PRESENTE.-Por medio de la presente hago constar que soy autor y titular de la obra
denominada
, en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto
Tecnológico y de Estudios Superiores de Monterrey (EL INSTITUTO) para que
efectúe la divulgación, publicación, comunicación pública, distribución,
distribución pública y reproducción, así como la digitalización de la misma, con
fines académicos o propios al objeto de EL INSTITUTO, dentro del círculo de la
comunidad del Tecnológico de Monterrey.
El Instituto se compromete a respetar en todo momento mi autoría y a
otorgarme el crédito correspondiente en todas las actividades mencionadas
anteriormente de la obra.
De la misma manera, manifiesto que el contenido académico, literario, la
edición y en general cualquier parte de LA OBRA son de mi entera
responsabilidad, por lo que deslindo a EL INSTITUTO por cualquier violación a
los derechos de autor y/o propiedad intelectual y/o cualquier responsabilidad
relacionada con la OBRA que cometa el suscrito frente a terceros.
Profiling and Analysis of Irregular Memory Accesses of
Memory-Intensive Embedded Programs-Edición Única
Title Profiling and Analysis of Irregular Memory Accesses of Memory-Intensive Embedded Programs-Edición Única
Authors Juan Alberto González Lugo
Affiliation Tecnológico de Monterrey, Campus Monterrey
Issue Date 2009-05-01
Item type Tesis
Rights Open Access
Downloaded 19-Jan-2017 00:40:20
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE M O N T E R R E Y
M O N T E R R E Y C A M P U S
P R O F I L I N G A N D A N A L Y S I S O F I R R E G U L A R M E M O R Y A C C E S S E S
O F M E M O R Y - I N T E N S I V E E M B E D D E D P R O G R A M S
T H E S I S
P R E S E N T E D A S A P A R T I A L F U L F I L L M E N T O F T H E R E Q U I R E M E N T S
F O R T H E D E G R E E O F
M A S T E R O F S C I E N C E W I T H M A J O R IN E L E C T R O N I C E N G I N E E R I N G
( E L E C T R O N I C S Y S T E M S )
B Y
G R A D U A T E P R O G R A M I N M E C H A T R O N I C S A N D
I N F O R M A T I O N T E C H N O L O G I E S
J U A N A L B E R T O G O N Z Á L E Z L U G O
SUPERIORES DE M O N T E R R E Y
M O N T E R R E Y C A M P U S
G R A D U A T E P R O G R A M I N M E C H A T R O N I C S A N D
I N F O R M A T I O N T E C H N O L O G I E S
T h e members of the thesis c o m m i t t e e hereby approve the thesis of Juan A l b e r t o
González L u g o as a partial fulfillment o f the requirements for the degree o f Master of
Science with major in
E l e c t r o n i c E n g i n e e r i n g
( E l e c t r o n i c S y s t e m s )
Thesis Committee
Alfonso Ávila, P h . D .
Thesis A d v i s o r
Sergio Martínez, P h . D .
Synodal
Graciano Dieck, P h . D .
Synodal
Joaquín A c e v e d o , P h . D .
Director of the Graduate Programs in Mechatronics and Information Technologies
P R O F I L I N G A N D A N A L Y S I S OF I R R E G U L A R M E M O R Y
ACCESSES OF M E M O R Y - I N T E N S I V E E M B E D D E D
P R O G R A M S
B Y
JUAN A L B E R T O GONZÁLEZ LUGO
THESIS
P R E S E N T E D T O T H E G R A D U A T E P R O G R A M IN M E C H A T R O N I C S A N D
I N F O R M A T I O N T E C H N O L O G I E S
T H I S T H E S I S IS A P A R T I A L R E Q U I R E M E N T F O R T H E D E G R E E
O F M A S T E R O F S C I E N C E W I T H M A J O R IN
E L E C T R O N I C E N G I N E E R I N G
( E L E C T R O N I C S Y S T E M S )
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE M O N T E R R E Y
M O N T E R R E Y C A M P U S
Acknowledgements
To my thesis advisor, Alfonso Ávila, Ph.D., for his teachings, guidance and friendship over these years. His patience is greatly appreciated. To my synodal Graciano Dieck Assad, Ph.D., for his valuables reviews and highlights to enrich and improve this thesis work. To the BioMEMS research group and its coordinator,Sergio Omar Martínez Chapa, Ph.D., for the financial support, and also for his comments and reviews on the final stage of this thesis.
To my parents, for their constant support, affection and comprehension. Thank you for encouraging me to meet all my aspirations. I love you both.
To beautiful girlfriend Giselle for her loving support and understanding during all the time. For listen me everytime I need it, for share your life with me and lull me with your wonderful voice. Je t'aime belle.
Special thanks to Ana Cecilia Puón Díaz, M.C., Carlos Alejandro Robles Rubio, M.C., and Miguel Angel Ríos Gastélum, M.C., for their friendship and support all over this years.
To all my friends and colleagues Victor, Omar, Saracho, Ernesto, Lenin, Rodolfo, Jorge, Carolina, Raúl, Ivan, Israel, Alberto, Andrhey and to everyone that made this time a better experience.
JIJAN A L B E R T O G O N Z Á L E Z L U G O
Instituto Tecnológico y de Estudios Superiores de Monterrey May, 2009
Abstract
As memory transactions have become a significant contributor to increment the amount of power consumption and the reduction of system performance, this work presents a methodology to select fragments of program code to map the most used memory locations to a small, fast and energy efficient memory (SPM scratch pad memory). This methodology achieves a performance improvement, a reduction of energy consumption and overcomes the memory wall problem.
The work is a part of the project “Design Space Exploration of Memory-Intensive Embedded Systems”, which has led us to the need of building a framework to perform a study of how the memory behavior impacts in the memory hierarchy efficiency in terms of power consumption. The methodology proposes the method to map to a SPM to validate this framework.
Contents
Acknowledgements i
Abstract iii
List of Figures ix
List of Tables xix
1 Introduction 1
1.1 Problem Statement . . . 2
1.2 Objectives . . . 3
1.3 Contribution . . . 3
1.4 Previous Work . . . 3
1.5 Thesis Outline . . . 5
2 Background 7 2.1 Introduction . . . 7
2.2 Power Consumption . . . 7
2.2.1 Power and Energy Relationship . . . 7
2.2.2 Power Dissipation . . . 8
2.2.3 Energy Consumption . . . 9
2.3 Energy and Power . . . 10
2.4 Memory Wall Problem . . . 10
2.5 Memory Hierarchy . . . 11
2.5.1 Registers . . . 12
2.5.2 Cache . . . 12
2.5.3 Main Memory . . . 14
2.5.4 Virtual Memory . . . 15
2.5.5 SPM . . . 15
2.6 Data Prefetching . . . 17
2.6.1 Software Data Prefetching . . . 17
2.6.2 Hardware Data Prefetching . . . 18
2.7 Program Analysis . . . 19
2.7.1 Static Analysis . . . 19
