Despliegue de EasyBuild y Lmod en la implementación de aplicaciones para cálculo científico
97
0
0
Texto completo
(2) Facultad de Ingeniería Eléctrica Departamento de Telecomunicaciones y Electrónica. TRABAJO DE DIPLOMA Despliegue de EasyBuild y Lmod en la implementación de aplicaciones para cálculo científico Autor: Patricia Morales Calvo Email: [email protected] Tutores: MSc. Ing. Carlos M. Bustillo Rodríguez Email: [email protected] Dr.C. Ing. Héctor Cruz Enríquez Email: [email protected]. Santa Clara 2016 “Año 58 de la Revolución”.
(3) Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería en Automática, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicados sin autorización de la Universidad.. Firma del Autor Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Autor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica.
(4) i. PENSAMIENTO. “Nunca consideres el estudio como una obligación, sino como una oportunidad para penetrar en el bello y maravillosos mundo del saber” Albert Einstein.
(5) ii. DEDICATORIA. A Dios. A mis padres, que tanto me quieren, son mi apoyo y mi guía en todo momento. A Euse, quien con su amor supo brindarme la tranquilidad y felicidad que necesité. A mis tíos, primas y abuelos, siempre incondicionales. A Laura, Jessica, Mary, Ana… sé que con su amistad puedo contar siempre. A mis compañeros de aula más cercanos, que se convirtieron en verdaderos amigos. A mis tutores Bustillo y Héctor por toda su dedicación. A Marki y a Tommy por siempre proporcionarme momentos de felicidad..
(6) iii. AGRADECIMIENTOS. Mis agradecimientos: A Dios por inspirarme en todo momento. A mis padres y a Euse, por su ayuda en la revisión de este trabajo. A mis tutores, en especial a Bustillo por siempre recibirme en cada momento de duda. A todas mis amigas, en especial a Laura por estar y compartir todos los días cada instante de estrés y de satisfacción. A los trabajadores de la Dirección de Informatización por su apoyo incondicional. A todos aquellos a los que de una forma u otra participaron en la realización de este trabajo..
(7) iv. RESUMEN. Los administradores de los clústeres de alto rendimiento invierten considerable tiempo y esfuerzo en la instalación y administración de aplicaciones para cálculo científico, a su vez, este personal de soporte técnico carece de herramientas adecuadas para administrar dichos paquetes de aplicaciones de una manera sencilla y consistente; mientras que los usuarios a menudo tienen dificultades al establecer correctamente su entorno de trabajo. Surge así la necesidad de encontrar la herramienta que permita desarrollar un procedimiento para la compilación eficiente de aplicaciones para cálculo científico. Se estudiaron las herramientas existentes y se propuso la metodología de instalación y administración de EasyBuild como gestor de paquetes, con Lmod como herramienta de módulo. Se describe cómo integrar esta herramienta a los clústeres de alto rendimiento a través de la configuración de las variables de entorno. Se construyeron dos scripts, el primero para automatizar todas las dependencias de EasyBuild en el proceso de instalación y el segundo, para incrementar el aprovechamiento del ancho de banda y de la capacidad de almacenamiento, a través de la recopilación de paquetes fuentes descargados por los usuarios, lo que a su vez contribuye a enriquecer el repositorio central..
(8) v. TABLA DE CONTENIDOS. PENSAMIENTO .....................................................................................................................i DEDICATORIA .................................................................................................................... ii AGRADECIMIENTOS ........................................................................................................ iii RESUMEN ............................................................................................................................iv TABLA DE CONTENIDOS .................................................................................................. v INTRODUCCIÓN .................................................................................................................. 1 Organización del informe ................................................................................................... 4 CAPÍTULO 1.. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE. CÁLCULO CIENTÍFICO ...................................................................................................... 6 1.1. SWTools................................................................................................................... 6. 1.1.1. Antecedentes. Objetivos perseguidos ............................................................... 7. 1.1.2. Implementaciones ............................................................................................. 8. 1.1.3. Secuencia de comandos .................................................................................. 10. 1.1.4. Metas futuras................................................................................................... 10. 1.1.5. Conclusiones ................................................................................................... 11. 1.2. Smithy .................................................................................................................... 11. 1.2.1. Objetivos perseguidos ..................................................................................... 11. 1.2.2. Métodos para la instalación de software ......................................................... 12. 1.2.3. Nomenclatura del software ............................................................................. 12. 1.2.4. Proceso de instalación ..................................................................................... 13. 1.2.5. Archivos de configuración .............................................................................. 16. 1.2.6. Conclusiones ................................................................................................... 17.
(9) vi 1.3. IVEC Build System ................................................................................................ 17. 1.3.1. Antecedentes. Objetivos perseguidos ............................................................. 18. 1.3.2. Proceso de automatización y creación de módulos de entorno ...................... 19. 1.3.3. Beneficios y metas futuras .............................................................................. 21. 1.3.4. Conclusiones ................................................................................................... 21. 1.4. Spack ...................................................................................................................... 21. 1.4.1. Antecedentes. Objetivos perseguidos ............................................................. 22. 1.4.2. Características generales de Spack ................................................................. 22. 1.4.3. Proceso de concretización ............................................................................... 26. 1.4.4. Soporte para lenguajes interpretados .............................................................. 27. 1.4.5. Limitaciones y metas futuras .......................................................................... 28. 1.4.6. Conclusiones ................................................................................................... 29. 1.5. EasyBuild ............................................................................................................... 29. 1.6. Conclusiones .......................................................................................................... 30. CAPÍTULO 2.. METODOLOGÍA DE INSTALACIÓN Y ADMINISTRACIÓN DE. EASYBUILD. 31. 2.1. Características de EasyBuild .................................................................................. 32. 2.1.1. Infraestructura de EasyBuild .......................................................................... 33. 2.1.2. Easyblock ........................................................................................................ 33. 2.1.3. Toolchains ....................................................................................................... 34. 2.1.4. Archivos Easyconfig ....................................................................................... 35. 2.1.5. Extensiones ..................................................................................................... 36. 2.2. Requerimientos de EasyBuild ................................................................................ 37. 2.2.1 2.3. Entorno de trabajo ........................................................................................... 38. Instalación de EasyBuild ........................................................................................ 42.
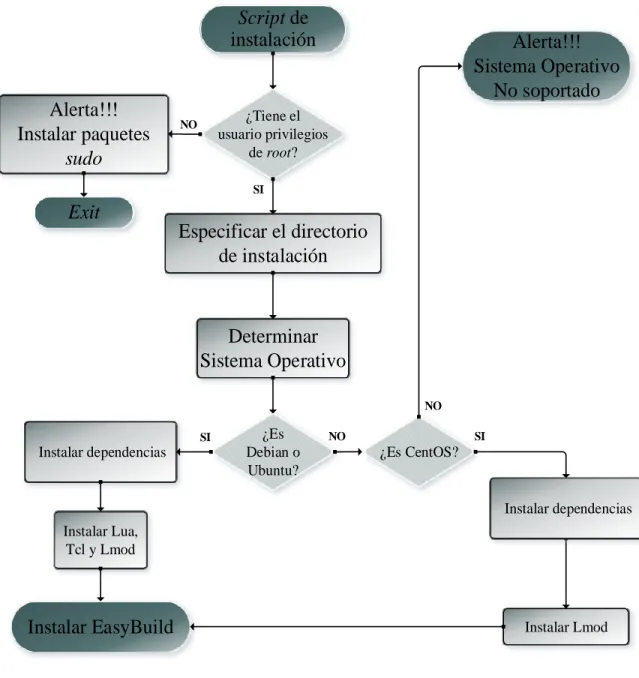
(10) vii 2.3.1. Lua .................................................................................................................. 42. 2.3.2. Tcl ................................................................................................................... 43. 2.3.3. Lmod ............................................................................................................... 44. 2.3.4. EasyBuild ........................................................................................................ 45. 2.4. Configuración y administración de EasyBuild ...................................................... 47. 2.4.1. Configuración mediante argumentos de líneas de comandos ......................... 48. 2.4.2. Configuración de las variables de entorno ...................................................... 48. 2.4.3. Configuración mediante archivos de configuración ....................................... 48. 2.4.4. Comandos de EasyBuild más utilizados ......................................................... 50. 2.5. Conclusiones .......................................................................................................... 52. CAPÍTULO 3.. INTEGRACIÓN CON SISTEMAS HPC ............................................... 53. 3.1. Configurar Lmod como módulo Tcl ...................................................................... 53. 3.2. Integración de EasyBuild en entornos HPC ........................................................... 54. 3.3. Despliegue en otros sistemas operativos ................................................................ 56. 3.4. Configuraciones útiles ............................................................................................ 57. 3.4.1. ¿Cómo actualizar EasyBuild? ......................................................................... 57. 3.4.2. Seguridad en túneles SSH ............................................................................... 57. 3.4.3. ¿Cómo especificar un tiempo mayor para las descargas? ............................... 58. 3.4.4. Soporte para proxy .......................................................................................... 59. 3.5. Script de instalación ............................................................................................... 59. 3.6. Script para recolectar fuentes de usuarios hacia el repositorio central .................. 60. 3.7. Resultados en el clúster HPC de la UCLV............................................................. 62. 3.8. Conclusiones .......................................................................................................... 63. CONCLUSIONES ................................................................................................................ 64.
