Estrategia para Extracción de Datos de Múltiples Fuentes Semi Estructuradas Edición Única
99
0
0
Texto completo
(2) INSTITUTO TECNOLÓGICO DE ESTUDIOS SUPERIORES DE MONTERREY DIVISIÓN DE TECNOLOGÍAS DE INFORMACIÓN Y ELECTRÓNICA PROGRAMA DE GRADUADOS EN TECNOLOGÍAS DE INFORMACIÓN Y ELECTRÓNICA. Los miembros del comité de tesis recomendamos que la presente tesis del Ing. Juan Fernando Rivera Pernía sea aceptada como requisito parcial para obtener el grado académico de Maestro en Ciencias en Tecnología Informática. Comité de tesis:. ______________________________. Dr. Juan Carlos Lavariega Jarquín Asesor. ______________________________. Dr. Guillermo Jiménez Pérez Sinodal. ______________________________. Dra. Lorena Guadalupe Gómez Martínez Sinodal. _________________________________________ Dr. Graciano Dieck Assad. Director del Programa de Graduados en Tecnologías de Información y Electrónica Diciembre de 2006.
(3) ESTRATEGIA PARA EXTRACCIÓN DE DATOS DE MÚLTIPLES FUENTES SEMI-ESTRUCTURADAS.. POR: JUAN FERNANDO RIVERA PERNÍA. TESIS. Presentada al Programa de Graduados en Tecnologías de Información y Electrónica Este trabajo es requisito parcial para obtener el grado de Maestro en MAESTRÍA DE CIENCIAS EN TECNOLOGÍA INFORMÁTICA. INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY. Diciembre de 2006.
(4) DEDICATORIA. A Dios por darme una vida llena de bendiciones, oportunidades y retos.. A mi familia, mis padres, hermanos y sobrinos, que siempre han estado cerca de mí y motivándome para seguir adelante.. A los amigos, que sin importar la distancia, siempre se alegran cuando se cumplen los sueños.. A ti, lector, porque este trabajo pueda ayudarte en alguna labor que estés realizando.. iv.
(5) AGRADECIMIENTOS. Al Dr. Juan Carlos Lavariega por creer en este trabajo y guiarme con sus consejos y observaciones. A los doctores Guillermo Jiménez y Lorena Gómez por sus sugerencias y aportaciones.. A mis compañeros de maestría y del trabajo que siempre fueron fuente de motivación.. Al Instituto por proporcionarme un reto que cumplir y una oportunidad para superación.. Gracias.. v.
(6) RESUMEN En la época actual, se vive una época donde una de las fuentes de información más importante es el World Wide Web, donde el formato primordial para documentos de información es el lenguaje HTML, que despliega información, que en ocasiones se requiere almacenar en un medio digital como una base de datos. De esta fuente de información en ocasiones se desea extraer información de los documentos HTML existentes en el World Wide Web, para almacenar esa información en una base de datos para usarla en explotación de datos para distintas aplicaciones futuras, pero en los documentos no se encuentra esa estructura. Es por ello que el presente trabajo de tesis, presenta una serie de pasos para extraer datos de documentos HTML referentes a un área de conocimiento, donde estos pasos pueden aplicarse en distintos documentos que traten la misma área de conocimiento. Para ello, se analizó la forma de detectar elementos de datos en documentos HTML, y distinguirlos de aquellos que describen la forma de presentarlos, para alimentar una base de datos, reduciendo el tiempo de alimentación de la misma. La información extraída puede utilizarse para aplicaciones de minería de datos para detectar o predecir tendencias. Tomando lo anterior como base para la elaboración del producto final, una estrategia para extracción de datos expuesta en esta tesis.. vi.
(7) TABLA DE CONTENIDOS DEDICATORIA AGRADECIMIENTOS RESUMEN TABLA DE CONTENIDOS TABLA DE IMÁGENES Capítulo 1. Introducción 1.1 Antecedentes 1.2 Objetivo 1.3 Situación Problemática 1.4 Hipótesis 1.5 Alcance 1.6 Justificación 1.7 Resultados Esperados Capítulo 2. Fundamentos técnicos y tecnológicos 2.1 Marco teórico 2.2 Trabajos sobre extracción de datos 2.2.1 Búsqueda de cambios en datos semi-estructurados 2.2.2 Transformación a documento bien formado 2.2.3 Extracción de datos de páginas Web 2.2.4 Estructura de búsqueda por dominio 2.2.5 Estructuras similares 2.2.6 Estrategia “Dividir y Vencer” 2.2.7 Extracción de datos usando XML 2.2.8 Modelo de búsqueda de información ANDES 2.2.9 Really Simple Syndication 2.3 Conceptos 2.4 Integración de datos 2.5 Conclusiones Capítulo 3. Fundamentos de la Extracción de Datos 3.1 Extracción de datos 3.2 Propuesta de la estrategia 3.3 Definición de estructura de Búsqueda 3.4 Fuente de Datos 3.4.1 Seguimiento en el tiempo de una misma fuente 3.4.2 Búsqueda de información en distintas fuentes 3.5 Transformación de página de red 3.6 Puntos de referencia 3.6.1 Búsqueda de cada elemento vii. iv v vi vii ix 1 5 6 7 9 10 10 11 13 13 14 14 15 16 17 18 19 21 22 22 23 25 27 29 29 31 32 38 39 40 41 44 45.
(8) 3.6.2 Buscar cada palabra de los tags 3.6.3 Mapeo de puntos de referencia a la estructura de datos 3.7 Conclusiones Capítulo 4. Casos Prácticos 4.1 Captura semi-automatizada de una fuente de datos 4.1.1 Definición de estructura de búsqueda 4.1.2 Fuente de Datos 4.1.3 Transformación de página de red 4.1.4 Puntos de referencia 4.1.5 Copiado de información a la base de datos 4.1.6 Comparativo con segunda fuente de datos 4.1.7 Observaciones del caso práctico 4.2 Seguimiento en el tiempo de una fuente de información 4.2.1 Definición de la estructura de búsqueda 4.2.2 Fuente de datos 4.2.3 Transformación de página de red 4.2.4 Puntos de referencia 4.2.5 Copiado de información a la base de datos 4.2.6 Observaciones del caso práctico 4.3 Conclusiones Capítulo 5. Aportaciones y Trabajo Futuro 5.1 Aportaciones 5.1.1 Estrategia genérica de extracción de datos 5.1.2 Reducción en tiempo de alimentación de base de datos 5.1.3 Seguimiento en el tiempo de una fuente de datos 5.2 Trabajos Futuros 5.2.1 Manejo de elementos desconocidos 5.2.2 Minado por seguimiento de páginas 5.2.3 Interacción con sistemas expertos 5.2.4 Disminución de intervención humana en el proceso 5.2.5 Agentes Inteligentes 5.3 Aplicaciones 5.3.1 Extracción de datos específicos de monitoreo de bases de datos 5.3.2 Aplicaciones de seguimiento de datos. 5.4 Conclusiones Capítulo 6. Conclusiones del trabajo REFERENCIAS BIBLIOGRÁFICAS Apéndice: Estructuras XML de datos de beisbol. VITA. viii. 46 46 48 49 49 50 50 50 55 58 59 61 62 63 63 65 66 67 67 68 70 70 70 71 72 72 72 73 74 75 76 77 77 78 79 80 82 85 91.
(9) TABLA DE IMÁGENES Figura 1.1. Propuesta básica de la estrategia. 2 Figura 1.2. Estilo común de presentar resultados de partidos de fútbol. 3 Figura 1.3. Estilo FIFA de representar partidos de fútbol 4 Figura 3.1. Flujo del proceso. 30 Figura 3.2. Proposición de la estrategia. 31 Figura 3.3. Ejemplo de partidos de fútbol 36 Figura 3.4. Formato del sitio www.mundosoccer.com antes de septiembre del 2006 37 Figura 3.5. Formato del sitio www.mundosoccer.com a partir de septiembre del 2006. 37 Figura 4.1. Datos de bateador de béisbol. 51 Figura 4.2. Datos de lanzador de béisbol 54 Figura 4.3. Imagen del sitio www.baseball-reference.com 60 Figura 4.4. Reporte de clima de la página weather.cnn.com 64. ix.
