Estimación del tiempo en tareas de proyectos de software utilizando técnicas de aprendizaje automático
102
0
0
Texto completo
(2) Pensamientos “La ignorancia afirma o niega rotundamente; la ciencia duda.” Voltaire “El éxito consiste en obtener lo que se desea. La felicidad, en disfrutar lo que se obtiene.” Ralph Waldo Emerson.
(3) Dedicatoria A mi mamá por ser el pilar de todas mis acciones y su dedicación, a mi papá por darme siempre su impulso a pesar de la distancia, a mis abuelos y mi tía, por su constante preocupación y apoyo incondicional. A mi padrastro por todo su apoyo y comprensión. A mi novia por soportar mis incontables momentos de estrés y por todo su amor. Jarvin A mis padres por el sacrificio que han hecho para que yo pueda lograr mis metas y por el apoyo que siempre me han dado. A mis abuelos por sus consejos y apoyo. A toda mi familia y en especial a mis tías que han sido de gran ayuda durante estos 5 años que he estado en Santa Clara. Luis.
(4) Agradecimientos A mi familia por creer siempre en mí y darme su apoyo en todos los momentos. A Luis, mi compañero de tesis que siempre me impulsa a ser mejor, aunque no llegue a ser tan bueno como él. A mis amistades en general, por ser parte de mi vida en estos cinco años. A Karelia, por darme buenas batallas y discusiones en las que casi nunca me dejó ganar, enseñándome que no siempre se tiene la razón. A Fernando, por ser un gran amigo, muestra de que existen personas transparentes, sencillas y divertidas, con las que siempre se puede contar. A Millo, por ayudarme crecer en mi carrera, por abrirme las puertas del ACM y su paciencia en tiempos de exámenes. A Osmany, por ser el amigo excepcional, con el que se puede contar en todo momento y por soportar todas mis bromas. A Guille, por saber guiarnos durante estos cinco años, por darnos momentos inolvidables y por soportarnos durante todo este tiempo. A Ana Evis, por brindarnos su hospitalidad para que pudiéramos llevar a cabo un importante paso de la investigación. A Sady, por sus consultas de psicológicas durante este tiempo. A Linet, por sus oportunas traducciones. A mis tutores, por su dedicación e incondicionalidad. A mis profesores, por darme una preparación de excelencia. A la familia Bello García, por sus aportes durante la investigación, sin la cual no sería posible obtener los resultados alcanzados. Al grupo de desarrollo del GESPRO, por su cooperación e incondicionalidad. Jarvin.
(5) A mi familia, por su apoyo incondicional e impulso a ser cada día mejor. A Jarvin, por aceptar el reto de esta tesis junto conmigo y aguantar mi carácter difícil en algunas ocasiones. A Mariela, por impulsarme a que me decidiera por estudiar esta carrera cuando no estaba seguro. A Ana Evis, por su apoyo y por impulsarme a dar lo mejor de mí cada día. A Royne, Carlos, Raúl G., Raúl A. e Igor, por ser amigos con los que se puede contar en todo momento. A mis amistades del pre y de la infancia, que a pesar de seguir caminos distintos siempre han sabido mantenerse presentes en mi vida. A las amistades que he conocido en la UCLV, las cuales han hecho de la universidad algo más que un lugar donde me he preparado profesionalmente. A mis tutores, por estar siempre dispuestos a brindarnos su ayuda cuando lo necesitamos. A mis profesores, por brindarme todos sus conocimientos. A la familia Bello García, por su apoyo en esta investigación, sin el cual no sería posible obtener los resultados alcanzados. A todos los que trabajan en el grupo de desarrollo del GESPRO, sin los cuales hubiera sido casi imposible el desarrollo de esta investigación. Luis.
(6) Resumen En la actualidad existe un auge creciente de las metodologías ágiles para el desarrollo de proyectos de software, en las cuales se prefiere el desarrollo, es decir la implementación, sobre la documentación. Este tipo de desarrollo hace énfasis en la planificación, donde se mantiene un interés especial en el desglose de los proyectos de software en tareas independientes, a fin de hacer más efectiva la supervisión del avance del proyecto. El presente trabajo se centra en la implementación de un modelo de estimación del tiempo de tareas individuales, utilizando técnicas de aprendizaje automático. Para ello se definieron las variables de estimación y se generó la base de casos de tareas. Posteriormente se determinó la técnica que mejores resultados aportó en la estimación para la implementación del modelo. Como resultado del trabajo se implementa el plug-in Estimador de Tareas para el software GESPRO, que permite predecir el tiempo de desarrollo de cada tarea de un proyecto de software, útil para la planificación de los recursos humanos por el jefe del proyecto..
(7) Abstract Nowadays there is an increasing height of agile methodologies to develop software projects, in which it’s preferred the development, that is to say the implementation, of documentation. This type of development makes an emphasis on planning, where a special interest is kept on outlining software projects into independent tasks, in order to make supervision of the project’s achievements more effective. The present paper is focused on the implementation of an Individual Tasks’ Estimation Model, using techniques of machine learning. To that purpose estimation variables have been defined, and a database of tasks cases has been generated. Afterwards, the estimation technique was set for the implementation of the model. As a result of the paper the plug-in Tasks Estimator is implemented for GESPRO software, which allows predicting the developing time of each task of a software project, useful for planning human resources by the head of the project..
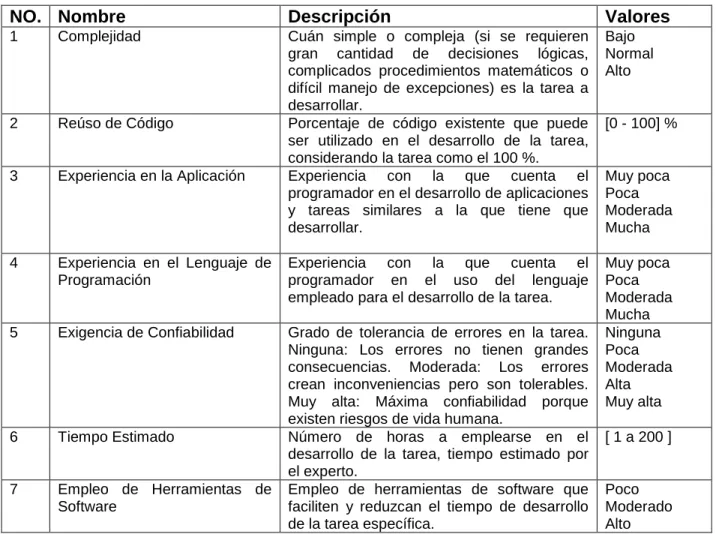
(8) TABLA DE CONTENIDOS INTRODUCCIÓN ............................................................................................................ 1 CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” ..................... 6 1.1 Estimación del esfuerzo utilizando técnicas de IA ................................................. 6 1.1.1 Razonamiento Basado en Casos (RBC) ......................................................... 7 1.1.2 Algoritmos Genéticos (AG)............................................................................ 11 1.1.3 Programación Genética (PG) ........................................................................ 13 1.1.4 Support Vector Regression (SVR) ................................................................ 14 1.1.5 Redes Neuronales Artificiales (RNA) ............................................................ 17 1.1.6 Sistemas de Inferencia Borrosos (SIB) y Lógica Difusa (LD) ....................... 19 1.1.7 Redes Bayesianas (RB) ................................................................................ 23 1.1.8 Árboles de Decisión (AD) .............................................................................. 24 1.1.9 Reglas de Asociación (RA) ........................................................................... 28 1.2 Criterios de Evaluación ........................................................................................ 30 1.3 Conclusiones parciales del capítulo..................................................................... 32 CAPÍTULO 2 “APLICACIÓN DE TÉCNICAS DE APRENDIZAJE AUTOMÁTICO PARA LA ESTIMACIÓN DEL TIEMPO EN TAREAS DE PROYECTOS DE SOFTWARE” ..... 33 2.1 Caracterización del problema .............................................................................. 33 2.2 Definición de las variables de estimación ............................................................ 35 2.3 Captura de la información de las variables de estimación ................................... 38 2.3.1 Marco de trabajo Ruby On Rails ................................................................... 38 2.3.2 Estimador de Tareas v1.0. Análisis, Diseño e Implementación ..................... 39 2.4 Técnicas de aprendizaje automático utilizadas para solucionar el problema de estimación ................................................................................................................. 43.
