Herramienta Computacional DASDE® para aplicaciones quimio bioinformática usando Optimización de Colonias de Hormigas en la construcción de multiclasificadores
95
0
0
Texto completo
(2) DICTAMEN Hago constar que el trabajo titulado “Herramienta Computacional DASDE® para aplicaciones quimio-bioinformáticas usando Optimización de Colonias de Hormigas en la construcción de multiclasificadores” fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Licenciatura en Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del Laboratorio. Fecha.
(3) PENSAMIENTO.
(4) El secreto de la sabiduría, del poder y del conocimiento es la humildad Ernest Hemingway.
(5) DEDICATORIA.
(6) A quienes merecen más que yo la satisfacción de este trabajo, A quienes han hecho posible este y muchos otros sueños, A quienes le debo más que un título, A mi familia.
(7) AGRADECIMIENTOS.
(8) Supongo que agradecer a la familia es lo más obvio, pues desde que nacemos son la fuente del desarrollo que logramos paso a paso; unido esto a la comprensión, el cariño, la modestia, la sencillez, la solidaridad, la confianza, la dedicación, la responsabilidad y sobre todo el amor de la que he sido afortunada de tener en todos estos años; por esto sobradas razones tengo para agradecer desde mi corazón a mi abuela Elena y a mi abuelo Pascual, a mi mamá, a mi tía Chuchi, a mi hermano Hasiel, a mi papá y a todos los que han estado ahí para mí en cualquier momento de mi vida. Tengo que dar muchas gracias a nuestros tutores Maricel, Leidys y Alfredo por su gran disposición, por el tiempo dedicado, por sus valiosas ideas y por sobre todo la paciencia que tuvieron, porque gracias a ellos fue posible. También quiero agradecer a mis amistades: Geily, Beatriz, Anita, Yerandy, Javier, Leonardo, Mirielis, Adis y a todas aquellas personas que crearon recuerdos inolvidables y lograban hacerme olvidar el estrés en aquellos momentos realmente difíciles, demostrándome lo valiosa que puede llegar a ser la amistad. Creo que lograr agradecer a todas aquellas personas que, incluso sin saberlo, han posibilitado que haya llegado a este momento es una tarea sumamente difícil; y aún más cuando estas palabras llegan para muchos con un profundo sentido de despedida. En la vida conocemos muchas personas desde aquellas que nos enseñan lo maravilloso que es estar en este mundo y hasta aquellos que de la forma más dura nos muestran como levantarnos de nuestros errores y sobreponernos a los tiempos difíciles, a todos los que han jugado ese rol en mi vida, muchas gracias. Por supuesto que tendría que agradecer a mis profesores que hicieron eco en mi formación profesional y personal, enseñándome que la vida no es una carrera de rapidez sino de resistencia. Por último y no por menos importante quiero agradecerle a todas las personas que sin darse cuenta me enseñaron que de mí solo depende la felicidad que pueda encontrar; que las cosas imposibles solo lo son cuando las aceptamos como tal; que debemos tener la voluntad de cambiar y de ser mejores cada día; que me revelaron que somos como los imanes que atraemos tanto cosas buenas como negativas a nuestras vida; pero sobre todo quiero agradecer a esas personas que intentaron romper mis esquemas y me crearon nuevas ilusiones. A todos aquellos que de una forma u otra han contribuido en el proyecto, gracias..
(9) RESUMEN La búsqueda de medicamentos contra enfermedades que azotan a la salud humana sigue siendo una de las prioridades a nivel mundial. Una de las pocas técnicas que tienen potencial para mejorar significativamente el descubrimiento y posterior desarrollo de fármacos son los métodos in silico. Gracias al avance de las ciencias computacionales, en los últimos años han surgido un conjunto de técnicas como los multiclasificadores y algoritmos de búsqueda heurística, que permiten identificar compuestos químicos activos frente a enfermedades prioritarias a nivel mundial. El software DASDE® 1.0 (Diversity Analysis, Selection and Discovery of best Ensemble from bases models), desarrollado en el 2013, permite elegir los clasificadores que se van a combinar en un multiclasificador mediante una búsqueda exhaustiva, la cual provoca grandes demoras en el tiempo de ejecución. La selección en este software de dichos clasificadores bases es una tarea compleja por las grandes cantidades de clasificadores individuales en aplicaciones de quimio-bioinformáticas y las múltiples combinaciones que ellos pueden generar, ante este problema combinatorio se propone en este trabajo el uso de la meta heurística ACO para obtener combinaciones de clasificadores diversos a través de medidas de diversidad y además obtener combinaciones de clasificadores con una exactitud superior a la mejor individual. Se aplica la nueva versión del software a dos bases de datos reales de quimiobioinformática obteniéndose buenos resultados. También se hace una comparación con la versión anterior del software, destacándose que las soluciones se pueden encontrar en menor tiempo de ejecución sin perder calidad en las mismas..
(10) ABSTRACT The search for medicaments against diseases that ravage human health remains a priority worldwide. One of the few techniques that have the potential to significantly improve the discovery and development of drugs are the in silico methods. Thanks to advances in computer science, in recent years there have been a number of techniques such as multiclassifiers and heuristic search algorithms that identify chemical compounds active against priority diseases worldwide. The DASDE® 1.0 software (Diversity Analysis, Selection and Discovery models of best Ensemble from bases), developed in 2013, allows you to choose the classifiers to be combined into a multiclassifiers through an exhaustive search, which causes long delays in time execution. The selection in this software such classifiers bases is a complex task for the large amounts of individual classifiers applications chemo-bioinformatic and multiple combinations that they can generate, before this combinatorial problem is proposed in this paper the use of the ACO metaheuristic for combinations of various classifiers through diversity measures and also obtain combinations of classifiers with an accuracy greater than the best individual. The new software version two real databases of chemo- bioinformatics applied with good results. Is also done a comparison with the previous version of the software, highlighting that solutions can be found in less runtime without losing quality in them is also done..
(11) ÍNDICE INTRODUCCIÓN ............................................................................................................ 1513 1. MULTICLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y OPTIMIZACION BASADA EN. COLONIA DE HORMIGAS. .............................................................................................. 2018 1.1 Combinación de clasificadores. ..................................................................................................... 2018 1.1.1 Métodos de Clasificación. ...................................................................................................... 2119 1.1.2 Descripción de sistemas multiclasificadores .......................................................................... 2220 1.1.2.1 ¿Por qué utilizar combinaciones de clasificadores? ........................................................ 2220 1.1.2.2 Modelos de construcción de multiclasificadores ............................................................ 2523 1.1.2.3 Estrategias de Combinación ............................................................................................ 2624 1.1.3 Actualidad en la combinación de clasificadores ..................................................................... 2826 1.2 Evaluación en la clasificación......................................................................................................... 2927 1.3 Caracterización de la diversidad. Medidas de diversidad ............................................................. 3129 1.3.1 Medidas de diversidad en forma de pares (pairwise) ............................................................ 3230 1.3.1.1 Coeficiente de correlación (ρ) ......................................................................................... 3331 1.3.1.2 El estadístico Q ................................................................................................................ 3331 1.3.1.3 Medida de diferencias ..................................................................................................... 3331 1.3.1.4 Medida de doble fallo ...................................................................................................... 3432 1.3.1.5 Combinación de la medida de diferencia y medida de doble fallo .................................. 3432 1.3.2 Medidas de diversidad para todo el conjunto (non-pairwise) ............................................... 3432 1.3.2.1 Entropía ........................................................................................................................... 3533 1.3.2.2 Varianza de Kohavi-Wolpert ........................................................................................... 3533 1.3.2.3 Medida de desacuerdo entre expertos ........................................................................... 3533 1.3.2.4 Medida de dificultad ....................................................................................................... 3634 1.3.2.5 Medida de diversidad generalizada ................................................................................ 3634 1.3.2.6 Medida de diversidad de coincidencia de fallos ............................................................. 3735 1.3.2.7 Medida de diversidad de distintos fallos ........................................................................ 3836 1.3.2.8 Medida de la diversidad global ....................................................................................... 3836 1.3.2.9 Medida de variabilidad.................................................................................................... 3937 1.3.3 Estandarización de varias medidas de diversidad .................................................................. 3937 1.3.4 Actualidad sobre medidas de diversidad ............................................................................... 4038 1.4 Optimización combinatoria: procedimientos meta heurísticos .................................................... 4139 1.4.1 Las Colonias de Hormigas Naturales ...................................................................................... 4543 1.4.2 De las Hormigas Naturales a la Meta heurística Optimización basada en Colonias de Hormigas ............................................................................................................................................ 4644 1.4.3 La Hormiga Artificial ............................................................................................................... 4745 1.4.4 Similitudes y Diferencias entre las Hormigas Naturales y Artificiales .................................... 4846.
