Los resultados finales de pronóstico del modelo BI y del modelo empírico de la UNAB para el período. El error final resulta del modelo BI y del modelo empírico de la UNAB para el período 2016-01 discriminado por desertores y no desertores.
PLANTEAMIENTO DEL PROBLEMA
La Universidad Autónoma de Bucaramanga UNAB es una institución dedicada al servicio de la Educación Superior, de carácter privado, con acreditación institucional de alta calidad, que hoy se consolida como la primera universidad del noreste de Colombia (Universidad Autónoma de Bucaramanga, 2016a). El Business Intelligence cubre un amplio abanico de posibilidades mediante la aplicación de diferentes herramientas y procedimientos, uno de ellos es la minería de datos, que cuenta con diferentes técnicas, cada una de ellas con diferentes algoritmos que permiten, más allá de la definición de patrones y tendencias, predecir comportamientos futuros. , incluidas oportunidades para identificar tempranamente a aquellos estudiantes con alto riesgo de abandonar los estudios.

JUSTIFICACIÓN
OBJETIVO GENERAL
OBJETIVOS ESPECÍFICOS
RESULTADOS ESPERADOS
ANTECEDENTES
Una lectura sobre la deserción universitaria en estudiantes de pregrado desde la perspectiva de la minería de datos. Minería de datos: predicción del abandono escolar mediante el algoritmo del árbol de decisión y el algoritmo de los k vecinos más cercanos.

MARCO TEÓRICO
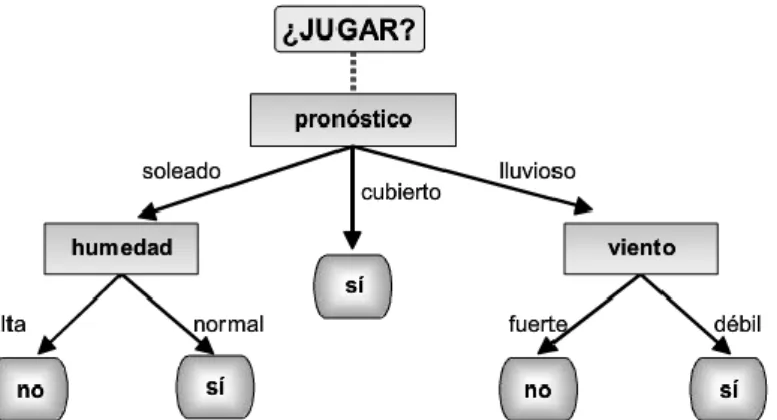
DESERCIÓN EN LA EDUCACIÓN SUPERIOR
Pero ¿por qué las tasas de deserción estudiantil son tan altas en la educación superior? Estos métodos estadísticos y predictivos se implementan a través de lo que se conoce como Minería de Datos, que a su vez forma parte fundamental del proceso general de Business Intelligence o BI.

BUSINESS INTELLIGENCE (BI) …
Luego, se presenta el concepto general de BI, minería de datos y diversas metodologías, que describen el proceso de adquisición de conocimientos con las principales técnicas de minería existentes. Así, la minería de datos se convierte en una base fundamental en los procesos de inteligencia de negocios, permitiendo extraer conocimiento de los datos de las organizaciones, conocimiento que se utiliza para guiar la toma de decisiones para lograr mejores resultados.
DATA MINING
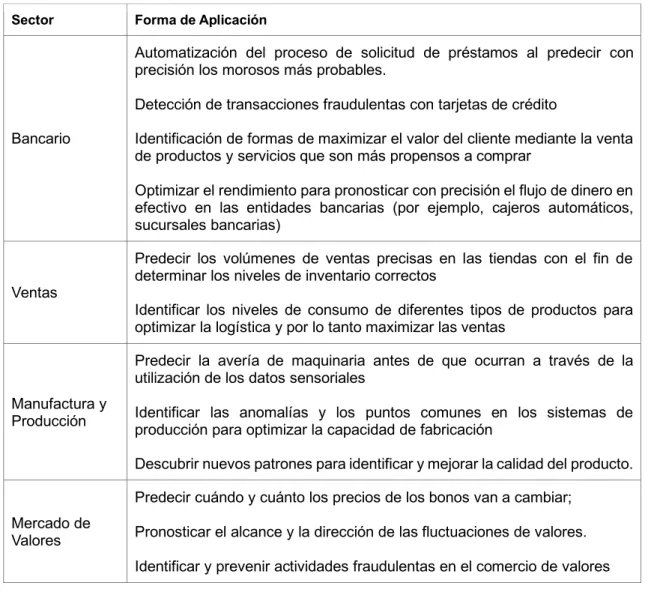
Predecir averías en la maquinaria antes de que ocurra utilizando datos sensoriales. La demanda prevista en diferentes ubicaciones para asignar mejor los recursos limitados de la organización.
METODOLOGÍAS DE MINERÍA DE DATOS
- Metodología CRISP-DM
- Metodología SEMMA
- Proceso KDD - Knowledge Discovery in Databases
SEMMA es el acrónimo de Sample, Explore, Modify, Model and Assess, que define las fases de un proyecto de minería de datos. Fase que permite evaluar la utilidad y confiabilidad de los resultados del proceso de minería de datos. Un quinto paso incluye la interpretación y evaluación de los resultados obtenidos según las técnicas de minería de datos aplicadas.

