Distribución de imágenes de bases de datos en conjuntos. Captura y predicción del resultado en tiempo real de RNC en el mapa.
Estado del arte
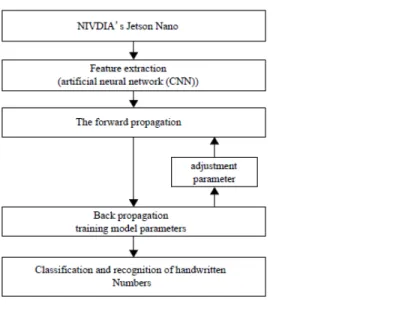
El primer paso consiste en procesar la imagen, donde el color RGB (rojo, verde, azul) original se convierte a HSV (tono, saturación, brillo), además de aplicar diversos filtros para eliminar el ruido. En este trabajo, se utiliza la biblioteca Tensor Flow para generar el modelo de red neuronal convolucional y se desarrolla directamente en la plataforma Jetson Nano como se muestra en el siguiente diagrama en la Figura 1.16:

Planteamiento del problema
Justificaci´ on
Hip´ otesis
Objetivos
Objetivo general
Objetivos espec´ıficos
Metas
Limitaciones
Metodolog´ıa
Distribución de las imágenes de la base de datos en los conjuntos de entrenamiento, prueba y validación. Modelar respuestas basadas en la arquitectura AlexNet; Arriba, comportamiento de la función de pérdida frente a los conjuntos de entrenamiento y validación.
Fundamentos te´ oricos 18
Aprendizaje autom´ atico
- Clasificaci´ on de los m´ etodos de aprendizaje
- Aprendizaje supervisado
- Aprendizaje no supervisado
- Aprendizaje semi-supervisado
- Redes Neuronales Artificiales
- Redes Neuronales Artificiales Unicapa
- Redes Neuronales Artificiales Multicapa
- Redes Neuronales Artificiales Profundas
- Redes Neuronales Convolucionales
- Etapa convolucional de las RNC
- Etapa de clasificaci´ on de las RNC
Este valor se procesa dentro de la neurona mediante una función de activación que devuelve un valor que se envía como salida de la neurona. Asimismo, se utiliza la técnica de suavizado de datos antes de ingresar los datos en la etapa de clasificación. Básicamente, lo que representa la ecuación 2.1 es invertir un núcleo de convolución k y desplazarlo a través de los elementos de la matriz de entrada I mientras se realiza el producto escalar de los elementos anidados.
Esta nueva matriz e imagen de salida S también se denomina versión filtrada de la imagen o mapa de características. En la Figura 2.11, el lado derecho muestra 16 mapas de características extraídos de la imagen de la izquierda. La idea principal detrás de la capa Pooling es "acumular" características de los mapas generados por el filtro de convolución en la imagen.
La forma más común de Pooling es "Max-Pooling", que aplica un filtro "Max" a una subregión de la imagen, donde obtiene el píxel con el valor máximo de dicha región, como se muestra en la Figura 2.12. El aplanamiento se realiza de tal manera que los datos de los mapas de características, una vez que han pasado por una reducción de su dimensionalidad con la capa Max-Pooling, queden acomodados en un vector unidimensional, esto con el fin de prepararlos para ser los datos de la capa de entrada de la futura red neuronal artificial. En este caso, el número de neuronas de la última capa de la red neuronal artificial corresponderá a las clases a identificar.

