UNIVERSIDAD NACIONAL DEL CENTRO DEL PERÚ
ESCUELA DE POSGRADO
UNIDAD DE POSGRADO DE LA FACULTAD DE INGENIERÍA DE SISTEMAS
TESIS
“MODELO DE RED NEURONAL PARA MEJORAR LA DOSIFICACIÓN DE CLORO GAS EN LA PLANTA DE
TRATAMIENTO DE AGUA POTABLE DE LA MUNICIPALIDAD PROVINCIAL DE TAYACAJA”
PRESENTADA POR:
Raúl PADILLA SÁNCHEZ
PARA OPTAR EL GRADO ACADÉMICO DE:
MAESTRO EN INGENIERÍA DE SISTEMAS
CON MENCIÓN EN GERENCIA EN TECNOLOGÍAS DE INFORMACIÓN Y COMUNICACIÓN
Huancayo – Perú
2021
ii
iii ASESOR:
ABRAHAM ESTEBAN GAMARRA MORENO
iv
UNIVERSIDAD NACIONAL DEL CENTRO DEL PERÚ
ESCUELA DE POSGRADO
UNIDAD DE POSGRADO DE LA FACULTAD DE INGENIERÍA DE SISTEMAS
TESIS:
“MODELO DE RED NEURONAL PARA MEJORAR LA DOSIFICACIÓN DE CLORO GAS EN LA PLANTA DE
TRATAMIENTO DE AGUA POTABLE DE LA MUNICIPALIDAD PROVINCIAL DE TAYACAJA”
PRESENTADA POR:
Raúl PADILLA SÁNCHEZ
PARA OPTAR EL GRADO ACADÉMICO DE:
MAESTRO EN INGENIERÍA DE SISTEMAS
CON MENCIÓN EN GERENCIA EN TECNOLOGÍAS DE INFORMACIÓN Y COMUNICACIÓN
APROBADA POR EL SIGUIENTE JURADO:
PRESIDENTE:
Dr. Anieval Cirilo Peña Rojas
PRIMER MIEMBRO:
MSc. Saúl Ernesto Arauco Esquivel
SEGUNDO MIEMBRO:
Dr. Abraham Esteban Gamarra Moreno
ASESOR DE TESIS:
Dr. Abraham Esteban Gamarra Moreno
Huancayo, …01… de ……octubre…… de 2021
v
DEDICATORIA
A mis padres, que Dios los tenga en su gloria.
A mi esposa Eugenia y a mis hijos Yulissa y Eduardo Felipe por su comprensión e infinita paciencia.
vi
AGRADECIMIENTO
A Dios por haberme dado la fortaleza, a mi asesor Dr. Abraham Esteban Gamarra Moreno por haberme guiado y compartido sus conocimientos, al señor Alcalde de la Municipalidad Provincial de Tayacaja por permitirme el acceso a las instalaciones de la planta de tratamiento de agua potable, a la Ing. Sandy Chamorro Canchanya por facilitarme los datos históricos, lo cual hizo posible la realización de la investigación, a mis hermanos Rafael, Maribel y Leonel, quienes me motivaron a continuar cuando sentía desvanecer y, a todos aquellos que de alguna forma contribuyeron en la culminación de mi tesis.
vii
ÍNDICE GENERAL
Pág.
DEDICATORIA ... v
AGRADECIMIENTO ... vi
ÍNDICE GENERAL ... vii
ÍNDICE DE TABLAS ... ix
ÍNDICE DE FIGURAS ... x
RESUMEN ... xi
ABSTRACT ... xii
INTRODUCCIÓN ... xiii
CAPÍTULO I ... 16
MARCO TEÓRICO ... 16
1.1. Antecedentes o marco referencial ... 16
1.2. Bases teóricas y conceptuales ... 20
1.2.1. Planta de tratamiento ... 20
1.2.1.1. Pretratamiento ... 20
1.2.1.2. Precloración ... 20
1.2.1.3. Coagulación-floculación ... 21
1.2.1.4. Sedimentación ... 21
1.2.1.5. Filtración ... 21
1.2.1.6. Desinfección ... 21
1.2.2. Química de la cloración ... 22
1.2.3. Factores que influyen en la desinfección ... 24
1.2.4. Red neuronal ... 25
1.2.4.1. Neurona artificial ... 26
1.2.4.2. Función de transferencia ... 26
1.2.4.3. Funciones de transferencia comunes ... 27
1.2.4.4. Topología de red neuronal ... 30
1.3. Metodología ... 31
1.3.1. Preparación de datos ... 31
1.3.1.1. Selección de datos ... 32
1.3.1.2. Normalización de datos ... 32
1.3.2. Algoritmo de red neuronal ... 33
1.3.2.1. Algoritmo de inicialización de pesos ... 33
viii
1.3.2.2. Algoritmo back-propagation ... 34
1.3.2.3. Algoritmo Levenberg-Marquardt ... 36
1.3.2.4. Procedimiento de entrenamiento ... 37
1.4. Criterio de correlación y regresión para la aproximación del modelo ... 41
1.5. Definición de términos básicos ... 43
1.6. Hipótesis de investigación ... 45
1.6.1. Hipótesis general ... 45
1.6.2. Hipótesis específicas ... 45
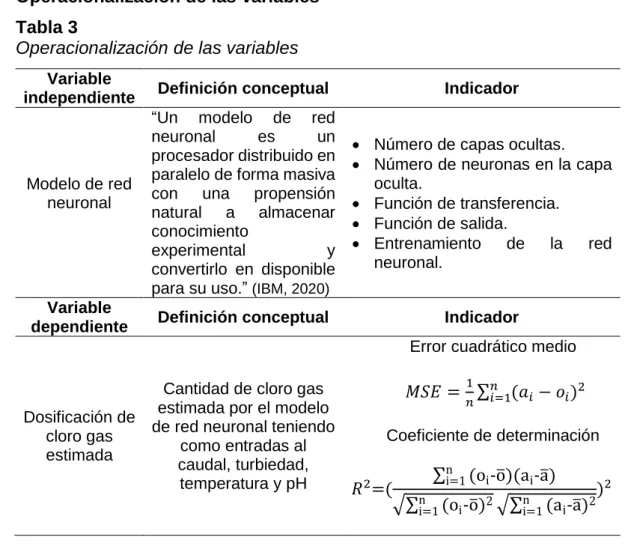
1.7. Operacionalización de las variables ... 46
CAPÍTULO II ... 47
DISEÑO METODOLÓGICO ... 47
2.1. Tipo y nivel de investigación ... 47
2.2. Métodos de investigación ... 47
2.3. Diseño de la investigación ... 48
2.4. Población y muestra ... 48
2.4.1. Población ... 48
2.4.2. Muestra ... 48
2.5. Técnicas e instrumentos de recopilación de datos ... 48
2.6. Técnica de procesamiento de datos ... 49
CAPÍTULO III ... 50
ANÁLISIS Y DISCUSIÓN DE RESULTADOS ... 50
3.1. Análisis estadístico ... 50
3.1.1. Prueba de normalidad ... 50
3.2. Simulación y resultados ... 51
3.2.1. Análisis de distribución de datos de entrada y salida ... 53
3.2.2. Normalización de las características ... 55
3.2.3. Determinación de hiperparámetros... 57
3.2.4. Entrenamiento de la arquitectura de la red neuronal ... 60
3.2.5. Prueba de hipótesis ... 63
3.3. Discusión de resultados ... 65
CONCLUSIONES ... 68
RECOMENDACIONES ... 69
REFERENCIAS BIBLIOGRÁFICAS ... 70
ANEXOS ... 76
ix
ÍNDICE DE TABLAS
Tabla 1 Formas comerciales del cloro ... 22
Tabla 2 Rango de coeficiente de correlación ... 41
Tabla 3 Operacionalización de las variables ... 46
Tabla 4 Instrumentos utilizados en la recopilación de datos ... 49
Tabla 5 Estadísticos descriptivos de las variables. ... 50
Tabla 6 Prueba de normalidad de las variables. ... 51
Tabla 7 Valores de MSE para diferentes configuraciones. ... 59
Tabla 8 Valores de pesos y bias del modelo de red neuronal. ... 62
Tabla 9 Prueba de normalidad de cloro gas objetivo y estimado. ... 63
Tabla 10 Prueba de hipótesis U de Mann-Whitney ... 64
Tabla 11 Correlación entre caudal y cloro gas ... 64
Tabla 12 Correlación entre pH, turbiedad, temperatura y cloro gas ... 65
x
ÍNDICE DE FIGURAS
Figura 1. Evolución de la cantidad de cloro residual libre. ... 23
Figura 2. Neurona con una entrada ... 26
Figura 3. Función Heaviside ... 28
Figura 4. Función lineal ... 28
Figura 5. Función logística ... 29
Figura 6. Función tangente hiperbólica ... 30
Figura 7. Red neuronal feed-forward ... 31
Figura 8. Suma del error cuadrático respecto a los pesos ... 35
Figura 9. Número de neuronas en la capa oculta ... 39
Figura 10. Regresión ideal entre los datos de salida pronosticados y los datos objetivo. ... 42
Figura 11. Regresión ruidosa entre los datos de salida pronosticados y los datos objetivo. ... 43
Figura 12. Diagrama de flujo de elaboración del modelo de red neuronal. ... 52
Figura 13. Histograma de cloro gas. ... 53
Figura 14. Histograma de caudal. ... 53
Figura 15. Histograma de turbiedad. ... 54
Figura 16. Histograma de temperatura. ... 54
Figura 17. Histograma de pH. ... 55
Figura 18. Diagrama de dispersión de caudal y cloro gas. ... 56
Figura 19. Diagrama de dispersión de turbiedad y cloro gas. ... 56
Figura 20. Diagrama de dispersión de temperatura y cloro gas. ... 57
Figura 21. Diagrama de dispersión de pH y cloro gas. ... 57
Figura 22. Curvas de entrenamiento y validación. ... 59
Figura 23. Arquitectura de la red neuronal. ... 60
Figura 24. Coeficientes de correlación del modelo de red neuronal. ... 61
Figura 25. Diagrama de simulink del modelo de red neuronal. ... 63
xi RESUMEN
