Desarrollo e implementación de algoritmos paralelos aplicados a las extensiones de la teoría de los conjuntos aproximados (Rough Sets)
80
0
0
Texto completo
(2) Hago constar que el presente trabajo fue realizado en la Universidad Central Marta Abreu de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencias de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del Seminario.
(3) Pensamiento. Emplearse en lo estéril cuando se puede hacer lo útil, Ocuparse en lo fácil cuando se tiene bríos para intentar lo difícil, Es despojar de su dignidad al talento. Todo el que deja de hacer lo que es capaz de hacer, Peca.. José Martí.
(4) Dedicatoria. Dedicatoria:. A mis padres, Eugenio Fernández Rodríguez y María Elena Cancio Abreu quienes con amor, constancia y sacrificio me han hecho lo que soy. A mi eterna compañera novia y amiga Anabel Fernández Niubó..
(5) Agradecimientos Agradecimientos. Al apoyo incansable de todos mis familiares en especial el de mi queridísima abuela “Cachi” , los cuales a lo largo de mi carrera me han ayudado en los momentos claves. Un agradecimiento especial a mi tutor y amigo Leonardo del Toro por apoyarme, aconsejarme, por estar ahí en cada momento y por darme el impulso necesario para llegar a la línea de meta.. Pido disculpas a quien resulte olvidado o víctima de mi mala memoria. A todos Muchas Gracias..
(6) Resumen. Resumen El análisis de la información incompleta ha encontrado aplicación en muchas áreas, en particular la relacionada con la extracción de conocimiento de grandes conjuntos de datos. Las extensiones de la Teoría de los Conjuntos Aproximados se han aplicado con bastante éxito en el procesamiento de estos conjuntos de datos, aunque los mecanismos son muy diversos y no existe uno en particular que supere al resto, ofrecen actualmente una posibilidad de tratar este problema. El otro punto medular es el tema de la semejanza entre objetos En este trabajo se describen fundamentalmente dos algoritmos utilizados en el trabajo con información incompleta y uno empleado en el enfoque de la semejanza entre objetos usando las extensiones de la Teoría de los Conjuntos Aproximados, de estos se ofrecen variantes secuenciales y alternativas paralelos. Además se muestran los resultados obtenidos experimentalmente sobre una serie de Sistemas de Información almacenados en repositorios internacionales..
(7) Abstract. Abstract The analysis of incomplete information has found applications in many areas particularly, in those related to the knowledge discovery of huge datasets. The extensions of the Theory of the Rough Sets have been successfully applied for processing this datasets and even though it exist many mechanisms, there is none, in particular, that we may say that outstrip the rest; they offer today a possibility to deal with this problem. Another important aspect is that of similarity among objects. In this work different algorithms are developed for the processing of incomplete information, and specifically of one based on the approach of the similarity among objects using the extensions of Theory of Rough Sets. Here we offer several serial variants and parallel alternatives that were experimentally tested on a set of information systems stored in international repositories..
(8) Indice Introducción ............................................................................................................................. 1 Capítulo 1 “Estudio sobre las diferentes extensiones de la teoría de los Conjuntos Aproximados al tratamiento de la información incompleta” ................................................ 4. 1.1 Conjuntos Aproximados (Rough Set) ................................................................................... 4 1.1.1 Sistema de información (SI) .......................................................................................... 5 1.1.1.1 Sistema de decisión (SD) ........................................................................................ 6 1.1.2 Relación de inseparabilidad ........................................................................................... 6 1.1.3 Aproximación de conjuntos ........................................................................................... 7 1.1.4 El problema de la información incompleta .................................................................... 8 1.1.4.1 Sistemas de información incompletos .................................................................... 8 1.1.4.2 Sistemas de decisión incompletos ........................................................................... 9 1.2 Acercamiento teórico a las extensiones de la teoría de los Conjuntos Aproximados para sistemas de información incompletos. ...................................................................................... 10 1.2.1 Relación I ..................................................................................................................... 11 1.2.2 Relación II.................................................................................................................... 12 1.2.3 Relación III .................................................................................................................. 12 1.2.4 Relación IV .................................................................................................................. 13 1.2.5 Relación V ................................................................................................................... 14 1.2.6 Relación VI .................................................................................................................. 15 1.3 Análisis del comportamiento de las relaciones sobre un ejemplo de SDI ......................... 17 1.3.1 La relación I ................................................................................................................. 17 1.3.2 La relación II ............................................................................................................... 18 1.3.3 La relación III .............................................................................................................. 19 1.3.4 La relación V................................................................................................................ 20 1.3.5 La relación VI .............................................................................................................. 21 1.4 El problema de la semejanza entre objetos ......................................................................... 22 1.4.1 Funciones de semejanza. .............................................................................................. 23 1.4.2 Relación de similaridad................................................................................................ 24 1.5 Conclusiones parciales ........................................................................................................ 27 Capítulo 2 “Propuesta de paralelización” .............................................................................28. 2.1 Conjuntos Aproximados (Rough Set) ................................................................................. 28 2.2 Procedimiento serial para clasificar a un SDI ..................................................................... 30 2.3 Método paralelo propuesto para el cálculo de la calidad en un SDI. .................................. 35 2.3.1 Descripción del algoritmo paralelo .............................................................................. 38 2.3.2 Pseudo código del algoritmo paralelo para clasificar un SD ....................................... 41 2.4 Algunas especificaciones generales. ................................................................................... 44 2.5 Conclusiones parciales ........................................................................................................ 44 Capítulo 3 “Evaluación de los resultados y descripción de las funciones” .......................45. 3.1 Herramientas y medidas ...................................................................................................... 45 3.2 Tecnologías utilizadas ......................................................................................................... 47 3.3 Estructuras de Datos ........................................................................................................... 47 3.4 Conjuntos Aproximados (Rough Set) ................................................................................. 48 3.4.1 La versión secuencial ................................................................................................... 49 3.4.2 El método paralelo ....................................................................................................... 52 3.4.3 Análisis de algunas métricas de rendimiento ............................................................... 54 3.5 Descripción de las funciones .............................................................................................. 57.
(9) Indice 3.6 Conclusiones Parciales........................................................................................................ 57 Conclusiones generales .........................................................................................................59 Recomendaciones ..................................................................................................................60 Referencias bibliográficas......................................................................................................61 Anexos .....................................................................................................................................63. Anexo 1 Funciones empleadas en el cálculo de la calidad ....................................................... 63 Anexo 2 Funciones auxiliares usadas en el cálculo de la calidad. ............................................ 66.
(10) Introducción. Introducción En la actualidad la Inteligencia Artificial (IA) cuenta con un arsenal de importantes técnicas que permiten extraer conocimiento de bases de datos; los Conjuntos Aproximados es una de ellas. Pero en muchas ocasiones la información con la que contamos no está completa y es necesario extraer conocimiento de grandes volúmenes de datos sin perder la calidad de la información, aún cuando esta esté incompleta. Otro problema se presenta al determinar cuándo podemos decir que dos objetos son semejantes y hasta qué punto podemos considerarlos como “iguales”. Los métodos utilizados para lograr esto varían en cuanto a formas e implementaciones, aunque todas ellas tienen en común el hecho de que hacen uso intensivo de los recursos computacionales y necesitan un tiempo considerable para su ejecución. Es por esto que en esta investigación se realiza un estudio de las extensiones a la Teoría de los Conjuntos Aproximados para tratar la falta de información en bases de casos ricas en conocimiento y para modelar una solución al problema de la semejanza entre objetos, en aras de lograr implementaciones paralelas que traten de subsanar dichos inconvenientes. A través de los años han tenido lugar grandes avances tecnológicos los cuales han permitido el procesamiento paralelo efectivo. Con el desarrollo de las investigaciones se adquirieron nuevos conocimientos sobre este tema, las cuales han posibilitado que los algoritmos distribuidos y paralelos se enfoquen no sólo en los viejos problemas, sino también en otros nuevos que han surgidos con el propio desarrollo tecnológico, creando así nuevas necesidades de cálculo. Problema de Investigación: Teniendo en cuenta todo lo anteriormente expuesto podríamos plantearnos entonces el siguiente problema: ¿Será posible obtener un algoritmo paralelo para implementar los principales conceptos de las extensiones de teoría de los Conjuntos Aproximados que mejore el rendimiento de versiones secuenciales?. 1.
