El volumen consta de nueve capítulos escritos por expertos en big data y aprendizaje automático y/o análisis económico, que se organizan de la siguiente manera. En el Capítulo 1, García Montalvo presenta una visión crítica de la aplicación de diversas técnicas de aprendizaje automático a conjuntos de datos masivos para resolver problemas como la calificación crediticia, el seguimiento económico de muy alta frecuencia y la construcción de indicadores de desempeño, crecimiento y desigualdad utilizando satélites. imágenes.
INTRODUCCIÓN
MACHINE LEARNING PARA ECONÓMETRAS
Un primer punto son los procedimientos de aprendizaje no supervisados que chocan con la visión tradicional de la econometría que se ocupa de los procedimientos supervisados. La teoría de la generalización y sus implicaciones respecto de la existencia de una muestra de entrenamiento y muestras de prueba representan otra novedad conceptual.
CALIFICACIONES CREDITICIAS, RECOMENDACIONES E INGENIERÍA INVERSA
En la figura 1 se muestra un ejemplo con los resultados de la tabla sobre préstamos hipotecarios a no clientes3. 3 El banco mantenía 13 tablas de puntuación en función del producto (hipoteca, consumo, subrogación de hipoteca, etc.) y de la relación del solicitante con el banco (cliente, no cliente).

BIG DATA, COVID-19 Y ECONOMÍA EN TIEMPO REAL
Una de las consecuencias más comunes de las pandemias es el aumento de la desigualdad (Wade, 2020). 5 El Banco de España también ha utilizado POS para realizar un seguimiento del gasto durante la pandemia (González, Urtasun y Pérez, 2020). una metodología para calcular la evolución de la desigualdad salarial utilizando datos de cuentas bancarias.
PREDICIENDO PRECIOS DE INMUEBLES A NIVEL DE CÓDIGO POSTAL
Predicción agregada a largo plazo
9 Véase García-Montalvo et al. 2018) para obtener detalles sobre cómo se seleccionan las variables y rezagos que se incluirán en la especificación final utilizando un procedimiento de maximización de la distribución posterior (MAP). Específicamente, se puede definir una combinación convexa de la distribución predictiva dadas las observaciones en t y una distribución estacionaria.
Modelo multinivel jerárquico
Sumar los datos del código postal muestra que el supuesto de linealidad con respecto a la evolución del precio total de la vivienda es apropiado en este caso (ver García-Montalvo et al., 2018). Los resultados de la distribución posterior de los coeficientes aparecen en el diagrama de caja de la Figura 4.
OTRAS APLICACIONES: LUCES Y ELECCIONES
Imágenes de satélite
Utilizando este procedimiento, Henderson, Storeygard y Weil (2012) demostraron que la intensidad de la luz por km2 puede predecir la tasa de crecimiento del PIB real. A partir de la correlación con el factor dado, se calculan los pesos de Gini, medidos con respecto a la luz.
Predicción de elecciones con nuevos partidos políticos
De manera similar, muestran que las encuestas son peores que las cuentas nacionales cuando se trata de aproximar los resultados que importan a las poblaciones con niveles de ingresos más bajos en los países en desarrollo11. La validación cruzada de este procedimiento utiliza datos de los países disponibles obteniendo un factor común para los estimadores disponibles en las diferentes bases de datos existentes.
CONCLUSIONES: LECCIONES APRENDIDAS
Teniendo en cuenta la baja relación señal-ruido de muchas bases de datos enormes, este defecto disciplinario se vuelve particularmente importante. En el caso de España, el uso de datos administrativos sigue estando muy por detrás de otros países, especialmente los escandinavos.
BASE DE DATOS: PLATAFORMA DE CONTRATACIÓN DEL SECTOR PÚBLICO
Definición y características generales
La base de datos original contiene información del año 2012, aunque se ha elegido un periodo de análisis de 2018 a 20203. Para llegar a esta cifra se ha realizado un proceso de limpieza previo de la base de datos original, donde se han encontrado entradas duplicadas4, valores extremos y errores en la asignación ha sido eliminada. precios, duración y número de postores.
Análisis descriptivo
Cabe destacar la importancia de la contratación pública simplificada en el caso de los contratos de inversión, que representan el 12% de los mismos. En primer lugar, hay una concentración de encargos para trabajos de corta duración (menos de seis meses).
