Sistema ETL para el almacén de datos de aspirantes de la UCLV
92
0
0
Texto completo
(2) Declaración Jurada. El que suscribe, Orlando José Rivera Gómez, hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Licenciatura en Ciencias de la Computación, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicado sin autorización de la Universidad.. ______________________________ Orlando José Rivera Gómez Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. ___________________________________ Firma del Tutor. __________________________________ Firma de la Cotutora. ____________________________ Firma del Jefe del Laboratorio. I.
(3) Dedicatoria. Este trabajo se lo dedico a mi familia, en especial a mis padres que siempre me han apoyado en los momentos difíciles de mi vida.. Orlando. II.
(4) Agradecimientos. A todos los que han colaborado en mi formación: mi familia, profesores y compañeros. Sin ellos este trabajo no sería una realidad. A mis tutores por ayudarnos a que el trabajo realizado quedara con calidad.. Orlando. III.
(5) Resumen En el departamento de posgrados de la UCLV se explota en la actualidad una base de datos de Control de Aspirantes, la cual crece aceleradamente. Con frecuencia los directivos necesitan analizar la información de manera no tradicional, buscando consultar datos de manera que se produzcan nuevos conocimientos. Esto es el caso en este proceso. Una de las partes de un sistema de ayuda a la toma de decisiones, es contar con procesos de extracción, transformación, limpieza y carga (ETL) que permitan obtener una vista unificada con la mayor calidad posible en forma de Almacén de Datos, a partir de fuentes que pueden ser heterogéneas, para dar respuesta a solicitudes de los decisores. Para lograr lo anteriormente expuesto se desarrolló un conjunto de pautas metodológicas para la creación de un ETL para ambientes nacionales y en base a estas se creó un módulo ETL específico para el Control de Aspirantes.. IV.
(6) Abstract In the department of graduate degrees of UCLV you explodes a database of Control of Applicants at the present time, which grows quickly. Frequently the directive need to analyze the information in a nontraditional way, looking for to consult data so that new knowledge take place. This is the case in this process. One of the parts of a system of help to the taking of decisions is to have extraction processes, transformation, cleaning and loading (ETL) that allow to obtain a view unified with the possible biggest quality in form of Data Warehouse, starting from sources that can be heterogeneous, to give answer to applications of the chefs. To achieve the previously exposed a group of methodological rules was developed for the creation of an ETL for national atmospheres and based on these it was created a module specific ETL for the Control of Applicants.. V.
(7) Contenido Resumen .................................................................................................................................................... IV Abstract ........................................................................................................................................................ V Introducción ................................................................................................................................................. 1 Capítulo 1. ................................................................................................................................................... 6 1.1 Modelado de datos en almacenes de datos................................................................................ 8 1.1.1 Diseño de los procesos ETL................................................................................................. 11 Calidad de los datos ........................................................................................................................ 13 Conformación .................................................................................................................................... 14 1.2 Preparación de los datos .............................................................................................................. 14 Integración de datos ........................................................................................................................ 15 Clío ..................................................................................................................................................... 16 BDK .................................................................................................................................................... 17 Merge ................................................................................................................................................. 18 DUMAS .............................................................................................................................................. 18 Hummer ............................................................................................................................................. 20 1.2.1 Extracción ................................................................................................................................ 20 1.2.2 Limpieza................................................................................................................................... 23 1.2.3 Transformación ....................................................................................................................... 25 1.2.4 Carga........................................................................................................................................ 26 1.3 Herramientas que se utilizan para realizar los procesos de ETL........................................... 27 1.3.1 Herramientas propietarias.................................................................................................... 27 1.3.2 Herramientas libres ................................................................................................................ 29 1.4 Tabla comparativa entre los software para la gestión de procesos ETL .............................. 41 VI.
(8) Ab Initio .............................................................................................................................................. 41 Oracle Data Integrator......................................................................................................................... 41 Apatar.................................................................................................................................................. 41 CloverETL .......................................................................................................................................... 41 Pentaho Data Integration..................................................................................................................... 41 Conclusiones Parciales ....................................................................................................................... 41 Capítulo 2. ................................................................................................................................................. 43 2.1 Comprobar el diseño del almacén de datos .............................................................................. 44 2.2 Comprobar si los datos requeridos en el almacén de datos están todos en los sistemas de información fuentes y sus formatos ............................................................................................. 45 2.3 Poblar la dimensión tiempo .......................................................................................................... 46 2.4 Poblar la dimensión geografía (si existe)................................................................................... 48 2.5 Poblar otras dimensiones ............................................................................................................. 49 2.6 Crear algoritmos correspondientes a la extracción de datos del sistema de información y su inserción en el almacén de datos sobre todo la tabla de hechos ........................................... 50 2.7 Revisar el completamiento de los datos como parte de la limpieza ...................................... 51 2.7.1 Funciones clásicas de las herramientas de limpieza ....................................................... 52 2.7.2 Algoritmo para las similitudes entre registros .................................................................... 58 2.7.3 Algoritmo soundex codes ...................................................................................................... 59 2.7.4 Implementación de un algoritmo de limpieza en seudocódigo ....................................... 60 Conclusiones Parciales ....................................................................................................................... 61 Capítulo 3. ................................................................................................................................................. 62 3.1 Descripción del Sistema de Información fuente. ...................................................................... 62 3.2 Estructura propuesta para el almacén de datos. ...................................................................... 63 3.3 Diagrama de Actores y Casos de Uso del Sistema ................................................................. 65 3.3.1 Descripción de los Actores del Sistema ............................................................................. 65 VII.
(9) 3.3.2 Descripción de los Casos de Uso del Sistema .................................................................. 66 3.4 Diagrama de clases....................................................................................................................... 66 3.5 Diagrama de Componentes ......................................................................................................... 67 3.5.1Descripción de los componentes del sistema ..................................................................... 68 3.6 Diagrama de actividad .................................................................................................................. 70 Conclusiones Parciales ....................................................................................................................... 71 Capítulo 4. ................................................................................................................................................. 72 Conclusiones Parciales ....................................................................................................................... 79 Conclusiones............................................................................................................................................. 80 Recomendaciones ................................................................................................................................... 81 Referencias Bibliográficas ...................................................................................................................... 82. VIII.
(10) Introducción Con el desarrollo de la Informatización las empresas que tienen acceso a grandes volúmenes de datos poseen un gran caudal histórico de análisis de sus perspectivas de desarrollo, unido a un óptimo desarrollo de sistemas capaces de manipularlos, sin embargo esto trae un gran problema ¿cómo manejar estos volúmenes de información tan grandes de manera exitosa? Hoy en día existen diversos tipos de sistemas de soporte para la toma de decisiones, pero el que ha tenido más auge a escala mundial en las grandes instituciones sin duda ha sido el Data Warehouse o Almacenes de Datos, convirtiéndose en el centro de atención de las organizaciones, puesto que provee un ambiente para hacer un mejor uso de la información administrada por diversas aplicaciones operacionales. La mayoría de las decisiones de empresas, organizaciones e instituciones se basan en información de experiencias pasadas. Generalmente, la información que es necesaria para investigar sobre un cierto dominio de la organización se encuentra en bases de datos, tanto internas como externas, y otras fuentes muy diversas, no necesariamente bases de datos. Muchas de estas fuentes son las que se utilizan para el trabajo diario. Tradicionalmente el análisis para la toma de decisiones se realizaba sobre estas mismas bases de datos de trabajo o bases de datos transaccionales. Esto implica simultanear el trabajo transaccional diario de los sistemas de información originales (OLTP, On-Line Transactional Processing) con el análisis de los datos en tiempo real sobre la misma base de datos (OLAP, On-Line Analytical Processing). En Cuba se ha llevado a cabo un intenso proceso inversionista y de formación de personal, que permite afirmar que existen varios especialistas, no solo graduados de carreras afines a la informática, en diferentes organismos e instituciones dedicadas al desarrollo de sistemas de información, que trabajan o han trabajado en la implementación y explotación de almacenes o mercados de datos a partir de varios sistemas históricos de información y que después aplican diferentes herramientas estadísticas y de búsqueda de información no revelada tradicionalmente en esos sistemas, para detectar tendencias industriales, comerciales, de servicio, etc. En la propia UCLV se han desarrollado varios trabajos aplicados a diferentes esferas, en calidad de tesis de diploma y de postgrado (maestrías y doctorados) que abordan la creación de almacenes de datos. 1.
