P
ropuesta de Notación Gráfica Para el
Modelo Orientado a Documentos de
MongoDB
Juan Pablo Poveda Galvis
Director:
Roberto Albeiro Pava Díaz
Trabajo de grado para optar por el título de Ingeniero Electrónico
Bogotá, Colombia 2015
A Dios por guiarme durante toda mi vida.
Agradecimiento
Contenidos
CAPÍTULO 1—PRELIMINARES
1.1 INTRODUCCIÓN . . . . 1
1.2 PLANTEAMIENTO EL PROBLEMA . . . . 3
1.3 JUSTIFICACIÓN. . . . 4
1.4 METODOLOGÍA . . . . 5
CAPÍTULO 2—CONOCIENDOMONGODB 2.1 BASES DE DATOSNOSQL . . . . 7
2.2 INTRODUCCIÓN AMONGODB . . . . 9
2.2.1 Componentes de una base de datos de MongoDB . . . . . . . . . . . . . 11
2.3 ACID, BASEYCAP. . . 12
2.3.1 ACID (Atomicity, Consistency, Isolation, Durability) . . . . . . . . . . . . 12
2.3.2 BASE (Basically Available, Soft-state, Eventually-consistent) . . . . . . . . . 12
2.3.3 Teorema CAP . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.4 JSON – JAVASCRIPTOBJECTNOTATION . . . 13
2.4.1 Valores . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4.2 Objetos . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4.3 Arreglos . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4.4 Números y cadenas de caracteres . . . . . . . . . . . . . . . . . . 15
2.5 BSON – BINARYJSON . . . 15
2.6 ESQUEMA DINÁMICO . . . 17
2.7 CRECIMIENTO Y RECOLOCACIÓN DE LOS DOCUMENTOS . . . 17
2.8 REPLICACIÓN . . . 18
2.8.1 Conmutación automática en caso de error . . . . . . . . . . . . . . . 19
2.9.2 Fragmentación . . . . . . . . . . . . . . . . . . . . . . . . 21
2.9.3 Estructura general de un clúster . . . . . . . . . . . . . . . . . . . 21
CAPÍTULO3—MODELOS DE DATOS 3.1 MODELOS PARA RELACIONES1:N . . . 24
3.1.1 Modelando Uno-a-Pocos . . . . . . . . . . . . . . . . . . . . . 24
3.1.2 Modelando Uno-a-Muchos . . . . . . . . . . . . . . . . . . . . 25
3.1.3 Modelando Uno-a-Muchísimos . . . . . . . . . . . . . . . . . . . 26
3.1.4 Referenciación de doble vía . . . . . . . . . . . . . . . . . . . . 27
3.1.5 Desnormalización con relaciones Uno-a-Muchos . . . . . . . . . . . . . 29
3.1.6 Desnormalización con relaciones Uno-a-Muchísimos . . . . . . . . . . . 31
3.2 CONSIDERACIONES PARA MODELAR RELACIONES1:N . . . 33
3.3 MODELOS CON ESTRUCTURAS DE ÁRBOL . . . 33
3.3.1 Estructura de árbol con referencias parentales . . . . . . . . . . . . . . 34
3.3.2 Estructura de árbol con referencias hijas . . . . . . . . . . . . . . . . 35
3.3.3 Estructura de árbol con arreglo de ancestros . . . . . . . . . . . . . . . 36
3.3.4 Estructura de árbol con rutas visibles . . . . . . . . . . . . . . . . . 37
3.3.5 Estructura de árbol con conjuntos anidados . . . . . . . . . . . . . . . 38
3.4 CONSIDERACIONES PARA LOS MODELOS EN ÁRBOL . . . 39
CAPÍTULO4—DIAGRAMASORIENTADOS A DOCUMENTOS 4.1 CONVENCIÓN DE NOMBRES . . . 42
4.2 COLECCIONES . . . 42
4.3 DOCUMENTOS . . . 43
4.4 CAMPOS . . . 44
4.4.1 Disponibilidad . . . . . . . . . . . . . . . . . . . . . . . . 44
4.4.2 Indexación . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.4.3 Tipo . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.4.4 Arreglo . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.4.5 Valor . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.5 CONJUNTOS DE CAMPOS . . . 47
4.6 DOCUMENTOS EMBEBIDOS . . . 47
4.7 RELACIONES. . . 48
4.7.1 Asociación . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.7.2 Composición . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.8 RESTRICCIONES . . . 53
4.8.1 Restricciones inter-relación . . . . . . . . . . . . . . . . . . . . 53
4.9 NOTAS . . . 56
CAPÍTULO 5—EJEMPLOS DE USO 5.1 ESQUEMAS SENCILLOS . . . 59
5.1.1 Modelo Uno-a-Pocos . . . . . . . . . . . . . . . . . . . . . . 60
5.1.2 Modelos Uno-a-Muchos y Uno-a-Muchísimos . . . . . . . . . . . . . . 60
5.1.3 Refereciación de doble vía. . . . . . . . . . . . . . . . . . . . . 61
5.2 LIBRERÍA . . . 62
5.3 REDES SOCIALES . . . 64
5.4 UNIVERSIDAD . . . 66
5.5 MUSEO DE ARTE . . . 69
CAPÍTULO 6—CONCLUSIONES Y TRABAJOS FUTUROS 6.1 CONCLUSIONES . . . 73
6.2 TRABAJOS FUTUROS. . . 74
Índice de Figuras
1.1. Metodología empleada en el desarrollo del proyecto . . . 5
2.1. Escalabilidad vertical contra escalabilidad horizontal . . . 9
2.2. Relación entre escalabilidad y características en las bases de datos . . . 9
2.3. Línea de tiempo con diferentes versiones de MongoDB.G:Disponibilidad general;E:estable;D:lanzamiento de desarrollo;R:candidato a definitivo 10 2.4. Componentes de una base de datos de MongoDB . . . 11
2.5. Esquema general de comunicación entre una aplicación cliente y un servi-dor MongoDB . . . 11
2.6. Clasificación de MongoDB dentro del teorema CAP . . . 13
2.7. Valores que puede tener JSON.Imagen tomada de [1] pág.2. . . 14
2.8. Estructura de los objetos JSON
Imagen tomada de [1] pág. 2. . . 14
2.9. Estructura de los arreglos JSON
Imagen tomada de [1] pág. 3. . . 15
2.10. Representación de la estructura de una cadena de caracteres en JSON. Ima-gen tomada de [1] pág. 5. . . 16
2.11. Formato BSON para el documento del Listado de código 2.2 . . . 16
2.12. Recolocación de un documento cuando supera el espacio adicional asignado 18
2.13. Conjunto de réplica con factor de replicación 3 . . . 18
2.14. Fragmentación de un sistema con 20 fragmentos y factor de replicación 3 . 21
2.15. Configuración general de un cluster y pasos de una petición . . . 22
3.1. Relación búsqueda–lectura en un disco duro.Imagen tomada de [2] pág.7. . . 24
4.1. Colección . . . 43
4.2. Colección.(a)Con relación de contención.(b)Con documento dentro . . . 43
4.3. Documento . . . 43
4.4. Conjunto de campos . . . 47
4.5. Documento embebido.(a) Con asociación de composición. (b)Con docu-mento embebido dentro. . . 48
4.6. Relación de asociación . . . 49
4.7. Diagrama que representa los modelos en árbol de la sección 3.3.(a)Con re-ferencias parentales.(b)Con referencias hijas.(c)Con arreglo de ancestros. (d)Con rutas visibles.(d)Con conjuntos anidados . . . 50
4.8. Relación de composición . . . 51
4.9. Representación alternativa de una composición/contención . . . 51
4.10. Relación de composición con condición definida . . . 52
4.11. Documento embebido con documentos embebidos.(a)Con asociación de composición.(b)Con documento embebido dentro. . . 52
4.12. Restricción inter-relación con objetivo compartido.(a) Disjunta-Completa. (b)Traslapada-Incompleta . . . 55
4.13. Restricción inter-relación con objetivo separado . . . 56
4.14. Anotación relacionada a una colección . . . 57
5.1. Diagrama que representa el modelo Uno-a-Pocos de la sección 3.1.1 . . . 60
5.2. Diagrama que representa el modelo Uno-a-Muchos de la sección 3.1.2 . . . 61
5.3. Diagrama que representa el modelo Uno-a-Muchísimos de la sección 3.1.3 . 61 5.4. Diagrama que representa el modelo de referenciación de doble vía de la sección 3.1.4 . . . 61
5.5. Jerarquía de notas, comentarios y respuestas . . . 62
5.6. Diagrama que representa el esquema de la base de datos de una librería . . 63
5.7. Diagrama que representa el esquema de la base de datos de un sistema de redes sociales . . . 65
5.10. Diagrama de un museo con las entidades y sus respectivas relaciones . . . 70
Capítulo
1
Preliminares
CONTENIDOS DEL CAPÍTULO
1.1 INTRODUCCIÓN
1.2 PLANTEAMIENTO EL PROBLEMA
1.3 JUSTIFICACIÓN
1.4 METODOLOGÍA
1.1 INTRODUCCIÓN
Las bases de datos han sido utilizadas ampliamente en informática para almacenar datos de manera estructurada que luego son consultados y modificados a través de una aplicación.
