INSTITUTO POLITÉCNICO NACIONAL
ESCUELA SUPERIOR DE INGENIERÍA
MECÁNICA Y ELÉCTRICA
APLICACIÓN DE LOS MODELOS ASOCIATIVOS ALFA-BETA EN EL
RECONOCIMIENTO DE DÍGITOS ESCRITOS A MANO.
T E S I S
PARA OBTENER EL TÍTULO DE
INGENIERO EN COMUNICACIONES Y ELECTRÓNICA
P R E S E N T A N
SÁNCHEZ LÓPEZ ELGAR BERNABE
TORRES CASANOVA ERNESTO EVERARDO
ASESORES: Dra. María Elena Acevedo Mosqueda Dr. Cornelio Yáñez Márquez
AGRADECIMIENTOS:
Estos Agradecimientos son para todas la personas que confiaron y no confiaron en mí.
Son tantas Personas las que confiaron en mí.
A Dios: Aunque no he mostrado mucha fe, te doy gracias, ya que fuiste la inspiración de mis Madre, de mis hermanas y de muchos de mis amigos y profesores. Les brindaste salud y fuerza espiritual para que siguieran adelante.
A mi Madre Maria: Por todo su apoyo que me ha brindado sobre toda mi carrera y toda mi vida, sin ti nunca hubiera podido conseguir lo que he logrado hasta el momento, gracias por tu preocupación y por tu bondad, sabes que por siempre serás mi inspiración y que siempre contaras con mi apoyo este cerca o lejos de ti.
A mis Hermanas Nohemi, Elizabeth y Diana: Gracias por su apoyo, aunque fue poco lo que me ayudaron con respecto a mí escuela, su apoyo real fue en la confianza y los ánimos que me dieron durante mi carrera y al igual que ustedes, saben que también contaran con mi apoyo.
A mis Profesores: Gracias a todos por la paciencia y gran apoyo durante toda mi vida de estudiante, sin ustedes jamás hubiera logrado conseguido esto que ahora tengo, y entre mis profesores tengo que agradecer a mi asesora de tesis Elena que estuvo con nosotros
durante el desarrollo de esta tesis, gracias por haber depositado su confianza en nosotros y esperamos no haberla decepcionado.
A todos mis amigos: Les agradezco por toda la aportación que me brindaron, ustedes
fueron un gran motor para seguir adelante, agradezco en especial a Carolina Isabel por la
el apoyo que me has brindado por todos los años que te conozco, por tener confianza en mi aunque sé que te he fallado en algunas ocasiones y espero que la que confianza que hay entre nosotros, jamás desaparezca. A mi compañero y amigo de tesis Ernesto, por su
apoyo, y a todos lo que me acompañaron en toda mi carrera profesional. Gracias a todos mis compañeros de trabajo, que me dieron su apoyo durante toda mi carrera.
Y no por menos importante.
A los que no confiaron en mí: Ya que también fueron de gran importancia durante mi
desempeño al tratarles de mostrar que aun con dificultades se puede lograr las cosas que uno se propone por mas difíciles que parezcan y bien lo dice la frase “Las personas no ganan nada sin tener que sacrificar algo a cambio”
AGRADECIMIENTOS:
Gracias a Dios
A Dios que me ha dado la oportunidad de vivir, y tener a mi lado a tantas personas maravillosas e importantes.
Gracias a mis padres
Por su cariño, comprensión y apoyo sin condiciones ni medida. Porque gracias a ustedes soy la persona que ahora soy.
Gracias a mi amor
Por tu apoyo, compresión y por llegar a mi vida, llenarla de amor y estar aquí siempre.
Gracias a mi asesores
Por permitirme ser parte del grupo de trabajo. Sus consejos, paciencia y opiniones sirvieron para que me sienta satisfecho en mi participación dentro de este
proyecto.
Gracias a cada uno de los maestros
Que supieron forjar al ingeniero que ahora soy, gracias por su tiempo, regaños y conocimientos.
Gracias a todos mis amigos
Que estuvieron conmigo compartiendo momentos agradables y momentos tristes, porque esos momentos son los que nos hacen crecer y valorar a las personas que
nos rodean.
ÍNDICE DE CONTENIDO
Resumen ... I
Planteamiento del problema ... II
Justificación ... III
Objetivo General ... IV
Objetivos Específicos ... IV
Metodología ... V
Software y equipo empleado ... VI
Capítulo 1: Introducción ... 1
1.1 Estado del arte ... 2
1.1.1 OCR ... 2
1.1.2 Reconocimiento de Caracteres Usando Una Red NAND ... 3
1.1.3 Reconocimiento Automático de Caracteres Manuscritos y Marcas, Orientado al Procesado de Encuestas ... 3
1.1.4 Identificador de Kanjis Empleando Memorias Asociativas ... 4
1.1.5 Reconocimiento de caracteres manuscritos usando la función spline natural ... 7
1.1.6 Reconocimiento de caracteres usando la segmentación para la comunicación computadora-humano ... 7
1.1.8 Aprendizaje eficiente de representaciones escasas con un modelo Energía-Base. ... 8
1.1.9 Aprendizaje no supervisado de las jerarquías invariantes de las características con aplicación al reconocimiento de un objeto ... 8
1.1.10 Organización del documento ... 9
Capítulo 2: Métodos de Memorias Asociativas Clásicas ... 11
2.1 Conceptos Básicos ... 11
2.2 Memorias Asociativas ... 14
2.2.1 Lernmatrix de Steinbuch ... 15
2.2.3 Linear Associator de Anderson-Kohonen ... 17
2.2.4 La Memoria Asociativa Hopfield ... 18
2.3 Memorias Asociativas no Clásicas ... 20
2.3.1 Memorias Asociativas Morfológicas ... 20
2.3.2 Memorias Heteroasociativas Morfológicas ... 23
2.3.3 Memorias Autoasociativas Morfológicas... 23
2.3.4 Memorias Asociativas Alfa-Beta... 24
Capítulo 3: Memorias Asociativas Bidireccionales (BAM) ... 35
3.1 Memorias Asociativas Bidireccionales ... 35
3.1.1 Memoria Asociativa Bidireccional de Kosko. ... 35
3.2 Modelos de Memorias Asociativas Bidireccionales a través del tiempo ... 38
3.3 BAM Alfa Beta ... 44
3.3.1 Descripción de las Memorias Asociativas Bidireccionales Alfa-Beta ... 45
Capítulo 4: Implementación. ... 54
Capítulo 5: Resultados ... 67
Experimentos ... 67
1. Comprobación de la BAM Alfa-Beta con imágenes propuestas. ... 67
2. Extracción de los dígitos de la base de datos MNIST ... 69
3. Elección del elemento estructurante para la dilatación y erosión. ... 71
4. Reconocimiento de dígitos manuscritos empleando la BAM Alfa-Beta. ... 73
5 Comparaciones ... 82
Conclusiones. ... 88
Trabajo futuro. ... 89
Apéndice A. ... 91
Operación del Software ... 91
Manejo de Archivos ... 93
Interpretación de Resultados. ... 94
Apéndice B ... 96
Base de dígitos ... 96
Fase de aprendizaje ... 97
Fase de recuperación ... 98
Simbología ... 107
Glosario ... 108
ÍNDICE DE FIGURAS
Figura I Modelo Propuesto ... V
CAPÍTULO 1
Figura 1.1.4. 1 Análisis de eficiencia de los 5 métodos de estudio. ... 5
Figura 1.1.4. 2 Lernmatrix simple con diferentes gruesos de línea (1,3 y 5 píxeles). ... 5
Figura 1.1.4. 3 Lernmatrix con complementos con diferentes gruesos de línea (1,3 y 5 píxeles). ... 5
Figura 1.1.4. 4 Lernmatrix con complementos gruesos con diferentes gruesos de línea (1,3 y 5 píxeles). ... 6
Figura 1.1.4. 5 Lernmatrix con porcentajes con diferentes gruesos de línea (1,3 y 5 píxeles). ... 6
Figura 1.1.4. 6 Lernmatrix con modificación original con diferentes gruesos de línea (1,3 y 5 píxeles). ... 6
CAPÍTULO 2
Figura 2.3.1.1. 1 Dilatación. (a) Elemento estructurante, (b) Imagen, (c) Imagen dilatada 22
Figura 2.3.1.1. 2 Erosión. (a) Elemento estructurante, (b) Imagen, (c) Imagen erosionada
... 22
Figura 2.4.1. 1 Gráfica comparativa de 6 distintos modelos de Memorias Asociativas ... 33
CAPÍTULO 3
Figura 3.1.1. 1 Funcionamiento de la BAM de Kosko ... 35
Figura 3.2. 1 Gráficas de los resultados de la capacidad de recuperación de los modelos de Wang (1991), Jeng, Wu, Zheng y Chartier. ... 43
Figura 3.3.1. 1 Esquema general de una Memoria Asociativa Bidireccional ... 45
Figura 3.3.1. 2 Modelo de Kosko según el esquema de la BAM general. ... 45
Figura 3.3.1. 3 Esquema de las etapas de una memoria asociativa bidireccional Alfa-Beta.