(11) En todos se nota que el estudio de los metadatos o estructura de los sistemas fuentes se realiza de forma manual y el desarrollador propone un modelo dimensional (esquema estrella o esquema constelación de estrellas) adecuado para los requerimientos del usuario, esto lo entendemos como el primer paso. A partir de ahí la mayor atención en el desarrollo siempre ha estado en la creación de las herramientas o software de limpieza, transformación y carga de los datos desde los diferentes sistemas de información al almacén, esto lo podemos considerar el segundo paso. Un tercer paso y quizá el más importante es el desarrollo de algoritmos, tablas, gráficos, etc., que reflejan la explotación del almacén, ya sea por métodos estadísticos, de inteligencia artificial, minería de datos, etc. En este trabajo de diploma se pretende resolver una situación específica referente al segundo paso de trabajo con los almacenes de datos, ejemplificando con un caso de estudio, pero es pretensión nuestra proponer una serie de pautas metodológicas específicas para nuestro ambiente, en cuanto al desarrollo de herramientas de ETL.. Situación Problemática: La UCLV cuenta con una Base de Datos de Control de Aspirantes que contiene información de más de una década de los aspirantes a doctores formados en esta universidad o trabajadores de la misma que se han formado en otras universidades. La misma fue desarrollada en Access XP y se explota actualmente en el Departamento de Postgrado de la UCLV. De esa información es posible realizar diferentes análisis no convencionales que permitan tomar decisiones que tiendan a mejorar la eficacia del proceso de Formación Doctoral, por lo que se estima que la creación de un Almacén de Datos a partir de esta información apoyaría a la Toma de Decisiones de ese problema. El presente trabajo partirá de un diseño hipotético (en modelo estrella) planteado por el tutor y se desarrollará entonces el sistema ETL correspondiente que permita cargar, transformar y limpiar la información de dicho sistema de información hacia el almacén de datos. Pero además, tomando en consideración situaciones reales que existen en diferentes sistemas de información de nuestro país, se determina que existen dificultades objetivas que atentan contra el buen desarrollo de módulos o algoritmos de ETL eficientes, y se hace necesario entonces establecer una serie de pautas específicas a tomar en cuenta en el desarrollo de estos programas, que sirvan de guía a otros analistas e informáticos en general dedicados a la creación y 2.
(12) explotación de Almacenes de Datos para contribuir a la mejor toma de decisiones en sus respectivas instituciones.. Objetivo General: Desarrollar un sistema ETL para un sistema de toma de decisiones (almacenes de datos), que incluya la carga, transformación y limpieza de los datos presentes en el Sistema de Control de Aspirantes de la UCLV, estableciendo previamente pautas metodológicas que establezcan como enfrentar este trabajo para otros almacenes.. Objetivos específicos: 1. Establecer las pautas metodológicas de creación de herramientas ETL para almacenes de datos a partir de sistemas de información desarrollados en nuestro medio. 2. Crear la estructura de base de datos del almacén sobre un gestor a partir de un diseño provisto por el tutor en forma de modelo estrella. 3. Implementar una herramienta o sistema, que permita realizar la carga, transformación y limpieza de datos desde el sistema de información Control de Aspirantes hacia el almacén de datos previamente desarrollado. 4. Evaluar la herramienta, al cargar, transformar y limpiar los datos del sistema de información Control de Aspirantes, que se explota en la UCLV, hacia el Almacén de Datos prototípico ya propuesto.. Preguntas de Investigación: 1-¿Qué herramientas de ETL existen en el mercado que puedan ajustarse a las necesidades del problema? 2-¿En qué medida será posible establecer pautas metodológicas propias para la creación de ETLs a partir de cualquier sistema de información nacional para un almacén determinado? 3-¿En qué medida la herramienta propuesta permite realizar las funciones de ETLs para el almacén de datos dado?. 3.
(13) Hipótesis: La creación de herramientas nacionales que ayude a analistas y usuarios de sistemas de información, a crear el módulo de ETL para un almacén de datos necesario a una entidad determinada, basado en los datos de un sistema de información específico, redundará en la productividad e independencia tecnológica en el desarrollo de Sistemas de Apoyo a la Toma de Decisiones de entidades cubanas.. Viabilidad: Existen trabajos previos desarrollados por el grupo de Bases de Datos del Centro de Estudios de Informática, sobre todo relacionados con la limpieza de datos, alrededor de la tesis doctoral de la cotutora Dra. Beatriz López Porrero, así como otros trabajos relativos a herramientas CASE de ayuda al desarrollo automatizado de Almacenes de Datos, todo esto dentro de un Proyecto de Investigación Nacional incluido en el Programa del MINCOM sobre el desarrollo de software. Por otra parte existen las condiciones materiales mínimas para el desarrollo de la investigación dentro del CEI de la UCLV.. Estructura de la tesis: Para una mejor comprensión del presente documento, la estructura del contenido queda conformada de la siguiente manera: Capítulo 1. Fundamentación Teórica: Marco teórico relativo a los conceptos necesarios para el desarrollo de este trabajo incluyendo Almacenes de Datos, herramientas CASE, etc. Capítulo 2. Planteamiento de Pautas Metodológicas: Se establecerán pautas o directrices metodológicas que permitan organizar y establecer orientaciones válidas para este y otros trabajos similares de creación de módulos ETL que a partir de sistemas de información nacionales puedan realizar las funciones adecuadas hacia un almacén de datos. En paralelo se hará una breve descripción del sistema de información tomado como caso de estudio: Sistema de Control de Aspirantes de la UCLV. 4.
(14) Capítulo 3. Análisis y Modelado de la Herramienta CASE: En este se realiza el análisis y diseño de la herramienta CASE que se propone como solución de este trabajo, en base a varios diagramas UML correspondientes y su explicación. Capítulo 4. Descripción de Características del CASE: Breve explicación de las características y opciones de la herramienta CASE desarrollada para permitir su explotación.. 5.
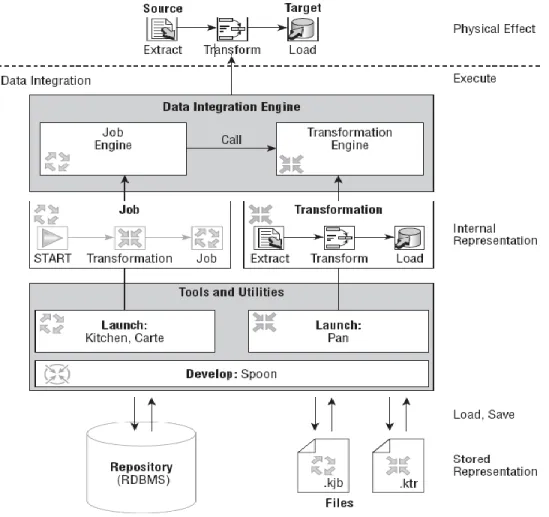
(15) Capítulo 1. “Fundamentación Teórica” En este capítulo se profundiza en la teoría sobre la que se sustenta el trabajo con ETL. También se realiza una descripción de algunas de las distintas herramientas que permiten crear la parte de ETL de forma adecuada, tanto libres como propietarias, existentes actualmente. Debido a que las bases de datos están diseñadas para el trabajo transaccional y no para el análisis de los datos, por lo que el análisis es lento y que los costes de almacenamiento masivo y conectividad se han reducido en los últimos años; una forma eficiente de operar consiste en copiar los datos necesarios para OLAP en un sistema unificado. Este es el origen de los almacenes de datos (data warehouses) y toda la tecnología asociada (data warehousing). Estos facilitan el análisis de los datos en tiempo real (OLAP) y no disturban el OLTP de las bases de datos originales. En el entorno de los almacenes de datos (ADs), se conoce como ETL (Extracción, Transformación, Carga) a los procesos responsables de la extracción de los datos de las fuentes de datos heterogéneas, su transformación (conversión, limpieza, normalización, etc.) y su carga en el AD. El diseño y mantenimiento de los procesos ETL es un elemento clave en el éxito de un proyecto de AD por diferentes razones, destacando que el desarrollo de los procesos ETL puede suponer hasta el 80% del tiempo de desarrollo de un proyecto de AD. (Sergio Luján-Mora1, 2009). Un proceso ETL bien diseñado extrae datos de las fuentes, hace cumplir estándares de calidad de datos, a fin de que los datos puedan ser utilizados por los desarrolladores para las aplicaciones y los usuarios finales puedan tomar decisiones estratégicas. Es decir, los datos son extraídos de los sistemas fuentes, los cuales pasan por una secuencia de transformaciones antes de que se carguen en el AD. El repositorio de los sistemas que contienen las fuentes de datos para un AD puede variar desde hojas de cálculo hasta sistemas mainframe. Las transformaciones complejas son. 6.
