El Capítulo 1 se centra en la gestión de datos, con especial énfasis en la obtención de datos de fuentes externas. La gestión de datos es muy importante antes de iniciar el procesamiento de datos y el análisis estadístico.
1 MANEJO DE DATOS
1 MANEJO DE LOS DATOS
La Tabla 1.3 presenta el conjunto de datos (variables y valores) que se utilizarán en esta sección. Incluir el valor de la variable género resuelve el problema del tipo de datos.

Importación / Exportación (I/E) del conjunto de datos
UBICA EL DIRECTORIO DONDE SE GUARDARÁ EL ARCHIVO CSV setwd("C:/Users/tiran/Desktop/Datos"). ESTABLEZCA EL DIRECTORIO DONDE SE UBICA LA CARPETA DE TEXTO setwd("C:/Users/tiran/Desktop/Datos").
Dataframe: Manipulación de datos
Respuestas de las autoevaluaciones
2 REPRESENTACIÓN GRÁFICA DE LOS DATOS
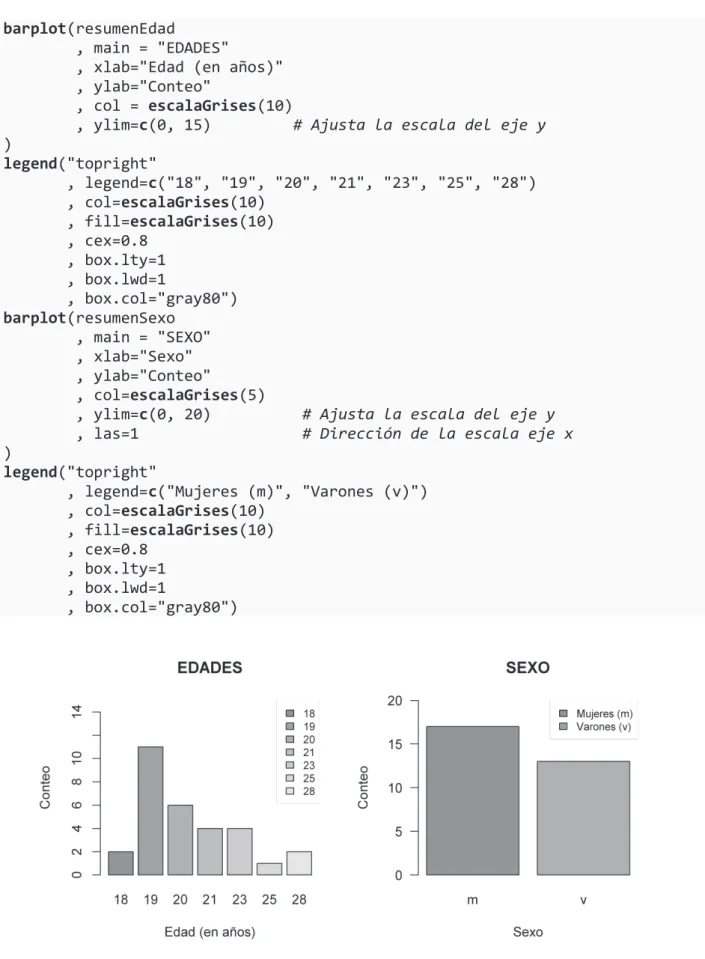
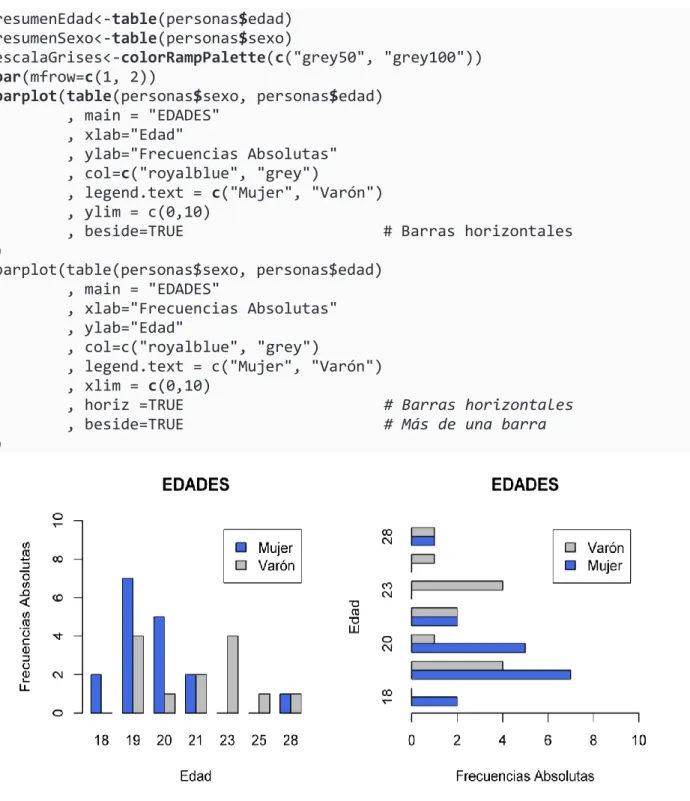
Los colores utilizados en los gráficos de barras de la Figura 2.2 provienen de una variable de escala de grises creada por la función colorRampPalette(), que crea fácilmente una paleta de colores. Finalmente, la Figura 2.5 revela uno de los usos más comunes de un gráfico de barras: comparar categorías.
Pastel
La función prop.table() recupera la frecuencia relativa (fr.c) para cada categoría a partir de la frecuencia absoluta (fa.c). La Figura 2.13 muestra el resultado de configurar los parámetros para la función boxplot(). En consecuencia, se presenta el uso de la función stripchart() en combinación con la función boxplot().

