My gratitude goes to my thesis advisor, Prof Sonia Berman, for allowing me to pursue my research interest and guiding me through the process. To my family, who have always encouraged me to pursue my academic goals and trust in my abilities. The ubiquity of P2P computing and its increasing application to a decentralized data sharing mechanism has fueled my research interests.
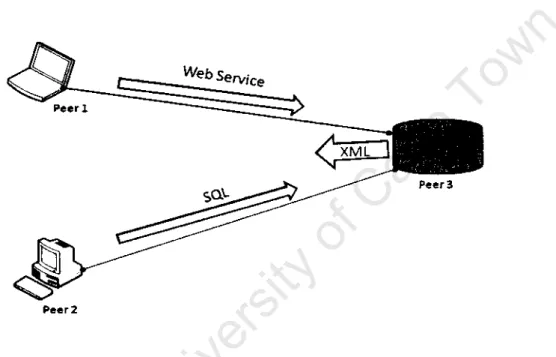
SQL queries and web services provide a data sharing mechanism that allows simple and flexible data access.
Introduction
Thesis Structure
Background
- Introduction
- Overlay network
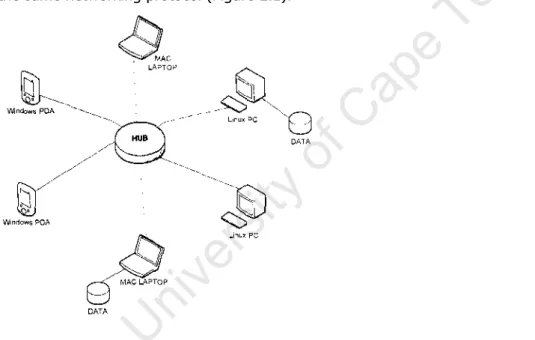
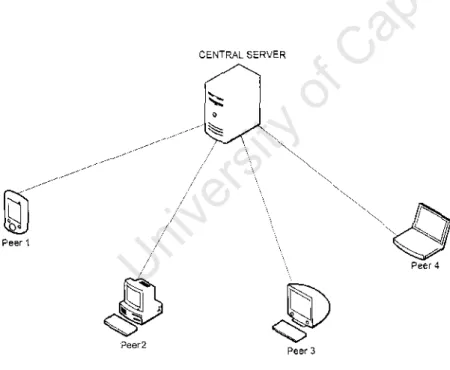
- Centralized and decentralized
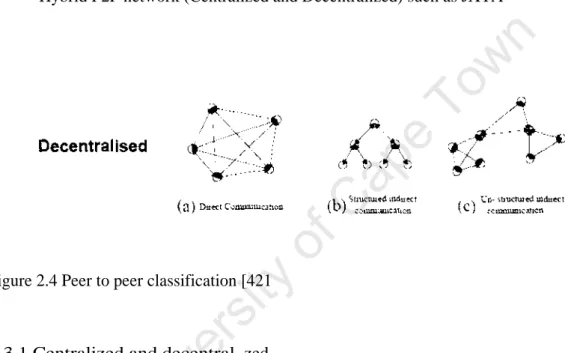
- Structured and Unstructured
- I hybrid
- P2P database management systems
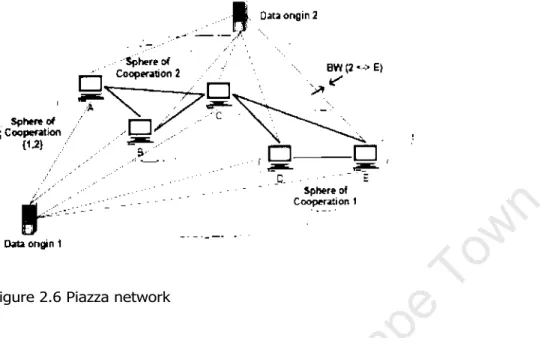
- The Piazza peer to peer system
- Hyperion
- Edutella
- Web services
The dynamic nature of the peer to peer system may impose constraints on data consistency and 12. SRDI's distributed algorithm creates an index of resources in the peer to peer network. The peer to peer dbShare system enables data sharing while maintaining system interoperability.
The NewsFinder Java class is called from the Headlines Java class and takes the input stream which is the URL of the my News web service as shown below. httpidocalhost:8080/news/resources/MN News/. The data retrieved from the myNews web service is used to build an XOM tree structure. XPath is then used to query the data and retrieve the title attribute.
IXTA and SRDI
The JXTA framework
The discovery of network resources makes use of advertisements published on the network [39]. The JXTA framework in Figure 3.2 accommodates several value-added services such as database and file sharing, seamless peer discovery, and database caching. The distributed nature of the database sharing application enables new nodes to join the network with the system scaling almost linearly [48].
