Universidad Nacional de Rosario
Facultad de Ciencias Exactas, Ingenier´ıa y Agrimensura
Departamento de Ciencias de la Computaci´
on
Tesina para optar por el t´ıtulo de
Licenciado en Ciencias de la Computaci´
on
“Selecci´
on de variables en problemas
anchos con alta correlaci´
on”
Autor: Mauro Di Masso
Director: Dr. Pablo Granitto
´
Indice
1. Introducci´
on
2
2. Conceptos b´
asicos
5
2.1. Aprendizaje automatizado . . . .
5
2.2. Support Vector Machines . . . .
8
2.3. Selecci´
on de variables . . . .
13
2.3.1. Estabilidad
. . . .
16
3. M´
etodos de selecci´
on de variables independientes
17
3.1. Recursive Feature Elimination . . . .
17
3.2. Fast Correlation Based Filter
. . . .
18
3.3. SVM-RFE con filtro MRMR . . . .
24
3.4. Stable Recursive Feature Elimination . . . .
27
3.4.1. El vector de penalizaci´
on P
. . . .
28
3.4.2. El m´
etodo SRFE . . . .
29
4. Resultados
32
4.1. Datos artificiales
. . . .
34
4.2. Datos reales . . . .
46
4.2.1. Espectrometr´ıa . . . .
46
4.2.2. Colorimetr´ıa . . . .
57
1.
Introducci´
on
El aprendizaje automatizado o
machine learning
es una ciencia que
na-ce a mediados del siglo XX y que ha estado en auge desde entonna-ces. Entre
sus objetivos se plantea la generaci´
on autom´
atica de modelos num´
ericos que,
basados en datos de entrenamiento, permitan la correcta predicci´
on sobre
observaciones nuevas. Las principales dificultades de dicho modelado
sub-yacen en la cantidad de variables medidas en los datos presentes, as´ı como
tambi´
en en su calidad en t´
erminos de ruido, y en la cantidad de mediciones
disponibles para llevar a cabo el entrenamiento.
Los avances en las tecnolog´ıas de medici´
on y almacenamiento han
facili-tado ampliamente la obtenci´
on de cantidades masivas de datos, pero con ello
tambi´
en han surgido inconvenientes para obtener informaci´
on ´
util a la hora
de analizarlos. Cuando se comienza a trabajar en espacios de mayor
dimen-sionalidad, se necesitan exponencialmente m´
as mediciones para obtener la
informaci´
on necesaria a fin de crear un modelo de predicci´
on. Este problema
es conocido como “maldici´
on de la dimensionalidad” o
curse of
dimensiona-lity
y afecta a los principales problemas del ´
area hoy en d´ıa, tales como los
microarrays de ADN y las espectrometr´ıas de suero sangu´ıneo. Asimismo,
con el correr de las d´
ecadas, el vol´
umen de variables que pueden ser
medi-das ha crecido a tal punto que su procesamiento es incluso costoso para las
computadoras m´
as potentes.
de aprendizaje automatizado sea costoso en t´
erminos temporales. Adem´
as,
por lo general, la buena calidad de las predicciones queda en contraposici´
on
con la facilidad para interpretar la informaci´
on obtenida.
La selecci´
on de variables o
feature selection
es una respuesta a los
proble-mas planteados ya que su meta es simplificar el espacio de variables quitando
de la ecuaci´
on aqu´
ellas irrelevantes a la soluci´
on, redundantes y/o con altos
niveles de ruido, etc. Para ello se utilizan m´
etodos que generan un ranking
de variables caracteriz´
andolas por su importancia o poder predictivo o de
clasificaci´
on. Este preprocesamiento sobre los datos contribuye a
incremen-tar la eficiencia de los algoritmos de aprendizaje permiti´
endoles centrar sus
esfuerzos en un grupo reducido de variables.
Hoy en d´ıa existen m´
ultiples algoritmos de selecci´
on de variables, entre
los cuales el de Eliminaci´
on Recursiva de Variables (
Recursive Feature
Eli-mination
) o RFE es uno de los m´
as utilizados. RFE permite la obtenci´
on de
Como objetivo de la presente se propone entonces el dise˜
no e
implemen-taci´
on de un m´
etodo de selecci´
on de variables, cuyo foco sea la obtenci´
on
de conjuntos de variables m´
as estables que permita a su vez una mayor
in-terpretabilidad sobre la importancia y correlaci´
on de las variables obtenidas;
aunque no alcance en algunos casos el mismo nivel de error que otros m´
etodos
m´
as codiciosos como RFE.
2.
Conceptos b´
asicos
2.1.
Aprendizaje automatizado
El aprendizaje automatizado es una rama de la inteligencia artificial cuyo
objetivo es el desarrollo de algoritmos que permitan a sistemas inform´
aticos
aprender conceptos o criterios de decisi´
on que no son f´
acilmente programables
de otra manera [1]. Esta dificultad se debe principalmente a una carencia en el
desarrollo te´
orico del ´
area de estudio en cuesti´
on que no permite determinar
las cualidades subyacentes del problema.
Formalmente, un algoritmo de aprendizaje automatizado genera una
fun-ci´
on de la forma
h
:
X
→
Y
tambi´
en llamada hip´
otesis, que transforma elementos del dominio de datos
X
al conjunto de datos
Y
de posibles valores objetivo definidos en base al
problema en cuesti´
on. El algoritmo de aprendizaje aprende de un subconjunto
de datos
D, llamado conjunto de entrenamiento, perteneciente al espacio
X
o
X
×
Y
.
D
=
{
x
1
, x
2
, . . . , x
m
} ∈
X
D
=
{
(x
1
, y
1
),
(x
2
, y
2
), . . . ,
(x
m
, y
m
)
} ∈
X
×
Y
En el primer caso, se dice que el problema es de aprendizaje no
super-visado, donde
h
s´
olo puede basarse en los elementos de entrada
x
i
y debe
entrenamiento; si los valores de
y
i
son discretos entonces se est´
a en presencia
de un problema de clasificaci´
on, en el que
h
subdivide el espacio de soluciones
para determinar c´
omo asignar los posibles valores o etiquetas. Estos ´
ultimos
problemas son los que trabaja esta tesina.
