Este capítulo contextualiza, desde la perspectiva encontrada en la literatura, los diversos problemas abordados por los autores en la implementación de sensores de bajo costo, presentando un panorama gráfico de las técnicas abordadas en las investigaciones de última generación que resuelven estos problemas. . Lo anterior permite comprender el tema actual del monitoreo e investigación de la contaminación atmosférica con la implementación de tecnologías IoT de bajo costo.
Introducción
En Colombia existe un Sistema de Control de la Calidad del Aire (SVCA) con el propósito de monitorear y monitorear los niveles de emisiones en el territorio nacional, el cual se divide en administraciones ambientales para cada zona del país [51]. Así, queremos mejorar la resolución y el seguimiento de las mediciones de PM2,5 en zonas urbanas, rurales y de difícil acceso.
Estado del arte
Tecnologías sensores de bajo costo para medir calidad del
Características propias de los sensores, aplicaciones con
Sin embargo, la respuesta del sensor depende de la forma de las partículas (índice de refracción), la temperatura y la humedad. En consecuencia, y gracias a las virtudes visualizadas de los modelos basados en MF, estas nuevas técnicas tienen la ventaja de permitir ajustes en las mediciones de la red sin ellos.

Objetivos
Objetivo principal
Por lo tanto, los métodos basados en MF se han distinguido muy bien en problemas de estimación y recuperación de información faltante de una base de datos escasa [37, 85], lo que describe el problema actual con la información generada por el proyecto Citizen Scientists. En este sentido, en el presente trabajo buscamos aprovechar las ventajas de las técnicas MF indicadas anteriormente para llegar a enfoques como el discutido por [23], donde se implementó un modelo de factorización matricial no negativa (NNMF) en la reconstrucción de señales, obteniendo soluciones cuya precisión es superior a la obtenida utilizando polinomios.
Objetivos específicos
Proponer un método de ajuste de los parámetros del modelo que garantice un buen ajuste a los datos sin pérdida de generalización. Desarrollar un procedimiento para evaluar la calidad de ajuste proporcionada por el modelo propuesto con respecto a las lecturas de referencia.
Planteamiento del problema
Para ello se realizó una búsqueda de algoritmos basados en MF, donde se evaluó su desempeño según una metodología de eliminación de datos, para posteriormente comparar las estimaciones realizadas por el método y los datos reales eliminados artificialmente. Se realizó el ajuste de parámetros en el algoritmo de mejor rendimiento a través de una búsqueda en cuadrícula, experimentando nuevamente con los datos siguiendo la metodología de eliminación de datos propuesta originalmente y comparándolos con algoritmos encontrados en la literatura de estimación de información faltante, como: MS, KNN y MOGP.

Metodología
Finalmente, se propuso una modificación del modelo MF, incluyendo Redes Neuronales (DMF) y el uso de variantes que implementen Embedding Layers, incorporando información geográfica e información sobre el estado del día y el día de la semana, para que esto sea posible. adaptar algoritmos al problema de datos faltantes y mejorar los resultados iniciales obtenidos con el algoritmo MF estándar.
Resultados o contribuciones
En este capítulo se elabora el primer objetivo del proyecto, que parte de identificar los tipos de datos perdidos, abordando una metodología de adaptación de la base de datos y eliminando datos anómalos mediante la aplicación de criterios estadísticos, que posteriormente permitirán la aplicación de modelos. Reconstrucción de información faltante.
Base de datos
- Nubes Ciudadanos Científicos
- Índice de calidad del aire
- Patrones de datos faltantes
- Detección de datos anómalos
- Depuración de datos anómalos
- RMSE
- MAPE
- EVS
Por ello, para depurar y limpiar la base de datos (datos anómalos) se utilizó el ICA, con el objetivo de conseguir la mejor calidad de datos posible e incorporar el menor sesgo posible. En el caso de la base de datos de Científicos Ciudadanos, es como si los datos perdidos surgieran consistentemente del fallo de un grupo de sensores que dejaron de medir en algún momento indeterminado del año. En este caso, asumimos que en el caso de la red Científico Ciudadano es cierto que el patrón de datos faltantes es MNAR, porque ninguno de los patrones anteriores aborda completamente el comportamiento de los datos faltantes creados por la red en 2018. .
El objetivo final es mitigar los efectos de los datos atípicos y asegurar que se introduzca el mínimo sesgo posible en futuros análisis de la información generada.