(10) Capítulo 1. Introducción El crecimiento del World Wide Web en los últimos años lo ha convertido en la fuente de información más rica y densa que el mundo ha visto [1], sin embargo la mayor parte de esta información se encuentra ordenada de una forma visual, mas no necesariamente en una estructura de datos lógica, lo cual puede verse como un problema si se desea utilizar esta información con aplicaciones que requieran una estructura de datos lógica. En particular, la difusión y utilización del lenguaje HTML es un fenómeno, dicho lenguaje es en la actualidad el principal medio para visualizar la información existente en el World Wide Web por las facilidades que otorga para la presentación de la misma hacia un ser humano, pero al realizar aplicaciones cuyo fin sea el acceso de datos se encuentran dificultades para dicho acceso, ya que no es objetivo del lenguaje; por ende, cualquier software que pretenda realizar procesos de automatización al acceso de datos contenidos en páginas escritas en lenguaje HTML lidiará con este problema. Entendemos por automatización al acceso de datos a un proceso realizado por un software para realizar determinadas acciones específicas. Dicha automatización se complica debido a la flexibilidad que caracteriza al lenguaje HTML al permitir a los creadores de páginas mostrar la misma información de distintas formas, que si bien se considera una ventaja del lenguaje el hecho de vislumbrar los mismos elementos de un dominio de datos de distintas formas, a la hora de aplicar un proceso de automatización puede presentar problemas para manejar dichos elementos. Como muestra, el órden en que se muestran los mismos elementos de información, varia entre distintas páginas HTML. Por lo tanto, dada la existencia de múltiples fuentes de información tratantes del mismo tema, es poco probable que dicha información se presente de la misma forma, aunque el área de conocimiento y los tipos de datos presentados sean los mismos. En gran medida esto se debe a que un mismo tema es abordado por diferentes creadores de páginas, los cuales definen diferentes formas de presentar la misma información. Un ejemplo muy sencillo son los resultados de una jornada en un torneo de futbol, una página puede mostrar los resultados en forma tabular de una jornada, mientras otra va llenando una matriz de juegos entre todos 1.
(11) los participantes. En ambas páginas HTML los elementos son los mismos: un conjunto de partidos entre dos equipos deportivos que tiene un marcador indicando el resultado del encuentro. Un observador puede determinar el marcador del último partido del equipo interesado en ambos casos pues la información es la misma, localizable para el aficionado que conoce la estructura del resultado de un partido de futbol. Es factible pensar en una forma de automatizar la búsqueda de información en páginas HTML sobre un tema ya que siempre existen elementos de información que permiten interpretar dicho tema. El presente trabajo aborda esta situación definiendo la problemática como la extracción de información de una estructura de datos con elementos de un dominio de datos sobre una o más fuentes de información. El núcleo de este trabajo radica en la estructuración de la estructura de datos y el llenado de dicha estructura, aun cuando las fuentes de información no necesariamente poseen una estructura de datos definida. La figura 1.1 presenta un panorama genérico de la estrategia a seguir en este trabajo:. Figura 1.1. Propuesta básica de la estrategia.. 2.
(12) La propuesta en este trabajo es una estrategia para manejar situaciones donde se busca extraer información referente a un área de conocimiento específica, donde dicha información puede radicar en distintos documentos HTML u otras fuentes de información1 y a su vez, no se encuentra estructurada de la misma forma en cada una de las fuentes. Supongamos la creación y alimentación de un catálogo de una determinada área de conocimiento, por ejemplo, un catálogo de torneos de fútbol soccer. Un torneo de fútbol soccer consiste de uno o más partidos que se disputan en más de una fase y eventualmente se obtiene un campeón. De igual forma, cada partido consiste de un equipo local que anota una cantidad finita de goles y un equipo rival, llamado visitante, que anota otra cantidad finita de goles. El resultado de dicho partido, si un equipo ganó, o si hay empate se determina en base a la diferencia entre los goles anotados por el equipo local contra los goles anotados por el equipo visitante. Se observa que la estructura de datos es la misma para cualquier torneo de fútbol soccer donde solo interesa guardar la información relevante a los partidos. No obstante dicha estructura puede mostrarse de distinta forma en distintas fuentes, como se ve en los siguientes ejemplos:. Figura 1.2. Estilo común de presentar resultados de partidos de fútbol.. 1. Estas fuentes de información pueden presentarse en otros formatos, sin embargo, en la actualidad, casi cualquier formato puede convertise a un equivalente en HTML. Esto se aborda con mayor detalle en los capítulos 3 y 4.. 3.
(13) Figura 1.3. Estilo FIFA de representar partidos de fútbol. En ambos casos, las estructuras reflejan los mismos marcadores, no obstante, los documentos HTML finales la muestran de manera diferente, un programa que busque la información indicada en la figura 1.2, presenta los resultados en el formato “Equipo_Local Marcador_Local – Marcador_Visitante Equipo_Visitante” no funcionará al buscar en la fuente que presente la información como en la figura 1.3, donde aparece como “Equipo_Local:Equipo_Visitante Marcador_Local:Marcador_Visitante”. Por ejemplo, el primer partido se interpreta que Alemania derrotó a Costa Rica por marcador de 4 goles a 2. La solución propuesta para este caso, que se plantea en este trabajo es una estrategia que permita extraer datos de documentos HTML. Los datos estarían definidos y delimitados por una estructura de datos, proponiendo que la definición de esta estructura sea en lenguaje XML. Hay varias aplicaciones propuestas: 1) Seguimiento de datos, en el tiempo y en diversas fuentes. Con el fín de hacer estudios comparativos y/o prospectivos. 2) Disminuir el tiempo de alimentación de una base de datos partiendo de una fuente, donde dicha fuente tiene una cantidad potencial de miles de registros de información. Estos registros pueden estar en uno o más documentos, los cuales pueden procesarse en más de una sesión, en el capítulo 4.1, se trata más sobre el tema. 4.
(14) 3) Alimentación de una base de datos en base a diversas fuentes de datos. El fin de esta estrategia es reducir el tiempo de alimentación y extracción de datos, mas no reemplazar de manera completa la intervención humana en el proceso, ya que esta intervención humana es importante para interpretar y validar los datos obtenidos durante el aplicación de la estrategia.. 1.1. Antecedentes. El lenguaje HTML es el medio más difundido para presentar información en el World Wide Web (el cual se referirá como red en el presente documento), pues permite la manipulación de elementos visuales que faciliten a un usuario localizar información que busque al usar un software de navegación en la red. No obstante, la mayor parte de los estatutos del lenguaje manipulan la presentación visual de los datos y no necesariamente se encuentran relacionados con los datos en sí. Esto, sin considerar la cantidad de elementos nativos de otros lenguajes ajenos al HTML, pero que interactúan con el navegador, tales como los mensajes pop-up y los scripts de lenguajes como JavaScript o PHP. La especificación del lenguaje HTML es una serie de instrucciones, los cuales serán referidos como tags, que indican al software navegador la forma de desplegar en pantalla lo que se encuentre delimitado por dichos tags. Estos tags están constituidos por una palabra clave de inicio y otra de final, no obstante, la sintaxis del lenguaje es muy relajada y un navegador puede interpretar el tag perfectamente, aún cuando no cumpla la regla sintáctica del HTML. Una tecnología derivada del HTML, es el lenguaje XML [2]. Este lenguaje poseé una sintaxis más estricta que el HTML, ya que se enfoca hacia la creación de lenguajes que faciliten el intercambio de información entre aplicaciones y no a la presentación de los datos que transporta. Es decir, el lenguaje XML es un lenguaje estructurado orientado a datos, mientras que el HTML puede verse como un lenguaje semi-estructurado cuya información define la forma de desplegar datos 5.
