Universidad Politécnica de Madrid
Escuela Técnica Superior de Ingenieros Informáticos
Grado en
«Ingeniería Informática»
Bachelor in
«Computer Engineering»
Trabajo Fin de Grado Final-Year Project
Mejora de la Detección de Cyberbullying en Twitter mediante el Contagio de Testigos Enhancing Cyberbullying Detection on Twitter
through Bystander Contagion
Autor / Author: <<Belén Ferrón Hurtado>> / <<Belén Ferrón Hurtado>>
Madrid, Septiembre, 2022 / September, 2022
This Final-Year Project has been deposited in the ETSI Informáticos de la Universidad Politécnica de Madrid.
Trabajo Fin de Grado / Final-Year Project Grado en
«Ingeniería Informática»
Bachelor in
« Computer Engineering»
Título: Mejora de la Detección de Cyberbullying en Twitter mediante el Contagio de Testigos
Title Project: Enhancing Cyberbullying Detection on Twitter through Bystander Contagion
«Septiembre, 2022» /«September, 2022»
Autor /Author: «Belén Ferrón Hurtado » / «Belén Ferrón Hurtado » Tutor / Supervisor:
Nombe y apellidos / Name and Surname/s: Syaheerah Lebai Lufti Título Académico / Academic degree: Doctora (Ph.D)
Universidad del Título Académico / University of the academic degree: Grupo de Technología del Habla (GTH), Universidad Politécnica de Madrid
Escuela / Facultad: Computer Science
Department / School: School of Computer Science
Universidad / University: Universiti Sains Malaysia (USM)
ESPAÑOL
Este proyecto de investigación fue realizado a lo largo del curso 2021/22. El primer semestre se realizó de manera remota y el segundo de manera presencial en la Universiti Sains Malaysia (USM), situada en Penang, Malasia. La tutora de dicho proyecto fue Syaheerah Lebai Lufti, doctora perteneciente a la Escuela de Informática de la USM.
La razón por la que este estudio se ha llevado a cabo es que los comportamientos agresivos de diversa índole, tales como el ciberacoso han proliferado en las redes sociales, especialmente con la pandemia del COVID-19 durante los últimos años y estos actos han de ser reducidos o eliminados
desde Enero hasta Junio de 2022. Los usuarios que saben acerca del acoso, pero actúan de manera pasiva o indirecta .
Hasta la fecha, la mayoría de estudios se han centrado en la víctima o en el acosador. Sin embargo, existe un reducido número de investigaciones que se enfocan en los testigos del ciberacoso. A pesar de ello, ninguno ha tenido en cuenta el contagio social en ese grupo.
Por ello, la innovación de este proyecto es el uso de características que definan el contagio de los testigos del ciberacoso. En primer lugar, los testigos del ciberacoso se pueden definir como aquellos usuarios que interactúan mediante mensajes, likes o retweets con otros usuarios que no son la víctima. En segundo lugar, gracias al estudio de otras investigaciones en las que se examina el contagio social en redes sociales, se pudo vislumbrar el potencial de aplicar sus técnicas al problema del ciberacoso, mejorando con ello el rendimiento de los modelos de
achine Learning utilizados para la detección del acoso en la red.
La cuestión que se propone resolver con esta investigación es la de saber si considerar el contagio de los testigos puede ayudar a mejorar la detección del ciberacoso en Twitter. Con este fin, se desarrolló una tubería (pipeline) que cuenta con las siguientes fases.
La primera fase es la obtención de los datos ara ello se utilizó una librería llamada tweepy en Python, la cual hace peticiones a la API de Twitter. Además de obtener el texto de los tweets, se pueden obtener otros campos como el recuento de likes o de retweets.
La segunda fase consta de 2 componentes: El preprocesado y el etiquetado de los datos. En cuanto al preprocesado, algunas de las tareas que se llevaron a cabo fueron de eliminación de caracteres repetidos, expansión de contracciones y jerga, así como traducción de
a palabras entre otros. Respecto al etiquetado, tres voluntarios se encargaron de clasificar el texto de los tweets en dos clases (relacionado con un valor de 1 y no relacionado con un valor de 0 con el ciberacoso).
La tercera fase consiste en la extracción de características para su posterior uso por parte de los modelos de achine Learning Para ello, se utilizaron técnicas de Procesamiento del
Lenguaje Natural (BoW) -
- Para la obtención de características de contagio en los testigos, se creó una característica llamada respuesta la cual tiene dos posibles valores: 0 ó 1. Si el tweet que se está analizando es una respuesta a un usuario que no es la víctima, el valor de esta característica será 1. En otro caso será cero. También se usó el recuento de likes y retweets como característica relacionada con el contagio de los testigos del ciberacoso.
el clasificador Bayes, máquina de vectores de soporte, árbol de decisiones, adaboost y bosque aleatorio.
La quinta fase es la evaluación del rendimiento de los modelos. Para ello se utilizaron distintas métricas como la exactitud (Accuracy), precisión (Precision), valor-F1 (F1-score), exhaustividad (Recall) y la curva ROC.
Los resultados obtenidos fueron que la adición de características relacionadas con el contagio de los testigos del ciberacoso mejoraba el rendimiento de los modelos con respecto al uso únicamente de características del texto.
En concreto, el mejor método de extracción de características fue la combinación de TF-IDF + 2- l modelo que obtenía la mejor exactitud (accuracy) era el bosque aleatorio con un valor de 73,3%.
El segundo mejor método era respuesta + BoW + 3-Gram. En este caso, el modelo que obtenía el mejor rendimiento era el árbol de decisiones con una exactitud (accuracy) de 72,1%.
Por último, el tercer mejor método era BoW + 3-Gram + reply + likes/retweets.
El bosque aleatorio fue el mejor modelo con una exactitud de 70,1%.
En el futuro, se podrían tener en cuenta textos escritos en otras lenguas o analizar otro tipo de datos como pueden ser vídeos, imágenes o gifs. Además, se podría considerar los distintos roles que tienen los testigos en el ciber acoso (pasivo, defensor de la víctima e instigador del ciberacoso).
A continuación, se presenta la memoria original en inglés que fue entregada para el Trabajo de Fin de Grado en la Universiti Sains Malaysia.
School of Computer Sciences
Undergraduate Research Project
Final Thesis
CAT401: Enhancing Cyberbullying Detection on Twitter through Bystander Contagion
BELÉN FERRÓN HURTADO BB7823
Supervisor: Syaheerah Lebai Lufti
Examiner 1: Zarul Fitri Zaaba
Examiner 2: Gan Keng Hoon
Academic Session
2021/2022
ii
DECLARATION
I declare that the following is my own work and does not contain any unacknowledged work from any other sources. This thesis was undertaken to fulfill the requirements of the Undergraduate Research Project for the Bachelor of Science in Computer Science (Honours) program at Universiti Sains Malaysia .
