Las restricciones de integridad en el modelado conceptual ER
155
0
0
Texto completo
(2) DEDICATORIA A quienes como yo, practican el difícil arte del modelado..
(3) AGRADECIMIENTO Doy gracias a Dios, el que ha puesto siempre a mi lado quien me ayude a continuar el camino. A mis padres, amigos, y colegas de dentro y fuera de mi Departamento quienes han estado siempre al tanto de esta investigación. A Alain Pérez, por todas sus sugerencias..
(4) RESUMEN En la práctica los esquemas Entidad Interrelación generados durante el modelado conceptual no son capaces de especificar muchas de las restricciones que gobiernan el universo de discurso, y que son necesarias para garantizar la integridad de un sistema de información. Aunque han existido intentos, la comunidad de diseñadores de bases de datos no ha adoptado aún una práctica para la expresión de las restricciones no asumidas por el modelo Entidad Interrelación. Por tanto es necesario identificar el lenguaje adecuado para expresar las restricciones de integridad de forma natural durante el modelado conceptual ER del universo de discurso. Luego se deben transformar en un lenguaje para representar restricciones de integridad de forma precisa y formal. Para ello se seleccionó RuleSpeak basado en SBVR, como el lenguaje apropiado para la expresión de restricciones de forma natural, y al Alloy como el lenguaje de representación. Finalmente se muestra la arquitectura, las reglas y el proceso para la transformación de restricciones explícitas, deónticas y condicionales de integridad expresadas en SBVR/RuleSpeak basadas en un esquema ER, hacia un esquema en Alloy..
(5) CONTENIDO. Introducción............................................................................................................................1 Capítulo I.El tratamiento de las restricciones de integridad en el modelado conceptual........6 I.1.El modelo, el modelado de datos y los modeladores....................................................6 I.1.1.Modelado conceptual de datos..............................................................................8 I.2.El modelo Entidad Interrelación...................................................................................9 I.2.1.La estructura del modelo ER.................................................................................9 I.2.2.La integridad en el modelo ER............................................................................12 I.2.3.Representación lógica..........................................................................................13 I.2.3.1.Tipos de entidades.......................................................................................14 I.2.3.2.Tipos de interrelaciones...............................................................................15 I.3.Restricciones de integridad.........................................................................................15 I.3.1.Clasificaciones.....................................................................................................16 I.3.1.1.Según el origen............................................................................................17 I.3.1.2.Según el alcance..........................................................................................18 I.3.1.3.Según causa de violación.............................................................................18 I.3.2.Formas de expresión............................................................................................18 I.3.3.Niveles de expresión............................................................................................19 I.4.Las reglas de negocio..................................................................................................20 I.4.1.Clasificación de las reglas de negocio.................................................................21 I.4.2.El modelo de hechos............................................................................................21 I.5.Lenguajes naturales.....................................................................................................23 I.5.1.Propiedades..........................................................................................................23 I.5.2.Clasificación según área de aplicación................................................................24 I.5.3.Clasificación según esquema PENS....................................................................25 I.5.4.Lenguaje de representación.................................................................................26 I.5.5.Ventajas de los lenguajes naturales controlados..................................................27.
(6) I.6.Lenguajes de especificación........................................................................................28 I.7.Las restricciones de integridad en el análisis con el MER..........................................29 I.8.Otros enfoques en la expresión de las restricciones de integridad..............................30 I.9.Selección del lenguaje natural.....................................................................................32 I.9.1.E2V......................................................................................................................32 I.9.2.Formalized English..............................................................................................33 I.9.3.Attempto Controlled English...............................................................................33 I.9.4.SBVR...................................................................................................................34 I.9.4.1.Structured English.......................................................................................35 I.9.4.2.RuleSpeak....................................................................................................35 I.9.5.Fundamentación del lenguaje natural utilizado...................................................36 I.10.Selección del lenguaje de especificación..................................................................38 I.10.1.Object Constraint Language..............................................................................39 I.10.2.Alloy..................................................................................................................39 I.10.3.Fundamentación del lenguaje de especificación utilizado................................40 I.11.Conclusiones del capítulo..........................................................................................40 Capítulo II.Expresión de las restricciones de integridad en SBVR/RuleSpeak y Alloy.......42 II.1.Expresión en SBVR/RuleSpeak de restricciones de integridad.................................42 II.1.1.Propósito de las plantillas...................................................................................42 II.1.2.Notación para las plantillas................................................................................43 II.1.3.Palabras claves...................................................................................................43 II.1.3.1.Cuantificadores...........................................................................................44 II.1.3.2.Operadores lógicos.....................................................................................44 II.1.3.3.Operadores modales...................................................................................44 II.1.3.4.Operadores de comparación.......................................................................45 II.1.4.Plantillas para SBVR/RuleSpeak.......................................................................46 II.1.4.1.Restricciones de rango................................................................................48 II.1.4.2.Restricciones de igualdad...........................................................................50 II.1.4.3.Restricciones de consistencia.....................................................................51 II.1.5.Correspondencia entre el modelo de hechos y el modelo ER............................54 II.2.Expresión en Alloy de restricciones de integridad.....................................................56.
(7) II.2.1.Fundamentos de Alloy........................................................................................56 II.2.2.Correspondencia entre elementos ER y Alloy...................................................58 II.2.3.Restricciones en Alloy........................................................................................61 II.2.4.Correspondencia entre SBVR y Alloy...............................................................63 II.2.4.1.Correspondencia de los cuantificadores.....................................................63 II.2.4.2.Correspondencia de los operadores lógicos...............................................64 II.2.4.3.Correspondencia de los operadores de comparación.................................64 II.3.Arquitectura...............................................................................................................64 II.3.1.Enfoques top-down............................................................................................65 II.3.2.Enfoque ER/SBVR2Alloy.................................................................................69 II.4.Conclusiones del capítulo..........................................................................................73 Capítulo III.El método de transformación ER/SBVR2Alloy................................................74 III.1.Los componentes de la transformación ER/SBVR2Alloy.......................................74 III.1.1.El componente ER2Alloy.................................................................................76 III.1.1.1.Transformación de tipos de entidad..........................................................77 III.1.1.2.Transformación de tipos de interrelación..................................................78 III.1.1.3.Transformación de la debilidad en identificación.....................................83 III.1.1.4.Transformación de jerarquías de generalización-especialización.............84 III.1.2.El componente SBVR2Alloy............................................................................85 III.1.2.1.Transformación de los cuantificadores.....................................................86 III.1.2.2.Transformación de los operadores lógicos................................................89 III.1.2.3.Transformación de los operadores de comparación..................................90 III.2.El proceso de transformación ER/SBVR2Alloy......................................................90 III.3.El caso de estudio: los bancos y sus empleados.......................................................93 III.4.Caso de estudio: contratos de préstamos..................................................................94 III.5.Conclusiones del capítulo.........................................................................................99 Conclusiones.......................................................................................................................100 Recomendaciones................................................................................................................101 Referencias bibliográficas...................................................................................................102 Anexo A.Restricciones asumidas por el modelo ER..........................................................113 Anexo B.Elementos de SBVR/RS para la expresión de restricciones de integridad.........114.
(8) Anexo C.Resumen sobre el lenguaje Alloy........................................................................117 Anexo D.Correspondencias entre modelos........................................................................126 Anexo E.Formulación semántica para una restricción de rango........................................130 Anexo F.Esquemas ER para los casos de estudio...............................................................131 Anexo G.Código en Alloy para el caso de estudio Contratos de préstamos......................133 Anexo H.Ilustraciones de la aplicación de cada regla de transformación ER2Alloy.........137 Anexo I.Pantallas de la validación con Alloy Analyzer.....................................................144.