Dado un problema de clasificaci´
on concreto, existen infinitas soluciones
consistentes con las observaciones dadas. Como no es posible conocer todos
los valores a clasificar (no tendr´ıa sentido), todos los algoritmos de
apren-dizaje trabajan sobre el supuesto de que cualquier hip´
otesis
h
que pueda
aproximar lo suficientemente bien la funci´
on ideal de clasificaci´
on
c
para un
conjunto de datos lo suficientemente grande
D
con puntos clasificados
x
i
,
tambi´
en la aproximar´
a lo suficientemente bien para los puntos no
clasifica-dos
x
o
. No es dif´ıcil concluir que si existen infinitas hip´
otesis, todo punto
no clasificado tiene la misma probabilidad de pertenecer a cualquiera de las
clases disponibles del problema. Hace falta que el algoritmo ignore algunas
de estas hip´
otesis para hacer posible el aprendizaje, lo que implica que el
algoritmo debe suponer algo arbitrario sobre la soluci´
on. Estas suposiciones
se conocen como sesgo inductivo o
inductive bias
.
iteraciones o
k-fold cross validation
subdivide el conjunto de entrenamiento en
k
subconjuntos, de los cuales utiliza
k-1 para entrenar y uno para validar; as´ı
k
veces hasta que se hubo utilizado cada uno para validar, y luego promedia
los errores. De esta manera, todos los datos colaboran en el aprendizaje y la
validaci´
on. El error de clasificaci´
on de una hip´
otesis
h
se define formalmente
como
E(h) =
N
e
N
t
donde
N
t
es la cardinalidad del conjunto de entrenamiento y donde
N
e
=
N
tX
i
=1
neq(h(x
i
), c(x
i
))
x
i
∈
D
siendo
D
el conjunto de datos sin particionar,
c
la funci´
on clasificadora ideal
y
neq(x, y
) =
0 si
x
=
y
1 si
x
6
=
y
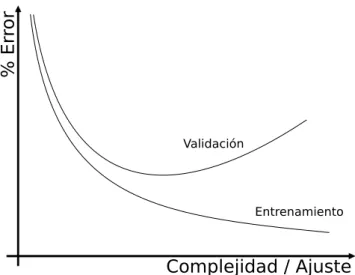
Complejidad / Ajuste
%
E
rr
or
Validación
Entrenamiento
Figura 1: la peor predicci´
on al aumentar la complejidad del modelo muestra
el fen´
omeno de sobreajuste.
2.2.
Support Vector Machines
Las m´
aquinas de vectores soporte, o SVM por sus siglas en ingl´
es, son
el m´
etodo de aprendizaje automatizado m´
as importante de los ´
ultimos a˜
nos.
Fueron desarrolladas en 1992 y posteriormente mejoradas en numerosas
oca-siones [2]. En su nivel m´
as b´
asico, son excelentes para problemas de
clasifi-caci´
on binarios en un espacio de datos linealmente separable, pero pueden
adaptarse para problemas no lineales, de multiclase y de regresi´
on [3].
de gran importancia en el uso de algoritmos de selecci´
on de variables que se
explican en la pr´
oxima secci´
on.
Formalmente, el hiperplano ´
optimo y la funci´
on objetivo de la SVM se
define como
m´
ax
w,b
m´ın
{||
x
−
x
i
||
:
w
T
x
+
b
= 0,
i
= 1, . . . , m
}
Las variables
w
y
b
pueden ser escaladas de tal forma que el punto m´
as
cercano al hiperplano
w
T
x
+
b
= 0 cumpla con
w
T
x
+
b
=
±
1. De esta
manera, para cada
x
i
se tiene que
y
i
[w
T
x
+
b]
≥
1, por lo que el ancho del
margen es 2/
||
w
||
. As´ı, el problema de encontrar el hiperplano ´
optimo puede
ser replanteado como el problema de optimizaci´
on de la funci´
on objetivo
τ(w)
tal que
m´ın
w,b
τ
(w) =
1
2
||
w
||
2
con las restricciones
y
i
[w
T
x
+
b]
≥
1
i
= 1, . . . , m
Para resolverlo se construye el lagrangiano
L(w, b, α) =
1
2
||
w
||
2
−
m
X
i
=1
α
i
(y
i
[x
T
i
w
+
b]
−
1)
donde
α
i
son multiplicadores de Lagrange, y su minimizaci´
on lleva a
m
X
i
=1
α
i
y
i
= 0
w
=
m
X
i
=1
De acuerdo con las condiciones de Karush-Kuhn-Tucker [11] se concluye
que
α
i
(y
i
[x
T
i
w
+
b]
−
1) = 0
i
= 1, . . . , m
Por lo tanto, los valores no nulos de
α
i
se corresponden con
y
i
[x
T
i
w+b] = 1,
lo que significa que los vectores que est´
an en el margen cumplen un rol crucial
en la soluci´
on del problema de optimizaci´
on. Estos vectores son los vectores
soporte del problema.
El problema puede trabajarse todav´ıa m´
as, llev´
andolo a su formal dual,
que es de la forma
m´
ax
α
W
(α) =
m
X
i
=1
α
i
−
1
2
m
X
i,j
=1
α
i
α
j
y
i
y
j
x
T
i
x
j
con restricciones
α
i
≥
0
i
= 1, . . . , m
y
m
X
i
=1
α
i
y
i
= 0
Usando la soluci´
on a este problema, la funci´
on objetivo se puede escribir
como
f(x) =
sgn(
m
X
i
=1
α
i
y
i
x
T
x
i
+
b)
Para problemas no linealmente separables en la dimensi´
on original de los
datos, el truco (literalmente, se lo llama
kernel trick
) es la utilizaci´
on de una
funci´
on
kernel
que construya una biyecci´
on de los puntos de entrenamiento
hacia una dimensi´
on superior donde s´ı sean separables. Esto se hace
reempla-zando el producto interno
x
T
x
0
por la funci´
on kernel
k(x, x
0
) = Φ(x)
T
Φ(x
0
),
por lo que la funci´
on objetivo queda
f
(x) =
sgn(
m
X
Figura 2: el panel superior muestra un problema donde los datos no son
lineal-mente separables. En el panel inferior se utiliza un
kernel trick
para agregar
una nueva dimensi´
on al problema que efectivamente permite la separaci´
on
lineal. Los puntos resaltados con halos definen los vectores soporte.