(15) en un navegador de red. Un documento HTML puede también ser un documento bien formado. A su vez, un derivado del lenguaje XML es el lenguaje XSL [3], este lenguaje es un estándar del W3C que describe estilos de formato y presentación para documentos XML. Entre estos estilos se pueden generar archivos HTML y XML. La característica principal del XML es estructurar información y asociar un significado semántico, dado que está orientado a definir contenidos, mas no presentación [4], ya que todos sus tags deben estar cerrados y anidados entre sí. A un documento XML que cumple esta característica se le llama bien formado, pero esta restricción no se aplica de manera completa en el lenguaje HTML. El lenguaje XHTML [5] fue diseñado para cumplir este requerimiento, ya que se caracteriza por la definición de documentos HTML que cumplan los requisitos de un documento XML bien formado. Por ello, partiendo del hecho de que existe una cantidad considerable de fuentes que tratan sobre un determinado tema en la red y que además, comparten el número de elementos de información sobre el mismo tema (o por lo menos, una parte), se piensa que es posible crear un proceso que de la manera más automática posible busque valores para poblar los elementos de la estructura de datos sobre el tema mencionado. Sin embargo, el hecho de que las estructuras de distintos documentos que hablen del mismo tema no necesariamente serán idénticas [6], se vislumbra como un área de oportunidad la creación de una estrategia general que pueda extraer información de un tema, de distintos documentos HTML.. 1.2. Objetivo. La propuesta del trabajo es: una estrategia cuya aplicación, permita facilitar la obtención de datos pertenecientes a una estructura de elementos referentes a un tema, pero que se encuentre desplegada de distintas formas, en documentos HTML de la red. Parte de la estrategia consiste en proveer un conjunto de reglas para crear la estructura de los elementos referentes a un área de conocimiento determinada, localizar datos referentes a estos elementos 6.
(16) en páginas de red y proporcione elementos de salida manipulables por un usuario. Esta estrategía va dirigida, en particular, hacia administradores de tecnologías de información que pueden encontrar utilidad en la obtención de información de un área de conocimiento, por ejemplo: Sistemas donde se capturen valores de manera periódica de distintas fuentes durante un lapso de tiempo determinado.. ●. Alimentar bases de datos nuevas, capturando información determinada de distintas fuentes, como un catálogo de materias de una carrera universitaria en distintas instituciones.. ●. Convertir la información en documentos a bases de datos, poseedoras de estructuras de almacenamiento de información diferentes a las existentes en estos documentos.. ●. Los objetivos particulares de la investigación son: 1) Proveer una estrategia cuya aplicación facilite una extracción de datos de distintas fuentes, enfatizando el uso en páginas Web, de forma repetitiva. 2) Aplicar la estrategia en casos prácticos para evaluar su uso. 3) Representar datos sobre un dominio de información de forma que, su contenido sea el mismo entre distintas fuentes de información que difieran en la forma de almacenar y/o desplegar estos datos. Hay que aclarar que no es objetivo de la estrategia reemplazar a un usuario humano para la obtención de datos, dado que éste será necesario para validar y verificar los datos obtenidos en el proceso; sino minimizar su rol en el proceso.. 1.3. Situación Problemática. Es común que los programas que permiten crear documentos para la red no cuiden que los tags de una página Web estén cerrados y/o anidados, aunque aquellos que manejen una interfaz WYSIWYG (Siglas en inglés de “Lo que se ve es lo que se toma”) generen páginas bien 7.
(17) formadas. En la actualidad existen muchas páginas cuya creación no ha seguido las reglas de un documento bien formado; lo cual aplica tanto a páginas estáticas como dinámicas, pues los lenguajes que permiten la generación de páginas HTML dinámicas, no impiden la generación de código HTML que no se encuentre bien formado. Al realizar una búsqueda sobre un documento que no se encuentre bien formado, se dificulta obtener el valor exacto asociado a un elemento de la estructura. Supongamos el siguiente ejemplo2: <font size="2" face="Arial, Helvetica, sans-serif"> <table cellSpacing="0" cellPadding="0" width="100%" border="0" id="table26"> <tr> <td bgColor="#e3eaf6"> <table cellSpacing="0" cellPadding="5" width="100%" border="0" id="table27"> <tr> <td bgcolor="#FFFFFF"> <p align="center">Copyright</font></p> </td> </tr> </table> </td> </tr> </table>. En este ejemplo, la causa de que el documento no esté bien formado es el tag <font>, que se abre después que el tag <table>, pero se cierra antes. Esto dificulta el valor exacto del tag <p>, ya que surgen dos posibles escenarios: 1). ¿Se considera el string “</font>” como parte del valor del tag <p>? Si es asi, ¿Hasta donde llega el valor del tag <font>?. 2). ¿Se considera el string “Copyright” como valor del tag <font> o del tag <p>?. Si bien existen herramientas que facilitan la búsqueda de información en documentos XML, o permiten ubicarse en una parte determinada de los mismos, requieren que los documentos estén bien formados, para evitar situaciones ambiguas como la presentada en el ejemplo. Además hay que considerar que una página de HTML se enfoca hacia la presentación; así, aunque se generen elementos bien formados que nos 2. El ejemplo fue tomado de la página http://www.pdaperformance.com, algunos tags fueron modificados con fines de ilustrar de mejor manera el punto.. 8.
(18) ayuden a buscar, un cambio en la estructura de la página original puede hacer que una futura extracción de datos sobre la misma página arroje resultados distintos a los esperados. El concepto de extracción de datos en el contexto de este trabajo será tratado a mayor profundidad en el capítulo 2. No obstante, la presentación puede variar entre documentos, mas no así la información que estos contengan y los datos que componen dicha información. Éste será un factor común que relacionará a los documentos que traten sobre el mismo tema.. 1.4. Hipótesis. La hipótesis es diseñar una estrategia general para obtener de forma semi-automatizada elementos que satisfagan los requisitos de una estructura XML. Esta estructura, definida partiendo de un dominio de datos, debe representar información contenida en múltiples fuentes de páginas de red, sin importar su estructura sintáctica o la presentación de los datos. Un factor común que relaciona páginas de red que traten sobre un determinado dominio de datos, o tema, son los elementos pertenecientes a dicho dominio. La existencia perenne de este factor común, es el que permite vislumbrar la posibilidad de crear una estrategia para buscar información sobre un tema definido y delimitado. Para explicar de manera más clara el punto anterior, se retomará el ejemplo del dominio de partidos de fútbol. Todo documento HTML que trate el tema, incorpora el concepto de un partido, así como el resultado del mismo. Toda persona que deseé obtener información sobre partidos de fútbol, al consultar fuentes de información que traten el tema, buscará la estructura que define un partido, para saber el resultado. La persona va a buscar determinados elementos, en este caso un equipo local, un equipo visitante y los respectivos marcadores, para interpretar el resultado de un partido. La interpretación de los elementos es importante. En la línea del partido del fútbol, es factible pensar que con el simple hecho de localizar un número ya se encuentra la cantidad de goles que anotó un equipo, sin embargo, existen equipos que llevan números en sus nombres 9.
(19) (ejemplo: Schalke 04 de la liga de fútbol alemana, o Bundesliga) por lo que es necesario interpretar la información existente antes de realizar algún proceso.. 1.5. Alcance. La presente investigación se enfocará principalmente a definir los fundamentos de la estrategia que permita la extracción de datos de fuentes de información semi-estructuradas, tal como una página de red (también llamadas Web). Así como su factibilidad, demostrable a través de dos casos prácticos: 1) La alimentación de una base de datos partiendo de un documento de HTML estático. Posteriormente, aplicar la estrategia de extracción en otro documento, para comparar los datos extraídos en ambos casos. 2) La alimentación de una base de datos partiendo de un documento HTML dinámico cuyo contenido cambia con el tiempo. Así como la usabilidad de la estrategia en ambos casos, la cual se propone medir de acuerdo al caso: 1) Tiempo invertido en el uso de la estrategia contra el tiempo invertido para la extracción de datos sin la misma. 2) Constancia en los datos al extraerse de la misma fuente de datos, pero en diferentes instantes de tiempo. En los capítulos posteriores se tocará este punto a mayor detalle.. 1.6. Justificación. Muchos sistemas requieren alimentación al principio de su ciclo de vida, así como de manera constante, a lo largo del tiempo de uso del sistema. La red puede ser una fuente de información para alimentar dichos sistemas, pues todo sistema se encuentra enfocado en una determinada área de información. Dado que las estructuras 10.