La tesis tiene como objetivo desarrollar un modelo de red neuronal artificial que permita predecir la dosificación de cloro gas, el tipo de investigación es aplicada, con un nivel de investigación correlacional ya que interesa conocer el grado de asociación que existe entre las variables objetivo y pronosticado por el modelo, la población está conformada por 118 registros históricos registrados durante los meses de junio a diciembre de 2018, luego de un análisis estadístico con el software SPSS, se identificaron 8 registros atípicos que fueron eliminados en el estudio, lo que permitió tener una muestra de 110 registros, los instrumentos utilizados en la lectura de datos de las variables turbidez, temperatura, pH y cloro gas se realizaron con equipos certificados y calibrados, con respecto al caudal se realiza una estimación de su valor. El modelo de red neuronal está compuesto por una capa oculta formada por 14 neuronas, una función tangente hiperbólica como función de activación y una función lineal como función de salida, como error cuadrático medio (MSE), se obtiene el valor de 0,00864298, como coeficiente de correlación 0.89815 que indica una fuerte relación lineal entre las salidas objetivo y las predichas por el modelo, el coeficiente de determinación tiene un valor de 0.81, lo que indica que hay un buen ajuste de los datos al modelo. La ecuación de regresión multivariante de entrada-salida no lineal predeterminada para nuestro modelo es y=b0+LW*tansig(bh+ones(1,N)+IW*x).
Palabras clave – Red neuronal artificial, feedforward, aproximación de función.
xii ABSTRACT
The thesis aims to develop an artificial neural network model that allows to improve the dosage of chlorine gas, the type of research developed is applied, with a correlational research level since we are interested in knowing the degree of association that exists between the target variables and those predicted by the model, the population is made up of 118 historical records recorded during the months of June to December 2018, after a statistical analysis with the SPSS software, 8 atypical records were identified that were eliminated in the study, which It allowed us to have a sample of 110 records. The instruments used in the data reading of the variables turbidity, temperature, pH, chlorine gas were made with certified and calibrated equipment. Regarding the flow, an estimate of its value is made. The neural network model is made up of a hidden layer made up of 14 neurons, a hyperbolic tangent function as an activation function and a linear function as an output function, as mean square error (MSE), the value of 0.00864298 is obtained, as coefficient of correlation 0.89815 which indicates a strong linear relationship between the target outputs and predicted by the model, the determination coefficient has a value of 0.81, indicating that there is a good fit of the data to the model. The default nonlinear input-output multivariate regression equation for our model is y=b0+LW*tansig(bh+ones(1,N)+IW*x).
Key words – Artificial neural network, feedforward, function approximation.
xiii
INTRODUCCIÓN
En la Convención sobre los Derechos del Niño y las Convenciones de Ginebra, se establece que el agua potable es un derecho fundamental para la supervivencia, según la OMS (2019) 2,200 millones de personas carecen de acceso a servicios de agua potable gestionados de forma segura y 297,000 niños menores de cinco años mueren cada año debido a enfermedades diarreicas causadas por las malas condiciones sanitarias o agua no potable.
En el Perú, entre 7 y 8 millones de peruanos no tienen agua potable, siendo Lima la ciudad más vulnerable. El río Rímac es el principal proveedor de luz y agua para la población de Lima y Callao, (74.5% de agua) y, al mismo tiempo, es la cuenca más deteriorada en términos ambientales. (OXFAM, 2021)
En la región Huancavelica existe una brecha significativa entre el acceso al agua potable y la calidad, estas diferencias son mucho más acentuadas en el ámbito rural, donde las encuestas de la Dirección Regional de Vivienda Construcción y Saneamiento (DRVCS) han verificado, que solo el 31,41% es agua potable.
En la planta de tratamiento de agua potable de la Municipalidad Provincial de Tayacaja, la eliminación de los microorganismos y parásitos se lleva a cabo en la etapa de desinfección, inyectando cloro en estado gaseoso (Cl2) directamente en la matriz mediante dos balones de gas de 68 Kg conectados en paralelo mediante un conmutador remoto hacia el clorador, la inyección del gas se lleva a cabo mediante una bomba de 0.5 HP luego del cual se espera que el gas reaccione con el agua durante 30 minutos en el tanque de almacenamiento, para finalmente ser distribuido a los 9272 beneficiarios mediante la red de distribución.
En el proceso de desinfección se inyecta siempre la cantidad de 19 libras de cloro gas al día, la cantidad de cloro residual según la directiva sobre desinfección 190-97-SUNASS debería encontrase entre 1 a 1.5 partes por millón (ppm), el problema surge cuando baja o sube el caudal ya que se está inyectando la misma cantidad de cloro, al no contar con un modelo matemático que permita automatizar este proceso se presentan niveles de cloro residual que están fuera de los rangos permitidos tal como se muestra en el monitoreo del año 2016 efectuada por la DIGESA en donde se alcanzaron valores de cloro residual libre inferiores a los 0.3
xiv
mg/lit. constituyendo una falta grave a la directiva sobre desinfección 190-97- SUNASS.
El contar con un modelo matemático permitiría automatizar el proceso de desinfección y evitar obtener valores de cloro residual libre que estén fuera de los límites permitidos por el reglamento de la calidad del agua para consumo humano.
La tesis responde a la pregunta general ¿Cómo se puede mejorar la dosificación de cloro gas en la planta de tratamiento de agua potable de la Municipalidad Provincial de Tayacaja empleando inteligencia artificial?, y las preguntas específicas: a) ¿Cuál es el modelo de red neuronal que permite encontrar la dosis adecuada de cloro gas en la planta de tratamiento de agua potable de la Municipalidad Provincial de Tayacaja?, b) ¿Cuáles son las variables de entrada y salida que permite entrenar el modelo de red neuronal para una eficiente dosificación de cloro gas en la planta de tratamiento de agua potable de la Municipalidad Provincial de Tayacaja?
La tesis tiene como objetivo general mejorar la dosificación de cloro gas en la planta de tratamiento de agua potable de la Municipalidad Provincial de Tayacaja empleando inteligencia artificial y como objetivos específicos a) Detetminar la relación entre la dosis de cloro gas estimada por el modelo de red neuronal y a la dosis de cloro gas objetivo en la planta de tratamiento de agua potable de la Municipalidad Provincial de Tayacaja, b) Determinar la correlación entre caudal y cloro gas en el modelo de red neuronal de la planta de tratamiento de agua potable de la Municipalidad Provincial de Tayacaja y c) Determinar la correlación entre turbiedad y cloro gas, temperatura y cloro gas y pH y cloro gas en el modelo de red neuronal de la planta de tratamiento de agua potable de la Municipalidad Provincial de Tayacaja.