(9) 2.4.1 Aplicación de Algoritmos del software WEKA ............................................... 45 2.5 Conclusiones parciales del capítulo..................................................................... 55 CAPÍTULO 3 “SOLUCIÓN DEL PROBLEMA DE ESTIMACIÓN DEL TIEMPO” ........... 56 3.1 Análisis de los resultados .................................................................................... 56 3.1.1 Influencia del uso de Bagging ....................................................................... 56 3.1.2 Selección de los mejores modelos ................................................................ 58 3.1.3 Comparación entre el mejor modelo y la estimación por el experto .............. 61 3.1.4 Análisis de la base de casos ......................................................................... 61 3.2 Estimador de Tareas v1.1. Análisis, Diseño e Implementación ........................... 63 3.3 Descripción del Estimador de Tareas v1.1 .......................................................... 65 3.3.1 Acceder al plug-in ......................................................................................... 65 3.3.2 Visualización y Edición de las variables de una tarea ................................... 66 3.3.3 Exportación de los datos ............................................................................... 68 3.3.4 Administración de las variables ..................................................................... 68 3.4 Conclusiones parciales del capítulo..................................................................... 71 CONCLUSIONES.......................................................................................................... 72 RECOMENDACIONES ................................................................................................. 74 REFERENCIAS BIBLIOGRÁFICAS .............................................................................. 75 ANEXOS ....................................................................................................................... 78 Anexo 1. Variables descritas en (Velarde Bedregal, 2010) ....................................... 78 Anexo 2. Variables del ISBSG ................................................................................... 81 Anexo 3. Multiplicadores de COCOMO ..................................................................... 83 Anexo 4. Encuesta..................................................................................................... 85 Anexo 5. Resultados de la Pregunta 1 de la Encuesta .............................................. 88 Anexo 6. Diagrama de clases del Plug-in. ................................................................. 90.
(10) Anexo 7. Resultados de la prueba de Wilcoxon usando MRE. .................................. 91 Anexo 8. Resultados de la prueba de Wilcoxon usando Ab. Res. ............................. 92.
(11) INTRODUCCIÓN La estimación es una de las primeras y más importantes actividades de un proyecto. Consiste en determinar el valor de una o varias variables desconocidas (esfuerzo, costo) a partir de otras conocidas, o de una pequeña cantidad de valores conocidos de esa misma variable; es decir, predecir. en fases iniciales del ciclo de vida,. características del software cuyo valor real solo puede conocerse en etapas posteriores o cuando el proyecto ha finalizado. Hoy en día, el software es el elemento más caro de la mayoría de los sistemas informáticos. Un gran error en la estimación del costo o del esfuerzo puede ser lo que marque la diferencia entre beneficios y pérdidas. Por ejemplo, si el esfuerzo de desarrollo es subestimado, un costo superior al previsto puede hacer que los beneficios obtenidos sean nulos o negativos, y una prolongación excesiva en el tiempo de entrega puede hacer que se pierdan futuros clientes. Sobrestimar el esfuerzo de desarrollo puede también afectar a la competitividad de la compañía, así como provocar pérdida de beneficios, por ejemplo podría contratarse personal en exceso para la realización del proyecto. Un ejemplo del impacto del fracaso de proyectos de software, es que se ha estimado que estos fracasos entre 2001 y 2006 han costado entre 25 y 75 billones de dólares a la economía de los Estados Unidos (Oliveira, 2006). Una de las causas más importantes de las fallas de los proyectos de software es la inexacta estimación de las necesidades de recursos. La construcción de modelos sobre diferentes aspectos del software requiere la recolección de numerosos datos procedentes de observaciones empíricas. Los avances tecnológicos actuales posibilitan la rápida obtención de grandes cantidades de datos de fuentes muy diversas, así como el almacenamiento eficiente de los mismos. La manipulación de estos datos representa un desafío en dependencia de los métodos a aplicar para la estimación, tanto de esfuerzo como de tiempo de cada proyecto. No se puede considerar a la estimación como una ciencia exacta ya que existen numerosas variables humanas, técnicas, del entorno, entre otras que intervienen en su proceso y.
(12) INTRODUCCIÓN. que pueden afectar los resultados finales. Sin embargo, cuando es llevada a cabo de forma sistemática, se pueden lograr resultados con un grado aceptable de riesgo y convertirla en un instrumento útil para la toma de decisiones. Resultados interesantes encontrados en (Moløkken and Jørgensen, 2004) demuestran que entre el 60 y el 80 por ciento de los proyectos analizados sobrepasaron el tiempo y esfuerzo planificados y que el método de estimación empleado de manera más frecuente es el basado en el juicio del experto, a pesar de que existen múltiples técnicas algorítmicas y no algorítmicas para resolver este problema ((Stutzke, 1996), (Sandhu et al., 2008a), (Attarzadeh and Hock Ow, 2010)). Muchos son los modelos algorítmicos de estimación de costo y esfuerzo, basados en el análisis regresivo de datos históricos. Entre los más populares se encuentran COCOMO81, COCOMOII, SLIM, Puntos de Función (PF) y Delphi (Hari et al., 2009). La exactitud de muchos de ellos está determinada por el tamaño del software, dado tanto en líneas de código fuente (Lines of Code - LOC) como en PF, valores que son muy difíciles de estimar en etapas tempranas del desarrollo del software. Entre sus otras variables de entrada también se pueden encontrar la complejidad del software, el número de pantallas de usuario, interfaces, entre otras. Lamentablemente, los modelos algorítmicos no han sido capaces de demostrar consistentemente resultados adecuados, con errores del 100% o mayores, incluso luego de ser calibrados (Schofield, 2010). Muchos de estos modelos no han podido presentar una solución adecuada que tenga en consideración los avances tecnológicos. Una posible razón de esto es que son incapaces de modelar adecuadamente el complejo conjunto de interrelaciones evidentes en múltiples ambientes de desarrollo de software. En la mayoría de los casos los modelos son exitosos en un ambiente bien restringido, pocos son lo suficientemente flexibles para funcionar fuera de su dominio. Considerando lo anteriormente expuesto, investigadores en la temática han empezado a dirigir su atención hacia alternativas de soluciones no algorítmicas para problemas de estimación, y en especial en un conjunto de técnicas que son consideradas como aprendizaje automático (machine learning). Son varios los ejemplos de estudios realizados buscando la combinación de modelos algorítmicos y no algorítmicos, con el. 2.
