INSTITUCI ´
ON DE ENSE ˜
NANZA E INVESTIGACI ´
ON
EN CIENCIAS AGR´ICOLAS
CAMPUS MONTECILLO
POSTGRADO EN SOCIOECONOM´IA-ESTAD´ISTICA E
INFORM ´
ATICA-ESTAD´ISTICA
Estimaci´
on Semiparam´
etrica en el An´
alisis de
encuestas complejas
Luis Fernando Contreras Cruz
T E S I S
PRESENTADA COMO REQUISITO PARCIAL PARA
OBTENER EL GRADO DE:
DOCTOR EN CIENCIAS
MONTECILLO,TEXCOCO, EDO. DE M´
EXICO
Luis Fernando Contreras Cruz
Colegio de Postgraduados, 2013
En la primera parte de este trabajo se muestra que no hay p´erdida significativa en la
precisi´on del estimador del total poblacional si calculamos el par´ametro de suavizamiento
del modelo de splines penalizados con informaci´on de la muestra en vez de utilizar toda
la informaci´on de la poblaci´on. El par´ametro de suavizamiento es obtenido fijando los
grados de libertad y resolviendo una ecuaci´on basada ´
unicamente en datos de la muestra.
Se discuten los resultados de un estudio de simulaci´on de la determinaci´on del par´ametro
de suavizamiento. Adem´as, se evalu´o el efecto de la propuesta de determinaci´on del
par´ametro de suavizamiento en la estimaci´on del total poblacional usando una poblaci´on
real. Para esta poblaci´on, los experimentos de simulaci´on muestran que la determinaci´on
del par´ametro de suavizamiento, ya sea con datos de la muestra o con los datos de toda la
poblaci´on, produce errores relativos similares en la estimaci´on del total poblacional. En
la segunda parte, se presenta y desarrolla un m´etodo semiparam´etrico de estimaci´on del
total poblacional para mejorar la precisi´on de los estimadores mediante la incorporaci´on
de informaci´on auxiliar multivariada. El modelo de superpoblaci´on utilizado es un modelo
de coeficientes variantes, que ha demostrado ser una herramienta semiparam´etrica simple
y eficiente en la regresi´on multivariada. En condiciones de dise˜
no est´andar, los estimadores
propuestos son asint´oticamente insesgados, consistente y asint´oticamente normales. Para
ilustrar el modelo y la metodolog´ıa de estimaci´on propuesta, se estudian dos poblaciones,
una poblaci´on real y otra simulada, que han proporcionado fuerte evidencia que corrobora
la teor´ıa asint´otica.
Semiparametric estimation in complex survey analysis
Luis Fernando Contreras Cruz
Colegio de Postgraduados, 2013
In the first part of this work, the aim is to show that there is no significant loss in
ac-curacy of the estimator of the population total if we calculate the smoothing parameter
of penalized spline model with sample information rather than using all the population
information. The smoothing parameter is obtained by fixing the degrees of freedom and
solving an equation based only on sample data. Results of a simulation study of the
determination of smoothing parameter are presented. In addition, the effect of the
pro-posed determination of smoothing parameter on the estimation of the population total
is evaluated using a real population. For this population, simulation experiments show
that determining the smoothing parameter with either sample data or with data from
the entire population, produces similar relative errors on the estimate of the
popula-tion total. In the second part, a model-assisted semiparametric method of estimating
finite-population totals is investigated to improve the precision of survey estimators by
incorporating multivariate auxiliary information. The proposed superpopulation model
is a varying-coefficient model which has proven to be a simple and efficient
semipara-metric tool in multivariate regression. Under standard design conditions, the proposed
estimators are asymptotically design-unbiased, consistent and asymptotically normal.
Both simulated and real data examples are given to illustrate the model and the
pro-posed estimation methodology, which have provided strong evidence that corroborates
with the asymptotic theory.
