Sistema pronóstico del paciente pediátrico
94
0
0
Texto completo
(2) Hago constar que el presente trabajo fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencias de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad. ________________. ________________. Firma del autor. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. ______________. ________________________. Firma del tutor. Firma del jefe del Seminario. II.
(3) Dedicatoria. A mis padres por estar siempre a mi lado mostrándome el camino correcto. A mi abuela por todos estos años de cariño y dedicación. A mi hermanita, por completar mi felicidad. A Liván por alentarme y darme fuerzas en los momentos difíciles. A mi tía y primas por hacerse presentes a pesar de la distancia A todos los que me han apoyado.. Mayelis. A mis padres por guiarme siempre por el camino correcto. A mis abuelos por darme todo su apoyo y cariño. A mis hermanos, que siempre están presentes. A Inti por hacer este sueño posible. A todos los que me han apoyado.. Mabel. III.
(4) Agradecimientos A nuestra tutora Yanet por brindarnos su ayuda en todo momento. A Morell por ser indiscutiblemente un tutor más y dedicarnos su tiempo. A Inti por ayudarnos siempre y sacarnos de las situaciones difíciles. A los especialistas Adonis, Rovira y Joaquín por hacer posible este trabajo. A nuestros amigos por brindarnos su apoyo y tantos momentos buenos a lo largo de la carrera.. Mabel y Mayelis. IV.
(5) “La experiencia no consiste en el número de cosas que se han visto, sino en el número de cosas que se han reflexionado.” Pereda. V.
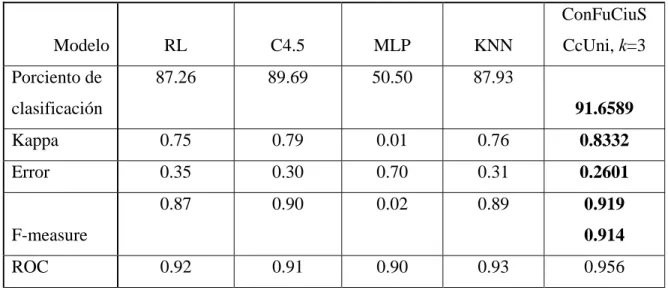
(6) Resumen. RESUMEN La valoración adecuada de un paciente pediátrico a la hora de ingresar en la Unidad de Cuidados Intensivos, es de gran interés, sobre todo si se da un pronóstico del nivel de gravedad del mismo atendiendo a rasgos epidemiológicos y clínicos. En esta investigación se desarrolla un sistema híbrido que combina conjuntos borrosos y Sistemas Basados en Casos explotando las ventajas que ofrece cada uno de ellos. El uso de conjuntos borrosos permite darle más naturalidad al planteamiento del problema al modelar los atributos numéricos como variables lingüísticas. El Sistema Basado en Casos es el que pronostica el nivel de gravedad de un paciente determinado y justifica la solución dada al mismo citando experiencias previas. El sistema implementado demostró su efectividad a partir de las pruebas practicadas.. VI.
(7) Abstract. ABSTRACT An adequate evaluation of pediatric patient arriving at Intensive Care Units is a very important task. It is necessary to give a correct diagnosis upon clinical and epidemic features of the patient. This investigation develops a hybrid system that combines fuzzy sets and Case Based Systems which explote the advantages offered by each of them. The use of fuzzy systems provides more naturality to the statement of the problem by modeling the numeric attributes as linguistic variables. The Case based System is the one that prognosticates the gravity of a patient and it justifies the solution of the case by citing previous experiences. The evaluation of the system shows it effectiveness based on several test.. VII.
(8) Índice. INTRODUCCIÓN ................................................................................................................1. CAPÍTULO 1. LA INTELIGENCIA ARTIFICIAL EN LA SOLUCIÓN DE PROBLEMAS MÉDICOS. ..................................................................................................4 1.1 Sistemas pronósticos .......................................................................................................4 1.2 Sistemas Basados en el Conocimiento inteligentes ......................................................6 1.2.1. Sistemas Basados en el Conocimiento ...........................................................7. 1.2.1.1 Definición y estructura de un Sistema Basado en el Conocimiento ...............7 1.2.1.2 Sistemas Basados en Reglas .........................................................................11 1.2.1.3 Sistemas Basados en Casos...........................................................................12 1.2.1.4 Sistemas conexionistas .................................................................................15 1.2.2. Sistemas híbridos ..........................................................................................18. 1.2.2.1 Los conjuntos borrosos y la teoría de la lógica borrosa................................18 1.2.2.2 Breve referencia al empleo de los conjuntos borrosos en varios de los sistemas anteriores ........................................................................................19 1.3 Desarrollo de SBC utilizando la herramienta de aprendizaje automático Weka...24 1.3.1. Sobre aprendizaje automatizado ...................................................................25. 1.3.2. Descripción general de Weka .......................................................................25. 1.3.3. Tipos de datos que Weka implementa ..........................................................25. 1.3.4. Implementación de ConFuCiuS en Weka.....................................................26. 1.4 Aplicaciones de la Inteligencia Artificial en la medicina..........................................27 1.5 Conclusiones parciales..................................................................................................30 CAPÍTULO 2. SISTEMA AUTOMATIZADO PREDICTOR DE RIESGO INFANTIL DE MORTALIDAD (SAPRIM)....................................................................31 2.1 Planteamiento del problema ........................................................................................31 2.2 Diseño del sistema desarrollado...................................................................................32 2.3 Modelación computacional del problema...................................................................36 2.3.1. Construcción de la base de casos..................................................................36. 2.3.2. Selección del resolvedor de problemas.........................................................37. 2.4 Facilitando el manejo de los atributos predictores multievaluados .........................39. VIII.
(9) Índice. 2.4.1. Agregando un nuevo tipo de dato en Weka..................................................39. 2.4.2. Modificaciones a ConFuCiuS para tratar rasgos multievaluados.................49. 2.4.3. Pruebas realizadas con el tipo de dato Set ....................................................50. 2.5 Implementación del sistema.........................................................................................52 2.6 Conclusiones parciales..................................................................................................53 CAPÍTULO 3. MANUAL DE USUARIO. EVALUACION Y VALIDACION DE RESULTADOS. ..................................................................................................................54 3.1 Requerimientos del sistema..........................................................................................54 3.2 Facilidades del sistema .................................................................................................54 3.3 Manual de usuario .......................................................................................................54 3.4 Evaluación y validación del software ..........................................................................64 3.5 Conclusiones parciales..................................................................................................66 CONCLUSIONES ..............................................................................................................68 RECOMENDACIONES ....................................................................................................69 REFERENCIAS BIBLIOGRÁFICAS..............................................................................70 ANEXOS..............................................................................................................................72. IX.
(10) Introducción. INTRODUCCIÓN. Elevar la calidad de la atención médica constituye una de las directivas específicas de la estrategia que se reitera en la política del ministerio de Salud Pública (MINSAP). La atención pediátrica reviste gran importancia y prioridad, siendo conveniente para la atención del paciente una adecuada evaluación de su estado de gravedad en el momento de su llegada al hospital. Esta evaluación permite orientar al paciente hacia la sala de destino en caso de que sea tributario de ingreso. Con este fin se desea realizar una estimación a partir de los datos clínicos y epidemiológicos del paciente sin incluir ningún tipo de análisis de laboratorio. El pronóstico obtenido puede ser grave o de cuidado, sugiriéndole al especialista el ingreso o no del paciente en la UCI (Unidad de Cuidados Intensivos). Este resultado conforma una primera apreciación del estado del paciente, permitiéndole al pediatra tomar las medidas adecuadas mientras espera los resultados de laboratorio para complementar su diagnóstico.. Objetivo general Desarrollar un sistema para pronosticar la gravedad de un paciente en el momento de su llegada al Hospital Infantil “José Luis Miranda” de Santa Clara, combinando la aplicación de varias técnicas de la Inteligencia Artificial (IA) con vistas a dar una valoración rápida del estado del paciente.. Objetivos específicos 9 Construir una base de casos a partir de la recopilación de información de pacientes graves y de cuidado. 9 Implementar un sistema computacional que permita discriminar los pacientes graves modelando los atributos numéricos como variables lingüísticas. 9 Facilitar el manejo de los atributos predictores multievaluados.. Preguntas de investigación 9 ¿Las técnicas de Inteligencia Artificial permitirán a partir de factores de riesgos epidemiológicos y clínicos discriminar entre pacientes graves y de cuidado? 1.