El modelo de bases de datos más utilizado hoy en día es el modelo relacional [3]. Este modelo nace en el año de 1970 cuando Edgar Frank Codd lo propone buscando que extensas cantidades de datos no se perdieran, conociendo como están organizados en una máquina [4]. El modelo relacional se caracteriza por almacenar todos los datos en conjuntos de datos (relaciones). Normalmente cada relación es representada como una tabla, en donde las filas son llamadas tuplas y las columnas son los campos. Teniendo esto en cuenta, una base de datos relacional es la reunión de varias tablas o relaciones.
El modelo relacional tiene ventajas que hacen que su uso sea tan extendido:
Álgebra relacional: proporciona un modelo matemático con la semántica adecua-da para representar adecua-datos almacenados en una base de adecua-datos relacional [5].
el análisis de una relación garantizando nivel mínimo de redundancia, nivel de normalización (hasta tercera forma Normal, incluida forma normal de Boyce-code) y calculo del conjunto de llaves.
Alto nivel de abstracción: gracias al alto nivel de abstracción se pueden recuperar los datos eficientemente [6].
Análisis y diseño: para el diseño de bases de datos relacionales se cuenta con metodologías como la del modelo entidad-relación, que se basa en una visión del mundo real que consta de entidades y relaciones entre esas entidades [7].
Aunque este modelo ha solucionado el problema de organización de información du-rante mucho tiempo, hoy en día se presentan problemas con el manejo de gran canti-dad de datos o Big Data. Cuando se hacen peticiones en las que se requieren datos de distintas tablas, son necesarias las operaciones de unión,join. Estas operaciones join se vuelven muy costosas computacionalmente cuando se busca unir datos de dos o más tablas de gran tamaño. En la práctica se ha encontrado que para peticiones complejas, el rendimiento de las bases de datos relacionales es menor que el de las bases de datos no relacionales orientadas a documentos [8].
Entre las opciones de modelos de bases de datos no relacionales, hay uno que llama la atención, MongoDB. MongoDB es la base de datos no relacional más utilizada en el mundo [3], además de ser una de las que mejores resultados presenta con el manejo de Big Data [9, 10]. Este sistema de bases de datos se caracteriza, como todos los modelos no relacionales, por ofrecer gran escalabilidad horizontal y tener un esquema flexible. Un esquema flexible permite que los datos sean almacenados sin seguir un esquema rígido, como en el modelo relacional y en el caso de MongoDB que sean almacena-dos en documentos sin la necesidad que toalmacena-dos los documentos sean idénticos en su estructura.
Para incrementar la productividad en la creación de bases de datos hay herramien-tas CASE (ej. MySQL Workbench, Database Designer for PostgreSQL, DB Constructor) que permiten generar código automáticamente a partir de diagramas, haciendo que el trabajo sea más rápido que con el código creado para tal fin. Sin embargo, en la actuali-dad no hay propuestas de diagramas para representar los esquemas de MongoDB; esto en parte por la dificultad en la representación de los esquemas debido a la flexibilidad que ofrece el modelo orientado a documentos.
1.2. Planteamiento el problema
1.2 PLANTEAMIENTO EL PROBLEMA
Cuando se piensa en un modelo de datos para MongoDB hay que analizar la estructura que tendrán los documentos y como se representarán las relaciones entre los datos en la aplicación. Hay dos herramientas que permiten a las aplicaciones representar esas relaciones: referencias y documentos embebidos.
En general los documentos embebidos proporcionan mejor rendimiento en las opera-ciones de lectura, y en la solicitud y recuperación de datos relacionados con una única operación con la base de datos. Sin embargo, embeber datos relacionados puede cau-sar situaciones en las que los documentos crecen después de su creación. Cuando un documento crece más del tamaño máximo asignado, es necesario reubicarlo en un nue-vo espacio de disco, ocasionando mayores tiempos de escritura y fragmentación de la información.
Referenciar documentos es adecuado para el uso de modelos normalizados. Éste mo-delo es ideal cuando: embeber datos puede resultar en mucha información redundante que no proporciona suficientes ventajas de lectura para compensar las consecuencias de la duplicación; para representar relaciones muchos-a-muchos más complejas; para modelar grandes conjuntos jerárquicos de datos. Sin embargo, las aplicaciones del la-do del cliente deben hacer más peticiones al servila-dor para resolver las referencias. Hay que tener en cuenta que MongoDB ofrece atomicidad a nivel de documento y no para operaciones sobre varios documentos.
Existe documentación que aborda la manera en la que se pueden usar varios modelos de datos para la creación de bases de datos en MongoDB (capítulo 4 de [11]). Sin em-bargo, no hay una propuesta formal de diagramas para representar los esquemas de datos de MongoDB.
El presente trabajo aportará una solución para la siguiente pregunta: ¿Se puede im-plementar una representación única para los diferentes modelos de datos que puede tener MongoDB y que eventualmente distintos modelos puedan converger en un solo diagrama?. Esta pregunta de investigación tiene como objeto relacionar las siguientes variables:
1. La definición de uno o unos esquemas para modelar bases de datos orientadas a documentos.
2. La creación de símbolos para cada uno de los elementos de MongoDB.
3. La representación de diferentes esquemas de datos en diagramas únicos.
Con base en las dos variables planteadas, surgen algunos interrogantes que pueden ayudar a determinar la solución del problema:
¿Se puede adaptar un esquema para modelar datos que pueden tener esquema dinámico?
¿Qué representación gráfica se le puede dar a la base de datos según el modelo de datos seleccionado?
¿Cómo lograr que esta herramienta pueda ser usada ampliamente por usuarios que no conocen el lenguaje para la creación de bases de datos de MongoDB?
En la actualidad no hay una propuesta formal para representar gráficamente el mo-delo orientado a documentos, así que para este propósito se deben adoptar elementos del modelo entidad-relación que no representan de forma correcta las capacidades de MongoDB.
1.3 JUSTIFICACIÓN
MongoDB es un sistema de bases de datos no relacional reciente [12] y sin embargo, se ubica como el cuarto sistema de bases de datos más usado y el primer NoSQL según la clasificación realizada por DB-Engines. [3].
La rápida acogida de MongoDB se debe a la gran cantidad y calidad de documentación que hay sobre este proyecto. MongoDB University se encarga de ofrecer cursos online gratuitos, instruídos por sus propios ingenieros, en los que más de 200000 personas se han documentado sobre sus fundamentos y uso adecuado [13].
Sin embargo, a pesar de toda la documentación existente, a un nuevo usuario que no conozca sobre bases de datos orientadas a documentos, le tomará por lo menos 7 semanas terminar un curso introductorio sobre MongoDB.
Por otra parte, la representación gráfica de modelos como el entidad-relación, ofrece un conjunto de herramientas para mejorar la comprensión del modelo y facilitar su representación. Una representación gráfica permite que personas que no conocen el lenguaje empleado por el modelo, entiendan su dinámica y puedan aportar al desarro-llo del mismo.
1.4. Metodología Usar los diagramas para la representación de diferentes modelos de datos Uso de diagramas Integrar la notación gráfica en diagramas de forma congruente Adaptación de diagramas Crear una notación gráfica para representar los elementos de MongoDB Representación de elementos Identificar las características de MongoDB Investigar sobre los últimos avances y esquemas que se pueden implementar con MongoDB Revisión de estado del arte Contextualización
Figura 1.1: Metodología empleada en el desarrollo del proyecto
1.4 METODOLOGÍA
Para el desarrollo de este proyecto se llevarán a cabo las etapas mostradas en la Figura 1.1.
