Análisis y agrupamiento de tráfico en internet
60
0
0
Texto completo
(2) 3. RESUMEN. El análisis y agrupamiento del tráfico de Internet es una tarea desafiante que abre un campo de aplicaciones con gran potencial, las cuales pueden generar beneficios como la utilización inteligente de los recursos de red para lograr garantizar la calidad en el servicio, asignación dinámica de ancho de banda para su explotación al máximo, aumento del rendimiento de los recursos y disminución del costo de infraestructura. La ingeniería de tráfico se puede beneficiar de aplicaciones que proporcionen mayor control de la red, caracterización de cargas de trabajo, aumento en la capacidad de planeación, modelado y provisión de rutas con la finalidad de disminuir congestión en las redes. Adicionalmente, puede generar avances en relación a la seguridad para la prevención y detección de intrusos a partir de comparación de patrones de comportamiento en las redes. El presente trabajo de investigación propone una metodología desarrollada para el agrupamiento de tráfico en Internet con una sólida base en el estado del arte actual y los resultados obtenidos durante las pruebas realizadas a lo largo de las distintas etapas de experimentación. El agrupamiento o clustering es una técnica común para análisis de datos estadísticos, el cual es utilizado en muchos campos incluyendo el reconocimiento de patrones, análisis de imágenes y bioinformática. La metodología desarrollada es utilizada para establecer a su vez una comparación del rendimiento de las técnicas de agrupamiento: K-Means, Fuzzy C-Means, Gustafson-Kessel, DBScan y Expectation Maximization en el paso de minería de datos mediante la experimentación utilizando diferentes escenarios de laboratorio y reales. La metodología propuesta establece una base para el desarrollo de sistemas basados en la minería de datos que puedan ser utilizados en el análisis y agrupamiento del tráfico de Internet, así como sus aplicaciones posteriores, respetando la privacidad de la información que fluye por la red al utilizar únicamente la información que proporcionan los recolectores de tráfico. la cual reduce enormemente la cantidad de información manejada logrando ir más allá de los límites de los enfoques de análisis de tráfico ya existentes.. Tesis - Ricardo Farrera Saldai'la. 29/11/2009.
(3) 4. CONTENIDO. RESUMEN .............................................................................................................................................3. CONTENID0 ......................................................................................................................................... 4. INTRODUCCIÓN .............................................................................................................................. 6 1.1 AGRUPAMIENTO DEL TRÁFICO DE INTERNET Y SUS APLICACIONES ........................... 6 1.2 IMPORTAl'ICIA DE LA CARACTERIZACIÓN DEL TRÁFICO EN INTERNET.. ................... 7 2 ENFOQUES UTILIZADOS EN LA ACTUALIDAD ....................................................................... 9 2.1 MUESTREO DE LOS DATOS ........................................................................................................ 9 2.2 MÉTODOS ESTADISTICOS ........................................................................................................ 10 2.3 MÉTODOS DE ESTIMACIÓN Y PRONÓSTICO ....................................................................... 12 2.4 MÉTODOS DE SUBESPACI0 ...................................................................................................... 13 2.5 MÉTODOS BASADOS EN GRAFOS ............................................................................................ IS 2.6 MÉTODOS DE AGRUPAMIENTO .............................................................................................. 18 2.7 NIVELES DE INFORMACIÓN .................................................................................................... 19 2.8 COMPARACIÓN DE RESULTADOS DE LAS TÉCNICAS ACTUALES ................................. 20 3 METODOLOGÍA DE AGRUPAMIENTO DE TRÁFIC0 ............................................................. 22 3.1 1NTRODUCCI Ó N .......................................................................................................................... 22 3.2 DEFINICIÓN DE LA BASE DE INFORMACIÓN ....................................................................... 23 3.3 SELECCIÓN ...............................................................................................,.................................. 24 3.4 PRE PROCESAMIENTO ............................................................................................................... 24. Tesis - Ricardo Farrera Salda11a. 29/11/2009.
(4) 5 3.5 TRANSFORMACIÓN ................................................................................•...................•.............. 25 3.6 MINERÍA DE DATOS ................................................................................................................... 26 3.6. I AIBFC - AGGLOMERA TIVE ITERATIVE BA YESIAN FUZZY CLUSTERING ........................ 28 3.6.2 K-MEANS .................................................................................................................... ................ 30 3.6.3 FUZZY C-MEANS ........................................................................................................................ 30 3.6.4 DBSCAN (DENSITY-BASED SPATIAL CLUSTERING OF APPLICA TIONS WITH NOISE) .... 32 3.6.5 EXPECTA TION MAXIMIZATION .............................................................................................. 32 3.6.6 GUST AFSON-KESSEL ................................................................................................................ 33 3.7 INTERPRETACIÓN ...................................................................................................................... 35 3.8 EVALUACIÓN ............................................................................................................................... 35 4 EXPERIMENTACIÓN Y ANÁLISIS DE RESULTADOS ............................................................. 37 4.1 PRIMERA FASE DE EXPERIMENTACIÓN: DISPOSICIÓN DE MÉTODOS ......................... 37 4.1.1 DESCRIPCIÓN DEL AMBIENTE ................................................................................................ 37 4.1.2 RESULTADOS ............................................................................................................................. 38 4.2 SEGUNDA FASE DE EXPERIMENTACIÓN: SELECCIÓN DE MÉTODOS ........................... 40 4.2.1 DESCRIPCIÓN DEL AMBIENTE ................................................................................................ 40 4.2.2 RESULTADOS ............................................................................................................................. 40 4.3 TERCERA FASE DE EXPERIMENTACIÓN: MEJORA DE MÉTODOS ................................. 42 4.3.1 DESCRIPCIÓN DEL AMBIENTE ................................................................................................ 42 4.3.2 RESULTADOS ............................................................................................................................. 44 4.4CUARTA FASE DE EXPERIMENTACIÓN: EVALUACIÓN DE MÉTODOS .......................... 45 4.4.1 DESCRIPCIÓN DEL AMBIENTE ................................................................................................ 45 4.4.2 RESULTADOS ............................................................................................................................ 46 4.5QUINTA FASE DE EXPERIMENTACIÓN: VALIDACIÓN DE J\IÉTODOS ............................ 51 4.5.1 DESCRIPCIÓN DEL AMBIENTE .............................................................................. .................. 51 4.5.2 RESULTADOS ...................................... ..................................................................... .................. 53 5 CONCLUSIONES Y PERSPECTIVAS ........................................................................................... 56. 6 REFERENCIAS Y BIBLIOGRAFÍA .............................................................................................. 59. t Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(5) 6. 1 INTRODUCCIÓN. 1.1 AGRUPAMIENTO APLICACIONES. DEL. TRÁFICO. DE. IN'.i.'ERNET. Y. SUS. La evolución de Internet en los últimos años ha sido caracterizada por cambios dramáticos en la forma en que los usuarios se comportan, interactúan y utilizan la red. La comunidad de investigadores y muchos operadores de red están respondiendo a estos cambios diseñando y desarrollando medidas de tráfico y arquitecturas de clasificación de complejidad creciente. De hecho. la observación del tráfico de redes se encuentra en el núcleo de muchas actividades de investigación, operación y mantenimiento fundamentales de redes tales como la implementación de garantías de calidad en el servicio, ingeniería de tráfico, prevención y detección de intrusión. Por otro lado, la acelerada introducción de nuevas categorías de aplicaciones como los juegos por red y punto-a-punto, el aumento de la presencia de tráfico malicioso y el amplio uso de técnicas de encripción, hacen que la medición, análisis y clasificación del tráfico de Internet sea una tarea desafiante. La comunidad de investigadores está siendo solicitada por lo tanto para atacar los temas relacionados al análisis de tráfico enfocándose en el diseño de algoritmos novedosos capaces de sobrepasar los límites de las técnicas de inspección de paquetes, las cuales se están convirtiendo rápidamente en poco efectivas. Similarmente, nuevas arquitecturas de análisis distribuidas y plataformas de análisis de tráfico en tiempo real deben ser definidas para manejar efectivamente las redes de alta velocidad de la actualidad y del futuro. La importancia de preservar la privacidad de