ECONOMETRÍA:
ECONOMETRÍA:
MODELOS Y PRONÓSTICOS
Cuarta edición
ROBERT S. PINDYCK
Massachusetts Institute of Technology
DANIEL L. RUBINFELD
University of California at Berkeley
Traducción
Jorge Alberto Velázquez Arellano
Traductor profesional
Revisión técnica
Víctor Aguirre Torres
Instituto Tecnológico Autónomo de México
Ma. Teresa López Álvarez
Consultor independiente
McGRAW-HILL
MÉXICO • BUENOS AIR ES • CARACAS • GUA TEMA LA • LIS BOA • MA DRI D NUEVA YORK • SAN JUAN • SANTAFÉ DE BOGOTÁ • SANTIAGO • SAO PAULO
Gerente de producto: Ricardo del Bosque Alayón
Supervisor de edición: Arturo González Maya
Supervisor de producción: Zeferino García García
ECONOMETRIA: MODELOS Y PRONÓSTICOS Cuarta edición
Prohibida la reproducción total o parcial de esta obra, por cualquier medio, sin autorización escrita del editor.
DERECHOS RESERVADOS © 2001, respecto a la primera edición en español por:
McGRAW-HlLL/INTERAMERlCANA EDITORES, S.A. de C.V. A Subsidiary of The McGraw-Hill Companies, Inc.
Cedro Núm. 512, Col. Atlampa, Delegación Cuauhtémoc, C.P. 06450, México, D.F.
Miembro de la Cámara Nacional de la Industria Editorial Mexicana, Reg. Núm. 736
ISBN 970-10-2925-9
Translated from the fourth English edition of: ECONOMETRIC MODELS AND ECONOMETRIC FORECASTS Copyright © 1998 by R. Pindick and D. Rubinfeld
Copyright © 1998 by the McGraw-Hill Companies, Inc. All rights reserved.
ISBN 0-07-913292-8
1234567890 098765432 01
Impreso en México Printed in México
Esta obra se terminó de imprimir en Octubre del 2000 en Impresora OFGLOMA S.A. de C.V. Calle Rosa Blanca Núm. 12 Col. Santiago Acahualtepec México, 13 D.F.
ACERCA
DE LOS AUTORES
ROBERT S. PINDYCK es Profesor Mitsubishi Bank de Economía Aplicada en la Sloan School of Management del Massachusetts Institute of Technology. El profesor Pindyck se incorporó al cuerpo docente del M.I.T. después de recibir un doctorado ahí en 1971. También ha sido Profesor Visitante de Economía en la Universidad de Tel Aviv y es Investigador Asociado del National Bureau of Economic Research. Es coautor, con Daniel Rubinfeld, de Microeconomics, que en la actualidad se encuentra en su cuarta edición.
DANIEL L. RUBINFELD es Profesor Robert L. Bridges de Leyes y Profesor de Economía en la University of California, Berkeley. El profesor Rubinfeld recibió un doctorado en 1972 del M.I.T. Ha enseñado en la Suffolk University, Wellesley College y en la University of Michigan. Ha sido miembro del National Bureau of Economic Research, The Center for Advanced Study in the Behavioral Sciences y The Guggenheim Foundation, y en la actualidad es coeditor de la revista
CONTENIDO
EJEMPLOS xiv
PREFACIO XV
INTRODUCCIÓN xix
PARTE 1 LOS FUNDAMENTOS DEL ANÁLISIS DE REGRESIÓN
1
1 Introducción al modelo de regresión 3
1.1 AJUSTE DE CURVA 3
1.2 DERIVACIÓN DE MÍNIMOS CUADRADOS 7
Apéndice 1.1 El uso del operador sumatoria 13
Apéndice 1.2 Derivación de los estimadores de parámetros de mínimos cuadrados 17
2 Estadística elemental: a revisión 20
2.1 VARIABLES ALEATORIAS 20
2.2 ESTIMACIÓN 25
2.3 PROPIEDADES DESEABLES DE LOS ESTIMADORES 30
2.4 DISTRIBUCIONES DE PROBABILIDAD 34
2.5 PRUEBA DE HIPÓTESIS E INTERVALOS DE CONFIANZA 40
2.6 ESTADÍSTICA DESCRIPTIVA 47
Apéndice 2.1 Las propiedades del operador de expectativas 50 Apéndice 2.2 Estimación de máxima verosimilitud 53
CONTENIDO
3 El modelo de regresión de dos variables 59
3.1 EL MODELO 59
3.2 MEJOR ESTIMACIÓN LINEAL INSESGADA 63
3.3 PRUEBA DE HIPÓTESIS E INTERVALOS DE CONFIANZA 69
3.4 ANÁLISIS DE VARIANZA Y CORRELACIÓN 73
Apéndice 3.1 Varianza del estimador de la pendiente
de los mínimos cuadrados 82
Apéndice 3.2 Algunas propiedades de los residuales de mínimos cuadrados 83
4 El modelo de regresión múltiple 87
4.1 EL MODELO 87
4.2 ESTADÍSTICAS DE REGRESIÓN 90
4.3 PRUEBAS F, R2Y R2CORREGIDA 91
4.4 MULTICOLINEALIDAD 98
4.5 COEFICIENTES ESTANDARIZADOS Y ELASTICIDADES 101
4.6 CORRELACIÓN PARCIAL Y REGRESIÓN POR ETAPAS 102
Apéndice 4.1 Estimación del parámetro de mínimos cuadrados 108
Apéndice 4.2 Coeficientes de regresión 109
Apéndice 4.3 El modelo de regresión múltiple en forma matricial 110
PARTE 2 MODELOS DE REGRESIÓN DE UNA SOLA ECUACIÓN 119
5 Usando el modelo de regresión múltiple 121
5.1 EL MODELO LINEAL GENERAL 121
5.2 USO DE VARIABLES INDICADORAS 126
5.3 EL USO DE PRUEBAS f Y FPARA HIPÓTESIS QUE INVOLUCRAN MÁS
DE UN PARÁMETRO 132
5.4 REGRESIQN LINEAL POR SEGMENTOS 141
5.5 EL MODELO DE REGRESIÓN MÚLTIPLE CON VARIABLES EXPLICATIVAS
ESTOCÁSTICAS 143 Apéndice 5.1 Pruebas que involucran coeficientes de variable indicadora 144
6 Correlación serial y heterocedasticidad 150
6.1 HETEROCEDASTICIDAD 151
6.2 CORRELACIÓN SERIAL 164
Apéndice 6.1 Estimación de mínimos cuadrados generalizados 177
7 Variables instrumentales y especificación del modelo 186 7.1 CORRELACIÓN ENTRE UNA VARIABLE INDEPENDIENTE Y EL
TÉRMINO DEL ERROR 187
CONTENIDO XI
7.3 ERROR DE ESPECIFICACIÓN 192
7.4 DIAGNÓSTICO DE REGRESIÓN 198
7.5 PRUEBAS DE ESPECIFICACIÓN 203
Apéndice 7.1 Estimación de variables instrumentales en forma de matricial 207
8 Pronóstico con un modelo de regresión de una sola ecuación 211
8.1 PRONÓSTICO INCONDICIONAL 213
8.2 PRONÓSTICO CON ERRORES CORRELACIONADOS EN FORMA SERIAL 224
8.3 PRONÓSTICO CONDICIONAL 231
Apéndice 8.1 Pronóstico con el modelo de regresión múltiple 234
9 Estimación de una sola ecuación: temas avanzados 239
9.1 MODELOS DE REZAGO DISTRIBUIDO 239
9.2 PRUEBAS PARA CAUSALIDAD 253
9.3 OBSERVACIONES FALTANTES 257
9.4 EL USO DE DATOS DE PANEL 261
Apéndice 9.1 Estimación de intervalos de confianza para elasticidades
a largo plazo 273
10 Estimación no lineal y de máxima verosimilitud 277
10.1 ESTIMACIÓN NO LINEAL 278
10.2 ESTIMACIÓN POR MÁXIMA VEROSIMILITUD 285
10.3 MODELOS ARCH Y GARCH 298
Apéndice 10.1 Estimación por el método de momentos generalizado 306
11 Modelos de elección cualitativa 312
11.1 MODELOS DE ELECCIÓN BINARIA 312
11.2 MODELOS DE ELECCIÓN MÚLTIPLE 334
11.3 MODELOS DE REGRESIÓN CENSURADA 340
Apéndice 11.1 Estimación de máxima verosimilitud de los modelos
logit y probit 345
PARTE 3 MODELOS DE ECUACIONES MÚLTIPLES 351
12 Estimación de ecuaciones simultáneas 353 12.1 INTRODUCCIÓN A LOS MODELOS DE ECUACIONES SIMULTÁNEAS 354
12.2 EL PROBLEMA DE LA IDENTIFICACIÓN 358
12.3 ESTIMACIÓN CONSISTENTE DE LOS PARÁMETROS 363
12.4 MÍNIMOS CUADRADOS DE DOS ETAPAS 365
12.5 ESTIMACIÓN DE ECUACIÓN SIMULTÁNEA CON CORRELACIÓN
Xii CONTENIDO
12.6 MÉTODOS DE ESTIMACIÓN MÁS AVANZADOS 375
