Asistente para la sustitución de valores ausentes en bases de datos
81
0
0
Texto completo
(2) Pensamiento. Pensamiento. “Los errores causados por los datos inadecuados son mucho menores que los que se deben a la total ausencia de datos.” Charles Babbage (1792-1871) Matemático e inventor británico.. ..
(3) Dedicatoria. Dedicatoria. Por todo el apoyo dado durante mis estudios, por la confianza puesta en mí y el cariño entregado; dedico mi tesis de diploma a mis padres..
(4) Agradecimientos. Agradecimientos. A todas las personas que me tendieron la mano, contribuyendo de una u otra forma a la realización de este trabajo. A ellas muchas gracias:. A mi familia; por estar junto a mí en los momentos más difíciles. A mi esposa Dailín por su entrega; por constituir mi soporte. A mi tutora Beatriz por su excepcional guía y por todas las enseñanzas dadas. A mis amistades por prender en mí la alegría y devolverme la confianza perdida: Yoanny, Yaniel, Ransés, Yerandy, Carlos Alberto, Carlos Armando, Adrián, Raidel, Aniel, Donis. A todos mis profesores por dejar su huella en mí y por ayudarme a ser un mejor profesional. A mis compañeras (os) de aula por los buenos momentos que compartimos; por haber sido mi otra familia durante cinco años..
(5) Resumen Resumen. El reemplazo de valores ausentes es una tarea de la limpieza de datos que tiene como objetivo eliminar la falta de información en las fuentes de datos; de forma que la ausencia del dato sea sustituida por un valor lo más cercano posible al que supuestamente debió existir. Para su desarrollo es necesario seleccionar el método apropiado, que dependerá de las particularidades del caso analizado. Esto conlleva a la necesidad de un estudio detallado de los métodos de reemplazo. El proceso puede desarrollarse de varias formas, una utilizada frecuentemente es el reemplazo de los valores perdidos por otros calculados a partir de información obtenida de los datos válidos en la tabla. La comprensión adecuada de los patrones de valores faltantes puede ayudar también a decidir el método a utilizar y lograr un reemplazo eficiente de los valores perdidos. El reemplazo de los valores ausentes proporcionará integridad y validez en los datos, permitiendo alcanzar el objetivo de mejorar la calidad de los mismos..
(6) Abstract Abstract The replacement of missing values is a task of cleaning up data that aims to eliminate the lack of information on sources of data so that the absence of data to be replaced by a value as close as possible to what was supposed exist. For its development is necessary to select the appropriate method, which depends on the specifics of the case analyzed, leading to the need for a detailed study of replacement methods. The process can develop in several ways, one is often used to replace missing values with other computed from information obtained from the data at the table. The proper understanding of the patterns of missing values can also help you decide which method to use and achieve efficient replacement of missing values. Replacing missing values provide integrity and validity of the data, allowing reaching the goal of improving their quality..
(7) Índice Índice de contenido Introducción .......................................................................................................................... 1 Capítulo 1: Limpieza de datos. Tratamiento de los valores faltantes .............................. 5 1.1. Limpieza de datos ........................................................................................................ 5 1.1.1. Proceso de Limpieza de Datos .............................................................................. 6 1.1.2. Desafíos y problemas que enfrenta la limpieza de datos ...................................... 6 1.2. El tratamiento de la información faltante .................................................................... 7 1.2.1. Definición de valores faltantes .............................................................................. 8 1.2.2. Tipos de valores faltantes ...................................................................................... 9 1.2.3. Tipos de patrones de valores faltantes................................................................. 10 1.2.4. ¿Por qué tratar la información faltante? .............................................................. 11 1.2.5. Técnicas más usadas............................................................................................ 12 1.3. Técnicas implementadas en el asistente ..................................................................... 13 1.4. Otros métodos para el tratamiento de la información faltante ................................... 17 1.5. Asistentes ................................................................................................................... 18 1.6. Conclusiones parciales ............................................................................................... 19 Capítulo 2: Descripción de algunos aspectos relacionados con el análisis y diseño del asistente ............................................................................................................................... 20 2.1. Pasos seguidos para la construcción del asistente ..................................................... 21 2.2. Modelación del sistema ............................................................................................. 25 2.2.1. Diagrama de Casos de uso .................................................................................. 25 2.2.2. Diagrama de Secuencia ....................................................................................... 36 2.2.3. Diagrama de Clases ............................................................................................. 36 2.3. Conclusiones parciales ............................................................................................... 41 Capítulo 3: Guía de usuario y valoración de los resultados de la herramienta a través de un caso de estudio ......................................................................................................... 42 3.1. Guía de usuario .......................................................................................................... 42 3.1.1. Requerimientos del software ............................................................................... 42 3.1.2. Descripción de la herramienta y sus funcionalidades ......................................... 42.
(8) Índice 3.1.3. Interfaz de usuario ............................................................................................... 43 3.2. Caso de estudio .......................................................................................................... 57 3.2.1. Pasos seguidos para desarrollar las pruebas: ....................................................... 57 3.2.2. Resultados ........................................................................................................... 58 3.2.2.1. Análisis de la base de casos Iris original ..................................................... 58 3.2.2.2. Análisis de las bases de casos con 5, 10 y 15% de información ausente ... 59 3.2.2.3. Análisis de las bases de casos después de realizar el tratamiento de información ausente. ................................................................................................. 61 3.3. Conclusiones parciales ............................................................................................... 67 Conclusiones ........................................................................................................................ 68 Recomendaciones ................................................................................................................ 69 Referencias bibliográficas .................................................................................................. 70.
(9) Introducción Introducción El tratamiento de la información faltante es una tarea muy importante dentro del proceso de limpieza de datos, que conduce a un incremento en la calidad de la información y de confiabilidad en los procesos y análisis realizados sobre los datos. Actualmente, cada vez más, las organizaciones toman decisiones sobre la base del conocimiento derivado de los datos almacenados en sus bases o almacenes de datos, aplicando el enfoque denominado Inteligencia del negocio. Por tanto, es de vital importancia que los datos contengan la menor cantidad de errores posibles ya que los datos sucios pueden conducir a decisiones erróneas, ocasionando pérdida de tiempo, dinero y credibilidad (Uribe and Ramírez, 2009). En (Redman, 1998) se plantea que aún habiéndose usado los métodos más sofisticados para tratar de evitar los errores, la razón de estos en los datos es de alrededor de un 5%. En (Damerau, 1964) se señala que en las bases de datos alrededor del 60% de los datos tienen algún problema de calidad. Un estudio más reciente señala que el 25% de los datos críticos de una empresa presentan errores y que estas en muchas ocasiones no tienen conciencia de ello (Gartner, 2007). Puede afirmarse que: “la mala calidad de los datos sobre los clientes, lleva a costos importantes, como el sobreestimar el volumen de ventas, el exceso de gastos en los procesos de contacto con los clientes y la pérdida de oportunidades de ventas. Sin embargo las empresas están descubriendo que la calidad de sus datos tiene una incidencia significativa en la mayoría de sus iniciativas empresariales estratégicas, y no solo en el área de ventas o investigación de mercados. Otras funciones como elaboración de presupuestos, producción y distribución también se ven afectadas” (Gartner, 2007). La importancia de contar con datos confiables, con los cuales se puedan tomar decisiones acertadas, es cada vez mayor. Conceptos como gestión del conocimiento, minería de datos e inteligencia de negocios, se están desarrollando a pasos agigantados, y de poco o nada sirven si se basan en datos errados (Uribe and Ramírez, 2009). Existen varias técnicas relacionadas con el tema que funcionan alrededor de la idea de sustituir la ausencia de valor por la información más cercana a los valores reales. Encontrar 1.