(11) Introducción. 9 ¿Los resultados que ofrece este sistema computacional están al nivel de los obtenidos por los expertos humanos al valorar un paciente?. Justificación de la investigación. Una adecuada valoración de la gravedad del paciente favorecería la concentración de los recursos humanos y materiales disponibles en la atención del paciente valorado como grave y evitar iatrogenia en los pacientes de cuidado. Por tanto, contar en una institución médica con un sistema computacional que asista satisfactoriamente al especialista en esta tarea, sería de gran utilidad.. Viabilidad de la investigación. El desarrollo de la informática y en particular de las técnicas de ingeniería del conocimiento y los lenguajes de programación de alto nivel permiten enfrentar con éxito el desafío de desarrollar una aplicación computacional como la que se pretende. En particular esta aplicación se desarrolla en el marco de la colaboración de especialistas del Hospital Infantil “José Luis Miranda” de Santa Clara y del grupo de IA de la UCLV, este último con una basta experiencia en el desarrollo de aplicaciones médicas.. Por otra parte Weka ha sido objeto de estudio de los tesiantes a lo largo de su carrera y por ello han adquirido los conocimientos y las habilidades necesarias para enfrentar esta tarea.. Teniendo en cuenta el volumen de trabajo que implica el presente proyecto se considera que el período de seis meses, para culminarlo, se ajusta a la cantidad de dos estudiantes.. Tipo de Investigación: Exploratoria.. Hipótesis de investigación 9 Es factible a partir de factores de riesgos epidemiológicos y clínicos discriminar entre pacientes graves y de cuidado mediante la aplicación de técnicas de clasificación supervisada de la IA. 2.
(12) Introducción. 9 Los resultados que ofrece este sistema computacional están al nivel de los obtenidos por los expertos humanos al valorar un paciente.. En el capítulo 1 se abordan las ideas esenciales de los sistemas pronósticos que sirvieron de antecedente a este trabajo. Se exponen las principales características de algunos de los Sistemas Basados en el Conocimiento y se hace énfasis en la necesidad del uso de sistemas híbridos para la consecución de mejores resultados. Se describen dos de estos sistemas híbridos FuzzySIAC y ConFuCius, de este último se analiza además su implementación en la herramienta de aprendizaje automatizado Weka. Finalmente se muestran varios ejemplos de aplicaciones de los Sistemas Basados en el Conocimiento en problemas de las Ciencias Médicas. En el capítulo 2 se retoma el planteamiento del problema y se propone la modelación computacional del mismo. Se elige el revolvedor de problemas y se hace una comparación con otros enfoques alternativos. Por último se hace una descripción de la implementación del Sistema Automatizado Predictor de Riesgo Infantil de Mortalidad (SAPRIM). En el Capítulo 3 se presenta el manual de usuario de SAPRIM, así como una evaluación. y. validación. de. los. resultados. obtenidos. con. el. software.. 3.
(13) Capítulo 1. CAPÍTULO 1. LA INTELIGENCIA ARTIFICIAL EN LA SOLUCIÓN DE PROBLEMAS MÉDICOS.. En este capítulo se analizará el concepto de sistema pronóstico y se mostrarán algunos de sus principales exponentes. Se analizarán los principales tipos de Sistemas Basados en el Conocimiento teniendo en cuenta ventajas y desventajas de los mismos, prestando especial atención a los sistemas híbridos. Se explicará en qué consiste la herramienta de aprendizaje automatizado Weka enfatizando en los tipos de datos que ella maneja. Finalmente se pondrán ejemplos de aplicaciones de los Sistemas Basados en el Conocimiento en el campo de las Ciencias Médicas.. 1.1 Sistemas pronósticos Los niños que necesitan cuidados intensivos suelen estar gravemente enfermos como resultado de un accidente, una enfermedad aguda o una intervención quirúrgica que pone en peligro su vida. Con tratamiento apropiado, la mayoría podrá restablecerse y llevar una vida normal y potencialmente productiva[1].. Es una necesidad en cualquier centro hospitalario establecer prioridades entre los pacientes, en base a determinadas características, en especial el nivel de gravedad o riesgo de fallecer. La adecuada valoración de la gravedad tiene gran influencia en la aplicación del tratamiento, ya que implica tomar las medidas necesarias en el momento apropiado, así como la concentración de los recursos materiales y humanos disponibles. Con el fin de asistir al especialista en esta tarea surgen los sistemas pronósticos[1].. Concepto de sistema pronóstico Es un sistema compuesto por un conjunto de variables, que da como resultado una puntuación predictiva de la mortalidad del paciente, o sea, del riesgo de fallecer. Para construir estas puntuaciones pueden ser usados varios tipos de variables entre ellas variables clínicas, fisiológicas y de laboratorio[2].. Funcionamiento 4.
(14) Capítulo 1. Los pacientes críticos se caracterizan por presentar una alteración del equilibrio corporal. Estas alteraciones se pueden estimar mediante la medición de cuán alejadas se encuentran una o más variables fisiológicas de su rango normal. Muchas puntuaciones o sistemas pronósticos han sido desarrollados a partir de dichas variables[2].. El funcionamiento de las puntuaciones predictivas se basa en la evaluación de una expresión donde están contenidas variables clínicas y de laboratorio, las cuales describen el estado del paciente. A estos parámetros se les adjudica una puntuación y su contribución al valor final deriva de su importancia específica en relación a la mortalidad. Puntuaciones más elevadas implican más gravedad y por tanto mayor riesgo de fallecimiento[1].. Entre los sistemas creados específicamente para los pacientes atendidos en los Servicios de Terapia Intensiva se encuentran: el PSI (Physiologic Stability Index) que constituyó un paso importante en el campo pediátrico, el PRISM (Pediatric Risk of Mortality Score)[3] y el PIM (Pediatric Index of Mortality)[4, 5]. El PRISM constituye una modificación del PSI donde se logró reducir las 34 variables de este último a 14, disminuyendo así el tiempo necesario para su ejecución en cada paciente. Desde la publicación del PRISM, el PSI ha quedado desplazado en lo que se refiere a predicción del riesgo de mortalidad, pero puede usarse con fines descriptivos como medida directa de la severidad de una enfermedad. El PIM y el PRISM constituyen hoy unas de las mejores herramientas para estimar la gravedad en pacientes pediátricos.. Los parámetros del PRISM se miden durante las primeras 24 horas de permanencia en la Unidades de Cuidados Intensivos Pediátricos (UCIP) y al aplicar esta escala se toman los peores valores del período considerado, obteniéndose finalmente una puntuación como medida de la severidad de la enfermedad. De las variables presentes en el PRISM al menos 5 de ellas son de laboratorio lo cual trae como consecuencia retraso en la evaluación del paciente[1].. 5.
(15) Capítulo 1. El PIM, con 10 variables, se usa con el mismo propósito que el PRISM, y comparte con este algunos parámetros predictivos. Sobre cuál tiene un mejor desempeño las opiniones de los especialistas varían[2].. Estos sistemas pronósticos tienen sus limitaciones ya que para valorizar algunas variables se hace necesario la ejecución de exámenes de laboratorio que son de costosa ejecución y traumáticos para el paciente. La espera que se genera en la obtención de los resultados de estas pruebas trae consigo un retraso considerable en la emisión del pronóstico. Tanto el PRISM como el PIM han sido validados sólo en algunos países[2].. 1.2 Sistemas Basados en el Conocimiento inteligentes El curso que sigue el desarrollo del mundo actual apunta cada vez más a la interacción entre diversas ciencias. El auge de la computación ha propiciado que esté presente en muchas de las esferas de la sociedad. dando solución a disímiles problemáticas. Las. ciencias computacionales han abierto nuevos horizontes en el campo de la medicina permitiendo el desarrollo de nuevas líneas de investigación y el perfeccionamiento de las ya existentes. Entre las ramas de la computación aplicadas a la solución de problemas médicos la IA se destaca por su efectividad.. La Inteligencia Artificial (IA) es una rama de la computación, que se encarga de hacer que la máquina simule ciertas capacidades físicas y mentales de los humanos, es decir, se dedica a la creación de software y hardware que imita el pensamiento humano[6].. Según Schildlt, un “programa inteligente” es uno que muestra un comportamiento similar al humano cuando se enfrenta a un problema. No es necesario que el programa resuelva realmente el problema de la misma forma que el hombre.. Alan Turing se expresa análogamente al expresar que “si durante el intercambio entre una computadora y el usuario este último cree que está intercambiado con otro humano, entonces se dice que el programa es inteligente”.. 6.
