Nuevas variantes de sistemas difusos genéticos para resolver problemas de regresión de alta dimensionalidad
76
0
0
Texto completo
(2) Dictamen Hago constar que el presente trabajo fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ______________ Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. _________________. ________________. Firma del tutor. Firma del Jefe del Seminario.
(3) Resumen Los sistemas difusos genéticos surgen como una fusión entre la Lógica Difusa y la Computación Evolutiva. Un sistema difuso genético es básicamente un sistema difuso con un proceso de aprendizaje incorporado basado en algoritmos genéticos. Se considera que la interpretabilidad (medida frecuentemente como el número de reglas generadas) de los sistemas difusos genéticos es su principal ventaja competitiva en comparación con otras técnicas por lo cual ha recibido atención especial. La obtención de un alto grado de interpretabilidad es contradictoria ante el objetivo de disminuir la precisión (obtenida como el error) por lo que es necesario alcanzar un buen balance entre ambos objetivos. Los sistemas difusos genéticos han sido utilizados para resolver diversos problemas, entre ellos, los problemas de regresión de alta dimensionalidad. La resolución de problemas de alta dimensionalidad puede influir en el decremento de la interpretabilidad de los modelos obtenidos. La alta dimensionalidad en los datos implica una mayor utilización de los recursos computacionales en la solución del problema. En este trabajo se realiza un estudio del algoritmo Embedded Genetic Learning of Highly Interpretable Fuzzy Partitions (EGLFP) diseñado para resolver problemas de regresión de alta dimensionalidad y se analizan las partes del mismo que provocan mayor número de evaluaciones. En base a este estudio se proponen tres variantes que mejoran el tiempo de ejecución del algoritmo original, logrando un buen balance entre interpretabilidad y precisión.. I.
(4) Abstract Genetic fuzzy systems emerge as a fusion between Fuzzy Logic and Evolutionary Computation. A genetic fuzzy system is basically a fuzzy system with a learning process incorporated based on genetic algorithms. The interpretability (often measured as the number of rules generated) of genetic fuzzy systems is their main competitive advantage in comparison to other techniques, so it has received special attention. Obtaining a high degree of interpretability is contradictory to the aim of reducing the accuracy (measured as the error), so it is necessary obtain a good trade of between these two objectives. Genetic fuzzy systems have been used to solve several problems, including high-dimensional regression problems. Solving high-dimensional problems may affect the interpretability of the obtained models. The high dimensionality in the data implies greater use of computational resources in the solution the problem. In this work we make a study of Embedded Genetic Learning of Highly Interpretable Fuzzy Partitions (EGLFP) algorithm, designed to solve high-dimensional regression problems, and we analyze the parts of it that cause the largest number of evaluations. Based on this study, we propose three alternatives that improve the execution time of the original algorithm, achieving a good trade of between interpretability and accuracy.. II.
(5) Tabla de Contenidos Introducción ................................................................................................................................................. 1 Capítulo I. Sistemas difusos genéticos, características y aplicaciones a problemas de alta dimensionalidad .......................................................................................................................................... 6 1.1. Introducción ................................................................................................................................. 6. 1.2. Origen de los sistemas difusos genéticos .............................................................................. 6. 1.3. Diseño de sistemas difusos genéticos basados en reglas ................................................ 10. 1.4 Tratamiento del balance entre interpretabilidad y precisión en sistemas difusos genéticos basados en reglas .............................................................................................................. 12 1.4.1. Particiones difusas fuertes .......................................................................................... 14. 1.4.2. Algoritmos multiobjetivo en el diseño de sistemas difusos genéticos.................. 16. 1.5. Sistemas difusos genéticos aplicados a problemas de alta dimensionalidad ................ 18. 1.6. Consideraciones Finales ......................................................................................................... 21. Capítulo II. Aprendizaje Genético Embebido de Particiones Difusas, variantes para mejorar el tiempo de ejecución. ................................................................................................................................ 22 2.1. Introducción ............................................................................................................................... 22. 2.2. Aprendizaje Genético Embebido de Particiones Difusas................................................... 22. 2.2.1. Esquema de codificación ................................................................................................ 23. 2.2.2. Inicialización ...................................................................................................................... 24. 2.2.3. Operadores ....................................................................................................................... 24. 2.2.3.1. Cruzamiento .............................................................................................................. 25. 2.2.3.2. Mutación de parámetros.......................................................................................... 26. 2.2.3.3. Mutación de granularidad........................................................................................ 27. 2.2.4. Enfoque de Aprendizaje Genético Embebido .............................................................. 29. 2.2.5. Mecanismo de inferencia ................................................................................................ 30. 2.2.6. Funciones Objetivos ........................................................................................................ 30. 2.3. Propuestas para mejorar la eficiencia computacional del EGLFP ................................... 30. 2.3.1. Generación de reglas difusas ......................................................................................... 31. 2.3.1.1. Propuesta 1: Ejemplos Ganadores ........................................................................ 32. 2.3.1.2. Análisis de la complejidad temporal de la generación de reglas difusas ........ 34. 2.3.2. Evaluación de los individuos .......................................................................................... 34. 2.3.2.1. Propuesta 2.1 Evaluación de individuos en base al error de los ejemplos ..... 35 III.
(6) 2.4. 2.3.2.2. Propuesta 2.2 Evaluación de individuos con selección de ejemplos aleatorios 36. 2.3.2.3. Análisis de la complejidad temporal de la evaluación de individuos. ............... 36. Conclusiones Parciales ........................................................................................................... 36. Capítulo III. Resultados Experimentales .............................................................................................. 38 3.1. Introducción ............................................................................................................................... 38. 3.2. Métricas y técnicas estadísticas utilizadas para la validación de los resultados ........... 38. 3.2.1. Técnicas Estadísticas ...................................................................................................... 38. 3.2.2. Métricas para la comparar las soluciones de algoritmos multiobjetivo .................... 39. 3.3. Estudio comparativo entre las propuestas realizadas y la variante original EGLFP ..... 40. 3.3.1. Comparación en cuanto a tiempo de ejecución .......................................................... 41. 3.3.2. Comparación del balance entre interpretabilidad y precisión ................................... 43. 3.3.3. Comparación entre tiempo de ejecución y cobertura ................................................. 50. 3.4. Conclusiones Parciales ........................................................................................................... 52. Conclusiones............................................................................................................................................. 53 Recomendaciones ................................................................................................................................... 54 Bibliografía ................................................................................................................................................ 55 Anexos ....................................................................................................................................................... 59 Anexo 1: Operador CPCX ................................................................................................................... 59 Anexo 2: Operador CAM ..................................................................................................................... 60 Anexo 3: Resultados de las variantes (EGLFP, P1, P2.1 y P2.2) ................................................ 61. IV.
(7) Lista de Figuras Figura 1. Definición de la altura utilizando conjuntos difusos...................................................... 7 Figura 2. Estructura básica de un sistema difuso basado en reglas ........................................... 8 Figura 3. Sistemas difusos genéticos dentro del área de softcomputing .................................... 9 Figura 4. Diseño embebido de sistemas difusos genéticos. ......................................................14 Figura 5. Ejemplo de una partición difusa fuerte .......................................................................15 Figura 6. Esquema del algoritmo NSGA II.................................................................................17 Figura 7. Problemas de regresión .............................................................................................19 Figura 8. Esquema evolutivo del algoritmo EGLFP ...................................................................23 Figura 9. Ejemplo de codificación de un cromosoma ................................................................24 Figura 10. Ejemplo de operación de cruce ................................................................................26 Figura 11. Ejemplo de funcionamiento de mutación de parámetros ..........................................27 Figura 12. Ejemplo de operador de fusión.................................................................................29 Figura 13. Ejemplo de operador de fisión ..................................................................................29 Figura 14. Esquema del algoritmo Wang y Mendel ...................................................................32 Figura 15. Evaluación del individuo ...........................................................................................35 Figura 16. Curva de balance entre interpretabilidad y precisión en los sistemas difusos genéticos ..................................................................................................................................43 Figura 17. Paretos obtenidos para abalone, pole y concrete .....................................................44 Figura 18. Comparación entre tiempo y cubrimiento (conjunto de entrenamiento) ....................50 Figura 19. Comparación entre tiempo y cubrimiento (conjunto de prueba)................................51. V.