los usuarios y la necesidad de reducir la cantidad de tráfico que es recolectada, guardada y procesada son cada vez más consideradas como algunos de los puntos más importantes que limitan el progreso en esta área de investigación. Una de las áreas más importantes de aplicación para el análisis del tráfico de Internet es la utilización inteligente de los recursos de red, la cual permite garantizar la calidad en el servicio, asignar dinámicamente el ancho de banda disponible y proporcionar herramientas para el análisis del tráfico y gestión de los recursos para lograr como consecuencia un aumento significativo en el rendimiento de la red y disminución del costo de infraestructura, explotando al máximo el ancho de banda. Así mismo, el área de ingeniería de tráfico se beneficia del análisis de la comunicación a través de Internet, pues ayuda a obtener mayor control de la red haciendo posible la caracterización y distribución de cargas de trabajo, brindando como consecuencia la capacidad de. t Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(6) 7 planeación, modelado y provisión de rutas con la finalidad de disminuir congestiones y aprovechar al máximo los recursos. El análisis de tráfico tiene aplicaciones importantes en cuanto a seguridad, pues puede funcionar como plataforma para permitir avanzar de manera significativa hacia la prevención de ataques de red y la detección de intrusos y tráfico malicioso o no deseado, teniendo siempre en cuenta la preservación de la privacidad de los usuarios. Otras aplicaciones muy interesantes pueden derivarse de la información que genera la caracterización del tráfico que pasa a través de una red, tales como la identificación de patrones de comportamiento de los usuarios, la cual que puede ayudar a los administradores de una red a predecir la demanda de recursos y a distribuirlos por tipo de tráfico generando grandes ventajas en cuanto a la economización de recursos y mejora de la calidad de servicio proporcionada a los usuarios.. 1.2 IMPORTANCIA Dl.L ANÁLISIS DEL TRÁFICO EN INTERNET. El análisis del tráfico de aplicaciones ha sido siempre un tema de gran interés para los operadores de redes, pues es un elemento importante de muchas tareas de administración de redes tales como priorización de flujos y monitoreo de diagnóstico. Adicionalmente muchos problemas de ingeniería de redes se benefician de una identificación de tráfico de redes exacta, tales como caracterización de cargas de trabajo y modelado, capacidad de planeación y provisión de rutas. En general las prácticas de análisis del tráfico generado por aplicaciones se basan extensivamente en el uso de los números de puertos de la capa de transporte. Mientras que esta práctica puede haber sido efectiva en los primeros días de Internet, actualmente no lo es, pues los números de puertos proporcionan información limitada y las aplicaciones y usuarios frecuentemente utilizan puertos de forma inconsistente. Estudios han confirmado que el análisis de tráfico basada en puertos no es efectivo. Un enfoque para el análisis de tráfico de manera confiable requiere la revisión del contenido de los paquetes, pero ésta no es una opción viable debido a las limitantes en cuanto a hardware y complejidad, debido a temas de privacidad y de origen legal, así como la creciente tendencia del uso de encripción de información por parte de las aplicaciones y polimorfismo. La clasificación basada en el contenido de los paquetes (payload) requiere un conocimiento previo de las firmas de los protocolos de aplicación, interacciones de protocolos y formatos de los paquetes. Este enfoque no podrá clasificar tráfico de otro tipo no definido previamente. Aplicaciones de punto a punto como BitTorrent han comenzado a eludir esta técnica utilizando métodos de ofuscación tales como cifradores de texto plano. empaquetado de longitud variable. y/o encripción. Lo mencionado anteriormente conlleva a que es necesario trabajar en el problema de análisis de tráfico utilizando solamente la información que proporcionan los recolectores de flujo.. Tesis - Ricardo Farrera Saldaiia. 29/11/2009.
(7) 8 El objetivo principal de la presente propuesta es lograr proponer una metodología para análisis y caracterización de tráfico en Internet, tomando como base las técnicas existentes a la fecha.. t Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(8) 9. 2 ENFOQUES UTILIZADOS EN LA ACTUALIDAD. Los enfoques que han surgido recientemente para tratar el problema de análisis de tráfico toman en cuenta las tendencias empíricas de las aplicaciones y se mueven dentro de las limitantes del problema de análisis de tráfico, las cuales indican que no es posible acceder a los datos llevados por los paquetes, además de que es necesario evitar asumir que el número de puerto de la capa de transporte puede indicar el tipo de tráfico que viaja por la red, por lo que solamente es posible utilizar la información capturada por recolectores de tráfico.. 2.1 MUESTREO DE LOS DATOS. En [4], se presenta un estudio del rendimiento de varios métodos de muestreo con la finalidad de clasificar el tráfico de redes de banda ancha. El objetivo es evaluar los efectos de ciertos parámetros de muestreo en la integridad de las muestras resultantes. Durante el estudio se evaluaron tres principales de esquemas de muestreo: • •. Muestreo sistemático - involucra selección de parámetros de forma determinística seleccionando el primer paquete de cada flujo. Muestreo aleatorio estratificado - se selecciona de manera aleatoria un paquete para cada flujo. Muestreo aleatorio simple - selecciona uniformemente n paquetes de la población total de forma aleatoria.. En [4] se implementaron los tres esquemas mencionados anteriormente para muestreo basado en paquetes y los dos primeros para muestreo basado en tiempo y evaluaron diferentes métricas para disparidad entre las distribuciones (i.e. x2 de Pearson, pruebas como Kolmogorov-Smirnov o Anderson Darling A2. medida de costo relativo), y finalmente decidieron utilizar el coeficiente phi (~). el cual se deriva a partir de la métrica x2 debido a que no es sensible al tama1io de la muestra y además se encuentra bien establecida en la literatura estadística. El coeficiente phi es una herramienta útil para demostrar que una técnica es generalmente superior a otra en cuanto al muestreo de fracciones e intervalos de muestreo pues caracteriza el grado de asociación entre las distribuciones de muestreo y la población total.. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(9) 10. Los experimentos consistieron en un gran número de muestras explorando el dominio basado en los siguientes parámetros: • • •. Clase del método de muestreo utilizada. Métodos basados en tiempo vs. basados en evento. Granularidad o fracción de muestreo. Intervalo o longitud de tiempo sobre la cual se realizó el muestreo.. Los resultados del análisis realizado en [4] revelaron que las técnicas basadas en el tiempo no tienen tan buen rendimiento como las basadas en paquetes. Adicionalmente, las diferencias de rendimiento entre clases son muy pequeiias.. 2.2 MÉTODOS EST ADISTICOS. Las primeras técnicas que consideran un análisis de tráfico distinto al que se venía manejando en el pasado utilizan métodos estadísticos, aún en los últimos años se siguen proponiendo técnicas con metodologías basadas en estadística. I. En el estudio publicado en [9] se presentan métodos para identificar ataques DDoS utilizando el cálculo de distribuciones de entropía y frecuencia ordenada (frequency-sorted) de atributos seleccionados de los paquetes. La hipótesis planteada es que el tráfico DDoS generado por algunas herramientas introduce características particulares en sus paquetes que hacen posible distinguirlos del tráfico normal y medidas estadísticas relativamente simples pueden ser usadas para discriminar tráfico DDoS de tráfico legítimo en los ruteadores principales con suficiente exactitud para mitigar el efecto del ataque. Los algoritmos presentados miden propiedades estadísticas de campos específicos en los encabezados de paquetes en varios puntos de la Internet. Los valores de entropía de varios campos de encabezados caen dentro de un rango delgado mientras la red no se encuentra bajo ataque, y cuando la red se encuentra bajo ataque, los valores de entropía exceden los rangos de una manera detectable. La estadística chi-square proporciona una medida útil de la desviación del perfil de tráfico actual desde la línea de fondo. El funcionamiento del prototipo desarrollado 1111c1a cuando el módulo de detección logra encontrar un flujo DDoS y el sistema utiliza sus algoritmos de detección y modelos estadísticos para caracterizar los paquetes DDoS; posteriormente se utilizan las características definidas para I. Un ataque DDOS (Distribute<l Denial Of Scrvicc Attack) o Ataque de Denegación <le Servicio Distribuido es un tipo especial de DoS consistente en la realización <le un ataque conjunto y coordinado enlrc varios equipos (que pueden ser cientos o miles) hacia un servidor victima. Esto es posible gracias a un cierto tipo <le sollware malicioso que permile obtener el control de esas múquinas y que un atacante ha instalado previamente en ellas, bien por intrusión directa o mediante algún gusano. Los DDoS consiguen su objetivo gracias a que agolan el ancho <le banda de la víctima y sobrepasan la capacidad de procesamiento de los rutcadores, consiguiendo que los servicios ofrecidos por la máquina atacada no puedan ser prestados.. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(10) 11 formar una regla de filtrado de paquetes, la cual filtrará los paquetes del ataque DDoS. Una vez que el detector determina que el ataque ha terminado, puede remover las reglas apropiadas de filtrado. En la evaluación de los detectores, se simularon los ataques superponiendo el tipo de tráfico de ataque generado por alguna herramienta existente de ataques DDoS sobre trazados de varias concentraciones. Las técnicas utilizadas en [9] presentan algunas desventajas, pues suponiendo que el atacante posea cierta sofisticación en sus herramientas y conocimiento sobre el funcionamiento del detector y su ambiente. la tarea de detección se vuelve más difícil. En el caso del detector chisquare frecuentemente fallará al intentar detectarlos o generará una gran cantidad de alertas falsas-positivas. En cuanto al detector de entropía, si el atacante tiene conocimiento del entorno del detector, entonces podrá generar tráfico que produciría cambios muy pequeiios en la entropía observada. El prototipo de [9] es capaz de determinar cuanJo una red se encuentra bajo ataque y desarrolla reglas de filtrado con exactitud. El esfuerzo de filtrado es inmediato y reduce el impacto del ataque casi instantáneamente. Los resultados experimentales mostraron que el prototipo bloquea substancialmente el tráfico de ataques DDoS generado por la herramienta Stacheldraht; por su naturaleza, las metodologías propuestas logran detectar fácilmente ataques que utilizan direcciones de origen aleatorias y puertos de destino secuenciales en la mayoría de los ambientes. Por otro lado, en [ 1] se publicó un proyecto que consiste en analizar trazados de redes para descubrir y clasificar las propiedades de escaneo de puertos~ (port scanning) utilizando estadísticas con relación al tiempo que transcurre entre los paquetes que viajan por la red, con el fin de ayudar a generar sistemas de detección de intrusos (IDS - lntrusion Detection Systems) mejorados e incrementar la seguridad de las redes en general. La idea básica del trabajo en [ 1] es que al definir un conjunto de heurísticas y aplicarlas a los datos de trazados de redes es posible aislar paquetes sospechosos y agruparlos en conjuntos de escaneo, los cuales pueden ser analizados posteriormente para extraer propiedades del tráfico y recolectar estadísticas relevantes. La metodología propuesta utiliza una ventana de tiempo suficientemente larga para detectar ataques que puedan intentar evadir la detección incrementando el tiempo entre paquetes consecutivos. También combinan escaneos que parecen coordinados, en el caso de que muchos paquetes con direcciones IP fuente distintas, dentro de la misma subred, tengan como destino el mismo conjunto de dispositivos y puertos; esto, con la finalidad de detectar intentos de evasión de atacantes que utilicen computadoras "zombis", es decir, que se encuentran bajo el control del atacante. En cuanto a las reglas de clasificación, se separó el tráfico de escaneo de puertos de otro tráfico cuando se encuentran dos o más paquetes con la misma dirección IP y mismo número de puerto dentro de un intervalo de 120 segundos. Adicionalmente se mantiene el estado de los destinos guardando información de 500 destinos que no sean parte de los escaneos conocidos al momento y que tienen un intervalo de hasta 60 segundos entre paquetes consecutivos.. El escaneo de puertos_ normalmente es una práctica de usuarios maliciosos en búsqueda de vulnerabilidades, existen herramientas que pueden <,letenninar debilidades en los sistemas y ademús el mejor método para atacarlos, algunas de ellas adicionalmente pueden utilizar direcciones IP aleatorias y cambiar el ürdL,1 e intervalos entre paquetes.. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(11) 12 Los autores de [ 1] mencionan que la mayoría de los escaneos encontrados fueron realizados sobre el protocolo TCP y algunos cuantos en UDP, y se encontró que gran pa11e de los escaneos fueron verticales. Además se localizó geográficamente el origen de la mayor parte de los ataques en Europa y Norte América. Por su parte, los autores de [5] se presentan un proceso automático para la clasificación de tráfico en tiempo real y para la detección de comportamientos anormales en el tráfico IP, el cual pretende detectar anomalías asociadas a un servicio particular y reconocer automáticamente el servicio asociado a una secuencia dada de paquetes en la capa de transporte además del reconocimiento de servicios en redes multiservicios, tomando como base los aspectos funcionales de las aplicaciones. El método propone que durante un periodo de actividad, una aplicación intercambia secuencias típicas de paquetes de control con un dispositivo remoto. Las secuencias de paquetes de control TCP ~Jn estadísticamente diferentes de una aplicación a otra, lo cual puede ser capturado o modelado como una cadena de Markov de primer orden. Los diferentes tipos de paquetes de control intercambiados constituyen el espacio de estados de la cadena de Markov y las probabilidades de transición (matriz de transición) entre los estados identifican una 'firma' distintiva para cada aplicación. El enfoque propuesto por [5] se descompone en un paso de aprendizaje y un paso de decisión. En el paso de aprendizaje se identifica cada aplicación. modelando la secuencia de sus paquetes en la capa de transporte utilizando una cadena de Markov de primer orden. y a partir de un conjunto de datos de entrenamiento que consta de un gran número de aplicaciones y un gran número de flujos por cada aplicación. En el segundo paso se decide cual servicio debe ser asociado a cualquier nueva secuencia de paquetes. El problema de inferir una aplicación a partir de los paquetes de control es un problema de decisión multi-hipótesis y el número de hipótesis puede ser muy grande pues existe una gran cantidad de aplicaciones. Por lo que para la creación de la regla de decisión, los autores utilizaron la teoría de decisión basada en el criterio de similitud (likelihood criterion) y en pruebas Neyman-Pearson, así como la entropía y la distancia KL. Durante la evaluación [5] observaron que las aplicaciones que utilizan diferentes protocolos son fácilmente diferenciables a partir de un número de paquetes pequeño. Mientras que aplicaciones que cuentan con protocolos similares (i.e. HTTP y HTTPS) requieren de una cantidad mayor de observaciones para lograr una discriminación con pocas falsas alarmas. La metodología propuesta produjo resultados favorables con un rendimiento considerablemente bueno en relación a las pruebas realizadas.. 2.3 MÉTODOS DE ESTIMACIÓN Y PRONÓSTICO En el año 2004 también aparecen estudios acerca del problema de clasificación de tráfico con diferentes enfoques que van más allá de la estadística, y utilizan técnicas de estimación y pronóstico, también se comienzan a introducir métodos de agrupamiento así como redes neuronales y se compara su rendimiento.. 1 Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(12) 13 La clasificación de tráfico en redes aplicando algoritmos de pronóstico realizada por [3] con el propósito de caracterizar ataques propone un enfoque para detección de intrusos basado en anomalías, enfocándose en la comprensión de la actividad de redes a través de su comportamiento. La caracterización del tráfico de red involucra filtrado en los campos de encabezados y correlaciona los eventos anómalos en diferentes conjuntos de datos para formar caracterizaciones de eventos únicos. Inicialmente en [3] filtran los datos a partir de ciertos puertos buscando actividad de virus y escaneas de puertos u otras actividades relacionadas con puertos. Algunos de los datos se filtran nuevamente utilizando como base el tipo de protocolo usado o banderas de TCP. Posteriormente. se aplica el algoritmo Holt-Winters a estos datos para encontrar eventos anómalos detectables que pueden ser caracterizados. El método de pronóstico Holt-Winters tiene el fin de distinguir patrones de ataques, el cual es un algoritmo exponencial de predicción suavizada, de tal forma que los datos son filtrados con el propósito de que ciertos tipos de actividad maliciosa pueden ser más claramente expuestos y más fácilmente detectables. El algoritmo Holt-Winters funciona básicamente de la siguiente manera: una vez que se conoce un valor predicho, entonces se compara con el valor real para indicar tráfico que no se encuentra dentro del rango de tolerancia del algoritmo, lo cual se logra generalmente utilizando una ventana deslizante, y en el caso de que se detecte un número de violaciones mayor al número preseleccionado entonces se etiqueta como una anoma!ía. En [3] concluyen que la detección y caracterización de una amplia variedad de tráfico de red puede ser realizada monitoreando los campos de encabezados de los paquetes. Pero se requiere del filtrado de combinaciones complejas de los valores de los campos y correlacionarlos para comprender el tráfico de redes debido a un gran número de diferentes tipos de actividad maliciosa. En [3] introducen el concepto de modelado de tipos de actividad en redes como un vector de condiciones basado en los campos de encabezados de los paquetes que están siendo monitoreados, acumulados y filtrados.. 2.4 MÉTODOS DE SUBESPACIO Los investigadores [ 18] proponen también en el mismo año 2004 el método del subespacio en gran escala aplicado al diagnóstico de anomalías en el tráfico de redes, el método de subespacio trabaja examinando las series de tiempo de todos los flujos origen-destino simultáneamente para luego separarlas en atributos normales y anómalos. El tráfico normal es determinado directamente por los datos, definido por los patrones temporales más comunes de los flujos. La extracción de las tendencias comunes se realiza con el análisis de los componentes principales (PCA - Principal Componen! Analysis). de los cuales solamente un pequeño conjunto de ellos son suficientes para capturar los patrones temporales dominantes que son comunes a todos los flujos. Posteriormente se utiliza el error de predicción cuadrático (llx x '112) para detectar el tiempo de una anomalía en el vector residual. Y para detectar anomalías que ocurren en el subespacio normal se usa la estadística t2, al igual que se utiliza en el control de procesos de múltiples variables, la cual tiene un umbral asociado basado en el nivel de confianza.. Tesis - Ricardo Farrera Saldafia. 29/11/2009.
