A los miembros del jurado por su apoyo en el desarrollo del trabajo de investigación. El desarrollo de proyectos de investigación es una actividad que busca descubrir nuevos conocimientos y aplicar los conocimientos actuales para resolver problemas sociales. El propósito de esta investigación es recomendar artículos científicos para la formulación de proyectos de investigación utilizando técnicas de minería de textos.
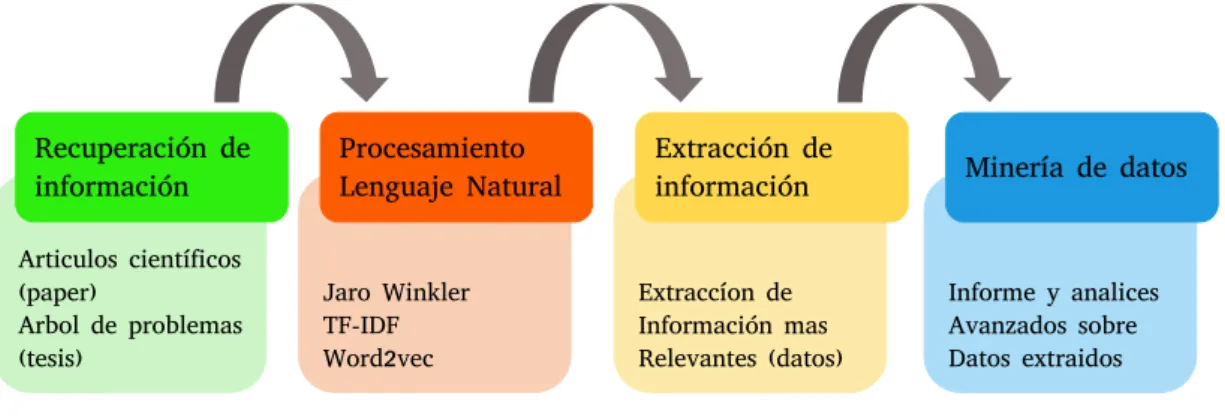
La primera etapa de este proceso es la recuperación de información, para ello se utilizó un método de recolección de datos manual, se seleccionaron aleatoriamente artículos científicos y trabajos de investigación y se clasificaron según áreas de investigación informática.
Abstract
Introducción
El primer capítulo documenta el planteamiento y definición del problema, donde se explica la descripción de la realidad problemática, las metas a alcanzar, justificación y significado y variables. El segundo capítulo explica el marco teórico, el cual incluye los antecedentes de la investigación, las bases teóricas y definición de conceptos necesarios para comprender el estudio de esta investigación. El tercer capítulo revela el tipo y nivel de la metodología de investigación, el alcance temporal y espacial, población, muestra, técnicas e instrumentos de recolección de datos, procedimientos y análisis de datos.
Finalmente, el cuarto capítulo documenta todos los resultados, conclusiones y recomendaciones del mismo experimento, que se llevó a cabo para cumplir los objetivos planteados en el proyecto.
Planteamiento del problema
- Descripción y formulación del problema
- Objetivos
- Objetivo general
- Objetivos específicos
- Justificación e importancia
- Variables
La gran mayoría de los estudiantes universitarios peruanos carecen de una sólida formación en la formulación y ejecución de proyectos de investigación para optar a un título profesional. Estas dificultades surgen debido a la falta de información y conocimiento sobre las áreas de investigación en la comunidad universitaria. Recomendar artículos científicos para la formulación de proyectos de investigación utilizando técnicas de minería de textos.
Aplicar algoritmos de minería de textos para recomendar artículos académicos para formular proyectos de investigación.
Marco Teórico
Antecedentes
El algoritmo Jaro-Winkler (J-W) es un comparador de cadenas bien conocido y ampliamente utilizado que se utiliza a menudo en estos problemas de asociación de registros. Los algoritmos tradicionales de detección de duplicados de texto largo son difíciles de aplicar en las situaciones actuales, por lo que se necesita un algoritmo de detección de duplicados de texto corto más eficiente. Basado en el modelo de bolsa de palabras de Word2vec, este artículo propone una especie de algoritmo de detección de duplicados con semántica incorporada para textos cortos.
Para mejorar la tasa de coincidencia de texto y la precisión del cálculo del método de clasificación de textos breves, este artículo estudia la optimización del método de clasificación de textos breves del algoritmo Word2Vec (Lei, 2020).
