UNIVERSIDAD
A U T ~ N O M A
METROPOLITANA
UNIDAD
:
IZTAPALAPA
DIVISI~N: CIENCIAS BÁSICAS
E
INGENIERÍA
CARRERA
:
INGENIERÍA
ELECTR~NICA
MATERIA
:
PROYECTO TERMINAL
TÍTULO
:
SERVICIOS
DE CRIPTOGRAFÍA
FECHA
:
16 DE FEBRERO DEL 2000
ALUMNOS
:
RICARDO ARABEDO SOLIS 892302,
44
JOAQUÍN GARCÍA
MORENO
91225644
- .
INTRODUCCIóN
A LA CRIPTOGRAFÍA
Para entablar una comunicación son necesarios tres elementos básicos; un emisor, un mensaje y finalmente un
receptor. También puede ser posible que exista no sólo un receptor sino un número ilimitado de receptores a los
cuales se desea que llegue el mensaje. Otro posible caso es que el emisor tenga la intención de enviar su mensaje a
receptores específicos y no pueda evitar, debido al medio de comunicación que otros receptores reciban el mensaje.
En la actualidad los medios de comunicación electrónica han tomado un lugar muy importante en nuestra sociedad
y muchas de las actividades de hoy giran en tomo a ellos. Nadie negaría que la comunicación a través dt:
INTERNET juega un papel muy importante en la cultura, la economía, la tecnología, las relaciones humanas, etc.
Un problema inherente a la INTERNET es el hecho de que la información que tenemos puede ser obtenida por
cualquier otro usuario de la red si no tomamos las precauciones necesarias. Cuando enviamos información a través
del correo electrónico se corre el riesgo de que otros usuarios, los cuales son no deseados, puedan recibir esa
información. Como una solución a este tipo de problemas surge la Criptografía en la cual se da el intercambio de
información entre participantes evitando que otros puedan accesarla. Para evitar que otros puedan leer la
información lo que se hace es transformar la información de tal manera que sólo los participantes puedan
transformarla a su forma original y así recuperarla.
Los sistemas criptográficos están clasificados generalmente a lo largo de tres dimensiones independientes;
1.- El tipo de operaciones utilizadas para transformar el texto plano en texto cifrado. Todos los algoritmos de
encripción están basados en dos principios generales: la sustitución, en el cual cada elemento en el texto plano (bit,
letra, grupo de bits o letras) es mapeado en otro elemento, y la transposición, en la cual los elementos en el texto
plano son reordenados. El requerimiento fundamental es que ninguna información debe perderse, esto es, todas la:<
operaciones son reversibles. L a mayoría de los sistemas, referidos como producto de los sistemas, envuelven etapais múltiples de sustitución y transposición.
2.- El número de llaves utilizadas. Si ambos emisor y receptor utilizan la misma llave, el sistema es referido como
encripción simétrica, de una llave, de llave secreta o convencional. Si el emisor y el receptor utilizan cada uno 1lave:s
diferentes, el sistema es referido como encripción asimétrica, de dos llaves o de llave pública.
3.- L a forma en la cual el texto plano es procesado. Un cifrador de bloque procesa un bloque de elementos de entrada a la vez, produciendo un bloque de salida para cada bloque de entrada. Un cifrador orientado a bit procesa al
entrada de elementos de manera continua, produciendo una salida tal como esta se va llegando.
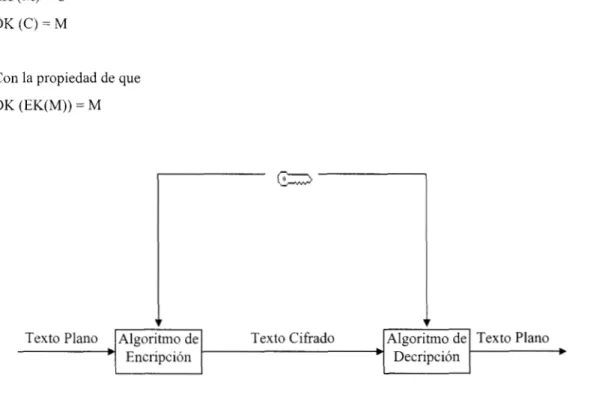
Dentro de la terminología que se usa dentro de la criptografía se tienen los siguientes conceptos: El Texto Plano
(Plaintext) debe entenderse como el mensaje en su forma original. Mientras que el Texto Cifrado (Ciphertext) debe
entenderse como el mensaje puesto en clave. También es posible definir dos procesos; uno de ellos nos lleva del
texto plano al texto cifrado y se conoce como Encripción o Codificación, el otro nos lleva del texto cifrado al texto
Servicios de Cr@tografia
Texto Cifrado Algoritmo de Texto Plano
Decripción b
Fig. 1.1 Encripción y Decripción.
Relacionados con la Criptografía que es el arte de mantener los mensajes seguros, y la cual es practicada por los
criptógrafos, tenemos a los Criptoanalistas, los cuales se enfocan en romper el texto cifrado, y finalmente tenemos a
la Criptología, la cual se encarga de ligar a la criptografía con el criptoanálisis.
En este trabajo el texto plano o mensaje lo denotaremos por M, el cual puede estar constituido por una cadena de
bits, un archivo de texto, un mapa de bits, una cadena de voz digitalizada, una imagen de video digital, etc. Desde el
punto de vista computacional M es simplemente datos en forma binaria. El texto cifrado lo denotaremos por C y este
también debe interpretarse como datos binarios, los cuales pueden ser del mismo tamaño que M, más grande o
también más pequeño (usando encripción más compresión). La hnción de encripción E opera entonces sobre M y
da como resultado C, matemáticamente
E ( M ) = C
entonces el proceso inverso, la función de decripción D opera sobre C y produce M
D (C) = M
podemos mencionar que si nuestro objetivo final es recuperar el mensaje original entonces se cumple que
D (E(M)) = M .
Cabe mencionar que un buen esquema de criptografía además de la confiabilidad debe ofrecer los siguientes
servicios encaminados a la seguridad:
Autenticación.- Debe ser posible para el receptor de un mensaje determinar su origen, un intruso no debe ser
capaz de disfrazarse como alguien más.
Integridad.- Debe ser posible para el receptor de un mensaje verificar que este no ha sido modificado durante SLI
transito, un intruso no debe ser capaz de sustituir o falsear un mensaje legitimo.
No Rechazo.- Este provee al receptor de un mensaje con la capacidad de probar a una tercera parte que el emisor
realmente fue quien envió el mensaje. Un emisor no debe ser capaz de negar falsamente más tarde que él no envió
un mensaje.
Privacidad- Este provee la habilidad para que el receptor deseado sea quien lea el mensaje, manteniendo a los
Prueba de Sometimiento.- Esto permite al emisor verificar que el mensaje fue tomado por el sistema de entrega
del correo. Esto puede hacerse quizás al firmar el mensaje digerido del contenido de los mensajes.
Prueba de Entrega.- Es la verificación de que el receptor ha recibido el mensaje.
Confidencialidad del Flujo de Mensajes.- Esta es una extensión de la privacidad de tal forma que si A envía un
mensaje a B y C es un receptor no deseado, entonces C no sólo no es capaz de conocer el contexto del mensaje sino
que no puede incluso determinar cuando A envía un mensaje a B.
Anonimato.- Es la habilidad para enviar un mensaje tal que el receptor no pueda encontrar la identidad del
emisor.
Contención.- Es la habilidad de la red para mantener ciertos niveles de seguridad de la información de que esta
salga de ciertas regiones.
Intervención.- La habilidad de la red para que esta pueda grabar eventos que podrían tener alguna relevancia en
seguridad de tal forma que si A envía un mensaje a B en una fecha en particular. Esté sería bastante directo de
implementar. Aunque esto no esta especificado en los estándares.
Integridad en la Secuencia de los Mensajes.- La confianza de que una secuencia entera de mensajes llegó en el
orden transmitido, sin ninguna perdida.
ALGORITMOS Y LLAVES
Para poder llevar a cabo la encripción y la decripción de los mensajes es necesario recurrir a los algoritmos.
En un principio se utilizaban los Algoritmos Criptográficos Restringidos los cuales basaban su seguridad en
mantener oculto cual era su modo de operación. Esto acarrea distintos problemas. El primero de ellos se genera
cuando es utilizado por grupos numerosos los cuales cambian continuamente, pues cada vez que un integrante deja
el grupo es necesario cambiar el algoritmo. Cuando el algoritmo es descubierto entonces es necesario de nuevo
cambiar el algoritmo o algoritmos.