2.7.2 Dynamic Analysis . . . 19
2.7.3 Compilers . . . 20
3 Proposed Strategy and Trace Generation Approach 23 3.1 Methodology . . . 23
3.2 Seamless a Co-Verification Environment . . . 24
3.3 VHDL Trace Generator . . . 28
4 Trace Analysis and Power Analysis 33 4.1 Matlab Trace Analyzer . . . 33
4.2 Seamless Profiler: Getting Power Consumption Results . . . 39
5 Review of Results 43 5.1 Experimental Setup . . . 43
5.2 Analyzed Programs: workload . . . 44
5.2.1 Bubble Sort . . . 45
5.2.2 Binary Tree . . . 45
5.2.3 Livermore Loops . . . 45
5.3 Metrics . . . 45
5.3.1 Profiler Power Estimation . . . 46
5.4 Workload Results . . . 47
5.5 Example of Individual Results: Bubble . . . 54
6 Conclusions and Future Work 59 6.1 Conclusions . . . 59
CONTENTS vii
A Results 61
A.1 Bubble Results . . . 61
A.1.1 Trace Analyzer Results . . . 61
A.1.2 System Power Analysis Results . . . 63
A.2 Kernel 1 Results . . . 68
A.2.1 Trace Analyzer Results . . . 68
A.2.2 System Power Analysis Results . . . 70
A.3 Kernel 2 Results . . . 75
A.3.1 Trace Analyzer Results . . . 75
A.3.2 System Power Analysis Results . . . 77
A.4 Kernel 3 Results . . . 82
A.4.1 Trace Analyzer Results . . . 82
A.4.2 System Power Analysis Results . . . 84
A.5 Kernel 4 Results . . . 89
A.5.1 Trace Analyzer Results . . . 89
A.5.2 System Power Analysis Results . . . 91
A.6 Kernel 5 Results . . . 96
A.6.1 Trace Analyzer Results . . . 96
A.6.2 System Power Analysis Results . . . 98
A.7 Kernel 6 Results . . . 103
A.7.1 Trace Analyzer Results . . . 103
A.7.2 System Power Analysis Results . . . 105
A.8 Kernel 7 Results . . . 110
A.8.1 Trace Analyzer Results . . . 110
A.8.2 System Power Analysis Results . . . 112
A.9 Kernel 9 Results . . . 117
A.9.1 Trace Analyzer Results . . . 117
A.9.2 System Power Analysis Results . . . 119
A.10 Kernel 10 Results . . . 124
A.10.1 Trace Analyzer Results . . . 124
A.10.2 System Power Analysis Results . . . 126
A.11 Kernel 11 Results . . . 131
A.11.2 System Power Analysis Results . . . 133
A.12 Kernel 12 Results . . . 138
A.12.1 Trace Analyzer Results . . . 138
A.12.2 System Power Analysis Results . . . 140
A.13 Kernel 16 Results . . . 145
A.13.1 Trace Analyzer Results . . . 145
A.13.2 System Power Analysis Results . . . 147
A.14 Kernel 17 Results . . . 152
A.14.1 Trace Analyzer Results . . . 152
A.14.2 System Power Analysis Results . . . 154
A.15 Kernel 19 Results . . . 159
A.15.1 Trace Analyzer Results . . . 159
A.15.2 System Power Analysis Results . . . 161
A.16 Kernel 22 Results . . . 166
A.16.1 Trace Analyzer Results . . . 166
A.16.2 System Power Analysis Results . . . 168
A.17 Kernel 23 Results . . . 173
A.17.1 Trace Analyzer Results . . . 173
A.17.2 System Power Analysis Results . . . 175
A.18 Kernel 24 Results . . . 180
A.18.1 Trace Analyzer Results . . . 180
A.18.2 System Power Analysis Results . . . 182
A.19 Binary Tree Results . . . 187
A.19.1 Trace Analyzer Results . . . 187
A.19.2 System Power Analysis Results . . . 189
B Listing of the C Programs 195 B.1 Bubble Sort . . . 195
B.2 Livermore Loops . . . 195
B.2.1 Kernel 1 . . . 195
B.2.2 Kernel 2 . . . 196
B.2.3 Kernel 3 . . . 197
B.2.4 Kernel 4 . . . 197
CONTENTS ix
B.2.6 Kernel 6 . . . 198
B.2.7 Kernel 7 . . . 199
B.2.8 Kernel 9 . . . 199
B.2.9 Kernel 10 . . . 200
B.2.10 Kernel 11 . . . 201
B.2.11 Kernel 12 . . . 201
B.2.12 Kernel 16 . . . 202
B.2.13 Kernel 17 . . . 203
B.2.14 Kernel 18 . . . 204
B.2.15 Kernel 19 . . . 205
B.2.16 Kernel 22 . . . 205
B.2.17 Kernel 23 . . . 206
B.2.18 Kernel 24 . . . 206
B.3 Binary Tree . . . 207
C VHDL Code 213 C.1 Trace Generator . . . 213
C.2 Integration of the trace generator to the ARM model . . . 215
C.3 Code to modify the cache size . . . 215
D Trace Analysis Code 217 D.1 Principal Program . . . 217
D.2 Auxiliar Functions Generated . . . 220
D.2.1 Instruction Decoding . . . 220
D.2.2 Binary Vectors to Decimal Values . . . 221
D.2.3 Basic Blocks Builder . . . 221
D.2.4 Nodes Selection . . . 223
Bibliography 225
List of Figures
2.1 CMOS Inverter . . . 8
2.2 Traditional Hierarchical Memory Structure . . . 11
2.3 Cache Architecture . . . 12
2.4 Cache in the memory system . . . 13
2.5 Memory Gap: The performance of memory and CPU over time . . . 14
2.6 Energy per Access Values for Caches and Scratch Pad Memories . . . 16
2.7 SPM Architecture . . . 16
2.8 Modern Memory Hierarchy presenting SPM Advantages . . . 17
2.9 Division of Data Address Space between SRAM and DRAM[1] . . . . 18
2.10 A compiler . . . 20
3.1 Methodology Workflow . . . 24
3.2 Seamless Architecture . . . 26
3.3 Co-Verification Environment . . . 27
3.4 Structure of the monitor block . . . 29
3.5 Monitor Program Flow . . . 31
4.1 XRAY Debugger Register Editor . . . 34
4.2 Post-Trace Generation Analysis Workflow . . . 35
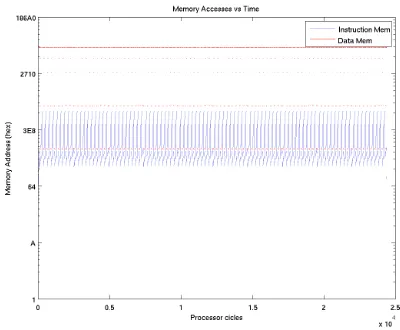
4.3 Example of Memory Accesses Vs. Time (Bubble). . . 35
4.4 Example of Memory Accesses Vs. Memory Map (Bubble) . . . 36
4.5 Example of Memory Access Vs. Basic Blocks (Bubble) . . . 37
4.6 Example of Basic Blocks Flow (Bubble) . . . 38
4.7 Example of Modification Power Parameters in Profiler . . . 40
4.8 Example of Memory Range Selection . . . 40
4.9 Example graphic for SPM Configuration (Kernel 1) . . . 41
5.1 Flow of Methodology in the Experimental Setup . . . 44
5.2 Totals of Power Consumption of the workload (Bubble - Kernel 6) . . 49
5.3 Totals of Power Consumption of the workload (Kernel 7- Binary Tree) 50 5.4 Consumption of Basic Blocks when mapped to the Main Memory and the SPM . . . 52
5.5 % of reduction in power consumption by each configuration. . . 53
5.6 Comparative of consumption for each configuration (Bubble) . . . 54
5.7 Main memory and Basic Blocks without cache and without SPM (Bub-ble) . . . 56
5.8 Main memory and Basic Blocks with 8Kb SPM configuration (Bubble) 56 5.9 Main memory and Cache consumption with 8 Kb cache configuration (Bubble) . . . 57
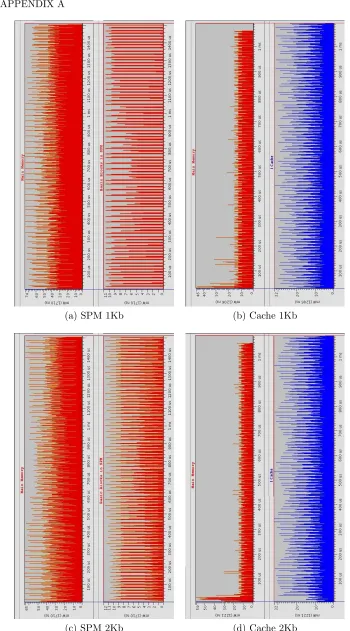
A.1 Memory Accesses Vs. Time: Bubble . . . 61
A.2 Accesses Concentration in the Memory Map: Bubble . . . 62
A.3 Histogram of the Basic Blocks: Bubble . . . 62
A.4 Results of power consumption for each configuration: Bubble . . . . 64
A.5 Main Memory and Basic Blocks without Optimization: Bubble . . . 64
A.6 Consumption Comparation 1Kb and 2Kb: Bubble . . . 65
A.7 Consumption Comparation 4Kb and 8Kb: Bubble . . . 66
A.8 Consumption Comparation 16Kb: Bubble . . . 67
