión del clasificador disminuye. Por otro lado, dentro de los métodos de representación de textos se encuentran varios, uno que llama la atención es la Indexación Semántica Latente. Este método tiene resultados superiores a otros métodos de representación, ya que elimina la polisemia y sinonimia de palabras en los textos. En este trabajo se propone: primero representar los textos mediante Indexación Semántica Latente. Segundo, sobre esta representación utilizar Redes Neuronales Convolucionales para la extracción de características, y finalmente aplicarlos sobre bases de datos con textos multi-clase y multi-etiqueta. Los resultados de los experimentos realizados, muestran que el modelo que se propone tiene una alta precisión cuando los textos a clasificar son grandes, mientras que con textos menor cantidad de caracteres el rendimiento del modelo disminuye.. E. Palabras Clave: Redes Neuronales Convolucionales, Clasificación Multi-Etiqueta, Clasificación de Textos, Indexación Semántica Latente.. III.
(5) A BSTRACT. n the field of machine learning, many applications are carried out, such as the classification and clustering of data. The data classification can be of two types: binary when you have a class and multi-class when you have more than one class. Both restrict that an instance to be classified belongs to a single class. But in the classification of texts it is logical to think that a text can belong to one or more classes; this type of classification is called multi-label classification and is part of multi-label learning. On this type of classification binary or multi-class classifiers have difficulties to solve it, because they restrict the classification to a single label. In order to face this type of classification, there have been proposed some ways of solving it. Some authors propose to transform the multi-label classification into binary classification as the Binary Relevance (BR) method. With this method the correlation of the labels is lost and in turn the size of the training data set increases. Other proposals that have been made are to adapt binary or multiclass classification algorithms such as Support Vector Machines or Neural Networks. On the other hand, recent research uses deep learning techniques (Deep Learning) such as: Convolutional Neural Networks and Recurrent Neural Networks for the classification of texts and sentences. By now these only work with binary and multi-class classification. Analyzing the model proposed by Zhang, which is a classification model that use a representation of text at the level of characters and convolutional neural networks as a classifier, it was found that this model tends to lose information, with which, the accuracy of the classifier decreases. On the other hand, there are several texts representation method’s, one of them is Latent Semantic Indexing. This method has superior results in contrast to other methods of representation, since it eliminates the polysemy and synonymy of words in the texts. In this work we propose: first, represent the texts by Latent Semantic Indexing; second, on this representation use Convolutional Neural Networks for the extraction of characteristics, and finally apply them on databases with multi-class and multi-label texts. The results of the experiments show that the proposed model has a high precision when the texts to be classified are large, while in texts with less number of characters the performance of the model decreases.. I. Keywords: Convolution Neural Network, Multi Label Classification, Text Classification, Latent Semantic Indexing.. IV.
(6)
(7) Í NDICE G ENERAL. Página Índice de tablas. IX. Índice de figuras. XI. 1. 2. Introducción. 1. 1.1. Motivación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 1. 1.2. Definición del Problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 4. 1.3. Relevancia del problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 5. 1.4. Objetivos de la investigación . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 6. 1.4.1. Objetivo general . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 6. 1.4.2. Objetivos específicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 6. 1.5. Principales Contribuciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 7. 1.6. Organización del trabajo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 7. Conceptos Previos. 8. 2.1. Aprendizaje Automático . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 8. 2.1.1. Definición . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 8. 2.1.2. Aprendizaje Supervisado . . . . . . . . . . . . . . . . . . . . . . . . . .. 9. 2.1.3. Aprendizaje no Supervisado . . . . . . . . . . . . . . . . . . . . . . . . 13. 2.1.4. Aprendizaje Semi - Supervisado . . . . . . . . . . . . . . . . . . . . . . 13. 2.2. Redes Convolucionales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 2.2.1. La operación de convolución . . . . . . . . . . . . . . . . . . . . . . . . 15. VI.
(8) 2.3. 2.4. 2.5. 2.2.2. Max Pooling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17. 2.2.3. Entrenamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19. Clasificación Multi - Etiqueta . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 2.3.1. Notación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22. 2.3.2. Técnicas utilizadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22. 2.3.3. Métricas para la evaluación . . . . . . . . . . . . . . . . . . . . . . . . . 29. Reducción de la Dimensionalidad . . . . . . . . . . . . . . . . . . . . . . . . . . 34 2.4.1. Análisis de Componentes Principales . . . . . . . . . . . . . . . . . . . 34. 2.4.2. Descomposición de Valores Singulares . . . . . . . . . . . . . . . . . . 36. Indexación Semántica Latente . . . . . . . . . . . . . . . . . . . . . . . . . . . 37 2.5.1. 3. 4. Trabajos Relacionados. 42. 3.1. Aprendizaje Multi-Etiqueta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42. 3.2. Clasificación de Textos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47. 3.3. Reducción de la Dimensionalidad . . . . . . . . . . . . . . . . . . . . . . . . . . 50. Modelo Propuesto 4.1. 4.2. 4.3. 5. Descomposición en valores singulares . . . . . . . . . . . . . . . . . . . 38. 54. Consideraciones Iniciales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54 4.1.1. Modelo bolsa de palabras . . . . . . . . . . . . . . . . . . . . . . . . . . 54. 4.1.2. Modelo basado en caracteres . . . . . . . . . . . . . . . . . . . . . . . . 55. Modelo Propuesto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57 4.2.1. Arquitectura de la Red Neuronal Convolucional . . . . . . . . . . . . 58. 4.2.2. Clasificador Multi-Etiqueta . . . . . . . . . . . . . . . . . . . . . . . . . 60. Evaluación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61 4.3.1. Bases de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61. 4.3.2. Criterios de Evaluación . . . . . . . . . . . . . . . . . . . . . . . . . . . 64. Experimentos 5.1. 68. Aspectos preliminares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68 VII.
(9) 5.2. Bases de Datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69 5.2.1. 6. Discusión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71. Conclusiones. 73. 6.1. Consideraciones Finales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73. 6.2. Principales Contribuciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74. 6.3. Trabajos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74. VIII.
(10) Í NDICE DE TABLAS. TABLAS. Página. 2.1. Clasificación con Simple - Etiqueta Y ∈ {0, 1} . . . . . . . . . . . . . . . . . . . . . 21. 2.2. Clasificación Multi - Etiqueta Y ⊆ {λ1 , ..., λL } . . . . . . . . . . . . . . . . . . . . . 22. 2.3. Ejemplo de conjunto multi etiqueta: libros asociados con etiquetas en función de su temática (Avila Jiménez, 2013) . . . . . . . . . . . . . . . . . . . . . . . . . . 23. 2.4. Método BR aplicado a los datos de la tabla 2.3 (Avila Jiménez, 2013) . . . . . . 24. 2.5. Método de copia ponderada aplicado a los datos de la tabla 2.3 (Avila Jiménez, 2013) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25. 2.6. Método de transformación máxima y mínima, aplicados a los datos de la tabla 2.3 (Avila Jiménez, 2013) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26. 2.7. Matriz de confusión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29. 2.8. Matriz de términos y documentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39. 2.9. Matriz SVD de términos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39. 2.10 Matriz de valores singulares. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40 2.11 Matriz de documentos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40 2.12 Matriz de valores singulares para reducir en dos dimensiones. . . . . . . . . . . 40 2.13 Matriz resultante en dos dimensiones para los documentos. . . . . . . . . . . . . 40 2.14 Aproximación en dos dimensiones de la matriz de términos y documentos. . . . 41 4.1. Codificación One - Hot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55. 4.2. Configuración de las capas de convolución y pooling. . . . . . . . . . . . . . . . . 59. 4.3. Configuración del perceptron multi-capa. . . . . . . . . . . . . . . . . . . . . . . . 59. IX.
(11) Índice de tablas. 4.4. Base de datos AG’s News . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62. 4.5. Base de datos DbPedia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63. 4.6. Base de datos Yahoo Answers. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64. 4.7. Base de datos Sogou News. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64. 5.1. Resultados sobre los datos de prueba en Reuters RCV1. . . . . . . . . . . . . . . 69. 5.2. Accuracy en la base de datos AG’s News. . . . . . . . . . . . . . . . . . . . . . . . . 69. 5.3. Accuracy En la base de datos DbPedia. . . . . . . . . . . . . . . . . . . . . . . . . . 70. 5.4. Accuracy en la base de datos Yahoo. . . . . . . . . . . . . . . . . . . . . . . . . . . 70. 5.5. Accuracy en la base de datos Sogou News. . . . . . . . . . . . . . . . . . . . . . . . 71. X.