(11) viii RECOMENDACIONES ....................................................................................................... 65 REFERENCIAS BIBLIOGRÁFICAS ................................................................................. 66 GLOSARIO .......................................................................................................................... 70 ANEXOS .............................................................................................................................. 75 Anexo I. Pasos para la instalación de EasyBuild ........................................................... 75. Anexo II. Script de instalación automatizada de EasyBuild ....................................... 79. Anexo III. Script para recolectar fuentes de usuarios hacia el repositorio central ....... 86.
(12) INTRODUCCIÓN. 1. INTRODUCCIÓN. En diferentes ámbitos de la ciencia moderna existen problemas muy complejos que requieren gran capacidad de cómputo, entre ellos se pueden citar los de modelación numérica. Si bien las computadoras personales son cada vez más rápidas y eficientes, para obtener un buen resultado en las aplicaciones de cálculo científico, se necesita mucha mayor capacidad de procesamiento y memoria. La simulación, junto a la teoría de modelos y el cómputo masivo, ha abierto una frontera a la posibilidad de abordar aplicaciones de la ciencia que hasta el momento permanecían vedadas. La mecánica de fluidos, la mecánica de sólidos, la solución de ecuaciones diferenciales parciales, la predicción de terremotos, el descubrimiento de galaxias, la simulación de reacciones nucleares, los avances en la genética, entre otros, son solo algunas de las problemáticas existentes en la actualidad, para las cuales es necesario disponer de una alta capacidad de cómputo. El cálculo científico es el área de la ciencia que se encarga del empleo de ordenadores, especialmente potentes, para la realización de tareas o la resolución de problemas numéricos. Cuando estos problemas requieren de herramientas u ordenadores muy potentes, la solución idónea es utilizar un clúster de computadoras o clúster de alto rendimiento (HPC). Un clúster de computadoras es un conjunto o conglomerado de ordenadores, construidas con componentes de hardware comunes, que se comportan como una única computadora. También se denomina clúster a un conjunto de ordenadores, llamados nodos, que están conectados entre sí a través de una red de cómputo de alta velocidad. El nodo controlador o de gestión, que controla y realiza el servicio de limpieza en el clúster y muchas veces constituye el nodo de inicio de sesión para los usuarios, se conoce como nodo maestro; los nodos restantes se denominan esclavos. [1].
(13) INTRODUCCIÓN. 2. Cada nodo del clúster tiene componentes de hardware y de software. El hardware está compuesto por procesadores, memoria, interfaz de red, discos duros, entre otros. En cuanto al software, se define un nivel bajo que corresponde al sistema operativo, un nivel medio que consiste en las librerías de paralelización y un nivel alto, que representa la aplicación que se desea ejecutar en el clúster. La red de comunicaciones entre los nodos juega un papel muy importante en la eficiencia del equipo. Se debe considerar el gran volumen de datos y la velocidad con la que son requeridos, por lo que se necesitan conmutadores especializados. Además, de ellos depende garantizar capacidad de memoria intermedia para evitar congestionamiento y pérdida de datos, así como un bajo tiempo de latencia, es decir, tiempo de espera al enviar datos de un nodo a otro. Una aplicación o programa diseñado para clústeres se ejecutan en el nodo maestro; el sistema operativo y la librería de paralelización se encargan de hacer copias de este programa en los nodos esclavos del clúster. Todas estas instancias de la aplicación se ejecutan en paralelo y trabajan en conjunto al enviar datos para colaborar en el cálculo de la solución final. [1] En la actualidad, los administradores de los sistemas HPC invierten mucho tiempo y esfuerzo en la instalación y administración de aplicaciones para cálculo científico. Una práctica bien establecida consiste en proporcionar módulos de entorno para facilitar a los usuarios la preparación de su entorno de trabajo. Sin embargo, durante este proceso, tanto administradores como usuarios se enfrentan a varios problemas: la carencia de herramientas adecuadas para administrar paquetes de aplicaciones para cálculo científico de una manera fácil y consistente, que obstaculiza el trabajo al personal de soporte técnico; y las dificultades que enfrentan los usuarios para establecer su entorno de trabajo correctamente. En los clústeres de alto rendimiento, hoy en día, para dar solución a dichos problemas se utiliza una amplia variedad de métodos y herramientas durante la instalación de aplicaciones para cálculo científico, entre ellos se encuentran: Instalación manual: se instalan paquetes de programas siempre que se dispongan de guías de instalación actualizadas y suficientemente detalladas..
(14) INTRODUCCIÓN. 3. Secuencia de comandos: se utilizan colecciones de scripts para automatizar el proceso de configuración e instalación de paquetes de aplicaciones. Herramientas personalizadas: se comienza con una colección de scripts y continúa con el incremento de operaciones locales complejas para la instalación de las aplicaciones. Creación de archivos de módulo: se refiere a la tendencia de considerar archivos de módulos lo suficientemente simples como para ser creados manualmente. Gestores de paquete: proporcionan apoyo adecuado para muchos de los aspectos relacionados con la instalación de paquetes de aplicaciones para cálculo científico, los cuales incluyen actualizaciones, desinstalaciones, entre otras. Muchas de las instalaciones de sistemas HPC más grandes en el mundo utilizan estas herramientas. La Universidad Central “Marta Abreu” de Las Villas (UCLV) cuenta con un clúster de alto rendimiento para el cálculo científico y simulaciones que demanden alto costo de procesamiento. La gestión de paquetes se realiza mediante la herramienta Puppet y para la configuración de las variables de entorno se emplea module. Aunque esta solución contribuye al despliegue masivo de nuevas aplicaciones, las mismas deben ser desplegadas por los administradores del sistema. Esta práctica, que depende totalmente de la gestión de los administradores, puede traer consigo una carga excesiva de trabajo debido a las características que presentan las aplicaciones que demandan los usuarios. La situación mencionada conduce a la siguiente pregunta: ¿Qué herramientas pueden contribuir al despliegue de aplicaciones para cálculo científico en el clúster de alto rendimiento de la Universidad Central “Marta Abreu” de Las Villas? Para darle respuesta a la misma, es necesario tener en cuenta: ¿Cuáles son las herramientas existentes para facilitar el despliegue de aplicaciones de cálculo científico? ¿Qué beneficios presentan EasyBuild y Lmod para mejorar el entorno de trabajo de los usuarios y de los administradores de los clústeres?.
