Análisis de Técnicas de Detección de Anomalías, Diseño de una Herramienta de Monitoreo
108
0
0
Texto completo
(2) Universidad Central “Marta Abreu” de Las Villas Facultad de Ingeniería Eléctrica Departamento de Telecomunicaciones y Electrónica. TRABAJO DE DIPLOMA Análisis de Técnicas de Detección de Anomalías, Diseño de una Herramienta de Monitoreo. Autor: Daikel De la Cruz Cruz. [email protected]. Tutor: Msc. Samuel Montejo Sánchez [email protected]. Santa Clara 2008 "Año 50 de la Revolución".
(3) Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería en Telecomunicaciones y Electrónica, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicado sin autorización de la Universidad.. Firma del Autor Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Tutor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica.
(4) i. En la ciencia no hay calzadas reales, y sólo tendrán esperanzas de acceder a sus cumbres luminosas aquellos que no teman fatigarse al escalar por senderos escarpados. Karl Marx; Londres, Marzo 18 de 1872..
(5) ii. Con mucho cariño, para mis abuelos Carmen y Pepe, como un importante paso en el camino hacia la “casa de placa” que siempre prometí; A mi papá por confiar siempre en su “ingeniero”; A mi mamá y a mi hermana por ser siempre su niño lindo, A mi tía y mis primos por quererme tanto, A todos aquellos que algún día contribuyeron a formarme tal como soy; y muy especial a Yanelys, mi novia, por ser la luz que me guía cada día, a todos ellos, les dedico este, mi modesto esfuerzo..
(6) iii. A Samuel, mi tutor, por ser más que eso, un amigo; A mi buen amigo Yoandy porque sin su ayuda no hubiera sido posible; A Yanelys, por ser la mejor novia del mundo; A Mercedes y mis queridos suegros por su valioso aporte; A Maylín y Alejandro por apoyarme siempre; A mi eterno profesor de marxismo Chang, porque ¿qué es sino la vida una eterna política? A todos aquellos que me apoyaron en este difícil camino y a los que no también, por hacerme más fuerte; A Elenis por acogerme en su casa como familia y a mis insuperables, nuevos y viejos amigos porque con sus risas hicieron esta etapa de mi vida inolvidable; a todos ellos ¡muchas gracias!.
(7) iv. TAREA TÉCNICA. 1. Estudiar los sistemas de detección de anomalías. 2. Describir las principales técnicas de detección de anomalías en red. 3. Estudiar las principales características del lenguaje PHP. Profundizar en las relacionadas con el trabajo a nivel de red. 4. Diseñar el software usando las funciones de PHP anteriormente seleccionadas y un soporte Web para este, capaz de lograr la interacción en la red necesitada. 5. Adicionar prestaciones a la herramienta como ejecución de tareas programadas. 6. Poner a prueba la herramienta implementada, con el objetivo de verificar sus potencialidades y validar su aplicación. 7. Documentar el sistema con el objetivo de su comprensión por parte de los posibles operadores de la herramienta y de los desarrolladores de aplicaciones similares, extendiendo así su valor teórico-práctico.. Firma del Autor. Firma del Tutor.
(8) v. RESUMEN. El presente trabajo aborda una descripción y análisis de las principales técnicas de Detección de Anomalías, haciendo énfasis en tres de los enfoques más significativos; basados en el Análisis de los Componentes Principales por su gran aplicabilidad de manera global, en el Análisis de la Carga Útil como un caso complementario del enfoque basado en el Análisis de la Cabecera de Paquetes y en los Modelos Ocultos de Markov por su estudio sobre el tráfico ARP, mostrando sus características y su aplicación. En el capítulo 3 se aborda el diseño de una herramienta de monitoreo, como complemento de un posible proceso final de estos sistemas de detección después de haber obtenido una “lista negra” de presuntos sospechosos, utilizando para la implementación el lenguaje de programación PHP y la integración de herramientas y comandos de red tales como NMAP, PING, NBTStat..
(9) vi. TABLA DE CONTENIDOS. PENSAMIENTO.. ...................................................................................................................i DEDICATORIA… ................................................................................................................ ii AGRADECIMIENTOS ........................................................................................................ iii TAREA TÉCNICA................................................................................................................iv RESUMEN. v. INTRODUCCIÓN ..................................................................................................................1 CAPÍTULO 1.. Técnicas de Detección de Anomalías, visión general. ...............................4. 1.1. Detección de Intrusos (IDS). ..........................................................................5. 1.2. Técnicas de Detección de Anomalías. ............................................................8. 1.2.1. Premisas de la detección de anomalías. ..........................................................8. 1.2.2. Técnicas usadas en la detección de anomalías................................................9. 1.2.2.1. Detección estadística de anomalías. ..........................................................9. 1.2.2.2. Técnicas basadas en aprendizaje automático. .........................................14. 1.2.2.2.1 Análisis secuencial basado en llamada al sistema...............................14 1.2.2.2.2 Método de la ventana deslizante. ........................................................15 1.2.2.2.3 Redes Bayesianas. ...............................................................................16 1.2.2.2.4 Análisis de los componentes principales.............................................18 1.2.2.2.5 Modelos de Markov. ...........................................................................19.
(10) vii 1.2.2.2.6 Análisis de las cabeceras de paquetes. ................................................21 1.2.2.3. Detección de anomalías basado en la minería de datos...........................22. 1.2.2.3.1 Detección de intrusos basado en clasificación. ...................................23 1.2.2.3.2 Agrupamiento y detección de objetos aislados. ..................................27 1.2.2.3.3 Descubrimiento de Reglas de Asociación...........................................30 1.3. Sistemas Híbridos. ........................................................................................31. 1.4. Principales retos: un camino por delante. .....................................................33. CAPÍTULO 2.. Descripción y aplicación de tres técnicas significativas de detección de anomalías..................................................................................................36. 2.1. Sistemas de detección de anomalías basado en el Análisis de los Componentes Principales..............................................................................36. 2.1.1. Análisis estadístico multivariado. .................................................................36. 2.1.1.1. Distancia. .................................................................................................36. 2.1.1.2. Análisis de los Componentes Principales................................................37. 2.1.1.3. Detección de objetos aislados..................................................................39. 2.1.2. El esquema de detección de anomalías propuesto. .......................................42. 2.1.3. Estudio del funcionamiento de este sistema (método PCC) a través de la. comparación de este con otros enfoques.......................................................................45 2.1.3.1 2.2. Medidas de desempeño............................................................................46 Detección de anomalías basado en el análisis de la Carga útil.....................47. 2.2.1. Conocimientos asociados..............................................................................48. 2.2.1.1. Detección de anomalías HTTP................................................................48. 2.2.1.2. Detección de Anomalías en el Nivel de Aplicación................................48. 2.2.1.3. PAYL (Detección de Anomalías basado en la Carga Útil). ....................49. 2.2.2. Un método eficiente......................................................................................50.