Los algoritmos restringidos no permiten un control de calidad o estandarización. Cada grupo de usuarios debe
tener su propio algoritmo único, l o cual rompe con la portabilidad del algoritmo al no ser compatible con el
hardware y el software exterior al grupo de trabajo dado. Cada grupo tiene que desarrollar su propio algoritmo e
implementarlo. Si nadie en el grupo es un buen encriptador tendrán duda sobre la eficiencia del mismo y sobre s u
grado de seguridad.
En la actualidad se siguen utilizando los algoritmos restringidos, pero sólo en aplicaciones en las que se requiera
una muy baja seguridad.
Como otra alternativa se recurrió a los Algoritmos Criptográficos Públicos, en los cuales se da a conocer cual es el
algoritmo utilizado pero como medio para conseguir la seguridad se implementa una Llave (key) denotada por K .
La filosot’ia de la llave es que esta puede tomar cualquier valor de un gran número de valores. El conjunto de todo:$
los posibles valores que puede tomar la llave se denomina Espacio de la Llave (Keyspace). Entonces las 0peracione:s
Servicios de Cr@tografiá
EK (M) = C
DK (C) = M
Con la propiedad de que
DK (EK(M)) = M
Texto Plano Algoritmo de Texto Cifrado Algoritmo de Texto Plano
Encripción Decripción
-
Fig. 1.2 Encripción y decripción con una llave.
Existen algoritmos en los cuales la encripción se da con una llave mientras que l a decripción se da con otra. Si la llave de encripción es KI y es diferente de la llave de decripción K2, entonces matemáticamente
EK1 (M) = C
DK2 (C) = M
DK2 (EK1 (M)) = M
Entonces podemos concluir que la seguridad de estos algoritmos se basa en la llave (o llaves) y no en los detalles del
algoritmo. Como ya mencionamos el algoritmo puede hacerse público y de esta manera ser analizado. En este caso
no importa que todo el mundo conozca tu algoritmo, ya que, si no saben cuál es la llave nunca podrán decriptar tus
mensajes.
Finalmente podemos definir que un Criptosistema consiste de un algoritmo, todos los posibles mensajes a enviar,
7
Llave Pública B ’SLlave Privada
Usuario Testo Plano Algoritmo
A
Texto Plano
Decripción
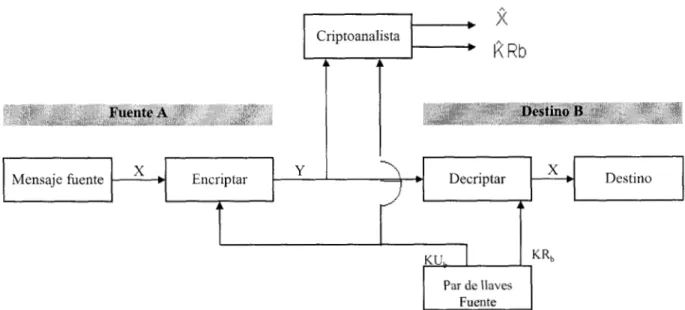
Fig. 1.3 Encripción y decripción con dos llaves diferentes.
TIPOS DE FUNCIONES CRIPTOGRÁFICAS
Existen tres tipos generales de funciones criptográficas: dos funciones basadas en llaves; Los Algoritmos de Llave
Secreta (o Simétricos) y Los Algoritmos de Llave Pública, mientras que el tercer tipo no utiliza llaves y se denomina
Función de Hash (o Digestores de Mensajes).
Los algoritmos de llave secreta o simétricos son aquellos en los cuales l a llave de encripción puede calcularse de la llave de decripción y viceversa. En la mayoría de los algoritmos simétricos las llaves de encripción y decripción son
la misma. En estos algoritmos se necesita que tanto el emisor como el receptor sepan o estén de acuerdo en cual es la
llave antes de que puedan establecer una comunicación segura. Entonces la seguridad del algoritmo simétrico descansa sobre la llave.
Matemáticamente la encripción y decripción con un algoritmo simétrico se denota por
EK (M)
=C
DK (C) =
M
Los algoritmos simétricos se pueden dividir en dos categorías. Unos operan sobre el texto plano en un sólo bit a la
vez, estos son llamados Algoritmos Orientados a Bit (bit stream), otros operan en el testo plano sobre grupos de
bits, los grupos de bits se llaman bloques y los algoritmos se llaman Algoritmos de Bloque.
Un Algoritmo de Llave Pública esta disellado de tal manera que l a llave usada para l a encripción es diferente de l a
llave usada para la decripción. Entonces, l a llave de decripción no puede calcularse de la llave de encripción. Estos algoritmos se llaman de “llave pública” debido a que la llave de encripción puede hacerse pública, entonces el
Servicios de Criptografia
dirigido lo puede decriptar. Entonces la llave usada para encriptar la información se llama Llave Pública, mientras
que la llave usada para decriptar la información se llama Llave Privada ( o Secreta).
La encripción usando la llave publica la denotaremos como
Ee (M) = C
mientras que la decripción con la llave privada l a denotaremos
Dd (C) = M
Nuevamente tenemos la propiedad de que
Dd (Ee(M)) = M
Los Algoritmos de Hash también se conocen como mensajes digeridos o transformaciones en un sólo sentido.
Una función de hash criptográfica es una transformación matemática que toma un mensaje de longitud arbitraria
(transformado en una cadena de bits) y calcula de él un número de longitud fija (corto).
Llamaremos al hash de un mensaje m, h(m). Si tiene las siguientes propiedades:
Para cualquier mensaje m, es relativamente fácil calcular h(m). Esto sólo significa que para ser prácticos éste no
puede tomar gran parte del tiempo de procesamiento para calcular el hash.
Dada h(m), no hay manera de encontrar un m que nos lleve a h(m) en una forma que sea substancialmente fácil ir a
través de todos los posibles valores de m y calcular h(m) para cada uno.
Aún pensando que es obvio que muchos diferentes valores de m serán transformados al mismo valor h(m) (debido a
que hay mucho más valores posibles de m). no es factible computacionalmente encontrar dos valores que nos lleven
al mismo resultado.
Un ejemplo del tipo de funciones que podrían trabajar es tomar el mensaje m, tratarlo como un número, sumar una
constante grande, cuadrarlo y tomar la mitad de los n dígitos como el hash. Puedes ver que mientras esto no es
difícil de calcular, no es obvio como podrías encontrar un mensaje que produciría un hash en particular, o como uno
CRIPTOANÁLISIS
El objetivo principal de la criptografía es mantener en secreto ú oculto el texto plano (o la llave o ambos) de los
posibles adversarios. Es conveniente asumir que los adversarios tienen el acceso completo a los sistemas de
comunicación entre el emisor y receptor.
Con el uso del criptoanálisis es posible recuperar el mensaje o texto plano sin tener acceso a la llave.
Entonces un criptoanálisis exitoso puede recuperar el texto plano o la llave. Para lograr su objetivo el criptoanálisis
es capaz de encontrar las debilidades existentes en un criptosistema como base para obtener buenos resultados.
Un intento criptoanalítico se llama un ataque. Es necesario establecer que l a seguridad del algoritmo debe residir fundamentalmente en la llave. Kerckhoffs asume que el criptoanalista tiene detalles completos del algoritmo
criptográfico y de su implementación. En la práctica no siempre los criptoanalistas tienen tal información de manera
detallada. Cuando un algoritmo no puede romperse aún con el conocimiento de cómo trabaja, entonces es más dificil
de romper si no se tiene ningún dato de éste.
Desde el punto de vista del criptoanálisis hay cuatro tipos generales de atacar un algoritmo criptográfico. En cada
uno de ellos es necesario considerar que el criptoanalista tiene conocimiento completo del algoritmo de encripción
que esta siendo utilizado:
1.- Ataque con Sólo Texto Cifrado (Only-Ciphertext Attack). El criptoanalista tiene el texto cifrado de varios
mensajes, los cuales han sido encriptados con el mismo algoritmo de encripción. En este caso el objetivo del
criptoanalista es recuperar el texto plano de la mayor cantidad de mensajes como le sea posible, otra opción es
deducir l a llave (o llaves) usada para encriptar los mensajes, como base para poder decriptar otros mensajes
encriptados con la misma llave.
Dado C 1 = EK(P l), C2 =EK(P2), . . . .,Ci = EK(Pi)
Deducir : Cualquiera de PI,P2,. .Pi; K;
O un algoritmo para inferir Pi+ I , de Ci+ 1 = EK(Pi+ 1)
2.- Ataque Conociendo Texto Plano (Know-Plaintext Attack). En este caso el criptoanalista ha logrado accesar no
sólo a l texto cifrado de varios mensajes sino también a l texto plano de esos mensajes. Entonces su trabajo es deducir
la llave (o llaves) utilizadas para encriptar los mensajes o un algoritmo para decriptar cualquiera de los nuevos
mensajes encriptados con la misma llave (o llaves).
