Bibliografía
[Ange-96] Angeline, P.J., Saunders, G.M. and J.B. Pollack, “An Evolutionary Algorithm that Constructs Recurrent Neural Networks”, IEEE Transactions on Neural Networks, vol. 5, nº 1, 1996.
[Ben-92] Bennani, Y. and P. Gallinari, “Task Decomposition Through a Modular Connectionist Architecture: A Talker Identification System”, Artificial Neural Networks, 2, I. Aleksander and J. Taylor (eds.), Elsevier Sience, 1992.
[Bill-80] Billings, S.A., “Identification of Nonlinear Systems - a survey”, IEEE proceedings Vol 127, N. 6, pp 272-285, 1980.
[Born-78] Born, J., “Evolutionsstrategien zur numerischen Lösung von Adaptation-soufgaben”, A dissertation, Humboldt-Universität, Berlin, 1978.
[Bot-91] Bottou, L. and P. Gallinari, “A Framework for the Cooperation of Learning Algorithms”, Advances in Neural Processing Systems 3, R. Lippmann, J. Moody and D. Touretzky (eds.), Morgan Kaufman, 1991.
[Cat-94] Catfolis, T., “Mapping a Complex Temporal Problem into a Combination of Static and Dynamic Networks”, SIGART Bulletin, vol. 5, nº 3, 1994.
[Cat-97] Catfolis, T. and K. Meert, “Hybridization and Specialization of Real-time Recurrent Learning-based Neural Networks”, Connection Science, vol. 9, nº 1, 1997.
[Chal-90] Chalmers, D.J. “The Evolution of Learning: An Experiment in Genetic Connectionism”, Proceedings of the 1990 Connectionist Models Summer School, (Touretzky, D.S., Elman, J.L., Sejnowski, T.J. and G.E. Hinton, eds.), Morgan Kaufmann, 1990.
[Chen-95] Chen, H.W, “Modelling and Identification of Parallel Nonlinear Systems: Structural Classification and Parameter Estimation Methods”, Proceedings of the IEEE, vol. 83, nº 1, 1995.
[Chen-98] Chen, S.H. and Y.F. Liao, “Modular Recurrent Neural Networks for Mandarin Syllable Recognition”, IEEE Transactions on Neural Networks, vol. 9, nº 6, 1998.
[Cyb-89] Cybenko, G., “Approximation by superpositions of a sigmoidal function”, Math. Control, Sygnals and Systems, vol. 2, nº 4, 1989.
[Dav-91] Davis, L. (ed.), Handbook of Genetic Algorithms, Van Nostrand Reinhold, 1991.
[Elsh-94] Elsherif, H. and M. Hambaba, “On Modifying the Weights in a Modular Recurrent Connectionist System”, Proceedings of the World Congress on Neural Networks, 1994.
[Esco-97] Escobet, T. Aportació a la identificació paramètrica de sistemes dinàmics. Phd Thesis, Universitat Politècnica de Catalunya, 1997.
[Fau-94] Fausett, L., Fundamentals of Neural Networks, Prentice Hall, 1994.
[Fog-66] Fogel, L.J., Owens, A.J. and M.J. Walsh, Artificial Intelligence through Simulated Evolution, Wiley, 1966.
[Fog-93] Fogel, D.B. “Using Evolutionary Programming to Create Neural Networks that Are Capable of Playing Tic-Tac-Toe”, Proceedings of the International Conference on Neural Networks, 1993.
[Fogel-93] Fogelman Soulié, F., Lamy B. and E. Viennet, “Multi-Modular Neural Network Architectures: Applications in Optical Character and Human Face Recognition”, Int. Journal of Pattern Recognition and Artificial Intelligence, vol. 7, nº 4, 1993.
[Gol-89] Goldberg, D.E., Genetic Algorithms in Search, optimization and Machine Learning, Addisson Wesley, 1989.
[Hab-90] Haber, R. and H. Unbenhauen, “Structure Identification of Non Linear Dynamic Systems - A survey on input/output Approaches”, Automatica, vol. 26, nº 4:651-677, 1990.
[Hap-94] Happel, B.L.M. and J.M.J. Murre, “The design and evolution of modular neural network architectures”, Neural Networks, 7: 985-1004, 1994.
[Harp-91] Harp, S.A. and T. Samad, “Genetic Synthesis of Neural Network Architecture”, Handbook of Genetic Algorithms (L. Davis, ed.), 1991.
[Hertz-91] Hertz, J., Krogh, A. and R.G. Palmer, Introduction to the Theory of Neural Computation, Addison-Wesley, 1991.
[Hor-89] Hornik, K., Stinchcombe, M. and H. White, “Multilayer Feedforward Networks are Universal Aproximators”, Neural Networks, vol. 2, nº 5, 1989.
[Hor-91] Hornik, K. “Approximation Capabilities of Multilayer Feedforward Networks”, Neural Networks, vol. 4, 1991.
[Hor-93] Hornik, K. “Some New Results on Neural Network Approximation”, Neural Networks, vol. 6, 1993.
[Hunt-92] Hunt, K.J., Sbarbaro, D., Zbikowski, R. and P.J. Gawthorp, “Neural Networks for Control Systems – A Survey”, Automatica, vol 28, nº 6, 1992.
[Hush-98] Hush, D.R. and B. Horne, “Efficient Algorithms for Function Approximation with Piecewise Linear Sigmoidal Networks”, IEEE Transactions on Neural Networks, vol 9, nº 6, 1998.
[Jac-93] Jacobs, R.A. and M.I. Jordan, “Learning Piecewise Control Strategies in a Modular Neural Network Architecture”, IEEE Transactions on System, Man and Cybernetics, vol 23, nº2, 1993.
[Jac-94] Jacobs, R.A. and M.I. Jordan, “Hierarchical Mixtures of Experts and the EM Algorithm”, Neural Networks, vol. 6, 1994.
[Jor-91] Jordan, M.I. and D.E. Rumelhart, “Forward Models: Supervised Learning with a Distal Teacher”, MIT, Center for Cognitive Science, Occasional Paper #40, 1991.
[Koehn-94] Koehn, P., Combining Genetic Algorithms and Neural Networks: The Encoding Problem, MsC Thesis, The University of Tennessee, 1994.
[Kus-94] Kusçu, I. and C. Thornton, “Design of Artificial Neural Networks Using Genetic Algorithms: review and prospect”, Cognitive and Computing Sciences, Tech. Rep., Univ. of Sussex, 1994.
[Lev-93] Levin, A.U. and K.S. Narendra, “Control of Nonlinear Dynamical Systems Using Neural Networks: Controllability and Stabilization”, IEEE Transactions on Neural Networks, vol 4, nº 2, 1993.
[Lev-96] Levin, A.U. and K.S. Narendra, “Control of Nonlinear Dynamical Systems Using Neural Networks – Part II: Observability, Identification and Stabilization”, IEEE Transactions on Neural Networks, vol 7, nº 1, 1996.
[Ljung-87] Ljung, L., System Identification – Theory for the User, Prentice-Hall, 1987.
[McD-93] McDonnell, J.R. and D. Waagen, “Evolving Neural Network Connectivity”, IEEE International Conference on Neural Networks, 1993.
[McD-96] McDonnell, J.R and R. Waagen, “Evolving Recurrent Perceptrons”, IEEE Transactions on Neural Networks, vol. 5, nº 1, 1996.
[Mel-96] Meltser, M., Shoham, M. and L.M. Manevitz, “Approximating Functions by Neural Networks: A Constructive Solution in the Uniform Norm”, Neural Networks, vol. 9, nº 6, 1996.
[Mil-89] Miller, G.F., Todd, P.M. and S.U. Hedge, “Designing Neural Networks Using Genetic Algorithms”, Proceedings of the Third International Conference on Genetic Algorithms, 1989.
[Mor-95] Morcego, B., Català, A. and N. Piera. “Qualitative Approach to Gradient Based Learning Algorithms”, Proceedings of the International Workshop on Artificial Neural Networks, 1995.
[Mor-96a] Morcego, B., Fuertes, J.M., and G. Cembrano, “Neural Modules. Design of a Nonlinear Dynamic Systems Modelling Library of Neural Networks”, Reporte técnico, Institut de Cibernètica (UPC - CSIC), 1996.
[Mor-96b] Morcego, B., Fuertes, J.M. and G. Cembrano. “Neural Modules: Networks with Constrained Architectures for Nonlinear Function Identification”, Proceedings of the International Workshop on Neural Networks for Identification, Control, Robotics and Signal/Image Processing. 1996.
[Mor-97] Morcego, B., Fuertes, J.M., Codina, J. and G. Cembrano. “Modular Neural Network Framework for Nonlinear Dynamic Systems Modeling”, TEMPUS Workshop MODIFY’97, 1997.