... 46
Figura 3.3.1. 5 Esquema del proceso realizado en el sentido de y x. ... 48
CAPÍTULO 4
Figura 4. 1 Modelo Propuesto ... 54Figura 4. 2 Diagrama a bloques ... 55
Figura 4. 3 Lectura de archivos de MNIST ... 57
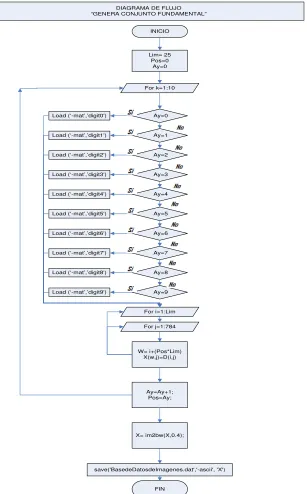
Figura 4. 4 Genera conjunto fundamental ... 58
Figura 4. 5 Memoria Máx y Mín. ... 60
Figura 4. 6 Elementos Estructurantes. ... 62
Figura 4. 7 Dilatación y Erosión. ... 63
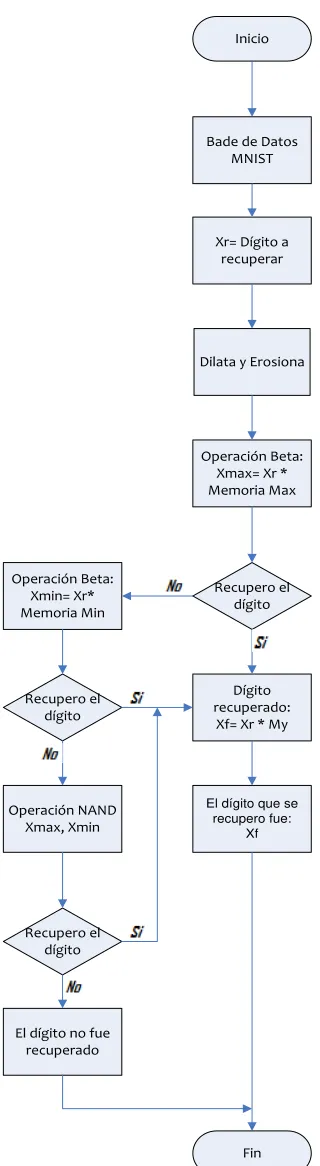
Figura 4. 8 Fase de recuperación ... 64
Figura 4. 9 Fase de recuperación (continuación) ... 65
CAPÍTULO 5
Figura 5.1. 1 Imágenes propuestas ... 67Figura 5.1. 2 (a) Imagen del conjunto fundamental (b) Imagen con ruido aditivo, (c) Imagen con ruido sustractivo. ... 68
Figura 5.1. 3 (a) Imagen con ruido combinado, (b) Imagen dilatada, (c) Imagen erosionada. ... 68
Figura 5.1. 4 (a) Imagen con ruido combinado, (b) Imagen dilatada, (c) Imagen erosionada. ... 69
Figura 5.2. 1 Base de Datos MNIST ... 69
Figura 5.2. 2 (a) Dígitos a escala de grises, (b) Dígitos Binarizados. ... 70
Figura 5.3. 1 Elementos estructurantes ... 71
Figura 5.3. 2 Primer elemento estructurante, (a) Dilatación, (c) Erosión ... 71
Figura 5.3. 3 Segundo elemento estructurante, (a) Dilatación, (b) Erosión ... 72
Figura 5.3. 4 Tercer elemento estructurante, (a) Dilatación, (b) Erosión ... 72
Gráfica 5.4. 1 Análisis de resultados empleando 30 imágenes por dígito ... 74
Gráfica 5.4. 2Análisis de resultados empleando 100 imágenes por dígito ... 75
Gráfica 5.4. 3 Análisis de resultados empleando 200 imágenes por dígito ... 76
Gráfica 5.4. 4 Análisis de resultados empleando 30 imágenes por dígito ... 77
Gráfica 5.4. 5 Análisis de resultados empleando 100 imágenes por dígito ... 78
Gráfica 5.4. 6 Análisis de resultados empleando 200 imágenes por dígito ... 79
Gráfica 5.4. 8 Análisis de resultados empleando 100 imágenes por dígito ... 81
ÍNDICE DE TABLAS
CAPÍTULO 1
Tabla 1 Tasa de error ... 9
CAPÍTULO 3
Tabla 3.2. 1 Modelos de BAM a través del tiempo ... 42CAPÍTULO 4
Tabla 4. 1 Asociaciones realizadas ... 59CAPÍTULO 5
Tabla 5.4. 1 Análisis de resultados empleando 30 imágenes por dígito ... 73Tabla 5.4. 2 Análisis de resultados empleando 100 imágenes por dígito ... 74
Tabla 5.4. 3 Análisis de resultados empleando 200 imágenes por dígito ... 75
Tabla 5.4. 4 Análisis de resultados empleando 30 imágenes por dígito ... 76
Tabla 5.4. 5 Análisis de resultados empleando 100 imágenes por dígito ... 77
Tabla 5.4. 6 Análisis de resultados empleando 200 imágenes por dígito ... 78
Tabla 5.4. 7 Análisis de resultados empleando 30 imágenes por dígito ... 79
Tabla 5.4. 8 Análisis de resultados empleando 100 imágenes por dígito ... 80
Tabla 5.4. 9 Análisis de resultados empleando 200 imágenes por dígito ... 81
Tabla 5.5. 1 Porcentaje Total de resultados tomando el primer elemento estructurante ... 83
Tabla 5.5. 2 Porcentaje Total de resultados tomando el segundo elemento estructurante 83 Tabla 5.5. 3 Porcentaje Total de resultados tomando el tercer elemento estructurante .... 83
Tabla 5.5. 4 Porcentaje Total de resultados tomando el primer elemento estructurante ... 83
Tabla 5.5. 5 Porcentaje Total de resultados tomando el segundo elemento estructurante 84 Tabla 5.5. 6 Porcentaje Total de resultados tomando el tercer elemento estructurante .... 84
Tabla 5.5. 7 Porcentaje Total de resultados tomando el primer elemento estructurante ... 84
Tabla 5.5. 8 Porcentaje Total de resultados tomando el segundo elemento estructurante 84 Tabla 5.5. 9 Porcentaje Total de resultados tomando el tercer elemento estructurante .... 85
Tabla 5.5. 10 Tabla comparativa... 85
Tabla 5.5. 11 Tabla comparativa... 86
Resumen
En este trabajo se presenta el reconocimiento de dígitos escritos a mano como aplicación de los modelos asociativos, caso particular de la BAM Alfa Beta.
El reconocimiento de Dígitos escritos a mano es de suma importancia, ya que a partir de esto, se pueden hacer distintas tareas, entre las que destacan, el reconocimiento y reconstrucción de caracteres.
La Memoria Asociativa Bidireccional Alfa Beta, tiene la capacidad de recuperar en su totalidad patrones aprendidos a partir de patrones de entrada, utilizando esta memoria como la mejor alternativa en el reconocimiento de dígitos.
El reconocimiento de dígitos, para este trabajo, no se da a partir del reconocimiento convencional, el cual está basado en la extracción de características a partir de la forma particular del caracter bajo análisis, tales como: la inclinación de las líneas, la posición relativa de cada línea, el ancho de las diferentes partes de la línea, etc. Sino a partir de una memoria capaz de aprender dígitos manuscritos, y a su vez, poderlos reconocer.
La escritura de cada persona es diferente; por lo que es necesario utilizar una base de datos que contenga un gran número de dígitos escritos a mano. En nuestro caso, utilizaremos la “MNIST”.
Se hacen uso de dos operaciones morfológicas: dilatación y erosión. Estas operaciones le permiten dar un panorama mayor a la BAM Alfa Beta para reconocer el dígito. Estas operaciones no producen error a la BAM Alfa Beta dada sus características.