Dado C 1 = EK(Pl), C2 =EK(P2), . . ..,Ci = EK(Pi)
Deducir : Cualquier K;
Servicios de Crlptografia
3.- Ataque Tomando Texto Plano (Chosen-Paintext Attack). En este caso el criptoanalista ha accesado al texto
cifrado de varios mensajes y al texto plano asociado a varios de los mismos y además es capaz de obtener el texto
plano de los mensajes que estaban encriptados. Este tipo de ataque es muy poderoso debido a que el criptoanalista
puede tomar bloques específicos de texto plano para encriptados. En este caso el trabajo del criptoanalista es
deducir la llave (o llaves) utilizadas para encriptar los mensajes o un algoritmo para decriptar cualquiera de los
nuevos mensajes encriptados con la misma llave (o llaves).
Dado C 1 = EK(Pl), C2 =EK(P2),
. . .
.7 Ci = EK(Pi) Donde el criptoanalista ha logrado tomar Pl,P2,. .PiDeducir : Cualquiera
K;
O un algoritmo para inferir Pi+ 1, de Ci+ 1 = EK(Pi+ 1)
4.- Ataque Adaptivo Tomando Texto Plano (Adaptive-Chosen-Plaintext Attack). Este es un caso especial del
anterior. El criptoanalista no sólo toma el texto plano que está encriptado, sino que é1 puede modificar su opción
basado en los resultados de encripción previos.
Existen al menos otros tres tipos de ataques criptoanalíticos.
5.- Ataque Tomando Texto Cifrado (Chosen-ciphertext Attack). El criptoanalista puede tomar diferentes textos
cifrados para decriptarlos y tener acceso al texto plano decriptado. Su trabajo es entonces deducir la llave.
Dado C1, P1 = DK(C l), C2, P2 = DK(C2),
.
. . ..Ci,
Pi = DK(Ci) DeducirK.
6.- Ataque Tomando la Llave (Chosen-Key Attack). Este implica que el criptoanalista tiene algún conocimiento
acerca de las relaciones entre las diferentes llaves.
7 . - Criptoanálisis de Aprobación Automática por Hostigamiento (Rubber-hose Cristoanalisis). El criptoanalista
amenaza, chantajea o tortura a alguien hasta que obtiene la llave. El soborno es algunas veces referido como Ataque
por Compra de Llave. Estos son ataques muy poderosos y frecuentemente los mejores para romper un algoritmo.
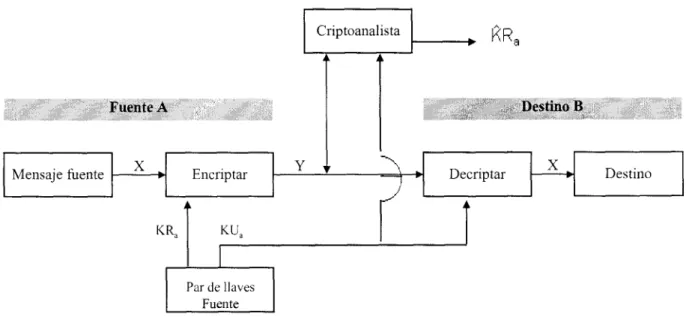
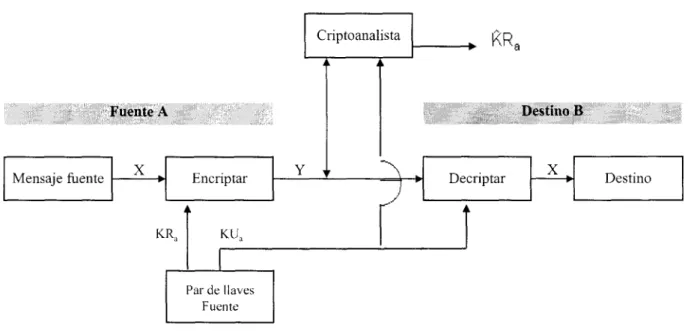
CRIPTOGRAFÍA DE LLAVE SECRETA
En esté capítulo se describe de una manera muy general cual es el funcionamiento de un algoritmo de llave
secreta. Expondremos como funcionan los algoritmos DES e IDEA. En general estos algoritmos toman del mensaje
un bloque de longitud fija, toman una llave de longitud fija y generan un bloque de salida (de la misma longitud que
La Encripción de Llave Secreta también es referida como Encripción de una Sola Llave, Encripción
Convencional o Encripción Simétrica, este f i e el Único tipo de encripción antes del desarrollo de la criptografía de
llave pública. Este sigue siendo el más ampliamente usado de los dos tipos de algoritmo de encripción
Un modelo general del proceso de encripción convencional es el siguiente: Tomemos un mensaje el cual se
encuentra de manera inteligible, referido como Texto Plano, y transformémoslos en una aparente tontería aleatoria,
referida como el Texto Cifrafo. El proceso de encripción consiste entonces de un algoritmo y una llave. En este
caso la llave es un valor completamente independiente del texto plano que controla el algoritmo. Entonces para cada llave diferente y un mismo texto plano, el algoritmo producirá diferentes textos cifrados de salida.
I
Criptoanalista"
.
;
Encripción Decripción Destino
T
Canal Seguro
I
fuente
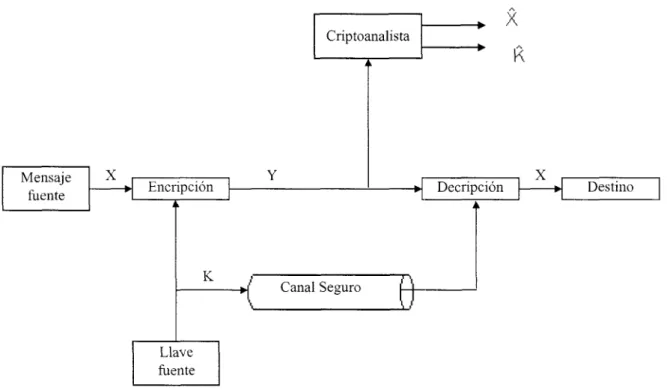
Figura 2 Modelo de un Criptosistema de Llave Privada
El siguiente paso una vez que se ha producido el texto cifrado, es transmitirlo. Una vez que es recibido el texto
cifrado, entonces se puede llevar a cabo el proceso inverso y transformarlo en el texto plano original utilizando un
algoritmo decodificador y la misma llave con la cual fue encriptado.
La seguridad del algoritmo de llave secreta descansa en varios factores. Primero el algoritmo debe ser
suficientemente poderoso tal que es impráctico decodificar un mensaje basándose en el texto cifrado solamente. M á s
allá de que, la seguridad de la encripción convencional depende de la secretidad de la llave, y no en la secretidad del
Servicios de Criptografia
conocimiento del algoritmo de encripcióddecripción, Es decir lo que necesitamos mantener en secreto en l a llave
no el algoritmo.
Esta característica de l a encripción convencional es lo que la hace factible para un uso extendido. El hecho de que
el algoritmo no necesita mantenerse secreto significa que los fabricantes pueden y han desarrollado
implementaciones de chips a bajo costo de algoritmos para la encripción de datos. Esos chips son ampliamente
permitidos e incorporados en una gran cantidad de productos. Con el uso de la encripción convencional, el principal
problema de seguridad es mantener la llave en secreto.
Mirando a los elementos esenciales de la encripción convencional podemos identificar lo siguiente:
Hay alguna fuente para un mensaje, la cual produce un texto plano; X=:[Xl,X2,..,XM]. Los M elementos de X son
letras en algún alfabeto finito. Tradicionalmente, el alfabeto consiste de 26 letras mayúsculas. Hoy en día, el
alfabeto binario (0,l) es típicamente utilizado. Para la encripción, una llave de la forma K=[Kl,K2,..,Kj] es
generada. Si l a llave es generada en la fuente del mensaje, entonces esta también debe ser provista al destinatario por
medio de un canal seguro. Alternativamente, una tercera parte podría generar la llave y enviarla de manera segura a
ambos fuente y destino.
Con el mensaje X y la llave de encripción K como entrada, el algoritmo de encripción forma el texto cifrado
Y=[Y 1 ,Y2,. .;yN]. Podemos escribir esto como
Y = EK(X)
Esta notación indica que Y es producida al usar el algoritmo de encripción
E
como una función del texto plano X,por la función especifica determinada por la llave K.