Ocurre a veces que las clases est´
an muy superpuestas y no es posible
construir un hiperplano que las separe aun usando funciones kernel, ya sea
por errores de medici´
on, datos equ´ıvocos o por la naturaleza misma de los
datos de entrenamiento. En esta situaci´
on se relaja el problema de
optimi-zaci´
on utilizando variables
slack
y entra en juego un par´
ametro de las SVM
llamado
C, que determina el balance entre la precisi´
on de entrenamiento de
la m´
aquina y el ancho del margen
m´ın
w,b,ξ
1
2
||
w
||
2
+
C
m
X
i
=1
ξ
i
con restricciones
Y el problema dual queda definido como
m´
ax
α
W
(α) =
m
X
i
=1
α
i
−
1
2
m
X
i,j
=1
α
i
α
j
y
i
y
j
x
T
i
x
j
con restricciones
0
≤
α
i
≤
C
i
= 1, . . . , m
y
m
X
i
=1
α
i
y
i
= 0
Esto se traduce en que se le permite a la m´
aquina desplazar aquellos
pun-tos superpuespun-tos hacia el subespacio que les pertenecer´ıa seg´
un el clasificador,
desentrelazar los datos y poder trazar la divisi´
on. El m´
odulo de
C
determina
la rigidez de dichos desplazamientos y lo que se llama margen blando o
soft
margin
.
Figura 3: una SVM clasificando con clases parcialmente superpuestas.
y “uno contra uno” o
one vs one
. En
one vs all
, se entrenan
c
clasificadores,
uno para cada clase, considerando el resto de las clases como una sola;
mien-tras que en
one vs one
, se entrena un clasificador para cada par de clases,
para un total de
c(c
−
1)/2 clasificadores. La clase se termina definiendo por
votaci´
on de los clasificadores [6].
2.3.
Selecci´
on de variables
La selecci´
on de variables o
feature selection
es el proceso por el cual se
filtran las variables m´
as influyentes de un problema de aprendizaje
automa-tizado para poder construir mejores modelos [4]. Es una t´
ecnica de
preproce-sado de los datos que aporta grandes beneficios. Los algoritmos de selecci´
on
de variables permiten reducir el n´
umero de dimensiones del espacio del
pro-blema mejorando la relaci´
on entre variables y observaciones, permitiendo un
modelado de mayor calidad predictiva e interpretabilidad humana, ya que
elimina variables que no aportan nada nuevo a las ya seleccionadas
(varia-bles redundantes) o que no aportan informaci´
on en general al contexto del
problema (variables irrelevantes).
Existen dos tipos de algoritmos de selecci´
on de variables: los de tipo filtro
o
filter
y los de tipo envoltorio o
wrapper
, que si bien llevan a cabo diferentes
rendimiento de ese algoritmo en particular. Suelen tener un desempe˜
no mejor
que los filtros en cuanto a precisi´
on, pero son computacionalmente costosos
ya que construyen una gran cantidad de modelos de datos en cada iteraci´
on.
Los algoritmos de selecci´
on de variables parten de la base de que en todo
problema de selecci´
on de variables, en especial en los de tipo ancho, se pueden
encontrar tres tipos de variables:
fuertemente relevantes
d´
ebilmente relevantes
irrelevantes
Sea
F
el conjunto de todas las variables,
F
i
una variable en particular,
C
una clase y
S
i
=
F
− {
F
i
}
, las clasificaciones anteriores se definen como:
Relevancia fuerte:
una variable
F
i
es fuertemente relevante si y s´
olo si
P
(C
|
F
i
, S
i
)
6
=
P
(C
|
S
i
)
Relevancia d´
ebil:
una variable
F
i
es d´
ebilmente relevante si y s´
olo si
P
(C
|
F
i
, S
i
) =
P
(C
|
S
i
)
∧
∃
S
i
0
⊂
S
i
:
P
(C
|
F
i
, S
i
0
)
6
=
P
(C
|
S
0
i
)
Irrelevancia:
una variable
F
i
es irrelevante si y s´
olo si
∀
S
i
0
⊆
S
i
:
P
(C
|
F
i
, S
i
0
) =
P
(C
|
S
0
Por ejemplo, sea
{
F
1
, . . . , F
5
} ∈
Bool, con
F
2
= ¯
F
3
, F
4
= ¯
F
5
y el concepto
a aprender
c(F
1
, F
2
), se puede determinar que
F
1
es fuertemente relevante
para la soluci´
on,
F
2
y
F
3
son d´
ebilmente relevantes (la soluci´
on no cambia
mientras alguna est´
e presente) y
F
4
y
F
5
son completamente irrelevantes.
Para obtener la soluci´
on ´
optima a un problema de este tipo, el conjunto de
variables seleccionadas debe incluir a todas aquellas fuertemente relevantes,
ninguna de las irrelevantes y un subconjunto de variables d´
ebilmente
relevan-tes. Sin embargo, no se dispone de un m´
etodo para decidir qu´
e subconjunto
debe utilizarse, por lo que debe definirse alg´
un tipo de redundancia entre las
variables relevantes. Normalmente, la redundancia entre variables se mide en
torno a la correlaci´
on entre ellas. Cuando dos variables est´
an completamente
relacionadas, como
F
2
y
F
3
, la eliminaci´
on de una no afecta la precisi´
on y
mejora la soluci´
on. Sin embargo, en la pr´
actica no siempre se dan casos tan
sencillos, y puede que una variable est´
e parcialmente correlacionada con otra,
o con un conjunto de otras variables.
Cobertura de Markov:
dada una variable
F
i
, y sea
M
i
⊂
F, F
i
∈
/
M
i
,
M
i
es una cobertura de Markov de
F
i
si y s´
olo si
P
(F
−
M
i
−
F
i
, C
|
F
i
, M
i
) =
P
(F
−
M
i
−
F
i
, C
|
M
i
)
La cobertura de Markov no s´
olo pide que
M
i
cubra toda la informaci´
on
que proporciona
F
i
sobre
C, sino que adem´
as cubra la informaci´
on sobre
to-das las otras variables contenito-das en
F
. Si se procede desde el conjunto total
de variables, si se encuentra una variable
F
i
tal que tenga una cobertura de
es demostrable que una variable fuertemente relevante no posee coberturas
de Markov. Las variables irrelevantes quedan excluidas de la definici´
on de
redundancia. Es f´
acil ver que una variable redundante que es eliminada
se-guir´
a siendo redundante sin importar la sucesi´
on de eliminaciones.
Variable redundante:
sea
F
0
el conjunto actual de variables, una variable
se considera redundante y debe ser eliminada de
F
0
si y s´
olo si es d´
ebilmente
relevante y tiene una cobertura de Markov dentro de
F
0
.
Las definiciones de relevancia dividen entonces a las variables en
fuerte-mente relevantes, d´
ebilmente relevantes e irrelevantes. A su vez, la definici´
on
de redundancia divide las variables d´
ebilmente relevantes en redundantes y
no redundantes. El objetivo es entonces encontrar el subconjunto de variables
tal que contenga variables fuertemente relevantes o no redundantes.