Bases teóricas
- Inteligencia artificial
- Minería de Textos
- Procesamiento Lenguaje Natural
- Metodología
- Algoritmos propuestos
- Jaro Winkler
- Término Frecuencia - Frecuencia inversa del documento (TF-IDF)
- Word2vec
- Contexto de investigación científica en el Perú
- Producción científica en la universidades
Por lo tanto, en este estudio se utiliza la minería de textos en el procesamiento de documentos digitales para ser utilizados en la clasificación de documentos no estructurados con base en la siguiente hipótesis: La minería de textos facilita el procesamiento de documentos digitales a través de los métodos de extracción y clasificación de información, lo que hace que posible para organizar documentos. El procesamiento del lenguaje natural (PNL) es un proceso de transformación de información textual en datos numéricos (Di Giuda et al., 2020). Un aspecto fundamental a considerar es que la mayor parte del conocimiento humano está codificado en lenguaje natural escrito o hablado, por lo que entender cómo manejar el lenguaje y cómo construir programas informáticos que lo utilicen con la misma habilidad y facilidad que los humanos es fundamental para el avance de la inteligencia artificial. (AI).
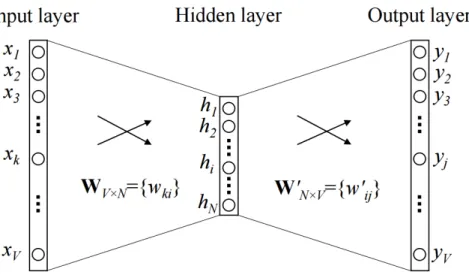
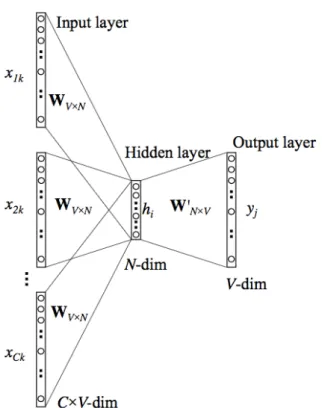
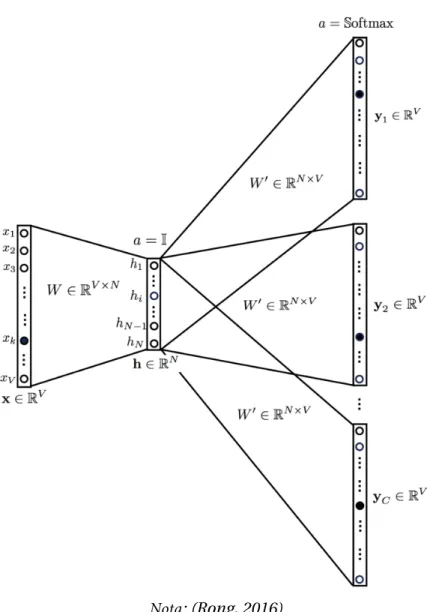
Esta es una de las áreas en las que los primeros investigadores de IA pensaron que el progreso se lograría mucho más rápido de lo que realmente fue. Pero, en general, el objetivo general de la minería de textos es convertir texto en datos para que sean adecuados para el análisis (Zanini y Dhawan, 2015). Pondera la matriz de ponderaciones que asigna las salidas de la capa oculta a la capa de salida final (matriz dimensional N∗V).
Las neuronas de la capa oculta simplemente copian la suma ponderada de las entradas a la siguiente capa. Para obtener más detalles sobre las matemáticas del modelo Wor2vec, consulte (Rong, 2016). Los resultados mostraron un pequeño desarrollo de la investigación y el desarrollo tecnológico a nivel nacional en comparación con los países latinoamericanos miembros de la Organización para la Cooperación y el Desarrollo Económico (OCDE), de la que el Perú quiere formar parte.
En este sentido, el objetivo de este trabajo es analizar el estado de la investigación y el desarrollo en el Perú en comparación con otros países de la región miembros de la OCDE, respecto del papel de las universidades en la creación de conocimiento. Es necesario promover una cultura de investigación desde el nivel de pregrado en las universidades de la región latinoamericana en general, especialmente en Ecuador, que forme y desarrolle estas habilidades con el fin de incrementar la producción científica en relación con la solución de problemas sociales (Daher Nader, Panunzio y Hernández Navarro, 2018).
Definición de términos
La investigación abre un mundo nuevo e interesante donde se puede experimentar una mejora personal y profesional continua, y es una garantía de calidad para las instituciones de educación superior. Un buen nivel de investigación no se consigue por diversos motivos, pero una tarea fundamental para poder alcanzar un buen nivel de investigación es tener en cuenta el nivel técnico actual, es decir, adquirir conocimientos de otras investigaciones dentro de la misma línea de investigación. . El árbol de problemas es una técnica utilizada para identificar una situación problemática (un problema central).
