ESTADÍSTICA DESCRIPTIVA
- INTRODUCCIÓN
- Media aritmética
- MEDIDAS DE TENDENCIA CENTRAL
- Mediana
- Media geométrica
- MEDIDAS DE POSICIÓN: CUANTILES
- MEDIDAS DE DISPERSIÓN
- Varianza y desviación típica
- Rango intercuartílico
- Coeficiente de variación
- REPRESENTACIONES GRÁFICAS
- Diagrama de barras
- Histograma y polígono de frecuencias
- Gráfico de tallo y hojas
- Diagrama de caja
- REFERENCIAS
Si cada uno de los datos de una muestra se multiplica por una constante, la media de la muestra resultante es igual a la media inicial multiplicada por la constante utilizada; si yi = cxi, entonces y = c x. Si cada uno de los datos de una muestra se multiplica por una constante, la media de la muestra resultante es igual a la media inicial multiplicada por la constante utilizada; si yi = cxi, entonces.

PROBABILIDAD
- INTRODUCCIÓN
- CONCEPTO Y DEFINICIONES DE PROBABILIDAD
- PROBABILIDAD CONDICIONAL E INDEPENDENCIA DE SUCESOS La probabilidad de un suceso puede depender de la realización de otro suceso. Así, por
- REGLA DE LA PROBABILIDAD TOTAL
- TEOREMA DE BAYES
- REFERENCIAS
Por tanto, la probabilidad de un evento puede depender de la ocurrencia de otro evento. La sensibilidad es la probabilidad de obtener un resultado positivo de la prueba diagnóstica entre sujetos verdaderamente enfermos, S = P(+|D).
VARIABLES ALEATORIAS Y DISTRIBUCIONES DE PROBABILIDAD
- INTRODUCCIÓN
- DISTRIBUCIONES DE PROBABILIDAD DISCRETAS
- Distribución binomial
- Distribución de Poisson
- Aproximación de Poisson a la distribución binomial
- DISTRIBUCIONES DE PROBABILIDAD CONTINUAS
- Distribución normal
- Aproximación normal a la distribución binomial
- Aproximación normal a la distribución de Poisson
- COMBINACIÓN LINEAL DE VARIABLES ALEATORIAS
- REFERENCIAS
Estos valores y sus probabilidades constituyen la función de masa de probabilidad de la variable número de sobrevivientes, que se muestra en la Figura 3.1(a). Los valores de la función de distribución en y 4 se muestran en la tercera columna de la Tabla 3.1; así, por ejemplo, la función de distribución en 1 es F(1). En particular, la función de distribución F(x) de una variable aleatoria X se define como la probabilidad de observar un valor menor o igual a x,.

PRINCIPIOS DE MUESTREO Y ESTIMACIÓN
- INTRODUCCIÓN
- PRINCIPALES TIPOS DE MUESTREO PROBABILÍSTICO
- Muestreo aleatorio simple
- Muestreo sistemático
- Muestreo estratificado
- Muestreo por conglomerados
- Muestreo polietápico
- ESTIMACIÓN EN EL MUESTREO ALEATORIO SIMPLE
- Estimación puntual de una media poblacional
- Error estándar de la media muestral
- Teorema central del límite
- Estimación de una proporción poblacional
- REFERENCIAS
En el muestreo sistemático, el ordenamiento de los elementos de la población determinará las posibles muestras. De los resultados de la Sección 3.4, el valor esperado de la distribución muestral de x.

INFERENCIA ESTADÍSTICA
- INTRODUCCIÓN
- ESTIMACIÓN PUNTUAL
- ESTIMACIÓN POR INTERVALO
- Intervalo de confianza para una media poblacional
- CONTRASTE DE HIPÓTESIS
- Formulación de hipótesis
- Contraste estadístico para la media de una población
- Errores y potencia de un contraste de hipótesis
- REFERENCIAS
Ejemplo 5.4 Para cualquier distribución poblacional, la media muestral es un estimador insesgado de la media poblacional y su error estándar. Es decir, el objetivo es probar la hipótesis nula H0: μ = μ0 contra la hipótesis alternativa bilateral H1: μ ≠ μ0, donde μ0 es un valor predeterminado de la media poblacional. La elección entre la hipótesis nula y la hipótesis alternativa dependerá de los resultados obtenidos en la muestra o, más concretamente, de la compatibilidad de las medias muestrales.