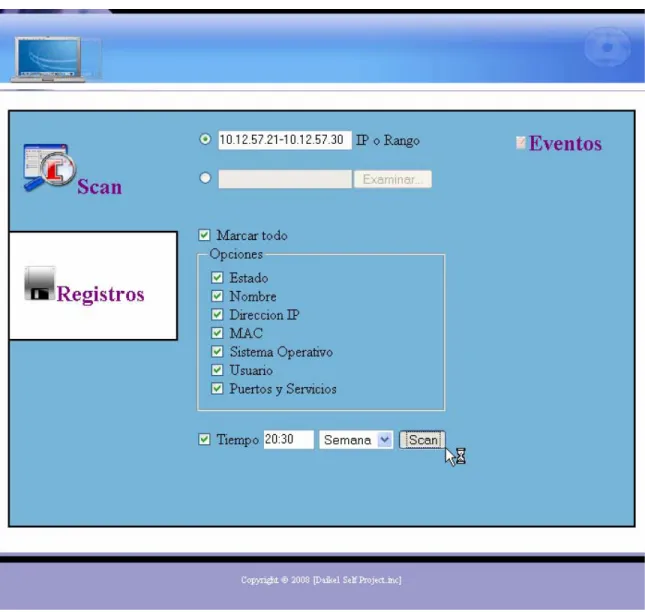
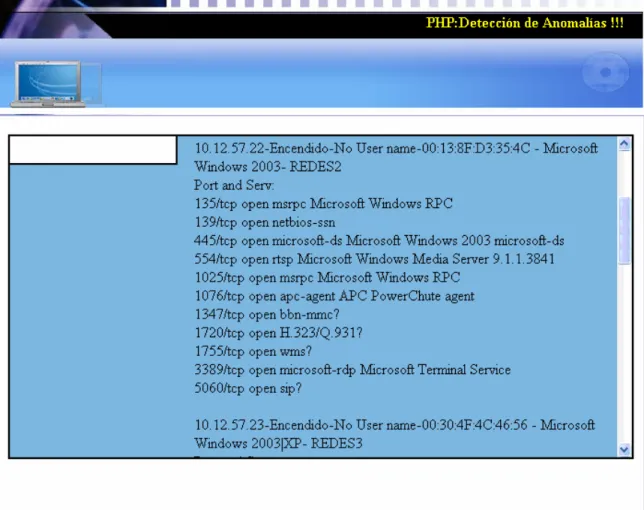
(11) viii 2.2.2.1. Fase de entrenamiento. ............................................................................50. 2.2.2.2. Fase de detección.....................................................................................55. 2.3. Detección de anomalías usando el Modelo Oculto de Markov (específicamente, anomalías ARP). ..............................................................56. 2.3.1. Anomalías ARP. ...........................................................................................56. 2.3.2. Descripción del Modelo Oculto de Markov. ................................................57. 2.3.3. Por qué usar HMM. ......................................................................................57. 2.3.4. Modelado del comportamiento normal del tráfico ARP con HMM. modificado. ...................................................................................................................58 2.3.5. Detección de Anomalías utilizando MHMM................................................60. 2.3.6. Obtención de un valor acertado para el umbral. ...........................................64. 2.3.7. Período de entrenamiento. ............................................................................64. 2.4 CAPÍTULO 3.. Conclusiones parciales..................................................................................65 Descripción y diseño de la herramienta de monitoreo. ............................67. 3.1. Herramientas implicadas...............................................................................68. 3.2. Descripción general. .....................................................................................69. 3.2.1. Sección Scan. ................................................................................................69. 3.2.2. Secciones Registros y Eventos. ....................................................................71. 3.2.1. Implementación en el lenguaje PHP.............................................................73. 3.3. Resultados de las pruebas realizadas. ...........................................................75. 3.4. Conclusiones parciales..................................................................................77. CONCLUSIONES Y RECOMENDACIONES ...................................................................78 Conclusiones.....................................................................................................................78 Recomendaciones .............................................................................................................79 REFERENCIAS BIBLIOGRÁFICAS .................................................................................80.
(12) ix GLOSARIO DE TÉRMINOS. .............................................................................................85 ANEXOS. 87. Anexo A. Modelo generalizado de un sistema típico de detección de intrusos. ...........87. Anexo B. Sumario de los sistemas estadísticos de detección de anomalías. ................89. Anexo C. Sumario de los sistemas de detección de anomalías basados en el aprendizaje automático. ................................................................................90. Anexo D. Fases de detección de intrusos y entrenamiento de ADAM. ........................91. Anexo E. Sumario de los sistemas de detección de anomalías basados en la minería de datos. .............................................................................................................92. Anexo F. Diagrama de bloques básico del ADA basado en HMMM. .........................93. Anexo G. Datos KDD’99. .............................................................................................94. Anexo H. Datos DARPA’99. ........................................................................................95. Anexo I. Winpcap. .......................................................................................................96.
(13) INTRODUCCIÓN. 1. INTRODUCCIÓN. Hoy en día, Internet junto con las redes corporativas juegan un mayor papel en la creación y avance de vías de aprendizaje y negocios. En este sentido se necesita tener compañías y gobiernos motivados a través de todo el mundo para desarrollar sofisticadas y complejas redes de información. Tales redes contemplan diversas series de tecnologías, incluyendo almacenamiento de datos distribuidos, técnicas de encriptación y autentificación, voz y video sobre IP, accesos remotos e inalámbricos y servicios Web, permitiendo una mayor accesibilidad para lograr la interacción directa con todos los servicios que se ofrecen. Todos estos aspectos hacen a las redes de hoy muy vulnerables a los ataques así como a los intrusos. Ejemplo; en la encuesta anual de seguridad y cibercrimen del 2005, realizada por el Computer Security Institute y el FBI en los Estados Unidos, se señaló que las pérdidas financieras debido a ataques e intrusiones en sus redes corporativas fueron de alrededor de los $130 millones de dólares (Institute, 2005). Según los estudios recientes, de veinte a cuarenta nuevas vulnerabilidades en redes y productos de computadoras comúnmente usados son descubiertos como promedio cada mes. Tales vulnerabilidades provocan una inseguridad en el ambiente de la informática y sistemas de redes. Todo este ambiente de inseguridad ha dado origen al desarrollo en todo el mundo del campo de la prevención y detección de intrusos, o sea a la elaboración de sistemas de detección de intrusos para complementar el trabajo de los firewalls (cortafuegos). Estos sistemas de detección de intrusos de red, por sus siglas en inglés (NIDS) pueden clasificarse ya sea como la detección de firmas (huellas) o de anomalías en red. El enfoque basado en las firmas, generalmente sobre la base de las huellas ya conocidas de ataques o vulnerabilidades, es ampliamente desplegado en diversos productos de la industria de.
(14) INTRODUCCIÓN. 2. seguridad. Mientras que la detección de anomalías, trata de identificar los ataques basados en los perfiles de actividades normales de la red y se encuentra todavía, en muchos aspectos, en fase de investigación. Anomalía de red típicamente se refiere a las circunstancias cuando las operaciones de red se apartan de la conducta normal de esta. Las anomalías pueden surgir debido a diversas causas, tales como mal funcionamiento de los dispositivos de red, la mala configuración en los servicios de red y sistemas operativos, la sobrecarga de la red, ataques maliciosos de denegación de servicio, aplicaciones no recomendadas instaladas por los usuarios, un elevado nivel de esfuerzo de los usuarios para descubrir la red y recabar información sobre la misma y sus dispositivos y las intrusiones que perturban la prestación normal de servicios de red. Estos eventos anómalos perturban el comportamiento normal de algunos datos mesurables de la red. La definición de la conducta normal para medir los datos de la red depende de varios factores específicos tales como la dinámica de la red estudiada en términos de volumen de tráfico, tipo de datos de red disponibles y los tipos de aplicaciones que se ejecutan en la red. Diversas son las técnicas empleadas por los sistemas de detección de anomalías y muchas de ellas se encuentran documentadas en nuestros días, una revisión de las principales abordando sus ventajas e inconvenientes, constituirá de relevante interés en dicho campo de investigación. Como resultado final de todas estas técnicas, pudiera ser presumiblemente, una “lista negra” que incluye un conjunto de identificadores de hosts o usuarios los cuales serían presuntos agentes de comportamiento anómalo, lograr un constante chequeo de estos resulta de vital importancia para conocer su actividad y avisar a las autoridades pertinentes para una completa gestión de seguridad de red. Las técnicas existentes de monitoreo de red son diversas, lograr la utilización de una, con funcionalidades específicas constituiría una notable ayuda para los encargados de mantener el correcto funcionamiento de su red de computadoras. Hacia ese fin, se dirige el presente trabajo, el cual aborda en el capítulo 1 el estudio y descripción de las técnicas existentes para la detección de anomalías y de intrusos como un aspecto general; se revisa el estado del arte de estos, se describe y se toma decisiones en.
(15) INTRODUCCIÓN. 3. cuanto a sus ventajas e inconvenientes. En el capítulo 2 son descritas y analizadas tres relevantes técnicas empleadas por los sistemas de detección de anomalías; observando sus particularidades y su aplicabilidad en el entorno de trabajo. Ya en el capítulo 3 se propone el diseño de la aplicación de monitorización específica de dispositivos de red abordando las posibles implicaciones y creación de bases de datos para el registro de los historiales. Se implementa el sistema de análisis de red realizando pruebas que sustentan su aplicabilidad y la validación. de los resultados, terminando así con la documentación de dicha. herramienta. Objetivo General: Estudiar las características y potencialidades de los sistemas de detección de anomalías en red y diseñar e implementar una herramienta de monitoreo personalizada de dispositivos de red. Objetivos Específicos: 1. Estudiar las técnicas de detección de anomalías en red. 2. Analizar y describir relevantes técnicas de detección de anomalías en red. 3. Estudiar las facilidades del lenguaje PHP para el procesamiento de datos. 4. Diseñar un software capaz de monitorizar el comportamiento de parámetros específicos de la red usando el lenguaje PHP. 5. Crear una plataforma Web de interfaz sencilla y de fácil operatividad para poner en práctica dicho software. 6. Poner a prueba la herramienta diseñada, con el objetivo de verificar sus potencialidades y validar su aplicación. Interrogantes Científicas: ¿Cuáles son las principales técnicas empleadas en la detección de anomalías? ¿Cuáles son sus características generales y formas de aplicación? ¿Cómo utilizar el PHP en función del monitoreo de parámetros de red?¿Cómo procesar la información obtenida? ¿Cómo detectar cambios anómalos o fraudulentos en dispositivos de la red?.
(16) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 4. CAPÍTULO 1. Técnicas de Detección de Anomalías, visión general.. Un sistema de detección de intrusos recolecta y analiza información de varias áreas dentro de una computadora o una red para identificar posibles brechas de seguridad. En otras palabras detección de intrusos es el acto de poder detectar las acciones que atentan y comprometen, la confiabilidad, la integridad, o la accesibilidad de un sistema de red. Tradicionalmente los sistemas de detección de intrusos han sido clasificados como un sistema de detección de huellas o firmas, un sistema de detección de anomalías, o un sistema compuesto o híbrido de detección. La diferencia de los dos primeros antes mencionado, es que el sistema de detección de huellas identifica patrones de tráfico o aplicaciones de datos que se presumen como maliciosos, mientras que el sistema de detección de anomalías compara las actividades realizadas contra un supuesto patrón “normal” buscando desviaciones significativas. Un sistema híbrido combina las técnicas de estos dos métodos. Ambos sistemas de detección tienen en común ventajas y desventajas, la primera ventaja del sistema de detección de huellas está dada por su conocimiento de los ataques, característica que le proporciona una detección muy confiable de los mismos con una baja razón de falsos positivos. La mayor desventaja de este método es que requiere definir una huella para cada uno de los posibles ataques que se pueden lanzar contra una red, lo que imposibilita la detección de nuevos ataques que no estén registrados en su conjunto de huellas definidas. Ahora, un sistema de detección de anomalías posee dos ventajas muy importantes sobre el método antes analizado, la primera consiste en su habilidad sobre otros sistemas de detectar ataques desconocidos, debido a su capacidad de modelar un comportamiento normal de una red y detectar desviaciones considerables de este. Una segunda ventaja es que su modelo de operación normal es hecho a la medida de cada.
(17) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 5. sistema, aplicación y/o sistema de red, y por consiguiente se hace muy difícil para un atacante saber con certeza qué actividades puede llevar a cabo en dicho sistema y evitar su propia detección. No obstante el método de detección de anomalías posee igualmente desventajas, como, la complejidad intrínseca del sistema, el alto porcentaje de falsas alarmas y la dificultad asociada a la determinación de los eventos específicos que activan estas alarmas. Tales desventajas representan desafíos para la realización de un sistema de detección de anomalías. 1.1. Detección de Intrusos (IDS).. Un sistema de detección de intrusos es una herramienta de software usada para detectar accesos no autorizados a una computadora común, un servidor o una red. Este debe ser capaz de detectar todo tipo de tráfico malicioso en la red, incluyendo además ataques contra: servicios vulnerables, aplicaciones de datos y terminales de red; tales como escalamiento de privilegios, logins desautorizados, acceso a archivos privados o sensibles y esparcimiento de softwares dañinos. Es una entidad de monitoreo dinámico que se complementa con la habilidad de monitoreo estático de un firewall. Los paquetes de red son recolectados y analizados por unas reglas de violación por un algoritmo de patrones de reconocimiento, cuando las reglas de violación son detectadas el sistema alerta al administrador. Uno de los primeros trabajos que propone la detección de intrusos por la identificación de comportamiento anormal puede ser atribuido a Anderson (Anderson, 1980), este propone un modelo de amenazas clasificándolas como penetraciones externas e internas y abuso de autoridad. Las penetraciones externas se refieren a intrusiones que son llevadas a cabo por un usuario no autorizado por el sistema, las penetraciones internas se refieren a intrusiones llevadas a cabo por usuarios autorizados que acceden a datos comprometidos a los cuales no tienen autorización y el abuso de autoridad se refiere al uso indebido de acceso autorizado al sistema y a sus datos. Un modelo generalizado de un sistema típico de detección de intrusos se muestra en la figura del Anexo A. Históricamente la investigación de la detección de intrusos se ha concentrado dentro de la etapa de análisis y detección del modelo de arquitectura mostrado en la figura del Anexo.
(18) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 6. A. Como ha sido mencionado con anterioridad, los algoritmos para el análisis y detección de intrusos / ataques son tradicionalmente clasificados dentro de las siguientes categorías: ► Detección de huellas es una técnica para la detección de intrusos que se apoyó en un conjunto de huellas definidas para diferentes ataques. En busca de patrones específicos, el sistema de detección de intrusos basado en la detección de huellas compara los paquetes entrantes y/o las secuencias de comandos de las huellas de los ataques conocidos. En otras palabras, la decisión se toma basada en el conocimiento adquirido del modelo del proceso intrusivo y del camino que este deja en el sistema. Un comportamiento legal o ilegal puede ser definido y comparado con el comportamiento observado. Este sistema trata de reunir pruebas de la actividad intrusiva, independientemente de la conducta normal del sistema. Una de las ventajas de este sistema es que los ataques son conocidos y por lo tanto pueden ser confiadamente detectados con una baja razón de falsos positivos. Otro de los beneficios que tiene es que comienza la protección de los equipo/sistema de red inmediatamente después de instalado. Uno de los mayores problemas de este sistema de detección de intrusos por detección de huellas es mantener la información del estado de las huellas en la cual una actividad intrusiva abarca múltiples eventos discretos, es decir que una firma de ataque completo se extiende por múltiples paquetes. Otra de las desventajas de este sistema es que debe tener una huella definida para cada posible ataque que se pueda iniciar. Esto requiere frecuentes actualizaciones de firmas para mantener la base de datos de firmas actualizadas. ► Sistema de detección de anomalías primero crea una línea inicial del perfil del sistema, red o actividad de programas normales. En lo sucesivo alguna actividad que se desvíe de esa línea inicial es tratada como posible intrusión. Este tipo de sistema ofrece varios beneficios: 9 Son capaces de detectar ataques de abuso de información privilegiada. Por ejemplo, si un usuario o alguien usando una cuenta robada comienza a ejecutar acciones que se salen del comportamiento normal de un usuario común, un sistema de detección de anomalías generará una alarma..
(19) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 7. 9 Está basado en perfiles hechos a la medida, esto hace que sea muy difícil para un atacante conocer con certeza qué actividad llevar a cabo sin provocar que el sistema active una alarma. 9 Tiene la habilidad de detectar previamente un ataque desconocido por el hecho de que la detección de una actividad intrusiva no está basada en firmas o huellas específicas representativas de actividades intrusivas conocidas. Una actividad intrusiva genera una alarma al ser percibida que se desvía de la actividad normal, no por la comparación con una firma específica de un ataque. No obstante, un sistema de detección de anomalías sufre de varias desventajas: 9 El sistema debe pasar por un período de entrenamiento en el que se crean los perfiles de usuario mediante la definición de perfiles de tráfico ''normal''. 9 Crear un perfil “normal” es una difícil tarea, la creación de un perfil de tráfico normal inapropiado puede conducir a malos resultados. 9 Dado que el sistema de detección de anomalías está buscando acontecimientos anómalos en lugar de ataques, son propensos a ser afectados por las falsas alarmas. Estas falsas alarmas en algunas circunstancias se clasifican en falsos positivos o falsos negativos. Un falso positivo ocurre cuando un IDS reporta como un intruso un evento que es de hecho una legítima actividad de red. La parte afectada por los falsos positivos es que un ataque o una actividad maliciosa en la red puede pasar desapercibido a causa de todos los previos falsos avisos. Esta falla para detectar un ataque es conocida como falso negativo. Un elemento fundamental de los sistemas modernos de detección de anomalías es el Módulo de Alerta de Correlación. Sin embargo, el alto porcentaje de falsas alarmas que se generan habitualmente en sistemas de detección de anomalías hacen que sea muy difícil asociar alarmas específicas con los eventos desencadenados. Finalmente un obstáculo de este método es que un usuario malicioso puede entrenar a un sistema de detección de anomalías para que acepte comportamiento malicioso como normal. ► Un sistema de detección híbrido o compuesto combina ambos enfoques. En esencia, un sistema híbrido es un sistema de detección de intrusos que toma una decisión usando un.
(20) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. “modelo híbrido”. 8. que se basa en el comportamiento normal del sistema y del. comportamiento anómalo del intruso. 1.2. Técnicas de Detección de Anomalías.. Un método de detección de anomalías usualmente consiste en dos fases: una fase de entrenamiento y una de prueba. En el primer caso, el perfil de tráfico normal se define, en este último, el perfil entrenado se aplica a nuevos datos. 1.2.1. Premisas de la detección de anomalías.. La premisa central de la detección de anomalías es que la actividad intrusiva es un subconjunto de la actividad anómala. Considerando que un intruso, que no tiene idea de los patrones de actividad legítima de un usuario, invade a un servidor, entonces habrá una fuerte probabilidad que la actividad del intruso sea detectada como anómala. En el caso ideal, el conjunto de actividades anómalas será el mismo que el conjunto de actividades intrusivas, en este sentido, mostrando todas las actividades anómalas como intrusivas no resultan en falsos positivos y en falsos negativos, sino en detecciones reales de actividades intrusivas. No obstante, éstas no siempre coinciden con las actividades anómalas. Investigadores del tema (Patcha and Park, 2007), sugieren que existen cuatro posibilidades, cada una con una probabilidad diferente de cero: 1. Intruso pero no anómalo: Este es el llamado falso negativo. Un sistema de detección de intrusos falla en detectar este tipo de actividad como no anómala. Se denomina falso negativo porque el sistema reporta falsamente la ausencia de intrusos. 2. No intruso pero anómalo: Este es el llamado falso positivo. En otras palabras la actividad no es intrusiva, pero como es anómala el sistema la reporta como una intrusión. Se denomina falso positivo porque el sistema de detección falsamente reporta la existencia de un intruso. 3. No intruso y no anómalo: Este es el llamado verdadero negativo. La actividad no es intrusiva y no se reporta como tal. 4. Intruso y anómalo: Este es el verdadero positivo. La actividad es intrusiva y se detecta y reporta como tal..
(21) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 9. Cuando se necesita minimizar los falsos negativos, se bajan los umbrales que definen una actividad anómala. Esto da como resultado varios falsos positivos y reducen la eficiencia del mecanismo automático para la detección de intrusos. Esto crea una sobrecarga para el administrador de seguridad, igualmente para el que debe investigar cada incidente y excluir eventuales falsos positivos. Ahora, ¿cómo definir en una escala global qué actividades de red son catalogadas como normales? Maxion y Feather (Maxion and Feather, 1990) caracterizan el comportamiento normal en una red por el uso de diferentes plantillas que se derivan de tomar la desviación estándar de la carga Ethernet y del conteo de paquetes en varios períodos de tiempo. Una observación se declara anómala si excede un umbral definido con anterioridad. No obstante, ellos no consideran el carácter no estacionario del tráfico de red, el cual podría resultar en una pequeña desviación en el tráfico de red que pasaría inadvertida. 1.2.2. Técnicas usadas en la detección de anomalías.. En este epígrafe, se presenta una revisión de un número de diferentes métodos que han sido propuestos para la detección de anomalías. Este incluye detección estadística de anomalías, métodos basados en la minería de datos, y técnicas basadas en aprendizaje automático. 1.2.2.1 Detección estadística de anomalías. En los métodos estadísticos para la detección de anomalías, el sistema observa el asunto en cuestión, o sea, la actividad a chequear, y genera perfiles para representar su comportamiento. Un perfil típico incluye; medida de actividad intensa, medida de distribución de los registros de auditoría, medidas categóricas (la distribución de una actividad sobre una categoría) y medidas ordinarias (tales como el uso del CPU). Típicamente se mantienen dos perfiles; uno actual y otro almacenado, como son procesados los eventos del sistema/red (por ejemplo los registros diarios de auditoría, los paquetes entrantes, entre otros), el sistema de detección de intrusos actualiza el perfil y periódicamente calcula un rango de anomalía (indicando el rango de irregularidad para el evento específico) por comparación del perfil actual con el almacenado usando una función de desviación de todas las medidas dentro del perfil. Si el rango de anomalía es más alto que el umbral acordado, el sistema de detección genera una alerta..
(22) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 10. Estos métodos estadísticos para la detección de anomalías poseen un gran número de ventajas. Primeramente estos sistemas como la mayoría de los sistemas de detección, no requieren un conocimiento previo de de las banderas de seguridad y/o de los propios ataques. Como resultado, tales sistemas tienen la capacidad de detectar los ataques más recientes. En adición a esto, los métodos estadísticos pueden proveer notificaciones exactas de actividades maliciosas que típicamente ocurren durante períodos de tiempo prolongados que son buenos indicadores del inminente ataque de denegación de servicio (DoS). Un ejemplo muy común de tales actividades lo constituye un “portscan”, típicamente la distribución del escaneo de puertos es altamente anómala en comparación con la distribución usual de tráfico. Esto es particularmente cierto cuando un paquete tuvo rasgos inusuales (Ej. Un paquete hecho a mano). Un escaneo de puerto que sea distribuido sobre un extenso período de tiempo será registrado porque el mismo será inherentemente anómalo. No obstante estos métodos estadísticos tienen ciertas desventajas también; un atacante experto puede entrenar un sistema de detección estadístico de anomalías para aceptar comportamientos anormales como normales. Además se hace un tanto trabajoso la determinación de un umbral que logre un balance entre las posibilidades de falso positivo y falso negativo. En adición a esto, estos métodos estadísticos requieren distribuciones estadísticas exactas y no todos los comportamientos pueden. ser modelados usando. puramente métodos estadísticos. De hecho, una mayoría de técnicas estadísticas de detección de anomalías requieren la suposición de un proceso cuasi-estacionario, el cual no puede ser asumido. para la mayoría de los datos procesados por los sistemas de. detección de anomalías. Uno de los primeros sistemas de detección de intrusos basado en la detección estadística de anomalías fue el denominado Haystack (Smaha., 1998). Este define un rango de valores que es considerado normal para cada aspecto. Si durante una sesión un aspecto colapsa fuera del rango normal, se plantea el rango para el sujeto en cuestión. Asumiendo que los aspectos son independientes, se calcula la probabilidad de distribución de los rangos, si esta es muy grande se activa una alarma..
(23) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 11. Haystack mantiene una base de datos de perfiles individuales de usuario, si un usuario no ha sido previamente detectado, se crea un nuevo perfil de usuario con capacidad mínima usando restricciones basadas en los miembros de grupo del usuario. Este sistema fue diseñado para detectar seis tipos de intrusiones: 1. Intento de break-ins por usuarios no autorizados. 2. Ataques enmascarados. 3. Penetración del sistema de control de seguridad. 4. Fugas 5. Ataques de denegación de servicios (DoS). 6. Uso malicioso. Una de las mayores desventajas del sistema Haystack es que fue designado a trabajar offline, o sea sin conexión. El intento de utilizar los análisis estadísticos en tiempo real para sistemas de detección de intrusos falló, ya que ello requiere de sistemas de alto rendimiento y a causa de su dependencia de mantenimiento de perfiles, un problema común para los administradores de sistemas es la determinación de los atributos que constituyen buenos indicadores de la actividad intrusiva. Otro de los sistemas de detección de intrusos se desarrolló en el Stanford Research Institute (SRI) en los primeros decenios de 1980 y fue llamado el Sistema Experto de Detección de Intrusos, por sus siglas en inglés (IDES)(Lunt et al., 1992, Newman et al., 2002). Era un sistema que continuamente monitoreaba el comportamiento de los usuarios y detectaba eventos sospechosos a medida que se producían. En IDES se activaban las alarmas por la detección de desviaciones de los patrones “normales” individuales establecidos para los usuarios. Como maduró el análisis de las metodologías desarrolladas para IDES, los científicos en SRI desarrollaron una versión mejorada del IDES, llamada la Próxima Generación de Sistemas Expertos de Detección de Intrusos, por sus siglas en inglés (NIDES) (Anderson et al., 1994, Anderson et al., 1995). NIDES fue uno de los pocos sistemas de detección de intrusos de su generación que pueden actuar en tiempo real para el seguimiento continuo de.
(24) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 12. la actividad de los usuarios o puede ejecutar en un modo por lotes 1 para el análisis periódico de los datos auditados, no obstante la principal ventaja del modo de operación de NIDES es que se ejecuta en tiempo real. A diferencia de IDES, que es un sistema de detección de anomalías, NIDES es un sistema híbrido que tiene un motor mejorado de análisis estadístico. En ambos IDES y NIDES, la unidad de análisis estadístico mantiene unos perfiles normales de comportamiento sobre la base de un conjunto de variables seleccionadas. Este habilita al sistema para comparar las actividades actuales de la red con los valores esperados de las variables de detección de intrusos revisadas que han sido almacenadas en los perfiles y entonces advertir de una anomalía si la actividad revisada está lo suficientemente lejos del comportamiento esperado. Cada variable almacenada en el perfil refleja la medida en que un determinado tipo de comportamiento es similar al perfil que se construyó para él “bajo condiciones normales”. La forma en que este se computa es por la asociación de cada variable con una variable aleatoria correspondiente. La distribución de frecuencia es elaborada y actualizada sobre el tiempo, cuanto más auditorías almacenadas sean analizadas. Ésta es calculada como una suma exponencial con una vida media de 30 días. Esto implica que el valor de vida media hace que los archivos de la auditoría que se almacenaron hace 30 días contribuyan en la mitad del peso de los archivos recientes, aquellos recogidos hace 60 días contribuyen en ¼ del peso y así sucesivamente. Usando esta distribución de frecuencia y el valor de las correspondientes medidas para los registros de la auditoría actual es posible computar un valor que refleje que tan lejos del valor normal de la medida está el valor actual. NIDES crea un valor que está correlacionado con cuan anormal es esta medida. Combinando los valores obtenidos para cada medida y. 1. … modo por lotes se denomina al modo de funcionamiento de un programa que se ejecuta en modo no. interactivo sobre una gran cantidad de datos. Generalmente, se diseñan programas para su funcionamiento en "modo por lotes" cuando la misma tarea se debe aplicar a una gran cantidad de información, porque sería tedioso hacerlo manualmente. Un programa que funciona en reacción inmediata a las acciones del usuario es un programa interactivo..
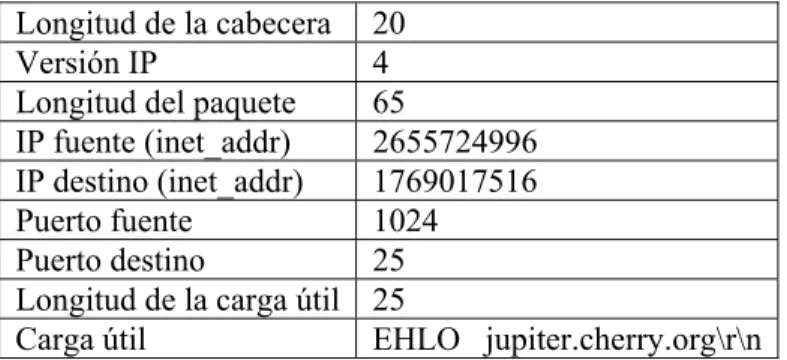
(25) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 13. tomando en consideración la correlación entre medidas, la unidad calcula un índice de lo lejos que están los archivos recientes de la auditoría del estado normal, los que estén más allá del umbral son tomados como posibles intrusiones. No obstante, estas técnicas usadas poseen varias desventajas, primeramente las técnicas son sensibles a la suposición de normalidad, si un dato en una medida no está normalmente distribuido, las técnicas podrían dar al traste con un alto rango de falsas alarmas. Segundo, las técnicas son predominantemente univariantes en que un perfil normal estadístico es construido para solamente una medida en la actividad de un sistema. Sin embargo, las intrusiones frecuentemente afectan múltiples medidas de actividades colectivas. El Motor de Detección de Anomalías por Paquetes Estadísticos, por sus siglas en inglés (SPADE) (Staniford et al., 2002) es un sistema de detección de anomalías usado para la detección de escaneo silencioso de puertos. Este fue uno de los primeros trabajos que propuso el uso del concepto de “puntaje de anomalía”, por sus siglas en inglés AS, para detectar escaneos de puertos, en lugar de utilizar el enfoque tradicional de ver los intentos p durante q segundos. En SPADE los autores usan un método denominado de simple frecuencia, para calcular el puntaje de anomalía de un paquete. Estos definen anomalía como el grado de extrañeza basado en actividades pasadas y recientes. Una vez cruzado el umbral por el puntaje de anomalía los paquetes son enviados a un procesador de correlación que está designado para detectar escaneo de puertos. La mayor desventaja de este sistema es que tiene una alta tasa de falsas alarmas debido a que clasifica todos los paquetes desconocidos como ataques sin importar si son intrusiones actuales o no. Las anomalías como resultado de intrusiones pueden causar desviaciones en múltiples medidas en una manera colectiva más que a través de manifestaciones separadas en medidas individuales. Para superar este problema, se presentó una técnica (Ye et al., 2002) que utiliza el test de Hotellings T 2 para analizar las actividades auditadas en un sistema de información y detección de intrusiones, basado en host. La suposición que se hace es que las intrusiones basadas en host dejan huellas en los datos auditados. En otro documento, Kruegel y otros (Kruëgel et al., 2002) muestran que es posible encontrar la descripción de un sistema que calcula la distribución de bytes de carga útil y combina esta información con características que se extrajeron de la cabecera del paquete..
(26) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 14. En este enfoque, los caracteres ASCII resultantes se ordenan por frecuencia y luego son agregados dentro de seis grupos. Sin embargo, este planteamiento lleva a una clasificación torpe de la carga útil. Recientemente se han llevado a cabo estudios analíticos de los sistemas de detección de anomalías, los cuales evalúan la calidad de los métodos de detección de anomalías, determinan parámetros del sistema y elaboran modelos haciendo uso de varias informaciones tales como entropía y ganancia de información (Patcha and Park, 2007). Las características principales de algunos de los esquemas abordados en esta sección se presentan en la tabla del Anexo B. 1.2.2.2 Técnicas basadas en aprendizaje automático. Este aprendizaje de máquina puede ser definido como la habilidad de un programa y/o sistema para aprender y mejorar su funcionamiento en el desempeño de una tarea o un grupo de tareas en el tiempo. Sin embargo, a diferencia de los métodos estadísticos los cuales tienden a fijar su atención a la comprensión de los procesos que generan los datos, las técnicas basadas en aprendizaje de máquinas fijan su atención a la construcción de un sistema que mejore su funcionamiento basado en los resultados previos. En otras palabras, un sistema que se base en el paradigma del aprendizaje automático tiene la habilidad de cambiar su estrategia de ejecución en la base de la nueva información adquirida. 1.2.2.2.1 Análisis secuencial basado en llamada al sistema. 2 Este método es una de las técnicas basadas en aprendizaje de máquina más ampliamente usada para la detección de anomalías, que involucra conocer el comportamiento de un programa y reconocer desviaciones significantes de lo “normal”. Uno de los investigadores del tema, Forrest (Forrest et al., 1996), establece una analogía entre el sistema inmune. 2. … la "llamada al sistema" (System Call) es el mecanismo usado por un programa aplicativo para solicitar. un servicio al Sistema Operativo. Los programas son un conjunto de instrucciones organizadas con un objetivo. Un proceso es conceptualmente un programa en ejecución. En los sistemas operativos multitarea, puede haber varios procesos ejecutándose concurrentemente. Cada proceso puede requerir el uso de recursos de hardware, como periféricos, o espacio de memoria principal, u otros recursos..
(27) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 15. humano y uno de detección de intrusos. Para esto propone una metodología que involucra analizar las secuencias de llamada al sistema de un programa para elaborar un perfil normal y establece que la correlación en secuencias de longitud fija de llamadas del sistema podría ser usada para elaborar un perfil normal de un programa. Por consiguiente, los programas que muestren secuencias que están desviadas del perfil de secuencia normal podrían ser considerados como víctimas de un ataque. Este método está diseñado para ser usado sin conexión, consultando los datos previamente recolectados y usando un algoritmo simple de tabla de localización para adquirir los perfiles de programas. Otro investigador del tema Hofmeyr (Hofmeyr et al., 1998) hizo una extensión del trabajo de Forrest, en la cual se elabora una base de datos de comportamiento normal para cada programa de interés. Una vez elaborada una base de datos estable para un programa dado en unas condiciones particulares, la base de datos es entonces usada para monitorear el comportamiento del programa. Las secuencias de llamada del sistema forman un conjunto de patrones normales para la base de datos, y las secuencias no encontradas en esta, son entonces indicadores de anomalías. 1.2.2.2.2 Método de la ventana deslizante. Este es otro método que ha sido frecuentemente usado en el entorno en el que nos encontramos. Es una metodología de aprendizaje secuencial, que convierte el problema de aprendizaje secuencial en el clásico problema de aprendizaje. Construye una ventana clasificadora hw que mapea una ventana de entrada de ancho w dentro de un valor individual y de salida. Específicamente, tenemos que d = (w - 1)/2 que es la mitad del ancho de la ventana. Entonces hw predice yi ,t usando la ventana: (xi,t _ d,xi, t _ d+1, . . .,xi, t, . . .,xi, t + d_1,xi, t + d). La ventana clasificadora hw es preparada para la conversión de cada ejemplo secuencial de entrenamiento (xi, yi) dentro de la ventana y entonces aplicar un algoritmo de aprendizaje automático estándar. Una nueva secuencia x es clasificada convirtiéndola en una ventana, aplicando hw para predecir cada yt y luego concatenar los yt para formar las secuencias y predichas. La ventaja evidente de este método de la ventana deslizante es que permite que sea aplicado a cualquier algoritmo clásico de aprendizaje supervisado. Si bien, el método de ventana.
(28) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 16. deslizante da suficiente rendimiento en muchas aplicaciones, en este no se aprovechan las correlaciones entre valores cercanos de yt .Específicamente, la única relación entre valores cercanos de yt que se capturan, es que son previsibles de los valores cercanos de xt. Si hay correlación entre los valores de yt que son independientes de los valores xt, entonces estos no son capturados. El método de la ventana deslizante ha sido utilizado con éxito en una serie de técnicas de aprendizaje automático basados en la detección de anomalía (Cohen, 1995, Eskin et al., 2001, Warrender et al., 1999). Warrender y otros. (Warrender et al., 1999) propone un método que utiliza ventanas deslizantes para crear una base de datos de secuencias normales para la realización de pruebas en contra de los casos de prueba. Eskin y otros. (Eskin et al., 2001), mejora el método tradicional de la ventana deslizante al proponer una metodología de modelado dinámico que utiliza la longitud de una ventana deslizante dependiente del contexto de la secuencia de llamada al sistema. Sin embargo, los métodos basados en llamada al sistema para sistemas de detección de intrusos basado en host sufren de dos inconvenientes. En primer lugar, los gastos generales de cómputo que están implicados en la supervisión de cada llamada al sistema son muy altos. Estos altos gastos conducen a una degradación del rendimiento del sistema de monitoreo. El segundo problema es que las llamadas al sistema son irregulares por naturaleza. Esta irregularidad conduce a la alta tasa de falsos positivos, ya que es muy difícil diferenciar entre las llamadas de sistema normales y anómalas. 1.2.2.2.3 Redes Bayesianas. Una red Bayesiana codifica las relaciones probabilísticas entre variables de interés. Cuando se usa en ejecución con técnicas estáticas, las redes Bayesianas tienen una serie de ventajas para el análisis de datos (Heckerman, 1995). Primeramente, porque estas codifican las interdependencias entre variables que pueden manejar la situación donde hayan pérdidas de datos. En segundo lugar, las redes Bayesianas tienen la habilidad de representar relaciones causales, por consiguiente, ellos pueden ser usados para predecir las consecuencias de una acción. Por último, porque las redes Bayesianas tienen ambas relaciones, causales y probabilísticas, por lo que pueden ser usados para modelar problemas donde se necesite combinar conocimientos previos con datos..
(29) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 17. Algunos investigadores del tema tienen ideas adaptadas de estadísticas bayesianas para crear modelos para la detección de anomalías (Kruegel et al., 2003, Valdes and Skinner, 2000, Ye et al., 2000). Valdés y otros (Valdes and Skinner, 2000) desarrollaron un sistema de detección de anomalías que emplea redes bayesianas naives 3 (ingenuas) para ejecutar la detección de intrusos en ráfagas de tráfico. Este modelo que es parte de EMERALD (Patcha and Park, 2007), ha sido capaz de potenciar la detección de ataques distribuidos en los cuales cada ataque individual a una sesión no es lo suficientemente sospechoso como para generar una alerta. Sin embargo, este esquema también tiene desventajas; primeramente la clasificación de la capacidad de las redes bayesianas ingenuas es idéntica al sistema basado en un umbral que calcula la suma de los productos obtenidos de los nodos hijos. En segundo lugar, porque los nodos hijos no interactúan entre sí y su salida sólo influye en la probabilidad del nodo raíz, incorporando información adicional que se vuelve dificultosa como las variables que contienen la información que no puede interactuar directamente con los nodos hijos (Kruegel et al., 2003). Otra área dentro del dominio de la detección de anomalías, donde las técnicas bayesianas han sido frecuentemente usadas, es en la clasificación y supresión de falsas alarmas. Kruegel (Kruegel et al., 2003) propone un método de fusión de censor múltiple, donde las salidas de sensores de SDI son agregadas para producir una única alarma. Este método es basado en la suposición de que cualquier técnica de detección de anomalías no puede clasificar un conjunto como una intrusión con suficiente confianza.. 3. … una red bayesiana naive es una red que ha sido restringida a solamente dos capas y asume la total. independencia entre los nodos de información (es decir, las variables aleatorias que se pueden observar y medir). Estas limitaciones resultan en una red con forma de árbol con un solo nodo hipótesis (nodo raíz) que tiene flechas que apuntan a un número de nodos de información (nodos hijos). Todos los nodos hijos tienen exactamente un nodo pariente, es decir, el nodo raíz, y no es permitida ninguna otra relación de causalidad entre nodos..
(30) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 18. Aunque el uso de redes bayesianas para la detección de intrusos o la predicción del comportamiento de intrusos puede ser efectiva en determinadas aplicaciones, sus límites deben considerarse en la aplicación real. Dado que la precisión de este método es dependiente de ciertas suposiciones que son típicamente basadas en el modelo de comportamiento del sistema de destino, y desviándose de esas suposiciones se reducirá su exactitud. Seleccionando un modelo inexacto dará lugar a un sistema de detección inexacto. Por lo tanto, la selección de un modelo preciso es el primer paso hacia la solución del problema. Lamentablemente la selección de un modelo de comportamiento exacto no es una tarea fácil porque estas redes y/o sistemas típicos son complejos. 1.2.2.2.4 Análisis de los componentes principales. Las bases de datos para los sistemas de detección de intrusos, típicamente son muy largas y multidimensionales 4 . Para enfrentar el problema de la alta dimensionalidad de las bases de datos,. algunos. investigadores. han. desarrollado. una. técnica. de. reducción. de. dimensionalidad conocida como Análisis de los Componentes Principales, por sus siglas en inglés (PCA)(Patcha and Park, 2007, Wang and Battiti, 2006). En términos matemáticos, PCA es una técnica donde n variables aleatorias correlacionadas son transformadas dentro de d ≤ n variables no correlacionadas. Las variables no correlacionadas son combinaciones lineales de las variables originales y pueden ser usadas para expresar los datos en una forma reducida. Típicamente, el componente principal de la transformación es la combinación lineal de las variables originales con alta varianza. En otras palabras el primer componente principal es la proyección en la dirección en la cual la varianza de esta es maximizada. La segunda componente principal es la combinación lineal de la segunda variable original con la segunda varianza más alta y ortogonal a la primera componente principal, y así sucesivamente. En varias bases de datos, la primera componente principal aporta la mayor parte de la varianza en la base de datos original, así que el resto puede ser prescindido con un mínimo de pérdida de la varianza para la reducción dimensional de la base de datos. PCA ha sido ampliamente usado en el dominio. 4. …el número de dimensiones es equivalente al número de atributos..
(31) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 19. de la compresión de imágenes, reconocimiento de patrones y detección de intrusos, en el próximo capítulo se realiza un análisis más detallado de dicho enfoque. 1.2.2.2.5 Modelos de Markov. Los modelos de Markov han sido usados también para la detección de anomalías. En Ye y otros.(Ye and Borror, 2004) se presenta una técnica de detección de anomalías que es basada en los modelos de Markov. El modelo oculto de Markov, otra técnica popular de Markov, como la mostrada en la Figura 1.1, es un modelo estadístico donde el sistema modelado es asumido como un proceso de Markov con parámetros desconocidos. El reto es la determinación de los parámetros ocultos desde los parámetros observables. A diferencia del modelo regular de Markov, donde las probabilidades de transición de estado son solamente parámetros y el estado del sistema es directamente observable, en un modelo oculto de Markov, el único elemento visible son las variables del sistema que son influenciadas por el estado del sistema, el cual está propiamente oculto. Un estado oculto de este modelo representa algunas condiciones no visibles del sistema modelado. En cada estado, existe una probabilidad certera de producir alguna de las salidas de sistema visibles y una probabilidad separada indicando la probabilidad del próximo estado. Considerando las diferentes distribuciones de probabilidad de salida en cada estado y la autorización del sistema a cambiar estado sobre el tiempo, el modelo es capaz de representar secuencias no estacionarias. Estados ocultos. X1. X2. X3. Xn. Y1. Y2. Y3. Yn. Estados observables Figura 1.1 Ejemplo de un Modelo oculto de Markov..
(32) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 20. Para estimar los parámetros de un modelo oculto de Markov para el modelado del comportamiento normal del sistema, las secuencias de los eventos normales recolectadas de la operación normal del sistema son usadas como datos de entrenamiento. Para estimar estos parámetros se usa un algoritmo de expectación-maximización (EM). Una vez que el modelo oculto de Markov sea entrenado, cuando se confronte con datos de pruebas, las medidas de probabilidad pueden ser usadas como umbrales para la detección de anomalías. En el orden de usar el modelo oculto de Markov para la detección de anomalías, se necesitan resolver tres problemas importantes. El primer problema, conocido también por el nombre de problema de evaluación, es la determinación de que dada una secuencia de observación, cuál es la probabilidad de que la secuencia observada fue generada por el modelo. El segundo es el problema de aprendizaje, este implica la construcción de un modelo a partir de los datos auditados, o un conjunto de modelos, que correctamente describan. el comportamiento observado. Dado un modelo oculto de Markov y las. observaciones asociadas, el tercer problema, también conocido como el problema de desciframiento, involucra la determinación del conjunto de estados ocultos más probable que tienen que inducir esas observaciones. Warrender y otros. (Warrender et al., 1999) compara el funcionamiento de cuatro métodos, es decir, enumeración simple de secuencias observadas, comparación de frecuencias relativas de diferentes secuencias, técnica de reglas de inducción y modelo oculto de Markov en representación del comportamiento exacto normal y reconocimiento de intrusiones en las bases de datos de llamada al sistema. El autor muestra que mientras el modelo oculto de Markov funciona mejor que los otros tres métodos, el alto rendimiento viene ligado a un alto costo computacional. En el modelo propuesto, el autor usa el modelo oculto de Markov con estados completamente conectados, esto es, las transiciones son permitidas de cualquier estado a otro. Por consiguiente, un proceso que emite S llamadas de sistemas tendrá S estados. Esto implica que tendremos aproximadamente 2S2 valores en la matriz de transición de estados. En otro artículo, Yeung y otros. (Yeung and Ding, 2003) describe el uso del modelo oculto de Markov para la detección de anomalías basado en la perfilación de secuencias de llamada al sistema y las secuencias de comando de Shell, un análisis más detallado de una aplicación basada en el Modelo Oculto de Markov se realiza en el Capítulo 2..
(33) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 21. 1.2.2.2.6 Análisis de las cabeceras de paquetes. Mahoney y otros (Mahoney and Chan, 2001, Mahoney and Chan, 2002a) propone un método que localiza el problema de detección de anomalías en el uso de protocolos por inspección de cabeceras de paquetes. El común denominador de todo esto es la aplicación sistemática de técnicas de entrenamiento para automáticamente obtener perfiles de comportamientos normales para protocolos de diferentes capas. Mahoney experimentó con detección de anomalías sobre la base de datos DARPA (Lippmann et al., 2000); ver Anexo H, poniendo en orden coincidente los campos de cabecera de paquetes. El Detector de Anomalías por Cabeceras de Paquetes, por sus siglas en inglés (PHAD) (Mahoney and Chan, 2001), Reglas de Entrenamiento para la Detección de Anomalías (LERAD) (Mahoney and Chan, 2002a) y el Detector de Anomalías en Capa de Aplicación (ALAD) (Mahoney and Chan, 2002b) usan un modelo basado en el tiempo, en el cual la probabilidad de un evento depende del tiempo transcurrido desde la última vez que ocurrió. Para cada atributo, ellos colectan un conjunto de valores permitidos y resaltan los valores noveles como anómalos. PHAD, ALAD, Y LERAD difieren en los atributos que ellos monitorean. PHAD monitorea 33 atributos de Ethernet, IP y cabeceras de paquetes de la capa de transporte. ALAD modela peticiones entrantes de servidores TCP: fuente y destino de direcciones IP, y puertos, apertura o cierre de banderas TCP y la lista de los comandos (la primera palabra en cada línea) en la carga útil de la aplicación. Dependiendo de los atributos, este construye modelos separados para cada host, número de puerto (servicio), o la combinación host/puerto. LERAD también modela conexiones TCP. El conjunto de datos consiste en el tráfico de datos de una red multivariante que contiene los campos extraídos de la cabecera de paquetes, los autores descomponen el problema multivariado en un conjunto de problemas univariados y en una suma ponderada de la gama de los resultados coincidentes a lo largo de cada dimensión. Aunque la ventaja de este enfoque esté dada por ser más computacionalmente eficiente y efectivo en la detección de intrusos en la red, la ruptura de los datos multivariados en univariados resulta en importantes inconvenientes sobre todo en la detección de ataques. Por ejemplo, en un típico ataque de inundación SYN un indicador del ataque, es teniendo más demandas SYN de lo habitual, observando una tasa ACK inferior a la normal. Porque.