Apéndice 12.1 El problema de la identificación en forma matricial 383 Apéndice 12.2 Mínimos cuadrados de dos etapas en forma matricial 389 Apéndice 12.3 Estimación de regresión aparentemente no relacionada en
forma matricial 392
13 Introducción a los modelos de simulación 398
13.1 EL PROCESO DE SIMULACIÓN 399
13.2 EVALUACIÓN DE MODELOS DE SIMULACIÓN 404
13.3 UN EJEMPLO DE SIMULACIÓN 410
13.4 ESTIMACIÓN DEL MODELO 416
13.5 MODELOS NO ESTRUCTURALES: AUTORREGRESIONES VECTORIALES 420
13.6 MODELADO CON DATOS LIMITADOS 427
14 Comportamiento dinámico de los modelos de simulación 434 14.1 COMPORTAMIENTO DEL MODELO: ESTABILIDAD Y OSCILACIONES 435 14.2 COMPORTAMIENTO DEL MODELO: MULTIPLICADORES Y RESPUESTA
DINÁMICA 443
14.3 LA FUNCIÓN DE RESPUESTA AL IMPULSO Y AUTORREGRESIONES
VECTORIALES 453
14.4 AJUSTE DE MODELOS DE SIMULACIÓN 457
14.5 SIMULACIÓN ESTOCÁSTICA 461
Apéndice 14.1 Un modelo macroeconómico pequeño 464
PARTE 4 MODELOS DE SERIES DE TIEMPO 487
15 Suavizamiento y extrapolación de series de tiempo 491
15.1 MODELOS DE EXTRAPOLACIÓN SIMPLE 491
15.2 SUAVIZAMIENTO Y AJUSTE ESTACIONAL 502
16 Propiedades de las series de tiempo estocásticas 514 16.1 INTRODUCCIÓN A LOS MODELOS DE SERIES DE TIEMPO ESTOCÁSTICAS 514 16.2 CARACTERIZACIÓN DE SERIES DE TIEMPO: LA FUNCIÓN
DE AUTOCORRELACIÓN 520
16.3 PRUEBAS PARA CAMINATAS ALEATORIAS 532
16.4 SERIES DE TIEMPO COINTEGRADAS 539
Apéndice 16.1 La función de autocorrelación para un proceso estacionario 542
17 Modelos lineales de series de tiempo 547
17.1 MODELOS DE PROMEDIO MÓVIL 548
17.2 MODELOS AUTORREGRESIVOS 553
CONTENIDO Xiii
17.4 PROCESOS NO ESTACIONARIOS HOMOGÉNEOS: MODELOS ARIMA 564
17.5 ESPECIFICACIÓN DE MODELOS ARIMA 567
Apéndice 17.1 Estacionariedad, invertibilidad y homogeneidad 570
18 Estimación y pronóstico con modelos de series de tiempo 575
18.1 ESTIMACIÓN DEL MODELO 575
18.2 VERIFICACIÓN DIAGNÓSTICA 581
18.3 PRONÓSTICOS CON ERROR CUADRÁTICO MEDIO MÍNIMO 586
18.4 CÁLCULO DE UN PRONÓSTICO 588
18.5 EL ERROR DE PRONÓSTICO 589
18.6 INTERVALOS DE CONFIANZA DE PRONÓSTICOS 590
18.7 PROPIEDADES DE LOS PRONÓSTICOS ARIMA 591
18.8 DOS EJEMPLOS 599
19 Aplicaciones de los modelos de series de tiempo 606
19.1 REVISIÓN DEL PROCESO DE MODELADO 607
19.2 MODELOS DE VARIABLES ECONÓMICAS: INVERSIÓN EN INVENTARIOS 608 19.3 PRONÓSTICO DE DATOS TELEFÓNICOS ESTACIONALES 613 19.4 COMBINACIÓN DEL ANÁLISIS DE REGRESIÓN CON UN MODELO
DE SERIES DE TIEMPO: MODELOS DE FUNCIÓN DE TRANSFERENCIA 617 19.5 UN MODELO COMBINADO DE REGRESIÓN Y SERIES DE TIEMPO
PARA PRONÓSTICO DE FLUJOS DE DEPÓSITO DE AHORROS
A CORTO PLAZO 619
19.6 UN MODELO COMBINADO DE REGRESIÓN Y SERIES DE TIEMPO
PARA PRONÓSTICO DE TASAS DE INTERÉS 624
TABLAS ESTADÍSTICAS 631
EJEMPLOS
1.1Promedio de calificaciones, 10
1.2La explosión de los litigios, 12
1.3Precios de acciones de compañías de servicio públicas, 13
2.1Covarianza y correlación, 24
2.2Error cuadrático medio, 32
2.3Distribución normal, 36
2.4Éxito en las solicitudes de empleo, 46
3.1Promedio de calificaciones, 68 (continuación)
3.2Gastos de consumo, 72
3.3Ventas de automóviles al menudeo, 78
3.4Promedio de calificaciones, 80 (continuación)
3.5Inscripción en universidades públicas y privadas, 80
4.1 Ventas de automóviles, 89
4.1Ventas de automóviles, 94 (continuación)
4.2Tasas de interés, 95
4.3Función de consumo, 96
4.4El valor de los boletos de fútbol revendidos, 104
4.5Ventas de bienes duraderos, 106
5.1 Una función de costo para la industria de ahorros y préstamos, 124
5.2Predicción de precios de vinos, 125
5.3Diferenciales de salarios, 130
5.4Certificados de depósito, 131
5.5Demanda de vivienda, 135
5.6Demanda de vivienda, 138
5.7Demanda de vivienda, 139
6.1Gastos de vivienda, 156
6.2Prueba de Goldfeld-Quandt, 159
6.3Pruebas de Breusch-Pagan y White, 162
6.4Corrección de la heterocedasticidad, 163
6.5Carbón bituminoso, 173
6.6Tasas de interés, 174
6.7Consumo agregado, 177
7.1Demanda de dinero, 197
7.2El efecto de la contaminación del aire y el crimen en el valor de la propiedad, 201
7.3 Prueba para error de medición en un modelo de gasto público, 206
8.1Pronóstico de promedios de calificaciones, 221
8.2Pronóstico de tasas de interés, 222
8.3Pronóstico de tasas de interés, 226
8.4Pronóstico de la demanda de carbón, 227 9.1Función de consumo, 250
9.2Inversión en inventario, 251 9.3El petróleo y la economía, 255
9.4¿Cuál fue primero: la gallina o el huevo?, 256
9.5Ayuda a los estados, 260
9.6Aplicaciones de patentes y gasto en investigación y desarrollo, 268
9.7 Ayuda extranjera, 271
10.1Función de consumo, 284
10.2Energía, clima y el valor de la vivienda residencial, 292
10.3Prueba de la linealidad de una función de consumo, 297
10.4Tasas de interés a largo plazo, 301
10.5Rendimiento de acciones, 304
11.1Predicción de incumplimiento de bonos, 317
11.2Comportamiento de la votación, 321
11.3Votación para un presupuesto escolar, 328
11.4Predicción del comportamiento de asistencia a la universidad, 330
11.5Logro ocupacional, 337
11.6Voto del Congreso sobre Medicare, 339
11.7La demanda de escuelas públicas, 343
12.1Demanda de electricidad, 368
12.2Gasto público, 372
12.3Asistencia pública, 379
12.4Modelo macroeconómico, 381
13.1 Modelado de la dinámica del mercado de la calefacción con petróleo, 422
14.1Modelo St. Louis, 445
14.2Demanda de automóviles, 448
14.3Otro modelo macroeconométrico, 450
14.4Comportamiento dinámico del mercado del petróleo para la calefacción, 455
15.1 Pronóstico de las ventas de una tienda de departamentos, 497
15.2Construcción residencial nueva mensual, 505
15.3Construcción residencial nueva mensual, 508
16.1Tasa de interés, 526
16.2Precios diarios de cerdos, 528
16.3Producción porcina, 530
16.4¿Los precios de las mercancías siguen caminatas aleatorias?, 535
16.5 La cointegración del consumo y el ingreso, 541
17.1Inversión en inventario, 560
17.2Precio del papel periódico, 568
17.3Tasas de interés, 569
17.4Producción porcina, 570
18.1Tasas de interés, 583
18.2Producción porcina, 585
18.3Pronóstico de tasas de interés, 599
18.4Pronóstico de la producción porcina, 602
PREFACIO
Las nuevas tendencias en econometría, así como los comentarios y sugerencias de una gran cantidad de usuarios de las primeras tres ediciones de este libro, nos han conducido a realizar cambios extensos en esta cuarta edición. Hemos agregado varios temas y ejemplos nuevos y actualizado muchos de los ejemplos anteriores. Además, hemos reestructurado el libro en cuatro partes en lugar de tres.