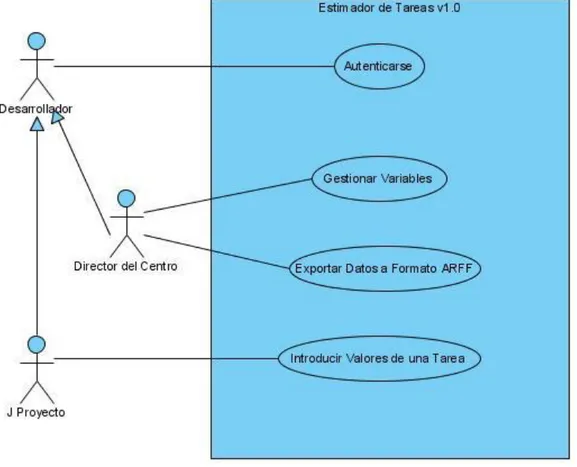
(13) INTRODUCCIÓN. objetivo de mejorar su funcionamiento y por ende su exactitud en la estimación de software. Los modelos de predicción basados en técnicas de aprendizaje automático, de acuerdo a numerosos estudios (Burgess and Lefley, 2001, Oliveira et al., 2010, Wen et al., 2012) han demostrado ser superiores a los modelos tradicionales. Los resultados de la aplicación de estas técnicas en los estudios realizados, generalmente se han visto relacionados con la estimación del esfuerzo en proyectos completos. Sin embargo, en la actualidad existe una tendencia a dividir el trabajo en tareas más concretas, apoyada por el uso creciente de las metodologías ágiles, en las cuales se le concede gran importancia al desarrollo (implementación), por encima de otros aspectos como la documentación. En este entorno, la estimación del esfuerzo y por consiguiente del tiempo que requiere cada tarea es imprescindible, llegándose a adaptar los métodos de estimación convencionales y a desarrollarse otros nuevos con este objetivo (Adekile, 2008). Una oportunidad para realizar la estimación del tiempo en tareas de software la proporcionan las herramientas para realizar la gestión de proyectos (Lang, 2012). Estas permiten una división de los mismos en tareas específicas, que luego son asignadas a grupos de desarrolladores, lo que facilita el control del trabajo de cada programador y el ajuste de las tareas al cronograma del proyecto. Objetivo general: Implementar un modelo de estimación de tiempo en tareas de desarrollo de software utilizando técnicas de aprendizaje automático, que se comporte similar o superior a las estimaciones realizadas por el experto humano. Objetivos específicos: 1. Determinar un conjunto adecuado de variables de entrada para realizar la estimación del tiempo, de acuerdo a las características de las tareas y al entorno de desarrollo del proyecto de software. 2. Evaluar diferentes técnicas de aprendizaje automático que aplicadas sobre los datos obtenidos, permitan estimar el tiempo de duración de una tarea.. 3.
(14) INTRODUCCIÓN. 3. Seleccionar el modelo de estimación a partir del análisis de los resultados obtenidos de la aplicación de las técnicas de aprendizaje automático. 4. Implementar el estimador seleccionado en una herramienta de gestión de proyectos de software. Hipótesis El empleo de algunas técnicas de aprendizaje automático en la estimación del tiempo en tareas de desarrollo de software, proporciona resultados similares o superiores a las estimaciones realizadas por el experto humano. En esta investigación se hace un estudio de un conjunto amplio de técnicas de Inteligencia Artificial (IA), en especial de las potencialidades de algunas técnicas de regresión. Esto hace que los resultados obtenidos posean un valor científico al brindar un modelo que resuelve el problema de estimación de tiempo en tareas de un proyecto de software. El valor práctico del trabajo investigativo está enmarcado en la creación de un plug-in realizado al gestor de proyectos GESPRO. Esta herramienta facilita la captura de los datos necesarios para la investigación y la administración de las variables; así como permite realizar la estimación del tiempo a partir de la implementación del modelo seleccionado, de gran utilidad para los jefes de proyectos. El presente trabajo está organizado en 3 capítulos. En el Capítulo 1 se hace un estudio de las principales investigaciones que se han realizado en el campo de la estimación de esfuerzo de un proyecto de software, haciendo uso de técnicas de IA, destacándose sus principales cualidades y sus aportes en la creación de técnicas novedosas. Se tratan, además, los principales criterios de evaluación de los modelos de estimación. En el Capítulo 2 se hace un estudio de las variables que pueden influir en la duración de una tarea de implementación de software y se plantea el diseño y la implementación de un plug-in para el gestor de proyectos GESPRO para la recolección de datos de tareas. También se aborda la aplicación de un conjunto de algoritmos de aprendizaje automático implementados en el sistema WEKA. El Capítulo 3 está conformado, por el análisis de los resultados de la aplicación de los algoritmos descritos en el capítulo. 4.
(15) INTRODUCCIÓN. anterior, y la selección del mejor modelo predictor. Se realiza además una comparación de la exactitud de las estimaciones realizadas por el experto y por el modelo, así como un análisis de la base de casos con la que se trabajó y las especificaciones del plug-in final que permite la estimación mediante el modelo propuesto.. 5.
(16) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” En este capítulo se hace un estudio de las técnicas de IA, que han sido utilizadas en la Ingeniería de Software, en especial aquellas orientadas a la estimación de esfuerzo y costo en proyectos de software. Se realiza un análisis de las ventajas y desventajas que cada una de estas técnicas brinda para la estimación, así como los resultados obtenidos cuando se han utilizado en la estimación de esfuerzo. También se describen algunas métricas empleadas en la evaluación de las técnicas de estimación, que posteriormente serán usadas para determinar el mejor modelo de estimación.. 1.1 Estimación del esfuerzo utilizando técnicas de IA La estimación en proyectos de software se ha realizado utilizando una variedad de modelos algorítmicos de acuerdo a trabajos investigativos que aparecen en (Boehm, 2000, Hari et al., 2009). Sin embargo, a partir de la década de los 90 ha aparecido un interés creciente en utilizar modelos no algorítmicos para realizar la estimación. Según un estudio publicado en (Wen et al., 2012), varias técnicas de aprendizaje automático han sido aplicadas para estimar el esfuerzo de desarrollo de software. En esta investigación se analizarán las siguientes técnicas de IA: Razonamiento Basado en Casos (RBC) Algoritmos Genéticos (AG).
(17) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” Programación Genética (PG) Support Vector Regression (SVR) Redes Neuronales Artificiales (RNA) Redes Bayesianas (RB) Árboles de Decisión (AD) Reglas de Asociación (RA) Sistemas de Inferencia Borrosos (SIB) y Lógica Difusa (LD) De las técnicas relacionadas anteriormente, RBC, RNA y AD son las más usadas. Juntas abarcan el 80% de los estudios aplicados a la estimación del esfuerzo desde los años 90 hasta la actualidad, aunque se evidencia un aumento del uso de técnicas como AG, PG, RB y SVR en los últimos años. Otro elemento a destacar es que se ha generalizado el uso de enfoques híbridos en la estimación, donde técnicas de aprendizaje automático se combinan con otras que pueden ser o no de aprendizaje automático. Esta combinación ha sido liderada por AG y la LD. En el conjunto de estudios seleccionados en (Wen et al., 2012), los AG han sido combinados con RBC, RNA, y SVR. La LD, ampliamente usada en el manejo de incertidumbre e imprecisión de la información, ha sido combinada también con RBC, RNA y AD, para mejorar el funcionamiento de los modelos a través del preprocesamiento de sus datos de entrada. En los subepígrafes que continúan se realiza una descripción de cada una de las técnicas mencionadas al inicio. 1.1.1 Razonamiento Basado en Casos (RBC) De forma general, resolver problemas por analogías implica relacionar algunos problemas resueltos o experiencias, con el actual problema no resuelto, de manera que se facilite la búsqueda de una solución aceptable. El problema a ser resuelto se denomina objetivo de la analogía y el problema anterior se denomina fuente de la analogía. La formación de la analogía ocurre cuando se percibe una. 7.