(16) Capítulo 1. Para Forsyth la IA se relaciona con problemas que han escapado de una caracterización matemática.. La IA proporciona técnicas para enfrentar dos clases de problemas: los que. por su. dimensión hacen inaplicable un algoritmo conocido y los que carecen de algoritmo para resolverlos[7]. El poder enfrentar estos problemas hace de la IA un complemento de la computación tradicional. Dentro de los campos de aplicación de la IA se encuentran los Sistemas Basados en el Conocimiento.. 1.2.1 Sistemas Basados en el Conocimiento Los Sistemas Basados en el Conocimiento (SBC) se desarrollaron para dar solución adecuada a problemas orientados a aplicaciones, cosa que los métodos de solución a problemas generales no podían hacer ya que resultaban insuficientes[8].. El conocimiento representado en los SBC se obtiene a partir de los expertos en el dominio. Un experto es una persona que tiene habilidades que provienen generalmente de un conocimiento detallado de los problemas que maneja y de la experiencia adquirida en su desarrollo vital. El conocimiento en cualquier especialidad puede ser de dos clases: público y privado. Los expertos humanos poseen conocimiento público (definiciones, hechos y teorías publicadas), pero usualmente tienen además conocimiento privado, el cual resulta de suma utilidad en la solución de los problemas de un dominio específico[8].. 1.2.1.1 Definición y estructura de un Sistema Basado en el Conocimiento Un Sistema Basado en el Conocimiento según [8] se puede definir como sigue: “Un sistema computarizado que usa conocimiento sobre un dominio para arribar a una solución de un problema de ese dominio. Esta solución es esencialmente la misma que la obtenida por una persona experimentada en el dominio del problema cuando se enfrenta al mismo problema”.. También se puede definir un SBC como : “Un sistema informático que simula el proceso de aprendizaje, de memorización, de razonamiento, de comunicación y de acción de un 7.
(17) Capítulo 1. experto humano en una determinada rama de la ciencia, suministrando de esta forma, un consultor que puede sustituirle con unas ciertas garantías de éxito”[9].. Sin embargo esto no basta para definir correctamente un SBC, ya que este se diferencia de los programas basados en búsqueda general en aspectos tales como: 9 La separación del conocimiento de cómo este es usado 9 El uso de conocimiento muy específico del dominio. 9 Naturaleza heurística, en lugar de algorítmica, del conocimiento empleado. 9 No requieren analizar completitud. 9 Pueden dar múltiples soluciones. Los SBC presentan notables ventajas, de ahí el amplio uso del que han sido objeto en los últimos tiempos. Entre ellas se encuentran la preservación y distribución de la experticidad, gran accesibilidad y fácil modificación, así como la posibilidad de evaluar el efecto de nuevas estrategias añadiendo o modificando conocimiento. La explicación de la solución obtenida se logra de manera natural presentando consistencia en las respuestas, aún en problemas que incluyan datos incompletos. En resumen, un SBC constituye un entrenador en el dominio de aplicación.. A pesar de sus virtudes los SBC tienen sus limitaciones: las respuestas del sistema no siempre son correctas presentando incluso ausencia de sentido común, además no reconocen el límite de su conocimiento y este se encuentra restringido al dominio de experticidad[8].. Los Sistemas Basados en el Conocimiento están compuestos por la base de conocimiento (BC), un mecanismo de inferencia (MI), una interfaz de usuario (IU) y módulos opcionales: módulo explicativo (ME), módulo de cálculo de certidumbre (MCC) y módulo de autoaprendizaje (MA)[10]. SBC = BC+ MI + IU + [ME] + [MCC] + [MA]. Base de conocimiento 8.
(18) Capítulo 1. La BC es la componente más importante del SBC, ya que la potencia de un SBC radica en el conocimiento que posee. En dependencia de la naturaleza del conocimiento se divide en tres tipos: numérico, simbólico y mixto. Cada tipo de conocimiento tiene asociado un formato el cual indica como el conocimiento se representa internamente. A este formato se denomina Forma de Representación del Conocimiento (FRC)[11].. Dentro de la representación numérica se encuentran las probabilidades, las frecuencias y los pesos de la Redes Neuronales Artificiales (RNA).La representación simbólica comprende entre otros: Reglas de producción: son la FRC más popular. Tienen la forma IF <condición> THEN <acción/conclusión>. La interpretación de una regla es que si el antecedente se puede satisfacer entonces se obtiene el consecuente.. Frames (Marcos): es una estructura de datos compleja que contiene un agregado de información acerca de un objeto. La información almacenada en el frame se distribuye en diferentes campos llamados slots (aspectos), cada slot contiene la información sobre un atributo del objeto que se modela. Scripts: Los scripts son estructuras de datos complejas designadas para almacenar el conocimiento sobre una secuencia estereotipada de acciones. Este conocimiento le dice a los sujetos que intervienen en la secuencia de eventos lo que puede suceder en una situación, que evento sigue y que papel debe jugar cada quien en la actividad social que se describe.. Redes semánticas: una red semántica consiste en puntos llamados nodos, conectados por enlaces llamados arcos que describen las relaciones entre los nodos. Los nodos representan objetos, conceptos o eventos. Los arcos pueden definirse de varias formas, dependiendo de la clase de conocimiento representado.. Strip: es la generación de una secuencia de acciones o programa de acción para un agente. Las acciones cambian un estado del universo sobre el que se desarrolla la planificación a otro. En. 9.
(19) Capítulo 1. el formalismo strip las acciones se modelan en una forma similar a las reglas de producción, y estas cambian una descripción de un estado en otra[8].. Un ejemplo de conocimiento mixto lo constituyen los casos o ejemplos de un dominio de aplicación, estos contendrán datos numéricos, textos y otros.. Métodos de solución de problemas (mecanismo de inferencia) La búsqueda es una técnica de solución de problemas .La búsqueda de la IA difiere de la búsqueda convencional sobre estructuras de datos esencialmente en que se realiza en un espacio problema, no en una pieza de dato particular. Se localiza un camino que conecte la descripción inicial del problema con una descripción del estado deseado para el mismo, es decir, el problema resuelto. Este camino representa los pasos para encontrar la solución[12].. La MI es el intérprete del conocimiento almacenado en la BC. Esta implementa algún método de solución de problemas con una dirección (forward o backward) de búsqueda dada.. Interfaz de usuario Permite al usuario interactuar con el sistema, recibe como entrada un problema y brinda una solución como respuesta.. Módulos opcionales El MA permite incorporar a la BC los nuevos problemas que se resuelvan .El ME permite conocer por qué y cómo se obtuvo una solución determinada y el MCC manipula la incertidumbre, la cual aparece a causa de información o conocimiento impreciso, información incompleta o por conceptos o palabras que son inexactos principalmente.. Los SBC se diferencian en la Forma de Representación del Conocimiento (FRC), en el Método de Solución del Problema (MSP), en las fuentes de conocimiento y en la forma en. 10.
(20) Capítulo 1. que se explica una solución obtenida principalmente. La tabla con los principales SBC se encuentra en el anexo 1.. 1.2.1.2 Sistemas Basados en Reglas Los Sistemas Basados en Reglas (SBR) son SBC donde la FRC son las reglas de producción, estas reglas tienen un formato IF- THEN, donde la parte del IF es la condición, premisa o antecedente y la parte del THEN es la acción, conclusión o consecuente. Si se prueban las condiciones establecidas en el IF se realizará lo establecido en el THEN.. El MSP de los SBR es usualmente búsqueda primero en profundidad con dirección backward o forward, este proceso de búsqueda crea una cadena de inferencias entre el planteamiento del problema y su solución (un camino solución). El conocimiento que se emplea es el de los expertos del dominio fundamentalmente.. Los SBR permiten el manejo de la incertidumbre, la cual se origina debido a las imprecisiones en los datos y falta de seguridad en las reglas. Estos sistemas son capaces de dar explicaciones al usuario en caso que este las requiera.. Entre las ventajas de estos sistemas tenemos su elevada modularidad, ya que cada regla es una unidad independiente, a la cual se le pueden aplicar los cambios que se estime necesarios sin afectar al resto de las reglas. La uniformidad resulta otra de sus ventajas, ya que todo el conocimiento que posee el sistema queda expresado en el mismo formato. En los SBR las reglas están expresadas de una forma natural, muy cercana a la forma de pensar del experto o de cualquier ser humano.. A pesar de las ventajas estos sistemas tienen sus limitaciones: el encadenamiento infinito que resulta como consecuencia de emplear una búsqueda primero en profundidad con una implementación que no sea la correcta, la adición de nuevas reglas cuyos consecuentes entren en desacuerdo con los de las reglas ya existentes en la BC, la modificación de las reglas con las que se cuenta puede llevar a un incremento considerable de la BC al intentar considerar casos específicos. 11.
