Notación matricial en el entrenamiento de redes neuronales
5
0
0
Texto completo
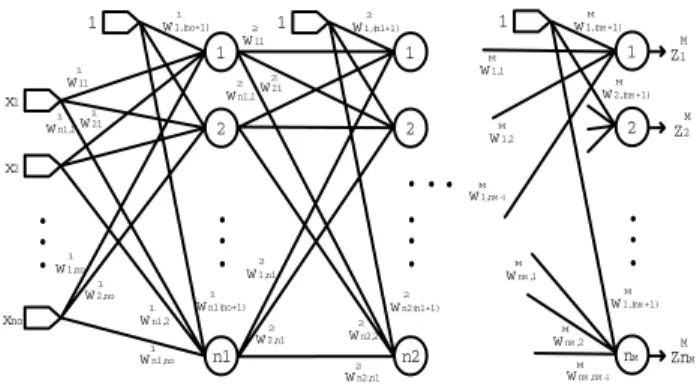
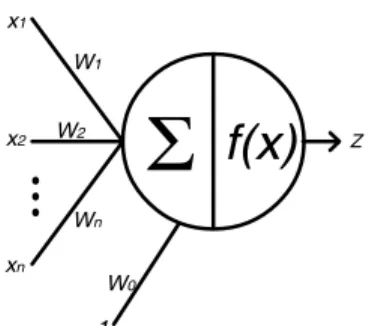
(2) Scientia et Technica Año XIII, No 34, Mayo de 2007. Universidad Tecnológica de Pereira. 104. manera que E sea mínimo; en cuyo caso, las matrices darán una aproximación considerable a las entradas del conjunto de entrenamiento [2]. El mínimo valor que toma E es cero, cuando las salidas del conjunto de entrenamiento son iguales a las salidas de la red para todo 1 ≤ k ≤ K.. x1 W1 x2. Σ. W2. f(x). Z. Wn xn. El paradigma usado para ajustar las matrices de pesos es:. W0 1. W(t + 1) = W(t ) + ∆W(t ). Figura 2. Neurona genérica de una red neuronal.. Si ésta es la neurona i correspondiente a la capa L, la L i está. salida z. dada por [2]:. nL−1 ⎛ L ⎡ z L −1 ⎤ ⎞ ⎛ ⎞ ziL = f ⎜ wiL, nL−1 + ∑ wijL x j ⎟ = f ⎜ w i ⎢ ⎥ ⎟⎟ ⎜ 1 j =1 ⎝ ⎠ ⎣ ⎦⎠ ⎝. Donde ∆W(t) tiene varios métodos de cálculo; en este artículo se va a usar el llamado Backpropagation, pues contiene cálculos relativamente simples. Este método consiste en hacer que el paso ∆W(t) sea un pequeño incremento de las matrices de pesos en la dirección del gradiente negativo de E respecto a W, que es la dirección del máximo descenso de E en el punto W(t) [5], esto es:. 3. ENTRENAMIENTO DE LA RED NEURONAL Partiendo de un conjunto de datos experimentales de un modelo desconocido de cualquier índole (por ejemplo un sistema físico), se pueden obtener dos subconjuntos de datos, uno para entrenar y otro para validar. El objetivo de este procedimiento es que pueda obtenerse un criterio de generalización para el modelo, en el caso en que la entrada no coincida con las entradas del conjunto de entrenamiento, lo cual es muy probable. Se dan entonces, en este orden, los conjuntos: {x(l ), d(l ); l ∈ Ω1} y {x(l ), d(l ); l ∈ Ω 2 } En los que Ω1 y Ω2 son disjuntos y definen los conjuntos de entrenamiento y de validación. Para realizar el entrenamiento de la red, se ajusta la colección de matrices WL para producir el resultado deseado [3]. Esto se realiza minimizando la función definida como el promedio de los errores medios cuadráticos de las salidas de la capa M entre todo el conjunto de entrenamiento {x(k ), d( k );1 ≤ k ≤ K } [4]:. E=. 