(18) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” similitud entre la fuente y el objetivo, cuyas bases dependen del dominio del problema a resolver. Elementos similares entre la fuente y el objetivo son mapeados unos con otros y este mapeo entonces es usado para formar inferencias analógicas que generan información para facilitar la solución del problema (Mukhopadhyay et al., 1992). Un marco más específico para la solución de problemas por analogías propuesto por investigadores que trabajan en la construcción de modelos computacionales de este tipo, es el modelo basado en casos. Este, a diferencia de la teoría más general de razonamiento por analogías (donde se debe acomodar la fuente cuyos elementos son conceptualmente distintos a los del objetivo),. se centra en. situaciones donde la fuente se deriva del mismo dominio general del problema que el objetivo y en las cuales ambos tienen la misma representación estructural (Mukhopadhyay et al., 1992). Según (Huang and Chiu, 2006) este es un proceso cíclico compuesto fundamentalmente por cuatro etapas: 1. Recuperar el caso más similar. 2. Reusar este caso para resolver el problema. 3. Revisar la solución sugerida si es necesario. 4. Retener la solución y el nuevo problema como un nuevo caso. En (Wittig and Finnie, 1997) se pueden encontrar múltiples ventajas que ofrece el RBC. Entre ellas se localizan las siguientes: Evita. problemas asociados. con. la. adquisición. y. codificación. de. conocimiento. Soporta. mejor. la. colaboración. con. los. usuarios,. quienes. están. frecuentemente más dispuestos a aceptar soluciones que provienen de sistemas basados en analogías pues. se derivan de una forma de. razonamiento más parecida a la forma humana de resolver problemas. Hace frente a dominios pobremente conocidos (por ejemplo, varios aspectos de la Ingeniería de Software como es el caso de la estimación en. 8.
(19) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” la gestión de proyectos) ya que las soluciones están basadas en lo que realmente pasó al contrario de modelos hipotéticos. Sin embargo, la misma fuente bibliográfica hace mención a que las medidas de similitud utilizadas en RBC, traen consigo algunas desventajas entre las que se pueden citar: Que los rasgos simbólicos son problemáticos, ya que aunque hay varios algoritmos que han sido propuestos para acomodar los rasgos categóricos, estos tienden a ser bastante crudos pues tienden a adoptar una aproximación booleana donde los rasgos coinciden o fallan en la comparación con ningún punto medio. Que pueden fallar al tomar en cuenta información que puede estar derivada de estructuras de datos, es decir que son débiles para rasgos de alto orden de interrelación como los que se pueden esperar en los sistemas legales. También existen dominios de problemas que no son bien manejados por el RBC. Algunas características que pueden provocar esto son: La falta de casos relevantes, lo cual puede ocurrir cuando se trabaja con dominios extremadamente nuevos. La escasez de casos disponibles debido a la falta de datos organizados sistemáticamente, lo que puede estar provocado porque la información no es guardada o porque está primariamente en formato de lenguaje natural, y los modelos de RBC no tratan con grandes cantidades de texto no estructurado (Wittig and Finnie, 1997). Múltiples investigaciones tratan el RBC para la estimación del esfuerzo en proyectos de software (Mukhopadhyay et al., 1992, Finnie et al., 1997, Huang and Chiu, 2006, Wu et al., 2010, Patnaik et al., 2004). En (Mukhopadhyay et al., 1992) se propone un modelo computacional llamado Estor. En este, el conocimiento específico del dominio está contenido en una base. 9.
(20) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” de conocimientos separada, la cual está formada por tres tipos diferentes de conocimiento del dominio: La representación de los casos (es decir, proyectos de software) la cual incluye el valor real del esfuerzo requerido y las variables de entrada que utilizan los modelos COCOMO y PF. El conocimiento para seleccionar un caso análogo apropiado para cada caso objetivo, que consiste en una función de distancia y el caso que la minimice es el seleccionado como la fuente de la analogía. El conocimiento para ajustar la estimación basado en la interacción entre la representación del caso fuente y el caso objetivo, para lo cual se creó una base de reglas. En el estudio se realizaron cuatro tipos de estimaciones: Juicio del experto, Estor, COCOMO y PF a 15 proyectos de software, de los cuales 10 se tomaron como conjunto de entrenamiento y los 5 restantes como prueba. La comparación del rendimiento fue realizada en términos de precisión y consistencia. La medida de precisión utilizada fue la magnitud del error relativo (Magnitude of Relative Error MRE)1. La consistencia fue medida como el coeficiente de correlación entre el esfuerzo real y el esfuerzo estimado. La media del MRE (Mean Magnitude of Relative Error - MMRE), para cada proyecto, de Estor (52.79 %) no fue tan bueno como el del experto humano, pero sí fue superior al correspondiente a COCOMO y PF. Lo mismo ocurrió con el coeficiente de correlación, confirmándose que los resultados del experto y de Estor son igualmente consistentes y a su vez más consistentes que los que se obtuvieron con los modelos algorítmicos COCOMO y PF. Por su parte, en (Finnie et al., 1997) se realiza una comparación entre RBC, RNA, PF y modelos de regresión. Aquí se obtiene como resultado que no hubo diferencias significativas en la estimación dada por las RNA y el RBC, aunque. 1. Los criterios de evaluación son detallados en el epígrafe 1.2. 10.
(21) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” estas si fueron muy superiores respecto a las otras dos técnicas utilizadas en la comparación. También se concluye que el RBC tiene ventajas sobre las RNA pues permite el desarrollo de una base de casos dinámica, incorporando cada nuevo caso automáticamente mientras que las RNA requieren reentrenarse para incorporar nuevos datos. En (Patnaik et al., 2004) se examina la utilización de RBC sobre la base de proyectos IBM. Aquí se analiza la influencia del valor de k en el algoritmo del vecino más cercano (K Nearest Neighbor - KNN) y se comparan los resultados con los brindados por un modelo de regresión algorítmico. Como resultado, se obtuvo que k igual a uno ofreció los mejores resultados en cuanto a precisión, en comparación con los otros valores de k analizados. Por su parte, la comparación con el modelo de regresión arrojó que el modelo de RBC propuesto superaba ampliamente al modelo de regresión. Al utilizar RBC, escoger un adecuado peso para cada atributo de entrada tiene un gran impacto en la exactitud del modelo. Investigaciones más recientes afirman que el método RBC con los pesos optimizados mediante la Optimización por enjambre de partículas (Particle Swarm Optimization - PSO) o AG, puede mejorar eficazmente los resultados en la estimación. Otro enfoque donde se utiliza PSO aparece en (Wu et al., 2010), donde se aplican métodos de combinación lineal para integrar los resultados de diferentes métodos de RBC con pesos optimizados. En (Huang and Chiu, 2006) se utilizan los AG para determinar una adecuada medida pesada de similitud para un modelo de RBC. Este modelo mejoró la precisión de las estimaciones del esfuerzo, en comparación con otros modelos no pesados. 1.1.2 Algoritmos Genéticos (AG) Los AG fueron desarrollados como una técnica alternativa, basada en la teoría de la selección natural, para afrontar problemas generales de optimización con largos espacios de búsqueda. Ellos tienen la ventaja de que no necesitan ningún. 11.
(22) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” conocimiento anterior, opinión de un experto o lógica relacionada con el problema en particular a resolver (Burgess and Lefley, 2001). Los AG ocasionalmente pueden producir la solución óptima, pero para la mayoría de los problemas con grandes espacios de búsqueda, una buena aproximación al óptimo es la salida más probable. El proceso básico de los AG es el siguiente: 1. Generación aleatoria de una familia de soluciones. 2. Creación de una nueva familia de soluciones partiendo de la previa, aplicando los operadores genéticos a los cromosomas o pares de cromosomas más adecuados de la población anterior. 3. Repetición del paso 2 hasta que cualquiera de los cromosomas converja a la solución, o cuando se haya producido un número de iteraciones anteriormente. especificado.. La mejor solución de la última población es tomada como la mejor aproximación al óptimo del problema en cuestión. El proceso completo normalmente se repite un número de veces con diferentes poblaciones iniciales aleatorias y se escoge la mejor de las soluciones obtenidas. En la bibliografía revisada para realizar la estimación del esfuerzo, los AG aparecen en combinación con otras técnicas. Por ejemplo, en (Oliveira et al., 2010) se propone el uso de las siguientes técnicas para la estimación de esfuerzo: Support Vector Machine (SVM), red neuronal MLP y model trees M5P tratadas posteriormente. Los AG, en este caso, han sido utilizados para seleccionar el subconjunto de rasgos de entrada y los parámetros óptimos de las técnicas de aprendizaje automático. Utilizando el MMRE y Pred(25) como criterios de evaluación, los autores concluyen que las variantes de los métodos basadas en AG fueron capaces de mejorar la precisión de las tres técnicas de aprendizaje automático consideradas. Además, el uso de AG logró. 12.