Al Consejo Nacional de Ciencia y Tecnolog´ıa (CONACYT) por el apoyo econ´omico
brindado durante la realizaci´on de mis estudios.
Al Colegio de Postgraduados, por haberme brindado la oportunidad de seguir mi
forma-ci´on acad´emica en sus aulas.
A los integrantes de mi Consejo Particular:
Al Dr. Jos´e El´ıas Rodr´ıguez Mu˜
noz mi m´as sincero agradecimiento por ser un excelente
gu´ıa y amigo, por sus atinadas indicaciones y consejos, as´ı como su calidad humana,
mismos que me fueron de gran utilidad en la realizaci´on del presente trabajo de tesis.
Al Dr. Jos´e A. Villase˜
nor Alva, por ser un gu´ıa durante mis estudios y por sus consejos
tan atinados y por dedicar parte de su tiempo en la revisi´on de este trabajo de tesis.
A los doctores: Javier Su´arez Espinosa, Gilberto Rend´on S´anchez e Ignacio M´endez
Ram´ırez por sus colaboraciones desinteresada en el presente trabajo.
Un agradecimiento muy especial al Dr. F. Jay Breidt, del Departamento de Estad´ıstica de
la Universidad Estatal de Colorado E.U.A., por permitirme trabajar con ´el y por dedicar
parte de su tiempo en la discusi´on y desarrollo de algunos temas de este trabajo.
A la familia C´ardenas Ram´ırez y en especial a la Familia Gaona C´ardenas por el apoyo
recibido durante mi estancia en Estados Unidos.
A mis compa˜
neros de clase: Ra´
ul A. P´erez Ag´amez, Juan Diego Hern´andez Jarqu´ın y
Jaime Dionisio Cuevas Dom´ınguez, por los momentos de discusi´on de algunos temas en
estad´ıstica.
DEDICATORIA
A mis padres: Fernando Contreras Avalos y B´elgica Cruz L´opez, que me han ense˜
nado
que la ´
unica forma de concluir satisfactoriamente una meta es trabajar d´ıa a d´ıa.
A mis hermanos: Carlos Arturo Contreras Cruz y Marcos Contreras Cruz.
A mis abuelos: Ana Mar´ıa Avalos Jes´
us
†, Rosal´ıo Contreras Garc´ıa
†, Catalina L´opez
Dam´ıan
†y Antonio Cruz G´omez
†.
1. Introducci´
on
1
2. Objetivos
5
2.1. Objetivos Generales
. . . .
5
2.2. Objetivos Particulares
. . . .
5
3. Muestreo de poblaciones finitas
6
3.1. Poblaci´on, muestra y selecci´on de muestras
. . . .
6
3.2. Dise˜
no de muestreo
. . . .
7
3.3. Probabilidades de inclusi´on
. . . .
8
3.4. Par´ametros poblacionales y sus estimadores
. . . .
11
3.5. Distribuci´on aproximada de un estimador
. . . .
12
3.6. Teor´ıa asint´otica en muestreo de poblaciones finitas
. . . .
13
3.7. Estimador de Horvitz-Thompson
. . . .
16
3.8. Muestreo para unidades poblacionales
. . . .
17
3.8.1. Muestreo Bernoulli
. . . .
17
3.8.2. Muestreo aleatorio simple sin reemplazo
. . . .
19
´
Indice
3.8.4. Muestreo estratificado
. . . .
24
3.8.5. Muestreo de conglomerados en una sola etapa
. . . .
26
3.9. Muestreo de poblaciones finitas asistido por modelos
. . . .
31
3.9.1. Estimaci´on en la poblaci´on finita
. . . .
32
3.9.2. Estimaci´on en la muestra
. . . .
32
3.9.3. Estimador de regresi´on general
. . . .
33
4. Regresi´
on semiparam´
etrica en muestreo de poblaciones finitas
37
4.1. Introducci´on
. . . .
37
4.2. Regresi´on local polinomial
. . . .