(16) usualmente implementadas en programas procedimentales, ya sea fuera de bases de datos como por ejemplo (en C, Java, PASCAL, etc.) o dentro de base de datos.(Mufioz, 2011) Según (Inmon, 1992) un almacén de datos es: “un conjunto de datos orientado a temas, integrado, no volátil, variante en el tiempo, como soporte para la toma de decisiones”. Los almacenes de datos proporcionan acceso a datos para análisis complejos, revelación de conocimientos y toma de decisiones. Dan respuesta a las demandas de alto rendimiento de datos e información de una organización. Soportan varios tipos de aplicaciones, como OLAP, DSS y aplicaciones de minería de datos.(Villanueva, 2008) OLAP (on-line analitical processing): análisis de datos complejos del almacén de datos. (Villanueva, 2008) Los DSS (decission support systems) proporcionan a las personas que han de tomar decisiones importantes dentro de una organización, datos de nivel superior para la toma de decisiones complejas.(Villanueva, 2008) La minería de datos se emplea para el descubrimiento de conocimiento: es un proceso de búsqueda, a partir de los datos, de conocimientos nuevos y no anticipados. (Villanueva, 2008) Las bases de datos tradicionales soportan OLTP:(Villanueva, 2008) Operaciones de inserción, actualización y borrado que implican sólo algunas tuplas por relación. Aunque también soporta requisitos de consultas de información, están optimizadas para procesar consultas que abarcan una pequeña parte de la base datos. Por lo tanto, no pueden ser optimizadas para OLAP, DSS o minería de datos. Para examinar los almacenes de datos y distinguirlos de las bases de datos transaccionales es necesario contar con un modelo de datos que sea apropiado.(Villanueva, 2008) . El modelo de datos multidimensional es una buena opción para las tecnologías OLAP y de soporte a la toma de decisión.. 7.
(17) . Un almacén de datos posee con frecuencia datos integrados provenientes de fuentes diversas, procesados para su almacenamiento en un modelo multidimensional.. . Los almacenes de datos suelen mantener series de tiempo y análisis de tendencia, que necesitan más datos históricos de los que contienen generalmente las bases de datos transaccionales.. . Los almacenes de datos son no volátiles. Esto significa que la información contenida en el almacén de datos cambia con menos frecuencia y puede considerarse como tiempo no real con actualización periódica.. . La información del almacén de datos es menos precisa (de grano grueso) y se actualiza de acuerdo a una política de actualización, elegida con cuidado, y que es generalmente incremental.. . Las actualizaciones del almacén de datos las realiza el componente de adquisición del almacén, que proporciona todo el procesamiento previo necesario.. Características distintivas de un almacén de datos: (Villanueva, 2008) Visión conceptual multidimensional. Dimensionalidad genérica. Dimensiones ilimitadas y niveles de agregación. Operaciones de dimensiones cruzadas sin restricciones. Tratamiento de matriz sparse y dinámica. Arquitectura cliente-servidor. Soporte multiusuario. Accesibilidad. Transparencia. Manipulación de datos intuitiva. Buen rendimiento al crear informes consistentes. Creación de informes flexibles.. 1.1 Modelado de datos en almacenes de datos Los modelos multidimensionales se prestan fácilmente a representaciones jerárquicas en lo que se conoce como exploración ascendente (roll-up) y exploración descendente (drill- down). 8.
(18) La exploración ascendente desplaza la jerarquía hacia arriba, agrupándola en unidades mayores a través de una dimensión. Por ejemplo: resumiendo los datos semanales en trimestrales o en anuales. La exploración descendente ofrece la función contraria (de grano más fino). Por ejemplo: disgregando las ventas nacionales en ventas por regiones y después éstas en ventas por subregiones.(Villanueva, 2008) Tres son los esquemas multidimensionales comunes: Esquema en estrella: formado por una tabla de hechos con una única tabla para cada dimensión. Esquema en copos: es una variante del esquema de estrella en el que las tablas dimensionales de este último se organizan jerárquicamente mediante su normalización. Constelación de hechos: es un conjunto de tablas de hechos que comparten algunas tablas de dimensiones. Esquema en estrella (Mondéjar, 2005) Ventajas: . Fácil de entender por los usuarios.. . Reduce el número de uniones físicas. . Respuestas rápidas para la mayoría de las consultas.. . Metadatos sencillos.. . Soportado por la inmensa mayoría de las aplicaciones.. Inconvenientes: . El aumento del tamaño de la tabla de hechos con datos agregados puede empeorar el rendimiento general. . . Las dimensiones tienen un tamaño enorme. . . Por ello se recomienda tablas de hechos agregados al margen.. Alrededor de 50 atributos. (Kimball and Caserta, 2004). Es poco robusto o susceptible a cambios.. 9.
(19) Esquema en copos (Mondéjar, 2005) Ventajas: . Fácil para definir jerarquías.. . Podría salvar espacio en disco, pero no demasiado.. . Mejora considerablemente cuando un gran número de requerimientos solicitan datos agregados o de niveles superiores de jerarquías. . Los requerimientos escanean un reducido números de filas.. Inconvenientes . Aumenta el número de tablas (Aumenta el número de uniones). . Algunos requerimientos pueden demorarse en exceso.. . Aumenta la complejidad de diseño y mantenimiento.. . Requiere una clave primaria más por cada nivel de jerarquía normalizado.. . No es soportado por todas las herramientas del mercado.. Constelación de hechos(Mondéjar, 2005) Ventajas: . Rapidez de respuestas a consultas de datos agregados.. Inconvenientes: . Un gran número de tablas de agregados.. . Cada tabla de agregados se usa para calcular su nivel. . Navegar por jerarquías requiere escanear distintas tablas.. . Aumenta el tamaño de los metadatos.. . Dificulta su gestión y mantenimiento ya que para cada carga nueva de datos se ha de recalcular todas las tablas de hechos.. . Puede haber requerimientos que necesiten varias tablas.. Tablas de dimensiones (Mondéjar, 2005) . Describen el contexto para analizar los hechos: Datos textuales (Alfanuméricos). 10.
(20) Datos desnormalizados. . Cada fila contiene su clave primaria y los atributos descriptores de todos los niveles de jerarquía.. . Tablas más pequeñas que las tablas de hechos.. Tablas de hechos (Mondéjar, 2005) . Actividades básicas de empresas.. . Cada fila se compone de: Clave primaria (compuesta por claves ajenas de las dimensiones). Medidas (Datos numéricos).. . Generalmente las relaciones son muchos-muchos (m-n) con dimensiones y uno-muchos (m-1) en particular con cada dimensión.. 1.1.1 Diseño de los procesos ETL Con respecto al diseño de los procesos ETL y, a pesar de la importancia de especificar el mapeo desde las fuentes de datos operacionales a las estructuras de los AD (a través de restricciones y transformaciones), desafortunadamente, existen muy pocos modelos que se puedan utilizar para este objetivo. Hasta el momento, la mayor parte de la investigación en el área del modelado conceptual de los almacenes de datos se ha centrado en los usuarios finales (front-end), mientras que pocas propuestas se han centrado en el modelado conceptual de estos procesos ETL (backstage) [(Vassiliadis, 2002a),(Trujillo, 2003)]. Hasta el momento, podemos afirmar que no existe un modelo que pueda combinar (a) el nivel de detalle deseado para la integración y representación de datos a nivel de atributo y (b) un formalismo de modelado ampliamente aceptado como pueda ser el modelo ER o UML. La principal razón para esta situación es que ambos formalismos no están pensados para tal fin; por el contrario, tratan los atributos como entidades débiles (también denominados atributos o ciudadanos de segunda clase) con un único y principal papel descriptivo. Un problema principal derivado de esta situación es que en ambos formalismos los atributos no pueden servir como un final en una asociación o cualquier otra relación.. 11.