Signature :
Name :
BELÉN FERRÓN HURTADO
Date : 06/07/2022
FERRON
HURTADO BELEN - 02574830A
Firmado digitalmente por FERRON HURTADO BELEN - 02574830A
ABSTRAK
Sejak permulaan akses beramai-ramai ke Internet, tingkah laku agresif seperti buli siber telah berleluasa di seluruh rangkaian sosial, satu fenomena yang perlu dihentikan. Persoalan kajian yang dirumuskan dalam kajian ini ialah "Bolehkah mempertimbangkan penularan orang ramai meningkatkan pengesanan buli siber di Twitter?".
Objektif kajian ini adalah untuk menjawab soalan ini dan menjelaskan sama ada penularan orang ramai merupakan faktor penting untuk dipertimbangkan apabila mengesan buli siber di Twitter. Untuk perkara ini, ciri yang sah perlu diekstrak, jadi, dalam penyelidikan ini, kejuruteraan ciri telah digunakan.
Dalam tesis ini, sampel - Tweet - dikelompokkan kepada dua kelas: 1) Berkaitan dengan buli siber dan 2) tidak berkaitan buli siber. Memandangkan set data yang sesuai tidak tersedia dalam talian, set data baharu perlu dibina. Rangka dan pelabelan data telah dilakukan oleh tiga sukarelawan bebas dalam lencana 428 Tweet. Tweet ini mengandungi bilangan penunjuk buli siber yang tinggi supaya ia sesuai untuk kajian ini.
Dari segi Model Pembelajaran Mesin, algoritma Naïve Bayes, Decision Tree, Adaboost, Random Forest dan SVM akan digunakan untuk mengklasifikasikan Tweet dan data berkaitan pengguna untuk mengesan tweet berkaitan buli siber. Persekitaran dalam talian yang agresif boleh membawa kepada perkembangan sikap negatif, jadi, hasil yang dijangkakan ialah orang ramai yang berkawan dengan penghasut - dalam erti kata lain, orang ramai yang menggalakkan pembuli - akan lebih berkemungkinan menjadi penghasut juga. Untuk membuktikan hipotesis ini, ketepatan model yang menggunakan ciri pemerhati harus mengatasi ketepatan penggunaan ciri teks. Oleh itu, pengesanan buli siber akan diperhalusi lagi, dan ia akan membantu mencegah serta mengurangkan buli siber.
Terima kasih kepada penggunaan pelbagai ciri berkaitan penularan penonton seperti ciri "balas" atau suka dan tweet semula, prestasi algoritma ML yang digunakan dalam tesis ini bertambah baik, menjawab soalan yang dirumuskan dalam projek ini.
iv
ABSTRACT
Since the dawn of mass access to the Internet, aggressive behaviors like cyberbullying have been rampant throughout social networks, a phenomenon that has to be stopped. The research question formulated in this study is
.
The objective of this study is to answer this question and clarify whether bystander contagion is an important factor to consider when detecting cyberbullying on Twitter. For this matter, valid features have to be extracted, so, in this research, feature engineering was applied.
In this thesis, the samples Tweets are clustered into two classes: 1) cyberbullying- related and 2) non-cyberbullying related. Since a suitable dataset was not available online, a new dataset had to be built. The data crawling and labeling has been done by three independent volunteers in a badge of 428 Tweets. These Tweets contain a high number of cyberbullying indicators, so they are suitable for this study.
In terms of Machine Learning Models, the Naïve Bayes, Decision Tree, Adaboost, Random Forest, and SVM algorithms will be used to classify the Tweets and user-related data to detect cyberbullying-related tweets. An aggressive online environment may lead to developing a negative attitude, so, the expected results are that bystanders who befriend instigators in other words, bystanders who encourage the bullying will be more likely to become instigators as well. To prove this hypothesis, the accuracy of the models using bystander features should surpass the accuracy of using textual features. Therefore, cyberbullying detection will be refined further, and it will help prevent and reduce cyberbullying.
Thanks to the use of various bystander contagion-related features like the
feature or likes and retweets, the performance of the ML algorithms used in this thesis improved, answering the question formulated in this project.
Keywords: Cyberbullying, Contagion, Bystander, Twitter, Machine Learning
ACKNOWLEDGEMENTS
I thank my family, friends, and everyone involved in this project.
vi
TABLE OF CONTENTS
DECLARATION ... ii
ABSTRAK ... iii
ABSTRACT ... iv
ACKNOWLEDGEMENTS ... v
TABLE OF CONTENTS ... vi
LIST OF TABLES ... ix
LIST OF FIGURES ... x
LIST OF ABBREVIATIONS AND SYMBOLS ... xii
1 INTRODUCTION ... 1
1.1. Background ... 1
1.2. Motivation ... 2
1.3. Research Problem ... 3
1.4. Objectives of the Research ... 4
1.5. Assumptions and Constraints ... 5
1.6. Scope of Research ... 5
2 BACKGROUND & RELATED WORK ... 9
2.1. Cyberbullying and bystander roles ... 9
2.2. Bystander contagion ... 10
2.3. Summary ... 12
3 RESEARCH QUESTION AND METHODOLOGY ... 13
4 IMPLEMENTATION ... 14
4.1. Research Procedure ... 14
4.2. Pipeline Workflow ... 14
4.2.1. Data Crawling ... 14
4.2.2. Labeling strategy ... 16
4.2.3. Data Preprocessing ... 17
4.2.4. Feature Extraction ... 18
4.2.5. Classification ... 18
4.2.6. Performance Assessment ... 19
4.3. Detecting Bystander Contagion ... 19
4.3.1. Bystanders reply feature ... 19
4.3.2. Like and Retweet Count features ... 20
5 RESULTS & EVALUATION ... 21
5.1. Baseline results ... 21
5.2. N-grams results ... 21
5.2.1. 2-Gram results ... 21
5.2.2. 3-Gram results ... 22
5.3. Bystander Features results ... 22
5.3.1. ... 22
5.3.2. ... 23
5.4. Discussion of Results ... 23
viii
6 CONCLUSION & FUTURE WORK ... 25
6.1. Summary of Results ... 25
6.2. Research Contribution ... 25
6.3. Future Work ... 26
REFERENCES ... 27
APPENDICES ... 29
6.4. ... 29
LIST OF TABLES
Table 4.2-1: Tweet fields extracted using tweepy ... 14
Table 4.2-4.2-2: Expansion fields extracted using tweepy ... 15
Table 4.2-4.2-3: Possible labels given to samples ... 17
Table 5.4-5.4-1: Possible combinations of feature extraction methods ... 23
Table 5.4-2: Comparison between accuracy with/without bystander features ... 24
x
LIST OF FIGURES
Figure 1-1: Diagram portraying the behavior of cyberbullying actors. ... 2
Figure 2-1: Cyberbullying roles regarded in this research ... 10
Figure 2-2: Depiction of the Emotional Contagion Mechanism ... 11
Figure 3-1: Machine Learning Pipeline used in this project ... 13
Figure 4-1: Example of a Twitter Thread used in this project ... 15
Figure 0- ... 29
Figure 0-2: C -IDF ... 29
Figure 0- -Gram ... 30