(15) INTRODUCCIÓN. 4. ¿Cuáles son las características de EasyBuild y Lmod que permiten obtener mayor. eficiencia en el despliegue de aplicaciones para cálculo científico en los clústeres de alto rendimiento? ¿De qué forma EasyBuild contribuye al aprovechamiento del ancho de banda durante la descarga masiva de paquetes fuentes para las aplicaciones del clúster de alto rendimiento? Por tales motivos, el objetivo general del presente trabajo es: “Desarrollar un procedimiento para la compilación eficiente de aplicaciones para cálculo científico, mediante la implementación de EasyBuild y Lmod, en el clúster de alto rendimiento de la Universidad Central “Marta Abreu” de Las Villas”. Del mismo se derivan los objetivos específicos siguientes: Analizar las implementaciones existentes para aplicaciones de cálculo científico. Describir las ventajas de las herramientas EasyBuild y Lmod, para mejorar la experiencia del usuario y la eficiencia del personal de soporte técnico. Implementar EasyBuild y Lmod en el clúster de alto rendimiento de la institución. Evaluar el desempeño de la herramienta EasyBuild a través de su contribución al aprovechamiento del ancho de banda, mediante la creación de un repositorio de paquetes fuentes de las aplicaciones de cálculo científico que esté disponible para todos los usuarios del clúster. Organización del informe El informe está estructurado de la siguiente forma: introducción, capitulario, conclusiones, recomendaciones, referencias bibliográficas, glosario de términos y anexos. A continuación se resume brevemente el contenido de los capítulos. Capítulo 1: Métodos y herramientas para aplicaciones de cálculo científico. Se dedica a la caracterización de cinco herramientas que se utilizan en el proceso de administración e instalación de aplicaciones para cálculo científico en sistemas HPC. Se explica de cada una de ellas, las principales características, objetivos, antecedentes, proceso de instalación, metas futuras, entre otras temáticas..
(16) INTRODUCCIÓN. 5. Capítulo 2: Metodología de instalación y administración de EasyBuild. Se describe de manera general la herramienta EasyBuild, para ello se tienen en cuenta conceptos generales como easyblock, toolchains, archivos easyconfig, entre otros; además se tratan los requerimientos de software que posee la misma así como los posibles entornos de trabajo. Se tratan también los pasos para su instalación, entre ellos la instalación de Lua, Tcl, Lmod y finalmente EasyBuild. Se mencionan las principales vías para su configuración, así como los comandos más utilizados. Capítulo 3: Integración con sistemas HPC Se dedica al análisis de los resultados. Se muestra un script de instalación que permite automatizar todo el proceso de instalación de EasyBuild. Además, se explica cómo configurar las variables de entorno, tanto en el administrador del clúster como en los usuarios para integrar EasyBuild en sistemas HPC. Por otra parte, se expone cómo contribuir al aprovechamiento del ancho de banda ante la descarga masiva de paquetes fuentes de aplicaciones. Se muestran también algunas configuraciones útiles como las actualizaciones de EasyBuild y los resultados obtenidos en el clúster de la UCLV, a partir de su instalación..
(17) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 6. CIENTÍFICO. CAPÍTULO 1.. MÉTODOS Y HERRAMIENTAS PARA. APLICACIONES DE CÁLCULO CIENTÍFICO. Los administradores de los clústeres de alto rendimiento en todo el mundo se encuentran a diario con diversos inconvenientes a la hora de enfrentarse a las aplicaciones para cálculo científico. Surge entonces la necesidad de herramientas adecuadas que permitan administrar estas aplicaciones de una manera más sencilla y estable. El presente capítulo trata diversas herramientas y métodos que se utilizan en el proceso de administración e instalación de aplicaciones para cálculo científico en sistemas HPC. Se explican de forma abreviada las principales características de las cinco herramientas que se presentan, así como los antecedentes y objetivos que persigue cada una de ellas. Los principales comandos, el proceso de instalación, las metas futuras y conclusiones parciales son otros de los contenidos que se discuten a lo largo del capítulo. 1.1. SWTools. Software Tools (SWTools) es una herramienta basada en código Python combinado con una jerarquía de directorio y reglas para crear una infraestructura para la administración de software. A partir de enero de 2008, la infraestructura SWTools comenzó a desarrollarse de forma activa [2] en el Centro Nacional de Ciencias de la Computación (NCCS) y el Laboratorio Nacional de Oak Ridge (ORNL) [3]. El nuevo diseño, que se crea para ayudar a administrar instalaciones de software de terceros en diversos centros de cálculo, incorpora la automatización de las nuevas instalaciones de software y pruebas en los ya existentes. SWTools permite mantener dichas instalaciones en un entorno estable, consistente y actualizado, mientras que se trata de evitar y reparar problemas encontrados con los repositorios de software anteriores. [4].
(18) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 7. CIENTÍFICO. 1.1.1 Antecedentes. Objetivos perseguidos Antes del despliegue de SWTools, el NCCS utilizaba un sistema de archivos llamado /apps, que es un directorio montado en NFS. En /apps se han instalado todas las bibliotecas, herramientas y aplicaciones para todos los sistemas, sin embargo, existían problemas que obstaculizaban la utilidad a largo plazo del directorio /apps, entre ellos: la carencia de un flujo de trabajo estandarizado para las instalaciones de software y de datos de información para las aplicaciones ya instaladas. La falta de un flujo de trabajo estandarizado llevó a la inconsistencia en el nombramiento y en la estructura de directorios, lo que hace que sea difícil para los usuarios utilizar los sistemas. Este inconveniente trajo consigo que tareas tales como los inventarios y las actualizaciones, necesiten mayor personal para atenderlas y al igual que la documentación de apoyo al usuario, están en riesgo de quedar desactualizadas rápidamente. Además de problemas de organización, también existía una falta de documentación para el software instalado. Aunque el mismo es aún utilizable, las actualizaciones para futuras versiones, a menudo requieren un esfuerzo significativo para descubrir el compilador adecuado y desarrollar sus opciones. Otra de las dificultades encontradas es que no existían mecanismos automatizados para la recopilación de información. Esto da lugar a un trabajo adicional debido a que los instaladores y el personal que elabora la documentación para los usuarios son a menudo diferentes personas, lo cual trae consigo que sea aún más difícil mantener la documentación y los inventarios actualizados. [2] Basado en las experiencias anteriores, el principal objetivo del nuevo diseño es tener un sistema que sea fuertemente jerárquico, con reglas de nomenclatura, instalación y documentación que permitan ejecutar todo el proceso de forma automatizada. Inicialmente se deseaba ser capaces de construir, vincular o probar cualquier aplicación instalada en cualquier sistema, en cualquier momento. Uno de los inconvenientes encontrados es que todos los instaladores y administradores de software se enfrentaban a problemas con las actualizaciones, ya sean del compilador, del sistema operativo o actualizaciones de las aplicaciones. Cada vez que uno de estos eventos ocurría, se generaba una gran cantidad de trabajo, pues una vez instalada la actualización, todas las aplicaciones que dependen de ella deben ser reevaluadas..