El receptor deseado, en posesión de la llave, es capaz de invertir l a transformación;
X = DK(Y)
Un oponente, observando Y pero sin tener acceso a K o X, debe intentar recobrar X o K o ambos. Se supone que
el oponente tiene el conocimiento de los algoritmos de encripción (E) y decripción (D): Si el oponente solo esta
interesado en este Único mensaje en particular, entonces é1 enfocará su esfuerzo en recuperar X al generar un texto
plano estimado X’. Frecuentemente, sin embargo, el oponente esta interesado en ser capaz de leer mensajes futuros
ESTANDAR PARA ENCRIPCIÓN
DE
DATOS
(DATA ENCRIPTION STANDAR, DES)D E S C R I P C I ~ N DE DES.
DES se puede clasificar como un algoritmo de encripción en bloque; el tamaño de los bloques es de 64 bits de
longitud. Si lo vemos como un caja negra la entrada lo constituye un bloque de 64 bits de texto plano, la iünción lo
constituye el algoritmo que procesa la información de entrada y finalmente l a salida lo constituye un bloque de 64 bits que pertenecen al texto cifrado. DES es un algoritmo simétrico, es decir, se utiliza la misma llave tanto para la
encripción como para la decripción
44
.'""
4
52
Permutación InicialI
Pennutación seleccionada1
'I
Iteración 1 K1 Pennutación seleccionada Cambio circular a la
2 izauierda
.I
Iteración 2 Pennutación seleccionada Cambio circular a la
2 izauierda
Cambio circular a la izauierda
Servicios de Crlptogsafia
L a llave tiene una longitud de 64 bits, pero de ellos 56 bits realmente constituyen la llave y 8 bits son para verificar paridad y asegurar con ello que no se transmita una llave errónea. L a llave se divide en palabras de 8 bits en las cuales el octavo bits es de paridad. L a llave puede ser cualquier número de 64 bits y puede cambiarse en cualquier momento. Si tomamos un intervalo de pocos números entonces se considera que la llave es débil, pero esto es fácil
de evitar. En este algoritmo toda l a seguridad descansa en la llave. El principio de encripción de este algoritmo se basa en dos procesos: confusión y difusión. Entonces el bloque fundamental para la implementación de DES es
una simple combinación de estas técnicas sobre el texto, basadas en la llave. Este proceso se conoce como una ronda.
DES tiene que ejecutar 16 rondas, en las cuales se aplican las mismas técnicas sobre el bloque de texto plano 16
veces. Ver figura 2.1.
Lo que hace el algoritmo es ejecutar operaciones de aritmética y lógica estándar sobre números de 64 bits a lo más.
L a naturaleza repetitiva del algoritmo lo hace ideal para utilizarse en chip de propósito especial.
BOSQUEJO DEL ALGORITMO
DES opera sobre un bloque de 64 bits del texto plano. El primer paso consiste en efectuar una permutación inicial,
luego el bloque se parte en dos: una mitad izquierda y una mitad derecha. Las mitades entonces tienen una longitud de 32 bits. El siguiente paso es que se ejecuten las 16 rondas. Entonces hay 16 rondas de operaciones idénticas,
llamadas Función F, en la cual los datos se combinan con la llave. Al finalizar las rondas se unen de nuevo las
mitades izquierda y derecha para fonnar el bloque de 64 bits. El último paso es efectuar una permutación final la
cual es el inverso de la permutación inicial.
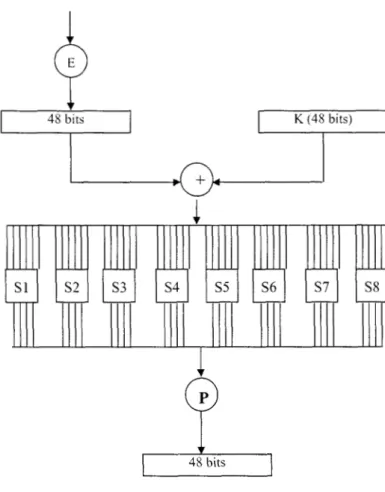
En cada ronda (fig. 2.2) los bits de la llave se cambian y entonces 48 bits se seleccionan de los 56 bits con que
cuenta la llave. L a mitad derecha del dato se expande a 48 bits a través de una permutación de expansión, combinada con 48 bits de una llave expandida y conmutada vía una XOR, enviándola a través de 8 cajas-S produciendo 32 nuevos bits y permutándolos otra vez. Esas cuatro operaciones hacen la Función F. L a salida de la Función F entonces se combina con la mitad izquierda vía una XOR. El resultado de esas operaciones se convierte en la nueva mitad derecha; la antigua mitad derecha se convierte en la nueva mitad izquierda. Esta operación se
repite 16 veces, haciendo las 16 rondas de DES.
Si Bi es el resultado de la i-ésima iteración, Li y R i son las mitades izquierda y derecha de Bi, Ki es el bit 48 de la
llave para la ronda i, y F es la función que hace todas las sustituciones y permutaciones y pasándola a través de la
XOR con la llave, entonces una ronda se ve como
Li = R i-1
48 bits K (48 bits)
1
I
n
I
I
L
48 bitsFigura 2.2 Calculo de (R,K)
La Permutación Inicial.
L a permutación inicial ocurre antes de que se efectúe la primera ronda; este transpone el bloque de entrada como se describe en la tabla 2.1 Esta tabla se lee de izquierda a derecha y de arriba hacia abajo. Por ejemplo l a permutación inicial mueve el bit 58 del texto plano al bit de posición 1, el bit 50 al bit de posición 2, el bit de posición 42 al bit
de posición 3 y así se continúa.
TABLA 2.1 PERMUTACION INICIAL
58 50 42 34 26 18 10 2 60 52 44 36 28 20 12 4
62 54 46 38 30 22 14 6 64 56 48 40 32 24 16 8
57 49 41 33 25 17 9 I 59 51 43 35 27 19 I I 3
Servicios de Crlptografla
La Transformación de la llave.
Inicialmente la llave DES de 64 bits se reduce a una llave de 56 bits, al ignorar cada octavo bit. Esto se describe en
la tabla 2.2. Estos bits pueden usarse para checar la paridad y asegurar que la llave esta libre de errores. Después de
que la llave de 56 bits se extrae, una llave diferente de 48 bits se genera para cada una de las 16 rondas. Estas sub-
llaves, Ki, se determinan de la siguiente manera.
Primero, la llave de 56 bits se divide en dos mitades de 28 bits, entonces las mitades se rotan circularmente a la
izquierda, ya sea, por uno o dos bits, dependiendo de la ronda. Estos cambios se dan en la tabla 2.3.
TABLA 2.2
PERMUTACION DE LAS LLAVES
S7 49 41 33 2.5 17 9 I S8 S0 ,42 34 26 18 10 2 S9 51 43 35 27 19 I I 3 60 5 2 44 36 63 S 5 47 39 31 23 i 5 7 62 54 4 6 38 30 22 14 6 61 53 45 37 29 21 13 5 28 20 12 4
Después de ser cambiados, 48 de los 56 bits de salidas se seleccionan. Debido a que esta operación permuta el
orden de los bits así como también selecciona un semi-bloque de bits, esta se llama permutación de compresión.
Esta operación provee un semi-bloque de 48 bits. La tabla 2.4 define l a permutación de compresión. Por ejemplo,
el bit en la posición 33 de la llave cambiada se mueve a la posición 35 de la salida y el bit en la posición 18 de la llave cambiada se ignora.
Debido al cambio, un semi-bloque de los bits de la llave se usa en cada sub-llave.
TABLA 2.3
NúMERO DE BITS DE LA LLAVE CAMBIADOS POR RONDA
Ronda 1 2 3 4 5 6 7 8 9 10 I I 1.2 13 14 I S 16
Ntilnero I 1 2 2 2 2 2 2 I 2 2 2 2 2 2 1
TABLA 2.4.
PERMUTACION DE C O M P R E S I ~ N
L a Permutación de Expansión.
Esta operación expande la mitad derecha de la palabra de 32 bits hasta 48 bits. Debido a que esta operación cambia el orden de los bits así como también repite ciertos bits, se conoce como permutación de expansión. Esta
operación tiene dos propósitos; hacer que la mitad derecha tenga el mismo tamaño que la llave para que se realice la
operación XOR y así proveer un resultado más largo que pueda comprimirse durante la operación de sustitución.
Sin embargo, para ninguno de ellos su propósito es criptográfico. Al permitir que un bit efectúe dos sustituciones, la
dependencia de los bits de salida sobre los bits de entrada se propaga más rápido. Esto se conoce como efecto de
avalancha. DES esta diseñado para alcanzar la condición en la que cada bit del texto cifrado depende de cada bit del
texto plano y de cada bit de la llave. Tan rápido como sea posible.