(20) representantes del dominio de datos que abarque dicha área de información será la misma sin importar la forma y/o cantidad de documentos, puede existir una forma de minimizar el tiempo de alimentar dichos sistemas, automatizando la mayor parte de dicho proceso. Se parte de la suposición de que el tiempo invertido en revisar información es menor, que en capturar los datos que constituyen la misma. Como ya se ha mencionado, la necesidad de interpretar los datos es la que permite la existencia de reglas para definir elementos del área de conocimiento, ya que estas reglas definen el orden de presentación de datos, o los elementos que constituyen a cada dato. Estas reglas existirán en todo documento contenedor de información del área de conocimiento. Por ejemplo, para una estructura que represente el resultado de un partido de fútbol, se pueden apreciar las siguientes reglas: 1) Deben existir dos equipos participando en el partido y los respectivos marcadores de cada equipo. 2) El equipo, que juega la mayoría de sus partidos en el estadio donde se realiza el mismo, se considera local. 3) El otro equipo se considera visitante. 4) El marcador de cada equipo es una cantidad numérica mayor a cero. 5) El orden por defecto para presentar estos datos es: Equipo local, marcador local, marcador visitante, equipo visitante.. 1.7. Resultados Esperados. La investigación se aplicó en dos casos prácticos: 1) Extracción masiva de una fuente de información de miles de elementos. La finalidad de este caso es analizar el comportamiento de la estrategia para encontrar registros que cumplieran la estructura de búsqueda definida, así como el manejo de situaciones donde no se encuentran todos los 11.
(21) elementos de dicha búsqueda. El objetivo es verificar si esta estrategia puede ayudar a la alimentación masiva de una base de datos. 2) Seguimiento en el tiempo de una misma fuente de información. Con el fin de corroborar si la extracción de información de una misma fuente de datos en el tiempo, permanece constante. El detalle de los resultados de los casos prácticos se explicarán con mayor detalle en el capítulo 4. El documento está organizado de la siguiente manera: El capítulo 1 consiste en la introducción y definición de los objetivos y alcance del documento.. ●. El capítulo 2 consiste en los fundamentos teóricos y tecnológicas de esta investigación. En este capítulo se abordan otros trabajos y se explican, de manera breve, que diferencias tienen contra el actual documento. También se describen los distintos conceptos manejados a lo largo del documento.. ●. El capítulo 3 describe la estrategia general de extracción, así como los fundamentos de la extracción de datos.. ●. El capítulo 4 describe los casos prácticos sobre los que se aplicó la estrategia, haciendo relación con los conceptos y pasos definidos en el capítulo 3.. ●. El capítulo 5 contiene las aportaciones del trabajo, así como trabajos futuros, y aplicaciones propuestas.. ●. ●. El capítulo 6 contiene las conclusiones generales del trabajo.. Al final del documento se incluye un apéndice con información detallada de las estructuras usadas en los casos prácticos.. ●. 12.
(22) Capítulo 2. Fundamentos técnicos y tecnológicos En este capítulo se discutirá el marco teórico en que se fundamenta la investigación, así como la mención de trabajos alternos y conceptos que se manejarán a lo largo del documento.. 2.1. Marco teórico. A lo largo del documento, se mencionará el lenguaje XML. Este lenguaje permite representar documentos bien formados, los cuales definimos como aquellos que describen estructuras de datos usando etiquetas, también llamadas tags, proveyendo una semántica a sus contenidos. No obstante la rigidez que este tipo de documentos puede poseer, sigue siendo menor a la que presentan otras herramientas que almacenan estructuras de datos como puede ser una forma para una base de datos [7]. Los tags llegan a tener cantidades de información sumamente específica. Otro tipo de documentos son los semi-estructurados, cuyas diferencias principales con respecto a los documentos bien formados son: 1) Un documento semi-estructurado no necesariamente exige que cuando se abre un elemento se cierre antes de abrir el siguiente. Esta situación se mencionó en la sección 1.3. 2) Los tags delimitan gran cantidad de información relevante a un determinado dominio de interés. Como en los documentos de lenguaje HTML, cuyos tags contienen información concerniente al desplegado visual de información, principalmente en navegadores de Web. Un documento HTML es un ejemplo de documento semi-estructurado, pues posee los tags que regulan la forma de presentación visual de los datos, sin embargo, los tags de tipo <p> (paragraph) contienen información que puede separarse de manera granular. Hay que notar 13.
(23) que esta información tiene un significado semántico para un lector humano, pero no tendrá una relación sintáctica directa con una estructura de datos definida. El hecho de que un documento bien formado tenga su información de manera granular lleva a pensar que es fácil realizar una búsqueda de información, pero no necesariamente es así, debido a que el lenguaje permite el almacenamiento de datos, pero no provee operaciones para la consulta de los mismos. Se han desarrollado herramientas cuyo objetivo es facilitar esa funcionalidad al usuario, tales como XQL o XQuery.. 2.2. Trabajos sobre extracción de datos. Existen proyectos enfocados a extraer información de documentos bien formados (o semi-estructurados), de los cuales varios se exponen a continuación.. 2.2.1. Búsqueda de cambios en datos semi-estructurados. Definido en [6]. El trabajo de Chawathe, Abiteboul y Widom se enfoca en representar cambios en páginas HTML, a las que en el documento, se consideran como documentos semi-estructurados. Ellos proponen un modelo para representar un registro de los cambios en datos semiestructurados, incluyendo un lenguaje para la realización de búsqueda de datos considerando ese registro de cambios. El trabajo trata de resolver el problema de buscar información en documentos semi-estructurados. Es uno de los primeros trabajos que proponen una solución al problema de buscar datos en documentos semi-estructurados debido a “la irregularidad y carencia de un esquema” en los mismos [6]. La propuesta radica en comparar dos páginas de Web, que son documentos semi-estructurados para propósitos del trabajo, con el fin de localizar los cambios y llevar un registro de dichos cambios en los mismos datos. La aproximación es interesante y sirve para ilustrar los primeros pasos en la búsqueda de extracción de información de documentos 14.
(24) semi-estructurados. El punto más importante es que considera la estructura de datos existentes para buscar las diferencias. El modelo propuesto en el trabajo es capaz de detectar diferencias de contenido, debido a la existencia de palabras clave que sirven como punto de referencia para detectar cambios en la información de la página, mas no cambios en la presentación de la misma. Son de destacar los siguientes puntos: 1) La distinción realizada entre la información contenida en los documentos, sobre la presentación de los mismos. 2) La necesidad de realizar transformaciones en los documentos semi-estructurados dadas las limitantes de un documento de este tipo para la realización de búsquedas de datos.. 2.2.2. Transformación a documento bien formado. Definido en [8]. Este trabajo propone la transformación de un documento semi-estructurado a un documento bien formado, expandiendo el concepto de transformación del documento semiestructurado, mencionado en la sección anterior. El documento presenta las siguientes justificaciones para la transformación de los documentos semi-estructurados de lenguaje HTML, hacia documentos bien formados siguiendo las reglas del lenguaje XML: 1) Eliminación de ambigüedades y errores generados durante la creación del documento semi-estructurado HTML. 2) El hecho de que el documento bien formado, cumpla con los requisitos de un documento bien formado de XML, permite la utilización de técnicas y herramientas que puedan trabajar sobre dicho tipo de documentos. Un ejemplo de los trabajos que se pueden realizar sobre este tipo de documentos es alimentar una base de datos. Es posible ver este trabajo como un antecedente a la definición del lenguaje XHTML [5], ya que este lenguaje define la creación de documentos HTML, pero bien formados. 15.
(25) En el trabajo [9] se propone otra razón por la cual es necesario realizar la transformación de un documento semi-estructurado HTML hacia un documento bien formado. Un documento semi-estructurado posee una importante característica que es el acomodo de su información en una estructura jerárquica. Esta característica es compartida por un documento bien formado, con el beneficio añadido de que en los documentos de este tipo la estructura se encuentra definida de manera más rigurosa. Esta rigidez en la definición de la estructura, facilita la transición de los datos contenidos en la estructura hacia un modelo de datos relacional, donde la rigidez de las tablas que almacenan la información facilita relacionarlo con los elementos del documento bien formado.. 2.2.3. Extracción de datos de páginas Web. Definido en [1]. El trabajo de Jussi Myllymaki, es base para el modelo de extracción de información ANDES3. Aborda conceptos y problemas al extraer información de documentos semi-estructurados HTML. Si bien, el lenguaje HTML es el mayor conductor de información a través del World Wide Web y provee una forma conveniente de desplegar información a lectores humanos; sin embargo, “es una estructura retadora para automáticamente extraer información relevante a servicios orientados a datos o a aplicaciones” [1], debido a los siguientes factores: 1) La mayor parte describe formato irrelevante a los datos desplegados en la página, mas no para la comprensión visual de la información desplegada. 2) Por la displicencia de los navegadores de páginas del World Wide Web a interpretar documentos HTML que no se encuentren bien formados. 3) La existencia de código que despliega anuncios publicitarios o contenidos que varían de forma dinámica por cada conexión al servidor que contiene las páginas. Generalmente, este código es irrelevante con respecto a la información desplegada en la página final que se muestra al usuario. 3. La relación del modelo ANDES en el marco de esta tesis, se explica con mayor detalle en la sección 3.1.. 16.