[Nar-90] Narendra, K.S. and K. Parthasaranthy, “Identification and Control of Dynamic Systems Using Neural Networks”, IEEE Transactions on Neural Networks, vol. 1, N. 1, 1990.
[Nar-90] Narendra, K.S. and K. Parthasarathy, “Identification and Control of Dynamical Systems Using Neural Networks”, IEEE Transactions on Neural Networks, vol. 1, nº 1, 1990.
[Nar-97] Narendra, K.S. and J. Balakrishnan, “Adaptive control using multiple models”, IEEE Transactions on Automatic Control, 1997.
[Pear-97] Pearson, R.K. and B.A. Ogunnaike, “Nonlinear Process Identification”, In Henson M.A. and D.E. Seborg (eds.), Nonlinear Process Control, Prentice Hall, 1997.
[Petri-98] Petridis, V. and A. Kehagias, Predictive Modular Neural Networks. Applications to Time Series, Kluwer Academic, 1998.
[Rad-93] Radcliffe, N.J, “Genetic Set Recombination and Its Aplication to Neural Network Topology Optimisation”, Neural Computing and Aplications, vol. 1, 1993.
[Rum-86] Rumelhart, D.E., Hinton, G.E. and R.J. Williams, “Learning Internal Representations by Error Propagation”, Parallel Distributed Processing, vol. 1, chap. 8, 1986.
[Shar-96] Sharkey, A.J. (ed.) “Special Issue: Combining Artificial Neural Nets: Ensemble Approaches”, Connection Science, vol 8, nº 3 & 4, 1996.
[Shar-97] Sharkey, A.J. (ed.) “Special Issue: Combining Artificial Neural Nets: Modular Approaches”, Connection Science, vol 9, nº 1, 1997.
[Shar-99] Sharkey, A.J. (ed.) Combining Artificial Neural Nets. Ensemble and Modular Multi-Net Systems. Springer-Verlag, 1999.
[Sjö-95] Sjöberj, J., Zhang, Q., Ljung, L, Benveniste, A., Delyon, B., Glorennec, P., Hjalmarsson, H. and A. Juditsky, “Nonlinear Black-box Modelling in System Identification: a Unified Overview”, Automatica, vol 31, nº 12, 1995.
[Söd-89] Söderstrom, T. and P. Stoica, System Identification, Prentice-Hall, 1989.
[Solla-89] Solla, S.A, “Learning and Generalization in Layered Neural Networks: the Contiguity Problem”, In L. Personnas and G. Dreyfus (eds.), Neural Networks: from Models to Aplications. Paris: I.D.S.E.T., 1989.
[Suy-96] Suykens, J.A.K, Vandewalle, J.P.L and B.L.R De Moor, Artificial Neural Networks for Modelling and Control of Non-Linear Systems, Kluwer Academic Publishers, 1996.
[Tao-96] Tao, G. and P.V. Kokotovic, Adaptive Control of Systems with Actuator and Sensor Nonlinearities, John Wiley & Sons, 1996.
[Wai-89] Waibel, A. “Modular Construction of Time-Delay Neural Networks for Speech Recognition”, Neural Computation, vol. 1, 1989.
[Yao-93] Yao, X., “Evolutionary Artificial Neural Networks”, International Journal of Neural Systems, vol. 4, nº 3, 1993.
Apéndice B: Resultados de las pruebas de modelado
Este apéndice contiene, resumidos, los resultados de los tres problemas que se modelan en el capítulo 5. El resumen de una ejecución se compone de 2 páginas. En la primera se encuentran los datos que caracterizan el problema y los resultados del algoritmo de EP y en la segunda página hay una comparación de los mejores modelos obtenidos. Cuando una ejecución ha obtenido resultados destacables, entonces se amplía el resumen con una página por cada modelo neuronal de interés, con una descripción completa de éste.
La página de resumen del problema contiene, de arriba abajo: los parámetros del algoritmo de EP, las funciones de error utilizadas, dos gráficas que representan la evolución del mínimo alcanzado a lo largo del proceso, el valor numérico del mínimo, información adicional sobre el proceso de optimización y las funciones de transferencia de los sistemas lineales que actúan como información previa.
La página de los mejores modelos contiene cuatro gráficas en las que se comparan los 20 mejores modelos de la ejecución. En las dos superiores se representa la bondad de cada modelo (en términos de sus índices ISE e IAE) respecto a su complejidad, que es el número de parámetros variables de cada uno. En las dos gráficas inferiores se considera también el criterio de bondad empleado en el proceso de optimización evolutiva (generalmente FPE y AIC). La gráfica izquierda presenta una comparación absoluta de los valores de bondad y la de la derecha muestra la bondad respecto a la complejidad del modelo.
Finalmente, las páginas de descripción de los modelos contienen, de arriba abajo: la lista de módulos que componen el modelo; tres gráficas que representan la salida obtenida y la salida del modelo, el error, y un test de correlación entre los errores y la entrada al 97.5% de confianza; por último, está la matriz de adyacencia de la red, con la que se puede construir la red de módulos.
B.1 Resultados de modelado del motor de corriente continua simulado
0 5 10 15 20 0
0.01 0.02 0.03 0.04 0.05 0.06 0.07
Error AIC2 e ISE normalizados
AIC2 ISE
18 20 22 24 26
1.6 1.65 1.7 1.75 1.8
1 2 3
4
5 6
7 8
9 10 11 1213 14
15 16
17 18 19
20 ISE vs número de parámetros
18 20 22 24 26
25 25.2 25.4 25.6 25.8 26 26.2
1 2
3 4
5
6 7
8 9 10 11 1213 14
15 16 17
18 19
20 IAE vs número de parámetros
18 20 22 24 26
2.85 2.9 2.95 3 3.05 3.1 3.15 x 10
-3
1 2
3
4 6 5
7 8
9 10 11 1213
14 15 16 17
18 19 20
0 5 10 15 20 0
0.1 0.2 0.3 0.4
Error AIC2 e ISE normalizados
AIC2 ISE
18 20 22 24
30 35 40 45 50 55
1
23 4
5 6 7
8 910 11
12 13
14 15
16 17 18 19
20 ISE vs número de parámetros
18 20 22 24
110 115 120 125 130 135 140 145
1
23 4
5 6 7
8 910 11
12 13
14 15
16 17 18 19
20 IAE vs número de parámetros
18 20 22 24
0.05 0.06 0.07 0.08 0.09 0.1
1
23 4
5 6 7
8 910 11
12 13
14 15
16 17 18 19
0 5 10 15 20 0
0.02 0.04 0.06 0.08 0.1 0.12
Error FPE e ISE normalizados
FPE ISE
25 26 27 28 29 30
2.4 2.5 2.6 2.7 2.8 2.9
1 2 3
4 5
6 7 8 91011 12
13 14 15 16
17 1820 19 ISE vs número de parámetros
25 26 27 28 29 30
30.5 31 31.5 32 32.5
1 2 3 4
5 6 7 8
9 10
11 12
13 14 15 16
17 18 19
20
IAE vs número de parámetros
25 26 27 28 29 30
4.4 4.6 4.8 5 5.2x 10
-3
1 2 3 4
5 6 7
8 910
11 12
13 14 15
0 5 10 15 20 0
0.05 0.1 0.15
Error FPE e ISE normalizados
FPE ISE
39 40 41 42 43
2.2 2.4 2.6 2.8
1
23 4 56
7 89
10
11 1213 14
15 1617
18 19
20 ISE vs número de parámetros
39 40 41 42 43
29.5 30 30.5 31 31.5 32 32.5
1
23 4 56
7
8 9 10
11 12
13 14
15 16
17
18 19
20 IAE vs número de parámetros
39 40 41 42 43
4.2 4.4 4.6 4.8 5 5.2 5.4x 10
-3
1
23 4 56
7 89
10
11 1213 14
15 1617
18 19
B.2 Resultados de modelado del sistema con histéresis
0 5 10 15 20 0 0.01 0.02 0.03 0.04
Error AIC2 e ISE normalizados AIC2
ISE
22 24 26 28 30 32
2.8 2.85 2.9 2.95 1 2 3 4 5 6 78 910 11 12 13 14 15 16 17 18 19 20
ISE vs número de parámetros
22 24 26 28 30 32
25.5 26 26.5 27 27.5 28 28.5 29 1 2 3 4 5 6 78 910 11 12 13 14 15 16 17 18 19 20
IAE vs número de parámetros
22 24 26 28 30 32
6.2 6.25 6.3 6.35 6.4 6.45
6.5 x 10 -3 1 2 3 4 5 6 7 8 910 11 12 13 14 15 16 17 18 19 20
0 5 10 15 20 0
0.01 0.02 0.03 0.04 0.05
Error AIC2 e ISE normalizados AIC2
ISE
28 30 32 34 36
3.45 3.5 3.55 3.6 3.65 3.7
12 3
4 5 678 91011 12 13 14
15 16
17 18
19 20 ISE vs número de parámetros
28 30 32 34 36
32.8 33 33.2 33.4 33.6 33.8 34 34.2
1 23
4 5
6
7 8
9 10 11
12 13 14
15 16
17 18
19 20 IAE vs número de parámetros
28 30 32 34 36
7.7 7.8 7.9 8 8.1 8.2 8.3x 10
-3
12 3
4 5