(11) Introducción. Hipótesis de la Investigación: -. Al aplicar las técnicas de paralelización a la extensión de la teoría de los Conjuntos Aproximados se logran implementaciones paralelas que mejoran el comportamiento de las implementaciones de esta teoría.. -. Un diseño adecuado de los módulos computacionales y su implementación paralela usando MPI permitirá construir una biblioteca de funciones que pueda ser reutilizada por otras aplicaciones.. El objetivo general en este trabajo es paralelizar los algoritmos que implementan las extensiones seleccionadas de la Teoría de los Conjuntos Aproximados usando MPI. Los objetivos específicos que nos permitirán dar solución a esta problemática son: . Seleccionar los algoritmos más apropiados de aquellos que implementan las extensiones de la Teoría de los Conjuntos Aproximados. . Determinar las etapas donde es posible aplicar técnicas de paralelización en los algoritmos seleccionados.. . Proponer una alternativa de algoritmos paralelos para implementar los principales conceptos de esta teoría.. . Desarrollar una biblioteca con las implementaciones paralelas de los algoritmos seleccionados.. . Desarrollar una biblioteca que contenga la implementación de una función de semejanza para el trabajo con objetos de rasgos continuos.. . Comprobar el desempeño de los algoritmos implementados.. En este trabajo se propone una alternativa paralela, para la obtención de una aplicación sobre un cluster de computadoras que implemente los conceptos básicos de las extensiones de la teoría de los Conjuntos Aproximados. He aquí su valor científico.. 2.
(12) Introducción El valor práctico del mismo radica en que este trabajo ofrece una herramienta basada en técnicas paralelas que permite medir el grado de consistencia de un Sistema de Decisión Incompleto, presentando rendimientos superiores a sus equivalentes secuenciales. Su principal aporte es la creación de una de librería y de una aplicación que permiten desarrollar nuevas herramientas, así como también el ya mencionado análisis de grandes volúmenes de datos haciendo uso de las bondades de la programación en paralelo y del juego de funciones MPI en C. La estructura del trabajo comprende tres capítulos de los cuales: . En el Capítulo 1 se muestra el marco teórico-referencial de la investigación, derivado de la consulta de la literatura nacional e internacional actualizada sobre diferentes extensiones de la teoría de los Conjuntos Aproximados.. . En el Capítulo 2 se exponen el conjunto de algoritmos propuestos para el cálculo de los principales conceptos de las extensiones de esta teoría y todo lo relacionado con el diseño y funcionalidad de los mismos.. . En el Capítulo 3 se presentan los resultados experimentales que, sobre determinados. archivos. de. datos,. brindan. las. aplicaciones. paralelas. desarrolladas, realizando comparaciones con sus similares secuenciales.. 3.
(13) Capítulo 1. Capítulo 1 “Estudio sobre las diferentes extensiones de la teoría de los Conjuntos Aproximados al tratamiento de la información incompleta” En este capítulo se realiza una recopilación de información basada en conceptos y definiciones de diferentes autores sobre las técnicas y métodos utilizados en el tratamiento del problema de la información incompleta con el objetivo de lograr la paralelización de algunos de esos métodos y su posterior comparación con la implementación secuencial que se ha obtenido en esta investigación.. 1.1 Conjuntos Aproximados (Rough Set) La teoría de los Conjuntos Aproximados fue introducida inicialmente por Z. Pawlak (Pawlak, 1982), esta teoría se ha enriquecido ampliamente durante estos años y ha sido introducida en muchas ramas de la ciencia. Algunas de estas ramas son: -. Medicina.. -. Finanzas.. -. Telecomunicaciones.. -. Análisis de ruido.. -. Agentes inteligentes.. -. Análisis de imágenes.. -. Reconocimiento de patrones.. -. Procesos industriales. La teoría clásica de Conjuntos Aproximados hace uso de una serie de conceptos como por ejemplo los de sistema de información, sistema de decisión, relación de inseparabilidad, aproximaciones (inferior y superior) y reductos; los cuales están presentes también en sus extensiones.. 4.
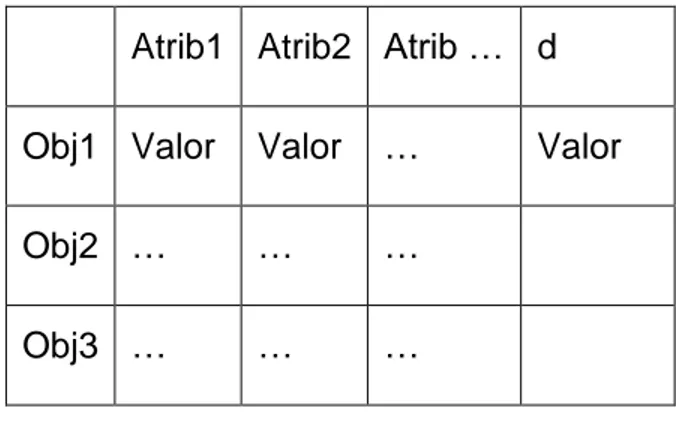
(14) Capítulo 1 1.1.1 Sistema de información (SI) Un sistema de información usualmente está compuesto por un conjunto de atributos (A) los cuales representan características o propiedades de un objeto o fenómeno y de una serie de casos u objetos (U) a los cuales se les evaluó o se les midió los valores de los atributos. Estos dos elementos se combinan en una tabla tal como la que se muestra en la Fig. 1, donde las columnas representan los atributos (A) y las filas los objetos (U). Los valores que se muestran en la tabla varían de acuerdo a las características del problema en cuestión. Estos pueden ser binarios, enteros, reales o simbólicos en algunos casos. Es decir, la entrada en la columna q y en la fila x tiene el valor f(x, q) por tanto, para cada par (objeto, atributo) se conoce un valor denominado descriptor. Cada fila de la tabla contiene descriptores que representan la información correspondiente a un objeto del universo. Utilizamos la noción de atributo en lugar de la de criterio porque el primer término es más general que el segundo debido a que el dominio (escala) de un criterio ha de ordenarse8 de menor a mayor preferencia, mientras que el dominio de los atributos no ha de ser ordenado (Segovia et al., 2003). Atrib1 Atrib2 Atrib Obj1 Valor. Valor. …. Obj2 …. …. …. Obj3 …. …. …. Fig. 1.1 Ejemplo de un Sistema de Información. Formalmente un sistema de información se compone de un par S (U , A) donde U, como ya se explicó anteriormente, es un conjunto no vacío y finito de objetos o casos y A un conjunto no vacío y finito de atributos. (Komorowski et al., 1998). 5.
(15) Capítulo 1 1.1.1.1 Sistema de decisión (SD) Un sistema de decisión (SD) es un sistema de información (Fig. 1.2) al cual se le adiciona un atributo que representa la decisión o resultado en cada caso u objeto. Teniendo en cuenta los valores de los atributos esto se plantea como: S (U , A d ) donde d no pertenece a A.(Komorowski et al., 1998). Atrib1 Atrib2 Atrib … d Obj1 Valor. Valor. …. Obj2 …. …. …. Obj3 …. …. …. Valor. Fig. 1.2 Ejemplo de Sistema de Decisión. 1.1.2 Relación de inseparabilidad Antes de tratar el concepto de relación de inseparabilidad debemos tener en cuenta la definición de relación de equivalencia y clase de equivalencia definidas en (Komorowski et al., 1998) como: Definición 1.1 Una relación de equivalencia es una relación binaria R X x X que es: - reflexiva (cuando un objeto está relacionado con el mismo xRx ) - simétrica (si xRy entonces yRx ) y - transitiva (si xRy y yRz entonces xRz ) Definición 1.2 Una clase de equivalencia de un elemento x X es el conjunto de todos los objetos y X tal que xRy .. 6.
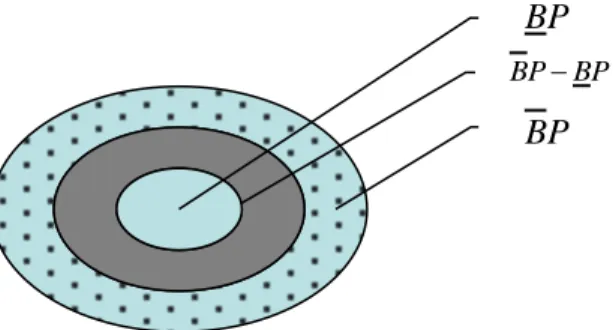
(16) Capítulo 1 Definición 1.3 La relación de inseparabilidad se establece cuando un par de objetos “a”, “b” de un (SI) S = <U,A>, tienen una relación de equivalencia con cualquier conjunto de atributos B A para los cuales se cumple que:. INS S ( B) {(a, b) U 2. x B x(a) x(b)}. Esto se conoce como relación de inseparabilidad de B. Si (a, b) INS S ( B ) entonces los objetos “a” y “b” son inseparables uno del otro teniendo en cuenta los atributos en B. La clase de equivalencia de la relación de inseparabilidad se denota como X B .. 1.1.3 Aproximación de conjuntos La relación de inseparabilidad aplicada a un (SI) causa una fragmentación del universo de objetos donde estos fragmentos constituyen nuevos subconjuntos del universo. Supongamos que tenemos el (SI) S (U , A) y definimos a B A y P U . Es posible aproximar a P usando sólo la información de los atributos en B, construyendo lo que se conoce como aproximaciones inferiores y superiores de P, estas se denotan como BP y BP respectivamente, donde BP {x xB P} y. BP {x xB P } . Los objetos en BP son los elementos que pueden ser clasificados ciertamente como miembros de P sobre la base de los atributos en B, mientras que los objetos en BP sólo pueden ser clasificados como posibles miembros de P sobre la base de B. Existe un grupo de objetos que no se encuentra en ninguna de las dos aproximaciones, este conjunto está ubicado en una zona que se llama frontera BN (ver Fig. 1.3), la cual se define como BN BP BP .. 7.
(17) Capítulo 1 BP BP BP. BP. Fig. 1.3 Aproximaciones y frontera.. 1.1.4 El problema de la información incompleta En la práctica puede que no conozcamos el valor de algunos o de ninguno de los atributos que caracterizan a un objeto en un (SI) o en un (SD). Este desconocimiento puede ser provocado por errores en el proceso de medición de los datos, por la incomprensión de los datos, o por la dificultad que puede existir a la hora de adquirir algún valor. En general, procesar información que contiene redundancias, imprecisiones o datos omitidos puede llevar a resultados falsos o parcialmente erróneos. En este trabajo supondremos que los valores del atributo o de los atributos de decisión de todos los objetos son conocidos.. 1.1.4.1 Sistemas de información incompletos Como pudimos apreciar en el epígrafe 1.1.1, un sistema de información (SI) I, es una dupla <U, A>, para todo ai є A, ai : U Vai , donde Vai es el dominio del atributo ai. Al sistema de información en el cual algún dominio Vai contiene valores perdidos denotados por un “*”, se le llama sistema de información incompleto (SII)(Kryszkiewicz, 1998), tal como el que se muestra en la tabla de la figura 1.4.. 8.
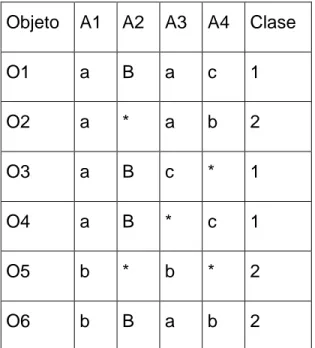
(18) Capítulo 1. Atrib 1. Atrib 2. Atrib 3. Obj1 3. 6. *. Obj2 *. *. 7. Obj3 8. 1. 3. Fig. 1.4 Sistema de información incompleto.. 1.1.4.2 Sistemas de decisión incompletos Un sistema de decisión incompleto (SDI) según (Kryszkiewicz, 1998) no es más que un sistema de información incompleto (SII) S=<U, A>, donde U es el universo y A es el conjunto de atributos (A=C clase). En la tabla de la figura 1.5 se muestra un ejemplo de un SDI en el cual las dos terceras partes de los objetos presentan información incompleta representada por un *. Objeto. A1. A2. A3. A4. Clase. O1. a. B. a. c. 1. O2. a. *. a. b. 2. O3. a. B. c. *. 1. O4. a. B. *. c. 1. O5. b. *. b. *. 2. O6. b. B. a. b. 2. Fig. 1.5 Sistema de decisión incompleto.. 9.
(19) Capítulo 1 1.2 Acercamiento teórico a las extensiones de la teoría de los Conjuntos Aproximados para sistemas de información incompletos. Existen dos formas de tratar el problema de los datos incompletos en la teoría de los Conjuntos Aproximados. La primera es una vía indirecta, mediante la cual el sistema de información incompleto se transforma en uno completo utilizando algún método de completamiento; la segunda es una alternativa directa en la cual se extiende la teoría de los Conjuntos Aproximados para procesar los sistemas de información incompletos. En esta segunda línea se ubican los trabajos de M. Kryszkiewicz (Marzena, 1998a) y (Marzena, 1998b).También los de S. Greco (Salvatore et al., 1999), (Greco et al., 2000), (Greco et al., 2001) y otros, en los cuales se han realizado extensiones para el caso de datos incompletos, de modo que la relación de inseparabilidad se define como una relación direccional donde un sujeto se compara con un objeto referente, este último un objeto completo, es decir, se conocen los valores para todos sus atributos. Los principales conceptos de la teoría clásica de los Conjuntos Aproximados, la cual no es más que un caso particular de la teoría extendida, están igualmente definidos en sus extensiones. Los conceptos más importantes que fueron añadidos a esta teoría son relación de tolerancia y clase de tolerancia: Definición 1.4: Una relación de tolerancia es cualquier relación binaria entre dos objetos que trate la pérdida de información. Debemos señalar que las relaciones de tolerancia no tienen que cumplir ninguna de las restricciones que cumplen las relaciones de equivalencia (reflexivilidad, simetría y transitividad) las que, de hecho, son un subconjunto de las relaciones de tolerancia. Definición 1.5: Una clase de tolerancia de un elemento x U es el conjunto de todos los objetos y U tal que xTy , donde T es una relación de tolerancia.. 10.
(20) Capítulo 1 A continuación se muestran algunas de las extensiones de la teoría de los Conjuntos Aproximados, basadas en relaciones de tolerancia.. 1.2.1 Relación I El hecho de tener objetos que pueden estar descritos por un número mayor o menor de atributos, no sólo por la inconsistencia de los valores sino también por la posibilidad de que ese objeto no pueda ser descrito por dicho atributo, nos da la idea de que un objeto “x” es similar a un objeto “y” si y sólo si (ssi) la descripción de “x” está incluida en la descripción de “y”, según (Slowinski, 1995). Sean “x”, “y” U, donde “y” es el sujeto y “x” es el objeto referente. Decimos que “y” es inseparable de “x”, con respecto al conjunto de atributos P C, denotándolo por yIPx, si para todo q P, se cumple:. i). f(x,q)*,. ii). f(x,q)=f(y,q) or. f(y,q)=*.. Donde f: UxP Vai , siendo Vai el dominio de valores que toma el atributo “ai” Ej.: En la Fig. 1.5 f (O1,A1)= a. y. f(O3,A4)= *. (Nótese que el objeto referente “x” no puede tener valores desconocidos en el conjunto de atributos P). La clase de objetos inseparables de “x” se representa como:. IP(x)= {y U : yIPx} La relación IP no es necesariamente reflexiva ni simétrica, pero si transitiva. Para cada P C se define el conjunto UP de objetos sin valores desconocidos para los atributos en P. UP = {xU : f(x,q)* para cada qP} 11.
(21) Capítulo 1 A partir de estas definiciones y la relación I (IP), se puede construir la aproximación inferior y superior de un conjunto X U con respecto a un conjunto de atributos de condición P C , según la definición 1.1: Las aproximaciones de un conjunto según la relación I son: IP*(X)={ x UP : IP(x) X}. (1.1). IP*(X)= { x UP : IP(x) X }. 1.2.2 Relación II Una relación muy conocida dentro de esta teoría es la que define (Kryszkiewicz, 1998) según la cual dos objetos “x, y” U se dicen inseparables si están relacionados según. x,yU (TA (x, y) aA ((a(x) *) (a(y) *) (a(x) a(y))) (La relación T es reflexiva y simétrica, pero no es transitiva) La aproximación inferior se define como:. X A {x x U I A ( x) X }, T. Y la aproximación superior: T. X A {x x U ( I A ( x) X )} . Donde. I A ( x) { y | y U TA ( x, y)}. 1.2.3 Relación III Según (Jerzy and Alexis, 1999) dos objetos son inseparables ssi están relacionados según:. x,yU (SB (x, y) bB ((b(x) *) (b(x) b(y)))) 12.
(22) Capítulo 1 Que evidentemente no es simétrica pero es reflexiva y transitiva. Se definen además la aproximación inferior. S. S. X B y la aproximación superior X B. del conjunto X U basadas en la relación de similitud no simétrica S como:. X B {x | x U R B ( x) X }, S. S. S. XB . R. S B. ( x). xX. Donde R B ( x) { y | y U S B ( x, y)}, S. S. R B ( x) { y | y U S B ( y, x)}. 1.2.4 Relación IV La relación de tolerancia (relación II) propuesta por (Kryszkiewicz, 1998) está basada en la asunción de que el valor faltante “*” puede ser igual a cualquier valor conocido del atributo, lo que puede conducir a que dos elementos que sean distintos se clasifiquen en la misma clase de tolerancia. En la relación de similitud no simétrica (relación III) propuesta por (Jerzy and Alexis, 1999), el valor perdido es tratado como inexistente en vez de desconocido. Es decir, el objeto no puede ser caracterizado por ese atributo lo que puede provocar que objetos claramente parecidos puedan ser incluidos en clases diferentes. Por esta razón se introduce el concepto de relación de similitud no simétrica con restricciones (relación IV). Según (Yin et al., 2006) la relación de similitud no simétrica con restricciones se plantea como sigue: Si se tiene un SII I = <U,A>, B A , la relación IV puede definirse como: x, yU C B x, y bB bx * PB x, y bB b PB x, y bx b y . Donde. PB(x,y) = b | b B bx * b y *. (Evidentemente la relación es reflexiva, no simétrica y no transferible) Las aproximaciones superiores e inferiores basadas en la relación anteriormente definida pueden expresarse como sigue:. 13.