(23) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” una significativa reducción del número de atributos de entrada para dos de las seis bases de datos de proyectos analizadas. En (Huang and Chiu, 2006) se utilizan los AG mezclados con RBC (en el epígrafe 1.1.1 se hace referencia a esta investigación). En (Huang et al., 2008) también se aplican AG. En esta ocasión se combinan con Análisis Relacional Gris (Grey Relational Analisys - GRA). Un modelo de estimación de esfuerzo de software utilizando GRA identifica uno o más proyectos históricos que son similares al proyecto que está siendo estimado y deriva una estimación para él. El propósito de utilizar AG en este enfoque es para mejorar u optimizar los pesos de cada uno de los rasgos involucrados en las medidas de similitud en GRA. En este estudio se utilizaron dos bases de datos de proyectos: COCOMO y Albrecht. Se obtuvieron resultados superiores en comparación con modelos de RNA, RBC y AR, aunque se reconoce que la integración GRA y AG para la estimación de esfuerzo presenta una complejidad superior del modelo que puede afectar su uso en la práctica. 1.1.3 Programación Genética (PG) PG es una extensión de los AG que elimina la restricción de que un cromosoma sea una cadena binaria de tamaño restringido. Generalmente en PG el cromosoma es un tipo de programa que es ejecutado para obtener los resultados requeridos. Una forma simple de estos programas es un. árbol binario que. contiene operandos y operadores, es decir cada solución es una expresión algebraica que puede ser evaluada (Burgess and Lefley, 2001). En (Afzal and Torkar, 2011) se menciona que (Dolado et. al, 1998) utiliza PG y otras técnicas de aprendizaje automático como RNA para estimar esfuerzo, tomando como variables independientes las LOC y los PF. Para esto emplea la información de cinco bases de proyectos, concluyéndose que RNA y PG mostraron ser métodos mucho más flexibles en comparación con las técnicas utilizadas.. 13.
(24) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” En (Burgess and Lefley, 2001) se muestra una investigación donde se utiliza PG para la estimación de esfuerzo. Aquí se realiza. una comparación de los. resultados obtenidos con PG y los obtenidos con otros modelos basados en RNA y RBC. En este trabajo se llega a la conclusión de que el sistema construido utilizando PG puede mejorar la exactitud de la predicción con respecto a las otras técnicas. Sin embargo, se resalta la necesidad de realizar un mayor trabajo para mejorar la consistencia de la estimación y para determinar cuáles son. las. medidas más apropiadas para la selección del mejor modelo en la práctica. Además se destaca la complejidad de su configuración e interpretación. En (Afzal and Torkar, 2011) se hace una revisión de la utilización de PG en la Ingeniería de Software. Específicamente en la estimación de esfuerzo se precisa que los resultados no son concluyentes para decir que PG es un método efectivo, sobre todo debido a que cuando se optimiza una medida de precisión se degradan las otras. 1.1.4 Support Vector Regression (SVR) El algoritmo Support Vector (SV) es una generalización no lineal del algoritmo Generalized Portrait desarrollado en Rusia en los años sesenta. En su forma actual SVM fue largamente desarrollado en AT&T Bell Laboratories en la década del 90 del pasado siglo. En poco tiempo los clasificadores SV se volvieron competitivos con los mejores sistemas de Reconocimiento Óptico de Caracteres (Optical Character Recognition - OCR), pero también en regresión, tomando el nombre de SVR, fueron obtenidos excelentes resultados rápidamente (Smola and Scholkopf, 2004). Suponiendo que se tiene un conjunto de entrenamiento con la forma , donde (por ejemplo,. denota el patrón del conjunto de entrada. ), en regresión ε-SV, el objetivo es encontrar la función. que tenga como máximo una desviación ε de los valores objetivos reales recolectados,. , para todo el conjunto de entrenamiento. En otras palabras, no se. preocupa por los errores que sean menores que ε, pero no acepta ninguna. 14.
(25) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” desviación mayor que esa. En el problema de la estimación de esfuerzo consistiría en el conjunto de valores que caracterizan al proyecto y. sería el. esfuerzo. En ε-SVR, la función. depende de un vector de pesos ( ) y un umbral ( ), los. cuales son escogidos optimizando el siguiente problema (Oliveira, 2006): minimizar. ⟨. ⟩. ∑ ⟨ | ⟩. ⟨ | ⟩. sujeto a. La constante. determina el equilibrio entre la optimalidad de. y el monto de. las desviaciones mayores que ε que son toleradas. Las variables de holgura ξi, ξi miden el costo de los errores en los puntos de entrenamiento, ξi mide las desviaciones que exceden el valor del objetivo por un valor mayor que ε y ξi mide desviaciones que están más que ε por debajo del valor del objetivo. La idea de SVR es minimizar una función objetivo en la cual se considere tanto la norma del vector. (‖ ‖. ⟨. ⟩. como las pérdidas medidas por las variables de. holgura. El algoritmo SVR incluye el uso de multiplicadores de Lagrange que pueden estar acompañados por funciones kernel. Para obtener más detalles se puede consultar (Smola and Scholkopf, 2004). SVR ha superado el comportamiento de otras técnicas más tradicionales en la solución de varios problemas. Por esto en (Oliveira, 2006) se propone el uso de SVR para estimar el esfuerzo en el desarrollo de proyectos de software. Para determinar la efectividad de la estimación en esta investigación, se realizó una comparación de los resultados obtenidos con SVR y los obtenidos con regresión lineal y la Red Neuronal Radial Basis Function (RBF), sobre la base de proyectos de la NASA. Luego de analizados los resultados se llegó a la conclusión de que SVR logró mejorar la precisión de la estimación por encima de los otros dos métodos.. 15.
(26) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” En (Corazza et al., 2011a) se analiza el empleo de SVR para la estimación de esfuerzo en el desarrollo de proyectos Web y se comparan varias configuraciones de SVR para determinar la que brinda el mejor comportamiento. Aquí se confrontan los resultados obtenidos utilizando dos tipos de funciones kernel: Polinomial y RBF. Además, para determinar si la aplicación de una de estas transformaciones kernel puede mejorar la exactitud de la predicción, también se consideró SVR sin una transformación kernel, también conocido como kernel Lineal. Los resultados obtenidos con SVR fueron comparados con los brindados por RBC, que es una de las técnicas más utilizadas para la estimación de esfuerzo en proyectos de software, para determinar si SVR logra un mejor desempeño. Para todos los análisis realizados fue utilizada la base de proyectos Tukutuku. Después de examinar los resultados logrados con las distintas configuraciones de SVR se determinó que el uso del kernel RBF brindó el mejor resultado. Luego de confrontar el comportamiento de esta configuración de SVR con el obtenido por RBC, se llegó a la conclusión de que SVR fue significativamente superior en la precisión de la estimación. Seleccionar la mejor combinación de valores de los parámetros en SVR, puede tener una gran influencia en su efectividad. Sin embargo no hay líneas directrices generales disponibles para seleccionar estos parámetros, algo que también depende de las características de los datos que son usados. Esto motivó el trabajo descrito en (Corazza et al., 2011b), donde se propone el uso de la metaheurística Búsqueda Tabú (Tabu Search - TS) para obtener los valores óptimos de los mismos. Aquí se diseñó TS para buscar los parámetros tanto del algoritmo SVR como de la función kernel empleada, en este caso RBF. De modo práctico se evaluó la efectividad de este método para la estimación de esfuerzo usando diferentes bases de datos de proyectos del repositorio PROMISE y la base de datos Tukutuku.. Fueron. tomadas. en. consideración. varias medidas de. comparación para evaluar ambos aspectos, la efectividad de TS para definir los parámetros de SVR y la exactitud de la predicción de la metodología propuesta. 16.