La fig. 2.3 define la permutación de expansión. Esta es llamada algunas veces la caja E. Por cada bloque de
entrada de 4 bits, el primero y cuarto bits representan dos bits del bloque de salida, mientras que el segundo y tercer
bits representan un bit del bloque de salida. La tabla 2.5 indica l a relación entre las posiciones de salida y las posiciones de entrada. Por ejemplo el bit en la posición 3 del bloque de entrada se mueve a la posición 4 del bloque
de salida, y el bit de la posición 2 1 del bloque de entrada se mueve a las posiciones 30 y 32 del bloque de salida. Aunque el bloque de salida es más largo que el bloque de entrada, cada bloque de entrada genera un ímico bloque
de salida.
TABLA 2.5.
PERMUTACION DE EXPANSIóN
3 2 1 2 3 4 5 4 5 6 7 8 9
8 9 I O 1 1 12 13 12 13 14 15 16 17
16 17 18 19 20 21 20 21 22 23 24 25 24 25 26 2 1 28 29 28 29 39 3 1 32 1
La Caja- S de Sustitución.
Una vez que la llave comprimida y el bloque expandido han pasado por las XOR, los 48 bits resultantes se
mueven a una operación de sustitución. Las sustituciones se llevan a cabo por ocho cajas de sustitución o cajas S.
Cada caja S tiene una entrada de 6 bits y una salida de 4 bits, hay 8 diferentes cajas. El bloque de 48 bits es dividido
en 8 sub-bloques de 6 bits cada uno. Cada bloque es procesado de manera individual por cada una de las cajas de
manera individual. Entonces el primer bloque es procesado sólo por la caja 1, el segundo bloque es procesado sólo
por la caja 2, y así sucesivamente. Ver la fig. 2.4.
Cada caja S se puede ver como una tabla compuesta por 4 renglones y 16 columnas. Cada entrada a la caja
representa un número de 4 bits. Los 6 bits de entrada a la caja S los cuales serán el renglón y columna que se verá a
Setvicios de Cr1ptografia
4 bits de entrada
Decodificador 4 a 16
P
1
ó
n
I I
I
I
I
I
4 bits de salida
Figura 2.4 Caja S
Los bits de entrada especifican una entrada en la caja S de una manera particular: Considere una entrada a la caja S
de 6 bits, etiquetadas b l , b2, b3, b4, b5 y b6. Los bits b l y b6 se combinan para formar un número de 2 bits, de O a
3, el cual corresponde a un renglón en la tabla, los bits intermedios b2 a b5, se combinan para formar un número de
4 bits, de O a 15 los cuales corresponden a una columna en la tabla.
Por ejemplo, suponga que la entrada a la sexta caja S es 11001 1. El primero y último bits se combinan para
formar 1 1, el cual corresponde al renglón 3 de la sexta caja S. Los 4 bits intermedios se combinan para formar 1 O0 1 ,
el cual corresponde a la columna 9 de la misma caja S. La entrada bajo el renglón 3, columna 9 de la caja S número
6 es 14. El valor 11 10 es sustituido por 110010.
La caja S de sustitución es el paso crítico en DES. Debido a que en el algoritmo esta operación es no lineal y en
consecuencia no es tan fácil de analizar, en comparación con las operaciones lineales. Entonces podemos reafirmar
que las cajas S dan seguridad a DES.
L a Caja P de Permutación.
Los 32 bits de salida de la caja S de sustitución son permutados de acuerdo a la caja P. Este mapea cada bit a la
llamada una permutación convencional o simplemente permutación. La tabla 2.7 muestra a que posición se mueve
cada bit. Por ejemplo, el bit 2 I se mueve al bit 4, mientras que el bit 4 se mueve al bit 3 l. Finalmente el resultado de
la caja P de permutación va a una XOR con la mitad izquierda del bloque de 64 bits inicial.
TABLA 12.6 CAJAS S
Caja-S 1 Caja-S 2
1 4 4 1 3 I 2 1 5 1 1 8 3 1 0 6 1 2 S 9 0 7 15 I 8 1 4 6 1 1 3 4 9 7 2 1 3 1 2 0 S 1 0
0 1 5 7 4 1 4 2 13 1 1 0 6 1 2 1 1 9 5 3 8 3 1 3 4 7 I S 2 8 1 4 1 2 O 1 I O 6 9 1 1 S
4 1 1 4 8 1 3 6 2 1 1 1 5 12 9 7 3 1 0 S O O 1 4 7 1 1 I O 4 13 1 S 8 1 2 6 9 3 2 1 5 15 12 8 2 4 9 I 7 S 1 1 3 14 I O O 6 13 13 8 10 I 3 1 5 4 2 I I 6 7 12 O 5 14 9
Caja-S 3 Caja-S 4
I O O 9 14 6 3 I S 5 1 13 12 7 I I 4 2 8 7 13 14 3 O 6 9 1 0 I 2 8 S I l l 2 4 I S 13 7 O 9 3 4 6 IO 2 8 S 14 1 2 1 1 15 I 13 8 1 1 5 16 I S O 3 4 7 2 12 1 I O 14 9 13 6 4 9 8 15 3 0 1 1 I 2 12 5 1 0 14 7 IO 6 9 O 1 2 1 1 7 1 3 1 5 1 3 14 5 2 8 4
1 1 0 13 O 6 9 8 7 4 15 14 3 1 1 5 2 1 2 3 1 5 O 6 1 0 1 1 3 8 9 4 5 I I I 2 7 2 1 4
Caja-S 5 Caja-S 6
2 1 2 4 1 7 1 0 1 1 6 8 S 3 15 1 3 0 1 4 9 12 I 1 0 1 5 9 2 6 8 O 13 3 4 1 4 7 S 1 1
1 4 1 1 2 1 2 4 7 13 1 S 0 1 5 I O 3 9 8 6 I O I S 4 2 7 12 9 5 6 I 1 3 14 O 1 1 3 8 4 2 1 1 1 I O 1 3 7 8 1 5 9 1 2 5 6 3 O 1 4 9 1 4 15 S 2 8 12 3 7 O 4 I O 1 1 3 1 1 6
I I 8 12 7 I 1 4 2 1 3 6 15 O 9 I O 4 5 3 4 3 2 1 2 9 5 1 5 1 O l l 14 1 7 6 0 8 1 3
Caja-S 7 Caja-S 8
4 1 1 2 1 4 IS O 8 1 3 3 12 9 7 S 1 0 6 5 13 2 8 4 6 1 5 1 1 I I O 9 3 14 S O 1 2 7 13 O I I 7 4 9 1 1 0 1 4 3 5 12 2 1 5 8 6 1 1 5 13 8 I O 3 7 4 12 5 6 I I O 1 4 9 2 I 4 1 1 1 3 12 3 7 1 4 1 0 1 5 6 8 O S 9 2 7 1 1 4 1 9 12 14 2 O 6 1 0 13 15 3 S 8
6 1 1 13 8 1 4 IO 7 9 S O I S 14 2 3 1 2 . 2 I 14 7 4 IO 8 1 3 I S 12 9 O 3 S 6 I I
Tabla 2.7
CAJA- P DE
PERMUTACION
16 7 20 21 29 12 28 17 1 15 23 26 5 18 31 IO 2 8 24 14 32 27 3 9 19 13 30 6 22 1 1 4 25
La Permutación Final.
La permutación final es la función inversa de la pennutación inicial y esta se describe en la tabla 2.8. Debe
notarse que las mitades izquierda y derecha no son cambiadas despuks de la ultima ronda de DES; en lugar de eso el
Servicios de Cr@tograf/b
Tabla 2.8 PERMUTACION FINAL
40 8 48 16 56 24 64 32 39 7 47 15 55 23 63 31
38 6 46 14 52 22 62 30 37 5 45 13 53 21 61 29
36 4 44 12 50 20 60 28 35 3 43 1 1 51 19 59 27
34 2 42 I 0 48 18 58 26 33 I 41 9 49 17 75 25
Decripción de DES.
(Decodificación de DES)
Para el proceso de decripción se utiliza el mismo algoritmo con que se encriptó el mensaje. La única diferencia es
que las llaves deben usarse en el orden inverso. Esto es, si las llaves de encripción para cada ronda son K1, K2, K3,
. . . . , K16 entonces las llaves para la decripción son K16, .
. . .
, K3, K2, K1. El algoritmo que genera la llave paracada ronda es circular también. El cambio de la llave es un cambio a la derecha y el número de posiciones
cambiadas es O, 1 , 2 , 2 , 2 , 2 , 2 , 2 , 1, 2 , 2 , 2 , 2 , 2 , 2 , 1.
