Más recientemente, en Quito, Ecuador, se comenzó a restringir la circulación de vehículos según el último número de la patente en marzo de 2010. El segundo término de la derecha en (1) representa las externalidades, es decir, los costos sociales (marginales). es el costo privado (promedio) más las externalidades.

Análisis Económico de las Políticas de Restricción de Circulación
Sin embargo, sólo dos años después todas las concentraciones aumentaron, incluso por encima del nivel anterior a la aplicación de la medida. Así, en el mediano y largo plazo, los beneficios de la política se perdieron debido al aumento del parque vehicular, representado tanto por vehículos nuevos como por vehículos de vieja tecnología transferidos desde otros municipios.

El Costo Económico del Pico y Placa en Bogotá
Sin la restricción, el beneficio se acerca a un millón de euros por día durante el período pico, mientras que con la restricción el excedente del consumidor es de 0,6 millones de euros, lo que resulta en una pérdida social neta de aprox. 0,4 millones de euros al día. Los resultados de este análisis implican que la pérdida de utilidad para los consumidores (usuarios) por la restricción de facturación durante los periodos punta en Bogotá será del orden de 118 millones de euros al año.
Conclusiones
En este trabajo se desarrollan y comparan cuatro modelos de optimización que permiten la asignación de salas durante intervalos de tiempo específicos, respetando las prioridades del paciente. Las pruebas realizadas muestran que la elección del modelo depende de las características de los escenarios.
Introducción
No obstante, no podrán ser incluidos en la programación los pacientes que por sus características no puedan ser asignados en el periodo de programación. Se permiten reinversiones (horas extras de la jornada laboral habitual) en el horario que determine el hospital para la programación de salas quirúrgicas.
Métodos Desarrollados
Por otro lado, la forma en que se construyen λH y λS permite hacer más comparables los términos de la función objetivo del modelo propuesto. Esto tiene en cuenta la duración de la operación (que no supera la duración del día), la disponibilidad del médico que puede realizar la operación y si la operación es especial (no pueden operarse por la tarde).

Resultados
Este valor representa la calidad de la solución en función de la solución obtenida de todos los modelos y permite comparar los resultados de los modelos en un mismo escenario. En cambio, cuando la duración de las intervenciones se acerca a la mitad de la duración de los días, disminuyen las combinaciones que obtienen buenos resultados en el uso del pabellón. Para esta parte se analizaron diferentes valores de α en el estudio de la variante del modelo de programación lineal entera.
Este escenario corresponde a 100 pacientes, 10 días disponibles, duración promedio de la intervención del 37,5% de los días de duración y días disponibles a priori de 2,5 promedio por día. paciente.