(10) Introducción el dato ausente es la técnica más precisa, pero a la vez, la más difícil o engorrosa de utilizar. El uso de las diferentes técnicas de sustitución está restringido por la naturaleza o el tipo de dato del valor a sustituir, ya sea numérico continuo o discontinuo, cadena, fecha, booleano u otro tipo (Montero, 2009), así como por los porcentajes de valores ausentes que presenten los datos analizados. Este trabajo aborda el tema de la limpieza de datos y dentro de este particularmente y como objeto de estudio el tratamiento de la información faltante. Antecedentes de la investigación De la revisión bibliográfica realizada sobre el tema se ha podido establecer que las técnicas para la sustitución de los valores ausentes se encuentran de forma general en herramientas dirigidas a realizar procesamientos estadísticos y en otras que en lugar de hacerse sustituciones, tratan los valores ausentes sin sustituirlos, como por ejemplo las herramientas de minería de datos. Además no existe un software que desde la perspectiva de las bases de datos reúna las diferentes técnicas que se reportan en la bibliografía para realizar la sustitución de los valores ausentes. En la actualidad algunos gestores de bases de datos introducen en sus utilitarios algunos de estas técnicas, que generalmente son las básicas, y no brindan una información adicional sobre cuál técnica utilizar en cada caso. En las tesis (Montero, 2009, Martina, 2005, Paz. et al., 2006) se comenzó el estudio de estas técnicas para construir un software que desde la perspectiva de las bases de datos realizará la sustitución de los valores ausentes. Este software incorporó las siguientes técnicas: Casos Completos (Martín and CaberoMoran, 2008), Media, Mediana, Moda (Pyle, 1999), Regresión lineal y Regresión lineal múltiple (Cañizares et al., 2004), y permitió la conexión a todos los gestores de base de datos. Se implementó en Delphi y la principal dificultad que presentó para desarrollar el proceso de limpieza de datos es que requiere que el usuario tenga un conocimiento especializado sobre las técnicas incorporadas. Es por ello que se decide crear un software con interfaz de asistente para tratar la información ausente, lo cual permitirá facilidad en el trabajo, ya que no será necesario que el analista de datos sea un experto en el dominio de las diferentes técnicas.. 2.
(11) Introducción Planteamiento del problema La inexistencia de un asistente en la UCLV que guíe a los analistas de datos en la sustitución de valores ausentes en bases de datos. Objetivo general Obtener una nueva versión del software para la sustitución de valores ausentes que trabaje sobre los gestores SQL Server, MySql y PostgresSQL, y que esté desarrollado en forma de asistente. Objetivos específicos • Crear el asistente, programar e incorporar a este las técnicas de reemplazo de valores ausentes implementadas en la herramienta anterior, usando Java como lenguaje de programación y considerando los elementos necesarios para el desarrollo de un asistente. • Programar e incorporar al asistente el método Hot Deck. • Verificar la efectividad del software con bases de datos reales. Pregunta de Investigación ¿Será posible combinar las técnicas reportadas en la literatura sobre reemplazo de valores ausentes en un procedimiento que ayude a especialistas no expertos en estadísticas en esta tarea? Justificación de la Investigación El asistente para la sustitución de valores ausentes en bases de datos tiene como objetivo proporcionar gran facilidad y confiabilidad para desarrollar el reemplazo de valores ausentes en una base de datos y de esta forma lograr mayor precisión en la información que se obtiene del procesamiento de los datos con información faltante, lo cual mejorará la toma de decisiones basada en esta información. La verificación del sistema con base de datos reales mostrará cuán eficiente es el mismo y contribuirá a su perfeccionamiento, ya que permitirá realizar los ajustes necesarios en función de los errores encontrados. El presente documento está estructurado de la siguiente forma: Capítulo 1. Limpieza de datos. Tratamiento de valores faltantes. Se presentan las características generales del problema abordado, definición y tipos de datos faltantes y la necesidad de tratar la información faltante o ausente. Capítulo 2. Descripción de algunos aspectos relacionados con el análisis y diseño del asistente. 3.
(12) Introducción En este capítulo se presentan los pasos seguidos para crear el asistente y se da una descripción detallada del caso de uso Reemplazar valores ausentes. Además se muestra el diagrama de clases usado para implementar la herramienta y una especificación del mismo atendiendo a las clases relacionadas con el método Hot Deck. Capítulo 3. Guía de usuario y valoración de los resultados de la herramienta a través de un caso de estudio. Primeramente se describen los aspectos fundamentales de cada una de las vistas del sistema, donde se especifica qué hace y cuál será la próxima interfaz mostrada para cada uno de los casos. Luego, se muestra un caso de estudio para el cual se utiliza la base de casos Iris, que tiene por objetivo valorar la efectividad del software.. 4.
(13) Capítulo 1 Capítulo 1: Limpieza de datos. Tratamiento de los valores faltantes 1.1. Limpieza de datos Son varias las formas descritas en la literatura científica para referirse al tema de la limpieza de datos. Entre estas podemos encontrar: comprobación de errores, limpieza de datos (término utilizado en esta investigación), depuración de datos, lavado de datos y corrección de errores. La limpieza de datos es crucial para una gran variedad de aplicaciones en disímiles áreas, y puede convertirse en un proceso abrumador si los volúmenes de información crecen de manera explosiva. Esta tarea es el acto de descubrimiento, corrección o eliminación de datos erróneos de una base de datos y se hace aún más necesaria cuando existen varias fuentes de datos que requieren de integración. Este proceso permite identificar datos incompletos, incorrectos, inexactos, no pertinentes, duplicados, etc., y luego substituir, modificar o eliminar estos datos sucios. Las inconsistencias descubiertas, modificadas o eliminadas pueden haber sido causadas por: Diferentes definiciones en el diccionario de datos de entidades similares, errores de entrada del usuario. Corrupción en la transmisión o el almacenaje. Campos perdidos. Errores tipográficos, etc. Aunque según (K. Kaewbuadee, 2009, Montero, 2009) los datos en general tienen alguna semántica de dependencia y estas usualmente ayudan a evitar tales errores. Varias veces estas semánticas de dependencias son ignoradas o desapercibidas durante el diseño de la base de datos. En (Chapman, 2005) se define la limpieza de datos como un proceso utilizado para determinar los datos inexactos, incompletos o no razonables y la mejora de la calidad a través de la corrección de errores y omisiones detectadas. El proceso puede incluir el chequeo de formato, chequeos de la integridad, verificaciones de razonabilidad, verificaciones de límites, la revisión de los datos para identificar valores atípicos (geográfica, estadística, temporal o ambiental) u otros errores, y la evaluación de los datos por expertos en materia (por ejemplo, especialistas en taxonomía). Estos procesos suelen 5.
(14) Capítulo 1 dar lugar al marcado, documentación y posterior chequeo y corrección de los registros sospechosos. 1.1.1. Proceso de Limpieza de Datos Para desarrollar la limpieza de datos deben considerarse una serie de pasos encaminados a estructurar este proceso, los cuales garantizan la obtención de. resultados sólidos y. satisfactorios. El proceso de Limpieza de datos puede verse de la siguiente manera (Wikipedia, 2010): . Auditoría de datos: los datos son revisados con el empleo de métodos estadísticos para descubrir anomalías y contradicciones. Esto da una indicación de las características de las anomalías y sus posiciones.. . Definición de flujo de trabajo: la detección y la eliminación de las anomalías se realizan por una secuencia de operaciones sobre los datos denominada flujo de trabajo. Para determinar un flujo de trabajo apropiado debe identificarse las causas de las anomalías y errores. Si por ejemplo se encuentra que una anomalía es un error en la etapa de entrada de datos, la disposición del teclado puede ayudar en la solución de estos problemas.. . Ejecución de flujo de trabajo: en esta etapa, el flujo de trabajo es ejecutado después de que su especificación es completada y su corrección es verificada. La implementación del flujo de trabajo debe ser eficiente aún sobre volúmenes grandes de datos, lo cual inevitablemente plantea un reto, debido a que la ejecución de las operaciones de limpieza pueden ser computacionalmente costosas.. Post-Proceso y control: los datos que no puedan ser corregidos durante la ejecución del flujo de trabajo, deberán, de ser posible, ser corregidos manualmente. El resultado es un nuevo ciclo en el proceso de limpieza de datos donde los datos son revisados nuevamente para ajustarse a las especificaciones de un flujo de trabajo adicional y realizar un tratamiento automático. 1.1.2. Desafíos y problemas que enfrenta la limpieza de datos A continuación se muestran los desafíos y problemas al desarrollar el proceso de limpieza de datos (Wikipedia, 2010): . Corrección de error y pérdida de información: el mayor desafío dentro de la limpieza de datos es la corrección de valores pues incluye el quitar duplicados y. 6.