(19) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 8. CIENTÍFICO. De igual manera, con SWTools se perseguía como objetivo automatizar la recogida de datos de información tanto como fuese posible. En el nuevo sistema, toda la documentación es escrita por los instaladores de las aplicaciones, lo cual, en teoría, mantiene la documentación lo más actualizada posible. Además, el inventario y documentación del usuario se mantienen actualizados de forma dinámica. El equipo de administración de software principal debe ser en última instancia, responsable de asegurarse que todas las aplicaciones y los paquetes se ajusten a las normas que han sido establecidas y que toda la información que se presenta sea de alta calidad. 1.1.2 Implementaciones Estructura de directorios En el diseño de la estructura de directorios para el sistema de gestión de software, se elige una estructura jerárquica en niveles, con documentación individual e instalaciones de software. en. cada. máquina,. para. lo. que. se. sigue. la. estructura:. <root>/<machine>/<application>/<version>/<build>. En la raíz del sistema se crea una única carpeta para cada máquina. Se establece un compromiso en relación con el tema de las carpetas para las máquinas que son casi idénticas en el uso y el hardware. Esto constituye un intento de encontrar la solución que equilibre la duplicación del trabajo y el riesgo de incompatibilidad entre todas las máquinas. Dentro de cada directorio en el “nivel máquina”, hay una carpeta para cada aplicación. Además, se tiene un directorio llamado “archivos de módulo” que también se encuentra en este nivel, el mismo se utiliza para almacenar módulos para cada pieza de software instalado. Cada archivo de módulo contiene la información necesaria para configurar una aplicación. Una vez que se ha inicializado el paquete de módulos, el entorno puede ser modificado en función de cada módulo mediante el comando “module” que interpreta los archivos de módulo. Los mismos pueden ser compartidos por muchos usuarios en un sistema y los usuarios pueden tener su propia colección para complementar o sustituir los archivos de módulo compartidos. [5].
(20) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 9. CIENTÍFICO. En el “nivel máquina” se utiliza una estructura de directorios con nombres genéricos inespecíficos para la versión. Sin embargo, dentro de cada carpeta de la aplicación, hay una carpeta para cada versión del software. Cada carpeta de la versión se nombra mediante el número de versión y se crea una carpeta para cada compilación del software dentro del directorio de versión. Estos directorios de construcción se denominan a través del formato de nombre: Sistema operativo_compilador [opciones]. Por ejemplo, una construcción en Jaguar puede llamarse “sles9.2_pgi7.0.7_i8”. La primera abreviatura es para el sistema operativo, en este caso Suse Linux Enterprise Server 9.2. La segunda abreviatura corresponde al compilador, que en este caso es el grupo de compiladores “Portland Group Incorporated”. La última abreviatura, i8, significa que esta construcción se ha elaborado para soportar enteros de ocho bytes. [2] Archivos utilizados por SWTools El primer nivel en el que se producen archivos para almacenar información y automatizar tareas es en el “nivel aplicación”. Cada carpeta de la aplicación contiene una carpeta para cada versión de la aplicación instalada en la máquina. Dentro de este nivel existen cuatro archivos utilizados por las herramientas de software [2]: 1. El archivo .check4newver 2. El archivo description 3. El archivo support 4. El archivo versions En el “nivel versión” no hay archivos especiales usados por SWTools. Es simplemente una carpeta para cada generación presente dentro de la carpeta de la versión. Por otra parte, en el nivel de construcción existen siete archivos separados que son utilizados por SWTools: rebuild, relink, retest, .owners, status, build-notes y dependencies [2]. Excepciones El archivo .exceptions juega un papel clave en la herramienta SWTools, y se puede colocar dentro de una aplicación o carpeta de la versión. Con este archivo se utilizan tres palabras clave: controlled, noweb y vendor..
(21) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 10. CIENTÍFICO. La primera implica que esta aplicación o la versión del software no están abiertas a un usuario general del sistema. Así, cuando se realizan grandes operaciones, a menos que la persona que ejecuta el trabajo sea miembro de todos los grupos controlados, no será capaz de realizar acciones en algunos archivos. La palabra clave noweb implica que esta aplicación o la versión no deben aparecer en el sitio web. Por otra parte, las versiones o aplicaciones que están marcados como vendor, solo aparecen en el sitio web y son ignorados por todos los demás aspectos de la infraestructura SWTools. 1.1.3 Secuencia de comandos Python fue elegido como el primer lenguaje para el sistema, aunque se utilizan muchos scripts de consola en el producto final. A continuación se presentan una serie de scripts que utiliza SWTools [2]: swaddpackage y swaddbuild: Estos dos scripts facilitan el proceso de instalación de nuevas aplicaciones. Una función importante que cumplen es establecer correctamente los permisos. Todos los archivos gestionados por el personal de SWTools necesitan permisos de escritura en grupo. swbuild, swlink y swtest: Realizan la reconstrucción de secuencias de comandos y luego vuelven a enlazar y probar las mismas. swversion: Es utilizado para actualizar de forma proactiva tantas aplicaciones como sea posible. swduplicate: Está diseñado para automatizar las actualizaciones. swreport: Todas las funciones de informe de SWTools se encapsulan dentro de swreport. Actualmente, swreport es compatible con tres modos de funcionamiento: conform, html y text. 1.1.4 Metas futuras Aunque el sistema se diseña para sistemas HPC, todavía es un desafío hacer frente a las numerosas excepciones que se encuentran en las arquitecturas de sistemas extremadamente complejos que están presentes en los centros HPC. Aplicaciones sensibles, proveedor de aplicaciones, y sistemas de archivos especiales son solo algunos de los retos presentes en el diseño de este sistema. La principal característica que le falta a SWTools es la capacidad de.
(22) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 11. CIENTÍFICO. resolver las dependencias de aplicación cuando se realiza la reconstrucción de un gran número de aplicaciones. El trabajo futuro pudiese estar orientado a construir un gráfico acíclico de dependencias de aplicaciones y luego generar una lista ordenada de aplicaciones. [2] Por otra parte, SWTools anuncia soporte para SAP Business One y asegura que todas las normas de seguridad serán manejadas por este. [6] 1.1.5 Conclusiones De manera general, SWTools ayuda a gestionar las instalaciones de software de terceros, proporciona una infraestructura de prueba, utiliza una jerarquía estructurada, ayuda a garantizar un entorno consistente y estable en las instalaciones a través de paquetes, comprueba la conformidad con las normas establecidas y crea páginas web que contribuye a la documentación actualizada. Estas ventajas hacen que el manejo de software de terceros sea más eficiente. [4] Este proyecto se inicia con un modelo relativamente simplista para la gestión de software, sin embargo, se propusieron modificaciones cuando se encontraron problemas. [2] Solo una de las versiones está disponible públicamente, SWTools versión 1.0, el cual fue lanzado el primero de enero de 2011. [4] 1.2. Smithy. Smithy es una herramienta de compilación e instalación de software, desarrollada también en el NCCS y ORNL [7] y toma las ideas en gran medida del sistema de gestión de paquetes Homebrew para Mac OS X y de su antecesor SWTools. Está diseñado para administrar diversos software y se construye dentro de un entorno HPC en GNU/Linux, donde se utilizan archivos de módulo para cargar software en la consola de un usuario. [8] 1.2.1 Objetivos perseguidos A partir de los errores e inconvenientes presentados por SWTools, mencionados en el epígrafe anterior, Smithy tiene como objetivo hacer una variante de SWTools más fácil y.
(23) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 12. CIENTÍFICO. menos propensa a errores, por lo que es superior, pues proporciona una interfaz de línea de comandos simple, donde se generan y administran archivos de módulo. [7] 1.2.2 Métodos para la instalación de software Existen dos formas para la instalación de software: mediante scripts de creación y mediante fórmulas de instalación.[9] El problema que se encuentra con los scripts de creación es que se duplican para cada instalación del software. Esto puede hacer que la instalación del nuevo software sea tediosa ya que se tienen que observar los scripts de creación existentes y copiar los pasos relevantes para la creación del nuevo script. También puede conducir a que futuras instalaciones sean difíciles de reproducir y mantener. Por otra parte, el objetivo de las fórmulas de instalación en Smithy es construir un paquete de software en cualquier sistema en un solo archivo. Esto elimina el problema de los scripts de creación duplicados y la pérdida de pasos relevantes en la creación de los nuevos scripts. Las fórmulas pueden incluir: dependencias que definen la carga de módulos, establecimiento de las variables de entorno, aplicación de parches, creación o modificación de Makefiles, ejecución de la compilación, ejecución de pruebas y definición de un archivo de módulo. Las fórmulas están escritas en Ruby y pueden ser tan flexibles y dinámicas como se desee. [7] 1.2.3 Nomenclatura del software Todos los software deben tener el siguiente formato de nombre: aplicación / versión / construcción, es decir, tres partes diferentes separadas por barras diagonales: Aplicación: se refiere al nombre con caracteres en minúsculas. Versión: describe la versión de la aplicación, aunque se recomienda que la misma esté ordenada de la más antigua a la más reciente. Construcción: consiste en el sistema operativo previsto y el compilador, separados por guiones. Es importante utilizar los números de versión del compilador que corresponden a la versión del módulo. La estructura debe ser como en el ejemplo siguiente: sles11.1_gnu4.6.2 corresponde a SuSE Linux Enterprise Server 11.1 y el compilador GNU gcc 4.6.2..