(21) Capítulo 1. Los SBR son ineficientes ya que la MI debe examinar cada regla durante cada ciclo para ver cual resulta aplicable, la visión global del conjunto de reglas se pierde y resulta muy difícil examinar una BC para predecir cuándo ocurrirá una acción determinada, además se tiene el caso de dominios donde las entradas varían mucho y se necesitarán muchas reglas para tratar todas las situaciones que puedan presentarse. Luego de este análisis queda claro que los SBR son muy naturales y que hay problemas que prácticamente sugieren su empleo, pero por otra parte sus limitaciones restringen su uso[8].. 1.2.1.3 Sistemas Basados en Casos Los Sistemas Basados en Casos son un tipo de SBC cuya FRC son los casos, el MSP que emplean es el Razonamiento Basado en Casos (RBC), las fuentes de conocimiento son los ejemplos y la explicación de una solución determinada se logra a través de los casos similares con los que cuenta el sistema.. Definición de RBC Según J. Kolodner Razonamiento Basado en Casos (RBC) significa usar experiencias anteriores para comprender y resolver nuevos problemas. En el RBC la solución de problemas se logra con la adaptación de soluciones conocidas a problemas semejantes. Estructura de los Sistemas Basados en Casos Los Sistemas Basados en Casos cuentan con una base de casos que almacena los ejemplos del dominio y un mecanismo de inferencia. Este último se encarga de: recuperar casos relevantes, seleccionar el o los casos más similares, derivar una solución por adaptación, evaluarla y almacenar el caso recién resuelto en la base de casos[8].. El proceso que realiza un sistema de Razonamiento Basado en Casos se puede representar como un ciclo de actividades (Ciclo de las 4 R): 9 Recuperar (Retrieve) el o los casos mas semejantes al problema actual. 9 Reutilizar (Reuse) la información y el conocimiento de dicho caso para intentar resolver el problema. 12.
(22) Capítulo 1. 9 Revisar (Revise) la solución propuesta si es necesario. 9 Retener (Retain) la parte útil de esta experiencia para utilizarla en la solución de otros problemas en el futuro.. Base de casos (formada por casos) Un caso no es más que un conjunto arbitrario de rasgos usados para describir un concepto particular. Un caso contiene: 9 Descripción del problema o situación. 9 Solución. 9 Resultado de la ejecución (si existe retroalimentación). 9 Si luego de la ejecución ocurrió algún error: 9 Explicación de las anomalías. 9 Estrategia de reparación. 9 Referencia al próximo resultado.. Los casos pueden organizarse de forma lineal o jerárquica en la base de casos, ambas formas de ubicación tienen sus ventajas y desventajas, en dependencia del problema y sus necesidades se elegirá el enfoque a utilizar[8].. Recuperación de casos relevantes Este proceso consiste en la selección de un conjunto de casos candidatos a partir de la descripción del problema, para ello se debe contar con un buen sistema de índices para los casos. Los índices, rasgos o etiquetas, son aquellos que distinguen a un caso del resto, deben ser abstractos para que los casos sean aplicables a gran variedad de situaciones, relevantes de manera tal que si los volvemos a ver puedan predecir algún aspecto importante del resto de la situación y concretos para que se puedan reconocer en situaciones futuras.. Selección del o los casos más similares a la descripción del problema Existen diversos métodos de selección de los casos más similares: 9 Por recuperación asociativa (mediante funciones de semejanza). 13.
(23) Capítulo 1. 9 Por similaridad estructural. Adaptación de la solución La adaptación es el proceso de ajustar una solución conocida a las restricciones impuestas por el problema a resolver. Esta puede realizarse a partir de la solución de uno o varios casos similares. Existen varias técnicas de adaptación[13].. Evaluación de la solución Dicha evaluación consiste en explicar las diferencias entre lo que se obtuvo y lo que se esperaba, en justificar las diferencias entre la solución propuesta y la usada en el pasado y ordenar las alternativas de solución.. Almacenar el caso recién resuelto en la base de casos Los pasos del proceso para almacenar el caso recién resuelto en la base de casos son: determinar que se almacenará, cómo indexar el caso (aspecto más importante) y cómo integrar lo aprendido a la memoria de los casos.. Entre las ventajas de RBCasos tenemos que a diferencia de los métodos clásicos de solución de problemas de la IA la búsqueda de la respuesta a un problema no se inicia a partir de los datos o el objetivo, por lo que el camino se acorta considerablemente. El aprendizaje incremental permite una mejora gradual de la calidad del sistema. Los RBCasos constituyen una alternativa a los SBR, en especial, cuando la cantidad de reglas no es manejable o cuando la teoría del dominio es débil o incompleta. Este modelo es recomendable en áreas donde los casos individuales o precedentes gobiernan el proceso de toma de decisiones[8].. Aprendizaje basado en instancias Dentro de los Sistemas Basados en Casos se encuentran los métodos con aprendizaje basado en instancias. En el aprendizaje basado en instancias no se construye una descripción explícita del rasgo objetivo hasta que una nueva instancia deba ser clasificada. Cada vez que una nueva consulta es realizada se examinan ejemplos previamente 14.
(24) Capítulo 1. recuperados para asignar un valor al rasgo objetivo de la nueva instancia. Los métodos basados en instancias son métodos perezosos (lazy), clasifican una nueva instancia analizando instancias similares y representan las instancias como puntos con valor en el espacio n-dimensional Euclideano. Dentro de los métodos basados en instancias se encuentra K-NN (k-Nearest Neighbor). Este método recupera los k vecinos más cercanos y en estos k vecinos más cercanos busca el rasgo objetivo que más aparezca y ese será el valor que asigne al rasgo objetivo de la instancia que espera clasificación[14].. 1.2.1.4 Sistemas conexionistas Las neuronas o células nerviosas son los bloques constructivos del cerebro humano. La masa cerebral está compuesta por neuronas que se encuentran conectadas unas con otras y son las encargadas del control de las funciones mentales. Una neurona está compuesta por tres partes fundamentales: el cuerpo de la célula; el axón, fibra principal que se extiende desde el cuerpo de la célula y constituye el camino sobre el cual las señales pueden viajar desde el cuerpo hacia otros puntos del cerebro y las dendritas, que son las que ofrecen la principal superficie física sobre la cual la neurona recibe las señales.. Una Red Neuronal Artificial (RNA) es un modelo computacional que pretende simular el funcionamiento del cerebro a partir del desarrollo de una arquitectura que toma rasgos del funcionamiento de este órgano sin llegar a desarrollar una réplica del mismo[12].. A partir de esta visión del cerebro el modelo computacional desarrollado consiste de un conjunto de elementos computacionales simples (llamados también unidades o celdas), los cuales constituyen neuronas artificiales, que están unidos por arcos dirigidos que le permiten comunicarse. Cada arco tiene asociado un peso numérico Wij que indica la significación de la información que llega por este arco, o sea, la influencia que tiene la activación alcanzada por la unidad Ui sobre la unidad Uj. Cada celda Ui calcula una activación a partir de las activaciones de las celdas conectadas directamente a ella, de los. 15.
(25) Capítulo 1. pesos de los arcos a través de los cuales llega cada activación y usando un algoritmo que generalmente es el mismo para todas las unidades[12].. Las RNA se conocen por diversos nombres: como modelos conexionistas o modelos de procesamiento distribuido paralelo, ya que exploran muchas hipótesis simultáneamente y con este paralelismo logran alcanzar una alta potencia de procesamiento. Existen diferentes modelos de redes neuronales, los elementos que los especifican son: la topología de la red, el modelo de neurona y las reglas de aprendizaje.. La topología de una red neuronal comprende la distribución espacial de las neuronas y los enlaces entre ellas. Entre las topologías básicas tenemos: 9 Neurona simple 9 Red simple 9 Red con elementos de asociación. 9 Redes multicapas 9 Topología del modelo interactivo 9 Topología del modelo interactivo desarrollado. El modelo de la neurona define el comportamiento de la misma al recibir una entrada para producir una respuesta (nivel de activación). Para calcular la activación se emplea la siguiente expresión[15]:. (1.1). Si = ∑wij * xj +biasi j. Donde wij es el peso del enlace, xj es el valor de la información que fluye por esa conexión y el bias indica la predisposición de la neurona a reaccionar.. 16.
