ESTRUCTURA WEB: Son los datos que describen la organización del contenido dentro de un sitio. El Capítulo 2 observa detalladamente la selección de la técnica de Web Mining para el desarrollo del proyecto.
MARCO DE REFERENCIA
DESCUBRIMIENTO DE CONOCIMIENTO EN BASES DE DATOS (KDD)
Se selecciona un conjunto de datos y la búsqueda se centra en subconjuntos de variables y/o muestras de datos en los que se va a realizar el proceso de descubrimiento de conocimiento. Actualmente, esta minería de datos se ha expandido para ayudar a gestionar los datos que existen en línea, lo que se conoce como minería web o minería de datos en línea.

MINERÍA DE DATOS
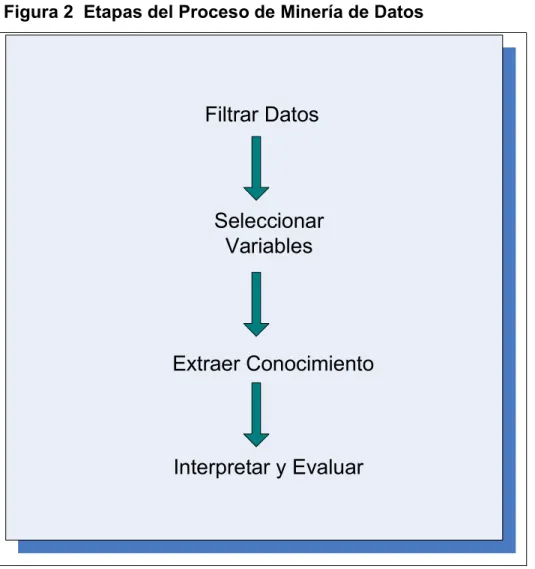
El proceso de extracción de datos consta de diferentes etapas, entre las que se encuentran: 4 (Ver Figura 2). Dada la base de datos anterior, podemos obtener, entre otras, las siguientes reglas de conexión: (ver tabla 2).
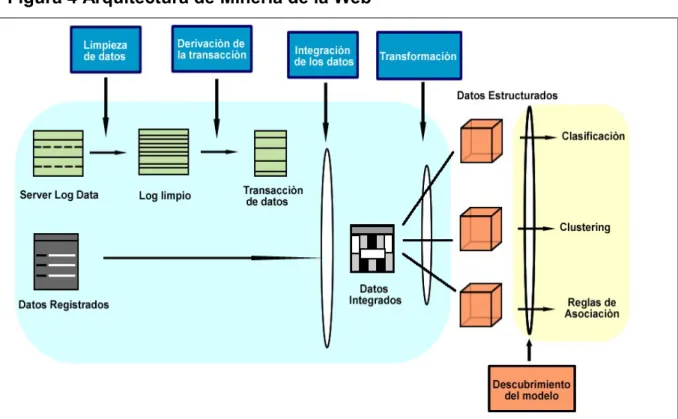
MINERÍA DE DATOS EN LA WEB
A continuación se describe cada proceso descrito en la Figura 3 de la arquitectura de minería web. Todos los pasos descritos anteriormente tratan de la transformación de datos para utilizar técnicas de minería de datos.

MINERÍA DE USO DE LA WEB
PROCESO DE MINERÍA DEL USO DE LA WEB
Los datos de ingreso son los logs producidos por el Servidor Web Intra-UNAB, estos logs son proporcionados por el departamento de sistemas de la UNAB. Los registros registran todas las acciones realizadas por los usuarios miembros intra-UNAB. A continuación se explican en detalle varios algoritmos de reglas de asociación que se han investigado para el desarrollo de la aplicación.
En AIS, una regla de asociación es una implicación de la forma XY [s,c], donde X es un conjunto de elementos, Y es un elemento (no incluido en confiabilidad [confianza]. SETM, como AIS, genera candidatos en cada iteración, mientras realiza un recorrido secuencial de la base de datos. Los algoritmos de la familia Apriori realizan múltiples recorridos de la base de datos para obtener los conjuntos de elementos relevantes.
La etapa final del proceso completo de minería de uso de la web para identificar los hábitos de uso del sitio web es el análisis de.