(12) 1.4.5 Modo de Funcionamiento y Estructura Genérica de un Algoritmo ACO ............................... 5048 1.4.6 Búsqueda Local ....................................................................................................................... 5250 1.4.7 Pasos a Seguir para Resolver un Problema Mediante ACO .................................................... 5250 1.4.8 Modelos de Optimización basada en Colonias de Hormigas ................................................. 5452 1.4.8.1 El Sistema de Hormigas Max-Min (MMAS) ..................................................................... 5452 1.4.9 Relación entre ACO y otras Meta heurísticas ......................................................................... 5654 1.4.9.1 Relación entre ACO, Computación Evolutiva y Algoritmos de Estimación de Distribuciones ................................................................................................................................ 5654 1.5 Consideraciones finales del capítulo ............................................................................................. 5755. 2. DISEÑO E IMPLEMENTACIÓN SOBRE EL SOFTWARE DASDE. ................................. 5856. 2.1 Diseño e Implementación del software DASDE v1.0 ..................................................................... 5856 2.1.1 Incorporación al software de medidas de diversidad no pareadas. ...................................... 5957 2.2 Modificaciones sobre el software ................................................................................................. 6058 2.2.1 Diseño e implementación del nuevo módulo ........................................................................ 6159 2.2.2 Modelación de la Meta Heurística ACO ................................................................................. 6462 2.2.2.1 Búsqueda Local ............................................................................................................... 6462 2.2.2.2 Modelación de ACO para obtener combinaciones de modelos diversos ....................... 6664 2.2.2.3 Modelación de ACO para obtener las mejores combinaciones de modelos individuales .................................................................................................................................... 6765 2.3 Consideraciones finales del capítulo ............................................................................................. 7169. 3. DISEÑO DE EXPERIMENTOS Y ANÁLISIS DE SUS RESULTADOS ............................... 7270. 3.1 Descripción general de los experimentos ..................................................................................... 7270 3.1.1 Análisis de la base de datos Trypanosoma cruzi con el software DASDE v2 .......................... 7371 3.1.2 Análisis de la base de datos Trichomonas vaginalis con el software DASDE v2 ..................... 7775 3.2 Comparación con búsqueda exhaustiva ........................................................................................ 8078 3.3 Modificaciones en la interfaz visual del software DASDE v1 ......................................................... 8280 3.3.1 Modificaciones en “Diversity Measure” ................................................................................. 8381 3.3.2 Panel Ensemble Methods ....................................................................................................... 8482 3.4 Consideraciones finales del capítulo ............................................................................................. 8684. CONCLUSIONES ............................................................................................................ 8785 RECOMENDACIONES .................................................................................................... 8886 REFERENCIAS BIBLIOGRÁFICAS ..................................................................................... 8987.
(13) Índices De Figuras. Figura 1 Razón estadística sobre la elección de la combinación de clasificadores ................................. 2423 Figura 2 Razón computacional sobre la elección de la combinación de clasificadores .......................... 2423 Figura 3 Razón representacional en la elección de la combinación de clasificadores ............................ 2524 Figura 4 El comportamiento de la colonia termina por obtener el camino más corto entre dos puntos. ................................................................................................................................................................ 4645 Figura 5 Diagrama de clases del paquete ACO ....................................................................................... 6362 Figura 6 Diagrama de las principales clases ........................................................................................... 6362 Figura 7 Valores estadísticos de los modelos más diversos .................................................................... 7574 Figura 8 Mejores resultados de los mejores modelos ensamblados ...................................................... 7776 Figura 9 Valores estadísticos de los modelos más diversos .................................................................... 7978 Figura 10 Mejores resultados de los mejores modelos ensamblados .................................................... 8079 Figura 11 Tiempo de ejecución en el panel Diversity Measures ............................................................. 8180 Figura 12 Tiempo de ejecución en el panel Ensamble Method............................................................... 8281 Figura 13 Vista de las búsquedas posibles ............................................................................................. 8382 Figura 14 Vista configuración ACO para diversidad ............................................................................... 8483 Figura 15 Ventana de diálogo: Configuración de los datos. ................................................................... 8584 Figura 16 Ventana de diálogo: Selección de los mejores modelos. ........................................................ 8584 Figura 17 Vista del ensamble de modelos individuales. ......................................................................... 8685.
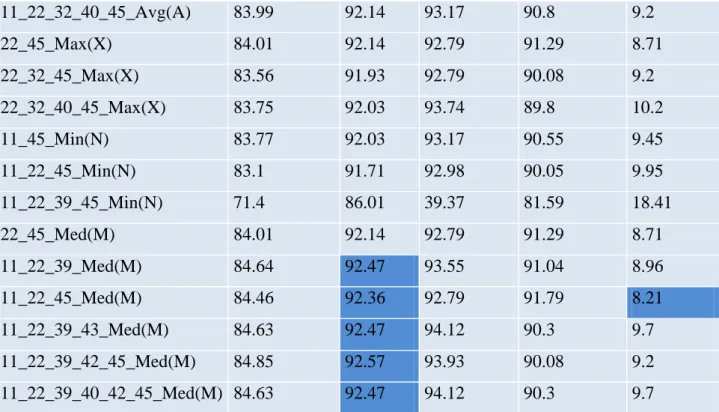
(14) Índices de Tablas Tabla 1 Matriz de confusión ................................................................................................................... 3028 Tabla 2 Clasificación entre los resultados de los clasificadores Ci y Cj para una instancia. ................... 3230 Tabla 3 Clasificación entre los resultados de los clasificadores Ci y Cj para todo el conjunto de instancias. ................................................................................................................................................................ 3230 Tabla 4 Medidas de diversidad. .............................................................................................................. 3937 Tabla 5 Resultados para los modelos más diversos ................................................................................ 7674.
(15) INTRODUCCIÓN En la actualidad con el incremento de la cantidad de datos biológicos se han generado dos problemas: el almacenamiento y manejo eficiente de la información y la extracción de información útil (Partalas et al. 2006). Investigar la esencia de la vida en estos grandes volúmenes de datos biológicos ha llevado a la necesaria unión de varias ciencias como la biología, la matemática y la ciencia de la computación; constituyendo lo que se conoce como bioinformática. A lo largo de la historia, el descubrimiento de nuevos fármacos y terapias, ha sido fundamental para el entendimiento de la vida y la evolución En el tratamiento de enfermedades como: la malaria (con una incidencia de 500 millones de personas afectadas), enfermedad de Chagas (16 a 20 millones de personas infectadas en el continente americano), leishmaniasis (más de 12 millones de personas afectadas en el mundo y 350 millones a riesgo de contraerla), trichomonosis (180 millones de personas afectadas en el planeta), entre otras, siguen siendo un azote tanto para los países subdesarrollados como los que están en vías de desarrollo. El interés dentro de la industria farmacéutica en la búsqueda de fármacos contra enfermedades principalmente tropicales, como las mencionadas anteriormente, está en decadencia desde hace muchos años. La razón principal es sin duda económica. En un mercado cada vez más global y competitivo, se tiene que comparar solamente los altos costes del desarrollo (estimados actualmente en los EEUU de 200-400 millones de dólares por compuesto puesto en el mercado) y con las bajas perspectivas de rentabilidad económica, se puede apreciar la naturaleza real del problema, y que el cambio en este sentido a corto plazo está muy lejano. Dada esta deprimente situación, los investigadores se han centrado en desarrollar ensayos menos costosos para la búsqueda racional de nuevos compuestos y desarrollar estrategias terapéuticas mejoradas usando los fármacos ya existentes, realizando una quimioterapia combinatoria u optimizando la administración de los fármacos de referencia (MonteroTorres et al. 2005). El descubrimiento y desarrollo de medicamentos cada vez más efectivos, seguros y adecuados, es una tarea que requiere del esfuerzo coordinado e inteligente de un elevado número de profesionales de distinta formación científica; o sea es una tarea de carácter interdisciplinaria, en la cual el cómputo científico aplicado a las ciencias básicas no ha sido ajeno al avance de la investigación farmacéutica..