38
4.3. Regresi´on por Splines Penalizados
. . . .
41
4.4. Estudio de Simulaci´on
. . . .
43
4.5. Conclusiones
. . . .
45
5. El efecto sobre la estimaci´
on del total poblacional de la estimaci´
on
basada en la muestra del par´
ametro de suavizamiento de regresi´
on por
spline penalizado en muestreo de poblaciones finitas
47
5.1. Introducci´on
. . . .
47
5.2. Selecci´on del par´ametro de suavizamiento basada en la muestra
. . . . .
49
5.3. Estudio de simulaci´on
. . . .
51
5.3.1. Algoritmo
. . . .
51
5.3.2. Resultados emp´ıricos
. . . .
53
5.4. Aplicaci´on a datos reales
. . . .
55
6. Modelo de coeficientes variantes en muestreo de poblaciones finitas
59
6.1. Modelo de coeficientes variantes en muestreo de poblaciones finitas
. . . .
60
6.2. Selecci´on de los par´ametros de suavizamiento
. . . .
63
6.3. Propiedades del estimador del total poblacional
. . . .
66
6.4. Estudio de simulaci´on
. . . .
67
6.5. Aplicaci´on a datos reales
. . . .
71
6.6. Conclusiones
. . . .
72
7. Conclusiones y trabajos futuros
73
Referencias
74
Anexos
79
Anexo A: C´odigos de Programas en R usados en el Cap´ıtulo 4
. . . .
79
Anexo B: C´odigos de Programas en R usados en el Cap´ıtulo 5
. . . .
83
Anexo C: C´odigos de Programas en R usados en el Cap´ıtulo 6
. . . .
94
Anexo D: Demostraci´on del Teorema 1 del Cap´ıtulo 6
. . . 133
Anexo E: Demostraci´on del Teorema 2 del Cap´ıtulo 6
. . . 135
´
Indice de tablas
4.1. Raz´on de ECM relativo al estimador de spline penalizado, basado en 1000
r´eplicas de tama˜
nos de muestra
n
= 50 de una poblaci´on fija de tama˜
no
N
= 1000.
. . . .
46
5.1.
q
d
RM SE(λ
s) para los 16 experimentos.
. . . .
54
5.2.
q
d
RM SE(ℓ
s) para los 16 experimentos.
. . . .
55
5.3.
√
RM SE
de los estimadores.
. . . .
56
5.4. Errores Relativos de Estimaci´on(ERE).
. . . .
57
6.1.
q
RM SE(b
t
y,V C) y %RB(b
t
y,V C).
. . . .
69
6.2. Modelos de Coeficientes Variantes: %RB
V
b
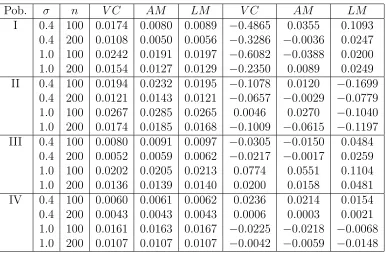
bλopt,i5.1. Diagramas de dispersi´on de las estimaciones del total. Las estimaciones
del total usando ˆ
λ
sest´an sobre el eje horizontal y las estimaciones usando
λ
Uest´an sobre el eje vertical. Las l´ıneas horizontales y verticales indican
Cap´ıtulo 1
Introducci´
on
Los recursos econ´omicos para realizar censos de poblaci´on y vivienda se tornan cada
vez m´as dif´ıciles de obtener. Sin embargo, las necesidades de informaci´on estad´ıstica
contin´
uan creciendo en varios sentidos. Se demanda:
1. Mayor frecuencia;
2. Mayor cobertura tem´atica;
3. Mayor capacidad para el estudio de relaciones entre temas;
4. Mayor desagregaci´on geogr´afica;
5. M´ınima disminuci´on en la precisi´on de la informaci´on producida.
Pa´ıses con infraestructura adecuada han basado la producci´on de informaci´on sobre la
totalidad de sus poblaciones y subpoblaciones, en los registros administrativos. Para otro
conjunto de pa´ıses, sus particulares condiciones pol´ıticas, econ´omicas y sociales hacen
que este enfoque no sea viable. Aunque algunos consideran que este es el camino a seguir
en el futuro y ya trabajan para alcanzarlo, otros consideran impensable el disponer alg´
un
d´ıa de por lo menos un registro de poblaci´on en el cu´al basar tal enfoque.