Contextualización: Al finalizar la etapa de contextualización se comprende la estruc-tura general de MongoDB y su modelo de datos.
Estado del arte: El producto de esta etapa es el conocimiento de la situación actual de MongoDB y los desarrollos que se están llevando a cabo.
Representación de elementos: Como resultado se obtiene el planteamiento de una notación gráfica para cada uno de los elementos que hacen parte de MongoDB.
Adaptación de diagramas: Cada uno de los elementos de MongoDB con su respectiva notación gráfica es usado en diagramas que modelan los diferentes esquemas que se pueden implementar.
Capítulo
2
Conociendo MongoDB
CONTENIDOS DEL CAPÍTULO
2.1 BASES DE DATOSNOSQL 2.2 INTRODUCCIÓN AMONGODB 2.3 ACID, BASEYCAP
2.4 JSON – JAVASCRIPTOBJECTNO
-TATION
2.5 BSON – BINARYJSON
2.6 ESQUEMA DINÁMICO
2.7 CRECIMIENTO Y RECOLOCACIÓN DE LOS DOCUMENTOS
2.8 REPLICACIÓN
2.9 DISPONIBILIDAD
2.1 BASES DE DATOSNOSQL
Comúnmente las bases de datos no relacionales son denominadas NoSQL [8, 9]. El término NoSQL inicialmente se refería bases de datos que no usaban el estándar de consultas SQL1 (Structured Query Language – Lenguaje de Consulta Estructurado). Sin embargo con el paso de los años y un uso más extendido, el término NoSQL se entiende en la actualidad comoNot Only SQLoNo Sólo SQL, haciendo referencia a que las bases de datos no relacionales también pueden soportar el lenguaje de consultas SQL.
Las bases de datos NoSQL son desarrolladas en respuesta al aumento en el volumen de los datos almacenados por los usuarios, la frecuencia en que son consultados los datos y el rendimiento y procesamiento que esto requiere. También se caracterizan por el uso de BASE en lugar de ACID (ver Sección 2.3).
Los sistemas NoSQL son distribuídos por naturaleza. Un sistema distribuido es un conjunto de computadores interconectados, que comparten un estado ofreciendo una visión de sistema único, en el que una aplicación cliente o el usuario no percibe la diferencia entre una red y un sistema centralizado [14]. Para esto, las bases de datos NoSQL soportan fragmentación automática, lo que significa que de forma nativa propagan los datos a través de un número arbitrario de servidores; los datos son balanceados automática-mente en los servidores, y cuando un servidor se cae, puede ser reemplazado de forma rápida y transparente sin interrumpir la aplicación.
NoSQL agrupa una gran variedad de diferentes tecnologías de bases de datos [15], entre las que se encuentran:
Orientadas a documentos una reunión de claves con una estructura de datos comple-ja, se conoce como un documento. Un documento puede contener muchos pares clave-valor diferentes, pares clave-arreglo, o documentos anidados.
Orientadas a gráficos son usadas para almacenar información sobre redes, como las conexiones sociales.
Clave valor son las bases de datos NoSQL más simples. Cada ítem en la base de datos se almacena como un nombre o clave.
Por columnas están optimizadas para peticiones sobre grandes conjuntos de datos. Almacenan conjuntos de columnas en lugar de filas.
La Tabla 2.1 muestra ejemplos de bases de datos, para los modelos descritos.
La clasificación mostrada en la Tabla 2.1 es el puesto en el que se encuentra catalogada la base de datos según DB-Engines [3]. Para calcular el puntaje dado a cada base de datos, se miden los siguientes parámetros [16]
Número de veces que se menciona el sistema en los sitios web: Se mide con el número de resultados de las búsquedas en los motores de Google y Bing.
Interés general en el sistema: Para esta medición, se usa la frecuencia de búsque-das en Google Trends.
Frecuencia de discusiones técnicas sobre el sistema: Se usa el número de pregun-tas relacionadas y el número de usuarios interesados de los sitios Stack Overflow y DBA Stack Exchange.
Número de ofertas de trabajo en las que el sistema es mencionado: Se usa el número de ofertas proporcionadas en los motores de búsqueda de trabajo Indeed y Simply Hired.
2.2. Introducción a MongoDB
Tabla 2.1:Algunos ejemplos de bases de datos NoSQL, agrupados por tipo de tecnología
Modelo de datos Base de datos Clasificación [3]
Orientado a documentos MongoDB Couchbase CouchDB RavenDB 4 25 24 45
Orientado a gráficos
Neo4j Titan OrientDB ArangoDB 21 42 44 98 Clave-valor Redis Memcached Amazon DynamoDB Riak 10 22 27 31 Por columnas Cassandra Hbase Accumulo Hypertable 8 16 57 133 Escalabilidad horizontal Escalabilidad vertical
Figura 2.1: Escalabilidad vertical contra es-calabilidad horizontal
Características RDBMS MongoDB
Escalabilidad +velocidad
Figura 2.2:Relación entre escalabilidad y ca-racterísticas en las bases de datos
2.2 INTRODUCCIÓN AMONGODB
El nombre MongoDB viene de la palabra humongous que significa enorme [17]. Es un sistema de bases de datos NoSQL orientado a documentos que proporciona alto rendi-miento, alta disponibilidad y fácil escalabilidad. La filosofía de MongoDB es conseguir mayor velocidad y escalabilidad, conservando por lo menos el 80 % de las característi-cas (Figura 2.2).
Figura 2.3: Línea de tiem-po con diferentes versiones de MongoDB. G: Disponibilidad general; E: estable; D: lanza-miento de desarrollo; R: can-didato a definitivo
2.1.02.2.02.3.x2.4.02.5.x 2.6.02.7.x
03-feb-12 29-ago-12 23-oct-12 19-mar
-13
22-may-13 08-abr
-14
03-may-14
D E D E D E D
2.8.0
04-dic-14
R 1.2.0
0.9.31.0.0 1.3.01.4.01.5.x1.6.01.7.x 1.8.01.9.22.0.0
29-may-09 27-ago-09 10-dic-09 31-dic-09 25-mar
-10
09-abr
-10
05-ago-10 04-sep-10 16-mar
-11
15-ago-11 12-sep-11
G D G E E D E D E E E
1.1.0 14-sep-09 3.0.0 03-mar -15 E 3.1.0 17-mar -15 D 3.2.0 rc4 24-nov-15
lista para su uso en producción. En la Figura 2.3 se muestra una línea de tiempo con las versiones más relevantes de MongoDB [18]. Desde la versión 2.0.0, las versiones impares son lanzamientos de transición (lanzamientos de desarrollo) hacia versiones definitivas, mientras que las versiones pares son lanzamientos estables a las que solo se hace corrección de errores.
Debido a la popularidad alcanzada por MongoDB, la compañía 10gen se cambió el nombre por MongoDB Inc. y ahora enfoca todos sus esfuerzos al desarrollo de la base de datos [19]. MongoDB es el sistema de gestión de bases de datos con mayor creci-miento en 2013 [20], el sistema NoSQL más usado [21], y el cuarto sistema de bases de datos a nivel mundial [3].
A continuación se lista empresas que han utilizado MongoDB exitosamente para el desarrollo de sus plataformas [22]:
BOSH: creando nuevos negocios mediante la conexión de sensores con análisis en tiempo real.
ebay:entregando todos los metadatos multimedia a sus usuarios con un 99,999 % de disponibilidad.
McAfee: con un repositorio de datos centralizado para la plataforma global de detección de amenazas.
Adobe: Almacenamiento de datos multi-petabyte para el gestor de experiencia de Adobe.
Forbes:entregando un sistema de gestión de contenidos en dos meses y un nuevo sitio móvil en un mes.