(15) Capítulo 1 entradas inválidas. En muchos casos, la información disponible sobre tales anomalías es limitada e insuficiente para determinar las transformaciones necesarias o correcciones, conduciendo a la eliminación de tales entradas como la única solución. La eliminación de datos conduce a la pérdida de información y puede ser en particular costosa si hay una cantidad grande de datos suprimidos. . Mantenimiento de datos limpios: la limpieza de datos es cara y el tiempo consumido es grande. Después de haber realizado la limpieza de datos y alcanzar una colección de datos sin errores, se querría evitar la relimpieza de datos íntegramente después de que se realizan algunos cambios en la base de datos. El proceso sólo debería ser repetido sobre los valores que se han cambiado.. . Limpieza de datos en entornos virtualmente integrados: en fuentes integradas virtualmente (por ejemplo, DiscoveryLink de la IBM), la limpieza de datos tiene que ser realizada accediendo siempre a datos de diferentes fuentes, con una considerable disminución del tiempo de respuesta y aumento de eficacia.. . Limpieza de datos en el área de trabajo: en muchos casos es posible llegar a un procedimiento completo de limpieza de datos que guíe el proceso por adelantado. Esto hace que la limpieza de datos sea un proceso iterativo que implique. la. exploración significativa y la interacción que puede requerir un área de trabajo, es decir, un marco que incluya una colección de métodos para la detección de errores y la eliminación de estos. Esto puede ser integrado con otras etapas informáticas como la integración y el mantenimiento. 1.2. El tratamiento de la información faltante El tratamiento de la información faltante es una tarea que puede considerarse como un proceso medular dentro de limpieza de datos. Está dirigida a la obtención de información clara y precisa, lo cual conduce al incremento en la calidad de la información en todos los procesos y análisis realizados sobre los datos. En (Little, R.J. and D.B. Rubin, Statistical Analysis with Missing Data, New York: John Wiley and Sons, 1987) se establece que es importante reconocer de qué manera se han producido las ausencias de valor antes de proceder a decidir el método para sustituirlos. Existen tres tipos de ausencias que se clasifican como:. 7.
(16) Capítulo 1 Completamente Aleatoria. (MCAR – Missing Completely At Random,. cuando la probabilidad de ausencia del valor de una variable es completamente independiente del valor del mismo y de cualquier otra variable) Aleatoria (MAR – Missing At Random, la ausencia del valor de una variable no depende del valor mismo, pero sí del valor de alguna otra variable) No Ignorable (cuando la ausencia está relacionada con la variable en sí misma y no es predecible desde ninguna otra variable del conjunto). La mayoría de los algoritmos de imputación asumen el supuesto de que los datos faltantes siguen un patrón completamente aleatorio (MCAR). Sin embargo es frecuente que en la práctica, particularmente en encuestas, esta hipótesis no se satisfaga. 1.2.1. Definición de valores faltantes La ausencia de la información es un aspecto delicado que puede traer problemas dentro de cualquier tarea de procesamiento de datos, por lo que requiere ser tratada antes de desarrollar el análisis u otra operación sobre una base de datos. La información ausente o faltante, como también. se conoce, es la unión entre los valores nulos y los valores. ausentes, aspecto este que será tratado más adelante. Los valores faltantes son un problema común y la mejor implementación para minimizarlos es a través de una cuidadosa administración y asegurando la calidad de los datos. Cuando estos valores son menores que 1% son generalmente considerados triviales, de 1-5 % manejables, de 5-15% requieren de métodos sofisticados para manejarlos y más de un 15% afectan seriamente cualquier clase de interpretación (López-Porrero, 2011, McDermeit et al., 1999). Es importante destacar que la información faltante está relacionada con los tipos de datos. De aquí que se defina como información faltante, en primer lugar los valores NULL presentes en los diferentes campos sin importar el tipo, además los valores cero para los campos numéricos y las cadenas vacías para campos tipo cadena, pues es muy común en entornos de datos que no se utilice la marca NULL para indicar ausencia de valores y sí el cero o la cadena vacía dependiendo del tipo de dato del atributo en cuestión.. 8.
(17) Capítulo 1 1.2.2. Tipos de valores faltantes La existencia de valores ausentes puede estar dada por diferentes causas: ausencia de respuesta del cliente (por ejemplo, en una encuesta), errores de entrada del usuario, mal funcionamiento de los sistemas de adquisición de datos, entre otras. La definición de estos involucra dos formas diferentes de ver la ausencia de información (Pyle, 1999): Dato ausente: es un valor que no está en nuestro conjunto de datos; pero que existe en el mundo real, sencillamente por algún error no aparece en nuestra base de datos operacional. Dato nulo (o vacío): es un valor que está fuera de la definición de cualquier dominio, el cual permite dejar el valor del atributo “latente”. En otras palabras, un valor nulo no representa el valor cero, ni una cadena vacía, estos son valores que tienen significado; implica ausencia de información porque se desconoce el valor del atributo o simplemente para ese objeto no tiene sentido. Es un dato que falta, o sea, no existe en el mundo real. Un ejemplo pudiera ser el siguiente: se quiere controlar de un restaurant el plato fuerte seleccionado, (pollo o embutido) los cuales son excluyentes y además el sexo de quien realizara el pedido. Llega entonces el cliente y realiza su pedido, pero no desea plato fuerte. Si además el operador encargado de recoger los datos para el control, olvida introducir al sistema el sexo del cliente, habrá entonces dos campos sin valor: sexo y tipo de plato fuerte, el primero existe (el cliente tiene un sexo determinado), sin embargo el segundo no existe (el cliente no quería plato fuerte) (Montero, 2009). En los sistemas de bases de datos habitualmente no se hace diferencia entre un tipo de valor y otro, sencillamente se deja vacío el campo o en el mejor de los casos se utiliza el valor NULL para mostrar la falta de información. En Cuba es común que no se utilice la marca NULL y en su lugar se escribe 0 (si es un dato numérico) o una cadena vacía en el caso de cadenas. Esto trae una complejidad adicional en el tratamiento de ausentes, pues el cero y la cadena vacía pueden tener significados concretos diferentes a la ausencia de valor. En (Camacho, 2000) se define dato nulo o valor nulo como un indicador que dice al usuario que el dato falta o no es aplicable. Por conveniencia, un dato que falta normalmente se dice que tiene el valor Null, pero el valor Null no es un valor de dato real sino una señal o recordatorio de que el valor falta o es desconocido. Otra definición para dato ausente (Missing value) es:. 9.
(18) Capítulo 1 Sea S un conjunto de nombres de atributos, que se define como: S = {a | a ∈ R (A) ∧ a atributo obligatorio}, es decir, S ⊆ R (A). Existe un valor ausente en un atributo a ∈ S, si y sólo si: ∃ t ∈ r: v (t, a) = null. Ejemplo: la ausencia de valor en el atributo obligatorio “nombre” del cliente. La ausencia de valor en un atributo opcional, no es considerado un problema de calidad de datos (Oliveira et al., 2007). La existencia de los valores ausentes puede ser consecuencia de: - Existencia de tuplas con ciertos atributos desconocidos en el momento de la entrada de la información. - Necesidad de añadir un nuevo atributo a una tabla ya existente; atributo que en el momento de introducirse no tendrá ningún valor para ninguna de las tuplas de la relación. - Posibilidad de atributos inaplicables a ciertas tuplas. Ejemplo: DNI. NOMBRE. DIRECCIÓN. 35784843. María Gutiérrez. Null. La siguiente tupla: { (dni, 35784843), (nombre, María Gutiérrez), (dirección, Null) } que se puede denotar como tupla T, es una representación de esta función mediante pares (atributo, valor). En esta tupla el atributo dirección tiene valor ausente indicando que se desconoce la dirección de esta persona (Camacho, 2000). 1.2.3. Tipos de patrones de valores faltantes Un aspecto importante dentro del tratamiento de la información ausente es el análisis de los patrones de valores faltantes, tarea que sin duda puede ayudar a decidir que método de imputación utilizar. Estos patrones son un modelo en el que cada fila de la tabla analizada es una cadena de ceros y unos, donde el cero significa que el dato está ausente y el uno que el dato es válido. Al analizar un patrón, el orden de las variables es importante, debido a que este puede hacer que el patrón varíe. De aquí que para su clasificación se tenga en cuenta el orden en que aparecen los valores ausentes. Según (Montero, 2009) estas clasificaciones son:. 10.