En función del contenido del libro, la parte uno abarca temas que proporcio-nan al estudiante una comprensión básica del modelo de regresión múltiple. El capítulo 2, que expone la estadística elemental, ha sido revisado y ampliado. También se incluye material y ejemplos nuevos sobre estadística descriptiva.
La parte dos cubre temas sobre modelos de regresión de una sola ecuación. El capítulo 10 es nuevo, presenta un tratamiento profundo de la estimación no lineal y de máxima verosimilitud. La adición de este capítulo refleja la creciente importancia de estos temas en años recientes. El capítulo 10 también contiene una sección nueva sobre la estimación y uso de los modelos Arch y Garch, los cuales han encontrado muchas aplicaciones en las finanzas y la macroecono-mía. Otros cambios importantes en la parte dos es que se incluye material nuevo sobre pruebas para heterocedasticidad en el capítulo 6 y la sección sobre el uso de los datos de panel en el capítulo 9.
La parte tres del libro se concentra en los modelos de ecuaciones múltiples. Además de contener ejemplos nuevos y actualizados, se ha revisado gran parte de la exposición y hemos incluido un pequeño modelo macroeconómico especi-ficado y estimado de nuevo (construido por Michael Donahue del Colby Colle-ge) en el apéndice 14.1.
En la parte cuatro se incluye una exposición revisada y actualizada de los análisis de series de tiempo. El capítulo 18 combina dos capítulos de la tercera edición, el primero sobre estimación y el segundo sobre pronóstico con modelos de series de tiempo.
XVi PREFACIO
Como en la edición anterior, los datos para muchos de los ejemplos se han incluido en el texto mismo o en el Manual del maestro. Acompañando a esta edición, proporcionamos un disquet con los datos de los ejemplos. El Manual del maestro contiene las respuestas a todas las preguntas planteadas al final de los capítulos. Todas las preguntas empíricas se relacionan con los conjuntos de datos proporcionados en el texto y en el Manual del maestro, además de incluirse en el disquet, de modo que los maestros puedan usar en forma directa las tareas en sus cursos.
Al elaborar este libro para la cuarta edición, nos hemos beneficiado mucho de los comentarios y críticas de nuestros colegas y estudiantes al igual que de las sugerencias que nos hicieron una gran variedad de personas. Agradecemos a Steven Dietrich y Annette Hall, quienes nos ayudaron a planear y editar la primera edición; a Bonnie Lieberman y Susan Norton, quienes ayudaron con la segunda edición, y a Scolt Stratford, quien inspiró nuestro trabajo para la tercera edición. Lucille Sutton y sus asociados en McGraw-Hill han sido de gran ayuda en la preparación de esta cuarta edición.
No nos es posible agradecer a todas las personas que nos proporcionaron ayuda con esta nueva edición, pero deseamos agradecer en especial a Sergio Schmukler, quien nos ayudó a redactar de nuevo y actualizar muchos de los ejemplos; a Michael Donahue, quien elaboró el nuevo modelo macroeconómico que aparece en el apéndice del capítulo 14, y a Jeanette Sayre y Lynn Steele, por proporcionar un valioso apoyo editorial y administrativo. También deseamos dar las gracias a nuestros colegas Ernst Berndt, Bronwyn Hall, Paul Ruud y Thomas Stoker por ofrecernos numerosos comentarios y sugerencias útiles.
También deseamos agradecer a los revisores que nos orientaron durante la planeación y elaboración de la cuarta edición; Walter Park de la American University; Houson Stokes de la University of Illinois-Chicago; William Parke de la University of North Carolina, Chapel Hill; Walter Mayer de la University of Mississippi; Mukhtar M. Al de la University of Kentucky; Tom Taylor de la Wright State University; Cari Moody del College of William and Mary; David Selover de la Wesleyan University; Steven Hansen de la Western Washington University. Además, debemos mencionar a algunas de las personas que han establecido correspondencia con nosotros, sugiriendo muchos cambios y mejo-ras para el libro. Nos referimos a Imad Al-Akhdar del Central Bank of Jordán; Walter Bell de la Princeton University; Christiaan Heij y Marius Ooms de la Universidad Erasmo en Rotterdam; Hiroyuki Kawakatsu de la University of California en Irvine, California; Huston McCulloch de la Ohio State University; Jeffrey Perloff de la University of California en Berkeley; Roben Rycroft del Mary Washington College; Sergio Schmukler de Berkeley, California, y Kenneth White de la University of British Columbia.
PREFACIO XVii
El Manual del maestro se actualizó a partir de la tercera edición. Se encuen-tran disponibles dos guías en software: el manual EVIEWS de Hiroyuki Kawakatsu y el manual TSP de Sergio Schmukler. Estas guías en software, al igual que el Manual del maestro, pueden obtenerse en forma directa en McGraw-Hill.
INTRODUCCIÓN
Las personas que pretendan predecir el futuro serán consideradas alborotadoras bajo la subdivisión 3, sección 901 del código criminal, y se harán acreedoras a una multa de 250 dólares y lo seis meses de prisión.
Sección 889, Código de Procedimientos Penales del Estado de Nueva York. Este libro es una introducción a la ciencia y el arte de construir y usar modelos. Al contrario de las leyes penales de Nueva York, dirigidas a aquellos que preten-dan predecir con bolas de cristal, creemos que estos modelos pueden ser una herramienta de pronóstico muy útil. La ciencia de la construcción de modelos consiste de un conjunto de herramientas cuantitativas que se usan para cons-truir y luego probar representaciones matemáticas del mundo real. La elabora-ción y uso de estas herramientas se incluyen bajo el encabezado temático de la econometría. El arte de construir modelos es, por desgracia, difícil de describir con palabras, pues consiste principalmente de juicios intuitivos que se hacen durante el proceso de modelado. En vista de que no hay reglas definidas para hacer estos juicios, el arte de la construcción de modelos también puede ser difícil de dominar. No obstante, uno de los propósitos de este libro es transmitir la naturaleza de este arte. Esto se logrará en parte con ejemplos y exposiciones de la técnica, pero también alentando a los lectores a construir sus propios modelos.
XX INTRODUCCIÓN
tativa. Entonces, se usan los datos para estimar los parámetros de la ecuación o ecuaciones, y las relaciones teóricas se prueban en forma estadística. Esto aún deja una gama bastante amplia de modelos de donde escoger. En un extremo de esta gama podría determinarse el efecto de políticas monetarias alternativas en el comportamiento de la economía estadounidense, construyendo un modelo econométrico grande de ecuaciones múltiples de la economía y luego simularlo usando diferentes políticas monetarias. El modelo resultante sería bastante complicado y supondría explicar una estructura compleja en el mundo real. En el otro extremo de la gama podría desearse pronosticar el volumen de ventas de una empresa y, creyendo que dichas ventas siguen un patrón cíclico fuerte, usar un modelo de series de tiempo para extrapolar a partir del comportamiento pasado de las ventas.
Esta gama de modelos es el tema de este libro y el objetivo es dar al lector alguna comprensión de la ciencia y arte de determinar qué tipo de modelo cons-truir -el más apropiado-, probar el modelo en forma estadística y luego aplicarlo a problemas prácticos en pronóstico y análisis.
1 ¿POR QUÉ MODELOS?
Muchos de nosotros a menudo usamos o hacemos pronósticos de una forma u otra. Pocos de nosotros reconocemos, sin embargo, que alguna clase de estruc-tura lógica o modelo, está implícita en cada pronóstico. Considere, por ejemplo, que un corredor de bolsa le dice que el Promedio Industrial Dow Jones se ele-vará el próximo año. El corredor de bolsa puede haber hecho este pronóstico debido a que el promedio Dow Jones se ha elevado durante los años anteriores y el corredor siente que sea lo que sea que ha hecho que aumente continuará haciéndolo en el futuro. De manera alternativa, el sentimiento de que el Dow Jones se elevará el próximo año puede resultar de una creencia de que esta variable está vinculada con un conjunto de variables económicas y políticas a través de una serie de relaciones compleja. El corredor de bolsa puede creer, por ejemplo, que el promedio Dow Jones está relacionado, de cierta manera, con el producto interno bruto y con las tasas de interés, de modo que dadas otras creencias acerca del comportamiento futuro más probable de esas variables, parecería probable un incremento en el promedio Dow Jones.