Figure 0- -IFD + 2-Gram ... 30
Figure 0- -Gram ... 31
Figure 0- -IFD + 3-Gram ... 31
Figure 0-7: Classifie ... 32
Figure 0-8 -Gram + reply ... 32
Figure 0- -Gram + reply ... 33
Figure 0- -IDF + reply ... 33
Figure 0- -IDF + 2-Gram + reply ... 34
Figure 0- -IDF + 3-Gram + reply ... 34
Figure 0- .... 35
Figure 0- -IDF + 2-Gram + reply + likes/retweets ... 35
Figure 0- -IDF + 3-Gram + reply + likes/retweets ... 36
Figure 0-16 -IDF + reply + likes/retweets 36
Figure 0- F-IDF + 2-Gram + reply +
likes/retweets ... 37
Figure 0- -IDF + 3-Gram + reply +
likes/retweets ... 37
xii
LIST OF ABBREVIATIONS AND SYMBOLS
ML - Machine Learning
NLP - Natural Language Processing BoW - Bag of Words
TF-IDF - Term Frequency-Inverse Document Frequency LoL - League Of Legends
SVM - Support Vector Machine
1 INTRODUCTION
and traces so that cyberbullying ultimately gets reduced. For this purpose, bystanders are at the center of this research since they are often overlooked and they provide valuable insight into subtler signs of cyberbullying (van Hee et al., 2018).
In this study, the following research question has been answered:
Could considering the bystander contagion enhance cyberbullying detection on Twitter? . As stated before, bystanders have been neglected in research and they are actors that are involved in a cyberbullying incident. Moreover, the number of bystanders online is potentially bigger than the number of bullies. Therefore, studying whether they act on their own or they act as a each other and making them post is something worth considering.
Thanks to the use of ML algorithms and appropriate bystander features that will be explained in detail later, the research question has been answered since the performance of the ML models has improved when compared to the baseline of NLP feature extraction methods. The baseline used is composed of the BoW and TF-IDF techniques respectively.
1.1. Background
The main challenges in this research are building a suitable dataset, preprocessing the samples so that the relevant features can be subsequently extracted, and finally, feeding the processed samples to a ML algorithm. As stated in the abstract, most of the available datasets online that were labeled as cyberbullying datasets did not contain cyberbullying samples where there is repeated aggression towards an individual, but rather exclusively racist, aggressive or sexist remarks or insults.
The preprocessing tasks are done so that the model can apply NLP techniques to classify the tweets correctly. Some of these tasks include removing information that is not relevant such as mentions e.g., @user -, links, English stopwords, repeated characters, numbers, and punctuation marks. Moreover, making all the text lowercase
2
and turning emojis into words are some of the other tasks performed on text.
In addition to textual features the ones extracted using NLP techniques such as BoW and TF-IDF , feature engineering had to be applied to build valid bystander features that can be used to measure contagion. The bystander features used in this study are the
, likes, and retweets.
Figure 1-1: Diagram portraying the behavior of cyberbullying actors.
As depicted in Figure 1-1, the role of a user in a cyberbullying incident can be identified by checking whether they are replying to a tweet posted by the victim or another user. If they are replying to a victim, they can potentially be bullies e.g. they insult the victim . On the other hand, if they reply to other users, they are considered bystanders and can have two types of behavior: instigator or defender. Further explanation about bystander roles is done in Section 1.3.
1.2. Motivation
(Dorol--Beauroy-Eustache & Mishara, 2021) states that Cyberbullying has several negative consequences in children and adolescents, such as anxiety, depression, and substance abuse. Furthermore, it increases the risk of suicidal thoughts and self-harm.
Such destructive consequences should be avoided by eliminating cyberbullying.
Therefore, cyberbullying detection should be refined and made as accurate as possible.
Several improvements have been done, like including user and network features (Tahmasbi & Rastegari, 2018) or including detection (van Hee et al., 2018).
However, Social contagion and bystander roles have not been studied in-depth in
cyberbullying. (Song et al., 2022)
online community are emergent, arise through the accumulation of micro-social other words, each interaction in an online community shapes the social norms of that group. Hence, if the interactions are mainly negative, aggressive, or toxic, that type of behavior will become the default. These findings can be applied to cyberbullying too.
Furthermore, cyberbullying detection has focused nearly exclusively on successfully identifying explicit attacks toward the victim. However, more subtle interactions
(Tahmasbi & Rastegari, 2018), the usage of sarcasm (Chatzakou et al., 2019), and positive words with ill intentions cannot be captured and considering bystanders can be a helpful technique to be able to recognize those subtle remarks as (van Hee et al., 2018) suggests.
1.3. Research Problem
As (van Hee et al., 2018) declared, Cyberbullying research has to take into account the different types of participant roles involved in a bullying situation. Traditionally, these Moreover , further splitting into sub-roles can be done, such as i) who knows about the cyberbullying but does not act , ii) who reinforce or encourage the bullying . In real life, bystanders would be individuals that talk to or sit next to the victim in class or at work whereas online, it would be the users who see the posts, videos, or photos where the bullying occurs and react to it by replying to a bully or liking or retweeting the tweets involved in the thread. Hence the number of bystanders in an online incident is elevated and their power to intervene positively or negatively is substantial. In addition, the first type of bystander i) will not be considered as it does not generate any text or traceable activity.
As the research was undertaken, several problems arose such as the existence of sarcasm in the Twitter thread, which can be complex to interpret by an ML algorithm. To help tackle this problem, context should be provided to the model, that is the reason why emojis and emoticons are converted into words so that they can provide meaning.