(12) Í NDICE DE FIGURAS. F IGURAS. Página. 2.1. Perceptrón (Aggarwal, 2015). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11. 2.2. Perceptrón Multicapa (Aggarwal, 2015) . . . . . . . . . . . . . . . . . . . . . . . . 12. 2.3. Aprendizaje Semi - supervisado (Han, 2011) . . . . . . . . . . . . . . . . . . . . . 14. 2.4. Representación de los filtros y el mapa de características como neuronas en una capa de convolución (Buduma, 2016). . . . . . . . . . . . . . . . . . . . . . . . 15. 2.5. Operación de convolución (Bengio et al., 2015). . . . . . . . . . . . . . . . . . . . . 16. 2.6. Max Pooling vista como neuronas (Bengio et al., 2015). . . . . . . . . . . . . . . . 18. 2.7. Max Pooling vista matricial (Buduma, 2016). . . . . . . . . . . . . . . . . . . . . . 18. 2.8. Ejemplo de una red convolucional (Strigl et al., 2010). . . . . . . . . . . . . . . . 19. 2.9. Utilizando el método BR se entrenará la misma base de datos por cada etiqueta como un clasificador binario. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24. 2.10 Descomposición de la matriz de documentos. . . . . . . . . . . . . . . . . . . . . . 37 2.11 Vista gráfica de la matriz de términos y documentos en dos dimensiones (Schütze et al., 2008). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41 3.1. Ejemplo del método Relevancia Binaria (Tsoumakas and Zhang, 2009). . . . . . 43. 3.2. Arquitectura de la red neuronal BP-MLL propuesto por (Zhang and Zhou, 2006). 44. 3.3. Arquitectura de la red neuronal propuesta por (Zhu et al., 2017). . . . . . . . . . 46. 3.4. Modelo BOC (del inglés Bag Of Concept) propuesto por Alahmadi (Alahmadi et al., 2013). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47. XI.
(13) Índice de figuras. 3.5. (a) Arquitectura de la red neuronal utilizada por Nam (Nam et al., 2014), (b) Muestra como el threshold para un ejemplo de entrenamiento es estimado basado en la predicción de la salida o de la red neuronal. . . . . . . . . . . . . . 48. 3.6. Modelo de Red Convolucional propuesto por Zhang y LeCun (Zhang and LeCun, 2015). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49. 3.7. Modelo de Red Recurrente propuesto por Lain et al., (Zhang and LeCun, 2015). 50. 3.8. Modelo Basado en LSI propuesto por Martinez (Martínez-Torres, 2015). . . . . 52. 3.9. Modelo Basado en LSI y Redes Convolucionales propuesto por Shen et al. (Shen et al., 2014). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53. 4.1. Comparación de la codificación propuesta por Zhang y el sistema Braille (Zhang and LeCun, 2015). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55. 4.2. Vista gráfica de la representación de la palabra beca utilizando la codificación one - hot. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56. 4.3. Flujo general de la propuesta, utilizando indexación semántica latente y redes convolucionales para la clasificación de textos multi-etiqueta. . . . . . . . . . . . 58. 5.1. Promedio del total de caracteres en cada base de datos de acuerdo a los textos.. 5.2. Porcentaje de documentos en cada base de datos, de acuerdo al umbral 1014. . 72. XII. 72.
(14) CAPÍTULO. 1. I NTRODUCCIÓN. 1.1. Motivación. Con el pasar de los años los datos han ido creciendo rápidamente, de acuerdo al informe presentado por el EMC (DellEMC) en colaboración con el IDC (International Data Corporation) entre 2013 y 2020, pasará de 4.4 millones de millones de gigabytes hasta 44 millones de millones de gigabytes (Computerworld, 2014). El informe indica que, con la aparición de las tecnologías inalámbricas, los productos inteligentes y los sistemas de información están incrementando el volumen mundial de datos. La capacidad de almacenamiento de las memorias se ha hecho grande y a la vez el precio es bastante reducido. Esto hizo que sea fácil conservar datos e información, ya sean estos relevantes o no, pero no solo es necesario almacenar y recuperar datos. También es necesario métodos que permitan obtener información y conocimiento útil a partir de estos datos. Por otro lado, las técnicas de minería de datos realizan procesos para el descubrimiento. 1.
(15) CAPÍTULO 1. INTRODUCCIÓN. de conocimiento. En estos conjuntos de datos, se realizan búsqueda y descubrimiento de patrones. A pesar de que la minería de datos abarca un amplio rango de aplicaciones, muchas de estas técnicas también son utilizados en el Aprendizaje Automático (Machine Learning, ML). Los cuales trata de extraer información o conocimiento de un conjunto de ejemplos, viendo similitudes entre los datos, y a su vez generalizando estas similitudes con los otros ejemplos. El Aprendizaje Automático puede dividirse en dos tipos: supervisado y no supervisado. El primero es aquella en la que se tiene un conjunto de datos que sirve como datos de entrenamiento para un algoritmo, y otro conjunto de datos para realizar las pruebas sobre el algoritmo ya entrenado. Y por otro lado el aprendizaje no supervisado, trabaja sobre datos en los cuales se trata de ver relaciones entre los datos para después agruparlos mediante una medida de distancia o similitud (Aggarwal, 2015). A pesar de que el aprendizaje supervisado tradicional tiene resultados satisfactorios, hay muchas tareas de aprendizaje, como objetos del mundo real que pueden ser complicados y podrían tener múltiples significados semánticos de forma simultánea. Por ejemplo: en la categorización de textos, un artículo científico de ciencias de la computación podría categorizarse como machine learning y base de datos simultáneamente; en la recuperación de información musical, una pieza de sinfonía podría transmitir varios sonidos musicales como las de un piano, música clásica, jazz; en la clasificación de videos, un clip de video podría estar relacionado con algunos escenarios, como la urbana, parques, cerros, edificaciones, población (Zhang and Zhou, 2014). A diferencia del aprendizaje supervisado tradicional, el aprendizaje multi-etiqueta, asocia una instancia a un conjunto de etiquetas en lugar de una sola etiqueta. El problema es entrenar un algoritmo que pueda predecir el conjunto de etiquetas adecuadas para las. 2.
(16) CAPÍTULO 1. INTRODUCCIÓN. instancias que no la tienen (Zhang and Zhou, 2014). El aprendizaje multi-etiqueta se aplica en distintos campos como: la clasificación semántica de imágenes y textos, problemas de bioinformática relacionados con la selección de funciones de genes y proteínas, diagnósticos médicos, categorización de sonidos. Los métodos de clasificación existentes para múltiples etiquetas no son escalables y/o tienen un rendimiento insatisfactorio, debido a la alta dimensionalidad del espacio de salida, debido a que una instancia puede crecer dependiendo al número de etiquetas a la que pertenece. Además, el proceso de entrenamiento que se realiza para cada instancia depende directamente del número de etiquetas a la que pertenece dicha instancia. Se han propuesto dos tipos de soluciones: en primer lugar, algunos autores proponen transformar la clasificación multi-etiqueta a un problema de clasificación binaria. Por ejemplo, el método Binary Relevance (Luaces et al., 2012), el cual construye un clasificador binario para cada etiqueta. Mientras que el trabajo de Boutell (Boutell et al., 2004) se propone utilizar ranking mediante una sola etiqueta, también utiliza un clasificador binario para cada clase y obtiene la probabilidad de pertenencia para cada etiqueta. El problema de estos es que no toma en cuenta la correlación entre etiquetas, además que se incrementa el conjunto de datos. En segundo lugar, se han adaptado algoritmos de clasificación tradicionales, como es el caso de Maquinas de Soporte Vectorial y Redes Neuronales, en el caso de las Redes Neuronales se proponen utilizar una función de error que tome en cuenta la correlación entre las etiquetas (Zhang and Zhou, 2006) este algoritmo es denominado Backward Propagation Multi Label Layer (BP - MLL). Por otra parte, se han propuesto utilizar técnicas de Deep Learning como son las. 3.
(17) CAPÍTULO 1. INTRODUCCIÓN. Redes Convolucionales y Redes Recurrentes (Zhang et al., 2015; Lai et al., 2015) para la clasificación de textos y oraciones. Pero estos solo trabajan con clasificación binaria y no con clasificación multi-etiqueta. Las técnicas de Deep Learning necesitan que los textos se representen de alguna forma numérica. Para ello se pueden utilizar métodos como Bolsa de Palabras, o TF-IDF (del inglés Term frequency – Inverse document frequency) el cual representa la frecuencia de ocurrencia de las palabras en los documentos. Si las bases de datos de textos contienen documentos con grandes cantidades de palabras; los métodos de representación de textos tenderán a una alta dimensionalidad. En las cuales se debe utilizar métodos de reducción de dimensión entre las cuales se tienen SVD (del inglés Sigular Value Decomposition), PCA (del inglés Principal Component Analysis) y otras (Maimon and Rokach, 2005). Dos problemas grandes al que se enfrentan las técnicas de representación de textos, son la sinonimia y polisemia. Ante ello surge la Indexación Semántica Latente, una técnica en el cual no se presenta la sinonimia ni la polisemia. Debido a que esta técnica es estrictamente matemática, no se considera el idioma en el que estan escritos los textos. Por lo tanto, tomando en cuenta lo comentado anteriormente, el problema de clasificación multi-etiqueta es de gran interés y elevada actualidad, por lo que se propone un modelo de clasificación integrando Indexación Semántica Latente y Redes Neuronales Convolucionales para la Clasificación de Textos.. 1.2. Definición del Problema. El Aprendizaje Multi Etiqueta (MLL del inglés Multi Label Learning) es un paradigma de aprendizaje supervisado. El cual ha atraído una gran atención en los últimos años debido 4.