INTRODUCCIÓN XXi
Por tanto, incluso un pronosticador intuitivo construye algún tipo de mode-lo, quizá sin percatarse de que lo hace. Por supuesto, es razonable preguntar ¿por qué uno podría querer trabajar con un modelo explícito para producir pro-nósticos? ¿Valdría la pena, por ejemplo, que nuestro corredor de bolsa leyera este libro para construir un modelo explícito, estimarlo y probarlo en forma estadística? Nuestra respuesta es que hay varias ventajas en trabajar con mode-los de manera explícita. Construir modemode-los obliga al individuo a pensar con claridad y explicar todas las interrelaciones importantes implicadas en un pro-blema. Fiarse de la intuición puede ser peligroso a veces debido a la posibilidad de que se ignoren o se usen de manera inapropiada relaciones importantes. Además, es importante que las relaciones individuales sean validadas de alguna manera. Por desgracia, generalmente no se hace esto cuando se realizan pronós-ticos intuitivos. Sin embargo, en el proceso de construir un modelo, una persona debe validar no sólo el modelo en conjunto sino también las relaciones indivi-duales que forman el modelo.
Al hacer un pronóstico, también es importante proporcionar una medida de la precisión que esperamos del pronóstico. El uso de métodos intuitivos, por lo general, impide cualquier medida cuantitativa de confianza en el pronóstico resultante. El análisis estadístico de las relaciones individuales que forman un modelo, y del modelo como un conjunto, hace posible adjuntar una medida de confianza a los pronósticos del modelo.
Una vez que se ha construido un modelo y se ha adecuado a los datos, puede usarse un análisis de sensibilidad para estudiar muchas de sus propiedades. En particular, pueden evaluarse los efectos de cambios pequeños en variables indi-viduales en el modelo. Por ejemplo, en el caso de un modelo que describe y predice tasas de interés, uno podría medir el efecto en una tasa de interés par-ticular de un cambio en el índice de inflación. Este tipo de estudio de sensibili-dad sólo puede realizarse si el modelo está en forma explícita.
2 TIPOS DE MODELOS
En este libro se examinan tres clases generales de modelos que pueden cons-truirse para propósitos de pronóstico o análisis de políticas. Cada una implica un grado diferente de complejidad de modelo y supone un nivel diferente de com-prensión acerca de los procesos que uno está tratando de modelar.
Modelos de series de tiempo En esta clase de modelos suponemos no saber nada sobre la causalidad que afecta a la variable que estamos tratando de pronosticar. En lugar de ello, examinamos el comportamiento pasado de una serie de tiempo a fin de inferir algo acerca de su comportamiento futuro. Cada método usado para producir un pronóstico puede implicar el uso de un modelo determinista simple como una extrapolación lineal o el uso de un modelo esto-cástico complejo para pronóstico adaptable.
XXii INTRODUCCIÓN
ción. Otro ejemplo puede ser la elaboración de un modelo estocástico lineal complejo para número de pasajeros en una línea aérea. Los modelos de series de tiempo se han usado para el pronóstico de la demanda de capacidad para la aerolínea, la demanda telefónica estacional, el movimiento de las tasas de inte-rés a corto plazo y otras variables económicas. Estos modelos también son útiles en particular cuando se sabe poco acerca del proceso subyacente que uno está tratando de pronosticar. La estructura limitada de los modelos de series de tiem-po los hace confiables sólo a corto plazo, pero no obstante son bastante útiles.
Modelos de regresión de una sola ecuación En esta clase de modelos la variable bajo estudio es explicada por una función única (lineal o no lineal) de un número de variables explicativas. La ecuación a menudo será dependiente del tiempo (es decir, el índice de tiempo aparecerá de manera explícita en el modelo), de modo que uno puede predecir la respuesta a través del tiempo de la variable bajo estudio ante los cambios en una o más de las variables explica-tivas.
Un ejemplo de un modelo de regresión de una sola ecuación podría ser una ecuación que relacione una tasa de interés particular, como la tasa de un bono de Tesorería a tres meses, con un conjunto de variables explicativas como la oferta de dinero, el índice de inflación y la tasa de cambio en el producto interno bruto.
Modelos de ecuaciones múltiples En estos modelos la variable que se va a estudiar puede ser una función de diversas variables explicativas, las cuales ahora son relacionadas entre sí al igual que la variable bajo estudio por medio de un conjunto de ecuaciones. La construcción de un modelo de ecuaciones múltiples comienza con la especificación de un conjunto de relaciones indi-viduales, cada una de las cuales es ajustada a los datos disponibles. La simula-ción es el proceso de resolver estas ecuaciones simultáneamente sobre algún intervalo.
Un ejemplo de un modelo de ecuaciones múltiples sería un modelo completo de la industria textil estadounidense que contiene ecuaciones que explican variables como la demanda textil, la producción textil, el empleo de trabajadores de producción en la industria textil, la inversión en la industria y los precios textiles. Estas variables se relacionarían entre sí y con otras variables (como el ingreso nacional total, el índice de precios al consumidor y las tasas de interés) por medio de un conjunto de ecuaciones lineales o no lineales. Dadas las supo-siciones acerca del comportamiento futuro del ingreso nacional, las tasas de interés, etc., uno podría simular este modelo en el futuro y obtener un pronós-tico para cada una de las variables del modelo. Un modelo como éste puede usarse para analizar el impacto en una industria de los cambios en variables económicas externas.
INTRODUCCIÓN XXiii
información que la suma de cinco ecuaciones de regresión individuales. Esto es, el modelo no sólo explica las cinco relaciones individuales sino también descri-be la estructura dinámica implicada por la operación simultánea de estas rela-ciones.
La elección del tipo de modelo a elaborar implica hacer intercambios entre tiempo, energía, costos y la precisión deseada del pronóstico. La construcción de un modelo de simulación de ecuaciones múltiples puede requerir grandes gastos de tiempo y dinero. Las ganancias de este esfuerzo pueden incluir una mejor comprensión de las relaciones y estructura involucrada al igual que la capacidad para hacer un mejor pronóstico. Sin embargo, en algunos casos estas ganancias pueden ser lo bastante pequeñas para ser superadas por los grandes costos im-plicados. Debido a que el modelo de ecuaciones múltiples necesita una buena cantidad de conocimiento sobre el proceso que se está estudiando, la construc-ción de estos modelos puede ser extremadamente difícil.
La decisión de construir un modelo de series de tiempo, por lo general, ocurre cuando se sabe poco o nada sobre los determinantes de la variable que se está estudiando, cuando se dispone de una gran cantidad de puntos de datos y cuando el modelo se va a usar en gran medida para pronósticos a corto plazo. Sin embargo, dada alguna información sobre los procesos relacionados, puede ser razonable que un pronosticador construya ambos tipos de modelos y compare su desempeño relativo.
3 QUÉ CONTIENE EL LIBRO
El libro está dividido en cuatro partes, cada una de las cuales contiene una clase diferente de modelos. La clase más fundamental, expuesta en la primera y se-gunda partes del libro, es el modelo de regresión de una sola ecuación. Estos métodos econométricos elaborados y usados para construir modelos de regre-sión de una sola ecuación encontrarán aplicación, con modificaciones, en la construcción de los modelos de ecuaciones múltiples y los modelos de series de tiempo.
Los capítulos 1 y 2 inician la parte uno con una introducción a los conceptos básicos del análisis de regresión y una revisión de la estadística elemental. Lue-go se desarrolla en detalle el modelo de regresión, comenzando con un modelo de dos variables en el capítulo 3 y procediendo hasta el modelo de regresión múltiple en el capítulo 4.
XXiV INTRODUCCIÓN
res causados por una especificación errónea, concentrándose además, en la ela-boración de la técnica de estimación por variable instrumental y diagnósticos de la regresión.
El capítulo 8 expone el uso de un modelo de regresión de una sola ecuación para propósitos de pronóstico. El capítulo no sólo expone los métodos con los que se produce un pronóstico sino también las medidas que describen la confiabilidad de éste, como los intervalos de confianza y el error del pronóstico.