Las redes neuronales son un modelo de creación cuyo sistema se basa en la función del cerebro humano, formadas por diferentes nodos que actúan como neuronas y transmiten señales e información entre ellas. La minería de datos es el proceso de encontrar anomalías, patrones y correlaciones en grandes conjuntos de datos para predecir resultados. Algoritmos Un algoritmo es una serie de pasos organizados que describen el proceso a seguir para resolver un problema específico.
Semejanza, La similitud que representa la producción científico-intelectual con otra u otras, orienta el desarrollo de la tesis o trabajo de investigación.
Metodología
Tipo y nivel de investigación
Ámbito temporal y espacial
Población y muestra
Técnicas e instrumentos de recolección de datos
Procedimientos
- Recuperación de información
- Procesamiento Lenguaje Natural
- Jaro Winkler
- Término Frecuencia - Frecuencia inversa del documento (TF-IDF)
- Word2vec
- Extracción de datos
- Minería de Datos y resultados
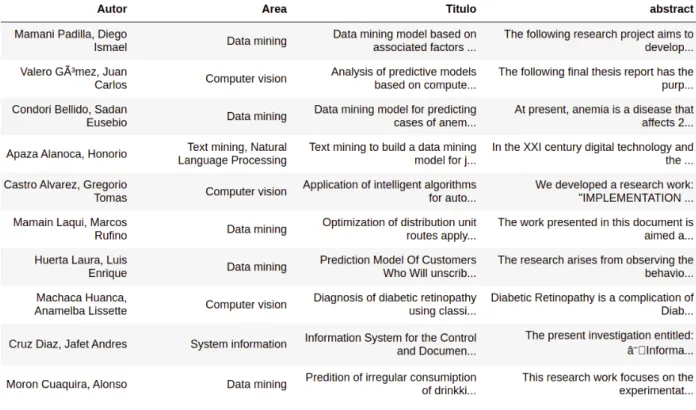
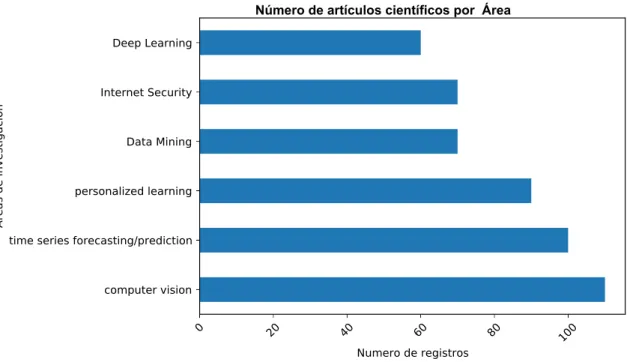
El primer conjunto de datos corresponde a la recopilación de artículos científicos de 6 áreas informáticas: Visión por ordenador, Aprendizaje personalizado, Previsión/predicción de series temporales, Seguridad en Internet, Minería de datos y Aprendizaje profundo, como se puede observar en la Figura III.1. Los campos combinados con el título de la tesis, área y resumen, como se puede observar en el gráfico III.3. En el presente caso utilizamos las siguientes dos cadenas de texto: la primera cadena de texto son los textos correspondientes al título de tesis y resumen, la segunda cadena corresponde al área del artículo, título, palabra clave y resumen, nuestro objetivo es medir en porcentaje. la similitud entre cadenas de tesis vs.
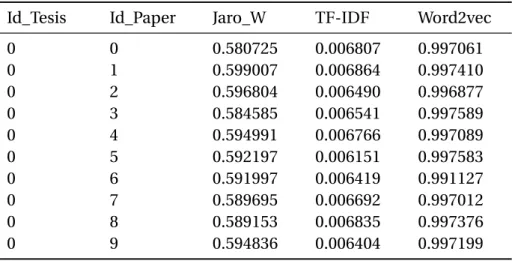
TF-IDF (frecuencia de términos-frecuencia de documentos inversa) es un valor estadístico que evalúa la relevancia de los términos de un documento en una colección de documentos, esta técnica tiene dos métricas importantes, primero el cálculo de la frecuencia de términos en un mismo documento, el otro es la frecuencia inversa del documento de la palabra en la colección de documentos. En esta investigación se mide la relevancia de cada uno de los conceptos escritos en las tesis en relación a los textos escritos en artículos científicos, el objetivo es calcular la relevancia promedio de cada uno de los documentos de tesis en relación a los documentos de artículos científicos. En la tabla III.1 se puede observar una estructura de datos compuesta por los valores cuantitativos calculados por los tres algoritmos desarrollados en.