2.3.1.
Estabilidad
3.
M´
etodos de selecci´
on de variables independientes
El problema de la correlaci´
on entre variables ya ha sido tratado por otros
autores y m´
ultiples algoritmos han surgido de dichos an´
alisis. De ellos, dos
m´
etodos resultan particularmente interesantes de analizar por sus aportes
conceptuales al problema. Estos son:
Fast Correlation Based Filter de Lei Yu y Huan Liu [12].
SVM-RFE with MRMR filter de Piyushkumar A. Mundra y Jagath C.
Rajapakse [8].
Adem´
as, para el desarrollo de esta tesina se utiliz´
o como referencia y
control el m´
etodo RFE con SVM como clasificador [5].
3.1.
Recursive Feature Elimination
El algoritmo de Eliminaci´
on Recursiva de Variables, o RFE por sus siglas
en ingl´
es, es uno de los m´
etodos de selecci´
on de variables m´
as utilizados,
tanto por su desempe˜
no a nivel temporal como por la calidad de predicci´
on
de sus modelos.
una iteraci´
on dada, como lo hacen los algoritmos de
backward elimination
y
forward selection
[7], su foco est´
a puesto en estimar el cambio en la precisi´
on
debido a la eliminaci´
on de una o m´
as de dichas variables. Esto no resulta
tan preciso como generar los modelos, pero es lo que permite al m´
etodo ser
temporalmente factible para problemas con un gran n´
umero de variables a
considerar. Al usar SVM lineales, est´
a demostrado [5] que la reducci´
on del
error est´
a dada por el desplazamiento en la direcci´
on del vector perpendicular
al hiperplano de separaci´
on. Por eso, el valor de una variable
i
en un ranking
R
queda definido como
r
i
=
w
i
,
donde
w
i
es la componente correspondiente a
i
en el vector
W
perpendicular
al hiperplano de separaci´
on.
RFE es un algoritmo que agresivamente minimiza el error en cada
ite-raci´
on para el clasificador que use; por lo cual, si bien las tasas de error
ser´
an bajas, puede sufrir el problema de la estabilidad descrito en la secci´
on
anterior para problemas de variables altamente correlacionadas.
3.2.
Fast Correlation Based Filter
de b´
usqueda tiene como ventaja sobre otros algoritmos que al separar ambos
an´
alisis evita la b´
usqueda exhaustiva del subconjunto ´
optimo y computa una
buena aproximaci´
on de forma eficiente.
La correlaci´
on se utiliza ampliamente en el contexto del aprendizaje
au-tomatizado como medici´
on de relevancia. Com´
unmente, las mediciones de
correlaci´
on se clasifican en lineales y no lineales. Al trabajar sobre
medicio-nes del mundo real, no es seguro suponer correlaciomedicio-nes del primer tipo, por
lo que suele trabajarse con el concepto de la teor´ıa de la informaci´
on llamado
“entrop´ıa”, que es una medida de incertidumbre de una variable aleatoria.
La entrop´ıa
H
de una variable discreta
X
se define como
H(X) =
−
X
i
P
(x
i
) log
2
P
(x
i
),
y la entrop´ıa de
X
luego de observar valores de otra variable aleatoria
Y
es
H(X
|
Y
) =
−
X
j
P
(y
j
)
X
i
P
(x
i
|
y
j
) log
2
P
(x
i
|
y
j
),
donde
P
(x
i
) es la probabilidad a priori de todos los valores de
X
y
P
(x
i
|
y
j
)
es la probabilidad a posteriori de todos los valores de
X
dadas las ocurrencias
de los valores de
Y
.
La reducci´
on en la entrop´ıa de
X
dada la ocurrencia de
Y
se denomina
ganancia de informaci´
on o
information gain
y se define como
De acuerdo con esta medida se puede ver que una variable aleatoria
Y
est´
a m´
as correlacionada con una variable
X
que con otra variable
Z
si
IG(X
|
Y
)
> IG(Z
|
Y
)
Se puede probar que
IG
es una medici´
on sim´
etrica y asegura que el orden
de dos variables no altera el resultado de la medici´
on [10]. Como
IG
tiende
a favorecer variables con m´
as valores posibles se la normaliza con respecto a
la entrop´ıa, de modo que se obtiene lo que se llama incertidumbre sim´
etrica
o
symmetrical uncertainty
SU
(X
|
Y
) = 2
IG(X
|
Y
)
H(X)
−
H(Y
)
SU
compensa el sesgo de la ganancia de informaci´
on para con las
varia-bles con m´
as valores y restringe el resultado al intervalo [0,
1] en problemas
de clasificaci´
on binaria. Un valor de 1 significa la completa predicci´
on de los
valores de una variable dada la otra, y un valor de 0 significa total
inde-pendencia. Las mediciones basadas en entrop´ıa utilizan mediciones discretas,
por lo que los conjuntos de datos continuos deber´
an discretizarse de alguna
manera para poder trabajar con esta medida.
Al usar
SU
como medida de correlaci´
on ya se puede comenzar a definir
el algoritmo de selecci´
on de variables. Primero se definen dos tipos de
corre-laci´
on para el problema.
C-correlaci´
on:
la correlaci´
on entre una variable
F
i
y una clase
C
, denotada
por
SU
i,c
.
F-correlaci´
on:
la correlaci´
on entre un par de variables
F
i
y
F
j
con
i
6
=
j
,
Para mantener la eficiencia en un primer plano se calcula la C-correlaci´
on
para cada variable y se utiliza un m´
etodo heur´ıstico para el c´
alculo de las
F-correlaciones. Se dice que
F
i
es relevante si est´
a altamente correlacionada
con la clase
C
(SU
i,c
> δ
definido por el usuario). Para el c´
omputo de la
re-dundancia surge la dificultad de no calcular todas las combinaciones posibles
por su alto costo computacional en problemas de alta dimensionalidad, raz´
on
por la que se busca aproximar el resultado. Partiendo de la definici´
on de
co-berturas de Markov, en lugar de buscar una medida exacta de redundancia se
busca ahora una aproximaci´
on. Se parte de la suposici´
on de que una variable
con mayor C-correlaci´
on que otra tiene m´
as informaci´
on sobre la clase, y se
determina la existencia de una cobertura aproximada de Markov entre dos
variables de la siguiente manera:
Cobertura aproximada de Markov:
para dos variables relevantes
F
i
y
F
j
con
i
6
=
j
,
F
j
forma una cobertura aproximada de Markov para
F
i
si y s´
olo
si
SU
j,c
> SU
i,c
∧
SU
i,j
> SU
i,c
Al contrario que las coberturas de Markov, la cobertura aproximada no
asegura que la eliminaci´
on de una variable siga siendo v´
alida en futuras
ite-raciones. Sin embargo, esto puede solventarse si s´
olo se eliminan variables
para las cuales se encuentre una cobertura aproximada de Markov formada
por una variable predominante.
