La ciencia de datos se centra en generar conocimiento a partir de datos (Dhar, 2013). La ciencia de datos surge en la industria por la necesidad de analizar una mayor cantidad de información, es interdisciplinaria y se basa principalmente en 3 habilidades: matemáticas y estadística, programación y experiencia en el tema.

Objetivos
Metodología
Descripciones Generales
Descripciones Generales
- Descripción de la empresa
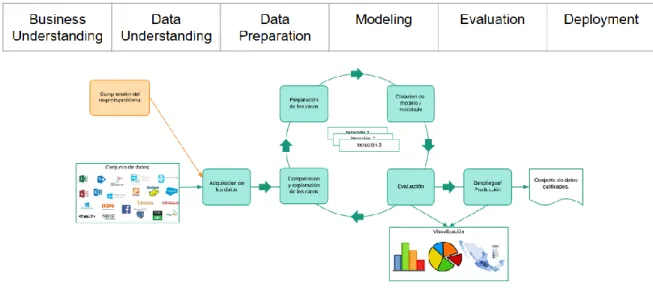
En la empresa trabajo en el área encargada de Data Science, la cual se enfoca principalmente en la venta de la plataforma para Data Science y Big Data Dataiku DSS, ya que la empresa se encarga de su venta y distribución para toda Latinoamérica y para brindar soluciones en Ciencia de Datos e Inteligencia Artificial a las empresas que las necesiten. La etapa de preparación de datos suele ser la más larga y consiste en selección de datos, limpieza de datos, construcción de nuevos datos, transformación de datos, integración, etc.

Proyecto “Predicción de Obsolescencia”
Proyecto “Predicción de Obsolescencia”
- Objetivo del Proyecto de Obsolescencia de la empresa “A”
- Solución propuesta
- Desarrollo del proyecto
- Integración de Base de Datos
- Limpieza y preprocesamiento
- Entrenamiento de modelos de clasificación
- Visualización de resultados
Por motivos de privacidad de datos, no se divulgan el nombre de la empresa ni los datos personales de los clientes; Por lo tanto, para este proyecto “Predicción de Obsolescencia” diremos que fue realizado para la empresa “A”. La empresa “A” es responsable de la comercialización, arrendamiento y servicios en el sector automotriz, incluyendo automóviles, camiones, motocicletas, maquinaria y equipos de construcción. 14 preprocesamiento y exploración del historial de transacciones de repuestos (más de 10 años) de la empresa “A” para identificar patrones relacionados con la clasificación de repuestos, incluidas las piezas consideradas obsoletas.
También se seleccionarán, entrenarán y evaluarán modelos de aprendizaje automático para la correcta clasificación de repuestos de la empresa “A”, especialmente para la detección de repuestos obsoletos, a partir de un conjunto de entrenamiento obtenido del historial de transacciones de dicha empresa. La solución propuesta para implementar en el POC consiste en desarrollar un flujo de trabajo para la clasificación de repuestos de la empresa “A” aplicando las etapas del proceso de Ciencia de Datos. Limpieza y preprocesamiento de las bases de datos propuestas para el entrenamiento del Modelo de Clasificación.
Diseño e implementación de un Escenario para la automatización de la aplicación Workflow, incluyendo la clasificación de nuevos datos utilizando el Modelo de Clasificación de mayor eficiencia encontrado. El área verde en la Figura 11 muestra las predicciones de clasificación realizadas, podemos ver que después de realizar y crear los conjuntos de datos de predicción, los conjuntos de datos se fusionaron para realizar análisis posteriores de resultados específicos solicitados por la empresa "A", que como resultado de La confidencialidad no está incluida en este informe. 36 El Gráfico 8 muestra los resultados obtenidos con la evaluación del modelo de pronóstico de insumos en los próximos 3 meses (mayo, junio y julio) de 2019.
El Gráfico 9 muestra los resultados obtenidos durante la evaluación del modelo de pronóstico de demanda para los próximos 3 meses (mayo, junio y julio) de 2019.