(16) Gracias al avance de las ciencias computacionales, en los últimos años ha sido posible el diseño de modelos computacionales capaces de evaluar virtualmente un número elevado de moléculas, que por el clásico método in vitro resultaría muy laborioso. Dichos modelos virtuales permiten analizar entidades teóricas, aún no sintetizadas, como método de síntesis racional dirigida. A través de estos procedimientos in silico se evita la síntesis de compuestos químicos que van a resultar inactivos en los ensayos in vitro, así como ensayos in vivo innecesarios, priorizando el análisis en el laboratorio de aquellas moléculas con mayor probabilidad de ser activas y que posteriormente puedan convertirse en fármacos exitosos.(Farmacia 2016) . En los últimos años, investigadores del Centro de Bioactivos Químicos (CBQ) y de la Facultad de Farmacia (FM) de la Universidad Central “Marta Abreu” de las Villas (UCLV), han desarrollado varios modelos de predicción usando el descriptor molecular TOMOCOMD CARDD (TOpological Molecular COMputer Design - Computer Aided Rational Drug Design) (Marrero-Ponce et al. 2005) y análisis discriminante lineal para identificar nuevos compuestos activos frente a distintas enfermedades parasitológicas. Para dar continuidad al descubrimiento de nuevos compuestos mediante el uso de modelos QSAR (Quantitative Structure Activity Relationship), donde se utilizan grandes bases de datos internacionales, es necesario encontrar aquellos modelos que muestren una mayor precisión de forma conjunta. El empleo de multiclasificadores (clasificadores que se fusionan para obtener un resultado mejor que los clasificadores individuales) ha sido una estrategia muy efectiva en la identificación o clasificación de medicamentos, que puede mejorar el poder predictivo de los modelos individuales. Para dar solución a este problema en el año 2013 fue desarrollado el software DASDE® 1.0 (Diversity Analysis, Selection and Discovery of best Ensemble from bases models) (Meneses & Cedré 2013). El software DASDE versión 1.0 tiene varias funcionalidades, dentro de ellas combinar las salidas de varios modelos individuales de clasificación para obtener mejores predicciones. En las aplicaciones quimio-bioinformática no solo existen grandes volúmenes de datos sino que además las bases de datos requieren de la aplicación de un número considerable de modelos individuales de clasificación por lo que se hace difícil la elección de cuáles modelos combinar de forma tal que el resultado que se obtenga supere el mejor obtenido por los clasificadores individuales, pues con tan solo un pequeño número de clasificadores se pueden generar grandes cantidades de combinaciones por lo que estamos frente a un problema combinatorio..
(17) Otra de las funcionalidades del software DASDE versión 1.0 es la selección de las combinaciones de los modelos más diversos con el objetivo de combinar aquellos que no sean idénticos entre sí, pues entonces la combinación no arrojaría resultados superiores. La selección anterior se realiza mediante el uso de varias medidas estadísticas llamadas en la literatura “medidas de diversidad”(Kuncheva & Whitaker 2003), pero nuevamente estamos en presencia de un problema combinatorio por la misma razón, pues la existencia de un gran número de clasificadores individuales genera grandes cantidades de posibles combinaciones. Ante la presencia de los dos problemas combinatorios descritos anteriormente en el software DASDE versión 1.0, se hace necesario aplicar una de las meta-heurísticas existentes pues la búsqueda exhaustiva de las soluciones provoca grandes demoras en las ejecuciones y también dependiendo de las capacidades de memoria de la máquina en varios casos no es posible encontrar soluciones. Precisamente las meta heurísticas ofrecen la posibilidad de no tener que explorar todo el espacio de búsqueda de esas “posible soluciones”. En trabajos recientes como (Hernández 2014) se ha modelado este problema para otra herramienta utilizando la meta heurística Algoritmos Genéticos por lo que se pretende en este trabajo aplicar otra de las meta heurísticas existentes: Optimización basada en Colonia de Hormigas (Yijun 2011; Palanisamy & Kanmani 2012; Kuncheva & Jain 2000) y además ver sus resultados específicamente en el campo de la quimio-informática, por todo lo anteriormente expuesto se enuncia el siguiente objetivo general: Objetivo general Incorporar a la herramienta computacional DASDE la implementación de la meta heurística Optimización basada en Colonias de Hormigas (ACO1) para obtener soluciones eficientes y eficaces en aplicaciones quimio-bioinformática. Para lograr dicho objetivo general, se proponen los siguientes objetivos específicos: Objetivos específicos: 1. Analizar los conceptos básicos de las medidas de diversidad y de la meta heurística ACO para adaptarlos a la modelación del problema.. 1. En inglés se conoce como Ant Colony Optimization..
(18) 2. Incorporar a la herramienta computacional DASDE la implementación de las medidas de diversidad no pareadas: Varianza de Kohavi-Wolpert y Medida de dificultad. 3. Incorporar a la herramienta computacional DASDE la implementación de la modelación de la meta heurística ACO para obtener combinaciones de los modelos más diversos. 4. Incorporar a la herramienta computacional DASDE la implementación de la modelación de la meta heurística ACO para obtener combinaciones de modelos que superen la clasificación individual. 5. Validar el desempeño de la meta heurística mediante la solución a dos problemas reales de quimio-bioinformática. Se formularon las siguientes preguntas de investigación: Preguntas de investigación: 1. ¿Cómo incorporar al software DASDE la implementación de la meta heurística ACO para obtener combinaciones de clasificadores diversos? 2. ¿Cómo incorporar al software DASDE la implementación de la meta heurística ACO para obtener combinaciones de modelos que superen la clasificación individual? 3. ¿Resolverá la incorporación de la meta heurística ACO, de manera eficiente y eficaz problemas reales de Bioquímica? Como conclusión de la revisión bibliográfica se enuncia la siguiente hipótesis de investigación: Hipótesis de investigación: La incorporación de la meta heurística ACO al software DASDE permite obtener soluciones eficientes y eficaces en aplicaciones reales de la bioquímica. El trabajo que se presenta se estructura de la siguiente forma: Capítulo 1 Multiclasificación, medidas de diversidad y optimización basada en colonia de hormigas. Este capítulo está dividido en cuatro secciones principales. La primera de ellas recoge los conceptos esenciales de los métodos de clasificación existentes, así como los modelos clásicos de multiclasificación que se han utilizado ampliamente en la solución de problemas reales con éxito. Le sigue un estudio sobre varias medidas estadísticas para.
(19) evaluar la clasificación. Luego se presentan las medidas de diversidad que se reportan en la literatura; agrupándolas por pares o grupales y se explica el intervalo de valores esperados, el extremo de mayor diversidad. Posteriormente se analiza la viabilidad de utilizar determinadas meta heurísticas en problemas de optimización combinatoria para encontrar una solución que sea lo bastante buena como para no tener que explorar todo el espacio de búsqueda. Se profundiza principalmente en la meta heurística que utiliza la Optimización basada en Colonia de Hormigas. Capítulo 2 Diseño e Implementación sobre el software DASDE En este capítulo se presenta un breve resumen del funcionamiento del software DASDE v1 como antecedente de este trabajo, para comprender mejor su funcionamiento así como el diseño e implementación del mismo. Se detalla la modelación del problema con la meta heurística ACO para obtener combinaciones de modelos diversos y combinaciones de modelos que superan la mejor exactitud individual. También se muestran diagramas de clases, haciendo énfasis en los nuevos módulos implementados. Capítulo 3 Diseño de experimentos y análisis de sus resultados. En este capítulo se muestra el diseño de varios experimentos para validar los resultados así como una comparación con los obtenidos al aplicar una búsqueda exhaustiva. En estos, se usaron las diferentes funcionalidades que brinda el programa para la identificación de los modelos idóneos ensamblados, optimizando el tiempo y el coste de la investigación. Finalmente, se presenta un manual de usuario de los nuevos componentes incorporados a la interfaz visual del software para explicar la forma de trabajar con las nuevas funcionalidades del mismo. El trabajo culmina con la presentación de las conclusiones y de varias recomendaciones a tener en cuenta en un futuro cercano. Finalmente se presentan las referencias bibliográficas..