Para poder generar la BAM Alfa Beta, se toman varias imágenes por dígito (0 al 9), asociándoles su correspondiente número digital. Así mismo, para reconocer el dígito manuscrito, se toma un dígito cualquiera, el cual se dilata y erosiona, y se opera en la memoria aprendida, obteniendo como resultado el correspondiente número digital.
Planteamiento del problema
En la actualidad el reconocimiento de dígitos escritos a mano, no sólo engloba la reconstrucción de caracteres, sino la estructuración de los documentos (títulos, subtítulos, bloques de texto, etc.)
El reconocimiento comenzó aplicándose en documentos para los cuales ninguna forma electrónica estaba disponible. A medida que evoluciona la tecnología, sus aplicaciones han ido en aumento.
Los resultados obtenidos hasta ahora, distan mucho de ser perfectos. El reconocimiento de dígitos sigue siendo un problema complejo, que tropieza con dificultades aún no resueltas y que son actualmente aún objeto de numerosas investigaciones. Por mencionar alguno, el ruido es un factor determinante en el reconocimiento de dígitos.
Existen dispositivos táctiles para el reconocimiento de dígitos, un dispositivo muy utilizado en la actualidad son las PDAs (Asistente Digital Personal); dispositivo de pequeño tamaño que combina una computadora, teléfono/fax conexiones de red. La mayoría de PDAs empezaron a usarse con una especie de bolígrafo en lugar de teclado, por lo que incorporaban reconocimiento de caracteres escritos a mano. Hoy en día los PDAs pueden tener teclado y/o reconocimiento de escritura. Algunos PDAs pueden incluso reaccionar a la voz, mediante tecnologías de reconocimiento de voz.
Justificación
La inteligencia artificial es un área de las ciencias computacionales que no ha sido muy explotada para aplicaciones comerciales. A través del tiempo, se han realizado algunos estudios para desarrollar aplicaciones que utilicen todos estos conocimientos. Sin embargo, es muy difícil su estudio, puesto que su teoría se basa en un modelo que intenta reproducir el funcionamiento del cerebro humano, el cual está constituido de forma muy compleja, debido a los miles de conexiones de neuronas que existen en él.
Si bien es relativamente sencillo conseguir que una máquina capte lo que le rodea, no lo es tanto el conseguir que sea capaz de interpretarlo y/o reconocerlo.
En los últimos años, se han utilizado otros métodos como las redes neuronales para el reconocimiento de dígitos, para lo cual es necesario un entrenamiento extenso del sistema, ya que la escritura de cada persona es diferente. Así mismo, mediante este proyecto se pretende darle a conocer a todas aquellas personas que no están familiarizadas con esta rama de las ciencias computacionales; la utilización de este método de reconocimiento propuesto en la solución de algunos problemas en específico.
Los modelos asociativos se han utilizado ampliamente en el área de Inteligencia Artificial, en particular en el reconocimiento de patrones habiéndose obtenido muy buenos resultados. Es por ello que en este trabajo se propone la aplicación de la Memoria Asociativa Bidireccional Alfa Beta (BAM Alfa Beta), para el reconocimiento de dígitos escritos a mano.
La aplicación de la BAM Alfa Beta en el reconocimiento de dígitos escritos a mano, nos muestra una clara ventaja, ya que recupera correctamente el 100% de patrones de salida dados patrones de entrada pertenecientes al conjunto fundamental.
Objetivo General
Usar los Modelos Asociativos Bidireccionales Alfa-Beta para reconocer dígitos escritos a mano.
Objetivos Específicos
• Estudiar el funcionamiento de los Modelos Asociativos Alfa-Beta, en
particular, el modo bidireccional.
• Aplicar los métodos de dilatación y erosión a los dígitos escritos a mano.
• Utilizar estos modelos para la asociación de las características obtenidas
con sus correspondientes patrones digitales.
Metodología
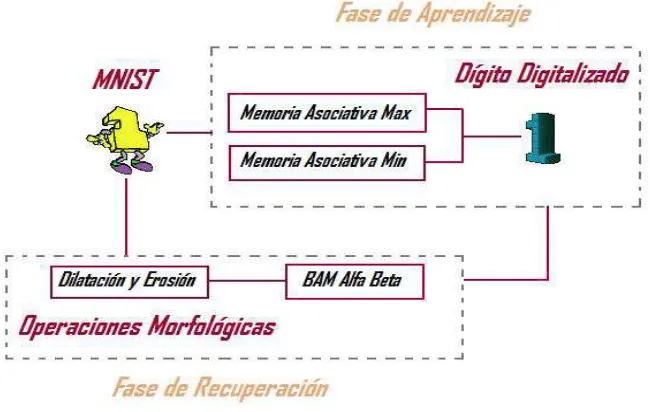
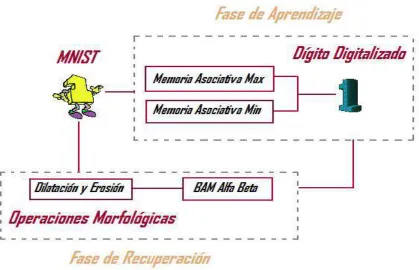
[image:15.612.144.473.182.388.2]A continuación, se propone un modelo tal que, sea nuestro punto de partida para la solución del problema. Sin embargo, es importante mencionar las características que presenta el modelo.
Figura I Modelo Propuesto
Debido a que la escritura de cada persona es diferente, se requiere tener una base de datos que contenga un número suficiente de imágenes de números manuscritos. Para ello se utiliza una base de datos llamada “MNIST”.
La base de datos de dígitos manuscritos de MNIST, ha establecido un programa de capacitación de 60,000 ejemplos, y una prueba de 10,000 ejemplos. Los dígitos han sido segmentados y escaladas a igual tamaño.
Es una buena base de datos, para las personas que quieran probar las técnicas de aprendizaje y métodos de reconocimiento de patrones de datos del mundo real, mientras que el gasto de esfuerzos en pre procesamiento y formato son mínimos.
Para poder interactuar con la base de datos de MNIST, es necesario generar un programa para leer las imágenes de dicha base, y así poder obtener las características de los dígitos que vamos a emplear.
Ya realizada la Fase de Aprendizaje, se procede a la Fase de Recuperación, que será la fase donde tomaremos cualquier otro dígito de la Base de Datos MNIST, y una vez procesada, se opera el dígito a la BAM Alfa Beta, obteniendo el dígito manuscrito de forma digital.
Para garantizar el reconocimiento del dígito, en la fase de recuperación de nuestra BAM Alfa Beta, se generará un programa utilizando las operaciones básicas
morfológicas, es decir, la dilatación y la erosión, estas operaciones serán de gran ayuda y de suma importancia, ya que algunos dígitos a reconocer pueden estar dañados con ruido sustractivo, aditivo o combinado.
Software y equipo empleado
A continuación se presenta el equipo y software a utilizar:
• Laptop con procesador Intel Core 2 Duo, Memoria RAM 1GB con disco duro
de 100GB.
• Sistema Operativo Windows Vista 32 Bits.
• Software MatLab 7.0
La elección del Software y lenguaje de programación varía de acuerdo a nuestras necesidades, ya que éste va enfocado a nuestra aplicación. En este caso, el trabajo requiere crear algoritmos para el procesamiento de imágenes, lo que conlleva a generar y manipular matrices.
Ya que uno de los principales factores que tenemos en cuenta es la factibilidad y viabilidad del equipo y software, es decir, con el mínimo tiempo posible obtener los mejores resultados; se propone utilizar un software llamado MatLab.
MatLab es un Software matemático que ofrece un entorno de desarrollo integrado (IDE) con un lenguaje de programación propio (lenguaje M).
Es considerado un programa de cálculo numérico orientado a matrices. Por lo tanto, será más eficiente si se diseñan los algoritmos en términos de matrices y vectores.
MatLab posee una herramienta adicional llamada MATLAB Builder, este permite utilizar funciones MATLAB como archivos de biblioteca, que pueden ser usados con ambientes de construcción de aplicación .NET o Java. De igual forma, MatLab puede llamar funciones y subrutinas escritas en C.
Capítulo 1: Introducción
En este capítulo se presentan algunos trabajos realizados en el reconocimiento de caracteres, obteniéndose resultados no muy satisfactorios y con poca eficiencia. Debido a esto, se presenta la BAM Alfa Beta en el reconocimiento de dígitos escritos a mano. Aunque esto último se explicará mas a detalle en los capítulos 2 y 3.