Para verificar que realmente se utiliza el mismo algoritmo, invirtiendo el orden de uso de las llaves, y llegar del
texto cifrado al texto plano se hace el análisis de la figura x en la cual el diagrama del lado izquierdo representa el
proceso de encripción y el diagrama del lado derecho representa el proceso de decripción. En el diagrama se puede
ver que, en cada etapa, el valor intermedio del proceso de decripción es igual al correspondiente valor del proceso
de encripción con las dos mitades del valor intercambiadas. Puesto de otra forma, dejemos que la salida de la
i-ésima etapa de encripción sea Li/jRi (Li concatenada con Ri). Entonces la correspondiente entrada a la i-ésima
etapa de decripción es RillLi.
Para verificar l o anterior vayamos a través de los diagramas. Después de la ultima iteración del proceso de
encripción, las dos mitades son intercambiadas, así que la entrada a la etapa IP-1 es R1611L16. La salida de la etapa
es el texto cifrado. Ahora, toma el texto cifrado y úsalo como entrada al algoritmo DES. El primer paso es llevar el
texto cifrado a través de la etapa IP, produciendo la cantidad de 64 bits LdO// Rdo. Pero hemos visto que IP es el
inverso de IP- l. Por lo tanto
LdOll RdO = IP(texto cifrado)
texto cifrado = IP-l(R1611L16)
LdO// RdO= IP(IP-l(R1611L16)) = R1611L16
De esta forma, la entrada a la primera etapa del proceso de decripción es igual a los 32 bits intercambiados de la 160
etapa del proceso de encripción.
Ahora vamos a mostrar que la salida de la primera etapa de del proceso de decripción es igual a los 32 bits
L16 = R15
R16 = L15
+
f(R15,K16)En el lado de la decripción:
Ldl = RdO = L16 = R15
R d l = L dO
+
f(R dO,K16)= R16
+
f(R15,K16)= (L15
+
f(R15,K16))+
f(R15,K16)Recordando que la XOR tiene las siguientes propiedades:
[ A + B ] + C = A + [ B + C ]
D + D = O
E + O = E
De esta forma, tenemos Ldl = R15 y R d l = L15 Por lo tanto, la salida de la primera etapa del proceso de
decripción es L15 = R15 la cual es los 32 bits intercambiados de la salida de la 160 etapa de encripción . Esta
correspondencia toma todos los caminos a través de las 16 iteraciones. Podemos fundir este proceso en términos
generales. Para la i-esima iteración del algoritmo de encripción:
Li = Ri- 1
Ri = L i- 1+ f(R i- 1, Ki)
Reordenando términos:
Ri- 1 = Li
L i- I= Ri+ f(Ri- 1 ,Ki) = Ri
+
f(Li,Ki)De esta forma, hemos descrito las entradas a l a i-esima iteración como una función de las salidas, y esas ecuaciones
confirman las asignaciones mostradas en el lado derecho de la figura x.
Finalmente, vemos que la salida dela ultima etapa del proceso de decripción es ROIJLO. Un intercambio de 32 bits
es ejecutado así que la entrada a la etapa IP- les LOIIRO. Pero
Servicios de Cr&ograf/h
Así el texto plano original es recuperado, demostrando la validez del proceso de decripción DES.
El Uso de una Llave de 56 Bits
Con una longitud de llave de 56 bits, hay 256 posibles llaves lo cual es aproximadamente igual a 7.2 x 1016
llaves. De este modo, por un lado, un ataque de fuerza bruta aparece como impráctico. Suponiendo que en promedio
la mitad del espacio de la llave ha sido recorrida, una simple maquina ejecutando encripción DES por microsegundo
tomaría más de 1000 años romper en romper el código.
Sin embargo, la suposición de una encripción por microsegundo es bastante conservativa. Remontándonos a 1997,
Diffie y Hellman postularon que existía la tecnología para construir un nlaquina paralela con 1 millón de dispositivos
de encripción, cada uno de los cuales podría ejecutar una encripción por microsegundo. Ellos estimaron que el costo
podría ser de alrededor de $ 2 0 millones de dólares en 1997.
Los análisis recientes más rigurosos del problema hechos por Wiener y basados en un ataque con texto plano
conocido. Esto es, se asume que el atacante tiene al menos un par (texto plano, texto cifrado). Wiener tiene cuidado
de proveer los detalles de su diseño.
Wiener reporta en el diseño de un chip que usa técnicas de paralelismo para alcanzar una taza de investigación de
llave de 50 millones de llaves por segundo. Usando costos de 1993, el diseñó un modulo que cuesta $ 100 O0 y
contiene 5 760 chips investigadores de llave. Con su diseño se obtuvieron los siguientes resultados
Costo de la Máquina Tiempo Esperado de Obtención
$ 100 O00 35 horas
$ I O00 O00 3.5 horas
$ 1 0 O00 O00 21 minutos
Además, hay más de un ataque para alcanzar la llave que simplifican el correr a través de todas las posibles llaves. A
menos que texto plano conocido sea provisto, el analista puede ser capaz de reconocer texto plano como texto plano.
Si el mensaje es solo texto plano en Inglés entonces el resultado sale inmediatamente, aunque la tarea de reconocer
Inglés tendría que ser automatizada. Si el mensaje de texto ha sido comprimido antes de la encripción, entonces el
reconocimiento es más dificil. Y si el mensaje es un tipo de dato más general, tal como un archivo numérico, y esté
ha sido comprimido, el problema se vuelve incluso más dificil de automatizar. De este modo, para complementar el
ata que de fuerza bruta, algún grado de conocimiento acerca del texto plano esperado en necesario, y algún medio
automático distinguidor de texto plano de uno confuso es también necesario.
El diseiio Wiener representa la culminación de años de preocupación acerca de la seguridad de DES y puede en
Modos de DES.
Existen cuatro modos de operación: ECB, CBC, OFB y CFB. Los estándares de operación ANSI especifican ECB
y CBC para la encripción, y CBC y n-bit CFB para la autenticación. En el mundo del software comercial el modo
ECB es el más frecuente, aunque es el más vulnerable a los ataques. CBC se usa ocasionalmente, a pesar de que
provee más seguridad.
Modo ECB (ELECTRONIC CODEBOOK)
El modo ECB es la manera más obvia de usar un codificador de texto. Un bloque de texto plano se encripta en un
bloque de texto cifrado. Puesto que el mismo bloque de texto plano siempre se encripta al mismo bloque de texto
cifrado, es teóricamente posible crear un código de texto plano y correspondiente texto cifrado. Sin embargo, si el
tamaíío del bloque es de 64 bits, el registro de códigos tendrá 264 entradas (es mucho, tanto para calcular como para
almacenar). Y recordando que cada llave tiene un registro de códigos.
Este es el modo más fácil para trabajar. Cada bloque de texto plano es encriptado independientemente. No tienes
que encriptar un archivo de manera lineal, sino que, puedes encriptar primero los 10 bloques a la mitad del archivo,
luego los bloques al final del archivo y finalmente los bloques al inicio del archivo. Esto es importante para
encriptar archivos que se accesan aleatoriamente, como una base de datos. Si una base de datos es encriptada en
modo ECB, entonces un registro puede ser agregado, eliminado, encriptado o decriptado independientemente de
cualquier otro registro, asumiendo que cada registro consiste de un número discreto de bloques de encripción. Y el
procesamiento es paralelizable, si tienes múltiples procesadores de encripción, ellos pueden encriptar o decriptar
diferentes bloques sin considerar a cada uno de los otros.
El problema con el modo ECB es que si un criptoanalista tiene el texto plano y el texto cifrado para varios
mensajes, el puede comenzar a recopilar un registro de códigos sin el conocimiento de la llave. Y finalmente ser
capaz de obtener la llave.
Modo CBC (CIPHER BLOCK CHAINING).
Encadena y agrega un mecanismo de retroalimentación a un algoritmo codificador de bloque. El resultado de la
encripción de bloques previos son retroalimentados a la encripción del bloque en turno. En otras palabras, cada
bloque es utilizado para modificar la encripción del siguiente bloque. Cada bloque de texto cifrado es dependiente
no sólo del bloque de texto plano que lo generará sino más bien de todos los bloques previos de texto plano.
En el modo CBC, el texto plano es llevado a una XOR junto con el bloque de texto cifrado previo antes de ser
encriptado. Después de que un bloque de texto plano es encriptado el texto cifrado resultante es también almacenado
en un registro de retroalimentación. Antes de que el siguiente bloque de texto plano sea encriptado, este es llevado a
Servicios de Criptograf/b
cifrado resultante es otra vez almacenado en el registro de retroalimentación, para ser llevado a la XOR con el
siguiente bloque de texto plano y así hasta que finalice el mensaje. La encripción de cada bloque depende de todos
los bloques previos.