The SRDI which is part of the JXTA 2.0 framework indexes the advertisements and distributes the index for efficient retrieval of desired data.
Peer Management
Advertisements take the form of XML messages when peers join, discover and share content. The dynamic discovery process using the Peer Discovery Protocol (PDP) is used to discover peers in the network either through multicast messages or rendezvous peers [15]. Once the peer holding the required data has been identified using the DOT, it will share its data (Figure 3.4) directly with the requesting peer, without following the route taken during the request.
Shared Resource Distributed Index
Publishing an advertisement
Each rendezvous peer has a rendezvous peer view (RPV), which is an ordered list of other known rendezvous peers in its peer group. As shown in Figure 3.5, for example, if the function returns R5, it will push the index to that meeting peer. The index can be replicated to other rendezvous peers to increase the probability of locating a peer.
Querying advertisements
Survey
Description of Survey
If there was an Internet-based application that could meet most of your information needs, such as weather reports and news, you would consider using it.
Participants
A fair number of the sample (33.8%) use the Internet as their main source of information. 84% of respondents who use the Internet as a primary source of information retrieval want to access the information regularly (> 5 times). On the other hand, only 26.8% of the respondents use non-internet medium such as newspaper.
The data shows that 45.2% of respondents prefer to use mobile phones to receive information. 66.1% of survey participants would consider using an Internet-based information sharing application. The indexed ad contains the Peer ID as shown above to locate the source of the requested data.
The JXTA peer group is a virtual grouping of peers that enables SQL and web service frontends to share data using the peer resolver protocol (PRP). Our implementation makes use of the Java API for XML Web Services (JAX-WS) version 2.0. Entity classes are created from the data source and contain the attributes of the relational data tables.
Using the web service approach has also been useful, providing peers with easy access to shared data. However, the version of the peer software to run on mobile devices is reserved for future work.
Survey results and discussion 35
System Design
- Overview of the dbShare system
- Using dbShare
- Database metadata
- Web service metadata
- High level user view
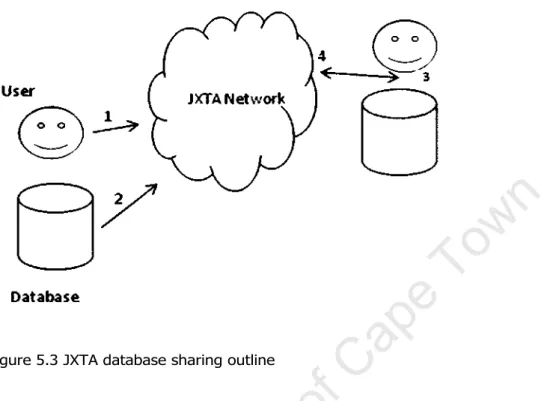
For easy access to data, the entire source is retrieved; Alternatively, SQL or XPath can be used to extract only some of the data that meets specific search criteria. The data from the non-relational source can be converted to XML format and exposed by the peer via web services. When a query is performed, the peer will evaluate the metadata in its local cache before requesting the data on the P2P network.
For the database query using SQL and retrieving all the data in its entirety, dbShare creates a query as shown below. DbShare will follow a similar process as shown above to identify the peer containing the requested data and whether the data is exposed via a web service interface. The query using the web service implementation, which also retrieves all data in its entirety, calls the web service URI as shown below.
The data manager transforms the )(NIL data into a format suitable for the user interface, as shown in the output below. User-specific search for movies as shown below (database access) retrieves only data that meets certain criteria. The search follows a similar process as shown in scenario 1 above to locate the peer with the data.
The results from multiple sources are merged and then returned to the dbShare user interface, as shown below. It contains information as shown in section 5.4 (for database metadata) and section 5.5 (for web service metadata).
Implementation
- JXTA I mplementation
- Schema Advertisement
- Client application frontend
- SQL Query Implementation
- Web Services
- XML data transformation
Queries are initiated from a client application that sends an SQL or Web service request to the peer where the data source resides. When a peer needs flexible access to queries, knowledge of SQL syntax is required, but this allows the peer to query interesting data. Once the XML data is received from the source nodes, the data is stored in the memory of the requesting peer node for sorting and filtering.
By means of the resolving protocol it sends and receives messages to and from peers in the peer group [49]. HandlerName is a string that specifies how the query should be handled. Query LD is the query ID. SrcPeerlD is the ID of the peer initiating the query Query is the query being initiated.
The persistence unit configuration is stored in a file called persistence.xml, which contains credentials and a data source. The XML object model in the dbShare prototype is applied at the client requesting the data (client-side processing) to convert the retrieved XML content into an appropriate subset and format. Some nodes in the tree can be processed while the document is being built, allowing dual streaming and allowing programs to run almost as fast as the underlying (SAX) parser can provide data.