The approach of this research is to reduce cyberbullying effectively by considering bystander contagion. Thus far, bystanders have been regarded as individual entities, and
4
not as a network of interconnected users in the Twittersphere their connection would be following and/or follower which might reciprocally influence each other. This influence can be comments or reactions like likes, retweets, dislikes, etc. Furthermore, in (Yokotani
& Takano, 2021) and (Song et al., 2022), it was proved that Social Contagion is, in fact, an important factor that drives users to join active conversations, especially if they involve aggressive or toxic language.
1.4. Objectives of the Research
The research question for this study is Could considering the bystander contagion enhance cyberbullying detection on Twitter? . To answer this question the following objectives were stablished:
1. Building suitable bystander features.
To achieve this goal:
a. for this project.
b. To measure contagion in bystanders using features, the likes and retweets were used.
2. Enhancing cyberbullying detection models by integrating bystander features using BoW/TF-IDF and language models.
To achieve this goal:
a. The corpus was divided into two classes: cyberbullying-related with a value of 1 or not with a value of 0 .
b. Using a bundle of feature extraction methods, e.g., BoW/TF-IDF + N-Gram + bystander features.
3. Verifying the models performance by comparing the results with and without bystander features.
To achieve this goal:
c. A graph will be built to show the performance metrics of the models to compare them.
1.5. Assumptions and Constraints
Manual data labeling was performed by three independent volunteers due to a time constraint. A ground truth was built so that the labeling could be done correctly, and every label was subjected to a majority vote before being included in the final dataset.
In this research, it is assumed that bystanders are users who like, retweet, or reply to users other than the victim who are aggressive towards him/her. Bullies are users that attack and therefore mention directly the victim. Passive bystanders are ignored since they do not generate any data that can be used for analysis.
1.6. Scope of Research
This is an undergraduate-level project, so the number of samples is not elevated due to a couple of reasons. First, the type of access provided for the Twitter API was only essential at the beginning of the research. Therefore, there were some limitations when crawling tweets like only being able to retrieve tweets from the past week.
Moreover, some features were only available in the Academic Research or Elevated Access, like the access to the API v.1.0, which has some endpoints not available in the API v.2.0. Towards the end of the project, the academic research access was granted and the dataset size increased from approximately 70 tweets to 428 tweets.
Furthermore, due to a time constraint, the samples had to be labeled by three independent volunteers, instead of experts or resorting to crowdsourcing with a bigger number of volunteers. However, thanks to the amount of time spent reading different papers regarding the definition of cyberbullying, a ground truth could be extracted and applied to the labeling step.
Mainly the objectives of this research are: i) Building suitable bystander features, ii) Enhancing cyberbullying detection by adding bystander contagion-related features.
To achieve these goals several steps were followed. First, retrieving the tweets using the Twitter API, labeling, and preprocessing them so that the supervised ML algorithms can use the data. Secondly, applying NLP to extract textual features from the tweets and adding bystander contagion-related features. Thirdly, classifying the
6
samples into cyberbullying-related or non-cyberbullying-related. Finally, assessing the performance of each one of the models with a different set of features.
The expected outcome is that, by adding to the baseline bystander contagion features, the performance of the ML models will improve.
Outline of Thesis
(i) Background & Related Work.
1. Cyberbullying and bystander roles 2. Bystander contagion
3. Summary
(ii) Research Question and Methodology (iii) Implementation
1. Research Procedure 2. Pipeline Workflow
Data Crawling Labeling strategy Data Preprocessing Feature Extraction Classification
Performance Assessment 3. Detecting Bystander Contagion
Bystanders reply feature Like and retweet count feature (iv) Results & Evaluation
1. Baseline results 2. N-Gram results
8
2-Gram results 3-Gram results 3. Bystander Features results
likes and retweets 4. Discussion of results
(v) Conclusion & Future Work 1. Summary of Results 2. Research Contribution 3. Future Work
(vi) References (vii) Appendices
2 BACKGROUND & RELATED WORK
In this section, the main works related to bystanders and their roles in cyberbullying, as well as bystander contagion are discussed.
2.1. Cyberbullying and bystander roles
The majority of researchers have concluded that the cyberbullying data is either negative or profane words (Dinakar et al., 2012), (Nurrahmi & Nurjanah, 2018), (Perera & Fernando, 2021). Nonetheless, combining textual, user, and network features can increase cyberbullying detection accuracy as seen in (Tahmasbi &
Rastegari, 2018). Furthermore, in their study, they investigated the structure of social networks around a cyberbullying incident to emphasize the importance of context and the characteristics of actors involved, as well as their position in the network structure.
In previous research, there have been attempts to classify into roles that are slightly different than the traditional ones. For instance, in (Chatzakou et al., 2017b) and (Chatzakou et al., 2019) three roles were identified: cyberbullies, cyber-aggressors, and regular users. In addition, in (Chatzakou et al., 2017a) they differentiated between abusive and regular users.
The approach followed in this research of having 4 roles bully, victim, bystander- defender, and bystander-instigator has already been used in other studies like (van Hee et al., 2018). In their research, they concluded that defenders e.g., bystanders or the victim defending him/herself are the hardest to identify. The reasons behind this conclusion are the absence or reduced appearance of abusive/aggressive language and shorter messages. Furthermore, bystander-instigators were not excessively widespread, so they were not considered representative. The ironic or short comments, misspelled words or grammatical errors often led to misclassification.
In (Balakrishnan, 2018) - her,
ully-victims are people with dual roles they have bullied someone, and they have been bullied as well . In her study, she concludes that people who have been bullied or were bullies in school tend to fall into the same roles after entering college or university, especially in a digital form i.e., cyberbullying .
10
According to (Balakrishnan et al., 2020), bystanders are the largest group of participants in a cyberbullying incident. So, it is highly beneficial to take them into account in this research since they provide valuable information to tackle the cyberbullying problem. The approach followed in their research was to analyze a group of tweets made by the same author since only one tweet does not provide enough context to detect whether the author is a bystander or not and their role.
Figure 2-1: Cyberbullying roles regarded in this research
2.2. Bystander contagion
Bystander contagion has yet to be studied since no papers regarded this as their main topic in cyberbullying-related literature.
Thus far, only social contagion has been studied in different areas of aggressive online language like toxicity (Obadimu et al., 2021), (Shen et al., 2020).
In (Obadimu et al., 2021), the main objective of their research was to determine whether removing certain toxic users can improve the health of a social media network in their case, YouTube by reducing its toxicity level. They attempted to identify information brokers and gatekeepers who are in charge of bridging multiple toxic communities. The conclusion that they reached is that by removing these bridges, the overall health of the network improves. Furthermore, they discovered that highly toxic commenters are more likely to form groups with commenters with high toxicity and low toxic commenters tend to cluster with commenters who are less toxic.