(19) Capítulo 1 • Patrón de valores faltantes monótono: para un conjunto de datos con variables Y Y , Y ,…, Y 1,. 2. 3. p. (en ese orden) se dice que el patrón de valores faltantes es. monótono si la variable Y tiene valor faltante para un caso en particular y para j. todos los k donde k > j, Y tiene valor faltante para ese mismo caso. k. Alternativamente si Y no tiene valor faltante en un caso en particular entonces para j. todos los k donde k < j, Y no tiene valor faltante para ese mismo caso. k. • Patrón de valores faltantes arbitrario: para un conjunto de datos con variables Y Y , Y ,…, Y 1,. 2. 3. p. (en ese orden) se dice que el patrón de valores faltantes es. arbitrario si la variable Y tiene valor faltante para un caso en particular y para al j. menos un k donde k>j, Y no tiene valor faltante para ese mismo caso. Todo patrón k. que no es monótono es arbitrario. En el proceso de sustitución para el caso de un patrón de valores faltantes monótono se sugiere aplicar principalmente el método paramétrico de regresión lineal múltiple, que asume normalidad multivariante y en el caso de que el patrón sea arbitrario se sugiere el método de Monte Carlo con cadena de Markov (Yuan, 2000, Pyle, 1999). 1.2.4. ¿Por qué tratar la información faltante? El tratamiento de la información faltante es sin duda un aspecto de suma importancia con lo cual se busca lograr mayor grado de exactitud en la información, mejorando con ello los resultados de los procesos de análisis aplicados sobre almacenes y base de datos. Los datos faltantes disminuyen el tamaño muestral efectivo, de manera que las estimaciones son menos precisas. (tienen intervalos de confianza más amplios) y las. pruebas estadísticas tienen menos potencia para excluir la hipótesis nula estadística para las asociaciones observadas. Este problema es agravado en los análisis multivariados (por ejemplo, análisis estratificado o regresión logística), dado que la mayoría de estos procedimientos eliminan toda observación a la cual le falte un valor en cualquiera de las variables del análisis. Así, un modelo logístico con ocho variables puede perder fácilmente el 30% de las observaciones aún si ninguno de las variables individuales tiene más de 10% de valores faltantes (Schoenbach, 2004).. 11.
(20) Capítulo 1 Además de las razones anteriormente expuestas existen otras fuentes que también se refieren a la necesidad de reemplazar los valores perdidos: 1. Algunas técnicas de modelación no pueden lidiar con valores faltantes y desechan todos los valores de una instancia si una de las variables tiene valor faltante. 2. Las herramientas de modelación que usan métodos de reemplazamiento por defecto pueden introducir distorsión si el método es inapropiado. 3. El modelador debería conocer y controlar las características de algún método de reemplazo. 4. Muchos métodos de reemplazo por defecto descartan la información contenida en los patrones de valores faltantes (Montero, 2009). Los resultados de análisis y operaciones realizadas sobre bases de datos con información faltante pueden resultar no reales. De aquí que sea tan importante el tratamiento de valores ausentes, con el cual se espera obtener información con la calidad adecuada, capaz de proporcionar resultados concretos y exactos al realizar cualquier tarea de procesamiento de datos. 1.2.5. Técnicas más usadas Seleccionar una u otra técnica para el reemplazo de valores ausentes es un aspecto esencial para poder garantizar la calidad de los datos. Escoger el método adecuado implica tener en cuenta aspectos como el tipo del conjunto de datos, tamaño del archivo, objetivos de la investigación, software disponible, distribuciones de frecuencia de cada variable, análisis de los mecanismos de pérdida de datos entre otros aspectos. Un camino muy fácil para tratar los valores perdidos es ignorándolos, pero de esta forma se ve afectada la calidad de la base de datos que contiene los valores perdidos (Redman, 1992). Algunas de las técnicas descritas en. (Rubin, 1996) imputan los valores ausentes,. considerando cada atributo sin relación con los demás. Otras técnicas son más complejas, utilizan la regresión, las redes bayesianas, los árboles de decisión y otros métodos que son descritos en (Coppola et al., 2000, Farhangfar et al., 2004, Hu et al., 1998, Graham, 2009, Lakshminarayan et al., 1999, Little and Rubin, 1987). La mayoría de las técnicas asumen que la ausencia de valor es del tipo MAR o MCAR (López-Porrero, 2011).. 12.
(21) Capítulo 1 Como característica importante de los métodos de imputación se señala que no deben producir sesgo (unbiased estimators), de forma que no cambien las características más importantes de los valores presentes cuando son incluidos los valores imputados (LópezPorrero, 2011). Los datos perdidos que no representan un gran porcentaje (<5%) se pueden reemplazar usando la media (si es normal), mediana (si es sesgado) o moda (si es categórico), donde el propósito es comparar varios grupos (las condiciones del género o tratamiento), y a menudo es deseable hacer este reemplazo dentro de cada grupo (McDermeit et al., 1999). Si el porcentaje de los valores perdidos excede el 5%, un nuevo problema surge. Reemplazar todos los registros por un solo valor disminuirá la varianza y aumentará la significación de cualquier prueba estadística basada en el mismo. En estos casos es recomendable el uso de métodos avanzados como pueden ser la imputación Hot-Deck, la imputación múltiple (que modela la incertidumbre a los datos que faltan mientras usa los datos existentes (Rubin, 1987) o un modelo de regresión (que predice el valor que falta en función de los demás datos disponibles) (Montero, 2009). Muchas de estas técnicas tienen gran complejidad matemática, son computacionalmente costosas o pueden introducir sesgo sobre los datos analizados. En este sentido, se reafirma la relevancia de seleccionar la técnica adecuada para obtener buenos resultados al aplicarse la imputación de valores ausentes. A continuación se muestran las técnicas implementadas en el asistente y otras que también están dirigidas al tratamiento de la información faltante. 1.3. Técnicas implementadas en el asistente Análisis de Casos Completos: En este tipo de análisis, el investigador simplemente elimina aquellos casos que presentan datos perdidos. Es el sistema estandarizado en la mayoría de los paquetes estadísticos comerciales, y se conoce con el nombre de listwise (Costas et al., 1997). En estudios de simulación se ha encontrado que aunque la base de datos tenga tan sólo un 10% de datos faltantes, al realizar un análisis multivariado con la opción listwise (Análisis de casos completos) se pierde 59% de los datos (Carracedo-Martínez and Figueiras, 2006). La pérdida de información relevante es directamente proporcional al número de ausentes, esta se traduce en sesgo y falta de precisión de las estimaciones (García et al., 2006). La 13.
(22) Capítulo 1 solución a este problema suele radicar en eliminar aquellas variables con un mayor porcentaje de valores ausentes. En cualquier caso, si el patrón de ausentes no es MCAR, el tamaño del sesgo depende, entre otros aspectos, del grado de asociación entre la variable ausente y otras variables de la investigación, de la cantidad de datos perdidos así como de las características intrínsecas del análisis que se esté llevando a cabo (Costas et al., 1997). Como ventajas se destaca su simplicidad, la obtención de estimadores válidos y el hecho de que todos los estadísticos se calculan utilizando el mismo tamaño muestral (García et al., 2006). La utilización de esta técnica es muy común cuando la cantidad de casos de valores ausentes en grandes bases de datos es menor que un 5% (Garson, 2006). Sustitución por medidas de tendencia central: Esta técnica consiste en calcular el valor de una medida de tendencia central (media, mediana, moda o desviación estándar) para cada variable del conjunto de datos y posteriormente son reemplazados los valores ausentes de esa variable por un valor que no modifique el valor de la medida calculada (Giménez, 2000). El uso de uno u otro estadígrafo depende de la naturaleza del dato. Para variables “categóricas” o “de clase” se utiliza la moda (el valor de mayor frecuencia); para variables “enteras” u “ordinales”, se emplea la mediana (el valor que se encuentra “en medio” de la lista de datos ordenada de forma ascendente, es decir, el valor que cumple que la mitad de los valores de la variable son menores a él y la otra mitad son mayores que él) y para variables “reales” o “continuas” se emplea el promedio. (la sumatoria de los valores de la variable divididos por su. frecuencia), o la desviación estándar (Montero, 2009). La sustitución por las medidas de tendencia central puede generar sesgo en los datos, pues imputa un mismo valor para cada ausencia de una misma variable (es decir, si una variable está ausente en 20 registros diferentes, habrán 20 nuevas ocurrencias de la “media” en esa variable), lo cual puede afectar los resultados de los análisis posteriores realizados sobre los datos. (por ejemplo, si se aplicara una “clasificación”, la súbita aparición de más. ocurrencias de los valores medios podría causar mucha “afluencia” de registros hacia una clase en particular) (Montero, 2009). Imputación por regresión: En los métodos que utilizan la interpolación por regresión, los valores ausentes para un registro dado son imputados por un modelo de regresión basado en los valores completos 14.