678 910
11 13 12
14 15
16 17
18 20 19
0 5 10 15 20 0
0.02 0.04 0.06 0.08
Error FPE e ISE normalizados FPE
ISE
40 45 50 55
1.05 1.1 1.15
1 2 3 45
6 7 8 9
10 11
1213 14
15 16
17181920 ISE vs número de parámetros
40 45 50 55
16.6 16.8 17 17.2 17.4 17.6 17.8
1 2 3
4 5 7 6
8 9
10 11
1213 14
15 16
17 18 1920 IAE vs número de parámetros
40 45 50 55
2.4 2.5 2.6 2.7
x 10-3
1 2 3 45 7 6
8
9 10
B.3 Resultados de modelado del elemento piezoeléctrico
0 5 10 15 20 0 0.05 0.1 0.15 0.2 0.25
Error AIC2 e ISE normalizados AIC2
ISE
8 9 10 11 12 13
120 130 140 150 160 170 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ISE vs número de parámetros
8 9 10 11 12 13
64 66 68 70 72 74 76 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 IAE vs número de parámetros
8 9 10 11 12 13
0 5 10 15 20 0 0.2 0.4 0.6 0.8
Error AIC2 e ISE normalizados AIC2
ISE
2 4 6 8
0 500 1000 1500 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
17 1820 19
ISE vs número de parámetros
2 4 6 8
50 100 150 200 250 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
IAE vs número de parámetros
2 4 6 8
0 5 10 15 20 25 30 35 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
17 1820 19
0 5 10 15 20 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35
Error AIC2 e ISE normalizados AIC2
ISE
10 15 20 25
80 90 100 110 120 130 140 1 2 3 4 5 6 7 8 9 10 11 1213 14 15 16 17 18 19 20
ISE vs número de parámetros
10 15 20 25
55 60 65 70 75 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
IAE vs número de parámetros
10 15 20 25
2.6 2.8 3 3.2 3.4 1 2 3 4 5 6 7 8 9 10 11 1213 14 15 16 17 18 19 20
0 5 10 15 20 0 0.05 0.1 0.15 0.2 0.25
Error AIC2 e ISE normalizados AIC2
ISE
6 7 8 9 10 11
100 110 120 130 140 150 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ISE vs número de parámetros
6 7 8 9 10 11
55 60 65 70 75 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
IAE vs número de parámetros
6 7 8 9 10 11
2.2 2.4 2.6 2.8 3 3.2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
0 5 10 15 20 0
0.1 0.2 0.3 0.4
Error FPE e ISE normalizados FPE
ISE
4 6 8 10 12 14
140 160 180 200 220 240
12 34 5 68 7 9
10 11
12 13 1415
16 17 18 19 20
ISE vs número de parámetros
4 6 8 10 12 14
70 75 80 85 90 95 100 105
12 34 5 6 7 8
9 10
11 12
13 1415 16
17 18
19 20
IAE vs número de parámetros
4 6 8 10 12 14
3 3.5 4 4.5 5 5.5 6
12 34 5 6
7 8
9 10
11 12
13 14 15 16
17 18 19 20
Apéndice A: Sintonía de los parámetros del entorno de
optimización evolutiva
El entorno de optimización evolutiva, junto con el simulador de redes neuronales, es una aplicación compleja en la que intervienen un número apreciable de parámetros. El buen funcionamiento de esta aplicación depende, en alguna medida, de sus valores. Sin embargo, es muy difícil dar con el conjunto óptimo de valores por las siguientes razones: el número de experimentos necesarios para determinarlos haría prohibitivo, hoy por hoy, el tiempo de simulación necesario; el conjunto no es único puesto que cada proceso que se quiera modelar puede tener parámetros diferentes; además, pueden existir conjuntos diferentes con resultados equivalentes. Por todo ello, se ha llevado a cabo un proceso previo de sintonía de los parámetros del entorno de optimización que se describe a continuación.
A.1 Sintonía de los parámetros del simulador neuronal
En el apartado 4.4.2 se enumeran y describen algunos de los parámetros del entorno de optimización, pero el simulador de redes neuronales también requiere el ajuste de valores, como el clásico learning rate de backpropagation. En total son 11 los parámetros necesarios para determinar el funcionamiento de la aplicación en conjunto.
La sintonía de estos parámetros se ha realizado por grupos. Primero se han simulado los módulos neuronales con diferentes algoritmos de aprendizaje hasta encontrar el que, para cada uno, tiene el mejor comportamiento, tanto en velocidad de aprendizaje como en capacidad de generalización. Los resultados de este proceso se resumen en la tabla A.1.
Tipo de módulo neuronal Algoritmo de aprendizaje η β γ κ
Umbral Delta-Bar-Delta 0.7 0.33 4·10-5
Relé con histéresis QuickProp through time 0.001 0.7
Saturación Delta-Bar-Delta 0.7 0.33 2·10-6
Zona Muerta Delta-Bar-Delta 0.7 0.33 2·10-6
Valor absoluto No hay aprendizaje
Fricción Delta-Bar-Delta 0.7 0.33 4·10-5
Juego de engranajes Delta-Bar-Delta through time 0.7 0.33 4·10-5
Tope mecánico Delta-Bar-Delta through time 0.7 0.33 4·10-5
Limitador de velocidad Delta-Bar-Delta through time 0.7 0.33 4·10-6
Sistemas dinámicos lineales Delta-Bar-Delta through time 0.7 0.33 4·10-8
Tabla A.1: parámetros de aprendizaje en los módulos neuronales; los símbolos que se utilizan para designar a cada uno siguen la notación original de los autores de los algoritmos
A.2 Descripción del marco de sintonía
El entorno de optimización evolutiva está parametrizado a través de 7 variables que matizan el comportamiento de los operadores y, en consecuencia, el resultado de la búsqueda. La sintonía de estos parámetros tiene el inconveniente principal de que plantea, en sí misma, un problema de optimización complejo. Para simplificar el proceso y, teniendo en cuenta que éste no es el objeto del trabajo sino un paso intermedio necesario, se ha fragmentado la sintonía en dos partes. Primeramente se ha sintonizado el operador de selección y posteriormente el de mutación, utilizando siempre, el mejor conjunto de parámetros disponibles hasta el momento.
En cada experimento se evalúan un número fijo de redes (el número de generaciones puede variar dependiendo del tamaño de la población) con los mismos datos de entrada y salida. Las secuencias de entrada y salida tienen una longitud de 375 muestras (7.5s con periodo de muestreo de 0.02s) y están obtenidas con entradas generadas a partir de ruido blanco limitado en ancho de banda.
A.3 Parámetros del operador de selección
En este experimento se sintoniza el tamaño de la población (parámetro nIndviduos), el tipo
de selección (parámetro tipoSeleccion) y el número de contendientes en cada competición
(parámetro tournSize).
nIndviduos puede variar desde 10 hasta 85. tipoSeleccion solamente puede tomar
valores de 1 y 2. El primero indica que la selección se realiza entre la población formada por los individuos mutados y evaluados y éstos antes de sufrir las mutaciones. Este tipo de selección es útil cuando se sabe de antemano que la mutación puede dar lugar a individuos construidos incorrectamente. Si tipoSeleccion = 2, entonces la selección se realiza únicamente entre los
individuos mutados y evaluados, como es habitual. Por último, tournSize toma valores
enteros entre 2 y nIndviduos-1. Aquí se han sometido a prueba valores entre 2 y 4, porque
números mayores hacen converger toda la población a un solo individuo muy rápidamente, estancando la búsqueda en una región demasiado limitada del espacio de errores.
El primer conjunto de pruebas consiste en 12 ejecuciones (2 valores para nIndviduos, 2 para tipoSeleccion y 3 para tournSize) repetidas 10 veces con datos de entrada y salida
diferentes. En total 120 ejecuciones. Los resultados de estas pruebas se dan en la tabla A.2.