A.9 Memory Accesses Vs. Time: Kernel 1 . . . 68
A.10 Accesses Concentration in the Memory Map: Kernel 1 . . . 68
A.11 Histogram of the Basic Blocks: Kernel 1 . . . 69
A.12 Basic Blocks Flow for 8 Kb: Kernel 1 . . . 69
A.13 Results of power consumption for each configuration: Kernel 1 . . . . 70
A.14 Main Memory and Basic Blocks without Optimization: Kernel 1 . . . 70
A.15 Consumption Comparation 1Kb and 2Kb: Kernel 1 . . . 72
A.16 Consumption Comparation 4Kb and 8Kb: Kernel 1 . . . 73
A.17 Consumption Comparation 16Kb: Kernel 1 . . . 74
A.18 Memory Accesses Vs. Time: Kernel 2 . . . 75
A.19 Accesses Concentration in the Memory Map: Kernel 2 . . . 75
A.20 Histogram of the Basic Blocks: Kernel 2 . . . 76
LIST OF FIGURES xiii
A.22 Results of power consumption for each configuration: Kernel 2 . . . . 77
A.23 Main Memory and Basic Blocks without Optimization: Kernel 2 . . . 77
A.24 Consumption Comparation 1Kb and 2Kb: Kernel 2 . . . 79
A.25 Consumption Comparation 4Kb and 8Kb: Kernel 2 . . . 80
A.26 Consumption Comparation 16Kb: Kernel 2 . . . 81
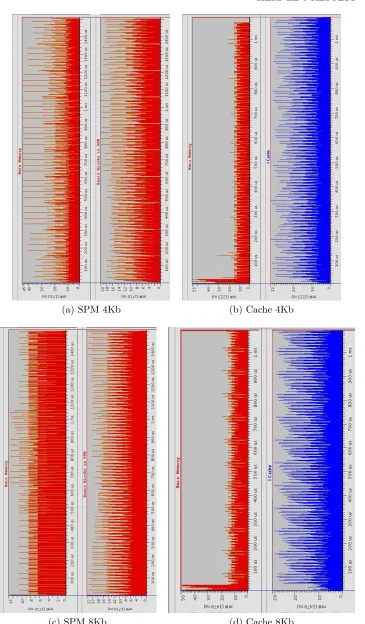
A.27 Memory Accesses Vs. Time: Kernel 3 . . . 82
A.28 Accesses Concentration in the Memory Map: Kernel 3 . . . 82
A.29 Histogram of the Basic Blocks: Kernel 3 . . . 83
A.30 Basic Blocks Flow for 8 Kb: Kernel 3 . . . 83
A.31 Results of power consumption for each configuration: Kernel 3 . . . . 84
A.32 Main Memory and Basic Blocks without Optimization: Kernel 3 . . . 84
A.33 Consumption Comparation 1Kb and 2Kb: Kernel 3 . . . 86
A.34 Consumption Comparation 4Kb and 8Kb: Kernel 3 . . . 87
A.35 Consumption Comparation 16Kb: Kernel 3 . . . 88
A.36 Memory Accesses Vs. Time: Kernel 4 . . . 89
A.37 Accesses Concentration in the Memory Map: Kernel 4 . . . 89
A.38 Histogram of the Basic Blocks: Kernel 4 . . . 90
A.39 Basic Blocks Flow for 8 Kb: Kernel 4 . . . 90
A.40 Results of power consumption for each configuration: Kernel 4 . . . . 91
A.41 Main Memory and Basic Blocks without Optimization: Kernel 4 . . . 91
A.42 Consumption Comparation 1Kb and 2Kb: Kernel 4 . . . 93
A.43 Consumption Comparation 4Kb and 8Kb: Kernel 4 . . . 94
A.44 Consumption Comparation 16Kb: Kernel 4 . . . 95
A.45 Memory Accesses Vs. Time: Kernel 5 . . . 96
A.46 Accesses Concentration in the Memory Map: Kernel 5 . . . 96
A.47 Histogram of the Basic Blocks: Kernel 5 . . . 97
A.48 Basic Blocks Flow for 8 Kb: Kernel 5 . . . 97
A.49 Results of power consumption for each configuration: Kernel 5 . . . . 98
A.50 Main Memory and Basic Blocks without Optimization: Kernel 5 . . . 98
A.51 Consumption Comparation 1Kb and 2Kb: Kernel 5 . . . 100
A.52 Consumption Comparation 4Kb and 8Kb: Kernel 5 . . . 101
A.53 Consumption Comparation 16Kb: Kernel 5 . . . 102
A.55 Accesses Concentration in the Memory Map: Kernel 6 . . . 103
A.56 Histogram of the Basic Blocks: Kernel 6 . . . 104
A.57 Basic Blocks Flow for 8 Kb: Kernel 6 . . . 104
A.58 Results of power consumption for each configuration: Kernel 6 . . . . 105
A.59 Main Memory and Basic Blocks without Optimization: Kernel 6 . . . 105
A.60 Consumption Comparation 1Kb and 2Kb: Kernel 6 . . . 107
A.61 Consumption Comparation 4Kb and 8Kb: Kernel 6 . . . 108
A.62 Consumption Comparation 16Kb: Kernel 6 . . . 109
A.63 Memory Accesses Vs. Time: Kernel 7 . . . 110
A.64 Accesses Concentration in the Memory Map: Kernel 7 . . . 110
A.65 Histogram of the Basic Blocks: Kernel 7 . . . 111
A.66 Basic Blocks Flow for 8 Kb: Kernel 7 . . . 111
A.67 Results of power consumption for each configuration: Kernel 7 . . . . 112
A.68 Main Memory and Basic Blocks without Optimization: Kernel 7 . . . 112
A.69 Consumption Comparation 1Kb and 2Kb: Kernel 7 . . . 114
A.70 Consumption Comparation 4Kb and 8Kb: Kernel 7 . . . 115
A.71 Consumption Comparation 16Kb: Kernel 7 . . . 116
A.72 Memory Accesses Vs. Time: Kernel 9 . . . 117
A.73 Accesses Concentration in the Memory Map: Kernel 9 . . . 117
A.74 Histogram of the Basic Blocks: Kernel 9 . . . 118
A.75 Basic Blocks Flow for 8 Kb: Kernel 9 . . . 118
A.76 Results of power consumption for each configuration: Kernel 9 . . . . 119
A.77 Main Memory and Basic Blocks without Optimization: Kernel 9 . . . 119
A.78 Consumption Comparation 1Kb and 2Kb: Kernel 9 . . . 121
A.79 Consumption Comparation 4Kb and 8Kb: Kernel 9 . . . 122
A.80 Consumption Comparation 16Kb: Kernel 9 . . . 123
A.81 Memory Accesses Vs. Time: Kernel 10 . . . 124
A.82 Accesses Concentration in the Memory Map: Kernel 10 . . . 124
A.83 Histogram of the Basic Blocks: Kernel 10 . . . 125
A.84 Basic Blocks Flow for 8 Kb: Kernel 10 . . . 125
A.85 Results of power consumption for each configuration: Kernel 10 . . . 126
A.86 Main Memory and Basic Blocks without Optimization: Kernel 10 . . 126
List of Tables
4.1 Example of Results Table . . . 42
5.1 Results of the Workload . . . 48 5.2 Table of Results for Bubble . . . 55
A.1 Results for Bubble . . . 63 A.2 Results for Kernel 1 . . . 71 A.3 Results for Kernel 2 . . . 78 A.4 Results for Kernel 3 . . . 85 A.5 Results for Kernel 4 . . . 92 A.6 Results for Kernel 5 . . . 99 A.7 Results for Kernel 6 . . . 106 A.8 Results for Kernel 7 . . . 113 A.9 Results for Kernel 9 . . . 120 A.10 Results for Kernel 10 . . . 127 A.11 Results for Kernel 11 . . . 134 A.12 Results for Kernel 12 . . . 141 A.13 Results for Kernel 16 . . . 148 A.14 Results for Kernel 17 . . . 155 A.15 Results for Kernel 19 . . . 162 A.16 Results for Kernel 22 . . . 169 A.17 Results for Kernel 23 . . . 176 A.18 Results for Kernel 24 . . . 183 A.19 Results for Binary Tree . . . 190
Chapter 1
Introduction
The current technological advances, that enable the design of heterogeneous systems on a chip, have led to the convergence of computers, communications, and multimedia into embedded electronic systems within everyday consumer products. According to the Moore’s Law [2], the advances in technology duplicate the number of transistors on a single silicon chip every 18 months. This resulted in an exponential increase in the number of transistors on a chip, from 2,300 in an Intel 4004 to 42 millions in Intel Itanium processor [3]. The Moore’s Law has withstood for 40 years and is predicted to remain valid for at least another decade [4]. All these technological advances, has led to a need for rapid system-level exploration and design to enable the introduction of new products into the market under increasingly shorter periods.