(8) Lista de Tablas Tabla 1. Sistemas difusos genéticos para la solución de problemas de regresión ....................20 Tabla 2. Porciento de ejemplos ganadores para cada base de casos .......................................33 Tabla 3.Promedio de los tiempos de ejecución de las variantes propuestas y el algoritmo original. .....................................................................................................................................41 Tabla 4. Rankings asociados a los algoritmos (tiempo).............................................................42 Tabla 5. Test de Holm para un valor de confianza de 0.05 (tiempo) ..........................................42 Tabla 6. Promedio de la cobertura del Pareto real sobre los paretos obtenidos por las variantes propuestas y la variante original para el conjunto de entrenamiento .........................................46 Tabla 7. Rankings asociados a los algoritmos (cobertura, conjunto de entrenamiento).............47 Tabla 8. Test de Holm para un valor de confianza de 0.05 (cobertura, conjunto de entrenamiento) ..........................................................................................................................47 Tabla 9. Promedio de la cobertura del Pareto real sobre los paretos obtenidos por las variantes propuestas y la variante original para el conjunto de prueba .....................................................48 Tabla 10. Rankings asociados a los algoritmos (cobertura, conjunto de prueba) ......................49 Tabla 11. Test de Holm para un valor de confianza de 0.05 (cobertura, conjunto de prueba) ...49. VI.
(9) Introducción. Introducción Actualmente se dispone de gran cantidad de datos que son fácilmente recogidos, transmitidos, almacenados y copiados gracias a los adelantos en la ciencia y la tecnología. Estos datos se adquieren para diferentes propósitos: extraer patrones, realizar predicciones, visualizar características, identificar relaciones o subgrupos, realizar clasificaciones, etc., dependiendo del objeto de estudio de los mismos. Cada día se vuelve más necesario tratar con problemas que manipulan datos de alta dimensionalidad. Los conjuntos de datos consisten en un sistema de información descrito por un conjunto de atributos y los objetos que representan con combinaciones de valores válidos dentro del dominio de cada atributo. La alta dimensionalidad en los datos puede ser vista en los problemas de dos formas diferentes: la alta dimensionalidad en cuanto al número de ejemplos y la alta dimensionalidad asociada al número de atributos que describen los ejemplos. Los métodos de solución de problemas clásicos provenientes de la Estadística o la Inteligencia Artificial no fueron diseñados originalmente para tratar con problemas de alta dimensionalidad por lo que pueden tener un comportamiento no deseado frente a un problema de esta índole. En la literatura la forma más común de tratar con problemas de alta dimensionalidad es mediante la selección de los atributos que describen los ejemplos reduciendo de esta forma la dimensionalidad en los datos. Se han utilizado técnicas de regresión con este fin como la regresión multivariada (Ya et al., 2012) , los mínimos cuadrados (Kramer et al., 2008), análisis de componentes principales (Cai et al., 2013) y la técnica LASSO1 (Jian et al., 2006). Se han utilizado con este propósito además, máquinas de soporte vectorial (Cherkassky and Ma, 2004) y redes neuronales (Hinton and Salakhutdinov, 2006). Estas técnicas han demostrado ser precisas aunque las soluciones que brindan pueden resultar complejas de interpretar. Los sistemas difusos son útiles para modelar aspectos cualitativos del conocimiento humano y del razonamiento sin la necesidad de emplear análisis cuantitativos (Herrera, 2008). En múltiples aplicaciones el conocimiento que se requiere puede que no esté disponible con facilidad y para las personas puede resultar complejo extraer conocimiento de un gran volumen de datos numéricos. Esta situación motiva el desarrollo de técnicas computacionales para extraer y representar el conocimiento por sistemas difusos basados en reglas. Un aspecto importante en estos sistemas es el balance entre dos criterios importantes, precisión e 1. Least Absolute Shrinkage and Selection Operator. 1.
(10) Introducción interpretabilidad (Gacto et al., 2011). La precisión es un aspecto crítico ya que los sistemas pueden predecir valores con errores pequeños que se propagan y finalmente se reflejan como errores en el comportamiento posterior. La interpretabilidad de los modelos (capacidad de expresar el comportamiento del sistema real en una forma comprensible) ha ganado una atención especial considerando que un modelo interpretable es consistente y compacto. La interpretabilidad usualmente es medida con el número de reglas generadas por el sistema difuso, aunque existen otras alternativas. Un sistema difuso genético es básicamente un sistema difuso con un proceso de aprendizaje incorporado basado en Algoritmos Genéticos (Cordón et al., 2004, Cordón, 2011). Los algoritmos genéticos están basados en las leyes de la genética natural y proveen capacidades de búsqueda robusta en espacios complejos por lo que constituyen un enfoque válido para los problemas que requieren un proceso de búsqueda eficiente y efectivo. En (Cordón et al., 2004) se realiza un análisis de la literatura que muestra que los tipos de sistemas difusos genéticos más destacados son los sistemas difusos genéticos basados en reglas (Cordón et al., 2001a). En este tipo de sistema, el proceso genético aprende o ajusta, diferentes componentes de un sistema difuso basado en reglas. Para lidiar con el problema del balance entre la precisión y la interpretabilidad usualmente se diseñan sistemas con técnicas de optimización multiobjetivo debido a su capacidad para tratar con criterios de optimización que entran en conflicto entre sí (Fazzolari et al.). Aplicaciones recientes han demostrado la competitividad de los sistema difusos genéticos en la solución de problemas de alta dimensionalidad, en (Gheyas and Smith, 2010, Lughofer and Kindermann, 2010) se exponen enfoques de sistemas difusos genéticos que abordan el problema de selección de rasgos en alta dimensionalidad. En (Di et al., 2007) se presenta un enfoque de sistema difuso genético aplicado al problema de agrupamiento con alta dimensionalidad en los datos. Los problemas de clasificación han sido ampliamente abordados por sistemas difusos genéticos, reportes actuales demuestran que los problemas de clasificación para altas dimensiones de datos también están siendo tratados por los sistemas difusos genéticos, ejemplo de lo cual encontramos en (Alcala-Fdez et al., 2010, Mansoori et al., 2008). La realización de predicciones o regresión consiste en inferir una respuesta o valor asociado a un elemento en particular, por ejemplo, pronosticar variables meteorológicas como la temperatura teniendo en cuenta otros factores. Los problemas de regresión de alta 2.
(11) Introducción dimensionalidad también han sido abordados desde la perspectiva de los sistemas difusos genéticos (Alcalá et al., 2009, Cococcioni et al., 2011, Gacto et al., 2009b, Pulkkinen and Koivisto, 2010). Una de las principales ventajas del uso de los sistemas difusos genéticos es la interpretabilidad de los resultados de los mismos frente al uso de otras técnicas. Sin embargo, la resolución de problemas de alta dimensionalidad puede influir en el decremento de la interpretabilidad de los modelos obtenidos. Además, los sistemas diseñados deben ser flexibles y permitir obtener un conocimiento compacto. Las propuestas previamente comentadas no preservan en muchos casos buena interpretabilidad en problemas grandes y además, carecen del uso de metodologías adecuadas para el análisis experimental de los resultados obtenidos con los algoritmos multiobjetivo. El diseño de un sistema difuso genético flexible que permita la obtención de un conocimiento compacto y aprenda el número de variables y el número de etiquetas por variable, que permita la obtención de reglas de tamaño variable y el ajuste de la funciones de pertenencia, hace que el aprendizaje sea complejo, especialmente por los cambios estructurales que suponen el aprendizaje del número de etiquetas, lo que ha devenido en el uso del meta-aprendizaje (Cordón et al., 2001b). El algoritmo Embedded Genetic Learning of Highly Interpretable Fuzzy Partitions (EGLFP) (Casillas, 2009) soluciona el problema de regresión mediante meta-aprendizaje utilizando un sistema difuso genético basado en el algoritmo de aprendizaje multiobjetivo NSGA-II (Deb et al., 2002). El algoritmo EGLFP optimiza varios aspectos importantes: el error, el conjunto de reglas y el número de particiones difusas, realizando un aprendizaje de reglas basado en los ejemplos del conjunto de datos. Para este aprendizaje es utilizado el algoritmo propuesto por Wang y Mendel (Wang and Mendel, 1992). A pesar de las ventajas para gestionar bases de conocimiento flexibles mediante metaaprendizaje, esto supone un inconveniente cuando aumenta el tamaño del problema ya que no se debe renunciar a la flexibilidad en el diseño de la base de conocimiento por lo que es necesario encontrar mecanismos que hagan eficiente el aprendizaje. El tiempo que demora un método en resolver un problema siempre aumenta cuando aumenta la dimensión del mismo. El número de ejemplos que determina el conjunto de reglas difusas con la utilización del algoritmo de Wang y Mendel es menor que el total de los ejemplos que contiene la base de casos sin embargo el algoritmo los analiza a todos cada vez que genera una base de reglas.. 3.