(13) 14. El método de subespacio propuesto por [ 18) designa un intervalo de tiempo durante el cual el tráfico es anómalo. Los autores muestran una distribución de las anomalías en conjuntos tomando en cuenta el tipo de tráfico (bytes. paquetes o flujos), el tiempo y el flujo mismo. La metodología realiza la detección de anomalías solamente, no incluyendo la identificación de las mismas. La caracterización de las anomalías detectadas fue realizada a través de métodos heurísticos, basándose en la noción de un rango dominante de direcciones lP y/o puertos y también confiando en la información de los puertos utilizados. Los autores logran clasificar todas las anomalías en ocho categorías: • • • • • • • •. Alfa - transferencias de gran cantidad de información punto a punto DOS, DDOS - ataques de negación de servicio (DoS - Denial of Service) contra una sola víctima. FLASH, CROWD - gran demanda de un recurso o servicio SCAN - escaneo de un dispositivo o red en busca de un puerto vulnerable. WORM - código de propagación propia que se extiende a través de una red explotando la falta de seguridad. POINT TO MUL TIPOINT - distribución de contenido de un servidor a múltiples usuarios. OUT AGE - eventos que ocasionan decrementos en el tráfico que se intercambia entre una dirección origen y otra destino. lNGRESS-SHIFT - movimiento del tráfico de un punto de ingreso a otro punto de mgreso.. En [18) se muestra que cuando los flujos de tráfico son analizados al nivel de origen-destino, se puede obtener información abundante en relación a las anomalías existentes en toda la red. generando un espectro muy amplio de tipos de eventos. Adicionalmente, la mayoría de las anomalías son pequei'ias en tiempo y espacio. El artículo [28) demuestra que es posible clasificar las aplicaciones por las distribuciones de tamaños de los paquetes recolectados y las estimaciones de cantidades correspondientes a cada aplicación, se busca la detección y estimación de características del tráfico de Internet con base en las aplicaciones a las cuales pertenecen los paquetes recolectados. Los autores [28) proponen la construcción de histogramas con tamaiios variables y análisis de la colección de histogramas utilizando algoritmos de agrupamiento con la idea de que la distribución total de los tamaños de paquetes en un nodo en particular dentro de la red es la combinación de la distribución de las aplicaciones individuales; de tal forma que se proporcionan una comparación de tres métodos de estimación del porcentaje de tráfico en cada clase con el fin de estimar la probabilidad de que una aplicación específica esté presente en un flujo de tráfico. Los métodos son: mínimos cuadrados restringidos, proyección en conjuntos convexos (POCS Projection Onto Convex Sets) y redes neuronales. Los resultados obtenidos por el análisis realizado en [28] muestran que todos los métodos son capaces de tomar en cuenta las limitantes impuestas por el hecho de que las cantidades estimadas son probabilidades. Los métodos POCS pueden manejar incertidumbre en la matriz base usando un enfoque similar a cuadrados mínimos totales (TLS - Total Least Squares). Las redes neuronales artificiales produjeron los mejores resultados en las pruebas realizadas. La. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(14) 15 arquitectura utilizada fue una sola capa oculta sencilla con una sola neurona de salida. Las neuronas de la capa oculta utilizaron una función de activación logarítmica-sigmoidal. Para la estimación, la neurona de la capa de salida utilizó una función lineal, y se utilizaron seis neuronas en la capa oculta. En el caso de detección se utilizó una función logarítmica-sigmoidal en la neurona de salida y dos neuronas en la capa oculta. Por su parte, [25] presenta un sistema de detección de anomalías basado en la recolección periódica de datos SNMP, se trata de un sistema de detección de anomalías el cual pretende detectar intrusiones comparando la actividad del recurso examinado en un tiempo determinado contra un perfil establecido de actividad ·normal', en un inicio se construye un perfil para el comportamiento 'normal' de la red y luego se etiquetan las desviaciones de dicho perfil como posibles ataques. La metodología de [25] es un esquema de detección de anomalías no supervisado que utiliza el análisis de componentes principales (PCA - Principal Componen! Analysis) el cual es un método de variables múltiples que define la estructura varianza-covarianza de un conjunto de variables a través de unas cuantas variables propias las cuales son combinaciones lineales de las originales. Adicionalmente se utiliza la distancia Mahalanobis y se asume que las anomalías pueden ser detectadas como los componentes más alejados del conjunto generado a partir del análisis de los componentes principales. Los resultados reportados por [25] muestran que se obtuvo el 91.67% de precisión teniendo una tasa de alarmas falsas de 2%, y hasta el 68.57% de tasa de detección con una tasa de alarmas falsas del 6%. Una de las mayores ventajas del sistema propuesto es que no requiere de un periodo de entrenamiento. Además, el utilizar datos SNMP es simple, consume una cantidad de recursos aceptable, y el tamaño de los datos utilizados depende solamente del periodo de recolección. Estas ventajas permiten que el sistema pueda ser utilizado para la detección de anomalías en tiempo real de forma automática. La herramienta propuesta no pretende identificar los diferentes tipos de ataques o sus orígenes.. 2.5 MÉTODOS BASADOS EN GRAFOS. En [16] los autores exploran la clasificación de tráfico utilizando un enfoque diferente en cuanto a la clasificación de tlujos de tráfico de acuerdo a las aplicaciones que los generan. En contraste con previos métodos, se basa en observar e identificar patrones de comportamiento de los dispositivos en la capa de transpo11e. Se analizan los patrones mencionados en tres diferentes niveles de detalle en aumento: social, funcional y de aplicación. El objetivo principal es ofrecer una herramienta a los operadores de redes que provea de una clasificación significativa por aplicación y proporcionar una vista al comportamiento del tráfico; esto último puede facilitar la detección de anomalías en el tráfico, comportamiento malicioso o identificación de nuevas aplicaciones. En [16] se realizó una clasificación de los dispositivos en tres diferentes niveles: social, funcional y de aplicación, en donde cada nivel proporciona conocimiento mayor del comportamiento .del. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(15) 16 dispositivo y la identificación de aplicaciones específicas depende de la información capturada en los tres niveles. El nivel social captura el comportamiento de un dispositivo como lo indican sus interacciones con otros dispositivos examinando la popularidad de un nodo (número de dispositivos con los que se comunica) utilizando la función de distribución acumulada y se identifican comunidades de nodos (identificando y agrupando dispositivos que interactúan con el mismo conjunto de dispositivos) que pueden representar clientes con intereses similares o miembros de una aplicación distribuida. El nivel funcional captura el comportamiento de un dispositivo en términos de su rol funcional en la red, determinando si es que actúa como proveedor, consumidor de un servicio o ambos. 