TournSize
2 3 4
0.1578 0.1689 0.2543 20
Selección 1 0.1604 0.1475 0.1641 65
Selección 2
0.1513 0.1508 0.1342 20
0.1397 0.1199 0.1135 65
Tabla A.2: resultados del experimento de sintonía del operador selección
El segundo conjunto de pruebas consiste en 6 ejecuciones (6 valores para nIndviduos)
repetidas 30 veces con datos de entrada y salida diferentes. En total 180 ejecuciones. Los resultados de estas pruebas se presentan en la tabla A.3.
Nindividuos
10 25 40 55 70 85
Error final 0.1608 0.1633 0.1748 0.1612 0.1611 0.1895
Tabla A.3: resultados de la sintonía del tamaño de la población
El primer conjunto de pruebas permite deducir que el tipo de selección realizado entre redes ya mutadas únicamente tiene un comportamiento superior al que se realiza también con las redes sin mutar. El parámetro tournSize parece influir de diferente manera según el tamaño de la
población y el tipo de selección empleado. En el caso del tipo de selección 2, se aprecia un ligero descenso del error con valores grandes de tournSize. Puesto que la relación no es
estadísticamente respaldable y la experiencia de diferentes autores sugiere valores pequeños para favorecer la diversidad de soluciones, se toma una solución de compromiso con un valor de 3.
El segundo conjunto de pruebas tiene como finalidad establecer una relación entre el tamaño de la población y la bondad de la solución. Sin embargo, los resultados son, de nuevo, poco significativos como para escoger un tamaño de población estadísticamente respaldado. Además, tampoco parecen seguir una tendencia clara para correlacionar el tamaño de la población con el error mínimo alcanzado. Por esta razón se ha tomado un tamaño de población pequeño, de manera las iteraciones sean más rápidas y el operador de selección tenga más oportunidades de intervenir.
Como conclusión, los parámetros tomarán los siguientes valores:
– nIndividuos: 15
– TournSize: 3
A.4 Parámetros del operador de mutación
En este experimento se sintonizan los parámetros pMutarFuncion y maxIncParametro.
El primer parámetro sirve para asignar la probabilidad de que la mutación de un nodo se dé en la función que realiza o en los parámetros de ésta y toma valores entre cero y uno. El segundo permite controlar el porcentaje de variación máxima de estos parámetros y está limitado a valores entre cero y uno.
Las pruebas consisten en 25 ejecuciones (5 valores para pMutarFuncion y 5 para maxIncParametro) repetidas 10 veces con datos de entrada y salida diferentes. En total 250
ejecuciones. Los resultados de estas pruebas están representados en la figura A.1.
0 0.5
1 0
0.5
1 0.1
0.2 0.3 0.4
parámetro
pMutarFuncion
[image:51.595.196.433.307.465.2]Parámetro maxIncParametro
Fig. A.1: resultados de las pruebas de sintonía de los parámetros del operador de mutación
Capítulo 6
Conclusiones del estudio
6.1 Conclusiones y aportaciones principales
Tras centrar, en la introducción, la familia de sistemas que se desea modelar y el marco de modelado, en el segundo capítulo se ha justificado el uso de las redes neuronales en el ámbito del control de sistemas dinámicos y, en concreto, en el modelado e identificación de sistemas no lineales. Se ha visto que tienen ventajas sobre otros modelos e inconvenientes como la imposibilidad de interpretar físicamente sus resultados o el de añadir conocimiento previo para acelerar el proceso de modelado.
Se ha propuesto un modelo que aprovecha las ventajas de las redes neuronales y minimiza sus inconvenientes. Se trata de las redes modulares, que están compuestas por módulos neuronales.
Un módulo neuronal es una red neuronal que aprovecha el uso de restricciones estructurales para forzar un tipo de comportamiento en el modelo. Este concepto se ha creado a propósito en este estudio, apoyado por el argumento de que las restricciones topológicas constituyen un método más versátil y efectivo que el propio mecanismo de aprendizaje para facilitar comportamientos deseados en una ANN.
De esta forma, una vez aplicado el proceso de identificación, el modelo resultante es una red neuronal compuesta por módulos, cada uno de los cuales representa un bloque funcional del sistema con un significado fácilmente interpretable.
familia de funciones. Se ha descrito con detalle el diseño de módulos que permiten discriminar la pertenencia del valor de entrada a un rango y el de módulos que aproximan funciones lineales a tramos.
También se describe un conjunto de módulos neuronales que resulta útil en el modelado de sistemas dinámicos no lineales. Este conjunto está formado por nueve no-linealidades duras y los sistemas lineales sin restricción de orden. Las primeras corresponden a los comportamientos más comunes en los modelos de sistemas físicos, como la saturación, la zona muerta, la histéresis o la fricción. Los sistemas lineales se han modelado siguiendo la representación de entrada y salida.
En el tercer capítulo se ha realizado un estudio formal en el que se han caracterizado los sistemas que se pueden aproximar mediante redes de módulos neuronales, el conjunto ΣNM, y se ha establecido una cota del error de esta aproximación.
ΣNM está formado por la unión infinita de conjuntos NLN i que, a su vez, están ordenados jerárquicamente según NLN ⊂ NLN2⊂…⊂ NLN i. El conjunto NLN contiene sistemas lineales, sin restricción de orden, modificados en sus entradas y salida por características no lineales estáticas, continuas y derivables.
ΣNM es un conjunto interesante porque cuando se modela un proceso físico es habitual dividirlo en subsistemas más sencillos, de manera que el producto de uno de ellos, su salida, es la entrada de otro. Estos subsistemas suelen considerarse lineales, aunque si contienen características no lineales es habitual que se trate no-linealidades duras, como las tratadas en este estudio. De esta forma, las partes del proceso corresponden a elementos de NLN y su composición corresponde a un elemento de NLN i, que está en ΣNM.
Se ha demostrado, en la sección 3.3, que si un sistema no lineal se puede representar mediante sumas y composiciones de sistemas más sencillos, elementos de NLN, entonces existe una red de módulos neuronales que lo aproxima con un grado arbitrario de precisión.
El conjunto ΣNM está construido solamente con dos módulos neuronales. Por ello, en la última sección de este capítulo se discute la utilidad de los restantes módulos. Se concluye, primeramente, que los módulos estáticos (saturación, zona muerta, valor absoluto y fricción) cumplen las condiciones necesarias para no alterar los resultados anteriores. En segundo lugar se presentan resultados experimentales que permiten suponer que los módulos dinámicos (juego, tope, limitador de velocidad e histéresis) pueden resultar muy útiles en el modelado de ciertos sistemas no lineales.
En el cuarto capítulo se consideran los aspectos de creación y optimización del modelo propuesto en los capítulos anteriores.
Primeramente, y puesto que se trata de una red neuronal, se repasan los mecanismos existentes en la literatura para adaptar los parámetros del modelo al problema. En este sentido, se ha diseñado un algoritmo de aprendizaje específico para redes neuronales modulares, el modular backpropagation.
MBP es un algoritmo de gestión del aprendizaje en redes modulares. Su característica principal es que permite la utilización de otros algoritmos, como backpropagation o backpropagation through time, de forma local en los módulos de la red. Además, se ha comparado su coste computacional frente al de otros algoritmos clásicos y es más eficiente en estructuras modulares.
El problema de determinar la estructura del modelo, es decir, los módulos que forman parte de él y su patrón de interconexión, es extremadamente complejo. Se han sugerido, para resolverlo, las técnicas de optimización evolutiva y, en concreto, la programación evolutiva.
Finalmente, se describe una herramienta de modelado, diseñada a propósito, como método para crear y optimizar, de forma automática, redes de módulos neuronales. Esta herramienta combina la programación evolutiva, algoritmos clásicos de aprendizaje neuronal y el gestor de aprendizaje, MBP, con la finalidad de resolver problemas de modelado de sistemas no lineales mediante redes de módulos neuronales.
En el capítulo cinco se describe el proceso de modelado de sistemas no lineales utilizando las herramientas desarrolladas en este estudio. Se ha creado una aplicación (miga) que permite
El proceso de modelado consta de cuatro pasos:
– Obtención y análisis de datos. Se recomienda obtener secuencias de datos significativas respecto a los regímenes de operación del sistema y suficientemente largas, para poder crear los conjuntos de aprendizaje, test y validación.
En este punto es destacable que este método permite incorporar información previa para sesgar y acelerar la búsqueda del modelo.
– Diseño y ejecución de las pruebas. Se sugiere organizarlo jerárquicamente en pruebas, experimentos y ejecuciones.
La aplicación miga realiza todas las pruebas programadas de forma automática en
un entorno distribuido.
– Selección de resultados. Cada prueba desprende un gran número de resultados. Estos se ordenan para realizar una selección según la complejidad del modelo y los errores de test.
– Validación, análisis y refinado de resultados. Los modelos resultantes se someten a un proceso de validación convencional para seleccionar el mejor.