(21) Quizás se podría pensar que la forma actual de modelado es suficiente y que no hay una necesidad real de extenderla para capturar los mapeos y transformaciones a nivel de atributo. Sin embargo, podemos proporcionar varias razones en contra de este argumento: (i) documentar los AD complejos es un problema y, se está demostrando que un formalismo adecuado como pueda ser el ER o UML para la fase del diseño conceptual, facilita enormemente esta tarea, (ii) el diseño conceptual del AD debería permitir el análisis “Qué-pasa-si” de cambios posteriores. Capturar los atributos y sus relaciones como ciudadanos de primer orden mejora el diseño significativamente con respecto a estas metas. Además, la forma en que este aspecto se manejaría podría incluir una documentación informal y sencilla a través de notas de UML y, (iii) en líneas de investigación previas [(Vassiliadis, 2002b)], se ha mostrado que con el modelado de las relaciones entre atributos podemos tratar los artefactos de diseño como un grafo y medir las metas mencionadas anteriores. De nuevo, esto sería imposible con los actuales formalismos de modelado. Para alcanzar todos los objetivos mencionados anteriormente, se debe proporcionar una aproximación que nos permita modelar las particularidades de los procesos ETL en varios niveles de detalle, a través de un formalismo ampliamente aceptado (UML). En [(Trujillo, 2003)] se presenta el modelado de los procesos ETL especificando la serie de transformaciones (ej. generación de claves) que se necesitan realizar a las fuentes de datos operacionales antes de cargar los datos en el AD. Con el diagrama de mapeo de datos se extiende el UML formalmente para tratar los atributos como elementos de modelado de primera clase. Una vez realizado esto, los atributos pueden participar en asociaciones que determinan los mapeos entre atributos, junto con cualquier transformación y restricción necesaria. Una de las principales ventajas de esta propuesta es que está totalmente integrada en una aproximación global que nos permite realizar el diseño conceptual, lógico y el correspondiente diseño físico de todos los componentes del AD utilizando la misma notación. [(Luján-Mora, 2002a);(Luján-Mora, 2002b);(Luján-Mora, 2003);(Trujillo, 2001)] El diseño de un proceso de ETL se compone generalmente de seis tareas definidas en:(Trujillo, 2003) 12.
(22) . Seleccionar los datos para la extracción: se definen los datos de las fuentes (generalmente provienen de diversa fuentes heterogéneas).. . Transformar las fuentes: una vez que los datos se hayan extraído de las fuentes de datos pueden ser transformados o esos nuevos datos pueden ser derivados. Algunas de las tareas más comunes de este paso son: filtración de datos, conversión de códigos, cálculos de valores derivados, transformación entre diversos formatos de datos, generación automática de números secuenciales (llaves derivadas), etc.. . Unir las fuentes: las diversas fuentes pueden unirse para ser cargadas al almacén como una sola fuente.. . Seleccionar el destino para la carga: el destino o los destinos son seleccionados para cargar los datos posteriormente.. . Unir los atributos de las fuentes de datos con los atributos del destino: los atributos (campos) que se obtuvieron de las fuentes de datos pueden ser mapeados con los correspondientes destinos.. . Cargar los datos: el almacén en poblado con los datos transformados.. Calidad de los datos La calidad de los datos es un término que abarca tanto el estado de los datos, así como el conjunto de procesos para lograr dicho estado. El objetivo es disponer de datos libre de errores, duplicados, omisiones, variaciones y datos innecesarios. Los datos deben ser correctos, inequívocos, coherentes y completos: (PAZ, 2012) . Datos correctos: Los valores y las descripciones de los datos deben describir su verdadera definición.. . Datos inequívocos: Los valores y las descripciones de los datos sólo pueden tener un único significado.. . Datos coherentes: Los valores y las descripciones de datos deben usar una notación constante para transmitir su verdadero significado. Ejemplo: para mantener la coherencia de los datos se debe utilizar solo una nomenclatura.. . Datos completos: Se debe garantizar que los valores individuales y las descripciones de los datos, se definan para cada caso, permitiendo identificar que valores posibles puede 13.
(23) tomar cada dato y se debe asegurar que el número total de registros completados después que se realice el proceso de integración debe ser del 100% completo asegurando que no se pierde información en alguna parte del flujo de datos. Conformación Cuando la información se encuentra limpia y con una calidad adecuada, esta es unificada, conformada y normalizada. Los indicadores son calculados de una forma racional, lo mismo que los atributos de las dimensiones, para que estén unificados y en todos los sitios donde aparezcan tengan la misma estructura y el mismo significado. (JAVLIN, 2011a). 1.2 Preparación de los datos La extracción, transformación y carga (load) no son más que procedimientos (herramientas) destinados a obtener los datos de las fuentes operacionales, limpiarlos, convertirlos a los formatos de utilización y cargarlos en el repositorio final. Lo cual constituye un proceso decisivo en la construcción del AD, generalmente un equipo de desarrolladores enfrentan el trabajo de construir un Sistema de ETL para el AD, que como todo sistema pasa por una fase de análisis de los requerimientos, desde su planeación constituye un desafío para los integrantes del equipo quienes deben establecer esos requerimientos que debe cumplir tal sistema. Un proceso ETL es extremadamente complejo, propenso a errores y consume mucho tiempo (A. Simitsis, 2005). Además, se ha argumentado ampliamente, en la literatura, que los procesos ETL son costosos y que son una de las partes más importantes del desarrollo de un AD. (Inmon, 2005) Entre los requerimientos a analizar están: las necesidades del negocio, establecer el perfil de los datos (data profiling), los requerimientos de seguridad y la integración de datos entre otros. Necesidades del negocio se trata de los requerimientos de información de los usuarios finales del AD, o sea, la información que los usuarios finales necesitan para la toma de decisiones informada. En particular este requerimiento es esencial para identificar el conjunto de fuentes de datos que el equipo de ETL debe introducir en el AD. Data profiling es el proceso que emplea métodos analíticos para examinar los datos con el propósito de entender su contenido, su estructura y su calidad.. 14.
(24) Requerimientos de Seguridad, con respecto a la seguridad existe una contradicción aparente entre el establecimiento de un sistema de seguridad para los usuarios finales del AD y la misión final del AD que es publicar los datos y dar acceso amplio a ellos para su acceso. Así que con respecto a la seguridad de los datos se recomienda definirla a través de un sistema de roles con un sistema LDAP. Pero establecer la seguridad de los usuarios finales no es directamente una tarea del equipo de ETL, sin embargo el equipo de ETL necesita trabajar en un escenario especial ya que debe tener acceso completo de lectura o escritura a las tablas físicas del AD. Integridad de los datos: Los datos cumplen condiciones de integridad cuando se ajustan a todos los estándares de valor y completitud. Todos los datos del AD deben ser datos correctos. En el AD están todos los datos necesarios para la Toma de Decisiones, es completo (no existen más datos fuera de él). La credibilidad del AD depende de la integridad de sus datos. El uso del AD depende de la percepción de los usuarios y de la confianza que tengan en su contenido. De la integridad de datos depende el éxito del proyecto. El primer paso de integración es la extracción de los datos de la fuentes, lo que también se puede entenderse como selección sistemática de los datos para poblar el almacén. Aquí debe considerarse que cada origen de datos consta de una serie de características distintivas que necesitan ser tenidas en cuenta para la efectividad de la extracción de los datos en el proceso ETL. Este proceso de ETL necesita integrar sistemas que tienen diferentes SGBDs, sistemas operativos, hardware y protocolos de comunicación.. Integración de datos La integración de datos proporciona un mecanismo para unir datos de diferentes fuentes en un esquema único. La integración se lleva a cabo en dos etapas: (PRÉSTAMO, 2004) . Homogenización: transformación de la información del formato original de las fuentes naturales al formato y modelo de datos del AD.. . Integración: la información recuperada es agregada y organizada al esquema del AD.. La integración de datos de expresión como lo define (Matt Casters, 2010) se refiere al proceso de combinación de datos desde fuentes diferentes para proporcionar una única vista comprensible sobre todo de los datos combinados. 15.