(9) FIGURAS. Ilustración I.1: Esquema del Modelo Entidad-Interrelación.................................................10 Ilustración I.2: Construcciones del modelo EER según metamodelo de (Fidalgo et al., 2013)......................................................................................................................................11 Ilustración I.3: Pirámide de términos, hechos y reglas.........................................................22 Ilustración II.1: Taxonomía de restricciones para la elaboración de plantillas.....................46 Ilustración II.2: Propuesta de arquitectura............................................................................65 Ilustración. II.3:. Proceso. de. desarrollo. basado. en. SBVR. según. el. enfoque. SBVR2UML/OCL................................................................................................................67 Ilustración II.4: Enfoques top-down en la transformación de restricciones y esquemas......68 Ilustración II.5: Arquitectura del enfoque ER/SBVR2Alloy.................................................72 Ilustración III.1: Clasificación de transformaciones de modelos según (Beydeda et al., 2005).....................................................................................................................................75 Ilustración III.2: Ambigüedad en un código Alloy para interrelaciones recursivas..............81 Ilustración III.3: Similitudes entre las plantillas...................................................................86.
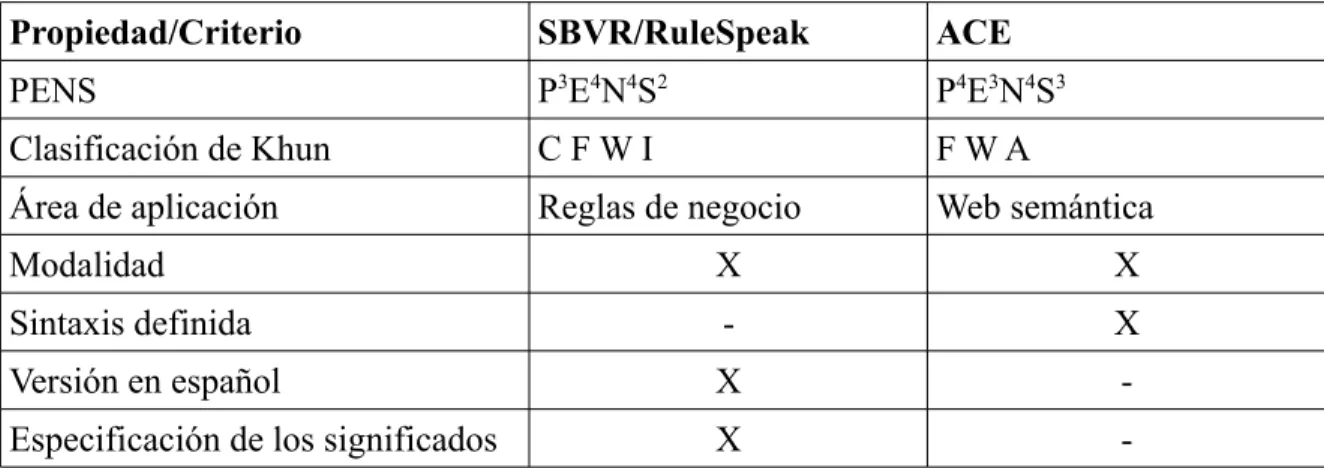
(10) TABLAS. Tabla I.1: Clasificación según Khun a partir del área de aplicación del CNL......................24 Tabla I.2: Antecedentes en el tratamiento de restricciones para el modelo ER....................31 Tabla I.3: Comparación entre SBVR/RuleSpeak y ACE......................................................37 Tabla II.1: Palabras claves para los operadores de comparación..........................................45.
(11) INTRODUCCIÓN. Desde que Peter Chen en su célebre artículo The Entity Relationship Model: Towards a Unified View of Data (Chen, 1976), lanzó al mundo su propuesta; el modelo Entidad Interrelación (ER) se ha convertido en una de las herramientas más populares dentro del diseño de bases de datos (Thalheim, 1999; Halpin & Morgan, 2008). Esto ha ocurrido a pesar de que, para 1976, la mayoría de los investigadores se habían concentrado en la construcción de modelos para representar la estructura de los sistemas (Wand & Weber, 2002). De modo que en algunos artículos se comenzó a describir este fenómeno con un término un tanto peyorativo: YAMA (Yet Another Modeling Approach). Aún son escasos los libros sobre temas de bases de datos, que no dedican al menos un capítulo del contenido para explicar los fundamentos de la construcción de esquemas ER. Sin embargo, quizás por ello, los diseños de bases de datos carecen de un correcto soporte para expresar las reglas que garantizan la integridad en el sistema que se desea implementar. Es notable el hecho de que cuando Peter Chen ideó el modelo ER, solo dio provisión para la representación de las entidades e interrelaciones a través de las cuales se describe la estructura del universo de discurso (UoD), mientras que el aspecto de la integridad quedó pobremente tratado. Sin embargo, un buen modelo debe contener tres componentes fundamentales: la parte estática o estructura, un conjunto de operadores que permitan la consulta y manipulación de los datos, y la integridad (Connolly & Begg, 2005; Date, 2004). Investigaciones más recientes, sobre todo aquellas realizadas por la Comunidad de Reglas de Negocios (BRC, por sus siglas en inglés), han contribuido decididamente al tema de la integridad. Con este enfoque radical basado en las reglas de negocio, logran involucrar con prontitud a los modeladores, no solo en el aspecto estructural de un sistema, sino también en las reglas que gobiernan sus posibles estados y transiciones, las cuales provienen de aquellas que guían y controlan el negocio (Von Halle, 2006; Ross, 1997; Ross, 2007). Son esas reglas del sistema, representadas a través de condiciones orientadas a garantizar la 1.
(12) integridad de un sistema de información (SI), a las que comúnmente se les llama restricciones de integridad (RI), o simplemente restricciones (Olivé, 2007). Según afirman (Date, 2001; Thalheim, 2011; Miguel Castaño & Piattini Velthuis, 1999), las restricciones suman más del 90% de las sentencias necesarias para garantizar la integridad de una base de datos, la cual es el núcleo de un SI. Por tanto, resulta contradictorio que la parte del modelo de datos que más esfuerzo demanda, sea tratada tan tardíamente en el proceso de desarrollo del sistema y que no haya tenido siquiera, a pesar de tantos años de investigación del tema, un tratamiento teórico unificado, como se reclama en (Thalheim, 2011). Ciertamente, la utilización del modelo ER ha provocado que las restricciones sean rápidamente implementadas sin antes ser expresadas de manera clara, sistemática y controlada durante el modelado conceptual, práctica mediante la cual se obtiene una descripción del UoD. Tal descripción debe ser independiente de la tecnología de implementación, precisa y formal; al tiempo que debe ser expresada en términos que la comunidad del negocio entienda. Investigadores relacionados con el MDA (Model Driven Arquitecture), un estilo del enfoque de desarrollo de software donde el modelo y las transformaciones entre ellos son centrales, han descrito la problemática en términos similares. Por lo que han generado aproximaciones que tratan las restricciones en todas las plataformas prescritas por MDA (Pau & Cabot, 2008; Nemuraite et al., 2010; Imran Sarwar Bajwa et al., 2011; I.S. Bajwa et al., 2011; Bajwa et al., 2010; Afreen et al., 2011). Ello equivale a un tratamiento desde los niveles de expresión de mayor nivel de abstracción, hasta aquellos más concretos o ligados a un tecnología específica. La mayoría de tales investigaciones, incorporan algún grado de automatización en la generación de RI. En consecuencia, estas restricciones son expresadas en una manera comprensible por el personal del negocio a través de un lenguaje cercano al natural, sin afectar la agilidad en el desarrollo del software para lo cual media el mecanismo de transformación automática hacia una versión, donde el lenguaje utilizado es preciso y formal. Así, todos las propiedades necesarias para el modelado conceptual se obtienen con este enfoque transformacional. En la Universidad Central “Marta Abreu” de Las Villas (UCLV), se ha desarrollado una investigación sobre temas muy relacionados, a cargo de los miembros del Grupo de Bases de Datos del Centro de Estudios Informáticos (CEI). Una parte de los resultados se han 2.