(23) Capítulo 1 de los atributos para ese registro (Uribe, 2010). La selección de uno u otro método de regresión está relacionada con el tipo de dato de la variable con información ausente. Si el valor que ha de imputarse es un número (por ejemplo, la edad, el salario o los valores de presión arterial) y las variables que intervienen forman un patrón de valor faltante monótono se puede emplear la regresión múltiple. En caso que sea una variable categórica, como sexo, el estatus socio-económico o la práctica de ejercicio físico en el tiempo libre, podría emplearse la regresión logística y hacer la imputación según la probabilidad que el modelo de regresión estimado otorgue a cada categoría para el sujeto en cuestión (Cañizares et al., 2004). Estos métodos preservan la varianza y la covarianza de las variables con valores ausentes (Montero, 2009). Además al igual que en el análisis de los casos completos, tienen la ventaja de trabajar con la base de datos completa y que se pueden desarrollar empleando los procedimientos y paquetes estadísticos estándares. Sin embargo, la ventaja sobre el análisis de casos completos está en el hecho de que no hay pérdida de información, puesto que se trabaja con todas las unidades que fueron estudiadas (Cañizares et al., 2004, Uribe and Ramírez, 2009). Si los errores son ignorados cuando los valores perdidos son predichos, puede inflar el poder del modelo de predicción puesto que los valores perdidos de las variables dependientes fueron presentados perfectamente como predictores. Además esta técnica depende de un orden de acuerdo al cual las variables serán reemplazadas (Montero, 2009). Método probabilístico basado en la distribución de los datos no perdidos: (Montero, 2009). La idea de esta técnica es estimar la distribución de los datos disponibles en la variable donde queremos restablecer los valores perdidos y entonces, generar estos de acuerdo a dicha distribución. Puede ser implementado en 4 pasos: 1. Calcular la frecuencia de los valores válidos. Para asegurar la menor acumulación de errores en el procedimiento los datos deben ser ordenados de forma ascendente con respecto a la frecuencia de los valores válidos. 2. Calcular el porcentaje válido (depende de la frecuencia) y porcentaje acumulado. 3. Calcular el porcentaje de valores perdidos y el número de valores a ser reemplazados. 4. Reemplazar los valores ausentes por el valor válido correspondiente a la frecuencia analizada. Disminuir la cantidad de los valores perdidos. 15.
(24) Capítulo 1 Este método se repite hasta que la cantidad de valores perdidos sea cero. Imputación Hot Deck: Con el propósito de preservar la distribución de probabilidad de las variables con datos incompletos, los estadísticos de encuestas desarrollaron el procedimiento de imputación no paramétrico denominado Hot Deck (Nisselson et al., 1983, Uribe, 2010). Este método tiene como objetivo llenar los registros con campos vacíos (receptores) con la información de registros con los datos completos (donantes) y los datos faltantes se reemplazan a partir de una selección aleatoria de los valores observados (Uribe, 2010). El algoritmo consiste en ubicar registros completos e incompletos, identificar características comunes de donantes y receptores y decidir los valores que se utilizarán para imputar los datos omitidos. Para la aplicación del procedimiento es fundamental generar agrupaciones que garanticen que la imputación se llevará a cabo entre observaciones con características comunes y la selección de los donantes se realiza de forma aleatoria, evitando que se introduzcan sesgos en el estimador de la varianza (Medina and Galván, 2007). Hot Deck identifica las omisiones y sustituye el valor faltante por uno presente de algún registro “similar”, utilizando para ello un conjunto de covariables correlacionadas con la variable de interés, logrando preservar mejor la distribución de probabilidad de las variables imputadas. La aplicación del método requiere adoptar algún criterio que permita identificar cuál de los valores observados será utilizado en la imputación (Medina and Galván, 2007, Uribe, 2010). Los métodos de imputación Hot Deck asumen que el patrón o mecanismo de ausencia de los datos es MAR dentro de cada grupo o clase de imputación (Lavrakas, 2008). Cuando se usa Hot Deck existe el peligro de duplicar el mismo valor si en los grupos de clasificación hay muchos valores faltantes y pocos valores registrados. Por ello resulta mejor cuando se trabaja con tamaños de muestras grandes. Una ventaja de este método es la conservación de la distribución de la variable (Goicoechea, 2002b, Uribe, 2010). Este método tiene algunas desventajas, ya que distorsiona la relación con el resto de las variables, carece de un mecanismo de probabilidad y requiere tomar decisiones subjetivas que afectan a la calidad de los datos, lo que imposibilita calcular su confianza. Otros de los inconvenientes son:. 16.
(25) Capítulo 1 1. Las clases han de ser definidas con base en un número reducido de variables, con la finalidad de asegurar que habrá suficientes observaciones completas en todas las clases. 2. La posibilidad de usar varias veces a una misma unidad, es decir un mismo valor en varias imputaciones (Goicoechea, 2002b). Es importante destacar que existen diferentes técnicas de imputación Hot Deck las cuales (Uribe, 2010) describe de la siguiente forma: . Hot Deck con muestreo aleatorio simple (Juárez, 2003). . Hot Deck por clases (Juárez, 2003). . Hot Deck secuencial (Useche and Mesa., 2006). . Hot Deck vecino más cercano (Juárez, 2003).. En el procedimiento de imputación Hot Deck con muestreo aleatorio simple (Juárez, 2003), los donantes se extraen de manera aleatoria. Dado un esquema de muestreo equiprobable, la media se puede estimar como la media de los receptores y los donantes. 1.4. Otros métodos para el tratamiento de la información faltante Imputación múltiple: La imputación múltiple es una técnica que se ha desarrollado en las últimas décadas, en esta al igual que en el resto de imputaciones un aspecto muy importante es la definición del modelo de imputación y el método de imputación. Es fundamental que el modelo empleado en las estimaciones de los valores faltantes contenga las variables que se van a emplear posteriormente en los análisis estadísticos ordinarios, con el fin de preservar las relaciones entre las variables (Goicoechea, 2002). En esta técnica los valores perdidos son sustituidos por m >1 valores simulados. Consiste en la imputación de los casos perdidos a través de la estimación de un modelo aleatorio apropiado. Esta imputación es realizada m veces y como resultado se obtienen m archivos completos con los valores imputados. Posteriormente, se lleva a cabo el análisis estadístico ordinario con las m matrices de datos completas y se combinan los resultados con una serie de fórmulas específicas proporcionadas por Little y Rubin (Little and Rubin, 1987). El objetivo de la imputación múltiple es hacer un uso eficiente de los datos que se han recogido, obtener estimadores no sesgados y reflejar adecuadamente la incertidumbre que la no-respuesta parcial introduce en la estimación de parámetros, para lo cual este método 17.
(26) Capítulo 1 es una de las mejores soluciones. En el caso de imputación simple tiende a sobreestimar la precisión ya que no se tiene en cuenta la variabilidad de las componentes entre las distintas imputaciones realizadas (Goicoechea, 2002). Asignación al azar de los casos que faltan: Un enfoque más sofisticado que el de realizar la imputación de valores ausentes, utilizando un único valor, es el de sacar los valores imputados de una distribución. De esta forma, las observaciones sin valores faltantes (los casos con datos completos) pueden ser usadas para generar una distribución de frecuencias para la variable. Esta distribución de frecuencias puede entonces ser usada como base para generar un valor al azar para cada observación a la que le falta una respuesta. Por ejemplo, si la educación fue medida en tres categorías – “menos de secundaria” (25% del conjunto de casos completos), “secundaria completa” (40%) o “más de secundaria” (35%) – entonces por cada observación, para la cual falta la educación, se saca un número al azar entre 0 y 1 de una distribución uniforme y se reemplaza el valor que falta con “menos de secundaria” si el número al azar es igual o menor que 0.25, “secundaria completa” si el número fue mayor que 0.25 pero igual o menor que 0.65 o “más de secundaria” si el número fue mayor que 0.65. Este método evita introducir una categoría de respuesta adicional y mantiene la forma de la distribución; pero si los datos que faltan no lo hacen completamente al azar (MCAR) la distribución igual será sesgada (Schoenbach, 2004). 1.5. Asistentes Un asistente es un software donde la interfaz de usuario se presenta a través una secuencia de cuadros de diálogos, con el fin de guiar a dicho usuario a través de una serie de pasos bien definidos. Usualmente este tipo de software se emplea para resolver tareas complejas que no son realizadas con frecuencia, facilitando su empleo y ejecución por parte de quien los utiliza. En el 2001, los asistentes se habían convertido en un mecanismo común en la mayoría de sistemas operativos orientados al consumidor. Muchas aplicaciones web, por ejemplo, los sitios de reserva en línea, hacen uso del paradigma del asistente para completar largos procesos de interacción.. 18.