(25) Teniendo presente la definición anterior se puede concluir que la integración de datos es el proceso de combinar los datos de diferentes fuentes heterogéneas entre sí con el fin de ofrecer al usuario una vista unificada de los datos limpia, libre de anomalías y con la calidad requerida.. Algoritmos de integración de datos Según explica (Hogg, 2009) en su libro ‘El análisis de la integración de datos’ existen varios algoritmos para la integración de datos, dentro de los que se destacan los siguientes: Clío, BDK, Merge, Dumas y Hummer. Para tener en cuenta el funcionamiento de estos algoritmos existen 4 criterios: 1. Entrada: tipo de datos que debe tomar el algoritmo. 2. Etapas: etapas de integración que se implementan o Pre-integración o Comparación del esquema o Conformación del esquema o La fusión y restructuración Complementar y corregir Minimalidad Comprensibilidad 3.. Información auxiliar: herramientas externas que utiliza.. 4. Salida: forma de salida del resultado de la integración.. Clío El algoritmo Clío aborda el problema de la transformación de conceptos en el esquema, en tres pasos principales: (Danay López Burgos, 2013) 1. Extracción de concepto: este proceso extrae las entidades del mundo real en el esquema, junto con sus dependientes y relaciones. 2. Principio de correlación y fusión: el concepto de mapeo y la fusión de proceso se consigue mediante la comparación de los conceptos extraídos y la búsqueda de los que corresponden. La herramienta de mapeo de generación de Clío se utiliza para obtener una especificación de una mejor relación. 16.
(26) 3. Refinamiento del esquema integrado: paso final de Clío, refina el esquema con la ayuda del usuario. La restricción de coincidencia es un concepto aceptado y permitido, se presenta al usuario con algunas versiones diferentes para elegir de un esquema final. A partir de los conceptos, Clío coincide con los comunes a ambas fuentes de datos. La fusión inicial tiene lugar en este punto. La entrada del usuario se solicita para refinar los resultados de integración. Clío acepta como su entrada esquemas XML o base de datos relacional y su salida es un esquema integrado.. BDK El nombre BDK tiene origen en las iniciales de sus autores, es una "técnica general" para la integración de datos, tiene un enfoque formal: se define como una generalización de todos los esquemas, está ideado de tal manera que un operador binario fusione a la vez conmutativa y asociativamente. El modelo de transformación está realizado para preservar las relaciones, restricciones y así permitir la traducción de cualquier modelo de otra fuente y viceversa. (Danay López Burgos, 2013) Existen restricciones de activar la habilidad para describir los modelos alternativos, como el esquema relacional (ER) y funcional. Los modelos BDK son esquemas que se pueden representar como un conjunto de grafos dirigidos donde los atributos son nodos y las relaciones son aristas. Hay dos tipos de relaciones que son permitidas, “atributo” y “especialización”. En la etapa de fusión se destruyen objetos del mismo nombre de los dos modelos en el objeto con el mismo destino. Con el fin de hacer frente a las clases implícitas en el esquema, el modelo se debilita antes de la integración, se utilizan después para eliminar un conjunto de reglas y volver a derivar las clases del nuevo esquema. (Danay López Burgos, 2013) BDK no ofrece restricciones a su entrada ya que es un modelo genérico para la integración, su salida es un modelo genérico de alto nivel también. (Danay López Burgos, 2013). 17.
(27) Merge El algoritmo Merge (combinar) está basado en el BDK. Este algoritmo integra dos modelos en base a sus correspondencias comunes. No está atado a una aplicación particular, ya sea de base de datos, XML u ontología. (Danay López Burgos, 2013) Consta de 5 etapas: (Danay López Burgos, 2013) 1. Inicialización: el resultado de la fusión, G, se inicializa a un modelo vacío θ. 2. Elementos: una relación de equivalencia es creada por el cotejo de los elementos de A, B y MapAB. Inicialmente, cada elemento está contenido en su propio grupo, sin embargo, si existe una relación entre un elemento en ambos A y B y una asignación está contenida en MapAB, entonces estos se agrupan. 3. Propiedades del elemento: la propiedad de cada elemento se calcula por un conjunto de reglas definidas. 4. Relaciones: por cada par de elementos de G, ahora se crean relaciones entre los grupos en la que cada elemento está en un grupo diferente a la otra y no existe ninguna relación. 5. Resolución de conflictos: tras los pasos anteriores, G es ahora una unión de A, B y MapAB sin duplicados. Sin embargo, durante este proceso pueden producirse conflictos dentro del modelo. Para cada conflicto, verifica si hay una regla definida para la resolución de conflictos, si no se aplica una regla predeterminada. Este algoritmo no hace restricciones a su entrada o salida, ya que recibe y ofrece un modelo genérico.. DUMAS El algoritmo DUMAS acepta únicamente bases de datos relacionales como entrada. No implementa las etapas de pre-integración, conformación o restructuración. Tiene variables que se pueden modificar para variar el rendimiento del algoritmo: (Danay López Burgos, 2013) . K- duplicados a utilizar para la creación de la matriz de similitud promedio.. . TokenThreshold- valor en el que dos símbolos se definen como duplicados. 18.
(28) . K Threhold- el valor en el que dos tuplas se definen como duplicados.. El algoritmo está compuesto de tres pasos que describen su funcionalidad y como se implementa. El paso 1 consiste en tomar cada fila de la primera tabla, tratando toda la fila como una cadena. A continuación se compara esta cadena con cada fila de la otra tabla, también como una cadena. Para la comparación de cadenas, se usa SoftTFIDF, una forma modificada de un TFIDF (Términos de frecuencia, frecuencia inversa de documento, esto es que si el término es frecuente en la coincidencia y no es frecuente en el documento, se obtiene una puntuación superior a uno, común en el documento) de la suite SecondString. El autor lo describe como un "TFIDF basado en la distancia métrica, ampliado para usar " soft " como señal de coincidencia. En concreto, las fichas se consideran una coincidencia parcial si consiguen un buen resultado utilizando un comparador de cadena interior". (Danay López Burgos, 2013) Se recibe una puntuación de la instancia comparador y se compara con el k Threshold. A continuación se agrega como "marcador" de tamaño K. Una vez que este proceso se ha repetido, se obtiene una lista de los duplicados K superior. (Danay López Burgos, 2013) En el paso 2 las tuplas duplicadas K superiores, se comparan cada campo de la primera tabla con cada uno en la segunda. Esto muestra como resultado una matriz de similitud de campo, un conjunto de puntuaciones de SoftTFIDF para cada comparación por campo. Para estas dos tuplas implica que cualquier valor por encima de tokenThreshold corresponde a una coincidencia en las dos columnas. La variación de tokenThreshold afecta a los resultados en este punto, un umbral más bajo puede identificar incorrectamente dos columnas duplicadas y a la inversa, también puede pasar por alto coincidencias correctas. El problema está parcialmente mejorado en la siguiente etapa. (Danay López Burgos, 2013) En el paso 3, al final de la segunda etapa, se obtuvieron matrices de similitud K. Para tener una visión general de las tablas, se promedian las matrices para crear una matriz de similitud acumulada. Para obtener el resultado final, los valores de esta matriz se comparan con token Threshold, los valores anteriores son ahora las columnas finales coincidentes. (Danay López Burgos, 2013) DUMAS genera una lista de pares de columnas duplicadas. 19.