(24) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 13. CIENTÍFICO. 1.2.4 Proceso de instalación Instalación mediante scripts de creación A continuación se muestra el flujo de trabajo típico para añadir una nueva compilación de software a través de scripts de creación. Por ejemplo, se desea instalar petsc 3.2 y para ello se utiliza el compilador Cray, de acuerdo a los siguientes pasos [9]: 1. Creación de la construcción Se va a usar petsc/3.2/cle4.0_cray8.0.1 como el nombre del nuevo paquete, a partir de las reglas de nomenclatura del software mencionadas anteriormente. Este nombre significa que petsc está diseñado para ejecutarse en un nodo de cómputo cle4.0 y se utiliza como compilador el Cray CCE 8.0.1. Se puede facilitar el trabajo y optimizar el tiempo si se informa donde se encuentra el archivo fuente tar para petsc. Esto se realiza al ejecutar: $ smithy new petsc/3.2/cle4.0_cray8.0.1. $ smithy new -t petsc-3.2-p7.tar.gz petsc/3.2/cle4.0_cray8.0.1.. La opción -t, permite extraer el archivo del directorio fuente y también se puede descargar un archivo desde una URL determinada. 2. Edición y Creación del software Una vez creada la construcción puede que tanto esta como los módulos de entorno tengan que ser actualizados (rebuild y remodule) antes de la creación del software. Ambos archivos se encuentran dentro del prefijo de software. Para el ejemplo mostrado, los archivos se encuentran en /sw/xk6/petsc/3.2/cle4.0_cray8.0.1. Este y cualquier otro archivo relacionado se puede editar mediante el comando “edit”: $ smithy edit build petsc/3.2/cle4.0_cray8.0.1. Una vez que se haya editado el archivo, se procede a construir mediante la ejecución de “smithy build last”. Los resultados de la ejecución se muestran en la pantalla y al mismo tiempo se registran en build.log dentro de la carpeta de prefijo del software. 3. Crear y editar un archivo de módulo Este paso se realiza después que se han creado todas las construcciones para una aplicación en particular. Cuando se crea una nueva versión del software se crea también un nuevo.
(25) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 14. CIENTÍFICO. archivo. de. módulo.. Para. el. petsc. instalado,. la. localización. es. en:. /sw/xk6/petsc/3.2/modulefile. Smithy establece lo que debe contener el archivo de módulo. Para asegurarse que el archivo de módulo está actualizado en cada construcción, se puede verificar con el comando: $ smithy module create last. Luego se añaden las variables relevantes para la aplicación. A continuación, se debe realizar una prueba para asegurar que para cada construcción, las variables de entorno se cargan correctamente y que no hay errores. Para añadir el archivo de módulos a $MODULEPATH se utiliza: $ smithy module use last. Una vez que el archivo de módulo está listo, puede copiarse mediante el comando: $ smithy module deploy last. 4. Descripción del sitio web. Si se trata de una nueva aplicación, se tiene que añadir información para el archivo de descripción. Para este ejemplo, petsc se encuentra en: /sw/xk6/petsc/description. Este es un archivo. con. formato. HTML.. Alternativamente,. se. puede. encontrar. en. /sw/xk6/petsc/description.markdown. Si el archivo de descripción falta, se puede generar uno al ejecutarse: “smithy repair last”. Para publicar en la página web se debe ejecutar: “smithy publish petsc”. Instalación mediante fórmulas A continuación se muestra cómo instalar el software cuando se utilizan las fórmulas existentes. Para ello, en Smithy existen los siguientes subcomandos [9]: new: crea una nueva fórmula. list: muestra listas de fórmulas conocidas. which: muestra la ubicación de una fórmula. display: muestra una fórmula. install: instala un paquete por medio de una fórmula. create_modulefile: crea un archivo de módulo para un paquete dado..
(26) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 15. CIENTÍFICO. Una vez que se ha escrito una fórmula, el proceso de instalación es sencillo con la utilización del comando “install”. Por ejemplo, para instalar la raíz de su software bajo el directorio subversion/1.7.8/sles11.1_gnu4.3.4, se debe ejecutar: $ smithy formula install subversion/1.7.8/sles11.1_gnu4.3.4.. El formato de instalación para los subcomandos es: smithy formula install [opciones de comando] APLICACIÓN | APLICACIÓN/VERSIÓN | APLICACIÓN/VERSIÓN/CONSTRUCCIÓN Las opciones de comando incluyen: --[no-]clean: elimina todos los archivos existentes en el directorio de destino antes de realizar la instalación. --formula-name: por defecto, Smithy establece el nombre de la fórmula basado en el directorio de destino, APLICACIÓN/VERSIÓN/CONSTRUCCIÓN. Sin embargo, es posible que se desee instalar en un lugar llamado de manera diferente; en este caso, se utiliza -formula-name para definir cuál es la fórmula a usar. Por otra parte, el directorio de destino que se va a instalar es: APLICACIÓN | APILACIÓN/VERSIÓN | APLICACIÓN/VERSIÓN/CONSTRUCCIÓN. Si se omiten los directorios CONSTRUCCIÓN o VERSIÓN/CONSTRUCCIÓN, Smithy define la versión en base a la fórmula, la construcción en base al sistema operativo y la versión de gcc disponible. En caso de duda, se debe especificar el destino completo. Una vez que ya está instalada la subversión con el comando anterior y la raíz del software es /sw/xk6/, la estructura de directorios se define como en la figura 1.2.1.. Figura 1.2.1 Estructura de directorios para la raíz del software /sw/xk6. [9].
(27) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 16. CIENTÍFICO. La carpeta de los archivos de módulo se crea junto al directorio sles11.1_gnu4.3.4 como se muestra en la figura 1.2.1, de manera que el archivo de módulo pueda ser probado. Para probar un archivo de módulo es necesario agregar a la carpeta de archivos de módulo la variable de entorno $MODULEPATH. Luego se pueden ejecutar los siguientes comandos: $ smithy module use last $ smithy module use subversion/1.7.8/sles11.1_gnu4.3.4 $ module use /sw/xk6/subversion/1.7.8/modulefile/subversion. Se utiliza “last” como un alias de la última compilación del software y el comando “smithy show last” muestra la última construcción en la que se ha trabajado. Una vez cargado, debe ser capaz de interactuar con el nuevo archivo de módulo al ejecutarse: $ module avail subversion/1.7.8 $ module display subversion/1.7.8 $ module load subversion/1.7.8. Por último, se procede a implementar el módulo para que esté disponible para otros usuarios. Esto debe hacerse una vez que se asegure que el archivo de módulo funciona correctamente. Para hacerlo funcionar, se ejecuta: $ smithy module deploy last smithy module deploy subversion/1.7.8/sles11.. 1.2.5 Archivos de configuración La mayoría de las opciones especificadas en un archivo de configuración pueden ser cambiadas con opciones de línea de comandos globales. Entre ellos se encuentran [9]: software-root: Se utiliza para dar ubicación a los directorios. file-group-name: Define el nombre del grupo utilizado para la instalación del software. hostname-architectures: Puntualiza los nombres que están en los directorios. download-cache: Este directorio se utiliza cuando se descargan archivos de software a través de fórmulas o a través de “smithy new --tarfile=opción”. formula-directories: Especifica los directorios donde se almacenan las fórmulas. global-error-log: Este archivo registra los errores internos encontrados..