Para poder entender una memoria Asociativa, es necesario tener bien definido lo que es el reconocimiento de patrones. A continuación se da una definición formal del término.
El reconocimiento de patrones, también llamado lectura de patrones,
identificación de figuras y reconocimiento de formas, es el reconocimiento de patrones en señales. No sólo es un campo de la informática sino un proceso fundamental que se encuentra en casi todas las acciones humanas.
El punto esencial del reconocimiento de patrones es la clasificación: se quiere clasificar una señal dependiendo de sus características. Señales, características y clases pueden ser de cualquiera forma, por ejemplo se puede clasificar imágenes digitales de letras en las clases «A» a «Z» dependiente de sus píxeles o se puede clasificar ruidos de cantos de los pájaros en clases de órdenes aviares dependiente de las frecuencias.
El objetivo es clasificar patrones con base en un conocimiento a priori o información estadística extraída de los patrones. Los patrones a clasificar suelen ser grupos de medidas u observaciones, definiendo puntos en un espacio multidimensional apropiado.
Un sistema de reconocimiento de patrones completo consiste en un sensor que recoge las observaciones a clasificar, un sistema de extracción de características que transforma la información observada en valores numéricos o simbólicos, y un sistema de clasificación o descripción que, basado en las características extraídas, clasifica la medición.
por un sistema probabilístico. El reconocimiento estructural de patrones está basado en las relaciones estructurales de las características [2].
Existen numerosas investigaciones acerca del reconocimiento de Dígitos escritos a mano, con la única desventaja de que éstas no presentan un índice de recuperación en su totalidad. A continuación se presentan algunos métodos empleados en el reconocimiento de Dígitos escritos a mano, o mejor conocido como Reconocimiento de caracteres.
1.1 Estado del arte
1.1.1 OCR
Existen en la actualidad gran cantidad de programas de OCR comercializados. Están principalmente destinados al reconocimiento de caracteres impresos (Multi-Font CR), y funcionan en su mayoría en ordenadores personales tipo PC-IBM Compatible o Macintosh. Su tasa de reconocimiento normalmente se halla entre
80% y 95%, obteniendo los mejores resultados cuando funcionan con tipos de
letra para los que han sido "afinados" o entrenados. Estos sistemas incluyen a menudo "reconocedores de composición", siendo capaces de separar columnas y bloques de texto y de distinguir a éstos de las figuras.
En condiciones poco favorables (enorme número de escritores, condiciones de escritura incontroladas) como es el caso cuando se quieren reconocer los códigos postales (ZIP codes), los resultados empeoran, lográndose un promedio de 92% de reconocimiento, variando entre 85% y 97%. Lo mismo ocurre si se intenta reconocer un conjunto de formas mayor que el de los dígitos, como las 26 letras inglesas: 88% o el kanji: 86.7% (con símbolos difíciles).
1.1.2 Reconocimiento de Caracteres Usando Una Red NAND
Es un método para el reconocimiento de caracteres utilizando una red NAND, donde este tipo de red transforma el bitmap en una representación del mismo por medio de números, y para ello se escogió el método de Glucksmann, llamado Characteristic Loci[4]. Y luego, otra etapa de pre-procesamiento, para finalmente dejar los datos en forma booleana, y así trabajarlos con la red NAND.
Finalmente se procedió a entrenar la red, que consistía en ir sacando y agregando conexiones entre las neuronas del primer y segundo nivel.
Este tipo de red presenta desventajas, debido a que se pierde cierta información al pasar los datos de decimal a datos booleanos. Otra mejora sería aumentar el número de direcciones aplicadas a la Characteristics Loci. (1)
1.1.3 Reconocimiento Automático de Caracteres Manuscritos y
Marcas, Orientado al Procesado de Encuestas
Este trabajo describe la implementación de un sistema de reconocimiento de caracteres manuscritos y marcas, relevante para la toma de información del contenido de grandes volúmenes de formularios (encuestas).
El presente trabajo aborda la implementación de una aplicación software para reconocimiento de marcas y caracteres manuscritos basada en procesamiento digital de imágenes y redes neuronales, aplicable a la toma del contenido de una encuesta. El manejo de los datos de forma automática evita el proceso tedioso de digitación manual necesario para el archivado de grandes cantidades de documento.
Se logró implementar un sistema de carácter cooperativo capaz de extraer automáticamente la información de una encuesta que contiene datos de marcas y/o letras mayúsculas y números; el sistema tiene una precisión para reconocimiento de marcas del 100% y del 90% para caracteres.
1.1.4 Identificador de Kanjis Empleando Memorias Asociativas
Este trabajo desarrolla un sistema sobre un dispositivo móvil, que permite el reconocimiento de ideogramas japoneses (Kanjis) dentro del rango estimado de 30 ideogramas. (3)
Dicha técnica emplea dos memorias, la memoria “morfológica” y la “Lernmatrix”. Esta última es aplicada con distintos métodos, a continuación se presentan algunas de ellas:
• Lernmatrix simple.
• Lernmatrix con Completos.
• Lernmatrix con Porcentajes.
• Lernmatrix con Complementos gruesos.
• Lernmatrix Modificada.
Los resultados obtenidos en dicho trabajo van a depender tanto de los gruesos de línea, como de las distintas formas en que se opera la memoria “Lernmatrix”. Obsérvese que los resultados obtenidos distan mucho de lo que nos presenta el Modelo Asociativo Alfa Beta.
La figura I muestra los resultados obtenidos entre el uso de los diferentes métodos a emplear, cada versión que se evalua esta indicada con un color diferente, siendo el de mejor resultado la tabla de color verde que corresponde al método de la Lernmatrix con empleo de Porcentajes.
La figura II ejemplifica los resultados empleando la Lernmatrix Simple con tres diferentes gruesos de línea (1, 3 y 5 pixeles). Donde cabe destacar los resultados arrojados con un grosor de 5 pixeles, indicado en color verde.
De igual forma se ejemplifican los resultados arrojados en la figura III, IV, V y VI, utilizando Lernmatrix con Complementos, con Porcentajes, con complementos gruesos y con modificación original respectivamente. Siendo el de color verde (5 Pixeles) en todos los casos, los mejores resultados obtenidos.
Figura 1.1.4. 1 Análisis de eficiencia de los 5 métodos de estudio.
Figura 1.1.4. 2 Lernmatrix simple con diferentes gruesos de línea (1,3 y 5 píxeles).
Figura 1.1.4. 4 Lernmatrix con complementos gruesos con diferentes gruesos de línea (1,3 y 5 píxeles).
Figura 1.1.4. 5 Lernmatrix con porcentajes con diferentes gruesos de línea (1,3 y 5 píxeles).
1.1.5 Reconocimiento de caracteres manuscritos usando la
función spline natural
Este artículo propuesto por investigadores de la Sección de Estudios de Posgrado e Investigación (SEPI) de la Escuela Superior de Ingeniería Mecánica y Eléctrica (ESIME), Unidad Culhuacán, propone un algoritmo de reconocimiento dinámico de caracteres. En el algoritmo, los puntos significativos para cada carácter se estiman
usando una función spline natural llamada Slalom. Posteriormente, partiendo de
los puntos significativos se construye un modelo para cada carácter.
La etapa de reconocimiento consiste en dos niveles de clasificación. En la primera etapa, usando las características locales de los trazos, se determina a cual carácter pertenece los puntos significativos del carácter de entrada. La tasa de reconocimiento global del sistema propuesto es aproximadamente de 96.0%. Los resultados de dicho trabajo pueden ser consultados en la referencia (4).
1.1.6 Reconocimiento de caracteres usando la segmentación
para la comunicación computadora-humano
¿Cómo le dice una computadora lo de un humano? La situación se plantea con frecuencia en Internet, cuando las encuestas en línea se llevan a cabo, se pide cuentas indeseable, e-mail que se reciben, y salas de chat son correo basura. El enfoque que utilizamos es el de crear un problema visual que sea fácil a los seres humanos, pero difícil para un equipo. Más concretamente, Nuestro reto es reconocer una cadena al azar de caracteres distorsionados. Para superar el reto, el tema debe escribir en una correcta cadena ASCII correspondiente.
Desde un punto de vista de OCR, este problema es interesante porque nuestro objetivo es utilizar la gran cantidad de conocimientos acumulados para derrotar el arte de la técnica de los algoritmos OCR.