The growing gap between memory and processor performance results in the mem-ory subsystem becoming the primary system-level bottleneck, particularly for memmem-ory- memory-intensive embedded system applications that process large volumes of data under de-manding throughput, cost and power constraints. Due to this, it is critical to address the exploration of the embedded system design space using memory criteria as the ini-tial design driver. The exploration of embedded system design will allow a system-level designer to focus on potentially feasible design schemes and possibilities for mixed hard-ware/software implementations of memory-intensive embedded applications. Memory transfers are a major contributor to increment the amount of power consumption and to reduce system performance. Embedded systems are usually designed with restricted amount of memory resources and reducing the unnecessary traffic in the cache be-comes an important issue. Modern mobile devices are deployed with an extended list
of new capabilities and while they are still powered by low capacity batteries. There-fore, the reduction in energy consumption of embedded processors employed in mobile devices has become a very important research topic. The energy consumption of the memory accesses, according to related research efforts, has reached about 32% of the total amount consumed by a suband decoder chip for external memory references[5]. The energy consumption of the internal memory can consume 33% of the total power compared to the 28% of the datapath and 7% of the control section [5].
System performance is also a key factor for embedded systems with strict real time constrains. The impact of the memory traffic in the performance of embedded systems is significant and reaches up to 75% of the total execution time of MPEG video decoding applications [6]. Thus, the focus of this research effort is to find ways to reduce energy consumption, using as a starting point the memory system hierarchy and the analysis of programs that combines static and dynamic analysis of programs. This way we can propose a better distribution of the program information in memory.
1.1
Problem Statement
We need a framework to perform the study of how the memory access behavior impacts in the memory hierarchy, also we need to be able to estimate the power consumption and performance of an embedded system. With this, an exploration of scratch pad memories customizations can be performed.
1.4 OBJECTIVES 3
1.2
Objectives
The general objective is to analyze the behavior of memory references found on memory intensive applications, and propose a methodology to improve performance, resources use and power consumption in embedded systems.
The specific objective of this thesis is to develop a memory analysis strategy capable of:
• Collecting execution traces of programs.
• Apply an instruction memory placement technique using the frequency of instruc-tion blocks.
• Reduce power consumption by placing frequently accessed instruction blocks at SPMs.
1.3
Contribution
Mayor contributions are:
• A memory analysis strategy based on estimation from Seamless Co verification.
• A method to improve performance, resources usage and power consumption.
– Gathering of execution traces with Seamless by implementing the model of a performance monitor.
– Identification of the most frequently used basic blocks of programs.
– Use of the Profiler and Seamless for configurations of RAM, SPM and Cache
1.4
Previous Work
in [13] proposes the elimination of unused data. Other efforts as [14, 15] are focused in developing methods to determining the best data cache size for given applications; these works show that for a specific implementation a customized memory offers better benefits, with a longer time in the design phase, and surely a more expensive memory system.
An alternative solution that overcomes the power consumption and cost issues of caches are the scratch pad memories (SPM). SPMs are very similar to caches in terms of size and speed, with no dedicated logic for dynamic swapping of contents. It is the designers responsibility to explicitly map addresses of external memory to locations of the SPM. This may be impractical in general-purpose architectures, but it becomes feasible in embedded systems context. Where the designer has control over both the software and hardware. References [16, 17, 18] present some possible architectures for embedded processors with SPM.
Many of the techniques for mapping data onto small and fast memories tradi-tionally applied to caches are now applied to SPMs as well [19, 20]. Scalar and array variables are separately managed, and arrays are entities to be monolithically mapped in the addressing space. However, these approaches take into account speed but not energy.
Power, area and speed optimizations, using SPMs, are explored in [21] and [22]. These approaches rely on the support provided by specific compilers, to postulate the availability of source code for a target application with invariant hardware. The results of these efforts show improvements above 20%, after comparing a cache subsystem with a SPM architecture. This improvement covers aspects like execution cycles, energy consumption and die area.
Others works dealing with SPMs are [23], [24], [25] and [26]. These works from Kandemir et. al explore choices of banking, tiling and allocation. Reference [25] intro-duces ways to dynamically move blocks of data from RAM to the SPM and vice versa. But, the static placement still seems to be a feasible option in embedded applications.
1.5 THESIS OUTLINE 5
1.5
Thesis Outline
Chapter 2
Background
2.1
Introduction
During the early days of mobile devices like PDAs, mobile phones, laptops and audio were not even in the picture, and the major concerns were performance, area and cost. New semiconductors technology, new developments in systems designs and new trends in device miniaturization have converge into a wide variety of hand held and portable devices. Power and energy consumption parameters have become one of the most important design constraints. Many researchers are dedicated to reduce the energy consumption of systems by optimizing energy consumption of every component.
2.2
Power Consumption
2.2.1
Power and Energy Relationship
In designing low power and energy-efficient devices one of the major concerns is to understand the physical phenomenon that lead to power dissipation. Nowadays most digital circuits are implemented using CMOS technology, due to their negligible power consumption in stand by operation mode. Therefore, the equations involved in power and energy consumption analysis for the CMOS technology, is a fundamental starting point in the energy efficiency analysis.
2.2.2
Power Dissipation
Electrical power is defined as the product of the electrical current times the voltage at the terminals of an electronic device and is measured in Watts. Figure 2.1 illustrates how to estimate the electric power dissipated by a CMOS inverter. A typical CMOS circuit consists of a pMOS and an nMOS transistor and a small load capacitance. The power dissipated by any CMOS circuit can be divided into static and dynamic terms as follows:
PCM OS =Pstatic+Pdynamic (2.1)
In an ideal CMOS circuit, no static power is dissipated when the circuit is in a stand-by mode (no switching signal), because there is no open path from source (Vdd )
to ground (Gnd). Since MOS transistors are never perfect insulators, there is always a small leakage current Ilk that flows from Vdd to Gnd. The leakage current is inversely
proportional to the device dimensions and exponentially related to the threshold voltage
Vt, working in subthreshold mode. For example, the leakage current is approximately
10-20 pA per transistor for 130 nm process with 0.7 V threshold voltage, whereas it exponentially increases to 10-20 nA per transistor when the threshold voltage is reduced to 0.3 V [28].
Figure 2.1: CMOS Inverter
For instance, the static powerPstatic dissipated due to leakage currents is roughly
2.2 POWER CONSUMPTION 9 7.5 for each technological generation and is expected to account for a significant portion of the total power in deep sub-micron technologies [29]. Therefore, the leakage power component grows to 20-25% at 130 nm [28].
The dynamic component, Pdynamic, of the total power is dissipated during the
switching between logic levels and is due to charging and discharging of the capacitance and to small short circuit currents. A change in the input signal of the CMOS inverter from one logic level to the opposite, generates a short circuit current with both pMOS and nMOS transistors in the on state. This small short circuit current Isc flows from Vdd to Gnd. Short circuit power can consume up to 30% of the total power if the circuit
is active and the transition times of the transistors are substantially long. However, through a careful design to transition edges, the short circuit power component can be kept below 10-15% [30].
The other component of the dynamic power is due to the charge and discharge cycle of the output capacitance C. During a high-to-low transition, energy stored in the capacitance equals to CVdd2 is drained from Vdd through Ip. During the reverse
low-to-high transition, the output capacitance is discharged. In CMOS circuits, this component accounts for 70-90% of the total power dissipation [30]. So the power dissipated by a CMOS circuit can approximated to be its dynamic power component and is represented as follows:
PCM OS ≈αf CVdd2 (2.2)
where, α is the switching activity and f is the clock frequency supplied to the CMOS circuit. Therefore, the power dissipation in a CMOS circuit is proportional to the switching activity α, clock frequency f , capacitive load C and the square of the supply voltageVdd .
2.2.3
Energy Consumption
Every computation requires a specific interval of time T to be evaluated. Formally, the energy consumed E by a system for the computation is the integral of the power dissipated over a time interval T and is measured in Joules.
E =
Z T
0
P(t)dt=
Z t
0
The energy consumption decreases if the time T required to perform the com-putation decreases and/or the power dissipation P(t) decreases. Assuming that the measured current does not show a high degree of variation over T and considering that the voltage is kept constant during this period, Equation 2.3 can be simplified to:
E ≈V ∗Iavg∗T (2.4)
2.3
Energy and Power
According to its definition on equation 2.2, power in a CMOS circuit is dissipated at a given time instant. In contrast, energy 2.3 is the sum of the power dissipated during a given time period. A compiler optimization reduces energy consumption if it reduces the power dissipation of the system and/or the execution time of the application. However, if an optimization reduces the peak power but significantly increases the execution time of the application, the power optimized application will not have optimal energy consumption.