1 K. 1 ∑ 2 ∑ ⎡⎣d ( k ) − z ( k )⎤⎦ K. k =1. nM. q =1. q. M q. ∆W(t ) = −η. El proceso se realiza iterativamente hasta obtener una tolerancia de error medio cuadrático, o un número de iteraciones dado, para un η dado. La dificultad de este proceso está en que todas las matrices de pesos están acopladas mediante operaciones matemáticas no lineales, y el cálculo del gradiente puede ser costoso. A continuación se presenta la deducción de una metodología de cálculo para este gradiente. Para una capa dada, se tiene:. ⎛ u1L ⎞ ⎜ L⎟ nL−1 u2 L u = ⎜ ⎟ , uiL = wiL( nL−1 +1) + ∑ wijL z Lj −1 , 1 ≤ i ≤ nL (1) ⎜ ⎟ j =1 ⎜ L⎟ ⎜ un ⎟ ⎝ L⎠ Por lo cual:. (. El error E es función de las matrices WL y el problema de entrenamiento consiste en hallar dichas matrices de tal. ). T ⎡ z L −1 ⎤ L L −1T L u = WL ⎢ ⎥ = W z ,1 , donde ⎣ 1 ⎦. 2. Aquí, k se refiere a la muestra de entrenamiento evaluada del conjunto de K muestras y q es una neurona genérica en la capa de salida. Cada superíndice L hace referencia a la capa L en un total de M capas, a su vez cada capa tiene nM neuronas. Se usará el subíndice i para denotar neuronas de la capa actual y el subíndice j para denotar neuronas de la capa anterior, de modo que cada matriz de pesos WL se asigna a la capa L y tiene dimensiones nL x (nL-1 + 1), y L = 1 corresponde a la primera capa oculta.. ∂E ∂W. ( ). z = f u , L. 1≤ L ≤ M. L. 0. Se entiende que en la capa de entrada z se toma como el vector de entrada. 2 ∂E 1 K nM ∂ ⎡ d k − zqM ( k ) ⎤⎦ = = ∑∑ L L ⎣ q( ) 2 K k =1 q =1 ∂W ∂W. {. 1 = 2K. }. ∂zqM ( k ) M ⎡ ⎤ −2 ⎣ d q ( k ) − z q ( k ) ⎦ ∑∑ ∂W L k =1 q =1 K. Para determinar. nM. ∂zqM ( k ) ∂W L. se tiene:.
(3) Scientia et Technica Año XIII, No 34, Mayo de 2007. Universidad Tecnológica de Pereira. ∂zqM ( k ) ∂w. L ij. entonces: 1 ∂E =− ∂wijL K. ∂zqM ( k ) ∂uiL ( k ). =. =. ∂zqM ( k ) ∂uiL ( k ) ∂u. L i. (k ). Con lo anterior se obtiene que:. ∂w. L ij. ⎧ 1 K nM M L L −1 ⎪− ∑∑ ⎡⎣ d q ( k ) − zq ( k ) ⎤⎦ δ i ( k , q ) z j ( k ) ,1 ≤ j ≤ nL −1 ∂E ⎪ k k =1 q =1 =⎨ ∂wijL ⎪ 1 K nM − ∑∑ ⎣⎡ d q ( k ) − zqM ( k ) ⎦⎤ δ iL ( k , q ) , j = nL −1 + 1 ⎪ k k =1 q =1 ⎩. ∂zqM ( k ) ∂uiL ( k ) M ⎡ ⎤ d k − z k ( ) ( ) ∑∑ q ⎣ q ⎦ ∂u L ( k ) ∂wL k =1 q =1 i ij nM. K. 105. ∂zqM ( k ) ∂ziL ( k ) ∂zqM ( k ) ' L = f u k ( ) ( i ) ∂z L ( k ) ∂ziL ( k ) ∂uiL ( k ) i. Para recuperar la notación matricial mencionada al principio, se presenta a WL como un arreglo por filas:. zqM (k ) es función de urL +1 ( k ) ; con 1 ≤ r ≤ n L+1 , y urL +1 ( k ). es función de ziL ( k ) ; con 1 ≤ i ≤ nL , por lo cual, aplicando la regla de la cadena [5] se tiene:. ∂zqM ( k ). ∂ziL ( k ) Por lo tanto: ∂z. M q L i. ∂z. = ∇zqM ( k ). u. L+1. (k ). •. ∂u L +1 ( k ) ∂ziL ( k ). L L w i = ⎡⎣ wiL1 , … , wiL( nL−1 ) , wiL( nL−1 +1) ⎤⎦ , es una fila de W .. Entonces:. ∂z ( k ) ∂u ( k ) (k ) =∑ ( k ) r =1 ∂u ( k ) ∂z ( k ) nL+1. De la ecuación (1):. L +1 r L i. M q L +1 r. ∂uiL ( k ). ⎡ z L −1 ( k ) ⎤ = ⎢ ⎥ L ∂wi ⎣ 1 ⎦ independiente del valor de i : 1 ≤ i ≤ nL .. ∂urL +1 ( k ) = wriL +1 L ∂zi ( k ). L+1. ∂uiL ( k ). nL+1. = f ' ( uiL ( k ) ) ∑. ∂zqM ( k ). L +1 (k ) r =1 ∂ur. wriL +1 .. L +1. wi. = ⎡⎣ w1Li +1 ,… , w(Ln+L1−1 )i ⎤⎦ es la columna i .. Así:. Se define:. δ iL ( k , q ). δ iL ( k , q ). ∂zqM ( k ) ∂u. L i. (k ). nL+1. ∑δ (k, q) w. , de manera que,. r =1. nL+1. f ' ( uiL ( k ) ) ∑ δ rL +1 ( k , q )wriL +1 r =1. Este último hecho, hace que el cálculo de. δ. L i. (k, q). ). Donde δ(r) es la función delta de Kronecker [6]: ⎧1, r = 0 δ (r ) = ⎨ ⎩0, r ≠ 0. L +1 r. L +1 ri. L +1 L +1 = ⎡⎣ w i ⎤⎦ δ ( k , q ) donde T. δ L +1 ( k , q ) = ⎡⎣δ1L +1 ( k , q ) ,… , δ nL+1 ( k , q ) ⎤⎦ L+1. se. haga recursivo, calculando sus valores a partir de los mismos en capas posteriores, haciendo un flujo de datos hacia atrás respecto a las capas; de allí que reciba el nombre de error Backpropagation [4]. Dado que el cálculo es recursivo, requiere una inicialización en la última capa, que se obtiene derivando la salida en la última capa: ∂z M ( k ) δ iM ( k , q ) = qM = f ' uiM ( k ) δ ( q − i ) ∂ui ( k ). (. (2). Se puede presentar también W como un arreglo por columnas: L +1 L +1 L +1 L +1 W = ⎡⎣ w1 , … , w nL , w nL +1 ⎤⎦ , donde. con lo cual:. ∂zqM ( k ). W L = ⎡⎣ w iL ⎤⎦ i =1:nL. ⎡ w1L ⎤ ⎢ L⎥ ⎢w ⎥ = ⎢ 2 ⎥ donde, ⎢ ⎥ ⎢ w nL ⎥ ⎣ L⎦. Con lo cual:. δ iL ( k , q ) = f ' ( uiL ( k ) ) ⎡⎣ w iL +1 ⎤⎦ δ L +1 ( k , q ) T. De la ecuación (1), se tiene:. ( ) (. ) ). (. ). ⎡ w L +1 ⎢ 1 ⎢ L +1 w δ L ( k , q ) = f ' u L ( k ) ∗ ⎢⎢ 2 ⎢ ⎢ L +1 ⎢⎣ w nL. (. T. δ L +1 ( k , q ) ⎤. ⎥ ⎥ δ ( k , q )⎥ ⎥ ⎥ T ⎥ L +1 δ ( k , q )⎥ ⎦ T. L +1.
(4) Scientia et Technica Año XIII, No 34, Mayo de 2007. Universidad Tecnológica de Pereira. 106. El operador * entre dos vectores de igual dimensión se define aquí, como la multiplicación de ellos componente a componente, es decir:. ( ). x ∗ y = diag ( x ) y = ⎡⎣ x ⋅ diag y ⎤⎦. Con todo:. ) ((. (. δ L ( k , q ) = f ' u L ( k ) ∗ ⎡⎢ ⎣. nL +1). W L +1. ). T. T 1. δ L +1 ( k , q ) ⎤⎥. L. ⎡⎣ d q ( k ) − zqM ( k ) ⎤⎦ δ L ( k , q ) = ekq δ L ( k , q ) ,. para todo 1 ≤ k ≤ K , puede escribirse en forma matricial; así:. Λ qL. ⎦. ⎡e1q δ L (1, q ) , e2q δ L ( 