1.1.8 Aprendizaje eficiente de representaciones escasas con un
modelo Energía-Base.
En este, se describe un nuevo método de supervisión para el aprendizaje escaso. El modelo utiliza un codificador lineal y un decodificador lineal. El método funciona tal que al dar una entrada, el código minimiza la distancia entre la salida del decodificador y la entrada. El proceso se aprende en dos fases: (1) calcular el mínimo código de vector de energía, (2) ajustar los parámetros del codificador y decodificador a fin de disminuir la energía. Utilizando el método propuesto sin inicializar la primera capa de un red convolucional, se ha conseguido una tasa de error ligeramente menor al mejor informado, sobre el resultado obtenido de la base de datos MNIST. (6)
1.1.9 Aprendizaje no supervisado de las jerarquías invariantes de
las características con aplicación al reconocimiento de un objeto
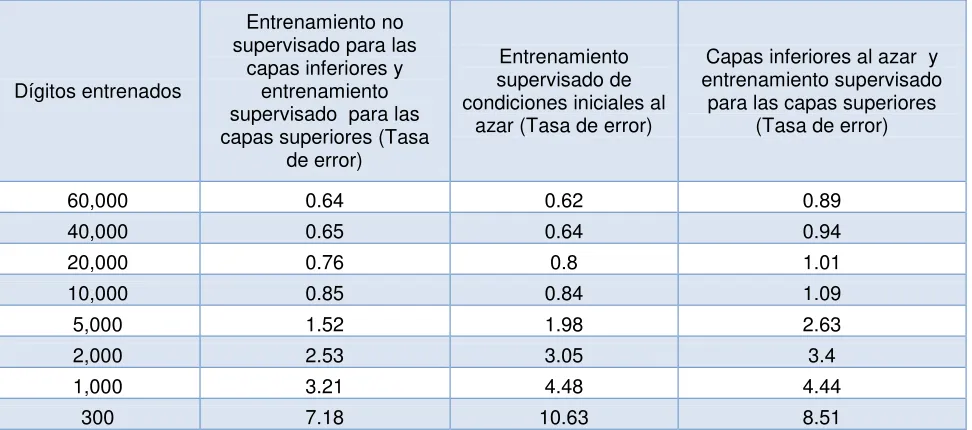
Se presenta un método para el aprendizaje de una jerarquía de escasas detecciones de características, que son invariables para los pequeños cambios y distorsiones. La característica resultante de la extracción, consiste en múltiples filtros de convolución, seguido por un “pointwise” de no linealidad, que calcula el máximo de ventanas de cada filtro en las salidas adyacentes. Un segundo nivel de los más grandes y más invariantes se obtiene mediante la capacitación del mismo algoritmo sobre los parches de las características de primer nivel. La formación supervisada de este clasificador de estas características de rendimiento, es de 0,64% de error utilizando la base de datos MNIST, y el 54% de tasa de reconocimiento de Caltech. Si bien el resultado de la arquitectura es similar a una red convolucional, el “pointwise” sin formación, alivia el procedimiento exceso de parametrización, con problemas que afectan puramente el método supervisado y los procedimientos de aprendizaje, el rendimiento y un buen desempeño con muy pocas muestras de dígitos de entrenamiento. (7)
Dígitos entrenados
Entrenamiento no supervisado para las
capas inferiores y entrenamiento supervisado para las capas superiores (Tasa
de error)
Entrenamiento supervisado de condiciones iniciales al
azar (Tasa de error)
Capas inferiores al azar y entrenamiento supervisado
para las capas superiores (Tasa de error)
60,000 0.64 0.62 0.89
40,000 0.65 0.64 0.94
20,000 0.76 0.8 1.01
10,000 0.85 0.84 1.09
5,000 1.52 1.98 2.63
2,000 2.53 3.05 3.4
1,000 3.21 4.48 4.44
[image:26.612.86.572.71.286.2]300 7.18 10.63 8.51
Tabla 1 Tasa de error
1.1.10 Organización del documento
En este capítulo se han presentado: Introducción y estado del arte. El resto del documento de tesis está organizado como sigue:
En el capítulo 2 y 3, se detalla la evolución de las Memorias Asociativas Clásicas, desde la “Lernmatrix”, hasta la creación de la “Memoria Asociativa Bidireccional (BAM)” de Bart Kosko en 1988. Así mismo, se muestran los algoritmos utilizados para cada una de las memorias que se tratan en dichos capítulos.
De igual manera se presentan las Memorias Asociativas no Clásicas, entre las que destacan las Memorias Morfológicas, las Memorias Asociativas Alfa-Beta, y las Memorias Asociativas Bidireccionales Alfa-Beta, el cual tomaremos esta última para su aplicación en el reconocimiento de patrones.
Se vera la gran ventaja que tiene la Memoria Asociativa Bidireccional Alfa Beta con respecto a las demás, debido a que esta recupera el 100% de los patrones de salida dados los patrones de entrada pertenecientes al conjunto fundamental. Para ello, se anexan unas gráficas donde se muestra la capacidad de recuperación de la Alfa Beta con respecto a las demás.
El capitulo 5, presenta aspectos experimentales: primeramente, se comparan los distintos elementos estructurantes, y los resultados que arroja éste. Además, se realiza una serie de experimentos aplicando la BAM Alfa Beta en el reconocimiento de dígitos empleando cada uno de los elementos estructurantes para un conjunto fundamental de 300, 1,000 y 2,000 dígitos.
También, se realiza una comparación de los resultados obtenidos empleando la BAM Alfa Beta en el reconocimiento de dígitos, con respecto a los métodos estudiados en el estado del arte.
En este mismo capítulo, se presentan las conclusiones finales obtenidas a partir del reconocimiento de dígitos empleando la BAM Alfa Beta; se incluye, además, algunos trabajos a futuro derivados de este trabajo de tesis.
Capítulo 2: Métodos de Memorias Asociativas
Clásicas
En este capítulo se detalla la evolución de las Memorias Asociativas Clásicas, desde la “Lernmatrix”, hasta la creación de la “Memoria Asociativa de Hopfield. Así mismo, se muestran los algoritmos utilizados para cada una de las memorias.
De igual manera se presentan las Memorias Asociativas no Clásicas, entre las que destacan las Memorias Morfológicas y las Memorias Asociativas Alfa Beta, el cual tomaremos esta última para su aplicación en el reconocimiento de patrones.
Se muestran las ventajas que presenta la Memoria Asociativa Alfa Beta con respecto a las demás. De igual forma, se explican dos operaciones básicas en la morfología matemática; dilatación y erosión.
Finalmente se anexa una gráfica comparativa entre las memorias asociativas Clásicas con respecto a la Memoria Asociativa no Clásica Alfa Beta, obteniendo esta última, resultados muy satisfactorios.
2.1 Conceptos Básicos
El propósito principal que debe presentar una memoria asociativa es recuperar correctamente patrones completos a partir de patrones de entrada, los cuales pueden estar alterados con ruido aditivo, sustractivo o combinado. Los conceptos aquí mencionados se presentan en la referencias (8) (9) (10)
Una Memoria Asociativa puede formularse como un sistema de entrada y salida, idea que se esquematiza a continuación:
En este esquema, los patrones de entrada y salida están representados por
vectores columna denotados por x y y, respectivamente. Cada uno de los
patrones de entrada forma una asociación con el correspondiente patrón de salida,
M
la cual es similar a la una pareja ordenada; por ejemplo, los patrones x y y del
esquema anterior forman la asociación (x,y).
Los patrones de entrada y salida se denotarán con las letras negrillas, x y y,
agregándoles números naturales como superíndices para efectos de
discriminación simbólica. Por ejemplo, a un patrón de entrada x1 le corresponderá
el patrón de salida y1, y ambos formarán la asociación (x1,y1); del mismo modo,
para un número entero positivo k específico, la asociación correspondiente será
(xk,yk).
La memoria asociativa M se representa mediante una matriz, la cual se genera a
partir de un conjunto finito de asociaciones conocidas de antemano: este es el
conjunto fundamental de aprendizaje, o simplemente conjunto fundamental.
El conjunto fundamental se representa de la siguiente manera:
{(xµ, yµ) | µ = 1, 2, ..., p}
donde p es un número entero positivo que representa la cardinalidad del conjunto
fundamental.