In addition, (Shen et al., 2020) states that they were able to provide empirical evidence that toxicity is contagious among players through their study. The online game that they focused on was LoL. They discovered two contagion mechanisms: a) Group norms and b) Emotional contagion. The first mechanism refers to the social rules that decide which types of behaviors are deemed acceptable and which are not.
These rules are developed in the minds of individuals. The problematic side is that if anti-social behaviors have no negative consequences, they potentially become normalized. The second mechanism according to the authors refers to the capacity that emotions have, to infuse groups with more positive or negative moods which can influence cognition, behaviors,
Figure 2-2: Depiction of the Emotional Contagion Mechanism
In the context of online gaming, another major finding that they discovered was that, even between friends when toxicity occurs, it can snowball easily. Their hypothesis If friends or clan members further reinforce the normativity of toxicity, these behaviors would be more pervasive and contagious than when playing with strangers in which norms are not as salient due to a less cohesive group identity In other words, knowing the other user personally increases the probability of imitating their behavior.
However, regarding cyberbullying and especially concerning Twitter the number of papers is rather scarce. (Yokotani & Takano, 2021) studied the Social Contagion of Cyberbullying in a Japanese online game called Pigg Party. Nonetheless, bystanders were not involved in their study. As stated in the Motivation section of this thesis, (Song et al., 2022) concluded that if the interactions in a social network are mainly
12
negative, aggressive, or toxic, that type of behavior will become the default. Hence, studying social contagion focusing on bystanders seems like a logical next step toward understanding social contagion.
2.3. Summary
Thus far, some papers have tried to categorize the participants in a cyberbullying incident to try to understand this issue more deeply. Different types of roles have arisen. However, the most common ones are 3 main roles: bully, victim, and bystander. And within bystanders, depending on how they react to cyberbullying, sub- roles like defenders who defend the victim , instigators who encourage or reinforce the bullying and passive bystanders who choose not to intervene . In this research, all the aforementioned roles will be regarded, except passive bystanders since they do not generate any data.
Regarding contagion, it is still an uncharted field of research, so it is a gap waiting to be exploited. A number of research studies have studied social contagion in the digital context of social media networks. However, none focused on bystanders.
In most research, degree centrality or betweenness centrality are the techniques used to measure the contagion as they provide a suitable representation of the network and influential users and connections to other users can easily be identified (Obadimu et al., 2021; van Hee et al., 2018). In this research that is the approach that will be followed.
3 RESEARCH QUESTION AND METHODOLOGY
The main research question of this study is:
As it has been already proven in previous research papers regarding social contagion, such as (Shen et al., 2020; Yokotani & Takano, 2021), social contagiousness of negative and toxic behaviors is a valuable resource to tackle the cyberbullying problem since it can rely on understanding how users interact with each other, rather than just classifying their comments/tweets. In other words, refining the performance of ML
This way, the evolution of the network can be studied, and further actions can be enforced, such as flagging/blocking bullies or instigators.
As presented in the Background & Related works section, social contagion in bystanders has not been regarded in the cyberbullying field. So, it is an important gap that should be explored.
In this project the following pipeline was followed to attempt to answer this question:
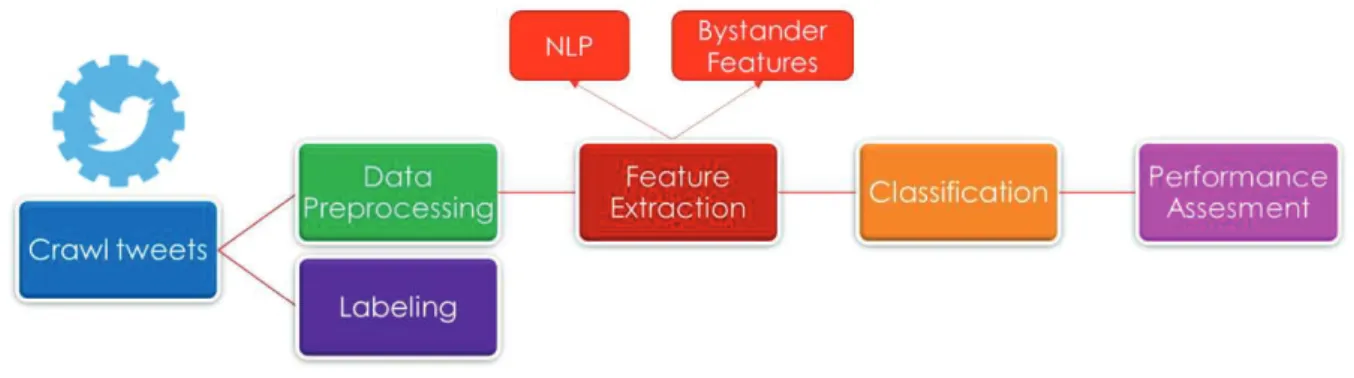
Figure 3-1: Machine Learning Pipeline used in this project
Each part of the pipeline will be explained in detail in Section 4.
14
4 IMPLEMENTATION 4.1. Research Procedure
To answer the question posed in Chapter 3, several subsections have been defined.
Section 4.2 explains in detail each component of the pipeline and 4.3 explains the details regarding the bystander contagion-related features. These sections are used to try to answer the research question: Could considering the bystander contagion
.
4.2. Pipeline Workflow
4.2.1. Data Crawling
In this step, tweet data requests were sent to the Twitter API using a wrapper called tweepy in Python.
The tweet fields, illustrated in Table 4.2-1, were extracted:
Tweet field Description
id Unique id assigned to the Tweet
text Text of the Tweet
conversation_id Groups related Tweets together created_at Creation time of the Tweet
public_metrics Public engagement metrics for the Tweet at the time of the request (e.g., retweet_count, like_count)
Table 4.2-1: Tweet fields extracted using tweepy
One of the most important fields is the conversation_id, which is a parameter that groups together tweets that are involved in the same conversation. In this case, direct replies to the victim's tweets or indirect replies (a user replies to another user who has replied to the victim's tweet).
The public_metrics field is relevant since the retweets and likes count will be used as bystander contagion features.
Aside from these fields, several expansion fields were retrieved to obtain information related to users, to be used
Expansion field Description
author_id Author of the Tweet
in_reply_to_user_id If the represented Tweet is a reply, this field will contain the necessarily always be the user directly mentioned in the Tweet.