La decripción es sólo directa. Un bloque de texto cifrado es decriptado normalmente y también salvado en el
registro de retroalimentación. Después el siguiente bloque es decriptado, este es llevado a una XOR con los
resultados del registro de retroalimentación. Luego el siguiente bloque de texto cifrado es almacenado en el registro
de retroalimentación y así sucesivamente, hasta el final del mensaje.
Matemáticamente esto se ve como:
Ci = Ek (Pi ( Ci-1 )
Pi = Ci-1 ( Dk ( C i )
Modo OFB (OUTPUT-FEEDBACK).
El modo OFB es un método de correr un cifrador de bloque como un cifrador orientado a bit síncrono. Este es
similar al modo CFB, excepto que n bits del bloque previo de salida se mueven a ocho posiciones más a la derecha de l a cola. L a decripción es el reverso de este proceso. Este es llamado n-bit OFB. En ambos lados la encripción y
la decripción, el algoritmo de bloque es utilizado en su modo de encripción. Llamado algunas veces
retroalimentación interna, debido a que el mecanismo de retroalimentación es independiente de ambos. las filas de
bits de texto plano o texto cifrado.
Si n es el tamaño de bloque del algoritmo, entonces los n-bits OFB se ven como
Ci = Pi ( Sii Si = Ek(S(i-1)) Pi = Ci ( Sii Si = Ek(S(i-1))
Si es el estado, el cual es independiente de cualquiera de los dos el texto plano o el texto cifrado.
Una agradable característica del modo OFB es que la mayoría del trabajo puede ocurrir fuera de línea, antes de que el mensaje en texto plano incluso exista. Cuando el mensaje finalmente llega, este puede ser llevado a una XOR
con la salida del algoritmo para producir el texto cifrado.
Modo CFB (CIPHER-FEEDBACK).
En el modo CBC, la encripción no puede comenzar hasta que el bloque completo de datos sea recibido. Esto es un
problema en algunas aplicaciones de red. En u n ambiente seguro de red una telminal debe ser capaz de transmitir
cada carácter al host como este es introducido. Cuando el dato ha sido procesado en bloques del tamaño de un byte,
En el modo CFB, los datos pueden ser procesados en unidades más pequeñas que el tamaño del bloque. Puedes
encriptar datos un bit a l a vez usando i bit CFB, aunque utilizando una encripción completa de un bloque cifrado aparece como una gran cantidad de trabajo, un cifrado orientado a bit parece una mejor idea. También se puede usar
CFB de 64 bits o cualquier CFB de n bits donde n es menor o igual que el tamaño de bloque.
Un algoritmo de bloque en modo CFB opera sobre una cola de un tamaño igual al tamaño del bloque de entrada.
Inicialmente la cola se rellena con un IV, como en el modo CBC. L a cola es encriptada y los ocho bits más a la izquierda del resultado son llevados a una XOR con el primer carácter de 8 bits del texto plano para volverse el
primer carácter de 8 bits del texto cifrado. Este carácter puede ahora transmitirse. Los mismos ocho bits se mueven
también más a la derecha ocho bits de posición en l a cola, y todos los demás bits se mueven ocho a la izquierda. Los ocho bits más a la izquierda son descartados. Luego el siguiente carácter del texto plano es encriptado de
l a
misma manera; La decripción es el inverso de este proceso. Sobre ambos lados la encripción y la decripción; el
algoritmo de bloque es utilizado en su modo de encripción.
Si el tamafio del bloque del algoritmo es n, entonces CFB de n bits se mira como
Ci = Pi ( Ek( Ci-1 ) Pi = Ci ( Ek( Ci-1 )
Como el modo CBC, el modo CFB enlaza los caracteres del texto plano juntos tal que el texto cifrado depende de
todo el texto plano precedente.
ALGORITMO DE ENCRIPCIÓN DE DATOS INTERNACIONAL
(INTERNATIONAL DATA ENCRIPTION ALGORITHM, IDEA)
UNA OJEADA A IDEA
Al igual que DES, IDEA en un cifrador de bloque; este opera sobre bloques de 64 bits. La llave tiene una
longitud de 128 bits. Y el mismo algoritnlo se usa tanto para la encripci6n como para l a decripción
También utiliza la confusión y difusión como sus principales técnicas de encripción. La filosofía de diseño detrás
del algoritmo es uno de "una mezcla de operaciones de diferentes grupos algebraicos". Tres grupos algebraicos se
mezclan, y todos ellos son fácilmente implementados en software y hardware:
- XOR
- Adición módulo 2 .
...
- Multiplicación módulo 2 16
+
1. (Esta operación puede verse como las cajas-S de IDEA).Todas las operaciones lo hacen sobre sub-bloques de 16 bits. Debemos mencionar que en este algoritmo no hay
Servicios de Crlptografia
Descripción de IDEA.
Este algoritmo maneja bloques de 64 bits, pero a diferencia de DES, este divide el bloque en 4 sub-bloques de 1 6
bits: los bloques se denotan
X1,
X2,X3
y X4. Estos cuatro sub-bloques convierten la entrada en la primera ronda del algoritmo. El número total de rondas es de ocho. En cada ronda los cuatro sub-bloques se pasan a través de XOR , luego se suman y multiplican con algún otro y con seis sub-llaves de 16 bits. Entre las rondas, el segundo ytercer sub-bloque son intercambiados. Al final los cuatro sub-bloques se combinan con cuatro sub-llaves en una
transformación de salida.
Para cada ronda la secuencia de eventos es la siguiente:
Se multiplica
X1
y la primer sub-llave. Se suma X2 y la segunda sub-llave.Se suma X3 y la tercer sub-llave.
Se multiplica X4 y la cuarta sub-llave.
Se pasa a través de una
XOR
el resultado de los pasos(1)
y ( 3 ) .Se pasa a través de una
XOR
el resultado de los pasos (2) y (4).Se multiplica el resultado del paso (5) con la quinta sub-llave.
Se suman los resultados de los pasos (6) y (7).
Se multiplican el resultado del paso ( X ) con la sexta sub-llave.
Se suman los resultados de los pasos (7) y (9).
Se pasan a través de una
XOR
los resultados de los pasos (1) y (9).Se pasan a través de una
XOR
los resultados de los pasos (3) y (9).Se pasan a través de una XOR los resultados de los pasos (2) y (1 O).
Se pasan a través de una XOR los resultados de los pasos (4) y (10).
L a salida de la ronda son los cuatro sub-bloques que son los resultados de los pasos
(1
l), (12),(13)
y (14) Intercambia los bloques internos (excepto para la última ronda) y esa es l a entrada a la siguiente ronda.Después de la octava ronda, hay una transfornlación de salida final:
Multiplica X1 y la primera sub-llave.
Suma X2 y la segunda sub-llave.
Suma X3 y la tercera sub-llave.
Multiplica X4 y la cuarta sub-llave.
Crear las llaves es también fácil. El algoritmo usa 52 de ellas (seis por cada una de las ocho rondas y cuatro más
para la transformación de salida). Primero la llave de 128 bits es dividida en ocho subllaves de 16 bits. Esas son las
primeras ocho subllaves para el algoritmo (las seis para la primera ronda y las primeras dos para la segunda).
Entonces la llave se rota 25 bits a la izquierda y otra vez se divide en ocho subllaves.
Las primeras cuatro subllaves se usan en la segunda ronda, las últimas cuatro subllaves se usan en la tercera ronda.
La llave se rota otros 25 bits a la izquierda para las siguientes ocho subllaves y así hasta finalizar el algoritmo.
La decripción es exactamente lo mismo, excepto que las subllaves son invertidas y ligeramente diferentes. Las llaves de decripción son, ya sea, el inverso multiplicativo o el inverso aditivo de las subllaves de encripción. El
cálculo de ellas toma algo de tiempo hacerlas, pero sólo se tiene que hacer para cada subllave de decripción.
HASH Y MENSAJES DIGERIDOS
Introducción
Una función Hash H(M) unidireccional opera en mensajes de longitud arbitraria M, y regresa una longitud fija del
mensaje : 11 = H(M).
Muchas hnciones pueden procesar una entrada de longitud variable y la regresan con longitud fija. pero las
funciones Hash tienen como característica adicional que es unidireccional.
Especificada M, es fácil para computar h.
Especificada h, es dificil de computar M, tal como H(M) = h.
Especificada M, es dificil encontrar otro mensaje
M’
tal como H(M) = H(M’).Sin embargo; en algunas aplicaciones la unidireccionalidad es insuficiente, es necesario un requerimiento
adicional, llamado resistencia a la colisión.