(18) CAPÍTULO 1. INTRODUCCIÓN. a su capacidad de mejorar el rendimiento de muchas aplicaciones actuales. Tales como la clasificación en datos multimedia, la predicción de las funciones de genes y proteínas, el marketing, o la minería de redes sociales. Todas estas aplicaciones tienen en común que, cada instancia requiere múltiples salidas o etiquetas. Además de tratar con múltiples etiquetas, MLL tiene que hacer frente a los retos de tendencias tales como la relación entre las etiquetas, los costos computacionales, la presencia de etiquetas desequilibradas, o la alta dimensionalidad de los datos de salida. Se debe considerar que el costo de entrenamiento de un clasificador multi-etiqueta está fuertemente afectada por el número de etiquetas que está asociada a cada instancia, que hacen que los algoritmos existentes no sean escalables y/o tengan un rendimiento insatisfactorio. También se ha visto que la aplicación de técnicas de Deep Learning sobre la clasificación de textos, pero estos solamente trabajan con datos de clasificación binaria, y no con datos multi-etiqueta, razón por la cual se plantea la siguiente pregunta para el problema de investigación: ¿Cómo integrar las Redes Convolucionales y los Algoritmos de Aprendizaje Multi Etiqueta para la clasificación de textos?. 1.3. Relevancia del problema. La utilidad de la investigación, radicó en la necesidad de modelar el problema de clasificación de textos en un contexto de aprendizaje multi-etiqueta. Debido a la ambigüedad que existe en la clasificación de textos, ya que un documento puede pertenecer a dos o más clases, por ejemplo, un texto en Ciencias de la Computación puede ser clasificado como “Aprendizaje Automático” y “Base de Datos” al mismo tiempo. 5.
(19) CAPÍTULO 1. INTRODUCCIÓN. Por otra parte, debido a que la cantidad de datos de texto en la web y en las bibliotecas digitales está aumentado rápidamente (Nam et al., 2014), esta gran cantidad de datos hace que los modelos de clasificación no sean escalables. Además, en el aprendizaje multietiqueta, la escalabilidad viene dada por la gran cantidad de etiquetas que pueden tener estos en el espacio de salida (Gibaja and Ventura, 2014). Por lo tanto, nuestra propuesta se centra en un modelo que permitirá, resolver el problema de clasificación de textos utilizando Redes Convolucionales e Indexación Semántica Latente, investigaciones recientes muestran cómo aplicar redes convolucionales en la clasificación de textos (Zhang et al., 2015; Lai et al., 2015).. 1.4. Objetivos de la investigación. 1.4.1. Objetivo general. Integrar técnicas de deep learning y algoritmos de aprendizaje multi-etiqueta para la clasificación de textos.. 1.4.2. Objetivos específicos. • Explorar y recopilar los métodos de clasificación de textos multi-etiqueta. • Establecer e implementar el modelo de clasificación multi-etiqueta para la clasificación de textos utilizando redes convolucionales. • Evaluar y comparar la propuesta con los modelos de clasificación recopilados, realizando experimentos sobre conjuntos de datos usados en la literatura.. 6.
(20) CAPÍTULO 1. INTRODUCCIÓN. 1.5. Principales Contribuciones. Las principales contribuciones del presente trabajo son las siguientes: Estudiar e implementar técnicas de aprendizaje profundo con base de datos de textos, además explorar e implementar técnicas de clasificación de textos con múltiples etiquetas, los cuales se describen en el Capítulo 3. Se realizó la integración de las Redes Neuronales Convolucionales, la Indexación Semántica Latente y las técnicas de clasificación de múltiple etiqueta, esta integración es descrita en el Capítulo 4.. 1.6. Organización del trabajo. El presente trabajo está organizado de la siguiente manera:. • En el Capítulo 2 se describen la terminología básica y los conceptos preliminares necesarios para la compresión de este trabajo. • En el Capítulo 3 se describen los principales trabajos relacionados al problema de investigación. • En el Capítulo 4 se describe la propuesta de trabajo, las técnicas y métodos utilizados. • En el Capítulo 5, se describen los experimentos y resultados obtenidos. • Y finalmente en el Capítulo 6, se enumeran las conclusiones a las cuales se llegaron.. 7.
(21) CAPÍTULO. 2. C ONCEPTOS P REVIOS. 2.1 2.1.1. Aprendizaje Automático Definición. El Aprendizaje Automático según Han (Han, 2011) se define como la manera en que las computadoras pueden aprender (o mejorar su rendimiento) en base a los datos que tienen. Una definición más formal que muchos autores toman en cuenta, es la definición de Mitchell (Mitchell et al., 1997) “Un programa de computadora se dice que aprende de la experiencia E con respecto a alguna clase de tareas T y una medida de rendimiento P si su desempeño en las tareas en T, medido por P, mejora con experiencia E”. El aprendizaje automático se puede clasificar en 3: Aprendizaje Supervisado, Aprendizaje no supervisado, y Aprendizaje Semi - supervisado (Han, 2011).. 8.
(22) CAPÍTULO 2. CONCEPTOS PREVIOS. 2.1.2. Aprendizaje Supervisado. El aprendizaje supervisado es una técnica de aprendizaje que utiliza datos de entrenamiento y sobre la observación de estos crea una función capaz de predecir el valor de un nuevo dato que la función no haya visto. La supervisión en este tipo de aprendizaje se da mediante instancias etiquetadas en un conjunto de datos de entrenamiento. Por ejemplo, se tiene una base de datos de correos electrónicos, cada correo tiene un atributo que indica si este es o no un spam. Estos datos sirven como datos de entrenamiento para un algoritmo de clasificación, el cual quiere determinar si un nuevo correo es o no spam. Clasificación La clasificación trabaja sobre conjuntos de datos ya particionados en grupos, categorías o clases. Este conjunto de datos sirve para entrenar un algoritmo de clasificación. A continuación, se presentan algunos de estos algoritmos.. 1. Regresión Logística: En esta técnica se busca una ecuación la cual pueda predecir las clases a la que pertenece una instancia, en el caso de clasificación binaria la función debería de dar 0 o 1 (Harrington, 2012). La regresión logística utiliza la función sigmoide, esta función está dada por la siguiente ecuación 2.1: (2.1). σ( z ) =. 1 1 + ²− z. La regresión logística multiplica todos los atributos con un peso cada una, y luego las suma. A este resultado se le aplica la función sigmoide, del cual se obtiene un valor entre 0 y 1. Si el valor está por encima de 0.5 se clasifica como 1, y si está por debajo de 0.5 se clasifica como 0.. 9.
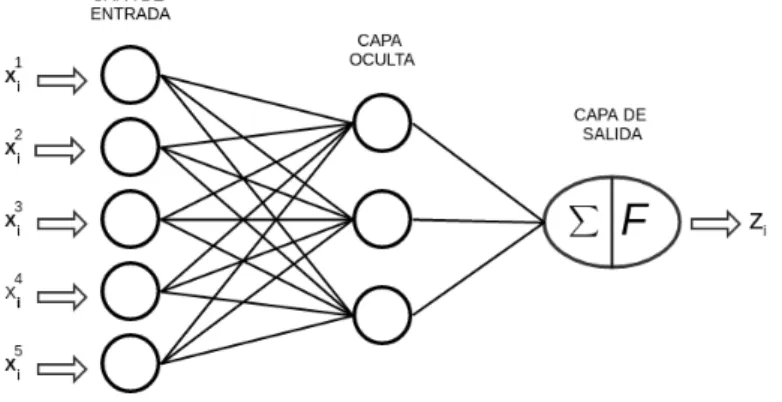
(23) CAPÍTULO 2. CONCEPTOS PREVIOS. El reto está en encontrar los mejores pesos para cada atributo, una manera de optimizar el proceso para encontrar estos pesos, es utilizar Gradiente Descendente. La gradiente de una función f ( x, y) está dada por la siguiente ecuación 2.2: (2.2). h. Ã ∂ f (x,y)) !. f ( x, y) =. ∂x ∂ f (x,y) ∂y. La ventaja que tiene es que es computacionalmente bajo, fácil de implementar y la representación del conocimiento fácil de interpretar. Pero esta propenso a underfitting (bajo aprendizaje), y puede tener poca precisión. Funciona con valores numéricos, así como nominales (Harrington, 2012). 2. Máquinas de Soporte Vectorial: Las Máquinas de Soporte Vectorial o SVM (por sus siglas en inglés Support Vector Machines) son naturalmente definidas para clasificación binaria. La clasificación binaria puede ser generalizada para el caso de múltiples clases. Las SVM usan un hiperplano como frontera de decisión entre dos clases (Aggarwal, 2015). Considere un hiperplano que separa dos clases linealmente separables. El margen del hiperplano se define como la suma de las distancias a los puntos de entrenamiento más cercanos en cada una de las dos clases. Suponga que se construyen dos hiperplanos paralelos que tocan los datos de entrenamiento de las clases opuestas a cada lado, y no tienen ningún dato entre ellos. Los datos que están en cada hiperplano se conocen como los vectores de soporte, y la distancia entre los dos hiperplanos es el margen. La frontera de decisión estaría en la mitad de estos dos hiperplanos. 3. Redes Neuronales: Las redes neuronales son modelos que simulan el sistema nervioso humano. La clave para la eficacia de una red neuronal es la arquitectura utilizada para organizar las conexiones entre nodos. Existe una amplia variedad de 10.