2.2. Introducción a MongoDB
Colección Documento
Base de datos RepresentaciónBinaria
Figura 2.4:Componentes de una base de datos de MongoDB
Aplicación cliente Servidor MongoDB
PyMongo BSON
BSON
controlador
petición
0BSON
Figura 2.5:Esquema general de comu-nicación entre una aplicación cliente y un servidor MongoDB
2.2.1 Componentes de una base de datos de MongoDB
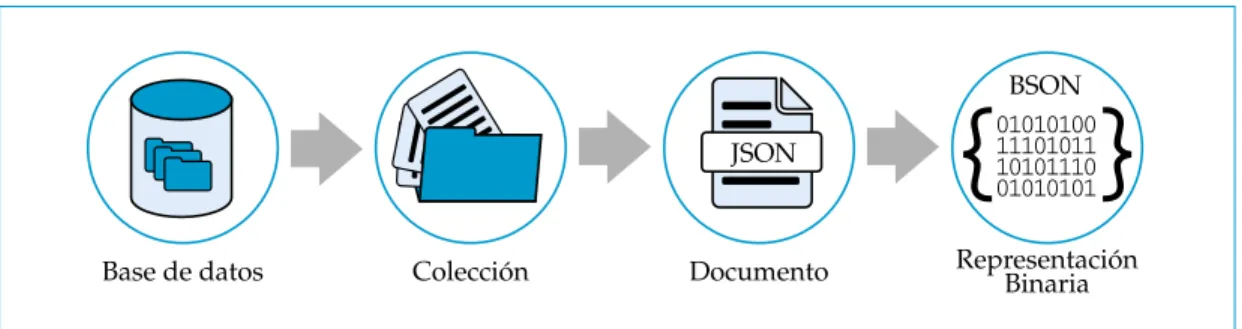
La Figura 2.4 muestra las partes que componen una base de datos de MongoDB.
Las bases de datos en MongoDB se encuentran conformadas por colecciones. A su vez una colección es un conjunto de varios documentos agrupados en ella.
Los documentos se muestran al usuario en formato JSON (Sección 2.4) para facilitar su lectura. La interacción entre el usuario y los documentos JSON, se hace por medio de una terminal que usa el lenguaje de programación JavaScript. Con la ayuda de JavaScript se pueden hacer consultas y modificar los documentos JSON.
Para hacer más eficiente la codificación, decodificación, transporte y el almacenamien-to de los diferentes tipos de daalmacenamien-tos, se usa BSON (Sección 2.5). BSON es la representa-ción binaria de los documentos JSON.
2.3 ACID, BASEYCAP
2.3.1 ACID (Atomicity, Consistency, Isolation, Durability)
ACID es un termino que describe el conjunto de propiedades necesarias para garanti-zar que las transacciones en una base de datos se realicen de forma confiable [23]. Las propiedades se describen a continuación
Atomicidad Una transacción es atómica cuando es imposible para otra parte de un sistema encontrar pasos intermedios. Si una parte de la transacción falla, toda la transacción falla y no se permiten cambios en la base de datos.
Consistencia La base de datos será consistente si la transacción empieza y termina. Llevará de un estado válido a otro estado válido.
Aislamiento Define como y cuando los cambios producidos por una operación se ha-cen visibles para las demás operaciones concurrentes. Cada transacción debe ser independiente de otras.
Durabilidad Una vez confirmada la transacción, ésta persistirá y no se podrá deshacer aunque falle el sistema.
2.3.2 BASE (Basically Available, Soft-state, Eventually-consistent)
BASE es un concepto opuesto a ACID usado por las bases de datos NoSQL. Las pro-piedades de BASE se describen a continuación
Disponibilidad básica El almacén funciona la mayoría de tiempo, incluso ante fallos, gracias al almacenamiento distribuído y replicado.
Soft-state Ni los almacenes ni sus réplicas tienen por qué ser consistentes todo el tiem-po. El programador puede verificar esa consistencia.
Consistencia eventual La consistencia se da eventualmente.
2.3.3 Teorema CAP
El teorema CAP (Consistency, Availability, Partition tolerance) establece que un sis-tema distribuido puede tener máximo dos de las tres propiedades: Consistencia (C), Disponibilidad (A), Tolerancia a particiones (P) [24].
2.4. JSON – JavaScript Object Notation
Consistencia
MongoDB
Tolerancia a particiones
Disponibilidad
Figura 2.6:Clasificación de MongoDB dentro del teorema CAP
cuenta con un sistema de único maestro o primario, y las operaciones de escritura en la base de datos se hacen en el primario antes de replicarse a otros equipos. Como las consultas se hacen al primario, se asegura que la información que se recibe es la misma que se ha escrito en la base de datos. Sin embargo el administrador de la base de datos puede habilitar la lectura desde los equipos secundarios, haciendo que el sistema sea eventualmente consistente lo que genera que algunos resultados puedan estar desactualizados. También hay alta tolerancia a particiones. Cuando se presenta un fallo, el sistema conmuta automáticamente para buscar la mejor configuración del conjunto de réplica (Subsección 2.8), garantizando que la caída de un equipo no afecte la operación del sistema.
2.4 JSON – JAVASCRIPT OBJECT NOTATION
JSON es un formato de texto que facilita el intercambio de datos estructurados entre distintos lenguajes de programación. Actualmente JSON está descrito por dos están-dares internacionales, el estándar ECMA-404 que describe la sintaxis permitida, y la norma RFC 7159 que describe además algunas consideraciones de seguridad [1, 26].
El texto JSON se codifica bajo el estándar Unicode para facilitar su tratamiento infor-mático. El conjunto de caracteres incluye 6 caracteres estructurales, cadenas de texto, números y tres caracteres de nombre literal.
Los caracteres estructurales son paréntesis cuadrado izquierdo [, corchete izquierdo
{, paréntesis cuadrado derecho], corchete derecho}, dos puntos:y coma,. Los tres caracteres de nombre literal son verdaderotrue, falsofalse, y nulonull.
Figura 2.7: Valores que puede tener JSON. Imagen tomada de [1] pág.2.
objeto
arreglo
número
cadena de caracteres
true
false
null valor
Figura 2.8: Estructura de los objetos JSON
Imagen tomada de [1] pág. 2.
cadena de caracteres valor objeto
{ }
2.4.1 Valores
Los valores JSON pueden ser un objeto, arreglo, número, cadena de caracteres,true,
falseonull, como se muestra en la Figura 2.7.
2.4.2 Objetos
Es una estructura que se representa en un par de corchetes{}, que puede estar vacío o tener pares nombre-valor. El nombre siempre es de tipo string. Si hay más de un par nombre-valor, se deben separar por coma. La Figura 2.8 muestra la estructura general de los objetos.
En MongoDB no es necesario que un nombre dentro de un objeto esté encerrado entre comillas, si el nombre empieza con una letra. El Listado de código 2.1 muestra un ejemplo de objeto JSON: en la línea 3 se ve el caso en el que el nombre no está encerrado entre comillas, lo que es permitido en MongoDB; en la línea 4 se muestra un nombre que empieza con el caracter#, lo que hace obligatorio el uso de comillas en el nombre.
Listado de código 2.1:Ejemplo de objeto en JSON
1 {
2 "ciudad": "Cartagena",
3 ciudad: "Bucaramanga",
4 "#_habitantes": 15000
2.5. BSON – Binary JSON
valor ]
[ arreglo
Figura 2.9: Estructura de los arreglos JSON
Imagen tomada de [1] pág. 3.
2.4.3 Arreglos
Un arreglo es una estructura representada dentro de paréntesis cuadrados [], que puede contener cero (0) o más valores. Los valores deben separarse por comas y el orden en que se colocan se mantiene. La estructura de un arreglo se muestra en la Figura 2.9.
2.4.4 Números y cadenas de caracteres
Los números representan en base decimal. Pueden ser negativos, decimales y pueden tener exponentes de diez con el prefijoe.
Una cadena de caracteres es un conjunto de código Unicode dentro de comillas. La estructura general de una cadena de caracteres de representa en la Figura 2.10.
2.5 BSON – BINARY JSON
BSON representa los documentos JSON de forma binaria y permite la representación de tipos de datos que no hacen parte de la especificación JSON, como datos de tipo fecha y datos de tipo binario (arreglo de bytes).
Hay cuatro tipos de datos básicos que se usan en el resto de la gramática [27]
byte 1 byte (8-bits)
int32 4 bytes (32-bit entero con signo, complemento a dos)
int64 8 bytes (64-bit entero con signo, complemento a dos)
double 8 bytes (64-bit IEEE 754 punto flotante)
La Figura 2.11 muestra el formato BSON generado para el documento JSON que se muestra a continuación
Listado de código 2.2:Documento JSON usado en el formato BSON de la Figura 2.11
Cualquier punto de código excepto ” o \ o caracter de control
comillas
barra inversa
barra inclinada
retroceso
salto de página
salto de línea
retorno de carro
tabulación
4 dígitos hexadecimales "
\
b
f
n
r
t
u
" "
/
/ cadena de caracteres
Figura 2.10:Representación de la estructura de una cadena de caracteres en JSON.Imagen tomada de [1] pág. 5.