Conclusiones
En cuanto al respeto de la prioridad, el algoritmo de tipo Backtracking produjo los mismos resultados que el algoritmo basado en un modelo de viabilidad, que por construcción produce el mejor resultado desde el punto de vista de la prioridad. La variante del modelo de programación lineal entera presenta algunos problemas con respecto a la prioridad. Desde el punto de vista del uso del pabellón, este método suele mostrar mejores resultados porcentuales en comparación con los otros modelos.
Desde el punto de vista de la calidad del resultado, es fácil observar que siempre produce la mejor solución en cuanto al cumplimiento de la prioridad, pero los tiempos de ejecución están muy por encima del máximo permitido en una implementación rutinaria.
Support Vector Machines
La formulación dual permitirá la construcción de funciones de clasificación no lineales, lo que normalmente conduce a un mayor poder predictivo, como se presentará en la Sección 2.3. Los multiplicadores correspondientes a αi > 0 se denominan vectores de soporte, ya que son los únicos involucrados en la construcción del hiperplano de clasificación. La proyección se realiza con la función kernel K(x,y) =φ(x)·φ(y) que define el producto interno en H.
También existen varios enfoques que apuntan a una selección más eficiente utilizando medidas estadísticas clásicas basadas en la distribución de los datos [1].
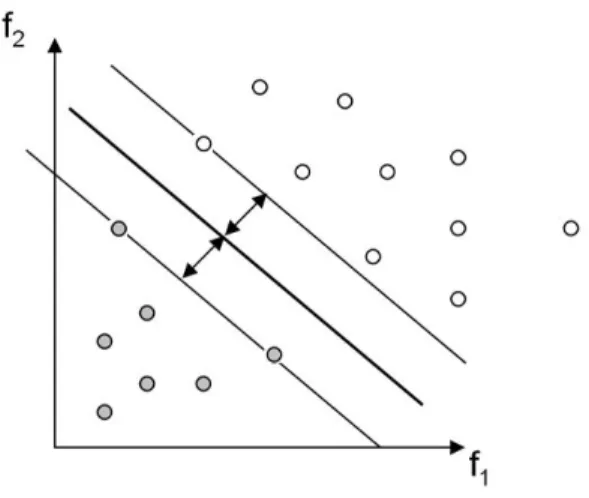
Selección de Atributos para SVMs
Estos métodos buscan un subconjunto óptimo de atributos al construir la función de clasificación. Por un lado, la selección de atributos puede verse como un problema de optimización. La selección de atributos con factores de escala se realiza escalando las variables de entrada con un vector σ ∈ [0,1]n.
Guyon [10] sugiere que la unificación del proceso de selección de atributos y de selección de modelos es uno de los temas relevantes para la investigación en el aprendizaje informático actual.
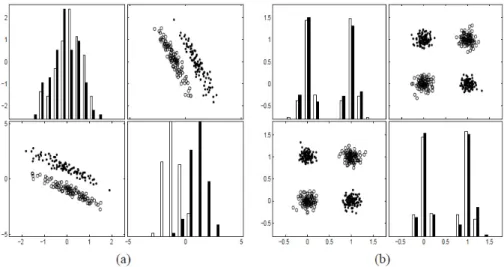
Metodología Propuesta
La idea básica del método propuesto es eliminar aquellos atributos cuya eliminación implica un menor número de errores en un conjunto de validación independiente. A continuación se muestra el algoritmo iterativo para eliminar atributos: .. 3.repetir. a) División aleatoria del conjunto de datos (hold-out) b) entrenamiento del modelo (ecuación (18)). c) para cada atributo p con σp = 1, calcule E(−p)(α,σ), el número de errores de clasificación cuando se elimina el atributo p. d) eliminar el atributo j con el valor más bajo de E(−p)(α,σ). Partición de datos: el conjunto de datos se divide en dos subconjuntos: entrenamiento, con aproximadamente el 70% de los ejemplos, y validación, con el 30% restante.
E(−p)(α,σ) es, en última instancia, el número de errores en el conjunto de validación cuando se elimina el atributo.
Resultados
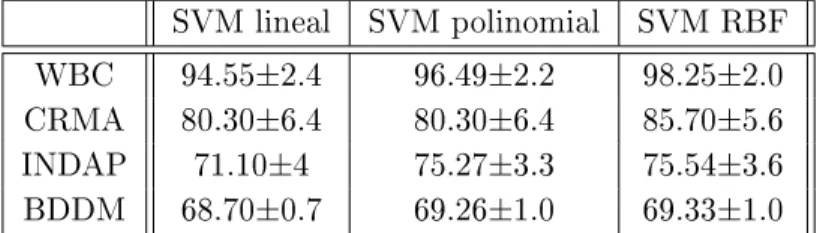
Como segunda etapa, se compara el rendimiento de la clasificación para diferentes estrategias de selección de atributos presentadas en este trabajo (Fisher, RFE-SVM, FSV y nuestro enfoque HO-SVM). Las cifras muestran que HO-SVM logra un rendimiento consistentemente superior en las cuatro bases de datos estudiadas. Para enfatizar la importancia del criterio de parada del método HO-SVM, se estudia el rendimiento de cada algoritmo de selección de atributos para un número fijo de atributos, obtenido cuando el método HO-SVM alcanza el criterio de parada.
De la Tabla 2, podemos concluir que el método propuesto logra un rendimiento significativamente mejor en todas las bases de datos.
Conclusiones
El primer autor también agradece a CONICYT por financiar su estudio de Doctorado en Ingeniería de Sistemas de la Universidad de Chile. Este trabajo presenta un modelo de simulación de la operación de la terminal, desde la llegada de los pasajeros a los mostradores hasta la carga del equipaje en los aviones. En el Aeropuerto Internacional de Santiago existe un BHS bastante avanzado, pero no es totalmente automático.
A partir de los resultados de las simulaciones se podrá analizar en profundidad BHS para el área naviera nacional e internacional, identificar cuellos de botella en la operación, así como los procesos críticos y su impacto en el resto del sistema.
El Sistema BHS de Embarques
Una vez que llegas a la posada correspondiente a tu vuelo, el equipaje se coloca en la cinta en una bandeja especial y el encargado de la posada lo ingresa al sistema mediante una pistola de códigos de barras. La caja espera en la entrada del colector hasta que se crea una abertura espacial en el colector. El sistema de vuelo del operador donde cada operador se encarga exclusivamente de la preparación de un solo vuelo, tal como se describe en el párrafo anterior.
El sistema pool se utiliza principalmente en la preparación de vuelos domésticos de baja demanda, mientras que la asignación del operador del vuelo se utiliza en el caso de destinos internacionales.