(20) 1 MULTICLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y OPTIMIZACION BASADA EN COLONIA DE HORMIGAS. A lo largo de la historia, los problemas propuestos a resolver por los métodos de automatización se han centrado principalmente en los llamados problemas de clasificación. A partir de la década de los 90 surge una nueva metodología de clasificación que, a diferencia de las técnicas tradicionales que se basan en clasificar nuevos patrones utilizando un único clasificador, tienen en cuenta todas las decisiones aportadas por múltiples clasificadores. Actualmente muchos investigadores han arribado a la conclusión de que la clasificación conjunta puede ser superior a la individual si existe diversidad y precisión, procurando tener pocos errores y diversos. Pero encontrar una combinación que cumpla con estos criterios resulta bastante difícil, ya que en ocasiones se cuenta con un número de clasificadores bastante elevado y la cuestión radica en cuáles incluir en el sistema y cuáles no. Precisamente, las meta heurísticas como método de búsqueda de soluciones en un espacio no siempre pequeño, se aplican comúnmente a problemas de este tipo en los que no existe un procedimiento algorítmico para obtener la solución de un problema, o bien, es costoso explorar la totalidad del espacio de búsqueda. Dentro de las meta heurísticas más comúnmente usadas se encuentra la Optimización basada en Colonias de Hormigas(ACO), la cual se aplica fácilmente a problemas de optimización combinatoria. En este capítulo se presenta la teoría relativa a los métodos de clasificación existentes así como los modelos clásicos de multiclasificación, mencionando también los más recientes aportes en la combinación de clasificadores; además se explican detalladamente las medidas de diversidad reportadas en la literatura para determinar cuán diverso es un grupo de clasificadores y por último se muestran los elementos esenciales relacionados con la meta heurística ACO.. 1.1 Combinación de clasificadores. A continuación se presenta la teoría referente a los métodos de clasificación existentes así como los modelos clásicos de multiclasificación, abordando también una explicación breve por qué se deben utilizar combinaciones de clasificadores; puntualizando estrategias para la combinación de las salidas de los clasificadores individuales, específicamente la fusión de clasificadores. Finalmente se mencionan los más recientes aportes en la combinación de clasificadores..
(21) 1.1.1 Métodos de Clasificación. El término clasificación se ha utilizado para denotar el reconocimiento y agrupación de objetos que pueden estar representados de distinta forma dentro de un determinado sistema. Actualmente existen diversos métodos matemáticos de clasificación disponibles, que se utilizan en la solución de problemas reales. Estos métodos están caracterizados fundamentalmente porque se conoce la información acerca de la clase a la que pertenece cada uno de los objetos. Cuando la variable de decisión, función o hipótesis a predecir es continua, a los algoritmos relacionados con los problemas supervisados se les conoce como métodos de regresión. Si por el contrario la variable de decisión, función o hipótesis es discreta, ellos se conocen como métodos de clasificación o simplemente clasificadores. En un problema de clasificación tenemos un conjunto de objetos, elementos, instancias u observaciones a los cuales se les asigna una clase de acuerdo a los rasgos o características que lo describen y a un conjunto de reglas de clasificación. La mayoría de las veces este conjunto de reglas no es conocido y la única información conocida es el conjunto de ejemplos etiquetados, de forma tal que las etiquetas representan las clases. Los algoritmos de aprendizaje supervisado inducen las reglas de clasificación a partir de los datos. La clasificación puede dividirse en tres procesos fundamentales: pre-procesamiento de los datos, selección del modelo de clasificación y, entrenamiento y prueba del clasificador (Bonet Cruz 2008). De manera general, se puede decir que los métodos de clasificación son un mecanismo de aprendizaje y por lo tanto un proceso de inducción del conocimiento (Pérez 2012), donde la tarea es tomar cada instancia y asignarla a una clase en particular. Entre los métodos de clasificación más usados están los algoritmos basados en casos, los árboles de decisión, las redes bayesianas, las redes neuronales artificiales, el análisis discriminante y la regresión logística, pero estos no son los únicos. Durante varios años han surgido un número considerable de métodos de clasificación, y aunque en algunos casos podamos reconocer uno de ellos como el mejor dotado para la tarea que pretendemos afrontar, no es lo habitual disponer de un clasificador perfecto que alcance una buena precisión. En otros muchos casos no podemos ni tan siquiera disponer de una lista ordenada que nos facilite el nombre del mejor sistema de clasificación. Por lo que ante la gran diversidad de diseños de clasificadores; si antiguamente, el objetivo era encontrar el mejor clasificador; actualmente, es sacar el mejor provecho de la gran variedad que existen para obtener mayor eficiencia y precisión..
(22) 1.1.2 Descripción de sistemas multiclasificadores Muchos autores se refieren a multiclasificadores como conjuntos de clasificadores que realizan predicciones que se fusionan mediante algún criterio, y se obtiene como resultado un único valor que expresa la exactitud del conjunto. En la literatura internacional los multiclasificadores son citados a través de distintos términos, entre ellos: métodos de ensamble (ensemble methods)(Yan & Goebel 2004); modelos múltiples (multiple models) (Maclin & Shavlik 1995)(Smyth 1995; Jacobs 1996); sistemas múltiples de clasificación (multiple classifier systems); combinación de clasificadores (combining classifiers)(Kittler et al. 1998); integración de clasificadores (integration classifiers); mezcla de expertos (mixture of experts) (Jacobs 1996); comité de decisión (decision committee) (Webb 2000); comité de expertos (committee experts); fusión de clasificadores (classifier fusion) (Cho & Kim 1995), entre otros. El uso de los multiclasificadores ha aumentado en los últimos años ya que resuelven los problemas de sobre adaptación (overfitting) y es posible obtener buenos resultados con conjuntos de entrenamiento de pocas muestras. También la idea de la combinación de diferentes clasificadores se realiza con el principal propósito de mejorar las predicciones de la clasificación con la inclusión de uno de los clasificadores individuales. Asimismo, los multiclasificadores pueden servir para descomponer un problema complejo en múltiples subproblemas que sean más sencillos de entender y resolver(E 2010). 1.1.2.1. ¿Por qué utilizar combinaciones de clasificadores?. Existen muchas razones del por qué combinar clasificadores. Cada método de clasificación se basa en conceptos o procedimientos de estimación diferentes, tratando de aunar las mejores propiedades de cada uno de ellos combinándolos de alguna forma. La combinación de estos muestra mayor precisión que cualquiera de ellos de manera individual. Entre los aspectos que demuestran que los multiclasificadores pueden ser mejores que un único clasificador se pueden destacar: . La decisión combinada mejora a las decisiones individuales.. . Los errores correlacionados de los clasificadores individuales pueden ser eliminados por medio de la combinación, considerándose el total de las decisiones..
(23) . Los patrones de entrenamiento pueden no proporcionar la información suficiente para seleccionar el mejor clasificador.. . El algoritmo de aprendizaje puede no ser adaptado para solucionar el problema.. . El espacio individual de búsqueda puede no contener la función que se propone.. Hansen y Salomon establecen la precisión y la diversidad como requisitos necesarios y suficientes para llevar a cabo con éxito la combinación de dos o más sistemas de clasificación (Hansen & Salomon 1990). Krogh y Vedelsby probaron después, que el error conjunto puede dividirse en un término que mide el error de generalización medio de cada clasificador individual y un término que recoge el desacuerdo entre los clasificadores, o sea, que la combinación ideal consiste en clasificadores con alta precisión que estén el mayor número de veces posible en desacuerdo(Krogh & Vedelsby 1995). Dietterich plantea tres razones para justificar la superioridad de la combinación de clasificadores sobre los individuales: razón estadística, razón computacional y razón representacional, las cuales se describen a continuación: Razón estadística Un sistema de aprendizaje puede verse como la búsqueda dentro de un determinado espacio de hipótesis. Escoger un clasificador que resuelva el problema entraña un riesgo, ya que este puede no ser el más capacitado para resolver el caso que se está tratando, o que el conjunto de datos posea un tamaño demasiado pequeño en comparación con el tamaño del espacio de hipótesis. Debido a esto, puede que la combinación no nos proporcione mejores resultados que el mejor clasificador individual que se dispone, pero sí que elimina o mitiga el riesgo de equivocarnos en la selección. En la Figura 1, f representa el mejor clasificador, H es el espacio de hipótesis, y la región central contiene los clasificadores que clasifican bien en el problema a tratar (Dietterich 2000)..