Figura 2.11: Forma-to BSON para el do-cumento del Listado de código 2.2
23 a ∅ 3 b ∅ 4 xyz ∅ ∅
"b": "xyz"
valor valor
clave clave
longitud valor tipo valor (utf-8)
tipo valor (int-32)
tamaño documento fin de objeto
2.6. Esquema dinámico
Como se ve en la Figura 2.11, el documento BSON empieza con el tamaño del docu-mento, 23 bytes, seguido por: el tipo de valor del primer objeto (número en formato int-32); la clave del primer objeto,a; el valor del primer objeto,3; el tipo de valor del segundo objeto (cadena de caracteres en formato utf-8); la clave del segundo objeto,b; la longitud de la cadena de caracteres,4; el valor del segundo objeto,xyz; y un valor nulo∅ que indica el fin del objeto. Nótese que cada cadena de caracteres siempre va seguida de un valor nulo∅.
El principal uso del formato BSON es el almacenamiento y transferencia de datos de las bases de datos de MongoDB. Un servidor de MongoDB trabaja con BSON de forma nativa.
2.6 ESQUEMA DINÁMICO
Los documentos en MongoDB tienen un esquema dinámico. Esquema dinámico signi-fica que los documentos de una misma colección no necesitan tener la misma estructu-ra, y los campos comunes a varios documentos pueden tener diferentes tipos de datos. En los Listados de código 2.3 y 2.4, se ve como los dos documentos de la misma colec-ción tienen diferente estructura. Mientras que la clave"Natalicio"del primer docu-mento tiene un valor numérico, la clave"Natalicio"del segundo documento tiene como valor una cadena de caracteres; también se ve como el primer documento tiene un par clave-valor"Ciudad": "Lituania" que el segundo documento no tiene y de la misma forma, el segundo documento tiene el par clave-valor"Cod_postal": 1234que el primer documento no contiene.
Listado de código 2.3: Documento de Mon-goDB perteneciente a la colección docentes
{
"_id" : ObjectId("5462 ee906994db65eeab3075"), "Natalicio": 1911,
"Nombre": "Kazys",
"Apellido": "Gabriunas", "Ciudad": "Lituania" }
Listado de código 2.4: Documento de Mon-goDB perteneciente a la colección docentes
{
"_id" : ObjectId("5462 ee956994db65eeab3076"), "Nombre": "Vytautas", "Apellido": "Gabriunas", "Natalicio": "desc.", "Cod_postal": 1234 }
2.7 CRECIMIENTO Y RECOLOCACIÓN DE LOS DOCUMENTOS
D1 D2 D3
espacio adicional (a)
D1vacíoD3 D2
movimiento (b)
Figura 2.12: Recolocación de un documento cuando supera el espacio adicional asignado
Figura 2.13: Conjunto de réplica con factor de replicación 3
a
b
c
Primario a
b
c Secundario
a
b
c Secundario
documentos
réplica
réplica
Cuando se agota el espacio adicional asignado, se tiene que hacer una operación de movimiento para dar más espacio al documento. Una operación de movimiento es cos-tosa computacionalmente, por lo que hay que evitar que los documentos crezcan más de lo asignado usando una estrategia de asignación de espacio adecuada. Las opera-ciones de movimiento de documentos son efectuadas automáticamente por MongoDB.
2.8 REPLICACIÓN
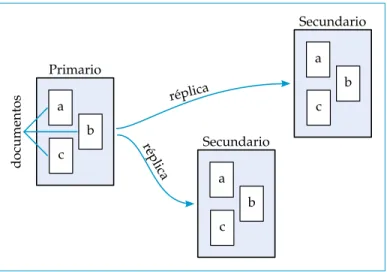
La replicación consiste en contar con varias copias de la misma información en varios equipos. Esto con el fin de tener alta disponibilidad de los datos en caso de error, y asegurar copias de seguridad para recuperar los datos en caso de desastre. Al conjunto de equipos que contiene la misma información, se le llamaconjunto de réplica. La Figura 2.13, muestra el diagrama de un conjunto de réplica.
2.8. Replicación
de documentos que hay en el sistemadT
RF·n = dT (2.1)
3·100×106 = 300×106
En cada conjunto de réplica solo puede haber un equipo primario o maestro que es el que replica la información a los equipos secundarios o esclavos. Esto se hace para que solo el miembro primario del conjunto pueda aceptar operaciones de escritura, y de esta manera asegurar estricta consistencia en todas las lecturas que se hagan en él.
2.8.1 Conmutación automática en caso de error
Los conjuntos de réplica proveen alta disponibilidad de los datos usando conmuta-ción automática en caso de error. La conmutaconmuta-ción permite que un miembro secundario llegue a ser primario, si el primario no está disponible.
Cuando el primario no está disponible, los secundario hacen una votación para elegir un nuevo primario. En algunos casos la operación de conmutación requiere revertir las operaciones de escritura para mantener la consistencia entre los miembros del con-junto de réplica. El ganador de la votación del concon-junto de réplica se da por mayoría absoluta.
2.8.2 Preferencias de lectura
Por defecto las operaciones de lectura se hacen en el equipo primario para asegurar consistencia en los datos. Sin embargo, el administrador de la base de datos puede indicarle al sistema que cambie este comportamiento. Hay que tener en cuenta que cuando se consulta información en un equipo secundario, ésta puede ser obsoleta, lo que se denomina consistencia eventual. Las opciones de lectura disponibles en Mon-goDB se describen a continuación:
Primario Modo por defecto. Todas las operaciones de lectura se hacen desde el prima-rio del conjunto de réplica actual.
Preferir primario En la mayoría de situaciones, las operaciones de lectura se hacen desde el primario, pero si éste no se encuentra disponible, se hacen desde los miembros secundarios.
Secundario Todas las operaciones de lectura se hacen desde los miembros secundarios del conjunto de réplica. Nunca desde el primario.
El más cercano Las operaciones de lectura se hacen desde el miembro del conjunto de réplica con menor latencia en la red, independientemente del tipo de miembro.
2.9 DISPONIBILIDAD
Cuando alguno de los miembros del conjunto de réplica se encuentra fuera de opera-ción, el administrador de la base de datos puede reconfigurar el conjunto. Una recon-figuración solo se puede hacer si la mayoría del conjunto está en operación y si hay un primario disponible.
La primera configuración del conjunto de réplica es almacenada por todos los miem-bros como la 1.0 y la primera reconfiguración como la 2.0.
En caso de que un miembro del conjunto de réplica se encuentre fuera de operación durante una reconfiguración y se recupere después de ésta, comparará su versión con la versión de configuración del primario y entonces procederá a actualizar su configu-ración.
En la reconfiguración también se puede especificar un servidor con mayor prioridad para ser primario. Dicho servidor será elegido entre los miembros del conjunto de réplica como primario, cuando la reconfiguración se halla efectuado.
2.9.1 Árbitros
Un árbitro es un servidor que ayuda en casos en los que es necesario votar para elegir un primario. Un árbitro no tiene copia de la réplica de datos, por lo que no puede ser primario ni votar por él mismo.
Los árbitros se permiten en conjuntos de réplica en los que hay un número par de miembros y se necesite desempatar la votación. Es importante no ejecutar árbitros en los equipos que alojen miembros primarios o secundarios del conjunto de réplica, para evitar que el árbitro no salga de operación en caso de falla de dicho equipo.
Existen dos maneras en las que el administrador de la base de datos puede influir en los resultados de la votación para elegir primario:
Establecer la prioridad:Se puede establecer la prioridad de un miembro del con-junto para ser elegido como primario. Si se establece prioridad 0 en algún servi-dor, éste nunca llegará a ser primario. La prioridad se establece con cualquier número real positivo, y entre mayor sea, más posibilidades tendrá el servidor de ser primario. Por defecto es 1.