(27) Capítulo 1 1.6. Conclusiones parciales Uno de los problemas que más afecta la calidad de los datos es la ausencia de valores, motivo por el cual el tratamiento de valores ausentes juega un papel fundamental dentro del proceso de limpieza de datos. Debido a la gran cantidad de técnicas reportadas en la literatura, a veces es difícil decidir la técnica a utilizar para tratar la información faltante, por lo que se hace necesario realizar el análisis adecuado para lograr éxito. Si se garantiza aplicar el método adecuado, se podrá entonces asegurar el incremento en la calidad de los datos obtenidos, objetivo principal en esta tarea.. 19.
(28) Capítulo 2 Capítulo 2: Descripción de algunos aspectos relacionados con el análisis y diseño del asistente El presente capítulo aborda algunos aspectos del análisis y diseño del Asistente propuesto, con lo cual se obtiene parte de su documentación. Esto facilita la comprensión de su estructura y funcionamiento. Además brinda gran apoyo para cualquier modificación o cambio que pueda sufrir en el futuro. Documentar un programa no es sólo un acto de buen hacer del programador por aquello de dejar la obra rematada. Es además una necesidad que sólo se aprecia en su debida magnitud cuando hay errores que reparar o hay que extender el programa con nuevas capacidades o adaptarlo a un nuevo escenario (Mañas, 2003). Por una u otra razón, todo programa que tenga éxito será modificado en el futuro, bien por el programador original o por otro que le sustituya, y es pensando en esta revisión de código que es importante que el programa se entienda (Mañas, 2003). La forma de documentar un software no es solamente comentando cada línea del código implementado, también pueden usarse varios diagramas para describir su estructura y funcionamiento. Para implementar esta aplicación se utilizó. Rational Unified Process. (RUP) como. metodología de desarrollo, la cual utiliza Unified Modeling Language. (UML) como. lenguaje para la realización de los diagramas. Dicho lenguaje ofrece varias ventajas que son descritas por la fuente (Zamitiz, 2004) tales como : . Mejora los tiempos totales de desarrollo (de 50 % o más).. . Modela sistemas (y no sólo de software) utilizando conceptos orientados a objetos.. . Establece conceptos y artefactos ejecutables.. . Crea un lenguaje de modelado utilizado tanto por humanos como por máquinas.. . Mejora el soporte a la planeación y al control de los proyectos.. . Permite una alta reutilización y minimización de los costos.. . Fácil actualización o modificado del software a programar.. Un asistente como su nombre lo indica es un software que conduce a los actores del sistema a través de un proceso que se presenta como un flujo de trabajo, concebido a partir de un procedimiento que da solución a un problema. 20.
(29) Capítulo 2 Como se explica en el capítulo 1, el software elaborado para el tratamiento de los valores ausentes presentó como principal impedimento para su utilización la necesidad de conocimiento, por parte de los usuarios o analistas de datos de las empresas, de los métodos y técnicas a emplear para realizar el proceso de sustitución. Es por eso que se decidió emprender el trabajo de construcción de un asistente con este objetivo, para lo cual fue necesario, a través de un estudio previo, establecer los pasos que guiarán el mismo. 2.1. Pasos seguidos para la construcción del asistente Como existe una gran variedad de técnicas para la imputación de valores ausentes se propone a continuación un procedimiento que ayuda a desarrollar esta tarea, combinando diferentes técnicas que aparecen en la literatura y sobre las cuales se implementa el “Asistente para el tratamiento de los valores ausentes” (DBNulos). El procedimiento no es completamente automático, pues el criterio del especialista que hace el análisis no se puede ignorar y en muchas situaciones la tarea a realizar dependerá del conocimiento que tenga el mismo sobre los datos. Paso 1: Determinar la base de datos y la tabla con la cual se trabajará. Este paso es obvio, pero es necesario tener presente que la unidad con que se trabajará en la imputación de ausentes es una tabla. En este paso el usuario deberá realizar la conexión con la base de datos, usando JDBC y como resultado se mostrarán las tablas que contiene la misma, a fin de que se pueda seleccionar una de ellas. Paso 2: Creación de una tabla auxiliar donde se harán la imputación de los valores ausentes. Después de sustituidos los valores ausentes es muy difícil reconocerlos. Además pudiera querer revertirse el proceso y sería muy complejo el hacerlo si no se cuenta con dicha tabla. Una vez seleccionada la tabla se crea una copia de la misma en la cual se procederá a hacer las sustituciones de los valores ausentes. Paso 3: Determinación de algunas estadísticas necesarias. Se determinará en este paso la cantidad de ausentes en cada uno de los atributos de la tabla (y el porcentaje que representa del total de tuplas), el porcentaje de ausentes totales de la tabla y los patrones de valores ausentes. Para estas estadísticas se tendrán en cuenta, en primer lugar, los valores NULL presentes en los diferentes campos. También se pueden tener en consideración los valores 0 (para los 21.
(30) Capítulo 2 campos numéricos) y las cadenas vacías (para campos tipo cadena), pues, como se ha referido en el presente capítulo, es muy común en nuestros entornos de datos no utilizar la marca NULL para indicar ausencia de valores y sí emplear el cero o la cadena vacía. Paso 4: Ignorar valores ausentes. La variante más sencilla para eliminar los valores ausentes es eliminar las tuplas que los contienen; esta técnica es muchas veces denominada “Análisis de Casos Completos” (Martín and Cabero-Moran, 2008). Esto es muy sencillo, pero solo aplicable cuando la cantidad de valores ausentes es poca, por ello se propone cuando los valores ausentes no sobrepasan el 1% del total (Stones, 2003, Little and Rubin, 1987, Rubin, 1996), aunque hay autores que plantean que se puede utilizar hasta el 5% (Garson, 2006). Hay otro caso a tener en cuenta y es ignorar no todas las tuplas que tengan valores ausentes sino aquellas que tengan mayor cantidad de ellos y que se consideren no utilizables. Para ello se define el concepto de umbral de usabilidad (UU) que se fija en 0,5 (considerando que si más de la mitad de los atributos en una tupla están ausentes la información que ella proporciona es de escaso valor) y se calcula el grado de incompletitud (GI) para cada patrón de valores ausentes encontrado: GI . m n , donde n es el grado de la tabla (cantidad de atributos) y m la cantidad de valores. ausentes en el patrón. Se seleccionan los patrones cuyo grado de incompletitud sea mayor que el umbral de uso definido ( GI > UU), se determinan cuántas tuplas cumplen con estos patrones y se propone su eliminación. Es importante aclarar que el umbral puede ser modificado en dependencia del conocimiento que el analista tenga de los datos. Paso 5: Imputar valores ausentes a partir de valores conocidos. En la literatura se reportan diferentes procedimientos estadísticos para imputar los valores ausentes, pero en ocasiones el valor ausente puede ser reemplazado por algún valor presente en la tabla que se analiza o en alguna otra que exista en la base de datos, o por el resultado de una expresión que se calcule con estos valores. En este paso el analista analiza y determina si tales valores o expresiones existen y, en caso de ser valores de otras tablas, generalmente es necesario realizar un acople entre ambas tablas, para lo que se solicita los campos a través de los cuales se debe realizar la operación. 22.