(12) Introducción Otro proceso costoso en el algoritmo EGLFP es la evaluación de los individuos que constituye el criterio de parada del mismo. Se analiza en este trabajo ¿cómo mejorar la eficiencia en cuanto al tiempo de ejecución del algoritmo EGLFP utilizando menor cantidad de ejemplos en la formación de la base de reglas y realizando una selección de casos2 en la evaluación de los individuos, sin perder el balance entre interpretabilidad y precisión?, constituyendo el objetivo general del mismo: Proponer nuevas variantes de sistemas difusos genéticos para la solución de problemas de regresión de alta dimensionalidad basadas en el algoritmo EGLFP que tengan menor costo computacional en cuanto a tiempo, garantizando el balance entre interpretabilidad y precisión de los mismos. Este objetivo general fue desglosado en los objetivos específicos siguientes: 1. Proponer variantes del sistema difuso genético EGLFP para problemas de regresión de alta dimensionalidad cuyo tiempo de ejecución se minimice mediante la reducción de ejemplos en el diseño de la base de reglas difusas y la selección de casos en la evaluación de los individuos. 2. Realizar la implementación computacional de las variantes propuestas. 3. Establecer comparaciones estadísticas entre los resultados que brindan las variantes implementadas y la propuesta original EGLFP. El estudio de los sistemas difusos genéticos y su aplicación a los problemas de regresión de alta dimensionalidad y la factibilidad de su aplicación. para encontrar una solución. suficientemente buena en comparación con la obtenida por otros enfoques, adquiere un significado relevante en la vida práctica ya que diversos problemas de regresión con alta dimensión se encuentran en la vida cotidiana. La realización de la investigación presenta entonces motivaciones de carácter teórico y práctico. Desde una perspectiva teórica, se ofrecen nuevas variantes de sistemas difusos genéticos que mejoran la eficiencia temporal y mantienen el balance entre precisión e interpretabilidad. En el orden práctico se realiza la implementación computacional de las variantes propuestas.. 2. En el trabajo se refiere indistintamente a ejemplos y casos como las filas de una base de casos o conjunto de datos.. 4.
(13) Introducción El presente informe incluye, además de esta introducción, tres capítulos, conclusiones, recomendaciones, bibliografía y anexos. En el Capítulo I aparecen algunas consideraciones de carácter teórico sobre el origen y diseño de Sistemas Difusos Genéticos. Se destaca el especial tratamiento al balance entre precisión e interpretabilidad y la aplicación de los sistemas difusos genéticos a diferentes problemas de Aprendizaje Automático en especial la regresión. El Capítulo II dedica su espacio al tratamiento de los aspectos generales relacionados con el algoritmo EGLFP. Se realizan, además, tres propuestas para mejorar el tiempo de ejecución del algoritmo EGLFP. En el Capítulo III se ofrecen valoraciones acerca de los resultados obtenidos por las variantes propuestas respecto a la original estableciendo comparaciones estadísticas que permiten analizar los tiempos de ejecución obtenidos por los algoritmos y el balance entre interpretabilidad y precisión de cada uno.. 5.
(14) Capítulo I. Capítulo I. Sistemas difusos genéticos, características y aplicaciones a problemas de alta dimensionalidad 1.1 Introducción El capítulo inicial de este trabajo aborda aspectos esenciales del origen y el diseño de los sistemas difusos genéticos haciendo énfasis en el tratamiento entre la precisión y la interpretabilidad, siendo esta última, una de las características que los distinguen frente a otros métodos de solución de problemas. Se aborda, además, la aplicación de los sistemas difusos genéticos a diferentes problemas del Aprendizaje Automático fundamentalmente a los problemas de regresión que son para los cuales está diseñado el algoritmo que será objeto de estudio en este trabajo.. 1.2 Origen de los sistemas difusos genéticos En el lenguaje natural abundan conceptos vagos e imprecisos como “hoy hace mucho calor” o “Pedro es alto”. Estas sentencias son difíciles de traducir en un lenguaje más preciso sin que pierdan la semántica, por ejemplo, Pedro mide 1.60 no necesariamente quiere decir que Pedro sea alto. En 1965 Lotfi A. Zadeh publicó el trabajo "Fuzzy Sets” (Zadeh, 1965) que describe la teoría de los conjuntos difusos como una alternativa para traducir términos imprecisos del lenguaje natural como “alto” en expresiones matemáticas que definen el grado de pertenencia en este caso de Pedro al conjunto de los hombres altos. La idea de Zadeh es hacer que un rango de valores de pertenencia de un elemento a un conjunto pueda variar en el intervalo 0,1. en lugar de limitarse a uno de los valores del par. 0,1 , es decir el Falso Verdadero de la Lógica Clásica. Zadeh además, extiende los operadores lógicos clásicos logrando de esta forma introducir la Lógica difusa como extensión de la Lógica Clásica. Un conjunto difuso se caracteriza por una función: μA: X[0,1] tal que μA x se interpreta como el grado de pertenencia a A de cada x ∈ X. Existen varios tipos de funciones de pertenencia utilizadas para representar los conjuntos difusos, entre ellas las funciones: triangular, trapezoidal, gausiana. En la Figura 1 se muestra un ejemplo de la definición de la altura de una persona utilizando conjuntos difusos. 6.
(15) Capítulo I. Figura 1. Definición de la altura utilizando conjuntos difusos. A decir de Zadeh los sistemas difusos son el resultado de la fusificación de un sistema convencional y operan con conjuntos difusos en lugar de números logrando una representación de la información que imita el mecanismo de razonamiento de la mente humana. Dentro de los sistemas difusos los más difundidos son los sistemas difusos basados en reglas en los que se obtiene una colección de reglas basadas en el conocimiento humano. En la Figura 2 se define la estructura básica de un sistema difuso basado en reglas en el que intervienen diferentes componentes: . Interfaz de Fusificación: Convierte la entrada nítida a un valor difuso.. . Base de datos: Contiene la definición lingüística de las variables.. . Base de reglas: Contiene el conjunto de acciones a realizar en función del estado.. . Mecanismo de inferencia: Realiza el proceso de razonamiento para estimar la salida en función de la entrada.. . Interfaz de Defusificación: Convierte la salida difusa a valor nítido.. 7.
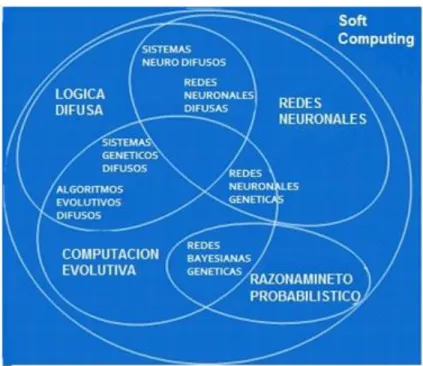
(16) Capítulo I. Figura 2. Estructura básica de un sistema difuso basado en reglas. Una regla difusa Si-Entonces es una declaración expresada por medio de: Si <Proposición Difusa> Entonces <Proposición Difusa> Donde una <Proposición Difusa> es una declaración simple o una composición de declaraciones simples “y”, “o” y “no”, representando la intersección, unión y el complemento difuso respectivamente. Definiendo una declaración simple como x es A donde x es la variable lingüística y A es un valor lingüístico de x. Dentro de los sistemas difusos basados en reglas se encuentran: . Sistemas difusos tipo Mamdani: Basado en reglas difusas del tipo Si-Entonces.. . Sistemas difusos tipo Takagi-Sugeno-Kang (TSK): No necesitan interfaz de defusificación. El consecuente es una fórmula matemática en función del antecedente Si de la regla difusa.. En la década de los 90 se generó un interés especial en adicionar a los sistemas difusos capacidad de aprendizaje, dos de los enfoques más exitosos estuvieron dentro del área de softcomputing en la que diferentes técnicas como las evolutivas y las redes neuronales proporcionaron a los sistemas difusos la capacidad de aprendizaje. Los sistemas neuro-difusos (Fuller, 1999, Nauck et al., 1997) y los sistemas difusos genéticos constituyen dos ejemplos de lo anteriormente expuesto. En la Figura 3 se muestran los sistemas difusos genéticos dentro del área de softcomputing.. 8.