(24) Figura 1 Razón estadística sobre la elección de la combinación de clasificadores. . Razón Computacional. Aun teniendo un volumen de datos que haga desaparecer el problema estadístico mencionado anteriormente, existe el problema de determinados sistemas de clasificación que realizan algún tipo de búsqueda local por lo que pueden quedar atrapados en un óptimo local. La combinación de clasificadores obtenidos realizando la búsqueda local desde puntos iniciales distintos, logrará una mejor aproximación a la función objetivo buscada a diferencia de lo que consiguen acercarse estos clasificadores individualmente. En la Figura 2, f representa el mejor clasificador, H es el espacio de hipótesis y las líneas discontinuas muestran la trayectoria hipotética de los clasificadores durante su entrenamiento (Dietterich 2000).. Figura 2 Razón computacional sobre la elección de la combinación de clasificadores. . Razón representacional. Se presenta cuando el espacio de búsqueda no contiene ninguna solución que sea una buena aproximación a la función inicial. Mediante combinaciones de hipótesis relativamente sencillas se puede llegar a una mejor aproximación, ya que la combinación.
(25) puede darnos la oportunidad de expandir el espacio de las funciones que pueden ser representadas, con la posibilidad que esto acarrea de que consigamos incluir el objetivo. En la Figura 3, f representa el mejor clasificador y H es el espacio de hipótesis(Dietterich 2000).. Figura 3 Razón representacional en la elección de la combinación de clasificadores 1.1.2.2. Modelos de construcción de multiclasificadores. Entre la gran diversidad de formas que se pueden construir multiclasificadores hay una serie de algoritmos desarrollados, algunos para problemas generales y otros para problemas específicos, pero todos tienen como partes fundamentales: la selección de los clasificadores de base y la elección de la forma de combinar las salidas (Bonet Cruz 2008). Entre los modelos más populares que combinan clasificadores están Bagging, Boosting, Stacking, métodos basados en rasgos y Vote, los cuales se describen a continuación: . Bagging: Es uno de los primeros algoritmos de multiclasificación. Se basa en crear diferentes conjuntos de entrenamiento, extraídos del conjunto inicial de manera aleatoria y con remplazo, con lo cual asegura la diversidad. Este modelo necesita la selección de un modelo de clasificador inestable, o sea, un modelo que con pequeños cambios obtenga valores diferentes. Además usa un único modelo de clasificador y la combinación de los clasificadores resultantes se realiza con la técnica de voto mayoritario (Breiman 1996)(Witten & Frank 2005).. . Boosting: Es parecido a Bagging porque usa el método de crear bases de entrenamiento aleatorias con reemplazo, a partir de la base original y un único modelo de clasificación para los clasificadores de base, de ahí que la diversidad la garantice de la misma forma. Sin embargo, este algoritmo se realiza de.
(26) manera secuencial, donde los clasificadores se van entrenando uno detrás del otro porque usan información del anterior. Otra diferencia es que Boosting le da un peso al modelo por su rendimiento, en lugar de dar peso igual a todos los modelos. El reemplazo se realiza estratégicamente de forma que los casos mal clasificados tienen mayor probabilidad que los bien clasificados, de pertenecer al conjunto de entrenamiento del siguiente clasificador del sistema (Schapire 1990). . Stacking: Es un método diferente a los anteriores pues la diversidad se determina con el empleo de diversos modelos de clasificación. Es menos utilizado que Bagging y Boosting, ya que es difícil de analizar teóricamente. Stacking combina múltiples clasificadores generados por diferentes algoritmos para un mismo conjunto de datos en una primera fase. Para combinar las salidas no utiliza voto mayoritario, sino que introduce un meta clasificador que aprende la relación entre las salidas de los clasificadores de base y la clase original (Wolpert 1992) .. . Métodos basados en rasgos: En la construcción de un multiclasificador, los clasificadores de base pueden ser obtenidos a partir de subconjuntos de rasgos diferentes, lo cual es otra forma de buscar diversidad. La selección de rasgos tiene como objetivo lograr una mayor eficiencia en los cálculos así como una mayor exactitud del multiclasificador. De esa manera puede que los clasificadores individuales no sean tan precisos o exactos, pero sí sean más diversos. Existen muchos modelos de multiclasificadores que utilizan subconjuntos de rasgos diferentes como los descritos por Kuncheva (Kuncheva 2004).. . Vote: Al igual que Stacking, establece la diversidad con la utilización de diferentes modelos de clasificación como clasificadores base. Las salidas de estos clasificadores están dadas por vectores con una distribución de probabilidad para cada una de las clases. Vote combina estas probabilidades utilizando diferentes criterios como voto mayoritario y promedio, mínimo, máximo o mediana de las probabilidades.. 1.1.2.3. Estrategias de Combinación. En la literatura se proponen varias estrategias para realizar la combinación de las salidas de los clasificadores individuales, siendo las más usadas: selección y fusión de clasificadores (Shipp & Kuncheva 2002)(Bulacio 2006).Este trabajo se basará en la estrategia de fusión..
(27) La estrategia de fusión de clasificadores asume que todos los clasificadores son competitivos y complementarios (igualmente expertos). Por este motivo, cada uno de ellos emite una decisión respecto a cada patrón de prueba que se presenta. Esta se puede aplicar siempre que exista redundancia en el análisis, o sea, si hay más de un clasificador capaz de evaluar el problema (Bulacio 2006). La misma se basa en combinar, mediante alguna función, las salidas de los diferentes clasificadores, estas pueden ser un valor concreto, o un vector de probabilidades con una probabilidad asociada a cada clase. Varios son los métodos descritos en la literatura internacional que combinan las salidas de los diferentes clasificadores, los más usados son: voto mayoritario, promedio, producto, máximo, mínimo, mediana, cuentas de borda, cuentas de borda por peso, integrales borrosas (Meneses & Cedré 2013). A continuación se describen algunos de ellos. . Voto mayoritario. La técnica de Voto Mayoritario funciona de forma similar a como el ser humano realiza el proceso de elecciones políticas. La votación por mayoría, es considerada una regla que interpreta cada resultado de clasificación como voto para una de las clases de datos y asigna el patrón de la entrada a la clase que recibe mayoría de votos (Giacinto & Roli 2001).Esta técnica se divide en: Voto Mayoritario Simple y Voto Mayoritario Ponderado . Promedio. Este operador realiza el promedio en cada una de las clases sobre todo el conjunto de clasificadores. La salida global es la clase que alcanza el mayor valor promedio. . Producto. Si los vectores de las características usados por los clasificadores individuales son distintos, se puede establecer la regla del producto como la multiplicación de las probabilidades de una misma clase en todos los clasificadores. . Máximo. Se calcula el máximo valor de las probabilidades de una misma clase que haya sido asignada en todos los clasificadores individuales y se asigna la clase con el mayor valor. . Mínimo. Se calcula el mínimo valor de las probabilidades de una misma clase que haya sido asignada en todos los clasificadores individuales y se asigna la clase con el menor valor..