MODELOS DE MINERÍA DE DATOS …
- Modelo Descriptivo
- Modelo Predictivo
Tienen como objetivo estimar valores futuros o desconocidos de variables de interés, llamadas variables objetivo o variables dependientes, utilizando otras variables o campos en las bases de datos llamados variables predictivas o independientes (Hernández Orallo, Ramírez Quintana y Ferri Ramírez, 2004). Para cada uno de los modelos definidos, existe un conjunto de métodos mediante los cuales se pueden alcanzar los objetivos de descripción o los objetivos de agrupación. Por ejemplo, dentro del modelo descriptivo se consideran los métodos de agrupación (clustering) y asociación, mientras que dentro del modelo predictivo se clasifican los métodos de clasificación y regresión.
MÉTODOS DE MINERÍA DE DATOS
- Método de Clasificación
- Método de Regresión
- Método de Agrupamiento (Clustering)
- Método de Asociación
Define la capacidad de construir eficientemente un modelo de predicción con una gran cantidad de datos. Los datos históricos de un proyecto de regresión normalmente se dividen en dos conjuntos de datos: uno para construir el modelo y otro para probarlo. El objetivo principal de la regresión es identificar relaciones entre elementos en grandes cantidades de datos que no son observables a primera vista.
TÉCNICAS DE MINERÍA DE DATOS …
- Arboles de Decisión
- Redes Neuronales Artificiales
- Clasificadores bayesianos
- Reglas de Clasificación
- Regresión Lineal
- Reglas de Asociación
- K-Vecinos
- K-Medias
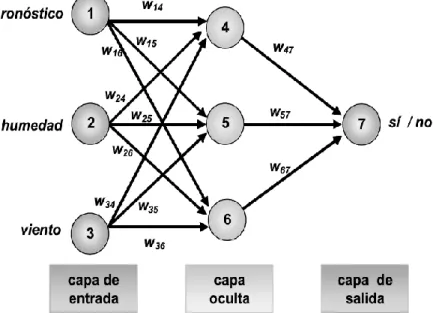
Cada nodo de la capa de entrada está conectado a cada nodo de la capa oculta. Los nodos de la capa oculta se pueden conectar a otros nodos de otra capa oculta o a los nodos de la capa de salida, como se ve en la Figura 10. Donde la parte "IF" (o izquierda) se conoce como predecesora de la regla. o condición anterior.
HERRAMIENTAS SOFTWARE PARA LA MINERÍA DE DATOS
- Weka
- RapidMiner
- Orange
Es una plataforma de software desarrollada por la empresa del mismo nombre que proporciona un entorno integrado para aprendizaje automático, minería de datos, minería de textos, análisis predictivo y análisis de negocios. Orange es un paquete de software completo basado en componentes para aprendizaje automático y minería de datos, desarrollado en el Laboratorio de Bioinformática de la Facultad de Ciencias de la Computación e Informática de la Universidad de Ljubljana en Eslovenia en apoyo de la comunidad de código abierto (Universidad de Ljubljana, 2016 ). Clasificación mediante la implementación de múltiples algoritmos de aprendizaje automático supervisados, como árboles de decisión, modelos bayesianos y reglas de inducción.
MARCO METODOLÓGICO
METODOLOGÍAS IMPLEMENTADAS
HIPÓTESIS
POBLACIÓN Y MUESTRA
RECOLECCIÓN DE LA INFORMACIÓN
PLAN DE INVESTIGACIÓN
- Aplicación de la Metodología CRIPS-DM
- Descripción de los mecanismos de análisis de Datos
RESULTADOS
SOFTWARE DE MINERÍA DE DATOS
El creciente interés de empresas, universidades e investigadores en general por la analítica de datos también ha provocado el crecimiento de diversas herramientas de analítica avanzada, también llamadas herramientas de ciencia de datos, análisis estadístico, análisis predictivo, etc. Proporcionan una interfaz gráfica que facilita el flujo de trabajo en los procesos de análisis de datos. El análisis de Muenchen (2017) publicado en 4stats muestra la popularidad de diferentes herramientas de software de análisis de datos en diferentes contextos, incluida la popularidad entre anuncios de empleo, publicaciones de artículos académicos en revistas científicas, empresas de investigación de TI, encuestas de uso y foros de discusión.
ALGORITMO DE CLASIFICACIÓN …
Dentro de las categorías analizadas, Weka destaca en anuncios de empleo, artículos académicos y encuestas de uso, mientras que RapidMiner y Knime destacan principalmente por su uso en empresas del sector TI. Weka es particularmente popular en proyectos académicos, mientras que RapidMiner y Knime se utilizan principalmente en entornos comerciales, donde también ofrecen versiones empresariales. Considerando el alcance académico del proyecto, se eligió Weka como herramienta de Minería de Datos para análisis predictivo, considerando además que, a nivel de funcionalidad, en comparación con RapidMiner y Knime, las diferencias no son significativas, lo que sí, la posibilidad de que Weka dispone de integración con diferentes herramientas de análisis de datos, especialmente con el lenguaje R, lo que permite ampliar la funcionalidad natural que ofrece el software.
INTRODUCCIÓN A WEKA
- Instalación
- Interfaz de Preprocesamiento
- Pestaña de Clasificación …
- Resultados Weka
La primera pestaña permite hacer todo lo relacionado con el preprocesamiento de los datos que serán analizados. Abra BD: consulte datos de la base de datos a través del controlador jdbc. En la pestaña de clasificación, Weka cuenta con varios algoritmos y estrategias para probar los datos que fueron previamente cargados en la pestaña de preprocesamiento.