![Figura 2.2: Procedimiento inicial para la depuración de la base de datos [51]](https://thumb-us.123doks.com/thumbv2/123dok_es/12434769.0/45.892.271.639.428.638/figura-2-procedimiento-inicial-depuración-base-datos-51.webp)
Factorización de matriz (MF)
- Algoritmo MF
- Algoritmo MF + Regularización
- Algoritmo MF + Bias
- Algoritmo MF + Regularización + Bias
- Comparación entre las funciones de costo propuestas
Por lo tanto, la función de error cuadrático que se muestra en la ecuación (3.4) se puede minimizar utilizando la función de costo definida en la ecuación (3.11). En la Figura 3.3 y Figura 3.4 se presentan los resultados obtenidos con el algoritmo MF + Regularización, mostrando el error MAPE obtenido para cada porcentaje de información excluida artificialmente y su correspondiente reconstrucción de una ventana de 24 horas analizada para un 40% de información faltante, ya que este es el promedio. información faltante, presentada por la red en 2018. En la Figura 3.5 y Figura 3.6 se presentan los resultados obtenidos con el algoritmo MF + Bias, mostrando el error MAPE obtenido para cada porcentaje de información extraída artificialmente y su correspondiente reconstrucción de la ventana de 24 horas analizada para 40% de información perdida porque este es el promedio de información faltante que presentó la red en 2018.
La Tabla 3.1 y la Figura 3.9 muestran una comparación del rendimiento de cada una de las variantes propuestas del algoritmo MF.

Algoritmos de optimización basados en GD
Momentum
Finalmente, para suavizar la curva de gradiente y preservar su efecto, se sugiere mantener el parámetro de sensibilidad β cerca y menor que 1. Por lo tanto, la velocidad para cada parámetro de la función de costo se actualiza como se muestra a continuación:
RMSprop
Evaluación de los algoritmos de optimización propuestos
En consecuencia, podemos reescribir la función de costos como en la ecuación. Para minimizar la ecuación (3.5), seguimos el algoritmo de descenso de gradiente estocástico SGD. En la Figura 3.1a y Figura 3.2 se presentan los resultados obtenidos con el algoritmo MF propuesto, mostrando el error MAPE obtenido para cada porcentaje de información extraída artificialmente y su correspondiente reconstrucción de una ventana de 24 horas analizada para un 40% de información faltante, ya que este es el promedio. información perdida, que la red presentó en 2018. Finalmente, se evalúa la efectividad del algoritmo propuesto en una ventana de 24 horas previamente seleccionada (ver Figuras 3.7 y 3.8).
Después de evaluar la función de costos Ec. (3.26) en cada uno de los algoritmos de optimización propuestos, se verifica en la Tabla 3.2 que el algoritmo SGD para el 40% de los datos eliminados tiene mejor rendimiento que los algoritmos Momentum y RMSprop.
Comparación de desempeño del modelo MF sintonizado vs algo-
- Enfoque de evaluación general
- Enfoque de evaluación particular
- Embedding Layers
- Modelo DMF propuesto (DMF1)
- Función de pérdida y algoritmo de optimización
- Comparación algoritmo DMF1 y MF
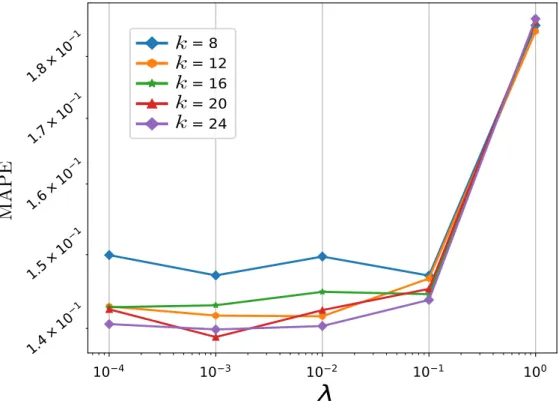
La Figura 4.1 muestra los resultados de aplicar la búsqueda a la grilla, donde se ve claramente que para el valor de λ = 0.001 y k = 20, es. Luego explica los resultados negativos representados por los puntos oscuros generados por el mapa de calor en la Figura 4.4d. Los resultados de la Figura 4.6 muestran claramente el desempeño de cada algoritmo, para lo cual se utilizaron los siguientes métodos de evaluación de errores: RMSE, es una medida de la distancia entre los datos reales y los estimados, dándole más importancia a los mayores errores obtenidos.
Lo anterior se puede confirmar en los resultados obtenidos en la Figura 4.4, ya que según el mapa de calor del modelo MOGPs se obtuvieron áreas (series de tiempo) donde el método no generó estimaciones (áreas oscuras), y en la Figura 4.6 sí puede Se puede observar que el modelo es mejor que la técnica MF en todas las medidas de desempeño analizadas, lo que refleja inconsistencia entre los datos reales y las estimaciones no generadas (altos errores debido a la no convergencia).