A los patrones que conforman las asociaciones del conjunto fundamental se les
llama patrones fundamentales. La naturaleza del conjunto fundamental
proporciona un importante criterio para clasificar las memorias asociativas:
Una memoria es Autoasociativa si se cumple que xµ = yµ ∀µ ∈ {1, 2, ..., p}, por
lo que uno de los requisitos que se debe de cumplir es que n = m.
Una memoria Heteroasociativa es aquella en donde ∃µ ∈ {1, 2, ..., p} para el que
se cumple que xµ≠yµ. Nótese que puede haber memorias heteroasociativas con n
= m.
asociativa a partir de las p asociaciones del conjunto fundamental, y la fase de
recuperación que es donde la memoria asociativa opera sobre un patrón de entrada, a la manera del esquema que aparece al inicio de esta sección.
A fin de especificar las componentes de los patrones, se requiere la notación para
dos conjuntos a los que llamaremos arbitrariamente A y B. Las componentes de
los vectores columna que representan a los patrones, tanto de entrada como de
salida, serán elementos del conjunto A, y las entradas de la matriz M serán
elementos del conjunto B.
No hay requisitos previos ni limitaciones respecto de la elección de estos dos conjuntos, por lo que no necesariamente deben ser diferentes o poseer características especiales. Esto significa que el número de posibilidades para escoger A y B es infinito.
Por convención, cada vector columna que representa a un patrón de entrada
tendrá n componentes cuyos valores pertenecen al conjunto A, y cada vector
columna que representa a un patrón de salida tendrá m componentes cuyos
valores pertenecen también al conjunto A. Es decir:
xµ∈An y yµ∈Am∀µ ∈ {1, 2, ..., p}
La j-ésima componente de un vector columna se indicará con la misma letra del
vector, pero sin negrilla, colocando a j como subíndice (j∈ {1, 2, ..., n} o j∈ {1, 2, ...,
m} según corresponda). La j-ésima cómponente del vector columna xµ se
representa por: xµj
Con los conceptos básicos ya descritos y con la notación anterior, es posible expresar las dos fases de una memoria asociativa:
1. Fase de Aprendizaje(Generación de la memoria asociativa). Encontrar los
operadores adecuados y una manera de generar una matriz M que
almacene las p asociaciones del conjunto fundamental {(x1,y1), (x2,y2), ...,
(xp,yp)}, donde xµ ∈An y yµ∈ Am ∀µ ∈ {1, 2, ..., p}. Si ∃µ ∈ {1, 2, ..., p} tal
que xµ≠ yµ, la memoria será heteroasociativa; si m = n y xµ = yµ ∀µ ∈ {1,
2. Fase de Recuperación (Operación de la memoria asociativa). Hallar los operadores adecuados y las condiciones suficientes para obtener el patrón
fundamental de salida yµ, cuando se opera la memoria M con el patrón
fundamental de entrada xµ; lo anterior para todos los elementos del
conjunto fundamental y para ambos modos: autoasociativo y heteroasociativo.
Se dice que una memoria asociativa M exhibe recuperación correcta si al
presentarle como entrada, en la fase de recuperación, un patrón xω con ω ∈ {1, 2,
..., p}, ésta responde con el correspondiente patrón fundamental de salida yω.
Una memoria asociativa bidireccional también es un sistema de entrada y salida, solamente que el proceso es bidireccional. La dirección hacia adelante se describe de la misma forma que una memoria asociativa común: al presentarle una entrada
x, el sistema entrega una salida y. La dirección hacia atrás se lleva a cabo
presentándole al sistema una entrada y para recibir una salida x.
2.2 Memorias Asociativas
De manera breve, se realizará un recorrido por los Modelos de Memorias Asociativas que fueron el punto de partida, dando lugar al surgimiento de las Memorias Asociativas Bidireccionales.
Las Memorias Asociativas que se presentarán, son los modelos más representativos que sirvieron de base para la creación de modelos matemáticos que sustentan el diseño y operación de memorias asociativas más complejas, y el modelo incluido, el de Hopfield (11), es la base fundamental que tomó Kosko (12) para crear su famosa BAM. Para cada modelo se describe su fase de aprendizaje y su fase de recuperación.
Se presentan cuatro modelos clásicos basados en el anillo de los números
racionales con las operaciones de multiplicación y adición: Lernmatrix (13),
Correlograph (14), Linear Associator(15) y Memoria Hopfield (11). Además de dos
no Clásica Alfa Beta, por lo que se incluye una gráfica comparativa, donde se muestra la capacidad de recuperación de cada uno de estos modelos. Los algoritmos mostrados a continuación hacen referencia en los libros y artículos (11) (12) (13) (14) (15) y (16).
2.2.1 Lernmatrix de Steinbuch
Karl Steinbuch fue uno de los primeros investigadores en desarrollar un método
para codificar información en arreglos cuadriculados conocidos como crossbar
(17). La importancia de la Lernmatrix (18) (19) se evidencia en una afirmación que
hace Kohonen (20) en su artículo de 1972, donde apunta que las matrices de correlación, base fundamental de su innovador trabajo, vinieron a sustituir a la
Lernmatrix de Steinbuch.
La Lernmatrix es una memoria heteroasociativa que puede funcionar como un
clasificador de patrones binarios si se escogen adecuadamente los patrones de salida; es un sistema de entrada y salida que al operar acepta como entrada un
patrón binario n,
A
∈
µ
x A={0,1} y produce como salida la clase yµ∈Ap que le
corresponde (de entre p clases diferentes), codificada ésta con un método que en
la literatura se le ha llamado one-hot [22’]. El método funciona así: para
representar la clase k ∈ {1, 2, ..., p}, se asignan a las componentes del vector de
salida yµ los siguientes valores: µ =1,
k
y y yµj =0 para j = 1, 2, ..., k-1, k+1, ..., p [7,
8, 9].
Algoritmo de la Lernmatrix
Fase de Aprendizaje
Se genera el esquema (crossbar) al incorporar la pareja de patrones de
entrenamiento
(
)
n pA
A ×
∈
µ µ y
x , . Cada uno de los componentes mij de M, la
Lernmatrix de Steinbuch, tiene valor cero al inicio, y se actualiza de acuerdo con la
= = − = = + = ∆ caso otro en 0 1 y 0 si 1 si µ µ µ µ ε ε i j i j
ij x y
y x
m
donde ε una constante positiva escogida previamente: es usual que εes igual a 1.
Fase de Recuperación.
La i-ésima coordenada yiωdel vector de clase yω∈Ap se obtiene como lo indica la
siguiente expresión, donde ∨ es el operador máximo:
[
]
∑ = ∑ = =∨
= = caso otro en 0 . . si1 1 ω 1 1 ω
ω hj j
n j p h j ij n j i x m x m y
2.2.2 Correlograph de Willshaw, Buneman y Longuet-Higgins
El correlograph es un dispositivo óptico elemental capaz de funcionar como una
memoria asociativa (21). La memoria es tan simple, que podría ser construido en cualquier laboratorio escolar.
Algoritmo del Correlograph
Fase de Aprendizaje
La red asociativa se genera al incorporar la pareja de patrones de entrenamiento
(xµ, yµ) ∈ An x Am. Cada uno de los componentes mij de la red asociativa M tiene
valor cero al inicio, y se actualiza de acuerdo con la regla:
= = = caso otro en 1 si 1 anterior valor x y
mij i j
Fase de Recuperación
Se le presenta a la red asociativa M un vector de entrada xω ∈ An. Se realiza el
producto de la matriz M por el vector xω y se ejecuta una operación de
umbralizado, de acuerdo con la siguiente expresión:
∑ ≥ = = caso otro en 0 . si
1 1m x u
y ij j
n j i
ω ω
donde u es el valor de umbral. Una estimación aproximada del valor de umbral u
se puede lograr con la ayuda de un número indicador mencionado en el artículo
(21) de Willshaw et al. de 1969: log2n
2.2.3
Linear Associator
de Anderson-Kohonen
El Linear Associator tiene su origen en los trabajos pioneros de 1972 publicados
por Anderson y Kohonen (22) (20). A continuación se muestran los algoritmos del Linear Associator en sus dos fases.
Para presentar el Linear Associator consideremos de nuevo el conjunto
fundamental:
{(xµ, yµ) | µ = 1, 2, ..., p} con A = {0, 1} , xµ∈An y yµ∈Am
Algoritmo del Linear Associator
Fase de Aprendizaje.