INFERENCIA SOBRE MEDIAS
- INTRODUCCIÓN
- INFERENCIA SOBRE UNA MEDIA Y VARIANZA POBLACIONAL
- Inferencia sobre la media de una población
- Inferencia sobre la varianza de una población
- COMPARACIÓN DE MEDIAS EN DOS MUESTRAS INDEPENDIENTES Hasta ahora se han revisado las técnicas estadísticas para realizar inferencias sobre el
- COMPARACIÓN DE MEDIAS EN DOS MUESTRAS INDEPENDIENTES
- Comparación de medias en distribuciones con igual varianza
- Contraste para la igualdad de varianzas
- Contrate para la igualdad de varianzas
- Comparación de medias en distribuciones con distinta varianza
- COMPARACIÓN DE MEDIAS EN DOS MUESTRAS DEPENDIENTES
- REFERENCIAS
A partir de la distribución χn2−1 del estadístico (n – 1)s2/σ 2 es fácil calcular un intervalo de confianza para la varianza poblacional. En el caso de varianzas heterogéneas, los grados de libertad para la distribución de la diferencia de medias están determinados por el enfoque de Welch, a saber. En el caso de varianzas heterogéneas, los grados de libertad para la distribución de la diferencia de medias están determinados por la aproximación de Welch.

INFERENCIA SOBRE PROPORCIONES
INTRODUCCIÓN
INFERENCIA SOBRE UNA PROPORCIÓN POBLACIONAL
A menudo queremos saber la proporción de individuos que poseen una determinada característica en la población. Ejemplo 7.1 Utilizando los controles del estudio EURAMIC, se pretende estimar la proporción de individuos de la población de referencia de dicho estudio que tienen niveles de colesterol HDL menores o iguales a 0,90 mmol/l (niveles bajos según el "Programa Nacional de Educación para el colesterol". Ejemplo 7.1 Utilizando los controles del estudio EURAMIC, se pretende estimar la proporción de individuos de la población de referencia de dicho estudio que tienen niveles de colesterol HDL menores o iguales a 0,90 mmol/l (niveles bajos según el "Programa Nacional de Educación para el colesterol".
COMPARACIÓN DE PROPORCIONES EN DOS MUESTRAS INDEPENDIENTES
Como ya se señaló en la sección 5.2, la proporción muestral p es un buen estimador puntual de la proporción poblacional, ya que p es el estimador insesgado y consistente de con el error estándar más bajo. El método más simple para obtener un intervalo de confianza es reemplazar el error estándar de p con su estimación p(1 p)/n y resolver para encontrar la proporción poblacional. Además, para determinar si los datos de la muestra son compatibles con una proporción subyacente del 30%, se probó la hipótesis H versus H1: 0,30 utilizando la estadística.
COMPARACIÓN DE PROPORCIONES EN DOS MUESTRAS INDEPENDIENTES Supongamos ahora que el interés radica en comparar la proporción de sujetos con una
En general, los resultados de una comparación de una variable dicotómica en dos muestras independientes suelen organizarse en una tabla 2×2 (Tabla 7.1). Se utiliza estadística para la prueba bilateral de la hipótesis nula de igualdad de proporciones poblacionales H0: 1 = 2. Se utiliza estadística para la prueba bilateral de la hipótesis nula de igualdad de proporciones poblacionales H0: π1 = π2.