2.9. Disponibilidad
S1 S2
m=20
S20
. . . S3
RF=3 a d g
documentos
Figura 2.14: Fragmenta-ción de un sistema con 20 fragmentos y factor de re-plicación 3
2.9.2 Fragmentación
La fragmentación consiste en dividir la información en varias partes, para repartir la carga de trabajo entre varios equipos del sistema [28]. Cada fragmentoSmpuede estar
alojado en un conjunto de réplica. El número de fragmentos se representa con la letra m. En la Figura 2.14 se tienen 20 fragmentos de la informaciónm=20.
Conociendo el número de fragmentos y la cantidad de documentos distintos en el sis-teman =100×106, se puede estimar con la ecuación (2.2) la cantidad aproximada de documentos por equipode. La precisión de esta estimación dependerá del estado del
balance de documentos en los fragmentos.
n
m ≈ de (2.2)
100×106
/20 ≈ 5×106 (2.3)
De acuerdo con (2.3) hay aproximadamente 5 millones de documentos por equipo.
2.9.3 Estructura general de un clúster
Un conjunto de computadores o clúster en MongoDB, puede tener servidores con los siguientes tipos de procesos:
mongos se comunican con los procesos mongod y con los servidores de configuración para obtener metadatos, de tal forma que cuando el cliente realice una petición, el proceso mongos tenga la información necesaria para decidir a qué fragmento Sm enviar la petición. Los procesos mongos no tienen un estado persistente (no
hay archivos de datos en ellos), en realidad son como un equilibrador de carga entre fragmentos.
Figura 2.15: Configu-ración general de un cluster y pasos de una petición
conjunto de
mongod mongod . . . mongod
mongos mongos . . . servidor
config.
cliente cliente cliente . . . 1
2
3 4
5
6 réplica
S1 S2 Sm
La Figura 2.15 muestra un diagrama de la configuración general de un clúster con los pasos llevados a cabo en una petición por parte del cliente. Dichos pasos se describen a continuación:
1. El cliente envía una petición a MongoDB, que está configurado para que sea aten-dida por un servidor con proceso mongos.
2. El proceso mongos reenvía la petición al servidor de configuración para obte-ner metadatos con información sobre en que fragmento se encuentran los datos solicitados por el cliente.
3. El servidor de configuración responde al proceso mongos con los metadatos so-licitados.
4. El proceso mongos redirige la petición hecha por el cliente al proceso mongod en el fragmento en el que se encuentran los datos solicitados.
5. El proceso mongod responde enviando los datos solicitados por el proceso mon-gos.
Capítulo
3
Modelos de datos
CONTENIDOS DEL CAPÍTULO
3.1 MODELOS PARA RELACIONES1:N
3.2 CONSIDERACIONES PARA MODE
-LAR RELACIONES1:N
3.3 MODELOS CON ESTRUCTURAS DE ÁRBOL
3.4 CONSIDERACIONES PARA LOS MODELOS EN ÁRBOL
MongoDB es un sistema de bases de datos orientado a documentos, que permite mode-lar datos de muchas formas gracias a que cuenta con esquemas dinámicos. Las posibili-dades que ofrece hacen que la formulación de modelos de datos para casos específicos pueda traer confunción, sobre todo cuando hay que decidir si embeber o referenciar los documentos.
En lo posible, siempre es recomendable embeber los documentos. Cuando se embeben documentos se logra que la operación de la base de datos sea más eficiente ya que solo es necesario hacer una petición para obtener los resultados deseados.
Por el contrario, cuando se referencian documentos es necesario hacer varias peticiones para encontrar la información. Implícitamente cada petición tiene que hacer búsque-das aleatorias en disco, por lo que a mayor número de peticiones, mayor cantidad de búsquedas aleatorias, y en consecuencia, mayor tiempo de búsqueda. En el disco duro de un servidor, el tiempo de búsqueda puede variar entre 4 ms y 10 ms, y tener una tasa de lectura de 160 MiB/s (esto depende de factores como la distancia entre las pis-tas) [29]. Si se asume una consulta de 1024 bytes de información, entonces el tiempo de lectura sería de aproximadamente 6, 4µs, como se muestra en la Figura 3.1.
Figura 3.1:Relación búsqueda–lectura en un disco duro. Imagen tomada de [2] pág.7.
Búsqueda: Lectura: 4 ms 6,4µs
Sin embargo, hay casos en los que la información de los documentos embebidos es grande y sobrepasa el límite de 16 MB de espacio asignado para cada documento. Cuando un documento agota el espacio asignado, se hace un movimiento de dicho documento a otro lugar que ofrezca el espacio necesario. Estos movimientos son cos-tosos computacionalmente y en algunos casos se pueden evitar usando referenciación.
El manual de MongoDB presenta una breve guía sobre modelos con referencias y mo-delos con estructura de árbol (sección 4.3.2 de [11]). En las secciones 3.1 y 3.2 se descri-ben los modelos de datos propuestos por William Zola y las reglas para el diseño de un modelo 1:N. Por otra parte, en la sección 3.3 se describen brevemente los modelos con estructura de árbol, concluyendo en la sección 3.4 donde se exponen las ventajas y desventajas a tener en cuenta para la elección de un modelo de árbol adecuado.
3.1 MODELOS PARA RELACIONES1:N
Los modelos de relaciones 1:N se formalizan y se acotan por el autor William Zola, clasificándolos según la cardinalidad del modelo como Uno-a-Pocos, Uno-a-Muchos y Uno-a-Muchísimos. A continuación de esa formalización, el autor muestra como opti-mizar el rendimiento de dichos modelos nombrandolos como referenciación de doble vía, desnormalización con relaciones Uno-a-Muchos y desnormalización con relacio-nes Uno-a-Muchísimos respectivamente [30].
3.1.1 Modelando Uno-a-Pocos
En una relación 1:N, cuando el lado N es menor que cientos, se puede considerar que la relación es de Uno-a-Pocos. En este caso se puede embeber la información del lado N en el lado de 1.
3.1. Modelos para relaciones 1:N
Listado de código 3.1:Ejemplo de modelado de 1-a-pocos
1 > db.buses.findOne()
2 {
3 placa: "UDB-015",
4 empresa: "Egobus",
5 tipo: "Busetón",
6 ciudad: "Bogotá",
7 mantenimiento: [
8 { dia: "Domingo", hora: "13:15", rev: "Revisión motor" },
9 { dia: "Miércoles", hora: "09:40", rev: "Lavado general"}
10 ]
11 }
Este modelo tiene como ventajas que solo es necesaria una petición a la base de datos para acceder a los detalles de los documentos embebidos, y que al ser operaciones sobre un solo documento, son operaciones atómicas. La desventaja es que no se puede acceder a los detalles incrustados como entidades independientes.
3.1.2 Modelando Uno-a-Muchos
Se considera que un modelo 1:N es de Uno-a-Muchos cuando el lado N está compuesto por varios de cientos, pero por menos de un par de miles. En este caso, se colocan referencias a los documentos del lado de “Muchos” desde los documentos del lado de “Uno”.
Un ejemplo pueden ser los estudiantes que conforman un determinado grupo de estu-dio en una universidad. En cada grupo de estuestu-dio pueden haber cientos estudiantes, pero nunca un par de cientos o menos. Este es un buen caso para usar referencias.
Para cada estudiante hay un documento y éste a su vez, tiene un código único que se usa como identificador de objeto (ObjectID).
Listado de código 3.2: Documento de un estudiante para el ejemplo de modelado de 1-a-muchos
1 > db.estudiantes.findOne()
2 {
3 _id : ObjectID("20072005055"),
4 nombre: "Luis Alberto Bustamante",
5 carrera: "Ingeniería Electrónica",
6 facultad: "Ingenierías",
7 num_cel: 3214567890
8 }
Cada grupo de investigación debe tener su propio documento, que debe contener un arreglo de referencias ObjectID a los estudiantes que conforman el grupo
1 > db.grupos.findOne()
2 {
3 _id: "FI08745",
4 nombre: "GLUD",
5 categoria "Software libre",
6 id_estudiantes: [
7 20072005055,
8 20072005059,
9 20081005077,
10 // etcétera
11 ]
12 }
Como se ve en la línea 6 del listado de código 3.3 hay un arreglo de referencias que apuntan a cada uno de los integrantes del grupo. La línea 7 apunta al documento del estudiante del listado de código 3.2.