Los últimos tres capítulos en la parte dos presentan una visión más amplia del modelo de regresión. Estos capítulos son un poco más avanzados y pueden ser omitidos por estudiantes principiantes. El capítulo 9 trata de los problemas de observaciones faltantes, modelos de retraso distribuido, el uso de datos de panel y las pruebas de causalidad. El capítulo 10 expone la estimación no lineal y la de máxima verosimilitud, incluyendo los modelos Arch y Garch. El capítulo 11 trata de los modelos en los que la variable que se va a explicar es de naturaleza cualitativa. En estos modelos se incluyen los modelos de probabili-dad lineal, probit, logit y de regresión censurada.
Los fundamentos de econometría de las partes uno y dos son esenciales para la elaboración de modelos de ecuaciones múltiples en la parte tres del libro. Esta parte comienza con un capítulo sobre técnicas de estimación particulares para modelos de ecuaciones simultáneas. Éste incluye problemas de identificación del modelo al igual que técnicas como mínimos cuadrados en dos etapas y en tres etapas. Los capítulos 13 y 14 exponen la metodología para construir y usar modelos de ecuaciones múltiples. El capítulo 13 es una introducción a los mo-delos de simulación en los que se incluyen una exposición del proceso de esti-mación, métodos para evaluar los modelos de simulación, métodos alternativos para estimar modelos de simulación y enfoques generales de la construcción de modelos. El capítulo 14 es de naturaleza más técnica y expone métodos para analizar el comportamiento dinámico de los modelos de simulación, además de incluir aspectos de estabilidad del modelo, multiplicadores dinámicos y métodos para afinar y ajustar modelos de simulación. El capítulo 14 concluye con una exposición del análisis de sensibilidad y de la simulación estocástica. Se cons-truye un macromodelo pequeño de la economía estadounidense y se usa para un análisis simple de políticas en el apéndice del capítulo.
La parte cuatro de este libro está dedicada a los modelos de series de tiempo, los cuales pueden verse como una clase especial de los modelos de regresión de una sola ecuación. Por tanto, las herramientas econométricas elaboradas en las partes uno y dos encontrarán una aplicación extensa en la parte cuatro. Los capítulos 15 y 16 dan inicio a la parte cuatro, en éstos se exponen técnicas de suavización y extrapolación básicas, introducen las propiedades básicas de las series de tiempo aleatorias al igual que la noción de un modelo de series de tiempo. El capítulo 16 también expone las propiedades de las series de tiempo estacionarias y no estacionarias, la función de autocorrelación, las pruebas de raíz unitaria y el concepto de series de tiempo cointegradas.
INTRODUCCIÓN XXV
modelos de promedio móvil, modelos autorregresivos, modelos mixtos y por último modelos de series de tiempo no estacionarias. El capítulo 18 desarrolla métodos de regresión que pueden usarse para estimar un modelo de series de tiempo como también métodos para verificación diagnóstica que pueden usarse para asegurar lo bien que se "ajusta" a los datos el modelo estimado. El capítulo 18 también trata del cálculo del pronóstico con error cuadrático medio mínimo, el error de pronóstico y los intervalos de confianza del pronóstico.
El último capítulo de la parte cuatro se dedica por completo a ejemplos de la construcción y uso de los modelos de series de tiempo. Después de que revi-samos el proceso de modelado, construimos modelos de diversas variables eco-nómicas y los usamos para producir pronósticos a corto plazo. Por último, de-mostramos cómo pueden construirse modelos que combinen series de tiempo con análisis de regresión.
4 USO DE HERRAMIENTAS MATEMÁTICAS
Este libro está escrito en un nivel bastante elemental, y puede ser comprendido por lectores con un conocimiento limitado de cálculo y sin conocimiento del álgebra matricial. Las derivaciones y pruebas matemáticas, por lo general, se reservan para los apéndices o se suprimen por completo. En las partes uno y dos del libro, la elaboración del modelo de regresión en forma matricial se incluye en los apéndices. Por tanto, la mayor parte del libro, si no es que todo, deberá ser accesible para los estudiantes de licenciatura avanzados como para los estudian-tes graduados.
Es deseable que el lector tenga algunos antecedentes de estadística. Aunque el capítulo 2 contiene una revisión breve de probabilidad y estadística, un estu-diante sin estos antecedentes puede encontrar algunas dificultades en algunas partes del libro. De manera típica, este libro se usaría en un curso de econome-tría aplicada o de pronóstico comercial que un estudiante podría tomar después de terminar un curso introductorio de estadística.
5 USOS ALTERNATIVOS DEL LIBRO
El libro tiene el propósito de tener un espectro amplio de usos. Estos usos en los planes de estudio incluyen un curso de licenciatura o introductorio de posgrado sobre econometría y un curso de licenciatura o de posgrado en pronóstico de negocios. Además, este libro puede ser de valor considerable como libro de re-ferencia para personas que hacen análisis estadísticos de datos económicos y comerciales o para el científico social o analista de negocios interesados en la aplicación de modelos de simulación dinámica para pronóstico o análisis de políticas.
XXVi INTRODUCCIÓN
de otras alternativas. A continuación enumeramos varios usos alternativos del libro, pero enfatizamos que por la variedad del material se deja una buena can-tidad a criterio del maestro.
1. Econometría para licenciatura (un semestre)
a) Estándar
Parte uno: capítulos 1 a 4
Parte dos: capítulos 5 a 7; porciones de los capítulos 8 a 11 opcionales
b) Énfasis en la simulación
Parte uno: capítulos 1 a 4 Parte dos: capítulos 5, 6, 8 Parte tres: capítulos 12 a 14
Ambos cursos omitirían todos los apéndices de matrices. 2. Primer año de posgrado en econometría
a) Un semestre
Parte uno: capítulos 1 a 4
Parte dos: capítulos 5, 6, 8; capítulos 9 a 11 opcionales Parte tres: capítulos 12 a 14
Fragmentos de lo anterior y los apéndices pueden ser opcionales.
b) Dos semestres
Parte uno: capítulos 1 a 4 Parte dos: capítulos 5 a 11 Parte tres: capítulos 12 a 14
Parte cuatro: capítulos 15 a 17; algunas secciones del capítulo 17 a 19 opcionales
El énfasis en la simulación y/o el análisis de series de tiempo dependería del interés del maestro.
3. Pronóstico de negocios (posgrado o estudiantes de licenciatura avanzados)
a) Un semestre
Parte dos: capítulo 8 más una revisión de los capítulos 1 a 7 Parte tres: capítulos 13, 14
Parte cuatro: capítulos 15 a 19 (fragmentos seleccionados)
b) Dos semestres
Parte uno: capítulos 1 a 4 Parte dos: capítulos 5 a 8 Parte tres: capítulos 12 a 14 Parte cuatro: capítulos 15 a 19
4. Métodos cuantitativos para el análisis de políticas
a) Licenciatura, un semestre
Parte uno: capítulos 1 a 4 Parte dos: capítulos 5 a 8 Parte tres: capítulos 13, 14
b) Posgrado, un semestre
INTRODUCCIÓN XXVii
c) Posgrado, dos semestres Parte uno: capítulos 1 a 4
Parte dos: capítulos 5 a 8; capítulos 9 a 11 opcionales Parte tres: capítulos 12 a 14 Parte cuatro: capítulos 15 a 19
El libro también puede ser usado para cursos sobre modelado cuantitativo en ciencias sociales (como se enseña en los departamentos de sociología o cien-cias políticas). Es probable que un curso así que use este libro como texto abar-caría la mayor parte de las partes uno a tres.
6 ¿QUÉ DISTINGUE A ESTE LIBRO DE OTROS?
La mayor parte de los libros de texto sobre econometría elaboran el modelo de regresión de una sola ecuación como una entidad autónoma y aislada. El lector a menudo infiere que los modelos de regresión estadística son algo distintos e independientes de otros aspectos del modelado, así como el análisis de la estruc-tura dinámica del modelo y el uso de análisis de series de tiempo para pronos-ticar una o más variables exógenas en el modelo. Por supuesto que éste no es el caso. Al elaborar un modelo de ecuación múltiple, por ejemplo, uno debe estar informado no sólo de los métodos de regresión sino también acerca de la forma en que el comportamiento dinámico de un modelo resulta de la interacción de sus ecuaciones individuales.