XOM makes it possible to provide filters so that only relevant parts of the document are parsed. It also effectively allows documents to be processed piece by piece, providing some of the benefits of the SAX parser at a much lower level, allowing the processing of huge documents that would otherwise not fit in memory.
Testing
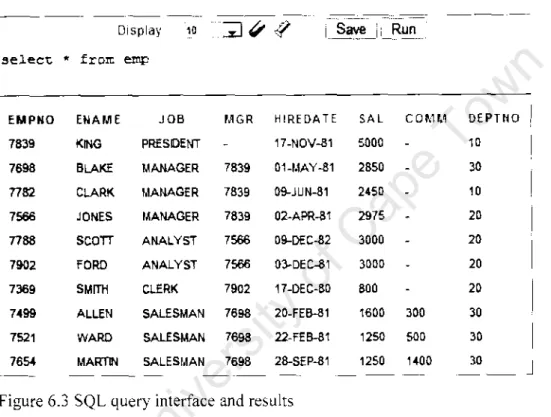
The example above shows the command line tool that was built into the dbShare prototype for SQL data access. The query illustrates the flexible access that the requesting peer provides to the patient record of Suhen Pather (1D=100). In this example, the peer providing the service will expose the medical_records table in the distributed catalog as metadata.
The use of web services was tested with the Glassfish lava application server displaying dynamic content from the data source. The web service "myNews" has accessed data related to the attributes, category, popularity, reporter and title. The Firefox browser is used to provide the XML content when the myNews web service is requested.
Filtering was tested by reading data from the My SQL database and building an XML Object Model (XOM) from the data. The Headlines Java class is the main java class that is the launcher application (Listing 3). The NewsFinder Java class is called from the Headlines Java class and takes the input stream which is the URL of the my News web service as shown below.
The data retrieved from the myNews web service is used to build a XOM tree structure. An array list is created from the results and then returned to the Headlines Launcher application.

Conclusion
Summary
While other P2P database sharing systems exist and web services are now widely used, the dbShare architecture provides a simple and integrated way to use each approach. The dbShare implementation based on the JXTA platform accomplishes the goals of providing interoperability for a simple and flexible information sharing application in a peer-to-peer distributed environment.
Future work
Conte, Whitepaper "Enabling peer-to-peer web service architectures with JXTA-SOAP Information Technology Department. 34;Secure routing for structured peer-to-peer overlay networks", ACM Special Interest Group on Operating Systems (SIGOPS), VoL 36, No. Zhang, “SCOPE: Scalable Consistency Maintenance in Structured P2P Systems,” IEEE INFOCOM 2005, Miami, 24th Annual Joint Conference of the IEEE Computer and Communications Societies, vol.
Suciu, "What Can Databases Do for Peer-to-Peer?" Proceedings of the Fourth International Workshop on the Web and Databases, WebDB 2001, Santa Barbara. Böttcher, "XPath query transformation based on XSLT stylesheets", Fifth ACM CIKM (Conference on Lnformation) and Knowledge Management) International Workshop on Web Information and Data Management (WLDM 2003), New Orleans, Louisiana, USA, 7-8. November 2003. Pitoura, -Content-based overlay networks for xml peers based on multilevel bloom filters, " in Proceedings of the Tnternational VLDB Workshop on Databases, Information Systems and Peer to Peer Computing (DBISP2P), 2003.
Loser, "Super-Peer-Based Routing Strategies for RDF-Based Peer-to-Peer Networks", Web Semantics: Science. Nejdl, "HyperCuP Hypercubes, Ontologies and Efficient Search on P2P Networks," Agents and Peer-to-Peer Computing, First International Workshop, AP2PC 2002. In Proceedings of the 2001 Conference on Applications, Technologies, Architectures and Protocols for Computer Communications (San Diego.
Chiuch, “An Integrated Approach for P2P File Sharing in Multihop Wireless Networks,” IEEE International Conference on Wireless and Mobile Computing. Traversal, White Paper "Project JXTA 2.0 Super-Peer Virtual Network," (Project JXTA, May 2003), describes the inner workings of the super-peer meeting network in intricate detail, accessed June 2008.

![Figure 2.7 Hyperion database [5]](https://thumb-us.123doks.com/thumbv2/123pdforg/7646900.38888/22.892.138.653.284.627/figure-2-7-hyperion-database-5.webp)
![Figure 2.8 Hyperion database components [5]](https://thumb-us.123doks.com/thumbv2/123pdforg/7646900.38888/22.892.142.436.736.1020/figure-2-8-hyperion-database-components-5.webp)