(27) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” con respecto a otras técnicas de estimación de esfuerzo ampliamente utilizadas, como RBC, SVR (sin uso de TS), etc. En este estudio se determinó que el uso de TS permite obtener los parámetros idóneos para ejecutar SVR. Además se concluyó que la combinación de TS y SVR superó significativamente el comportamiento de todas las demás técnicas con las que fue comparada. En (Braga et al., 2007) se propone mejorar el comportamiento de diferentes métodos de regresión, para la estimación de esfuerzo en el desarrollo de proyectos de software, aplicando Bagging2 a diferentes técnicas de aprendizaje automático, entre ellas a SVR. El estudio ofreció como resultado que el uso de Bagging fue capaz de mejorar la precisión de la estimación producida por todos los métodos de regresión analizados menos para SVR, lo que demuestra que SVR es un método estable para las bases de datos consideradas en los experimentos. 1.1.5 Redes Neuronales Artificiales (RNA) Según (Finnie et al., 1997), las Redes Neuronales Artificiales (RNA) son reconocidas por sus habilidades para proveer buenos resultados cuando están lidiando con problemas donde existen complejas interacciones entre las entradas y las salidas y donde los datos de entrada son distorsionados por altos niveles de ruido, y el potencial para predecir con precisión es muy bueno. El modelo está diseñado para capturar las relaciones causales entre la variable dependiente y las variables independientes. Las RNA típicamente consisten en una capa de nodos de entrada, una o más capas de nodos ocultos y una capa de nodos de salida (Park and Baek, 2008).. 2. Bagging es una técnica para generar un estimador agregado mediante el uso de múltiples versiones del mismo estimador. Cada versión del estimador es entrenada usando una versión diferente del conjunto de entrenamiento, pero el mismo algoritmo de aprendizaje. Una versión del conjunto de entrenamiento es creada seleccionando aleatoriamente un subconjunto del conjunto de entrenamiento original. La predicción final está dada por el promedio de las predicciones de cada modelo de regresión individual. Esta técnica ha presentado buenos resultados cuando el algoritmo de aprendizaje es inestable, es decir algoritmos que generan modelos de regresión suficientemente diversos cuando se aplica a datos con pequeñas diferencias.. 17.
(28) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” Las RNA pueden conducir a desarrollar modelos que pueden ser precisos a través de un ejemplo dado, pero fallan cuando las condiciones cambian. Carecen de la capacidad de explicación o justificación de la estimación realizada y no proveen un ambiente para una adaptación directa por el usurario de los datos, es decir una recalibración del modelo. Para poder incorporar un nuevo caso al conjunto de casos válidos del propio modelo, necesitan ser reentrenadas, generando un modelo nuevo (Finnie et al., 1997). Existen varias investigaciones que han abordado esta técnica, desarrollando varias arquitecturas de RNA como en (Finnie et al., 1997). En (Briand and Weiczorek, 2002), se hace un estudio de anteriores investigaciones donde se evalúa el funcionamiento de las RNA con otros modelos como los de regresión, inducción de reglas y RBC. Aquí se evidencia que las RNA presentan una exactitud superior a los modelos de regresión y una exactitud muy cercana a la de los modelos basados en RBC. Son muy buenas cuando existen valores atípicos en los datos. Se tomaron como variables de entrada: el número de reportes, el número de pantallas, el número de creaciones, el número de actualizaciones, el ambiente de programación, las LOC, 14 características generales del sistema y las variables utilizadas en los modelos de análisis por PF. El estudio realizado en (Briand and Weiczorek, 2002), para crear un modelo nuevo de estimación de esfuerzo, se basó en un conjunto de 148 proyectos terminados. Se realizó una selección de las variables de entrada partiendo de un conjunto de 36 variables, que según una encuesta realizada a 300 profesionales en Ingeniería del Software eran las más importantes para la estimación y realizando un análisis de frecuencia a sus opiniones, se determinó un conjunto de 18 variables de entrada, y luego de un análisis de regresión estadística, se determinó el conjunto final de siete variables. Se propuso el análisis a tres topologías distintas de RNA y se evaluó la precisión de estos modelos con modelos clásicos de regresión y el juicio de un experto, arrojando como resultado que el modelo de siete variables fue el que menor MMRE presentó. En este estudio se evidencia que la precisión. 18.
(29) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” de la estimación realizada por un modelo basado en RNA depende mucho de las variables de entrada. Los modelos de RNA también se han combinado con enfoques de la lógica difusa donde el conocimiento se describe mediante reglas. En (Marza and Teshnehlab, 2009), se presenta esta combinación, donde las RNA tienen dificultades en el uso de reglas del conocimiento y por tener una estructura de caja negra, dificultan la extracción del mismo, recurriéndose a los Sistemas de Inferencia Borrosos (SIB) que pueden incorporar reglas base y permiten una fácil interpretación e implementación, aunque no pueden aprender el conocimiento lingüístico, estos sistemas se abordan en el siguiente epígrafe. Como se evidencia en múltiples estudios (Barcelos et al., 2006, Zeng and Rine, 2004, Jun and Lee, 2001 ), los modelos basados en RNA son capaces de dar un adecuado modelo de estimación. Su comportamiento en gran medida depende de los datos que se empleen en su entrenamiento y el grado de disponibilidad de los datos adecuados del proyecto, determinarán el grado en el que el modelo de estimación pueda ser desarrollado (Finnie et al., 1997). 1.1.6 Sistemas de Inferencia Borrosos (SIB) y Lógica Difusa (LD) Los SIB hacen uso de la lógica difusa, que según (Raynor, 1999) es un sistema basado en la manipulación de conjuntos borrosos. En estos sistemas el conocimiento se describe mediante reglas como: if x es A1 and y es B1 then z es c1 if x es A2 then z=2x-1. Donde A1 y A2 son términos lingüísticos definidos sobre un universo X donde x toma valor. Similarmente. B1 y C1 son términos. lingüísticos de variables. lingüísticas definidas sobre los universos Y y Z respectivamente. En los SIB los términos lingüísticos se modelan mediante conjuntos borrosos, se utilizan modelos de inferencias como los de Mandani, Sugeno y Tsukamoto y. 19.
(30) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” proporcionan una técnica para tratar la imprecisión, la vaguedad y el desconocimiento de los datos en un dominio determinado (Bello et al., 2002). Según (Cuauhtemoc, 2011), dos consideraciones podrían justificar la decisión de implementar un modelo fuzzy en la estimación del esfuerzo de desarrollo de un software: primero, es imposible desarrollar un modelo matemático preciso del dominio y segundo, las métricas solo producen estimaciones de la complejidad real. De acuerdo con estos criterios, la formulación de un pequeño conjunto de reglas naturales describiendo la interrelación entre las métricas del software y la estimación del esfuerzo, podría fácilmente mostrar su intrínseca y amplia correlación. Las desventajas de un modelo difuso pueden ser, según (Cuauhtemoc, 2011): 1. Requieren una gran cantidad de datos. 2. El estimador debe ser familiar con los programas desarrollados históricamente. 3. No son útiles con programas que sean más largos o más cortos que los que se tienen en los datos históricos usados. Un modelo borroso, como cualquier otro modelo, proporciona un mapeo de las variables de entrada hacia las variables de salida. Para obtener un modelo borroso a partir de los datos, existen dos vías principales: 1. El conocimiento verbal del experto, basado en la correlación de un par de variables, es traducido en una regla if-then, luego esta correlación es representada en una función de membresía y tanto el peso de las reglas como las propias funciones de membresía pueden ser ajustadas a través de los datos de entrada y los de salida (Marza and Seyyedi, 2009). 2. No existe un conocimiento previo sobre el sistema de estudio y el modelo es construido a partir de los datos, basado en un determinado algoritmo, donde se espera que las reglas y las funciones de membresía puedan explicar el comportamiento del sistema.. 20.