2, q ) , …, ekq δ L ( K , q ) ⎤ ⎣ ⎦. donde Λ qL puede obtenerse como:. o también: δ. el vector:. ( k , q ) = diag ( f ' ( u L ( k ) ) ) ( ( n +1)W L+1 ) δ L+1 ( k , q ). Λ qL. T. L. Donde la notación. ( p). A indica que a la matriz A se le ha. retirado la columna p, de manera que la notación matricial queda: ∂E 1 =− L ∂W K. ⎡z ( k )⎤ ∑∑ ⎣⎡d ( k ) − z ( k )⎦⎤δ ( k , q ) ⎢ 1 ⎥ L −1. nM. K. M q. q. k =1 q =1. 1{nL ,1} es un vector columna de nL unos, y la operación * se ha definido antes. Con lo anterior:. T. (3). L. ⎣. q L L L 1{nL ,1} e ∗ ⎡⎣δ (1, q ) , δ ( 2, q ) , … , δ ( K , q ) ⎤⎦. ∂E 1 =− L K ∂W. ⎦. ⎡ z L −1 ( k ) ⎤ e δ (k, q) ⎢ ⎥ ∑∑ q =1 k =1 ⎣ 1 ⎦ nM. K. T. L. q k. o también: ∂E 1 =− ∂W L K. ∑∑ ⎡⎣d ( k ) − z ( k )⎤⎦δ ( k , q ) ⎡⎣⎢( z ( k ) ) K. nM. M q. q. k =1 q =1. L −1. L. T. ,1⎤ ⎦⎥. L Esto debido a que en (2), ∂ui (k ) no depende de i sino ∂wijL solo de j y por tanto la expresión:. ∂zqM ( k ) ∂uiL ( k ) ∂u. L i. (k ). ∂w. L ij. 1 ∂E =− K ∂W L. Sea:. ⎡ Z L −1 ⎤ ⎡ z L −1 (1) z L −1 ( 2 ) … z L −1 ( K ) ⎤ =⎢ = ⎢ ⎥ ⎥ 1 1 ⎦ … ⎣ 1 ⎣1{1, K }⎦ T. 1Z. L −1. ∂E 1 =− L ∂W K. da como resultado el producto externo:. La expresión (3) se puede simplificar aun más, si se tiene en cuenta lo siguiente:. ⎡ z L −1 ( k ) ⎤ L M ⎡ ⎤ δ d k z k k q , − ( ) ( ) ( ) ⎢ ⎥ ∑∑ q ⎣ q ⎦ q =1 k =1 ⎣ 1 ⎦ nM. K. y sea:. ekq = d q ( k ) − zqM ( k ). 1. y. Dicha operación es conmutativa.. eq = ⎡⎣ e1q ,… , ekq ⎤⎦. nM. ∑Λ q =1. L q. 1Z L −1. Con todo se pasa a especificar la función f(u), la cual puede tomar varias formas. Entre éstas están las formas diferenciables que son necesarias para evaluar cualquier algoritmo basado en el gradiente. Estas formas son las siguientes [2]:. T. tal como se define el producto externo en [7].. 1 ∂E =− K ∂W L. T. Ahora el cálculo del gradiente se reduce a:. para todo 1 ≤ i ≤ nL , 1 ≤ j ≤ nL −1 + 1. ∂zqM ( k ) ⎡ ∂uiL ( k ) ⎤ ⎢ L L ⎥ ∂u ( k ) ⎣ ∂ w i ⎦. ⎡ z L −1 (1) z L −1 ( 2 ) … z L −1 ( K ) ⎤ Λ qL ⎢ ⎥ ∑ 1 … 1 ⎦ q =1 ⎣ 1 nM. T. Nombre Logística o Sigmoid Tangente hiperbólica Lineal. Fórmula 1 f ( x) = 1 + e− x e x − e− x f ( x) = x −x e +e f ( x) = x. Derivada f. '. ( x ) = f ( x ) ⎣⎡1 − f ( x )⎦⎤. f ' ( x ) = 1 − ⎡⎣ f ( x ) ⎤⎦. 2. f ' ( x) = 1. Tabla 1. Funciones de activación diferenciables.. Nótese que para el entrenamiento se hace necesario evaluar las derivadas de las funciones de activación para las neuronas, y con las funciones mencionadas antes se pueden calcular de forma directa a partir del valor de la.