Descripci´ on del hardware utilizado
- Tarjeta de desarrollo Jetson Nano
- C´ amara de video Raspberry Pi
Descripci´ on del software utilizado
- OpenCV
- TensorFlow y Keras
Dactilolog´ıa de la Lengua de Se˜ nas Mexicana
Todo el entrenamiento y las pruebas se realizaron con las imágenes de la base de datos integrada mencionada en el capítulo 3. Respuestas del modelo RNC propuesto; Arriba, el comportamiento de la función de pérdida frente a los conjuntos de entrenamiento y validación. Respuestas del modelo optimizadas; Arriba, el comportamiento de la función de pérdida frente a los conjuntos de entrenamiento y validación.
Captura y resultado de la predicción en tiempo real del RNC en el mapa Jetson Nano. La Tabla 4.2 muestra el vector de probabilidad generado por la capa de salida del RNC optimizado. Capturas de pantalla del resultado de la clasificación de las 21 clases de personajes LSM con la tarjeta Jetson Nano y el RNC optimizado.
Implementación y comparación de métodos KNN y CNN para el reconocimiento de caracteres estáticos de la Lengua de Señas Mexicana. La siguiente sección presenta la adquisición y procesamiento de la base de datos, así como el desarrollo de los dos métodos mostrados en este trabajo. El comportamiento de precisión con los conjuntos de prueba y validación para diferentes valores impares y enteros de K en el rango [1,39] se muestra en la Figura 5.

Desarrollo Metodol´ ogico 35
Estandarizaci´ on de las im´ agenes
- Preparaci´ on de los conjunto de entrenamiento, pruebas y validaci´ on 37
- Arquitectura AlexNet
- Arquitectura de RNC propuesta
- Optimizaci´ on de la RNC propuesta
Segunda capa oculta: se utilizaron núcleos de tamaño 5 x 5 y paso 1 para la operación de convolución y se generaron 256 mapas de características de tamaño 9 x 11. Más A continuación, se utiliza una ventana de concatenación de 2 x 2 para la operación de recuperación de muestras, por lo que los 256 mapas de características se reducen a un tamaño de 5 x 6. La tercera capa oculta: los núcleos de tamaño No. 3 x 3 y el paso 1 se utilizan para la operación de convolución, y se crean 384 mapas de características con un tamaño de 5 x 6.
Cuarta capa oculta: de manera similar, se usaron núcleos de tamaño 3 x 3 y un paso de 1 para la operación de convolución y se generaron 384 mapas de características de tamaño 5 x 6. Posteriormente, se usó una ventana de desagrupación de 3 x 3 para la operación de submuestreo. los 256 mapas de características se reducen a un tamaño de 3 x 3. Dado que tienen 21 clases de caracteres diferentes, la capa de salida contiene 21 neuronas a las que se aplica la función de activación softmax.
El modelo RNC propuesto en su fase de convolución contiene tres capas de convolución en las que se aplican a cada capa núcleos de tamaño 4 x 4 y pasos de 1, así como la función de activación ReLU. La etapa de clasificación requiere un vector unidimensional, por lo que los mapas de características se suavizan. Posteriormente, se utiliza una ventana de agrupación de 2 x 2 para la operación de submuestreo, de modo que los 32 mapas de características se reducen a un tamaño de 36 x 44. Luego, el proceso de optimización de los valores de tasa de aprendizaje del optimizador Adam, el número de núcleos de convolución se muestra por capa y número de capas de convolución ocultas.

Generaci´ on de un modelo exportable para la tarjeta de desarrollo Jetson
Además, se presenta la optimización de los hiperparámetros del RNC propuesto ejecutando 10 versiones diferentes del mismo y seleccionando la que presenta mejor comportamiento en términos de precisión con el conjunto de entrenamiento y validación. Finalmente, la mejor versión del RNC propuesto se transforma al formato apropiado para que la ejecute la tarjeta Jetson Nano y realice la detección de tokens en tiempo real. El usuario se ubica frente a la cámara Jetson Nano y detrás del monitor que mostrará la señal detectada por el sistema como se muestra en la figura 4.8.
Tras procesar las imágenes, se logró completar una base de datos de 10.500 imágenes, que podría servir como comparativa de futuros modelos y así profundizar en el estado del arte en el campo de la clasificación en tableros LSM. Este artículo presenta el reconocimiento automático de caracteres estáticos pertenecientes al alfabeto dactilar de la Lengua de Señas Mexicana (LSM) utilizando dos técnicas diferentes: una red neuronal convolucional (CNN) y un clasificador basado en el método de los k vecinos más cercanos (KNN). El mejor rendimiento reportado en la técnica anterior para un sistema de reconocimiento de huellas dactilares LSM es del 95,8% [2] y del 93% [3].
Se utilizó la distancia euclidiana para determinar la similitud entre la imagen a clasificar y el resto de imágenes de la base de datos. Diccionario de lengua de señas español-mexicana (Dielseme), estudio introductorio al léxico LSM. Traductor automático de Lengua de Signos Española al Español mediante visión por ordenador y redes neuronales.