(26) La propuesta de Myllymaki [1] propone que el proceso clave para la extracción de datos, contenidos en documentos HTML, es convertir dichos documentos a documentos bien formados y estructurados de tipo XHTML, para aprovechar las herramientas existentes para trabajar con documentos de este tipo. Esto ya es un paso adelante del trabajo propuesto en [8], ya que el lenguaje XHTML está plenamente definido y cumple con los requerimientos planteados en dicho trabajo. Otro concepto importante que se define en este trabajo es el punto de referencia para buscar un determinado dato. La existencia de un punto de referencia permite evitar buscar en todo un documento por un determinado dato. Las propuestas de este trabajo, son analizadas a mayor detalle en el capítulo 3, donde se propone la estrategia general para la extracción de datos.. 2.2.4. Estructura de búsqueda por dominio. Definido en [10]. Este proyecto propone un modelo de extracción basados en un esquema de datos, donde no se necesita interacción humana, pero se basa en una estructura de búsqueda4 perteneciente a un dominio de datos. El trabajo de Arasu y García propone que muchos servidores de Web tienen grandes colecciones de páginas que tienen una estructura visible, donde dicha estructura describe la forma en como se guarda esa información, como en una base de datos. Estas páginas no suelen ser documentos estáticos, sino que se generan de manera dinámica en un servidor obteniendo información de la base de datos; mas no hay que olvidar que el resultado final de dicha generación es un documento HTML estático interpretado por un navegador. Dentro de este documento estático, si bien es posible percibir la estructura de información mencionada por los autores, distinguirla sin otorgarles un significado es difícil, principalmente por dos razones:. 4. Este concepto se desarrolla a mayor detalle en el capítulo 3. 17.
(27) 1) Existen niveles de anidamiento de información arbitrarios, que no necesariamente se repetirán en todas las páginas. Un ejemplo se aprecia en la clasificación taxonómica de plantas, ya que algunos géneros tienen sub-géneros, a su vez, dentro de los subgéneros, vienen las especies; pero otros géneros no poseen ese nivel intermedio y contienen directamente a las especies. Eso sin contar, que algunos sub-géneros podrían contener sub-subgéneros, o que algunas especies cuentan con sub-especies y/o razas. 2) La distinción de la presentación y los datos en sí. De manera sintáctica, no existe virtualmente nada que ayude a distinguir el texto que es la presentación y el texto que contiene los datos. Un ejemplo es la omisión de los tags de encabezados <th> dentro de una tabla, ya que el uso de esas etiquetas ayudan a distinguir los encabezados de una tabla, pero no siempre se usan y no son requisito fundamental para el desplegado de un tabla en un documento HTML. Estos problemas se atacan, proponiendo un algoritmo que, partiendo de una estructura de datos a buscar definida por el aplicador del algoritmo, clasificará páginas de web de acuerdo a la inclusión de datos de dicha estructura, encontrará posibles equivalencias con la estructura y finalmente extrae los valores que se consideran correctos. La meta final de la investigación de Arasu y García es atacar el problema de extraer datos con aplicaciones de integración de sistemas, la meta compartida en esta tesis es el aspecto referente hacia la extracción de datos.. 2.2.5. Estructuras similares. Definido en [11]. En este caso se propone interpretar los documentos a buscar como estructuras similares, además introduce el concepto de frecuencias en los documentos de búsqueda. La idea de estructura similar se traduce en que todo documento HTML puede interpretarse como un documento bien formado, sin embargo, difiere en que la similitud radica en distinguir los elementos a buscar, como listas o celdas de tablas.. 18.
(28) El trabajo de Flesca, Manco, et al, aborda un aspecto no contemplado en el trabajo anterior [10]: los niveles de anidamiento. Por medio de la serialización de documentos XML en representaciones numéricas, para posteriormente, buscar la frecuencia de dichas representaciones numéricas en otros documentos codificados de dicha forma, apoyándose en herramientas matemáticas como transformaciones de Fourier para lograr dicho propósito. Hay que hacer notar que no es el único trabajo que se apoya en herramientas matemáticas para la extracción de datos, otro ejemplo es la propuesta de PXML [12]. La idea central es: partir de un documento XML que define una estructura de datos a buscar y representarlo de una determinada forma numérica; si se localiza otro documento, que al ser representado también numéricamente, tiene similitudes con la estructura de datos a buscar, es posible que satisfaga los datos que dicha estructura define. El concepto de estructura similar es interesante, pues páginas que contengan información sobre el mismo tema tendrán elementos en común, mas su orden de presentación no será idéntico, de ahí que se use la palabra similar, denotando que son parecidos, mas no iguales.. 2.2.6. Estrategia “Dividir y Vencer”. Definido en [13] y [14]. Esta propuesta se basa en una estrategia de dividir y vencer, para encontrar árboles de datos. Parte de esta estrategia fue adaptada para los ciclos de búsqueda, donde se busca que los datos ya estén acomodados en una estructura de datos de un dominio; ya que los datos contenidos en un dominio, generalmente poseen un orden determinado. La premisa parte de [14], donde se propone la búsqueda de contenido similar, por medio de reglas de asociación en partes de un documento bien formado, mas no en la totalidad de éste. La idea se complementa en [13], donde el objetivo es buscar en la menor cantidad de elementos diferentes dentro de un documento XHTML, obtenido al transformar el documento HTML en un documento bien formado, ya que los datos quedan contenidos en un número restringido de elementos. Esto se explica a mayor profundidad en la sección 3.5 de este documento.. 19.
(29) Los autores Feng, Hsu y Lee [13] proponen que al buscar una determinada estructura de búsqueda, denominado árbol en su trabajo, tiene un determinado orden, es posible distinguir elementos de dicho árbol en otras estructuras ordenadas a un determinado orden, lo cual ayudaría a buscar solo determinadas ocurrencias de un conjunto de los elementos en lugar de buscar toda la estructura. El concepto de “árbol” puede considerarse una aplicación del concepto “Punto de Referencia” mencionado en la sección 2.2.3. Retomando los ejemplos concernientes a partidos de fútbol En determinados torneos, como la Copa del Mundo de Fútbol Soccer, una definida cantidad de partidos tienen relevancia dentro de un grupo que abarca determinados equipos, ya que cada equipo de ese grupo solo realizará partidos contra los de su mismo grupo, al menos durante una definida fase del torneo. En este caso, supongamos una estructura de la siguiente forma: <ronda> <grupo>. <partido/> .... </grupo> <grupo> <partido/> .... </grupo> </ronda>. Si el tipo de datos que estamos buscando son los resultados de partidos, es lógico asumir que una vez encontrado un grupo, donde después de ese grupo hubo partidos, si se vuelve a encontrar un grupo, en la misma ronda, también tendrá partidos. A esta situación es la que se describe como estructura similar. Otro trabajo, que puede considerarse relacionado en este tópico, es [15], donde se maneja el concepto de “Búsquedas de objetos cercanos”. En este concepto se propone que dada la proximidad de un elemento en una estructura de búsqueda; si dicho elemento se encuentra en el documento semi-estructurado que funge como fuente de datos, existe una fuerte posibilidad de encontrar elementos que estén cercanos a éste, o se consideren “hijos” del mismo.. 20.