(29) Hummer Este algoritmo de integración se basa en el algoritmo DUMAS expuesto anteriormente. Hummer, combina varios proyectos en su sistema. El algoritmo consta de tres pasos principales, lleva como título: "Fusión de datos en tres pasos". (Danay López Burgos, 2013) 1. Esquema de combinación y transformación de datos: el primer paso en el proceso es la alineación de esquema. Para ello se utiliza el algoritmo DUMAS. El esquema se transforma mediante la designación de una fuente elegida y cambia el nombre de todos los nombres semánticamente similares para que coincida con la fuente elegida. La transformación se completa tomando la unión externa completa de las tablas. (Danay López Burgos, 2013) 2. Detección de duplicados: Una vez que una alineación del esquema propuesto es producido, se presenta al usuario para agregar o quitar manualmente emparejamientos erróneos. Hummer entonces detecta los duplicados, no sólo teniendo en cuenta sus nodos de texto, sino también los de sus hijos, al identificar duplicados. (Danay López Burgos, 2013) 3. Resolución de conflictos: el paso final consiste en resolver la representación de los objetos del mundo real. Esta declaración es consecuente con los pasos de integración anteriores, devuelve los resultados apropiados una vez que se toman en consideración. También es posible realizar operaciones tales como la especificación de un precedente de una correspondencia duplicada. (Danay López Burgos, 2013) Hummer acepta esquemas XML o base de datos relacional como su entrada y ofrece como salida una tabla con una representación para cada objeto del mundo real.. 1.2.1 Extracción La extracción de datos es la selección sistemática de datos operacionales usados para poblar el componente de almacenamiento físico (NADER, 2003). El objetivo principal de este paso es recuperar todos los datos necesarios desde el sistema de origen como sea posible, debe ser diseñado de manera que no afecte negativamente el sistema de origen en términos de rendimiento. Este proceso tiende a ser intensivo en E/S y por lo tanto, puede interferir con las 20.
(30) operaciones críticas, por lo que debe realizarse de forma tal que se minimice el tiempo total requerido por el proceso. Se realiza sobre la fracción de los datos que fue cambiada despúes de la ejecución anterior del proceso. Se emplean varias técnicas: Algoritmos para diferenciar instantáneas de los datos, el análisis de los ficheros (.log) para reconstruir los cambios desde la extracción anterior y el uso de disparadores (triggers). El proceso de identificar los datos que han cambiado se suele llamar CDC (Change Date Capture). Un almacén de datos necesita una integración consistente de datos con calidad. Existen diversas variantes para realizar el proceso: (Javlin, 2011b) . Notificación de actualizaciones: Si el sistema de origen es capaz de proporcionar una notificación de que un registro ha cambiado y describir el cambio, esta es la forma más sencilla de obtener los datos.. . Extracto incremental: algunos sistemas pueden no ser capaces de proporcionar una notificación de que una actualización se ha producido, pero son capaces de identificar los registros que han sido modificados y proporcionar un extracto de dichos registros.. . Extracto completo: algunos sistemas no son capaces de identificar qué datos se han cambiado en absoluto, por lo que un extracto completo es la única forma de poder obtener los datos del sistema. El extracto completo requiere mantener una copia del último extracto en el mismo formato con el fin de ser capaz de identificar los cambios. El extracto completo maneja supresiones también.. Al utilizar extractos incrementales o completos, la frecuencia de retorno es extremadamente importante. Particularmente para los extractos completos, los volúmenes de datos pueden ser de decenas de gigabytes. Antes de comenzar la construcción de un sistema de extracción, se necesita un mapa de datos lógicos que documente la relación entre los campos de la fuente origen y los campos destino en las tablas. Mapa de datos lógico El mapa de datos lógico describe la relación entre los puntos de partida extremos y los puntos finales extremos de su sistema de ETL. 21.
(31) La implementación física puede ser una catástrofe si no es cuidadosamente diseñada antes de su implementación. Al igual que con cualquier otra forma de construcción, usted debe tener un plan antes de llegar al primer clavo. Antes de iniciar el desarrollo de un único proceso ETL, debe asegúrese de que tiene la apropiada documentación por lo que el proceso cumple lógica y físicamente con sus políticas establecidas ETL, procedimientos y normas. (Kimball and Caserta, 2004) Componentes de los mapas de datos lógicos: Nombre de la tabla. El nombre físico de la tabla, como aparece en el almacén de datos. Nombre de la columna destino. El nombre de la columna en la tabla del almacén de datos. Tipo de Tabla. Indica si la tabla es un hecho, dimensión, o subdimensión (estabilizadores). Tipo SCD (slowly changing dimension). Para las dimensiones, este componente indica un enfoque de tipo -1, -2, -3 o cambiar la dimensión lentamente. Este indicador puede variar para cada columna de la dimensión. Base de datos origen. El nombre de la instancia de la base de datos donde residen los datos origen. Este componente es usualmente la cadena de conexión necesaria para conectarse a la base de datos, también puede ser el nombre de un archivo. En este caso, la ruta del archivo también debe ser incluida. Nombre de la tabla origen. El nombre de la tabla donde se producen los datos origen. Habrá muchos casos en los que serán requeridas más de una tabla. En esos casos, simplemente se ponen en una lista todas las tablas necesarias para poblar la tabla relativa en el almacén de datos destino. Nombre de la columna fuente. La columna o columnas necesarias para poblar el objetivo. Basta enumerar todas las columnas necesarias para cargar la columna destino. Transformación. La manipulación exacta requerida de los datos origen por lo que se corresponde con el formato esperado del objetivo. Este componente está generalmente anotado en SQL o pseudo-código. 22.
(32) 1.2.2 Limpieza La limpieza de los datos es el proceso que trata de detectar y eliminar los conflictos en el nivel extensional cuando se integran dos o más fuentes de datos. Esta etapa es una de las más importantes, ya que garantiza la calidad de los datos en el almacén. Fases en que se divide la limpieza de datos: (Luis Enrique Sánchez Crespo, 2000) Limpieza pre-integración: un almacén tiene datos de entrada de diferentes fuentes. La limpieza pre-integración consiste en limpiar los datos de las fuentes de datos individuales antes de combinarlas en forma de almacén. En esta etapa, el mecanismo de limpieza en cada fuente de datos suele estar consciente del metadato de otra fuente de datos y del metadato del resultado del almacén. Un ejemplo de limpieza pre-integración puede ser hacer cierto que un campo particular que es resultado de combinar diferentes fuentes es acotado dentro del mismo dominio. Limpieza post-integración: después de la limpieza pre-integración el dato es integrado para formar un sencillo almacén de datos. Los datos combinados pueden no tener integridad a pesar del hecho que las fuentes de datos individuales son íntegros. Esto puede ser debido a varias razones. Una de las principales es que se han referenciado enteramente nuevos metadatos y las condiciones que permitieron la integridad de cada una de las fuentes de datos individuales no son ya aplicables. Refinamiento post-integración: este paso puede ser considerado parte de la limpieza postintegración. Aquí las inconsistencias encontradas en pasos previos son eliminadas y los datos son realimentados al algoritmo de la limpieza post-integración hasta alcanzar un grado satisfactorio de limpieza. Los datos en el mundo real son sucios: incompletos: faltan valores de los atributos, faltan ciertos atributos de interés, o contienen solo agregados de datos. con ruido: contienen errores o valores fuera de límites. inconsistentes: contienen discrepancias en nombre o códigos. 23.