Pruebas y Resultados 47
Resultados del entrenamiento del modelo con la arquitectura propuesta . 50
En el estado del arte los dos mejores resultados se encontraron al crear sistemas de reconocimiento de señales LSM, que fueron los reportados por P'erez et al. Para iniciar el proceso de reconocimiento de señales por parte de la cámara de video, es necesario ejecutar el programa Python run rnc.py en la tarjeta Jetson Nano y en el directorio donde previamente se almacenó el modelo con extensión.on.pb. Los usuarios que utilicen el sistema de reconocimiento de caracteres LSM, el reconocimiento de los caracteres podrá verse de izquierda a derecha en la pantalla: U, A y B.
La Figura 4.11 muestra un ejemplo de cada uno de los 21 caracteres de huellas dactilares creados por un usuario, así como su clasificación asociada, indicada por una etiqueta de letra correspondiente al carácter predicho. Al analizar la matriz de confusión del RNC propuesto y optimizado, se observó que había una pequeña variación en la precisión de las predicciones de los modelos para las clases 6 y 7, donde estas clases corresponden a caracteres similares en la ejecución. H) permiten comprender la necesidad futura de realizar transformaciones en las imágenes. Sin embargo, la investigación actual contribuye al estado del arte y, debido a la contribución de la base de datos de 10.500 imágenes, también puede ser un motivo de comparación en futuros trabajos.
Los sistemas de reconocimiento automático de señales LSM se han orientado principalmente a la clasificación de señales estáticas y señales realizadas con una sola mano [1]. Este trabajo presenta la implementación de dos métodos de clasificación para el reconocimiento estático de huellas dactilares LSM, el primero basado en el método de K vecinos más cercanos (KNN) y el segundo en una red neuronal convolucional (CNN). Después de calcular todas las distancias de las imágenes en la base de datos con respecto a la imagen a clasificar, se seleccionaron las distancias 'K' más pequeñas y sus etiquetas de clase correspondientes.
Para analizar ambos comportamientos se utiliza un conjunto de validación y un conjunto de entrenamiento generado a partir del 15% y el 85% del conjunto de entrenamiento original.El comportamiento de la función de precisión y de costos se muestra en las Figuras 3 y 4. Comparaciones entre clasificadores con diferentes métodos se presentaron para el reconocimiento automático de caracteres estáticos del alfabeto dactilar de la Lengua de Señas Mexicana.

Sensor Leap Motion, Weichert y cols. (2013)
Sensor kinect, Murillo (2012)
Sistema desarrollado por Matallana (2019), primera parte
Sistema desarrollado por Matallana (2019), segunda parte
Diagrama de bloques propuesto por P´ erez y cols. (2017)
Imagen segmentada con el algoritmo FCM (P´ erez y cols. (2017))
Arquitectura del sistema propuesto por Jimenez y cols. (2017)
Errores de clasificaci´ on en el sistema desarrollado por Jimenez y cols. (2017). 8
Gesto obtenido por el controlador Leap Motion, N´ ajera y cols. (2016)
Hardware adaptado por Sol´ıs y cols. (2016)
Fondo uniforme contrastante en color verde, Sol´ıs y cols. (2016)
Interfaz y gesto obtenido por Sol´ıs y cols. (2016)
Ejemplo del conjunto de datos MNIST mostrado por Chen y cols. (2019). 11
Ejemplo de imagen multiclase y respuesta obtenida por el modelo de Zhang
Metodolog´ıa propuesta adaptada de (Su´ arez (2015))
Aprendizaje supervisado: Clasificaci´ on, seg´ un ejemplifica G´ eron (2019)
Aprendizaje supervisado: Regresi´ on, seg´ un ejemplifica G´ eron (2019)
Partes generales de una neurona biol´ ogica como se muestra en Garcia (2019). 22
Red Neuronal Unicapa, Wong (2017)