(23) Capítulo 1 C. Si se tiene un SII I = <U,A>, B A y X U , la aproximación inferior X B C. aproximación superior. XB. y la. del conjunto X U basado en la relación de similitud. no simétrica S con restricciones están definidas por:. X B {x | x U R B ( x) X }, C. C. C. XB . R. C B. ( x). xX. Donde R B ( x) { y | y U C B ( x, y)}, C. C. R B ( x) { y | y U C B ( y, x)} C. C. (Debido a la falta de simetría de la relación C, R B y R B son dos conjuntos diferentes).. 1.2.5 Relación V Según (Wang, 2002) se puede definir una relación más exacta que la II y la III, si se tienen en cuenta sólo aquellos atributos conocidos en el par de objetos a comparar. Wang la nombra relación de tolerancia limitada, siendo una relación binaria L definida sobre un SII, S=<U,A> y un subconjunto de atributos B A. Además Wang establece que dos objetos “x,y” son inseparables ssi están relacionados según L LB(x,y) la cual se expresa como sigue: LB ( x, y) bB (b( x) b( y) *) (( P( x) P( y) ) (b B ((b( x) *) (b( y) *) (b( x) b( y))))). Siendo PB ( x) {b | b B b( x) *} L. Si se tiene un SII, I = <U,A>, B A y X U las aproximaciones inferior X B L. superior. XB. y. del conjunto X U , basadas en la relación de tolerancia limitada. pueden ser definidas por:. X L {x | x U I BL ( x) X }, B. L. X B {x | x U I BL ( x) X }. Donde I BL ( x) { y | y U LB ( x, y)}. 14.
(24) Capítulo 1 1.2.6 Relación VI Según (E. A. Rady, 2007) se le puede hacer una modificación a la relación de similitud (relación II) para mejorar los resultados de esta, pero antes de mostrar como se define MSIM(x,y) es necesario establecer algunas notaciones y definiciones. Por ejemplo:. xa o ( x, a), donde xa = v significa que el objeto “x” tiene el valor “v” para el atributo ”a” donde v U y a A (A es el conjunto de los atributos de decisión del sistema).. ( xa , ya ) denota al par de valores que toma el atributo ”a” en los objetos “x” , “y” respectivamente. Definición 1.6: Se dice que xa es conocido ssi xa *. Definición 1.7: El objeto “x” está completamente definido ssi xa * para todo a A. Definición 1.8: El número “EP”, EP = | ( xa , ya ) | es el número de rasgos en que coinciden los objetos “x”, “y”. respectivamente, donde xa y ya son valores. definidos. Ej.. Para los objetos 1 y 2 de la Fig. 1.5 EP=2. Para los objetos 3 y 4 de la Fig. 1.5 EP=2.. Definición 1.9: El número |mx|, |mx| denota al número de atributos perdidos del objeto “x”. Definición 1.10: De un elemento “x” se dice que: Está bien definido sobre el conjunto A ssi: |mx| . N 1 N si N es par o |mX| si N es impar 2 2. Está pobremente definido ssi: 15.
(25) Capítulo 1 |mx| . N 1 N si N es par o |mX| si N es impar 2 2. Donde N es el número de atributos del conjunto A, N= |A|. Definición 1.11: El número |nmx|, |nmx| denota al número de valores conocidos del objeto “x”. Ya aclaradas todas las notaciones y definiciones podemos ilustrar como se define la relación de similitud modificada MSIM: i.. (x,x) MSIM(A) para todo x U.. ii.. (x,y) MSIM(A) para N=|A| > 1 ssi a). xa = ya , a A siendo xa y ya valores definidos.. b) EP . N , 2. si N es par. N 1 , si N es impar 2. Definición 1.12: MSA(x) denota al conjunto {y U : (x,y) MSIM(A)} de los elementos “y” que son inseparables de “x” según A. Si se tiene un SII, I = <U,AT>, A AT y X U las aproximaciones inferior X M. y. superior. XA. del conjunto X U basadas en la relación de similitud. modificada MSIM(A) se definen como:. X A = {x U , MS A ( x) X } {x X , MS A ( x) X }. M. M. XA. M A. = {x U , MS A ( x) X } . {MS. A. ( x), x X }.. 16.
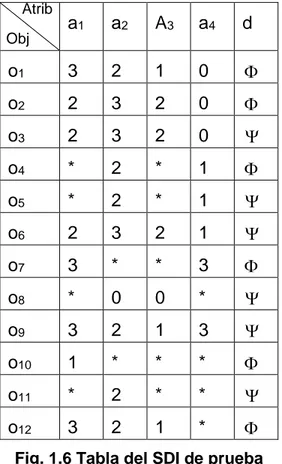
(26) Capítulo 1 1.3 Análisis del comportamiento de las relaciones sobre un ejemplo de SDI Antes de finalizar este capítulo queremos mostrar qué se obtiene al aplicar cada una de las relaciones a un SDI de pequeña escala para obtener la esencia de cada una de ellas. Para esto tomaremos como base de casos de estudio al siguiente SDI: Atrib. a1. a2. A3. a4. d. o1. 3. 2. 1. 0. . o2. 2. 3. 2. 0. . o3. 2. 3. 2. 0. . o4. *. 2. *. 1. . o5. *. 2. *. 1. . o6. 2. 3. 2. 1. . o7. 3. *. *. 3. . o8. *. 0. 0. *. . o9. 3. 2. 1. 3. . o10. 1. *. *. *. . o11. *. 2. *. *. . o12. 3. 2. 1. *. . Obj. Fig. 1.6 Tabla del SDI de prueba. En dicho sistema U = {o1…o12} son los objetos del sistema, A= {a1… a4} son cuatro atributos de condición y “d” es el atributo de decisión. El dominio de los cuatro atributos de condición es Va= {1, 2, 3,4} y el del atributo de decisión es { , }. 1.3.1 La relación I Analizando el SDI anterior con la relación I obtenemos los resultados siguientes:. 17.
(27) Capítulo 1 Las clases de inseparabilidad de cada objeto según el conjunto de atributos A por la relación IA son:. I AI (o1 ) {o1 , o11 , o12 } I AI (o2 ) {o2 , o3 } I AI (o3 ) {o2 , o3 } I AI (o6 ) {o6 } I AI (o9 ) {o7 , o9 , o12 } (En este caso recordemos que sólo se calculan las de aquellos objetos que están completamente definidos) Las aproximaciones inferiores ( IA , AI ) y superiores ( IL , LI ) de los conjuntos. , por la relación IA y según el conjunto de atributos A son: IA ,. AI {o6 },. IA {o1 , o2 , o3 , o6 , o9 }, IA {o1 , o2 , o3 , o9 }. En los resultados anteriores algunos objetos debieron ser bien clasificados y sin embargo no fueron bien tratados por la relación IA. Tenemos, por ejemplo, una completa información del objeto o1 el cual no colisiona con ningún otro objeto del SDI y desafortunadamente o1 no es la aproximación inferior de ; esto está provocado por la falta de información en el objeto o11 , lo trae como consecuencia que este sea tratado por IA como similar a o1.. 1.3.2 La relación II Al analizar la tabla con la relación II TA obtenemos los siguientes resultados Las clases de inseparabilidad de cada objeto según el conjunto de atributos A por la relación T son:. 18.
(28) Capítulo 1 I AT (o1 ) {o1 , o11 , o12 },. I AT (o2 ) {o2 , o3 }. I AT (o3 ) {o2 , o3 },. I AT (o4 ) {o4 , o5 , o10 , o11, o12}. I AT (o5 ) {o4 , o5 , o10 , o11 , o12 },. I AT (o6 ) {o6 }. I AT (o7 ) {o7 , o8 , o9 , o11 , o12 },. I AT (o8 ) {o7 , o8 , o10}. I AT (o9 ) {o7 , o9 , o11 , o12 },. I AT (o10 ) {o4 , o5 , o8 , o10 , o11}. I AT (o11 ) {o1 , o4 , o5 , o7 , o9 , o10 , o11 , o12 }, I AT (o12 ) {o1 , o4 , o5 , o7 , o9 , o11 , o12 } Las aproximaciones inferiores ( TA , AT ) y superiores ( TA , TA ) de los conjuntos. , por la relación T y según el conjunto de atributos A son: TA ,. AT {o6 },. TA U ,. TA {o1 , o2 , o3 , o4 , o5 , o7 , o8 , o9 , o10 , o11, o12}, Los resultados anteriores no son buenos, es más, algunos objetos pueden ser clasificados intuitivamente y sin embargo no fueron bien tratados por la relación TA., Tenemos, por ejemplo, una completa información del objeto o1 el cual no colisiona con ningún otro objeto del SI. y desafortunadamente o1 no es la. aproximación inferior de ; esto esta provocado por la falta de información en el objeto o11 lo que trae como consecuencia que este sea tratado por TA como similar a o1.. 1.3.3 La relación III Si hacemos un análisis de cómo trata la relación III (SA) la tabla anterior, los resultados en este caso serían el conjunto de objetos a los que el objeto “oi” es similar ( R A1 (oi ) ) y el conjunto de objetos que son similares al objeto “oi” ( R A (oi ) ), según el conjunto de atributos A por la relación S:. 19.