PARTE
UNO
LOS FUNDAMENTOS
DEL ANÁLISIS DE REGRESIÓN
La parte uno de este libro trata de los conceptos más básicos del modelado econométrico, centrándose en los modelos de regresión de una sola ecuación, los cuales son simples en la forma, pero bastante poderosos en función de la variedad de sus posibles aplicaciones en los negocios y la economía. En estos modelos, la variable bajo estudio se considera una función lineal de diversas variables explicativas. Los modelos de regresión de una sola ecuación son im-portantes, no sólo porque pueden usarse para probar hipótesis y para pronosti-car, sino también debido a que forman la base para el análisis de modelos de ecuaciones simultáneas y modelos de series de tiempo.
En el capítulo 1 se exponen los conceptos elementales de ajuste de curvas y la noción de mínimos cuadrados. El capítulo 2 contiene una revisión extensa de las ideas estadísticas básicas que son necesarias para los análisis que siguen. En el capítulo 3 el modelo de dos variables se usa como un medio para enfocarse en las propiedades estadísticas que son necesarias para las estimaciones de pará-metros de regresión. Este capítulo pone énfasis en la prueba de hipótesis y en la medición de la bondad de ajuste. El capítulo 4 extiende el modelo de regresión al caso de variables múltiples. La presencia de más de una variable explicativa en el modelo de regresión conduce a problemas econométricos adicionales, in-cluyendo la multicolinealidad que afecta la interpretación de los coeficientes de regresión. También se comentan las estadísticas de regresión adicionales que ayudan con estos problemas.
CAPÍTULO
1
I
NTRODUCCIÓN AL MODELO
DE REGRESIÓN
En este capítulo comenzamos nuestra exposición de la econometría con el mo-delo de regresión lineal de dos variables. En la primera sección, se comenta el ajuste de la curva usando un ejemplo basado en los promedios de calificaciones de los estudiantes. Se presenta el criterio de mínimos cuadrados para el ajuste de la curva y se compara con varios esquemas alternativos para este ajuste. En la segunda sección derivamos el procedimiento de estimación de mínimos cua-drados. El capítulo concluye con tres aplicaciones elementales de la técnica de regresión de mínimos cuadrados.
1.1 A
JUSTE DE CURVALos datos que resultan de la medición de variables pueden provenir de cualquier cantidad de fuentes y en diversas formas. Los datos que describen el movimien-to de una variable a lo largo del tiempo son llamados damovimien-tos de series de tiempo y pueden ser diarios, semanales, mensuales, trimestrales o anuales. Los datos que describen las actividades de personas individuales, empresas u otras unidades en un punto dado en el tiempo son llamados datos de corte transversal. Estos datos pueden ser empleados, por ejemplo, en un estudio de mercado que tiene que ver con los gastos familiares en un tiempo dado. También podrían usarse para examinar un grupo de declaraciones de contabilidad comercial, con el pro-pósito de estudiar patrones de comportamiento entre empresas individuales en una industria. Los datos combinados, los cuales combinan datos de series de tiem-po y de corte transversal, pueden usarse para estudiar el comtiem-portamiento de un grupo de empresas a lo largo del tiempo.
4 PARTE UNO: Los fundamentos del análisis de regresión
CUADRO 1.1
PROMEDIO DE CALIFICACIONES E INGRESO FAMILIAR
Y X
(promedio de calificaciones) (ingreso de los padres en miles de dólares)
4.0 21.0
3.0 15.0
3.5 15.0
2.0 9.0
3.0 12.0
3.5 18.0
2.5 6.0
2.5 12.0
Supóngase que estamos interesados en la relación entre dos variables X y Y.
Para describir esta relación de manera estadística necesitamos un conjunto de observaciones para cada variable y una hipótesis que exponga la forma matemá-tica explícita de la relación. El conjunto de observaciones se llama muestra} Nos interesaremos inicialmente en el caso en que se supone que la relación entre X
y y es lineal, es decir, descrita por una línea recta. Dada la linealidad, nuestro objetivo es especificar una regla por la que pueda determinarse la "mejor" línea recta que relacione a X y Y.
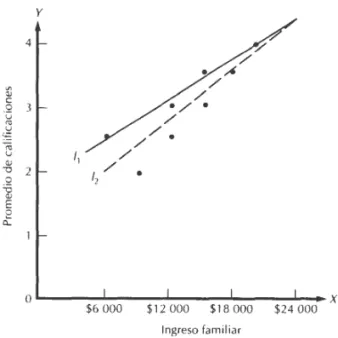
Por ejemplo, supóngase que deseamos probar la hipótesis de que el prome-dio de calificaciones de un estudiante puede explicarse por el ingreso económico de sus padres. Se obtuvieron (hipotéticamente) ocho puntos muéstrales que se describen en el cuadro 1.1. y se colocaron en una gráfica como un diagrama de dispersión en la figura 1.1. Pueden elegirse muchas líneas rectas para ajustar los puntos, una de ellas podría conectar los puntos del valor menor de X con el valor mayor de X (línea l1), o se podría dibujar una línea punteada que parezca ajus-tarse a la dispersión completa de puntos (línea l2). Un procedimiento mejor podría ser elegir una línea de modo que la suma de las distancias verticales (positiva y negativa) de los puntos en la gráfica a la línea sea cero. (Estas dis-tancias, conocidas como desviaciones, se muestran en la figura 1.2). Este criterio aseguraría que a las desviaciones que son iguales en magnitud e iguales en signo se les da igual importancia. Por desgracia, este procedimiento tiene la propiedad indeseable de que las desviaciones que son iguales en tamaño pero de signo opuesto se cancelan, y como resultado, se podría encontrar una línea (o más de una, respecto a eso) que tenga una suma de desviaciones igual a cero pero que no se ajuste a los datos como se pretende.
Se puede mejorar este método si minimizamos el valor absoluto de las des-viaciones de los puntos muéstrales de la línea ajustada. Aquí está implícito el juicio de que la importancia de la desviación es proporcional a su magnitud. Aunque la minimización de la suma de las desviaciones absolutas es atractiva,
1 Los datos de una muestra son observaciones que se han elegido de una población subyacente,
CAPITULO 1: Introducción al modelo de regresión 5
Figura 1.1
Diagrama de dispersión.
sufre de varias desventajas. La primera es que el procedimiento es difícil desde el punto de vista del cálculo. También podría ser que las desviaciones grandes serán tratadas con una atención relativamente mayor que las desviaciones pe-queñas. Por ejemplo, es probable que una predicción que implique un error de dos unidades se consideraría peor que una predicción que implicara dos errores de una unidad cada uno.
Existe un procedimiento cuyo cálculo es simple y que penaliza relativamen-te más los errores grandes que los errores pequeños. Ésrelativamen-te es el método de
míni-Figura 1.2
PARTE UNO: Los fundamentos del análisis de regresión
mos cuadrados. El criterio de mínimos cuadrados es el siguiente: Se dice que la "línea de mejor ajuste" es aquella que minimiza la suma de las desviaciones al cuadrado de los puntos de la gráfica desde los puntos de la línea recta (con distancias medidas en forma vertical). Veremos en los dos capítulos siguientes que los mínimos
cua-drados también son convenientes porque permiten realizar pruebas estadísticas. En este libro nos basaremos mucho en el procedimiento de mínimos cua-drados, pero también hay otras técnicas de estimación que son factibles y en ocasiones deseables. Podemos ver cómo los mínimos cuadrados se relacionan con algunas de estas técnicas alternativas observando la figura 1.3a y b. En la figura 1.3a se presenta la gráfica de la desviación de un punto de los datos desde la línea recta en el eje horizontal y la "pérdida" asociada con esta desviación en el eje vertical. Con los mínimos cuadrados, la pérdida asociada con cada desvia-ción individual es esa desviadesvia-ción al cuadrado. Con la estimadesvia-ción del valor abso-luto mínimo, la pérdida es el valor absoabso-luto de la desviación. Las funciones de pérdida asociadas con los mínimos cuadrados y con los valores absolutos míni-mos, son simétricas con respecto al signo de la desviación, pero la función de pérdida de mínimos cuadrados penaliza más las desviaciones grandes que la función de pérdida del valor absoluto mínimo.