1) Para cada una de las p asociaciones (xµ, yµ ) se encuentra la matriz yµ ⋅
( )
xµ tde dimensiones m x n
2) Se suman la p matrices para obtener la memoria
de manera que la ij-ésima componente de la memoria M se expresa así:
µ µ
µ i j
p ij y x
m
∑
=
=
1
Fase de Recuperación.
Esta fase consiste en presentarle a la memoria un patrón de entrada xω, donde
{
1,2,...,p}
∈
ω y realizar la operación
( )
µ ω µµ
ω y x x
x
M⋅ ⋅
⋅ =
∑
= t p 12.2.4
La Memoria Asociativa Hopfield
En el modelo que originalmente propuso Hopfield, cada neurona xi tiene dos
posibles estados, a la manera de las neuronas de McCulloch-Pitts: xi = 0 y xi = 1;
sin embargo, Hopfield observa que, para un nivel dado de exactitud en la recuperación de patrones, la capacidad de almacenamiento de información de la memoria se puede incrementar por un factor de 2, si se escogen como posibles
estados de las neuronas los valores xi = -1 y xi = 1 en lugar de los valores
originales xi = 0 y xi = 1. (11)
Al utilizar el conjunto {-1, 1} y el valor de umbral cero, la fase de aprendizaje para la memoria Hopfield será similar, en cierta forma, a la fase de aprendizaje del
Linear Associator. La intensidad de la fuerza de conexión de la neurona xi a la
neurona xj se representa por el valor de mij, y se considera que hay simetría, es
decir, mij = mji. Si xi no está conectada con xj entonces mij = 0; en particular, no hay
conexiones recurrentes de una neurona a sí misma, lo cual significa que mij = 0. El
estado instantáneo del sistema está completamente especificado por el vector
columna de dimensión n cuyas coordenadas son los valores de las n neuronas .
Algoritmo Hopfield
Fase de Aprendizaje
La fase de aprendizaje para la memoria Hopfield es similar a la fase de
aprendizaje del Linear Associator, con una ligera diferencia relacionada con la
diagonal principal en ceros, como se muestra en la siguiente regla para obtener la
ij-ésima componente de la memoria Hopfield M:
= ≠ ∑ = = j i j i x x m j i p ij si 0 si 1 µ µ µ
Fase de Recuperación
Si se le presenta un patrón de entrada x~a la memoria Hopfield, ésta cambiará su
estado con el tiempo, de modo que cada neurona xi ajuste su valor de acuerdo
con el resultado que arroje la comparación de la cantidad n ij j
j
x m
1
=
∑ con un valor de
umbral, el cual normalmente se coloca en cero.
Se representa el estado de la memoria Hopfield en el tiempo t por x(t); entonces
xi(t) representa el valor de la neurona xi en el tiempo t y xi(t+1) el valor de xi en el
tiempo siguiente (t+1).
Dado un vector columna de entrada x~, la fase de recuperación consta de tres
pasos:
1) Para t = 0, se hace x(t)=~x; es decir, xi(0)=x~i, ∀i∈ {1,2,3,...,n}
2) ∀i∈ {1,2,3,...,n} se calcula xi(t+1) de acuerdo con la condición siguiente:
3) Se compara xi(t+1) con xi(t) ∀i ∈ {1, 2, 3,...,n} . Si x(t+1) = x(t) el proceso
termina y el vector recuperado es x(0)=x~. De otro modo, el proceso continúa
de la siguiente manera: los pasos 2 y 3 se iteran tantas veces como sea necesario hasta llegar a un valor t = τ para el cual xi(τ+1) = xi(τ) ∀i ∈ {1, 2,
3,...,n}; el proceso termina y el patrón recuperado es x(τ).
Una clara desventaja del modelo de Hopfield, es la capacidad de recuperación, ya que únicamente tiene la capacidad de recuperar 0.15 patrones, aunque en el trabajo de Abu-Mostafa & St. Jacques (23) se estableció formalmente que una cota superior para el número de vectores de estado arbitrarios estables en una
memoria Hopfield es n.
2.3 Memorias Asociativas no Clásicas
2.3.1 Memorias Asociativas Morfológicas
La diferencia fundamental entre las memorias asociativas clásicas (Lernmatrix,
Correlograph, Linear Associator y Memoria Asociativa Hopfield) y las memorias
asociativas morfológicas radica en los fundamentos operacionales de éstas
últimas, que son las operaciones morfológicas de dilatación y erosión; el nombre
de las memorias asociativas morfológicas está inspirado precisamente en estas dos operaciones básicas. Estas memorias rompieron con el esquema utilizado a través de los años en los modelos de memorias asociativas clásicas, que utilizan operaciones convencionales entre vectores y matrices para la fase de aprendizaje y suma de productos para la recuperación de patrones. Las memorias asociativas morfológicas cambian los productos por sumas y las sumas por máximos o mínimos en ambas fases, tanto de aprendizaje como de recuperación (24).
Hay dos tipos de memorias asociativas morfológicas: las memorias max,
simbolizadas con M, y las memorias min, cuyo símbolo es W; en cada uno de los
dos tipos, las memorias pueden funcionar en ambos modos: heteroasociativo y autoasociativo.
Se definen dos nuevos productos matriciales:
El producto máximo entre D y H, denotado por C = D ∇ H, es una matriz [cij]mxn
(
ik kj)
r
k
ij d h
c =
∨
+=1
El producto mínimo de D y H denotado por C = D∆H, es una matriz [cij]mxn cuya ij
-ésima componente cij es
(
ik kj)
r
k
ij d h
c =
∧
+=1
Los productos máximo y mínimo contienen a los operadores máximo y mínimo, los cuales están íntimamente ligados con los conceptos de las dos operaciones
básicas de la morfología matemática: dilatación y erosión, respectivamente.
2.3.1.1 Operaciones Binarias
Dilatación Binaria
La dilatación, primera de las dos operaciones básicas de la morfología matemática, es la transformación morfológica que combina dos vectores utilizando la suma. La dilatación binaria fue usada primero por Minkowski, y en la literatura matemática recibe el nombre de suma de Minkowski. (25)
La dilatación de A por B, denotada como A ʘ B, es la suma de Minkowski de A y
B; es decir, es el conjunto que resulta de sumar cada elemento de A con cada elemento de B:
AʘB ={ x=a + b ∈ X | a ∈ A Λb∈ B }
Figura 2.3.1.1. 1 Dilatación. (a) Elemento estructurante, (b) Imagen, (c) Imagen dilatada
Erosión Binaria
La operación de erosión consiste en hacer decrecer un conjunto A a través de un proceso controlado de eliminación de elementos, tomando como referencia un elemento estructurante. Al igual que sucede en la dilatación, el tamaño y forma finales del conjunto erosionado dependerá fuertemente del tamaño y forma del elemento estructurante B. (25)
La erosión de A y B se denota A ɵ B y su definición es:
A ɵ B ={ x∈ X | x+b ∈ A, ∀b ∈ B }
2.3.2 Memorias Heteroasociativas Morfológicas
Algoritmo de las memorias morfológicas max
Fase de Aprendizaje
1. Para cada una de las p asociaciones (xµ, yµ) se usa el producto mínimo para
crear la matriz yµ ∆ (-xµ)t de dimensiones m x n, donde el negado transpuesto
del patrón de entrada xµ se define como µ
(
µ µ µ)
n t
x x x , ,...,
)
(−x = − 1 − 2 .
2. Se aplica el operador máximo ∨ a las p matrices para obtener la memoria M.
[
t]
p
) (
1
µ µ
µ
x y M=
∨
∆ −=
Fase de Recuperación
Esta fase consiste en realizar el producto mínimo ∆ de la memoria M con el patrón
de entrada xω, donde ω ∈ {1, 2, ..., p}, para obtener un vector columna y de
dimensión m:
y = M∆xω
Las fases de aprendizaje y de recuperación de las memorias morfológicas min
se obtienen por dualidad.
2.3.3 Memorias Autoasociativas Morfológicas
Para este tipo de memorias se utilizan los mismos algoritmos descritos anteriormente y que son aplicados a las memorias heteroasociativas; lo único que cambia es el conjunto fundamental. Para este caso, se considera el siguiente conjunto fundamental:
2.3.4 Memorias Asociativas Alfa-Beta
Las memorias Alfa-Beta (26) utilizan máximos y mínimos, y dos operaciones
binarias originales α y β de las cuales heredan el nombre.