(30) Retomando el ejemplo abordado en esta sección, vemos que el elemento “grupo” se considera hijo del elemento “ronda”. Al realizar una búsqueda de información en un documento semi-estructurado que contenga la palabra “ronda” es posible inferir que valores que satisfacen el elemento “grupo”, o el elemento “partido”, se encontrarán en dicho documento, encontrados posteriormente a la ocurrencia del elemento “ronda”. De esta forma, al encontrar una ocurrencia de un determinado elemento en la estructura de búsqueda y dicho elemento tiene elementos “hijos”, es fácil asumir que por cada ocurrencia de este elemento, tendrá también valores que satisfacen los valores de uno o más de sus “hijos”.. 2.2.7. Extracción de datos usando XML. Mostrado en [16]. Es un trabajo orientado a la generación de un marco de trabajo para la extracción de datos de documentos XML. La interpretación que se da en dicho trabajo al concepto de extracción de datos se traduce en el hallazgo de patrones, aplicados a una gran cantidad de información aparentemente sin relación entre sí y generar reglas de asociación que permita establecer relaciones, si es que las hay. El concepto planteado es interesante, debido a que “ha habido muy poco trabajo en el dominio de minado por reglas de asociación de documentos XML” [16]. Este trabajo se considera, porque el propósito fundamental es el mismo: extracción de datos de documentos bien formados. Se toman los siguientes conceptos de dicho trabajo: 1) Las reglas de asociación que pudieron generarse durante la primera ejecución del marco de trabajo propuesto, facilitan la extracción de datos en futuros documentos. Dicho concepto se ve reflejado en el concepto de estructura de búsqueda de esta estrategia de extracción. Agregando además la posibilidad de que dicha estructura puede modificarse para adaptarse a otra fuente, aunque no de manera automática como propone el trabajo [16].. 21.
(31) 2) Un documento XML se debe organizar de una manera adecuada para poder realizar una búsqueda más eficiente. Es muy importante resaltar que este apartado se refiere al documento XML fuente de información. Este concepto se ve reflejado en la transformación de la página de HTML en un documento XML bien formado XHTML, eliminando los elementos referentes a la presentación de la información, ya que la información en un documento XHTML queda en elementos muy determinados. Se detalla más este concepto en la sección 3.5 de este trabajo.. 2.2.8. Modelo de búsqueda de información ANDES. Mostrado en [2]. Este modelo puede ser considerado una aplicación del trabajo mostrado en [16], ya que realiza aplicaciones repetitivas de documentos XML y XSL sobre documentos HTML para extraer información, para depositar la información obtenida en una estructura de datos XML definida previamente. Este modelo se considera como punto de partida de la estrategia mencionada en esta tesis, considerando tanto el uso de lenguaje XML para la creación de estructuras de búsqueda de información, como del repositorio de información. Se discute a mayor detalle en la sección 3.1, dada su importancia como base de este trabajo.. 2.2.9. Really Simple Syndication. La popularidad del formato de archivos Really Simple Syndication [17] (RSS por sus siglas en inglés), ha aumentado debido a su uso en la difusión de cambios o adición de contenidos en sitios de Internet. Este formato permite a un usuario, por medio de un software que lea este tipo de archivos, percatarse de cambios en los contenidos de un sitio de Internet, lo cual puede interpretarse como el seguimiento en el tiempo de un sitio. Un ejemplo del uso de este tipo de archivos, es en los portales de periódicos, donde por medio de estos archivos se le informa a un usuario sobre los artículos más recientes en dicho portal. Esta tecnología arroja un concepto usado en este trabajo: el seguimiento de información de una fuente a través del tiempo. El formato RSS permite al usuario 22.
(32) mostrar las diferencias que han ocurrido en una fuente con el paso del tiempo, si bien, no facilita realizar la captura de dicha información y almacenarla en una base para futuros cotejos, lo cual es la raíz del caso práctico Seguimiento en el tiempo de una fuente de información el cual se ve en la sección 4.2.. 2.3. Conceptos. El primer concepto a explicar, ya mencionado con anterioridad en el documento, es el de dominio de datos, que consiste en una serie de reglas y elementos relacionados con un área del conocimiento determinada. Dada la granularidad que caracteriza los documentos bien formados, es posible representar las reglas que definen un dominio de interés en lugar de la información correspondiente a dicho dominio, pues esta descripción tiene que ser lo más concreta posible, dejando la información definida en documentos semi-estructurados, que no necesitan ser tan rígidos. Retomando el ejemplo de un partido deportivo como área de interés mencionado previamente, una representación del dominio es la siguiente: <encuentro> <participante> <nombre>string</nombre> <local>Boolean</local> <marcador>numero</marcador> </participante> </encuentro>. El ejemplo es un documento bien formado, pues cada pieza de información está contenida en una unidad pequeña. En este caso en particular cada tag que contendrá datos, tiene el tipo de dato que contendrá y donde el nombre del tag, es el nombre del dato a almacenar. A la estructura cuya descripción se encuentra en el documento bien formado de este tipo, se le llama estructura de búsqueda.. 23.
(33) Ahora, hay que buscar los datos que cumplirán los elementos especificados en la estructura de búsqueda. Estos datos se encuentran en documentos de texto libre, o en el mejor de los casos en documentos semi-estructurados. Al proceso de búsqueda y extracción de estos datos, en distintos documentos, se le llama extracción de datos. La forma en que pueden estar estos datos varía considerablemente, consideremos una nota de periódico: En un trepidante partido, los Rayados del Monterrey fueron capaces de imponerse a su acérrimo rival, los Tigres por marcador de 3 goles a 1.. Los participantes son los strings “Rayados de Monterrey” y “Tigres” y los marcadores son “3” y “1” respectivamente. El valor del campo local no tiene una correspondencia directa con alguna palabra en el párrafo anterior, pero el significado semántico de la redacción de la nota para un lector humano es que Rayados es el participante local. Ahora consideremos un fragmento de una página de red HTML que contiene los resultados de una jornada. Rayados. 3. 1 Tigres. Donde parte del código HTML para obtener el desplegado anterior, en el documento semi-estructurado, es el siguiente: <tr> <td>Rayados</td> <td>3</td> <td>1</td> <td>Tigres</td> </tr>. Es exactamente la misma información que en la nota periodística, pero se encuentra representada de manera diferente. Dado que es un fragmento de una tabla que contiene más resultados, es posible inferir que el primer participante es el que cumple el requerimiento de local. En este punto se ha ilustrado que la información puede encontrarse almacenada en más de una forma, aun cuando sea la misma información. Al documento que contiene la información a ser extraída se le llama fuente de datos. 24.
(34) La fuente de datos si bien posee la información que llene la estructura de búsqueda, no necesariamente contiene dicha información en el orden especificado en dicha estructura de búsqueda. Por eso, cualquier fuente de datos pasa por un proceso de transformación [7], que consiste en la aplicación de un conjunto de reglas, donde cada tipo de regla cumple un propósito diferente: •. Reglas de selección: Buscan los tags definidos en la estructura de búsqueda. El propósito de estas reglas es detectar en la fuente de datos donde están localizados los nombres de los datos.. •. Reglas de extracción: Buscan la información en estructuras cercanas a donde fueron localizados los nombres de los datos.. •. Reglas de estructura: Buscan cumplir las especificaciones de la información que contendrá el dato y cuyas características se encuentran en el documento de estructura de búsqueda.. •. Reglas de procesamiento: Realizan transformaciones necesarias sobre los datos para cumplir requerimientos en el documento de estructura de búsqueda. Este tipo de regla aplica cuando existe un requerimiento determinado para el dato y se encuentra un valor que no corresponde con el requerimiento. Esta regla es propuesta en este trabajo y no se encuentra en las sugeridas por [7].. 2.4. Integración de datos. De acuerdo al dominio de datos del cual se desea obtener información, es posible definir en una estructura los datos que se desean extraer de las páginas semi-estructuradas HTML. Sin embargo, la estructura pudiera ser percibida de manera semántica por un lector humano, es más complejo para una aplicación automatizada de datos [1]. Dicha complicación puede obedecer a diversos factores [4]: Modelos de datos diferentes: Las fuentes de información, en este caso, los documentos HTML mostrados en un navegador5,. ●. 5. Si bien estos documentos pueden crearse, seleccionando información de una base de datos existente en un servidor, el usuario del navegador de World Wide Web, no tiene acceso directo a la estructura de dicha. 25.