La elección del modelo de red neuronal se realiza primero, eliminando de la población los datos atípicos que podrían causar distorsión en los resultados, a continuación se implementan arquitecturas con diferentes números de neuronas en la capa oculta, con una diferencia de 1 neurona entre una y otra, para la elección de la arquitectura se elige la que presenta un menor error cuadrático medio en validación, seguidamente ya teniendo definido el número de neuronas en la capa oculta se procede a entrenar el modelo para observar los errores y los coeficientes de correlación y determinación.
xv
El modelo de red neuronal está conformada por 14 neuronas en su capa oculta, una función tangente hiperbólica como función de activación y una función lineal como función de salida, un MSE=0.00864298, r=0.89815, r2=0.81, como ecuación de regresión multivariante de entrada-salida no lineal y=b0+LW*tansig(bh+ones(1,N)+IW*x), como variables de entrada el caudal, turbiedad, temperatura y pH y como variable de salida el cloro gas.
El primer capítulo aborda el marco teórico, en donde se explica que la red neuronal recomendada para encontrar una función de ajuste es la feed-forward con una arquitectura de una capa oculta, una función de activación sigmoide en la capa oculta y una función lineal en la capa de salida, un algoritmo de aprendizaje supervisado y un método de entrenamiento backpropagation. La metodología comprende dos fases: preparación de datos y entrenamiento de la red neuronal. La preparación de datos implica la selección de datos en la cual se identifica los datos atípicos, la normalización de datos la cual evita el desbordamiento de la función de activación, la inicialización aleatoria de pesos a través del algoritmo Nguyen- Widrow que mejora la velocidad de aprendizaje, el algoritmo back-propagation que permite actualizar los pesos y el error entre los datos aproximados y los datos deseados, este proceso de actualización se acelera haciendo uso del algoritmo Levenberg-Marquardt y finalmente el entrenamiento que consta de cuatro pasos:
inicialización, entrenamiento, validación y generalización
El segundo capítulo aborda el diseño metodológico de investigación con un alcance correlacional y enfoque cuantitativo a las técnicas de recolección de datos que se emplea.
El tercer capítulo aborda el tratamiento estadístico, simulación, análisis y discusión de resultados.
Finalmente, las conclusiones respecto a los objetivos de investigación, seguido de las recomendaciones y los anexos.
16 CAPÍTULO I MARCO TEÓRICO 1.1. Antecedentes o marco referencial
Pavón (2019) “Modelo para el pronóstico de la demanda de agua potable de EMAPA-I aplicando redes neuronales artificiales”. Tesis para optar el grado de Ingeniera Industrial. Universidad Técnica del Norte. Ibarra-Ecuador.
El plan y la ruta del sistema de distribución de agua potable constituyen las variables a la entrada de la red neuronal y la variable a pronosticar la cantidad de demanda de agua potable en EMAPA-I, utiliza el método general del pronóstico donde se identifica el horizonte temporal a mediano plazo.
Para las redes neuronales, la metodología propia de la inteligencia artificial, la arquitectura con la que se entrena la red corresponde a una red de 2 entradas 1 capa oculta de 10 neuronas y una capa de salida con una neurona.
Pavón (2019) afirma que “El MSE para las redes neuronales es 4.71%
frente al 7.69% de Box Jenkins SRT y la correlación 0.95 frente a 0.55 respectivamente, indicando esto que existe una mejor relación para las redes neuronales artificiales” (p. 66).
Apesteguia y Huarcaya (2018) “Redes neuronales artificiales aplicadas a la detección de fugas no visibles en las redes de agua potable de la ciudad de Lima”. Tesis para optar el grado académico de Maestro en Ciencias de la Electrónica, con mención en Control y Automatización. Universidad Nacional del Callao. Callao-Perú.
17
En el trabajo de investigación se identificó como variable independiente a los sonidos capturados por el geófono, el que permite la detección de las fugas, como variable dependiente la detección de fugas, el tipo de investigación es estadística, experimental tecnológica, aplicada o I+D, científica y transversal, la metodología utilizada es la del modelamiento de las redes neuronales, su población está constituida por 6214 fugas de agua potable detectadas: industriales, comerciales y residenciales y la muestra haciendo uso de la fórmula estadística para una población infinita es de 300 fugas de los 3 tipos: fuga en caja, fuga en línea y fuga en corporation de diferentes distritos bajo una presión de agua constante de 30 y 40 libras.
Apesteguia & Huarcaya (2018) afirman que “con las redes neuronales de MATLAB aplicadas a la identificación de fugas no visibles de agua potable se hizo posible diseñar una red PMC que pudo identificar y reconocer las fugas de agua hasta con una precisión del 93 %, este porcentaje de precisión es mayor respecto a su contraparte humana que es aproximadamente de 60%.” (p. 102)
Quispe (2018) “Formulación de un modelo de red neuronal artificial para el pronóstico de concentración de oxígeno disuelto y clorofila en la bahía interior de Puno”. Tesis para optar el grado académico de Magíster Scientiae en Ingeniería Química. Universidad Nacional del Altiplano. Puno-Perú.
El modelamiento de las RNA se realizó en dos bloques, el primero tuvo como variables de entrada: potencial de hidrogeniones, conductividad eléctrica y temperatura, 4 neuronas en la capa oculta y como variable de salida el oxígeno disuelto; el segundo bloque tuvo como variable de entrada:
potencial de hidrogeniones, conductividad eléctrica, oxígeno disuelto, temperatura, fosfatos y nitratos, 10 neuronas en la capa oculta y como variable de salida la clorofila alfa, se manejaron 360 datos por cada variable en ambos casos, en el primer bloque se alcanzó un MSE de 0.9930 en la fase de prueba y en el segundo bloque se alcanzó un MSE de 0.9999, en ambos casos se utilizó una red MLP y el gradiente a escala conjugada como algoritmo de entrenamiento. El tipo de investigación es descriptiva- correlacional, se hizo uso de la metodología prueba – error. La población está conformada por las variables fisicoquímicas, incluyendo las variables
18
respuesta concentración de oxígeno disuelto y la concentración de clorofila alfa, la muestra constituida por las variables: sales, temperatura, clorofila alfa, oxígeno disuelto, conductividad, nitratos y fosfatos.
Quispe (2018) afirma que “la prueba estadística empleada fue significativa, tanto para el oxígeno disuelto como para la clorofila alfa, siendo los más relevantes para el caso de oxígeno disuelto y temperatura, en el caso de la clorofila alfa las variables significativas fueron los nitratos y los fosfatos cuyos elementos influyen en el modelado de red neuronal para la clorofila alfa. Con un nivel de significancia del 95%.” (p. 67)
Peña (2016) “Uso de redes neuronales artificiales para optimizar la dosificación de coagulantes en la Planta de Tratamiento de Agua Potable – Huancayo”. Tesis para optar el grado de Doctoris Philosophiae en Ingeniería y Ciencias Ambientales. Universidad Nacional Agraria La Molina. Lima-Perú.
Las variables de entrada que su utilizaron en el estudio fueron turbidez, pH, conductividad, color y sólidos disueltos totales con una temperatura y caudal promedio de 10 ºC y 148 l/s respectivamente y la variable de salida es la dosis de coagulante a emplear.
La investigación concluye que la topología más adecuada para pronosticar la dosis de coagulante es la de regresión generalizada con dos capas ocultas, llegando a tener una asertividad de 96.9% frente a los datos reales y una correlación de 98.4%, evidenciando que las variables más influentes son: color, turbidez y pH.
Peña (2016) afirma que “la red seleccionada finalmente permitió predecir la dosificación de coagulante óptimo con una probabilidad de error máximo de 1.6 por ciento y en tiempo real con nuevos valores de entrada en el agua a tratar sin necesidad de recurrir a la Prueba de Jarras el cual sólo se realiza posteriormente para enriquecer su aprendizaje.” (p. 12)
Barajas y León (2015) “Determinación de la dosis óptima de sulfato de aluminio (Al2(SO4)3 18H2O) en el proceso de coagulación - floculación para el tratamiento de agua potable por medio del uso de una red neuronal artificial”. Tesis para optar el grado de Ingeniera Ambiental. Universidad Santo Tomás. Bogotá-Colombia.