(31) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” En (Cuauhtemoc, 2011) se crea un modelo de estimación teniendo en cuenta la primera vía, partiendo de la correlación que existe entre el código nuevo y cambiado (N&C) para la implementación de un software, y el esfuerzo. Se tiene en cuenta también la correlación entre el reúso de código y el esfuerzo, llegándose a un conjunto de 2 reglas: Regla 1: if (N&C es poco) and (reúso es poco o reúso es mucho) then esfuerzo es bajo. Regla 2: if (N&C es mucho) and (reúso es poco o reúso es mucho) then esfuerzo es alto. Las funciones de membresía consideradas en el modelo fueron triangulares debido a que se ha demostrado que proveen mayor exactitud por encima de otras como la Gaussiana y la Trapezoidal. En el estudio se demuestra que no existen diferencias significativas entre la estimación arrojada por el modelo borroso. y un modelo de regresión lineal. aplicado al mismo conjunto de datos. Un inconveniente de los modelos borrosos es que necesitan el ajuste por parte del experto en algunos estados de su heurística de generación. Sin embargo, los modelos estáticos presentan una generación con un procedimiento bien definido. No obstante, la combinación de ambos puede generar resultados superiores a cada uno por separado. Un ejemplo de esta combinación para la estimación del esfuerzo de desarrollo de un software se puede ver en (Marza and Seyyedi, 2009) donde se combinan modelos de regresión con conceptos borrosos para el manejo de datos discretos, creándose un Modelo Borroso de Regresión. Otros estudios han mostrado que los modelos basados en la lógica difusa consiguieron buenos resultados, siendo solamente superados por los modelos de redes neuronales con un número mayor de variables de entrada. Un casamiento entre estas dos técnicas es llamado Neuro-Fuzzy, término introducido en la. 21.
(32) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” estimación del costo en (Hodgkinson and Garratt, 1999). Estos sistemas pueden tomar los atributos lingüísticos de los sistemas difusos y combinarlos con los atributos de aprendizaje y modelado de las redes neuronales, para producir sistemas transparentes y adaptativos. El uso de estos sistemas Neuro-Fuzzy en la estimación, puede encontrarse en (Sandhu et al., 2008b) donde un sistema de este tipo es utilizado para aproximar la función no lineal del esfuerzo con mayor precisión, sobre otros modelos algorítmicos conocidos como Halstead, Walston-Felix, Bailey-Basili and Doty. Los resultados muestran que el sistema Neuro-Fuzzy tiene los menores valores de MMRE, afirmándose que el modelo propuesto puede ser utilizado para la estimación del esfuerzo en cualquier tipo de proyecto. La lógica difusa también ha sido ampliamente usada con otras técnicas de aprendizaje automático para mejorar el rendimiento de un modelo, preprocesando las entradas de dichos modelos (Wen et al., 2012, Attarzadeh and Hock, 2010), donde a partir de un modelo desarrollado en tres pasos: “fuzzificación” de las variables de entrada propuestas en COCOMO II (tamaño, multiplicadores de costo y factores de escala), aplicación de un SIB y “defuzzificación” de la variable de salida, se obtiene como resultado el esfuerzo. Este resultado, al ser comparado con los obtenidos de aplicar COCOMO II a 193 proyectos muestran que el MMRE para el modelo propuesto es de 0.369637508, inferior al 0.406713037 que se obtiene al aplicar COCOMO II, asegurándose la factibilidad de este modelo para problemas donde la manipulación de datos, como es el caso de los multiplicadores de costo, es vaga o incierta. Un enfoque similar es el que aparece en (Huang et al., 2007) donde se utiliza una RNA combinada con la lógica difusa para mejorar el desempeño del modelo COCOMO, aprovechando las características ventajosas del enfoque Neuro-Fuzzy de habilidad de aprendizaje y mejor interpretación de la solución. Otro enfoque, en este caso aplicando las características de COCOMO’81, se puede localizar en (Idri et al., 2000) y en (A. Ahmed et al., 2005).. 22.
(33) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” 1.1.7 Redes Bayesianas (RB) Una Red Bayesiana es una técnica de modelado para tratar interrelaciones causales basadas en inferencias bayesianas. La red es representada como un grafo acíclico con nodos para cada variable imprecisa y aristas dirigidas para cada interrelación entre las variables (Wagner, 2010). Por cada nodo o variable existe una tabla de probabilidades del nodo. Estas tablas definen las interrelaciones y las imprecisiones de las variables y sus valores usualmente son discretos con un número fijo de estados. Para cada estado, la tabla muestra la probabilidad que tiene la variable. Si existen nodos padres; por ejemplo, un nodo que influye sobre un nodo actual, las probabilidades se definen en dependencia del estado de los nodos padres. El proceso de construcción de una red bayesiana sugiere una serie de pasos importantes que no son triviales: 1. Identificación. de. las. principales. variables. que. serán. modeladas,. representándolas como nodos. 2. Construcción de la topología de la red. 3. Definición de la tabla de probabilidades del nodo. Primero, la identificación de las variables incluye la suposición de que el constructor del modelo puede decidir sobre la base de lo que es importante. Una posibilidad es incluir muchas variables y usar un análisis de sensibilidad para eliminar nodos insignificantes. Segundo, la creación de la topología utiliza la suposición de que el constructor del modelo puede decidir sobre la dependencia e independencia de las variables definidas. Y tercero, el problema de la construcción de la tabla de probabilidades de los nodos; que involucra la definición de relaciones cuantitativas entre las variables. Existen varios métodos para esta cuantificación, como la probabilidad circular y la regresión de datos recolectados empíricamente. Ambos tienen elementos a favor y en contra.. 23.
(34) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” Un modelo completo de la situación no es usualmente flexible, porque la red se hace muy compleja, muy complicada de construir y en la mayoría de los casos no hay conocimiento disponible sobre varias de las variables definidas. Una de las mayores ventajas de las redes bayesianas es su capacidad para simular diferentes escenarios. Un escenario involucra la introducción de información adicional al modelo, es decir; adicionar una observación a un nodo determinado. De esta forma la incertidumbre es eliminada y la incidencia para los otros nodos puede ser calculada. En las redes bayesianas es posible hacer una inferencia tanto hacia delante como hacia detrás, por ejemplo, la información puede ser añadida a cualquier nodo y los efectos pueden ser calculados en cualquier dirección del grafo. Las redes bayesianas tienen la habilidad de representar la incertidumbre explícitamente usando probabilidades, la habilidad de incorporar el conocimiento existente de expertos dentro de los datos empíricos y la habilidad de actualizar el modelo cuando nuevos datos están disponibles (van Koten and Gray, 2006a). Es por eso que aunque son limitados los estudios realizados en la Ingeniería del Software usando esta técnica, presentan características que posibilitan futuras aplicaciones. Según (Corazza. et al., 2011b), los modelos de redes bayesianas existentes. tienen restricciones en el uso de funciones de densidad de probabilidad continua. Consecuentemente, estas restricciones limitan el uso de estos modelos a los casos donde se involucran solamente variables discretas. 1.1.8 Árboles de Decisión (AD) AD es una técnica que construye un modelo en forma de árbol, dividiendo recursivamente el conjunto de datos hasta que un criterio de parada es satisfecho. Esta división se realiza con el propósito de alcanzar la máxima homogeneidad posible, relativa a la variable de salida o dependiente, entre los ejemplos que alcanzan el nodo. Todos los nodos en el árbol, menos los terminales (también llamados hojas), especifican una condición basada en una de las variables que. 24.
