EL USO DEL BIG DATA WEB 2.0 PARA EL POSICIONAMIENTO DE PRODUCTOS DEL AGRONEGOCIO: EL CASO DEL MEZCAL 1. Con el auge de la comunicación en la era digital, la interacción entre los usuarios de la red ahora es más fácil.
Justificación
Ríos (2014) indica que las empresas hoy en día necesitan procesar una gran cantidad de datos, lo que en el mundo de la informática cae bajo el concepto de Big Data, lo que redunda en una mejor gestión empresarial. En el mismo sentido, Ortiz Morales et al. 2016) han enfatizado que la implementación de Big Data y analítica de datos no solo es un desafío, sino también una gran oportunidad para las empresas y sus departamentos de marketing, pues con su uso es posible crear Obtener información relevante sobre el cliente, sus gustos y sus criterios de compra. y otros datos.
Preguntas de investigación
5 puntos críticos en el camino desde la extracción de datos brutos de plataformas web hasta la generación de conocimiento que permita a una empresa agrícola posicionarse en el entorno digital. Por ello, este trabajo sobre Big Data en plataformas web aplicado al producto mezcal busca contribuir a un acercamiento respecto del grupo objetivo y los contenidos que buscan en dichas plataformas.
Objetivos de investigación
Objetivo general
Identificar los puntos críticos que permiten transformar los datos obtenidos de las plataformas online en información sobre el público objetivo y las características de los contenidos utilizados en Internet, utilizando herramientas Big Data, para contribuir al conocimiento para la implementación de la estrategia de posicionamiento. en torno a los productos agrícolas.
Objetivos particulares
Hipótesis
Estructura de la tesis
La tercera sección describe la metodología llevada a cabo para lograr los objetivos de la investigación. En la cuarta parte, los resultados obtenidos se presentan y discuten en el contexto de otras investigaciones.
Penetración del internet en México
La AMIPCI (2016) también destaca que, en términos de penetración de redes sociales, Facebook sigue siendo la red de referencia (con 92%), seguida de Whatsapp (con 79%) y YouTube (con 66%); Twitter, por su parte, se sitúa en cuarta posición con un 55%. Otro estudio de AMIPCI (2014) afirma que el 79% de las empresas están presentes en Facebook (con un promedio de siete publicaciones por semana) y el 80% están en Twitter, emitiendo 21 tweets por semana.

Web 2.0 y la nueva mercadotecnia
Como cuarta idea y comprensiva de los apartados anteriores, se destaca la necesidad de medir indicadores que permitan diagnosticar, definir y proponer una estrategia sólida de posicionamiento de marca. Al respecto, Oviedo García et al. 2015) mencionan, por ejemplo, que un paso que deben dar las empresas para rentabilizar sus esfuerzos de marketing en redes sociales es intentar medir.
Redes sociales
Además, hay que destacar la inmediatez que caracteriza a todas estas actividades dentro de las plataformas. Mencionan que un negocio en red es aquel donde el usuario paga el acceso con su información personal (perfil de usuario), participa enviando fotos y videos y crea una audiencia para vender publicidad.
17 posicionamiento significa aumentar el tráfico y en consecuencia mejorar la visibilidad de los sitios web. Como resultado, el esfuerzo que la empresa afectada invierte en publicidad, marketing y en general en construcción de reputación beneficia a sus competidores.
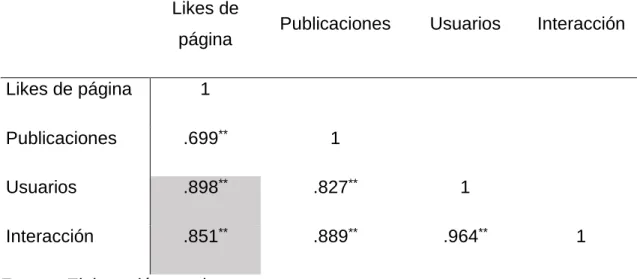
Dentro de esta información, los “me gusta” nos permiten obtener datos naturales sobre los hábitos y patrones de vida de las personas. Cabe señalar que no es necesario darle “me gusta” a la página para poder acceder e interactuar con las publicaciones de una Fanpage.