Un problema con los mínimos cuadrados ocurre cuando hay una o más desviaciones grandes. Supóngase que se cometió un error de reporte con respec-to al promedio de calificaciones del primer estudiante, habiéndose reportado
Figura 1.3
a) Función de pérdida
b) función de pérdida
alternativa.
a)
CAPÍTULO 1: Introducción al modelo de regresión 7
una calificación de 1.0 en lugar de la cifra correcta de 4.0. Si la línea l2en la
figura 1.1 fuera considerada como una posible línea de mínimos cuadrados, la desviación asociada con el primer punto de los datos sería muy grande y la desviación al cuadrado sería aún más grande. La recta de mínimos cuadrados de mejor ajuste cambiaría en forma considerable, es decir, su pendiente se haría más plana. La penalidad grande asociada con los mínimos cuadrados ha forzado al procedimiento de estimación a poner mayor énfasis en la relación entre la línea recta y el primer punto de los datos. El resultado es que la pendiente (y el intercepto) de la recta de mínimos cuadrados es muy sensible a los puntos que se encuentran lejos de la verdadera línea de regresión. Llamamos puntos atípicos
a aquellos puntos que están a más de una cierta distancia de la línea de regre-sión. Por supuesto, los puntos atípicos pueden representar información impor-tante acerca de la relación entre diversas variables, por tanto, nunca deben desecharse sin un mayor análisis. El examen cuidadoso de los puntos atípi-cos puede ayudarnos a encontrar errores, en cuyo caso puede hacerse una co-rrección.
¿Qué puede hacerse con respecto a la sensibilidad de los mínimos cuadrados con los puntos atípicos? La solución más simple es volver a calcular la recta de mínimos cuadrados eliminando el punto atípico. Al reportar tanto la pendiente de mínimos cuadrados original como la nueva y las intersecciones, podemos determinar la sensibilidad de nuestros resultados ante la presencia de pun-tos atípicos. Debido a que la decisión es arbitraria respecto a cuáles son punpun-tos atípicos, un procedimiento mejor colocaría relativamente menos peso en las desviaciones grandes. Un ejemplo de este procedimiento se da en la figura 1.3b,
en la cual se muestra una función de pérdida que es menos sensible a los puntos atípicos que los mínimos cuadrados o el valor absoluto mínimo.
1.2 DERIVACIÓN DE MÍNIMOS CUADRADOS
El propósito de construir relaciones estadísticas es, por lo general, predecir o explicar los efectos de una variable resultante de los cambios en una o más variables predictoras o explicativas. Para la dispersión de puntos en la figura 1.1, podemos escribir la ecuación lineal Y = a + bX, donde Y, la variable de la izquier-da, es llamada variable dependiente y X, la variable de la derecha, es llamada
variable independiente. Debido a que se trata de explicar o predecir movimientos en Y, es natural elegir como nuestro objetivo la minimización de la suma vertical de las desviaciones cuadráticas a partir de la recta ajustada.2
8 PARTE UNO: Los fundamentos del análisis de regresión
Para obtener la fórmula de mínimos cuadrados para calcular los valores de
a y b, debemos usar algunas herramientas matemáticas básicas. Se sugiere una revisión del apéndice 1.1, el cual habla acerca de las propiedades de los operadores de sumatoria y enfatizamos que no es importante que se entiendan todos los detalles sobre el uso de derivados parciales.
El criterio de los mínimos cuadrados puede replantearse de manera formal como sigue:
(1.1)
donde Ŷi= a + bXirepresenta la ecuación para una línea recta con un intercepto a
y pendiente b. En esta notación Yi es el valor real de Y para la observación i y
corresponde al valor de X para esa observación, mientras que N es el número de observaciones. Ŷi, llamado valor ajustado o pronosticado de Yi, es el valor de Y en
la línea recta asociado con la observación Xi. Esto puede verse con claridad en la
figura 1.4, donde la desviación se calcula restando el valor ajustado de Yidel
valor real. Es decir, para cada observación en X, hay una desviación correspon-diente del valor ajustado del valor real de Y. La suma de cuadrados de estas desviaciones es la que deseamos minimizar y que nos permitirá (en el capítulo 3) calcular una medida de lo bien que se ajusta la línea recta a los datos.
El problema es elegir valores para a y b que minimicen la expresión en la ecuación (1.1). Esto puede hacerse usando cálculo elemental o álgebra. Los detalles de la derivación del cálculo se estudiarán en el apéndice 1.1.3 Como se muestra ahí, las soluciones de mínimos cuadrados para la pendiente y el inter-cepto son:
(1.2)
(1.3)
donde Y
y X
son las medias muéstrales de Y y X, respectivamente.Ahora consideremos cómo las fórmulas en las ecuaciones (1.2) y (1.3) se simplifican en el caso especial, donde X y Y tienen medias muéstrales igual a 0. Primero, escribiendo de nuevo la ecuación (1.3), notamos que:
a = Y
− bX
= 0 (1.4)CAPÍTULO 1: Introducción al modelo de regresión 9
Figura 1.4
Valores ajustados.
Por tanto, cuando las medias muéstrales de X y Y son 0, el intercepto de la línea de regresión ajustada será 0. Para obtener la estimación de la pendiente corres-pondiente en este caso especial, se divide tanto el numerador como el denomi-nador de la ecuación (1.2) entre N2:
Sustituyendo Y
y X
nos da
PeroY
= X
= 0 por suposición. Por consiguiente,
(1.5)
El hecho de que la ecuación (1.5) sea menos complicada que la ecuación (1.2) sugiere que simplificará las cosas e incrementará nuestra comprensión si escri-bimos los estimadores de mínimos cuadrados en función de variables que son expresadas como desviaciones de sus respectivas medias muéstrales, sean o no estas medias cero. Para hacer esto, transformamos los datos a forma de desviacio-nes expresando cada observación en X y Y en términos de desviaciones de sus respectivas medias:
Con esta definición, el estimador de la pendiente de mínimos cuadrados .puede obtenerse (en el caso general) directamente de la ecuación (1.5), en vista de que las variables x y y tienen media cero.4 En efecto hemos centrado los datos mo-
10 PARTE UNO: Los fundamentos del análisis de regresión
viendo el origen de la gráfica que relaciona X y Y a la media muestral. En este caso las variables en minúscula son versiones "centradas" de las variables en mayúscula.
El estimador de la pendiente de mínimos cuadrados es:
(1.6)
El proceso de centrado que transforma las variables en forma de desviacio-nes se describe en la figura 1.5 a y b. La línea de regresión se representa en la gráfica a usando las observaciones originales, mientras que en b se usan las desviaciones. Nótese que las pendientes estimadas de ambas líneas de regresión son idénticas. Esto es obvio a partir de la ecuación (1.6), en vista de que sólo las variables en forma de desviaciones entran en el cálculo. Sin embargo, el inter-cepto de la línea de regresión en la figura 1.5b es idénticamente igual a 0. Esto se deriva de la ecuación (1.4) y del hecho de que x y y¯ son iguales a 0. Por
tanto, si elegimos trabajar con los datos en forma de desviaciones, se mueve el origen de la línea de regresión a la media muestral pero no se altera la pendiente. Observe también que la línea en la figura 1.5b pasa por el origen. Esto es equivalente al hecho de que la línea en la figura 1.5a pasa por el punto de las medias ( Y
, X
).EJEMPLO 1.1 Promedio de calificaciones
En el ejemplo del promedio de calificaciones descrito en el texto, el procedi-miento de mínimos cuadrados nos permite obtener un intercepto de 1.375 y una
Figura 1.5 Uso de la forma de desviaciones.
Ingreso familiar (en miles de dólares)
a) Recta de regresión original
CAPÍTULO 1: Introducción al modelo de regresión 11
pendiente de .12, produciendo la línea Ŷ = 1.375 + .12X.5 Los detalles de los cálculos aparecen en el cuadro 1.2. (La línea de regresión l2y los puntos de
los datos originales se muestran en la figura 1.2.) Para cualquier ingreso fami-liar dado X, la línea de regresión nos permite predecir un valor para el promedio de calificaciones Y. Por ejemplo, un ingreso familiar de 12 mil dólares nos lleva-ría a un promedio de calificaciones pronosticado de Ŷ= 1.375 + .12(12) = 2.815. Aunque el promedio de calificaciones pronosticado no dará necesariamente una estimación exacta cada vez, proporcionará una buena aproximación. Por ejem-plo, podríamos notar que los dos estudiantes en la muestra original (véase el cuadro 1.1) con padres que tienen ingresos de 12 mil dólares tenían promedios de calificaciones de 3.0 y 2.5. El promedio de calificaciones pronosticado resulta encontrarse entre los dos puntos de datos reales.
La pendiente nos dice que un cambio de mil dólares en el ingreso familiar conduciría a un cambio esperado de .12 en el promedio de calificaciones. El valor positivo para la pendiente es consistente con la hipótesis de que los estu-diantes con promedios de calificaciones relativamente altos vienen de familias con ingresos relativamente altos. El interceptó de 1.375 nos dice que si el ingre-so familiar fuera proyectado a cero, la mejor predicción para el promedio de calificaciones sería 1.375. En vista de que ninguna de las familias en nuestra muestra tenía un ingreso cercano a cero, no confiaremos mucho en este resul-tado.