Table 4.2-4.2-2: Expansion fields extracted using tweepy
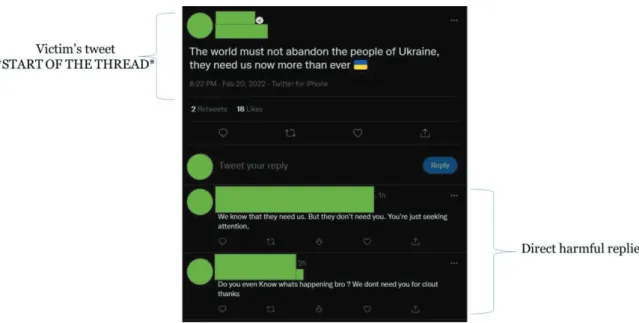
The tweets that were selected to be crawled are the replies to a selection of tweets posted by an online influencer in their Twitter feed. For every tweet he publishes, several aggressive comments are posted against his appearance, nationality, and career. His feed is suitable for this research because it is rich in bullying signals and the number of bystanders is considerable too. Furthermore, several bystanders actively participate in his threads, mostly, instigating the bullying.
Figure 4-1: Example of a Twitter Thread used in this project
As it can be observed in Figure 4- the thread a
Twitter thread is composed of a main tweet and all the replies to it and the replies are the samples to be used in later steps of the pipeline.
16
4.2.2. Labeling strategy
Based on the criterion used in (van Hee et al, 2018), the following labeling strategy will be undertaken:
Threat/blackmail: expressions containing physical or psychological threats or indications of blackmail.
Insult: expressions meant to hurt or offend the victim.
General insult: general expressions containing abusive, degrading, or offensive language that is meant to insult the addressee.
Attacking relatives: insulting expressions towards relatives or friends of the victim.
Discrimination: expressions of unjust or prejudicial treatment of the victim.
Two types of discrimination are distinguished (i.e., sexism and racism). Other forms of discrimination should be categorized as general insults.
Curse/exclusion: expressions of a wish that some form of adversity or misfortune will befall the victim and expressions that exclude the victim from a conversation or a social group.
Defamation: expressions that reveal confident or defamatory information about the victim to a large public.
Sexual Talk: expressions with a sexual meaning or connotation. A distinction is made between innocent sexual talk and sexual harassment.
Defense: expressions in support of the victim, expressed by the victim himself or by a bystander.
Bystander defense: expressions by which a bystander shows support for the victim or discourages the harasser from continuing his actions.
Victim defense: assertive or powerless reactions from the victim.
Encouragement to the harasser: expressions in support of the harasser.
Other: expressions that contain any other form of cyberbullying-related behavior than the ones described here.
In this case study, we will add some other relevant categories:
Body shaming: expressions
Ironic statements: expressions that may seem like they have a positive meaning but are, in fact, negative.
Table 4.2-3 illustrates the values for the two possible classes. Any sample that
Label Value
Cyberbullying-related 1 Non-cyberbullying-related 0
Table 4.2-4.2-3: Possible labels given to samples
The dataset built is well-balanced, since -related
and -cyberbullying-related.
4.2.3. Data Preprocessing
The data preprocessing steps used in the study are as follows:
1. Lowercasing the tweets
o This step is necessary so that words that have the same meaning but are written differently will not be regarded as distinct words. E.g., Small,
are all regarded as the same word.
2. Removing repeated chars
o On the internet, it is common to repeat characters to emphasize the meaning of a certain word. For instance, helloooo will be interpreted as friendlier than hello .
3. Expanding contractions and slang
o On social media platforms, users tend to use slang and contractions, so, these words are expanded to their original form so that the ML model can use them more easily.
4. Translating emojis into words
o The usage of emojis is important online since facial expressions are an important feature to understand the tone of a comment. In digital contexts, emojis are used to display emotion.
5. Removing links and mentions 6. Removing unnecessary spaces
18
4.2.4. Feature Extraction
Several NLP techniques have been used to extract features:
1. BoW
o At first, the most elemental NLP technique was used to create a baseline and be able to later compare the results when adding more features.
2. TF-IDF
o As an upgrade, this technique was used as well to create another baseline from which to improve the performance results.
3. N-Gram + BoW
o The n-grams were used in addition to BoW. In this case, the 2-Gram and 3-Gram were used. 4-grams and bigger n-grams did not have a finer performance so they were discarded.
4. N-Gram + TF-IDF
o The n-grams were used in addition to TF-IDF. As in 3, 2-Grams and 3- Grams were employed.
The reason for using these techniques is that, according to the literature review made by (Elsafoury et al., 2021), when extracting text-based features, Bag of Words with word N-grams is the most popular text representation model used in their reviewed literature. TF-IDF was also used.
Bystander-related features were also extracted; however, they will be discussed further in Section 4.3.
4.2.5. Classification
Regarding the Machine Learning algorithms, some of the most widely used according to (Elsafoury et al., 2021), are Support Vector Machine (SVM) and Naive Bayes.
Other well-known models used are Logistic Regression (LR), Decision Trees (DT), k-
Nearest Neighbors (kNN), and Random Forests (RF). Despite the unavailability of labeled data, Unsupervised or Weakly Supervised Models were seldom used.
In this present literature review, it was discovered that the best performing model was the Random Forest (Balakrishnan et al., 2020; Chatzakou et al., 2017b, 2019;
Tahmasbi & Rastegari, 2018).
Therefore, in this present study five ML models were used:
Naïve Bayes SVM
Decision Tree Adaboost
Random Forest
4.2.6. Performance Assessment
Concerning Performance Metrics, (Elsafoury et al., 2021) states that, the most widespread metrics are accuracy, F1-score, precision, recall, as well as, Receiver Operating Characteristic-Area Under the Curve (ROC-AUC) scores.
Hence, these metrics will be used to measure the performance of the models.
4.3. Detecting Bystander Contagion
4.3.1. Bystanders reply feature This feature has two possible values,
be stored.
As explained in previous sections of this thesis, bystanders are characterized by their indirect interactions with the victim. They communicate with users other than them through reactions such as likes and retweets and replies.
To know whether there was a relatively representative number of bystanders in the
corpus ed. The result obtained was
29.7423887587822%. Therefore, this feature remained in the set of features used for classification as it is deemed representative.
20
4.3.2. Like and Retweet Count features
To measure the bystander contagion, likes and retweets were used. In studies like (Tahmasbi & Rastegari, 2018), these features count of likes and retweets were used to measure power of an individual in a network in terms of how often he/she can interrupt the flow of information or how often the person acts as a mediator of communication between any other two individuals in the network. , how viral a tweet can potentially be.