(24) CAPÍTULO 2. CONCEPTOS PREVIOS. arquitecturas, a partir de una red con una sola capa, y otras redes más complejas con múltiples capas (Aggarwal, 2015). La arquitectura más básica de una red neuronal es conocida como perceptrón, en la figura 2.1 se puede visualizar la arquitectura de un perceptrón. El perceptrón contiene dos capas de nodos, los cuales corresponden a los nodos de entrada y al nodo de salida. El número de nodos de entrada es exactamente igual a la dimensionalidad. d de una instancia. Cada nodo de entrada recibe y entrega un atributo numérico al nodo de salida. Los nodos de entrada solo transmiten valores de entrada para el nodo de salida, el nodo de salida es el único que realiza una función matemática en sus entradas. Al igual que en las SVM cada entrada está conectada por un peso hacia el nodo de salida. Se realiza la multiplicación de cada nodo con su peso y luego se suman, al resultado de esto se le aplica una función de activación y es el valor del nodo de salida.. Figura 2.1: Perceptrón (Aggarwal, 2015). En el caso de una red neuronal de múltiples capas (Figura 2.2), se tiene una capa de entrada, una capa de salida, y una o más capas intermedias llamadas capas ocultas. Lo mismo que antes, las salidas multiplicadas por sus pesos, es la entrada de la siguiente capa, sin olvidar que en cada nodo se aplica una función de activación. 11.
(25) CAPÍTULO 2. CONCEPTOS PREVIOS. Los nodos de salida son quienes dicen si la instancia pertenece a una clase o no, de acuerdo a la función de activación estos tomarán valores de 0 a 1, o de −1 a +1.. Figura 2.2: Perceptrón Multicapa (Aggarwal, 2015). Para entrenar a una neurona se realizan dos fases (Aggarwal, 2015): • Fase Forward: en esta fase se introducen los valores de una instancia en la capa de entrada de la red, los pesos se toman aleatorios. Esta fase se realiza hacia adelante, comenzando en la capa de entrada y terminando en la capa de salida. Los valores de la capa de salida son comparados con la etiqueta de la instancia para ver si se tiene un error. • Fase Backward: el objetivo de esta fase es corregir los errores en cada nodo. Recorre la red desde la capa de salida hacia la capa de entrada, en cada nodo se calcula el error y se actualizan los pesos de entrada que recibieron. El proceso de Forward y Backward se repite para cada instancia, al finalizar se vuelve a repetir todo el proceso para toda la base de datos de entrenamiento, hasta un número n de épocas necesario.. 12.
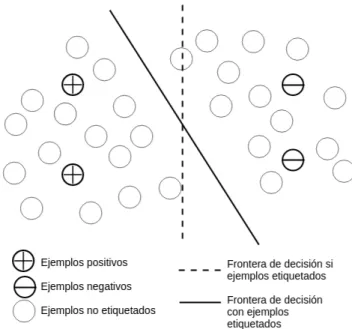
(26) CAPÍTULO 2. CONCEPTOS PREVIOS. 2.1.3. Aprendizaje no Supervisado. En el aprendizaje no supervisado no se tienen instancias etiquetadas, es decir que se tiene un conjunto de datos en la cual no existe ninguna clase. Lo que se trata de hacer es un agrupamiento de estos datos para encontrar o descubrir dichas clases.. 2.1.3.1. Agrupamiento. Muchas aplicaciones requieren el particionamiento de datos en grupos similares, una definición informal e intuitiva según Aggarwal (Aggarwal, 2015), el agrupamiento es “Dado un conjunto de datos, particionar estos en grupos que contengan datos muy similares”. Lo algoritmos de agrupamiento se basan en la distancia (o similitud) entre los datos para formar grupos, los grupos se crean y no existen relaciones jerárquicas entre los diferentes grupos. Una vez que se ha determinado los grupos, se puede utilizar una función de distancia para asignar datos a los grupos más cercanos a dichos datos. El algoritmo k - Means es el algoritmo más representativo en el agrupamiento, a partir de ella se realizaron distintas modificaciones. El algoritmo de k - Means, utiliza la distancia euclidiana para determinar la distancia entre dos datos. La distancia euclidiana puede definirse como (Ecuación 2.3): (2.3). D ist( X , Y ) = (. d X. | x i − yi |2 )1/2. i =1. 2.1.4. Aprendizaje Semi - Supervisado. Este es un aprendizaje que hace uso de instancias tanto etiquetadas como no etiquetadas, utiliza las instancias etiquetadas para el entrenamiento y las no etiquetadas para refinar el modelo. Por ejemplo, para un problema de dos clases (Figura 2.3), si no se considera los ejemplos no etiquetados la línea discontinua es la mejor frontera de decisión para. 13.
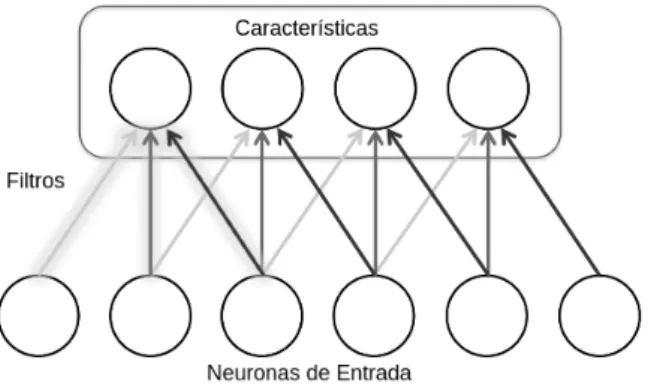
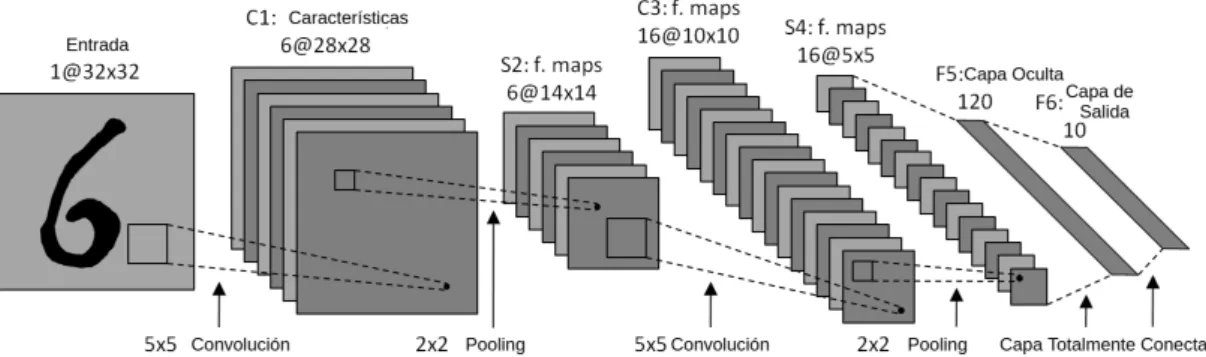
(27) CAPÍTULO 2. CONCEPTOS PREVIOS. clasificar los datos, pero al utilizar los ejemplos no etiquetados, se puede refinar la frontera de decisión a la línea continua (Han, 2011).. Figura 2.3: Aprendizaje Semi - supervisado (Han, 2011). 2.2. Redes Convolucionales. Las redes convolucionales son redes neuronales que usan convoluciones en lugar de multiplicación de matrices en al menos una de sus capas (Bengio et al., 2015). El nombre de “Redes Neuronales Convolucionales” indica que la red emplea una operación matemática llamada convolución, una red neuronal convolucional consiste en varias capas, estas capas pueden ser de tres tipos (LeCun et al., 1989):. • Convolución: una capa de convolución consiste en una grilla rectangular de neuronas. Se requiere que la capa anterior también sea una grilla rectangular de neuronas. Cada neurona toma como entrada una sección rectangular de la capa previa. Los pesos para cada sección rectangular son los mismos para cada neurona en la capa de. 14.
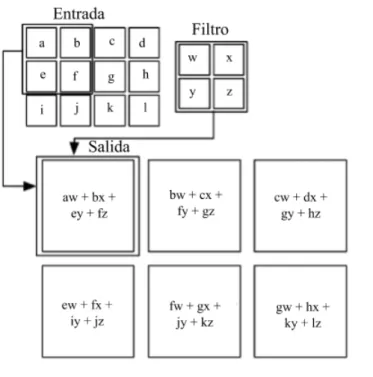
(28) CAPÍTULO 2. CONCEPTOS PREVIOS. convolución, así que, la capa de convolución es solo una imagen de convolución de la capa previa; donde los pesos especifican el filtro de convolución. • Pooling: después de cada capa de convolución puede haber una capa de pooling. Una capa de pooling toma pequeños bloques rectangulares de la capa convolucional y la resume produciendo una salida simple de ese bloque, Hay muchas maneras de hacer el pooling, se puede tomar el promedio o el máximo, o un aprendizaje de combinación lineal de neuronas. • Fully - Connected: después de muchas capas convolucionales y pooling, la clasificación sobre la red se hace mediante capas totalmente conectadas al igual de las redes neuronales multi-capa.. 2.2.1. La operación de convolución. En la capa de convolución se utilizan filtros, estos filtros son esencialmente detectores de características. Se toma cada filtro y se multiplica sobre el área entera de una imagen de entrada, y el resultado será un elemento o una neurona del mapa de características que se forma (Figura 2.4).. Figura 2.4: Representación de los filtros y el mapa de características como neuronas en una capa de convolución (Buduma, 2016).. Por lo tanto, dado una imagen de dos dimensiones I como entrada, y un filtro también 15.