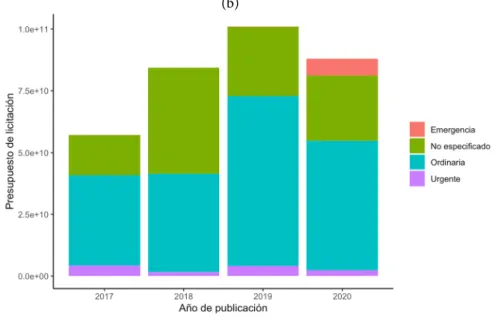
EJERCICIO DE PREDICCIÓN DEL CONSUMO PÚBLICO
Planteamiento del ejercicio
Metodología
Para asegurar que se elijan los parámetros e hiperparámetros que permitan generalizar mejor el modelo, también se utiliza la técnica de validación cruzada. En nuestro caso, la muestra de entrenamiento se divide en tres partes, por lo que cada uno de los modelos probados se entrena tres veces, dejando cada vez una parte diferente, con la que se calcula el error, del proceso de entrenamiento. pronóstico cuadrado.
Resultados
El error absoluto promedio del modelo de predicción del tiempo de recompensa es de solo 0,5 meses, en comparación con un valor de 0,7 para la regresión lineal con regularización Ridge. La Figura 13 muestra que el modelo Random Forest para predecir reducciones porcentuales en el precio de adjudicación es ineficiente.
CONCLUSIÓN Y APLICACIONES ADICIONALES
Una aplicación empírica de estas técnicas al conocido estudio de Angrist y Krueger (1991) sobre los efectos de la educación en los salarios sirve para ilustrar su creciente uso en la economía laboral. La séptima sección presenta una aplicación empírica de estos procedimientos para estimar los rendimientos salariales de la educación.
REGRESIÓN Y EFECTOS CAUSALES EN ECONOMÍA LABORAL
La segunda sección revisa la conexión entre los efectos causales y los modelos de regresión. En otras palabras, en la población con xi = x, la comparación de los ingresos de personas con diferentes niveles de educación es un contraste de "manzanas con manzanas" en lugar de "manzanas con peras".
SELECCIÓN DE CONTROLES EN MODELOS LINEALES CON VARIABLES EXÓGENAS (MCO)
Sin embargo, en el último caso, descartar un control que tiene un fuerte poder predictivo para di (por ejemplo, en la simulación anterior g = 0,8) puede conducir a un sesgo de variable omitida (SVO) significativo en el estimador de α, cuando el coeficiente β de esta variable en la ecuación a estimar es pequeña (en el PGD anterior, β = 0,2). Asimismo, si se utilizara un método de selección de variables para predecir di en la segunda ecuación de [7], xi se excluiría cuando g fuera pequeño, lo que sería incorrecto si la magnitud de β es grande.
SELECCIÓN DE CONTROLES EN MODELOS LINEALES CON TRATAMIENTO NO ALEATORIO (IV)
Bajo el supuesto de exogeneidad de xi, la expresión (A) en la expresión anterior es asintóticamente N E d(0, (i2 1)-. Para proceder con la regularización de los coeficientes en [10], son necesarios dos supuestos clave en ML : (I ) Parsimonia (escasez aproximada) en el conjunto de parámetros f en [10], lo que implica la existencia de un subconjunto de dichos coeficientes, con dimensión sn« pn, que son relevantes, mientras que el resto no lo son tanto; por por ejemplo, después de ordenar los coeficientes por magnitud, esta condición se verifica si |fj | ≤ Aj-a para j = 1,2,..,pn, donde A es una constante y a > 1, y (II) Isometría restringida, una propiedad del álgebra lineal aplicada a la matriz de covarianza de los controles, que implica la existencia de pequeños grupos de regresores que son cuasi-ortonormales, es decir, con una dependencia muy reducida.
MÉTODOS DE REGULARIZACIÓN EN ML
Aunque inicialmente analizamos el caso simple con p = 1 con fines ilustrativos, en la práctica el caso más realista en presencia de big data es el caso en el que p es muy grande, posiblemente dependiendo del tamaño de la muestra n, de modo que p = pn, donde p ≈ n o p »n. Lasso y Root Lasso identifican modelos con un tamaño óptimo sn (ver la definición de Parsimonia arriba) que, en el caso de |fj| ≤ Aj-a, resulta ser sn = n2a1.
REGULARIZACIÓN EN MODELOS NO LINEALES
De manera similar, la verdadera función x que predice y en forma reducida se denota por l0(x). De hecho, este procedimiento nos permite relajar parcialmente el supuesto de Parsimonia requerido al aplicar PSD a modelos lineales con una gran cantidad de controles.
APLICACIÓN EMPÍRICA
Específicamente, z es un conjunto de 510 variables que consta de: una constante, indicadores (dummies) de 9 años de nacimiento, 50 dummies de país de nacimiento y 450 interacciones de los dos conjuntos de dummies anteriores. El Cuadro 1 presenta estimaciones de los rendimientos de la educación utilizando MCB y FULL para diferentes conjuntos de instrumentos.