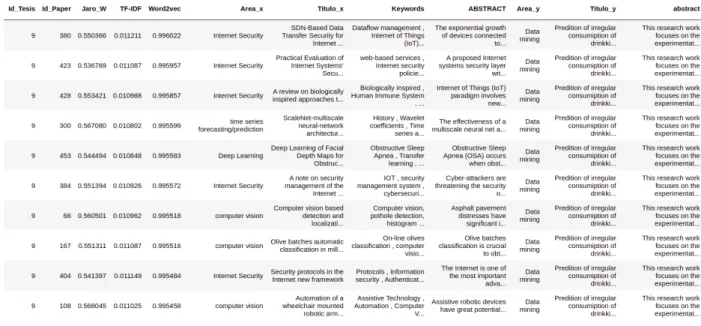
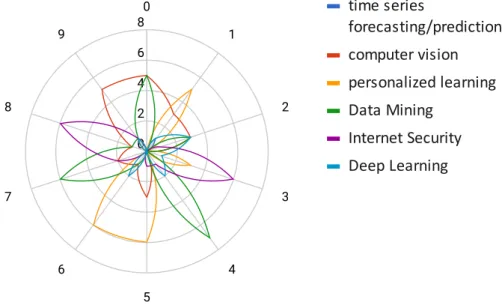
En esta investigación y en los siguientes párrafos se analizan los datos de los 10 primeros artículos y tesis científicas más importantes según los tres algoritmos aquí desarrollados. Con los datos obtenidos en la fase anterior es posible realizar algunos análisis de los documentos procesados, en el Gráfico III.5 se muestra la presencia de temas en las 10 tesis de diploma procesadas, lo que significa que podemos apreciar la presencia del contenido de el 6º tema o áreas de investigación que pertenecen a las áreas científicas que aquí se procesan los artículos. Respecto a la tesis número tres, existe evidencia clara de que el contenido de seguridad en Internet es el mismo tema presente en la tesis número ocho.
El análisis se puede realizar con cualquiera de las variables presentes en el estudio y los datos. En este caso, sólo se consideraron las 10 primeras variables más relevantes para cada algoritmo. Luego realizamos un análisis más avanzado y explícito para cada una de las diez tesis procesadas. El Gráfico III.6 muestra cifras estadísticas sobre la relevancia del contenido de los documentos. En el encabezado de cada uno de los subgrafos se encuentran la clave principal de las tesis y el área en cuestión, al costado se encuentran todas las áreas tomadas en cuenta en este estudio.
Análisis de datos
Resultados y discusión
2 T2 Minería de datos Un modelo de minería de datos para predecir casos de anemia en mujeres embarazadas en la provincia de Ilo. Un modelo de predicción basado en redes neuronales de clientes que se darán de baja del servicio HFC en la ciudad de Moquegua. En este caso particular, funciona mejor un método basado en encontrar similitudes en oraciones que constan de más de una palabra.
Además analizamos el área más recomendada, debido a que 7 de cada 10 tesis corresponden a áreas de artículos científicos procesados en esta investigación, en la Tabla IV.3 se muestra que el área más recomendada es la seguridad en internet, con un total de 118 artículos científicos, sin embargo , no hay tesis en esta área en las tesis tramitadas. Las siguientes áreas más recomendadas son la visión por computadora y la minería de datos, esto incluye artículos exitosos y no exitosos, en esta tabla nos enfocamos en la interacción de las áreas de artículos científicos.

Conclusiones
Recomendaciones
En Actas de la 23ª conferencia internacional anual de acm sigir sobre investigación y desarrollo en recuperación de información (págs. 357-359). Situación de la investigación y su desarrollo en el Perú: reflejo del estado actual de la universidad peruana. Comparación del algoritmo carp-rabin y la distancia jaro-winkler para determinar la similitud de las lenguas de la Sonda.
Publicación y factores relacionados entre profesores universitarios de investigación científica de facultades de medicina del Perú. Descargado de http://www.scielo.org.pe/scielo.php?script=. Purizaca-Rosillo, N., Cardoza-Jiminez, K., and Herrera-Añazco, P. Producción científica en una universidad pública peruana beneficiaria del canon. Métricas de comparación de cadenas y reglas de decisión mejoradas en el modelo Fellegi-sunter de vinculación de registros. Actas de la Sección de Métodos de Investigación de Encuestas.
And Proceedings of the 2018 2nd international conference on management engineering, software engineering and service sciences (pp. 188–191).
Anexos