(33) Tareas de la limpieza de datos: Llenar valores ausentes. Identificar valores fuera de límite y eliminar el ruido en los datos. Corregir las inconsistencias de los datos. Integración de datos. Anomalías más frecuentes que se detectan en el proceso de la unificación de datos: . No estandarización de valores o Esta anomalía consiste en la existencia de uno o varios campos que poseen datos escritos con formato diferente pero que significan lo mismo, o sea datos que no siguen un estándar o norma predeterminada. o Por ejemplo el caso típico de: (categorías de sexo Masculino / Femenino / Desconocido, M / F / null, hombre / mujer / no disponible, se convierten a la norma Masculino / Femenino / Desconocido).. Existencia de valores nulos. o Como su nombre lo indica en las fuentes se encuentran valores nulos o vacíos, lo cual atenta contra un adecuado análisis de la información. La solución que se brinda es remplazarlos por un valor normalizado o sea una constante. Esquemas no integrados. o Esta anomalía se pone de manifiesto cuando se trata de integrar varias fuentes de datos y en una de ellas aparece el nombre de un campo escrito de una forma y en la otra fuente aparece escrito con otro nombre, pero los valores que tienen ambas fuentes son equivalentes. Por ejemplo: una columna denominada raza y otra llamada color de piel y en ambos casos los valores son: Blanca, negra y mulata. La solución que se brinda es integrarlas a ambas en una sola columna bajo un mismo nombre.. 24.
(34) Existencia de duplicados. o Como su nombre lo indica es cuando se está en presencia de dos o más filas donde coinciden todos o casi todos los valores de sus campos. La solución que se ofrece es eliminar los valores duplicados o repetidos. La información obtenida durante el proceso de limpieza puede ser usada para identificar la causa de los errores en el origen y por tanto, mejorar la calidad de los datos. Dentro de los problemas a resolver por la limpieza de datos se encuentra el de calidad de los datos que puede aparecer en una fuente o en múltiples fuentes. En una fuente puede estar dado a nivel de esquema (carencias de restricciones, mal diseño del esquema) o a nivel de instancia (errores en la entrada de datos). En múltiples fuentes puede estar dado a nivel de esquema (modelos de datos y diseño de esquemas heterogénos) o a nivel de instancia (datos solapados, contradictorios e incosistentes).. 1.2.3 Transformación La transformación de datos es el proceso para realizar otros cambios en los datos operacionales para reunir los objetivos de orientación a temas e integración principalmente (NADER, 2003). En general, la forma requerida es un conjunto de archivos, uno por cada tabla identificada en el esquema físico. La transformación de los datos puede involucrar la división o la combinación de registros fuente. En ocasiones, los errores de datos que no fueron corregidos durante la limpieza son encontrados durante el proceso de transformación. Como en la limpieza, cualquier dato incorrecto es rechazado. La transformación es particularmente importante cuando necesitan mezclarse varias fuentes de datos, este proceso se llama consolidación. En estos casos, cualquier vínculo implícito entre datos de distintas fuentes necesita volverse explícito (introduciendo valores de datos explícitos). Además, las fechas y horas asociadas con el significado que tienen los datos en los negocios, necesitan ser mantenidas y correlacionadas entre fuentes; un proceso llamado “sincronización en el tiempo”. Las operaciones de transformación pueden ser intensivas tanto en E/S como en CPU. (Villanueva, 2008) Transformaciones (sumarizaciones): Los datos sumarizados aceleran los tiempos de análisis. Las sumarizaciones también ocultan complejidad de los datos, estas pueden incluir acoples (joins) de múltiples tablas, además de que proveen múltiples vistas del mismo conjunto de datos detallados (dimensiones). 25.
(35) 1.2.4 Carga El proceso de carga es la inserción sistemática de datos en el componente de almacenamiento físico AD (NADER, 2003). Este paso incluye entre otras tareas de procesamiento: el movimiento de los datos transformados y consolidados hacia la base de datos de apoyo para la toma de decisiones, la verificación de su consistencia (es decir, verificación de integridad) y la construcción de cualquier índice necesario. Se realiza en un procesamiento por lotes. El administrador debe poder controlar el proceso de carga; debe discriminarse entre los datos nuevos y los existentes; además de que puede hacerse de forma incremental o total. Movimiento de datos Por lo general, los sistemas modernos proporcionan herramientas de carga en paralelo. En ocasiones formatearán previamente los datos para darles el formato físico interno requerido por el SGBD de destino antes de la carga real. Una técnica alternativa consiste en cargar los datos en tablas de trabajo que se asemejan al esquema de destino:(Villanueva, 2008) La verificación de la integridad necesaria puede ser realizada en esas tablas de trabajo. Posteriormente, se puede usar los INSERTs de conjunto para mover los datos desde las tablas de trabajo hacia las tablas de destino. Verificación de integridad La mayor parte de la verificación de integridad de los datos puede ser realizada antes de la carga real, sin hacer referencia a los datos que ya están en la base de datos. Sin embargo, ciertas restricciones no pueden verificarse sin examinar la base de datos existente. Ejemplo: una restricción de unicidad tendrá que ser verificada, por lo general, durante la carga real. (Villanueva, 2008) Construcción de índices La presencia de índices puede hacer significativamente lento el proceso de carga. La mayoría de los SGBDs actualizan los índices conforme cada fila es insertada en la tabla subyacente. En ocasiones es buena idea eliminar los índices antes de la carga y luego volverlos a crear. Sin embargo, este enfoque presenta problemas:(Villanueva, 2008) 26.
(36) No vale la pena cuando el volumen de los nuevos datos es pequeño respecto a los ya existentes. La creación de un índice grande puede dar lugar a errores de asignación irrecuperables. La mayoría de los SGBDs soportan la creación de índices en paralelo (agilizar los procesos de carga y de construcción de índices).. 1.3 Herramientas que se utilizan para realizar los procesos de ETL Existen una amplia variedad de herramientas que se pueden utilizar en los procesos de ETL, las empresas productoras de software compiten entre sí para darle mayor popularidad a sus productos. Estos software se pueden clasificar en dos géneros, software libre y propietario, la primera categoría le ofrece la posibilidad al usuario de acceder al código fuente de estos productos para concebir modificaciones ofreciéndole popularidad a las herramientas que se encuentran dentro de esta clase además el valor de estos productos son más bajos haciendo que mayor cantidad de usuarios accedan a ellos. Por otra parte el software propietario es más costoso y no permite acceder al código fuente, pero es más utilizado por empresas ya que ofrece una mayor seguridad del producto a sus usuarios a través del soporte que provee la empresa dueña del software.. 1.3.1 Herramientas propietarias SSIS SQLServer Integration Services El gestor de base de datos SQL Server posee entre sus principales características facilidad de instalación, distribución y utilización. Entre sus herramientas posee un administrador corporativo y un analizador de consultas. Puede utilizarse el mismo motor de base de datos a través de plataformas que van desde equipos portátiles hasta grandes servidores con varios procesadores que ejecutan Microsoft Windows en sus más recientes versiones. Entre sus funcionalidades se encuentra el almacenamiento de datos, incluye herramientas para extraer y analizar datos resumidos para el procesamiento analítico en línea (acrónimo del inglés Online Analitycal Processing (OLAP)). También se utiliza para combinar datos de almacenes de datos heterogéneos, llenar almacenamientos de datos y puestos de datos, limpiar y normalizar datos,. 27.