Histograma de frecuencia Absoluta
Una vez determinado el número de clases (k), el intervalo de clases se calcula utilizando el promedio de la ecuación 2.2. La función layout() inventa una distribución de la salida gráfica, mientras que la función par(), junto con el parámetro mar, determina los límites de la distribución de salida. Finalmente, el parámetro add en la función boxplot() debe tomar el valor VERDADERO para ser integrado en el histograma creado por la función hist().
Histograma de Frecuencia Relativa
La frecuencia relativa indica el valor porcentual que representa la frecuencia absoluta de cada clase de la distribución de frecuencias. El histograma de frecuencia relativa se logra estableciendo el parámetro de probabilidad de la función hist() en VERDADERO. Otra forma de ver los resultados en la Figura 2-20 es usar dos histogramas en un gráfico, consulte la Figura 2-21.
Polígono de frecuencia
Para construir el polígono de frecuencias relativas, primero se calculan los puntos medios de cada clase. La variable x es un vector que contiene: el límite inferior (min(h.peso$break)), todos los puntos medios (h.peso$mids) y el límite superior (max(h.peso$break)). La variable y es un vector que contiene: la altura (0) correspondiente al límite inferior, la frecuencia de cada clase (h.peso$scores) y la altura (0) del límite superior.
Histograma de frecuencia acumulado
La primera etapa es crear una variable que contenga el objeto creado por la función hist(), en nuestro caso será h.weight. En h.peso$counts encontramos los valores de frecuencia absoluta, los cuales transformaremos usando la función cumsum(), que realiza la suma acumulativa de una forma muy sencilla: h.peso$counts<-cumsum (h.peso$counts) . En este punto tenemos la suma acumulada almacenada en el objeto de histograma h.weight, que trazaremos usando la función plot(h.weight,…) para obtener el histograma de frecuencia acumulada.
Polígono de frecuencia acumulado
Un gráfico de distribución acumulativa, llamado ojiva, muestra valores de datos en el eje horizontal y frecuencias acumuladas, frecuencias relativas acumuladas o frecuencias porcentuales acumuladas en el eje vertical [25]. La característica de la ojiva es que sus líneas convergen en puntos (el límite superior de cada clase, la frecuencia acumulada de cada clase), con dos excepciones: la primera línea que se origina en un punto (límite inferior, 0) y la última línea que termina en un punto (límite superior, frecuencia acumulada de la última clase).
Función densidad y curva normal
La gráfica de la función de densidad de una distribución nos dice cómo es esa distribución y, en algunos casos, es útil compararla con la curva normal para analizar visualmente si la distribución representada por la función f(x) se ajusta a la curva normal. . distribución. Para crear la curva normal se utiliza la función curve() que busca los datos de la curva normal obtenidos a través de la función dnorm(), la cual toma en un vector un conjunto de valores entre los valores mínimo y máximo. de la distribución en el eje x, la media y la desviación estándar. La media se calcula con la función mean() y la desviación estándar con la función sd().
Tallo y hojas
En una muestra de 20 personas sobre el uso de tres repelentes se obtuvo la siguiente información: a) Crear un gráfico de barras 3D con colores vara de oro3 y verde oliva oscuro1 b) Agregar etiquetas a los sectores y explicaciones al gráfico. En una muestra de 20 personas sobre el uso de tres repelentes se obtuvo la siguiente información: a) Crear un gráfico de barras 3D con colores vara de oro3 y verde oliva oscuro1 b) Agregar etiquetas a los sectores y explicaciones al gráfico. En una muestra de 20 personas sobre el uso de tres repelentes se obtuvo la siguiente información: a) Crear un gráfico de barras 3D con colores vara de oro3 y verde oliva oscuro1 b) Agregar etiquetas a los sectores y explicaciones al gráfico.
3 DESCRIBIR, EXPLORAR Y COMPARAR DATOS
3 DESCRIBIR, EXPLORAR Y COMPARAR DATOS
Cuando el número de observaciones n es impar, la media es el valor de la observación en la posición n. Me1<-ronda(mediana(atleta$levantador de pesas1), 2) # Calculando la media Me2<-ronda(mediana(atleta$levantador de pesas2), 2) # Calculando la media Me3<-ronda(mediana(atleta$levantador de pesas3), 2) # Calculando la media Me<-data.frame(Pesador1=Me1, Levantador de pesas2=Me2, Levantador de pesas3=Me3). Tenga en cuenta que se encuentra que el levantador 2 tiene la media y la mediana más altas, pero el levantador 3 tiene una moda mejor.