ASOCIACIÓN ESTADÍSTICA EN UNA TABLA DE CONTINGENCIA
A partir de esta tabla 22 pretendemos comparar la proporción de sujetos con niveles bajos de colesterol HDL ( 0,90 mmol/l) entre casos p1 = c/m1. De este resultado se deduce que p1 - p2 es un estimador puntual insesgado de la diferencia de riesgo subyacente 1 - 2 entre expuestos y no expuestos, E(p1 - p2) = 1. Así, los casos de infarto de miocardio tienen significativamente más probabilidades de presentar niveles bajos de colesterol HDL que los pacientes libres de la enfermedad (P < 0,001), con una diferencia en proporciones del 12,5% (IC al.
ASOCIACIÓN ESTADÍSTICA EN UNA TABLA DE CONTINGENCIA En este apartado se presenta una prueba de significación estadística para evaluar de
Ejemplo 7.6 La Tabla 7.2 muestra los valores observados de la asociación entre la mortalidad por enfermedades cardiovasculares y el colesterol total en el estudio prospectivo NHANES II. Para evaluar la independencia de las variables en la Tabla 22, las frecuencias observadas y esperadas se comparan utilizando la estadística. La hipótesis nula de independencia entre las variables de una tabla 22 equivale a la igualdad de dos proporciones poblacionales.

TEST DE TENDENCIA EN UNA TABLA r 2
Los grados de libertad corresponden al número de frecuencias esperadas independientes para el cálculo del estadístico, una vez determinados los marginales de la tabla r×c. Ejemplo 7.8 La Tabla 7.5 muestra las muertes por enfermedades cardiovasculares entre los participantes en el estudio NHANES II con colesterol sérico total inferior a 5,20 mmol/l (nivel deseable), entre 5,20 y 6,19 mmol/l (nivel límite), alto) y mayor o igual a 6,20 mmol/l (hipercolesterolemia). Los grados de libertad corresponden al número de frecuencias esperadas independientes para el cálculo del estadístico, una vez determinados los marginales de la tabla rc.
TEST DE TENDENCIA EN UNA TABLA r×2
Este resultado confirma que el riesgo de mortalidad por enfermedades cardiovasculares aumenta significativamente al aumentar los niveles de colesterol total. es la proporción total de muertes por enfermedades cardiovasculares entre todos los participantes de NHANES II. Este resultado confirma que el riesgo de mortalidad por enfermedades cardiovasculares aumenta significativamente al aumentar los niveles de colesterol total.
MEDIDAS DE EFECTO EN UNA TABLA DE CONTINGENCIA
- Riesgo relativo
- Odds ratio
Ejemplo 7.10 De la Tabla 7.2 se desprende que la proporción de muertes debidas a enfermedades cardiovasculares es p en los participantes del estudio NHANES II con niveles de colesterol total superiores a 6,20 mmol/l y p2. Además, si la probabilidad de enfermarse es baja en los sujetos expuestos y la razón de probabilidades entre expuestos y no expuestos se determina mediante En tales circunstancias, si la incidencia de la enfermedad es baja y el diseño del estudio retrospectivo es apropiado (es decir, casos incidentes y controles representativos del nivel de exposición en la población libre de la enfermedad), el odds ratio es una buena aproximación de la probabilidad relativa subyacente. riesgo.
COMPARACIÓN DE PROPORCIONES EN DOS MUESTRAS DEPENDIENTES
Debido a que la incidencia de infarto agudo de miocardio es relativamente baja en la población masculina adulta, este odds ratio puede interpretarse como un riesgo relativo y se puede concluir que las personas con un colesterol HDL superior a 0,90 mmol/l tienen un riesgo 42 % menor de sufrir un infarto agudo de miocardio. tener un ataque al corazón. un infarto de miocardio que aquellos con un colesterol HDL inferior a 0,90 mmol/l. El odds ratio es una medida del efecto multiplicativo cuya distribución muestral es notablemente asimétrica (Figura 7.2(c)), mientras que la transformación logarítmica log(OR) tiende a distribuirse normalmente (Figura 7.2(d)) con una varianza aproximadamente igual a la suma de la inversa de las frecuencias de una tabla de 2×2. 27 Debido a que la incidencia de infarto agudo de miocardio es relativamente baja en la población de hombres adultos, este odds ratio puede interpretarse como un riesgo relativo y se puede concluir que las personas con un colesterol HDL superior a 0,90 mmol/l tienen un 42% de un menor riesgo de sufrir un ataque cardíaco. sufren un infarto de miocardio que aquellos con un colesterol HDL inferior a 0,90 mmol/l.
COMPARACIÓN DE PROPORCIONES EN DOS MUESTRAS DEPENDIENTES Hasta este punto se han presentado distintos métodos para la comparación de proporciones a
Si el número de pares b incompatibles con el caso expuesto es mayor que el número de pares. En la Tabla 7.7 hay 6 pares incompatibles donde solo el caso de ataque cardíaco tiene un nivel alto de colesterol HDL y 17 pares incompatibles donde el Ejemplo 7.18. En la tabla 7.7 hay 6 pares incompatibles donde solo el caso de infarto tiene un nivel alto de colesterol HDL y 17 pares incompatibles donde solo.