Para la definición de las operaciones binarias α y βse deben especificar los
conjuntos A y B, los cuales son:
A = {0, 1} y B = {0, 1, 2}
La operación binaria α: A x A→B se define como:
La operación binaria β: B x A→A se define como:
x y β(x, y)
0 0 0
0 1 0
1 0 0
1 1 1
2 0 1
2 1 1
Los conjuntos A y B, las operaciones binarias α y β junto con los operadores ∧
(mínimo) y ∨ (máximo) usuales conforman el sistema algebraico (A, B, α, β, ∧, ∨)
en el que están inmersas las memorias asociativas Alfa-Beta [libro rojo, tesis maestras].
x y α(x, y)
0 0 1
0 1 0
1 0 2
Se requiere la definición de cuatro operaciones matriciales, de las cuales se usarán sólo 4 casos particulares:
Operación αmax: Pmxr Qrxn
[ ]
fij mxnα α =
∇ , donde ( , )
1
kj ik r
k
ij p q
fα
∨
α=
=
Operación βmax: Pmxr Qrxn
[ ]
fij mxnβ β =
∇ , donde ( , )
1 ik kj
r
k
ij p q
f β
∨
β=
=
Operación αmin:
[ ]
mxn ij rxn mxr Q h
P ∆α = α , donde ( , )
1
kj ik r
k
ij p q
hα
∧
α=
=
Operación βmin: Pmxr Qrxn
[ ]
hij mxnβ β =
∆ , donde ( , )
1 ik kj
r
k
ij p q
hβ
∧
β=
=
La tesis presentada por el Dr. Cornelio Yáñez (26), muestra los resultados
obtenidos al utilizar las operaciones que involucran al operador binario α con las
componentes de un vector columna y un vector fila dados, y se analiza el caso en
el que se opera una matriz de dimensiones m x n con un vector columna de
dimensión n usando las operaciones∇β y ∆β.
2.3.4.1 Memorias Heteroasociativas Alfa-Beta
Se tienen dos tipos de memorias heteroasociativas Alfa-Beta: tipo V y tipo Λ. En
la generación de ambos tipos de memorias se usará el operador ⊗ el cual tiene la
siguiente forma:
( )
[
µ µ]
α(
µ µ)
j i ij t x y , = ⊗ xAlgoritmo Memorias Alfa-Beta tipo V
Fase de Aprendizaje
Paso 1. Para cada µ = 1, 2, ..., p, a partir de la pareja (xµ, yµ) se construye la
matriz
( )
[
]
mxnt
µ µ x
y ⊗
Paso 2. Se aplica el operador binario máximo ∨ a las matrices obtenidas en el paso 1: ] ) ( [ 1 t p µ µ µ x y V=
∨
⊗=
La entrada ij-ésima está dada por la siguiente expresión:
) , ( 1 µ µ µ
α i j
p
ij y x
v
∨
=
=
Fase de Recuperación.
Se presenta un patrón xω, con ω∈ {1, 2, ..., p}, a la memoria heteroasociativa αβ
tipo V y se realiza la operación ∆β: V ∆βxω.
Dado que las dimensiones de la matriz V son de m x n y xω es un vector
columna de dimensión n, el resultado de la operación anterior debe ser un vector
columna de dimensión m, cuya i-ésima componente es:
(
ω)
(
µ)
β β ij j
n
j
i v ,x
1
Algoritmo Memorias Alfa-Beta tipo
Λ
Fase de Aprendizaje
Paso 1. Para cada µ = 1, 2, ..., p, a partir de la pareja (xµ, yµ) se construye la
matriz
( )
[
]
mxnt
µ µ x
y ⊗
Paso 2. Se aplica el operador binario mínimo ∧ a las matrices obtenidas en el paso 1: ] ) ( [ 1 t p µ µ µ x y Λ=
∧
⊗ =La entrada ij-ésima está dada por la siguiente expresión:
) , ( 1 µ µ µ α
λ
∧
p yi xj=
=
Fase de Recuperación.
Se presenta un patrón xω, con ω∈ {1, 2, ..., p}, a la memoria heteroasociativa αβ
tipo Λ y se realiza la operación ∇β: V ∇βxω.
Dado que las dimensiones de la matriz Λ son de m x n y xω es un vector
columna de dimensión n, el resultado de la operación anterior debe ser un vector
columna de dimensión m, cuya i-ésima componente es:
(
ω)
(
µ)
β β λij j n
j
i ,x
1
∨
= = ∇ x2.3.4.2 Memorias Autoasociativas Alfa-Beta
Si a una memoria heteroasociativa se le impone la condición de que yµ = xµ∀µ ∈
{1, 2, ..., p) entonces, deja de ser heteroasociativa y ahora se le denomina
autoasociativa.
Memorias Autoasociativas Alfa-Beta tipo V.
Las fases de aprendizaje y recuperación son similares a las memorias heteroasociativas Alfa-Beta.
Fase de Aprendizaje.
Paso 1. Para cada µ = 1, 2, ..., p, a partir de la pareja (xµ,xµ) se construye la matriz
[
]
nxnt
) ( µ
µ x
x ⊗
Paso 2. Se aplica el operador binario máximo V a las matrices obtenidas en el paso 1:
[
t]
p
) ( 1
µ µ µ
x x V=
∨
⊗=
La entrada ij-ésima de la memoria está dada así:
(
µ µ)
µ α i j p
ij x x
v ,
1
∨
= =y de acuerdo con que α: A x A →B, se tiene que vij ∈B, ∀i ∈ {1, 2, ..., n}. ∀j∈ {1,
2, ..., n}.
Fase de Recuperación.
La fase de recuperación de las memorias autoasociativas Alfa-Beta tipo V tiene dos casos posibles. En el primer caso el patrón de entrada es un patrón
segundo caso, el patrón de entrada NO es un patrón fundamental, sino la versión distorsionada de por lo menos uno de los patrones fundamentales; lo anterior
significa que si el patrón de entrada es ~x, debe existir al menos un valor de índice
ω ∈ {1, 2, ..., p} , que corresponde al patrón fundamental respecto del cual x~ es
una versión alterada con alguno de los tres tipos de ruido: aditivo, sustractivo o mezclado.
CASO 1:Patrón fundamental. Se presenta a un patrón xω, con ω∈ {1, 2, ..., p} a
la memoria autoasociativa Alfa-Beta tipo V y se realiza la operación ∆β:
V∆βxω
El resultado de la operación anterior será el vector columna de dimensión n.
(
)
( , )1
ω ω
β β ij j n
j
i
∧
v x= = ∆ x V
(
)
= ∆ = =∧
µ µ ω µ ωβ β α i j j
p n
j
i (x ,x ) ,x
1
1
V
x V
CASO 2: Patrón alterado. Se presenta el patrón binario ~x (patrón alterado de
algún patrón fundamental xω) que es un vector columna de dimensión n, a la
memoria autoasociativa Alfa-Beta tipo V y se realiza la operación
x V∆β~
Al igual que en el caso 1, el resultado de la operación anterior es un vector
columna de dimensión n, cuya i-ésima componente se expresa de la siguiente
manera:
(
~)
( ,~ )1 ij j
n
j
i β v x
β
∧
= = ∆ x V(
)
= ∆∧
∨
== i j j
p n
j
i x x x
~ , ) , ( ~ 1 1 µ µ µ
βx β α
2.3.4.4 Ventaja de la Memoria Autoasociativa Alfa Beta tipo V
Dado los teoremas 4.28 y 4.30 presentados en el trabajo con referencia (16), se enumeran las ventajas que tiene este tipo de Memoria Autoasociativa con respecto a las no Clásicas.
• La memoria autoasociativa Alfa-Beta tipo V recupera de manera perfecta el
conjunto fundamental completo.
• La memoria V recupera el conjunto completo de patrones fundamentales en
forma perfecta.
• El número de patrones que puede aprender una memoria autoasociativa
Alfa-Beta tipo V, con recuperación perfecta, es máximo.
• Las memorias autoasociativas Alfa-Beta tipo V son inmunes a cierta
cantidad de ruido aditivo.
2.3.4.5 Memorias autoasociativas Alfa-Beta
Λ
Fase de Aprendizaje
Paso 1. Para cada µ = 1, 2, ..., p, a partir de la pareja (xµ,xµ) se construye la matriz
[
]
nxnt
) ( µ
µ x
x ⊗
Paso 2. Se aplica el operador binario máximo Λ a las matrices obtenidas en el paso 1:
[
t]
p
) ( 1
µ µ µ
x x
Λ=
∧
⊗=
La entrada ij-ésima de la memoria está dada así:
(
µ µ)
µ
α λij p xi ,xj
1