(29) CAPÍTULO 2. CONCEPTOS PREVIOS. de dos dimensiones k, la operación de la convolución está dada por (Ecuación 2.4):. S ( i, j ) = ( I ∗ K )( i, j ) =. (2.4). XX. I ( m, n)K ( i − m, j − n). m n. En el contexto del aprendizaje automático, el algoritmo debe de aprender los valores apropiados para la matriz K . En la figura 2.5, se puede observar la operación de una convolución, en el que se tiene una entrada de dos dimensiones, y un filtro también de dos dimensiones.. Figura 2.5: Operación de convolución (Bengio et al., 2015).. Entonces, una convolución toma un volumen de entrada, este volumen tiene las siguientes características:. • Su ancho w i n. • Su alto h i n. • Su profundidad d i n.. 16.
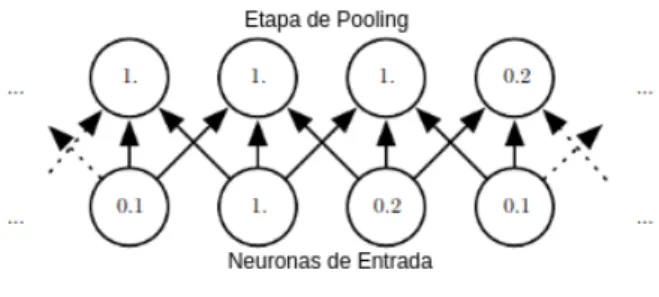
(30) CAPÍTULO 2. CONCEPTOS PREVIOS. • Su padding P .. Este volumen es procesado por un total de k filtros, que representan los pesos y las conexiones en una red convolucional, además, estos filtros tienen algunos parámetros que se describen a continuación:. • La variable e, que es igual al ancho y alto de los filtros. • El salto s, o la distancia entre los resultados consecutivos del producto del filtro y una sección del volumen de entrada, • El sesgo b, es el parámetro de aprendizaje, que se añade a cada componente de la convolución.. En resultado de aplicar los filtros, resulta una salida con las siguientes características:. • La función f que se aplica a la entrada de cada neurona en el volumen de salida, para determinar su valor final. • El nuevo ancho w out =. h. • La nueva altura h out =. w in − e+2p s. h. i. h i n− e+2p s. +1. i. • La profundidad d out = k. 2.2.2. Max Pooling. Para reducir la dimensionalidad del mapa de características resultado de las convoluciones; se utiliza la capa de pooling. La idea esencial detrás de la capa de pooling es dividir el mapa de características en porciones de igual tamaño, entonces, de cada porción se seleccionará. 17.
(31) CAPÍTULO 2. CONCEPTOS PREVIOS. un elemento que la represente, en el caso de Max Pooling, se selecciona el máximo de los elementos (Figura 2.6, 2.7).. Figura 2.6: Max Pooling vista como neuronas (Bengio et al., 2015).. En la figura 2.7 e puede apreciar una vista gráfica del Max Pooling, sobre el primer cuadro se toma 16 áreas de 2 x 2 denotados por las lineas verdes. De cada área se toma el máximo valor, el máximo valor es representado por aquellos puntos donde el color de intensidad sea más fuerte (más oscuro). Resultando una imagen más pequeña de 4 x 4.. Figura 2.7: Max Pooling vista matricial (Buduma, 2016).. Después de obtener las características utilizando la capa de convolución; la capa depooling sustituye a la salida de la convolución en un determinado lugar con un resumen estadístico de las salidas cercanas. En la figura 2.8 se puede observar una red convolucional, con sus capas de convolución y pooling respectivamente.. 18.
(32) CAPÍTULO 2. CONCEPTOS PREVIOS. Figura 2.8: Ejemplo de una red convolucional (Strigl et al., 2010).. 2.2.3. Entrenamiento. 2.2.3.1. Propagación hacia adelante. La red neuronal convolucional como se ha visto anteriormente tiene 3 tipos de capas: capas de convolución, capas de pooling, y capas totalmente conectadas. La propagación hacia adelante o hacia atrás será diferente dependiendo en que capa se esté haciendo la propagación.. Capa de convolución Tomando en cuenta que se tiene alguna entrada de neuronas de N × N , y se tiene un filtro w de m × m; La salida de la capa de convolución aplicando el filtro será de tamaño ( N − m + 1) × ( N − m + 1). Entonces un elemento de la capa de salida x li j se calcularía de la siguiente manera (Ecuación 2.5). (2.5). x li j =. m −1 m −1 X X a=0 b=0. wab y(il −+1a)( j+b). Entonces a cada salida de la ecuación 2.5, se le aplica una función de activación 2.6. (2.6). yil j = σ( x li j ). 19.
(33) CAPÍTULO 2. CONCEPTOS PREVIOS. Capa de pooling En la capa de pooling simplemente se toma una región de tamaño k × k de la salida obtenida en la capa de convolución. Entonces, si dicha salida tenía un tamaño de N × N , la N k. salida aplicando pooling será de tamaño. ×N k , cada bloque de k × k se reduce justamente. aplicando alguna función de pooling.. 2.2.3.2. Propagación hacia atrás. Capa de convolución Se asume que se tiene alguna función de error E , mediante el cual se conoce el error en la capa de convolución. Entonces, lo que se quiere es calcular el error en la capa anterior, y cuál es la gradiente para cada peso en la capa de convolución. El error que se conoce y que se necesita calcular para la capa anterior es igual a la µ ¶ ∂E deriva parcial con respecto a cada neurona de la capa de salida . Antes de calcular l ∂ yi j. esto, se debe calcular la gradiente de cada peso, aplicando la regla de la cadena, se tendría lo siguiente (Ecuación 2.7): ∂E. (2.7). ∂wab. =. NX − m NX −m i =0. l ∂E ∂ x i j. l j =0 ∂ x i j. ∂wab. =. NX − m NX −m i =0. ∂E. yl −1 l (i +a)( j + b) j =0 ∂ x i j. Se debe sumar sobre todas las expresiones x li j en las cuales wab interviene (esto debido a los pesos compartidos en esta capa), de acuerdo a la propagación hacia adelante se sabe que. ∂ x li j ∂wab. = y(il −+1a)( j+b) .. Entonces se necesita saber el valor de. ∂E ∂ x li j. (a los cuales a menudo se les llama “ deltas”),. y nuevamente aplicando la regla de la cadena se tiene (Ecuación 2.8): (2.8). ∂E ∂ x li j. =. l ∂E ∂ yi j. ∂ yil j ∂ x li j. =. ∂E. ´ ∂E ∂ ³ l σ ( x ) σ0 ( x li j ) ij = l l l ∂ yi j ∂ x i j ∂ yi j. 20.
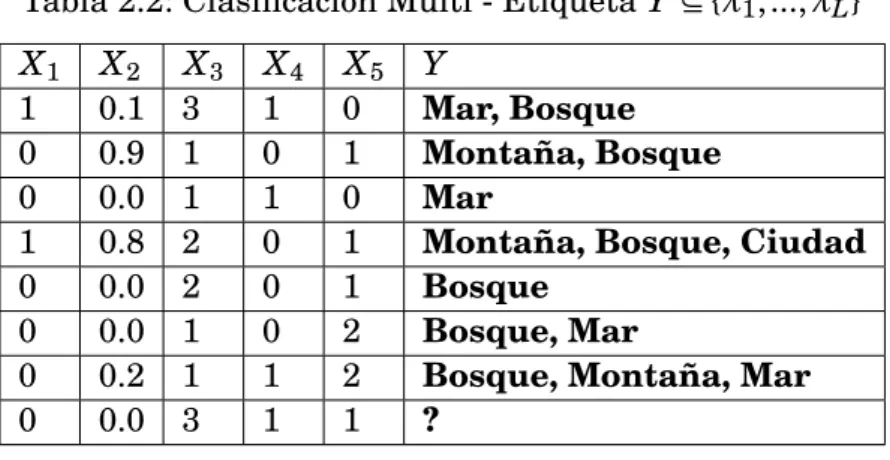
(34) CAPÍTULO 2. CONCEPTOS PREVIOS. Como se puede apreciar, ya se conoce el error en la capa actual fácilmente los deltas. ∂E ∂ x li j. ∂E ; ∂ yil j. se puede calcular. en la capa actual justamente derivando la función de activación. σ0 ( x).. Finalmente se puede calcular los pesos, propagando el error hacia atrás, o hacia la capa anterior, y nuevamente utilizando la regla de la cadena se tiene (Ecuación 2.9): ∂E. (2.9). 2.3. ∂ yil −j 1. =. m −1 m −1 X X. l ∂ x(i −a)( j − b). ∂E. l a=0 b=0 ∂ x(i −a)( j − b). ∂ yil −j 1. =. m −1 m −1 X X. ∂E. l a=0 b=0 ∂ x(i −a)( j − b). wab. Clasificación Multi - Etiqueta. La clasificación multi-etiqueta es un aprendizaje supervisado que ha tenido una gran atención en recientes años, dado que es más adecuado en muchas aplicaciones actuales como son la clasificación de datos multimedia, la predicción de funciones de genes y proteínas, la minería en redes sociales (Gibaja and Ventura, 2014). Todas estas aplicaciones tienen un punto en común, que cada instancia del conjunto de datos puede tener una o más etiquetas. En la tabla 2.1 podemos ver ejemplos que pertenecen a una sola etiqueta, mientras que en la tabla 2.2 se puede apreciar que cada ejemplo puede pertenecer a una o más etiquetas. Tabla 2.1: Clasificación con Simple - Etiqueta Y ∈ {0, 1}. X1 1 0 0 1 0 0. X2 0.1 0.9 0.0 0.8 0.0 0.0. X3 3 1 1 2 2 3. X4 1 0 1 0 0 1. 21. X5 0 1 0 1 1 1. Y Mar Bosque Mar Ciudad Mar ?.