APÉNDICE: CORRECCIÓN POR CONTINUIDAD
Luego se calculan los intervalos de confianza asociados y las pruebas de hipótesis utilizando la corrección por continuidad. Luego se calculan los intervalos de confianza asociados y las pruebas de hipótesis utilizando la corrección por continuidad. En general, utilizar la corrección de continuidad conduce a resultados más conservadores; es decir, intervalos de confianza más amplios y valores P más altos de los contrastes.
Sin embargo, los resultados con y sin corrección son muy similares, ya que el tamaño de muestra utilizado en este ejemplo es bastante grande. La corrección por continuidad también se aplica a la comparación de proporciones en muestras independientes o dependientes y a la prueba de asociación chi-cuadrado en una tabla 2 × 2, ya que estos métodos de inferencia utilizan una distribución continua (normal o chi-cuadrado) para representar los valores una distribución de frecuencia discreta. El objetivo principal de esta corrección es aumentar la cobertura de los intervalos de confianza y reducir la posibilidad de error tipo I en los contrastes, especialmente cuando el tamaño de la muestra es pequeño.
MÉTODOS NO PARAMÉTRICOS
- INTRODUCCIÓN
- TEST DE LA SUMA DE RANGOS DE WILCOXON
- TEST DE LOS RANGOS CON SIGNO DE WILCOXON
- TEST EXACTO DE FISHER
- REFERENCIAS
En la Tabla 8.2 se presenta una versión corregida por continuidad de la prueba de suma de rangos de Wilcoxon (con o sin empates). Por lo tanto, el estadístico de suma de rangos de Wilcoxon con corrección de continuidad. Bajo la hipótesis nula de simetría de las diferencias alrededor de 0, el valor esperado de la suma de rangos positivos.

DETERMINACIÓN DEL TAMAÑO MUESTRAL
- INTRODUCCIÓN
- TAMAÑO MUESTRAL PARA LA ESTIMACIÓN DE UN PARÁMETRO POBLACIONAL
- Tamaño muestral para la estimación de una media
- Tamaño muestral para la estimación de una proporción
- TAMAÑO MUESTRAL PARA LA COMPARACIÓN DE MEDIAS
- Tamaño muestral para la comparación de medias en dos muestras independientes Supongamos que se pretende contrastar la hipótesis nula H 0 : μ 1 = μ 2 de igualdad de medias
- Tamaño muestral para la comparación de medias en dos muestras independientes
- Tamaño muestral para la comparación de medias en dos muestras dependientes Supongamos que se planea seleccionar n parejas de datos dependientes procedentes de dos
- TAMAÑO MUESTRAL PARA LA COMPARACIÓN DE PROPORCIONES En esta sección se aborda el problema de la determinación del tamaño muestral en
- TAMAÑO MUESTRAL PARA LA COMPARACIÓN DE PROPORCIONES
- Tamaño muestral para la comparación de proporciones en dos muestras independientes
- Tamaño muestral para la comparación de proporciones en dos muestras dependientes
- Tamaño muestral para la comparación de proporciones en dos muestras dependientes Supongamos que se pretende contrastar la hipótesis nula H 0 : π 1 = π 2 frente a la hipótesis alternativa
- REFERENCIAS
La fórmula del tamaño de la muestra presentada en esta sección se basa en la aproximación normal de la distribución muestral de una población. La determinación del tamaño de la muestra para la comparación de medias en más de dos muestras dependientes o independientes sigue argumentos similares a los descritos en esta sección. El cálculo del tamaño de la muestra se puede extender a la comparación de tres o más proporciones en muestras dependientes o independientes.