PREPARACIÓN DE LOS DATOS Y DISEÑO DE LA HERRAMIENTA
CAPTURA DE REQUERIMIENTOS
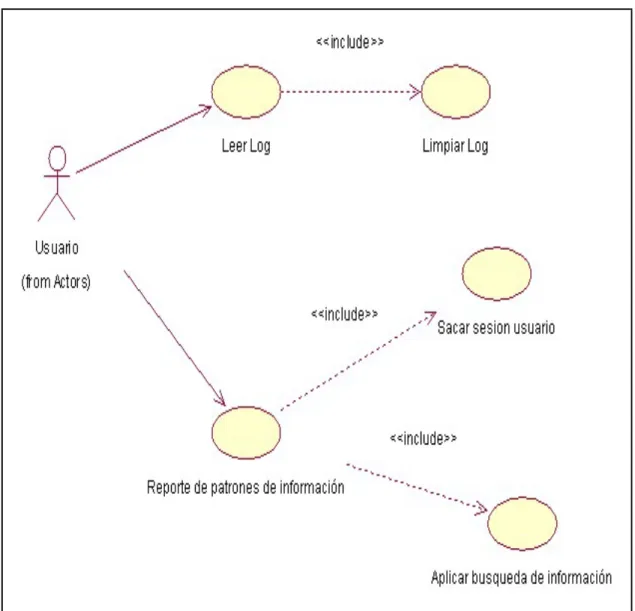
Las descripciones correspondientes de cada caso de uso generalmente abordan el conjunto de pasos que sigue un actor para realizar una "acción" y tienen dos funciones fundamentales: un flujo alternativo y un flujo normal (ver apéndices).
PROCESOS BASICOS DE LA HERRAMIENTA
Los datos seleccionados son los registros creados por el servidor web Intra-UNAB, toda esta información es proporcionada gracias al servidor, donde, adecuadamente procesada, se utiliza para obtener información de interés. Los datos utilizados para desarrollar esta investigación fueron del mes de marzo de 2004, la cantidad de datos fue de 91.161 diarios vírgenes. 2, número 1 de acm sigkdd exploraciones, el boletín del grupo de interés especial de acm sobre descubrimiento de conocimientos y minería de datos.
Proceso en el que se aplica el algoritmo de Reglas de Asociación predictivas a priori seleccionado para extraer patrones de comportamiento de uso intra-UNAB. Como se puede observar, el proceso comienza con un conjunto de datos de la interacción del usuario con el sitio web, el cual contiene toda esta información en el log del servidor Intra-UNAB. En la fase de limpieza (Data Clean), algunos de los datos del log no sirven para generar las reglas, por lo que solo se tienen en cuenta aquellos que son relevantes.
Este proceso se llevó a cabo obteniendo las direcciones IP del servidor Proxy, fue posible determinar las actividades realizadas por el usuario durante una sola visita al sitio web.