(35) pueden desplegar de manera distinta la misma información. Esquemas de datos diferentes: Entre diferentes modelos de datos, puede existir alguno de los siguientes escenarios: Una palabra puede referirse a elementos diferentes en distintos modelos. Un elemento puede referirse de distinta forma en modelos diferentes.. ●. Instancias de datos diferentes: El hecho de que dos fuentes de información diferentes, se refieran al mismo elemento, de forma contradictoria entre sí. Por ejemplo: una persona con dos fechas de nacimiento diferentes.. ●. Sin embargo, existe un factor común en las distintas fuentes de datos sobre un dominio de datos y es el dominio de datos en sí. Los elementos que pertenecen a dicho dominio, deben aparecer en las distintas fuentes de datos que tengan información sobre dicho tema. Por lo tanto, es necesaria la existencia de un factor que permita heterogeneizar la información que se desea obtener y que satisfaga un dominio de datos determinado. Se considera que una estructura que cumpla con los requisitos del lenguaje XML, es decir, un documento bien formado, cumple con este propósito. La utilización de estructuras definidas en este lenguaje se explica a mayor detalle en el capítulo 3. Además, hay que considerar un cierto principio de incertidumbre que existe en todo dominio de datos [12]. Este principio se puede resumir en las siguientes preguntas: ¿Existen en el documento todos los elementos que conforman la estructura de datos?. ●. ¿Existe la certeza de que los valores de las fuentes son válidos dentro del dominio de datos?. ●. Dado que no es sencillo responder a estas preguntas antes de realizar la extracción de datos, es necesario crear mecanismos que permitan lidiar con estas preguntas.. base de datos. Por esta razón se consideran como fuente de información los documentos generados.. 26.
(36) 2.5. Conclusiones. La variedad existente de mostrar información, puede dificultar la tarea de un proceso de extracción automatizada de la misma, cuando se trata de extraer dicha información de documentos con estructuras diferentes, o de un mismo documento, cuyo formato para presentar la información ha cambiado en el transcurrir del tiempo. Si bien existen varios trabajos sobre la extracción de datos de documentos bien formados o semi-estructurados, como los mencionados en este capitulo, se considera que éstos adolecen de flexibilidad para extraer información de distintas fuentes, o bien pudieren tener dificultad para lidiar con cambios en una misma fuente. Por cada trabajo se exponen las siguientes diferencias: Estructura de búsqueda por dominio [10]: No considera el uso de una misma palabra en distintos dominios de información; así como el uso de distintas palabras para referenciar el mismo elemento de información. Estructuras similares [11]: Si bien la idea de estructuras similares para buscar tiene utilidad, el lenguaje HTML permite desplegar de distintas formas una misma información. En esta situación se considera que una estructura de búsqueda, a como está planteada en el trabajo, batalla en páginas diferentes que muestren la misma información, como tablas anidadas dentro de tablas. De igual forma, si una página cambia su estructura, o los nombres de los elementos que crearon la representación numérica también cambian, la utilidad de dicha representación disminuye. Estrategia “Dividir y Vencer” [13]: La idea base de este trabajo, se ve reflejada en la estrategia de extracción propuesta en esta tesis. Sin embargo, de la manera definida del trabajo [13] se considera el siguiente punto débil: se asume que un elemento va a tener exclusivamente un valor concerniente a un elemento de la estructura de búsqueda que se trata de llenar, no se tiene contemplado que sucede cuando en un mismo elemento puede haber valores que satisfagan a más de un elemento de la estructura de búsqueda.. 27.
(37) Extracción de datos usando XML [16]: Proporciona la idea y justificación del uso de una estructura de búsqueda en lenguaje XML. Sin embargo, su orientación dirigida hacia la búsqueda de patrones relacionando información, difiere del propósito central de la actual tesis, orientado hacia el uso de una estructura de búsqueda previamente definida. En el capítulo 3 se expone a mayor detalle las aportaciones de esta tesis que complementan los trabajos mencionados en este capítulo. Se propone el uso de las estrategias de extracción para alguno de los siguientes escenarios: 1) Llenar una base de datos a partir de distintas fuentes, como un catálogo de carreras, de un área de conocimiento determinada, de distintas universidades. 2) Estandarizar distintas estructuras de información en una sola. 3) Copiado masivo de información hacia una base de datos. 4) Seguimiento en el tiempo de una misma fuente de información. Es de notar, que la idea de almacenar información en una base de datos relacional, donde los datos se guardan en tablas definidas por una determinada estructura, presentan una diferencia primordial con los elementos semi-estructurados de donde se desea extraer la información; ya que éstos tienen como característica importante, una estructura jerárquica donde se almacena la información [9]. Un documento bien formado facilita la transformación de datos, localizados en una estructura jerárquica hacia una estructura relacional. En el siguiente capítulo, se explicará la extracción de datos que se hará a los distintos documentos de web, aplicando los conceptos mencionados en este capítulo.. 28.
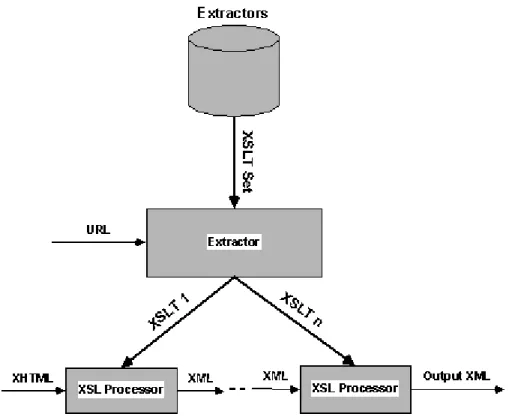
(38) Capítulo 3. Datos. Fundamentos de la Extracción de. En este capítulo se explicará a mayor profundidad la extracción de datos que se realizará sobre documentos semi-estructurados para obtener información. Primero se abordará la explicación de la metodología ANDES, que sirvió como punto de partida para este trabajo, posteriormente se desarrollarán conceptos que se manejarán a lo largo del documento y dentro de cada concepto, las actividades a realizar para la obtención de datos. De igual forma, en las secciones donde se considera conveniente, se mencionan los puntos en desacuerdo con los trabajos mencionados en el capítulo anterior, o en su defecto, los puntos que se han incorporado de dichos trabajos en la realización de las estrategias de extracción de información sugeridas en este documento.. 3.1. Extracción de datos. La extracción de datos es un proceso que toma elementos de procesos ya definidos previamente de la extracción de datos en páginas Web [1] y del modelo de búsqueda de información ANDES [18]. El resultado final es mostrar el resultado de la extracción en un documento XML bien formado [2]. Hay que destacar que este documento va a contener los datos extraídos ANDES es un conjunto de siglas que quiere decir “A Nifty Data Extraction System” en inglés. Es un método propuesto por Jussi Myllymaki de IBM, que define una plataforma sobre la cual “construir un proceso de extracción de datos en red con calidad de producción” [18]. La figura 3.1 muestra la metodología del modelo ANDES original. Esta metodología propone definir un conjunto de extractores, que son estructuras definidas en XML, aplicadas de manera iterativa sobre un documento HTML, de forma que al aplicar el último de los extractores se genera una estructura de salida deseada. 29.
(39) Figura 3.1. Flujo del proceso.. Sin embargo, se ven algunos inconvenientes que este trabajo busca responder: 1) Un primer paso es que el extractor se aplica sobre un documento XHTML. Si bien es posible extraer información, se considera que el documento debe estar bien formado de acuerdo a los estándares XML, como es propuesto en [8]. Además la proliferación de códigos para el formato del documento de manera dinámica como JavaScript y CSS, puede confundir al extractor de información y no se considera relevante para la información contenida en el documento. 2) La dificultad de localizar datos dentro de celdas en tablas, no especificadas en el caso de ANDES, pero que se propone en este trabajo para realizar una extracción más efectiva. 3) Desde un punto de vista de mantenimiento de estructuras de 30.
(40) búsqueda, puede ser complicado manejar varios niveles de extracción y acomodo. Por lo que se considera más práctico manejar una estructura final única.. 3.2. Propuesta de la estrategia. La figura 3.2, representa la estrategia propuesta en este trabajo, según la cual, el punto de partida es un documento escrito en lenguaje HTML, que puede provenir ya sea del World Wide Web, o como alternativa, se puede convertir un documento de otro formato, a lenguaje HTML. Para garantizar que sea un documento bien formado, se procede a transformarlo en un documento XHTML, un documento de información HTML que cumple con las reglas sintácticas del XML, convirtiéndolo en un documento estructurado bien formado.. Figura 3.2. Proposición de la estrategia.. 31.