Lo anterior ha conducido a algunas oficinas nacionales de estad´ıstica a explorar y, en
algunos casos, a iniciar ya la instrumentaci´on del uso combinado o alternativo de las
fuentes para la generaci´on de informaci´on estad´ıstica que recibir´a el mismo uso que la
censal. En particular, se tiene informaci´on de:
3. Registros administrativos y censos (Espa˜
na);
4. Encuestas rotatorias (Francia).
En nuestro pa´ıs el INEGI ha estado analizando e instrumentando algunas de las anteriores
opciones. Fue as´ı como se decidi´o que el censo mexicano del a˜
no 2000 utilizara un
esque-ma combinado: un cuestionario b´asico, aplicado a la totalidad de la poblaci´on (el censo
propiamente dicho), y durante el mismo operativo censal una muestra de la poblaci´on
recibi´o una ampliaci´on al anterior cuestionario (encuesta). Lo anterior puede ser ejemplo
de lo se˜
nalado para lo referente a Estados Unidos, aunque ´este incluye adem´as a las
en-cuestas intercensales. En principio, para el censo del 2010 tambi´en se hizo un cuestionario
b´asico y al menos uno ampliado.
En este mismo sentido, parece que aquellos esquemas que recurren al uso de
encues-tas por muestreo suponen grandes tama˜
nos de muestra para conseguir
representativi-dad”(precisi´on adecuada) a niveles peque˜
nos de desagregaci´on geogr´afica, con lo que no
se atiende a la reducci´on de costos, como en la encuesta levantada simult´aneamente con
el Censo 2000.
Adicionalmente, parece que el aspecto de reducci´on de costos puede ser atendido al
relacionar los resultados de las encuestas con los de las otras dos fuentes: la censal y la
registral (registros administrativos); tomando en cuenta las experiencias internacionales,
as´ı como los ejemplos de aplicaci´on basados en informaci´on mexicana que pueden ser a´
un
mejorados. En caso de contar con metodolog´ıas que permitiesen lo anterior, se podr´ıa
concebir un esquema de generaci´on de informaci´on en el que se integran el censo y tanto
sus encuestas simult´aneas como las levantadas durante el per´ıodo intercensal para:
1. Lograr una reducci´on en los tama˜
nos de muestra que implicar´ıa ahorros sustanciales,
si no para el ejercicio censal propiamente dicho, s´ı para los muestrales;
2. Contar con informaci´on geogr´aficamente desagregada con mayor frecuencia;
3. Mantener la precisi´on alcanzada en los ejercicios muestrales.
1. Introducci´
on
Para el caso de estimaci´on semiparam´etrica en muestreo de poblaciones finitas, se han
hecho algunos avances. En el trabajo de (Breidt y Opsomer,
2000) se ha desarrollado
el estimador del total por regresi´on localmente polinomial. Adem´as en (Breidt
et al
.,
2005) se propone un estimador para encuestas complejas utilizando splines penalizados.
El concepto de encuestas complejas se refiere a la complejidad del dise˜
no de muestreo
utilizado. Este tipo de dise˜
nos son estratificados, en dos o m´as etapas y en la ´
ultima
etapa, las unidades de muestreo pueden ser conglomerados de unidades poblacionales.
Este tipo de dise˜
nos de muestreo son utilizados, por ejemplo, en las encuestas peri´odicas
del INEGI.