Uno de estos modelos es una estructura manipulable, al mismo nivel, que un diagrama de bloques convencional, con bloques no lineales.
Finalmente, los problemas que se han sometido al proceso de modelado con redes neuronales modulares son: motor de corriente continua, sistema no lineal con histéresis y elemento piezoeléctrico. En los tres casos se ha llegado a una solución satisfactoria que permite confirmar la utilidad de las herramientas desarrolladas en este estudio.
6.2 Vías futuras de trabajo
Este estudio representa un punto de partida que ha abierto direcciones de investigación prometedoras. Seguidamente se apuntan algunas de las más interesantes.
En el ámbito de las redes neuronales
– Completar el esquema de modelado modular para abarcar sistemas más complejos: sistemas con no-linealidades de más de una entrada (como el producto de señales), sistemas con características no lineales analíticas (como las trigonométricas, por ejemplo), estudiar la viabilidad del modelado de sistemas realimentados, etc.
– Extender MPB a redes modulares de propagación recurrente entre módulos. Esta extensión es perfectamente viable, pero no se ha realizado por no ser necesaria para el tipo de redes que se tratan en este estudio.
En el ámbito de los algoritmos de optimización evolutiva
– El estudio de criterios más potentes de optimización de modelos. En este trabajo se han utilizado los criterios clásicos de la teoría de identificación de sistemas (AIC, FPE, ISE, MDL, etc.) pero la naturaleza de los algoritmos evolutivos permite el uso de criterios arbitrarios. En este sentido parece interesante profundizar en criterios que ponderen la ‘interpretabilidad’ del modelo, además de su precisión.
– Introducción de reglas para simplificar los modelos en el proceso de búsqueda. Se pueden incluir reglas invariantes respecto al comportamiento del modelo o reglas de ‘podado’, como algunos algoritmos de aprendizaje neuronal, que simplifican el modelo a costa de modificar ligeramente su comportamiento.
En la automatización del proceso de modelado existen múltiples vías de continuidad
– Creación de herramientas más potentes de análisis de los modelos resultantes.
Por un lado, es importante eliminar de forma automática los modelos poco interesantes mediante técnicas de validación más abiertas y, por otro, conviene mejorar y explotar al máximo la característica más propia del modelado con módulos neuronales: la extracción de información sobre el sistema del modelo resultante.
Capítulo 5
Resultados experimentales
En este capítulo se examina el uso de los módulos neuronales y los algoritmos de optimización evolutiva para el modelado de sistemas no lineales y la identificación de los parámetros que caracterizan los modelos resultantes.
En primer lugar se propone una metodología de utilización de las herramientas descritas en este trabajo y, seguidamente, se modelan tres sistemas dinámicos como ejemplos de aplicación. Los dos primeros son sistemas simulados y el último es un sistema real con datos obtenidos a partir de lecturas en los sensores y actuadores del mismo.
Además, los apéndices A y B también están relacionados con este capítulo porque en ellos se detallan la sintonía de los parámetros de la herramienta de modelado y los resúmenes de los resultados de todas las pruebas descritas en las siguientes secciones.
5.1 Proceso de modelado con la herramienta de optimización evolutiva y redes de módulos neuronales
El proceso de modelado e identificación puede realizarse de forma casi automática con ayuda de los procedimientos que se describen en esta sección, que están integrados en una aplicación de Matlab cuyo nombre es miga. Esta aplicación, que incorpora la herramienta de modelado
descrita en el capítulo 4, también se explica, sucintamente, en esta sección.
5.1.1 Obtención y análisis de datos
La obtención de datos útiles para el modelado e identificación de sistemas dinámicos es, en sí, un tema extremadamente complejo (véase, por ejemplo [Codi-96] y [Esco-97]). Los modelos sólo pueden reflejar aquella información que esté contenida en los datos y, como se apuntaba en la introducción de este trabajo, los sistemas no lineales son difíciles de excitar en las diferentes regiones de operación de su dinámica. No entraremos aquí, por consiguiente, en cómo han de ser los datos sino, más bien, en qué hay que hacer con ellos.
Primero es conveniente dividir el conjunto de datos en tres subconjuntos. Cada uno de ellos servirá para las fases de aprendizaje, test (o reconocimiento) y validación, respectivamente. El tamaño de los conjuntos depende mucho de la disponibilidad de datos. Si se puede disponer de un número suficientemente elevado, entonces los tres conjuntos pueden ser del mismo tamaño. Si el número de datos está limitado se suele reservar un 30% para test y un 10% para validación, criterio que varía según los autores.
La parte que marca la diferencia entre éste y otros métodos de modelado, en este punto, es la recolección de información previa. Toda aquella información del sistema que pueda ser codificada a través de los módulos neuronales acelerará la obtención de resultados.
Por un lado, es importante considerar los elementos no lineales que el sistema en cuestión pueda incluir, pero es casi más importante descartar aquéllos que con certeza no debería incluir el modelo. Eliminando módulos candidatos se reduce el espacio de búsqueda drásticamente.
Por otro lado, el algoritmo de optimización evolutiva parte de una serie de módulos lineales que nosotros codificamos. Consecuentemente, también será conveniente estudiar la dinámica lineal del sistema a modelar. Esta información se puede obtener a partir de leyes físicas o a partir de métodos clásicos de identificación (modelos ARMAX obtenidos por minimización de errores cuadráticos, por ejemplo).
Fig. 5.1: pantalla de introducción de información previa
La información previa recolectada se puede introducir a través de una interficie de usuario (véase la figura 5.1) habilitada para tal efecto en la aplicación miga.
5.1.2 Planteamiento y ejecución de las pruebas
Las técnicas de optimización evolutiva, como se explica en el capítulo 4 de esta memoria, tienen un carácter estocástico en el proceso de búsqueda. Ésta y otras razones, como la diversidad de enfoques en la búsqueda (formas de incluir la información previa, tipos de datos de entrada y salida, aprendizaje conservador o no, etc.) hacen que, en combinación con el entorno de simulación neuronal, se tienda a realizar un número elevado de pruebas. Para sistematizar el proceso de modelado y reducir su tiempo conviene jerarquizar el diseño de experimentos. Aquí, se propone una jerarquía que comprende problemas, pruebas, experimentos y ejecuciones, conceptos que se detallan a continuación.
– Problema: es un proceso que se desea modelar.
– Prueba: es un conjunto de experimentos con un objetivo de modelado concreto, por ejemplo, contemplar la inclusión de cierta información previa o minimizar medidas del error de diferente índole (ISE, FPE, AIC, etc.). Las pruebas pueden dar soluciones con un interés específico cada una.
– Experimento: define los datos de entrada y salida y los valores iniciales del generador de números aleatorios en una prueba.
Así, el modelado de un proceso se puede plantear como un conjunto de pruebas (diferentes objetivos), para las que se ejecutarán grupos de experimentos (diferentes puntos de partida) y que se podrán repetir con ligeras variaciones en los parámetros del algoritmo de optimización evolutiva o en los del simulador neuronal.
La aplicación miga también dispone de pantallas para la configuración de pruebas,
[image:60.595.70.498.218.528.2]experimentos y ejecuciones.
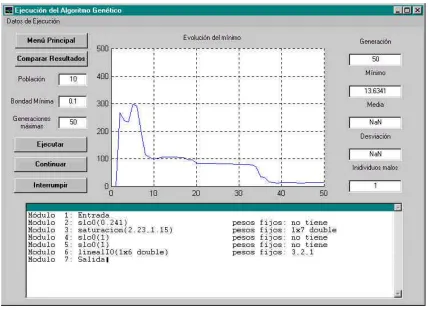
Fig. 5.2: aspecto de la pantalla principal de ejecución de los experimentos
Cuando todas las pruebas han sido programadas ya es posible ejecutarlas (en la figura 5.2 aparece la visualización correspondiente a un experimento en plena ejecución).
5.1.3 Recolección de resultados
El mecanismo de modelado maneja conjuntos de soluciones candidatas y, cuando acaba, puede haber evaluado miles de ellas. El análisis exhaustivo de estos resultados es prácticamente inviable, a parte de poco provechoso. Por esto, es recomendable seguir un proceso sistemático de análisis de los resultados, con la finalidad de reunir un conjunto reducido de modelos sobre el que se realizará la validación. Este proceso se resume seguidamente:
– Cada experimento da, como resultado, los modelos con menor error para el problema. El número de modelos que se considera es veinte, valor obtenido heurísticamente en base a pruebas experimentales.
– El conjunto formado por todas las soluciones se ordena según el error sobre los datos de test y se seleccionan los primeros modelos de esta lista. De nuevo, el número de modelos seleccionados se ha obtenido heurísticamente, y en este caso es treinta.