(31) Capítulo 2 Paso 6: Imputación utilizando estimadores para atributos individuales. En este paso se sustituyen los valores ausentes de un atributo por valores calculados a partir de los datos presentes. Se recomienda cuando el por ciento de valores ausentes no sobrepase el 5% del total. Para aplicarla es necesario suponer que los valores ausentes se distribuyen de la misma forma que los valores presentes en los datos. En estos casos los valores que se utilizan para sustituir los valores ausentes son: Media: Se calcula a partir de los datos presentes y se sustituyen todos los datos ausentes por este valor. Esto hace que la media de los datos se mantenga. Se utiliza en el caso de valores numéricos. Moda: Se calcula a partir de los datos presentes y se sustituyen todos los datos ausentes por este valor (Martín and Cabero-Moran, 2008). Esto hace que la moda del conjunto de datos se conserve. Se utiliza en el caso de valores numéricos y categóricos. Puede suceder que no exista la moda y entonces esta técnica no es aplicable. Mediana: Se calcula a partir de los datos presentes y se sustituyen todos los datos ausentes por este valor (Pyle, 1999), lo que hace que la mediana se preserve. Se utiliza para el caso de valores numéricos. Desviación Standard: Se trata de preservar la desviación estándar de los datos (Pyle, 1999). Se calcula el valor que la mantenga a partir de los datos presentes usando la siguiente expresión:. El valor calculado sustituye el primer valor ausente. Luego, se calcula el siguiente valor teniendo en cuenta el ya calculado y se sustituye el segundo valor ausente; y así sucesivamente hasta que todos los valores estén reemplazados. Este proceso hace que la varianza del conjunto de datos se mantenga y se utiliza para datos numéricos reales.. 23.
(32) Capítulo 2 Método probabilístico basado en la distribución de los valores válidos: Para aplicar este método se calcula el porcentaje de aparición de cada uno de los valores válidos, luego se reemplaza de manera aleatoria el mismo porcentaje de valores ausentes. Se utiliza para valores discretos. (ya sean numéricos o alfanuméricos). El proceso de reemplazo se. comienza por los valores con mayor porcentaje de aparición, lo que contribuye a mantener la probabilidad de aparición de los valores válidos y se puede aplicar en caso de que la moda falle o que la frecuencia de los valores no sea desproporcionada para alguno de ellos. Este método no se ha encontrado descrito de esta manera en la literatura revisada. Cualquiera de estos métodos tiene que ser aplicado con cuidado ya que puede introducir un sesgo en los datos, pues imputa un mismo valor para cada ausencia de una misma variable (es decir, que si una variable está ausente en 20 registros diferentes, habrá 20 nuevas ocurrencias de la “media” en esa variable), lo cual puede afectar a otras técnicas de minería de datos hasta el punto de invalidarlas (por ejemplo: si se aplicara una “clasificación”, la súbita aparición de más ocurrencias de los valores medios, podría causar mucha “afluencia” de registros hacia una clase en particular). Paso 7: Reemplazo de valores ausentes usando relaciones entre variables. El uso de la regresión se reporta reiterativamente en la literatura como un método para imputar valores ausentes, por el hecho de que tiene en cuenta no solamente los valores de una variable en particular, sino la interrelación que puede existir entre las diferentes variables. A partir del patrón de valores ausentes se determina si es monótono o no. En caso de ser monótono, se propone el uso de la regresión como técnica de reemplazo. Si el valor que ha de imputarse es numérico, se puede emplear la regresión múltiple. En caso de que sea una variable categórica, podría emplearse la regresión logística y hacer el reemplazo según la probabilidad que el modelo de regresión estimado otorgue a cada categoría para el sujeto en cuestión (Cañizares et al., 2004). Si los patrones de valores ausentes no son monótonos, se propone usar el método MCMC (Markov Chain Monte Carlos) (Schafer, 1997) para imputar algunos valores y convertir los patrones en monótonos para luego aplicar los métodos de regresión. Paso 8: Aplicación de otras técnicas para el reemplazo de valores ausentes.. 24.
(33) Capítulo 2 Existen otras técnicas que también pueden ser aplicadas con el fin de aumentar la calidad de la información, entre las cuales se encuentran: -Imputación Hot Deck (Stones, 2003): Los datos ausentes son reemplazados con valores seleccionados aleatoriamente, presentados en un grupo de datos completos similares; o sea, identifica los casos más semejantes al caso del valor perdido y sustituye el valor perdido por ese (Anónimo, 2004). Es una técnica semejante a la aplicada en los Sistemas Basados en Casos, pero aquí es necesario utilizar alguna métrica para determinar cuándo los casos son similares. -Árboles de Decisión (Wright and Jagannathan, 2008): Este método sustituye los valores ausentes utilizando algoritmos tales como ID3 (Quinlan, 1986) o C4.5 (Quinlan, 1993). Se construye un clasificador con las tuplas que no tengan valores ausentes y se toma como atributo clase el que tiene valores ausentes. A partir del procedimiento anteriormente expuesto se creó un software para el reemplazo de valores ausentes. En dicha herramienta están implementadas todas las técnicas descritas hasta la imputación usando el método Hot Deck. 2.2. Modelación del sistema 2.2.1. Diagrama de Casos de uso El diagrama de casos de uso representa la forma en que un actor opera con el sistema en desarrollo, además de la forma, tipo y orden en cómo los elementos interactúan. El caso de uso es una operación o tarea específica que ayuda a los desarrolladores de software a trabajar con los usuarios finales del producto, con el objetivo de determinar la forma en que será usado el sistema que se está desarrollando (Montero, 2009). A través de estos se involucra a los usuarios en las etapas iniciales de análisis y diseño del sistema, lo cual aumenta la posibilidad de que el nuevo software sea de mayor provecho para dichos usuarios en lugar de ser una serie de expresiones de cómputo que les resulten incomprensibles e inaplicables. A continuación se muestra el diagrama de casos de uso utilizado para la implementación del asistente propuesto, software que esta dirigido a facilitar el trabajo de los usuarios o analistas de datos que necesitan realizar el tratamiento de la información ausente.. 25.
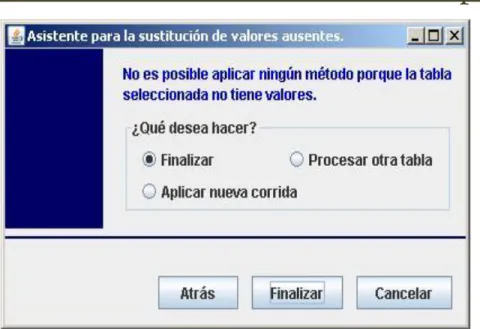
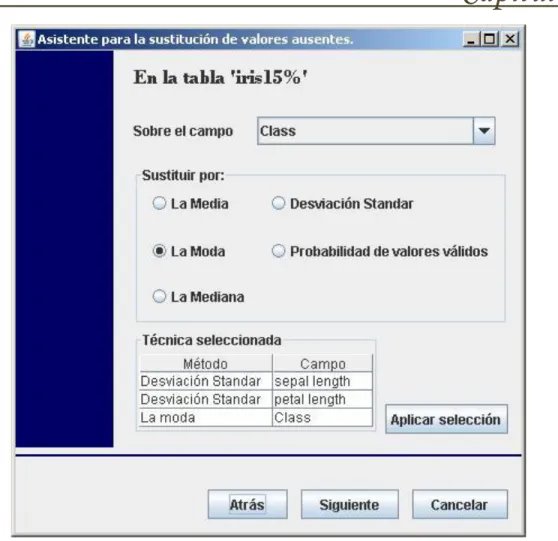
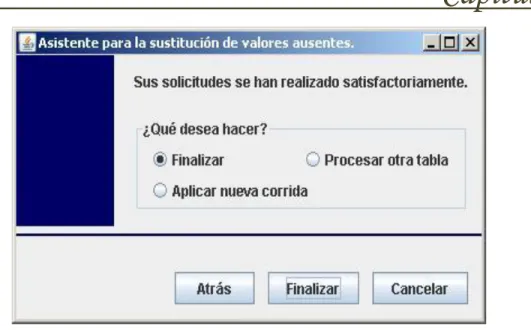
(34) Capítulo 2. Figura 2.1 Casos de uso para el actor analista de datos. Para dar una descripción detallada de este diagrama se hace necesario definir algunos términos, los cuales se refieren a las imágenes del software que son descritas en el capítulo 3, específicamente en el epígrafe 3.1.3 nombrado “Interfaz de usuario”. Dicha descripción se hace a través de la siguiente tabla: Término. Significado. Nro. Imagen. V1. Vista inicial del sistema.. V2. Vista en la que se selecciona el gestor de datos con el que se va a trabajar.. 3.1.1 3.1.2. V3. Vista en la cual se realiza la conexión a la base de datos.. 3.1.3. V4. Vista en la que se selecciona la tabla a procesar.. 3.1.4. V5. Vista en la cual se seleccionan que estadísticas de la tabla analizada se desean observar.. V6. Vista en la cual se observan los resultados de las estadísticas seleccionadas.. V7. Vista que se muestra en caso de que la tabla seleccionada no tenga valores.. V8. Vista que se muestra cuando la tabla seleccionada no tiene. 3.1.5. 3.1.6. 3.1.7 3.1.8 26.