(28) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 17. CIENTÍFICO. descriptions-root: Cambia la forma de manejar los archivos de descripción. compilers: Esta opción le permite anular la definición del compilador para crear archivos de módulo. Igualmente, cualquier comando o subcomando en Smithy puede tener el prefijo “help” para mostrar todas las opciones y argumentos relevantes [7]. El formato a seguir es “smithy help COMANDO” o “smithy help COMANDO SUBCOMANDO” [9]. También existen líneas de comandos para la implementación de las etiquetas bash y zsh. 1.2.6 Conclusiones De manera general, Smithy soluciona muchos de los inconvenientes presentados por SWTools, mediante el uso de las fórmulas como método de instalación de software. El NCCS utiliza github.com para almacenar un repositorio con todas sus fórmulas, lo cual permite un fácil intercambio de las mismas y la colaboración con la comunidad de HPC. Nuevas fórmulas o cambio de las existentes se pueden enviar como sugerencias entre los centros HPC. [7] Sin embargo, la actividad de desarrollo se ha ralentizado significativamente desde septiembre de 2013, con cambios ocasionales, que en su mayoría se centran en correcciones de fallos. Las fórmulas de Smithy están disponibles para aproximadamente 80 paquetes de software. [3] El equipo de soporte técnico de NCCS ha escrito más de 150 fórmulas que apoyan tanto al Cray como a los sistemas tradicionales de clústeres. Se espera que otros centros utilicen Smithy y puedan contribuir con sus propias fórmulas. [7] 1.3. IVEC Build System. La herramienta IVEC Build System (IBS), posteriormente conocida como Maali, fue desarrollada en el Centro de Computación de Pawsey y cofinanciado por el gobiernos de Australia Occidental, el CSIRO y cuatro universidades en el año 2012 [10] para soportar los sistemas de clústeres Epic (funciona desde mediados del 2011) y Fornax (funciona desde el inicio del 2012) [11]. Es un sistema automatizado de peso ligero para administrar un conjunto diverso de bibliotecas y aplicaciones científicas optimizadas en sistemas HPC..
(29) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 18. CIENTÍFICO. IBS o Maali es un conjunto de secuencias de comandos bash que están diseñados para permitir la automatización del proceso de autoconfiguración (autoconf), comúnmente utilizado por muchas aplicaciones HPC. Maali trabaja a partir de un conjunto de archivos de configuración a nivel de sistema que define un grupo de variables de entorno por defecto, lo cual controla varios aspectos de la instalación. [12] Existe un archivo de Maali para cada aplicación, entre otras cosas, para definir el entorno de programación Cray que debe ser utilizado. Esto significa, por lo general, seleccionar los entornos de programación PrgEnv-Cray, PrgEnv-Intel o PrgEnv-GNU [13]. Maali captura los módulos de entorno dependientes, así como las banderas de configuración y las optimizaciones del compilador que se seleccionan y utilizan para generar la aplicación. También captura los archivos de registro de las salidas de configuración y compilación útiles como referencia y para la depuración. Recientemente, Maali se ha modificado para manejar construcciones en CMake y Python. [12] 1.3.1 Antecedentes. Objetivos perseguidos El Centro de Computación de Pawsey identificó la necesidad de tener un enfoque sistemático para mantener software de aplicación. El trabajo inicial sobre Fornax permitió entender y perfeccionar el proceso de instalación del software y luego, al hacer uso de IBS, se hizo posible la reconstrucción de todo el software, tanto en Epic como Fornax. Originalmente el software se instaló en Epic, pero a pesar de cumplir con los requisitos de los investigadores, tenía varias deficiencias importantes: El proceso de compilación se realiza por cada compilador y se combinan bibliotecas de Interfaz de Paso de Mensaje (MPI). La falta de documentación sobre la compilación del software. Módulos de entorno en un directorio plano. El trabajo realizado no es respaldado. Además, todavía se necesitaba crear un archivo de módulo de entorno para cada aplicación, por lo que fue preciso ejecutar manualmente los scripts de creación para cada combinación de compilador y biblioteca MPI. Los resultados obtenidos, condujeron directamente al.
(30) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 19. CIENTÍFICO. desarrollo de IBS por David Schibeci. Posteriormente, IBS ha sido objeto de numerosas mejoras y se le han añadido funcionalidades, para llegar a su forma actual como Maali. 1.3.2 Proceso de automatización y creación de módulos de entorno Para proporcionar la flexibilidad necesaria para manejar múltiples sistemas Maali, se utiliza un script de configuración del sistema que define los valores de un par de claves. El mismo proporciona definiciones para las tareas básicas que se tratan de automatizar, aunque no se proponen definiciones para la documentación del procedimiento. A continuación se describe lo que hace Maali para cada una de estas tareas básicas [12]: 1. Descargar y descomprimir el software Maali usa para la descarga GNU Wget [14] y el script de creación establece la variable del par de claves MAALI_URL a la URL correcta para la aplicación que se desea instalar. La secuencia de comandos Maali es capaz de resolver la mayoría de los formatos de compresión (por ejemplo .bz2, .tgz, .xz). 2. Proceso de compilación e instalación La característica principal de Maali es que automatiza los proceso de configuración y compilación (configure, make y make install), desde el marco de trabajo de GNU Autotools cuyos componentes son GNU Autoconf [15], GNU Automake [16] y GNU Libtool [17]. El propósito de estas herramientas es facilitar a los usuarios la compilación los paquetes, lo cual implica que el software sea más portable. Se necesita aumentar la automatización en la instalación del software, por tanto, en el archivo MAALI_CONFIG se define MAALI_DEFAULT_ COMPILERS, que es una lista simple, Maali itera sobre esta lista y puede crear varias versiones de un solo comando. Los mismos se instalan en el directorio /apps, que es un subdirectorio del MAALI_ROOT. Los nombres del compilador han sido definidos en el archivo MAALI_CONFIG y las variables de entorno del sistema CRAYOS_VERSION se establecen en PrgEnv. 3. Creación de módulos de entorno La creación de archivo de módulos permite la fijación de un árbol de una estructura simple para la ruta de instalación del software, tal como se muestra en la Figura 1.3.1..
(31) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 20. CIENTÍFICO. Figura 1.3.1 Estructura en árbol de las aplicaciones. [12]. Existe un solo archivo de módulo por cada solicitud, independientemente del número de compiladores diferentes. Los archivos de módulo de entorno son plantillas utilizadas para modificar dinámicamente el entorno, es decir, agregar o quitar paquetes de las variables del sistema. Existen un número manejable de pares de claves Maali, necesarias para establecer correctamente el entorno de la mayoría de las aplicaciones o bibliotecas. Secuencia de comandos en Maali El comando maali utiliza un mínimo de tres argumentos, el primero es el nombre del paquete que se desea instalar, el segundo argumento es el número de versión de la aplicación y el tercero es el nombre del archivo de configuración del sistema “maali -t MAALI_TOOL_NAME”, “-v MAALI_TOOL_VERSION”, -c “MAALI_CONFIG”, por ejemplo, para instalar zlib-1.2.7 en el sistema Cray XC40 del Centro de Computación de Pawsey, Magnus, el comando que se utiliza es: $ maali -t -v zlib 1.2.7 -c magnus. A continuación se muestra una lista completa de las opciones del comando maali: -h: muestra mensaje. -t: nombre de la herramienta. -v: versión de la herramienta. -c: archivo de configuración de maali. -d: ejecutar en modo debug. -m: crear un archive de módulo..