Variable predominante:
una variable relevante es predominante si y s´
olo
si no tiene ninguna cobertura aproximada de Markov en el conjunto actual
Una variable predominante no ser´
a eliminada en ning´
un caso. Si una
variable
F
i
es eliminada debido a la presencia de una cobertura aproximada
dada por
F
j
, siempre se encontrar´
a una cobertura aproximada en las futuras
iteraciones: la misma
F
j
.
En resumen, el algoritmo filtra las variables relevantes, las ordena, y por
cada una procede a eliminar aquellas variables cubiertas. De esta manera,
se aproxima el subconjunto ´
optimo de variables a partir del conjunto de
variables predominantes.
FCBF es un filtro univariado, es decir, no toma en cuenta los casos donde
se necesita m´
as de una variable para determinar un concepto, como en el
caso de
xor
. Como tal, su precisi´
on de modelado est´
a seriamente
restringi-da. Adem´
as, el algoritmo no considera variables de relevancia similar como
posibles variables equivalentes y descarta una de ellas arbitrariamente sin
establecer cuidados sobre la estabilidad de la soluci´
on. Por ´
ultimo, la
pena-lizaci´
on de variables no es proporcional a su nivel de redundancia, sino que
directamente se elimina y ya no se la considera, privando al usuario de
infor-maci´
on sobre la variable en cuesti´
on.
Algoritmo FCBF
Entrada:
S
=
{
F
1
, . . . , F
n
, C
}
: conjunto de variables y clasificaci´
on.
δ: umbral de corte para variables relevantes.
Salida:
Pseudoc´
odigo
for
F
i
∈
S
do
Calcular
SU
i,c
para
F
i
.
if
SU
i,c
> δ
then
S
0
=
S
0
∪ {
F
i
}
.
end if
end for
Ordenar
S
0
por
SU
i,c
decreciente.
F
j
=
pop(S
0
)
repeat
F
i
=
next(S
0
, F
j
)
repeat
if
SU
i,j
> SU
i,c
then
S
0
=
S
0
− {
F
i
}
end if
F
i
=
next(S
0
, F
i
)
until
F
i
==
N U LL
F
j
=
next(S
0
, F
j
)
until
F
j
==
N U LL
R
=
S
0
3.3.
SVM-RFE con filtro MRMR
El m´
etodo de M´ınima Redundancia y M´
axima Relevancia o MRMR [8]
apunta, como su nombre lo indica, a seleccionar variables m´
aximamente
re-levantes y m´ınimamente redundantes para la clasificaci´
on, mediante la
com-binaci´
on del filtro MRMR con el algoritmo SVM-RFE.
El filtro MRMR fue introducido por Peng et al. [9]. Sea
S
=
{
F
1
, F
2
, . . . , F
n
}
un conjunto indexado de variables. Sean
C
las clases objetivos de las
mues-tras. La informaci´
on mutua entre la variable
F
i
y la clase
C
determinar´
a la
relevancia de
F
i
para la clasificaci´
on. Entonces, la relevancia
R
i
est´
a dada
por:
R
i
=
I(C, F
i
).
La redundancia de la variable
F
i
con las otras variables del subconjunto
S
est´
a dada por:
Q
S,i
=
1
|
S
|
2
X
F
j∈
S,F
j6
=
F
iI
(F
i
, F
j
)
Con el filtro MRMR, el ordenamiento de las variables se realiza
optimi-zando la proporci´
on entre el valor de relevancia de una variable contra el
valor de redundancia con las otras variables del conjunto. La variable m´
axi-mamente relevante y m´ıniaxi-mamente redundante
F
i
∗
en el conjunto
S
est´
a dada
por
F
i
∗
=
argmax
F
i∈
S
R
i
Q
S,i
que minimice la redundancia entre variables relevantes. Para eso, lo que se
plantea es ordenar las variables por el resultado de la combinaci´
on convexa
entre la relevancia marcada por los pesos de la SVM y los valores del filtro.
Para la
i-´
esima variable se define
r
i
=
β
|
w
i
|
+ (1
−
β)
R
i
Q
S,i
,
Algoritmo SVM-RFE con filtro MRMR
Entrada:
S
=
{
F
1
, . . . , F
n
, C
}
: conjunto de variables y clasificaci´
on.
β: factor de importancia entre RFE y MRMR.
Salida:
R: ranking ´
optimo de variables.
Pseudoc´
odigo
repeat
W
=
rf e(S)
for
F
i
∈
S
do
Calcular
R
S,i
y
Q
S,i
Calcular
r
S,i
end for
F
i
∗
=
argmin(r
i
)
R
=
R
∪ {
F
i
∗
}
S
=
S
\{
F
i
∗
}
until
S
=
∅
3.4.
Stable Recursive Feature Elimination
El algoritmo SRFE es el m´
etodo de selecci´
on de variables desarrollado
como eje de esta tesina. Es un algoritmo de la familia
wrapper
que intenta
minimizar, combinando los puntos fuertes de los algoritmos ya descriptos, el
problema de la estabilidad que se genera debido a altos niveles de
correla-ci´
on entre las variables. Combina un m´
etodo para seleccionar la variable a
penalizar de una manera estable siguiendo el ejemplo de FCBF con la base
de selecci´
on precisa y eficiente de SVM-RFE.
En esencia, el algoritmo cuenta en primera instancia con un filtro
ins-pirado en FCBF que se encarga de determinar los niveles de correlaci´
on y
discriminar las variables intercambiables en el momento del aprendizaje. De
esta manera, se genera un vector de penalizaciones siguiendo un criterio que
considera la estabilidad de la soluci´
on, la cual luego se combina con el ranking
obtenido a trav´
es de RFE para determinar qu´
e variables eliminar. Luego, se
itera hasta que todas las variables est´
en ordenadas.
La relevancia de una variable
F
i
en el problema queda determinada
en-tonces por la ecuaci´
on
r
i
=
βI
i
+ (1
−
β)P
i
,
donde
I
i
es la importancia de la variable en cuanto a su aporte a la soluci´
on y
P
i
es la penalizaci´
on a la misma por redundancia. Como el m´
etodo utiliza el
algoritmo SVM-RFE como base,
I
i
puede remplazarse por
w
i
, que representa
la componente asociada a la variable
F
i
en el vector que define el hiperplano
clasificador, quedando finalmente
3.4.1.