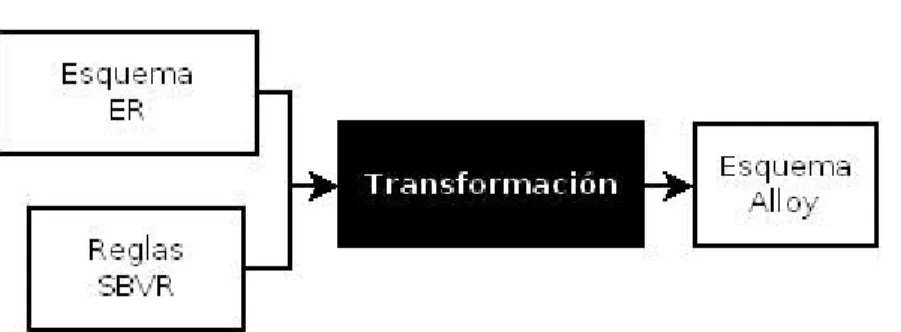
(13) vinculado al enfoque de reglas de negocio en el desarrollo de sistemas de bases de datos (Martínez Busto et al., 2012; Pérez Alonso, 2010; Pérez Alonso et al., 2009; Beatriz et al., 2008). Por otra parte, se han concretado investigaciones relacionadas con el modelado ER (García González, Rodríguez Morffi & González González, 2008; García González et al., 2007; García González, Rodríguez Morffi, Cabrera González, et al., 2008; García González, 2010; García González, 2010). Con estos resultados emerge la oportunidad de abordar el aspecto de la incapacidad del modelo ER para expresar la mayoría de las restricciones de integridad identificadas en el UoD. Mientras de un lado se obtiene el beneficio de la claridad y formalidad asociado al enfoque de reglas de negocio, del otro, la gran capacidad para representar conceptos y relaciones entre ellos de manera sencilla y sin perder expresividad, de un modelo con amplia tradición de uso en la comunidad de diseñadores de bases de datos. Después de todo, el modelo ER es elogiado por haber dibujado la línea entre la expresividad y la sencillez en un buen punto (Badia, 2004). Así, aunque han existido intentos (Simsion & Witt, 2005), la comunidad de bases de datos no ha adoptado una práctica para el tratamiento de la integridad de un SI a partir del modelado conceptual, dado un esquema ER del UoD. En consecuencia, se propone: obtener un esquema para la transformación de aquellas restricciones de integridad que no pueden ser representadas mediante el esquema ER del UoD, y expresadas de forma natural, en una versión más precisa y formal, con la ayuda de los lenguajes apropiados para la expresión en ambos niveles, con vistas a la adopción de una práctica que tome en cuenta la integridad durante el modelado conceptual ER para un sistema de información. Específicamente, es preciso: 1. Identificar el lenguaje adecuado para expresar las restricciones de integridad de forma natural durante el modelado conceptual ER del universo de discurso. 2. Identificar el lenguaje adecuado para representar las restricciones de integridad de forma precisa y formal, dado un esquema ER del universo de discurso más un conjunto de restricciones expresadas de forma natural. 3. Establecer la correspondencia entre el lenguaje identificado para la expresión de las restricciones, y el modelo ER. 3.
(14) 4. Establecer la correspondencia entre el lenguaje de expresión y el lenguaje de representación identificados. Ahora, algunas interrogantes surgen naturalmente a partir de los objetivos formulados: 1.. ¿Qué enfoques existen para el tratamiento de las RI en los SI?. 2. ¿Cómo expresar en forma natural las RI que no pueden ser representadas a través de un esquema ER del UoD? 3. ¿Cómo representar formalmente las RI expresadas en forma natural? 4. ¿Qué correspondencia existe entre los lenguajes de expresión natural y de representación formal de las restricciones de integridad? 5. ¿Qué reglas rigen el proceso de transformación de las RI expresadas en forma natural en una versión formal de las mismas? El origen de las restricciones está en la parte de la realidad sujeta a ser modelada, llamada UoD. Parte de esa misma realidad son las personas, las cuales imponen, violan o cumplen con las reglas vigentes. De manera tal que expresar las restricciones en una forma natural, comprensible fácilmente por la audiencia del negocio, ayuda a involucrarlos en el proceso de modelado y así cerrar la brecha que comúnmente separa al personal del negocio y al técnico. Pues mediante los modelos tradicionales, mientras el primero conoce a fondo el UoD y nada de las herramientas para modelar, el segundo conoce mucho de sus herramientas pero poco del UoD. Por otra parte, conocer las reglas que ayudan a la transformación de las restricciones provee de un marco adecuado para lograr, en caso de ser posible su formulación, una generación automática hasta lograr una versión implementada en un futuro. Así, esta investigación sirve de fundamento teórico para la posible confección de una herramienta que, dado un esquema ER del UoD y un conjunto de restricciones, obtenga la especificación de un modelo de datos para luego implementarlo en alguna tecnología específica de manera automática. Por último, la expresión adecuada de las restricciones en un nivel conceptual, ayuda a cubrir una carencia del modelo ER relativa a la apropiada representación de la integridad. En este terreno se han movido varias investigaciones, no obstante nuevos descubrimientos en el área de los lenguajes naturales y en la investigación de la naturaleza de las reglas. 4.
(15) serán explorados. De manera que la presente investigación reclama la solución a un antiguo problema, con la ayuda de nuevas herramientas. C. A. R Hoare, durante la conferencia en el Turing Award 1980, dijo haber llegado a la conclusión de que existen básicamente dos formas de diseñar un software: la primera es tan sencilla que no hay deficiencias que salten a la vista; la segunda, es tan compleja que tiene deficiencias obvias. En consecuencia, una práctica del diseño para un SI que tome en cuenta las RI desde el inicio, para luego transformarlas a otros niveles de expresión a través de reglas ya establecidas, redundará en un sistema más robusto y sencillo de diseñar e implementar. En cuanto a la estructura del informe de resultados, tres capítulos desarrollan el enfoque propuesto para la expresión de restricciones de integridad. El primero cubre la definición, descripción y clasificación de los conceptos básicos sobre el modelo ER, las restricciones de integridad y los lenguajes para su expresión. En él también se fundamenta la selección de tales lenguajes a partir de una revisión de los distintos enfoques que existen para el tratamiento de la integridad en el modelado conceptual. En el segundo capítulo se analiza cómo expresar las RI mediante la utilización de los lenguajes seleccionados, y cuál es la correspondencia de estos con el modelo ER. También se propone una arquitectura para el enfoque transformacional adoptado, en base al análisis de los enfoques revisados en el primer capítulo. En el tercero, se describen las reglas y el proceso de transformación de las restricciones de integridad y del esquema ER, con la ayuda de de dos casos de estudio para la validación de los argumentos presentados.. 5.
(16) CAPÍTULO I. EL TRATAMIENTO DE LAS RESTRICCIONES DE INTEGRIDAD EN EL MODELADO CONCEPTUAL. En el núcleo de todo sistema de información moderno se encuentra la base de datos. Se ha llegado a la afirmación de que las restricciones de integridad pudieran representar hasta un 90% de su definición. No obstante, es la parte menos atendida durante el modelado de los datos organizacionales, sobre todo, en aquel que utiliza al modelo ER para representar el UoD. En consecuencia, para estudiar las restricciones de integridad en el modelado conceptual, es necesario referirse a los conceptos fundacionales. Además, otros enfoques relacionados al dominio deberán ser mencionados y discutidos. De igual manera, se fundamentará la selección de las tecnologías y métodos sobre los cuales se construirá la propuesta.. I.1. El modelo, el modelado de datos y los modeladores En las bases de datos, un concepto fundamental es el de modelo de datos. Aunque esta disciplina de la ciencia de la computación es una de las más antiguas, no hay una definición universalmente aceptada. Inclusive, entre los autores consultados en esta materia, se encuentran matices diferentes. No obstante, por constituir un concepto fundacional en el estudio teórico de esta área del conocimiento, es prioritario declarar una definición sobre modelo de datos, que sirva de referente para el estudio de la integridad, un aspecto relacionado con los datos generalmente delegado a la cuestiones de implementación. La cuestión es si la integridad es o no componente del modelo de datos. En (Date, 2001), el modelo de datos es concebido como: (…) la definición lógica, independiente y abstracta de los objetos, operadores y demás que en conjunto constituyen la máquina abstracta con la que interactúan los usuarios. Los objetos nos permiten modelar la estructura de los datos. Los operadores nos permiten modelar su comportamiento. 6.