19
Los valores de entrada a la red neuronal fueron los niveles de turbidez inicial y las concentraciones de dosis óptima de sulfato de aluminio que se obtuvieron en los ensayos de jarras y el valor de salida lo constituye los niveles de turbidez final, en la parte metodológica se siguieron dos pasos: en laboratorio se determinó los parámetros fisicoquímicos más representativos para el cálculo de la dosis óptima de coagulante y luego se hizo una evaluación de la dosis óptima de sulfato de aluminio para diferentes escenarios mediante ensayo de jarras, se utilizó una red de base radial de 25 neuronas.
Barajas & León (2015) afirman que “los valores de pH con los que se obtuvieron los mejores resultados varían en un rango entre 7 a 8, rango dentro del cual se encontró la mayor cantidad de valores de turbidez final más bajos, indicando que el pH influye con la efectividad del proceso de coagulación y floculación, puesto que contribuye a que se obtenga una turbidez final más baja si se lleva a cabo su ajuste en el agua a tratar dentro del rango mencionado.” (p. 85)
Palacín (2011) “Visión artificial aplicada al monitoreo automatizado del proceso de cloración para mejorar la calidad del agua”. Tesis para optar el título de Ingeniero de Sistemas y Computación. Universidad Católica Santo Toribio de Mogrovejo. Chiclayo-Perú.
La tesis tiene como objetivo construir un sistema automatizado para identificar el nivel cloro residual libre a la salida de la planta de tratamiento de agua potable, la red neuronal artificial tiene una arquitectura con 12 neuronas de entrada, 10 neuronas en la capa oculta y 4 neuronas en la capa de salida, en la capa oculta y la capa de salida usa funciones sigmoideas como funciones de transferencia.
La entrada de la red neuronal está constituida por los estadísticos media, desviación estándar, valor mínimo y valor máximo de cada imagen RGB capturada de la muestra de agua con el reactivo DPD.
La salida de la red neuronal lo constituyen 4 neuronas que representan los 4 niveles de cloro residual libre 0.5, 1.0, 2.0 y 3.0.
La red neuronal ha sido entrenada por nivel de cloro residual libre, con un total de 200 imágenes RGB.
20
El algoritmo de entrenamiento el Levenberg-Marquardt y como parámetro de rendimiento el error cuadrático medio, el mejor rendimiento de validación se alcanza en la época 14 con un valor de 1.6968 e-12.
1.2. Bases teóricas y conceptuales 1.2.1. Planta de tratamiento
Chávez de Allaín (2012) afirma que “una planta de tratamiento de agua se define como el conjunto de operaciones unitarias que pueden ser de tipo físico, químico o biológico y que tienen como fin último eliminar o, en su defecto, reducir la contaminación (…)” (Citado en Caminati & Caqui, 2013, p. 27), cumpliendo de esta manera con los parámetros que hacen del agua un producto apto para consumo humano.
“A lo largo de la vida de la planta, se producirán variaciones importantes en la calidad del agua bruta, presentándose las denominadas “puntas de contaminación” de forma estacional, con las lluvias, estiaje, etc. o aleatoria (accidentes).” (Casero, 1987).
“El mayor riesgo a la salud pública debido a los microbios del agua se relaciona con el consumo de agua contaminada con heces humanas o de animales” (Organización Mundial de la Salud [OMS], 2018, p. 139). Es por esto que una planta de tratamiento de agua potable (PTAP) debe contar mínimamente con las siguientes operaciones unitarias:
1.2.1.1. Pretratamiento
Chávez de Allaín (2012) afirma que “en este paso lo que se pretende es remover los sólidos grandes y arenosos que por ser abrasivos pueden deteriorar los equipos mecánicos del tratamiento propiamente dicho. Para ello se utilizan rejillas o parrillas, tamices y desarenadores. En algunos casos, dependiendo del tipo de afluente, se utilizan trituradores para remover más fácilmente los sólidos grandes de éste.” (Citado en Caminati
& Caqui, 2013, p. 27) 1.2.1.2. Precloración
“En esta etapa se destruye la fauna y se reduce el número de bacterias fecales y agentes patógeno, contribuyendo esto a la eliminación de algas, además que nos ayuda a eliminar el amoníaco en el caso que el agua contenga un alto grado de ácido húmico y fúlvico.” (EPS SEDALORETO S.A, 2015)
21 1.2.1.3. Coagulación-floculación
“En la coagulación, se añaden compuestos químicos al agua para reducir las fuerzas que separan a los sólidos suspendidos menores a 10 µm (orgánicos e inorgánicos) de esta manera se forman los aglomerados, en la floculación las colisiones entre partículas favorecen el crecimiento de flóculos que van a ser eliminados en la sedimentación, es comun utilizar en esta etapa la cal, el sulfato de alumnio Al2(SO4)3 y los policloruros de aluminio.” (Comisión nacional del agua [CNA], 2007) 1.2.1.4. Sedimentación
Mediante la fuerza de gravedad los flocs se depositan en el fondo del sedimentador, algunos factores que influyen en la eficacia de la sedimentación son:
EPS SEDALORETO S.A (2015) afirma que “el tamaño, la forma y el peso de la masa flocosa; la viscosidad y por lo tanto la temperatura del agua; el tiempo de retención; el número de unidades la profundidad y la superficie de los depósitos; la tasa de rebose superficial; la velocidad de la corriente y el diseño de la entrada y de la salida (…)” (p. 10)
1.2.1.5. Filtración
En esta etapa lo que se busca es eliminar los mircroorganismos, obtener un agua con un color y turbidez adecuados a los parámetros organolépticos, “cerca del 90% de la turbiedad (…) son removidos por la coagulación y la sedimentación” (Hernández & Corredor, 2017, p. 38).
CNA (2007) afirma que la “arena, antracita, tierra de diatomeas, perlita y carbón activado en polvo o granulado se puede rellenar con un sólo tipo de medio o una combinación de éstos. El medio más común empleado es la arena de sílice y para filtros duales, arena con antracita. Se emplea carbón activado como medio filtrante cuando se pretende no sólo eliminar los sólidos en suspensión, sino también remover los materiales disueltos por adsorción.” (p. 121)
1.2.1.6. Desinfección
Desinfectar el agua, es eliminar los microorganismos existentes como bacterias, virus, protozoos y helmintos capaces de producir enfermedades. (Caceres, 1990)
22
La desinfección “se realiza mediante agentes químicos o físicos y debe tener un efecto residual en el agua potable, a fin de eliminar el riesgo de cualquier contaminación microbiana posterior a la desinfección”
(Cooperación Alemana, implementada por la Deutsche Gesellschaft für Internationale Zusammenarbeit (GIZ) GmbH, 2017, p. 20)
La desinfección del agua se consigue por:
a) Ebullición: “Para obtener un agua perfectame desinfectada, a nivel del mar se debe hervir por espacio de un minuto, se agrega un minuto adicional de ebullición por cada 1000 m de altitud.” (Organización Panamericana de la Salud [OPS], 1996)
b) Rayos ultravioleta: “Ligada a la calidad del agua a ser tratada, esta técnica no tiene efecto residual, por lo que no genera ningún subproducto.” (OPS, 1996)
c) Procesos químicos: “Los reactivos más comunes son el cloro y sus derivados y el ozono junto con el bióxido de cloro. El cloro en forma de cloro gaseoso, de hipoclorito de sodio (lejía) o de hipoclorito de calcio (en polvo), es el biocida más empleado y más antiguo.” (OPS, 1996)
Las diferentes formas comerciales del cloro se presentan en la siguiente tabla.
Tabla 1 Formas comerciales del cloro Formas comerciales del cloro
Producto Presentación Contenido de cloro
Cloro gaseoso (Cl2) Gas licuado a presión 99%
Hipoclorito de sodio (NaOCl) Solución líquida amarilla Máximo 15%
Hipoclorito de calcio (Ca(OCl)2) Sólido blanco Del 60 al 70%
Electrocloración chlorung Solución NaCl De 1 a 3 g/l tras electrodiálisis Nota. Adaptado de OPS (1996).
1.2.2. Química de la cloración
Como menciona (Ramos y Gentil, 2019), cuando agregamos cloro al agua, se producen dos tipos de reacción: hidrólisis e ionización.