Herramienta de Simulación del BHS
Si la maleta no es la primera en el tramo de la cinta (llamado Líder), la velocidad se fija en la inmediatamente anterior. Inyección de cajas en el colector Cuando las cajas se crean en el sistema, aparecen en una cinta que conecta el contador con la cinta colectora de la T correspondiente. Un fallo provoca la parada de un tramo completo de la cinta y de todos los tramos anteriores. hasta llegar al recolector en el sector del mostrador.
El resultado de cada simulación consta del detalle de la vida de cada bolsa que pasa por el sistema.

Aplicaciones
Una aplicación de herramientas de seguimiento ocular para analizar sus preferencias de contenido. Con el uso de la tecnología de seguimiento ocular la investigación se vuelve redundante, logrando un análisis más objetivo y preciso de las preferencias de los usuarios en un sitio web. De manera similar, una metodología de identificación de objetos clave es un objeto web que atrae la atención de los usuarios y caracteriza el contenido de un sitio web [16].
Mezclando ambos procesos [16], es posible estimar el tiempo que los usuarios pasan en el Objeto Web.

Trabajo Relacionado
También cabe mencionar los trabajos en el campo de la teoría y la práctica de la usabilidad en el desarrollo de sistemas basados en web [12]. El espejo corneal y el centrado de la pupila basado en vídeo es la técnica de seguimiento ocular más utilizada en la actualidad. Con estas características, es posible desacoplar los movimientos oculares de la cabeza, permitiendo calcular el punto de atención del usuario [14].
En la Figura 1 se puede observar el efecto pupila brillante y el reflejo de la córnea.

Mejorando la Detección de los Web Objects
Por tanto, quien sea elegido para realizar el experimento debe estar dentro del marco financiero del proyecto, y su precisión debe permitir identificar los objetos que está mirando un usuario. Como primer paso, lo ideal es que la delimitación de los objetos se realice con el administrador del sitio. Luego, una vez cargados los datos de los objetos y conceptos, se calculará la distancia conceptual entre los objetos según la Ecuación 1.
La idea principal es mapear las coordenadas ofrecidas por Eye Tracker, también en píxeles, a los objetos de la página que el usuario notó en un momento determinado, en función del tamaño de la página y de los objetos en píxeles y la ubicación de estos últimos.
Aplicación del Experimento y Análisis de Resul- tados
Para medir el interés de los usuarios por los objetos en línea, se midió y estimó el tiempo que dedican a ellos. El criterio para seleccionar las instalaciones más importantes fue el tiempo de permanencia en las mismas. Por otro lado, el segundo experimento consistió en sustituir los tiempos calculados a partir de los datos capturados por el Eye Tracker en la metodología anterior.
Se puede observar un aumento (del 15% al 20%) en la precisión al comparar ambos experimentos, lo que confirma que esta tecnología es útil para medir el interés de los usuarios.

![Tabla 1: Variación de Concentración de Material Particulado TSP 2004 2007 en Medellín - Fuente: [?]](https://thumb-us.123doks.com/thumbv2/123dok_es/12417320.0/14.744.90.665.687.998/tabla-variación-concentración-material-particulado-tsp-medellín-fuente.webp)




![Figura 5: Pérdida de Excedente del Consumidor Debido a Restricción en Perío- Perío-do Punta, Bogotá - Fuente: [?]](https://thumb-us.123doks.com/thumbv2/123dok_es/12417320.0/19.744.209.536.109.345/figura-pérdida-excedente-consumidor-debido-restricción-perío-bogotá.webp)

