Machine Learning: Subcampo de la inteligencia artificial que estudia algoritmos que mejoran automáticamente a través de la experiencia. MLOps: Conjunto de prácticas y herramientas destinadas a implementar y mantener modelos de aprendizaje automático en producción de manera consistente, confiable y eficiente.
Objetivos
Obtenga información sobre una de las plataformas de servicios en la nube más populares de la industria para que pueda implementar soluciones de aprendizaje automático a escala. Tiene una implementación en SageMaker que sirve como base para otros proyectos de ciencia de datos y aprendizaje automático con características similares.
Hip´ otesis
Caso de negocio
Estructura del documento
La ciencia de datos se refiere a: “El concepto que unifica la estadística, el análisis de datos, el aprendizaje automático y métodos relacionados, con el objetivo de comprender y analizar un fenómeno de la realidad” [4]. En la misma línea, otra publicación afirma que "La ciencia de datos es una combinación de habilidades en los campos de la estadística, el aprendizaje automático, las matemáticas, la programación, los negocios y la tecnología". lógicas de la información" [5].
Servicios en la nube
Por otro lado, el aprendizaje automático se refiere a: “El estudio de algoritmos informáticos que mejoran automáticamente a través de la experiencia” [6].
Estado del arte
En los últimos meses, la industria de servicios en la nube está haciendo una fuerte apuesta por desarrollar estas capacidades para sus plataformas de ciencia de datos y aprendizaje automático. También en el ámbito de la educación especializada en aprendizaje automático se hace hincapié en la formación para el uso de estas herramientas.
Amazon SageMaker
El proyecto se basa en un ciclo de vida híbrido, que combina un marco predictivo de alto nivel y un enfoque ágil durante la fase de ejecución del proyecto. El marco de previsión de alto nivel determina la división del proyecto en cuatro fases.
Planificaci´ on
- Diagrama de Gantt
- Detalle de la planificaci´ on
- Situaci´ on actual
- Propuesta de soluci´ on
- Ground Truth
Opinión: Se refiere a los datos de la opinión que el usuario ha dado sobre el pedido. ReviewState Estado de moderación de la opinión categórica Tabla 5.6: Descripción de la variable a predecir.
Amazon SageMaker
- Introducci´ on
- Herramientas
- Consola de administraci´ on
- SageMaker Studio
- Uso program´ atico
- Recursos
Es el punto de entrada al servicio y desde allí puede acceder y configurar cuadernos, generar y acceder a instancias de SageMaker Studio y administrar algunas de las herramientas. Componentes y registros de SageMaker: acceso visual y uso de muchas de las herramientas principales de SageMaker.
Ingesti´ on y an´ alisis de datos
Investigaci´ on
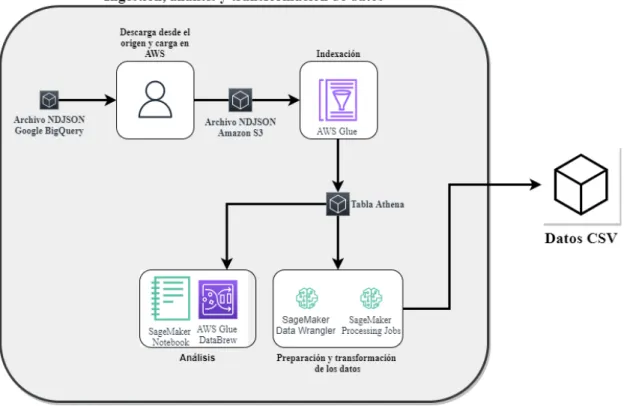
AWS Glue es un servicio ETL (extracción, transformación y carga de datos) que facilita la categorización, limpieza, mejora y movimiento de datos. Los rastreadores de AWS Glue utilizan clasificadores de rastreadores, que contienen una especificación sobre cómo analizar los datos.