En la hidrólisis se forma ácido hipocloroso (HOCl) y ácido clorhídrico (HCl) (ecuación 1). “Esta reacción tiene lugar en pocos segundos y a temperatura
23
normal”. (Asociación española de abastecimientos de agua y saneamiento, 1984)
Cl2+H2O ↔ HOCl+H++Cl- (1)
En la ionización el HOCl se disocia en ión hipoclorito (OCl-) e hidrógeno (ecuación 2). (Asociación española de abastecimientos de agua y saneamiento, 1984)
HOCl ↔ OCl-+H+ (2)
“El cloro presente en el agua en forma de Cl2, HOCl y OCl-, se llama cloro residual libre, CRL. El cloro residual combinado, CRC, se forma cuando el cloro en solución, reacciona con el amoníaco y los compuestos nitrogenados orgánicos presentes en el agua formando compuestos llamados cloraminas, siendo sus principales formas la monocloramina (NH2Cl), dicloramina (NHCl2) y tricloramina (NCl3). Tienen un poder desinfectante menor que el CRL.” (Perez, 1981).
"A la suma del cloro libre y el combinado se denomina cloro residual total”.
(Quispe y Torres, 2018, p. 32)
En la figura 1 se muestra la curva de demanda de cloro y la evolución de la cantidad de cloro residual libre.
Figura 1. Evolución de la cantidad de cloro residual libre. Tomado de Universidad de Salamanca (2020)
24
“Los primeros miligramos de cloro introducidos no garantizan la desinfección. De hecho; antes de que éste pueda garantizar realmente una acción eficaz, se deberá agregar una cantidad variable de desinfectante para que se produzca todas las reacciones químicas secundarias. Esta cantidad se denomina demanda de cloro.” (Tomaylla, 2017, p. 36)
1.2.3. Factores que influyen en la desinfección
a) Naturaleza y concentración de los microorganismos
“El número de microorganismos presentes en el agua, no afecta el proceso de desinfección. Ello quiere decir que se requiere la misma concentración y tiempo de contacto del desinfectante, para matar una gran cantidad de microorganismos que, para una pequeña, siempre en cuando la temperatura y pH del agua sean los mismos.” (Caceres, 1990, p. 38)
b) Concentración del desinfectante
(…) una concentración alta del desinfectante requerirá de menos tiempo para destruir todos los microorganismos que una concentración más débil. Para poseer un poder o intensidad efectiva, los desinfectantes se deben hallar uniformemente distribuidos en el agua, para actuar sobre todos los microorganismos presentes, Para ello se requiere que su aplicación se efectúe con una fuerte agitación del agua. (Caceres, 1990, p. 38)
c) Temperatura del agua
“La destrucción de microorganismos mediante la desinfección es mucho más rápida con el aumento de la temperatura. Es decir, cuanto más caliente sea el agua, más eficiente y rápida será la desinfección”.
(Caceres, 1990, p. 39)
d) Potencial de hidrógeno (pH)
“La acción de los desinfectantes es fuertemente influenciado por el pH de las aguas. Cada desinfectante tiene un rango de pH en el que se determina su máxima efectividad. En general, cuanto más alcalina sea el agua se requeriran mayores dosis para una misma temperatura y tiempo de contacto”. (Caceres, 1990, p. 39)
25 e) Tiempo de contacto
“Cuanto mayor es el tiempo de contacto, mas amplia será la oportunidad para la destrucción de los microorganismos. Bajo condiciones de flujo, el tiempo mínimo de desplazamiento del agua es un factor de suma importancia”. (Caceres, 1990, p. 39)
f) Caudal
Como menciona (Castro, 2002) la dosis de cloro esta en función del flujo de agua.
La ecuación que permite calcular el caudal de cloro gas a inyectar está dada por la (ecuación 3). (OPS, 1999)
D=CxQ (3)
Siendo
D (g de cloro/h): caudal de cloro indicado en el indicador volumétrico del clorómetro.
C (mg de cloro/litro de agua o g de cloro/m3 de agua): dosis de cloro a inyectar.
Q (m3/h): caudal de agua que se va a tratar.
g) Turbiedad
“Los microorganismos al encontrarse rodeados por partículas sólidas en suspensión pueden ser impenetrables por el cloro”. (Castro, 2002) 1.2.4. Red neuronal
Una red neuronal es un modelo matemático conformada por una terna ordenada (N,V,w) con dos conjuntos N, V y una función w, donde N es el conjunto de neuronas y V es el conjunto {(i,j)i,jN} cuyos elementos son llamados conexiones entre neuronas i y neuronas j. La función w :VR, define los pesos (w(i,j)) de las conexiones entre la neurona i y la neurona j, de forma simple wi,j. (Kriesel, 2005)
El conocimiento del cerebro humano no se había descubierto hasta que los neuroanatomistas y neurofisiólogos dieron a conocer el mecanismo de interconexión de la comunicación. McCulloch y Pitts hicieron la primera contribución de una red neuronal con el modelo perceptrón en 1943, este
26
modelo proporcionaba la descripción básica de las propiedades biológicas de las neuronas. De 1950 a 1968 se tuvo el primer pico de las Redes Neuronales Artificiales (ANN), durante este período, la estructura del perceptrón se había construido con éxito, este enfoque fue investigado por Marvin Minsky, Frank Rosenblatt, Bernard Widrow, et al., y casi se había convertido en la técnica clave de la inteligencia, hasta que se probó su incapacidad de resolver un problema de XOR. No fue sino hasta principios de la década de 1980, donde se vivió el segundo pico de ANN con las contribuciones de J. Hopfield con su función de energía, y el algoritmo de aprendizaje back-propagation (BP) de Parker y Werbos por separado.
(Wang, 2014)
1.2.4.1. Neurona artificial
Una neurona es una unidad de procesamiento que tiene algunas (generalmente más de una) entradas y una sola salida. (Hristev, 1998).
En la figura 2 se muestra una neurona con una sola entrada.
Figura 2. Neurona con una entrada. Tomado de Hagan, Demuth, Beale, & De Jesus (2014)
La entrada escalar p, se multiplica por el peso escalar w, para formar wp, uno de los términos que se envía al sumador. La otra entrada, 1, se multiplica por un bias (sesgo) b, luego se pasa al sumador. La salida n del sumador, a menudo denominada entrada neta, entra en una función de transferencia f, que produce la salida escalar a de la neurona. (Hagan et al., 2014)
1.2.4.2. Función de transferencia
Una función de transferencia, llamada también función de activación, se define como se muestra en la ecuación 4:
27
aj(t)=fact(netj(t),aj(t-1),j) (4)
La función de transferencia transforma la entrada de la red netj y el anterior estado de activación aj(t − 1) a un nuevo estado de activación aj(t), el valor threshold (umbral) juega un papel muy importante. La función de transferencia a menudo se define globalmente para todas las neuronas o al menos para un conjunto de neuronas y solo los valores threshold son diferentes para cada neurona. Los valores de threshold se pueden cambiar mediante un procedimiento de aprendizaje. Por lo tanto, puede ser necesario relacionar el valor umbral con el tiempo y escribir j(t) en lugar de solo j. (Kriesel, 2005)
1.2.4.3. Funciones de transferencia comunes
La función de transferencia en la figura 2 puede ser una función lineal o no lineal de n. Se elige una función de activación particular para satisfacer alguna especificación del problema que la neurona está intentando resolver. (Hagan, et al., 2014). Las funciones de transferencia más comunes son:
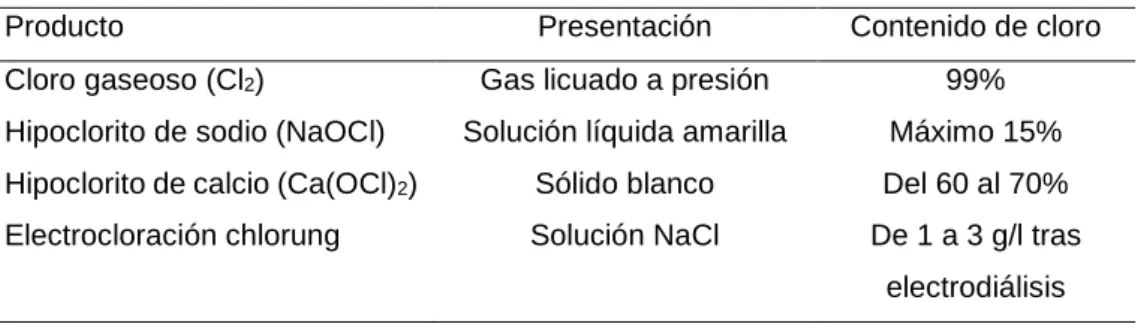
a) Función Heaviside
La función signo, es la función de transferencia más simple, solo puede tomar dos valores. Si la entrada está por encima de cierto umbral, la función cambia de un valor a otro, de lo contrario permanece constante. Esto implica que la función no es diferenciable en el umbral, por lo tanto su derivada es 0. Debido a este hecho, el aprendizaje BP es imposible (Kriesel, 2005). En la figura 3 se muestra la función Heaviside.