According to this, the relationship between power and energy optimizations de-pends on a third parameter, the execution time. There are optimization techniques which minimize the power dissipation of a system. For example, references [31, 32] perform instruction scheduling to minimize bit-level switching activity on the instruc-tion bus reducing its power dissipainstruc-tion. Mehta et al. [33] presented a register labeling approach to minimize transitions in register names across consecutive instructions. A different approach presented in reference [34] smoother the power dissipation profile of an application through instruction scheduling and reordering to increase the usable energy in a battery. All those approaches also minimize the energy consumption of the system as the execution time of the application either decreases or stays constants.
2.4
Memory Wall Problem
2.5 MEMORY HIERARCHY 11 which establishes that the performance of the entire system is not governed by the speed of the processor but by the speed of the memory [36].
Also the memory subsystem has been demonstrated to be the energy bottleneck. References [37, 25] demonstrate that the memory subsystem accounts for 50-70% to the total power budget of the system.
The memory wall problem is not a trivial issue and there is not a simple technique to solve it. But, in order to diminish the impact of the problem, it has been proposed to create memory hierarchies by placing small and efficient memories close to the processor and to optimize the application code such that the working context of the application is always contained in memories closer to the processor.
Figure 2.2: Traditional Hierarchical Memory Structure
2.5
Memory Hierarchy
techniques have been deploy for the most efficient use of the methodology. A description of each level is briefly described below. The figure 2.2 illustrates the traditional memory hierarchy structure of a microprocessor.
2.5.1
Registers
Registers are the smallest, fast storage buffers within the CPU. The Compiler is re-sponsible for managing their use, deciding which values should be kept in the available registers at each point in the program. They generate the fastest access to the CPU and because the registers work at the same speed as the processor, it would be ideal to save all the program’s data in them and not having any access out of the processor. The intensive and effective use of registers can reduce significantly the memory access time, but physical and economic limitations only permit to have a few of them in the processor (typically less than 32 [1]).
2.5.2
Cache
A cache its a small, fast memory made of SRAM that hold copies of some of the contents of the main memory made of DRAM. Because the cache is fast, it provides higher-speed access for the CPU; but since it’s small, no all requests can be satisfied by the cache.
2.5 MEMORY HIERARCHY 13 The cache is a hardware managed Tag-RAM. Due to its architecture design, the cache includes hardware to identify memory references that generate a cache miss or hit. A tag comparator identifies the missing references by comparing the upper bits of the address provided by the CPU with the bits located at the directory memory of the cache. The number of comparators in the cache depends on the cache’s associativity. Figure 2.3 shows the architecture for a typical cache.
Figure 2.4: Cache in the memory system
2.5.3
Main Memory
This level satisfies the demand of caches and serves as the I/O interface. The main memory is generally made up of DRAM and has relatively large storage capacity as compared to the caches(SRAMs), DRAMs principal characteristic is it’s high density and storage capacity. But DRAMs also have relatively larger access times as compared to SRAMs. More over, the dynamic nature of the DRAMs accounts for their reduced performance as compared to SRAMs. However the simplified design structure and cost feasibility has made DRAMs the choice for main memory. The size of the DRAM is incremented four times every three years according to Patterson and Hennessy [39], and the speed is incremented two times in about six years [40].
The development of memory with major capacities has been the principal interest of the industry for years, and recently the interest in the increment of velocity has become a major issue, this can be illustrated in the figure 2.5 [40] which shows a comparative between processors and memories, making obvious the memory gap.
Figure 2.5: Memory Gap: The performance of memory and CPU over time
2.5 MEMORY HIERARCHY 15
2.5.4
Virtual Memory
Systems generally require a greater number of memory locations than are available in the main memory. The entire portion of the address space that the CPU uses is stored on large magnetic or optical disks. Virtual memory is a common part of most operating systems on desktop computers. With virtual memory, the system can look for areas of RAM that have not been used recently and copy them onto the hard disk or secondary memory. This frees up space in RAM. This is done automatically and it makes the system feel like it has unlimited RAM space regardless of the limited amount of it. Hard-disk space is so much cheaper than RAM chips, so virtual memory also provides an economic benefit.
There are two important definitions to understand virtual memory, the real ad-dress space (RAS) and logic adad-dress space (LAS). The RAS consists of the entire amount of memory installed in the system, while the LAS consists of the space of addresses that can be generated by addressing pins from the processor, from zero to 2n−1, where n is the number of lines in the addressing bus.
The virtual memory maps the LAS to RAS using the remaining hard disk to achieve this. The area of the hard disk that stores the RAM image is called a page file. It holds pages of RAM on the hard disk, and the operating system moves data back and forth between the page file and RAM. Of course, the read/write speed of a hard drive is much slower than RAM, and the technology of a hard drive is not designed for accessing small pieces of data at a time. If a system has to rely too heavily on virtual memory, it will suffer a significant performance drop.
2.5.5
SPM
Figure 2.6: Energy per Access Values for Caches and Scratch Pad Memories
Figure 2.6 presents the energy per access values for SPM and caches for varying size and associativity. From the figure, it can be observed that the energy per access value for a scratch pad memory is always less than those for caches of the same size. However, the scratch pad memories, unlike caches, require explicit support from the software for their utilization. A careful assignment of instructions and data is a prerequisite for an efficient usage of the scratch pad memory.
Figure 2.7: SPM Architecture
2.6 DATA PREFETCHING 17 memory. Figure 2.9 shows how the logic addressing of the SPM is managed directly by the processor.
Figure 2.8: Modern Memory Hierarchy presenting SPM Advantages
2.6
Data Prefetching
The prefetching of data is a technique used to reduce the memory latency. Prefetching aims for placing in the cache the data required by the processor before the data is requested. Data prefetching is divided into two approaches: software data prefetching and hardware data prefetching.
2.6.1
Software Data Prefetching
Figure 2.9: Division of Data Address Space between SRAM and DRAM[1]
Some important issues involved in software prefetching include the ideal placement of prefetched instructions, whether or not to prefetch and the possible use of a separate prefetch buffer (instead of the cache) to place prefetched data[1].
To implement this technique, the compiler must be able to identify instructions related to predictable and deterministic memory accesses. However there are not de-terministic accesses and its complicated to achieve satisfactory results that justifies the use of this technique.
2.6.2
Hardware Data Prefetching
Hardware prefetching refers to the idea of fetching data and instructions from memory even before the processor request them. One common prefetching technique that takes advantage of spatial locality of reference, accesses requested the memory block, as well as the next continuous block, in anticipation of spacial locality [41, 39]. The fetching of the next block is transparent to the processor, so that if the data has arrived by the time the processor request it, a cache hit results.
2.7 PROGRAM ANALYSIS 19
2.7
Program Analysis
This refers to the process of analyzing the behavior of computer programs. There are two main approaches in program analysis: “static program analysis” and “dynamic program analysis”. The main application of these analysis are program optimization and program correctness. Program analysis is also used to facilitate the construction of compilers generating “optimal” code.
Static analysis is usually made at compile-time, it offers safe and efficient ap-proximations to the set of configurations or behaviors arising, the dynamic analysis is implemented at run time, it’s considered safe because is faithful to the semantics of the code[42].
2.7.1
Static Analysis
Static analysis is performed to computer programs without actually executing the code. In most of the cases this analysis is performed on source code, and in other cases in object code. Static analysis is usually performed by an automated tool, with human analysis being called program understanding or program comprehension.
The analysis sophistication vary from only consider the behavior of individual statements and declarations, to analyze the complete source code of a program. De-pending of the application, the information obtained from this analysis may help to found coding error, to get statistics of the program, which is our case, that may help to others studies or, as told before, may help the compiler or other tools to generate “optimal” code.
2.7.2
Dynamic Analysis
2.7.2.1 Profiling
A kind of dynamic analysis is the performance analysis, that is commonly known as profiling, this consist in investigating of program behavior using information gathered as the program executes. A common goal of profiling is to determine which sections of the program may be optimize, in our case what parts of the code may be fetch to an energy efficient and faster memory block.