POC: Amazon S3, AWS Glue (Data Catalog), Amazon Athe-
AWS Glue Databrew permite obtener un análisis exploratorio inicial muy completo con tan solo unos clics sin necesidad de escribir código. Como se ve en POC, el mismo tipo de análisis se puede realizar con muchas herramientas.
Preparaci´ on y transformaci´ on de datos
- Investigaci´ on
- POC: SageMaker Data Wrangler y SageMaker Processing Jobs 45
- Investigaci´ on
- POC: SageMaker Experiments, SageMaker Training Jobs y
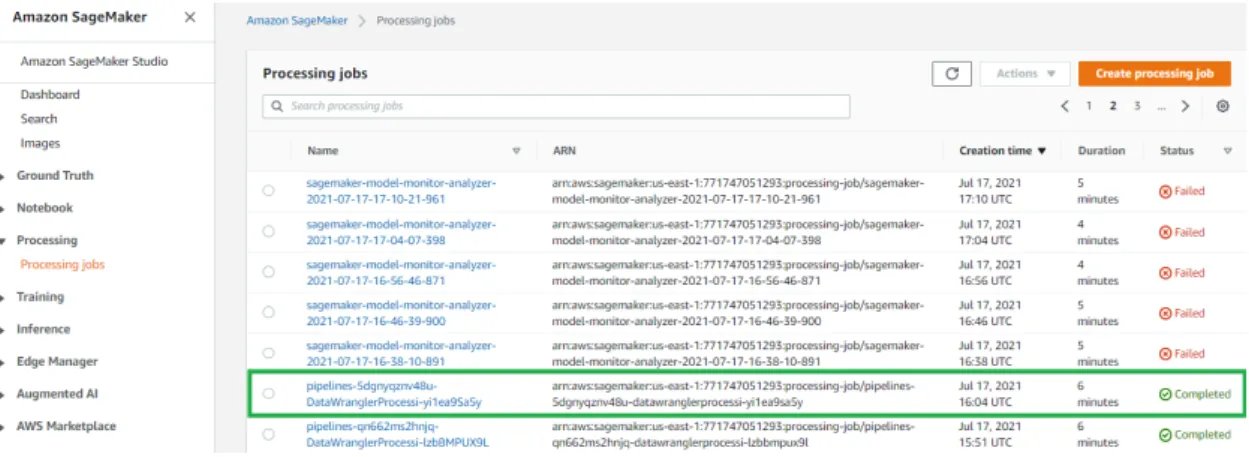
Los detalles completos se pueden consultar en la Sección 10.3, Apéndice 3 - POC - SageMaker Data Wrangler y SageMaker Processing Jobs. Especifique la preparación y el flujo de la transformación del conjunto de datos para una primera capacitación utilizando transformaciones integradas y personalizadas con SageMaker Data Wrangler.

Despliegue y gesti´ on de modelos
Investigaci´ on
Encapsulado con el modelo: Consiste en colocar la lógica de pre y post procesamiento y el modelo como una unidad. Para lograr esto último, se puede utilizar un Modelo SageMaker de tipo Pipeline Model, que incluye tanto el modelo como el código de pre y post procesamiento.
POC: SageMaker Model Monitor
La configuración requerida para habilitar la captura de datos para SageMaker Model Monitor es muy simple: simplemente agregue dos líneas de código a la plantilla de Amazon CloudFormation. Sin embargo, el trabajo que realiza el análisis de SageMaker Model Monitor no admite este formato como entrada. El error ocurre cuando se ejecuta el trabajo para el análisis de datos (los detalles se pueden ver en la Sección 10.5 Anexo 5 - POC - SageMaker Model Monitor).

MLOps
Investigaci´ on
Los puntos finales de SageMaker almacenan una referencia al modelo de registro de modelo de SageMaker que se implementa, y el registro de modelo de SageMaker almacena una referencia a la canalización de SageMaker con la que se creó el modelo. Por ejemplo, SageMaker Endpoints almacena datos como el número y tipo de instancias, SageMaker Model Registry almacena el artefacto del modelo en sí y SageMaker Pipelines almacena el conjunto de datos inicial y los archivos de entrenamiento, validación y prueba. SageMaker Projects se integra directamente con las herramientas descritas anteriormente, como SageMaker Model Registry y SageMaker Pipelines, y le permite ver un proyecto junto con todos sus recursos asociados desde SageMaker Studio.