Medidas de Dispersión o Variación
Esto significa que las medidas de centralidad no revelan el panorama completo de la distribución de un conjunto de datos. Las funciones hist(), lineas() y densidad() son adecuadas para la visualización gráfica de medidas de centralidad y dispersión. Como se puede ver en la Figura 3.0, las medidas de centralidad y dispersión se mostraron en un histograma de frecuencia y densidad.

Medidas de posición relativa
Respuestas de las autoevaluaciones 3-1 salario<-c(400,
En un estudio realizado en dos niveles de un curso de estadística, se tuvo en cuenta la edad de los participantes que obtuvieron puntuaciones superiores a 8. Gráfico de deciles de color verde oscuro detrás de la línea de densidad. Dibuja los percentiles con color marrón4 para la línea percentil.
4 DISTRIBUCIONES DE PROBABILIDAD
Si una variable aleatoria es discreta, tendrá un conjunto de valores definidos en el intervalo y tiene una distribución de probabilidad que describe su comportamiento. Si una variable aleatoria es continua, puede tomar una cantidad infinita de valores dentro de un intervalo, su distribución de probabilidad predice las probabilidades correspondientes a esos valores. Algunos usos prácticos de las distribuciones de probabilidad son: calcular intervalos de confianza para parámetros y calcular regiones críticas para pruebas de hipótesis, entre otros.
Distribución Normal
La distribución normal se describe mediante el pdf de búsqueda bastante complicado, Ecuación 3.0. Para calcular la probabilidad de algún evento dentro de los límites a y b pertenecientes a la función de densidad de la distribución normal (ecuación 3.0), se debe integrar f(x) como se muestra en la ecuación 3.1. Sin embargo, utilizando otros métodos como series de Taylor, series asintóticas, función gamma, entre otros, es posible obtener valores de probabilidad.
La distribución normal estándar
La nueva función f(z) (ecuación 3.3) se conoce como función de densidad de distribución normal estándar (PDF). El siguiente procedimiento explica cómo obtener la gráfica de la función de densidad de probabilidad para la distribución normal estándar en R. Con estos sencillos pasos es posible obtener la representación gráfica de la función de probabilidad acumulada para la distribución normal estándar.
Distribución Binomial
La función de densidad de la distribución binomial se traza utilizando la función pbinom(), que toma los parámetros: x, magnitud y probabilidad. Usando el teorema del límite central, veremos cómo calcular probabilidades para una variable aleatoria binomial usando la curva normal como aproximación a la distribución binomial. Trazar la distribución binomial en R no es diferente de lo que se revisó en las secciones anteriores.
Distribución de Poisson
Tuicha jave pe media distribución Poisson rehegua, ikatu hasy ojekalkula hagua umi probabilidad Poisson rehegua ojeporúvo calculadora. Péva he ise jajapo hagua gráfico distribución normal distribución Poisson ári jaguerekoha HE = HE ha HE = √HAR. Figura 4.9 ohechauka aproximación curva distribución normal rehegua distribución Poisson rehe.

Distribución de Weibull
Para trazar la función de densidad de probabilidad de Weibull, se utiliza la función dweibull() de R. Para trazar la distribución, utilizamos la función líneas() que toma como parámetro el resultado de la función densidad() aplicada a x. Traza la distribución normal con valores de -3 a 3 con el color de línea magenta.