CONCLUSIONES
En el caso de México, Guerrero y Mendoza (2019) optaron por utilizar exclusivamente datos específicos del país sin recurrir a evaluaciones de calidad de las estadísticas oficiales. Otra cuestión de ampliar la cobertura tiene que ver con la escala temporal, ya que a veces la longitud de las series de datos oficiales es relativamente corta y no permite un análisis adecuado de la economía.
COMBINACIÓN DE DATOS OFICIALES CON DATOS PROVENIENTES DE IMÁGENES DE SATÉLITES
Estimación del crecimiento del PIB verdadero para un país individual
Para corregir este problema, Guerrero y Mendoza (2019) muestran que se puede utilizar el ratio promedio de crecimiento del PIB oficial y luces nocturnas. Sin embargo, este estimador sólo utiliza el crecimiento de largo plazo de las dos variables involucradas, por lo que no se considera confiable para estimar el crecimiento anual del PIB.
Aplicación al crecimiento del PIB de México
La Figura 3 muestra los intervalos de error estándar ±2 del tipo [14] obtenidos con cuatro valores diferentes de λ. La Figura 4 nos permite ver cuatro observaciones fuera de banda, que es el número deseado, es decir un valor entero no mayor a (N-1)/4 = 4.
RETROPOLACIÓN DE LAS SERIES DE CUENTAS NACIONALES COMBINANDO FUENTES DIVERSAS
Descripción de los procedimientos estadísticos
Cuando la verificación arroja resultados favorables se puede concluir la validez de la serie preliminar y su respectivo modelo, lo que también infiere la validez de los resultados desagregados. La aplicación de los métodos anteriores produce la estimación lineal más eficiente que se puede obtener con las bases de datos oficiales del estado – disponibles en el INEGI.
Aplicación numérica de la metodología estadística
La Figura 6 presenta las gráficas de los subsectores manufactureros obtenidas al convertir los datos de la Ciudad de México. En la Tabla 3 se presentan los resultados de la estimación del modelo VAR de orden 1 con el que se obtienen los pronósticos irrestrictos.
CONCLUSIONES
Cada vez hay más aplicaciones de éxito, ya sea basadas en la actualización de la metodología estadística disponible o en el uso de nuevas bases de datos. Debido a la pandemia, desde el sector privado, Google y Apple hicieron públicos indicadores de movilidad basados en la información de sus usuarios.
INTEGRACIÓN FINANCIERA: ADAPTACIÓN DE TÉCNICAS TRADICIONALES
Piccolo (1990) propuso utilizar la distancia euclidiana entre los coeficientes de la representación autorregresiva de la serie. En línea con propuestas no paramétricas, Caiado et al. (2006) introdujeron los métodos en el dominio de la frecuencia y propusieron utilizar la distancia entre los periodogramas de la serie.
INDICADORES PARA LA MONITORIZACIÓN DE LA ACTIVIDAD ECONÓMICA EN TIEMPO REAL A TRAVÉS DE NOTICIAS
El uso de bases de datos basadas en noticias para la previsión y seguimiento de la actividad económica en tiempo real se lleva a cabo en tres pasos. En resumen, las noticias están disponibles con muy alta frecuencia, mucho antes de que tengamos datos estadísticos oficiales, y son útiles para pronosticar en tiempo real la actividad económica y monitorear la economía.
EURITO: GENERACIÓN DE INDICADORES EN ÁREAS VÍRGENES EURITO Research and Innovation Indicators (EURITO, 2018) es un proyecto financiado
Las bases de datos son heterogéneas y muestran diferencias y problemas importantes para la construcción de un indicador de actividad a partir del contenido de los textos. Las Figuras 5 y 6 muestran la evolución del nivel de actividad absoluta y relativa en inteligencia artificial en las tres bases de datos seleccionadas: Crunchbase, arXiv y GitHub (indicada como gh en el gráfico)5.
MOVILIDAD A PARTIR DE LA GEOLOCALIZACIÓN DE TELÉFONOS MÓVILES: NUEVOS INDICADORES PARA VIEJAS PREGUNTAS
La incidencia de la COVID-19 en la movilidad
Del 24 de junio al 30 de diciembre se recopiló información de movilidad los miércoles y domingos, renovando las definiciones de zona de residencia y destino de la matriz de movilidad diaria. 7 En la figura, los datos diarios durante el estado de alarma hasta el 23 de junio se presentan con una línea continua, mientras que los datos correspondientes a los miércoles y domingos desde el 24 de junio hasta el final de la muestra se muestran con espacios.