2.7.3
Compilers
Programming language are well formed and structured notations that complies with grammar rules, programming languages enables us to describing computations to people and to machines. The world as we know it depends on programming languages.
We all depend of programing languages, because all the software running on all the computers is written in some programming language. But computers doesn’t know how to interpret the semantics of languages, so before a program can be run, it first must be translated into a form in which it can be executed by a computer.
Figure 2.10: A compiler
The software systems that do this translation are called compilers. [43]
A compiler or interpreter for a programming language is often decomposed into two parts:
• Read the source program and discover its structure.
Chapter 3
Proposed Strategy and Trace
Generation Approach
3.1
Methodology
The Figure 3.1 shows the proposed workflow of the study. In the Figure every stage block is marked with the name of the program developed for each stage of this work, and shows the outputs of each one. This chapter describes the first block of the work-flow consisting of the VHDL monitor simulation. Chapter 4 explains the remaining stages: trace analysis and power analysis. The methodology focus on the study of the instruction memory, and the approach can be easily applied to data memory as well. The methodology is divided in three parts:
• Monitor Simulation: where a trace generator approach is integrated to a co-verification environment integrated by Seamless, ModelSim and the XRAY de-bugger. The results of this phase will a provide a trace of the memory accesses during execution time.
• Trace Analysis: in this section the traces generated by the simulation are quan-tized by a program implemented in Matlab. Results of this part will give graphics that describe the memory access behavior. Other result of this section is the list of the most accessed basic blocks, this selection will be used in following phase.
• Power Analysis: finally we use the Seamless Profiler to perform a power analysis study, where several configurations for the system are compared. This phase
includes the power consumption totals and generates the corresponding graphical analysis.
3.2
Seamless a Co-Verification Environment
Seamless from Mentor Graphics is a co-verification software for performance analysis of complex embedded designs. It helps generate the program traces of this work. This program enables embedded code execution against Verilog or VHDL hardware simulation. Simulates objects in standard binary formats such as ELF or COFF.
Figure 3.2 shows the major components of the Seamless co-verification architec-ture. Those components are:
Figure 3.1: Methodology Workflow
3.2 SEAMLESS A CO-VERIFICATION ENVIRONMENT 25 produced when cross-assemble or compile target software for the specific proces-sor. The Software Simulator Interface controls execution of the instruction set model (ISM) and performs operations such as single-stepping, examining registers and memory, and other typical software simulator functions.
• Co-verification Kernel controls communications between the software and logic co-verification. It sets up various aspects of the co-verification session through the Seamless session window and it coordinates access to memory through the Coherent Memory Server.
• Logic Simulator and Logic Simulation Kernel perform the hardware portion of a co-verification session. One or more bus-interface processor models and some optimized memory models are instantiated into the setup, which usually coded in a hardware description language (HDL). The Logic Simulator controls execution of the design. Then the Logic Simulation Kernel executes the HDL co-verification of the design.
To perform a co-verification, the first step is to build an executable image (.elf file) using cross-development tools, such as: assemblers, compilers, and linkers. YAGARTO is the selected toolchain to generate an executable image compatible with thee ARM926 processor available under Seamless. This executable image is later executed over the ARM processor model and additional hardware such as: memories, buses, displays, etc. to set-up a co-verification session. Figure 3.3 shows the co-verification environment of this phase.
3.2 SEAMLESS A CO-VERIFICATION ENVIRONMENT 27 Each Seamless Processor Support Package (PSP) includes both the bus-interface model and instruction set model (ISM). An ISM is a software application that models the functional behavior of a processor’s instruction set. An ISM is not a hardware model of the processor; it is an abstract model of the data processing that occurs during instruction execution. The ISM provided with any given PSP is developed using a targeted software simulator, such as the XRAY Debugger, included in the integrated development and testing environment. Each Processor Support Package has a set of tools with both the simulator required to perform co-verification and the level of software simulation that occurs during co-verification.
The ARM926EJS processor model supplied with the Seamless coded in VHDL, is simulated using ModelSim which targets the XRAY Debugger as the software simulator. The PSP also includes an implementation of an AMBA bus-interface to connect the CPU to a DRAM.
Figure 3.3: Co-Verification Environment
Setup menu[44].
The steps to generate the performance log files listed below. The performance data is captured in the log file directory specified in Step 1.
1. Select Setup - Performance Log file Directory.
2. In the dialog box specify the name of the directory where the performance data log files are to be generated.
3. Verify that the system performance profiling is enabled. The enable performance data logging switch should appear yellow. If not, click the enable performance data logging menu option.
4. Click OK.
5. Run your co-verification.
The System Profiler provides seven types of views: Code Profile, SW Gantt Chart, Memory Transactions, Memory Heatmap, Power Analysis, Bus Load, Arbitration De-lay, Bus Contention Matrix, Events, and Code Coverage. The features of each view are described briefly in the following list and in more detail in their individual sections. From first experiments with the System Profiler we observe that although the results by the program are very extensive, not all the information to generate the results is accessible to user. For example, an access graph gives the total accesses to the mem-ory, but the user is unable to gather the information that generates these graphics, and for some studies this information may be very helpful, as in a trace analysis. Other example is the memory heatmap, it shows memory accesses per address range per unit of time, but if the accesses are dissociated along all the memory map the graph is hard to analyze due the memory map dimensions.
3.3
VHDL Trace Generator
3.3 VHDL TRACE GENERATOR 29 should be connected where the CPU memory requests are issued. This monitor would be responsible to obtain all the requests of the CPU to main memory, and save all the information in a memory for later use in the trace analysis phase. The code of the profiler tool is shown in appendix C. Figure 3.4 shows the basic structure of the monitor, where we can see that the trace generator has signal entries, the ones provide the address of memory, both of instructions and data.
Figure 3.4: Structure of the monitor block
The next code shows how the monitor is integrated to the model of the ARM926EJS selected in the last section.
journal: sp_mem port map( addrDin=>DHADDR, data=>DHRDATA, addrIin=>IHADDR, inst=>IHRDATA, clk=>CLK );
Graphics. This model is an implementation of the bus AMBA to connect memories to the CPU. During the simulation for each memory transaction collected for the monitor a line of 65 bits was saved in monitor’s memory. These 65 bits consists of 3 parts. The first bit is the Id-Bit and indicates if the CPU is requesting information from the instruction memory (1) or data memory (0). Next 32-bits contained the address requested and the last 32-bits saves the information contained in the memory location. At the end of the run a complete log of each memory access is saved in the memory of the monitor. This information is exported to a text file that we use in the next stage of the study. The command used to export the memory file is:
mem save -o /folder/nameOfFile.mem -f mti -noaddress -data binary -addr hex -startaddress 0 -endaddress 2000000 -wordsperline 1 /arm926ejs_rev0_tb/journal/sp_ process/memory
This command exports the data in binary mode, with one access log per line. The size of the report varies depending on the time taken for the program to be completed, and the number of accesses that were executed. A typical size of the memory trace report was 3 Mb, this can be compared with average 1.5 Mb that the System Profiler’s log file sizes. An example of the first set of lines of a memory log is:
Bubble:
// memory data file for bubble
// instance=/arm926ejs_rev0_tb/journal/memory
// format=mti addressradix=h dataradix=b version=1.0 wordsperline=1 noaddress 1 00000000000000000000000100000000 11101000100100110000001100000000
1 00000000000000000000000100000100 11100101100111010011000000000000 1 00000000000000000000000100001000 11100010100000110011000000001010 1 00000000000000000000000100001100 11100101100111110010000101000100 1 00000000000000000000000100010000 11100001101000000011000110000011 1 00000000000000000000000100010100 11100000100000110011000000000010
In this code, a space between the parts is placed to a easily see the report informa-tion. From previous explanation, the reader may identify these entries as instructions with a start address of 0x100. The third group shows the instruction executed when the CPU access that address.
3.3 VHDL TRACE GENERATOR 31 if it is an instruction memory or a data memory access. This operation is performed by comparing with a previous value of the address. The complete Monitor Code is shown in Section C.