1. El nivel de aplicación modela cada aplicación capturando sus interacciones a través de graphlets los cuales reflejan el comportamiento más común para una aplicación particular. las propiedades enumeradas anteriormente se representan como nodos, y se conectan utilizando líneas cuando existe al menos un flujo cuyos paquetes las contienen. Algunos graphlets logran identificar tres tipos de ataques: •. •. Ataques típicos en donde un dispositivo escanea el espacio de direcciones para identificar vulnerabilidades en un puerto destino particular. Pueden ser identificados por que se encuentra un gran número de flujos enviados a un puerto destino dado. Ataques un poco más complicados en los cuales un dispositivo intenta conectarse a una gran cantidad de puertos vulnerables en el mismo dispositivo destino. Escaneo típico de puertos de un cierto dispositivo destino.. los resultados de [16] muestran que fue posible clasificar del 80% al 90% del tráfico con más de 95% de precisión. Para el caso de los flujos sin payload, BLINC solamente puede proporcionar pistas de comportamiento malicioso detectando puertos destino con gran actividad de flujos fallidos. En (14] y (13] se extendió la investigación en cuanto a la técnica basada en grafos sosteniendo el uso de Traffic Dispersion Graphs (TDGs) como una forma de monitorear, analizar y visualizar el tráfico de redes. los TDGs modelan el comportamiento social de los dispositivos, en donde los bordes pueden ser definidos para representar diferentes interacciones. Presentan un enfoque en las interacciones de dispositivos a través de toda la red (visto desde un router). El término TDG Traffic Dispersion Graph se refiere a la representación gráfica que muestra intuitivamente como interactúa un grupo de dispositivos, y va evolucionando en el tiempo y el espacio mientras varios nodos interactúan entre ellos. El analizar la interacción social de los dispositivos lleva a un grafo en donde cada nodo es una dirección IP, y cada borde dirigido representa una interacción entre dos nodos (origen y destino), los cuales se utilizan para identificar al iniciador de la interacción. En [14] y [13] muestran que el tráfico tiene estructura característica y provee visualizaciones de patrones que ayudan a distinguir la naturaleza de algunas aplicaciones; adicionalmente, se busca 1. Graphlet - estructura basada en grafos que captura interaccim;cs entre dispositivos.. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(16) 17 detectar fenómenos anormales en las redes, tales como nuevas aplicaciones que abusan de puertos y actividad maliciosa, por ejemplo: propagación de gusanos y escaneo de puertos, para ello se pretende modelar el comportamiento normal de los dispositivos a través de patrones de interacción o estructuras de grafos, y a partir de ello, cualquier desviación del comportamiento normal puede ser usada para activar una alarma. Los TDGs capturan varios patrones interesantes de interacciones entre nodos, se pueden identificar muchas estructuras distintivas y patrones en los TDGs. Los grados de los nodos y su conectividad en un TDG ayudan a determinar el tipo de relación que existe entre los nodos. El rol de un nodo puede ser inferido de la dirección de sus bordes. También se reflejan cadenas de nodos y comunidades de nodos. Los TDGs pueden ser usados para detectar anomalías específicas de tráfico. El método de visualización más efectivo en este sentido es el monitoreo humano. La clasificación de aplicaciones utilizando los TDGs requiere solamente de la revisión de los encabezados de los paquetes, permitiendo la implementación simple así como la habilidad de manejar transmisiones de grandes cantidades de información, para la identificación de aplicaciones se revisan las propiedades distintivas en el TDG del conjunto de flujos utilizando: •. Distribuciones de componentes - Una característica distintiva de los TDGs es la formación de un gran componente conectado que concentra la mayoría de los dispositivos IP participantes, lo cual sugiere la utilización de medidas de componentes para discriminar entre aplicaciones.. •. Distribución de grados - Con base en las distribuciones de grados, diferentes aplicaciones tienden a tener nodos con diferentes niveles de popularidad.. •. Propiedad de entrada y salida (Inü) - Definida como el porcentaje de nodos en un TDG que tienen grados de entrada y salida diferentes de cero, la cual es muy valiosa para caracterizar las aplicaciones P2P y brotes. Puede utilizarse la prevalecencia de grados de entrada o grados de salida para distinguir ataques DDoS (en donde se observa un gran número de nodos solamente con grado de entrada).. Los TDGs proveen de un buen mecanismo de visualización para identificar rápidamente brotes, además, las mismas medidas usadas para la identificación de aplicaciones combinadas con una métrica más (profundidad máxima) pueden ayudar a separar escaneos de puertos benignos, brotes infecciosos y aplicaciones P2P. Alta profundidad y alta Inü son características fuertes de brotes, mientras que alto promedio de grado y grado máximo con pequeño Inü y profundidad pequeña es característico de escaneos. Finalmente alto Inü, profundidad moderada y altos grados de nodos indican aplicaciones P2P. Una particularidad encontrada es que por la naturaleza de los trazados sobre los que se trabajó solamente se pueden detectar intentos de infección provenientes desde afuera de la organización hacia adentro y viceversa. Si un intento de infección logra entrar, no se podrá detectar la infección resultante interna, sino que solamente se observará el caso poco común cuando el mismo nodo infectado internamente envíe un intento de infección hacia afuera de la organización. Los resultados registrados por En [14] y [13] plasman que TDGs de diferentes aplicaciones y código maligno pueden ser discriminados efectivamente utilizando un número pequeiio de métricas, la mayoría de las cuales puede ser procesada a altas velocidades utilizando muestras muy pequeñas de un TDG.. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(17) 18. 2.6 MÉTODOS DE AGRUPAMIENTO. En [7] los autores proporcionan un enfoque alternativo para la clasificación de tráfico explotando las características distintivas de las aplicaciones cuando se comunican a través de una red, se utiliza un enfoque de máquinas de aprendizaje llamado clustering o agrupamiento para el problema de la identificación de tráfico de redes, el cual se basa en el análisis de clusters para identificar efectivamente grupos de tráfico que son similares utilizando solamente estadísticas de la capa de transporte. El objetivo de [7] es generar un número mínimo de clusters que contienen la mayoría de las conexiones, los cuales posteriormente se etiquetarán para convertirse en el modelo de clasificación. Los autores consideran los algoritmos no supervisados: K-Means y DBSCAN, que utilizan datos de entrenamiento agrupándolos con base en la similitud, y los compara con el algoritmo AutoClass para evaluarlos. Los algoritmos mencionados utilizan la distancia euclideana como medida de similitud, los objetos son las conexiones y las características son las estadísticas de la capa de transporte de las conexiones. •. K-means es un algoritmo basado en partición. Es uno de los más rápidos y simples, ya que genera clusters de forma esférica. Su precisión aumenta establemente al aumentar el número de clusters.. •. DBSCAN es un algoritmo basado en partición. Es uno de los más rápidos y simples, ya que genera clusters de forma esférica. Su precisión aumenta establemente al aumentar el número de clusters. Autoclass es un algoritmo basado en modelos probabilísticos. Permite la selección automática del número de clusters, los parámetros que gobiernan las distintas distribuciones de probabilidad de cada cluster, así como la asignación fraccionada de los objetos de los datos a más de un cluster con base en el algoritmo EM - Expectation Maximization. Utiliza la asignación más probable como la asignación de objetos. Tiene la mejor precisión de los tres algoritmos presentados. La fase de construcción consume una cantidad de tiempo extremadamente mayor en comparación con K-Means y DBSCAN.. En [8] los autores amplían su investigación utilizando metodologías de agrupamiento proponiendo una metodología para clasificación de tráfico que utiliza solamente estadísticas de flujos para ello; se trata de un enfoque semi-supervisado para el aprendizaje de un clasificador de tráfico de redes. En [8] realizaron la implementación de un clasificador en tiempo real en el Sistema de Detección de Intrusos (IDS - Intrusion Detection System) Bro. Adicionalmente se consideró la longevidad de los clasificadores, ya que los clasificadores son generalmente aplicables durante periodos de tiempo razonables, con la necesidad de re-entrenamiento cuando hay cambios significativos en los patrones de utilización de la red incluyendo la introducción de nuevas aplicaciones.. Tesis - Ricardo Farréra Saldaña. 29/11/2009.