CORRELACIÓN Y
REGRESIÓN LINEAL SIMPLE
INTRODUCCIÓN
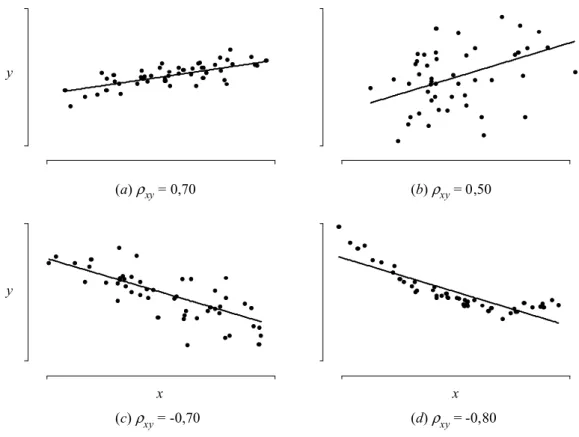
COEFICIENTE DE CORRELACIÓN
- Coeficiente de correlación muestral de Pearson
- Coeficiente de correlación de los rangos de Spearman
El coeficiente de correlación de Pearson r tiene una distribución muestral que es más asimétrica cuanto más se aleja la correlación subyacente ρ del valor 0. El coeficiente de correlación de Spearman rs se calcula simplemente como el coeficiente de correlación de Pearson reemplazando los valores observados (xi e i) por sus respectivos rangos (ri, si),. El coeficiente de correlación de Spearman rs se calcula simplemente como el coeficiente de correlación de Pearson reemplazando los valores observados (xi, yi) con sus rangos correspondientes (ri, si).
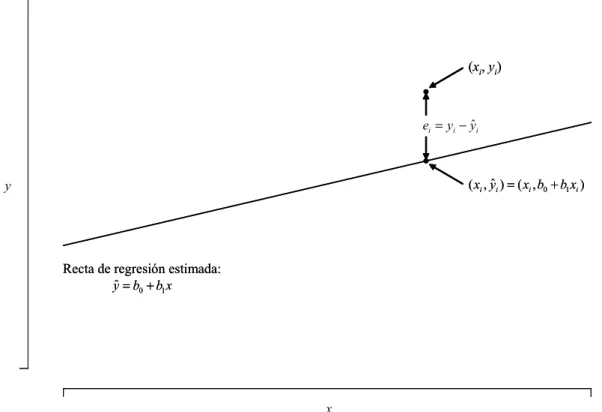
REGRESIÓN LINEAL SIMPLE
- Estimación de la recta de regresión
- Contraste del modelo de regresión lineal simple
- Inferencia sobre los parámetros de la recta de regresión
- Bandas de confianza y predicción para la recta de regresión
- Evaluación de las asunciones del modelo de regresión lineal simple
- Observaciones atípicas e influyentes
- Variable explicativa dicotómica
La realización del contraste de regresión se basa en el análisis de varianza de la variable respuesta. La realización del contraste de regresión se basa en el análisis de varianza de la variable respuesta. Estimaciones de la constante y pendiente de la recta de regresión después de excluir la observación correspondiente.