(26) Capítulo 1. Posteriormente se calcula el nivel de activación empleando una función que recibe como argumento la entrada total a la neurona. Entre las funciones que se emplean con este objetivo tenemos[15]: 9 Modelo lineal. 9 Modelo lineal con umbral. 9 Modelo estocástico. 9 Modelo continuo.. Una parte muy importante en la creación del modelo de red neuronal es la determinación del conjunto de pesos de la misma. Existen tres métodos para lograr este objetivo: 9 Programación prescriptiva de la red 9 Aprendizaje adaptativo (supervisado, no supervisado o semisupervisado ) 9 Aprendizaje no adaptativo. En el aprendizaje supervisado se conoce la respuesta deseada para cada elemento del conjunto de entrenamiento, por tanto tenemos un par (X, Z) por cada elemento del conjunto de entrenamiento, donde Z es la respuesta correcta para la entrada X.. La programación prescriptiva. fija los pesos asociados a cada enlace, el aprendizaje. adaptativo inicializa los pesos y luego se ajustan iterativamente según alguna regla y en el aprendizaje no adaptativo cada peso se calcula directamente empleando algún tipo de expresión matemática[12].. Entre las ventajas de las RNA tenemos: facilidades de aprendizaje, facilidades de representación (sobre todo en problemas de reconocimiento o clasificación), paralelismo y tolerancia al error entre otras. Entre las limitaciones de este SBC tenemos que dado un problema se desconoce la topología que lo va a solucionar de forma más eficiente, y puede resultar complejo averiguar por qué no funciona correctamente. Además precisa elevados requisitos de cómputo durante el aprendizaje y una vez entrenada resulta difícil interpretar su funcionamiento.. 17.
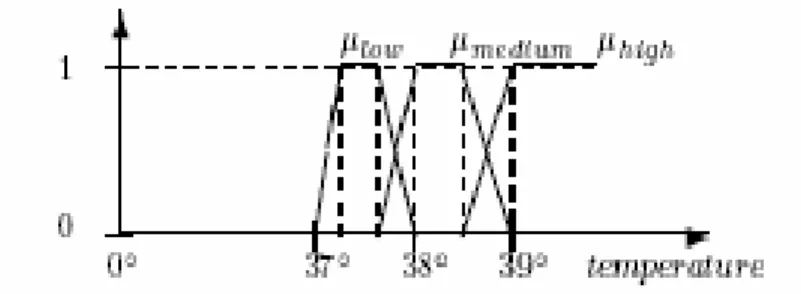
(27) Capítulo 1. 1.2.2 Sistemas híbridos Un sistema híbrido de inteligencia artificial está formado por la integración de varios subsistemas inteligentes, cada uno de los cuales mantiene su propio lenguaje de representación y un mecanismo diferente de inferir soluciones. El objetivo de los sistemas híbridos es mejorar la eficiencia y la potencia de razonamiento así como la expresión de los sistemas inteligentes aislados[16].. 1.2.2.1 Los conjuntos borrosos y la teoría de la lógica borrosa La lógica borrosa permite tratar información imprecisa, como por ejemplo: estatura media, temperatura alta o mucha fuerza en términos de conjuntos borrosos. Los conjuntos borrosos permiten describir el grado de pertenencia de un objeto al concepto dado por la etiqueta que lo nombra, asignando un número real entre 0 y 1. En términos matemáticos, un conjunto borroso F en U queda caracterizado por una función de inclusión o pertenencia ϕ que toma valores en el rango [0, l], es decir, ϕ: U Æ[0,1]; donde ϕ representa el grado en el que u Є U pertenece a1 conjunto borroso F[17].. Modelación de rasgos numéricos como variables lingüísticas La teoría de los conjuntos borrosos nos permite utilizar un lenguaje más natural para referirnos a valores de un rasgo [18, 19], es decir, nos permite modelar rasgos numéricos como variables lingüísticas y es precisamente el uso de términos lingüísticos el que posibilita que la situación o evento que se represente en los casos sea más clara y cercana a la realidad. Cuando se modela un atributo numérico a como variable lingüística consideramos como universo el conjunto de valores que para él aparecen en la BC. Denótese como Rp= {P1, P2,…, P/Rp/} el conjunto de términos lingüísticos definido, donde cada Pi representa un conjunto borroso y tiene por tanto asociado una función de pertenencia. Véase el siguiente ejemplo para aclarar lo antes planteado: el concepto temperatura corporal del paciente se puede modelar como variable lingüística, definiendo para ello tres términos lingüísticos:. 18.
(28) Capítulo 1. baja (“low”), media (“medium”) y alta (“high”), empleando una función de pertenencia trapezoidal (Figura 1.1).. Figura 1.1 Variable lingüística que representa temperatura.. Al adoptar esta alternativa de modelación para rasgos numéricos las ventajas son inmediatas[20], ya que se tiene en qué medida un valor del dominio real del rasgo está próximo a un valor representativo y si se presenta un problema de diagnóstico médico es más natural hablar de que un paciente tiene una temperatura “alta”, que hablar de magnitudes numéricas próximas a 38 grados; así como establecer la relación de pacientes con temperatura “alta” y cierta enfermedad. Resulta conveniente en muchas tareas de diagnóstico considerar intervalos discretos, debido a que los expertos usualmente tienen en cuenta solamente niveles de valores al realizar diagnósticos.. 1.2.2.2 Breve referencia al empleo de los conjuntos borrosos en varios de los sistemas anteriores A continuación se analizarán dos modelos computacionales que explotan los beneficios del uso de los conjuntos borrosos.. El modelo Fuzzy-SIAC El modelo Fuzzy-SIAC (Simple implementation of the Interactive Activation and Competition) constituye una extensión borrosa de la variante simplificada del modelo de RNA Activación Interactiva y Competencia[21]. El nuevo modelo se obtiene modificando la topología y el método empleado para el cálculo de los pesos en el modelo original. Sean a, b dos atributos de A. El valor etiquetado por wAi,Bj representa el peso del arco asociado entre las neuronas de procesamiento NAi and NBj correspondientes a los valores 19.
(29) Capítulo 1. representativos Ai y Bj respectivamente. Se emplea una medida basada en la frecuencia B. relativa y por tanto se obtiene una matriz de pesos no simétrica. Su extensión a un enfoque borroso se basa en utilizar la t-norma “producto” en lugar de la clásica intersección, y la cardinalidad mediante el uso de una extensión simple ∑-count[19].. wAi , B j. ∑ =. n k =1. f Ai (aik ) f B j (b jk ). ∑. n k =1. (1.2). f Ai (aik ). Cuando se presenta una solicitud q a la RNA ya entrenada, se divide el conjunto de rasgos en dos subconjuntos: el conjunto de rasgos predictores P (rasgos para los cuales se conoce su valor) y el conjunto de rasgos objetivos (para los cuales se desea inferir un valor). Sea t uno de estos rasgos objetivos, y T uno de sus valores posibles o representativos. El modelo Fuzzy-SIAC completa el patrón correspondiente a la solicitud q, a partir de calcular el grado de activación de las neuronas en el grupo del atributo objetivo t mediante la expresión (1.3) y luego determinando como valor inferido el asociado a la neurona que quedó activado con un mayor valor.. NetT ( q) = ∑. ∑w. a∈P Ai ∈Ra. Ai ,T. f Ai (a q ). (1.3). El modelo ConFuCiuS El modelo ConFuCiuS (Conecctionist Fuzzy Case-based System), es un modelo conexionista borroso para desarrollar Sistema Basado en Casos[22]. Este modelo se define como una instancia del clasificador basado en los vecinos más cercanos (k-NN or kNearest Neighbords), usando una función de distancia que utiliza los pesos del modelo Fuzzy-SIAC explicado anteriormente.. Este modelo es solamente aplicable a problemas de aprendizaje supervisado. Considérese la solicitud q= (q1, q2 ,…,qm-1), y se desea predecir el valor del rasgo objetivo t (qm). Este nuevo modelo basado en instancias define que: 20.