(35) CAPÍTULO 2. CONCEPTOS PREVIOS. Tabla 2.2: Clasificación Multi - Etiqueta Y ⊆ {λ1 , ..., λL }. X1 1 0 0 1 0 0 0 0. 2.3.1. X2 0.1 0.9 0.0 0.8 0.0 0.0 0.2 0.0. X3 3 1 1 2 2 1 1 3. X4 1 0 1 0 0 0 1 1. X5 0 1 0 1 1 2 2 1. Y Mar, Bosque Montaña, Bosque Mar Montaña, Bosque, Ciudad Bosque Bosque, Mar Bosque, Montaña, Mar ?. Notación. A continuación, se presenta una notación para la clasificación multi-etiqueta, es una notación sintetizada por Avila (Avila Jiménez, 2013) de la mayor parte de trabajos publicados. En un problema de clasificación multi-etiqueta se considerará al conjunto de etiquetas por L = {λ i : i = 1....n} siendo n el número máximo de etiquetas que puede tener asociadas una instancia. Al conjunto datos se le denotará por D = {D j : j = 1...m} conjunto de datos multi-etiqueta. Cada elemento del conjunto de datos D , estará compuesto por un par de elementos D j = ( X j , Y j ) siendo X j el vector de características asociadas a la instancia,.. Y j ⊆ L es el subconjunto de etiquetas asociadas con la instancia j , por lo tanto |Y j | será el número de etiquetas asociadas a la instancia j . El conjunto Y j puede representarse como un vector binario, cuyos elementos positivos indican qué etiquetas del conjunto L se encuentran asociadas con la instancia D j (Avila Jiménez, 2013).. 2.3.2. Técnicas utilizadas. El problema de clasificación multi-etiqueta puede tratarse de dos maneras, por una parte, se toman los datos de entrada, para convertirlos en datos de una sola etiqueta, y luego se aplican técnicas de clasificación binaria o multi-clase, por otra parte, se pueden utilizar técnicas o adaptar las técnicas existentes que puedan trabajar directamente con los datos. 22.
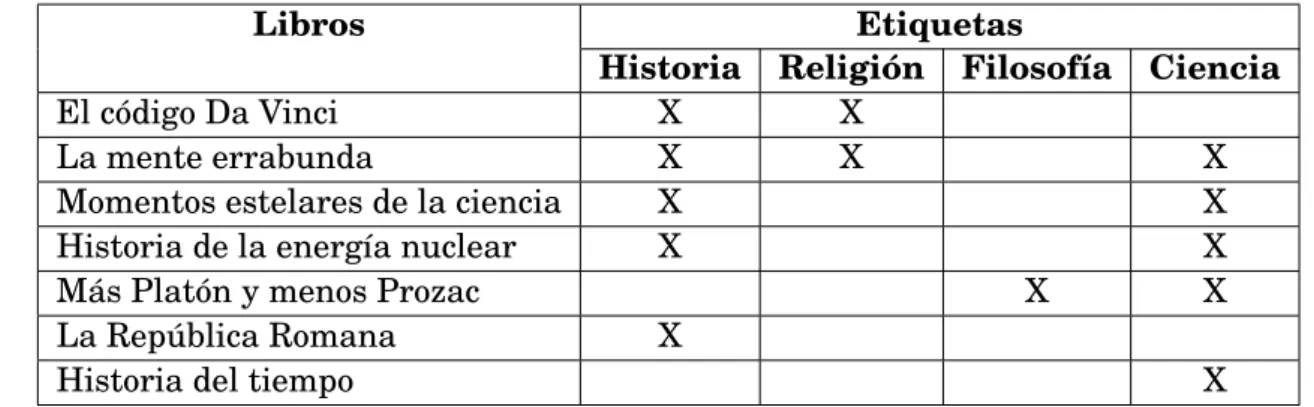
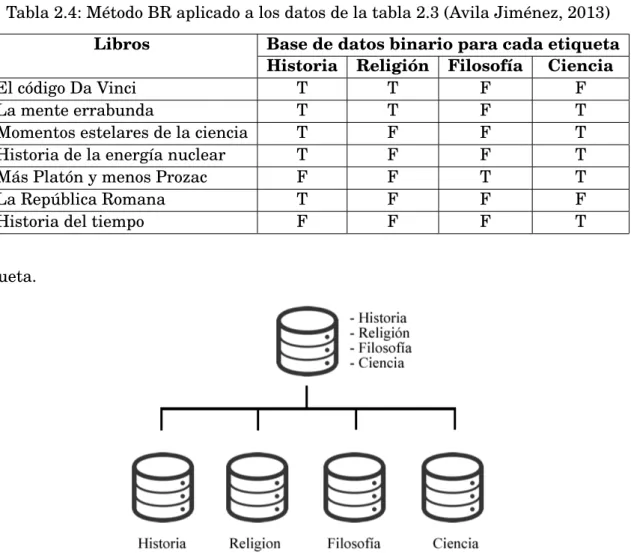
(36) CAPÍTULO 2. CONCEPTOS PREVIOS. multi-etiqueta (Gibaja and Ventura, 2014).. 2.3.2.1. Métodos de transformación de problemas. La tabla 2.3 muestra un conjunto de datos multi-etiqueta, que representan a libros que pertenecen a distintas temáticas (Historia, Religión, Filosofía o Ciencia), estos serán de ejemplo para los métodos descritos posteriormente. Tabla 2.3: Ejemplo de conjunto multi etiqueta: libros asociados con etiquetas en función de su temática (Avila Jiménez, 2013) Libros El código Da Vinci La mente errabunda Momentos estelares de la ciencia Historia de la energía nuclear Más Platón y menos Prozac La República Romana Historia del tiempo. Historia X X X X. Etiquetas Religión Filosofía X X. X. Ciencia X X X X. X X. Binary Relevance Este es el método comúnmente utilizado (BR del inglés Binary Relevance), este método genera conjuntos de datos binarios de acuerdo al número total de etiquetas. Cada conjunto generado contiene todas las instancias del conjunto original, y en cada uno está marcado como positivo las instancias al cual estaba asociado la etiqueta y como negativo el resto. El método BR es una transformación muy sencilla, pero presenta algunos inconvenientes. Primero toma las etiquetas independientemente; por lo tanto, implica la perdida de dependencia entre etiquetas, en segundo lugar, los conjuntos formados suelen estar desbalanceados (Avila Jiménez, 2013), en la tabla 2.4 se puede observar cómo se aplicó el método BR a los datos de la tabla 2.3. Así como se muestra en la figura 2.9, para cada etiqueta se creará un clasificador binario sobre la misma base de datos. Es como si se tuviera una base de datos para cada 23.
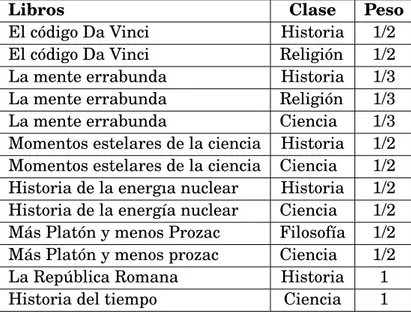
(37) CAPÍTULO 2. CONCEPTOS PREVIOS. Tabla 2.4: Método BR aplicado a los datos de la tabla 2.3 (Avila Jiménez, 2013) Libros El código Da Vinci La mente errabunda Momentos estelares de la ciencia Historia de la energía nuclear Más Platón y menos Prozac La República Romana Historia del tiempo. Base de datos binario para cada etiqueta Historia Religión Filosofía Ciencia T T F F T T F T T F F T T F F T F F T T T F F F F F F T. etiqueta.. Figura 2.9: Utilizando el método BR se entrenará la misma base de datos por cada etiqueta como un clasificador binario.. Ranking mediante una sola etiqueta Se tienen otros métodos ampliamente utilizados conocidos como Ranking Mediante una Sola Etiqueta (Ranking Via Single Label), estos a la vez se clasifican en tres métodos: métodos de copia, métodos de sel ecci ó n, y el método de i gnorar . Los métodos de copia transforman cada instancia en varias instancias de una sola etiqueta, para realizar esto copian varias veces la instancia con cada una de sus etiquetas. En estos métodos se mantienen todas las etiquetas, pero el número de instancias aumenta, siendo aquellos con más etiquetas los que tendrán más relevancia en el clasificador. 24.
(38) CAPÍTULO 2. CONCEPTOS PREVIOS. final (Tabla 2.5). Tabla 2.5: Método de copia ponderada aplicado a los datos de la tabla 2.3 (Avila Jiménez, 2013) Libros El código Da Vinci El código Da Vinci La mente errabunda La mente errabunda La mente errabunda Momentos estelares de la ciencia Momentos estelares de la ciencia Historia de la energıa nuclear Historia de la energía nuclear Más Platón y menos Prozac Más Platón y menos prozac La República Romana Historia del tiempo. Clase Historia Religión Historia Religión Ciencia Historia Ciencia Historia Ciencia Filosofía Ciencia Historia Ciencia. Peso 1/2 1/2 1/3 1/3 1/3 1/2 1/2 1/2 1/2 1/2 1/2 1 1. Los métodos de selección transforman los datos multi-etiqueta a un problema de simple etiqueta, dependiendo del método de selección utilizado, se tienen los siguientes:. • Selección Máxima: se selecciona la etiqueta que aparece con más frecuencia en el conjunto de datos (tabla 2.6). • Selección Mínima: se selecciona la etiqueta que aparece con menos frecuencia en el conjunto de datos (tabla 2.6). • Selección Aleatoria: se selecciona aleatoriamente la etiqueta a asignar a la instancia.. Este método no aumenta el tamaño de datos, pero pierde información sobre las demás etiquetas. El método de ignorar, solamente toma en cuenta las instancias que tienen más de una etiqueta, este método elimina de manera irreversible toda la información multi-etiqueta del conjunto de datos original.. 25.