(28) . Mediana. Se calcula el valor que es la mediana de las probabilidades de una misma clase que haya sido asignada en todos los clasificadores individuales y se asigna la clase con el máximo valor. 1.1.3 Actualidad en la combinación de clasificadores La combinación de clasificadores ha cobrado gran auge en la actualidad como se mencionaba anteriormente en otros epígrafes, a continuación se describen algunas de las investigaciones más recientes realizadas alrededor de este tema: . En el artículo (Díez-pastor et al. 2015) se propone un nuevo enfoque para la construcción de multiclasificadores de conjuntos de datos desequilibrados de dos clases, llamadas Balance Aleatorio, donde cada miembro del ensamble de Balance Aleatorio se entrenó con los datos incluidos en la muestra del conjunto de entrenamiento y aumentados por las instancias artificiales. La novedad en este trabajo radicó en que las proporciones de las clases para cada miembro del ensamble se eligen al azar. En este procedimiento la heurística de la diversidad propuesta garantiza que en el multiclasificador los clasificadores que la integran estén especializados en diferentes puntos de operación en el espacio ROC, lo que conduce a mayor exactitud en comparación con otros multiclasificadores. En este artículo se propuso un nuevo método de creación de multiclasificadores llamado RB-Boost que combina Balance Aleatorio con AdaBoost.M2.. . En (Kuncheva & Rodríguez 2014) se propone un marco probabilístico para la combinación de clasificadores, lo que da rigurosas condiciones de optimización (error de clasificación mínimo) para cuatro métodos de combinación: voto de la mayoría, mayoría de votos ponderados, combinador recuerdo y el combinador naive Bayes. El marco se basa en dos supuestos: la independencia de clase condicional de las salidas del clasificador y una suposición acerca de las precisiones individuales. Los cuatro combinadores se derivan posteriormente el uno del otro, al debilitar progresivamente y luego eliminar de la segunda suposición. En paralelo, el número de los parámetros entrenables aumenta de un combinador al siguiente; donde el orden de preferencia de los combinadores es: naive Bayes, el recuerdo, la mayoría ponderada y de mayoría. Los resultados ponen de manifiesto que definitivamente no hay mejor combinador entre los cuatro candidatos, dando una ligera preferencia a naive Bayes. Este combinador.
(29) fue mejor para los problemas con un gran número de clases debidamente balanceadas, mientras la mayoría de votos ponderados era mejor para los problemas con un pequeño número de clases no balanceadas. . En (Rahman & Tasnim 2014) se plantean diversos métodos de generación de multiclasificadores, los cuales se pueden clasificar en seis grupos que se basan en la manipulación de la formación parámetros, la manipulación de la función de error, la manipulación de la función de espacio, la manipulación de las etiquetas de salida, la agrupación, y la manipulación de los patrones de entrenamiento. También se enuncian diversas aplicaciones desarrolladas en este tema de estudio, como: sensor de calidad de datos, la predicción de cierre de granja de marisco y la identificación de la causa, reconocimiento de escritura, mapeo de hábitat.. . En el artículo (Kuncheva 2013) se plantea el uso de los diagramas kappa-error para obtener información acerca de por qué un método es mejor que otro en un determinado conjunto de datos, dicho diagrama se utilizó para conseguir puntos de vista en la comparación de conjuntos de clasificadores, kappa se calcula a partir de la matriz de contingencia 2x2 correcta / incorrecta. Los resultados experimentales demostraron que hay espacio factible en el diagrama de nuevos métodos del conjunto. También se encontró a través de simulaciones y experimentos de datos reales que la precisión individual es el factor principal para el éxito conjunto en comparación con la diversidad.. 1.2 Evaluación en la clasificación No existe un modelo clasificador mejor que otro de manera general; para cada problema nuevo es necesario determinar con cuál se pueden obtener mejores resultados, y es por esto que han surgido varias medidas para evaluar la clasificación y comparar los modelos empleados para un problema determinado. Las medidas más conocidas para evaluar la clasificación están basadas en la matriz de confusión que se obtiene cuando se prueba el clasificador en un conjunto de datos que no intervienen en el entrenamiento. En la Tabla 1 se muestra la matriz de confusión de un problema de dos clases, donde C1 es la clase negativa y C2 la clase positiva:.
(30) Clase obtenida Clase Real. C1. C2. C1. VN. FP. C2. FN. VP. Tabla 1 Matriz de confusión. Verdaderos positivos (VP) y verdaderos negativos (VN) son la cantidad de elementos bien clasificados de la clase positiva y negativa respectivamente. Falsos positivos (FP) y falsos negativos (FN) son la cantidad de elementos negativos y positivos mal clasificados respectivamente. Basados en estas medidas, se calcula el error, la exactitud (accuracy), la razón de VP (VP rate) o sensitividad, la razón de FP (FP rate), la precisión y especificidad, que se dan por las expresiones siguientes: Error . FP FN VP VN FP FN. Eq 1. Exactitud 1 Error. Razón de TP Sensitivid ad Razón de FP Precisión . Eq 2. VP VP FN. FP FP VN. VP VP FP. Especifici dad . VN VN FP. Eq 3. Eq 4. Eq 5. Eq 6. Otra forma de evaluar el rendimiento de un clasificador es por el análisis de la llamada Receiver Operator Curve (ROC) (Provost & Fawcett 1997). En esta curva es representado el valor de la razón de VP vs. la razón de FP, mediante la variación del umbral de decisión. Se denomina umbral de decisión a aquel que decide si una instancia x, a partir del vector de salida del clasificador, pertenece o no a cada una de las clases. Usualmente, en el caso de dos clases se toma como umbral por defecto 0.5; pero esto no es siempre lo más conveniente. Se usa el área bajo esta curva (Area Under the Curve, AUC) como un indicador de la calidad del clasificador. En tanto dicha área esté más cercana a 1, el comportamiento del clasificador está más cercano al clasificador perfecto (aquel que lograría 100% de VP con un 0% de FP). Pero estas medidas no son suficientes, usándolas así simplemente, para evaluar un clasificador. La forma de dividir los datos en conjunto de entrenamiento y prueba es.
(31) también muy importante. Existen varias técnicas para esto, la más vieja es el método R (resubstitution) el cual se basa en entrenar y probar el clasificador con la misma base de datos. Este método puede traer como consecuencia un sobre-aprendizaje del clasificador, o sea, que el clasificador más que generalizar el conocimiento de los datos, aprenda esto “de memoria”. Otro método usado es el método H (Hold-out), que divide la base a la mitad, una mitad para entrenamiento y otra para prueba. Una versión de éste es el data shuffle que realiza n veces el método H y promedia los resultados. El método de validación cruzada con k subconjuntos (k-fold cross-validation) es uno de los más usados, este método se basa en dividir la base en k segmentos y realizar k procesos de entrenamientos y pruebas, de forma que el proceso i toma el segmento i para prueba y el resto para entrenamiento. Sea I la cantidad de instancias de la base de datos, si k=I entonces el método se denomina validación cruzada dejando uno fuera (leave-one-out). El método boostrap se basa en la generación de n conjuntos de cardinalidad I desde el conjunto de datos original, con reemplazo(Bonet Cruz 2008). Actualmente se usa también en vez de dos conjuntos de datos, tres: uno para entrenamiento, uno para prueba y un tercero para validación. Este último se usa como seudo-entrenamiento, de tal manera que el proceso de entrenamiento se detiene cuando comience a decrecer el rendimiento sobre el conjunto de validación, aunque continúe aumentando sobre el conjunto de entrenamiento (Kuncheva 2004). Este método es muy útil para evitar el sobre entrenamiento. También se usa para ajustar parámetros y seleccionar un modelo apropiado. Tiene como desventaja que necesita un conjunto de datos muy grande. La mejor forma de organizar el experimento en entrenamiento y prueba realmente depende de las características de la base de datos.. 1.3 Caracterización de la diversidad. Medidas de diversidad Existen varios algoritmos desarrollados para construir multiclasificadores, pero en esencia todos estos métodos tienen dos partes importantes: la selección de los clasificadores base y la forma de combinar sus salidas. Al realizar la selección de los clasificadores base, es imprescindible que se logre diversidad en los mismos pues no tendría sentido combinar clasificadores idénticos entre sí. La diversidad en un grupo de clasificadores base es una condición necesaria para la mejora del desempeño de un ensamblado de clasificadores(Kuncheva 2004), ya que de esto dependerá en gran medida el resultado final del multiclasificador. La diversidad en los errores de los clasificadores.