– Se realiza una gráfica del error respecto a la complejidad del modelo y se escogen aquéllos que pueden resultar más interesantes.
El último punto requiere dos aclaraciones: la complejidad se mide en número de parámetros del modelo, es decir, número de pesos modificables de la red neuronal que lo lleva a cabo; se han considerado modelos interesantes aquéllos con menor error y aquéllos con menor cantidad de parámetros, dentro de valores del error pequeños. En la figura 5.3 se da un ejemplo de este tipo de gráficas y de una selección en la que se consideran modelos con error pequeño y modelos con un número de parámetros reducido.
10 17 21 23 132527
0 5 10 15 20 25 30
0 2 4 6 8 10
1 2
3 4
5
6 7 89
11
12 14
15 16 18
19
20 22 24
26 28 29
30 31 32 33 34 36
FPE vs número de parámetros
5.1.4 Validación, análisis y refinado de modelos
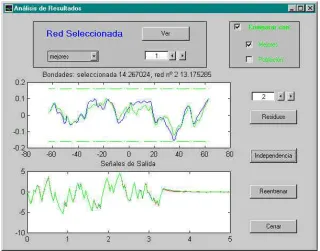
[image:62.595.124.444.239.490.2]La parte de validación consiste en estudiar la respuesta de los modelos escogidos ante entradas que no se han utilizado en los anteriores pasos de creación de los mismos. El resultado de esta prueba se puede evaluar a través de las medidas de error ya comentadas en la introducción de este trabajo (ISE, FPE, etc.) y utilizando también tests de independencia de los residuos respecto de la entrada, usuales en validación. La figura 5.4 muestra el aspecto de la pantalla que permite realizar este test.
Fig. 5.4: aspecto de la interficie de usuario de validación
Fig. 5.5: ejemplo de descripción de una red modular
El siguiente paso es la simplificación de los modelos. A menudo sucede que el mecanismo de optimización genera modelos con módulos que no participan en la salida o que lo hacen en una proporción ínfima. Si transformamos la red a un formato estándar de simulación (como Simulink, por ejemplo) es posible visualizar gráficamente la salida de cada uno de los módulos y comprobar su contribución a la salida global. De esta manera es posible eliminar algunos módulos o substituir otros por elementos más sencillos. Además, existe un conjunto de reglas, detalladas en [Net-87], que permiten realizar transformaciones entre elementos no lineales y que pueden reducir la complejidad del modelo.
Fig. 5.6: pantalla de ejemplo de ajuste fino de los parámetros de un modelo
5.2 Motor de corriente continua
El motor de corriente continua es un sistema simulado que responde al comportamiento de los bancos de prueba disponibles en el departamento de Enginyeria de Sistemes, Automàtica i Informàtica Industrial, de la Universitat Politècnica de Catalunya en Terrassa. La entrada de este sistema es la tensión aplicada a la armadura del motor y la salida es la velocidad de rotación del eje.
Se ha utilizado un sistema simulado porque este sistema ha servido para realizar la sintonía de la mayoría de los parámetros del optimizador evolutivo. De esta manera, se obtiene un sistema conocido, realista y en el que cualquier fuente de ruido ha sido eliminada.
ω(t)
α= 8 β = 1
β
α β
α
α= 1.5 β = 1
1 15 . 0
89 . 0 ) (
+ =
s s
G
[image:65.595.213.408.480.623.2]v(t)
Fig. 5.7: diagrama de bloques del sistema
5.2.1 Datos de entrada y salida e información previa
En este sistema los datos se obtienen mediante simulación, por ello, la disponibilidad de éstos no está limitada. Se han utilizado conjuntos de igual tamaño para las fases de aprendizaje, test y validación. Cada conjunto es de 601 puntos, que corresponde a la simulación de 12 segundos, utilizando un periodo de muestreo de 0.02s.
La información previa disponible es completa. Se dispone del número, tipo y parámetros de los bloques que componen el sistema. Sin embargo, se ha supuesto una situación razonable de conocimiento sobre el sistema. El conocimiento que se ha codificado para realizar la búsqueda evolutiva es el siguiente:
– Módulos no lineales estáticos, únicamente.
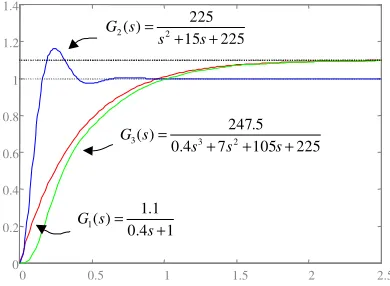
– Comportamiento lineal correspondiente a funciones de transferencia de primer, segundo y tercer orden, con características dinámicas similares. La figura 5.8 detalla las funciones de transferencia y su respuesta ante un escalón unitario.
0 0.5 1 1.5 2 2.5
0 0.2 0.4 0.6 0.8 1 1.2 1.4
225 105 7 4 . 0
5 . 247 )
( 3 2 3s = s + s + s+
G
1 4 . 0
1 . 1 ) (
1s = s+
G
225 15
225 )
( 2 2 s =s + s+
G
La constante de tiempo del sistema es de 0.15s, pero se ha supuesto que es del orden de 0.4s. Los datos han sido obtenidos con un periodo de muestreo de 0.02s, superior al mínimo teórico necesario de acuerdo con la suposición, para permitir la identificación de sistemas más rápidos.
Las secuencias de datos son las tensiones de alimentación del motor y las salidas son las correspondientes velocidades de giro transformadas a tensión mediante una dinamo tacométrica. En la figura 5.9 se da un ejemplo de secuencias de entrada y salida. Los valores de entrada se obtienen mediante dos generadores de ruido blanco limitado en ancho de banda. Uno de ellos produce valores grandes y el otro pequeños y se seleccionan unos u otros de forma aleatoria (con probabilidad de 0.6 para los valores grandes). De esta forma, aproximadamente el 40% de los puntos de una secuencia quedarán saturados, otro 40% estará dentro de la zona muerta y el 20% restante excitará directamente el comportamiento lineal del sistema.
0 2 4 6 8 10 12
-60 -40 -20 0 20 40
0 2 4 6 8 10 12
-2 0 2
Tensión de alimentación del motor
[image:66.595.151.411.297.512.2]Velocidad correspondiente, transformada a tensión
Fig. 5.9: ejemplo de secuencias de entrada y salida para el motor de corriente continua
Finalmente, cabe notar que la salida del sistema está alterada por ruido de lectura, blanco y limitado en ancho de banda, de ±1.5% del valor de salida, aproximadamente.
5.2.2 Pruebas realizadas
Cada prueba consta de 8 experimentos (excepto la prueba 3, que consta de 4 experimentos por ser mucho más costosos temporalmente), en los que se han variado los datos de entrada y salida y los puntos de partida de la búsqueda. Cada experimento se ejecuta durante 600 generaciones como máximo.
5.2.3 Resultados
Los resúmenes correspondientes a los resultados de este problema se encuentran en la sección B.1 del apéndice B. La tabla 5.1 muestra el error AIC, FPE e ISE de test del mejor modelo en cada experimento. Los mejores modelos corresponden a las pruebas 1 y 2, experimentos 3 y 7, respectivamente.
Exp. 1 Exp. 2 Exp. 3 Exp. 4 Exp. 5 Exp. 6 Exp. 7 Exp. 8
Prueba 1: AIC 0.1 0.08 0.0028 0.13 0.05 0.19 0.02 0.27
Prueba 2: FPE 0.0045 0.11 0.11 0.12 0.05 0.28 0.0043 0.26
Prueba 3: ISE 0.17 0.13 0.114 0.126 - - -
-Tabla 5.1: resumen de resultados (resaltados los mejores de cada prueba)
Antes de comentarlos es necesario aclarar que los experimentos de la prueba 3, a pesar de dar, en algunos casos, errores aceptables tanto en la fase de aprendizaje como en la de validación, no se han considerado para el análisis. Esto es debido a que el criterio ISE de minimización, aún cuando es muy habitual en otros métodos de optimización, aquí resulta poco adecuado. Este criterio no tiene en cuenta el número de parámetros del modelo y, por ello, es útil cuando el modelo se fija de antemano. Sin embargo, en el caso que nos ocupa, el modelo también es objeto de optimización y, entonces, el algoritmo tiende a mejorar las soluciones a base de añadir parámetros (módulos) más que explotando las combinaciones adecuadas entre ellos.
Los resultados de los experimentos correspondientes a la prueba 3 tienen entre 50 y 100 parámetros, o lo que es lo mismo, entre 40 y 80 módulos. Estos resultados no son desechables en sí, porque aproximan la función objetivo adecuadamente, pero su mayor inconveniente es que son poco interpretables, a parte de que existen otros modelos, como se verá a continuación, que con menor cantidad de parámetros consiguen igual o menor error.
estocástico de la búsqueda pues, ante condiciones similares de partida, se dan resultados que difieren en dos órdenes de magnitud.