(30) Capítulo 1. - Se tienen almacenadas instancias de entrenamiento que se representan como pares de atributo-valor. - El valor para la clase del problema a resolver se corresponde con la clase que más aparece (más probable) en los k casos más similares recuperados (majority vote), luego de calcular la probabilidad de cada clase atendiendo a las siguientes expresiones:. q m = ArgMaxc∈C ' Pr k (c q) Pr k (c q ) =. ∑1(e. ∀e∈Kq. m. (1.4). = c). (1.5). Kq. donde Kq es el conjunto de los k vecinos más cercanos, subconjunto del conjunto de instancias de entrenamiento; y que se seleccionan como resultado de comparar cada instancia de entrenamiento e con la solicitud q. Para cada conjunto de instancias se determina un valor de k óptimo o ideal, que se refiere al valor de k= 1...15 que minimice el LOOCE (leave-one-out cross error). - Para comparar dos instancias se utiliza la distancia euclidiana que emplea el k-NN estándar; y considerando como criterio de comparación a nivel de rasgo las funciones cuyas expresiones se presentan en (1.7) y (1.8), como instancias de la familia FADM de funciones definida a continuación: Función de distancia FADM entre conjuntos borrosos: Sean A y B ∈ F(X), C∈ F(Y). Se considera que la distancia entre dos conjuntos borrosos A y B es menor, en la medida que estos tengan igual medida de asociación con cada valor C posible para el atributo objetivo. La distancia FADM (Fuzzy Association Difference Metric), d: F(X) xF(X)→ℜ+ se define mediante la expresión siguiente:. d FADM ( A, B) =. ∑ [I ( A, C ) − I ( B, C )]. 2. (1.6). ∀C. donde I: F(X)xF(Y)→[-1,1].. La función FVDM[23] entre elementos queda definida mediante la expresión siguiente: 21.
(31) Capítulo 1. N ⎡N ⎤ d FVDM ( x, y ) = ∑ ⎢∑ A j ( x )I Pr ( A j , C ) − ∑ A j ( y )I Fr ( A j , C )⎥ ∀C ⎣ j =1 j =1 ⎦. (1.7). 2. La expresión de la distancia FCDM[23] entre elementos se define como:. N ⎡N ⎤ d FCDM ( x, y) = ∑ ⎢U A j (x ) ∗ I r ( A j , C ) − U A j ( y ) ∗ I r ( A j , C )⎥ ∀C ⎣ j =1 j =1 ⎦. 2. (1.8). Considerando la información pre-compilada que se utiliza en FADM y que se calcula como resultado de la función I(Ai, Cj), se corresponde con el valor del peso wi,j entre los términos lingüísticos Ai∈ F(X) y Cj ∈ F(Y) del modelo conexionista expuesto anteriormente.. En muchos campos de aplicación, como el diagnóstico médico, generalmente los especialistas relacionan síntomas (rasgos predictores) con un diagnóstico (clasificación). ConFuCiuS garantiza lo anterior al utilizar una instancia de la familia de funciones FADM. Al mismo tiempo es poco usual que la relación predictiva entre atributos de naturaleza numérica y la solución de un problema se refiera a cada valor específico del dominio de un rasgo; sino a valores que puedan ser representativos de todo un grupo de valores próximos a él a los cuales usualmente se refieren mediante términos.. Luego, aunque el algoritmo admita atributos numéricos, el tratamiento de esta información en el modelo computacional no se correspondería con el que en su mente hace el especialista. Esto se refiere a que las clases de objetos en la vida diaria no tienen siempre límites bien definidos, lo que constituye una fuente de imprecisión. Utilizar los conjuntos borrosos para representar este tipo de información, y contar con un modelo computacional que razone en base a esta definición, garantiza mayor naturalidad en la modelación computacional de un problema. A diferencia de emplear métodos de discretización, utilizar conjuntos borrosos permite manejar el grado de pertenencia del valor real a cada término. 22.
(32) Capítulo 1. lingüístico como una medida de similitud o compatibilidad, que permitiría ganar en precisión.. Las características de la función de distancia que utiliza ConFuCiuS compromete el enfoque puramente perezoso de la variante del k-NN propuesta, debido a que la función que se utiliza para comparar dos valores de un rasgo se basa en una función I() que generaliza la relación entre estos valores en el conjunto de instancias conocidas. Luego, al comparar un rasgo se tienen en cuenta dos tipos de conocimiento: los valores que para este rasgo aparecen en las instancias y el conocimiento pre-compilado del conjunto de instancias. Además esta función I() es general para todo tipo de rasgo, y con esta finalidad se define sobre una partición borrosa del dominio de los atributos numéricos. ConFuCiuS se diferencia esencialmente del k-NN estándar en los aspectos siguientes: - k-NN es puramente un enfoque perezoso, mientras que ConFuCiuS no. - Si el valor de x en una instancia e es desconocida, la distancia HEOM (Heterogeneus Euclidean-Overlap Metric) retorna valor 1 (máxima distancia); mientras que la función FADM retorna un valor atendiendo al valor conocido en la solicitud y el conocimiento generalizado sobre este rasgo en el conjunto de instancias. Solamente en la variante que ambos valores sean desconocidos, se considera entonces un valor constante (contrario al anterior que asume valor cero y distancia mínima). La distancia HEOM queda definida en la expresión (1.9) y permite manejar atributos simbólicos y numéricos a partir de combinar las expresiones (1.10) y (1.11).. ⎧1 si x = ? o y = ? ⎪ d heom ( x , y ) = ⎨δ overlap ( x , y ) si el atributo es simbólico ⎪ ⎩δ norm 1 ( x , y ) si el atributo es numérico. d norm1 ( x, y ) =. x− y. (1.9). (1.10). la − u a. ⎧0 si x = y d overlap ( x, y ) = ⎨ ⎩1 si e.o.c.. (1.11). 23.
(33) Capítulo 1. - Si el atributo a comparar es simbólico, la distancia HEOM retorna un valor binario (función overlap); mientras que FVDM se reduce como caso particular a VDM, función con buen desempeño para atributos simbólicos, y FCDM a la variante similar pero basada en coeficiente de correlación en lugar de la frecuencia relativa que muestra también muy buenos resultados. En ambas variantes se aumenta el rango de valores posibles para la función. - La función FADM define un criterio de comparación local uniforme para todo tipo de rasgo independientemente de su naturaleza; a diferencia de HEOM que especifica un cálculo de la medida de distancia diferenciado para cada tipo de rasgo. - ConFuCiuS es más costoso computacionalmente que el k-NN al requerir adicionalmente conocimiento pre-compilado del conjunto de entrenamiento. - ConFuCiuS modela los atributos numéricos como variables lingüísticas, permitiendo una modelación del problema más cercana a la realidad.. Además, nótese que el criterio de comparación que utiliza ConFuCiuS se define automáticamente a partir del conjunto de entrenamiento, definiendo un criterio más específico para un dominio de aplicación al considerar la asociación entre los valores presentes en un conjunto de instancias o ejemplos conocidos y disminuyendo la ingeniería del conocimiento requerida en los algoritmos de esta familia. Adicionalmente, la modelación borrosa de estos términos permitiría manejar el grado de pertenencia del valor a cada uno de estos términos como una medida de similitud o compatibilidad con estos; lo cual debe permitir soluciones efectivas[23].. 1.3 Desarrollo de SBC utilizando la herramienta de aprendizaje automático Weka En el mundo actual, los SBC están siendo ampliamente empleados en la realización de sistemas capaces de dar solución a problemas de diferente índole: en la medicina, en la educación, en el comercio, etc. La herramienta de aprendizaje automatizado Weka (Waikato Environment for Knowledge Analysis) contiene una colección de algoritmos de la IA, muchos de los cuales usan SBC para su implementación y resuelven disímiles problemáticas con un margen de error aceptable.. 24.