Otros indicadores de movilidad: Google y Apple
La Figura 8 refleja claramente la falta de movilidad del confinamiento, donde la categoría vivienda es la única con valores positivos respecto al periodo de referencia anterior al COVID-19, y la posterior flexibilización de las medidas que mantienen esta categoría en niveles positivos pero de menor magnitud. En la Figura 8 también se muestra la consiguiente reducción de visitas al resto de lugares durante el parto, siendo la categoría de Alimentación y Farmacia la que menor caída presenta, donde las visitas aún se reducen hasta valores que rondan el 60% respecto al año anterior. Período de referencia.
ALGUNOS RETOS Y VENTAJAS A PARTIR DE LOS EJEMPLOS
El desafío de analizar la coherencia de los indicadores obtenidos depende del ejemplo analizado. Análisis de la movilidad poblacional durante el estado de alerta por COVID-19 a partir de la población de teléfonos móviles.
ESTACIONALIDAD EN SERIES TEMPORALES
Estacionalidad univariante
Otros autores, como Box y Jenkins (1970), asumen que la estacionalidad es una característica constante de la serie. Esto se debe a que, con una estacionalidad estable, las medias de las series serán diferentes en diferentes puntos del ciclo estacional.
Estacionalidad multivariante
Por ejemplo, si S( )ij = bci( )j + vi( )j, donde ( ) es un componente estacional estocástico regular y v( )ij un vector de ruido blanco, las combinaciones ortogonales a b m-1 definen relaciones de cointegración estacional. Con muchas series, es más interesante estudiar los factores comunes, que suelen ser pocos, que las relaciones de cointegración, que pueden ser muchas.
UN MODELO FACTORIAL DINÁMICO ESTACIONAL
Un ejemplo de estacionalidad común
La idea básica es extraer la información presente en los datos, sobre el número y tipo de factores comunes, a partir de la estructura estadística común de asociación de las variables observables. Es bien sabido que la estructura de autocorrelación común de los factores comunes determina la de las variables observables (ver, por ejemplo, Peña y Box, 1987).

Propiedades del modelo factorial estacional
El número total de factores comunes es mucho menor que el número de variables observadas. Una vez identificados el número y tipo de factores comunes, es decir, r1, r2 y r3, se debe especificar un modelo estadístico ARIMA/SARIMA para los factores comunes.
Un ejemplo simulado
Vemos que la banda de confianza del primer valor propio (parte superior) prácticamente no contiene cero, por lo que podemos validar que el primer valor propio es positivo en cualquier rezago k. Serie del primer valor propio medio (arriba) y del segundo valor propio medio (abajo) de las matrices SGCV de la muestra simulada, con bandas de confianza del 95%.

ANÁLISIS DEL EFECTIVO EN CIRCULACIÓN EN LATINOAMÉRICA En esta sección aplicamos la metodología del análisis factorial en presencia de esta-
Antes de estimar los parámetros fijos del modelo, necesitamos identificar los modelos ARIMA/SARIMA para los tres factores comunes. En la Tabla 2 presentamos las estimaciones de los componentes de P, redondeados a dos decimales, y de las varianzas de los sonidos intrínsecos (×104).
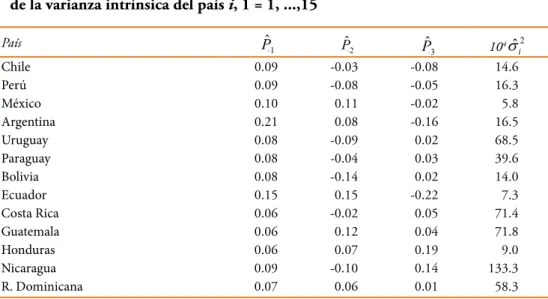
CONCLUSIONES
Estas técnicas se aplican en un contexto de series temporales de alta frecuencia caracterizado por la presencia de diferentes componentes (tendencia, ciclo, estacionalidad, efectos de calendario) lo que supone un aumento significativo de la dimensión efectiva del conjunto de datos. Las opiniones presentadas corresponden al autor, sin coincidir necesariamente con las de la Agencia Tributaria.
ESTACIONALIDAD Y CICLOS
De esta forma se obtiene una estimación de las componentes fundamentales adaptada a las propiedades dinámicas de la serie y, gracias al principio de descomposición canónica, sin elementos irregulares de tipo ruido blanco. La señal de tendencia del ciclo obtenida de esta manera permite la evaluación de un componente cíclico independiente aplicándole un filtro de paso de banda diseñado en el dominio de la frecuencia.