Longitud de las funciones Hash unidireccionales
El Instituto Nacional de Estándares y Tecnología (NIST), en el Estándar de Seguridad Hash (SHS), usa 160 bits para
el valor Hash. El siguiente método ha sido propuesto para generar un Hash largo:
Generar el valor Hash del mensaje, usando la hnción Hash unidireccional.
Calcular el valor Hash para el mensaje.
Generar el valor Hash de la concatenación del mensaje y el valor Hash.
Crear un Hash largo, consistiendo del valor Hash generado en el paso (1 ) concatenado con el valor Hash generado en
Servicios de Cr1ptografia
Repetir los pasos (1) al ( 5 ) , hasta terminar.
Función Hash Unidireccional
No es fácil diseíiar una función que acepte una entrada de longitud arbitraria, ni mucho menos hacerlo un una
dirección. En la realidad, las funciones Hash unidireccionales son construidas a partir de la idea de la función de
compresión. Esta función unidireccional tiene a la salida valores Hash de longitud
n,
especificada a la entrada algunam
de longitud larga. Las entradas a la función de compresión es un bloque de mensaje y a la salida bloques previos de texto, como se muestra en la sig. f-igura hi = f(Mi , hi-
1).Snefru
Snefm, es una función Hash unidireccional diseíiada por Ralph Merkle. Primeramente el mensaje es seccionado en
bloques de 512-m de longitud (m es la longitud del valor Hash). Si la salida es un valor Hash de 128 bits, entonces
el bloque restante será de 384 bits de largo.
Los primeros m bits H’s de salida son el Hash del bloque, el resto es descartado. El siguiente bloque es
aíiadido al Hash del bloque previo y se procede a calcular su valor Hash nuevamente. (El bloque inicial es aiiadido a
una cadena de ceros). Después los primeros m bits del último bloque (si el mensaje aparece en un número largo de
bloques, se usan ceros para rellenar el último bloque) son anexados a una representación binaria de la longitud del
mensaje.
La función H esta basada en E, con una función reversible del bloque cifrado. Esta opera en bloques de 5 12 bits. H, son los Últimos m bits de la salida de E función XOR con los primeros m bits de la entrada de E. La
seguridad de Snefm reside en la función E, con datos aleatorios en distintos pasos. Cada paso se compone de 64
partes aleatorias. En cada parte un byte del dato es usado en la entrada de la caja S, a la palabra de salida de la caja S
MD2
MD2, es otra función Hash unidireccional diseñada por Ron Rivest. La seguridad de MD2 depende de las
permutaciones aleatorias sobre los bytes. Esta permutación es fija y depende de los dígitos de (SO, S I , S2, . . . ,
S255) la permutación, para formar un Hash del mensaje M se lleva a cabo lo siguiente:
Rellenar el mensaje con y bytes de valor y dando como resultado mensajes múltiplos de 16 bytes de longitud.
Aiiadir al byte 16 del mensaje el chequeo de suma.
Inicializar un bloque de 48 bytes: XO, X I , X2, . . . X47. Establecer los primeros 16 bytes de X a O, los segundos 16
bytes de X con los primeros 16 bytes del mensaje, y los últimos 16 bytes de X serán los primeros 16 bytes de X
función XOR con los segundos 16 bytes de X.
L a función de compresión es: t = O
f o r j = O a 17
f o r k = O a 47
t = Xk XOR St
X k = t
t = (t + j ) módulo 256
Establecer los segundos 16 bytes de X como los segundos 16 bytes del mensaje, y los terceros 16 bytes de X serán
los primeros 16 bytes de X función XOR segundos 16 bytes de X. Ejecutar el paso (4). Repetir los pasos (5) y (4)
con todos los mensajes de 16 bits.
Los primeros I6 bytes de X son la salida.
MD4
MD4, es una función Hash unidireccional diseiiada por Ron Rivest. El algoritmo produce un Hash de 128 bits o
mensaje clasificado, del mensaje de entrada.
Los propósitos del algoritmo de Rivest son:
Es computacionalmente infactible encontrar para dos mensajes diferentes, a los que se les aplique la función Hash,
un mismo valor. Es más eficiente a los ataques.
La seguridad de MD4 no está basada en la suposición.
MD4 es satisfactorio en implementaciones de software de alta velocidad. Esta basado en simples manipulaciones de bit en operaciones de 32 bits.
Servicios de Cr@tografia
MD5
(Digestor de Mensajes
)
Es una versión mejorada de MD4, aunque es más complejo que MD4, su diseño es similar y también produce un
Hash de 128 bits. MD5 procesa el texto de entrada en bloques de 5 12 bits, divididos en 16 subbloques de 32 bits. La
salida del algoritmo es un conjunto de 4 bloques de 32 bits, los cuales se concatenan para formar un valor Hash de
128 bits.
Descripción de MD5.
Anexar bits de relleno.
El mensaje se rellena hasta que su longitud sea congruente con 448 módulo 5 12 (longitud
=
448 módulo 512). Estoes, la longitud del mensaje a rellenar es 64 bits menor que un entero múltiplo de 512 bits. Los bits de relleno se
agregan siempre aún cuando el mensaje sea de la longitud deseada. Por ejemplo si el mensaje tiene una longitud de
448 bits a este se le agregan 512 bits hasta llegar a una longitud de 960 bits. Entonces, el número de bits de relleno
esta en el intervalo de 1 a 5 12.
El relleno consiste de agregar un bit 1 seguido de la cantidad necesaria de bits 0.
Anexar la longitud.
Una representación de 64 bits con-espondiente a la longitud en bits del mensaje original (antes del relleno) es
anexado al resultado del paso I . Si la longitud original es mayor que 2'j4, entonces solamente los 64 bits de más bajo
orden son utilizados. Por lo tanto, el campo contiene la longitud del mensaje original modulo 264.
El resultado de los primeros dos pasos lleva un mensaje el cual tiene una longitud que es múltiplo entero de 5 12
bits. De igual forma el resultado es un múltiplo de 16 palabras de 32 bits. Dejemos que M(O,l,.,N-I) denote las
palabras de un mensaje resultante con N un entero múltiplo de 16. Entonces N = L x 16.
Inicializar un Buffer MD.
Un buffer de 128 bits es utilizado para tomar los resultados inicial y final de l a función Hash. El buffer puede ser
representado como 4 registros de 32 bits. Estos son inicializados a los siguientes valores hexadecimales,
A = OX01234567
B = OX89abcdef
D = OX765432 1 O
Procesar el Mensaje en Bloques de 512 Bits (16 palabras).
En este caso el modulo principal del algoritmo consiste de 4 “rondas” de procesamiento; este módulo esta
etiquetado como HMD5 en la figura. Las cuatro rondas tienen una estructura similar, pero cada una es una función
lógica primitiva diferente, referidas como F, G, H é I. En la figura las cuatro rondas están etiquetadas como fF, f(;, f,,
y f, . Para indicar que cada una de las rondas tiene la misma estructura funcional general,
f,
pero dependiendo de unafunción primitiva diferente (F, G,
U,
I).Nota que cada ronda toma como entrada el bloque de S12 bits que se esta procesando (Yq) y el calor del buffer
ABCD de 128 bits y luego actualiza el contenido del buffer. Cada ronda toma también un cuarto de una tabla
T[1,2,..,64] de 64 elementos construida de la función seno. El i-ésimo elemento de T, denotado por T[i], tiene el
valor igual a la parte entera de 2” x abs(sen(i)) donde i esta en radianes. Ya que, abs(sen(i)) es un número entre O y
1, cada elemento de
T
es un entero que puede representado por 32 bits.De manera general para los bloques Yt, el algoritmo toma Yq y un valor digerido intermedio MDq como entrada.
MDq se coloca en un buffer ABCD. La salida de la cuarta ronda se agrega a MDq para producir MDq+. La adición
es hecha de manera independiente para cada una de las cuatro palabras en el buffer con cada una de las
correspondientes palabras en MDq, usando adición módulo 232.
Salida.
Después de que todos los L bloques de 521bits se han procesado, la salida de la L-ésima etapa es el mensaje
digerido de 128 bits.
Rondas de MD5.
Cada ronda consiste de una secuencia de 16 pasos operando sobre el buffer ABCD. Cada paso es de la forma:
a t b
+
CLS,a+
g(b,c,d)+ X(k]+
T[i])donde
a,b,c,d = las cuatro palabras del buffer en un orden específico que varia a través de los pasos.
g = una de las funciones primitivas F,G,H.I.
CLS, = Corrimiento circular a la izquierda del argumento de 32 bits por S bits: