Sistema multiagente para la simulación de la defensa de un edificio ante un ataque enemigo
83
0
0
Texto completo
(2) Hago constar que el presente trabajo fue realizado en la Universidad Central Marta Abreu de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencias de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ______________________________________ Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. _____________________ Firma del tutor. __________________________ Firma del jefe del Seminario.
(3) A mi mamá, y a mi papá….
(4) Agradecimientos A mis padres, por apoyar mi ausencia durante cinco largos años A mis hermanos, por estar a pesar de la distancia A Isis, por ser más que mi tutora, por ser mi amiga A tío por siempre creer en mí A Nieto no sólo por crear este proyecto, sino también por toda la ayuda brindada a lo largo de él A mis amigos, por hacer lucir este tiempo como si fueran un par de semanas A todos los que no sólo han ayudado con este trabajo, sino que lo han hecho conmigo.
(5) Resumen. Resumen En este trabajo se hace el diseño y la implementación de un sistema multiagente para la simulación de la defensa de un edificio ante un ataque enemigo. Para esto se hace un estudio de las estrategias de simulación, los sistemas multiagentes y del aprendizaje reforzado como técnica de cooperación entre agentes. Se hace una revisión bibliográfica de la aplicación de estas técnicas en problemas reales. La simulación se basa en una estrategia sincrónica por intervalos de tiempo. Los agentes se diseñan como sistemas basados en reglas. Su cooperación se realiza mediante especialización y comunicación. Esta última se logra a través de aprendizaje reforzado y envío de mensajes. Para la implementación del sistema multiagente se diseña e implementa una jerarquía de clases con características extensibles para otros problemas que se ajusten a este modelo. Se implementan además objetos para la interfaz visual usando OpenGL..
(6) Abstract. Abstract In this work we design and implement a multi-agent system to simulate the defense of a building given an enemy attack. A study of the simulation strategies, the multiagent systems and of the reinforcement learning as cooperation technique among agents is made. Besides, a bibliographical revision on application of these techniques in real problems is made. The simulation is based on a synchronous methodology by time intervals. The agents are designed as rules based systems. Their cooperation is carried out by means of specialization and communication. This last one is achieved through reinforcement learning and messages sending. To implement the multi-agent system it is designed and implemented a class hierarchy with characteristic expandable for other problems with this model. Some objects to the visual interface using OpenGL are also implemented..
(7) Índice. Índice Introducción .................................................................................................................. 1 Capítulo 1. Estado del arte de estrategias de simulación y sistemas multiagentes....... 5 1.1 Estrategias de simulación.............................................................................. 5 1.1.1 Estrategia de simulación por intervalos de tiempo ............................... 5 1.1.2 Estrategia de simulación orientada a eventos ....................................... 6 1.1.3 Estrategia de simulación orientada a eventos con rastreo de actividades 6 1.1.4 Estrategia de simulación orientada a procesos ..................................... 6 1.2 Agentes y sistemas multiagentes .................................................................. 7 1.2.1 Agentes inteligentes.............................................................................. 9 1.2.2 Interacción y cooperación................................................................... 12 1.3 Comunicación en sistemas multiagentes .................................................... 16 1.3.1 Aprendizaje reforzado......................................................................... 17 1.3.2 Aprendizaje reforzado para sistemas multiagentes............................. 21 1.4 Trabajos realizados usando agentes basados en aprendizaje reforzado...... 22 1.5 Trabajos de simulación relacionados con la preparación para la defensa .. 24 1.5.1 Uso de agentes en la simulación de defensa....................................... 25 Capítulo 2. Diseño e implementación de un sistema multiagente para la simulación de la defensa de un edificio ............................................................................................. 27 2.1 Diseño e implementación de una jerarquía de clases con características extensibles para la implementación de sistemas multiagentes con aprendizaje reforzado ................................................................................................................. 27 2.1.1 Control del sistema ............................................................................. 28 2.1.1.1 Mecanismo de cooperación ................................................................ 29 2.1.2 Agentes................................................................................................ 31 2.1.3 Medio, estados y acciones .................................................................. 33 2.2 Diseño de la simulación de la defensa de un edificio en caso de ataque.... 34 2.2.1 Representación del medio................................................................... 35 2.2.2 Representación del conocimiento ....................................................... 37 2.2.3 Visualización de la información ......................................................... 38 2.3 Implementación de un sistema basado en agentes para simular la defensa de un edificio ............................................................................................................... 39 2.3.1 Modelación del sistema multiagente para las tropas invasoras .......... 39 2.3.2 Modelación del sistema multiagente para las tropas defensoras ........ 41 2.3.3 Modelación de los soldados................................................................ 43 Capítulo 3. Manual del programador y manual de usuario......................................... 47 3.1 Manual del programador para el uso de la herramienta para la construcción de sistemas multiagentes......................................................................................... 47 3.1.1 Clase MARL ........................................................................................ 48 3.1.1.1 Métodos públicos................................................................................ 48 3.1.1.2 Métodos protegidos............................................................................. 52 3.1.1.3 Atributos ............................................................................................. 54 3.1.2 Clases usadas para los agentes............................................................ 56 3.1.2.1 Métodos públicos................................................................................ 57.
(8) Índice. 3.1.2.2 Métodos protegidos............................................................................. 59 3.1.2.3 Atributos ............................................................................................. 61 3.1.3 Medio, estados y acciones .................................................................. 61 3.1.3.1 Clase FIELDS ..................................................................................... 62 3.1.3.2 Clase STATES ..................................................................................... 62 3.1.3.3 Clase ACTIONS .................................................................................. 63 3.2 Manual de usuario del sistema basado en agentes para simular la defensa de un edificio ............................................................................................................... 64 Conclusiones............................................................................................................... 68 Recomendaciones ....................................................................................................... 69 Referencias bibliográficas........................................................................................... 70 Anexos ........................................................................................................................ 73 Anexo 1. Diagrama de clases para la simulación ................................................... 73 Anexo 2. Diagrama de clases para el sistema multiagente ..................................... 74 Anexo 3. Diagrama de clases para la interfaz visual .............................................. 75.
(9) Introducción. Introducción Con el surgimiento de la Inteligencia Artificial, el hombre ha intentado recrear el comportamiento humano en los sistemas digitales. En este intento han surgido pruebas y técnicas novedosas como los sistemas expertos. Pero con el incremento de la complejidad de los problemas, se ha necesitado imitar ya no solo al hombre como entidad independiente, sino a la sociedad en sí, logrando que las problemáticas puedan ser tratadas por distintas entidades que interactúen entre sí, colaborando o compitiendo para lograr sus objetivos. Es así como surgen los sistemas multiagentes, los cuales han ido ganando, día tras día, más espacio en la Inteligencia Artificial. Estos sistemas permiten lograr la colaboración de entidades inteligentes, independientes y autónomas. En la actualidad se pueden dividir sus aplicaciones en varios campos: solución de problemas en sentido general, robótica colectiva, simulación multiagente, construcción de mundos hipotéticos, etc. (Asada et al., 1996, Beasley, 2001, Calfee and Rowe, 2005, Carreras, 1996, Dietterich and Zhang, 1995, Ernst et al., 2006, Ghory, 2004, Gronlund and Wright, 2004, Walker, 2000). La simulación multiagente es uno de los campos que mayor auge ha tomado en nuestros días para cualquier aplicación que intente representar un proceso de la vida real donde intervengan varias entidades interrelacionadas entre si con cierta “inteligencia”. Este tipo de sistemas es un híbrido entre estas dos técnicas computacionales, simulación y agentes, que nos permiten representar procesos del mundo real. La simulación computacional es también una técnica que es muy usada para poder acercarnos al estudio de procesos reales. Pero ésta se basa más bien en describir sistemas con el objetivo de conducir a experimentos que nos permitan el ensayo de situaciones complejas de predecir. De esta manera podemos hacer un estudio de estos escenarios bajo distintas condiciones, sin muchos gastos económicos. Pero la mayoría de los sistemas funcionan bajo la intervención de expertos que rigen el curso de la situación con su conocimiento y experiencia. Precisamente, en aras de incorporar este conocimiento y experiencia a los sistemas de simulación, es que ha surgido la simulación multiagente como una combinación de estas dos técnicas.. 1.
(10) Introducción. Este tipo de simulación es muy usada hoy en día en el campo del entretenimiento en la confección de juegos; en la industria, simulando procesos en los que se ven involucrados distintos expertos que abordan campos diferentes; en la defensa, permitiendo el ensayo de nuevas tácticas de combate y observando qué resultados podrían tener, o entrenando a los combatientes sin necesidad de gasto de recursos (un ejemplo de esto son los simuladores de vuelo). El campo de la defensa es muy importante para nuestro país, en el que por 47 años nos hemos encontrados amenazados por el imperio del norte de una invasión armada. Los sistemas que logren simular de forma computacional tareas de defensa son muy importantes, pues facilitan el estudio de las mismas ahorrando muchos recursos económicos. Precisamente en este trabajo se desarrolla una herramienta flexible para la implementación de sistemas multiagentes basada en aprendizaje reforzado como algoritmo de comunicación por ser el algoritmo más apropiado en este tipo de problemas. El uso de esta herramienta será ejemplificado en un problema real de las fuerzas armadas: la defensa de una edificación dentro de la ciudad ante un ataque enemigo. El problema a ejemplificar consiste de un ambiente que representa un terreno civil típico de cualquier lugar del país, el cual consta de varios edificios, rodeados de árboles y cualquier otro tipo de objetos. Tanto las tropas que defenderán como las que atacarán el edificio están organizadas en pelotones y escuadras y poseen un conjunto de armas y municiones. Para dar solución a esta problemática se trazaron las siguientes hipótesis: 1. Un paquete compuesto por una jerarquía de clases que represente a los agentes y un objeto manipulador que permita la comunicación y colaboración de los agentes, basándose en la teoría de Aprendizaje reforzado permitirá la implementación de ambiente multiagente para el campo de la defensa. 2. Con una biblioteca de enlace dinámico que encapsule las clases, con interfaces a los lenguajes de programación, se logra la extensión de este paquete a los mismos.. 2.
(11) Introducción. 3. Para visualizar toda la información contenida en esta simulación basta hacer una representación espacial de los objetos, mediante el uso de una estrategia de simulación basada en intervalos de tiempo donde se muestran, en cada instante de tiempo, las condiciones (posición, estado físico) de cada entidad del problema.. En correspondencia con las hipótesis de investigación nos trazamos los siguientes objetivos generales: 1. Implementar una jerarquía de clases extensible para facilitar la implementación de aplicaciones que necesiten ambientes multiagente basados en aprendizaje reforzado. 2. Diseñar e implementar un software con interfaz gráfica que permita visualizar la información contenida en la simulación de la defensa de un edificio en caso de ataque enemigo, que use las componentes multiagente para su funcionamiento. Los objetivos generales fueron desglosados en los siguientes objetivos específicos: 1.1 Estudiar aspectos teóricos de sistemas multiagentes y aprendizaje reforzado, así como su aplicación. 1.2 Diseñar e implementar una jerarquía de clases que permita el desarrollo de aplicaciones con ambiente multiagente que base su funcionamiento en la teoría de aprendizaje reforzado. 2.1 Diseñar e implementar un sistema multiagente, para la simulación de la defensa del edificio, que use la jerarquía de clases implementada. 2.2 Diseñar e implementar objetos para el trabajo gráfico. La tesis se estructura por tres capítulos. En el capítulo 1 se abordan aspectos teóricos sobre las distintas estrategias de simulación, sobre agentes y sistemas multiagentes. Además se hace un estudio de los diferentes usos de estas técnicas hasta el momento y sus aplicaciones en problemas relacionados con la defensa. El capítulo 2 muestra el diseño e implementación de la problemática expuesta, así como el desarrollo de la herramienta que nos sirvió de base para construir el sistema multiagente y sus. 3.
(12) Introducción. características extensibles. Y finalmente, el capítulo 3 presenta el manual del programador para el uso de la herramienta de implementación de sistemas multiagentes y el manual de usuario para el uso del sistema desarrollado para la simulación del proceso de defensa de la edificación.. 4.
(13) Capítulo 1. Capítulo 1. Estado. del. arte. de. estrategias. de. simulación y sistemas multiagentes 1.1 Estrategias de simulación El concepto de simulación tiene varias acepciones. Su concepto más práctico es: “Modelación y simulación es el conjunto de actividades asociado a la construcción de modelos del mundo real y su simulación mediante computadoras con el objetivo de dar solución a determinados procesos” (Moreno, 1972). En otras palabras, dado un proceso en un sistema real, el conjunto de actividades para convertirlo en un modelo es conocido como modelación, mientras que su representación en un sistema digital es conocida como simulación. Hoy en día la simulación tiene un campo amplio de aplicación, esta técnica nos permite el análisis del comportamiento de sistemas físicos, químicos, biológicos, económicos o sociales, a lo largo del tiempo. Lo interesante es que, a partir de experimentos basados en modelos matemáticos y lógicos, permite la realización de experimentos computacionales. El análisis de un proceso real que tiene características probabilísticas conlleva de manera natural a la simulación del mismo generando de forma estocástica los procesos que ocurren en él de forma simultánea a través del tiempo. Existen diversas estrategias de generar estos procesos, ellas pueden ser clasificadas en sincrónicas o asincrónicas en dependencia de si el tiempo se chequea a intervalos regulares o no. La “estrategia de simulación por intervalos de tiempo” es un ejemplo de las primeras. La segundas se pueden dividir en estrategias de simulación “orientadas a eventos”, con “rastreo de actividades” y “orientadas a procesos”.. 1.1.1 Estrategia de simulación por intervalos de tiempo La estrategia de simulación por intervalos de tiempo es una estrategia de modelación sincrónica. Basa su funcionamiento en dividir el tiempo del proceso en pequeños intervalos uniformes, para estudiar los cambios del sistema a lo largo de estos intervalos. 5.
(14) Capítulo 1. Esta estrategia tiene la desventaja de que no siempre es evidente la determinación del tamaño apropiado de los intervalos de tiempo. En la realidad la mayoría de las veces unas partes del sistema cambian mucho más frecuentemente que otras. En ocasiones es útil seguir ciertas partes del sistema más detalladamente y en este caso se nos hace útil otra estrategia que no base su funcionamiento en el tiempo.. 1.1.2 Estrategia de simulación orientada a eventos Dentro de las estrategias de simulación asíncrona, una de las más usadas es la estrategia de simulación orientada a eventos. La misma basa su funcionamiento también en intervalos de tiempo, pero no uniformes, sino dependientes de cada evento del sistema. Teniendo en cuenta que evento se define como un cambio del sistema que no consume tiempo, podemos decir que esta estrategia se basa en chequear el sistema cada vez que ocurra un cambio del mismo, sin importar si es casi inmediato o demasiado distante del anterior (Sheldon, 1999). Esta estrategia es conveniente cuando estamos en presencia de un problema donde las componentes son independientes.. 1.1.3 Estrategia de simulación orientada a eventos con rastreo de actividades La estrategia de simulación orientada a eventos con rastreo de actividades es una modificación de la estrategia discutida anteriormente, que tiene el objetivo de hacer un modelo general más claro y simple para implementar. La diferencia entre estas estrategias está precisamente en el concepto que se introduce aquí de actividad. Actividad es un cambio de estado del sistema que requiere de ciertas condiciones. Esta estrategia es muy útil para simplificar dependencia entre componentes.. 1.1.4 Estrategia de simulación orientada a procesos Esta nueva estrategia no es más que la combinación de las técnicas anteriores (orientada a eventos y con rastreo de actividades). Su novedad está en que la. 6.
(15) Capítulo 1. descripción de cada componente se implementa como una unidad, no se separan sus eventos o actividades sino que se ve todo como un único proceso. En término de implementación simplifica la dinámica de las componentes del sistema convirtiéndolas en procesos únicos, simples y fáciles de programar. Es una estrategia más orientada a programación y no a simulación.. 1.2 Agentes y sistemas multiagentes Desde el surgimiento de la ciencia de la computación, se han visto los programas como entidades independientes para resolver problemas. Con el paso del tiempo, se ha deseado que las máquinas resuelvan problemas cada vez más complejos, hasta el punto de desear que éstas puedan actuar como seres humanos. En este deseo se ha pretendido que las máquinas puedan ejercer el papel de expertos en problemas reales de nuestro entorno, ilustrándoles de alguna forma el conocimiento y el medio en el que se encuentran para que éstas tomen las decisiones que tomaría un experto real. Esta forma de ver a los programas como seres pensantes, encerrados en su propio mundo, es conocida como sistemas expertos. Estos son los programas que tratan de encapsular el conocimiento de humanos sobre tareas extremadamente complicadas que necesitan de conocimiento, experiencia y cierto tipo de razonamiento (Ferber, 1999). De esta manera se pueden ver los problemas de modo centralizado y secuencial, pero esta óptica tiene algunos problemas. En el plano teórico, un ser no es capaz de adquirir ciertas habilidades sin la ayuda de otros seres a su alrededor, sin verse inmerso en un medio social, un ejemplo de esto es que es imposible aprender un lenguaje articulado sin interactuar con otros seres que lo practiquen. En el plano práctico, como habíamos dicho antes, los problemas son cada vez más complejos, y deben ser divididos en pequeños subproblemas a resolver por entidades independientes capaces de interactuar entre ellas. En muchos casos, el conocimiento para desarrollar un proceso no depende de un solo experto, sino que está distribuido en un grupo en el que interactúan varios de ellos. En estos casos el conocimiento general del grupo no puede ser visto como la suma del conocimiento individual de cada experto, de hecho, en ocasiones dicho conocimiento puede ser hasta 7.
(16) Capítulo 1. contradictorio. Este conocimiento tiene que ser integrado en el sistema a pesar de que puedan surgir discusiones, modificaciones y hasta negociaciones para resolver los conflictos, pues es así como suele suceder en la vida real entre diferentes expertos. “Entonces, en vez de estar en presencia de una máquina – una entidad con una localización específica definida por su estructura y arquitectura – nos encontramos frente a un grupo de entidades interactivas, cada entidad definida de manera local, sin la percepción global de las acciones del sistema” (Ferber, 1999). El problema ha quedado enfocado de manera que una actividad cualquiera, ya sea simple o compleja, pueda ser resuelta como el resultado de la interacción. de. entidades relativamente independientes y autónomas, que llamaremos agentes, que operan en comunidades de acuerdo a ciertos modos de cooperación, conflicto y competencia con el objetivo de sobrevivir y lograr sus metas. De estas interacciones surgen estructuras organizadas que restringen y modifican el comportamiento de los agentes. La característica de enfatizar las interacciones, y más específicamente, analizar los sistemas de interacciones que existen entre los agentes es lo que distingue a los sistemas multiagentes (SMA) de los enfoques sistémicos más clásicos. Precisamente las acciones y las interacciones son consideradas los elementos motores en la construcción de un sistema tomado como un todo (Ferber, 1999). La selección de los métodos para el manejo de estas interacciones está en dependencia del problema específico que se trate. Han surgido muchos modelos para el manejo de las mismas que han sido desarrollados, basándose en el comportamiento humano o animal dentro de una comunidad, con el objetivo de encontrar factores importante en la descripción, autoorganización y evolución de comunidades de agentes. Cada agente actúa según la percepción que tenga del medio en el que se encuentra, y puede desechar mucha información, de manera que existan factores en el medio que no afecten su comportamiento. Esto no quiere decir que se pueda predecir siempre el comportamiento de estos sistemas, su evolución no es gobernada por puro determinismo, lo que no nos permite prever situaciones futuras a partir de un conjunto de condiciones iniciales. Tampoco significa que no existan leyes 8.
(17) Capítulo 1. gobernando dichas sociedades, concretamente estos sistemas nos facilitan la construcción de estructuras que con un poco de conocimiento produzcan comportamientos deseados en situaciones estables, pero que posean la capacidad de adaptarse a situaciones que no hayan sido predichas inicialmente. Lo interesante de estos sistemas es la posibilidad que brindan de experimentar teorías en pequeños modelos de sociedades. Teorías sociales o biológicas que pueden ser complejas, o incluso con condiciones inalcanzables, pueden ser validadas en estos universos sin necesidad de experimentar en un mundo real.. 1.2.1 Agentes inteligentes Un agente es una entidad física o virtual capaz de actuar en un ambiente, comunicarse con otros agentes, guiado por un conjunto de tendencias u objetivos, con recursos a su disposición, capaz de percibir (de manera total o parcial) el medio en el que se encuentra. Posee habilidades, es capaz de brindar servicios y de reproducirse por sí mismo (Ferber, 1999). Un agente racional debe ser capaz de actuar de manera tal que logre su mayor desempeño. Para medir el desempeño es necesario definir una medida que no necesariamente tiene que ser general para todos los agentes, más bien debe ser particular. Podría delegarse esta responsabilidad a los agentes, pero no todos serían capaces de saber cuán buenas han sido sus decisiones, o incluso algunos podrían falsear esta medida. Por esto es deseable que esta responsabilidad recaiga en alguna autoridad del sistema, o sea alguna entidad que observe el universo de manera global y pueda medir el desempeño de cada uno de los agentes. Pero es importante no confundir racionalidad con omnisciencia. Un agente racional debe tomar su mejor decisión, pero esto depende de la percepción que tenga del medio, los factores que no sea capaz de detectar no pueden influir en sus decisiones.. 9.
(18) Capítulo 1. Resumiendo, podemos decir que el nivel de racionalidad de una decisión está asociado con (Russel and Norving, 1995): •. la medida de desempeño. •. lo que el agente sea capaz de percibir. •. lo que sabe del medio. •. las acciones que puede desarrollar.. Otro aspecto importante es la autonomía de un agente. Inicialmente un agente es proveído de cierto conocimiento, pero si éste se rige únicamente por el conocimiento inicial, entonces carece de autonomía, simplemente la inteligencia pertenece a su diseñador. Así como los animales nacen con un conjunto de reflejos, pero se adaptan a las condiciones de vida en las que se desarrollen, los agentes deben también acumular cierta experiencia y regir su comportamiento en un principio, cuando no hayan acumulado dicha experiencia, por el conocimiento inicial que poseen. Pero, al adaptarse a un medio dado, deberán actuar teniendo en cuenta lo que ya han experimentado. Esto es muy importante en medios dinámicos que puedan cambiar, si el agente no es capaz de adaptarse a este medio no tendrá una conducta óptima. Los seres racionales tenemos un conjunto de reflejos; algunos condicionales, como montar bicicleta; otros incondicionales, como cerrar los ojos cuando se acerca algún objeto a ellos. La forma más simple de incorporar conocimiento a un agente es precisamente mediante estos reflejos. Estos no son más que una serie de respuestas a situaciones que puedan ser detectadas, si al montar bicicleta nos inclinamos a un lado entonces giramos el timón a este lado. Los agentes pueden percibir el estado del medio mediante sus sensores, y deben tener respuestas a situaciones que puedan presentarse. Una forma muy cómoda de integrar estos reflejos es mediante reglas. Retomemos el ejemplo de la bicicleta, cuando manejamos tenemos nuestra vista al frente captando constantemente el estado de la vía delante de nosotros, pero si queremos voltear debemos mirar hacia atrás para asegurarnos que no venga ningún vehículo que pueda chocarnos. En este caso ha habido un cambio de estado. Primeramente nos encontrábamos en un estado en el cual nos interesaba solamente la vía al frente de nosotros, y desechábamos completamente la parte trasera de ella. En. 10.
(19) Capítulo 1. este estado tenemos un conjunto de acciones que podemos llevar a cabo para manejar la situación, como acelerar el pedaleo, refrenar o voltear. Sin embargo, al desear voltear, hemos necesitado cambiar la percepción del medio, ya no es el frente el que capta nuestro interés, sino la parte trasera, e incluso tenemos nuevas acciones que debemos tener en cuenta, si está libre la vía debemos hacer señas de que vamos a doblar y ocupar el lado correspondiente. Es interesante también que los agentes lleven un control del estado en el que se encuentra el medio que los rodea, de manera que puedan tomar las decisiones que tengan sentido en dicho estado y percibir las características del medio que les sean necesarias en cada momento. Pero conocer el estado en el que nos encontramos no es suficiente para tomar las decisiones, al encontrarnos en una intercepción de dos calles debemos decidir si volteamos en la otra dirección o seguimos en la misma. Esta decisión va a estar en dependencia de los objetivos que persigamos. Debemos escoger una acción que nos ayude a alcanzar el lugar que buscamos. Muchas veces estas decisiones no son nada sencillas, sobre todo si no existe una acción directa que nos lleve a nuestros objetivos. En estos casos debemos trazarnos una estrategia, planificar nuestras acciones, o simplemente recordar frente a las situaciones anteriores la mejor elección hecha en el pasado para lograr nuestra meta. Éste es otro aspecto que rige el funcionamiento de los agentes, en todo momento sus decisiones estarán guiadas por sus objetivos. En un mismo medio el objetivo puede cambiar, no es necesario desechar toda la experiencia acumulada y adaptarse nuevamente al mismo solamente porque nuestro objetivo ya no sea el mismo que fue en un pasado, lo único que ha sucedido es que ha cambiado esta meta, pero el medio sigue siendo igual, y la experiencia acumulada en él sigue siendo válida para la situación actual. Tenemos un último problema, si existen más secuencias de acciones para lograr nuestros objetivos debemos escoger la mejor. Cuando nos dirigimos a algún lugar, podemos tomar muchas vías, sin embargo tomamos la más cercana o la más segura. Los agentes deben tener también funciones de utilidad para las decisiones, cuando tomen una serie de decisiones que lo lleven a satisfacer completamente un objetivo deben saber cuán buena fue dicha secuencia, deben poder valorar numéricamente esta. 11.
(20) Capítulo 1. solución para poder compararla con otras y decidir cuál tomar en un futuro. (Russel and Norving, 1995).. 1.2.2 Interacción y cooperación Como se había visto, las interacciones son la base de los sistemas multiagentes, pero, ¿qué son las interacciones? Éstas ocurren cuando al menos dos agentes entran en una relación mediante acciones recíprocas, provocando una serie de acciones que pueden condicionar el comportamiento de los agentes. Las interacciones no son más que los eventos en los que se ven envueltos los agentes mediante los cuales se relacionan, ya sea de manera directa, a través de otro agente o a través del medio. Ellas son la base de las sociedades, no son relaciones que surgen del simple contacto de los agentes, son relaciones que los unen y los convierten en seres sociales unidos entre si, resultando en la aparición de nuevas funcionalidades en éstos. Mediante las interacciones se logra que los agentes no centren su atención en ellos mismos sino en el bien de la comunidad, esta característica marca la diferencia con los sistemas clásicos de Inteligencia Artificial. Es importante notar que las interacciones pueden darse bajo ciertas condiciones. Cada situación de interacción está compuesta por distintos elementos. “Podemos considerar una situación de interacción como la suma de los comportamientos resultantes de agrupar agentes que tienen que actuar de manera que logren sus objetivos, prestando atención a los limitados recursos que estén disponibles para ellos y a sus habilidades personales” (Ferber, 1999). Ante estas condiciones existen medios para efectuar la cooperación: agrupamiento y multiplicación, comunicación, especialización, colaboración por reparto de tareas y recursos, coordinación de acciones y resolución de conflictos por arbitraje y negociación. Las situaciones de interacción definidas sobre la base de los objetivos, los recursos y las habilidades son las siguientes: Cuando los objetivos son compatibles, y las habilidades y recursos suficientes, los agentes son totalmente independientes, pueden operar libremente sin necesidad de interactuar entre ellos. Si dos ingenieros trabajan en proyectos distintos, y poseen los 12.
(21) Capítulo 1. recursos y conocimientos necesarios, no necesitan ponerse de acuerdo, sus proyectos son independientes. En este caso no se puede hablar de colaboración. Si los objetivos son compatibles y los recursos suficientes, pero son insuficientes las habilidades de los agentes es una colaboración simple. Los agentes deben compartir sus habilidades, generalmente por comunicación, para lograr sus objetivos. En estas situaciones es necesario distribuir las tareas para que puedan ser alcanzadas las metas finales de la comunidad. Un ejemplo de este caso son los sistemas multi-especialistas. En el caso de objetivos compatibles, con suficientes habilidades, pero insuficientes recursos, es una situación de obstrucción. Ejemplo claro de esta situación son los sistemas de control de tráfico aéreo. Para manejar los problemas generados en estos casos se deben usar técnicas específicas de coordinación de acciones. Una situación difícil de manejar es el caso de colaboración coordinada, en presencia de objetivos compatibles, e insuficientes recursos y habilidades. En estos casos hay que mezclar las técnicas distribución de tareas y coordinación con recursos limitados. Estos casos son muy comunes en la industria. Si los objetivos son incompatibles con recursos y habilidades suficientes, estamos en presencia de pura competencia individual. Los agentes luchan y negocian para lograr sus objetivos. Ejemplos de esta situación son las competencias deportivas. Objetivos incompatibles, con recursos suficientes y habilidades insuficientes es pura competencia colectiva. En esta situación, cuando los agentes carecen de habilidades para cumplir sus metas, deben formar coaliciones para lograr sus objetivos. Primeramente se forman los grupos por afinidad, luego se enfrentan unos contra otros. Un ejemplo de esta situación son las competencias deportivas por equipo. Cuando las habilidades son suficientes pero insuficientes los recursos e incompatibles los objetivos, estamos en presencia de conflictos individuales sobre los recursos. Hay innumerables ejemplos en la vida animal y humana de situaciones en las que un individuo intenta apoderarse de recursos que no pueden ser compartidos, como cuando un animal intenta defender su territorio ante la llegada de un adversario o cuando se lucha por una plaza de trabajo. El caso de conflictos colectivos sobre los recursos, cuando los objetivos son incompatibles, y los recursos y habilidades son insuficientes, combinan competencias 13.
(22) Capítulo 1. colectivas con conflictos individuales sobre los recursos. Se forman coaliciones para monopolizar recursos o bienes. Todo tipo de guerras por obtener el dominio sobre algún territorio o recurso, es un caso típico de esta situación. La cooperación es la actitud de los agentes de trabajar juntos. “Podemos decir que varios agentes están cooperando, o que están en una situación de cooperación, si se cumple una de las dos condiciones siguientes: la adición de un nuevo agente hace posible incrementar el nivel de rendimiento del grupo significativamente, o las acciones de los agentes ayudan a evitar o resolver conflictos actuales o potenciales” (Ferber, 1999). A continuación describiremos los diferentes tipos de colaboración ante las situaciones descritas anteriormente. La cooperación por agrupamiento y multiplicación es la más evidente de las formas de colaboración, pero a la vez es la menos usada. Ésta consiste en agrupar físicamente a los agentes. La idea está inspirada en el hecho de que los animales suelen agruparse para aumentar sus posibilidades de subsistencia, al ser un grupo les es más fácil defenderse de ataques, buscar comida o conquistar nuevos recursos. Por otra parte la reproducción permite precisamente aumentar el tamaño del grupo, que puede ser deseable a la hora de efectuar ciertas labores. Un ejemplo claro es el caso de la exploración, al aparecer nuevos caminos a explorar, puede ser más eficiente indicar a nuevos individuos la exploración de estas nuevas rutas. La comunicación es quizás el método de cooperación más usado, es difícil concebir un sistema social sin mecanismos de comunicación. Permite que los agentes compartan su conocimiento y su percepción del medio entre ellos. En sistemas cognitivos se realiza mediante el envío de mensajes, mientras que en medios reactivos, por la difusión de señales en el medio. Este tema será ampliado en la sección 1.3. La especialización tiene lugar cuando los agentes se adaptan mejor a ciertas tareas. En un grupo suele suceder que haya individuos que se especialicen en algunas tareas específicas. Es muy complicado mantener una alta eficiencia en todas las tareas que la sociedad impone, sin embargo, la especialización nos ayuda a alcanzar niveles de eficiencia más altos. 14.
(23) Capítulo 1. La colaboración por compartimiento de tareas y recursos no es más que la asociación de varios agentes en una tarea común. Este tipo de colaboración debe suponerse cuando de alguna manera se comparten las tareas, la información y los recursos para un fin común. Para resolver un problema de colaboración basta decidir lo que hará cada agente. Un método muy común para implementar esta técnica es a través del uso de ofertas y demandas. La coordinación de acciones es necesaria debido a que muchas veces las tareas a realizar son muy complejas, por lo que deben ser desglosadas en otras más sencillas. Estas nuevas tareas deben ser repartidas entre los agentes para que puedan ser llevadas a cabo de manera paralela y organizada. En un sistema multiagente, como en cualquier sociedad, pueden aparecer conflictos entre los agentes. Estos conflictos resultan en el deterioro del rendimiento de los agentes y del sistema en general. El arbitraje y la negociación son formas de resolver estos conflictos. Arbitraje no es más que el conjunto de reglas que rigen el comportamiento de los individuos de la sociedad. En las sociedades humanas existen un conjunto de leyes que rigen su comportamiento, y órganos que se encargan de hacer a los individuos cumplir con estas leyes. En los sistemas multiagentes cognitivos pueden ser implementadas estas leyes que hacen cumplir a los agentes con una conducta social, de manera que reciben un castigo si violan alguna de estas reglas. Los agentes serán capaces de sopesar si es conveniente proceder en contra de estas leyes en cada momento. Pero no siempre es útil un órgano que vele por cumplimiento de determinadas leyes. Por ejemplo en situaciones en las que los agentes compitan por cierto recurso, es aconsejable dejarlos resolver sus problemas sin la intervención de este órgano, de manera que dichos agentes en conflicto puedan obtener, mediante la negociación, un trato favorable para todas las partes involucradas en el problema.. 15.
(24) Capítulo 1. 1.3 Comunicación en sistemas multiagentes La comunicación, como se había visto, es la base de cualquier sociedad, sin ella los individuos estarían totalmente aislados, y no podrían cooperar. Ésta se efectúa a través de señales, señas, e indicios. Las señales son los elementos más primitivos. Se pueden ver como rastros, cambios en el medio, tanto en el plano mecánico (oído, tacto), como en el plano electromagnético (vista), como en el químico (paladar, olfato). Son capaces de llevar cierta información a aquellos capaces de percibirla. Estas señales se propagan por ellas mismas, no necesitan de un canal para esto. Para que la señal sea significativa, o sea, para que ofrezca información, debe cumplirse que exista una entidad capaz de percibirla (los humanos solamente somos sensibles a señales acústicas entre 30 y 16 000 Hz, las señales fuera de este rango no son perceptibles por nuestros oídos), y un sistema de interpretación de la señal que la transforme en su significado, y más tarde, en un comportamiento. Cuando las señales sólo producen un comportamiento, nos referimos a ellas como estímulos. Estos estímulos pueden reforzar una tendencia, y si este estímulo es lo suficientemente fuerte, hasta convertirla en un acto. Éste es el caso del comportamiento de los sistemas multiagentes reactivos. En estos sistemas se difunden señales a partir de las cuales los agentes definen su comportamiento. Si la señal no produce simplemente una reacción, sino que contiene información que puede ser llevada a un sistema cognitivo, entonces estamos en presencia de una seña. Una seña es un movimiento, un diagrama, un sonido o una expresión que puede ser traducida en una situación, un objeto, un procedimiento u otra expresión. Existen muchas formas de señas, las lingüísticas por ejemplo, que no son más que grupos de sonidos que juntos hacen palabras, que a su vez crean expresiones. Estas señas son las usadas en la comunicación de sistemas cognitivos. Estos sistemas basan su funcionamiento en la emisión de mensajes desde un transmisor hacia un receptor (o varios receptores, en el caso de las difusiones), mediante un canal (Ferber, 1999). Pero estas últimas son sólo un subconjunto de estas señas. Existen otras que no están basadas en la construcción de un lenguaje articulado, sino en la construcción de hipótesis. Esta clase de señas son conocidas como indicios. Para ilustrar esto veamos. 16.
(25) Capítulo 1. los siguientes ejemplos: si se ve humo, entonces hay fuego cerca; si se notan ciertos síntomas, se piensa en una enfermada asociada a ellos. El proceso mediante el cual un agente forma una hipótesis a partir de un indicio se conoce como abducción. Esta clase de comunicación es característica de los sistemas de razonamiento investigativo y de diagnosis (Russel and Norving, 1995). La comunicación a partir de señales, aunque sea un método un poco primitivo, tiene la peculiaridad de ser altamente eficiente y sencilla. Una forma de implementar este tipo de comunicación es a través del aprendizaje reforzado.. 1.3.1 Aprendizaje reforzado Existen muchas técnicas de aprendizaje supervisado, es decir, técnicas que basan el aprendizaje en ejemplos. Para estas técnicas se necesita un supervisor. Pero, ¿qué sucede si el medio no es tan generoso, si no existen ejemplos para aprender, ni función de utilidad que pueda predecir el resultado de los ejemplos? En muchas ocasiones debemos tomar de forma aleatoria una decisión y ver como se comporta el medio una vez tomada la misma. Incluso, en ocasiones, no es posible observar el comportamiento del medio de manera inmediata a tomar la decisión, sino que hay que aguardar por la llegada de un estado final que nos informe de la factibilidad de las decisiones tomadas a lo largo del camino. Una forma de indicar la factibilidad de una decisión es recompensándola según las condiciones obtenidas en el medio una vez tomada. A estas recompensas se les conoce también como reforzamientos. La tarea del aprendizaje reforzado es lograr definir una conducta a través de estas recompensas. Esta tarea no es tan sencilla si tenemos en cuenta que un simple error puede llevar a un estado final negativo, sin embargo, aunque la recompensa haya sido negativa, el agente debe ser capaz de determinar cuál fue el error, para no volver a cometerlo, pero sí mantener la postura obviando este error. En muchos casos, es imposible lograr un desempeño óptimo en un agente con otra técnica de aprendizaje. En los juegos, por ejemplo, es casi imposible inferir la optimalidad de las decisiones que se pueden tomar, sin embargo, es muy sencillo. 17.
(26) Capítulo 1. saber que en ciertos momentos la situación está intolerable o que se obtuvo una derrota (Russel and Norving, 1995). Este método consiste en que un agente interactúa, en intervalos de tiempo discretos, con el medio en el que se encuentra, para lograr su meta. En cada intervalo de tiempo el agente recibe de alguna forma información sobre el estado en el que se encuentra el medio, y escoge una acción que hará que el medio cambie a un nuevo estado y por la que recibirá una recompensa que hará variar su comportamiento en pos de aferrarse a esta decisión o descartarla. Siguiendo esta idea, los agentes crean una política de acción, que no es más que una función que asocia las acciones con los estados, indicando qué acción tomar en cada estado. Definiremos pt(st, at) como la probabilidad de tomar la acción a en el estado s en el tiempo t. El modo de trabajo de los agentes es tratar de maximizar la serie de recompensas a lo largo del camino hacia el estado final. Para ello deben tener en cuenta el futuro, no basta con que tome lo que parece ser la mejor acción en un estado si ésta lo conduce a un nuevo estado donde no obtendrá una buena recompensa. Por lo tanto es necesario que las decisiones presentes tomen en cuenta el futuro. En la literatura existen varias técnicas para este proceso, pero la más destacada es el modelo de horizonte infinito. En un modelo de horizonte finito, los agentes sólo toman en cuenta cierta cantidad de pasos, pero es muy complejo saber a priori cuantos pasos se necesitan para llegar a un estado final. En el modelo con descuento de horizonte infinito (discounted infinite horizon model), el agente toma en cuenta todas las recompensas recibidas hasta el final, pero cada recompensa es disminuida según el factor g y su distancia en el tiempo. Cada recompensa rt es multiplicada por gt, donde t es la diferencia de tiempo desde el estado actual (t = 0) hasta el estado en el que se recibirá esta recompensa y 0§ g <1. El valor óptimo alcanzado en un estado s en el tiempo t (V*(st)) es la suma descontada de las recompensas partiendo de este estado, hasta llegar a un estado final, siguiendo la política óptima:. 18.
(27) Capítulo 1. (. ). V * (σ t ) = max R(σ , a ) + γ ∑σ '∈S T (σ , a, σ ')V * (σ ') , ∀σ ∈ S a. (1.1). Siendo R la función de recompensas, S el universo de los estados, y T(s, a, s’) la función de transición, dado el estado s, con la acción a, el medio cambia de estado hacia s’. Existen varios algoritmos que implementan esta técnica, un ejemplo muy usado es el Q-Learning. La factibilidad de cada acción en cada estado es almacenada en una tabla de valores conocidos como Q-Values, y denotaremos esta factibilidad de la acción a en el estado s como Q(s, a). Llamemos Q*(s, a) como el valor óptimo de Q(s, a), o sea, el resultado de tomar la acción a en el estado s y seguir la política p*:. Q * (σ , a ) = R(σ , a ) + γ ∑σ '∈S T (σ , a,σ ') max Q * (σ ' , a ). (2.2). V * (σ ) = max Q * (σ , a ). (3.3). a. Donde: a. Para entrenar a un agente y actualizar sus Q-Values se utiliza el algoritmo siguiente: Algoritmo 1.1. Q-Learning Inicializar Q0(s, a) arbitrariamente Repetir Inicializar s Repetir Escoger a en s usando la política pQt derivada de Qt Tomar la acción a, observar la recompensa r y el nuevo estado s´ Actualizar Qt(s, a): Qt+1(s, a) Å Qt(s, a) + a(s, a)(r + gmaxa´ Qt(s´, a´) – Qt(s, a)) s Å s´ Hasta que s sea un estado final Hasta que los Q-Values estén estables. El parámetro de aprendizaje a establece la velocidad de aprendizaje, el balance de las nuevas recompensas y de los valores existentes en la tabla a la hora de actualizar. 19.
(28) Capítulo 1. estos valores. Este parámetro debe cumplir 0 < a < 1 y debe ser reducido en el tiempo (Verbeeck, 2004). Un aspecto que no se puede pasar por alto es la exploración en estos sistemas. Si nos preguntamos qué decisión tomar en una encrucijada, podría pensarse en tomar siempre la que mayor reforzamiento haya recibido en el pasado. Pero esta decisión no es tan sencilla. Si tomamos siempre lo que parece la mejor decisión, estamos olvidando las demás, sin dar lugar a la exploración de nuevas sucesiones de acciones que nos lleven a mejores soluciones. Por otro lado, no nos podemos mantener explorando nuevas soluciones todo el tiempo sin usar la experiencia adquirida hasta el momento. En esta situación no podremos saber cuán buenas fueron las decisiones que nos llevaron a la situación actual, ya que no se ha asegurado que hayamos seguido una buena conducta a partir de estas decisiones. Una posible solución a este problema es comenzar con un alto grado de exploración, e irlo disminuyendo en el tiempo, a medida que el agente vaya adquiriendo experiencia. La exploración puede verse como la toma de una acción de manera aleatoria a partir de una distribución uniforme de probabilidades. Pero existen otras técnicas para esta toma de acciones de manera que según el nivel de exploración se inserte esta aleatoriedad tomando en cuenta la experiencia acumulada hasta el momento. Un ejemplo de esto es la exploración distribuida semi-uniforme, en este caso se asigna una probabilidad p a la mejor decisión, y se distribuye 1-p para las demás acciones. Otro ejemplo es la exploración distribuida de Boltzmann, en la que la mejor acción sigue siendo la más propensa a ser seleccionada, pero las demás también tendrán probabilidad de ser tomadas según su reforzamiento actual:. P(a ) = e Qt (a ) / T / ∑b∈A e Qt (b ) / T. (4.4). Donde A es el universo de las acciones y T es un factor de temperatura que establece la exploración. Altos niveles de temperatura provocan mucha exploración (Verbeeck, 2004).. 20.
(29) Capítulo 1. 1.3.2 Aprendizaje reforzado para sistemas multiagentes Un problema a tratar en los sistemas multiagentes con aprendizaje reforzado es el emitir las señales reforzadas de manera que los agentes sean capaces de aprender a comportarse de manera óptima. Éste no es un problema sencillo desde el punto de vista del dinamismo del medio creado por la comunidad. Generalmente el aprendizaje de cualquier agente está influenciado por el comportamiento de los demás. A diferencia de los sistemas de agentes simples, en un sistema multiagente cuando uno de los agentes explora el medio sin tener en cuenta el resto de la comunidad puede interferir negativamente en su adaptación al medio, puede ser que su comportamiento simplemente comience a oscilar en dependencia de las decisiones de los demás agentes. Un método de organizar esta exploración es el aprendizaje reforzado con exploración egoísta (Exploring Selfish Reinforcement Learning). Este método organiza la exploración de manera que los agentes reducen el espacio de acciones conjuntas en diferentes intervalos de tiempo en el proceso de entrenamiento. En este proceso los agentes convergen a un punto atrayente del sistema. Luego entran en una fase de sincronización en la que excluyen la acción a la que convergieron de su espacio de acciones y comienzan el proceso nuevamente con un conjunto más reducido. Al finalizar, pueden decidir cuales son los mejore puntos en el sistema (Verbeeck et al., 2005). Este método es muy práctico en sistemas de un solo estado, pero, ¿qué sucede si el sistema puede cambiar de estado? Otro método usado es una variación del algoritmo 1.1 donde se cambia la expresión de actualización de los Q-Values, de manera que los agentes vean la factibilidad de una acción no como la ganancia que obtendrán ellos en particular, sino la que obtendrá el sistema en general. De esta manera, si un agente debe tomar una acción que le reporte un gran beneficio pero que dañe el comportamiento general del sistema deberá escoger otra, centrando su atención en el rendimiento de la comunidad. La expresión es:. 21.
(30) Capítulo 1. (. ). Qt +1 (σ , a ) = Qt (σ , a ) + α (σ , a ) * r + γ * ∑ag∈Ag max Qt (σ ' , a') − Qt (σ , a ) a'. (5.5). Donde Ag es el conjunto de todos los agentes existentes en el sistema.. 1.4 Trabajos. realizados. usando. agentes. basados. en. aprendizaje reforzado Los trabajos hechos utilizando agentes basados en aprendizaje reforzado son incontables y diversos. En muchos campos se trabaja para mejorar los problemas existentes actualmente. En el campo de la aplicación a la robótica se ha trabajado mucho. En (Asada et al., 1996) se propone un método para reducir el tiempo de aprendizaje del comportamiento de los robots segmentando el espacio de los sensores basado en la experiencia de los robots. Otro ejemplo es el presentado en (Asada et al., 1996) que presenta un método de aprendizaje modular que coordina múltiples comportamientos manteniendo cierto equilibrio entre el aprendizaje y la eficiencia. Otro tema muy conocido en este campo es la simulación de robots que coordinan sus esfuerzos para jugar fútbol. En esta problemática aparece un espacio muy amplio de estados y acciones (Fernandez and Borrajo, 1999). (Kalmar et al., 1998) propone el uso de un método de diseño sistemático para la transformación de las tareas a resolver en un conjunto de estados finitos, con tiempos discretos, que también es completamente observable. En (Kiriazov, 2001) se muestra un trabajo para minimizar el costo en tiempo y energía en el movimiento de robots basado en el funcionamiento humano. (Walker, 2000) describe un método novedoso usando aprendizaje reforzado, y experimentos que validan al mismo, mediante el cual un sistema capaz de establecer diálogos puede aprender de sus experiencias con humanos para optimizar sus selecciones de estrategias de diálogo. Pero no sólo en la robótica se han usado esta combinación de técnicas. En el campo de la recolección de datos, donde la información recopilada puede afectar las recompensas recibidas pero no el comportamiento óptimo de los agentes. (Strens, 2003) propone un algoritmo para, explotando esta característica, evaluar la política de 22.
(31) Capítulo 1. acción de un agente simultáneamente contra todas las posibles historias de estados ocultos. En los sistemas para el control de enrutamiento de una red también son muy usados los sistemas multiagentes. En particular, en la simulación de la paradoja de Braess, la adición de nuevas capacidades con agentes ISPA (Ideal Shortest Path routing Algorithm) puede reducir el rendimiento general del sistema. La teoría de diseño de inteligencia colectiva se refiere precisamente al tema de evitar efectos colaterales en las acciones que dañen la utilidad global. (Tumer and Wolpert, 2000) muestra que el enrutamiento basado en este diseño de inteligencia colectiva mejora substancialmente el rendimiento y evita esta paradoja. En la aproximación de funciones se han usado estas técnicas también. Se desarrolló un algoritmo para el cómputo de decisiones óptimas de reglas en sistemas multidimensionales (Sandjai, 2002). (Coulom, 2002) demuestra que las redes neuronales con conexiones hacia adelante pueden ser aplicadas satisfactoriamente para problemas de muchas dimensiones en la aproximación de funciones dentro del campo del aprendizaje reforzado. Las principales dificultades de usar redes backpropagation son expuestas y es propuesto un método simple para desarrollar eficientemente el método gradiente descendente. (Ernst, 2005) muestra un algoritmo derivado para la selección de un conjunto de ejemplos recuperados por un agente con aprendizaje reforzado interactuando con un medio determinista. El agente debe extraer políticas de los conjuntos de ejemplos resolviendo una secuencia de problemas de regresión lineal estándares supervisados. En la industria son usados en varios problemas. Se aplican métodos de aprendizaje reforzado para aprender heurísticas aplicadas a la planificación de compras (Dietterich and Zhang, 1995). (Ernst et al., 2006) propone el cómputo de una estrategia para la estructura óptima de un tratamiento para pacientes infectados con el VIH. Se muestra cómo el aprendizaje reforzado puede ser útil para extraer estas estrategias directamente de los datos clínicos, sin la necesidad de un modelo matemático preciso de la dinámica de la infección del VIH.. 23.
(32) Capítulo 1. Muchos problemas de optimización de fábricas, desde el control de inventario hasta la planificación y la fiabilidad, pueden ser formuladas como un proceso de decisión de Markov continuo en el tiempo. (Sridhar et al., 1997) propone un nuevo algoritmo de promediado de recompensas llamado SMART en procesos de decisión de este tipo. (Syafiie et al., 2005) presenta una solución al control de pH basado en un control inteligente libre del modelo usando aprendizaje reforzado. Esta técnica de control es propuesta porque el algoritmo da una solución general para los sistemas ácido-base, lo suficientemente simple para implementarlo en el hardware de control existente en el momento. En la teoría de juegos también tienen incontables aplicaciones. Un ejemplo es el expuesto en el proyecto que investiga las aplicaciones del algoritmo de aprendizaje reforzado TD (lambda) y las redes neuronales al problema de producir un agente que pueda jugar juegos de mesa (Ghory, 2004).. 1.5 Trabajos de simulación relacionados con la preparación para la defensa La simulación es una estrategia muy utilizada en este campo. Se ha trabajado tanto en sistemas para el entrenamiento de habilidades necesarias en el combate, como las habilidades de vuelo de pilotos de guerra, o de tiradores, o incluso habilidades de mando de estrategas, como en la obtención de resultados de posibles situaciones en el campo de batalla. La necesidad de uso del software de simulación para la obtención de vulnerabilidades ha crecido en los últimos años por el incremento del uso de la modelación y la simulación para el entrenamiento y la planificación operacional, del énfasis en las coaliciones ante las situaciones de guerra y la interoperabilidad, y el crecimiento de la conciencia de los riesgos de seguridad inherentes al compartimiento del software operacional. La comunidad de simulación militar ha sabido siempre que el usar imágenes reales para la visualización gráfica puede mejorar la precisión. Pero este proceso es muy costoso. Es por esto que SGI y la Fuerza Aérea de EU han desarrollado un proyecto 24.
(33) Capítulo 1. conjunto para poner en prueba el uso de imágenes de modo menos costoso. Se logró un sistema capaz de proveer imágenes con una buena resolución para objetos de hasta un metro, nuevos chips para la compresión de los datos y técnicas para maximizar el poder en el dibujado de los triángulos y los píxeles. Con estas técnicas, los nuevos simuladores de entrenadores de misiones han sido puestos a prueba en los simuladores de vuelo de naves F-16 (Beasley, 2001). Otro ejemplo es el simulador extendido de defensa aérea (EADSIM). Este producto de simulación de guerra aérea, de misiles y espacial provee análisis, entrenamiento, y planificación operacional para equipos de guerra (Watkins, 1989). Como parte de su campaña de publicidad, la Agencia de Defensa contra Misiles (MDA) mostró a la prensa su software de simulación de defensa contra misiles. Mientras MDA expuso las facilidades que brinda el software para el entrenamiento, los oficiales de MDA, así como el director General Ronald Kadish, expresaron su conformidad con el mismo adicionando que el software proveería mucha información adicional sobre la efectividad del sistema de defensa (Gronlund and Wright, 2004). (Hamilton et al., 2004) describe el proceso desarrollado por la Agencia de defensa contra misiles y la Universidad de Auburn para evaluar las vulnerabilidades potenciales en el software de simulación compartido. Este proceso puede ser aplicado a los sistemas de simulación para encontrar vulnerabilidades en ellos.. 1.5.1 Uso de agentes en la simulación de defensa El uso de técnicas de agentes en los sistemas de simulación para la defensa no es muy común en la literatura. Sin embargo se ha trabajado en cierto sentido, debe tenerse en cuenta que la mayoría de los trabajos que se realizan en este campo no se publican por problemas de seguridad. (K. Numrich et al., 2000) señala la importancia de las simulaciones orientadas al uso de agentes, como un concepto científico y una posibilidad tecnológica, para aumentar las posibilidades de los sistemas de simulación civiles y militares. Existe un laboratorio: Modeling & Simulation Laboratory, dedicado al estudio de nuevas técnicas aplicadas a la simulación computacional. Las investigaciones en este. 25.
(34) Capítulo 1. laboratorio están dirigidas a las redes de computadoras y las simulaciones orientadas al uso de agentes (Yilmaz, 2004). Este laboratorio ha efectuado trabajos valiosos para el ejército y la marina de guerra norteamericana. Trabajos como la confección de un modelo de recuperación activo para una fuerza semi-automática basada en rejillas, herramientas para la prueba y certificación de configuraciones dinámicas y distribuidas de un ambiente computacional para una embarcación, integración de un modelo de verificación al software de diseño educativo, análisis de las diferencias de arquitectura y sus aplicaciones, análisis de vulnerabilidades en las simulaciones MDA. Todos estos trabajos han sido confeccionados sobre la base de simulaciones orientadas al uso de agentes. La simulación del Crucero AEGIS de defensa aérea es un programa que modela la operación de un equipo del Centro de Información de Combate desarrollando defensa aérea desde un grupo de batalla de la marina de E.U. Este sistema ha sido desarrollado usando técnicas de simulación combinadas con sistemas multiagentes (Calfee and Rowe, 2005).. 26.