El vector de penalizaci´
on P
La construcci´
on del vector de penalizaci´
on
P
se da en el bucle inicial del
algoritmo, que consta del c´
alculo de la medida de
SU
para todos los pares de
variables y de las variables con las clases. Si bien tiene complejidad
O(n
2
), el
c´
alculo es sencillo y se realiza una sola vez, con lo cual se amortiza frente a
las
n
iteraciones posteriores del algoritmo de aprendizaje automatizado. Esto
determina el vector de C-correlaci´
on
SU
i,c
y la matriz de F-correlaci´
on
SU
i,j
.
Con estos valores se procede a la construcci´
on del vector
P
de penalizaci´
on
de variables mediante la b´
usqueda del par de variables tal que
(F
i
, F
j
) =
argmax(SU
i,j
)
SRFE, a diferencia de MRMR, penaliza a una sola de las variables del
par. Si los valores de correlaci´
on
SU
i,c
y
SU
j,c
difieren en menos de un umbral
de tolerancia
T
p
entonces se considera que
F
i
y
F
j
aportan el mismo valor
predictivo al modelo y, para mantener un criterio estable, se penaliza con un
valor de
−
SU
i,j
a aquella variable con mayor sub´ındice y se la remueve del
conjunto. Si la diferencia sobrepasa el umbral, se considera que las variables
son redundantes pero hay una clara relevancia de una por sobre la otra y
aquella con menor poder predictivo es penalizada con ese valor y removida.
El procedimiento se itera hasta completar el vector
P
. La severidad de la
pe-nalizaci´
on queda dada por el nivel de redundancia mismo entre las variables.
Durante la experimentaci´
on, el umbral
T
p
fue establecido en 0.05 o 5 % de
diferencia en la correlaci´
on para salvar perturbaciones dadas por el ruido y
el muestreo aleatorio.
las dem´
as tienen un valor
p
∈
[
−
1,
0) dependiendo del nivel de redundancia
medido. Sin embargo, es errado pensar que todas las variables deban ser
pe-nalizadas en base a una sola, ya que estar´ıamos implicando una redundancia
entre todas las variables. El problema es que, en la pr´
actica,
SU
i,j
es siempre
distinto de 0, aun para variables independientes. Para solventar esto y
mejo-rar el filtro se plante´
o la inclusi´
on de un umbral de correlaci´
on
T
c
, inspirado
en los algoritmos de clustering jer´
arquico. El valor de
T
c
determina el valor
de correlaci´
on en el cual dos variables ya no se consideran redundantes. De
esta manera,
T
c
act´
ua como mecanismo de corte del bucle (o del ´
arbol, si
se sigue con la idea de clustering) y determina un factor de agrupamiento
de las variables:
T
c
= 0 indica que todas las variables deben considerarse
redundantes entre s´ı (un solo cluster), mientras que
T
c
= 1 indica la
conside-raci´
on de independencia total de las variables (cada variable es un cluster).
Un valor adecuado de
T
c
generar´
a varios conjuntos de variables redundantes
en distinta medida con una de ellas especialmente relevante y sin penalizar.
3.4.2.
El m´
etodo SRFE
Una vez obtenido el vector de penalizaciones se procede al entrenamiento
del algoritmo de aprendizaje automatizado. En la implementaci´
on de SRFE
se decidi´
o utilizar SVM-RFE por su eficiencia ya descrita. Al obtenerse el
vector de pesos
W
se lo escala junto con el vector
P
en base a la cantidad
restante de variables y se los combina convexamente en base a un par´
ame-tro
β. Las peores variables son removidas de la lista y se repite el proceso
(incluyendo el escalado) hasta que se finaliza el ranking.
selecciones. Adem´
as, obtiene mejores resultados que FCBF en cuanto a error
en la clasificaci´
on debido a su naturaleza
wrapper
, y supera a SVM-RFE con
filtro MRMR, ya que considera una mejor escala al momento de combinar
las penalizaciones y deja de manera estable una variable de cada grupo sin
penalizar.
Algoritmo SRFE
Entrada:
S
=
{
F
1
, . . . , F
n
, C
}
: conjunto de variables y clasificaci´
on.
β: factor de balance entre importancia y redundancia.
T
p
: factor de tolerancia para determinar la equivalencia de dos variables.
T
c
: factor de corte en el c´
alculo de redundancia.
Salida:
R: ranking ´
optimo de variables.
Pseudoc´
odigo
for
F
i
∈
S
do
Calcular
SU
i,c
end for
for
F
i
, F
j
∈
S
do
Calcular
SU
i,j
end for
S
0
=
S
repeat
P
[j] =
−
SU
i,j
remove(F
j
)
else if
SU
j,c
> SU
i,c
(1 +
T
P
)
then
P
[i] =
−
SU
i,j
remove(F
i
)
else
w
=
min(i, j)
P
[w] =
−
SU
i,j
remove(F
w
)
end if
until
S
0
=
∅ ∨
SU
i,j
< T
C
repeat
W
=
rf e(S)
Escalar
W
y
P
[S]
F
i
∗
=
argmin(βW
+ (1
−
β)P
[S])
R
=
R
∪ {
F
i
∗
}
S
=
S
\{
F
i
∗
}
until
S
=
∅
4.
Resultados
La experimentaci´
on se realiz´
o sobre distintos conjuntos de datos o
data-sets
de diversas caracter´ısticas. Sobre todos ellos se corrieron los algoritmos
descriptos en el cap´ıtulo tres para la obtenci´
on de los rankings finales. A
continuaci´
on, se utiliz´
o el algoritmo SVM con los rankings como argumento
para medir la tasa de error en base a la cantidad de variables seleccionadas.
Asimismo, se evalu´
o la estabilidad de la selecci´
on. No se tuvo en
considera-ci´
on el factor temporal o de memoria para determinar la efectividad de los
m´
etodos.
Todos los m´
etodos utilizaron la misma entrada aleatoria y realizaron las
mimas validaciones para garantizar la equidad en la experimentaci´
on. La
obtenci´
on de los cien conjuntos de datos de entrenamiento y de prueba se
realiz´
o con el m´
etodo de
subsamples
del 75 % para entrenamiento y los
mo-delos generados se validaron internamente con las SVM utilizando la t´
ecnica
de
4-fold cross validation
. Las SVM utilizadas fueron configuradas con un
kernel lineal y el parametro de costos
C
se eligi´
o por validaci´
on interna entre
(0.01,
0.1,
1,
10,
100).