POC: SageMaker Pipelines y CI/CD
Puede utilizar un punto final de SageMaker para determinar qué versión del modelo está utilizando, qué SageMaker Pipeline y ejecución generó y qué artefactos utilizó en el proceso. Con SageMaker Projects, todos los recursos y la información del proyecto están agrupados y accesibles a través de la interfaz de SageMaker Studio. De forma predeterminada, la plantilla debe contener un modelo de SageMaker de tipo Model Pipeline (como se encuentra en SageMaker Autopilot).
AutoML
Investigaci´ on
Análisis de datos: recopile métricas sobre los datos (por ejemplo, distribución, datos faltantes, correlaciones, etc.). Detección de esquemas de conjuntos de datos: descubra qué tipos de atributos hay en el conjunto de datos. Cuaderno de Análisis de Datos: Permite sugerir aspectos que requieren un análisis manual del conjunto de datos.
POC: SageMaker Autopilot
Genera código para buscar un modelo candidato que incluye transformaciones, entrenamiento con algoritmos preseleccionados y búsquedas de hiperparámetros. Cuaderno de generación de candidatos: Incluye código de definición de canalización. El código generado no se puede reutilizar fácilmente para el caso específico en el que desee incluirlo en el proceso de SageMaker.

Revisi´ on humana y reentrenamiento
Investigaci´ on
Si la predicción tiene poca confianza, el cliente la remite a la herramienta A2I (a través de su API). Deje que el cliente obtenga la predicción final tomándola de Amazon S3 una vez generada. Procesa el JSON con los resultados de la revisión humana para devolver la predicción al cliente.
An´ alisis de costos en AWS
- Servicios utilizados
- Forma de cobro de los servicios
- Cr´ edito POC
- Acad´ emicos
- Profesionales
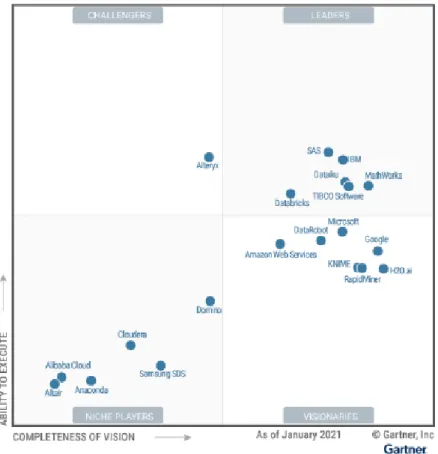
También puede utilizar la calculadora de precios a través del servicio AWS Pricing Calculator [28]. A continuación se muestran dos diagramas de alto nivel que muestran cómo funciona la solución. Obtuvimos conocimiento y comprensión de la arquitectura del servicio SageMaker, una plataforma de ciencia de datos y aprendizaje automático posicionada como visionaria en el cuadrante mágico de Gartner.

Hip´ otesis
Esta hipótesis está validada, SageMaker tiene disponibles diversas herramientas que facilitan la implementación y gestión de modelos en producción. SageMaker se encuentra en un nivel de madurez adecuado para adoptarlo en una organización a escala masiva. Trabajar con los datos: Se debe trabajar en incorporar nuevos atributos, en extraer atributos de los que ya están disponibles y en obtener mayor cantidad o mejor calidad de observaciones ya etiquetadas.
Desarrollo profesional
Available: https://cloud.google.com/blog/topics/developers-practitioners/google-cloud-launches-google-io-2021. Available: https://aws.amazon.com/es/blogs/machine-learning/deeplearning-ai-coursera-and-aws-launch-the-new-practical-data-science-specialization-with-amazon-wijsmaker/ . Available: https://aws.amazon.com/blogs/aws/amazon-sagemaker-named-as-the-outright-leader-in-enterprise-mlops-platforms/.