Proyecto “Predicción de Compras y Ventas”
Proyecto: “Predicción de Compras y Ventas”
- Objetivo del Proyecto de Compras y Ventas de la empresa “A”
- Solución propuesta
- Desarrollo del proyecto
- Limpieza y preprocesamiento
- Entrenamiento de modelos de clasificación y visualización de resultados. resultados
- Flujo de trabajo
Durante el proceso se definirá e implementará un flujo de trabajo que permitirá la limpieza, preprocesamiento y examen del historial de transacciones de repuestos (más de 10 años) de la empresa “A” para la identificación de patrones de compras y ventas. La solución propuesta a implementar en el POC consiste en desarrollar un flujo de trabajo para la previsión de los productos del inventario de la empresa “A”. Diseño e implementación de un Escenario para la automatización de la aplicación Workflow, incluyendo predicción de nuevos meses utilizando el Modelo de Regresión con mejor rendimiento encontrado.
Finalmente, se analizaron las variables de fecha y se extrajeron el año y el mes de la variable DateInvoice. Se realizó una unión utilizando la variable cmpFactura de los dos conjuntos de datos anteriores, realizando una limpieza de datos. Utilizando una receta Python se calculó el mínimo, el máximo, la desviación estándar y el promedio de la cantidad de repuestos comprados de un año anterior.
Luego se creó la variable Ventas, que se crea multiplicando Precio por Cantidad. Utilizando una receta de Python, se calculó el mínimo, el máximo, la desviación estándar y la media del monto de ventas realizadas para las existencias del año anterior. Se han implementado dos algoritmos predictivos, uno para el número de ventas de los próximos 3 meses y otro para el número de compras de los próximos 3 meses.
47 valor absoluto del tamaño de los coeficientes, en otras palabras, limita el tamaño de los coeficientes (Ramos Castillo, 2018).

Beneficios y Recomendaciones del uso de la Ciencia de Datos
Beneficios y Recomendaciones del uso de la Ciencia de Datos
- Beneficios
- Recomendaciones
El uso correcto y eficaz de la Ciencia de Datos puede aportar numerosos beneficios a las empresas como la detección de fraude y mitigación de riesgos, la predicción de evitación de clientes, la segmentación de usuarios, la personalización de la experiencia del cliente, la mejora y optimización de procesos, además, también puede tener beneficios que dependerán del sector al que pertenecen, por ejemplo, en el sector de la salud se pueden predecir enfermedades o encontrar el mejor tratamiento posible, en educación se puede predecir el abandono escolar, medir los logros escolares y mejorar las técnicas de aprendizaje. educación, pues los gobiernos pueden utilizarse para predecir fenómenos meteorológicos, incendios o contaminación, engrasamiento preventivo de carreteras, mantenimiento preventivo de edificios, etc. Esto se debe a que los POC deben demostrar el mayor valor de un sistema, asegurando que esté alineado con el cumplimiento de los objetivos estratégicos a largo plazo de la empresa, también demostrarán que existe toda la infraestructura adecuada y, en última instancia, eliminarán cualquier riesgo asociado con avanzando a toda velocidad con proyectos de ciencia de datos a escala. Para sacarle el máximo partido a la Ciencia de Datos en los objetivos que las empresas pretenden alcanzar es necesario contar con un equipo de científicos de datos capacitados y con conocimientos relevantes.
Según Nurturing a Productive Data Team de 2017, los mejores equipos de datos encuentran una manera de lograr un equilibrio entre soluciones nuevas, innovadoras y creativas y se encargan de garantizar que todas las soluciones basadas en datos estén bien pensadas. Todos deben ser conscientes de los proyectos de datos en curso y futuros y de cómo pueden afectar su trabajo o su trabajo. Involucrar a las personas adecuadas: esto incluye a los científicos de datos que serán responsables de realizar la POC, pero también.