(17) Capítulo I. Figura 3. Sistemas difusos genéticos dentro del área de softcomputing. Con el término de Computación Evolutiva se engloba al conjunto de técnicas que, basándose en la simulación de los procesos naturales y la genética, se utilizan para resolver problemas complejos de búsqueda y aprendizaje. Los algoritmos evolutivos no fueron diseñados expresamente como técnicas de aprendizaje automático, sin embargo una tarea de aprendizaje puede definirse como un problema de optimización y por tanto ser resuelta mediante algoritmos evolutivos debido a su capacidad de búsqueda potente en espacios complejos y mal definidos además de su flexibilidad de representación y capacidad para incorporar conocimiento existente. Dentro de estas técnicas encontramos la programación evolutiva, las estrategias evolutivas y quizá la más popular: los Algoritmos Genéticos (Goldberg, 1989). Un sistema difuso genético es básicamente un sistema difuso con un proceso de aprendizaje incorporado basado en Algoritmos Genéticos (Goldberg, 1989). Los Algoritmos Genéticos están basados en las leyes de la genética natural y proveen capacidades de búsqueda robusta en espacios complejos por lo que constituyen un enfoque válido para los problemas que requieren un proceso de búsqueda eficiente y efectivo (Cordón et al., 2004) Existen cuatro trabajos que se consideran pioneros en el desarrollo de los sistemas difusos genéticos (Karr, 1991, Valenzuela-Rendon, 1991, Thrift, 1991, Pham and Karaboga, 9.
(18) Capítulo I 1991).Luego de estos, han aparecido un gran número de contribuciones a los sistemas difusos genéticos.. 1.3 Diseño de sistemas difusos genéticos basados en reglas En (Cordón et al., 2004) se realiza un análisis de la literatura que muestra que los tipos de sistemas difusos genéticos más destacados son los sistemas difusos genéticos basados en reglas (Cordón et al., 2001a). En este tipo de sistema, el proceso genético aprende o ajusta, diferentes componentes de un sistema difuso basado en reglas. Varias investigaciones han abogado por la generación automática de la base de conocimiento de un sistema difuso genético basado en reglas con el uso de Algoritmos Genéticos, el punto es emplear un proceso de aprendizaje evolutivo para automatizar el diseño de la base de conocimiento, lo que puede ser considerado un problema de optimización o de búsqueda. Desde el punto de vista de la optimización la tarea de encontrar una base de conocimiento apropiada para un problema particular es equivalente a parametrizar la base de conocimiento difusa (reglas y funciones de pertenencia), y encontrar los valores óptimos de los parámetros con respecto al criterio de diseño. Los parámetros de la base de conocimiento constituyen el espacio de optimización, que es transformado en una representación genética apropiada sobre la que opera el proceso de búsqueda. El primer paso en el diseño de un sistema difuso genético basado en reglas es decidir qué partes de la base de conocimiento van a ser objeto optimización para el algoritmo genético. La base de conocimiento de un sistema difuso genético basado en reglas no tiene una estructura homogénea pero es la unión de componentes cualitativamente diferentes. Como ejemplo la base de conocimiento de un sistema difuso genético basado en reglas tipo Mamdani tiene dos componentes: . Base de Datos: contiene las definiciones de los factores de escala de las variables y las funciones de pertenencia de los conjuntos difusos asociados a las etiquetas lingüísticas.. . Base de Reglas: formada por la colección de reglas difusas.. La decisión de qué parte de la base de conocimiento se va a aprender depende de dos objetivos que entran en conflicto: la dimensionalidad y la eficiencia de la búsqueda. En un espacio de búsqueda de dimensión pequeña se realiza un proceso de aprendizaje rápido y simple, pero los resultados puede que no sean los óptimos. Una búsqueda del espacio que 10.
(19) Capítulo I contenga la base de conocimiento completa puede dar como resultado soluciones óptimas, pero el proceso de búsqueda puede ser lento e ineficiente. Tomando en cuenta estas consideraciones se debe encontrar un balance entre la completitud y dimensionalidad del espacio de búsqueda y la eficiencia de la búsqueda. Este balance ofrece diferentes posibilidades para el diseño de un sistema difuso genético basado en reglas dentro de las cuales se encuentran: . Ajuste genético de la base de datos: es la tarea de ajustar los factores de escala y funciones de pertenencia lo cual es de vital importancia en el diseño de sistema difuso genético basado en reglas. Ajustar es optimizar un sistema difuso genético basado en reglas existente. El proceso de ajuste asume la existencia de una base de reglas predefinida y tiene como objetivo encontrar un conjunto de parámetros óptimos para las funciones de pertenencia y los factores de escala (parámetros de la base de datos). Estas funciones son adaptadas por el algoritmo genético acorde a una función de aptitud que especifica el criterio de diseño de forma cuantitativa.. . Aprendizaje genético de la base de reglas: asume la existencia de un conjunto predefinido de funciones de pertenencia en la base de datos las cuales hacen referencia las reglas mediante etiquetas lingüísticas. Para aprender la base de reglas pueden tomarse en consideración fundamentalmente tres enfoques diferentes: Michigan (Ishibuchi et al., 1995), Pittsburgh (Hoffmann and Pfister, 1997, Pham and Karaboga, 1991) y el aprendizaje iterativo de reglas (Cordón and Herrera, 1997, González and Pérez, 1999), en los que la base de reglas puede representarse como una matriz (Thrift, 1991), una tabla de decisión (Pham and Karaboga, 1991), o una lista de reglas (Hoffmann and Pfister, 1997, González and Pérez, 1999). Las primeras dos representaciones son usadas solamente cuando se tiene un número de variables reducido (no más de 3), el resultado es un código que puede ser manejado solamente por el enfoque Pittsburgh. La tercera variante es la representación más utilizada y puede ser adaptada a los tres enfoques mencionados con anterioridad.. . Aprendizaje genético de la base de conocimiento: Se realiza en espacios de búsqueda heterogéneos debido a la composición de la base de conocimiento. El costo computacional de la búsqueda genética crece a medida que se incrementa la complejidad del espacio de 11.
(20) Capítulo I búsqueda. Un sistema difuso genético basado en reglas que codifica reglas individuales es una opción para mantener un espacio de reglas flexible y complejo en el que la búsqueda de soluciones permanece factible y eficiente. Podemos identificar cuatro formas diferentes para realizar el diseño de las particiones difusas dependiendo de dónde se integra en el proceso de aprendizaje (Casillas et al., 2003): . diseño preliminar: usualmente se hace mediante clusterización (Pedrycz, 2001). . diseño embebido: un meta-algoritmo genera diferentes particiones difusas y un método de aprendizaje simple y eficaz deriva conjuntos de reglas difusas de ellas (Cordón et al., 2001b, Cordon et al., 2000, Rojas et al., 2000, Cordón et al., 2001c, Ishibuchi and Murata, 1996, Alcalá et al., 2007). . diseño simultáneo: realizado mediante algoritmos evolutivos (Magdalena and MonasterioHuelin, 1997, Xiong and Litz, 2000). . diseño a posteriori: por lo general realizado mediante algoritmos evolutivos y redes neuronales (Casillas et al., 2005, Espinosa and Vandewalle, 2000).. El número de términos lingüísticos de las particiones difusas no es fácil de aprender, ya que implica cambios estructurales que influyen en los parámetros de la función de pertenencia y el conjunto de reglas difusas, esta es una de las razones que justifica el uso de los algoritmos genéticos para realizar el aprendizaje debido a su alta capacidad de tratar con estructuras flexibles y codificaciones mixtas. Aunque el ajuste genético de la base de datos, el aprendizaje genético de la base de reglas y el aprendizaje genético de la base de conocimiento son los diseños de sistemas difusos genéticos basados en reglas que han sido abordados, no son los únicos, pero si las líneas de desarrollo más comunes. En (Herrera, 2008) existe un análisis de estas y otras variantes existentes.. 1.4 Tratamiento del balance entre interpretabilidad y precisión en sistemas difusos genéticos basados en reglas Se considera que la interpretabilidad de los sistemas difusos genéticos basados en reglas es su principal ventaja competitiva en comparación con otras técnicas por lo cual ha recibido atención especial. La obtención de un alto grado de interpretabilidad en los sistemas difusos genéticos basados en reglas es contradictoria ante el objetivo de disminuir la precisión por lo que es necesaria la obtención de un buen balance entre ambos objetivos. 12.
