Análisis del comportamiento de la consistencia de los datos transformados mediante funciones kernels
Texto completo
Figure



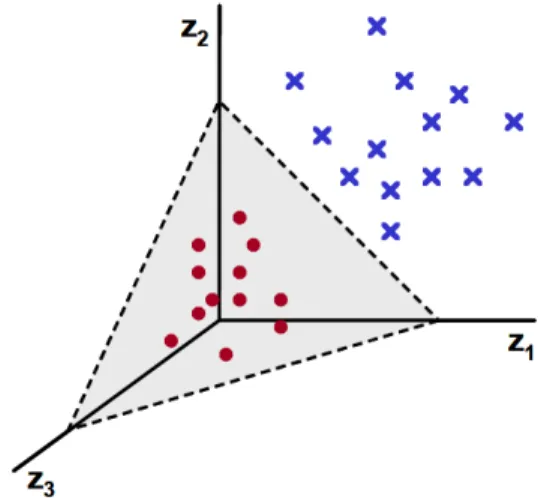
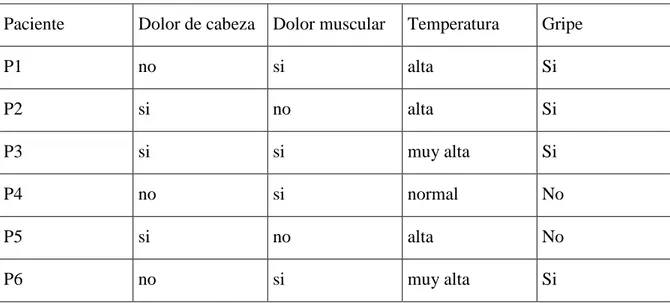

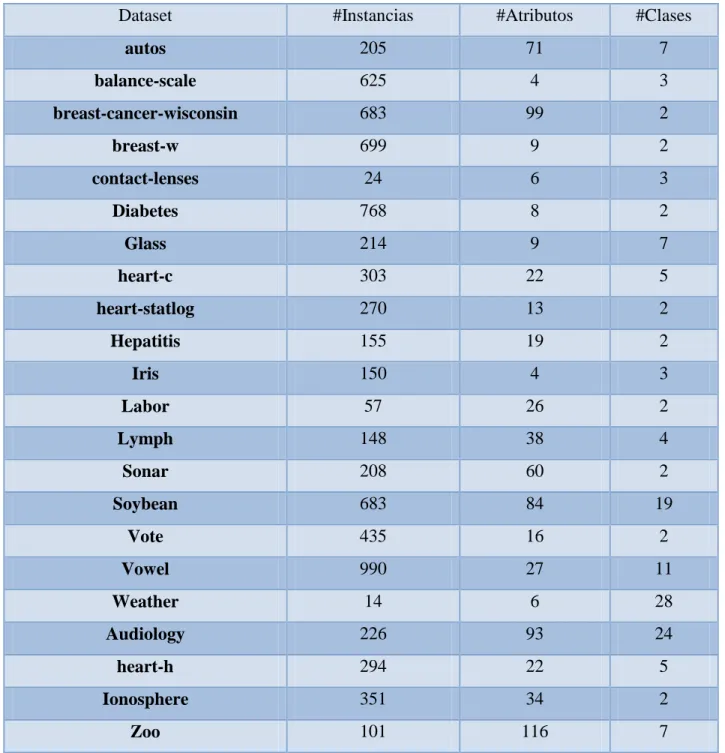

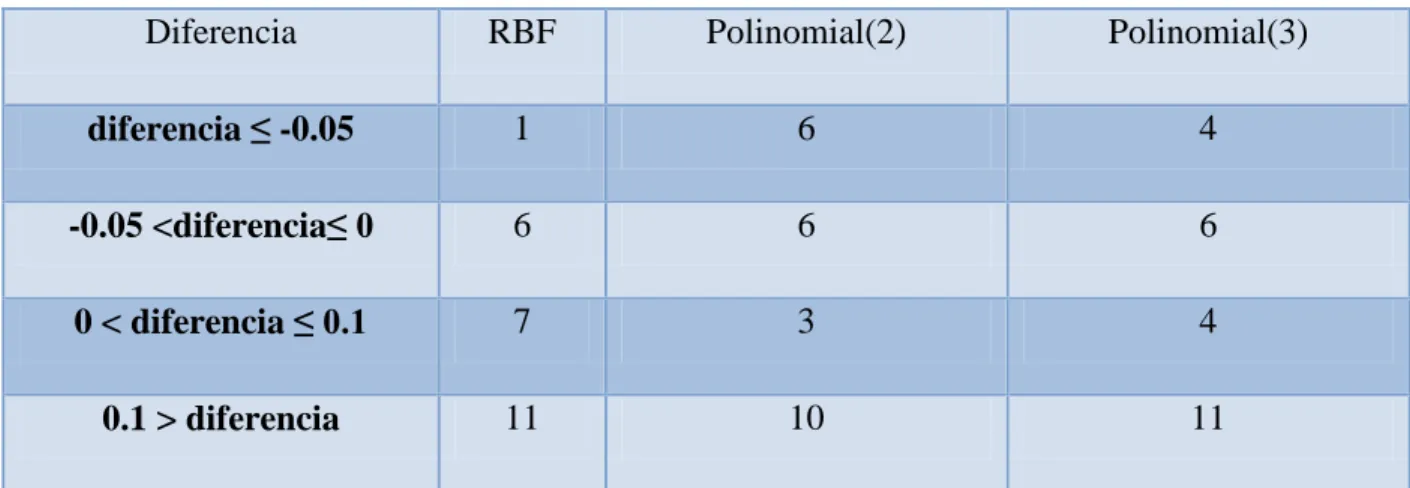

Documento similar
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
El nuevo Decreto reforzaba el poder militar al asumir el Comandante General del Reino Tserclaes de Tilly todos los poderes –militar, político, económico y gubernativo–; ampliaba
No había pasado un día desde mi solemne entrada cuando, para que el recuerdo me sirviera de advertencia, alguien se encargó de decirme que sobre aquellas losas habían rodado
d) que haya «identidad de órgano» (con identidad de Sala y Sección); e) que haya alteridad, es decir, que las sentencias aportadas sean de persona distinta a la recurrente, e) que
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
This section provides guidance with examples on encoding medicinal product packaging information, together with the relationship between Pack Size, Package Item (container)
Package Item (Container) Type : Vial (100000073563) Quantity Operator: equal to (100000000049) Package Item (Container) Quantity : 1 Material : Glass type I (200000003204)