(34) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 22. una superior o menor tasa o índice de SYN ACK por sí solo puede ocurrir en el uso normal (cuando la red está ocupada o inactiva),o sea señala el ataque la combinación de la más alta tasa de SYN y la más baja tasa ACK. Una de las mayores desventajas de muchas de las técnicas de aprendizaje automático, así como la llamada al sistema basado en el método del análisis de secuencia y el modelo oculto de Markov anteriormente mencionado, es que estos son recursos muy costosos. Por ejemplo, una técnica de detección de anomalías que esté basada en el modelo de Markov es computacionalmente muy cara porque ésta usa técnicas de estimación paramétricas basadas en los algoritmos de Bayes para el entrenamiento del perfil normal de los host/red bajo consideración. Si consideramos una larga cifra de datos auditados. y una frecuencia. relativamente alta de eventos que ocurren en computadoras y redes de hoy en día, tales técnicas para la detección de anomalías no serían lo suficiente escalables para la operación en tiempo real. Los rasgos más importantes de algunos de los esquemas examinados en esta sección son presentados en la tabla del Anexo C. 1.2.2.3 Detección de anomalías basado en la minería de datos. Para eliminar los elementos manuales y temporales del proceso de construcción de un sistema de detección de intrusos, los investigadores se inclinan cada vez más por el uso de las técnicas de “minería de datos” para la detección de anomalías (Lee and Stolfo, 1998, Lee et al., 2000). Existen autores que definen “minería de datos” como: “el descubrimiento de patrones, asociación, cambios, anomalías y estructuras estadísticas significantes y eventos en datos”(Patcha and Park, 2007). Simplemente, “minería de datos” es la habilidad de tomar datos como entradas, y extraer de estos, patrones o desviaciones que puedan no ser distinguidas fácilmente a simple vista. La “minería de datos” puede ayudar a mejorar los procesos de detección de intrusos adicionando un nivel de enfoque en la detección de anomalías. Identificando saltos para actividades válidas de la red, “minería de datos” ayudará a distinguir actividades de ataques del tráfico diario común en la red. Otro término también usado es “el descubrimiento del conocimiento”..
(35) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 23. 1.2.2.3.1 Detección de intrusos basado en clasificación. Un sistema de detección de intrusos que clasifica los datos auditados como normales o anómalos basados en un conjunto de reglas, patrones y otras técnicas afiliadas puede ser ampliamente definido como un sistema de detección de intrusos basado en clasificación. Este proceso de clasificación típicamente implica los siguientes pasos: 1. Identificar atributos de clases y clases de los datos de entrenamiento. 2. Identificar atributos para la clasificación. 3. Adquirir un modelo usando los datos de entrenamiento. 4. Usar el modelo adquirido para clasificar las muestras de datos desconocidos. Una variedad de técnicas de clasificación han sido propuestas en la literatura. Estas incluyen técnicas inductivas de generación de reglas, lógica difusa, algoritmos genéticos y técnicas basadas en redes neuronales. ► Algoritmos inductivos de generación de reglas implica la aplicación de un conjunto de reglas de asociación y patrones de eventos frecuentes para clasificar los datos revisados. En este contexto, si una regla declara que: “si el evento X ocurre, entonces el evento Y es probable que ocurra”, estos eventos X y Y pueden ser descritos como un conjunto de pares (variable, valor) donde el objetivo es encontrar los conjuntos X y Y tal que X implique Y. En el dominio de la clasificación, se fija Y y se intenta encontrar un conjunto de X el cual sea buen predictor para la clasificación correcta. Mientras que la clasificación supervisada deriva solamente reglas para un solo atributo, las técnicas inductivas de generación de reglas, las cuales son por lo general no supervisadas, derivan reglas relacionadas con alguno o todos los atributos. Por ejemplo, los algoritmos RIPPER (Cohen, 1995) y C4.5 directamente inducen reglas desde los datos empleando el método “divide y vencerás”. RIPPER ha sido exitosamente usado en un número de algoritmos de detección de anomalías basados en “minería de datos” para clasificar datos auditados entrantes y detectar intrusos. Unas de las ventajas primarias de usar RIPPER es que genera reglas que son fáciles de usar y verificar. Lee y otros.(Lee and Stolfo, 1998, Lee et al., 1999) usa RIPPER para caracterizar ocurrencias de frecuencias en datos normales por un conjunto pequeño de reglas que capturan los.
(36) CAPÍTULO 1. TÉCNICAS DE DETECCIÓN DE ANOMALÍAS, VISIÓN GENERAL.. 24. elementos comunes en estas secuencias. Durante el monitoreo, las secuencias que violan estas reglas son tratadas como anomalías. Un número elevado de este tipo de algoritmo ha sido propuesto en la literatura. Algunos de estos construyen un árbol de decisión 5 y entonces extraen un conjunto de reglas de clasificación del mismo. La ventaja de usar reglas es que estas tienden a ser simples e intuitivas, no estructuradas y menos rígidas, pero son también difíciles de mantener y en algunos casos, son inadecuadas para representar varios tipos de información. ► Las técnicas de lógica difusa (fuzzy) han estado en uso en el área de redes y computadoras desde la pasada década del 1990. Estas técnicas han sido usadas para la detección de intrusos por dos razones primarias (Bridges and Vaughn, 2000). Primeramente, por varios parámetros cuantitativos que son usados en el contexto de la detección de intrusos, Ej. Tiempo de uso de la CPU, intervalos de conexión, entre otros, que pueden ser potencialmente vistos como variables difusas. En segundo lugar, como afirma Bridges y otros. (Bridges and Vaughn, 2000), el concepto de seguridad es propiamente difuso. En otras palabras, el concepto de fuzzy contribuye a allanar la separación abrupta del comportamiento normal y el anormal. Es decir, un determinado punto de datos que quedan fuera / dentro de un intervalo ''normal'' definido, se considerará anómalo / normal en el mismo grado, independientemente de su distancia dentro / fuera del intervalo. Dickerson y otros. (Dickerson and Dickerson, 2000) desarrolló el Motor de Reconocimiento Fuzzy de Intrusos, por sus siglas en inglés (FIRE), utilizando conjuntos y normas fuzzy. FIRE utiliza técnicas simples de minería de datos para procesar los datos de. 5. …árbol de decisión es una poderosa y popular herramienta para la clasificación y predicción. Este método. está dado en gran parte a la representación de reglas. Un árbol de decisión tiene tres componentes fundamentales: nodos, arcos y hoja. Cada nodo es designado con un atributo destacado el cual es el más informativo entre los atributos aún no considerados en el camino desde la raíz, cada arco fuera de un nodo es designado con un valor destacado por la característica del nodo y cada hoja es designada con una categoría o clase. Un árbol de decisión es usado entonces para clasificar puntos de datos comenzando por una raíz del árbol y moviéndose a través de esta hasta que un nodo hoja sea alcanzado. El nodo hoja puede entonces proveer la clasificación de los puntos de datos..
Figure



+7




Documento similar