(21) Capítulo I La precisión es usualmente optimizada con la minimización del error cuadrático medio para los problemas de regresión, o la maximización del porciento de ejemplos correctamente clasificados para los problemas de clasificación. La forma de medir la interpretabilidad de un sistema difuso genético basado en reglas es un poco más controversial, debido a que es un concepto difícil de cuantificar. En (Gacto et al., 2011) se realiza un análisis profundo de diferentes medidas de interpretabilidad. En este trabajo se utilizará el número de reglas generadas para expresar la complejidad del modelo, bajo la premisa de que mientras menor es el número de reglas generado, más fácil de entender es el modelo. En la literatura se utiliza el término de compacto para definir los sistemas que logran una correcta representación de las relaciones entre las entradas y las salidas teniendo la menor cantidad de reglas posibles. Se hará uso de las particiones difusas fuertes (Valente de Oliveira, 1999) (ver en la sección 1.4.1) que han sido propuestas para incrementar la interpretabilidad debido a que cumplen restricciones de: . distinguibilidad: dos conjuntos difusos cumplen restricciones de distinguibilidad si se encuentran lo suficientemente separados entre sí como para expresar conceptos diferentes,. . normalidad: un conjunto difuso es normal si existe al menos un elemento cuya función de pertenencia es uno,. . y cubrimiento: una colección de conjuntos difusos definida sobre el universo de discurso es completo si cada elemento del universo de discurso pertenece al menos a uno de los conjuntos difusos,. como medida de la capacidad del sistema de expresar la realidad del problema tratado. Existen otras medidas para estimar la excelencia de la base de reglas generada como la . consistencia: cada combinación de antecedentes (una etiqueta por cada variable de entrada) debe tener solamente una posible etiqueta para el consecuente. Esto se relaciona a que el sistema no tenga reglas incoherentes;. . y completitud: cada ejemplo del conjunto de entrenamiento debe estar representado en al menos una regla difusa,. que son tratadas imponiendo restricciones y penalizaciones en el sistema difuso genético. 13.
(22) Capítulo I En la literatura podemos encontrar muchas alternativas para mejorar la interpretabilidad de los modelos difusos obtenidos automáticamente, tales como reducir el número de reglas difusas (Ishibuchi et al., 1995, Hong and Lee, 1999), usando un subconjunto de variables de entrada en el sistema (Hong and Chen, 1999, Lee et al., 2001, Gonzalez and Perez, 2001), o utilizar expresiones de reglas difusas más compactos (Gonzalez and Perez, 2001). Dentro de estas opciones, una de las aproximaciones más importantes implica aprender el número óptimo de términos lingüísticos por variable (Cordón et al., 2001b, Cordon et al., 2000, Espinosa and Vandewalle, 2000).De hecho, usar un número reducido de términos lingüísticos es crucial para entender el significado de las variables e influye exponencialmente en el tamaño del conjunto de reglas difusas. La tarea de aprender el número de términos lingüísticos con los sistemas difusos genéticos se realiza principalmente siguiendo el diseño embebido. La Figura 4 representa gráficamente esta actividad de aprendizaje.. Figura 4. Diseño embebido de sistemas difusos genéticos.. 1.4.1 Particiones difusas fuertes En (Valente de Oliveira, 1999) se propone el uso de particiones difusas tipo fuerte en cada variable para lograr mayor interpretabilidad y con el fin de reducir el espacio de búsqueda abordado por el algoritmo genético. Estas particiones se caracterizan por tener una cobertura total, es decir, la suma de los grados de pertenencia a todos los conjuntos difusos es. 14.
(23) Capítulo I exactamente 1 para cada valor del universo de discurso de la variable. Por lo tanto, en estas particiones los extremos del núcleo, (el intervalo de elementos en los que el grado de pertenencia es 𝜇𝐴 𝑥 = 1) de cada conjunto difuso coincide con los extremos del soporte (el intervalo de elementos en los que el grado de pertenencia es 𝜇𝐴 𝑥 < 1) de los conjuntos difusos adyacentes. Por consiguiente, los conjuntos difusos se cruzan en un grado de pertenencia igual a 0,5. La Figura 5 representa un ejemplo de este tipo de partición difusa, donde VS significa muy pequeño, S para pequeño, M para medio, L para grande y VL para muy grande. En este ejemplo, son necesarios seis valores reales (0,2, 0,3, 0,45, 0,7, 0,8, y 0,9) para definir los parámetros de las funciones de pertenencia.. Figura 5. Ejemplo de una partición difusa fuerte. Estas particiones difusas fuertes tienen algunas propiedades interesantes de interpretabilidad. En primer lugar, todos los elemento del universo de discurso tienen un grado de pertenencia de al menos 0,5 para un conjunto difuso (es decir, la cobertura es fuerte). En segundo lugar, el punto de intersección entre dos conjuntos difusos adyacentes es exactamente 0,5, y, finalmente, el núcleo de cada conjunto difuso está cubierto solamente por sí mismo, es decir, el grado de pertenencia de los conjuntos difusos restantes es 0. Aunque estas propiedades ayudarán a conseguir un buen grado de interpretabilidad, las particiones borrosas fuertes aún no garantizan un alto grado de distinguibilidad, es decir, cada función de pertenencia debe ser suficientemente distinta del resto. En este caso, este problema debe abordarse al obligar una distancia mínima entre los núcleos de los conjuntos difusos. Otra ventaja de la utilización de este tipo de particiones difusas es que los grados de libertad son menores, lo que reduce el espacio de búsqueda, permitiendo al algoritmo hacer una. 15.
(24) Capítulo I exploración eficaz. En el ejemplo de la Figura 5 sólo se necesitan codificar seis valores para definir las partición difusa debido a que los extremos del universo de discurso se encuentran fijos, en efecto, sólo se necesita un valor para definir el término lingüístico M debido a su forma triangular. La principal limitación del uso de particiones difusas fuertes es la limitada precisión que puedan alcanzar, razón por la cual se necesita de un buen diseño del algoritmo de optimización que las explote. 1.4.2. Algoritmos multiobjetivo en el diseño de sistemas difusos genéticos. La tendencia actual en los sistemas difusos genéticos para tratar el balance entre interpretabilidad y precisión se basa en el uso de optimización multiobjetivo debido a su capacidad inherente para operar con criterios de optimización contradictorios (Casillas et al., 2009, Botta et al., 2009, Gacto et al., 2009a). Existen varios algoritmos evolutivos multiobjetivo basados en los principios de Pareto para la búsqueda dentro del espacio de soluciones que han sido utilizados en el diseño de sistemas difusos genéticos. Estos algoritmos se caracterizan por dirigir la búsqueda a través de la relación de dominancia de Pareto. Se dice que un vector 𝑢 = 𝑢1 , ⋯ , 𝑢𝑘 domina 𝑣 = 𝑣1 , ⋯ , 𝑣𝑘 denotado por 𝑢 ⪯ 𝑣 si: ∀𝑖 ∈ 1, ⋯ , 𝑘 ∶ 𝑢𝑖 ≤ 𝑣𝑖 𝑦 ∃𝑖 ∈ 1, ⋯ , 𝑘 ∶ 𝑢𝑖 < 𝑣𝑖 La solución al problema sería un conjunto de vectores no dominados que no pueden ser mejorados sin empeorar al menos otro objetivo, estos vectores conforman el denominado frente de Pareto. Algunos ejemplos de estos algoritmos son: . MOGA (Multiobjective Genetic Algorithm) (Fonseca and Fleming, 1993). . NPGA (Niched Pareto Genetic Algorithm) (Horn et al., 1994). . (2+2)PAES (Pareto Archieved Evolutionary Strategy)(Knowles and Corne, 2000). . SPEA (Strength Pareto Evolutionary Algorithm) (Zitzler and Thiele, 1999). . SPEA2 (Improving the Strength Pareto Evolutionary Algorithm) (Zitzler et al., 2001). . NSGA (Nondominated Sorting Genetic Algorithm) (Srinivas and Deb, 1994). . NSGA II (Deb et al., 2002). 16.