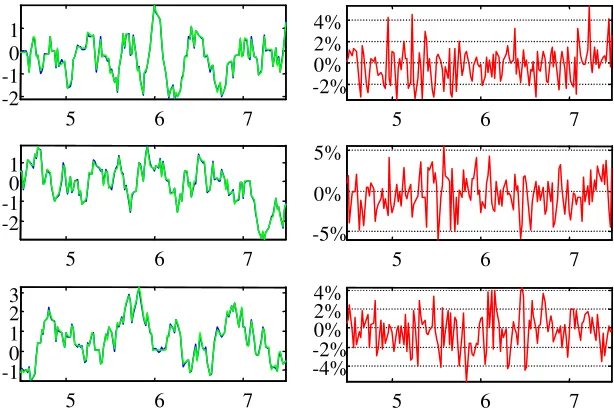
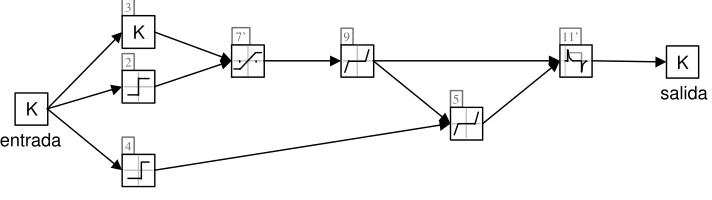
La red seleccionada como solución al problema de modelado del motor de corriente continua es la red nº 1 del experimento 3 de la prueba 1 (AIC). Esta red está compuesta por 17 módulos, como se muestra en la figura 5.10. Entre éstos figura un sistema lineal (módulo etiquetado con el número 11) un módulo de saturación (el número 7) y otros. El error de test es menor de 2.9·10-3, criterios FPE y AIC, y 2.7·10-3, con el criterio ISE. En la figura 5.11 se representa una
parte de la secuencia de test y el error porcentual que comete el modelo neuronal, que se mantiene dentro de la franja del 5%.
10
11
15 7
4 2
3
12
9
14
6 8
16 13
5 K
K K
salida entrada
K
K K
K K K
Fig. 5.10: diagrama de la red modular adoptada como solución del problema
5 6 7
-2 -10 1
5 6 7
-5% 0% 5%
Fig. 5.11: respuesta del modelo escogido y su error de test
5 6 7 -2
-10 1
5 6 7
-2%0% 2% 4%
5 6 7
-2 -10 1
5 6 7
-5% 0% 5%
5 6 7
-10 1 2 3
5 6 7
[image:69.595.158.465.103.310.2]-4% -2%0% 2% 4%
Fig. 5.12: respuesta del modelo ante secuencias de validación
Este modelo se ha evaluado comparándolo con otros modelos neuronales típicos. Para ello se ha utilizado una red feedforward clásica con retardos en las entradas y salidas y una red de tipo RBF (redes con función de activación gaussiana, en inglés Radial Basis Function neural networks).
En el primer caso se ha obtenido una red optimizada en cuanto al número de retardos y neuronas de la capa intermedia. Esta red neuronal, con 11 neuronas en la capa intermedia y 2 retardos para las entradas y las salidas, se ha entrenado durante 1000 ciclos con los mismos datos que el modelo modular seleccionado y ha sido sometida a pruebas similares. El resultado se puede ver en la figura 5.13. En ella hay una gráfica del error de test para entradas ideales, es decir, para un conjunto de valores creado a partir de las entradas y salidas deseadas. El error es cualitativamente comparable al del modelo modular, aunque cuantitativamente mayor si comparamos los índices ISE, puesto que el modelo clásico tiene un error de 5.56·10-3 y del
0 2 4 6 8 10 -10
-5 0 5
0 2 4 6 8 10
-5 0 5
Error de test, con entradas ideales
[image:70.595.137.433.104.281.2]Error de test, con entradas generadas por la red
Fig. 5.13: errores de test (porcentuales) de la mejor red de tres capas
Las redes de tipo RBF son muy indicadas en problemas de clasificación, pero también se emplean con éxito en aproximación de funciones y, de hecho, disponen de pruebas formales de capacidad de aproximar funciones, igual que las redes de tres capas. El modelado del motor de corriente continua con este tipo de redes se puede resumir notando que para llegar a cotas de error similares a las de la red modular son necesarias más de 150 neuronas. Teniendo en cuenta que cada neurona tiene asociados 6 pesos, se ve claramente que el número de parámetros de este modelo es muy superior al del modelo modular.
5.2.4 Análisis de los resultados
Se ha podido comprobar que el modelo de la figura 5.10, tomado como solución al problema de modelado del motor de corriente continua, cumple con la mayoría de las características deseables de un buen modelo: aproxima la función objetivo con poco error, tiene pocos parámetros y generaliza correctamente. Sin embargo, por el momento es un modelo que, a pesar de estar compuesto por módulos interpretables, es relativamente opaco, en el sentido de que, a simple vista, no es explicativo respecto al sistema que representa.
2
11’
4
7’ 3
K
K
salida K
entrada
9
[image:71.595.135.491.106.206.2]5
Fig. 5.14: versión simplificada del modelo de la figura 5.10
Se ha podido observar que la señal que genera el módulo 13 (ganancia estática de valor pequeño) apenas influye en la salida. En consecuencia, si lo consideramos superfluo y lo eliminamos, junto a aquéllos que lo alimentan, se puede reducir la complejidad del modelo en cuatro módulos (los etiquetados con los números 10, 12, 13 y 15). Además es posible realizar unas transformaciones sencillas, incluyendo las ganancias estáticas correspondientes a los módulos 14 y 16 en el módulo 11 y las correspondientes a los módulos 6 y 8 en el 7, de manera que el modelo resultante es el de la figura 5.14. Este último modelo consta de 7 módulos funcionales y en él se pueden identificar dos características del sistema original. Por un lado, la constante de tiempo del sistema lineal (módulo 11’) es de 0.1539 y, por otro, se aprecia que el sistema contiene una saturación en su entrada.
Toda esta información puede resultar extremadamente útil a la hora de construir un modelo a partir de ecuaciones físicas del sistema o, sencillamente, para comprender el funcionamiento del mismo.
5.3 Sistema no lineal simulado, con histéresis
5.3.1 Descripción
Este sistema se describe el apartado 3.7.2 de [Suy-96]. Se reproduce aquí su descripción para facilitar la comprensión. Se trata de un sistema interconectado (ver figura 5.15), que consta de dos sistemas lineales y dos no-linealidades: una curva de histéresis, f1, y la función tangente
hiperbólica, f2. Los sistemas lineales, L y M, son ambos de una entrada y una salida y de órdenes
(
( ) ( ( ))
( ) ) ( )) ( ( ) ( ) 1 ( ) ( 0 1 ) ( ) ( ) 1 ( 1 2 1 k w k x c f d k z c f k y k x c f b k z a k z k v k u b k x A k x T L M M T L M M L L + + = + = + + + = +donde v(k) y w(k) son ruido de proceso y medida, respectivamente, gaussianos de media cero y desviación estándar 0.01.
L f1 M f2
y w
[image:72.595.104.464.247.315.2]u v
Fig. 5.15: esquema de bloques del sistema no lineal simulado
Las matrices de estado de L y M son:
0 0 1 1 0 3 . 0 1 2 . 0 1 . 0 1 1 1 7 . 0 = = = − = = = = = L L L L M M M M d c b A d c b a
La no-linealidad f1 se muestra en la figura 5.16 y está definida de manera que la característica
0.2 0.8 1.2 1
f1
[image:73.595.205.410.109.278.2]x1
Fig. 5.16: característica no lineal con histéresis
5.3.2 Descripción de los datos
El conjunto de datos está formado por 1000 puntos para aprendizaje y 1000 puntos más para reconocimiento. Los datos de entrada se generan a partir de una señal aleatoria distribuida uniformemente en el intervalo [-1, 1]. Es de notar que en el problema original los datos de test no se utilizan en la creación del modelo (y aquí sí), por tanto los conjuntos de aprendizaje, test y validación se han dimensionado de la siguiente manera: 500 puntos para el aprendizaje, 500 puntos para el test y 1000 puntos para la validación. Así se conserva la relación original de 1000 puntos para la creación del modelo y 1000 para su validación.