28
Figura 3. Función Heaviside
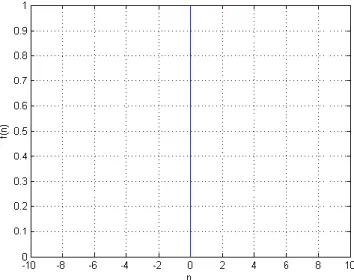
b) Función lineal
Se encuentran en la capa final de redes multicapa que se usan como aproximadores de funciones. Esto se muestra en redes neuronales multicapa con entrenamiento BP. (Hudson, Hagan, &
Demuth, 2018), la salida de una función de transferencia lineal es igual a su entrada (a=n). (Hagan, et al., 2014). En la figura 4 se muestra la función lineal.
Figura 4. Función lineal
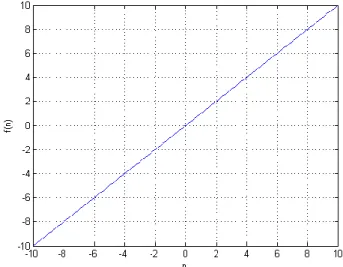
29 c) Función sigmoidea
Es una función con un gráfico en forma de S, y es la función más utilizada en la red neuronal artificial debido a su capacidad diferenciable, que es de vital importancia para aplicar el algoritmo BP.
Usualmente se usan dos tipos de funciones sigmoideas. (Wang, 2014) La función logística tiene un rango en el intervalo de [0 1], está representado por la ecuación 5 y su gráfica se muestra en la figura 5.
f(n)= 1
1+e-n (5)
Figura 5. Función logística
La función tangente hiperbólica tiene un rango comprendido en el intervalo de [-1 +1], está representado por la ecuación 6 y su gráfica se muestra en la figura 6.
f(n)= tanh(n)=1+e-n
1-e-n (6)
30
Figura 6. Función tangente hiperbólica
Una función sigmoidea es más rápida que lineal para señales pequeñas, aproximadamente lineal para señales intermedias y más lenta que lineal para señales grandes. Cuando se utiliza una función de transferencia sigmoidea en la capa 2, el patrón mejora el contraste;
los valores más grandes se amplifican y los valores más pequeños se atenúan. Todas las salidas de neuronas iniciales que son inferiores a un cierto nivel (llamado umbral de extinción) decaen a cero. Esto mejora la supresión de ruido de las funciones de transferencia más rápidas que lineales con el almacenamiento perfecto producido por las funciones de transferencia lineal. (Hagan, et al., 2014)
1.2.4.4. Topología de red neuronal
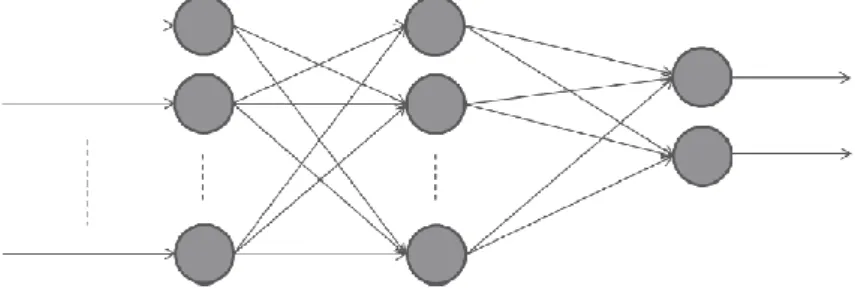
La topología de red neuronal se puede dividir en tres categorías: red feed-forward, red feed-back y red auto-organizativa. La más utilizada es la topología feed-forward. Se ha demostrado que una red neuronal feed- forward de dos capas tiene la capacidad de aproximar funciones. Una red neuronal feed-forward consiste en múltiples neuronas artificiales, con la salida de la neurona anterior conectada como la entrada de la neurona última, mientras que no hay otras conexiones en esta red. La figura 7 presenta una arquitectura de red neuronal de varias capas, donde hay una capa de entrada, una capa oculta y una capa de salida. Se ha demostrado que esta es la estructura más utilizada de la red neuronal para problemas de aproximación de funciones, y la aproximación universal también denota
31
que una red neuronal con una capa oculta de múltiples neuronas puede aproximar funciones. (Wang, 2014)
Figura 7. Red neuronal feed-forward. Tomado de Wang (2014)
En cada neurona artificial, se tienen los valores de entrada pi, con conexión de pesos wi, la entrada de la red es:
net(p)=∑ni=1piwi (7)
La salida de la red para una neurona es
ai=f(net(p)+wbi)+wobi (8)
Donde wbi es el valor del peso de bias de la capa oculta, y wobi denota el valor del peso de bias de la capa de salida.
Entonces, para una red neuronal de dos capas con H neuronas ocultas, la salida de la red es
a=∑Hj=1f(netj(p)+wbj)+wobj (9)
netj(p) es el valor jth de entrada de la red.
1.3. Metodología
El modelo de red neuronal se construye en dos partes: primero se prepara los datos y luego se entrena la red neuronal. (Wang, 2014)
1.3.1. Preparación de datos
(…) la calidad de los datos de entrada en los modelos de redes neuronales puede influir fuertemente en los resultados del análisis de datos (Sattler &
32
Schallehn, 2001), el efecto sobre el rendimiento de la red neuronal puede ser significativo si faltan datos de entrada importantes o están distorsionados (Lou, 1993), en la preparación de datos, uno de los pasos más importantes es la selección del subconjunto de datos, la selección del "mejor subconjunto" se considera un paso crítico, especialmente para un conjunto de datos grande y complejo, un subconjunto de datos adecuado no solo puede eliminar el error de predicción causado por parámetros de entrada irrelevante, sino que también puede reducir el costo de construir un modelo.
(Wang, 2014)
1.3.1.1. Selección de datos
Como afirma Wang (2014), el subconjunto de datos debe satisfacer el criterio de error cuadrático medio E (Xsub) y alcanzar los siguientes objetivos:
Seleccionar y eliminar los predictores innecesarios como el ruido o las variables irrelevantes.
Simplificar el modelo de predicción, usando solo datos necesarios.
Mejorar la precisión predictiva con el modelo.
Entrenar el modelo en un menor tiempo y a un mejor costo-beneficio.
Uno de los métodos más utilizados en la selección de subconjunto de datos se llama pesos de conexión, que calcula la suma de los valores de peso de cada variable, la variable que más contribuye, tiene la mayor suma de peso. (Olden & Jackson, 2002). Otro método popular llamado PaD utiliza las derivadas parciales de la variable de salida de la red con respecto a las variables de entrada, lo que permite determinar la influencia de las variables de entrada en la salida. (Gevrey, Dimopoulos, & Lek, 2003)
1.3.1.2. Normalización de datos
Como afirma Yu, Wang, & Lai (2006), antes del entrenamiento de la red neuronal, es mejor transformar el conjunto de datos para que las variables predictoras y de respuesta puedan exhibir características de distribución particulares.
Como menciona Wang (2014), la variable de respuesta debe convertirse al rango [0,1] para que se ajuste a las demandas de la función de transferencia (función sigmoidea) utilizada en la construcción de la red
33
neuronal. Esto se logra usando la fórmula:
Tn= Yn-min(Y)
max(Y)-min(Y) (10)
donde Tn es el valor de respuesta convertido para la observación n, e Yn es el valor de respuesta original para la observación n, min(Y) y max(Y) representan los valores mínimo y máximo respectivamente de la variable de respuesta Y.