Algunos de los autores que recomiendan el uso de Twitter para la investigación son Barberá & Rivero (2012), quienes mencionan que Twitter ofrece una extraordinaria oportunidad para el análisis de la opinión pública: los mensajes intercambiados por los usuarios pueden contener información valiosa sobre sus opiniones. su respuesta a mensajes y acontecimientos políticos en un entorno accesible al investigador. A esta idea se suman los trabajos de Carlos de la Paz, Gómez Masjuán, & Pérez Alonso (2016) y Litche Fragoso.

Los “influencers”
Encontrar 28 empleados que realmente se alineen con los mensajes de la marca no es una tarea fácil. Si bien cada vez son más las herramientas destinadas a automatizar los procesos de identificación de influencers, no debemos olvidar que trabajamos con personas y que la mejor forma de entender sus intereses y construir relaciones duraderas con ellas es a través de una comunicación fluida uno a uno. . El ejemplo claro se muestra en la Figura 9, donde un anuncio de una marca de dispositivos móviles está influenciado por el escrutinio de la figura pública que entregó el anuncio desde un teléfono de la competencia.

Conceptos de Big Data
Según Ríos (2014), el Big Data lo que consigue es la generación de valor añadido generando nueva información para la toma de decisiones, con la que es posible reducir costes o aumentar ingresos. Además señala que hoy esta nueva información también genera nuevos negocios. . De tal manera que como lo mencionan Díaz, Osorio, Amadeo, & Romero (2013), esta tecnología se encuentra en pleno desarrollo, encontrándose soluciones “de código abierto” que deben ser estudiadas e investigadas sistemáticamente para obtener resultados comparativos útiles.
Definición de Big Data
Por tanto, se utilizará big data para toda la información que no pueda ser procesada por los métodos tradicionales (López García, 2012). Finalmente, volvemos a las palabras de Ferrer-Sapena & Sánchez-Pérez (2013), quienes dicen que big data se refiere a grandes conjuntos de datos que tienen algún valor para las empresas, mencionando que en algunos casos lo eran.
Tipos de datos en el Big Data
33 generados por científicos, aunque los más conocidos provienen de los movimientos Facebook, Twitter y Google y que el tratamiento suele realizarse en tiempo real utilizando tecnologías cada vez más potentes de gestión, visualización y análisis de bases de datos. Cabe destacar que el Big Data no sólo se centra en datos no estructurados, sino también en datos no estructurados y semiestructurados.
Características del Big Data (las 3V)
El desafío del big data es cómo manipular, gestionar, almacenar, buscar y analizar grandes volúmenes de datos. Con el término Big Data nos referimos a ese gran desafío para las empresas que consiste en manejar y analizar grandes almacenes de datos (López García, 2012).
El desafío del análisis de datos
Los mismos autores antes mencionados enfatizan que se deben tener en cuenta las siguientes limitaciones en el uso productivo de la información: los datos están lejos de ser claros y definitivos y no existen datos sistemáticos y temporalmente estables. Colle (2013) por su parte dice que primero es necesario saber qué datos importantes recolectar, investigar las herramientas adecuadas para su análisis, recolectar una primera cantidad (suficiente para un análisis) y extraer lecciones de la experiencia; Señala que el pequeño secreto del Big Data es ese.
La minería de datos en el Big Data
38 ningún algoritmo puede decirte qué es importante o descubrir su significado, los datos se convierten entonces en otro problema a resolver. Los autores utilizan SMM en Twitter porque a través de sus enlaces explícitos visibles hace visible lo que hasta ahora ha permanecido invisible: la estructura de red de los climas de opinión y la identificación de aquellos nodos que tienen una influencia social desproporcionada en su red.
Importancia del análisis de redes sociales y conceptos de ARS
Es positivo si el número de enlaces dentro de los grupos es mayor que el número esperado por pura casualidad. En la Figura 10, el tamaño de los nodos es función de su indicador PageRank (Tabla 1). Por este motivo se puede observar que si bien el nodo B no es el nodo con mayor tasa de acceso, sí se posiciona como el nodo más central. nodo porque los nodos que lo conectan (A, C y G) tienen prestigio de segundo orden.