5.3.3 Pruebas realizadas
Este problema tiene una particularidad que lo diferencia de otros, como el motor de corriente continua. Se trata de la introducción de ruido de proceso. El autor del problema utiliza un modelo capaz de estimarlo a través de un filtro de Kalman, propio del modelo. Para ello es imprescindible alimentar al modelo con las señales de entrada y salida deseada del sistema, cosa que no se contempla en este trabajo. Antes de plantear las pruebas definitivas se realizaron algunas con ruido de proceso, pero los errores alcanzados eran, generalmente, mayores que los reportados en [Suy-96]. El mejor resultado se dio con un modelo de 22 módulos que tenía un error de test de 3.12·10-3, el doble del error declarado en el citado libro. Por todo esto, las
pruebas finales se han realizado sin ruido de proceso.
de primer y segundo orden, cuya respuesta se representa en la figura 5.17. Además, se ha tenido en consideración que el rango de las entradas y salidas es pequeño y que para alcanzar las cotas de error deseadas sería necesaria una fase de aprendizaje bastante intensiva. Para evitar esto, se han utilizado unos parámetros de aprendizaje algo mayores que los descritos en el apéndice A, a riesgo de inestabilizar algunos modelos.
0 5 10 15 20 25 30
0 0.2 0.4 0.6 0.8 1 1.2 1.4
1 5
1 ) ( 1s = s+
G
1 4 . 1
1 . 1 ) ( 2 2 s =s + s+
[image:74.595.183.379.200.347.2]G
Fig. 5.17: respuesta de G1 y G2 ante un escalón unitario
En definitiva, se han realizado 4 pruebas que difieren en el criterio de optimización (AIC y FPE) y en el tipo de módulos que participan en la optimización. Cada una está compuesta por 8 experimentos de 400 generaciones, no se ha incluido ninguna información previa particular y se ha acelerado un poco el aprendizaje neuronal. Finalmente, se han extendido hasta 1200 generaciones aquellos experimentos con menores errores.
5.3.4 Resultados
todos los módulos módulos estáticos Prueba 1 FPE Prueba 2 AIC Prueba 3 FPE Prueba 4 AIC
Exp. 1 0.0208
400
-0.0062
1200
-0.0344
400
-0.0188
1200
-Exp. 2 0.0183
400
-0.0149
400
-0.0112
1200
-0.0154
1200
-Exp. 3 0.0206
400
-0.0286
400
-0.0229
400
-0.0253
400
-Exp. 4 0.0165
1200
-0.0233
400
-0.0255
400
-0.0192
400
-Exp. 5 0.0111
1200
-0.0130
400
-0.0146
1200
-0.0142
400
-Exp. 6 0.0169
400
-0.0139
400
-0.0025
1200
-0.0195
1200
-Exp. 7 0.0206
400
-0.0233
400
-0.0202
400
-0.0225
400
-Exp. 8 0.0149
400
-0.0077
1200
-0.0237
400
-0.0257
400
-Tabla 5.2: resumen de resultados de las pruebas 1 a 4 (resaltados los mejores) con el número de generaciones de optimización realizadas
El experimento 6 de la prueba 3, prueba realizada con medida del error FPE y módulos estáticos únicamente, tiene dos redes modulares de comportamiento destacable. La mejor de ellas, red nº 1, está formada por 28 módulos (44 parámetros modificables) y reconoce las entradas de test (ver figura 5.18) con un error de 2.466·10-3. La red nº 3 está formada por 26 módulos (41
parámetros modificables) y reconoce las entradas de test con un error de 2.479·10-3.
200 250 300
-0.5 0 0.5
200 250 300
10-3 10-2 10-1
Los errores de validación tienen una media de 7.12·10-3, criterio FPE, para la red modular nº 1 y
de 7.30·10-3 para la red nº 3. La figura 5.19 muestra las gráficas correspondientes a dos pruebas de validación de la red nº 1 y la figura 5.20 muestra las de dos pruebas de validación de la red nº 3.
200 250 300
-0.5 0 0.5
200 250 300
10-3 10-2 10-1
-20 0 20
-0.5 0 0.5
200 250 300
-0.5 0 0.5
200 250 300
10-4 10-3 10-2
-20 0 20
[image:76.595.84.487.180.329.2]-0.2 0 0.2
Fig. 5.19: gráficas de las salidas y salidas deseadas, errores en escala logarítmica y correlación entre errores y entradas para secuencias de validación de la red nº 1
200 250 300
-0.5 0 0.5
200 250 300
10-3 10-2 10-1
-20 0 20
-0.2 0 0.2
200 250 300
-0.5 0 0.5
200 250 300
10-3 10-2 10-1
-20 0 20
-0.2 0 0.2
Fig. 5.20: gráficas de las salidas y salidas deseadas, errores en escala logarítmica y correlación entre errores y entradas para secuencias de validación de la red nº 3
5.4 Elemento piezoeléctrico
5.4.1 Descripción
[image:76.595.82.487.382.526.2]caracterizar el desplazamiento que sufre el piezoeléctrico bimórfico P-803.10 de Physik Instrumente, que nominalmente es de 50V - 100µ±20µ.
Una característica destacable de este sistema es que, aunque no se tiene un modelo preciso del mismo, se conocen sus rasgos principales de comportamiento. Se trata de un elemento que sigue una curva de histéresis aproximadamente lineal. El modelo que se busca, por tanto, tendría que reflejar esta característica.
5.4.2 Descripción de los datos
El principal inconveniente que plantea este problema es la escasez de datos. El proceso de medida, por tratarse de desplazamientos tan pequeños, es muy complejo y el conjunto de datos disponible (representado gráficamente en las figuras 5.21 y 5.22) está formado por, solamente, 59 pares de entrada-salida.
0 10 20 30 40 50
[image:77.595.186.438.332.514.2]0 20 40 60 80 1 0 0 1 2 0 1 4 0
0 20 40 60 80 100 120 140
salida
entrada
[image:78.595.159.410.106.287.2]0 10 20 30 40 50 60
Fig. 5.22: gráfica conjunta de los datos de entrada y salida frente al tiempo
Estos datos están divididos en cuatro lazos de excitación del elemento piezoeléctrico. La selección de los conjuntos de aprendizaje y de test se ha realizado tomando lazos completos, de tal forma que la cantidad de datos para ambos procesos sea parecida y que se dé similar peso a los lazos de excursiones largas y a los de excursiones cortas. La figura 5.23 muestra los dos conjuntos.
Datos para aprendizaje
Datos para test
0 10 20 30 40 50 60 70
0 20 40 60 80 100 120 140
Fig. 5.23: gráfica de los conjuntos de aprendizaje y test
[image:78.595.156.410.412.590.2]5.4.3 Pruebas realizadas
Este problema dispone de poca información previa para guiar la búsqueda. Se sabe, por un lado, que el modelo resultante corresponde a la característica estática del sistema y, por otro, que tiene que contener alguna forma de histéresis. La primera pauta nos sugiere la posibilidad de no utilizar los módulos neuronales de los sistemas lineales, mientras que la segunda permite plantear pruebas con módulos de tipo RELE, JUEGO o TOPE.
Teniendo todo esto en cuenta, se plantearon cinco pruebas iniciales y tres definitivas. Las pruebas iniciales tenían la finalidad de comprobar la necesidad de incluir los módulos neuronales correspondientes a las funciones ZONA MUERTA, SATURACION, FRICCION, TOPE, JUEGO y LIMITADOR DE VELOCIDAD. En las pruebas definitivas se utilizaron aquellos módulos que dieron resultados positivos en las anteriores y se realizaron más experimentos con ejecuciones más largas. El resumen de cada una de las pruebas se da en la tabla 5.3.
Prueba 1 2 3 4 5 Def. 1 Def. 2 Def. 3
Módulos que pueden formar parte de las soluciones ganancia umbral1 umbral2 relé hist. saturación z. muerta ganancia umbral1 umbral2 relé hist. tope ganancia umbral1 umbral2 relé hist. juego ganancia umbral1 umbral2 relé hist. fricción ganancia umbral1 umbral2 relé hist. limitador ganancia umbral1 umbral2 relé hist. saturación z. muerta tope juego ganancia umbral1 umbral2 relé hist. saturación z. muerta tope juego fricción ganancia umbral1 umbral2 relé hist. saturación z. muerta tope juego limitador Medida del error FPE AIC ISE FPE AIC ISE FPE AIC ISE FPE AIC ISE FPE AIC ISE FPE AIC FPE AIC FPE AIC
Nº gen. 200 200 200 200 200 500 500 500
Nº exp. 3 3 3 3 3 8 8 8
Tabla 5.3: resumen de las pruebas con el problema piezoeléctrico
5.4.4 Resultados
Los resúmenes de los resultados de las pruebas iniciales se encuentran en la tabla 5.4. En ellos se puede observar lo siguiente: las pruebas 1 y 4 (SATURACION+ZONAMUERTA y FRICCION)