Garantizar la autonomía: trabajar con los expertos del cliente para aprovechar y aprender mejor de sus conocimientos, pero sin perder la autonomía del equipo de ciencia de datos. Sea ágil pero enfocado: las mejores soluciones provienen de equipos que pueden dirigir diferentes soluciones en el menor tiempo posible, pero es importante nunca perder de vista los objetivos del POC (Dataiku, 7 Steps to Driving an Efficient Data Science POC: .Move Past Evaluación simple y aportación de valor, 2017).
Conclusiones
Optimización de los procesos de solicitud de compra: En función del proceso realizado para realizar las solicitudes de compra, se puede utilizar la IA para agilizar el proceso. Optimización de rutas para la logística de distribución hacia y entre almacenes (tenga en cuenta la georreferenciación): A partir de rutas de distribución, cree una aplicación web que le permita encontrar la ruta óptima para todos los puntos a los que necesita llegar, según las condiciones que se hayan marcado. Segmentación de clientes: en función de los datos que tenga sobre los clientes o prospectos, se pueden clasificar en grupos de correo de marketing, prospectos, clientes en riesgo, etc.
En resumen, con una industria puedes realizar múltiples proyectos con ciencia de datos o POC como se describe en ese informe de experiencia laboral, lo único que necesitas es un historial de datos o una base de datos. requeridos para el proyecto se pueden obtener de acuerdo a los objetivos marcados. Esto se debe a varias razones, ya que es una disciplina relativamente nueva y se requiere de muchos conocimientos para formar a un científico de datos. Sin embargo, dentro de la empresa (Plenumsoft) se ha establecido que esto se debe principalmente a una falta de conocimiento. respecto a este tema, porque se cree que para aplicarlo se necesita ser una empresa “grande” y tener muchos datos o pagar los servicios de un experto en Ciencia de Datos, ya que el beneficio económico de invertir en él no se puede entregar. conocido. Otra causa es que se desconoce qué se puede lograr implementando Ciencia de Datos; porque las grandes empresas saben que les beneficiará, pero no entienden cómo. Por lo tanto, el primer paso es concientizar a las empresas sobre lo que pueden esperar de un proyecto de Ciencia de Datos, de esta manera el enfoque de estos proyectos estará mejor enfocado a resolver las necesidades primarias de la empresa y dar valor a los productos o servicios. que ofrecen, este es un aspecto muy relevante ya que una de las habilidades más importantes al realizar Ciencia de Datos que no tiene que ver con estudios es el conocimiento que se tiene sobre el tema o campo de la empresa y no. No hay nadie que comprenda mejor su negocio que el propietario o los empleados de ese negocio.
Y esa es una forma en la que el proceso de desarrollo de proyectos de Data Science se vuelve más eficiente y consigue mejores resultados, que es cuando el cliente se implica en el proyecto y lo asimila como propio, siendo consciente de sus avances. , para resolver los problemas. que el equipo de Data Scientist reúne y proporciona. 66 conocer a los demás miembros de la empresa lo que se necesita conseguir, para que ellos también se sumen al proyecto y culturalicen la empresa.
Bibliografía
Anexos
Características centrales que integran la plataforma Dataiku DSS
Receta de agregación: le permite realizar agregaciones en cualquier conjunto de datos en Datatiku DSS, ya sea un conjunto de datos SQL o no. Receta de ventana: le permite realizar funciones de análisis en cualquier conjunto de datos en Dataiku DSS, ya sea un conjunto de datos SQL o no. Receta de separación: permite enviar filas de un conjunto de datos a otro conjunto de datos, según reglas establecidas.
Se puede ejecutar en cualquier conjunto de datos, ya sea un conjunto de datos SQL o no. Sin embargo, para que la receta sea útil, el conjunto de datos de salida debe preservar el orden de escritura. De esta manera, cuando cree una nueva receta de clasificación, el conjunto de datos de salida se configurará para preservar el orden escrito, si es posible.
La receta de descarga se ocupa únicamente de archivos: no interpreta los archivos y no crea un conjunto de datos que pueda usarse directamente. Una vez que se hayan creado la receta de descarga y su carpeta administrada de salida asociada, se puede crear un conjunto de datos.