(34) Capítulo 1. 1.3.1 Sobre aprendizaje automatizado El aprendizaje automatizado estudia cómo construir sistemas computacionales que se superen mediante la experiencia. En otros términos podemos concluir que un programa ha aprendido a desarrollar una tarea T si luego de proporcionarle una experiencia E el sistema es capaz de desempeñarse adecuadamente bien cuando se presentan nuevas situaciones de la tarea. El desempeño se mide empleando una métrica de calidad P, E es generalmente un conjunto de ejemplos de T y tanto T como E y P deben estar correctamente especificadas en un problema de aprendizaje[14].. Pese a los esfuerzos que se han realizado aún no se logra que las computadoras aprendan como las personas, pero vale aclarar que ciertos algoritmos propuestos en este campo han resultado útiles en varias tareas de aprendizaje.. 1.3.2 Descripción general de Weka Weka es una herramienta de aprendizaje automatizado, fue Ian Witten, profesor del Departamento. de Ciencias de la Computación de la Universidad de Waikato, Nueva. Zelanda (1992) quien la creó. La primera versión publicada contaba con algunos algoritmos en C, posteriormente se decidió rescribir Weka en Java y a partir de la versión 3 ya Weka quedó escrita totalmente en Java. Desde este momento se le comenzaron a hacer mejoras y se le agregaron nuevas facilidades apareciendo así diferentes versiones. Weka superó los límites del lugar de creación y hoy día en varios lugares del mundo diferentes personas se esfuerzan en la ampliación y perfeccionamiento de esta herramienta.. La herramienta Weka es un ambiente de trabajo para la prueba y validación de algoritmos de la IA. Tiene implementada una colección de algoritmos conocidos, varias maneras para preprocesar los archivos de datos a utilizar por dichos algoritmos; así como facilidades para validar los mismos. Posee interfaces gráficas de usuario (GUI: Graphical User Interface) y cuenta con herramientas para realizar tareas de regresión, clasificación, agrupamiento, asociación y visualización[24].. 1.3.3 Tipos de datos que Weka implementa 25.
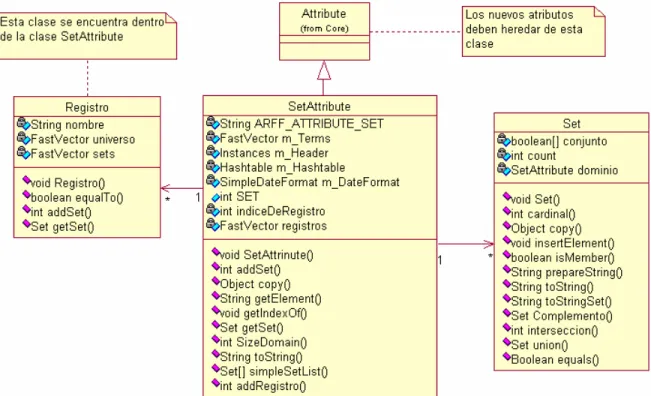
(35) Capítulo 1. Los tipos de datos que Weka acepta son: 9 Entero (Integer): expresa números enteros 9 Numérico (Numeric): expresa números reales 9 Fecha (Date): expresa fechas 9 Cadena (String): expresa cadenas de texto, con las restricciones del tipo String 9 Enumerado: expresa entre llaves y separados por comas los posibles valores (caracteres o cadenas de caracteres) que puede tomar el atributo. 9 Lingüístico (Linguistic): expresa atributos numéricos como variables lingüísticas, es decir, trata datos borrosos.. Luego de una adecuada valoración de los tipos de datos que se presentan se puede notar que no existe ningún tipo de dato que maneje los atributos multievaluados, lo cual resultaría de notable ayuda en problemas donde exista esta necesidad, ya que permitiría una BC con una estructura más comprensible y natural.. 1.3.4 Implementación de ConFuCiuS en Weka El modelo ConFuCiuS combina dos componentes fundamentales: la RNA Fuzzy-SIAC y la regla de los vecinos más cercanos (k-NN o k- Nearest Neighbords). La importancia de cada rasgo es tomada como valor uno para todos los atributos.. La implementación e incorporación de ConFuCiuS dentro de Weka se auxilia del clasificador IBk que implementa el algoritmo del k-NN estándar, ya presente en la herramienta. La clase IBk recibe como uno de sus parámetros de entrada el algoritmo de búsqueda de los k vecinos mas cercanos, Weka implementa dos: LinearNN y KDTree, el primero es el que aparece por defecto. Estos algoritmos de búsqueda reciben como parámetros una función de distancia que será utilizada para encontrar los vecinos más cercanos. ConFuCiuS consiste en una función de distancia que permite determinar cuánto se diferencian dos instancias dadas. Esta exige que los atributos del conjunto de datos sean nominales o lingüísticos. ConFuCiuS está implementado en la clase FuzzyVDM dentro del paquete “weka.core”[24].. 26.
(36) Capítulo 1. 1.4 Aplicaciones de la Inteligencia Artificial en la medicina La influencia de la computación en el desarrollo del pensamiento científico en medicina es notable, ya que se obliga al médico a buscar formas de descripción de los procesos biológicos, con la formalización matemática, más objetiva y precisa que la intuición. Por otra parte, el uso de la informática, herramienta del pensamiento médico, con la gran velocidad de desarrollo de los cálculos matemáticos, ofrece soluciones en el campo de probabilidades que hacen objetivizar realidades en los procesos biológicos, que por otros métodos quedarían inaparentes, o sólo a la vista de los clínicos de mayor intuición o agudeza del llamado "ojo clínico".. Muchas son las aplicaciones de los SBC en el campo de las Ciencias Médicas. EPILEP es una base de conocimientos, que junto con la máquina de inferencias ARIES constituyen un Sistema Experto cuyo objetivo central es servir como consultante a médicos que se enfrenten al complejo diagnóstico de pacientes con ciertos ataques, para establecer si éstos son de naturaleza epiléptica o no, así como todas las posibles acciones derivadas de ello. En general el proyecto ha sido concebido con el objetivo de agrupar las experiencias de un colectivo de especialistas, con vistas a que sea capaz de ayudar en el diagnóstico diferencial con otros tipos de ataques, la clasificación de las crisis, la etiología y el tratamiento, mientras que, paralelamente sea capaz de explicar cuál es el fundamento de su trabajo y conclusiones, posibilitando la adquisición de nuevos conocimientos de forma rápida y sencilla[25].. EDIMED se emplea en el diagnóstico de enfermedades pulmonares. Se consideraron catorce síntomas que son comunes en cinco enfermedades diferentes, dependiendo el diagnóstico del grado de incidencia con que cada síntoma se presente. Para cada síntoma (variable lingüística) se establecieron tres valores lingüísticos bajo, medio y alto) y de acuerdo a la información de un experto (médico especialista) se generaron las tablas que conforman la base de datos que serán consultadas para obtener, mediante el empleo del álgebra difusa, varios diagnósticos con grados de pertenencia entre 0 y 1, siendo el diagnóstico con grado de pertenencia más cercano a 1 el más acertado[26].. 27.
(37) Capítulo 1. SHRINK es un Sistema Basado en Casos del tipo solucionador de problemas específico para el diagnóstico en psiquiatría. En este sistema se usa un caso previo para generar una hipótesis sobre el diagnóstico del nuevo caso. La estimación de la similitud se combina con el proceso de clasificación, y todos los casos similares se almacenan en la jerarquía bajo la misma clasificación. Si a pesar de esto, el caso recuperado no es útil, el sistema usa la clasificación secundaria basada en fallos. Un caso que se recupera por esta vía se asume por el sistema que tiene mayor similitud con el problema debido a que ambos en su desarrollo tuvieron un fallo similar en su comportamiento anterior[13].. BOLERO, considerado un planificador basado en casos, combina realmente la planificación y el diagnóstico. Aparecen integrados en este producto un Sistema Basado en Casos y un Sistema Basado en Reglas, donde el razonador basado en casos actúa como el planificador del sistema basado en reglas, mientras que éste posee un escaso conocimiento sobre la estrategia de búsqueda a seguir. El Sistema Basado en Casos construye los planes de acuerdo al estado de la memoria de trabajo del sistema basado en reglas, y la máquina de inferencia de este último ejecuta esos planes. Este modelo es muy adecuado para el diagnóstico médico, pues se caracteriza por utilizar información incompleta e imprecisa que hacen necesario poder alterar dinámicamente el plan de búsqueda trazado.. Como parte de un proyecto de investigación conjunta entre la Universidad Central de Las Villas y la Universidad de Oviedo, hace algunos años se creó la “Proyección del Centro de Desarrollo Electrónico hacia la Comunidad” (PROCDEC) cuyo objetivo principal es desarrollar un estudio de personas supuestamente normotensas primero en la ciudad de Santa Clara y luego en toda la nación. El proyecto desarrolla un Sistema Basado en Casos para el diagnóstico de Hipertensión Arterial. La base de casos consta de 14 rasgos predictores y un rasgo objetivo.. La maloclusión se refiere a cualquier grado de contacto irregular de los dientes del maxilar superior con los del maxilar inferior, lo que incluye sobremordidas, submordidas y mordidas cruzadas. Debido a la importancia que tiene la obtención de un diagnóstico certero en la especialidad de ortodoncia, específicamente en el Síndrome de Maloclusión, 28.