DISEÑO
En el proceso de búsqueda de información descrito en la sección 1.2.1, aplicamos el algoritmo de reglas de asociación seleccionadas. Una vez aplicado el algoritmo genera las reglas con un nivel de confianza y con soporte, demostrando así su fortaleza y finalizando con la generación de un reporte de datos interpretados para su fácil comprensión por parte de los usuarios. La estructura del algoritmo predictivo a priori es la misma que el algoritmo Apriori, busca el número de ocurrencias de cada uno de los ítems, genera candidatos que cumplen con el nivel de soporte, la diferencia entre este algoritmo y el Apriori es, como su nombre digamos predice el nivel de soporte a través de una distribución binomial, como se puede ver en el algoritmo, lo primero que hace es calcular este soporte, el soporte es la fracción de datos que satisface la regla, cada registro que satisface el soporte puede estar correcta o incorrectamente clasificado, Cada vez que esté correctamente clasificado forma parte del fideicomiso. Para calcular este soporte, el algoritmo utiliza una distribución binomial, una distribución binomial es el número de éxitos en varios experimentos.
También es un lenguaje multiplataforma, es decir, cualquier programa creado en Java tiene la ventaja de poder ejecutarse en cualquier ordenador. En este diagrama, la aplicación recibe el registro procesado con las sesiones de usuario, le aplica el algoritmo de reglas de asociación y genera informes. Estos informes son las reglas generadas por el algoritmo Predictivo A priori. La aplicación de búsqueda de información utiliza el algoritmo a priori para buscar patrones interesantes y así genera informes con la información necesaria para el usuario. Este diagrama muestra que antes de aplicar la búsqueda de información, se debe procesar el Log para poder utilizar el algoritmo Apriori.
A continuación se muestra uno de los cuadros de actividades realizados para desarrollar el diseño.

CONSTRUCCIÓN DE LA HERRAMIENTA
SELECCIÓN DE LOS DATOS
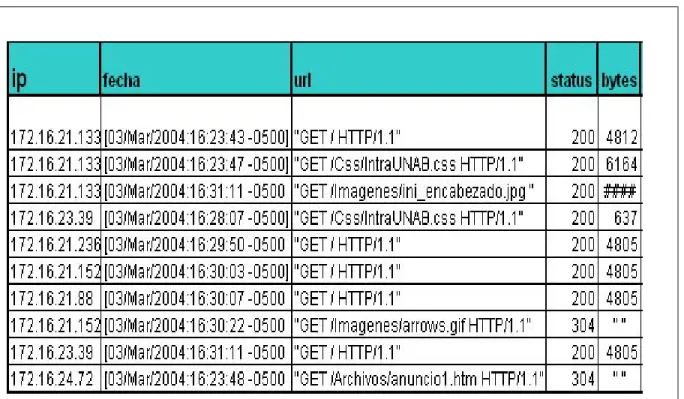
La información almacenada también depende de cada servidor y su configuración particular, pero en general los campos habituales que se incluyen son: fecha y hora de la solicitud, dirección IP, método de acceso (GET, PUT...), el archivo accedido (URL), el resultado de la solicitud, el tamaño en bytes de los datos recibidos y devueltos). A continuación se muestra un ejemplo de un registro común devuelto por el servidor Intra-UNAB.
ESTRUCTURA DE LA APLICACIÓN
Una vez obtenido el log se realizan las distintas operaciones necesarias para obtener conocimientos útiles. Esta fase se llama reprocesamiento de datos. Este es el archivo que registra el comportamiento de los usuarios en el portal. Aquí el registro se imprime una vez recibido el tratamiento de limpieza de datos, eliminando información redundante y eliminando sesiones de usuario según la dirección IP.
Esta es la clase principal de la aplicación, aquí es donde se realiza la limpieza y donde reside la API. Esta clase es responsable de establecer una conexión de limpieza con la base de datos. Estas instancias constan de las URL a las que accede el usuario, como podemos ver que en la primera línea, el usuario inició en validarUsuario.Intranet.jsp, luego aceptó realizar una solicitud a multimedia.jsp, y en la cuarta línea, la segunda el usuario inició desde la página principal //intranet/ y luego accedió a la página ver noticias, preguntas (?) significa que no hay ninguna página que cumpla con este nivel, lo que significa que el usuario ha terminado de navegar.
Esta clase se encarga de mostrar gráficamente las reglas obtenidas por el algoritmo mediante columnas para luego analizarlas.