5 ESTIMACIÓN E INTERVALOS DE CONFIANZA
Distribuciones muestrales
Para obtener la Figura 5.0, primero trazamos el histograma con la función hist(), pasando el conjunto de datos p (la altura de la población estudiantil) y estableciendo el parámetro de probabilidad en VERDADERO para ajustar la curva de la función de densidad. Luego con lineas() se dibuja la curva, líneas() toma como parámetro el resultado de la función densidad() que a su vez toma el conjunto de datos de la población p. La Figura 5.0 contiene la gráfica de las medias muestrales para m1, m2 y m3 e incluye la media poblacional para comprender mejor el problema de inferencia de la media poblacional.
Teorema del límite central
Si la población de la que se extrajeron las muestras tiene las características de una distribución normal con media. El siguiente código en R muestra lo expresado por Norean Sherpe; entonces tenemos la curva de distribución poblacional (variable de altura real) y la curva de distribución normal ideal. La Figura 5.1 muestra la distribución de altura normal ideal y real para la población estudiantil.
Teorema de Chebyshev
Norean Sherpe[53] señala acertadamente que nos hemos deslizado suavemente entre el mundo real, donde extraemos muestras aleatorias de datos, y el mundo de los modelos matemáticos, donde describimos cómo se comportarían las medias y proporciones muestrales si miramos en el mundo real. . La segunda, que modelamos con un modelo normal basado en el Teorema del Límite Central. MSampleMeans<-mean(SampleMeans) # Media de la media muestral SDSampleMeans<-sd(SampleMeans) # Desviación estándar de la # media muestral.
Regla Empírica
Para graficar la regla empírica, comenzaremos creando la variable aleatoria x con la función seq(), tomando límites de -4 a 4 en incrementos de 0,01; La densidad de la variable normal también se crea usando la función dnorm() que pasa como parámetro la variable aleatoria x y establece la media = 0 y la desviación estándar = 1, que corresponde a una distribución normal estándar. Esto continuará trazando la curva normal estándar usando la función plot() con los valores de la variable aleatoria x y la densidad normal. Como es una curva normal estándar, el valor de la media es μ=0 y el valor de la desviación estándar es σ=1.
Estimadores puntuales
Keller [56] simplemente define lo que representa un estimador puntual: un estimador puntual hace inferencias sobre una población estimando el valor de un parámetro desconocido utilizando un único valor o punto. Al mismo tiempo, afirma que un estimador de intervalo hace inferencias sobre una población estimando el valor de un parámetro desconocido utilizando un intervalo. Por lo tanto, una estimación puntual de un parámetro poblacional es cuando se usa un único valor para estimar ese parámetro, es decir, se usa un punto específico en la muestra para estimar el valor deseado.
Estimadores de intervalo
REPRESENTACIÓN DEL INTERVALO DE CONFIANZA IC<-data.frame(LI=li.IC, LS=ls.IC). REPRESENTACIÓN DEL INTERVALO DE CONFIANZA IC<-data.frame(LI=li.IC, LS=ls.IC). El coeficiente de confianza para la estimación requerida es 91. a) Encuentre el intervalo de confianza.

6 PRUEBA DE HIPÓTESIS
Fundamentos de la prueba de hipótesis
El propósito de la prueba de hipótesis es probar la validez de una hipótesis propuesta sobre una población a través de una muestra. Es posible establecer una prueba de hipótesis bilateral, donde el valor crítico estará entre −𝑍𝑍𝑍𝑍𝛼𝛼𝛼𝛼/2 y +𝑍𝑍𝑍𝑍𝛼𝛼𝛼𝛼/2. En la toma de decisiones, puede ocurrir uno de dos tipos de error al intentar validar una prueba de hipótesis.

Pruebas de hipótesis para muestras grandes (n>30)
La Figura 6.1 muestra que el estadístico z de la muestra (zm) se encuentra en la región de no rechazo. La Figura 6.5 muestra que Z de la muestra está ubicado en la región de no rechazo. La figura 6.6 nos muestra que la Z de la muestra se ubica en la región de rechazo.
Pruebas de hipótesis para muestras pequeñas (n<30)
Proponer la hipótesis
7 REGRESIÓN LINEAL SIMPLE
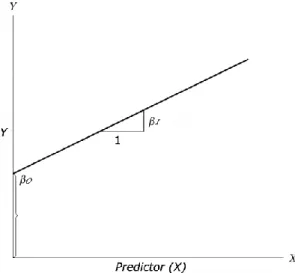
El trabajo de desarrollar una ecuación matemática puede ser bastante complejo porque necesitamos tener una idea sobre la naturaleza de la relación entre cada una de las variables independientes y la variable dependiente. Además, ϵ es el error de la parte de Y que el modelo de regresión no puede explicar. La Figura 7.1 muestra los diagramas de dispersión resultantes para las variables predictoras precio de compra y viaje versus la variable respuesta precio actual.