(17) Aunque en esta definición no aparece la integridad como parte del modelo de datos, más adelante, cuando caracteriza brevemente al modelo relacional, le describe a través de tres aspectos: el estructural, el de manipulación, y el de integridad. Solo que deriva este último aspecto del uso de lo operadores de manipulación, a partir de los cuales, afirma, es posible garantizar la integridad de la base de datos. Para (Miguel Castaño & Piattini Velthuis, 1999), el modelo de datos es “un conjunto de conceptos, reglas y convenciones que nos permiten describir y manipular (consultar y actualizar) los datos de un cierto mundo real que deseamos almacenar en la base de datos”. Puede que describir y manipular se asemejen a lo que Date llama modelar la estructura y el comportamiento de los datos. No obstante, debe estimarse el entendimiento que hace Miguel Castaño del término describir. Precisamente lo descrito son los elementos permitidos y los no permitidos, a los que llama la estática del modelo. De esta manera, la estructura llega a comprender la integridad como parte intrínseca, y son los elementos no permitidos los que también denomina como restricciones de integridad. En (Elmasri & Navathe, 2007) también se mencionan las restricciones de integridad como parte de la “estructura” que conforma el modelo de datos. Ello demuestra la tendencia a la inclusión de la integridad dentro de este concepto. Sin embargo, no incluye la manipulación como parte obligatoria de todo modelo de datos En (Connolly & Begg, 2005) se encuentra una definición más clara y completa, en la cual se menciona explícitamente a la integridad como parte integrante del modelo de datos y que es utilizada como referente en este estudio. Definición I.1: Modelo de datos. Un modelo de datos es la colección de conceptos que pueden usarse para describir un conjunto de datos, las operaciones de manipulación sobre los mismos y una serie de restricciones de integridad aplicables a los datos en una organización. En la Definición I.1, lo tres componentes de un modelo de datos se mencionan explícitamente. La inclusión de la integridad es un paso importante en el marco teórico de las bases de datos, en aras de reconocer su importancia en el modelado de los datos.. 7.
(18) I.1.1. Modelado conceptual de datos Si hay modelo, entonces también hay modelado de los datos. En este aspecto, Connolly se refiere al modelado de datos como el proceso de construcción de un modelo del uso de la información dentro de una organización. Sin embargo, no se produce por lo general un único modelo, sino que ha demostrado ser útil la división en varios niveles de abstracción. Dentro de la arquitectura ANSI-SPARC de una base de datos, el nivel conceptual o vista global está pensado para proporcionar independencia física de los datos, es decir, de la forma en que se implementan. Por tanto, el nivel conceptual es la forma en que son percibidos los datos de manera global, por parte de los usuarios. Dentro de este nivel, se distinguen dos grupos de modelos, los conceptuales y los lógicos. Los modelos conceptuales son aquellos que mantienen total independencia de los detalles de implementación, lo cual incluye al sistema gestor de bases de datos (SGBD) de destino. En (Halpin & Morgan, 2008) el modelo conceptual es una descripción del UoD, por lo que es independiente del sistema que pueda ser construido. En cambio, los modelos lógicos presuponen un conocimiento subyacente del SGBD de destino. Por conocimiento subyacente se entiende al conocimiento del modelo de datos que utiliza el gestor para que el usuario así lo perciba, con independencia de la manera en que el SGBD lo implementa. Las siguientes características son encontradas en los modelos conceptuales (Miguel Castaño & Piattini Velthuis, 1999): •. No suelen estar implementados en SGBD. •. Independientes del SGBD. •. Mayor nivel de abstracción. •. Mayor capacidad semántica. •. Más enfocados al diseño de alto nivel (modelado conceptual). •. Interfaz entre el modelador y el experto del dominio. Así, sobre la base de las consideraciones en (Halpin & Morgan, 2008), es convenida como definición de modelado conceptual la que a continuación se detalla.. 8.
(19) Definición I.2: Modelado conceptual. El modelado conceptual de los datos, conocido también como diseño conceptual, es el proceso de descripción precisa y clara del universo del discurso, pensado idealmente como una tarea preparada para las personas en lugar de las máquinas. Quienes dentro del personal técnico asumen la tarea de describir el UoD, es decir, el modelo conceptual de los datos, se les llama modeladores. Si se tiene suficiente conocimiento del dominio, entonces gran parte del modelado estará a cargo del modelador. Sin embargo, por lo general es necesario recurrir a un persona o colectivo de ellas, que estén más familiarizados con el dominio del negocio. Estas personas son conocidas como expertos del dominio. Por ello, el modelado de los datos es en realidad una tarea más colaborativa que individual. Esto último tiene repercusiones a la hora de escoger la herramienta adecuada para el modelado. Deberá tenerse en cuenta en lo adelante que los términos dominio, negocio y universo del discurso serán utilizados indistintamente para referirse a esa parte del mundo real que es modelada.. I.2. El modelo Entidad Interrelación La propuesta del modelado ER surgió a partir del célebre artículo de Peter Chen en (1976). A pesar de que otros enfoques, tales como el Orientado a Objetos, se han propuesto con posterioridad y han ganado aceptación, el modelo ER continúa utilizándose por los diseñadores de bases de datos.. I.2.1. La estructura del modelo ER Como lo indica su nombre, el modelo ER presenta dos conceptos fundamentales ante el modelador: las entidades y las interrelaciones. Las primeras se definen como objetos reales o abstractos sobre el cual se quiere tener información. Para (Chen, 1976) es una persona, lugar, cosa, concepto o suceso, real o abstracto, de interés para la empresa. Por su parte, una interrelación es la asociación o correspondencia entre entidades, por lo que su existencia depende de aquellas entidades que conecta. Aunque no existe un solo modelo ER ni una sola notación diagramática, sino una familia de 9.
(20) ellos, se han creado algunas especificaciones tales como la Information Engineering (Martin & Finkelstein, 1981), la Barker's notation (Barker, 1990), la IDEF1X (NIST, 1993); y el resultado de la Object Management Group (OMG) primeramente con el CWM (Common Warehouse Metamodel) (OMG, 2001) y luego con la propuesta revisada de IMM (Information Management Metamodel) (OMG, 2009). Quizás la especificación más prometedora entre las mencionadas sea la de IMM, producida por la OMG, una organización cuyos estándares han ido ganando relevancia en el mundo académico y en el comercial. El documento (OMG, 2009) presenta un metamodelo1 sobre el modelo ER; sin embargo, este no contiene algunos conceptos relevantes, tales como el tipo de entidad débil y la distinción entre los tipos de interrelación.. Ilustración I.1: Esquema del Modelo Entidad-Interrelación. Esta problemática ha sido apuntada y resuelta por (Fidalgo et al., 2012; Fidalgo et al., 2013). En su propuesta, describe un metamodelo a través de la notación de (Elmasri & Navathe, 2007) para el modelo extendido ER (EER), y afirma que en él se registra el 100% de los conceptos del modelo ER de Chen. También están presentes muchos de los. 1. Metamodelo: es un término utilizado en el contexto de la Model Driven Architecture para referirse a un esquema que especifica, generalmente a través de diagramas de clases en UML, los componentes de un modelo.. 10.
(21) conceptos agregados posteriormente, y altamente conocidos por la academia y los modeladores de bases de datos, como se demuestra en la Ilustración I.1. En este metamodelo, los conceptos se clasifican en nodos y arcos. A su vez, los nodos se clasifican en otros conceptos tales como la herencia, las categorías y lo que denomina “elementos”. Por otra parte, se dividen los arcos en arcos de especialización, arcos de herencia directa (también conocida como “ISA”) y en arcos de interrelación. Una muestra de las construcciones y sus elementos del diagrama, se presenta en la Ilustración I.2.. Ilustración I.2: Construcciones del modelo EER según metamodelo de (Fidalgo et al., 2013). Sobre el modelo ER, es necesario distinguir entre entidad, tipo de entidad y conjunto de entidades. El tipo de entidad es la estructura genérica, la entidad es una ocurrencia del tipo de entidad. El conjunto de entidades es un término análogo al de tipo de entidad, pero hace énfasis en la semántica de conjuntos que domina al modelo ER. Así, un conjunto de entidades se define como sigue (Miguel Castaño & Piattini Velthuis, 1999): Definición I.3: Conjunto de entidades. Sea e una ocurrencia del tipo de entidad E, entonces se denomina conjunto de entidades a {e | p(e)}, donde p(e) es el predicado asociado a E. 11.