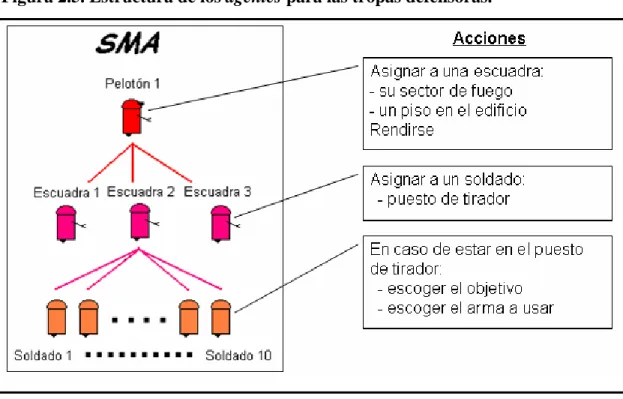
(35) Capítulo 2. Capítulo 2. Diseño e implementación de un sistema multiagente para la simulación de la defensa de un edificio Como se pudo ver anteriormente, como resultado del presente trabajo se ha desarrollado una herramienta flexible para la implementación de sistemas multiagentes, cuyo uso será ejemplificado en un problema real de las fuerzas armadas, la defensa de una edificación dentro de la ciudad ante un ataque enemigo. A continuación se explicará cómo se diseñó e implementó esta herramienta, cómo se modeló la simulación de la problemática expuesta, y cómo se integró el sistema multiagente en la simulación.. 2.1 Diseño e implementación de una jerarquía de clases con características extensibles para la implementación de sistemas multiagentes con aprendizaje reforzado Para implementar una herramienta útil para el desarrollo de sistemas multiagentes se implementó una jerarquía de clases en C++ que brinda las funcionalidades generales del sistema, como la comunicación y facilidades para la construcción del medio, los estados y las acciones. En el momento de usar esta herramienta para un problema en específico, se debe definir lo referente al problema en sí: el comportamiento de los agentes, construir el medio, los estados y las acciones. Estas clases se encapsularon en una biblioteca de enlace dinámico (dll) para poder ser usadas desde otros proyectos, de forma que los desarrolladores no se vean sujetos a utilizar el mismo lenguaje de programación. En la jerarquía de clases se brindan clases bases para la definición de los agentes que intervendrán en el sistema, de manera que pueda ser fácilmente extendida a cualquier problema. Se brinda una clase base que represente el sistema multiagente, así como clases para el medio, los estados y las acciones.. 27.
(36) Capítulo 2. Figura 2.1. Jerarquía de clases para desarrollar sistemas multiagentes Sistema multiagente (MARL) Medio (ENVIRONMENT) Estado (STATE) Acción (ACTION). Estados (STATES). Acciones (ACTIONS). Campos (FIELDS). Agente (AGENT). Agente desinteresado (SELFLESSAGENT). A continuación se muestra la clase MARL, con el mecanismo de comunicación entre los agentes, la clase AGENT, y las clases para construir el medio, los estados y las acciones.. 2.1.1 Control del sistema La clase MARL es la entidad encargada de observar y regular el comportamiento de los agentes, el medio y mantener la información sobre los estados. Será esta clase la que orientará la adaptación al medio por parte de los agentes, originará los cambios de estado a partir de las acciones de estos agentes y se apoyará en las decisiones de los mismos para tomar una decisión conjunta en cada instante de tiempo. Exige para su funcionamiento que el programador que la use defina el medio, los estados y los agentes que intervendrán en el sistema a partir de las clases bases que se ofrecen en la herramienta. Para ello ofrece un conjunto de métodos para añadir los agentes, el medio y los estados definidos. Además exige que el programador defina los métodos que identifican al problema en sí, cuáles son los estados finales e inicial, la función de transición de estados ante las acciones de los agentes, y la función de actualización del medio ante estas transiciones.. 28.
(37) Capítulo 2. Permite la selección de acciones conjuntas a partir de las decisiones de los agentes, seleccionando a voluntad del programador la mejor decisión de cada agente (lo que puede ser deseable en procesos determinísticos), o tomando estas decisiones de manera estocástica (para situaciones como la actual, en la que se desea simular un proceso). También permite entrenar a los agentes en un medio determinado, permitiéndoles adaptarse al mismo y reaccionar en las diferentes situaciones de forma óptima. Este entrenamiento se realiza sobre la base de que los agentes aprenden su conducta usando aprendizaje reforzado. La clase MARL es la encargada de difundir señales reforzadas (recompensas a las acciones de los agentes en el caso de ser favorables, o castigos en el caso contrario) que los agentes percibirán, logrando así la comunicación entre ellos para la cooperación. Pero, ¿por qué usar aprendizaje reforzado? 2.1.1.1 Mecanismo de cooperación Como se vio en el capítulo uno, existen muchos métodos de cooperación: agrupamiento y multiplicación, comunicación, especialización, colaboración por reparto de tareas y recursos, coordinación de acciones y resolución de conflictos por arbitraje y negociación. En situaciones similares a ésta, en las que se tienen varias entidades persiguiendo un objetivo común (lo que es muy común en simulaciones aplicadas a la defensa) es muy importante la comunicación entre entidades para compartir su percepción del medio, así como su experiencia. Con esta herramienta se persigue facilitar este proceso de comunicación, de manera que los desarrolladores de estos tipos de sistemas puedan crear simulaciones reales, en la que sus estructuras combativas puedan coordinar su ataque por medio de la comunicación. Se desea además que los agentes no necesiten sistemas que puedan generar e interpretar señales complejas (como las de un lenguaje articulado) para lograr esta comunicación, de forma que sea más sencilla la construcción de los mismos. Solamente deben aprender a reaccionar ante las situaciones dadas observando el resultado del medio en general una vez escogida una acción en un estado dado. Por otra parte, por cuestiones de eficiencia, es mucho mejor, una vez que los agentes se. 29.
(38) Capítulo 2. hayan adaptado al medio en el que se encuentran, que puedan reaccionar a las condiciones y no tener que crear y procesar en tiempo de ejecución los mensajes para la comunicación. En este sentido, la comunicación empleada fue basada en aprendizaje reforzado. Pero, ¿cómo se implementó esta comunicación? El algoritmo implementado fue el algoritmo 2.1 que es una versión del algoritmo 1.1 presentado en la sección 1.3.1. Algoritmo 2.1. Adaptación de los agentes al medio (Q-Learning) Mientras no estén estables los valores Q-Values Inicializar de forma aleatoria los estados Repetir C Å Estado Actual AC Å Acción Conjunta (Agentes) Para cada Agente R Å Calcular Recompensa Entregar R al agente Hasta que c sea un estado final Para cada Agente Actualizar Q-Values de agente Balance Å 1 – (1 - Balance) * (1 – Velocidad de aprendizaje) Temperatura Å 1 + (Temperatura - 1) * Factor de enfriamiento Balance Å 1. Este algoritmo permite que el desarrollador pueda definir antes del entrenamiento el factor de temperatura tan alto como lo desee, buscando altos porcentajes de exploración y a medida que el sistema vaya aprendiendo, este factor vaya disminuyendo según el factor de enfriamiento, así como el valor del balance que es el que define el balance que existe entre el conocimiento aportado por el agente y la experiencia obtenida en el medio a partir de este conocimiento. El balance es una medida de cuanta importancia dar al conocimiento y cuanta a la experiencia adquirida en el medio a través de este conocimiento en el momento de tomar una decisión. El desarrollador debe dar bajos valores a este balance antes de entrenar el sistema,. 30.
Figure




+5


Documento similar