(32) puede dar una medida del mayor valor posible que se puede aspirar con la combinación de esos modelos. Sin embargo, en algunos casos puede que no se logre una gran diversidad, lo que provoca que muchos casos no sean bien clasificados por ninguno de los clasificadores base, de ahí que sea necesario el uso de algunas medidas estadísticas que permiten hacer una estimación de cuán diversos son los clasificadores. En (Kuncheva & Whitaker 2003) se plantea que no hay una medida de diversidad involucrada de forma explícita en los métodos de generación de clasificadores, aunque asumen que la diversidad es el punto clave en cualquiera de los métodos. La elección de la medida a utilizar va a depender directamente de la cantidad de clasificadores a utilizar y de muchos otros aspectos que algunos autores (Kuncheva 2004)(Kuncheva & Whitaker 2003) han definido para estimar cuán diversos son los clasificadores. Las medidas de diversidad pueden clasificarse como medidas en forma de pares (pairwise) y medidas para todo el conjunto (non-pairwise). 1.3.1 Medidas de diversidad en forma de pares (pairwise) Las medidas en forma de pares se calculan por pares de clasificadores usando sus salidas, las cuales son binarias (1,0) que indica si la instancia fue correctamente clasificada o no por el clasificador. A continuación se indica el resultado de dos clasificadores (Ci, Cj) para una instancia en cuanto si la clasificaron correctamente o no. Cj correcto (1) Cj incorrecto (0) Ci correcto (1) a B Ci incorrecto (0) c D a+b+c+d=1 Tabla 2 Clasificación entre los resultados de los clasificadores Ci y Cj para una instancia.. Si se suman para todas las instancias los valores de a, b, c, d entre el par de clasificadores (Ci, Cj) se obtendrá el siguiente resultado, a partir del cual se calculan las medidas en forma de pares:. Ci correcto (1) Ci incorrecto (0). Cj correcto (1) Cj incorrecto (0) A B C D A +B + C + D = N. Tabla 3 Clasificación entre los resultados de los clasificadores Ci y Cj para todo el conjunto de instancias..
(33) Donde A sería igual a la suma total de los valores de a para todas las instancias y así respectivamente con los valores de B, C y D. N es el número total de casos. Un conjunto de L clasificadores produce 𝐿 ∗. 𝐿−1 2. pares de valores. Para obtener un único. resultado habría que promediar estos valores. Coeficiente de correlación (ρ). 1.3.1.1. El coeficiente de correlación entre dos clasificadores Ci y Cj se calcula como:. 𝐶 ,𝐶 = 𝑖. 𝑗. 𝐴∗𝐷−𝐵∗𝐶 √(𝐴 + 𝐵) ∗ (𝐶 + 𝐷) ∗ (𝐴 + 𝐶) ∗ (𝐵 + 𝐷). Eq. 7. , −1 ≤ ≤ 1. El valor final de la medida para un conjunto de clasificadores sería el promedio de los valores asociados a cada combinación de dos clasificadores que se extraiga del conjunto. Mientras menor sea el valor de ρ, mayor será la diversidad.(Kuncheva 2004). 1.3.1.2. El estadístico Q. El estadístico Q (Q Statistics) es otra de las medidas para pares de clasificadores. Se calcula de la siguiente forma: 𝑄𝐶𝑖 ,𝐶𝑗 =. 𝐴∗𝐷−𝐵∗𝐶 , −1 ≤ 𝑄 ≤ 1 𝐴∗𝐷+𝐵∗𝐶. Eq. 8. Para un par de clasificadores estadísticamente independientes, su valor de 𝑄𝐶𝑖 ,𝐶𝑗 va a ser 0. En general, el valor de Q va a oscilar entre −1 y 1. Aquellos clasificadores que tienden a reconocer los mismos objetos correctamente tendrán un valor positivo de Q, y aquellos que comentan errores en diferentes objetos poseerán un valor negativo de Q. La mayor diversidad de esta medida se alcanza mientras menor sea su valor(Kuncheva 2004). Para cualquier par de clasificadores, los valores de ρ y Q tendrán el mismo signo y se puede probar que Q (Kuncheva & Whitaker 2003). 1.3.1.3. Medida de diferencias. La medida de diferencias (The Disagreement Measure) introducida por (Skalak 1996), es la más intuitiva de las medidas entre un par de clasificadores, y es igual a la probabilidad de que los dos clasificadores discrepen en sus predicciones. Mientras mayor sea su valor mayor será la diversidad..
(34) 𝐷𝐶𝑖 ,𝐶𝑗 = 1.3.1.4. 𝐵+𝐶 ,0 ≤ 𝐷 ≤ 1 𝑁. Eq. 9. Medida de doble fallo. La medida de doble fallo (The Double-Fault Measure) fue introducida por (Giacinto & Roli 2001) y considera el fallo de los dos clasificadores al mismo tiempo. En (Ruta & Gabrys 2001) definen a esta medida como una medida no-simétrica. Esto quiere decir que si se intercambian los unos con los ceros en los resultados de los clasificadores, el valor de la medida no va a ser el mismo. Esta medida está basada en el concepto de que es más importante conocer cuando errores simultáneos son cometidos que cuando ambos tienen clasificación correcta. Mientras menor sea el valor mayor será la diversidad. 𝐷𝐹𝐶𝑖 ,𝐶𝑗 = 1.3.1.5. 𝐷 , 0 ≤ 𝐷𝐹 ≤ 1 𝑁. Eq. 10. Combinación de la medida de diferencia y medida de doble fallo. La última de las medidas para pares de clasificadores es una propuesta de una combinación entre la medida de diferencias y la medida de doble fallo (Montero 2011). Mientras mayor sea el valor de esta medida mayor será la diversidad entre los clasificadores. 𝑅𝐶𝑖 ,𝐶𝑗 =. 𝐷𝐶𝑖 ,𝐶𝑗 𝐷𝐹𝐶𝑖 ,𝐶𝑗. Eq. 11. ,0 ≤ 𝑅 ≤ 1. Como D y DF son medidas que difieren en el extremo hacia el cual alcanzan la mayor diversidad, es necesario llevar una de ellas hacia el extremo contrario. Este proceso se realizó restando a 1 la medida DF; lo cual forma parte del método de estandarización de las medidas de diversidad que se propone en (Hernández 2014) y se explica más adelante en este documento.. 1.3.2 Medidas de diversidad para todo el conjunto (non-pairwise) Las medidas de diversidad que se basan en todo el conjunto consideran a todos los clasificadores a la vez y calculan un único valor de diversidad para todo el conjunto. A continuación se explicaran algunas de estas medidas..
(35) 1.3.2.1. Entropía. La medida de Entropía (The Entropy Measure) (Kuncheva & Whitaker 2003) se basa en la idea intuitiva de que en un conjunto de N casos y L clasificadores la mayor diversidad se obtendrá si L/2 de los clasificadores clasifican una instancia correctamente y los otros L- L/2 la clasifican incorrectamente. Fue introducida por (Cunningham & Carney 2000). 𝑁. 𝐿. 𝐿. 1 2 𝐸= ∙ ∑ 𝑚𝑖𝑛 {(∑ 𝑦𝑗,𝑖 ) , (𝐿 − ∑ 𝑦𝑗,𝑖 )} , 𝑦𝑗,𝑖 ∈ {0,1}, 𝑁 𝐿−1 𝑗=1. 𝑖=1. Eq. 12. 𝑖=1. 0≤𝐸≤1 Donde 𝑦𝑗,𝑖 tendrá valor 1 si el clasificador i clasificó correctamente el caso j y 0 en caso contrario. Si E tiene valor 0 esto indica que no hay diferencia entre los clasificadores y un valor 1 indica la mayor diversidad posible. 1.3.2.2. Varianza de Kohavi-Wolpert. La varianza de Kohavi-Wolpert (Kohavi-Wolpert Variance), fue inicialmente propuesta en (Kohavi & Wolpert 1996). Esta medida es originada de la descomposición de la varianza del sesgo del error de un clasificador. Kuncheva y Whitaker presentaron en (Kuncheva & Whitaker 2003) una modificación para medir la diversidad de un ensamblado compuesto por clasificadores binarios, quedando la medida de diversidad como: 𝑁. 𝐿. 𝑗=1. 𝑖=1. 1 𝐾𝑊 = ∑ 𝑌(𝑧𝑗 ) (𝐿 − 𝑌(𝑧𝑗 )) , 0 ≤ KW ≤ 1 𝑑𝑜𝑛𝑑𝑒 𝑌(𝑧𝑗 ) = ∑ 𝑦𝑖,𝑗 𝑁𝐿2. Eq. 13. Con esta medida, la diversidad disminuye a medida que el valor de KW aumenta. 1.3.2.3. Medida de desacuerdo entre expertos. La medida de desacuerdo entre expertos (Measurement Interrater Agreement) (Fleiss 1981) se desarrolla como una medida de fiabilidad entre clasificadores. Puede usarse para medir el nivel de acuerdo dentro de un conjunto de clasificadores, por consiguiente, está también basada en el supuesto que un conjunto de clasificadores debe discrepar entre sí para ser diverso. La diversidad disminuye cuando el valor de k aumenta. El k se calcula por:.