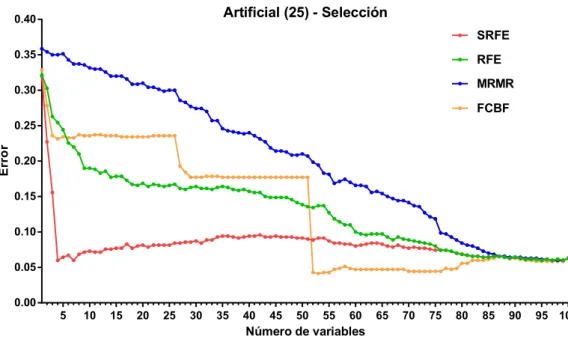
En la segunda, se pueden observar cuatro curvas en las que se comparan
los errores de clasificaci´
on del modelo generado con un n´
umero dado de
va-riables elegidas por los distintos m´
etodos. Esta gr´
afica sirve para mostrar que
el m´
etodo SRFE obtiene modelos de predicci´
on al menos tan buenos como
el resto de los m´
etodos ya publicados.
La tercera gr´
afica muestra, para cada m´
etodo en forma independiente, la
estabilidad de la selecci´
on para un n´
umero definido de variables. Para esto,
se grafica la probabilidad de una variable de ser seleccionada entre las
x
primeras sobre todos los experimentos realizados. En esta gr´
afica, se busca
que las probabilidades de las primeras
x
variables tiendan a 1, mientras que
el resto tienda a 0, lo que determina una selecci´
on estable. El valor de
x
se
determin´
o en todos los casos buscando un m´ınimo en las curvas de error de
la primera figura.
La ´
ultima gr´
afica muestra, para cada variable, la posici´
on final luego del
entrenamiento para cada uno de los rankings obtenidos por los m´
etodos. Se
presentan ordenadas de mejor a peor y se busca observar poca variaci´
on por
lo menos en las primeras
x
posiciones. Cuando se grafica el dataset completo,
cuanto m´
as se asemeja la gr´
afica a una diagonal, m´
as estable es el m´
etodo
de selecci´
on. La presencia de dos o m´
as posiciones distintas y bien marcadas
para una variable puede indicar una alta correlaci´
on con otras, lo que sugiere
que habr´ıan intercambiado lugares a lo largo de los experimentos.
El par´
ametro
β, donde aplica, fue configurado en 0.5 dando igual
impor-tancia a ambas partes en el ranking. Para SRFE, el par´
ametro
T
p
se defini´
o en
4.1.
Datos artificiales
Para mostrar con claridad las bondades del m´
etodo presentado en esta
tesina, se procedi´
o a la generaci´
on de un conjunto de datos que responda a
la problem´
atica que se intenta resolver: la selecci´
on estable de variables en
problemas anchos con una gran cantidad de variables correlacionadas.
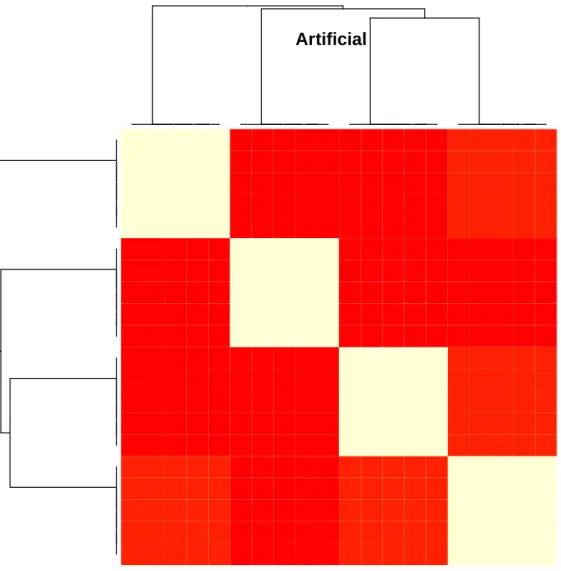
El dataset “artificial” consta de cien variables agrupadas en conjuntos
altamente correlacionados de veinticinco variables. A su vez, el concepto
ob-jetivo, que es binario, est´
a determinado por una conjunci´
on de los cuatro
grupos, lo que significa que es necesaria la presencia de al menos una
varia-ble de cada grupo para obtener la soluci´
on correcta. La Figura 4 muestra con
un heatmap la estructura de correlaciones entre las variables.
Para este caso particular se hicieron tres experimentos con cada vez menos
muestras para exponer c´
omo se va perdiendo la capacidad predictiva a medida
que disminuye la informaci´
on y el espacio se torna m´
as ralo. Adem´
as, se
muestra c´
omo la informaci´
on redundante elude los criterios de selecci´
on de
los m´
etodos distintos a SRFE.
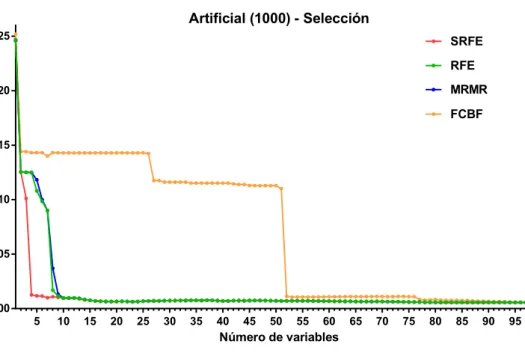
En la primera instancia, de mil variables para una relaci´
on 1 : 10 de
variables y muestras, se puede observar en la Figura 5 como ´
unicamente el
m´
etodo SRFE logra obtener el modelo ´
optimo al minimizar el error con cuatro
variables. Tanto RFE como MRMR mantienen variables redundantes en las
´
ultimas iteraciones y FCBF falla en obtener cualquier tipo de informaci´
on
de los datos porque elimina secuencialmente grupos enteros de variables (de
ah´ı los grandes saltos en la gr´
afica).
de posiciones que toma cada variable en el ranking a lo largo de todas las
corridas efectuadas. Mientras m´
as estable es un m´
etodo, m´
as angosta ser´
an
las distribuciones.
En dichas figuras de estabilidad se acent´
ua m´
as a´
un la diferencia en la
selecci´
on. MRMR muestra una estabilidad excelente, pero siempre elige dos
pares de variables correlacionadas, con lo cual el modelo resultante es malo.