(32) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 21. CIENTÍFICO. -l: utilizar las opciones de la última ejecución. -r: construir con un compilador específico. -b: construir la herramienta pero no crear un archivo de módulo. 1.3.3 Beneficios y metas futuras El número de paquetes que construyen las secuencias de comandos en el proceso de instalación sobrepasan los 380. El gran número de aplicaciones es buen indicador de cuán fácil es de utilizar Maali. El siguiente hito en su desarrollo es convertirlo en un proyecto de código abierto y construir una comunidad de usuarios alrededor de esta herramienta. Esto requiere de documentación de usuario mejorada y el desarrollo de un esquema de pruebas rigurosas. Otras áreas de trabajo futuro son [12]: Archivos de módulo prereqs. Scripts bash, utilizados para construir software, con varios compiladores y otras dependencias de módulo. [18] Pruebas de regresión de scripts de creación. Creación de páginas wiki. 1.3.4 Conclusiones Realizar cambios en un sistema de producción implica un cierto grado de riesgo. Sin embargo, tales cambios son necesarios para mantener la estabilidad, la seguridad y el rendimiento del sistema. Con el uso de Maali, se puede reducir la duración de la inactividad del sistema a través de un conjunto diverso de sistemas Cray XC, además de minimizar el esfuerzo del personal necesario para volver a instalar un software y controlar el impacto sobre los investigadores y sus proyectos. [12] 1.4. Spack. Supercomputing Package Manager (Spack), es un administrador de paquetes de software flexible para HPC, escrita en Python, que es similar a EasyBuild con respecto a la funcionalidad y los objetivos. Fue diseñado por científicos del Laboratorio Nacional Lawrence Livermore (LLNL). Spack opera en una amplia variedad de plataformas y.
(33) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 22. CIENTÍFICO. entornos HPC y permite que cualquier número de generaciones coexistan pacíficamente en el mismo sistema. [19] Spack proporciona una interfaz de línea de comandos de gran alcance y bien documentado que a su vez permite un control sobre las dependencias, las versiones de software, el compilador y la arquitectura, las cuales se deben utilizar para la instalación de un paquete de software en particular. También es compatible con algunas opciones particularmente útiles, como determinar automáticamente si una actualización para un paquete de software en particular está disponible, así se completan de forma automática especificaciones incompletas. [3] 1.4.1 Antecedentes. Objetivos perseguidos El software de simulación que se ejecutaba en las máquinas del LLNL era muy complejo; algunos códigos dependían de versiones específicas de más de 70 bibliotecas de dependencia. Además, requerían compiladores específicos e implementaciones de bibliotecas MPI para lograr un mejor rendimiento y que los usuarios pudiesen ejecutar varios códigos diferentes en el mismo entorno como parte de flujos de trabajos científicos más complejos. Desafortunadamente, la construcción de software científicos es un proceso notoriamente complejo, con sistemas de construcción inmaduras, difíciles de adaptar a las máquinas existentes. Spack tiene como objetivos, la administración eficiente de software científicos complejos, además de apoyar la composición rápida de configuraciones de paquetes, la gestión de las instalaciones en Python y las políticas de construcción específicas de una instalación. A pesar de estas complejidades, el algoritmo de concretización de Spack para la gestión de las restricciones se ejecuta en cuestión de segundos, incluso para grandes paquetes. Spack fue diseñado para resolver los problemas de software que son omnipresentes en los centros HPC, grandes multinacionales y las experiencias adquiridas son relevantes para toda la gama de instalaciones de HPC. 1.4.2 Características generales de Spack Al igual que los sistemas anteriores, Spack es compatible con un número arbitrario de instalaciones de software y, a diferencia de cualquier sistema anterior, proporciona un.
(34) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 23. CIENTÍFICO. lenguaje conciso para especificar y administrar el espacio de configuraciones de software en sistemas HPC. [20] Spack está diseñado para: los usuarios, los cuales necesitan instalar el software sin conocer todos los detalles sobre cómo se construye; los administradores de paquetes, que saben cómo un paquete de software en particular se construyen y codifican esta información en los archivos del paquete; y por último los desarrolladores que trabajan en Spack, que añaden nuevas características, y tratar de hacer el trabajo de los administradores de paquetes y los usuarios más fáciles. [21] Además Spack ofrece las características únicas siguientes: 1. Parametriza explícitamente la versión, plataforma, compilador, las opciones y dependencias. 2. Provee sintaxis de especificación recursiva para gráficos de dependencia y restricciones que ayudan en la administración del espacio de parámetros de construcción. 3. Brinda dependencias versionadas virtuales para manejar interfaces incompatibles. 4. Facilita un procedimiento de concretización moderno que traduce una especificación de construcción abstracta en una especificación de construcción concreta. 5. Proporciona una construcción de entorno que utiliza contenedores de compilador para hacer cumplir la consistencia de construcción y simplificar la escritura de paquetes. Lo anterior conlleva a dos conceptos clave en el diseño de software de Spack: las especificaciones, que son expresiones para describir la construcción del software, y los paquetes, que se encargan de construir el software de acuerdo con las especificaciones. Paquetes de Spack En Spack, los paquetes son scripts de Python que construyen mecanismos de software. El paquete implementa la mayor parte del proceso de construcción, proporciona subclases y tiene su propio método de instalación para manejar los detalles de los paquetes particulares. El implementador de paquetes debe garantizar que la función de instalación instala el paquete en el prefijo, pero Spack asegura que el prefijo se calcule de manera que sea único.
(35) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 24. CIENTÍFICO. para cada configuración de un paquete. Para simplificar aún más este proceso, se implementa un lenguaje de dominio específico incorporado (DSL). [20] Además, Spack puede ser configurado para usar los paquetes instalados externamente en lugar de construir sus propios paquetes. Esto puede ser deseable si las máquinas vienen con paquetes del sistema, tales como una biblioteca MPI personalizada que se debe utilizar en lugar de la construcción de su propia biblioteca MPI. Los paquetes externos se configuran a través de packages.yaml, archivo que se encuentra en /etc/spack/ o en el directorio del usuario ~/.spack/. [22] Especificaciones de Spack En Spack, cada archivo de paquete es una plantilla que puede ser configurado y construido de muchas maneras diferentes, de acuerdo con un conjunto de parámetros. Spack llama a una única configuración de generación, spec. Spack comunica dependencias y parámetros para empaquetar y para ello hace uso del argumento de especificación del método de instalación. Estructura Para entender las características se debe tener en cuenta la estructura del paquete mpileaks (herramienta desarrollada por LLNL). La misma cuenta con dos dependencias directas: las bibliotecas CALLPATH y MPI. Spack inspecciona de forma recursiva las definiciones de clase para cada dependencia y construye un gráfico de sus relaciones. Para garantizar una construcción constante y evitar la incompatibilidad de la interfaz binaria de aplicación (ABI), se crea el gráfico acíclico (DAG), con una sola versión de cada paquete. Por lo tanto, mientras que Spack puede instalar de forma arbitraria muchas configuraciones de cualquier paquete, no hay dos configuraciones de un mismo paquete que aparezcan en la misma construcción DAG. Los DAG para mpileaks se muestran en la Figura 1.4.1. Cada nodo representa un paquete y cada paquete tiene cinco parámetros de configuración que controlan la forma en que se construye: 1) la versión del paquete, 2) el compilador con el que se va a construir, 3) la versión del compilador, 4) opciones de llamada en tiempo de compilación de construcción y 5) la arquitectura de destino..