Para el caso de regresi´on localmente polinomial, (Breidt y Opsomer,
2000) proponen el
estimador del total poblacional y su respectiva varianza, para una muestra observada
denotada por
s
y un ancho de banda
h
N:
e
t
0y=
X
i∈sy
i−
m
b
0iπ
i+
X
i∈UN
b
m
0i,
donde
π
i=
P
(
i
∈
s
)
,
e
T1= (1
,
0
, . . . ,
0)
,
b
m
0i=
e
T1X
siTW
siX
si −1X
siTW
siy
s,
X
si= [1
,
(
x
j−
x
i), . . . ,
(
x
j−
x
i)p]
j∈s,
W
si=
diag
1
π
jh
NK
x
j−
x
ih
Nj∈s
.
Un estimador de la varianza de
e
t
0y
es:
\
V ar
e
t
0y
=
X
i,j∈s
π
ij−
π
iπ
jπ
ijy
i−
m
b
0iπ
iy
j−
m
b
0jπ
j,
donde
π
ij=
P
(
{
i, j
} ⊂
s
).
Para el caso de regresi´on por splines penalizados, (Breidt
et al
.,
2005) proponen el
esti-mador del total poblacional y su respectiva varianza, para una muestra observada
s
y un
par´ametro de suavizamiento
λ
:
b
t
y,spl=
X
i∈UN
b
donde
b
m
i=
X
iTX
sTΠs
X
s+
A
λ −1X
sTΠs
y
s,
X
iT=
1
, x
i, . . . , x
pi,
(
x
i−
K
1)
p+, . . . ,
(
x
i−
K
J)
p+i∈UN
,
Πs
=
diag
1
π
ii∈s
,
A
λ=
diag
{
0
, . . . ,
0
, λ, . . . , λ
}
.
Un estimador de la varianza del estimador es:
\
V ar
b
t
y,spl=
X
i,j∈s
π
ij−
π
iπ
jπ
ijy
i−
m
b
iπ
iy
j−
m
b
jπ
j.
Los m´etodos de estimaci´on semiparam´etrica en muestreo antes citados est´an orientados
principalmente para aplicarse al caso de una sola variable auxiliar. Cuando se tienen
dos o m´as variables, es necesario buscar otras alternativas. Una de estas alternativas
puede ser la estimaci´on por regresi´on con coeficientes variantes. Dicha metodolog´ıa ha
sido propuesta en los trabajos de (Cai
et al
.,
2000b) y (Cao
et al
.,
2010) en el contexto del
an´alisis de series de tiempo. Adem´as parece ser factible la adaptaci´on de esta metodolog´ıa
de estimaci´on semiparam´etrica al caso del an´alisis de encuestas complejas.
Por otro lado, en los trabajos de (Breidt y Opsomer,
2000) y (Breidt
et al
.,
2005), el
estimador de la varianza del estimador semiparam´etrico del total est´a basado en el
con-cepto de estimador por diferencia (ver Secci´on 6.3 de (Sarndal
et al
.,
1992)). Este tipo
de estimadores tiende a subestimar la varianza, por lo tanto es necesario explorar otras
formas de proponer estimadores de dicha varianza.
Cap´ıtulo 2
Objetivos
2.1.
Objetivos Generales
Desarrollar y adaptar un m´etodo de estimaci´on semiparam´etrica en el an´alisis de
encues-tas complejas.
2.2.
Objetivos Particulares
Desarrollar el modelo de coeficientes variantes para solucionar problemas de estimaci´on
de par´ametros poblacionales utilizando informaci´on multivariada de encuestas complejas.
Proponer un estimador del total poblacional y estudiar algunas de sus propiedades
es-tad´ısticas.
Proponer una forma de seleccionar los par´ametros de suavizamiento en el contexto de
muestreo de poblaciones finitas.
Realizar un estudio de simulaci´on para estudiar de manera empir´ıca la metodolog´ıa
prop-uesta.