CONOCIMIENTO DEL NEGOCIO
Cabe señalar que algunos algoritmos requieren que la variable de clasificación sea nominal, otros solo aceptan variables numéricas y algunos aceptan ambos tipos de variables. Finalmente, el botón de inicio permite iniciar el proceso de clasificación según los parámetros previamente configurados.
COMPRENSIÓN DE LOS DATOS …
Indicador de personalidad clínica - 1. 1 0 Indicador de personalidad clínica - 2B 1 0 Indicador de personalidad clínica - 3C 1 0 Indicador de personalidad clínica - 4E 1 0 Indicador de personalidad clínica - 5F 1 0 Indicador de personalidad clínica - 6G 1 0 Indicador de personalidad clínica - 7H 1 0 Personalidad indicador clínico – 8I 1 0 indicador clínico personalidad – 9L 1 0 indicador clínico personalidad – 10M 1 0 indicador clínico personalidad – 11N 1 0 indicador clínico personalidad – 12º 1 0 indicador clínico personalidad – 13Q 1 0 indicador clínico personalidad – 14R 1 0 indicador personalidad clínica – 15S 1 0 Indicador clínico personalidad – 16T 1 0. Indicador clínico personalidad – I1 1 0 Indicador clínico personalidad – I2 1 0 Indicador clínico personalidad – I3 1 0 Indicador clínico personalidad – I4 1 0 Indicador clínico personalidad – I5 1 0 Indicador personalidad clínica – NRT 1 0 Indicador de personalidad clínica – PST 1 0 Indicador de personalidad clínica – PAA. Se encontró que los registros contenían, en parte, datos académicos, psicológicos y financieros de los estudiantes; Algunos campos están vacíos, son nulos o tienen valores no válidos.
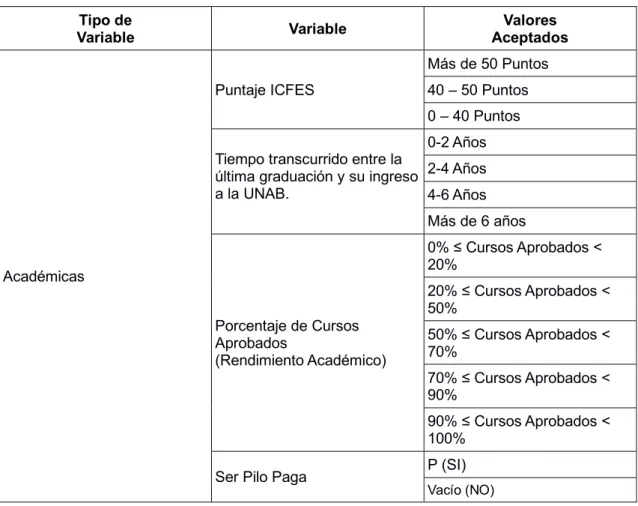
PREPARACIÓN DE LOS DATOS
Según la metodología CRISP-DM, el proceso de comprensión de los datos continúa con la identificación de problemas de calidad. Los registros tienen un campo llamado Caracterización que especifica si el estudiante está caracterizado o no. La información recibida se ubica en diversos archivos en formato Excel, que representan por separado a los estudiantes matriculados, datos académicos, datos financieros, datos psicológicos y datos de deserción.
MODELADO DE LOS DATOS
ANÁLISIS GENERAL DE LOS DATOS
Como se puede observar, Weka no logró identificar ningún patrón de predicción sobre los datos cargados, aunque los registros fueron clasificados correctamente y los que fueron clasificados incorrectamente, solo se clasificaron los estudiantes que no abandonaron, los estudiantes que abandonaron tuvieron una clasificación cero. La matriz de confusión que se ve al final de la figura se puede interpretar en términos de los valores que se muestran en la siguiente tabla, donde se identifican datos clasificados correctamente e incorrectamente en los registros de deserción y no deserción. Un análisis detallado de los registros para determinar las causas de la mala clasificación realizada por Weka reveló el siguiente problema: Registros desproporcionados de estudiantes que no abandonaron en comparación con los registros de estudiantes que abandonaron.