(36) 1. 𝑘 =1−. 𝐿. ∑𝑁 𝑗=1 𝑌(𝑍𝑗 ) (𝐿 − 𝑌(𝑍𝑗 )) 𝑁(𝐿 − 1)𝑝(1 − 𝑝). Eq. 14. , −1 ≤ 𝑘 ≤ 1. Donde el término de la derecha es la medida de concordancia de Kendall y p es la media de la exactitud de la clasificación individual, y se calcula como: 𝑁. 𝐿. 1 𝑝= ∙ ∑ ∑ 𝑦𝑗,𝑖 𝑁∙𝐿. Eq. 15. 𝑗=1 𝑖=1. 1.3.2.4. Medida de dificultad. La medida de dificultad (The Measure of "difficulty" ө) viene del estudio realizado por Hansen y Salamon (Hansen & Salomon 1990). Se calcula a través de la varianza de una variable aleatoria discreta que toma valores en el conjunto {0⁄𝐿, 1⁄𝐿, 2⁄𝐿, … ,1 } y denota la probabilidad de que exactamente i clasificadores hayan clasificado bien todas las instancias. Para conveniencia, θ suele ser escalada linealmente en el intervalo [0,1] tomando 𝑝(1 − 𝑝) como el mayor valor posible, donde p es la precisión individual de cada clasificador. La diversidad del ensamblado aumenta con el decremento del valor de la medida de dificultad. La intuición de esta medida puede ser explicada de la siguiente manera: un ensamblado de clasificadores diverso tiene un valor pequeño de medida de dificultad, dado que cada muestra de entrenamiento puede al menos ser clasificada correctamente por una proporción de todos los clasificadores base, lo cual es más probable con una baja varianza de X. Eq. 16. = 𝑉𝑎𝑟(𝑥) 1.3.2.5. Medida de diversidad generalizada. La medida de diversidad generalizada (Generalized Diversity) se enunció por Partridge y Krzanowski (Partridge & Krzanowski 1997) . Sea Y una variable aleatoria que representa la proporción de clasificadores que clasificaron incorrectamente una muestra x ϵ Rⁿ extraída aleatoriamente del conjunto de datos. Denotemos por 𝑝𝑖 la probabilidad de que 𝑌 = 𝑖/𝐿 y 𝑝(𝑖) la probabilidad de que i clasificadores extraídos de manera aleatoria fallen en clasificar correctamente un objeto.
(37) X extraído aleatoriamente. Supongamos que dos clasificadores son tomados de forma aleatoria del ensamblado D, Partridge y Krzanowski exponen en su trabajo que la máxima diversidad es lograda cuando uno de los dos clasificadores se equivoca en clasificar un objeto y el otro lo clasifica correctamente. En este caso la probabilidad de equivocarse los dos clasificadores es 𝑝(2) = 0. Por otra parte argumentan que la mínima diversidad se lograría cuando el fallo de un clasificador es siempre acompañado con el fallo del otro, entonces la probabilidad de que los dos clasificadores fallen es la misma que la probabilidad de que un clasificador escogido de forma aleatoria falle, esto es 𝑝(1). 𝐺𝐷 = 1 −. 𝑝(2) , 0 ≤ 𝐺𝐷 ≤ 1, donde 𝑝(1). 𝐿. 𝐿. 𝑖 𝑝(1) = ∑ ∗ 𝑝[𝑖] , 𝐿. 𝑝(2) = ∑. 𝑖=1. 𝑖=1. 𝑖 ∗ (𝑖 − 1) ∗ 𝑝[𝑖] 𝐿 ∗ (𝐿 − 1). Eq. 17. Eq. 18. El valor de GD varía entre 0 y 1, siendo 0 la menor diversidad cuando 𝑝(2) = 𝑝(1) y 1 la mayor diversidad cuando 𝑝(2) = 0 y L la cantidad de clasificadores. 1.3.2.6. Medida de diversidad de coincidencia de fallos. Esta medida (Coincident Failure Diversity) se enuncia por Partridge y Krzanowski (Partridge & Krzanowski 1997) , como una mejora a la medida anterior. Esta medida está diseñada de tal forma que tenga un valor mínimo 0 cuando todos los clasificadores siempre clasifiquen correctamente o cuando todos los clasificadores lo mismo clasifiquen correcta o incorrectamente al mismo tiempo. Su máximo valor 1 es alcanzado cuando todos los errores de clasificación son únicos, es decir cuando al menos un clasificador va a clasificar incorrectamente cualquier objeto aleatorio. 0, 𝐶𝐹𝐷 = {. 𝐿. 𝑝[0] = 1. Eq. 19. 1 𝐿−𝑖 ∗∑ × 𝑝[𝑖] , 𝑝[0] < 1 1 − 𝑝[0] 𝐿−1 𝑖=1. p[0]=1 cuando todos los clasificadores siempre son simultáneamente correctos o incorrectos, p[i] es el mismo término de la medida anterior y L es la cantidad de clasificadores. El valor de CFD está entre 0 y 1 y mientras mayor sea, mayor será la diversidad..
(38) 1.3.2.7. Medida de diversidad de distintos fallos. Esta medida (Distintic Failure Diversity) fue igualmente enunciada por Partridge y Krzanowski (Partridge & Krzanowski 1997), como una mejora a la medida anterior, pues ahora se va a tener en cuenta todas las instancias donde los clasificadores no coinciden en las clases asignadas, es decir, se consideran las distintas posibilidades de fallo teniendo en cuenta las clases. 0,. 𝑡[𝑖] = 0. 𝐿. 𝐿−𝑖 𝐷𝐹𝐷 = { ∑ × 𝑡[𝑖] , 𝑡[𝑖] > 0 𝐿−1. Eq. 20. 𝑖=1. Aquí t es un vector de probabilidades en el que cada posición se calcula determinando la cantidad de i clasificadores que hayan fallado en asignar la clase correcta dividido por el total de fallos ocurridos y L es la cantidad de clasificadores. El valor de DFD está entre 0 y 1 y mientras mayor sea, mayor será la diversidad. 1.3.2.8. Medida de la diversidad global. La medida de la diversidad global (Overall Diversity) fue enunciada por (Partridge & Krzanowski 1997) como una versión “pesada” de la medida de diversidad de distintos fallos. Dicha medida se calcula como: 0, 𝑂𝐷 = {. 𝐿. ∑ 𝑖=1. 𝑡[𝑖] = 0. 𝐿−𝑖 × 𝑡[𝑖] × 𝑤[𝑖] , 𝑡[𝑖] > 0 𝐿−1. Eq. 21. Cada posición de w representa el promedio de valores d para cada fila donde i clasificadores fallaron. Los valores d se calculan para cada instancia como; 𝐾. 𝐶𝑘𝑖 𝑑𝑖 = ∑ [√ 2 ] 𝑛𝑖. Eq. 22. 𝑗=0. Donde K es la cantidad de clases o categorías que se asignan a los casos, 𝐶𝑘 indica la cantidad de clasificadores que asignaron la clase k a la instancia i, siendo k una clase incorrecta y ni es el total de fallos ocurridos en la instancia i. El valor de OD está entre 0 y 1 y mientras mayor sea, mayor será la diversidad..
Figure



+7





Documento similar