(36) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 25. CIENTÍFICO. (a) Especificaciones para mpileaks.. (b) [email protected].. (c) [email protected] ˆ[email protected]+debug ˆ[email protected].. Figura 1.4.1 Restricciones aplicadas a las especificaciones mpileaks.. Sintaxis para las especificaciones Se ha desarrollado una sintaxis para las especificaciones que permite a los usuarios especificar únicamente las restricciones que son importantes para ellos. La misma puede representar de forma concisa los DAG suficientes para el uso de líneas de comandos. La sintaxis de especificación se define de forma recursiva para permitir a los usuarios especificar los parámetros dependientes, así como la raíz del DAG. Las restricciones de la versión se denotan con @, como se muestra en la Figura 1.4.1. Las mismas pueden ser precisas (@ 2.5.1) o denotar un rango (@ 2,5: 4,4), o también pueden ser abiertas (@ 2,5 :). Restricciones en los paquetes El usuario no es la única fuente de restricciones. Las aplicaciones pueden requerir versiones específicas de las dependencias. Estas limitaciones deben ser especificadas en un archivo de paquete, el nombre del mismo es también una especificación y la misma sintaxis de.
(37) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 26. CIENTÍFICO. restricción es utilizable a partir de la línea de comandos y se puede aplicar dentro de las directivas. Dependencias virtuales versionadas Spack soporta dependencias virtuales para permitir una rápida composición de las bibliotecas mediante una interfaz. Una dependencia virtual es un nombre abstracto que representa una interfaz de biblioteca en lugar de una implementación de biblioteca. Otros gestores de paquetes apoyan también las dependencias virtuales, pero Spack añade versiones de sus interfaces, que apoya directamente a conceptos como las versiones MPI. Spack maneja los detalles de la administración y el control de las limitaciones de versiones complejas. 1.4.3 Proceso de concretización Antes que Spack construya una especificación, se debe garantizar que: 1. Ningún paquete en la especificación DAG carece de dependencias. 2. Ningún paquete en la especificación DAG es virtual. 3. Todos los parámetros se establecen para todos los paquetes en el DAG. Si una especificación cumple con estos criterios, entonces es concreto. Concretización es el componente central del proceso de generación de Spack que le permite reducir una descripción abstracta sin restricciones a una construcción completa. La figura 1.4.2 muestra el algoritmo de concretización de Spack. El proceso se inicia cuando un usuario invoca “spack install” y solicita que una especificación debe construirse. Spack convierte la especificación a un DAG abstracto. A continuación, construye una especificación DAG separada para todas las restricciones codificadas por las directivas en los archivos del paquete. Spack analiza las limitaciones de los paquetes DAG, y se comprueba cada parámetro para restricciones. Las mismas pueden surgir si, por ejemplo, el usuario solicita inadvertidamente dos versiones del mismo paquete, o si un archivo de paquete depende de una versión diferente que la que solicita el usuario. Del mismo modo, si el paquete y el usuario especifican diferentes compiladores, variantes, o plataformas para algunos paquetes, Spack se detiene y notifica al usuario del conflicto. Si el usuario o el paquete especifican rangos de versión, que se intersecan y los intervalos no se.
(38) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 27. CIENTÍFICO. solapan, Spack genera un error. Cuando la intersección tiene éxito, Spack tiene un solo DAG con las restricciones fusionadas del usuario y los archivos del paquete.. Figura 1.4.2. Proceso de concretización de Spack.. La siguiente parte del proceso es iterativo. Si cualquier nodo es una dependencia virtual, Spack lo sustituye por un proveedor de interfaz adecuada mediante la construcción de un índice inverso de paquetes virtuales a los proveedores. Si varios proveedores satisfacen las limitaciones de la especificación virtual, Spack consulta las políticas del sitio y del usuario para seleccionar el “mejor” posible proveedor. El proveedor seleccionado puede tener en sí dependencias virtuales, por lo que este proceso se repite hasta que el DAG no tenga más paquetes virtuales. En el caso de una dependencia no virtual, Spack consulta de nuevo el sitio y las preferencias del usuario para las variantes, compiladores y versiones para resolver cualquier problema. La concretización permite a los usuarios y al personal construir con una especificación mínima, mientras que MPICH proporciona un mecanismo para el sitio, de modo que el usuario pueda tomar decisiones consistentes y repetibles para otros parámetros de construcción. Además, reduce la carga de los paquetes de software y los mismos no necesitan tener controles complicados, o ser demasiado específico acerca de las versiones. Otros sistemas como Nix, EasyBuild, y HashDist requieren que se escriba una especificación de construcción concreta con antelación. 1.4.4 Soporte para lenguajes interpretados En Python, el mantenimiento de los repositorios ha crecido y cada vez se hace más complejo con el paso del tiempo. El problema es similar a lo que llevó a crear Spack: diferentes. equipos. configuraciones.. necesitan. diferentes. bibliotecas. de. Python. con. diferentes.
(39) CAPÍTULO 1. MÉTODOS Y HERRAMIENTAS PARA APLICACIONES DE CÁLCULO. 28. CIENTÍFICO. Existen gestores de paquetes Python que bien, no son compatibles con la construcción de la fuente como Anaconda [23] y Conda [24] o son específicos del lenguaje como setuptools [25]. Las extensiones de Python suelen instalarse en el prefijo del intérprete de Python, lo que hace imposible la instalación de múltiples versiones. Por filosofía de diseño de Spack, se requiere una forma de gestionar con facilidad muchas versiones diferentes y también proporcionar un conjunto básico de extensiones sin necesidad de configuración del entorno. Para apoyar este modo de operación se añade el concepto de paquetes de extensión en Spack. Cada módulo de Python se instala en su propio prefijo de paquete como cualquier otro y cada módulo depende de una instalación de Python en particular. Sin embargo, las extensiones pueden ser activadas o desactivadas dentro de la instalación de Python dependiente. La operación de activación vincula simbólicamente cada archivo en el prefijo de extensión con el prefijo de instalación de Python, como si estuviera instalado directamente. Si se observa un conflicto de archivo de esta operación, se activa la falla, fails. Del mismo modo, la operación de desactivación elimina los enlaces simbólicos y restaura la instalación de Python a su estado inicial. Las extensiones de Python se instalan automáticamente en sus prefijos y están compuestos por bibliotecas de efectos complejos que otros gestores de paquetes no manejan. 1.4.5 Limitaciones y metas futuras La implementación actual de Spack tiene varias limitaciones. Spack es compatible con diferentes arquitecturas como parte del espacio de configuración, sin embargo, actualmente no se pueden factorizar las preferencias comunes de paquetes y las descripciones de arquitectura separada, lo que lleva a algunos desórdenes en los archivos del paquete cuando se acumulan demasiadas condiciones. Para resolver este inconveniente se añaden características que simplifican aún más las plantillas de generación de Spack. Por otra parte, Spack requiere más espacio en disco que los sistemas basados en módulo, pues posee paquetes con diferentes dependencias que deben ser construidos por separado. La sobrecarga de espacio exacta depende de la estructura del software instalado; algunas versiones pueden compartir más bibliotecas de dependencia que otras..
Figure
![Figura 1.2.1 Estructura de directorios para la raíz del software /sw/xk6. [9]](https://thumb-us.123doks.com/thumbv2/123dok_es/7318648.451486/26.918.392.573.850.1038/figura-estructura-de-directorios-para-raíz-del-software.webp)
![Figura 1.3.1 Estructura en árbol de las aplicaciones. [12]](https://thumb-us.123doks.com/thumbv2/123dok_es/7318648.451486/31.918.316.665.111.329/figura-estructura-árbol-aplicaciones.webp)


+7
![Figura 2.1.1 Diseño por secciones de EasyBuild [27]](https://thumb-us.123doks.com/thumbv2/123dok_es/7318648.451486/43.918.265.694.390.752/figura-diseño-por-secciones-de-easybuild.webp)




Documento similar