(38) Capítulo 1. por la dificultad que se presenta en ocasiones la diferenciación entre sus clases, se propone la implementación de un Sistema Basado en Casos que cuenta con una base de casos clínicos almacenados según la clasificación sindrómica de Moyers y tiene como propósito fundamental el logro de un modelo factible para el apoyo en el diagnóstico y clasificación de este síndrome[27].. MYCIN, es un SBR. Su función es la de aconsejar a los médicos en la investigación y determinación de diagnósticos en el campo de las enfermedades infecciosas. CASNET se emplea en oftalmología. INTERNIST en medicina interna, PIP en afecciones renales, Al/RHEUM. en el diagnóstico en reumatología, SPE. interpreta los resultados de. electroforesis de las proteínas del suero producidas por instrumentos de análisis y TIA se usa en la terapia de ataques isquémicos[28].. PROTOS es un Sistema Basado en Casos del tipo interpretativo para el diagnóstico de trastornos auditivos. Se diseñó de forma tal que los casos se usan para señalar la forma en que se razonaron experiencias previas para llegar a la predicción. En ese dominio de aplicación, muchos de los diagnósticos se manifiestan de forma similar y sólo existen diferencias no sustanciales, a partir de la retroalimentación con el usuario. PROTOS aprende cuales son esas diferencias. La similitud entre el problema y los casos recuperados se estima a partir de una explicación de cómo los rasgos brindan una evidencia equivalente para una clasificación. La similitud final se basa en la evaluación heurística de la calidad de la explicación anterior y en la importancia de los rasgos no similares. Sin embargo, sería aconsejable tener en cuenta la importancia de rasgos similares y no sólo la importancia de los rasgos no similares. La base de casos se organiza por clases; PROTOS primeramente elige la clase correspondiente con el nuevo problema y luego el caso más similar de esa clase. Aprende a clasificar irregularidades de la audición a partir de descripciones de rasgos en términos de síntomas de los pacientes, historia y resultados de pruebas a las cuales se somete al mismo, almacenadas con 200 casos secuenciales (en 24 categorías)[29].. El Sistema. para el Pronóstico de Malformaciones Cardiovasculares en Recién. Nacidos es un Sistema Basado en Casos interpretativo. A partir de caracterícticas de los 29.
(39) Capítulo 1. padres pronostica la presencia de malformaciones cardiovasculares en el recién nacido y la especificación de las mismas en caso afirmativo. El sistema brinda una justificación de la solución[13].. 1.5 Conclusiones parciales A partir de la revisión bibliográfica realizada podemos concluir que: 9 Los sistemas pronósticos son de gran ayuda al especialista aunque presentan deficiencias como el consumo de tiempo y recursos durante su aplicación en cada paciente, por lo que sería de gran utilidad contar con un sistema que no presentara dichos inconvenientes. 9 Los Sistemas Basados en el Conocimiento y en especial los enfoques híbridos brindan soluciones efectivas al aplicarse a problemas médicos. 9 El sistema de aprendizaje automático Weka no presenta un tipo de dato que permita definir atributos de selección múltiple, cuya presencia es muy común en problemas médicos y por tanto la presencia de un atributo de este tipo favorecería definiciones más cercanas a la realidad.. 30.
(40) Capítulo 2. CAPÍTULO. 2.. SISTEMA. AUTOMATIZADO. PREDICTOR. DE. RIESGO. INFANTIL DE MORTALIDAD (SAPRIM).. En este capítulo se realizará el diseño del sistema a desarrollar. Se escogerá el resolvedor de problemas a utilizar a partir de la realización de pruebas. Se describirá la implementación de un nuevo tipo de dato (Set) que permite modelar el problema con mayor naturalidad. Se abordará todo lo referido a dos nuevos filtros que resultan indispensables para el trabajo con el nuevo tipo de dato.. 2.1 Planteamiento del problema Elevar la calidad de la atención médica constituye una de las directivas específicas de la estrategia que se reitera en la política del ministerio de Salud Pública de nuestro país; dentro del cual la atención pediátrica reviste gran importancia y prioridad. La acción del médico ante su paciente incluye, además de llegar al diagnóstico, emitir un pronóstico sobre la posible evolución de la enfermedad y su nivel de gravedad. Atendiendo a esto se orienta la sala de destino si el paciente es tributario de ingreso. Existen tres escalas de atención: convencional, cuidados intermedios y cuidados intensivos; y los procederes diagnósticos y/o terapéuticos son diferentes en cada servicio.. En particular, se requiere decidir de forma adecuada y rápida si el paciente debe ingresar en las Unidades de Cuidados Intensivos (UCI), donde se atienden aquellos niños que tienen un estado de salud delicado y con mayor riesgo de fallecer. Los especialistas de este servicio en el Hospital Pediátrico “José Luis Miranda” de Santa Clara, no están satisfechos con los modelos extranjeros propuestos (PSI y PRIMS). El PSI realiza una valoración tomando los valores de 34 variables que se obtienen a partir de datos clínicos y complementarios del paciente; resultando un procedimiento muy engorroso, que incluye exámenes de laboratorio que no se realizan en nuestro país o son de muy costosa ejecución y traumáticos para el paciente, que retardarían además la definición de una conducta inicial a seguir. La aplicación del PRISM, aunque es una simplificación del PSI que utiliza solamente 14 variables, contempla al menos cinco exámenes de laboratorio. La realización de algunos de estos exámenes no es factible en nuestro país temporal o permanentemente 31.
(41) Capítulo 2. por limitaciones materiales. El PRISM es una herramienta válida únicamente en Europa y Norteamérica por lo cual no se garantizan resultados satisfactorios al utilizarla en otras latitudes[30].. Un estudio realizado en esta UCIP arrojó que al evaluar el PRISM en un grupo de pacientes que posteriormente fallecieron, sólo el 17,5% fueron dados como alto riesgo de fallecer. Los restantes pacientes fueron ubicados en la escala de bajo y moderado riesgo de mortalidad. Podemos concluir que el PRISM no tuvo un buen desempeño en la predicción de la gravedad en esta UCIP siendo esta una grave deficiencia a tener en cuenta[30].. Es por ello que se requiere la creación de un modelo pronóstico propio que ayude a la toma de decisiones en la gestión hospitalaria para asistir al especialista en determinar la necesidad o no del ingreso de un paciente en la sala de cuidados intensivos. Para ello se valoran solamente los datos clínicos y epidemiológicos del paciente, mientras se realizan los exámenes de laboratorio para complementar la valoración del estado actual del mismo.. 2.2 Diseño del sistema desarrollado Para desarrollar cualquier sistema computacional es necesario como primer paso lograr un diseño adecuado del problema que se trata. Para ello debemos hacer un correcto modelado del negocio, identificando los actores y casos de uso que intervienen en el mismo. Se analizarán las clases que se emplean en la implementación del sistema y los componentes del mismo, permitiendo de esta forma lograr una comprensión adecuada del problema a resolver.. Modelo del negocio Se efectuaron varias sesiones de trabajos con los expertos (médicos o especialistas), en las que se hizo un análisis detallado de su desempeño en el momento de la llegada de un paciente al hospital. Como resultado se identificaron los procesos claves. Se confeccionó un diagrama de actividad en el que se visualiza el flujo de dichos procesos, describiendo así el funcionamiento del negocio.. 32.
(42) Capítulo 2. Figura 2.1 Diagrama de actividad. Análisis de actores y casos de uso Se identificaron como actores del negocio en el problema los siguientes: el paciente y el pediatra. El paciente es el que suministra los datos clínicos y epidemiológicos. El pediatra es el encargado de tomar estos datos y efectuar a partir de ellos una valoración del estado de gravedad del paciente. A continuación se muestra un diagrama que ilustra lo planteado anteriormente.. Figura 2.2 Casos de uso del negocio. 33.
Figure



+7




Documento similar