(35) Capítulo 2 información ausente. V9. Vista donde se selecciona la técnica a aplicar.. 3.1.9. V10 - V15. Vistas que corresponden a las posibles técnicas a aplicar.. 3.1.10 – 3.1.15. V16. Vista donde se controlan las operaciones posteriores a la corrida de la técnica seleccionada.. V17. Vista donde se ilustran los resultados obtenidos al aplicar una técnica dada.. 3.1.16. 3.1.17. V18. Vista en la cual se indica que se han cumplido las solicitudes.. 3.1.18. V19. Vista en la que se indica la causa de los posibles errores.. 3.1.19. Descripción de los casos de uso: Caso de uso del sistema. Reemplazar valores ausentes.. Actor. Analista de datos.. Propósito. Reemplazar los valores ausentes presentes en la tabla analizada. El caso de uso se inicia cuando el analista de datos decide reemplazar los valores ausentes. Resumen. presentes en una tabla de una base de datos dada. Este termina cuando se eliminan los ausentes por uno de los métodos que cumplen esta función.. Responsabilidades. Este caso de uso es el encargado de eliminar los valores ausentes presentes en una tabla dada. Descripción. V1, V2, V3, V4, V5, V6, V7, V8, V9, V10, V11, V12, V13, V14, V15, V16, V17, V18, V19 Flujo normal de los eventos 27.
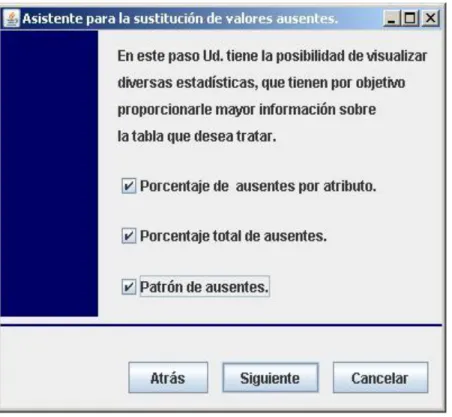
(36) Capítulo 2 Acción del Actor. Respuesta del Sistema. 1. Ejecuta el sistema.. 2. Muestra el formulario V1.. 3. Presiona el botón Siguiente.. 4. Muestra el formulario V2.. 5. Selecciona un gestor de datos y presiona el botón Siguiente.. 6. Muestra el formulario V3.. 7. Introduce los datos requeridos para establecer la conexión con la base de datos (nombre o dirección IP del. 8. Se conecta a la base de datos y. servidor, usuario, contraseña y el. muestra el formulario V4.. nombre de la base de datos) y presiona el botón Siguiente. 9. Selecciona la tabla a la cual desea reemplazar los valores ausentes y. 10. Muestra el formulario V5.. presiona el botón Siguiente. 11. Selecciona que estadísticas de la tabla. 12. Obtiene y muestra en el. seleccionada desea observar:. formulario V6:. A. Porcentaje de ausentes por atributo.. - El porcentaje de ausentes por. B. Porcentaje total de ausentes.. atributo si el usuario selecciona A.. C. Patrón de ausentes.. - El porcentaje total de ausentes si. D. Porcentaje de ausentes por atributo y. el usuario selecciona B.. porcentaje total de ausentes. E. Porcentaje de ausentes por atributo y patrón de ausentes. F. Porcentaje total de ausentes y patrón de ausentes. G. Porcentaje de ausentes por atributo,. - El patrón de ausentes si el usuario selecciona C. - El porcentaje de ausentes por atributo y el porcentaje total de ausentes si el usuario selecciona D.. porcentaje total de ausentes y patrón. - El porcentaje de ausentes por. de ausentes.. atributo y el patrón de ausentes si el usuario selecciona E. 28.
(37) Capítulo 2 …presiona el botón Siguiente.. - El porcentaje total de ausentes y el patrón de ausentes si el usuario selecciona F. - El porcentaje de ausentes por atributo, porcentaje total de ausentes y el patrón de ausentes si el usuario selecciona E.. 13. Observa los resultados y presiona el botón Siguiente.. 14. Muestra el formulario V9.. 15. Selecciona que técnica desea aplicar: A. Análisis de casos completos.. 16. Muestra el formulario:. B. Variante de casos completos.. - V10 si el usuario selecciona A.. C. Imputación con valores conocidos.. - V11 si el usuario selecciona B.. D. Otras técnicas.. - V12 si el usuario selecciona C.. E. Hot Deck.. - V13 si el usuario selecciona D.. F. Regresión lineal.. - V14 si el usuario selecciona E. - V15 si el usuario selecciona F.. …presiona el botón Siguiente. 17. Realiza las operaciones de acuerdo al escenario seleccionado en paso 15: Escenario 15 A: presiona el botón Siguiente. Escenario 15 B: selecciona sobre qué patrones desea realizar el reemplazo y presiona el botón Siguiente.. 18. Muestra el formulario V16.. Escenario 15 C: selecciona las tablas, atributos para el acople, atributo al que se reemplazará la información faltante, atributo del cual se obtendrán los valores para el reemplazo, el método en particular. 29.
(38) Capítulo 2 (la suma, el mayor, el menor, el promedio o el primero que aparezca) y presiona el botón Siguiente. Escenario 15 D: selecciona el método (media, moda, mediana, desviación estándar o probabilidad de valores válidos), el atributo sobre el cual lo aplicará y presiona el botón Siguiente. Escenario 15 E: Selecciona las variables independientes, la variable dependiente y presiona el botón Siguiente. Escenario 15 F: presiona el botón Siguiente. 19. Selecciona las operaciones para completar el proceso: A. Hacer que los cambios sean permanentes. B. Mostrar los cambios realizados sobre la tabla.. 20. Realiza una de las siguientes operaciones: - Elimina los valores ausentes y muestra el formulario V18 si el usuario selecciona A. - Crea una copia de la tabla. C. Aplicar otra técnica.. seleccionada, elimina en esta los. D. Hacer que los cambios sean. valores ausentes y muestra el. permanentes y mostrar los cambios. formulario V17 si el usuario. realizados sobre la tabla.. selecciona B.. E. Mostrar los cambios realizados sobre la tabla y aplicar otra técnica. F. Hacer que los cambios sean permanentes y aplicar otra técnica. G. Hacer que los cambios sean. - Va al paso 14, si el usuario selecciona C. - Elimina los valores ausentes y muestra el formulario V17 si el usuario selecciona D.. permanentes, mostrar los cambios. - Crea una copia de la tabla. realizados sobre la tabla y aplicar otra. seleccionada, elimina en esta los. 30.
(39) Capítulo 2 técnica.. valores ausentes y muestra el formulario V18 si el usuario. … presiona el botón Siguiente.. selecciona E. - Elimina los valores ausentes y va al paso 14 si el usuario selecciona F. - Elimina los valores ausentes y muestra el formulario V17 si el usuario selecciona G.. 21. Realiza las operaciones de acuerdo al escenario seleccionado en paso 19: A. Corresponde al escenario 19 A:. 22. Realiza una de las siguientes operaciones.. 1. Presiona el botón Finalizar.. - Cierra la aplicación si el usuario. 2. Selecciona y ejecuta Aplicar nueva. selecciona A1.. corrida. 3. Selecciona y ejecuta Procesar otra tabla.. - Va al paso 2 si el usuario selecciona A2. - Va al paso 9 si el usuario. B. Corresponde al escenario 19 B: observa. selecciona A3.. los resultados y presiona el botón. - Muestra el formulario V18 si el. Siguiente.. usuario selecciona B.. C. Corresponde al escenario 19 D:. - Muestra el formulario V18 si el. presiona el botón Siguiente.. usuario selecciona C.. D. Corresponde al escenario 19 E:. - Va al paso 14 si el usuario. presiona el botón Siguiente.. selecciona D.. E. Corresponde al escenario 19 G:. - Va al paso 14 si el usuario selecciona E.. …presiona el botón Siguiente. 23. Realiza las operaciones de acuerdo al escenario seleccionado en paso 21: A. Corresponde al escenario 21 B:. 24. Realiza una de las siguientes operaciones: - Cierra la aplicación si el usuario. 31.
Figure
+5

Documento similar