(41) El siguiente paso, es que este documento sufrirá una segunda transformación que consiste en: Enumerar celdas en tablas para poder distinguir filas y columnas, con el fin de facilitar la ubicación de celdas donde se localice información. ●. Eliminar elementos HTML que no contienen información, tales como los tags que definen lenguajes Javascript.. ●. ●. Eliminar tags HTML que definen formato, tales como <i> y <b>.. Estas transformaciones se realizan por medio de un archivo XSL, el cual genera un documento XHTML con los tags que deberían contener la información a extraer del documento. En base a dicho documento generado, se crea un segundo XSL que transformará el documento XHTML en la estructura XML que contendrá los elementos a buscar. Este documento XSL es el que contiene las reglas de selección y extracción de información. La razón por la cual se opta por dejar el resultado final en un documento XML es para aprovechar la características de los documentos de este lenguaje: poder usarlos en distintas aplicaciones. No obstante, se puede hacer la siguiente observación: ¿porqué realizar la transformación de un documento HTML a un XML, para luego volverlo a transformar a un documento XML? La respuesta reside en que hay documentos HTML generados de manera dinámica por el servidor de Web, obteniendo la información a mostrar en la página de una base de datos; pero la forma en que el usuario recibe esta información es por medio de las páginas, para no tener que otorgarle acceso directo a la base de datos. Aquí se propone extraer la información de los documentos que un usuario tiene acceso, en este caso, las páginas HTML generadas.. 3.3. Definición de estructura de Búsqueda. El primer paso es definir una estructura de datos XML que contiene los elementos a buscar en las páginas Web. Cada elemento debe tener un nombre, puede tener un valor por defecto y uno o varios sinónimos. La estructura propuesta tiene la siguiente forma: 32.
(42) <dato @multiple=”si” @requerido=”si” @delimitador=”|”>nombre1 <default>valor default 1</default> <dominio>dominio de datos</dominio> <tablas>fila</tablas> <sinonimo>sinonimo1</sinonimo> <sinonimo>sinonimo2</sinonimo> </dato> <dato @multiple=”no”>nombre2 ….</dato> Donde cada elemento del documento está definido de la siguiente forma: •. Dato: Su valor es la palabra que será usada como punto de referencia en la búsqueda. Además puede contener otros elementos de este tipo para representar datos jerarquizados. Este elemento tiene a su vez tres atributos: o Multiple: Puede haber más de una instancia en la base de datos que contenga un valor válido para este dato. Esta situación puede darse en estructuras de datos jerarquizadas. El valor por default para este atributo es si. o Requerido: En caso de no hallar un punto de referencia relacionado con el dato o con sus sinónimos, indica que debe proceder con el dominio o el default. o Delimitador: En caso de hallar el punto de referencia en el tag de XHTML, indica si toma los caracteres a partir del punto de referencia hasta el carácter indicado en el atributo. En caso de no proporcionase, considera el valor como el string que inicia a partir del fín del punto de referencia hasta el fin del tag.. •. Default: Un valor a colocar en la estructura de salida en caso de que no se halle ni un elemento, ni un sinónimo, ni un elemento del dominio de datos solo si el valor del atributo “requerido” es “si”. Es posible indicarlo si no existe valor del atributo “requerido”, pero el proceso lo ignorará. La inclusión de este elemento es una propuesta para resolver una de las preguntas planteadas en [12]: ¿Existen en el documento todos los elementos que conforman la estructura de datos?. •. Dominio: Es un dominio de datos que muestra que tipo de cadena 33.
(43) de caracteres debe buscar en la página en caso de no encontrar un punto de referencia que satisfaga el elemento o sus sinónimos. Se recomienda el uso de expresiones regulares para facilitar la búsqueda de datos. •. Tablas: Indica como debe buscar los datos en tablas. Aplica en aquellos casos donde el valor hallado en una tabla pudiera pertenecer a un determinado dato. Solo puede contener dos valores: o Fila. El valor por default. En esta situación, el valor del dato “padre” se encuentra en la primera columna y el valor de este dato hay que buscarlo en columnas a la derecha. o Columna. En esta situación, el valor del dato “padre” se encuentra en la primera fila y el valor de este dato hay que buscarlo en filas subsecuentes.. •. Sinonimo: En caso de que no se encuentre un punto de referencia con la palabra especificado en “Dato”, busca los valores de este elemento para crear los puntos de referencia.. La inclusión del elemento “Sinonimo” se da para cubrir lo que se considera un punto débil en el trabajo [10] de Arasu y García, mencionado en la sección 2.2.4. Los fundamentos para este elemento son los siguientes: 1) Una palabra que sirva para distinguir información en un dominio de datos determinado, puede servir también para otro dominio de datos y es necesario establecer la diferencia, ya que la búsqueda puede arrojar datos pertenecientes a otro dominio. Por ejemplo: En el dominio de partidos de fútbol soccer, la palabra local puede usarse para determinar al equipo cuyo estadio es aquel donde se desarrolla el partido; sin embargo, en el dominio de datos de información fiscal, la palabra significa el lugar donde reside la empresa. Esta situación es un ejemplo del problema “esquema de datos diferentes” mencionado en la sección 2.4. 2) De igual forma, se encuentra que diferentes palabras pueden referirse al mismo elemento [4] y es necesario agregarlas a la estructura de búsqueda inicial. Un ejemplo lo vemos si la búsqueda se realiza en documentos de diferentes idiomas. Este ejemplo se ilustra en el primer caso práctico, en la sección 4.1. 34.
(44) 3) La búsqueda puede traer datos inválidos para el dominio de datos, no obstante que estén asociados a una misma palabra. Puede ser debido a la no existencia de una separación por tags de HTML, errores de construcción en páginas dinámicas, o incluso localización de palabras del dominio cuando no incluyen datos. Retomando el ejemplo de partidos de fútbol, podemos tener una página donde de antemano se presente información de las jornadas de partidos, sin que éstos se hayan efectuado aún, y por ende no tengan marcadores. Tomemos el siguiente ejemplo para representar el marcador final de un partido de fútbol <dato @multiple=”no” @requerido=”si”>local <default>Equipo Local</default> <dominio>String</dominio> </dato> <dato @multiple=”no” @requerido=”si”>marcador_local <default>0</default> <dominio>numero</dominio> </dato> <dato @multiple=”no” @requerido=”si”>marcador_visita <default>0</default> <dominio>numero</dominio> </dato> <dato @multiple=”no” @requerido=”si”>visita <default>Equipo visitante</default> <dominio>String</dominio> <sinonimo>visita</sinonimo> </dato>. La estructura considera buscar un resultado de la forma Local Marcador_local – Marcador_visita Visita. Hay que notar lo siguiente en la estructura. Ninguno de los atributos es múltiple, solo puede haber una ocurrencia de cada elemento.. ●. Es frecuente hallar que al equipo visitante, también se le refiere como solamente “visita”, por eso se le agrega como sinónimo.. ●. Desde el instante que un partido se realiza, los marcadores de ambos equipos empiezan con cero, por eso se define ese valor por defecto.. ●. 35.
Figure



+7





Documento similar
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
Para recibir todos los números de referencia en un solo correo electrónico, es necesario que las solicitudes estén cumplimentadas y sean todos los datos válidos, incluido el
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
Abstract: This paper reviews the dialogue and controversies between the paratexts of a corpus of collections of short novels –and romances– publi- shed from 1624 to 1637:
Habiendo organizado un movimiento revolucionario en Valencia a principios de 1929 y persistido en las reuniones conspirativo-constitucionalistas desde entonces —cierto que a aquellas
Por lo tanto, en base a su perfil de eficacia y seguridad, ofatumumab debe considerarse una alternativa de tratamiento para pacientes con EMRR o EMSP con enfermedad activa
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
Ciaurriz quien, durante su primer arlo de estancia en Loyola 40 , catalogó sus fondos siguiendo la división previa a la que nos hemos referido; y si esta labor fue de