(25) Capítulo I En la Tabla 1 se muestra una relación en la que se puede apreciar algunos algoritmos multiobjetivo que han sido utilizados en sistemas difusos genéticos diseñados para resolver problemas de regresión. En este trabajo se hará referencia al algoritmo NSGA II, que es computacionalmente más eficiente que el NSGA (Deb et al., 2002). Es un algoritmo elitista ya que elige los mejores individuos de la unión de las poblaciones padre e hijo, además no utiliza memoria externa como los algoritmos SPEA y SPEA2. Este algoritmo inicialmente crea una población 𝑃0 de tamaño 𝑛 a partir de la cual se obtiene otra población 𝑄0 con igual tamaño mediante la utilización de los operadores genéticos de selección cruzamiento y mutación. Después de la primera generación las dos poblaciones a ser tomadas en cuenta por el algoritmo serán la actual y la obtenida por la iteración anterior. En la Figura 6 se muestra el funcionamiento general del NSGA II.. Figura 6. Esquema del algoritmo NSGA II. En cada paso del algoritmo se obtiene una población 𝑅𝑡 con el doble del número de individuos (2𝑛) formada por la unión entre las poblaciones 𝑃𝑡 y 𝑄𝑡 . La población es ordenada teniendo en cuenta la dominancia de Pareto creándose de esta forma tantos frentes como sean necesarios (el primer frente corresponde a los individuos no dominados de la población). Si el tamaño del primer frente es menor que 𝑛 se selecciona totalmente para formar parte de la población final de la iteración 𝑃𝑡+1 y de igual forma se van adicionando frentes a la población hasta completar un total de 𝑛 individuos. Si existiera la posibilidad de que un frente no pueda ser adicionado en su totalidad a 𝑃𝑡+1 se procede a ordenar sus soluciones de forma descendiente utilizando la distancia crowding (calculada como un estimador de cuán amplio es el espacio dominado por la 17.
(26) Capítulo I solución en cuestión) y seleccionando para pasar a la población final los individuos necesarios hasta completar el tamaño 𝑛 de la población.. 1.5. Sistemas difusos dimensionalidad. genéticos. aplicados. a. problemas. de. alta. En la actualidad se estudian problemas más complejos y se realizan análisis de grandes cantidades de datos obtenidos de fuentes diversas, todo debido al aumento de la capacidad de almacenaje y de cómputo de las computadoras modernas. Los conjuntos de datos3 consisten en un sistema de información descrito por un conjunto de atributos y los objetos que representan con combinaciones de valores válidos dentro del dominio de cada atributo. Si se tiene un conjunto de datos que caracterizan un problema, la alta dimensionalidad en los mismos puede verse de dos formas: alta dimensionalidad de los atributos descriptores o rasgos o la alta dimensionalidad en cuanto al número de elementos que forman el conjunto de datos. El tratamiento de problemas con alta dimensionalidad en los datos es un reto actual para los sistemas difusos genéticos, y está siendo abordado desde varias perspectivas y teniendo en consideración varios problemas del aprendizaje automático. Con el crecimiento actual de los volúmenes de información en bases de datos tanto científicas como corporativas, la necesidad de determinar qué información es realmente importante se convierte en un reto para los desarrolladores con fines de facilitar las tareas para la Minería de Datos y el Aprendizaje Automático. La selección de rasgos de un conjunto de datos es un problema en cuya solución se han utilizado una gran variedad de técnicas de la Inteligencia Artificial debido a su utilidad en diversas áreas que tienen como denominador común reducir la dimensionalidad de los problemas. De esta forma grandes volúmenes de datos pueden ser manipulados con facilidad al extraer de ellos solo la información necesaria que los describa, sin perder la calidad del sistema y obteniendo conocimiento sobre los mismos. En (Casillas et al., 2001) se expone un enfoque que aborda el problema de selección de rasgos en alta dimensionalidad.. 3. También puede encontrarse en a literatura como base de casos.. 18.
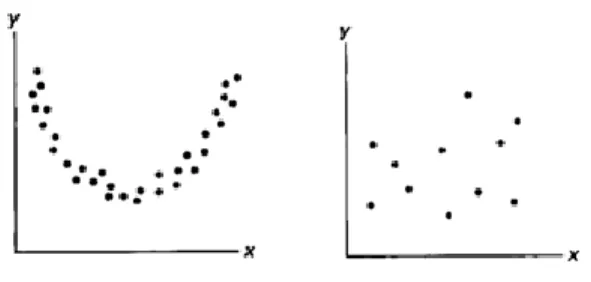
(27) Capítulo I La clusterización divide una base de datos en grupos diferentes, la meta principal de realizar el proceso de clusterización es encontrar grupos que son diferentes de los otros, y que sus miembros sean similares entre sí. Estos problemas de clusterización o agrupamiento han sido estudiados ampliamente por técnicas estadísticas y de Inteligencia Artificial. En (Di et al., 2007) se presenta un enfoque de sistema difuso genético aplicado al problema de clusterización con alta dimensionalidad en los datos. Uno de los cometidos básicos del aprendizaje automático es la clasificación de casos. Básicamente se tiene un conjunto de datos descritos por varios atributos de los cuales uno representa la clase a la que pertenecen, el objetivo es entonces predecir, a partir de la información aprendida de los datos existente, a cuál de las clases pertenece un nuevo caso. Reportes actuales demuestran que los problemas de clasificación para altas dimensiones de datos también están siendo tratados por los sistemas difusos genéticos, ejemplo de lo cual encontramos en (Alcala-Fdez et al., 2010, Berlanga et al., 2008, Berlanga et al., 2010). La regresión consiste en predecir, a partir de un conjunto de datos, algún valor asociado a los mismos. Por ejemplo la predicción del consumo de energía eléctrica en un horario determinado conociendo el consumo anterior (en horas, días, años), y algunas condiciones meteorológicas como la temperatura, etc. Esto puede ser abordado como un problema relativamente “sencillo” de ajuste a curvas en algunos casos mientras que en otros es complicado obtener un modelo matemático para la solución del problema debido a la dispersión de los datos, en la Figura 7 se muestra un ejemplo que visualiza lo anteriormente expuesto.. Figura 7. Problemas de regresión. En la Tabla 1 que se muestra a continuación se resumen aspectos del diseño de sistemas difusos genéticos que han sido utilizados para resolver problemas de regresión en los últimos 19.
(28) Capítulo I años. En estas propuestas se ha tratado la interpretabilidad y la precisión como objetivos de los algoritmos utilizados, se observa que la variante de reglas más explotada es la tipo Mamdani y se aprecian además variados enfoques en el diseño de las particiones difusas. Un resumen actual y más exhaustivo de la aplicación de sistemas difusos genéticos se encuentra en (Fazzolari et al.). Tabla 1. Sistemas difusos genéticos para la solución de problemas de regresión. Referencia. Reglas. Algoritmo multiobjetivo. Diseño Particiones. (Gacto et al., 2009b). Mamdani. SPEA2. Preliminar. (Alcalá et al., 2009). Mamdani. 2+2PAES. Simultaneo. (Casillas, 2009). Mamdani. NSGAII. Embebido. (Pulkkinen and Koivisto, 2010). Mamdani. NSGAII. Embebido. (Cococcioni et al., 2011). Takagi-Sugeno-Kang. 2+2PAES. Embebido. (Alcalá et al., 2011). Mamdani. NSGAII. Embebido. (Antonelli et al., 2011). Mamdani. 2+2PAES. Simultáneo. En (Casillas, 2009) se propone un sistema difuso genético que genera modelos difusos con particiones altamente interpretables preservando al mismo tiempo la precisión. El proceso de aprendizaje se ocupa de los siguientes componentes: el subconjunto de variables de entrada, el número de términos lingüísticos por variable, el tipo (triangular o trapezoidal) de la función de pertenencia, los parámetros de la función de pertenencia, y el conjunto de reglas difusas tipo Mamdani. El algoritmo llamado Aprendizaje Genético Embebido de Particiones Difusas (EGLFP por sus siglas en ingles: Embedded Genetic Learning of Fuzzy Partitions) tiene algunas características que lo hacen competitivo con respecto a otros métodos: . optimiza simultáneamente las partes estructurales (número de etiquetas) y paramétricas (forma de las funciones de pertenencia) de las particiones difusas considerando su independencia de forma efectiva. . usa particiones difusas tipo fuerte e incluye restricciones de distinguibilidad para lograr mayor interpretabilidad al restringir los operadores genéticos con el fin de explorar el espacio de búsqueda factible. . usa un esquema de codificación real de longitud variable, operadores de mutación y cruzamiento avanzados y optimización multiobjetivo para un proceso de búsqueda efectivo.. 20.