1.3.2. Algoritmo de red neuronal
La red neuronal se entrena en cuatro procedimientos: inicialización, entrenamiento, validación y generalización, para esto se considera la eficiencia y la precisión en las aplicaciones.
1.3.2.1. Algoritmo de inicialización de pesos
El primer paso para entrenar la red es inicializar los pesos de conexión de la red neuronal, para ello se genera de manera aleatoria los pesos de conexión con valores pequeños, ahora surge el problema de si los valores de peso se pueden aleatorizar de acuerdo con funciones específicas para que el procedimiento de entrenamiento sea más rápido. El algoritmo Nguyen-Widrow mejora la velocidad de aprendizaje mediante la inicialización de los valores de peso de las capas ocultas en sus propios intervalos. (Nguyen & Widrow, 1990) A partir de la ecuación 7, se puede ver que cada término de la suma es una función lineal de p en un intervalo pequeño, y este intervalo está determinado por los valores de los pesos de conexión. Por lo tanto, es razonable poner primero los pesos en su propio intervalo y luego entrenar la red en un menor tiempo. El algoritmo se basa en la teoría de aproximación de funciones con el método BP y la función de activación sigmoidea. (Wang, 2014)
Sea una red neuronal con una entrada, una salida y una capa oculta con H unidades, la función a aproximar está sobre el intervalo -1 y 1, luego cada unidad oculta toma el intervalo 2/H en promedio. Dado que la función sigmoidea es aproximadamente lineal durante el intervalo:
-1<pwi+wbi<1 (11)
34 Que genera el intervalo de p,
-1
wi-wbi<p< 1
wi-wbi (12)
Así,
2 wi=2
H (13)
wi=H (14)
Como sugiere Nguyen-Widrow, es preferible que los intervalos se superpongan ligeramente, por lo que se debe usar wi=0.7H, luego se selecciona wbi de manera aleatoria en la región -1 a 1. (Nguyen yG Widrow, 1990)
1.3.2.2. Algoritmo back-propagation
En un problema de aproximación de funciones, dada la entrada y los datos deseados asociados, el objetivo del entrenamiento de la red neuronal es minimizar el error entre los datos de salida de la red (datos aproximados) y los datos deseados, con el fin de lograr el "mejor" rendimiento de la red. Un proceso de minimización de errores ampliamente utilizado se llama Back- Propagation (BP), donde los pesos se actualizan de acuerdo con un algoritmo de error BP. (Rojas, 1996)
Como afirma Wang (2014), el algoritmo BP se divide principalmente en dos fases: feed-forward y back-propagation. Durante la fase feed-forward, las señales de entrada se transfieren a través del terminal de entrada al terminal de salida, y la salida de la red se obtiene de acuerdo con la ecuación 8.
Durante la segunda fase, la parte principal del algoritmo BP es calcular la suma del error cuadrático (SSE) entre los datos de salida de la red y los datos deseados:
E=12∑ni=1(ai-oi)2 (15)
35
donde 1/2 se usa para eliminar el efecto de la potencia de 2. Combinado con las ecuaciones 6 y 8, el SSE se puede expresar como una ecuación de pesos.
La relación entre dos variables se muestra en la figura 8, donde wi es el valor de peso de la red que se va a lograr. Por lo tanto, se puede minimizar la SSE a través del proceso de actualización de los pesos. Para obtener el mínimo valor de error, el gradiente de E (W) debe ser igual a cero. De acuerdo con el método gradiente decreciente, la función de error E (W) en el punto wi
disminuye más rápidamente en la dirección opuesta del gradiente de error
E, (Wang, 2014)
E=(wE
1,wE
2,…,wE
n) (16)
Entonces los pesos se actualizan con la regla delta,
wi+1=wi+wi (17)
wi=-Ei (18)
Donde es llamada la tasa de aprendizaje, quien determina el tamaño del paso de actualización.
Figura 8. Suma del error cuadrático respecto a los pesos. Tomado de Wang (2014)
36
Como afirma (Wang, 2014), los experimentos muestran que el rendimiento de la red basado en el algoritmo BP está altamente correlacionado con el orden de entrada de las muestras, por ejemplo, si los datos se entrenan uno por uno, los valores de actualización de peso en una iteración están más correlacionados con las últimas muestras de entrenamiento. Para eliminar el efecto causado por el orden de entrada de datos de entrenamiento, el algoritmo BP se combina con el entrenamiento por lotes, lo que significa que todas las muestras de entrenamiento se tienen en cuenta en cada paso de la iteración.
El algoritmo de BP es el siguiente:
1. Inicialice los parámetros para la red neuronal;
a) Pesos de conexión y pesos de sesgo;
b) Meta de SSE y tasa de aprendizaje ;
c) Número máximo de iteración M y el contador de iteración N = 0;
2. si E> objetivo && N <= M a) N = N + 1; E = 0
b) para i de 1 hasta n (n es el número de muestras), i. Calcule la salida de la red con la ecuación 8;
ii. Calcule la ESS con la ecuación 16;
iii. Actualice los pesos con las ecuaciones 18, 19.
1.3.2.3. Algoritmo Levenberg-Marquardt
Aunque el algoritmo BP fue el algoritmo más utilizado y es el método más básico y fácil, encontró algunos problemas en la implementación: el más grave es que la velocidad de convergencia es demasiado lenta y este efecto es significativo cuando la red está entrenado a un ritmo determinado. También tiene el problema con los mínimos locales, la capacidad de estabilidad, etc., con el fin de mejorar el rendimiento en el procedimiento de entrenamiento de la red, se han realizado modificaciones al BP, y uno de los más famosos y ampliamente utilizados es el algoritmo de Levenberg-Marquardt (LM), que proporciona una solución numérica al problema de minimizar la función no lineal con una convergencia rápida y estable. Como algoritmo de aprendizaje para el BP es difícil saber qué algoritmo de aprendizaje será el "mejor" en un determinado problema, debido a múltiples factores de influencia como: el
37
tamaño de la red, el objetivo del entrenamiento y la complejidad en computación. A partir de la experiencia sobre qué función de entrenamiento se debe utilizar, en la Guía de Usuario de MATLAB, se puede ver que para un problema de aproximación de funciones, cuando la red tiene pocos pesos y bias, el algoritmo LM funciona muy bien. (Wang, 2014)
El algoritmo LM es una combinación del método de descenso más pronunciado y el algoritmo de Gauss-Newton (GN), supera la convergencia lenta del método de descenso más pronunciado y fija la única aproximación cuadrática razonable de la función de error del algoritmo GN. (Milamowski & Irwin, 2011). El método de descenso más pronunciado se ha introducido antes, mientras que el algoritmo GN se basa en el método de Newton con la presunción de que todos los componentes de gradiente de la ecuación 16 son funciones de pesos y todos los pesos son linealmente independientes. Por lo tanto, el vector gradiente puede expresarse como el algoritmo de segundo orden, donde la matriz Hessiana H y la matriz Jacobia J son usadas para simplificación, y la regla de actualización del algoritmo GN es,
wi+1=wi-(JiTJi)-1Jiei (19)
e es el vector de error. La parte de modificación del algoritmo LM es hacer que la matriz de Hesse JTJ invertible, esto se hace mediante una matriz de Hesse aproximada con HJTJ+µJ, µ es el coeficiente de combinación. Si µ es muy grande, el algoritmo LM es igual al algoritmo de descenso más pronunciado, mientras que si µ es muy pequeño, el algoritmo es aproximado al algoritmo GN. (Wang, 2014)
1.3.2.4. Procedimiento de entrenamiento
El procedimiento de entrenamiento de la red neuronal de dos capas consta de cuatro pasos: inicialización, entrenamiento, validación y generalización.
En el primer paso, la inicialización de los pesos se asigna de acuerdo al algoritmo Ngyue-Widrow, los pesos se inicializan en su propio intervalo.
38
Como afirma Wang (2014), para preparar una red neuronal para el entrenamiento, también hay otros parámetros que se deben inicializar:
Objetivo de entrenamiento. El objetivo es el rendimiento de la red que se espera lograr, expresado como error cuadrático medio (MSE) y calculado por los datos de salida de la red y los datos que se espera alcanzar. El caso ideal es establecer la meta en cero, lo que significa que no hay error entre los datos pronosticados del modelo y los datos a alcanzar.
Época de entrenamiento. El número máximo de épocas de entrenamiento se utiliza para evitar el caso de over-fitting, que pertenece a la técnica de detención temprana.