(22) Para las interrelaciones existen distinciones similares, por lo que se habla de tipo, ocurrencia y conjunto de interrelaciones. Según (Chen, 1976) y (Olivé, 2007): Definición I.4: Conjunto de interrelaciones. Sea e1, e2, … , en una lista de ocurrencias y E1, E2, … , En una lista de tipos de entidades y r1, r2, … , rn los roles de los respectivos n tipos de entidades respecto al tipo de interrelación R, donde ei es una ocurrencia de Ei, entonces {(r1:e1, r2:e2, …, rn:en) | e i ∈Ei } es un conjunto de interrelaciones de grado n≥2.. Los elementos de un tipo de interrelación son el nombre; el grado o número de tipos de entidades que participan en un tipo de interrelación; el tipo de correspondencia o número máximo de ocurrencias de cada tipo de entidad que pueden intervenir en una ocurrencia del tipo de interrelación; y el rol que cada tipo de entidad tiene en un tipo de interrelación. Otro elemento fundamental del modelo ER son los atributos, los cuales se conciben como propiedades o características que están presentes en los tipos de entidades o tipos de interrelaciones. Un atributo se define (Chen, 1976), como se describe en la Definición I.5. Definición I.5: Atributo. Sea Ei un conjunto de entidades y Ri un conjunto de interrelaciones, se dice que la función f: E i o Ri → D1 X D2 X ... X Dn es un atributo de Ei o de Ri, donde Di es un conjunto de valores. La razón por la cual se elige un producto cartesiano como imagen de la aplicación, reside en la práctica común de los atributos compuestos. En (Elmasri & Navathe, 2007), sin embargo, se elige en su lugar al conjunto potencia, para así apoyar el caso de los atributos multivaluados.. I.2.2. La integridad en el modelo ER Hasta el momento, se han definido los componentes de la estructura del modelo. Para completarlo como modelo de datos solo resta la parte de manipulación y la de integridad. La primera no fue prevista por Chen en su definición inicial. Otros autores, como (Shoshani, 1978) y (McCue & Poonen, 1980), defendieron variantes de lenguajes 12.
(23) orientados a la manipulación de un esquema ER. No obstante, debido a que el MER se ha utilizado tradicionalmente para el diseño de la base de datos, tales lenguajes han carecido hasta el momento de valor práctico. La integridad, aunque muy pobremente, está contemplada en el modelo a través de restricciones sobre las posibles estructuras a representar (restricciones inherentes al modelo) y algunas restricciones que limitan los posibles estados del esquema. Estas últimas restricciones aparecen asociadas a los componentes del modelo ER, es decir, a las entidades, interrelaciones y atributos. Las restricciones de integridad más comunes que son reconocidas por el modelo ER, se muestran en el Anexo A. Por lo general es necesario distinguir entre el modelo básico que es el propuesto por Chen, y el así llamado modelo Entidad Interrelación Extendido. Las extensiones fueron ideadas con el objetivo de proveer al modelo ER de mayores posibilidades semánticas en la descripción del UoD, por lo que representan un conjunto más amplio de restricciones de integridad. No existe un conjunto universalmente aceptado de extensiones o notación, como tampoco existe un solo modelo ER, sino una familia de ellos. La carencia de un estándar ha sido una deficiencia relevante.. I.2.3. Representación lógica Hasta el momento se ha descrito la semántica del modelo ER que le permite, no sin deficiencias, presentarse como modelo de datos. Para ello se vale de la teoría de conjuntos, la cual es fundamental en la disciplina de bases de datos. No obstante, como modelo conceptual, es necesario también describir el fundamento formal que utiliza para representar el universo de discurso. Olivé (2007) afirma que la base formal de los lenguajes para el modelado conceptual es la lógica, de manera que cualquiera de ellos puede ser representado en alguno de los tipos de lógica que existen. La Fisrt Order Logic (FOL) resulta ser suficiente para la especificación de la mayoría de los esquemas conceptuales. En el modelo ER también se da un instrumento para el análisis de la parte de la realidad sujeta a modelarse, que efectivamente está fundado sobre la FOL (Chen et al., 1999). En (Abugessaisa & Sivertun, 2004; Calero et al., 2006) se muestra cómo en el desarrollo de un sistema de información existen dos etapas en el modelado conceptual, la que resulta del 13.
(24) análisis del dominio y la del diseño del sistema. Luego, es necesario mostrar la representación lógica de los componentes del modelo ER.. I.2.3.1. Tipos de entidades En el sentido del discurso, según Olivé (2007): Definición I.6: Tipo de entidad. Los tipos de entidades son conceptos cuyas instancias en un momento dado son objetos individuales identificables de los cuales la comunidad que observa y actúa en el dominio acuerda que existen en ese dominio y en ese momento. La definición anterior afirma que los tipos de entidades son conceptos. Por tanto las teorías cognitivas son aplicables a los tipos de entidades y es posible establecer que un tipo de entidad corresponde unívocamente a un concepto del UoD, lo cual no es más que la representación mental de un objeto real o abstracto, hecho, cualidad o situación. La segunda afirmación, clama que una instancia de un tipo de entidad es un objeto individual. Ello implica que a cada entidad corresponde uno y solo un objeto del dominio. En ocasiones pudiera surgir la duda de si las instancias de ciertos conceptos son o no entidades. La discusión sobre esta ambigüedad aparece en (Chen, 1976) y es anotada por (Date, 2001). Las entidades, por su parte, también deben ser “objetos identificables”. Ello significa que existe algún mecanismo en el dominio que permite diferenciar las entidades. La existencia de las entidades también es temporal, es decir, se considera solo en un momento específico de tiempo. Para otro instante, la misma entidad podría haber dejado de existir. Finalmente, la definición establece que la existencia del objeto, no solo depende del instante de tiempo, sino del acuerdo de la comunidad de personas que actúan y observan en el dominio. El acuerdo de la comunidad de persona establece la vista empresarial del modelo. En la notación de la FOL, un tipo de entidad es considerado un predicado unario, cuyos argumentos son entidades. Así, la clasificación de la entidad e como parte del tipo de entidad E, se representa por la fórmula E(e). Por ejemplo, cierto proveedor representado por 14.
(25) la variable p, puede escribirse como Proveedor(p). En la lógica, estos predicados unarios son llamados hechos. De esta manera, la relación de entre tipos y supertipos puede representarse por la fórmula: ∀ e ( E 1 ⇒ E 2 ) ; donde E1 es subtipo de E2.. I.2.3.2. Tipos de interrelaciones De manera acertada, (Date, 2001) dice que no existe una distinción sustancial entre entidades e interrelaciones. Cualquier definición que lo intente, argumenta, tiene serios defectos, dado que el mismo objeto en el mismo instante de tiempo podría ser visto legítimamente como entidad o vínculo en el mismo instante de tiempo. Esta falta de uniformidad en el tratamiento de los conceptos puede ser perjudicial, dado que cualquier operación o restricción podría ser distinta según se esté refiriendo a un tipo de entidad o de interrelación. No obstante, en beneficio de un entendimiento más preciso de este enfoque tan utilizado en el análisis y diseño de bases de datos, se distinguirá el tipo de interrelación como un concepto muy particular del cual no se puede pensar si no es en relación con al menos dos objetos del dominio. La representación en FOL de una interrelación es un hecho también, de nombre R (nombre único en el esquema elegido para la interrelación R, que tiene n argumentos, lo cuales denotan los n objetos que participan en la interrelación. La fórmula queda entonces como sigue: R(e1, e2, … , en). Para cada tipo de interrelación, el esquema incluye n restricciones de integridad implícitas, llamadas restricciones de integridad referencial; de manera que para un tipo de interrelación R(r1:e1, r2:e2, … , rn:en), se tienen: ∀ e i ∈E i R(e 1 , e 2 ,... , e n)⇒ E i (ei ). I.3. Restricciones de integridad El término restricciones de integridad puede ser encontrado en la literatura bajo los términos de restricciones semánticas, reglas, reglas de negocio o simplemente restricciones. No obstante, resulta conveniente el uso de restricciones de integridad, para así poder distinguirlas de otras posibilidades, tales como las restricciones de permiso, las cuales se mueven en el ámbito de la seguridad de los sistemas. 15.