(18) 19 El diseño de la solución combina métodos supervisados y no supervisados. La clasificación consiste en dos pasos: • Aplicación del algoritmo de clustering K-Means para dividir un conjunto de datos de entrenamiento que consiste en escasos flujos etiquetados combinados con una cantidad abundante de flujos no etiquetados. • Utilización de los flujos etiquetados para obtener un mapeo de los clusters hacia las diferentes clases conocidas mediante una asignación probabilística. Los resultados del sistema de [8] muestran que el proceso de etiquetado es uno de los pasos de la clasificación que consumen más tiempo. se confirmó que con una pequeña cantidad de flujos etiquetados en cada cluster. se cuenta con una base razonable para crear el mapeo con las aplicaciones, pues con dos flujos etiquetados por cluster y K = 400, se puede obtener el 94% de exactitud en la clasificación. Adicionalmente, se puede aumentar el tamai'lo de los flujos no etiquetados para aumentar la precisión de la metodología. En cuanto a la clasificación en tiempo real, se diseñó un sistema de clasificación por capas, en donde cada capa L., un modelo independiente que clasifica flujos de salida en uno de muchos tipos de clases utilizando las estadísticas de flujos disponibles en un momento dado. Los resultados de la experimentación mostraron que el rendimiento del clasificador tiene un rango de 70% a 90% de exactitud.. 2.7 NIVELES DE INFORMACIÓN Las metodologías basadas en grafos al igual que las probabilísticas y de pronóstico utilizan información básica obtenida de los encabezados de los paquetes: dirección ip origen, dirección ip destino, puerto TCP/UDP origen y puerto TCP/UDP destino. Por otro lado, unas técnicas de estimación proponen adicionalmente la utilización de la distribución de tamaños de paquetes como un indicador del tipo de aplicación, aún cuando el carácter de las distribuciones pueda evolucionar durante periodos largos de tiempo, las aplicaciones pueden ser distinguidas utilizando como base la estadística propuesta. Algunas de las técnicas estadísticas utilizan también el tiempo entre llegada de paquetes promedio. Las técnicas de estimación más novedosas manejan la información a nivel de flujos, al igual que las metodologías de agrupamiento, en donde se definen las conexiones o flujos como intercambio bidireccional de paquetes entre dos nodos o dispositivos. La mayoría de los estudios se enfoca en aplicaciones basadas en TCP y las características estadísticas de los flujos consideradas incluyen: número total de paquetes, tamaño de paquetes promedio, tamaño de payload promedio sin incluir encabezados. número de bytes transferidos (en cada dirección y combinados) y el tiempo entre llegada de paquetes promedio. Las medidas más avanzadas en técnicas recientes representan el tráfico de manera adicional a nivel de sesión. las cuales son sucesiones de flujos indicando periodos de actividad de las aplicaciones.. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(19) 20. 2.8 COMPARACIÓN DE RESULTADOS DE LAS TÉCNICAS ACTUALES El rendimiento de cada técnica utilizada para el análisis de tráfico depende no solamente de los algoritmos utilizados para el procesamiento de los datos, sino que gran parte de su precisión y eficiencia también se encuentra directamente relacionado a los pasos de captura de información, preprocesamiento y filtrado previos al procesamiento, así como los pasos posteriores al procesamiento como la interpretación y evaluación de los resultados obtenidos.. Tabla l. Comparación del rendimiento de metodologías para la caractc1üación y clasificación de tráfico.. l \ill•t1fflil,RWw.¿zt 2. BLINC & TDGs. K-means. DBSCAN. Autoclass. Markov. Del 80 al 90%. Depende de las clases previamente definidas. Depende de las clases previamente definidas. Depende de las clases previamente definidas. Depende de las clases previamente definidas.. Mayor a 90%. Grafos. Opera en los niveles de No es susceptible comportamiento social, a congestiones de funcional y de la red. aplicación de los dispositivos.. Alrededor del 80%. Método de Clusters clustering más rápido y simple.. Desde el 72% hasta el 75.6%. Clusters. De 88.7% a 92.4%. Algoritmo de Clusters clusters con la mayor precisión.. Depende del número de observacion es utilizadas.. Basado en firmas. Produce los mejores resultados de clusters.. Aplicaciones con diferentes protocolos son fácilmente distinguibles.. Basado en partición.. Basado en densidad.. Basado en modelos probabilísticos. Incluye en un paso de aprendizaje y otro de decisión basada en el criterio de similitud.. Las metodologías que modelan el tráfico utilizando herramientas gráficas presentan la desventaja de que la extracción e interpretación de la información para inducir un análisis y clasificación del tráfico es altamente complicada en relación a los otros métodos y además requieren una gran cantidad de recursos para hacerlo, lo que las hacen poco prácticas para su aplicación en ambientes que funcionan en tiempo real. Las técnicas estadísticas Entropy y Chi-square muestran resultados bajos en relación a las demás: se han utilizado básicamente para filtro de ataques DDoS y no se ha probado extensivamente para el catálogo y análisis de tráfico IP en general. Los modelos basados en clusters o grupos cuentan con muy buenos resultados en relación a la precisión, aunque sufren de algunas limitantes principalmente debido a que requieren pasos. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(20) •. 21 previos adicionales para el etiquetado de los clusters con la finalidad de identificar cada tipo de tráfico caracterizado.. Tabla 2. Comparación del rendimiento de metodologías para la detección y caracterización de ataques en redes IP.. : ,J Entropy y Chi-square. Limitado a 71.2% en ataques DDoS promedio. Método del Sub-espacio. 90% aprox.. 92% aproximadam ente. SNMP - PCA. Hasta 68.57%. Hasta 91.67%. El filtrado Estadístico resultante es casi inmediato. Extracción Trabaja en toda la amplitud de la de tendencias red. Extracción No requiere de de un periodo de tendencias entrenamiento.. : · ·Detálles 0· ·' Modela el tráfico típico como base para filtrar los ataques DDoS. Caracteriza las anomalías utilizando métodos heurísticos. Basado en la recolección periódica de datos SNMP.. Los métodos de extracción de tendencias presentan una muy buena precisión y demandan poca cantidad de tiempo para el procesamiento de los datos. La combinación de estas técnicas con los modelos basados en clusters parece ser una buena opción para proyectar futuros desarrollos en la materia de investigación. Aunque las técnicas de arupamiento aun no han sido aplicadas para la detección y caracterización de ataques en redes IP, tienen muchas características que los hacen prometedores para este tipo de análisis, además de que cuentan con muy buenos resultados en cuanto a la clasificación y caracterización del tráfico.. Tesis - Ricardo Farrera Saldaña. 29/i 1/2009.