Chapter 4
Trace Analysis and Power Analysis
4.1
Matlab Trace Analyzer
To perform simulation of the first stage the following tools are necessary: the Seam-less Co-Verification tool, with the ModelSim software as Hardware Simulator and the XRAY Debugger Application as Software Simulator. First, the hardware is synthesized by ModelSim, this includes all the components of the systems including the monitor block that will provide the information of the memory requests made by the CPU. Once the model is completed Seamless connects ModelSim with the XRAY Debugger that provides the object code to be analyzed. Six configurations were considered for simulation, one with the cache disabled (default configuration), and five with the cache enabled, varying the size of memory. The bits I(12), C(2), and M(1) from CP15 r1 are used to enable and disable I Cache and D Cache [45, 46] . This register can be directly set in the XRAY Debugger using the window menu, then opening the register dialog and setting directly the values needed in the register. Figure 4.1 shows the configura-tion for the cache enable [47]. The cache size can be modified by creating a file named coveracs.ami in the design directory [45]. In section C.3 is listed the file used in the experiments to modified the cache size.
The file generated by the trace monitor contains a trace of memory references. This file is processed by the trace analyzer to generate reports such as instructions count, trace for a specific memory location, identification of memory hotspots, memory use behavior among others. The analysis was made with an analyzer program written in Matlab. Scrips are divided in several phases, Figure 4.2 shows the complete analysis
Figure 4.1: XRAY Debugger Register Editor
diagram and the files needed for every phase of the study.
First, data collected from the previous section must be loaded. Matlab import the data as text array. These text arrays are divided into individual components (65 characters by array). Once the text is divided a function does an instruction count for some specific instructions. After generating the instruction count all the data is converted to numeric form and separated into sections(Id, Address and Data). When the data is ready to be evaluated by Matlab, exploration routines perform a distinction of the instructions, dividing the data into two groups: instructions memory and data memory accesses.
4.1 MATLAB TRACE ANALYZER 35
Figure 4.2: Post-Trace Generation Analysis Workflow
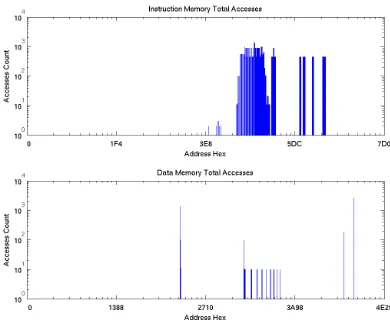
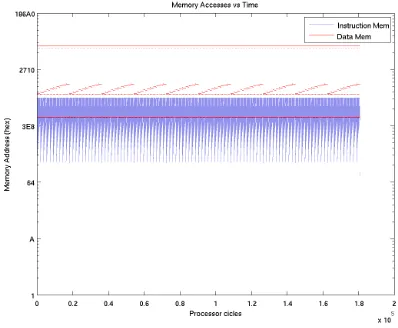
Figure 4.4: Example of Memory Accesses Vs. Memory Map (Bubble)
In Figure 4.3, there are sequential accesses to the memory with abrupt changes in the memory position. The sequential accesses are named basic blocks (BB). The next part of the program analyzer identifies these basic blocks and their incidences. To trace the routes generated by the memory accesses, the address field of the log is inspected, when the direction of access suddenly changes, the program saves a new BB; in execution of the program, several BB are executed more than one times. For efficiency reasons, it is faster to generate a new entry in the table rather than look for a previously saved block, so every time a new line is generated. At the end of the exploration, recurrent BB’s entries are eliminated. With the information, two more graphs are generated. The first one is a histogram for the basic blocks, where the total accesses for each BB are reported. This gives an intuitive answer to which blocks may be the best candidates to be placed into the SPM. Figure 4.5 gives an example of this type of graph. The graph shows the most accessed code BB. From here, we have clear view of how the program concentrates the accesses in some specific part of the code, we also can observe that the profile of the histogram is similar to the profile of the results of the graphics of Memory Accesses Vs Memory Map like Figure 4.4.
4.1 MATLAB TRACE ANALYZER 37
Figure 4.5: Example of Memory Access Vs. Basic Blocks (Bubble) 4.4
Since the purpose of this specific study is to reduce the I-Cache’s power consumption, a selection of the most accessed BBs are marked. To calculate which BBs were the most accessed, we use the following criterion:
Tinst = (
BBhigestaddress−BBlowestaddress
4 + 1)∗Incidences (4.1)
This equation was required because not necessarily the greatest block or the most accessed are the ones that give the biggest number of accesses during the execution time. After getting this information, the program selects the number of blocks that can be placed inside the SPM, using the past calculus as priority and the size of the SPM memory. To calculate which blocks can be mapped inside the memory, the next equation is used:
[SP Mcontent = [BBtopBBtop−1· · ·BBtop−n]] ⇐⇒
topX−n
x=top
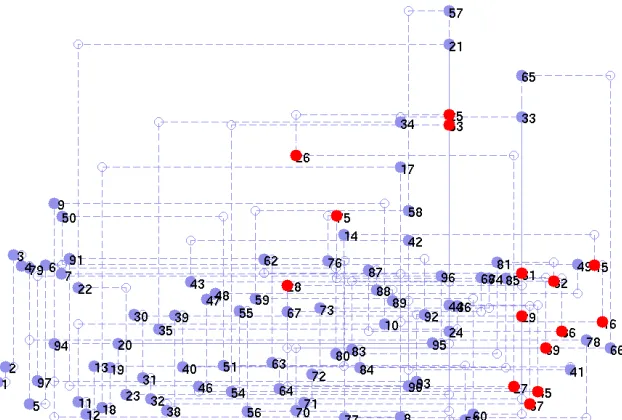
Size[BBx]<=SP Msize (4.2)
Figure 4.6 shows an example of the representation of program flow, showing the distribution of the the BBs across the the memory map. This graph assumes a 8Kb SPM memory. In the graph, the left size represents the lower addresses and the right the end of the address space. Marked nodes are the selected BBs to be mapped into the SPM.
Figure 4.6: Example of Basic Blocks Flow (Bubble)
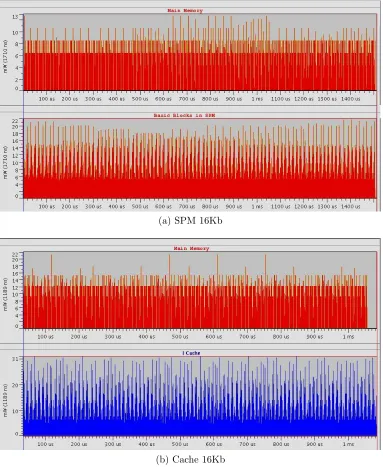
With the information gathered with the analysis previously described, a data placement technique is proposed to improve the performance of the code and to reduce the power consumption of the system. To evaluate the results of this methodology, the Seamless Profiler from Mentor Graphics is used. This evaluation is done for three different scenarios, and two scenarios have five variations:
• A system whose memory hierarchy has only the main memory. All memory accesses go directly to the main memory.
• A system that has 1Kb, 2Kb, 4Kb, 8Kb and 16K of cache, direct mapped. As shown in Figure 2.6 direct map cache is the configuration that is more similar in power consumption constrains to the SPM.
• A system that has 1Kb, 2Kb, 4Kb, 8Kb and 16K of SPM with static data prese-lected with the methodology proposed.
4.2 SEAMLESS PROFILER: GETTING POWER CONSUMPTION RESULTS 39 SPM memory. The basic of the heuristic consists in mapping the top accessed blocks to a SPM in the CPU.
4.2
Seamless Profiler: Getting Power Consumption
Results
From the first part of the methodology, we have several simulations logs. Five with cache enabled, one with each size configuration, and other with cache disabled. This one will be used to get the results from the configuration with just main memory accesses and the SPM configurations. The others logs will give the results for the system with the cache enabled.
The Seamless System Profiler generates the power consumption reports. This application has a power analyzer utility that takes the logged information from the initial simulation explained in the co-verification section. Once the logging data is loaded to the session, a click in the Power Analysis button will generate graphs and statistics of the total power consumption. Due to the configuration of the program, the power consumed by the CPU is always constant.
The simplest results are from the main memory and cache configurations. There is nothing to edit, and the graphics and statistics of power consumption can be obtained quickly. As the cache is included in the given CPU model, it’s not possible to modify the parameters, and the graphs obtained from this configuration can not be manipulated. The SPM is also inside the CPU and complicates evaluating the power consumption. To overcome this problem, it’s important to remember that the SPM belongs to the real address space, and the CPU handles the SPM in the same way as the main memory. Knowing this, we can modify the parameters of isolated memory blocks. These block are the ones that were selected in the past section.
As an advantage to the study, the Seamless Profiler has the Power Analyzer Dialog to modify parameters of the memories. Figure 4.7 is an example of a possible division of the address space to achieve simulation results.