RFE tiene una selecci´
on inestable y err´
onea que no aporta informaci´
on ´
util a
la interpretaci´
on de los resultados al igual que FCBF. SRFE elige de manera
estable una variable de cada conjunto.
En las segunda y tercera instancias, con relaciones 1 : 1 (Figuras 8 a 10) y
4 : 1 (Figuras 11 a 13), respectivamente, se puede observar como
progresiva-mente aumenta el error de los modelos de predicci´
on generados y disminuye
la estabilidad para todos los m´
etodos excepto para SRFE que demuestra su
robustez incluso cuando comienzan a surgir los errores de medici´
on
conse-cuencia de la escasez de muestras
1
.
1
Debido a que los c´
alculos con m´
etricas de entrop´ıa o informaci´
on requieren de variables
V20
V19
V18
V16
V17
V15
V14
V13
V11
V12
V5
V4
V3
V1
V2
V10
V9
V8
V6
V7
V7
V6
V8
V9
V10
V2
V1
V3
V4
V5
V12
V11
V13
V14
V15
V17
V16
V18
V19
V20
Artificial
Artificial (1000) - Selección
Número de variables
E
rr
o
r
5
10
15
20
25
30
35
40
45
50
55
60
65
70
75
80
85
90
95 100
0.00
0.05
0.10
0.15
0.20
0.25
RFE
SRFE
MRMR
FCBF
Artificial (1000) - Selección
Número de variables
E
rr
o
r
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
0.00
0.05
0.10
0.15
0.20
0.25
ume-Art
if
icia
l 10
00
E
sta
bili
d
ad
S
RF
E
V
ari
ab
le
Pro bab ilid ad de est ar en tre
las mej ore sc uat ro var iab les
V1 V2 6
V5 1
V7 6
V5 2
V7 9
V7 8
V8 1
V8 2
V5 3
V5 4
V5 7
V6 1
V6 7
V7 3
V7
7 V1
00 V2 V3 V4
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Art
ific
ial 1
000
- E
st
ab
ilid
ad
FC
B
F
V
ari
ab
le
Pro bab ilid ad de est ar en tre
las mej ore sc uat ro var iab les
V2 6
V1 V2 5
V2 4
V2 3
V2 V2 8
V2 1
V2 0
V2 2
V2 7
V1 7
V7 5
V5 V3 7
V1 1
V1 9
V7 2
V7 3
V7 4
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Art
ific
ia
l 1
000
- E
st
ab
ilid
ad
RF
E
V
ari
ab
le
Pro bab ilid ad de est ar en tre
las mej ore sc uat ro var iab les
V5 V4 2
V1 0
V3 1
V4 4
V1 1
V3 2
V4 1
V2 1
V4 3
V3 9
V1 8
V1 9
V2 3
V1 3
V3 5
V3 7
V7 V2 6
V3 0
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Art
ific
ial 1
000
- E
st
abili
da
d
MR
M
R
V
ari
ab
le
Pro bab ilid ad de est ar en tre
las mej ore sc uat ro var iab les
V2 4
V2 5
V4 9
V5 0
V1 V2 V3 V4 V5 V6 V7 V8 V9 V1 0
V1 1
V1 2
V1 3
V1 4
V1 5
V1 6
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
selec-V5
osicionamiento relativ
o
Artificial (1000): RFE
V26 V1 V76 V51 V2 V28 V5 V42 V31 V30 V19 V3 V8 V32 V21 V10 V23 V37 V44 V41 V35 V52 V85 V15 V18 V22 V11 V49 V13 V29 V43 V47 V78 V27 V53 V39 V14 V77 V6 V9
osicionamiento relativ
o _ ______________________________________________________________________________________________________________
_
Artificial (1000): SRFE
V50 V25 V49 V24 V48
V100 V23 V75 V47 V22 V46 V21 V99 V45 V74 V20 V44 V19 V43 V98 V18 V42 V73 V17 V41 V40 V16 V97 V39 V15 V72 V38 V14 V96 V37 V13 V36 V71 V35 V12
0.0
osicionamiento relativ
o _ _________________________
_
Artificial (1000): SVM−RFE c/MRMR
V26 V1 V25 V23 V24 V22 V20 V21 V19 V18 V17 V16 V15 V14 V13 V12 V11 V10 V9 V8 V7 V6 V5 V4 V3 V2 V99 V75 V97 V98 V74 V96 V70 V94 V95
V100 V68 V69 V72 V93
0.0
osicionamiento relativ
o
Artificial (1000): FCBF
Artificial (100) - Selección
Número de variables
E
rr
o
r
5
10
15
20
25
30
35
40
45
50
55
60
65
70
75
80
85
90
95 100
0.00
0.05
0.10
0.15
0.20
0.25
0.30
RFE
SRFE
MRMR
FCBF
Artificial (100) - Selección
Número de variables
E
rr
o
r
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
0.00
0.05
0.10
0.15
0.20
0.25
0.30
Art
ific
ial 1
00
- E
st
abil
ida
d S
RF
E
V
ari
ab
le
Pro bab ilid ad de est ar en tre
las mej ore sc uat ro var iab les
V1 V2 6
V7 6
V5 1
V5 2
V2 8
V2 V3 V4 V5 V6 V7 V8 V9 V1 0
V1 1
V1 2
V1 3
V1 4
V1 5
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Art
ific
ial 1
00
- Es
tab
ilida
d F
CB
F
V
ari
ab
le
Pro bab ilid ad de est ar en tre
las mej ore sc uat ro var iab les
V1 V2 6
V4 9
V5
0 V1
00 V9 9
V7 4
V7 3
V7 5
V7 6
V9 8
V2 4
V2 5
V2 8
V2 9
V3 8
V7 1
V7 2
V2 V3
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Art
ific
ial
10
0
Es
ta
bil
ida
d R
F
E
V
ari
ab
le
Pro bab ilid ad de est ar en tre
las mej ore sc uat ro var iab les
V1 8
V6 V2 6
V4 6
V1 1
V1 7
V2 1
V4 9
V4 3
V3 1
V1 0
V2 9
V3 7
V4 7
V4 V3 3
V3 5
V4 0
V7 V1 9
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Art
ifi
cial
1
00
Est
abili
d
ad
M
RM
R
V
ari
ab
le
Pro bab ilid ad de est ar en tre
las mej ore sc uat ro var iab les
V2 5
V5 0
V4 9
V2 4
V4 8
V2
3 V1
00 V1 V2 V3 V4 V5 V6 V7 V8 V9 V1 0
V1 1
V1 2
V1 3
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9