(29) Capítulo 1 R A1 (o1 ) {o1 },. R A (o1 ) {o1 , o11 , o12 },. R A1 (o2 ) {o2 , o3 },. R A (o2 ) {o2 , o3 },. R A1 (o3 ) {o2 , o3 },. R A (o3 ) {o2 , o3 },. R A1 (o4 ) {o4 , o5 },. R A (o4 ) {o4 , o5 , o11},. R A1 (o5 ) {o4 , o5 },. R A (o5 ) {o4 , o5 , o11},. R A1 (o6 ) {o6 },. R A (o6 ) {o6 },. R A1 (o7 ) {o7 , o9 },. R A (o7 ) {o7 },. R A1 (o8 ) {o8 },. R A (o8 ) {o8 },. R A1 (o9 ) {o9 },. R A (o9 ) {o7 , o9 , o11 , o12 },. 1 A. R A (o10 ) {o10 },. 1 A. R A (o11 ) {o11},. 1 A. R A (o12 ) {o11 , o12 },. R (o10 ) {o10 }, R (o11 ) {o1 , o4 , o5 , o9 , o11 , o12 }, R (o12 ) {o1 , o9 , o12 },. Las aproximaciones inferiores ( SA , AS ) y superiores ( SA , SA ) de los conjuntos. , por la relación S y según el conjunto de atributos A son: SA {o1 , o10},. AS {o6 , o8 , o9 }, SA {o2 , o3 , o4 , o5 , o6 , o7 , o8 , o9 , o11, o12},. SA {o1 , o2 , o3 , o4 , o5 , o7 , o10 , o11, o12},. Las aproximaciones resultantes de aplicar la relación no simétrica SA son más informativas que las arrojadas por la relación TA , incluso en las aproximaciones de los conjuntos y encontramos objetos que podemos colocar en ellas intuitivamente. Lógicamente, este enfoque es menos preciso que el de TA, dado que algunos objetos de los que se tiene muy poca información son precisamente clasificados en algún conjunto. Ejemplo de ello es el objeto o10.. 1.3.4 La relación V Por la gran semejanza entre las definiciones de las relaciones IV y V, el análisis correspondiente a la relación IV del SDI de la Fig 1.6 es omitido. Al analizar el SDI anterior con la relación V obtenemos los resultados siguientes: 20.
(30) Capítulo 1 Las clases de inseparabilidad de cada objeto según el conjunto de atributos A por la relación L son:. I AL (o1 ) {o1 , o11 , o12 },. I AT (o2 ) {o2 , o3 }. I AL (o3 ) {o2 , o3 },. I AT (o4 ) {o4 , o5 , o11 , o12 }. I AL (o5 ) {o4 , o5 , o11 , o12 },. I AT (o6 ) {o6 }. I AL (o7 ) {o7 , o9 , o12 },. I AT (o8 ) {o8 }. I AL (o9 ) {o7 , o9 , o11 , o12 },. I AT (o10 ) {o10 }. I AL (o11 ) {o1 , o4 , o5 , o9 , o11 , o12 }, I AL (o12 ) {o1 , o4 , o5 , o7 , o9 , o11 , o12 } Las aproximaciones inferiores ( LA , AL ) y superiores ( LA , LA ) de los conjuntos. , por la relación L y según el conjunto de atributos A son: LA {o10},. AL {o6 , o8 },. SA {o2 , o3 , o4 , o5 , o6 , o7 , o8 , o9 , o11, o12},. SA {o1 , o2 , o3 , o4 , o5 , o7 , o10 , o11, o12}, Teniendo en cuenta los resultados anteriores podemos concluir que la relación V (LA) contiene las ventajas de las relaciones II (TA) y III (SA) y descarta sus limitaciones. Un ejemplo de ello son los objetos o10 y o11 , los cuales no tienen valores conocidos iguales, lo que evita que puedan ser discernibles en la relación de tolerancia TA (relación II) pero sí pueden serlo en la relación de tolerancia limitada LA (relación V). En el otro extremo está el caso de los objetos o9 y o12 que tienen la mayoría de sus atributos iguales (c1,c2,c3) pero por la relación III (SA) son discernibles, situación que no se presenta con la relación V (LA). que si los. clasifica como inseparables.. 1.3.5 La relación VI Analizando el SDI de la figura 1.6 con la relación VI obtenemos los resultados siguientes. 21.
(31) Capítulo 1 Las clases de inseparabilidad de cada objeto según el conjunto de atributos A por la relación M son:. I AM (o1 ) {o1 , o12 },. I AM (o2 ) {o2 , o3 }. I AM (o3 ) {o2 , o3 },. I AM (o4 ) {o4 , o5 }. I AM (o5 ) {o4 , o5 },. I AM (o6 ) {o6 }. I AM (o7 ) {o7 , o9 },. I AM (o8 ) {o8 }. I AM (o9 ) {o7 , o9 , o12 },. I AM (o10 ) {o10 }. I AM (o11 ) {o11}, I AM (o12 ) {o1 , o9 , o12 } Las aproximaciones inferiores ( MA , AM ) y superiores ( ML , LM ) de los conjuntos. , por la relación M y según el conjunto de atributos A son: MA {o1 , o10},. AM {o6 , o8 , o11},. MA {o2 , o3 , o4 , o5 , o7 , o9 , o10 , o12},. MA {o2 , o3 , o4 , o5 , o6 , o7 , o8 , o9 , o11, o12}, De los resultados anteriores podemos inferir que la relación VI (MA) acaece de las deficiencias de la relación III (SA) dado que objetos de los que se conoce muy poco son clasificados como parte de la aproximación inferior de uno de los conjuntos ( ), tal es el caso del objeto o11 del cual se desconoce la mayor parte de su información (a1,a3, a4) y es clasificado inequívocamente como .. 1.4 El problema de la semejanza entre objetos Diariamente nos encontramos situaciones donde se tiene que distinguir entre grupos similares o se tiene que clasificar algunos elementos como similares. Es por esto que la medida de similaridad se convierte en una importante herramienta para decidir la semejanza (grado de similaridad) entre dos grupos o entre dos elementos. La misma puede definirse sobre un conjunto arbitrario de objetos de interés, tales como objetos físicos, situaciones, problemas, etc. El uso del término similaridad en la Inteligencia Artificial da la idea de una relación borrosa entre las representaciones de dos objetos (Rudolph, 1997) 22.
(32) Capítulo 1 1.4.1 Funciones de semejanza. La similaridad entre dos objetos se puede determinar a partir de su grado de semejanza. En (Wilson and Martínez, 1997) se presenta un detallado estudio de este tema; donde los atributos se clasifican en lineales o nominales. Los atributos lineales pueden ser continuos o discretos. Se consideran continuos aquellos que tienen como dominio los números reales y discretos aquellos cuyo dominio está formado por un conjunto finito de valores numéricos (por lo que existe un orden entre esos valores). Un atributo nominal o simbólico es un atributo discreto cuyos valores no guardan un orden entre sí, por ejemplo, la variable Color. Una manera para describir la función de semejanza que mide la similaridad entre dos objetos P y C es: n. P, C wi * iPi , Ci . (1.2). i 1. Donde wi es la importancia del rasgo, Pi y Ci son los valores que el rasgo i tiene en P y C respectivamente y i es la función de comparación para el rasgo i. Una de las funciones de comparación más simple es: 1 if a) x, y 0 if. x y x y. (1.3). Otras funciones de comparación de rasgos son: 1 b) i , 0 . c) Sea M i . (1.4). s. a , a at M t. t 1. i. para t 1,..., s 1. t 1. . . i , 1 (si a p , a p 1 y a p , a p1 ). ó 0 en otro caso. (1.5). 23.