(39) CAPÍTULO 2. CONCEPTOS PREVIOS. Tabla 2.6: Método de transformación máxima y mínima, aplicados a los datos de la tabla 2.3 (Avila Jiménez, 2013) Libros El código Da Vinci La mente errabunda Momentos estelares de la ciencia Historia de la energıa nuclear Más Platón y menos prozac La República Romana Historia del tiempo 2.3.2.2. Clase(max) Historia Ciencia Ciencia Ciencia Ciencia Historia Ciencia. Clase(min) Religión Religión Historia Historia Filosofía Historia Ciencia. Métodos de adaptación de algoritmos. Estos métodos utilizan las técnicas de clasificación clásicas, pero se las han adaptado para resolver el problema de clasificación multi-etiqueta. Máquinas de Soporte Vectorial Las máquinas de soporte vectorial (Support Vector Machine, SVM) es una técnica de clasificación lineal, el cual separa las características mediante hiperplanos maximizando la separación entre las clases. Inicialmente fueron concebidas para la clasificación binaria, pero se han extendido para trabajar con datos multi-etiqueta. A continuación, se describen algunas de estas modificaciones. En el trabajo de Xu (Xu, 2011) se propone un nuevo método basado en el clásico método uno contra todos. El cual trabaja con datos multi-etiqueta, basadas en las máquinas de soporte vectorial. La correlación de etiquetas se caracteriza explícitamente a través de los límites superiores de las variables. Elisseeff y Weston (Elisseeff and Weston, 2001) proponen un algoritmo llamado Rank − SV M , un sistema basado en SVM para resolver el problema multi-etiqueta. Presentan un enfoque basado en un sistema de ranking y construye un clasificador por cada etiqueta con un margen de separación. Wan y Xu (Wan and Xu, 2007) presentan una modificación para el caso multi-etiqueta. 26.
(40) CAPÍTULO 2. CONCEPTOS PREVIOS. en las SVM aprovechando la técnica uno contra todos. Al mismo tiempo que considera a las instancias con dos etiquetas como pertenecientes a una clase intermedia entre las dos. Se busca dos hiperplanos que separen las dos clases del área común donde están las instancias multi-etiqueta. En el trabajo de Jian et al. (Jiang et al., 2008) se presenta una adaptación de las SVM para resolver problemas de clasificación multi-etiqueta y ranking. Este clasificador devuelve un ranking de etiquetas, que se utilizan para determinar las etiquetas relevantes e irrelevantes. De esta manera, el algoritmo aprende simultáneamente el umbral más adecuado. Por otro lado, Rousu et al., (Rousu et al., 2006) utilizan las cadenas de Markov sobre las SVM para resolver el problema multi-etiqueta. El uso de las cadenas de Markov permiten modelar las relaciones entre los atributos. Árboles de decisión Los árboles de decisión son ampliamente utilizados en tareas de clasificación. Por ello estas técnicas también han sido adaptadas para el problema de clasificación multietiqueta. Dimitrovski et al., (Dimitrovski et al., 2010) proponen un ensembl e basado en árboles de decisión, en el cual utilizan un paradigma llamado Predictive Clustering Trees (PCT), en el cual el árbol de decisión realiza clustering, para agrupar todas las etiquetas posibles para una instancia, resolviendo de esta manera el problema multi-etiqueta. De la misma manera, en las propuestas de (Blockeel et al., 2006; Vens et al., 2008) utilizan un solo árbol de decisión para realizar predicciones simultaneas y asignar las etiquetas que corresponden a cada instancia. La propuesta de Noh et al., (Noh et al., 2004) se basa en los árboles de decisión multi-. 27.
(41) CAPÍTULO 2. CONCEPTOS PREVIOS. etiqueta, en el cual el criterio de decisión en cada nodo del árbol, se calcula realizando un test estadístico, en tanto Clare y King (Clare and King, 2001) adaptan el algoritmo C 4,5, definiendo una función de entropía multi-etiqueta. En el cual, permite determinar qué atributos se utilizarán para la construcción del árbol, también permite que en cada hoja del árbol haya múltiples etiquetas. A partir de este trabajo surgieron otras propuestas, como (Gibaja et al., 2010) en donde se adapta el algoritmo J 48 para problemas de datos multi-etiqueta. Redes Neuronales Se han propuesto muchas adaptaciones de las Redes Neuronales para tratar la clasificación multi-etiqueta. A continuación, se describen las más resaltantes: El algoritmo Back Propagation Multi Label Layer (BP-MLL) es propuesto por Zhang y Zhou (Zhang and Zhou, 2006). Quienes proponen utilizar una nueva función de error, que permite a la red tratar con datos multi-etiqueta. Otro trabajo similar es el de Crammer y Singer (Crammer and Singer, 2003), quienes utilizan ranking de etiquetas, el cual hace que las redes neuronales trabajen con datos multi-etiqueta, ellos proponen su algoritmo denominado Multi-label Multi-class Perceptron (MMP). Algunas variantes de las redes neuronales como el Adaptative Resonance Theory (ART) (Carpenter and Grossberg, 2011), también han sido adaptadas haciendo que la salida sea un vector de etiquetas. Otros autores proponen distintas arquitecturas con el número de capas, como el trabajo presentado por Zhang (Zhang, 2009), o la arquitectura presentada en (Ciarelli and Oliveira, 2009; Oliveira et al., 2008) sobre las redes neuronales probabilísticas.. 28.
(42) CAPÍTULO 2. CONCEPTOS PREVIOS. 2.3.3. Métricas para la evaluación. Para evaluar los clasificadores multi-etiqueta, de acuerdo al estado del arte se distinguen dos tipos de métricas (Zhang and Zhou, 2014): métricas basadas en las etiquetas ( label −. based ) y métricas basadas en los ejemplos ( exampl e − based ). La idea de las métricas basadas en las etiquetas es calcular una métrica de simple etiqueta para cada etiqueta; basados en el número de verdaderos positivos ( tp), verdaderos negativos ( tn), falsos positivos ( f p) y falsos negativos ( f n) (Tabla 2.7) y se obtiene un valor promedio. Por otra parte, las métricas basadas en los ejemplos están específicamente concebidas para problemas multi-etiqueta, es por ello que se calculan para cada ejemplo. Tabla 2.7: Matriz de confusión. Valores Reales. 2.3.3.1. Positivo Negativo. Valores predichos Positivo Negativo tp fn fp tn. Métricas basadas en etiquetas. Las métricas de evaluación binaria B, pueden ser utilizadas como base para este tipo de métricas. Estas medidas toman en cuenta la matriz de confusión (Tabla 2.7), en la que se representa para una determinada clase, la salida del clasificador frente al valor esperado. Entonces, t p indica el número de instancias positivas clasificados correctamente,. f p las instancias incorrectamente asignados o falsos positivos, t n las instancias negativas correctamente asignadas o verdaderos negativos y f n las instancias no asignadas o falsos negativos. Para promediar se pueden utilizar dos aproximaciones, denominados enfoques macro y micro (Maimon and Rokach, 2005). Bajo el primer enfoque se calculan las métricas para cada etiqueta y se hace la media por etiquetas para obtener el valor final (Ecuación 2.10). En tanto, en el segundo enfoque se agregan los valores de la matriz de confusión para las 29.
(43) CAPÍTULO 2. CONCEPTOS PREVIOS. etiquetas y posteriormente se calcula la métrica (Ecuación 2.11).. B macro =. (2.10). (2.11). B micro = B(. n 1X B( tp i , f p i , tn i , f n i ) n i=1. n X. tp i ,. i =1. n X. f pi,. i =1. n X. tn i ,. i =1. n X. f ni). i =1. Dos de las medidas para medir el rendimiento son la precisión y el recall (Maimon and Rokach, 2005). La precisión de un clasificador se define como la fracción de etiquetas correctamente asignadas entre todas las etiquetas asignadas por clasificador (Ecuación 2.12).. precision =. (2.12). tp tp + fp. El recall de un clasificador es la fracción de etiquetas correctamente clasificadas entre todas las etiquetas realmente positivas (Ecuación 2.19). recall =. (2.13). tp tp + fn. Ambas métricas pueden ser promediadas mediante las aproximaciones macro (Ecuación 2.10) y micro (Ecuación 2.11), siendo el resultado de su cálculo distinto según la aproximación que se use. La media armónica entre la precision y el recall, también denominada F − score (Ecuación 2.14), es utilizada cuando en ocasiones se puede aumentar el recall a costa de disminuir la precision y viceversa. (2.14). F − score =. 2 ∗ precision ∗ recall precision + recall. La ccuracy es la fracción de etiquetas correctamente clasificadas (Ecuación 2.15). (2.15). accurac y =. t p + tn t p + tn + f p + f n 30.