Anexo 1 - Acuerdo de uso de datos de PedidosYa
Anexo 2 - POC - Amazon S3, AWS Glue Data Catalog, Amazon
El conjunto de datos se especifica mediante una consulta SQL en Athena o apuntando a una ubicación en Amazon S3. Pandas es una biblioteca Python popular para análisis y manipulación de datos. Inicia sesión en AWS Glue DataBrew y conecta un nuevo conjunto de datos como se ve a continuación.
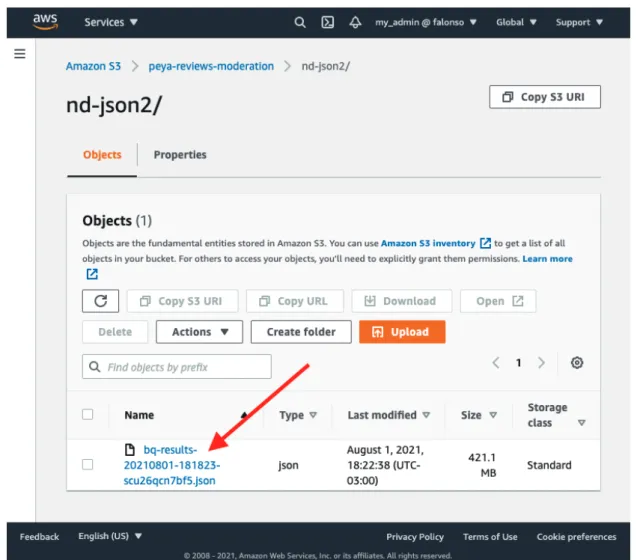
Anexo 3 - POC - SageMaker Data Wrangler y SageMaker Proces-
Esto se puede hacer desde SageMaker Studio verificando cómo se ve el conjunto de datos después de cada paso. Nuevamente, el resultado de la ejecución se puede ver desde la computadora portátil o, más simplemente, desde la consola de administración, como se muestra a continuación. Cuando lo descargue, podrá ver que el conjunto de datos se transformó según lo especificado.
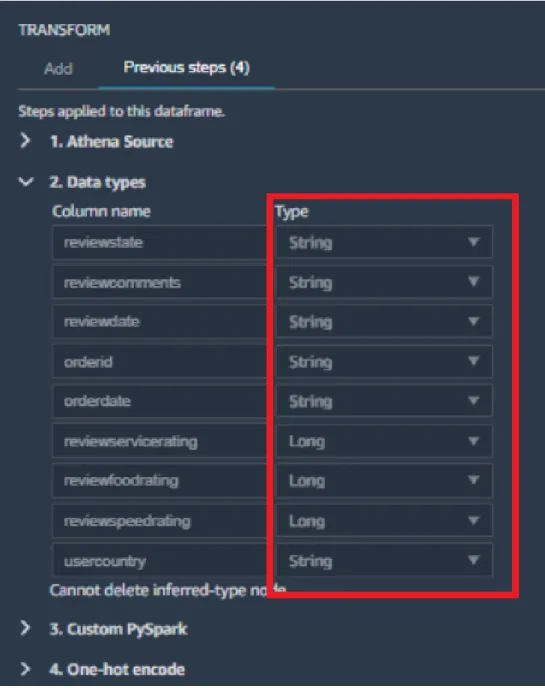
Anexo 4 - POC - SageMaker Experiments, SageMaker Training
Verá los detalles del componente de prueba (o paso de seguimiento) del tipo Entrenamiento. Se muestran los mismos datos que en el trabajo de capacitación de SageMaker que se muestra en el paso 2, más otros datos como el depurador, la explicabilidad del modelo y el informe de sesgo (aunque estos solo se generan si estos informes se han activado para el trabajo). Para cada prueba, también puede ver sus detalles, incluida, por ejemplo, la ubicación del script de preprocesamiento (que difiere entre las dos pruebas).