La pirámide de la información
Otro autor que apoya los conceptos es López García (2012), quien los define de la siguiente manera: Los datos son un elemento de información primaria que por sí solo no es relevante para la toma de decisiones. Con base en los principios anteriores, la Figura 11 presenta una imagen de la pirámide de información; a lo que, contrariamente a lo descrito anteriormente, desde nuestro necesario punto de vista, se le suma un paso adicional que es el de la extracción de datos, que es un proceso complejo que se puede definir como los mecanismos y técnicas mediante los cuales se obtienen.

Extracción depuración y análisis de datos para Google
Posteriormente, las palabras clave extraídas fueron enviadas a la herramienta Google Adwords para obtener el número de búsquedas mensuales realizadas en México, ocurridas en el periodo de enero a diciembre de 2015 (máximo .50 mostradas en un año). Con las palabras con estos dos datos, se dibujan en un diagrama de dispersión con como ejes el promedio de búsquedas mensuales y el número de resultados mostrados;

Extracción depuración y análisis de datos para Facebook
Este análisis nos ayudó a relacionar gráficamente el tipo de publicación con el que las empresas tenían mayor afinidad. Finalmente, a partir de la información recopilada se ha obtenido un listado de clientes potenciales con los que se puede poner en contacto; Además, los horarios en los que más interactúan, el tipo de publicación más empática con los clientes potenciales y si este arquetipo ya es utilizado por alguna empresa.

Extracción depuración y análisis de datos para Twitter
El análisis de los Retweets 1, representado en la Figura 17 con el apartado “B”, se trazó de tal forma que se mostraba el enlace del usuario al tweet. Un procedimiento similar se realizó con el análisis de los retuits 2, sólo que en lugar de considerar la centralidad de grado.

Importancia del mezcal como producto para el estudio de caso
En este trabajo optamos por elegir como objeto de estudio la cadena del mezcal, ya que es un producto agrícola representativo de la cultura mexicana y oaxaqueña, que además tiene un incipiente pero alto grado de integración de las empresas en las plataformas digitales. Al final de cada apartado también se presenta la utilidad de la información obtenida, que en este trabajo se denomina conocimiento que se genera.
Pechuga Mezcal: Son combinaciones que incluyen la palabra pechuga además de la palabra mezcal. Preparación: Son combinaciones de palabras relacionadas con cómo se obtiene el mezcal o cómo se puede preparar.

En la Figura 27 se realiza una representación gráfica mediante flechas de la peculiar interacción de los me gusta emitidos por los usuarios (representados por las letras C y D) contra las publicaciones (letras B y E) realizadas por una Fanpage (letra A). El segundo desafío es que una vez que se tiene la audiencia potencial, se debe identificar, clasificar y analizar el tipo de contenido que llama la atención de esta audiencia potencial (letra E) y determinar si este tipo de contenido es utilizado principalmente por alguno de los fanáticos. páginas.
Identificación del contenido de interés (análisis de hashtag y primera
En este caso se crearía empatía con un segmento de la población que la disfruta. Tweet que hace referencia al mezcal con una noticia Fuente: extraído de la cuenta @MAguMonero.

Acercamiento al público meta (ubicación, análisis de menciones y
Estudio cuantitativo del uso de la web 2.0 por parte de los líderes de las listas del PP y PSOE. Programas deportivos de radio española en redes sociales: estudio comparativo del periodo.