(35) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” tienen influencia en la variable dependiente. Luego de que el árbol es generado, el mismo se puede usar para realizar predicciones siguiendo un camino a través del árbol de acuerdo con los valores específicos de las variables del nuevo caso (Idri and Elyassami, 2011). Los AD han demostrado su superioridad en términos de exactitud de la predicción en varios campos. Los algoritmos más usados para la construcción de AD son ID3, C4.5 y Árbol de Clasificación y Regresión (Clasification And Regression Tree – CART). Entre las ventajas fundamentales del uso de la estimación mediante AD se encuentran: Pueden ser considerados como “cajas blancas”. Es simple entender y fácil explicar su proceso a los usuarios, al contrario de otros métodos de aprendizaje. Por sí mismo realiza selección de rasgos, lo que evita la utilización de otras técnicas para determinar los rasgos que verdaderamente influyen en el esfuerzo en los modelos de estimación. Los Árboles de Regresión (AR) son un tipo especial de AD desarrollado para tareas de regresión. En este tipo específico de AD la elección de cada nodo está usualmente guiada por el criterio del error cuadrado mínimo (Braga et al., 2007). En los AR los valores de la media o la mediana del nodo terminal pueden ser usados como el valor predicho. Como mismo los AR son un tipo especial de AD, los model trees son un tipo especial de AR. No obstante la principal diferencia entre AR y model trees es que las hojas en los AR presentan un valor numérico mientras que las hojas en los model trees tienen una función lineal (Braga et al., 2007). Los AR constituyen una de las técnicas que más han sido usadas para la estimación de esfuerzo de desarrollo en proyectos de software. En el estudio que se muestra en (Briand et al., 1999) se examinan los resultados obtenidos con varias técnicas como son: Regresión Ordinaria de Mínimos Cuadrados (Ordinary Least-Squares Regression -OLS), Análisis de Varianza progresivo (Analysis of. 25.
(36) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” Variance - ANOVA) para bases de datos no balanceadas, RBC, AR (algoritmo CART) y la combinación de CART con regresión OLS y RBC. Luego de comparar los resultados obtenidos con cada técnica se determinó que las técnicas OLS y ANOVA brindan resultados significativamente superiores a los obtenidos con las demás técnicas. También se resalta la facilidad de interpretación y uso de CART para la construcción de un modelo de estimación. En (Briand and Wust, 2001) se utiliza la regresión Poisson y AR, así como su combinación, para construir modelos de predicción de esfuerzo a partir de medidas de tamaño y diseño. En este estudio los resultados arrojan que el uso de modelos híbridos combinando la regresión Poisson y árboles de regresión CART claramente superan la exactitud de modelos que usan solamente la regresión Poisson. Por su parte, el estudio publicado en (Jeffery et al., 2001) analiza la precisión de diferentes técnicas de estimación y examina su comportamiento basado en bases de proyectos tanto de distintas compañías como de una misma compañía. Entre las técnicas que se usaron en esta investigación, una versión de árbol CART fue de las que mejores resultados brindó cuando se trabajó con datos de una misma compañía. Sin embargo, al utilizar los datos de varias compañías, fue la técnica que peores resultados ofreció. Al compararse las estimaciones basadas en una compañía y las basadas en varias, fue evidente que para casi todas las técnicas los resultados basados en una sola compañía fueron significativamente superiores. Aunque luego de ajustarse los valores del esfuerzo correspondientes a cada proyecto, atendiendo a la productividad de la compañía a la que pertenece el proyecto y a la productividad general de todas la compañías, se logró una significativa mejora para varias técnicas en la estimación sobre la base de datos con proyectos de varias compañías y en específico CART fue la que tuvo una mejora más drástica. A pesar de esto, en la investigación se plantean varias preguntas importantes que continúan sin respuesta, entre ellas:. 26.
(37) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” Sin datos propios ¿cómo una organización puede determinar si una base de proyectos de varias compañías podrá describir su tipo de operación? ¿Ulteriores variables para medir procesos y productos serán capaces de mejorar la precisión de las estimaciones a partir de bases de proyectos de varias compañías? Recientemente, los Árboles de Regresión Aditivos Múltiples (Multiple Additive Regression Trees - MART) han sido propuestos como un novedoso avance que extiende y mejora el modelo de los árboles basados en el algoritmo CART usando el gradiente estocástico fortalecido (stochastic gradient boosting). Boosting es un método general que trata de “fortalecer” la precisión de algún algoritmo de aprendizaje dado mediante el ajuste de una serie de modelos, cada uno teniendo un índice de error pequeño y combinándolos en un conjunto que puede desempeñarse mejor. En (Elish, 2009) se evalúa el potencial de este tipo de árbol para la estimación de esfuerzo de desarrollo de proyectos de software comparado con otros modelos publicados anteriormente, en términos de precisión. Luego de analizar los resultados logrados usando MART, con los que se referencian en otras publicaciones en las que se hace uso de SVR, Regresión Lineal y Redes Neuronales RBF, se llega a la conclusión de que el modelo obtenido con el uso de MART mejora la exactitud de la estimación de los otros modelos. Estos resultados se obtuvieron sobre la base de proyectos de la NASA. También en (Oliveira et al., 2010) se hace uso de AD para la estimación de esfuerzo en específico mediante el model tree M5P. Aquí se combinan varias técnicas con AG (en el epígrafe 1.1.2 se aborda esta investigación). En (Idri and Elyassami, 2011) se investiga el uso del algoritmo ID3 borroso para la estimación de esfuerzo. Este AD es diseñado integrando los principios de los árboles ID3 y la teoría de los conjuntos borrosos, permitiendo al modelo manejar datos dudosos e imprecisos cuando se describen los proyectos de software. En dicha investigación se comparan los resultados obtenidos por el modelo propuesto. 27.
(38) CAPÍTULO 1 “MODELOS DE ESTIMACIÓN DEL ESFUERZO EN PROYECTOS DE SOFTWARE UTILIZANDO TÉCNICAS DE INTELIGENCIA ARTIFICIAL” con los obtenidos con la versión precisa del ID3 sobre dos bases de proyectos muy conocidas, Tukutuku y COCOMO`81. La principal característica de los ID3 borrosos es que un ejemplo pertenece a un nodo con un grado de certidumbre. Los autores analizan dos modelos ID3 borrosos para la estimación de esfuerzo, cada uno con una forma distinta de calcular la entropía borrosa, dependiendo del operador de conjunción usado. Los resultados del estudio muestran que el uso de un nivel de significación óptimo y una adecuada fórmula de calcular la entropía borrosa mejoran grandemente la precisión de los estimados. Al compararse con la versión precisa del ID3 se nota una gran mejora en la exactitud de la estimación. 1.1.9 Reglas de Asociación (RA) Las reglas de asociación están entre las representaciones más populares de reconocimiento de patrones locales. Ellas pertenecen al modelado descriptivo y tienen como objetivo describir los datos y sus relaciones subyacentes con un conjunto de reglas que conjuntamente definen las variables objetivo (Bibi et al., 2008). El objetivo de esta técnica es encontrar combinaciones frecuentes de los valores de los atributos que están en la base de datos. Una regla de asociación es simplemente una declaración probabilística sobre la coocurrencia de ciertos eventos en la base de datos (Briand et al., 1999). Cada regla consiste en dos partes. La parte izquierda del cuerpo de la regla (antecedentes) es la condición necesaria para validar la parte derecha, la cabeza de la regla (consecuentes). Si el cuerpo de la regla es verdadero, entonces la cabeza de la regla también es verdadera con una probabilidad p. Es obvio que las RA son proposiciones booleanas con valores de verdadero y falso. Dado un conjunto de observaciones sobre los atributos A1, A2,…, An, en un conjunto de datos D, una simple RA tendría la siguiente forma: (A1 = X ^ A2 = Y) => A3 = Z Confianza: p (A3 – Z | A1 – X ^ A2 - Y). 28.
Figure


+7



Outline
Documento similar