5 RESULTS & EVALUATION
Using the performance metrics mentioned in Section 4.2.5, the ML models were assessed and the results using different sets of features will be compared to determine whether the research question has been answered and decide what set of features produces the best outcome.
As there are several charts, they have been added in the appendices section.
5.1. Baseline results
As mentioned previously, the baseline consists of using exclusively either BoW or TF-IDF. This is the equivalent of using a 1-Gram combined with either BoW or TF- IDF.
As illustrated in the bar Figure 0-1, the best performing model is the Random Forest, . It is also worth mentioning that the Naïve Bayes and the SVM have an recall value, the other performance metrics are not as high, therefore the Random Forest is more optimal.
In Figure 0-2, it can be appreciated that most models remain in similar values, except the SVM which increases approximately 6% its accuracy when compared to the BoW baseline. Furthermore, the recall improves by around 12% in the case of the Random Forest and the rest of the metrics remain in a similar range. Therefore, the Random Forest is still the best-performing ML algorithm.
5.2. N-grams results
The following subsections are the results of combining BoW/TF-IDF and 2-Grams or 3-Grams.
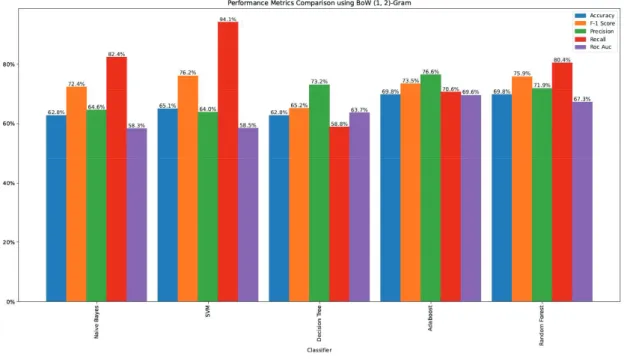
5.2.1. 2-Gram results
As depicted in Figure 0-3, when adding to the BoW baseline 2-Grams, the best performing models are the Random Forest and the Adaboost, both with an accuracy of
. Furthermore, the SVM increases its recall value by 8%.
22
After applying the TF-IDF + 2-Grams as feature extraction methods (Figure 0-4), the SVM increases the value of all of its metrics, therefore having a better performance.
Hence, it becomes the best-performing model along with the Random Forest.
5.2.2. 3-Gram results
With 3-Grams (Figure 0-5), the BoW method has a worse outcome in all models, except for the Adaboost. This ML algorithm maintains the same values and remains the top-performing model.
In Figure 0-6, it can be observed that the best-performing model is the Random Forest. It surpasses in accuracy all the previous TF-IDF combinations with n-grams.
The rest of the models have a poor performance when compared to TF-IDF 2-Gram.
5.3. Bystander Features results
In this section, the results of combining NLP techniques, n-grams, and bystander features are depicted.
5.3.1.
In this case, the results depicted in Figure 0-7 show that the performance is superior to ormance, however, it is lower than using N-grams and BoW. The best performing models are the Random Forest and Adaboost.
In Figure 0-8, it can be appreciated that the best performing classifier is the Random
When adding -gram with BoW (Figure 0-9), the
best performing , surpassing
the Random Forest.
In Figure 0-10, the best performing model is the Random Forest with an accuracy of The second best ML algorithm is the SVM.
In Figure 0-11, it can be observed that the best performing model so far is the accuracy.
In this case (Figure 0-12), the best-performing model is the SVM. However, its performance is inferior to the one obtained by the Random Forest with TF-IDF + reply + 2-gram.
5.3.2. likes and retweets
The performance of most models is worse than the previous feature extraction methods that used BoW. In this case (Figure 0-13), the Random Forest is the best model.
In Figure 0-14 (TF-IDF + 2-Gram + reply + likes/retweets), the best performing
In Figure 0-15 (TF-IDF + 3-Gram + reply + likes/retweets), the best-performing
model is still the Random Forest .
In this case (TF-IDF + reply + likes/retweets, Figure 0-16), the best performing model
is the Random Forest .
In Figure 0-17 (TF-IDF + 2-Gram + reply + likes/retweets), the best performing model is the Random Forest, with the same accuracy as the previous combination.
In Figure 0-18 (TF-IDF + 2-Gram + reply + likes/retweets), the best performing model is the Random Forest; however, its accuracy is lower than with 2-gram.
5.4. Discussion of Results
After analyzing all the possible combinations of feature extraction methods:
BoW + N-Gram TF-IDF + N-Gram
BoW + N-Gram + reply TF-IDF + N-Gram + reply
BoW + N-Gram + reply + likes/retweets TF-IDF + N-Gram + reply + likes/retweets
Table 5.4-5.4-1: Possible combinations of feature extraction methods
It can be inferred that the best-performing models using most combinations of feature selection methods is the Random Forest. Furthermore, the best method for extracting features is the TF-IDF + 2-Gram + reply. With that combination, the best ML
algorithm is the . Therefore, the
24
bystander contagion- performance of the
model and therefore its detection ability.
The second-best method for extracting features is -Gram. In this
case, the best performing model is the .
And after that, the combination of BoW + 3-Gram + reply + likes/retweets had a fairly positive outcome, enhancing the behavior of the models, and making them more optimal. The Random Forest is the best performing model, with an accuracy of
.
Furthermore, using any combination of feature extraction methods where bystander enhanced the performance of the models.
In the next table, there is a comparison between the usage of language modeling and/or BoW/TF-IDF and the addition of bystander features.
Classifier Accuracy without bystander features
Accuracy with bystander features
Comparison
Naïve Bayes 62,79 % 66,28 % + 3,49 %
SVM 60,46 % 70,93 % + 10,47 %
Decision Tree 62,79 % 72,09 % + 9,3 %
Adaboost 58,14 % 69,77 % + 11,63 %
Random Forest 68,60 % 73,25 % + 4,65 %
Table 5.4-2: Comparison between accuracy with/without bystander features
As it can be appreciated above, in all models there has been an improvement in accuracy thanks to the addition of bystander features.
6 CONCLUSION & FUTURE WORK
In conclusion, using bystander contagion-related features like th
and retweets have proved to be a valuable method to enhance or increase the performance of ML models used to tackle the cyberbullying problem.
6.1. Summary of Results
The best-performing model is the Random Forest, using a combination of the TF-IDF + 2-Gram + reply feature extraction methods. It reached an
The second-best -Gram. In this
case, the best performing model is the Decision Tree, with an accuracy of
after that, the combination i) BoW + 3-Gram + reply + likes/retweets had a fairly positive outcome. The Random Forest is the best performing model, with an accuracy
.