Número de iteración máximo de validación. El número de validación también se usa para monitorear el procedimiento de entrenamiento..
Tamaño oculto. El número de neuronas ocultas.
Después del primer paso, la red está preparada para el entrenamiento con un algoritmo de aprendizaje seleccionado. El paso de entrenamiento de la red también se llama la capacidad de aprendizaje de la red, dado los pares entrada y objetivo, la red se entrena con configuraciones de red predefinidas.
Se ha mencionado que cualquier problema de aproximación de funciones se puede resolver con una red neuronal de dos capas siempre que el tamaño oculto sea el adecuado. Por lo tanto, el número de capas ocultas es de una sola capa, pero el método para elegir un tamaño oculto adecuado es mucho más complejo que el nùmero de capas. No existe un teorema universal sobre el tamaño óptimo de una red neuronal, sin embargo, existe un equilibrio entre la precisión del modelo y el costo del modelo, y existe una limitación de la precisión del modelo debido al nivel de ruido de fondo. Se ha demostrado que un tamaño más grande de capa oculta no hace más preciso el rendimiento de la red. A veces, el tamaño de red grande causa un problema de ajuste excesivo. Por lo tanto, como regla general, se espera que cuanto menor sea el tamaño de la red, mejor, bajo alguna limitación precisa del modelo predefinido. Las experiencias muestran que el tamaño de capa oculta debe ser de 3 a 5 veces mayor que el número de parámetros de entrada.
39
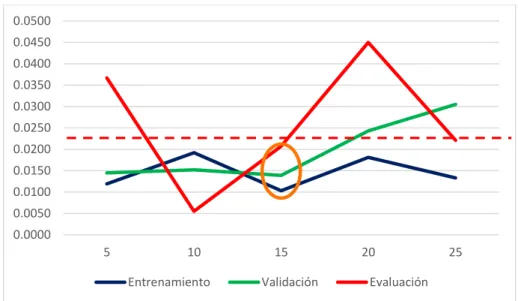
Si con el análisis de datos el número de variables de entrada es 5, y si se establece el tamaño de neuronas en la capa oculat en el intervalo 5 a 25, con un tamaño de paso de 5, como se muestra en la figura 9, se observa que, cuando el número de neuronas en la capa oculta aumenta, el rendimiento de la red tiende a crecer, el umbral que limita la precisión se muestra con una linea discontinua roja en la figura 9, el número más pequeño de neuronas en la capa oculta se muestra con una elipse naranja, por lo que 15 es el tamaño óptimo.
Figura 9. Número de neuronas en la capa oculta
El rendimiento de la red generalmente se denota como Error Cuadrático Medio (MSE),
𝑀𝑆𝐸 =1
𝑛∑𝑛𝑖=1(𝑎𝑖 − 𝑜𝑖)2 (20)
y se espera que cuanto más pequeño sea el MSE, mejor será el rendimiento de la red.
El entrenamiento de la red generalmente puede dar un resultado bastante bueno de la aproximación de funciones. Sin embargo, este buen resultado del procedimiento de entrenamiento de red no puede garantizar la generalización de una red neuronal entrenada. El fenómeno se denomina sobreajuste, lo que significa que la red específica entrenada ofrece un buen rendimiento de un conjunto de datos de muestra, mientras que el rendimiento de otro conjunto diferente de datos de muestra de la
0.0000 0.0050 0.0100 0.0150 0.0200 0.0250 0.0300 0.0350 0.0400 0.0450 0.0500
5 10 15 20 25
Entrenamiento Validación Evaluación
40
misma población es bastante peor. En este caso, la red simplemente memorizó las muestras de entrenamiento, pero no pudo generalizar a nuevas situaciones. Para evitar este fenómeno, se implementan varios métodos para mejorar la generalización de las ANN.
1. División de datos
La división de datos significa que los datos de la muestra se usan no solo para entrenamiento sino también para validación y evaluación. El punto clave de la división de datos es validar la red con un conjunto de datos totalmente diferente de los datos de entrenamiento.
En este trabajo, se selecciona el método de división aleatoria, con tres conjuntos de datos: datos de entrenamiento, datos de validación y datos de evaluación con la proporción 0.7, 0.15 y 0.15 respectivamente.
Durante el procedimiento de entrenamiento, los datos de entrenamiento se usan para el entrenamiento de la red neuronal, mientras que los datos de validación se usan para monitorear el rendimiento de la red. El entrenamiento continuará hasta que no haya una mejora en el rendimiento de validación para las iteraciones máximas de validación. Los datos de evaluación se utilizan para comparar diferentes estructuras de red en los mismos datos de muestra. (Wang, 2014)
Con el monitoreo del procedimiento de validación, la red puede proporcionar una buena capacidad de generalización, como se presenta en la figura 9, la línea azul indica el resultado del entrenamiento, mientras que la línea roja y la verde indican los datos de validación y prueba por separado. Cuando los tres conjuntos de datos tienen resultados similares, significa que la red tiene una buena generalización. (Wang, 2014)
2. Parada temprana
En la red neuronal artificial, la parada temprana es un método utilizado para evitar el sobreajuste de la red. Este método se combina con el método de validación durante el procedimiento de entrenamiento de la red. Si el error de validación sigue aumentando durante varias iteraciones, la red se detiene para el entrenamiento y da un resultado de falla. El aumento del error de validación significa que no hay mejora
41
en el rendimiento de la red para una mayor iteración. (Wang, 2014) 1.4. Criterio de correlación y regresión para la aproximación del modelo
El objetivo del análisis de correlación es ver si las variables predictoras y las variables de respuesta son covariables, y también detectar la fuerza de la relación lineal entre ellas, mientras que el análisis de regresión de un diagrama de dispersión da una impresión visual de la relación entre dos variables. El uso más común del análisis de correlación se denomina coeficiente de correlación de momento del producto de Pearson (PPMCC), que se calcula como:
R= ∑ni=1(oi-o̅)(ai-a̅)
√∑ni=1(oi-o̅)2√∑ni=1(ai-a̅)2
(21)
oi son los datos objetivos y ai son los datos de salida de la red.
Como regla general, el rango de R y la fuerza de la relación entre dos variables se muestran en la tabla 4.
Tabla 2 Rango de coeficiente de correlación Rango de coeficiente de correlación
Valor absoluto de R Fuerza de la relación
[0.5 1] Fuerte
[0.3 0.5] Moderado
[0.1 0.3] Débil
[0 0.1] Muy débil o ninguno
Nota. Tomada de Wang (2014).
Para la evaluación del modelo, el análisis de correlación toma el valor del coeficiente de correlación al cuadrado (R al cuadrado), que también se denomina coeficiente de determinación. Actúa como el valor de medición para dar una interpretación de qué tan bien los datos se ajustan a un modelo.
El coeficiente R2 denota la proporción de la variación lineal en los datos objetivo explicada por los datos pronosticados. Un criterio del modelo de aproximación se da como:
R2>0.80 (22)
42
Por otro lado, la relación de regresión entre los datos de salida pronosticados y los datos objetivo se expresa como una ecuación explícita:
Salida = a*Objetivo + b (23)
donde “a” denota la pendiente del coeficiente de regresión y “b” es la intersección. La regresión es usada para compararla con la recta y=x.
Idealmente, se espera que los datos de salida pronosticados sean iguales a los datos objetivo, y la relación de regresión entre dos variables a menudo se presenta en un diagrama de dispersión como se muestra en la figura 10, donde los círculos negros denotan los puntos de datos. El valor de los círculos negros perpendiculares a la etiqueta x denota los datos objetivo y a la etiqueta y denota los datos de salida de la estimación del modelo. Y la línea discontinua realiza la línea de regresión entre los datos de salida y de destino. En este caso, el resultado de la regresión es igual al resultado ideal.
Por lo tanto, se espera que “a” se aproxime a 1 y “b” se aproxime a 0.
Figura 10. Regresión ideal entre los datos de salida pronosticados y los datos objetivo. Tomada de Wang (2014)
De manera real, los datos suelen verse alterados por el ruido y, a veces, el efecto del ruido es de vital importancia, como en la figura 11, donde los círculos negros y la línea discontinua gris son las mismas que en la figura 10, y los círculos azules representan los datos ruidosos adicionales. Se puede observar que los datos objetivo son más grandes que los datos de salida.