(33) Capítulo 1 1.4.2 Relación de similaridad. Numerosas aplicaciones han revelado la necesidad de extender el enfoque clásico de los conjuntos aproximados. Una variante destacada de las extensiones realizadas es sustituir la relación de inseparabilidad por una relación de tolerancia (Sankar and Andrzej, 1999). De esta forma se puede obtener procedimientos de clasificación con una eficiencia comparable a la de otros métodos basados en casos, como k-NN, pero con más posibilidades para expresar lo que realmente sucede en los datos (Slezak and Wroblewski, 1999). Seguidamente se presenta una variante de este enfoque. Una generalización del enfoque clásico de los conjuntos aproximados es reemplazar la relación de inseparabilidad binaria, la cual es una relación de equivalencia, por una relación de similaridad binaria más débil. En la definición original del concepto de conjuntos aproximados, existe una relación R que define la inseparabilidad entre los objetos que tienen el mismo valor para los atributos considerados por R, debido a eso, cada relación es una relación de equivalencia. Tal definición de R puede ser muy restrictiva en muchos casos. Considerar el uso de una relación de similaridad en lugar de una relación de inseparabilidad resulta relevante. En realidad, debido a la imprecisión en la descripción de los objetos, pequeñas diferencias entre objetos no se consideran significativas en el proceso de discriminación (formación de las clases de equivalencias), como sucede frecuentemente con los atributos cuantitativos debido a imprecisiones en la medición de los mismos, fluctuaciones aleatorias de algunos parámetros, etc.. Una vía para el tratamiento de este problema puede ser discretizar tales atributos, peor esto pudiera traer consecuencias indeseadas como por ejemplo el hecho de asociar valores muy cercanos a valores discretos diferentes. Otra alternativa es considerar la similaridad entre los valores. En nuestra investigación dos objetos x,y con rasgos continuos, pertenecerán a una relación de similaridad S ssi la función semejanza β evaluada en ambos es mayor que un numero real gamma. Esto es S: ySx (x,y)> . 24.
(34) Capítulo 1 El propósito de esta relación es extender la relación de inseparabilidad R aceptando que los objetos que no son inseparables, pero sí suficientemente cercanos o similares se pueden agrupar en la misma clase. En otras palabras, construir una relación de similaridad R* a partir de R, flexibilizando las condiciones originales de inseparabilidad. En (Slowinski and Vanderpooten, 1995) se presentan los siguientes resultados al respecto. Definición 1.8: (Relación de similaridad extendida) Sea R una relación de inseparabilidad que es una relación de equivalencia definida sobre U. Se dice que R* es una relación de similaridad extendida desde R, si y sólo si, (i) Para todo x U, R(x)R*(x) (ii) Para todo x U, Para todo y R*(x), R(y)R*(x) Donde R*(x) es la clase de similaridad de “x”, es decir, R*(x)={yU:yR*(x)} Realmente,. las. relaciones. (1.6) de. similaridad. son. frecuentemente. definidas. directamente y no como extensiones de relaciones de equivalencia. Desde la perspectiva de las propiedades de las relaciones, el carácter transitivo de la relación de separabilidad es fundamental. Si la relación es transitiva, entonces ella define una partición de U en bloques de elementos indistinguibles; mientras que relaciones no transitivas dan pie al uso de relaciones de similaridad. Las similaridades entre los objetos se pueden representar por una relación binaria R que forma clases de objetos los cuales son idénticos o al menos no notablemente diferentes en términos de la información disponible sobre ellos. En general las relaciones de similaridad no generan particiones sobre el universo U, sino clases de similaridad para cada objeto x U. La clase de similaridad de “x”, de acuerdo a la relación de similaridad R se denota por R(x) y se define como: R(x)={ y U : yRx }. (1.7) 25.
(35) Capítulo 1 Se lee como conjunto de elementos ”y” similares a ”x” de acuerdo a la relación R. La relación R es sólo reflexiva (cada objeto es similar a si mismo). Pero no es transitiva: “x” puede ser similar a “y” y “y” puede ser similar a “z”, pero esto no implica que “x” sea similar a “z”. y R(x) y y R(z) NOT z R(x), para x, y y z U. La no transitividad de la relación de similaridad está dada por el hecho de que una serie de pequeñas diferencias no pueden ser propagadas manteniendo el carácter de pequeñas. Por ejemplo, sean: x=0.5. z=0.6. Dada la relación. y=0.7 xRy x-y 0.1:. x está relacionada con z, z está relacionada con y, PERO X NO ESTÁ RELACIONADA CON Y. Tampoco tiene que ser simétrica: “y” pede ser similar a “x” según R, pero esto no implica que “x” sea similar a “y” de acuerdo a R pues la relación R es direccional, donde el sujeto es “y”, y el referente es “x”. y R(x) NOT x R(y), para x, y U. Aunque la mayoría de las funciones de semejanza son simétricas, varios autores han argumentado el hecho de que la similaridad no debe ser tratada como una relación simétrica.. 26.
(36) Capítulo 1 1.5 Conclusiones parciales Podemos decir que después de haber estudiado las diferentes alternativas de las extensiones de la teoría de los Conjuntos Aproximados para el tratamiento de la información incompleta: -. Algunos de los métodos encontrados tienen limitaciones en cuanto a la calidad de la clasificación.. -. Las diferentes implementaciones de estos métodos, en su mayoría, están sobre aplicaciones secuenciales y muchas veces los programas sólo se limitan a llevar los SDI a sistemas de decisión completos.. -. La relación de tolerancia limitada L (relación V) es la más adecuada para tratar el problema de la información incompleta de acuerdo a los resultados teóricos anteriormente mostrados.. 27.
(37) Capítulo 2. Capítulo 2 “Propuesta de paralelización” 2.1 Conjuntos Aproximados (Rough Set) Al enfrentar una tarea que involucre el desarrollo de algoritmos paralelos para una aplicación determinada, es necesario realizar un profundo análisis sobre los posibles modelos de paralelización a seguir, así como del modelo serial que daría solución a la problemática planteada. Nuestra investigación no está desligada de este planteamiento. En el presente capítulo se muestra el conjunto de algoritmos propuestos para el cálculo de la calidad de SD y todo lo relacionado con el diseño y la funcionalidad de los mismos. El análisis de los sistemas de información incompletos es abordado por las extensiones de la teoría de los Conjuntos Aproximados. Después de haber hecho el análisis teórico de sus principales representantes contamos con varias alternativas encontradas en la literatura científica para abordar esta problemática en sistemas de decisión incompletos. Dos de las relaciones propuestas serán implementadas por el presente proyecto por la gran importancia que se les atribuyó a las mismas en múltiples trabajos científicos. El problema de la semejanza entre objetos en los sistemas de información completos con rasgos continuos es tratado también en las extensiones de la teoría de los Conjuntos Aproximados, su principal exponente son las relaciones basadas en funciones de semejanza por lo que decidimos desarrollar esta variante pero de una forma que la función de semejanza quedara abierta a los usuarios que quieran hacer uso de una propia y no de la implementada en esta investigación (suma pesada de rasgos). Las primeras dos variantes para el trabajo con perdida de información están basadas en relaciones de tolerancia. La primera (relación II, capítulo 1) es una de las más usadas y referenciadas en la bibliografía y la segunda (relación V, capítulo 1), como se. comprobó teóricamente, permite obtener resultados. superiores en el cálculo de la calidad con respecto al resto de las variantes (sus resultados son expuestos de forma experimentalmente en el capítulo 3).. 28.
(38) Capítulo 2 Por otra parte se implementó una función de semejanza que mide la similaridad entre dos objetos P y C con n rasgos de condición reales y un atributo de decisión que puede o no ser continuo, nombrada como la suma ponderada de los pesos. Su especificación se encuentra incluida dentro de la biblioteca libsemej.a, la que implementa dos variantes de funciones de comparación de rasgos (2.1 y 2.2) y que tiene como función de semejanza a (2.3) o (2.4) según sea la función de comparación de rasgos escogida. 1 if x, y 0 if. x y x y. 1 0 . i , . (2.1). (2.2). n. P, C wi * iPi , Ci . (2.3). i 1. n. P, C wi * i Pi , Ci . (2.4). i 1. Donde”x”, ”y”, Pi , Ci , α, y β son atributos, P y C son conjuntos de atributos, ε es un valor real que entre otras cosas decidirá, en caso de que sea 0 o diferente de 0, si se va a usar la (2.1) o (2.2) respectivamente. En esta implementación es muy importante destacar que la función funcionSemejanza(float * A, float * B, long columnas) desarrolla la función de semejanza, declarándose en el archivo Semejanza.h e implementada en libsemej.a. Por su propia concepción esta implementación puede variar según el usuario desee con sólo cambiar el archivo libsemej.a por otro que contenga el desarrollo de una nueva función de semejanza la cual deberá regirse por la declaración que está definida en Semejanza.h Estas implementaciones siguen un número de procedimientos indicados por sus algoritmos, los cuales se muestran a continuación.. 29.
(39) Capítulo 2 2.2 Procedimiento serial para clasificar a un SDI En la versión secuencial del algoritmo un solo nodo es el encargado de ejecutar todo el trabajo. El procedimiento básico empleado para calcular la calidad del sistema de información, independiente de la variante seleccionada, consta de dos pasos:. 1). Invocar a la función que determina la relación de tolerancia entre los objetos (función tolerancia, tolerancil o similitud).. 2). Imprimir la calidad de la aproximación del sistema.. Estas variantes se resumen en el mismo algoritmo secuencial, que se muestra a continuación: program calc_calidad; 1. cargar_SDI(name); SumAinf=0;. 2. Repetir Desde i:=0 hasta ctad_obj, hacer Si la clase_d (i) esta en array_cd entonces inc(array_cd[clase_d[i]]) ; sino add(clase_d[i],array_cd) ;. 3. Repetir Desde j:=0 hasta ctad_cd hacer Repetir Desde k:=0 hasta ctad_obj hacer Si clase_d(k) = array_cd(j) entonces n:=0; válido:=true; Mientras (n<= ctad_obj) y (válido=true) hacer Si clase_d(n) = clase_d(k) entonces válido = objATobjBCD (n,k); inc(n); Si (válido=true) entonces inc(SumAinf);. 4. calidad = SumAinf/ctad_obj;. 5. devolver(calidad);. 30.