(5) Scientia et Technica Año XIII, No 34, Mayo de 2007. Universidad Tecnológica de Pereira. función y no de su parámetro, esto resulta útil en el entrenamiento. 4. RESULTADOS OBTENIDOS Dada la formulación anterior, es realizado un algoritmo en Matlab ®, que calcula en cada iteración, el gradiente del error y actualiza las matrices de pesos con varias tasas de entrenamiento η. Además de esto se puede aplicar en algunos casos el método del momento, para varios valores de la constante de momento µ. El algoritmo con momento se da mediante la expresión [1, 2]: W ( t + 1) = W ( t ) + ∆W ( t ) + µ ⎡⎣ W ( t ) − W ( t − 1) ⎤⎦. Para hacer uso del algoritmo se ha realizado el entrenamiento de una red neuronal, como un sistema que modela el músculo humano del antebrazo en [8], en ésta se realizó el entrenamiento de once redes neuronales entre las cuales se obtienen resultados para el entrenamiento con una capa oculta y para dos capas ocultas como se muestra en las tablas 1 y 2. Parámetros. Error (Nm)2. Error porcentual. Tiempo de entrenamiento. η=0,006, µ=0,6 η=0,05, µ=0 η=0,07, µ=0. 23,9910 18,6003 22,6619. 0,09% 0,08% 0,09%. 41 min 25 min 33 min. Tabla 1. Resultados del entrenamiento del modelo del músculo, con 50 neuronas en la capa oculta.. Parámetros Capa 1, 25; Capa 2, 25. η=0,05, µ=0 η=0,07, µ=0. 107. La importancia de la expresión obtenida para el gradiente del error, es que solo debe realizar una suma por las neuronas de la ultima capa, pues el resto se calcula con una operación de multiplicación de matrices que se obtienen a partir de los datos de entrenamiento. Fue realizado un algoritmo en Matlab ®, que realiza las operaciones necesarias y sirve para entrenar en forma general una red neuronal de M capas con cualquier cantidad de neuronas en cada capa. En este se ha notado que el tiempo que tarda el algoritmo en realizar una actualización de las matrices de pesos no depende en forma estricta del número de neuronas en cada capa, ni del número de datos de entrenamiento, sino más bien del número de capas. Se ha mostrado como la notación matricial para el entrenamiento de redes neuronales además de simplificar el número de cálculos, también presenta un mejor rendimiento al ser implementada en Matlab ® ya que este programa esta basado en la computación matricial. 6. BIBLIOGRAFÍA [1] MathWorks, Neural Network Toolbox: User’s Guide Version 4. For Use with MATLAB, The MathWorks, Inc., Natick, MA, 2000. [2] Y. H. Hu and J.-N. Hwang, Handbook of Neural Network Signal Processing. CRC Press LLC, 2002. [3] B. Widrow and M. H. Jr., Adaptive Switching Circuits, IRE WESCON Convention Record, Pt. 4, pp. 96–104, 1960.. Error (Nm)2. Error porcentual. Tiempo de entrenamiento. 5,1495. 0,04%. 48 min. [4] M. T. Hagan, H. B. Demuth, and M. Beale, Neural Network Design. Boston, MA, USA: PWS Publishing Co., 1996.. 3,9447 2,0372. 0,04% 0,03%. 26 min 55 min. [5] T. M. Apostol, Calculus, 2nd ed., 1967, vol. 2.. Tabla 2. Resultados del entrenamiento del modelo del músculo, con 2 capas ocultas y con η=0,01 ,µ=0,2.. 5. CONCLUSIONES Y RECOMENDACIONES Se ha realizado la deducción de una forma matricial para el entrenamiento de una red neuronal Backpropagation, para lo cual se han usado propiedades básicas de las operaciones con matrices, que permiten calcular de forma directa el gradiente del error con respecto a todos los pesos de una capa. Lo anterior ha sido deducido para la forma general de una red neuronal multicapa, donde el gradiente es calculado por capas y de forma no recursiva. Se obtiene en cada capa, el valor del gradiente como una matriz que es entrada directamente al algoritmo de actualización de las matrices de pesos de la red neuronal.. [6] L. Kronecker, Mémoire Sur les Facteurs Irreductibles de l’expression x n − 1 , vol. 19, pp. 177–192, 1854, reprinted in Werke, Vol. I, pp. 77–92. [7] A. Gelb, J. Kasper, R. Nash, C. Prince, and A. Sutherland, Applied Optimal Estimation. USA: M.I.T. Press, 1974. [8] J. E. Molina, “Desarrollo de un sistema de control de un exoesqueleto para asistencia del movimiento tipo flexión y extensión”, Universidad Tecnológica de Pereira, 2006..
(6)
Figure
Documento similar
"No porque las dos, que vinieron de Valencia, no merecieran ese favor, pues eran entrambas de tan grande espíritu […] La razón porque no vió Coronas para ellas, sería
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
Esto viene a corroborar el hecho de que perviva aún hoy en el leonés occidental este diptongo, apesardel gran empuje sufrido porparte de /ue/ que empezó a desplazar a /uo/ a
En junio de 1980, el Departamento de Literatura Española de la Universi- dad de Sevilla, tras consultar con diversos estudiosos del poeta, decidió propo- ner al Claustro de la
por unidad de tiempo (throughput) en estado estacionario de las transiciones.. de una red de Petri
Missing estimates for total domestic participant spend were estimated using a similar approach of that used to calculate missing international estimates, with average shares applied
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
Ciaurriz quien, durante su primer arlo de estancia en Loyola 40 , catalogó sus fondos siguiendo la división previa a la que nos hemos referido; y si esta labor fue de