MEDIDA DE DISTANCIA
Matriz inicial de distancia
La matriz [9] representa, para cada par temporal (t, s), una medida de similitud entre las series zi,t y zj,t acumuladas hasta el par en cuestión. Para obtener una medida sintética de la distancia entre dos series, es necesario transformar la matriz en un escalar.
Algoritmo de alineación óptima
Si el número de observaciones es grande, la matriz D puede volverse grande, haciendo que su cálculo sea computacionalmente costoso. Como ya se mencionó, la matriz de distancia final [11] se calcula mediante los componentes básicos del vector2 de serie temporal.
FORMACIÓN DE CONGLOMERADOS
De manera similar, estas matrices servirán como métricas para los algoritmos de agrupamiento que se describen en la siguiente sección. En este trabajo los objetos a combinar son las series temporales asociadas a las componentes estacionales y cíclicas del vector de series temporales.
DATOS
Luego de revisar la asignación de las series temporales a los grupos, los nuevos centroides (representantes) se determinan según el mismo criterio de distancia mínima descrito anteriormente, y también se cambia la asignación según el criterio definido en la expresión [12]. En cuanto a las características de las series seleccionadas que resultan más interesantes en este trabajo, destacan la periodicidad mensual y su elaboración a nivel provincial.
RESULTADOS EMPÍRICOS
Aglomeración estacional
Teniendo en cuenta G = 6, el algoritmo k-medias descrito en la sección anterior da lugar a la distribución geográfica de los grupos que se ven en el mapa de la Figura 7. Para interpretar adecuadamente el patrón territorial, es útil investigar los perfiles estacionales. de los seis grupos, cuyo promedio temporal se muestra en la Figura 8.
Conformidad cíclica
El grupo 5, uno de los dos más grandes y relativamente homogéneo internamente, se caracteriza por una gama reducida de fluctuaciones estacionales y una ubicación geográfica predominantemente continental, con la notable excepción de las dos provincias canarias. Otra forma de comprobar la coherencia entre los dos grupos es comparar con él el factor total de las señales cíclicas de cada uno de los seis grupos considerados.
CONCLUSIONES
En este capítulo se realiza una aplicación del análisis de series temporales funcionales sobre las curvas de tipos de interés intradiarias acumuladas de los precios horarios de la electricidad de España en el Mercado Ibérico de Electricidad (MIBEL). Palabras clave: análisis de datos funcionales, bandas de previsión, precios horarios de electricidad, previsión, series temporales funcionales.
CURVAS DE RENDIMIENTOS INTRADÍA ACUMULADOS
Serie de rentabilidades intradiarias acumuladas de precios horarios de electricidad desde el 1 de enero de 2015 al 30 de septiembre de 2020 divididas en los siete días de la semana en horario de jueves. Rendimiento. Por ejemplo, es razonable preguntarse si los CIDR de los precios de la electricidad son estacionarios desde un punto de vista funcional.

ANÁLISIS DESCRIPTIVO FUNCIONAL DE LAS CURVAS DE RENDIMIENTOS INTRADÍA ACUMULADOS
Media funcional muestral y desviación estándar funcional muestral para los CIDR del precio de la electricidad. En particular, la Figura 7 muestra la función de autocorrelación funcional en [12] para los CIDR de los precios de la electricidad.
COMPONENTES PRINCIPALES FUNCIONALES DE LAS CURVAS DE RENDIMIENTOS INTRADÍA ACUMULADOS
Si observamos la figura y estos porcentajes, el primer M = 3 FPC, que se muestra en la figura 9, proporciona las principales fuentes de variación de los CIDR. El cálculo del FPC de los CIDR se realizó utilizando la función pca.fd de la biblioteca R fda.
PREDICCIÓN DE LAS CURVAS DE RENDIMIENTOS INTRADÍA ACUMULADOS
Luego, se considera la predicción de CIDR en un solo paso utilizando los procedimientos basados en FPC descritos anteriormente. Por tanto, las previsiones obtenidas no son las mejores entre el conjunto de previsiones de los últimos 100 días observados.
CONCLUSIONES
Objetivos
El principal objetivo de este trabajo es proponer un procedimiento k-NN donde no sea necesario calcular todas las distancias cada vez que tengamos que predecir un nuevo caso. Compararemos diferentes enfoques que han sido propuestos para completar las matrices de distancias (Dhillon, Sra y Tropp, 2005; De Soete, 1984; Lapointe y Kirsch, 1995) en combinación con el procedimiento k-NN en términos de error vectorial de la distancia. . y la clasificación de vecinos resultante.
Estructura