Para encontrar los estudiantes que integran un determinado grupo, se puede usar una unión a nivel de aplicación. Primero se busca el grupo identificado por su número de registro
> grupo = db.grupos.findOne({registro: "FI08745"})
y luego todos los estudiantes que integran el grupo
> estudiantes_grupo = db.estudiantes.find ({_id:{$in :grupo. estudiantes }}).toArray()
Para una operación eficiente, es necesario tener un índice engrupos.registro. Siem-pre habrá un índice enestudiantes._id, de modo que las peticiones siempre serán eficientes en esa colección.
Este estilo de referenciación tiene varias ventajas:
1. Cada estudiante tiene un documento independiente por lo que es fácil buscarlo y actualizar su información.
2. Un estudiante puede estar vinculado a varios grupos de investigación, por lo que un esquema uno-a-muchos se puede convertir en muchos-a-muchos sin necesi-dad de una tabla de unión.
3.1.3 Modelando Uno-a-Muchísimos
3.1. Modelos para relaciones 1:N
Un ejemplo de Uno-a-Muchísimos es el sistema de almacenamiento de búsquedas de un motor de búsqueda. Las búsquedas realizadas se almacenan para ofrecer resultados de búsqueda de acuerdo a los intereses del usuario. En cualquier momento la cantidad de búsquedas diferentes puede ser tan grande que supere el tamaño máximo de alma-cenamiento establecido para un documento de MongoDB, incluso si solo se almacena el ObjectID.
En el siguiente Listado de código se muestra el documento de un usuario de un deter-minado motor de búsqueda
Listado de código 3.4: Documento de usuario de un motor de búsqueda
1 > db.usuarios.findOne()
2 {
3 _id: ObjectID("507f191e810c19729de860ea"),
4 nombre: "Diego Medina",
5 apodo: "tuno90",
6 edad: 24
7 }
El siguiente listado de código muestra un documento donde se ha almacenado una búsqueda
Listado de código 3.5:Documento de una búsqueda almacenada
1 > db.busquedas.findOne()
2 {
3 _id: ISODate("2015-03-17T18:27:41.382Z"),
4 palabras: "ultimo juego de xbox",
5 ubicacion: "Bogotá D.C.",
6 usuario: ObjectID("507f191e810c19729de860ea")
7 }
Hay que hacer una petición un poco distinta para encontrar las 2000 búsquedas más recientes de un usuario. Primero se encuentra el documento del usuario, en este caso del usuario del Listado de código 3.4
> usuario = db.usuarios.findOne({Apodo: "tuno90"})
Luego se encuentran las 2000 búsquedas más recientes vinculadas con ese usuario
> mensajes = db.busquedas.find({usuario: usuario._id}).sort({tiempo : -1}).limit(2000).toArray()
3.1.4 Referenciación de doble vía
Tomando nuevamente el ejemplo usado en la sección 3.1.1, hay una colecciónbuses
que contiene documentos con información sobre los buses, una colecciónrutasque contiene documentos de las rutas de trabajo a cubrir, y una relación Uno-a-N debuses
haciarutas. La aplicación necesitará hacer un seguimiento de todas las rutas que cubre
un bus, así que es necesario crear una referencia debusesarutas.
En las líneas 7 a 12 del Listado de código 3.6, se muestra un arreglo de referencias a documentos derutas.
Listado de código 3.6: Referenciación de doble vía para la colección buses
1 > db.buses.findOne()
2 {
3 _id: ObjectID("UDB-015"),
4 empresa: "Egobus",
5 tipo: "Busetón",
6 ciudad: "Bogotá",
7 id_rutas: [
8 "T04",
9 "552",
10 "P64",
11 //etcétera
12 ]
13 }
Por otro lado, en otros contextos esta aplicación mostrará una lista de rutas y necesitará encontrar rápidamente el bus responsable para cada ruta. Esto se puede optimizar colocando una referencia adicional al bus en el documento de la ruta, como se muestra en el Listado de código 3.7. La línea 7 referencia al documento del bus encargado de la ruta.
Listado de código 3.7:Referenciación de doble vía para la colección rutas
1 > db.rutas.findOne()
2 {
3 _id: ObjectID("T04"),
4 origen: "Tres esquinas",
5 destino: "Terminal del sur",
6 fecha: ISODate("2015-04-03"),
7 id_bus: "UDB-015"
8 }
3.1. Modelos para relaciones 1:N
este diseño de esquema ya no es posible reasignar una ruta a un bus diferente con una única actualización atómica).
3.1.5 Desnormalización con relaciones Uno-a-Muchos
La desnormalización puede eliminar la necesidad de realizar operaciones de unión a nivel de aplicación, pero añade cierta complejidad adicional al realizar actualizaciones.
Desnormalizando de Muchos-a-Uno
Tomando el ejemplo de estudiantes de la sección 3.1.2, se puede desnormalizar el nom-bre del estudiante en el arregloestudiantes[]de la línea 6 del Listado de código 3.3.
Desnormalizar significa que no hay que realizar operaciones de unión a nivel de apli-cación cuando muestren todos los nombres de los estudiantes de un grupo, pero será necesario una operación de unión para consultar cualquier otra información acerca de un estudiante.
El Listado de código 3.8 muestra la desnormalización de los nombres de los estudiantes que conforman un grupo de investigación.
Listado de código 3.8: Documento con desnormalización del nombre de los estudiantes
1 > db.grupos.findOne()
2 {
3 _id: "FI08745",
4 nombre: "GLUD",
5 categoria "Software libre",
6 estudiantes: [
7 { id: ObjectID("20072005055"), nombre: "Luis Bustamante" },
8 { id: ObjectID("20072005059"), nombre: "Laura López" },
9 { id: ObjectID("20081005077"), nombre: "Tatiana Poveda" },
10 // etcétera
11 ]
12 }
Mientras se hace más fácil obtener los nombres de los estudiantes, se añade solo un poco de trabajo del lado del cliente para las operaciones de unión a nivel de aplicación.
Primero se obtiene el documento del grupo de investigación
> grupo = db.grupos.findOne({registro: "FI08745"})
Con la funciónmapse crea un arreglo de ObjectID que contiene solo los códigos de los estudiantes
Por último se obtienen todas los estudiantes que se encuentran en el grupo de investi-gación
> grupo_est = db.estudiantes.find({_id: { $in: cod_estudiante }}). toArray()
Desnormalizar ahorra una búsqueda de los datos no normalizados a costa de una ac-tualización más costosa computacionalmente: si se ha desnormalizado el nombre del estudiante en el documento del grupo, entonces cuando se actualice el nombre del es-tudiante, también se deben actualizar todos los lugares en donde se encuentre en la coleccióngrupos.
Desnormalizar solo tiene sentido cuando hacer consultas es lo común y las actualiza-ciones se hacen rara vez. Cuando las actualizaactualiza-ciones llegan a ser más frecuentes en relación a las consultas, disminuyen los beneficios de la desnormalización.
Por ejemplo, si se supone que el nombre de un estudiante nunca cambia o cambia con poca frecuencia, pero el número de celularnum_celcambia frecuentemente, tiene sentido desnormalizar el nombre del estudiante en el documento del grupo, pero no tiene sentido desnormalizar el número celular.
También hay que notar que si se desnormaliza un campo, se pierde la capacidad de realizar actualizaciones atómicas y aisladas en ese campo. Al igual que con la refe-renciación de doble vía mostrada en la sección 3.1.4, si se actualiza el nombre de un estudiante en el documento del estudiante, y luego en el documento del grupo, ha-brá un intervalo de algunas décimas de segundo donde elnombredesnormalizado en
el documento del grupo no reflejará el nuevo valor actualizado en el documento del estudiante.
Desnormalizando de Uno-a-Muchos
También se pueden desnormalizar campos del lado de “Uno” en el lado de “Muchos”. En el Listado de código 3.9, en las líneas 8 y 9, se observa como se desnormalizó el nombre del grupo de investigación y el número de registro del grupo.
Listado de código 3.9: Documento con desnormalización del nombre y el registro del grupo
1 > db.estudiantes.findOne()
2 {
3 _id : ObjectID("20072005055"),
4 nombre: "Luis Alberto Bustamante",
5 carrera: "Ingeniería Electrónica",
6 facultad: "Ingenierías",
7 num_cel: 3214567890,
8 grupo_inv: "GLUD",
9 reg_grupo: "FI08745"
3.1. Modelos para relaciones 1:N
En este caso, como se ha desnormalizado el nombre del grupo en el documento del estudiante, entonces cuando se actualice el nombre del curso, se deben también actua-lizar todos los lugares donde se encuentre en la colección estudiantes. De esta forma una actualización es más costosa computacionalmente, ya que se deben actualizar múl-tiples documentos de estudiantes en vez de un único grupo de investigación. Es signi-ficativamente más importante considerar la proporción de consulta-escritura cuando se desnormaliza de esta forma.