ANÁLISIS POR PERIODO ACADÉMICO
- Análisis Periodo 2014-02
- Análisis Periodo 2015-01
- Análisis Periodo 2015-02
- Análisis Periodo 2016-01
Dado que solo hay 72 registros de abandono, se deben seleccionar 72 de los 872 registros de no abandono. Dado que solo hay 40 registros de abandono, se tuvieron que seleccionar 40 de los 316 registros de no abandono. Dado que solo hay 105 registros de abandonos, se deben seleccionar 105 de los 999 registros de No desertores.

ANÁLISIS POR PERIODO ACADÉMICO ACUMULADO
- Periodos 2014-02 y 2015-01
- Periodos 2014-02, 2015-01 y 201502
- Periodos 2014-02, 2015-01, 201502 y 2016-01
De los resultados anteriores se desprende que el puntaje del ICFES y el rendimiento académico aparecen como variables que influyen en la deserción estudiantil. Se puede observar que los resultados de los registros clasificados correctamente tanto para los desertores (28) como para los no desertores (29) fueron bastante equilibrados. De los resultados se puede analizar que el rendimiento académico, los responsables y los empleados actuales aparecen como variables que inciden en la deserción estudiantil.

ANÁLISIS POR PERIODO ACADÉMICO ACUMULADO SIN
- Periodos 2014-02 y 2015-01
- Periodos 2014-02, 2015-01 y 201502
- Periodos 2014-02, 2015-01, 201502 y 2016-01
Se observa que, al igual que en el análisis anterior, los resultados de los expedientes correctamente clasificados fueron bastante equilibrados tanto para los estudiantes desertores (76) como para los no desertores (69). Árbol de decisión Weka a partir del análisis de los periodos 2014-02 y 2015-01 con el algoritmo J48 sin la variable Rendimiento Académico. Se observa que los resultados de los registros correctamente clasificados, tanto para los estudiantes desertores (30) como para los no desertores (25) respecto a los desertores (29) y no desertores (28) del análisis anterior, son bastante similares. .

ANÁLISIS DE RESULTADOS
- Análisis de Variables Determinantes de Deserción
- Comparación del modelo BI contra el modelo empírico de la UNAB 129
En PAA y PAA', los porcentajes de clasificación de los registros de no desertores fueron mayores. A diferencia de los resultados del análisis PAA, el análisis PAA mostró una gran diferencia entre el porcentaje de clasificación de registros de abandono y no abandono. El análisis preliminar es igualmente válido si en los resultados del análisis posterior al período acumulado (PAA) se tiene en cuenta únicamente el registro de abandonos.

RECOMENDACIONES Y TRABAJOS FUTUROS
Análisis de la deserción estudiantil de la Universidad Simón Bolívar, Facultad de Ingeniería de Sistemas, utilizando técnicas de minería de datos. Obtenido de ftp://ftp.software.ibm.com/software/analytics/spss/support/Modeler/Documentation/14/UserManual/CRISP-DM.pdf. Recuperado el 15 de abril de 2016, de http://www.mineducacion.gov.co/sistemasdeinformacion/1735/articles-254702_libro_desercion.pdf.