(37) generar BI en un proceso de transformación de datos y automatizar las funciones administrativas y la carga de datos (GRECOL, 2012). Ab Inito Herramienta ETL que se alimenta de diversas fuentes, procesando la información, aplicando reglas de negocio y alimentando otros sistemas o AD. La herramienta tiene un Front-End de desarrollo gráfico, implementado con módulos inter conectables que a su vez pueden ser programados con lógica específica (CORPORATION, 2010). Estos procesos se generan en background shell scripts de UNIX por lo que se requiere tener cierto conocimiento de línea de comandos UNIX, Linux, o similar. Oracle Data Integrator Oracle Data Integrator es la herramienta de integración de datos de Oracle (GIL, 2011). Es la apuesta de Oracle en cuestiones de integración de datos y sustituyó a OWB (Oracle Warehouse Builder). Forma parte de la solución OFM (Oracle Fusion Middleware) y está totalmente integrada con otras soluciones Oracle relacionadas con la gestión de datos. Ejecuta procesos con altos volúmenes de datos, obteniendo excelentes tiempos de respuesta. Actualiza los AD, data marts, cubos OLAP y sistemas analíticos en general. Gestiona de forma transparente las cargas totales o incrementales, considera dimensiones SCD (Slowly Changes Dimensions), asegura la integridad y consistencia de datos y facilita la trazabilidad del dato (origen del dato, detalle de transformaciones y destino del dato). Procesos de integración de datos basados en datos de entrada, procesos .batch, eventos y ejecución de servicios. Conectividad: ficheros planos, ficheros XML, directorios LDAP, conexiones vía ODBC, JDBC e integración con arquitecturas SOA. Alta disponibilidad y escalabilidad: Gestión y administración centralizadas (consola ODI). ODI se integra con la plataforma Oracle Fusion Middleware, ofreciendo sus componentes como aplicaciones Java EE, optimizados para aprovechar al máximo las capacidades de su servidor de aplicaciones Oracle WebLogic. Los componentes ODI están provistos de funcionalidades que permiten su despliegue en un entorno de alta disponibilidad, escalabilidad y seguridad. Alta productividad en el diseño de procesos de integración de datos. 28.
(38) 1.3.2 Herramientas libres Apatar Apatar es un proyecto de código abierto que fue fundado en el año 2005. La primera versión de la herramienta fue liberada bajo la licencia GPLv2 en febrero de 2007. Esta herramienta de integración de datos proporciona conectividad a una variedad de bases de datos, aplicaciones, protocolos, archivos y mucho más. Además permite a los desarrolladores, administradores de bases de datos y usuarios de negocios integrar la información entre una variedad de fuentes y formatos de datos y proporciona una interfaz de usuario intuitiva que no requiere codificación para configurar un trabajo de integración de datos. Apatar ofrece una serie de capacidades sin igual en un paquete de código abierto: la conectividad con Oracle, MS SQL, MySQL, Sybase, DB2, MS Access, PostgreSQL, XML, InstantDB, Paradox, BorlandJDataStore, CSV, MS Excel, QED, HSQL, ERP Compiere, SalesForce.Com, SugarCRM, Goldmine, de fuentes de datos JDBC. Ofrece una sola interfaz para gestionar todos los proyectos de integración, flexibles opciones de implementación, integración bidireccional, fácil personalización, código fuente de Java incluido. Independiente de la plataforma, se ejecuta en Windows, Linux, Mac, 100% basado en Java, sin codificación y con diseñador visual.(COMMUNITY, 2010) CloverETL Herramienta basada en Java. Marco de trabajo para la integración de datos y la creación de transformaciones de datos. El componente base sigue el concepto de gráficos de transformación que consisten en nodos individuales. Cualquier transformación puede ser definida como un conjunto de nodos interconectados a través del cual los datos fluyen. Se puede utilizar como una aplicación independiente o estar integrada en un proyecto mayor. CloverETL trabaja con todos los datos estructurados, permite la combinación, transformación y circulación de los datos de cualquier origen. Las aplicaciones para CloverETL: . Migración de datos.. . Recopilación de datos.. . ETL para Almacenes de Datos. 29.
(39) . Integración de datos.. . Licencias y políticas.. CloverETL Engine es una herramienta de código abierto distribuido bajo licencia dual (comerciales y LGPL), que permite una total transparencia y control sobre la herramienta, la fuente de código completo para el Engine está disponible para todos los clientes y usuarios.(GUTIÉRREZ, 2010) Pentaho Data Integration Pentaho es una suite de herramientas de Inteligencia de Negocios (BI) que tiene dos versiones, la versión comercial y la versión de código abierto. Todas sus herramientas están programadas en código 100% Java. Dentro de las que destaca un producto para la integración de datos llamado PDI. El cual utiliza un enfoque innovador y tiene una fuerte interfaz gráfica muy fácil de usar para el usuario. La compañía comenzó en torno a 2001 y no fue hasta 2002 cuando Kettle se integró en ella. Es líder mundial de sistemas de BI código abierto, ofrece una amplia gama de herramientas orientadas a la integración de información y al análisis inteligente de los datos de su organización. Cuenta con potentes capacidades para la gestión de procesos ETL, informes interactivos, análisis multidimensionales de información OLAP y minería de datos. Todos estos servicios están integrados en una plataforma Web, en la que el usuario puede consultar de una manera fácil e intuitiva. Los módulos incluidos por Pentaho pueden utilizarse de manera conjunta o de forma separada según las necesidades de su organización. Transforma e integra datos entre sistemas de información existentes y los Data marts que compondrán el sistema BI. Algunas de sus características más significativas: (Danay López Burgos, 2013) . Entorno gráfico de desarrollo.. . Uso de tecnologías estándar: Java, XML, JavaScript.. . Fácil de instalar y configurar.. . Basado en dos tipos de objetos: transformaciones (colección de pasos en un proceso ETL) y trabajos (orquestación de transformaciones).. . Permite rápida y eficientemente extraer datos, transformarlos, limpiarlos, validarlos, cargarlos, etc., desde donde se encuentren. 30.
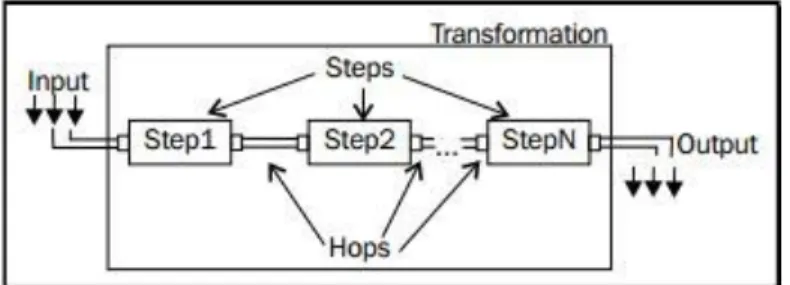
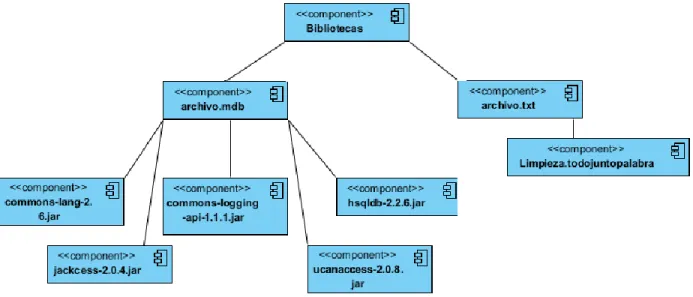
Figure


+7




Documento similar
b.10 Tabla MD_ESTACION_WBC En la Ilustración 71 se muestra la extracción de la información de la capa staging OWBSTG.T_ESTACION_WBC a un dataset, el cual es un almacén temporal
Necesidad de desarrollar un sistema para la extracción de datos provenientes del PDB y les realice las transformaciones para brindar información, que no está explícita en la
A partir de aquí se trabaja con los elementos contenidos dentro de vector2, que contiene la información para crear el nombre de una tabla, las columnas de la tabla de la base
Construcción y explotación de un almacén de datos para el análisis de información sobre alojamientos turísticos en Catalunya 3.12 Diseño Informes 3.12.1 Sobre la herramienta Para
En el proyecto este dato se registrará en la tabla de hechos de Tributaciones con el nombre de “num_retribuciones” y será de utilidad para calcular el número de personas en cada
Construcción y explotación de un almacén de datos para el análisis del sistema de prestaciones sociales 3.5 DISEÑO Y DESCRIPCIÓN DE LOS INFORMES CREADOS 3.5.1 TOTAL RETRIBUCIONES
ESTADO CASO DE Exitoso PRUEBA RESULTADO Mensaje de confirmación y se almaceno la información en la OBTENIDO base de datos.. ERRORES ASOCIADOS RESPONSABLE Samir Barros DE
Este CURSO ONLINE HOMOLOGADO de desarrollo de Componente Software y Consultas dentro del Sistema de Almacén de Datos le prepara para adquirir unos conocimientos específicos dentro