(40) Capítulo 2 En este pseudo código es necesario aclarar el significado de algunas funciones y variables: add:. Esta función adiciona una clase de decisión al arreglo de clases de decisión.. array_cd:. En este arreglo se almacenan las clases de decisión diferentes que tiene el SDI.. calidad:. Esta es la variable donde se guarda el objetivo final del programa, que es calcular la calidad de aproximación del SDI mediante los atributos entrados como parámetros.. cargar_SDI:. Esta función lee de un archivo cuyo nombre fue entrado como parámetro (name) el sistema de decisión y lo almacena en memoria.. clase_d:. Esta función devuelve el valor del atributo de decisión del objeto que se le pasa como parámetro.. ctad_cd:. Es el número de clases de decisión diferentes con que cuenta el sistema.. ctad_obj:. Es el número de objetos con que cuenta el sistema de decisión incompleto.. SumAinf:. En esta variable se van contabilizando todos los objetos que pertenecen a la aproximación inferior de un conjunto.. válido:. Esta bandera nos evita tener que recorrer todos los objetos de una clase de tolerancia para comprobar si este objeto no pertenece a la aproximación inferior del conjunto (siempre que el objeto a comparar no pertenezca a la aproximación inferior del conjunto), debido a que en el momento que se encuentre un objeto en la misma clase de tolerancia pero que tenga una clase de decisión diferente válido toma valor false y se detiene la búsqueda.. 31.
(41) Capítulo 2 La función objATobjBCD (n,k) marca la diferencia al utilizar tolerancia, tolerancil, o similitud. Para cada una de estas funciones el algoritmo varía dado al enfoque que teóricamente se le da, pero básicamente es la función que dice si dos objetos A y B (n,k) están en la misma clase de tolerancia. Para el anterior algoritmo tenemos que la función objATobjBCD varia en dependencia de la variante que se implemente. Por ejemplo objATobjBCD1 es la correspondiente a la primera extensión, la relación II del primer capítulo, objATobjBCD2 es la correspondiente a la segunda extensión. La relación V del primer capítulo y objATobjBCD3 es la correspondiente a la tercera extensión, o sea, la relación de similaridad, esta última consta básicamente solamente de la llamada a la función funcionSemejanza dado que dicha función, es la que define si dos objetos son o no similares y no objATobjBCD3. La función de comparación de objetos para la primera extensión se define por: función objATobjBCD1(n, k) 1.. iguales=true;. 2. Mientras (i<=ctad_rasgos) y (iguales=true) hacer Si (rasgo (i, n) <> rasgo (i, k)) y (rasgo (i, n)!=*) y (rasgo (i, k)!=*) entonces iguales = false; inc(i); 3.. devolver(iguales);. Esta es una función muy simple donde hay que aclarar que: - La función rasgo (i,n) devuelve el valor del rasgo i en el objeto n. - La variable ctad_rasgos tiene la cantidad de rasgos que se quieren analizar del SDI. - La bandera iguales que nos evita tener que recorrer todo el conjunto de rasgos si ya uno de ellos tiene un valor diferente en ambos objetos.. 32.
(42) Capítulo 2. La función de comparación de objetos para la segunda extensión se define por: función objATobjBCD2(n, k) 1.. iguales=true; valido=true; i=0; conocido;. 2.. Mientras (i<=ctad_rasgos) y (iguales=true) hacer Si ((rasgo (i, n) <> *) y (rasgo (i, k) <> *)) entonces iguales:=(rasgo (i, n)=rasgo (i, k)); inc(valido); Si ((rasgo (i, n) <> *) o (rasgo (i, k) <> *)) entonces inc(conocido); inc(i);. 3. Si (valido<>0) entonces devolver(iguales) sino Si (conocido<>0) entonces devolver(0); sino devolver(1); En esta función el procedimiento rasgo(i,n) es el mismo que en la variante anterior. Lo mismo pasa con la variable iguales y la variable ctad_rasgos. Tenemos además la bandera valido que usamos para verificar si la pareja de objetos tiene al menos un atributo conocido en común (cuando esto sucede el primer ciclo la incrementa). Es muy importante el papel que desempeña la variable conocido que es la encargada de almacenar si alguno de los dos objetos tiene al menos un atributo conocido en cuyo caso no seria posible que ambos fuesen semejantes por falta de información total (caso que es tratado de esa forma en la segunda relación del primer capítulo). Conviene describir el objetivo del ciclo usado en este pseudo código. El paso 2 (ciclo) verifica si los objetos están relacionados, es decir, si están en la misma clase de tolerancia, comprueba que los objetos tengan al menos un atributo común con valor conocido y que cualquiera de los dos objetos tenga al menos un atributo con valor conocido, almacenándolo en la variable conocido la. 33.
(43) Capítulo 2 cual será 0 ssi ambos objetos en cuestión tienen todos sus atributos desconocidos. La función de comparación de objetos para la tercera extensión (función de semejanza) se define por: función objATobjBCD3(n, k, gamma) 1.. iguales=true; i=0;. 2.. Si (gamma >=0) entonces iguales = (funcionSemejanza(n, k) >= gamma); sino gamma = gamma *(-1); iguales = (funcionSemejanza(n, k) <= gamma);. 3.. devolver(iguales);. Aquí es importante resaltar que gamma no es una variable de la función sino un 3. devolver(iguales); parámetro pasado a objATobjBCD3 (este parámetro ha de ser pasado a la llamada inicial de similitud) y según sea su signo la función similitud estará basada en una función de semejanza (cuando sea gamma > 0) o en una función de discrepancia (cuando sea gamma < 0). Recordemos que la función funcionSemejanza no está incluida en la biblioteca libext.a, el usuario puede implementarla como desee. No obstante, dentro de la biblioteca libsemej.a encontramos una implementación de esta que desarrolla una función de comparación de rasgos conocida, mediante la suma ponderada de los atributos. La funcionSemejanza brindada en la biblioteca tiene básicamente los siguientes pasos: función funcionSemejanza (n, k) 1.. epsilon=0; i=0; beta=0;. 2.. epsilon = loadPesos(array_pesos);. 3.. Repetir Desde i:=0 hasta ctad_rasgos hacer beta = beta + array_pesos[i] *( |(rasgo[i, n] - rasgo[i, k])| <= epsilon ) devolver(beta);. 4.. 34.
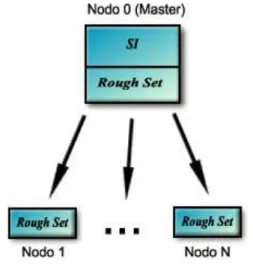
(44) Capítulo 2 En el caso de nuestra simple funcionSemejanza hay que aclarar que epsilon es una variable en la que se guarda el valor de retorno de la función loadPesos (la cual es responsable de cargar en la variable array_pesos el valor de los pesos que se le dan a los atributos mediante el archivo predeterminado pesos.txt) y que necesitamos para poder computar el valor de las expresiones 2.1 o 2.2, según sea el valor de este (cero, o diferente de cero respectivamente). El archivo pesos.txt es un archivo de texto que ha de tener en la primera línea el valor de epsilon y a partir de ahí el listado de los pesos que le queremos dar a los atributos (con que vamos a aproximar el sistema). Por ejemplo, para un SDI con 4 atributos de condición el archivo podría ser el siguiente: 0.2 0.5 1 0.9 1 Es muy importante señalar que si este archivo no tiene la cantidad de pesos estrictamente necesarios la función de semejanza no trabajará apropiadamente. Por ejemplo el archivo mostrado anteriormente deberá tener solo cinco líneas una para el epsilon y cuatro para los pesos que vamos a asignarle a cada uno de los atributos con que vamos a trabajar. En caso de que solo fuéramos a calcular la calidad del sistema con un subconjunto de todos los atributos, el archivo tendrá tantos pesos como elementos tenga este subconjunto.. 2.3 Método paralelo propuesto para el cálculo de la calidad en un SDI. La versión paralela de este módulo fue basada en un modelo de paralelización propuesto por (Ramos, 2007). Este modelo brinda la facilidad de que cada. elemento de procesamiento (nodo) se encargue de construir y trabajar (calcular las aproximaciones inferiores de cada clase de decisión) con sólo un subconjunto de las clases de tolerancia.. 35.