(21) 22. 3 METODOLOGÍA DE AGRUPAMIENTO DE TRÁFICO. 3.1 INTRODUCCIÓN El problema de análisis y caracterización de tráfico puede ser considerado como un problema que se encuentra dentro del área de minería de datos y descubrimiento del conocimiento, en donde se busca la extracción no trivial de patrones significativos, implícitos y estratégicos a partir de bases y almacenes de datos, con el fin de generar conocimiento nuevo. En el presente caso no se cuenta propiamente con información de referencia para hacer la agrupación del tráfico, es decir, no hay propiamente una clase que predecir, además de que no existe una guía de referencia o medida clara de éxito, por lo que podemos decir en un principio que se trata de un problema de clasificación y aprendizaje de carácter no supervisado. La metodología propuesta pretende ser un proceso de minería de datos que cuenta con los siguientes pasos:. l. Obtención de la base de información En el primer paso, se define y colecta la información en bruto del mundo real que se utilizará como base para todo el proceso. 2. Selección de los datos La cual se trata de un filtrado de la información recolectada en el paso anterior para trabajar posteriormente solo con la información relevante para el problema propuesto. 3. Preprocesamiento En este paso se busca aplicar ciertas técnicas a los datos filtrados anteriormente con el propósito de ajustarlos y adaptarlos para poder utilizarlos en los siguientes pasos. 4. Transformación de los datos Utilización de distintos métodos para generar información útil para el problema que se encuentra implícita en los datos originales y que no se muestra evidente en los datos preprocesados.. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(22) 23. 5. Minería de datos La minería de datos realiza extracción de tendencias y patrones significativos de los datos previamente transformados para el descubrimiento de conocimiento. 6. Interpretación Este paso es muy importante. pues asigna un significado específico al conoc1m1ento generado a partir del paso anterior y ayudará a la posterior evaluación de la metodología. 7. Evaluación La información generada de los pasos de minería e interpretación se utilizan para juzgar el valor del conocimiento descubierto y la efectividad de las técnicas utilizadas durante todo el proceso de la metodología En general podemos ver la metodología de la siguiente manera:. r----------, :. Caplura de. :. -----------~. :. Información. I. Preorocesamiclo. 1 :. I I. Selección de datos. ~--------. 1 1 1 -----+¡1 1 1 1 1 1 1 1 1. Transformación de los datos. 1. [---------, - - - - - - - - -, 1. 1. ln1eroretación. I. 1 1 1 1 Mmería de ~ ~ 1 1 • j dalos 1 1 1 1 Evaluación 1- - - - - - - - ~1 1 11 1I 1 ----------". ~----------__! Figura 1. Visla gem:ral de la metodología. A continuación se describirán los detalles de cada una de las etapas de la metodología aplicadas al análisis y caracterización de tráfico.. 3.2 DEFINICIÓN DE LA BASE DE INFORMACIÓN La base de información es generada a partir de capturas de tráfico de Internet utilizando una herramienta de monitoreo y análisis de protocolos de red. Existen muchas aplicaciones disponibles para en análisis de protocolos, pero se decidió utilizar Wireshark debido a que es el estándar a través de muchas industrias e instituciones educativas, además de que es una herramienta de código abierto y se encuentra disponible bajo licencia pública general (GNU General Public License). Wireshark ofrece un conjunto de facilidades muy enriquecido incluyendo: • •. La inspección profunda de cientos de protocolos, con más siendo añadidos todo el tiempo. Captura en vivo y análisis fuera de línea.. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
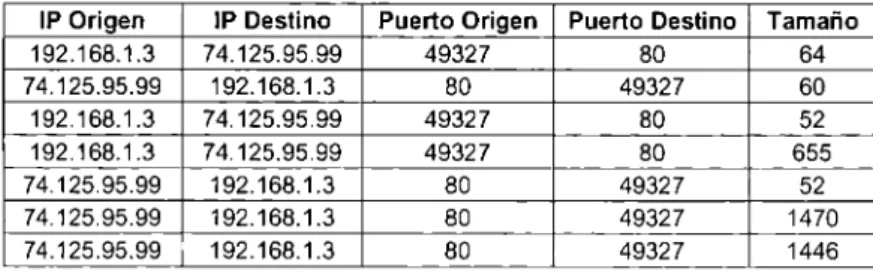
(23) 24 •. •. Cuenta con una interfaz gráfica que incluye explorador de paquetes estándar de tres paneles. Soporte para múltiples plataformas, incluyendo Windows, Linux, OS X, Solaris, entre otros. Los filtros más poderosos en la industria. Lectura y escritura de diferentes tipos de formatos de captura. La salida puede ser exportada a XML, PostScripts, CSV o texto plano.. La información generada por Wireshark se guarda en archivos con formato de documento de captura de red genérico, el cual cuenta con extensión .cap; una gran cantidad de diferentes analizadores de red utilizan esta extensión para representar datos capturados.. 3.3 SELECCIÓN Los archivos generados por Wireshark durante la etapa de captura de información contienen toda la información que pasa por la red en ese momento. En este caso, solamente nos interesa seleccionar algunos datos de la información capturada, los cuales son representativos de los paquetes capturados, siempre cuidando la privacidad de la información que circula por la red, pero que al mismo tiempo sea significativa y útil para los siguientes pasos de la metodología. En un inicio se seleccionó un conjunto de cinco características básicas de los paquetes capturados, que incluye: dirección IP origen, dirección IP destino, puerto de transporte origen, puerto de transpo11e destino y tamaño del paquete. En esta etapa de modelado de la metodología y experimentación se utilizan tráfico de protocolos de transporte TCP y UDP. El filtrado de la información se realiza utilizando la herramienta Tshark, que forma parte del aplicativo Wireshark, la cual genera un archivo de texto plano con los datos filtrados. Posteriormente, buscando mejorar la efectividad de la metodología, se aiiadieron las siguientes propiedades al conjunto de características básicas mencionado anteriormente: tiempo delta y tiempo relativo, para dar un total de siete atributos. El tempo delta es la diferencia de tiempo de la trama con respecto a la trama capturada previamente. El tiempo relativo, es el tiempo transcurrido desde la primera trama capturada que conforma al flujo.. 3.4 PREPROCESAMIENTO Posteriormente a la selección de los datos utilizando un primer filtrado. se aplica un preprocesamiento a los datos obtenidos para ajustarlos y adaptarlos con la finalidad de que puedan ser procesados en las siguientes etapas .. •. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(24) •. 25 En el preprocesamiento inicialmente se filtra la información para descartar tramas locales de control, las cuales no tienen ningún significado en relación a las aplicaciones que viajan por la red. Adicionalmente se incluye otro paso, el cual consiste en cambiar los datos nominales por numéricos, en este caso se consideran como datos nominales: dirección IP origen y dirección IP destino. El preprocesamiento se realiza utilizando una aplicación que ajusta los datos nominales reemplazándolos por numéricos y genera tablas de relación de las direcciones IP origen y destino como se muestra en las siguientes tablas, de esta manera se preparan los datos y se dejan listos para su posterior análisis.. Tabla 3. Ejemplo de datos gcnm1do después dd prcproccsamicnlo.. IP Origen. IP Destino. Puerto Origen. Puerto Destino. Tamaño. o. o. 1. 1. o o o. o. 80 1072 80 80 80. 1072 80 1072 1077 1076. 40 1492 40 40 40. 2 2. Tablas 4 y 5. Tablas de relación de dirccciont'S IP origen y destino.. ID. IP Origen. ID. IP Destino. o. 192.168.1.4 74.125.5.18. o. 74.125.5.18 192.168.1.4 208.117.236. 75. 1. 1 2. Después de algunos experimentos realizados en un ambiente controlado y pequeño, manejando capturas del orden de un par de horas, se pudo observar que el tamaño de los datos resultantes del preprocesamiento sigue siendo demasiado grandes y poco representativos de la muestra inicial como para utilizarse en un ambiente real contemplando la captura de tráfico de una red de tamaño considerable; por lo que se planteó manejar los datos en una forma diferente en lugar de utilizar los datos en su forma bruta tal cual son obtenidos de los pasos anteriores, es decir, como paquetes.. 3.5 TRANSFORMACIÓN En una instancia posterior, buscando que los datos utilizados en la minería de datos y procesamientos en pasos posteriores ayuden a que la efectividad y precisión de la metolodogía mejore, se manejan los datos como flujos o sesiones; esto es, se agrupan los paquetes que muestren interacción entre las mismas direcciones IP utilizando los mismos puertos de transpOI1e dentro de la misma captura y se generan las siguientes medidas estadísticas en tiempo y ·frecuencia:. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(25) 26. •. • • •. Media, desviación estándar y varianza del tamaño de paquete por flujo Media, desviación estándar y varianza del tiempo delta por flujo Media, desviación estándar y varianza del tiempo relativo por flujo Paquetes por sesión Tamaño de paquete promedio por sesión. Sumando un total de once atributos. Las direcciones IP origen y destino, así como los puertos de transporte origen y destino son descartados, pues se considera que pueden no ser representativos para la clasificación de los tipos de tráfico y posiblemente inducen ruido en la muestra. Esta transformación produce mejoras inmediatamente visibles en cuanto a la reducción tamaiio de información que se genera y pasa a las siguientes etapas de la metodología, además de que parece ser más representativa de los datos con un carácter general adecuado para el análisis y caracterización de los tipos de tráfico que fluyen por una red. Esta propiedad permite que la metodología sea utilizada en ambientes en donde existe gran flujo de paquetes a través de la red sin requerir una gran cantidad de recursos para almacenar la información así como recursos de cómputo en los pasos de procesamiento posteriores.. Tabla 6. Comparación de número de paquetes conb·a número de sesiones contenidas m un mismo archivo de captura. Captura No. 4. 5 6. Número de PaQuetes 14,712 44,861 80,086. Número de Sesiones 82 118 61. Durante los experimentos realizados se pudo observar que aunque este paso de la metodología disminuye enormemente los recursos necesarios para almacenar la información, el tiempo que tarda el programa generado en transformar los datos depende directamente del tamaño de los datos filtrados.. 3.6 MINERÍA DE DA TOS El problema de análisis y clasificación de tráfico podemos decir en un principio que se trata de un problema de aprendizaje de carácter no supervisado, pues no se cuenta propiamente con información de y no hay propiamente una clase que predecir. No existe una medida de evaluación concreta. Dentro de los métodos de aprendizaje y reconocimiento de patrones no supervisadas que existen, se tienen referencias de trabajos previos en donde se demuestra que las técnicas de clustering o agr~pamiento generan los mejores resultados en cuanto a completitud, precisión y además tienen. Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(26) 27. un alto nivel de automatización, por estas razones se decidió trabajar con algoritmos de agrupamiento en esta etapa de procesamiento utilizando minería de datos. El término clustering se refiere a la agrupación de objetos en diferentes conjuntos, más precisamente se refiere a particionar un conjunto de datos en subconjuntos, tal que los datos en cada subconjunto comparten características distintivas. Clustering es una técnica común para análisis de datos estadísticos, el cual es utilizado en muchos campos incluyendo el reconocimiento de patrones, análisis de imágenes y bioinformática. Existen diferentes tipos de algoritmos de agrupamiento. Los algoritmos jerárquicos encuentran clusters sucesivos utilizando clusters previamente establecidos. Los algoritmos jerárquicos pueden ser aglomerativos o divisivos. Los algoritmos aglomerativos inician con cada elemento siendo un cluster separado y el algoritmo los va uniendo en grupos sucesivamente más largos. Los algoritmos divisivos comienzan con un solo grupo y proceden a dividirlo en grupos sucesivamente más pequeños. Otros algoritmos de clustering son los llamados particionales, los cuales típicamente determinan todos los grupos al mismo tiempo. Uno de los pasos importantes en algoritmos de agrupamiento es la selección de una medida de distancia, la cual determinará como se calcula la similitud entre dos elementos. Esta medida influirá en la forma de los grupos. Algunas funciones de distancia comunes son:. • Distancia Euclideana (norma 2) • Distancia Manhattan (norma 1) •. Norma Máxima Distancia M::ihalanobis Distancia 1--Iamming. La mayoría de las técnica~. de clustering particionales requieren que el número de clusters sea previamente definido para procesar la información y agruparla. La cantidad de clusters puede ser establecida de manera manual y arbitraria, o utilizando recursos de algoritmos para: la predicción y estimación del número de clusters de un conjunto de datos, de tal forma que se pueda automatizar este proceso alimentando con el número de clusters a los otros algoritmos de agrupamiento que requieren de esta información previamente definida. Los algoritmos de clustering que han sido utilizados para el procesamiento en el modelado de la metodología son los siguientes.. • AIBFC • K-Means. • • • •. Fuzzy C-Means DBScan Expectation Maximization Gusta fson-Kessel. A continuación se describe cada uno de los algoritmos utilizados en las pruebas realizadas para el modelado del sistema de análisis y caracterización de tráfico .. •. Tesis - Ricardo Farrera Saldat'ia. 29/11/2009.
(27) 28. 3.6.1 AIBFC - AGGLOMERATIVE ITERA TIVE BA YESIAN FUZZY CLUSTERING En la presente investigación se utiliza el algoritmo de Agrupamiento Difuso Bayesiano Iterativo Aglomerativo (Agglomerative Iterative Bayesian Fuzzy Clustering, AIBFC), el cual cuenta con una estructura de aprendizaje difusa incorporada adecuadamente en una regla de decisión Bayesiana que se utiliza como base para generar índices de validez de clusters, a través de los cuales se determina el número óptimo de clusters. El algoritmo AIBFC ayuda a predecir el número de clusters dentro de los conjuntos de datos para el posterior procesamiento de los algoritmos de agrupamiento no supervisado que requieren de la previa definición de este parámetro para poder ser utilizados. Adicionalmente, el algoritmo AIBFC también proporciona los centros de los clusters determinados, facilitando el trabajo posterior de los algoritmos de procesamiento. A continuación se enumeran los pasos que constituyen al algoritmo AIBFC. Fase 1. Agrupamiento Inicial. Paso l. Inicialización. Decidir el valor, r. Para un conjunto de datos no etiquetado X= {x, . ... , x,}, normalizar los datos: · { } xk(ríe/o) -mmx 1. .(1111em). xk. J. (1). rnax{x)- min{x) J. .. J. .. Registrar el primer punto como el centroide del primer cluster local.. •. Paso 2. Actualización Iterativa. Parak= l, ... ,N, Decisión:. I= arg minllxk -. v;II. (2). Prueba de Vigilancia:. (3). Tesis - Ricardo Farrera Saldaña. 29/11/2009.
(28) 29 Si el ganador pasa la prueba de vigilancia, actualiza todos los centroides locales:. (4). En donde t es el número de iteración. En caso contrario, asigna. x, como el centroide del nuevo cluster local.. Paso 3. Prueba de Terminación . S,.. 11'. v, - v, (1). (1-). 11·,. .> e. para 'íl,, entonces regresa al paso 2.. En caso contrario, tumina el agrupamiento. Fase 2. Fusión y determinación del número de clusters. Paso 1. Fusión. Mientras que el número de clusters P > 1, Calcula un índice de validez de cluster .!(P):. ¿ max J(P) = P. i=I. {. .J.J'7"I. ¿. I. P {. 1=1. O¡. ] 1. Q¡. ¿. max. r=I. sen,. 10,1 (. ] 1. ,uJ<. J. (5). • )} Í!O 1( 1!!ix ,Ll¡ (x;,..J l r=I. '. Encontrar el par de clusters:. (i*, j*). = arg max (i.j). )}. . max ,LL¡,. 1eO,.se0 1. V¡,.+ V ·5 (. 2. .1. l. (6). Fusionar i* y j*-simos clusters locales. Paso 2. Determinar el número de clusters Encontrar el número óptimo de clusters: p' = arg min .!(P) /'. y restaura los índices de clusters correspondientes.. t Tesis - Ricardo Farrera Saldal'ia. 29/11/2009.
Figure




+7





Documento similar
Sólo que aquí, de una manera bien drástica, aunque a la vez coherente con lo más tuétano de sí mismo, la conversión de la poesía en objeto -reconocida ya sin telarañas
1) La Dedicatoria a la dama culta, doña Escolástica Polyanthea de Calepino, señora de Trilingüe y Babilonia. 2) El Prólogo al lector de lenguaje culto: apenado por el avan- ce de
6 Para la pervivencia de la tradición clásica y la mitología en la poesía machadiana, véase: Lasso de la Vega, José, “El mito clásico en la literatura española
d) que haya «identidad de órgano» (con identidad de Sala y Sección); e) que haya alteridad, es decir, que las sentencias aportadas sean de persona distinta a la recurrente, e) que
La siguiente y última ampliación en la Sala de Millones fue a finales de los años sesenta cuando Carlos III habilitó la sexta plaza para las ciudades con voto en Cortes de
Ciaurriz quien, durante su primer arlo de estancia en Loyola 40 , catalogó sus fondos siguiendo la división previa a la que nos hemos referido; y si esta labor fue de
Las probabilidades de éxito de este procedimiento serán distintas en función de la concreta actuación del reclamante antes de que se produjera la declaración de incons-.. En caso
La Ley 20/2021 señala con carácter imperativo los procesos de selección. Para los procesos de estabilización del art. 2 opta directamente por el concurso-oposición y por determinar