(26) Específicamente el término integridad es entendido de diversas maneras en la literatura. Para Date (2008; 2009), por ejemplo, la integridad es un estado de la base de datos en el cual no se viola ninguna de las restricciones de integridad definidas, concepto que en (Olivé, 2007) se conoce bajo el término de consistencia de la base de datos. La causa de tal entendimiento reside en que para Olivé la integridad es un concepto aún más amplio, relacionado con la validez y la completitud. Se podrá afirmar entonces que los datos tienen integridad si todos los hechos contenidos en el sistema de información son válidos y están presentes aquellos considerados como relevantes. Nótese que un sistema podrá estar en un estado consistente y no poseer el grado máximo de integridad si, por ejemplo, ciertas restricciones de integridad que debieran estar no se han incorporado en el sistema. En cambio, Date (2008; 2009) habla en términos de corrección, lo cual sería un reflejo verdadero de una base de datos del estado de cosas del mundo real, y para tener un “reflejo verdadero” es necesario que los datos registrados sean válidos y sean conocidos (lo verdadero no es desconocido, puesto que se conoce que es verdadero). Así, las restricciones de integridad son condiciones que, bajo ciertos mecanismo creados para ello, si son satisfechas entonces se podrá tener cierta confianza sobre la integridad del sistema de información (Olivé, 2007). Date (2008; 2009) coincide también en gran medida cuando expresa que una restricción de integridad es “una expresión booleana con un nombre, que requiere ser satisfecha en todo momento”. Por lo cual (Olivé, 2007):. Definición I.7: Restricción de integridad. Una restricción de integridad es una expresión basada en una condición booleana φ que requiere ser satisfecha en todo momento, en caso de lo cual se podrá mantener cierta confianza en la integridad de un sistema de información.. I.3.1. Clasificaciones Clasificar es un proceso mental que ayuda a la persona en su compresión de la realidad, e intenta resumir bajo ciertos términos todo aquello que posee características o rasgos comunes. Un beneficio directo es la precisión de aquello que es objeto de estudio, y una mejor sistematicidad en el análisis de los objetos que pertenecen a una misma clase. El énfasis en la importancia de las clasificaciones de las restricciones se demuestra con la 16.
(27) variedad de esquemas propuestos con estos fines por varios autores (Date, 2004; Ross, 1997; Von Halle, 2002; Miliauskaitė & Nemuraitė, 2005; Ullman & Widom, 2008). Con una clasificación adecuada de las restricciones de integridad, será posible descartar todas aquellas que no serán consideradas por causa del alcance de esta investigación, o porque ya son asumidas por el modelo ER. Para (Miguel Castaño & Piattini Velthuis, 1999) las restricciones, en el sentido más general, se clasifican en restricciones inherentes, y restricciones semánticas o de integridad. Las primeras son aquellas que asume e impone el modelo, son rigideces que no permiten describir todo tipo de estructuras. Según Olivé (2007), estas son restricciones implícitas. Las restricciones de integridad a su vez, se dividen en reconocidas por el modelo (explícitas), esas que no pueden ser asumidas si un modelador no las especifica antes a través de las herramientas del modelo, y aquellas no reconocidas por el modelo. Las restricciones implícitas y explícitas en el modelo ER ya fueron expuestas en el Anexo A. Por tanto, es posible concentrar el estudio en las restricciones de integridad no reconocidas por él. En (Olivé, 2007), tanto si son reconocidas o no, las restricciones se clasifican según: •. Origen: la fuente que dio origen a la formulación de la restricción.. •. Ámbito: los hechos involucrados por la restricción.. •. Violación: causa de la violación de la restricción.. I.3.1.1. Según el origen Según el origen de la restricción, es posible encontrar las siguientes clasificaciones: •. Analíticas: surge por la definición o el significado de los hechos involucrados. Por ejemplo: la edad de una persona no puede ser negativa.. •. Deónticas: surge de la imposición de una condición por parte de un agente autorizado. Por ejemplo: una persona no puede abrir dos o más cuentas bancarias en el mismo día.. •. Empíricas: surge de una condición que contiene empíricamente el dominio sin que nadie la establezca. Por ejemplo: la edad de una persona no puede ser mayor que 200 años.. 17.
(28) I.3.1.2. Según el alcance Usualmente, las restricciones involucran un conjunto limitado de datos y eventos que permite clasificarlas según el alcance en cinco grupos: •. Estáticas: involucran los datos de uno y cada uno de los estados del sistema.. •. De transición: involucran los datos de dos o más estados del sistema. Generalmente, restringen la transición de un estado, pero por extensión el término se usa para aquellas que deben ser satisfechas en algunos estados.. •. De evento: involucran un solo evento.. •. De eventos históricos: involucran dos o más eventos que ocurren al mismo tiempo, o en momentos diferentes.. •. Globales: involucran uno o más estado y uno o más eventos. Como subtipo, se distingue la pre-condición, la cual involucra un solo evento y el estado del sistema cuando ocurre el evento.. I.3.1.3. Según causa de violación En cuanto a la causa de violación, se conocen dos tipos, las de violación por evento y las de violación por tiempo. Puede que parezca evidente que la causa de violación es la ocurrencia de un evento, pero una restricción también podría ser evaluada luego de que transcurrió un lapso definido de tiempo sin la ocurrencia de un evento. En la presente investigación solo se tratarán aquellas restricciones de integridad no reconocidas por el modelo ER, estáticas y de violación por causa de eventos. El origen, en cambio, no es relevante para lograr una identificación acertada de las formas posibles de expresión de las restricciones, dado que solo se refiere al proceso mediante el cual el modelador las formuló.. I.3.2. Formas de expresión De la representación en la notación simbólica de la lógica, es posible encontrar dos formas de expresión. La forma condicional establece que una restricción de integridad es una fórmula cuantificada donde pueden existir o no variables lógicas libres. Suponga la restricción: un proveedor está autorizado a reunirse más de dos veces en el mismo día solo si se reúne en días diferentes. Su representación lógica será: 18.
(29) Proveedor ( p)⇒ ∀ r1 , r2 , d1 , d2 (enReunión (c , r1)∧enReunión(c , r1)∧r1≠r2∧Fecha (r1 , d1)∧Fecha (r2 , d2)⇒ d1≠d2) La misma restricción reformulada a la manera de predicado de inconsistencia se representa como sigue: reunionesSolapadas (c , r1 , r2)⇔ (enReunión (c , r1)∧enReunión(c , r1)∧r1≠r2∧Fecha (r1 , d )∧Fecha (r2 , d )) Nótese que el tipo de hecho reunionesSolapadas advierte sobre los valores de comité y reuniones que provocan un estado inconsistente en el sistema. Las restricciones de inconsistencia tienen la ventaja de mostrar los valores que violan una restricción, mientras que las condicionales solo pueden ser evaluadas en verdadero o falso. Sin embargo, aunque se tenga menos información, manejar restricciones condicionales puede resultar más sencillo. Así las restricciones bajo estudio se expresarán de forma condicional.. I.3.3. Niveles de expresión Según (Von Halle, 2002), son cuatro los niveles de expresión de las restricciones, cada uno según la audiencia a la cual está dirigida: 1. Conversación informal del negocio. 2. Versión en lenguaje natural. 3. Versión en lenguaje de especificación. 4. Versión en lenguaje de implementación. Von Halle (2002) explica además, que una restricción comienza su vida en la conversación informal del negocio, luego se realiza una versión de la misma más disciplinada en lenguaje natural cuya audiencia es la comunidad del negocio. El lenguaje natural presenta algunas insuficiencias tales como la falta de precisión y redundancia, por lo que se requiere de otra versión en un lenguaje que ya reúna tales cualidades. Tal es el caso del lenguaje de especificación. Es declarativo y disciplinado, y está dirigido tanto al personal del negocio como al técnico. Pero este lenguaje solo dice qué acometerse, no cómo. Por ello, las reglas se transforman hacia el lenguaje de implementación, de naturaleza procedural y con el potencial para ser ejecutado. La conversación informal que ocurre en el negocio, no resulta de interés para los fines 19.