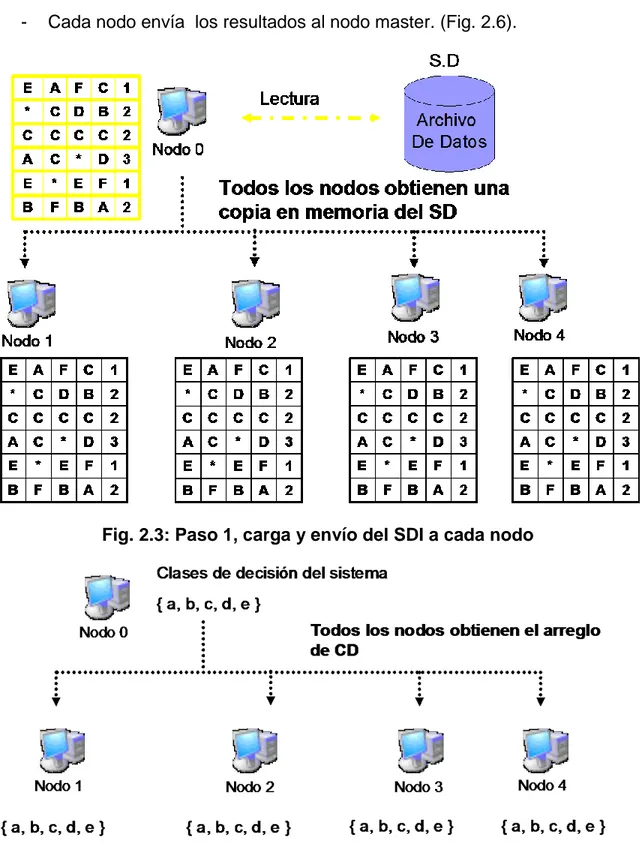
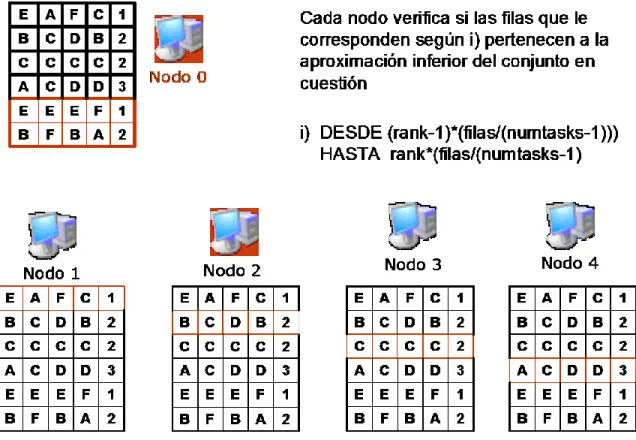
(45) Capítulo 2 Este modelo (Fig. 2.1) aprovecha, donde es posible, las ventajas de las técnicas paralelas, razón por la que sirvió de base al modelo propuesto en esta investigación para la implementación del cálculo de la calidad, usando extensiones de la teoría de los Conjuntos Aproximados en nuestra variante paralela.. Fig. 2.1 Conjuntos Aproximados El algoritmo a modo general consta de cuatro pasos los cuales se describen a continuación: 1). En este paso inicial se procede a la construcción de las clases de tolerancia (CT); el nodo 0 (master) procede a difundir todos los objetos (filas del Sistema de Decisión) al resto de los nodos. Una vez que los nodos reciben los objetos, estos se almacenan en memoria confeccionando una copia del SD en cada uno de los nodos del SD.. 2). Una vez terminado el paso 1, el nodo 0 envía la lista de clases de decisión del sistema a cada uno de los restantes nodos.. 3). Los esclavos junto al nodo 0 proceden a verificar si los objetos que le corresponden (indicados por 2.3 para el nodo master y por 2.4 para los esclavos) pertenecen a la aproximación inferior del conjunto de objetos cuya clase de decisión se esta analizando mediante la exploración de las clases de tolerancia de cada uno de los objetos. Desde (numtasks-1)*(filas/ (numtasks-1)) hasta filas. (2.4) 36.
(46) Capítulo 2 Desde (rank-1)*(filas/(numtasks-1)) hasta rank*(filas/(numtasks-1)). (2.5). Donde numtasks es el número de procesadores utilizados para ejecutar el programa y rank es el identificador del procesador (ID) que está ejecutando ese fragmento de código y filas es el número total de objetos con que cuenta el SD. 4). Cada nodo envía al nodo 0 la cantidad de objetos que pertenecen a la aproximación inferior de cada conjunto definido por las clases de decisión y este posteriormente, calcula la calidad de clasificación del sistema y devuelve el resultado.. Al analizar esta variante observamos que presenta un grupo de ventajas, de las cuales se pueden mencionar las siguientes: -. Se cuenta con un módulo que permite usar SI con otras características (diferentes separadores, números de filas, columnas y atributos, etc.). -. Todas las funciones que se brindan en la biblioteca pueden hacer uso de los archivos con formato arff, muy utilizado internacionalmente.. -. Se eliminaron envíos masivos de datos relacionados con el cálculo de la calidad sin afectar la eficiencia.. Para su implementación en rset.h se encuentra todo lo relacionado con las operaciones de los conjuntos aproximados (la construcción y operación de las clases de tolerancia).El módulo ext.h contiene todas las funciones públicas de la biblioteca:. tolerancia, tolerancil y similitud. En aprox.h se ubican. los. métodos implicados en el cálculo de las aproximaciones. En los archivos ext1.h ext2.h y ext3.h se encuentran las funciones de las que se auxilia ext.h, las cuales están desarrolladas dentro de la biblioteca y no son públicas. En xtras.h se encuentran una serie funciones auxiliares que permiten realizar la lectura de los objetos de la base de casos así como otras funciones auxiliares para el trabajo con los parámetros de entrada y salida. También dentro del archivo mstructs.h están declaradas las principales estructuras de datos utilizadas en el trabajo con los conjuntos aproximados. 37.
(47) Capítulo 2 Como es lógico, muchos de los procedimientos desarrollados hacen uso de funciones básicas ya implementadas en bibliotecas del C, las cuales están declaradas fundamentalmente en stdio.h, stdlib.h y string.h.. Fig. 2.2 Diagrama de colaboración. El diagrama de la Figura. 2.2, se corresponde con el gráfico de dependencias entre la librerías de las funciones.. 2.3.1 Descripción del algoritmo paralelo Nuestra alternativa paralela debe ser capaz distribuir el trabajo entre los nodos esclavos y el nodo master pero antes de hacer esto tiene que garantizar que cada nodo tenga una copia del SD. Para lograrlo el nodo 0 carga el SDI en memoria y lo difunde a cada unos de los nodos restantes. Los pasos son en esencia los siguientes: -. El nodo 0 carga el sistema y le envía una copia a sus esclavos (Fig. 2.3).. -. El master le envía el arreglo de clases de decisión al resto de los nodos (Fig.2.4). 38.
(48) Capítulo 2 -. Cada nodo realiza el trabajo con los objetos que le fueron asignados (Fig. 2.5).. -. Cada nodo envía los resultados al nodo master. (Fig. 2.6).. Fig. 2.3: Paso 1, carga y envío del SDI a cada nodo. Fig. 2.4: Paso 2, envío del arreglo de clases de decisión a cada nodo.. 39.
(49) Capítulo 2. Fig. 2.5: Paso 3 Cada nodo calcula las aproximaciones inferiores de los conjuntos según los objetos que le fueron encomendados.. Fig. 2.6: Paso 4, cada nodo envía hacia el 0 el resultado del cálculo de las aproximaciones inferiores para que este calcule la calidad. El nodo 0 obtiene así la cantidad de objetos que pertenecen a la aproximación inferior del conjunto en cuestión, por lo que todo lo que este tiene que hacer es. 40.
(50) Capítulo 2 repetir el proceso antes expuesto para cada una de las clases de decisión con el objetivo de calcular la calidad de la clasificación. En este modelo se pretende minimizar el tiempo de cálculo de las aproximaciones inferiores, puesto que el mismo era un punto importante en el desempeño del algoritmo y reservar para el nodo master el cálculo de la calidad y de las aproximaciones inferiores en un número menor de clases de tolerancia. La limitación de este esquema, como se puede apreciar, es que el mismo envía una gran cantidad de información de un nodo a otro, lo cual puede traer algunos inconvenientes en caso que se utilicen bases de casos de tamaño considerable.. 2.3.2 Pseudo código del algoritmo paralelo para clasificar un SD En la versión paralela del algoritmo cada nodo (incluyendo el nodo master) tiene que determinar cuáles de los objetos que le fueron asignados pertenecen a la aproximación inferior del conjunto de objetos identificados por una clase de decisión en particular. Al igual que en el procedimiento serial los pasos básicos empleados para calcular la calidad del sistema de información, independiente de la variante seleccionada, son sólo dos: 1) ¡Error! 2). Invocar a la función que determina la relación de tolerancia entre los objetos (función tolerancia, tolerancil o similitud). Imprimir la calidad de la aproximación del sistema.. 41.
Figure

+7

Documento similar