(29) Capítulo I Este algoritmo será utilizado en este trabajo utilizarlo como base en la propuesta de variantes que logren una mayor eficiencia computacional en la solución de problemas de alta dimensionalidad.. 1.6 Consideraciones Finales La interpretabilidad es una de las características de los sistemas difusos genéticos que hace que sobresalga frente al uso de otras técnicas por lo que su tratamiento en el diseño de los sistemas es un aspecto ampliamente abordado junto al tratamiento del balance entre la misma y la precisión, objetivos que entran en conflicto y que son tratados fundamentalmente con algoritmos de optimización multiobjetivo. Los sistemas difusos genéticos son diversos y se han aplicado a diferentes problemas del Aprendizaje Automático, entre ellos a los problemas de regresión, obteniéndose buenos resultados. La alta dimensionalidad en los datos supone un desafío para estos métodos de solución de problemas por lo que proveer a los sistemas difusos genéticos de mecanismos efectivos que logren un tratamiento adecuado de la dimensionalidad les proporciona competitividad respecto a otras técnicas.. 21.
(30) Capítulo II. Capítulo II. Aprendizaje Genético Embebido de Particiones Difusas, variantes para mejorar el tiempo de ejecución. 2.1. Introducción. En este capítulo se realiza una explicación del algoritmo Aprendizaje Genético Embebido de Particiones Difusas (EGLFP) propuesto en (Casillas, 2009) y se analizan partes del algoritmo donde se invierte un tiempo de cómputo elevado. Este algoritmo está diseñado para resolver problemas de regresión obteniendo un balance adecuando entre precisión e interpretabilidad. El análisis realizado conlleva a la propuesta de tres variantes que modifican el algoritmo original con el objetivo de disminuir el tiempo de ejecución del mismo. El tiempo de ejecución es un aspecto fundamental a tener en cuenta cuando aumenta la dimensionalidad de los problemas a tratar. La obtención de variantes del algoritmo que optimicen el tiempo de ejecución del mismo ante problemas de alta dimensionalidad manteniendo un buen balance entre interpretabilidad y precisión lo hacen competente frente a otras propuestas. Se realiza además un análisis de la complejidad temporal de las partes del algoritmo que fueron necesarias modificar para realizar las propuestas que suponen un aumento de la eficiencia del algoritmo.. 2.2. Aprendizaje Genético Embebido de Particiones Difusas. EGLFP es un algoritmo genético multiobjetivo con un enfoque evolutivo generacional que utiliza un operador de cruce que recombina los parámetros de la función de pertenencia, un operador de mutación que ajusta estos parámetros y otro operador de mutación que cambia la granularidad de las particiones, es decir, el número de términos lingüísticos que se utilizan en cada variable. El enfoque multiobjetivo se basa en el conocido algoritmo NSGA-II (Deb et al., 2002). Este algoritmo utiliza particiones difusas tipo fuerte considerando dos formas: la triangular y la trapezoidal. La Figura 8 muestra el esquema evolutivo del EGLFP.. 22.
(31) Capítulo II. Figura 8. Esquema evolutivo del algoritmo EGLFP. Las siguientes secciones detallan los diferentes componentes del EGLFP. 2.2.1. Esquema de codificación. Cada gen (𝑔) es una tupla que contiene la información relacionada con un término lingüístico de una variable específica. Se compone de dos campos de valor real (𝑔𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 , 𝑔𝑑𝑒𝑟𝑒𝑐 𝑜 ) que codifica los extremos derecho e izquierdo del núcleo del conjunto difuso asociado normalizado para el intervalo 0,1 . Un cromosoma es una cadena de longitud variable (la longitud dependerá del número de términos lingüísticos utilizados en cada variable) de los genes que codifican la definición completa de las particiones difusas de todas las variables de entradas y salida: 𝑛+𝑚 𝑙 𝑣 𝑣 𝑣 𝑔𝑖,𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 , 𝑔𝑖,𝑑𝑒𝑟𝑒𝑐 𝑜. 𝐶=. (1). 𝑣=1 𝑖=1. Siendo 𝑛 el número de variables de entrada, 𝑚 el número de variables de salida y lv el número de términos lingüísticos usados en la variable 𝑣 . La Figura 9 muestra un ejemplo de codificación de cromosoma, en un problema con dos variables de entrada, una variable de salida y tres, dos y cuatro términos lingüísticos, respectivamente, para cada variable.. 23.
(32) Capítulo II. Figura 9. Ejemplo de codificación de un cromosoma. Este esquema de codificación permite la ausencia de algunas variables mediante el uso de un término lingüístico solamente. Si la variable 𝑣 no se usa, habrá sólo un gen asociado al término v v con el valor (g1,izquierdo , g1,derecho ) = (0,1).. 2.2.2. Inicialización. El proceso de inicialización genera la primera población. El primer individuo generado va a estar codificado mediante particiones difusas fuertes uniformemente distribuidas, con el número máximo de términos lingüísticos permitidos para cada variable. El grupo restante se llena de forma aleatoria con individuos de dos tipos. Por un lado, algunos individuos (aproximadamente la mitad de la población) van a preservar en algún grado las particiones difusas uniformemente distribuidas pero con un número menor de términos lingüísticos. Para ello será aplicado un operador de fusión (que se describe más adelante) a las particiones difusas originales. Por otro lado, otros individuos (aproximadamente la otra mitad de la población) son generados completamente de forma aleatoria. Por lo tanto, el número de términos lingüísticos se asigna aleatoriamente a cada variable, entonces cada conjunto difuso adopta una forma triangular o trapezoidal de forma aleatoria y por último a los extremos de los núcleos de los conjuntos difusos se le asignan valores aleatorios. 2.2.3. Operadores. Los Algoritmos Genéticos trabajan a partir de una población inicial de estructuras artificiales que se van modificando repetidamente a través de la aplicación de los operadores genéticos que se definen en el algoritmo. A continuación se realizará un análisis de los operadores que se utilizaron en el EGLFP.. 24.
(33) Capítulo II 2.2.3.1. Cruzamiento. El cruzamiento genera dos individuos que heredan los parámetros de las funciones de pertenencia definidos por los dos padres incluso cuando estos padres tienen particiones difusas con diferente número de términos lingüísticos. El hecho de cruzar los parámetros de particiones difusas con diferentes granularidades, provee al EGLFP de un proceso de búsqueda potente (Casillas, 2009) . El operador de cruzamiento propuesto es centrado en los padres (García-Martinez et al., 2008) donde cada hijo es generado por un padre que juega el rol principal (padre dominante, también conocido como hembra en este operador) y el otro padre juega el papel secundario (padre recesivo, conocido como masculino). El hijo 𝑆1 es generado enfocado en el padre 𝐶1 pero usando el padre 𝐶2 para agregar la diversidad, análogamente se genera 𝑆2 . Dado que los cromosomas considerados tienen una longitud variable, se sigue un proceso para seleccionar un gen del padre recesivo que debe cruzarse con cada gen del padre dominante. Esta selección se basa en la distancia (ver Ecuación 6) donde, dado un conjunto difuso del padre dominante a ser cruzado, se elige el conjunto difuso más cercano del padre recesivo. Además, para mantener la interpretabilidad y una buena definición de las particiones difusas, se fija un intervalo de variación cada vez que el gen se va a cruzar. En la Figura 10(a) se muestra un ejemplo. Una vez que se fijan los genes dominantes y recesivos y se determina el intervalo de variación, se utiliza un operador de cruce de codificación real denominado CPCX (Parent Centric Crossover). Contrariamente a lo propuesto anteriormente por otros operadores de cruce centrado en los padres CPCX (García-Martínez et al., 2008) está diseñado para generar el gen hijo restringido a un intervalo dado, lo cual es crucial en el algoritmo EGLFP para garantizar particiones difusas bien definidas y distinguibles. El operador se describe en el algoritmo presentado en el Anexo 1: Operador CPCX y un ejemplo se muestra en la Figura 10(b). En la Figura 10(a) dado el gen de 𝑔 del padre dominante a ser cruzado que codifica el extremo derecho del núcleo del conjunto difuso etiquetado como M, se calcula la variación del intervalo permitido [0.25, 0.6] (líneas discontinuas) y se selecciona el gen que codifica el extremo derecho más cercano del conjunto difuso en el padre recesivo (S). En la Figura 10(b) se aplica el operador CPCX en el gen dominante 𝑔 = 0.5, el gen recesivo = 0.2, utilizando el intervalo de variación permitido 𝑚𝑖𝑛, 𝑚𝑎𝑥 = 0.25, 0.6 , y el intervalo de definición 𝑚, 𝑀 = 0, 1 , se genera un valor aleatorio en el intervalo 𝑙, 𝑟 = 0.35, 0.5 . 25.
