La primera propiedad de la probabilidad de un evento (A), denotada por la función P(A), es que siempre tendrá un valor entre 0 y 1. Por otro lado, la regla de complementariedad nos dice que la suma de las las probabilidades de un evento y su complemento es 1. Dado que se obtuvo un rey en el primer sorteo, ¿cuál es la probabilidad del evento B, que consiste en obtener otro rey en el segundo sorteo de una carta de la baraja?
En el análisis estadístico, a un evento aleatorio a menudo se le asigna un número llamado valor de la variable aleatoria. Cada uno de los diferentes valores de la variable está asociado únicamente a un número real llamado probabilidad. De esta forma, tenemos una función de probabilidad que relaciona la fracción de probabilidad con diferentes valores de la variable aleatoria.
Se llaman distribuciones porque la probabilidad total de 1 en cada caso se distribuye entre todos los valores diferentes posibles de la variable aleatoria. Distribución de probabilidad de la variable X, número de caras en el lanzamiento de tres monedas. Esto es diferente del caso de la distribución de frecuencia relativa (que se puede mostrar en un histograma de frecuencia relativa), donde la distribución se construye con datos reales, es decir, es una distribución empírica.
En una distribución de probabilidad, la probabilidad de un determinado valor de la variable aleatoria X es una proporción de la población; mientras que en el caso de la distribución de frecuencia relativa, la frecuencia de una clase particular es parte de la muestra. Como ocurre con cualquier distribución, la suma de las probabilidades asociadas con cada valor de la variable aleatoria es 1. Muchos fenómenos naturales, como la distribución de longitudes en una población o la distribución de errores de medición, exhiben un comportamiento que coincide con lo normal.
Para las distribuciones probabilísticas, hay tres elementos importantes: la media (medida de tendencia central), la desviación estándar (medida de dispersión) y el patrón de la distribución. El teorema del límite central proporciona información sobre estas tres características de la distribución muestral en las medias muestrales. La media de la distribución muestral de la media muestral es igual a la media poblacional.
La distribución muestral de la media muestral es aproximadamente normal, independientemente del patrón de distribución de la población. Observe cómo el error estándar disminuye a medida que aumenta el tamaño de la muestra. Efecto del tamaño de la muestra sobre la precisión de los valores de X como estimadores de μ.
Si 𝑿̅ es la media de una muestra aleatoria de tamaño n tomada de una población con media μ y varianza finita σ2, entonces la forma límite de la distribución de.

La prueba de hipótesis puede mostrar si una afirmación tentativa es respaldada o rechazada por evidencia de muestra.
Planteamiento de la hipótesis
Una hipótesis estadística es una afirmación o conjetura sobre el valor de un parámetro o parámetros en una población. Por ejemplo, podría ser útil determinar si la edad promedio de la población mexicana es de 25 años. Otra alternativa es sugerir que la edad promedio de la población mexicana es mayor a los 25 años.
Finalmente, una tercera opción para la hipótesis alternativa es que la edad promedio de la población mexicana difiere de los 25 años, o. Los primeros dos enfoques de la hipótesis alternativa implican una prueba de hipótesis de una cola de la distribución, el tercer enfoque requiere una prueba de hipótesis de dos colas.
Especificar el nivel de significación
Las diferencias entre muestras extraídas de la misma población se deben al azar y rara vez son idénticas. ¿Cuánto menor debe ser la media muestral que la media esperada para justificar o rechazar la hipótesis nula? La respuesta depende del nivel de error que esté dispuesto a tolerar, es decir, la probabilidad de que la muestra proporcione una media significativamente mayor que el valor hipotético debido a factores aleatorios.
El nivel de significancia es la probabilidad de que rechace una hipótesis nula verdadera o cometa el llamado error tipo I. Como α es la probabilidad de cometer un error tipo I, puedes elegir el valor más pequeño posible. La Figura 7 muestra que a medida que α disminuye (con la línea roja moviéndose hacia la línea de puntos verde), la probabilidad de aceptar una hipótesis nula falsa aumenta.
El error de no rechazar la hipótesis nula cuando es falsa se denomina error tipo II y suele representarse con la letra β. En el gráfico, el área bajo la curva azul, que corresponde a H1, aumenta a medida que el área α bajo la curva roja, que corresponde a H0, disminuye. El valor de β sólo puede determinarse si la hipótesis alternativa es exacta (de la forma μ = X y no de la forma μ < X o μ > X).
Plantear la regla de decisión
Un estadístico de prueba es una variable aleatoria, cuyo valor se utiliza para decidir si se rechaza o no una hipótesis nula. Puede ser un estadístico muestral como la media muestral 𝑋̅ o alguna otra variable Z. La región crítica es el rango de valores del estadístico de prueba que conducirá al rechazo de la hipótesis nula. La región de no rechazo es el rango de valores del estadístico de prueba que provocará la aceptación de la hipótesis nula.
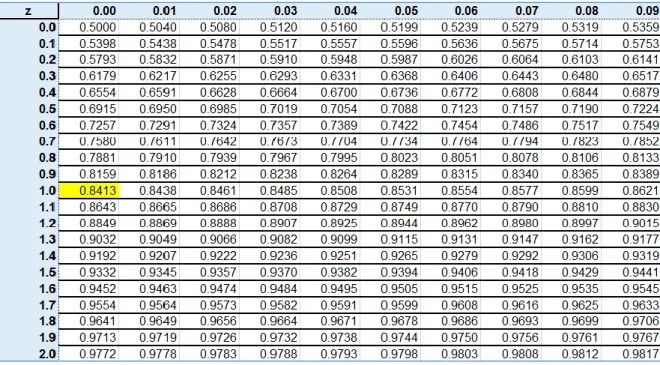
Cuando se utiliza Z como estadístico de prueba, el valor crítico de Z se obtiene de la tabla normal estándar. La Ilustración 8 muestra los diferentes tipos de regiones de aceptación y rechazo, dependiendo de la prueba de hipótesis de que se trate. Tenga en cuenta que en el caso de una prueba de dos colas, como en la parte c, α se divide en dos colas, cada una con probabilidad α/2.
Toma de decisiones
Cuando la hipótesis nula es falsa y no se rechaza, se trata de un error tipo II.