(30) declarados. Después de todo, no es más que el mundo real del cual se originan las restricciones. Pero el interés mostrado está sobre las descripciones de la realidad, el UoD, y en la especificación de las restricciones. Ello comprende el esquema conceptual que resulta del análisis y el esquema prescriptivo de los datos con independencia de la tecnología seleccionada para la implementación.. I.4. Las reglas de negocio Ronald Ross, padre de las reglas de negocio, defiende la idea de que las restricciones de integridad difieren de las llamadas reglas de negocio en un aspecto fundamental. Mientras las primeras pertenecen al sistema, las segundas están “bajo la jurisdicción del negocio”. Este aspecto ha sido malinterpretado en más de una ocasión. Inclusive, en los principios del desarrollo del enfoque de reglas de negocio, el término más tradicional de restricción de integridad se identificó con el más moderno de regla de negocio, como lo atestigua, por ejemplo, la definición encontrada en (Hay et al., 2000). El concepto de regla de negocio está restringido al de aquellas reglas que están relacionadas con la comunidad que actúa en el negocio. Como es propio de las reglas, es necesario que una sentencia de este tipo restrinja en alguna medida el grado de libertad, de lo contrario no es más que un consejo. Ahora, las reglas del negocio son el inicio del ciclo de vida de las restricciones, que comienza precisamente en el negocio. Una restricción de integridad, tal y como se ha definido, sea o no reconocida por el modelo, es una condición que restringe los estados posibles del sistema y que no existe si antes no es impuesta por el modelador. Y si el modelador la impone, es porque la infirió (analítica o empíricamente), o porque el experto del dominio la declaró como regla de negocio (restricción de origen deóntico). Por tanto, aunque el término de regla de negocio esté reservado para el ámbito del negocio, las restricciones de integridad tienen su origen directa o indirectamente en ellas, de manera que se está ante dos niveles distintos de expresión de acuerdo a si la “jurisdicción” es la del negocio o la del sistema. Como se declaró en el epígrafe anterior, una restricción tiene varios niveles de expresión, lo cual significa que la regla de negocio se transforma en otras versiones expresadas a través de lenguajes de mayor precisión y menor ambigüedad, hasta que es implementada a través de alguna tecnología. 20.
(31) Puede que en la primera trasformación, la cual ocurre cuando la regla de negocio pasa a la jurisdicción del sistema y se convierte en lo que se conoce como restricción de integridad, suceda alguna pérdida. Ello depende de la medida en que se haga cumplir la regla, es decir, de su operacionalización. Este término se refiere al proceso mediante el cual se obtiene como parte de la respuesta del sistema, el efecto deseado por la regla de negocio (Chisholm, 2004). Por tanto, una regla podría ser completamente operacionalizada (la respuesta del sistema logra el efecto deseado en el negocio), o solo en alguna medida.. I.4.1. Clasificación de las reglas de negocio Las reglas de negocio son clasificadas (Ross, 2013) en estructurales (definitional rules) y operacionales (behavioral rules). Una distinción a partir de la evaluación de la regla puede servir para identificarlas como de un tipo u otro. Las reglas estructurales expresan el sentido de necesidad o imposibilidad, y están relacionadas con la manera en que el negocio se organiza (estructura) en vez de la manera en que se comporta (operaciones). Tampoco es posible violarlas directamente; sino que solo puede ser mal concebidas, mal entendidas o incorrectamente aplicadas. Tales reglas son asumidas por el modelo ER, cuyos esquemas expresan la estructura de cierta organización. Por su parte, las reglas de negocio clasificadas como operacionales son las más abundantes en el dominio y expresan un sentido de obligación o prohibición. Por tanto, una regla operacional puede ser violada directamente, lo cual significa que dada una operación en el negocio es posible establecer si se ha violado o no. Solo que las restricciones de naturaleza operacional no son reconocidas en el modelo ER, por lo que es necesario encontrar un medio de expresión adecuado.. I.4.2. El modelo de hechos Un aspecto importante en la escritura de reglas de negocio, es la base sobre la que se construyen. El business rule mantra, un principio que procede del Manifiesto de las reglas de negocio (Business Rules Group, 2003), establece que las reglas están construidas sobre hechos, y los hechos, sobre términos. Esto es, las reglas de negocio se construyen sobre la base de un modelo de hechos.. 21.
(32) Ilustración I.3: Pirámide de términos, hechos y reglas. Ross y Lam (Ross & Lam, 2011) definen un modelo de hechos como un modelo semántico para el conocimiento del funcionamiento del negocio, el cual está construido como un vocabulario estructurado del negocio que consiste en: •. términos estandarizados para las cosas del negocio, más sus definiciones.. •. frases estandarizadas para tipos de hechos, las que relacionan los términos.. El conocimiento que estructura el modelo de hechos es básico (Ross, 2003), lo cual significa que no puede ser derivado o calculado a partir de otro conocimiento. Este modelo se representa a menudo de manera gráfica, y provee la terminología que se necesita para expresar las reglas de negocio de manera precisa y consistente (Ross & Lam, 2011). Pero no solo se provee de los términos y hechos. En este caso (Witt, 2012a) especifica que un modelo de hechos documenta: •. conceptos. •. terminología preferida para los conceptos. •. atributos, propiedades, o características de los conceptos. •. interrelaciones entre los conceptos. •. terminología preferida para las interrelaciones 22.
(33) I.5. Lenguajes naturales Por lenguaje natural, aplicado en este caso el problema de las restricciones de integridad, no se hace referencia al lenguaje humano; sino a uno más restringido y con base formal, que en ocasiones se le ha llamado lenguaje natural controlado (CNL, por sus siglas en inglés). El término se le ha conocido también bajo otros nombres, tales como lenguaje natural estructurado, procesable, simplificado, restringido, técnico o básico. Algunos de estos nombres aluden a ciertas propiedades que le caracterizan. Como lo atestigua la variedad en la nomenclatura de los CNL, hay muy poco acuerdo en su definición. Recientemente, en (Kuhn, 2013) se define:. Definición I.8: Lenguaje natural controlado. Un lenguaje natural controlado es un lenguaje construido, basado en cierto lenguaje natural, más restrictivo en lo concerniente al léxico, sintaxis y/o semántica mientras se preserva la mayoría de sus propiedades naturales.. I.5.1. Propiedades De manera más detallada, se dice que se está ante un lenguaje natural controlado si y solo si cumple las siguientes cuatro propiedades (Kuhn, 2013): 1. Está basado en exactamente un lenguaje natural. 2. La diferencia más importante con respecto a su lenguaje base, aunque no necesariamente la única, es su mayor restricción en cuanto al léxico, la sintaxis y/o la semántica. 3. Preserva la mayoría de las propiedades naturales de su lenguaje base, de manera que los hablantes de la lengua base pueden de manera intuitiva y correcta entender textos en el lenguaje natural controlado, al menos en un grado sustancial. 4. Es un lenguaje construido, lo cual significa que ha sido explícita y conscientemente definido, y no es el producto de un proceso implícito y natural (no obstante está basado en un lenguaje natural que es producto de un proceso implícito y natural). Las propiedades 1 y 3 se refieren al aspecto “natural” de lenguaje, mientras la 2 y la 4 a lo que le convierte en “controlado”. 23.