Planteamiento de arquitecturas DMF con características espacio -
- Prueba de hipótesis nula (H o ) test de Friedman
- Diagramas de distancia critica usando test de Nemenyi
- Arquitecturas DMF propuestas con características espacio
- Metodología de evaluación para el desempeño de las ar-
- Resultados evaluación de desempeño
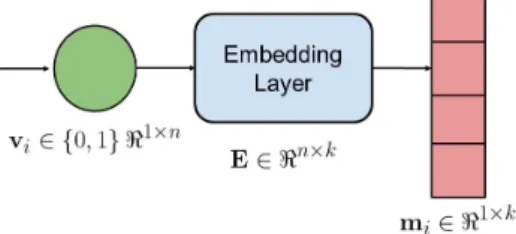
Este capítulo analiza el enfoque del modelo DMF como una mejora de la arquitectura del modelo MF desarrollada y ajustada en los Capítulos 3 y 4, y la evaluación de su desempeño en la estimación de datos faltantes de una WSN de bajo costo. Por lo tanto, el modelo intentará reconstruir las representaciones no observadas de,(s, t)∈Ω de la matriz M. Continuando con el enfoque de adaptación del modelo DMF1, la Figura 5.6 presenta el diseño de dos Redes de Incrustación para registrar las características espaciales (latitud y longitud) de cada nodo de las WSN de Citizen Scientist.
Se realiza el trazado de la grilla de la Figura 5.7, ya que la dinámica de la contaminación en la ciudad varía según la ubicación del nodo.
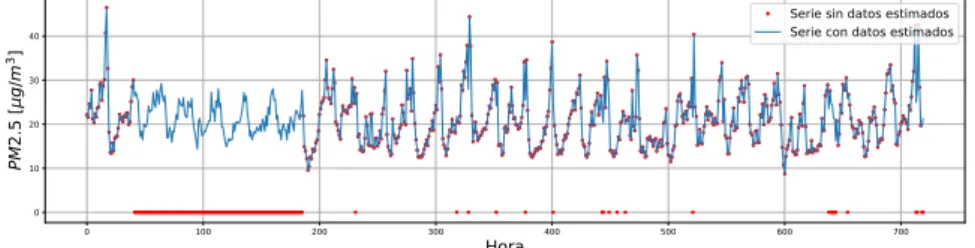
Estimación de datos perdidos usando DMF3
A partir de los experimentos realizados con los algoritmos evaluados y los escasos datos de WSN, se encontró que el modelo MF + Regularización + Bias (ajustado) presenta un mejor desempeño que los resultados obtenidos por las técnicas MS y KNN (ver Tabla 4.2). Como resultado, se puede ver en la Figura 4.6 que el modelo MF + Regularización + Sesgo (ajustado) supera al modelo MOGP en el sentido de que logra convergencia con una gran cantidad de información faltante, logrando así el cumplimiento del primer conjunto específico de objetivos. La Tabla 4.1 reconoce claramente que el modelo MF + Regularización + Sesgo (ajustado) representa una mejora del desempeño con respecto a los resultados obtenidos en la Sección 3. Con base en lo anterior, se puede concluir que los modelos MF responden al problema de recuperación de datos para Científicos Ciudadanos de bajo costo de las WSN, manteniendo a.
Sin embargo, los experimentos realizados mostraron que la inclusión de información espacio-temporal no mejoró el rendimiento del modelo Lost Information Estimation (DMF4).
Lineas futuras
Low-Cost Sensors for Measuring Atmospheric Composition: Topic Overview and Future Applications. Amperometric gas sensors as an emerging low-cost technology platform for air quality monitoring applications: A review. Low-Cost Sensors for Measuring Atmospheric Composition: Topic Overview and Future Applications.
Mapping urban air quality in near real time using observations from low-cost sensors and model information.
Desviación de los errores obtenidos por cada método DMF evaluado 73
Nodo 10 mes de Enero 2018
Nodo 108 mes de Abril 2018
Nodo 52 mes de Junio 2018
Nodo 34 mes de Mayo 2018
Nodo 12 mes de Enero 2018
Nodo 49 mes de Febrero 2018




![Figura 2.6: Mapa de calor de la red con información depurada de acuerdo con [51]](https://thumb-us.123doks.com/thumbv2/123dok_es/12434769.0/50.892.241.632.384.687/figura-mapa-calor-red-información-depurada-acuerdo-51.webp)