CUADRO 1.2
12 PARTE UNO: Los fundamentos del análisis de regresión
El modelo de regresión lineal de dos variables se examinará con mucho mayor detalle en el capítulo 3, pero es apropiado hacer aquí un comentario final. En el modelo Y = a + bX, la inclinación b es una estimación de dY/dX, la razón de un cambio en Y para un cambio en X Esto nos permite interpretar la pendiente de regresión en forma bastante natural. La interpretación de el intercepto, sin embargo, depende de si se dispone de suficientes observaciones cercanas a X= 0 para producir resultados estadísticamente significativos. Si éste es el caso, se puede interpretar el intercepto como un estimado de Y cuando X = 0. Sin embargo, si no se dispone de suficientes observaciones, la intersección tan sólo es la altura de la recta de mínimos cuadrados.
EJEMPLO 1.2 La explosión de los litigios
¿Qué tan rápido ha crecido con el tiempo el número de casos presentados en los tribunales de Estados Unidos, y qué tan constante ha sido este crecimiento? Un estudio reciente proporciona información útil sobre las tendencias en las de-mandas de derechos civiles.6 Usando datos de series de tiempo trimestrales para el periodo que comienza en el segundo trimestre de 1977 y llega al tercer trimes-tre de 1988, se estimó una ecuación de regresión que relaciona el número de demandas presentadas por trimestre Y, con una variable de tendencia de tiempo
T, la cual se define igual a 1 en el segundo trimestre de 1977 y con un incremento de 1 en cada trimestre posterior. La ecuación estimada es:
Ŷ= 13.00 + 51.03T
El coeficiente de la pendiente de regresión nos dice que en efecto hay una ex-plosión, en el número de casos presentados incrementándose por poco más de 51 en cada trimestre. Por supuesto, una ecuación de regresión no es esencial para calcular este índice de crecimiento de los litigios. Veremos en el capítulo 3 que una Ventaja importante, del enfoque de la regresión, es que nos permite determinar la significación estadística de la estimación de la razón de creci-miento.
El estudio encontró que el crecimiento de los litigios no fue constante a lo largo del periodo y que este crecimiento es sensible al ciclo comercial; entre mayor es el índice de desempleo U, es más probable que se presenten demandas de derechos civiles. La ecuación de regresión estimada es:
Ŷ= -144.38 + 168.91U
CAPÍTULO 1: Introducción al modelo de regresión 13
Esta ecuación nos dice que para cada incremento del 1% en el índice de desem-pleo, se presentaron casi 170 casos adicionales.
EJEMPLO 1.3 Precios de acciones de compañías de servicio públicas
Como parte de un ambicioso estudio financiero corporativo, se ha planteado la hipótesis de que las razones entre precio e ingresos para las compañías de ser-vicio públicas son influidas por sus razones entre deuda y capital contable. Esto es razonable, en vista de que uno esperaría que una razón mayor entre deuda y capital contable conduciría a un patrón de ingresos más variable para una com-pañía y que este riesgo añadido conduciría a un precio menor de las acciones, y por tanto a una razón menor entre precio e ingresos. El modelo puede expresar-se de manera formal como:
Y = a + bX
donde Y= la razón entre precio e ingresos de la compañía (el precio de una
acción de la reserva común dividida entre los ingresos por acción)
X = su razón entre deuda y capital contable (deuda a largo plazo dividi- da entre la deuda más el capital contable)
Esperamos que b tenga un valor negativo pero no tenemos una expectativa
a priori respecto al valor del intercepto. Se obtuvieron observaciones para las variables Y y X para un corte transversal de compañías de servicio públicas (en un punto fijo en el tiempo). El resultado de la regresión lineal es:
Ŷ = 10.2 - 4.07X
El coeficiente de -4.07 parece confirmar la hipótesis planteada. Sin embargo, para conocer con más detalle cuánta confianza debemos tener en la hipótesis, necesitamos usar algunas de las pruebas estadísticas que se exponen en el capí-tulo 2.
APÉNDICE 1.1
El uso del operador sumatoria
14 PARTE UNO: Los fundamentos del análisis de regresión
gamos que X representa la variable "ingreso familiar". Entonces, usando la no-tación con subíndices, se escribe:
X1, X2, . . ., XN
y representan los valores tomados por cada una de las N observaciones de ingre-so familiar. Entonces el ingreingre-so familiar total (X1 +X2 + … +XN) puede representarse
como
( A1 . l)
Las siguientes reglas del operador sumatoria son útiles.
Regla 1 La sumatoria de una constante por k veces una variable es igual a la constante por la sumatoria de esa variable.
(A1.2)
Regla 2 La sumatoria de la suma de observaciones en dos variables es igual a la suma de sus sumatorias.
N N N
Σ (Xi + Yi)= ΣXi + ΣYi (Al.3)
i =1 i =1 i =1
Regla 3 La sumatoria de una constante sobre N observaciones es igual al producto de la constante por N.
N
Σ k = kN (A1.4)
i =1
Usando estas tres reglas, se pueden obtener algunos resultados útiles con-cernientes a las medias, varianzas y covarianzas de variables aleatorias. En vista de que estos conceptos se exponen en forma más completa en el capítulo 2, nos restringiremos aquí a una exposición de propiedades algebraicas (en lugar de estadísticas). Primero, definiremos que la media o promedio de N observaciones en la variable X es:
(A1.5)
CAPITULO 1: Introducción al modelo de regresión 15
Regla 4 La sumatoria de las desviaciones de observaciones sobre X alrede-dor de su media es cero.
N
Σ (Xi - X ¯ )= 0 (A1.6)
i =1
(Véase la nota de pie de página 4 para la prueba.) En el texto tendremos oportunidades frecuentes para usar la forma de desviaciones. Usando letras minúsculas para representar la forma de desviaciones, es decir, xi = Xi –X
, laregla 4 se vuelve:
N
Σ xi = 0 (A1.7)
i=1
Ahora definimos la varianza de X como:
(A1.8)
y la covarianza de X y Y como:
(A1.9)
Usando estas definiciones y los resultados anteriores, se pueden demostrar las últimas dos reglas de sumatorias.
Regla 5 La covarianza entre X y Y es igual al promedio de los productos de observaciones en X y Y menos el producto de sus medias:
(Al.10)
PRUEBA
16 PARTE UNO: Los fundamentos del análisis de regresión
Ahora, recordando la definición de la media de X y la media de Y, se tiene:
La regla 6 se deriva con facilidad de la regla 5, en vista de que se aplica al caso en el que X y Y son la misma variable.
Regla 6 La varianza de X es igual al promedio de los cuadrados de las observaciones en X menos su media al cuadrado.
(Al.11)
Nótese, de manera incidental, que cuando X y Y resultan tener medias iguales a cero (como ocurre cuando son medidas como desviaciones alrededor de sus medias), las definiciones de covarianza y varianza se vuelven: (aquí se ha omi-tido el rango del índice)
En ciertas situaciones será necesario usar sumatorias que se aplican a dos variables aleatorias, llamadas sumatorias dobles. De manera específica, suponga-mos que Xij es una variable aleatoria que adopta N valores para cada resultado de i y j. Habrá, por supuesto, N2resultados totales. Ahora definimos la sumato-
ria doble de estos N2resultados como:
CAPÍTULO 1: Introducción al modelo de regresión 17
Regla 7
(Al.12) Nótese que la sumatoria doble en la regla 7 es muy diferente de la sumatoria sencilla ΣN i =1XiYi la cual contiene N (en lugar de N2)términos.
Regla 8
(A1.13)
APÉNDICE 1.2
Derivación de los estimadores de parámetros de mínimos cuadrados
Como se estableció en el texto, nuestra meta es minimizar Σ(Yi - Ŷi)2, donde Ŷi =a + bXies el valor ajustado de Yicorrespondiente a una observación Xi
par-ticular.
Minimizamos la expresión tomando las derivadas parciales con respecto a a Y b, estableciendo cada una igual a 0, y solucionando el par resultante de ecuaciones simultáneas:7
(Al.14)
(Al.15)
Al igualar estas derivadas a cero y dividirlas entre -2, obtenemos: Σ(Yi - a - bXi) = 0 (Al.16)
ΣXi(Yi- a - bXi) = 0 (Al.17)
Por último, escribiendo de nuevo las ecuaciones (Al.16 y Al.17) obtenemos un par de ecuaciones simultáneas (conocidas como las ecuaciones normales):
ΣYi =aN + bΣXi (Al. 18) ΣXiYi = aΣXi + bΣX 2i (Al. 19)
7 No aparece índice en los signos de sumatoria, pero se asume que el índice abarca todas las