Therefore, the bystander contagion- retweets have
enhanced the performance of the model and therefore its detection ability. With these results, the research question can be answered. Regarding bystander contagion in cyberbullying detection is a valuable idea. It helps in cyberbullying detection and therefore can be used to further refine ML algorithms so that bullies can be flagged or blocked, and cyberbullying statements can be identified promptly.
6.2. Research Contribution
The contribution is that bystander contagion has been investigated in the cyberbullying scope in this thesis. This investigation had the aim to use bystander contagion as a tool to further enhance cyberbullying detection. As stated in the Results section, this goal has been achieved and bystander contagion is a useful concept to use when trying to improve the performance of ML algorithms that are in charge of detecting cyberbullying.
26
6.3. Future Work
and tweets that have media (videos, pictures, and gifs) links are being removed from the corpus. However, further research should be done in that direction.
Furthermore, this project focused on tweets in the English language, however, the cyberbullying issue is a global problem so it can be expanded to other languages.
A more complex labeling strategy could be undertaken to have subclasses for each type of cyberbullying actor. However, the number of tweets involved in this research is not extremely elevated, so, having more than two classes might be a challenge since the number of samples in each class would be too little.
REFERENCES
Balakrishnan, V. (2018). Actions, emotional reactions and cyberbullying From the lens of bullies, victims, bully-victims and bystanders among Malaysian young adults. Telematics and Informatics, 35(5), 1190 1200.
https://doi.org/10.1016/j.tele.2018.02.002
Balakrishnan, V., Khan, S., & Arabnia, H. R. (2020). Improving cyberbullying
Computers and Security, 90. https://doi.org/10.1016/j.cose.2019.101710
Chatzakou, D., Kourtellis, N., Blackburn, J., de Cristofaro, E., Stringhini, G., &
Vakali, A. (2017a). Mean Birds: Detecting Aggression and Bullying on Twitter.
http://arxiv.org/abs/1702.06877
Chatzakou, D., Kourtellis, N., Blackburn, J., de Cristofaro, E., Stringhini, G., &
Vakali, A. (2017b). Hate is not Binary: Studying Abusive Behavior of
#GamerGate on Twitter. http://arxiv.org/abs/1705.03345
Chatzakou, D., Leontiadis, I., Blackburn, J., de Cristofaro, E., Stringhini, G., Vakali, A., & Kourtellis, N. (2019). Detecting Cyberbullying and Cyberaggression in Social Media. http://arxiv.org/abs/1907.08873
Dinakar, K., Jones, B., Havasi, C., Lieberman, H., & Picard, R. (2012). Common sense reasoning for detection, prevention, and mitigation of cyberbullying. ACM Transactions on Interactive Intelligent Systems, 2(3), 1 30.
https://doi.org/10.1145/2362394.2362400
Dorol--Beauroy-Eustache, O., & Mishara, B. L. (2021). Systematic review of risk and protective factors for suicidal and self-harm behaviors among children and adolescents involved with cyberbullying. Preventive Medicine, 152.
https://doi.org/10.1016/j.ypmed.2021.106684
F. Elsafoury, S. Katsigiannis, Z. Pervez and N. Ramzan (2021), When the Timeline Meets the Pipeline: A Survey on Automated Cyberbullying Detection. IEEE Access,vol.9,pp.103541-103563,https://doi.org/10.1109/ACCESS.2021.3098979.
28
Nurrahmi, H., & Nurjanah, D. (2018). Indonesian Twitter Cyberbullying Detection using Text Classification and User Credibility. 2018 International Conference on Information and Communications Technology, ICOIACT 2018, 2018-January, 543 548. https://doi.org/10.1109/ICOIACT.2018.8350758
Obadimu, A., Khaund, T., Mead, E., Marcoux, T., & Agarwal, N. (2021). Developing a socio-computational approach to examine toxicity propagation and regulation in COVID-19 discourse on YouTube. Information Processing and Management, 58(5). https://doi.org/10.1016/j.ipm.2021.102660
Perera, A., & Fernando, P. (2021). Accurate cyberbullying detection and prevention on social media. Procedia Computer Science, 181, 605 611.
https://doi.org/10.1016/j.procs.2021.01.207
Shen, C., Sun, Q., Kim, T., Wolff, G., Ratan, R., & Williams, D. (2020). Viral vitriol:
Predictors and contagion of online toxicity in World of Tanks. Computers in Human Behavior, 108. https://doi.org/10.1016/j.chb.2020.106343
Song, Y., Lin, Q., Kwon, K. H., Choy, C. H. Y., & Xu, R. (2022). Contagion of offensive speech online: An interactional analysis of political swearing.
Computers in Human Behavior, 127. https://doi.org/10.1016/j.chb.2021.107046 Tahmasbi, N., & Rastegari, E. (2018). A Socio-contextual Approach in Automated
Detection of Cyberbullying. Proceedings of the 51st Hawaii International Conference on System Sciences, 2151 2160. http://hdl.handle.net/10125/50157 van Hee, C., Jacobs, G., Emmery, C., DeSmet, B., Lefever, E., Verhoeven, B., de
Pauw, G., Daelemans, W., & Hoste, V. (2018). Automatic detection of cyberbullying in social media text. PLoS ONE, 13(10).
https://doi.org/10.1371/journal.pone.0203794
Yokotani, K., & Takano, M. (2021). Social contagion of cyberbullying via online perpetrator and victim networks. Computers in Human Behavior, 119.
https://doi.org/10.1016/j.chb.2021.106719
APPENDICES 6.4. Classifiers Performance results tables
Figure 0-1
Figure 0-2 -IDF
30
Figure 0-3 + 2-Gram
Figure 0-4 -IFD + 2-Gram
Figure 0-5 -Gram
Figure 0-6 -IFD + 3-Gram
32 Figure 0-7
Figure 0-8 -Gram + reply
Figure 0-9: g BoW + 3-Gram + reply
Figure 0-10 results using TF-IDF + reply
34
Figure 0-11 -IDF + 2-Gram + reply
Figure 0-12 -IDF + 3-Gram + reply
Figure 0-13:
Figure 0-14 -IDF + 2-Gram + reply + likes/retweets
36
Figure 0-15 -IDF + 3-Gram + reply + likes/retweets
Figure 0-16 -IDF + reply + likes/retweets
Figure 0-17 -IDF + 2-Gram + reply + likes/retweets
Figure 0-18 -IDF + 3-Gram + reply + likes/retweets