BASE DE DATOS
Los campos de IP se almacenan en la tabla de IP, que es la dirección IP del dispositivo y el campo de fecha es la fecha en que se realizó la transacción. El campo ID es la clave externa que se conecta al ID de la tabla de URL. Al evitar que se repita una URL para que el conteo se haga satisfactoriamente, esta tabla almacena el campo URL donde se almacenan las URL a las que pueden acceder los usuarios. Estos campos almacenan la IP, las fechas y las URL obtenidas de la limpieza y las sesiones. Los resultados se pueden ver en una página creada en PHP llamada query.php, donde se coloca un contador para contar el número de veces. se visita una página, como se muestra en la siguiente sección de código del archivo consulta.php:.
PRUEBAS Y ANÁLISIS DE RESULTADOS
DESCRIPCIÓN DE PRUEBAS
Al analizar la tabla 12, se encontró que las páginas más visitadas o las páginas más visitadas los fines de semana suelen ser: ver noticias, buscar un empleado y consultar cumpleaños, también se pudo estimar que los usuarios de la intranet utilizan el fin de semana para descargar software y que los horarios de mayor acceso por parte de los usuarios afiliados al portal fueron en la mañana y en la tarde. La semana con mayor acceso de usuarios al portal Intra-UNAB fue del 15 al 19 de marzo (de lunes a viernes (contando horas de entrada y salida de la oficina) con un porcentaje del 32%, y la semana con menos visitas fue el 3 de marzo. -5.Marzo (miércoles a viernes) con un porcentaje del 6% como se muestra en la Figura 18. También se puede observar que hay una tendencia de los usuarios a descargar por la noche.
Se puede observar que los usuarios acceden a las páginas a partir de las 20:30 como se muestra en la tabla 15. También se ve que los usuarios acceden al portal también durante la hora del almuerzo (12:00 - 14:00) y las páginas a las que accedieron, la mayoría ver cumpleaños (25%), solicitudes multimedia (16%) y ver anuncios clasificados (27%). A continuación se presenta la Figura 24 con los porcentajes correspondientes de las encuestas realizadas a los usuarios afiliados del portal Intra-UNAB.
Estadísticas de las encuestas realizadas a los integrantes de las páginas Intra-UNAB más visitadas por los usuarios.

RELACIÓN DE RESULTADOS
RECOMENDACIONES
CAPITULO 7. CONCLUSIONES Y TRABAJOS FUTUROS
DETERMINACIÓN DE LAS PREFERENCIAS DEL USUARIO INTRA-UNAB UTILIZANDO TÉCNICAS DE MINERÍA WEB Especificación de casos de uso Registro de lectura. El caso de uso lo inicia el usuario; aquí la aplicación lee el registro del servidor. DETERMINACIÓN DE LAS PREFERENCIAS DEL USUARIO INTRA-UNAB UTILIZANDO TÉCNICAS DE MINERÍA WEB Especificación de casos de uso Borrar registro.
El caso de uso se inicia cuando la aplicación lee el registro, limpiando así la información redundante en el registro. ESTABLECIMIENTO DE PREFERENCIAS DE USUARIO INTRA-UNAB UTILIZANDO TÉCNICAS DE WEBMINE Especificación de Caso de Uso Eliminar sesión de usuario. ESTABLECIMIENTO DE PREFERENCIAS DE USUARIO INTRA-UNAB UTILIZANDO TÉCNICAS DE MINERÍA WEB Especificación de casos de uso Recuperación de información de uso.
ESTABLECIMIENTO DE PREFERENCIAS DE USUARIO INTRA-UNAB UTILIZANDO TÉCNICAS DE ENLACE WEB Especificación del Informe de Casos de Uso de Patrones de Información. Este documento presenta la especificación funcional del caso de notificación de patrones de información. En este diagrama, la aplicación recibe el registro limpio con las sesiones de los usuarios y se le aplica el algoritmo de reglas de asociación y genera informes, estos informes son las reglas generadas por las reglas de asociación.