Figure 4.7: Example of Modification Power Parameters in Profiler
system.
Figure 4.8: Example of Memory Range Selection
To generate results of a complete system for the SPM configuration we have to make two groups of range selections. The group that includes the basic blocks with the power parameters modified, and the group that holds all the memory space out of the basic blocks that may remain with the same parameters of the main memory. Then generate the graphics for each case.
Figure 4.9 shows the memory power consumption for the main memory and the SPM. It can be seen how the SPM even containing the more used BB still shows a lower consumption of energy that the main memory.
4.2 SEAMLESS PROFILER: GETTING POWER CONSUMPTION RESULTS 41
Figure 4.9: Example graphic for SPM Configuration (Kernel 1)
Table 4.1: Example of Results Table
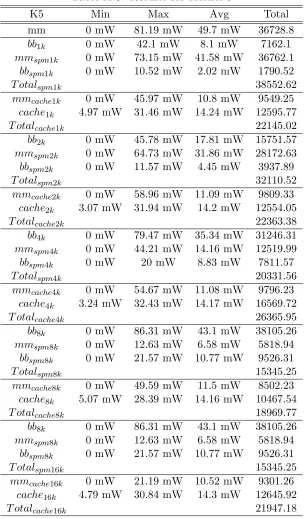
Label Min Max Avg Total
mm 6.31 mW 90 mW 41.24 mW 30442.1 mW bb1k 0 mW 90 mW 28.39 mW 25101.68 mW
mmspm1k 0 mW 87.73 mW 12.84 mW 11352.1 mW
bbspm1k 0 mW 22.68 mW 7.09 mW 6275.42 mW
T otalSP M1k 17627.52 mW
mmcache1k 0 mW 84.16 mW 8.89 mW 7863.48 mW
cache1k 0 mW 35.83 mW 14.46 mW 12783.27 mW
T otalCache1k 20646.75 mW
bb2k 0 mW 90 mW 33.52 mW 29639.49 mW
mmspm2k 0 mW 76.38 mW 7.7 mW 6814.28 mW
bbspm2k 0 mW 22.68 mW 8.38 mW 7409.87 mW
T otalSP M2k 14224.15 mW
mmcache2k 0 mW 25.71 mW 9.31 mW 8228.57 mW
cache2k 0 mW 37.5 mW 14.51 mW 12819.64 mW
T otalCache2k 21048.21 mW
bb4k 0 mW 90 mW 35.11 mW 31038.65 mW
mmspm4k 0 mW 44.62 mW 6.12 mW 5415.12 mW
bbspm4k 0 mW 22.68 mW 8.77 mW 7759.66 mW
T otalSP M4k 13174.78 mW
mmcache4k 0 mW 25.71 mW 9.31 mW 8228.57 mW
cache4k 0 mW 37.5 mW 14.51 mW 12814.28 mW
T otalCache4k 21042.85 mW
bb8k 0 mW 90 mW 35.26 mW 31174.78 mW
mmspm8k 0 mW 30.25 mW 5.97 mW 5278.99 mW
bbspm8k 0 mW 22.68 mW 8.81 mW 7793.69 mW
T otalSP M8k 13072.68 mW
mmcache8k 0 mW 77.69 mW 10.04 mW 7412.33 mW
cache8k 0 mW 32.17 mW 14.07 mW 10387.39 mW
T otalCache8k 17799.72 mW
bb16k 0 mW 90 mW 35.26 mW 31174.78 mW
mmspm16k 0 mW 30.25 mW 5.97 mW 5278.99 mW
bbspm16k 0 mW 22.68 mW 8.81 mW 7793.69 mW
T otalSP M16k 13072.68 mW
mmcache16k 0 mW 77.14 mW 9.29 mW 8215.71 mW
cache16k 0 mW 37.5 mW 14.49 mW 12814.28 mW
T otalCache16k 21029.99 mW
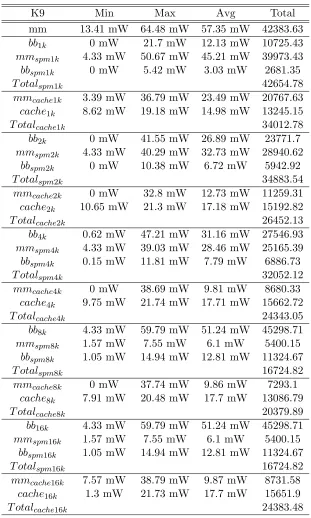
where:
• mm: consumption with main memory, no cache and no SPM.
• bbN k: consumption of the basic blocks of N Kb, just main memory.
• mmspmN k: consumption of the main memory with the SPM present of N Kb.
• bbspmN k: consumption of the basic blocks when mapped to the SPM of of N Kb.
• TotalspmN k: total consumption with SPM of N Kb and main memory configuration.
• mmcacheN k:consumption of the main memory with the cache of N Kb enabled.
• cacheN K: consumption of the cache of N Kb.
Chapter 5
Review of Results
This chapter presents the results obtained from simulations utilizing the methodology described in chapters 3 and 4. Section 5.1 presents the experimental setup. Section 5.2 describes the workload utilized for the simulations. Section 5.3 presents the parameters implemented to estimate the power consumption. The last section contains a review of the results, where estimations of power consumption for each configuration are shown. A more detailed report for individual programs is given in Appendix A.
5.1
Experimental Setup
The experimental setup includes a DELL M1210 XPS laptop, with 2.0 Dual-Core Pro-cessor, a 5400 RPMS disk and 4 GB of RAM. The cross-compile the programs to ARM target code Eclipse Europa IDE (Integrated Development Environment) and the YAGARTO[48] were utilized. For the VHDL monitor trace generation section Seam-less Version 5.5, ModelSim SE 6.3d and XRAY Debugger Version 4.9fpy from Mentor Graphics were utilized. The programs to do trace interpretation were written in Mat-lab 2008a from Mathworks. And for the power analysis, the System Profiler 2.3 from Mentor Graphics was used. The operating system used for the experimental setup was Fedora Core 9 Linux Kernel 2.6.27.5-41.fc9.i686.
Figure 5.1 describes the flow of the archives through all the experimental setup, how the initial benchmark in C code is compiled with the YAGARTO tool in the Eclipse IDE and generates an ARM executable image (.ELF file). This ELF file is targeted to the XRAY debugger and is executed over the ARM processor model which
is simulated in ModelSim. This model have attached the trace generator. From the co-verification process (see section 3.1), we obtain the Systems Profiler log file and the traces generated by the trace generator. In the next phase, the information from the trace generator is imported to the trace analyzer written in Matlab. This program analyzes the information and generates statistics and graphics of the memory accesses behavior. At the end, a list of directions of the most accessed basic blocks is produced. With this information, the set of blocks that fits in the SPM memory space is selected and saved to a text file. This text file and the log file generated from the co-verification are used to get the power analysis results from the Seamless Profiler tool. These results are the power analysis graphics and the statistic of power consumption for each memory configuration. An example of the graphics and results are presented at the end of this chapter.
Figure 5.1: Flow of Methodology in the Experimental Setup
5.2
Analyzed Programs: workload
5.3 METRICS 45
5.2.1
Bubble Sort
The bubble algorithm is a program that performs sorting functions. The algorithm runs several times over an array or list of data. It looks for the highest or lowest value and orders the values in ascending or descending order. The algorithm is known as “bubble sort” as it sorts “floated” towards the top of the list.
5.2.2
Binary Tree
A binary tree is a data structure with a more complex handling of pointers than other similar codes and has two dimensions. The program generates a tree expression taking a binary string entry that should bring together all the sub-expressions in parentheses. The first part of the program generates the tree and the second part traverses the tree in order, in preorder and postorder.
5.2.3
Livermore Loops
The Livermore Loops are a collection of 24 kernels or loops that perform various arith-metic functions originally written in Fortran and then translated to C. The kernels are pieces of code used in the Lawrence Livermore National Laboratory [49] and represent the kind of kernels that can be found in large-scale scientific computations.
These programs have been used in the evaluation of systems since the mid 60’s, however the choice of this benchmark was based on the variety of functions performed, from simple matrix multiplication to complex algorithms search and management, such as the Loop Search for Monte Carlo and the Loop PIC (particle-in-cell) in two dimen-sions. Seventeen out of twenty four kernels were tested and analyzed to generate results.