3.1.6 Desnormalización con relaciones Uno-a-Muchísimos
Es posible desnormalizar el ejemplo de la sección 3.1.3 de dos maneras:
1. Poner la información del lado de “Uno” (a partir del documento del usuario) en el lado de “Muchísimos” (la colección de búsquedas)
2. Poner la información del lado de “Muchísimos” en el lado de “Uno”
Por ejemplo, se desnormaliza el lado de “Muchísimos” colocando el apodo del usuario (del lado de “Uno”, Listado de código 3.4) en el documento de una búsqueda
Listado de código 3.10: Documento con el campoapododesnormalizado
1 > db.busquedas.findOne()
2 {
3 tiempo : ISODate("2015-03-17T18:27:41.382Z"),
4 palabras: "ultimo juego de xbox",
5 ubicacion: "Bogotá D.C.",
6 usuario: ObjectID("507f191e810c19729de860ea"),
7 apodo: "tuno90"
8 }
Con esto se facilita la petición para encontrar las búsquedas más recientes de un usua-rio con determinado apodo
> mensajes = db.busquedas.find({Apodo: "tuno90"}).sort({tiempo: -1}). limit(2000).toArray()
De hecho, si la cantidad de información que se quiere almacenar del lado de “Uno” es limitada, se puede desnormalizar todo en el lado “Muchísimos” y eliminar el lado “Uno” por completo
Listado de código 3.11:Documento con toda la información de usuario desnormalizada
1 > db.busquedas.findOne()
2 {
3 tiempo : ISODate("2015-03-17T18:27:41.382Z"),
5 ubicacion: "Bogotá D.C.",
6 nombre: "Diego Medina",
7 apodo: "tuno90"
8 edad: 24
9 }
Por otro lado, también se puede desnormalizar en el lado de “Uno”. En este caso, se quiere mantener registro de las últimas 1000 búsquedas de un usuario en el documento de usuario. Se pueden usar los operadores$each y $slice para mantener esa lista ordenada, y solo conservar los últimos 1000 mensajes.
Las búsquedas son almacenadas en documentos de la colecciónbusquedascomo tam-bién en la lista desnormalizada del documento de usuario: de esta forma el registro de la búsqueda no se pierde cuando no se encuentra en el arreglousuario.busquedas.
Primero se obtienen las palabras de la búsqueda del motor de búsqueda
busqueda = obtener_busqueda(); busqueda_aqui = busqueda.palabras; ubica_user = busqueda.ubicacion; apodo_user = busqueda.apodo;
Se averigua el tiempo actual
t_actual = new Date();
Se encuentra el _id para el usuario que se está actualizando. La proyección_id: 1se
usa para que solo se envíe la información del campo_id
doc_user = db.usuarios.findOne({apodo: apodo_user},{_id: 1}) id_user = doc_user._id
Ahora se inserta la búsqueda, la referencia parental y la información desnormalizada en el lado de “Muchos”
db.busquedas.save({tiempo: t_actual, palabras: busqueda_aqui, ubicacion: ubica_user, apodo: apodo_user, usuario: id_user})
Se coloca el resultado de la búsqueda desnormalizado en el lado de “Uno”
db.usuarios.update({_id: id_user}, {$push : {busquedas :
{$each: [{tiempo: t_actual, palabras: busqueda_aqui}], $sort: { tiempo : 1 }, $slice: -1000 }
}})
3.2. Consideraciones para modelar relaciones 1:N
3.2 CONSIDERACIONES PARA MODELAR RELACIONES1:N
La siguiente guía contiene 6 reglas a considerar cuando se esta diseñando un modelo 1:N para una base de datos:
1. Preferir embeber documentos a menos que haya una razón de peso para no ha-cerlo.
2. Necesitar acceso a los detalles de los documentos embebidos como entidades independientes, es una razón para no embeberlos.
3. Los arreglos no deben crecer ilimitadamente. Si hay más de un par de cientos de documentos en el lado “Muchos”, no se deben embeber; si hay mas de unos po-cos miles de documentos en el lado de “Muchos”, es mejor no utilizar un arreglo de referencias de ObjectID. Los arreglos de alta cardinalidad son una razón de peso para no embeber documentos.
4. No necesariamente debe evitarse hacer cálculo de uniones a nivel de aplicación: si se indexa correctamente y se usa el especificador de proyección (como el mos-trado en la sección 3.1.6), entonces las uniones a nivel de aplicación solo son un poco más costosas computacionalmente que las uniones del lado del servidor en una base de datos relacional.
5. Considerar la proporción escritura/lectura cuando se desnormaliza. Un campo que en su mayoría será consultado y solo se actualizará rara vez es un buen can-didato para la desnormalización: si se desnormaliza un campo que es frecuen-temente actualizado entonces el trabajo extra de encontrar y actualizar todas las instancias puede opacar las ventajas obtenidas con la desnormalización.
6. En MongoDB, el modelo de datos depende – completamente – de los patrones de acceso a los datos de la aplicación en particular. Lo recomendable es estructurar los datos para encontrar las formas en que la aplicación hace las peticiones y las actualizaciones.
La Tabla 3.1 sugiere el modelo de datos a utilizar según la cardinalidad y las caracte-rísticas del diseño de la base de datos.
3.3 MODELOS CON ESTRUCTURAS DE ÁRBOL
Tabla 3.1:Propuesta de modelos de datos según la cardinalidad y las características
Características
Cardinalidad
Uno-a-Pocos Uno-a-Muchos Uno-a-Muchísimos La cantidad de
lecturas es muy superior a la
cantidad de actualizaciones Modelando Uno-a-Pocos Modelando Uno-a-Muchos Modelando Uno-a-Muchísimos No es necesario
el acceso a los datos del lado N como entidades independientes
La cantidad de lecturas no es muy superior o es similar
a la cantidad de actualizaciones Modelando Uno-a-Pocos Desnormalización Uno-a-Muchos Desnormalización Uno-a-Muchísimos
La cantidad de lecturas no es muy superior o es similar
a la cantidad de actualizaciones
Referenciación de doble vía
Modelando Uno-a-Muchos
Modelando Uno-a-Muchísimos Acceso a los
datos del lado N como entidades independientes
La cantidad de lecturas es muy
superior a la cantidad de actualizaciones
Referenciación de doble vía
Desnormalización Uno-a-Muchos
Desnormalización Uno-a-Muchísimos
Estos modelos almacenan información de forma jerárquica, en donde un nodo padre puede tener varios nodos hijo.
La Figura 3.2, muestra la estructura de datos que se utilizará como referencia para explicar cada uno de los modelos con estructura de árbol. El nodo “Alemanas” es de primera jerarquía, los nodos “Volkswagen Group”, “Daimler AG” y “BMW Group” son de segunda jerarquía y el resto de nodos son de tercera jerarquía.
3.3.1 Estructura de árbol con referencias parentales
Esta estructura presenta relaciones 1:N unidireccionales, en donde los documentos hijo almacenan el identificador _id de su correspondiente documento padre: relaciones
hijo→padre.
Tomando en cuenta el diagrama de la Figura 3.2, el documento de la marca Porshe y los de jerarquía superior relacionados con él, se crearían con la siguiente estructura
Listado de código 3.12: Modelo de una estructura de árbol con referencias parentales



![Figura 2.7: Valores que puede tener JSON. Imagen tomada de [1] pág. 2. objeto arreglo número cadena de caracterestruefalsenullvalor Figura 2.8: Estructura de los objetos JSON Imagen tomada de [1] pág](https://thumb-us.123doks.com/thumbv2/123dok_es/5662024.739575/30.918.126.748.134.536/figura-valores-imagen-arreglo-número-caracterestruefalsenullvalor-figura-estructura.webp)
![Figura 2.10: Representación de la estructura de una cadena de caracteres en JSON. Imagen tomada de [1] pág](https://thumb-us.123doks.com/thumbv2/123dok_es/5662024.739575/32.918.134.747.191.636/figura-representación-estructura-cadena-caracteres-json-imagen-tomada.webp)