(34) Debe notarse además, que las propiedades que integran la definición se limitan a los lenguajes textuales y excluyen los lenguajes visuales tales como los diagramas. Dentro de los textuales, también excluye a los lenguajes naturales (dado que no son construidos), lenguajes tales como el Esperanto (dado que no son construidos sobre un solo lenguaje natural), y los lenguajes formales (dado que nos son entendidos de manera intuitiva).. I.5.2. Clasificación según área de aplicación La clasificación que a continuación se detalla en la Tabla 1.2 está basada no en el lenguaje en sí mismo, sino el área de aplicación o problema a resolver. Tabla I.1: Clasificación según Khun a partir del área de aplicación del CNL. Letra. Propiedad. C. El objetivo es la compresibilidad. T. El objetivo es la traducción. F. El objetivo es la representación formal (incluye la ejecución automática). W. El propósito del lenguaje es que sea escrito. S. El propósito del lenguaje es que sea hablado. D. El lenguaje está diseñado para un dominio específico bien reducido. A. El lenguaje tiene origen académico. I. El lenguaje tiene origen en el medio industrial. G. El lenguaje tiene origen en el medio gubernamental. De acuerdo al problema que el CNL debe resolver, se clasifica entonces con las tres primeras letras. Para mejorar la comunicación entre humanos, específicamente entre hablantes de diferentes lenguas, se crean los lenguajes de tipo C. Los de tipo T intentan mejorar la traducción manual, asistida por computadoras, semiautomática o automática. Por último los de tipo F, pretenden proveer una representación natural e intuitiva para las notaciones formales. Este último tipo incluye la ejecución automática de los textos lo cual requiere una correspondencia con algún formalismo que sea ejecutable. Nótese que como estas clasificaciones están más orientadas a los problemas que a los lenguajes, si alguno de ellos es reutilizado en otro dominio de problema entonces su clasificación puede cambiar aunque el lenguaje no haya cambiado. 24.
(35) La otra distinción es la de lenguajes escritos (W) o hablados (S). Debe aclararse que un lenguaje escrito puede ser hablado, y uno hablado podría, efectivamente, ser escrito. Por tanto la distinción se refiere al propósito para el que fue creado. El origen es el otro criterio que se maneja, a partir del cual se tienen lenguajes que se crearon en ambientes académicos (A), industriales (I) o por alguna agencia de las Naciones Unidas o gobierno (G). La letra D está reservada para aquellos que están pensados para un dominio específico independientemente del medio que le dio origen, es decir, no es un lenguaje de propósito general. Cualquiera de los códigos de letras utilizados se puede combinar, con la excepción de los tipos W y S.. I.5.3. Clasificación según esquema PENS Los códigos descritos están ligados más al problema que al lenguaje en sí. Otro esquema de clasificación que tome en cuenta características o propiedades de los lenguajes es también necesario, de manera que al diseñarlo o seleccionarlo se tenga una mejor idea no solo sobre el propósito y origen del lenguaje, sino también de los atributos deseados para él. El esquema de clasificación de PENS (Kuhn, 2013) describe cuatro dimensiones que ayudan a medir el grado en que cierto atributo está presente en un lenguaje. El grado es lo que distingue las cinco clases, numeradas de la 1 a la 5, que agrupan en conjuntos disjuntos los lenguajes y cubren una dimensión. Los extremos conceptuales en cada una de las dimensiones están dados por los casos del lenguaje natural (no construido), como el idioma Inglés, y el de la lógica proposicional, que es un lenguaje formal (entre ambos se mueven los CNLs). Las dimensiones son: •. Precisión: captura el grado en que el significado de un texto puede ser extraído del texto mismo. 1. Lenguaje impreciso (P1). 2. Lenguajes menos imprecisos (P2). 3. Lenguajes confiables en la interpretación (P3). 4. Lenguaje interpretado de manera determinista (P4) 5. Lenguajes con una semántica determinada (P5). 25.
(36) •. Expresividad: describe el rango de proposiciones que un lenguaje es capaz de expresar. Se restringe la expresividad a cinco características importantes: (a) cuantificación universal sobre individuos, (b) relaciones de grado mayor que 1, (c) estructura general de regla (sentencias if-then con múltiples cuantificadores universales), (d) negación y (e) cuantificación universal de segundo orden sobre conceptos y relaciones. 1. Lenguajes inexpresivos (E1). 2. Lenguajes con baja expresividad (E2). 3. Lenguajes con expresividad media (E3). 4. Lenguajes con alta expresividad (E4). 5. Lenguajes con máxima expresividad (E5).. •. Naturalidad: cuán cercano está el lenguaje a la lengua natural en términos de legibilidad y comprensibilidad de los hablantes de la lengua natural de base. 1. Lenguajes no naturales (N1). 2. Lenguajes con elementos predominantemente no naturales (N2). 3. Lenguajes con elementos naturales predominantes (N3). 4. Lenguajes con sentencias naturales (N4). 5. Lenguajes con textos naturales (N5).. •. Simplicidad: está relacionado con el esfuerzo necesario para implementar completamente la sintaxis y la semántica del lenguaje a través de un modelo formal, como es el de un programa de computadora. 1. Lenguajes muy complejos (S1). 2. Lenguajes sin descripciones exhaustivas (S2). 3. Lenguajes con grandes descripciones (S3). 4. Lenguajes con descripciones cortas (S4). 5. Lenguajes con descripciones muy cortas (S5).. Así, los lenguajes extremos mencionados, la lengua natural y la lógica proposicional, quedan clasificados como P1E5N5S1 y P5E1N1S5 respectivamente.. I.5.4. Lenguaje de representación Aunque los CNLs no siempre tienen una sintaxis posible o necesariamente descrita, como 26.
(37) en los grupos P1 al P3, es necesario encontrar alguna plataforma que permita al menos analizar la semántica con la precisión de la cual carecen, y con una expresividad cercana a la natural. Esto se ha logrado comúnmente en computación a través de la FOL. Es preciso reconocer que la FOL es mucho menor en expresividad que la lengua natural, la cual, por ejemplo, contiene a menudo expresiones de lógica de segundo orden. Tampoco es captada la modalidad, las implicaciones del tiempo verbal u otros matices propios de las lenguas naturales. Debido a que no es posible encontrar una gramática dentro de la jerarquía de Chomsky, las lenguas naturales no pueden ser computacionalmente analizadas. La FOL viene a ser entonces una forma de representar en alguna medida el significado para enmendar esta deficiencia, y que es suficientemente expresiva como para manejar mucho de lo que debe ser representado (Jurafsky & Martin, 2009). Una de las barreras que intenta traspasar la FOL es la ambigüedad y la vaguedad presentes en las lenguas naturales (Jurafsky & Martin, 2009). La ambigüedad ocurre cuando a una entrada lingüística puede corresponder más de una alternativa en su representación formal. La vaguedad, en cambio, a pesar de que no provoca múltiples representaciones, no precisa a qué estructuras se refiere cierta frase o término, es decir, es una expresión vaga. La FOL es, en el contexto de los lenguajes naturales, un lenguaje representacional (Jurafsky & Martin, 2009). Ello se refiere a la plataforma utilizada para especificar la sintaxis y la semántica de las estructuras formales que capturan el significado de los vocablos. La conclusión inmediata, es que otros lenguajes representacionales son posibles. Sin embargo la FOL es una opción apropiada para los lenguajes conceptuales. Con la FOL se tiene una plataforma común para el tratamiento del problema de las restricciones de integridad dado un esquema ER del UoD. Tanto las construcciones ER, como las restricciones de integridad y los lenguajes naturales, así como el modelado conceptual, tienen a la FOL como mecanismo preciso y expresivo para el análisis.. I.5.5. Ventajas de los lenguajes naturales controlados Cuando se habla de ventajas, es necesario aclarar con respecto a qué se presentan tales ventajas. En este sentido, las ventajas encontradas en los CNLs son relativas a la expresión de las RI. Luego, también es necesario establecer frente a cuáles alternativas se presentan las solicitadas ventajas. 27.
Figure




+7




Documento similar
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
Missing estimates for total domestic participant spend were estimated using a similar approach of that used to calculate missing international estimates, with average shares applied
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
Ciaurriz quien, durante su primer arlo de estancia en Loyola 40 , catalogó sus fondos siguiendo la división previa a la que nos hemos referido; y si esta labor fue de
Así, antes de adoptar una medida de salvaguardia, la Comisión tenía una reunión con los representantes del Estado cuyas productos iban a ser sometidos a la medida y ofrecía
b) El Tribunal Constitucional se encuadra dentro de una organiza- ción jurídico constitucional que asume la supremacía de los dere- chos fundamentales y que reconoce la separación
Para recibir todos los números de referencia en un solo correo electrónico, es necesario que las solicitudes estén cumplimentadas y sean todos los datos válidos, incluido el
Como asunto menor, puede recomendarse que los órganos de participación social autonómicos se utilicen como un excelente cam- po de experiencias para innovar en materia de cauces