(44) CAPÍTULO 2. CONCEPTOS PREVIOS. 2.3.3.2. Métricas basadas en los ejemplos. Existen dos tipos de métricas basadas en los ejemplos: métricas binarias, se utilizan para medir cualquier algoritmo de clasificación multi-etiqueta, y las métricas de ranking, se utilizan para medir los algoritmos de ranking. Métricas binarias Subset Accuracy, una métrica que calcula el porcentaje de los ejemplos que el clasificador ha acertado con todas sus etiquetas correspondientes (Ecuación 2.16). Es una métrica muy estricta, ya que, si el conjunto de etiquetas predicho no es exactamente igual al conjunto de etiquetas real, no se toma en cuenta. (2.16). subset accurac y =. m 1 X δ( P i = Y i ) m i=1. Siendo:. δ( x ) =. 1 si x = verdadero 0. si x = f also. Hamming loss o pérdida de Hamming, en esta métrica se considera tanto los errores de clasificación, como los errores por omisión. La medida que se calcula es la diferencia entre el conjunto de etiquetas predicho con el conjunto de etiqueta reales. Toma un valor cercano a 0 cuanto mejor sea el resultado del clasificador, como se puede apreciar en la ecuación 2.17. La operación |P i ∆Yi | representa la diferencia simétrica entre los conjuntos de etiquetas predichas y reales. (2.17). Hammingloss =. m |P ∆Y | 1 X i i m i=1 n. En el trabajo de Goldbole et al., (Chen et al., 2004), se han vuelto a definir las métricas accuracy, la precision y el recall. Se toma en cuenta los ejemplos y las etiquetas predichas, 31.
(45) CAPÍTULO 2. CONCEPTOS PREVIOS. es por ello que se forman parte de las métricas basadas en los ejemplos. Los autores definen; la precision (Ecuación 2.18) como el promedio de etiquetas acertadas frente a las predichas, el recall (Ecuación 2.19) como el promedio de etiquetas acertadas frente a las reales y la accuracy (Ecuación 2.20) como el promedio de la fracción de aciertos del clasificador frente a la unión de etiquetas reales y predichas. (2.18). precision =. (2.19). recall =. (2.20). accurac y =. m |Y ∩ P | 1 X i i m i=1 |P i |. m |Y ∩ P | 1 X i i m i=1 |Yi |. m |Y ∩ P | 1 X i i m i=1 |Yi ∪ P i |. La evaluación α − evaluation es otra medida de evaluación propuesta por Boutell et al., (Boutell et al., 2004). En la que se puntúan cada predicción realizada por el clasificador según la ecuación 2.21. µ. (2.21). score(P i ) =. |Y i ∩ P i | |Y i ∪ P i |. ¶α. (α ≥ 0. En la ecuación 2.21, el parámetro α se denomina forgiveness rate, este parámetro penaliza los errores en la clasificación. Cuando α tiende a 0 la medida es menos sensible a errores de clasificación. Por ejemplo, si α = 0, la puntuación de la medida sera máxima; basta que el clasificador haya asignado una etiqueta correctamente. Y un α grande o que tienda al in f inito la medida sera muy sensible a fallos. Por ejemplo, si α = ∞ el clasificador solamente obtiene una puntación si predice correctamente todas las etiquetas. De acuerdo a la puntación obtenida en la ecuación 2.21, se definen las medidas de. precision, recall , y accurac y para un subconjunto de clases C ⊆ L. La precision (Ecuación 2.22) mide la fracción de ejemplos que contienen realmente el conjunto de etiquetas C 32.
(46) CAPÍTULO 2. CONCEPTOS PREVIOS. frente a los que el clasificador le ha asociado el subconjunto C . El recall (Ecuación 2.23) mide la fracción de ejemplos que son clasificados como pertenecientes al subconjunto C frente a los que realmente lo contienen. Y la accurac y (Ecuación 2.24) mide el rendimiento global del clasificador, en función del forgiveness rate.. precision C =. (2.22). 1 X score(P i ) | D C | i ²D C. Donde D C = {D j |C = P i }. recall C =. (2.23). 1 X score(P i ) D C i ²D C. Donde D C = {D j |C = Yi } (2.24). 2.3.3.3. accurac yD =. 1 X score(P i ) | D | i ²D. Conjuntos de datos multi-etiqueta. Existen varios conjuntos de datos (dataset) que se utilizan para comparar las diversas propuestas de algoritmos orientados a resolver el problema de clasificación multi-etiqueta. Además, existen algunas métricas que se emplean sobre los conjuntos de datos. En este apartado se explican algunos de ellos. Métricas para la descripción de conjuntos de datos Una de las métricas más sencillas es el denominado distinc (Maimon and Rokach, 2005), el cual es el número de combinaciones de distintas etiquetas presentes en un conjunto de datos. También existen dos medidas más, que son la cardinalidad y la densidad (Tsoumakas et al., 2009b). La cardinalidad es la medida que calcula el promedio de etiquetas por ejemplo (Ecuación 2.25). (2.25). cardinal idad (D ) =. 33. m 1 X |Y i | m i=1.
(47) CAPÍTULO 2. CONCEPTOS PREVIOS. Mientras que la densidad calcula el promedio del número de etiquetas de un ejemplo entre el número total de etiquetas (Ecuación 2.26).. densidad (D ) =. (2.26). m |Y | 1 X i m i=1 |L|. Donde:. |Yi | es el número de etiquetas del ejemplo i. 2.4. Reducción de la Dimensionalidad. Como la entrada a los algoritmos de clasificación son vectores numéricos, muchas veces estos vectores son lo suficientemente grandes que hacen que el tiempo de entrenamiento de estos algoritmos sea lento. Es por ello que se requiere reducir la dimensión del vector de entrada, pero se debe reducir a un tamaño considerable para no perder mucha información.. 2.4.1. Análisis de Componentes Principales. El Análisis de Componentes Principales (PCA del inglés Principal Component Analysis), es una técnica estadística para la reducción de la dimensión o de variables. Reduce la complejidad de los datos e identifica las características más importantes del conjunto de datos. Se utiliza una matriz de correlación, la cual es una matriz de doble entrada tanto vertical como horizontal con las variables del conjunto de datos. Los valores de la matriz se calculan con un coeficiente de correlación o la relación de cada par de celdas expresadas en un valor entre 0 y 1. Si existen muchos valores con una correlación alta, esto indica que existe información redundante en el conjunto de datos. Por lo tanto, pocos de estos elementos representaran 34.
(48) CAPÍTULO 2. CONCEPTOS PREVIOS. la variabilidad del conjunto de datos. Entonces se debe identificar aquellos factores que recojan la variabilidad total del conjunto de datos. El primer factor recogerá la variabilidad del conjunto de datos total. El siguiente recogerá la variabilidad que no se obtuvo con el primer factor. Esto se realizará consecutivamente hasta determinar la cantidad de factores convenientes, a estos factores se les conoce como componentes principales. Los factores antes mencionados son calculados mediante el análisis de eigenvalues (valores propios) y eigenvectors (vectores propios), los cuales representan las características más importantes del conjunto de datos.. 2.4.1.1. Análisis de valores propios. En el análisis de valores propios también se ven los vectores propios. Dado un vector de valores numéricos, si se le multiplica por un valor escalar y su dirección no cambia, entonces a este escalar se le conocerá como valor propio, y el vector será el vector propio. En la ecuación 2.27, se denota v como los vectores propios y λ como los valores propios. (2.27). Av = λv. Una vez obtenido los vectores propios de la matriz de correlación, se pueden tomar los primeros N vectores los cuales indicaran la estructura de las características más importantes del conjunto de datos. Entonces se puede multiplicar el conjunto de datos por los primeros N vectores tomados, y se obtiene el nuevo espacio de salida (dimensión) del conjunto de datos.. 35.
(49) CAPÍTULO 2. CONCEPTOS PREVIOS. 2.4.2. Descomposición de Valores Singulares. La Descomposición de Valores Singulares (SVD del inglés Singular Value Decomposition), puede representar un conjunto de datos de manera reducida eliminando ruido e información redundante. Este método tiene muchas áreas de aplicación, uno de los primeros es la recuperación de la información. Sobre un conjunto de documentos, se puede crear una matriz de términos y documentos. Cuando se aplica SVD se extraen valores singulares que representan tópicos y conceptos, de esta manera se pueden realizar búsquedas más eficientes en todo el conjunto de datos. Otro de los usos es en los sistemas de recomendación, obteniendo tópicos y conceptos, los cuales se pueden comparar con los intereses de un lector. Y de esta manera poder recomendarle los libros más cercanos a sus intereses. Este método toma un conjunto de datos y a partir de ella crea 3 matrices. Si se considera una matriz D de tamaño m × n, las tres matrices que se crean son U de tamaño m × m, Σ de tamaño m × n y V T de tamaño n × n (Ecuación 2.28). (2.28). D = U ΣV T. La descomposición crea la matriz Σ la cual es una matriz diagonal, además los valores de la diagonal están ordenados de mayor a menor. Los valores de esta matriz representan los valores singulares de la matriz original D . Estos valores son el resultado de la raíz cuadrada de los valores propios de D T D . Mientras que, U es la matriz de vectores propios de D T D , y V es la matriz de vectores propios de DD T .. 36.
Figure
+7
Documento similar