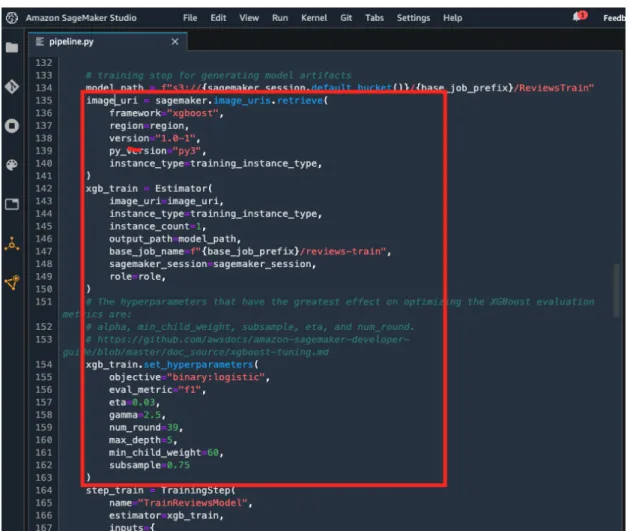
Anexo 5 - POC - SageMaker Model Monitor
Para generar una línea de base de calidad de datos, la documentación oficial recomienda (aunque no es obligatorio) utilizar el mismo conjunto de datos en el que se entrenó el modelo implementado. A continuación se muestra cómo obtener la ubicación del conjunto de datos de entrenamiento de SageMaker Studio. Luego, el archivo de referencia de calidad de los datos se genera con un cuaderno que utiliza una clase llamada "DefaultModelMonitor" del SDK de SageMaker para Python.
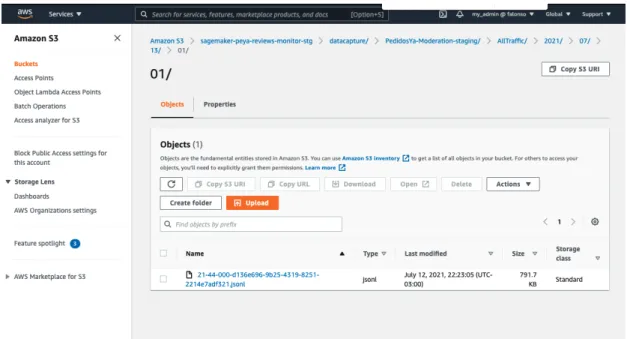
Anexo 6 - POC - SageMaker Pipelines y CI/CD
La ejecución de SageMaker Pipeline crea un grupo de modelos que contiene una versión de modelo 1. Cada confirmación desencadenó la compilación de un modelo al ejecutar la canalización CI/CD. Además, puede ver cómo la versión 6 del modelo se conecta a SageMaker Endpoint.
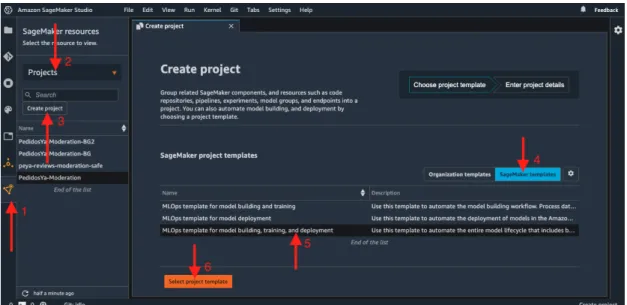
Anexo 7 - POC - SageMaker Autopilot
Divisor de datos: analiza la calidad de los datos y luego los divide en entrenamiento y validación. El estado de ejecución del trabajo del piloto automático se puede ver utilizando SageMaker SDK para Python. Cuando se completen estos trabajos, podrá ver el ranking de los modelos obtenidos con sus métricas asociadas, tanto usando SageMaker SDK para Python como desde SageMaker Studio.