(34) Capítulo II. Figura 10. Ejemplo de operación de cruce. 2.2.3.2. Mutación de parámetros. La mutación de parámetros cambia los valores reales de los parámetros de la función de pertenencia de las variables de entrada y de salida codificada en el cromosoma. Para ello EGLFP utiliza un operador de mutación de codificación real. Primeramente se realiza un proceso aleatorio para seleccionar el campo del gen que va a ser mutado. Cuando el gen a mutar codifica un conjunto difuso triangular, los campos izquierdo y derecho son mutados con el mismo valor para preservar el tipo original. Entonces dado el campo del gen g vi,e a ser mutado, se define un intervalo de variación alrededor de su valor con el fin de evitar la falta de distinguibilidad (dos conjuntos difusos muy cerca) y otros tipos de deformidades que disminuyan el grado de interpretabilidad. De esta manera, son utilizadas las siguientes ecuaciones, en la Figura 11(a) se muestra un ejemplo:. 𝑣 = 𝑚𝑖𝑛𝑔𝑖,𝑒. 𝑣 𝑔𝑖−1,𝑑𝑒𝑟𝑒𝑐 𝑜 + 𝛿𝑣. 𝑣 𝑣 𝑖𝑓 𝑒 = 𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 𝑜𝑟 𝑔𝑖,𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 = 𝑔𝑖,𝑑𝑒𝑟𝑒𝑐 𝑜. 𝑣 𝑔𝑖,𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜. 𝑣 𝑣 𝑖𝑓 𝑒 = 𝑑𝑒𝑟𝑒𝑐𝑜 𝑎𝑛𝑑 𝑔𝑖,𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 ≠ 𝑔𝑖,𝑑𝑒𝑟𝑒𝑐 𝑜. 0. 𝑖𝑓 𝑖 = 1. 26. (2).
(35) Capítulo II. 𝑣 = 𝑚𝑎𝑥𝑔𝑖,𝑒. 𝑣 𝑔𝑖+1,𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 − 𝛿𝑣. 𝑣 𝑣 𝑖𝑓 𝑒 = 𝑑𝑒𝑟𝑒𝑐𝑜 𝑜𝑟 𝑔𝑖,𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 = 𝑔𝑖,𝑑𝑒𝑟𝑒𝑐 𝑜. 𝑣 𝑔𝑖,𝑑𝑒𝑟𝑒𝑐 𝑜. 𝑣 𝑣 𝑖𝑓 𝑒 = 𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 𝑎𝑛𝑑 𝑔𝑖,𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 ≠ 𝑔𝑖,𝑑𝑒𝑟𝑒𝑐 𝑜. 1. (3). 𝑖𝑓 𝑖 = 𝑙𝑣. con 𝛿𝑣 = 1/(2 ∙ 𝑙𝑣 ). (4). Siendo 𝛿𝑣 la distancia mínima permitida entre los extremos de los núcleos de los conjuntos difusos de en aras de un buen grado distinguibilidad y lv es el número de términos lingüísticos usados en la variable v.. Figura 11. Ejemplo de funcionamiento de mutación de parámetros. Finalmente, se aplica a g vi,e un operador original de mutación real restringido al intervalo ming vi,e , maxg vi,e . Este operador se nombra CAM (Constrained Asymmetric Mutation) y se describe en el algoritmo del Anexo 2: Operador CAM. La Figura 11(b) muestra el resultado de usar la función de densidad de probabilidad asimétrica para mutar un valor. En la Figura 11(a) la extrema derecha del núcleo del conjunto difuso M se selecciona para ser mutado, entonces se define el intervalo de variación por las ecuaciones 2 y 3 con δ = 0.167 para lv = 3 ya que hay tres términos lingüísticos. En la Figura 11(b) se muestra la función de densidad de probabilidad asimétrica utilizada en el operador CAM para mutar el extremo derecho de los núcleos de M limitados por el intervalo [0.2, 0.733]. 2.2.3.3. Mutación de granularidad. La mutación de granularidad cambia el número de términos lingüísticos, tanto en las variables de entrada como en las de salida. Para hacer esto, se puede fusionar (unir) dos conjuntos difusos vecinos (lo que disminuye en uno el número de términos lingüísticos de la variable correspondiente) o realizar una fisión (división) del conjunto difuso en dos partes (lo que. 27.
(36) Capítulo II aumenta en uno el número de términos lingüísticos de la variable correspondiente). Cuando la fusión se aplica a una variable con dos términos lingüísticos, implica la eliminación de la variable del modelo difuso. Existen algunas limitaciones en la aplicación de la fusión y la fisión. Por un lado, si la fusión se aplica a una variable de entrada, esta variable debe tener al menos dos términos lingüísticos y, en caso de tener exactamente dos términos lingüísticos, debe haber al menos otra variable de entrada con al menos dos términos lingüísticos (con el fin de evitar un sistema difuso sin variables de entrada después de la fusión). Cuando la fusión se aplica a una variable de salida, esta variable debe tener al menos tres términos lingüísticos ya que la eliminación de la variable de salida no está permitida. Por otra parte, la fisión en variables con el número máximo de términos lingüísticos no está permitida. Se considera una segunda limitación para evitar la falta de distinguibilidad después de fisión la consideración de que si el ancho del núcleo del conjunto difuso asociado al gen a ser fisionado es menor que un valor inversamente proporcional al número de términos lingüísticos de la variable correspondiente, el núcleo de los dos conjuntos difusos resultantes de la fisión será demasiado estrecha y por lo tanto, la fisión no se permite. Esto significa que a los conjuntos difusos triangulares no se les puede aplicar el operador de fisión ya que su ancho del núcleo es cero. A continuación se explica en detalles como operar con la fusión y fisión. . Operación de fusión (Figura 12): Dado un gen 𝑔𝑖𝑣 a ser fusionado, sea el gen más cercano a 𝑔𝑖𝑣. =. 𝑣 𝑔𝑖−1 𝑣 𝑔𝑖+1 𝑣 𝑔𝑖−1 𝑣 𝑔𝑖+1. 𝑖𝑓 𝑖 = 𝑙𝑣 𝑖𝑓 𝑖 = 1 𝑣 𝑣 𝑖𝑓 𝑑 𝑔𝑖𝑣 , 𝑔𝑖−1 ≤ 𝑑 𝑔𝑖𝑣 , 𝑔𝑖+1 𝑜𝑡𝑟𝑜 𝑐𝑎𝑠𝑜. (5). con 𝑑 𝑔, = |(𝑔𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 + 𝑔𝑑𝑒𝑟𝑒𝑐 𝑜 ) 2 − (𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 + 𝑑𝑒𝑟𝑒𝑐 𝑜 ) ∕ 2 | Pasos para fusionar a 𝑔𝑖𝑣 y : 𝑣 𝑣 𝑣 1) Si 𝑔𝑖,𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 < 𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 entonces 𝑔𝑖,𝑑𝑒𝑟𝑒𝑐 𝑜 ← 𝑑𝑒𝑟𝑒𝑐 𝑜 ; si no 𝑔𝑖,𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 ←. 𝑖𝑧𝑞𝑢𝑖𝑒𝑟𝑑𝑜 28. (6).
Figure



+7




Outline
Documento similar