Muestreo de poblaciones finitas
En ocasiones en
Estad´ıstica
queremos estudiar una poblaci´on finita de inter´es. Cuando la
poblaci´on es demasiado grande, es imposible estudiar las caracter´ısticas individuales de
los elementos de la poblaci´on debido a tiempo y aspectos econ´omicos. Entonces se recurre
a estudiar solamente una
muestra
de esa
poblaci´
on
; donde la muestra seleccionada debe
reflejar las caracter´ısticas de inter´es de la poblaci´on. A partir de la muestra, se realizan
inferencias para conocer a toda la poblaci´on.
3.1.
Poblaci´
on, muestra y selecci´
on de muestras
Consideremos una poblaci´on constituida de
N
elementos etiquetados como
k
= 1
,
2
, . . . , N
.
Denotaremos a la poblaci´on finita como
U
=
{
1
, . . . , k, . . . , N
}
, asumiendo que
N
no es
necesariamente conocido. La caracter´ıstica de inter´es para cada elemento de la poblaci´on
se representar´a por
y
U=
{
y
1, y
2, . . . , y
N}
. Para el objetivo del presente cap´ıtulo,
y
j∈
R
,
j
= 1
,
2
, . . . , N
. En ocasiones es conveniente modelar la caracter´ıstica de inter´es con el
conjunto de variables aleatorias
Y
U=
{
Y
1, Y
2, . . . , Y
N}
, es decir, el valor de la
caracter´ısti-ca
y
Use concept´
ua como un posible valor de la variable aleatoria
Y
U.El espacio de probabilidad sobre el cual est´a definido el conjunto de variables aleatorias
Y
Uo la funci´on de distribuci´on conjunta del mismo, se denomina
modelo
de las caracter´ısticas
de inter´es.
Una
muestra
es cualquier subconjunto
s
de
U
. Por ejemplo una muestra
s
de tama˜
no
n
es
de la forma
s
=
{
k
1, . . . , k
n}
, donde
k
jrepresenta al
k
j−
esimo
´
elemento de la poblaci´on
U
.
3.2. Dise˜
no de muestreo
de selecci´
on
. Un procedimiento de selecci´on es un conjunto de experimentos cuyo objetivo
es seleccionar elementos de la poblaci´on para integrar la muestra.
3.2.
Dise˜
no de muestreo
Si
S
es un conjunto de muestras de
U
, entonces un
dise˜
no de muestreo
es la probabilidad
P
de obtener cada una de las muestras en
S
, siempre que
P
s∈SP
(
{
s
}
) = 1. Usualmente,
P
es la funci´on de probabilidad resultante del
procedimiento de selecci´
on
de la muestra.
Un conjunto de utilidad pr´actica de muestras
S
es el conjunto
{
s
∈
U
:
P
(
{
s
}
)
>
0
}
.
Si
S
tiene esta ´
ultima propiedad, a este conjunto se le denomina el
conjunto de posibles
muestras
de
U
bajo el dise˜
no de muestreo
P
. Con un conjunto de muestras
S
de este tipo
y con el dise˜
no de muestreo
P
es posible formar el espacio de probabilidad (
S,
2
S, P
). M´as
adelante se mostrar´a que este espacio de probabilidad es el usado para hacer inferencia,
siempre que dicha inferencia utilice ´
unicamente la aleatoriedad descrita por tal espacio.
Varios procedimientos de selecci´on de la muestra pueden producir un mismo dise˜
no de
muestreo
P
. Dado un dise˜
no de muestreo
P
, el conjunto de experimentos del
proced-imiento de selecci´on debe ser tal que la probabilidad resultante de seleccionar la muestra
coincida con el dise˜
no de muestreo
P
.
En ocasiones un dise˜
no de muestreo se conoce por su procedimiento de selecci´on y no
por su probabilidad de seleccionar una muestra, por ejemplo, en el “
muestreo aleatorio
simple sin reemplazo
”(MSR).
Ahora veamos dos procedimientos de selecci´on para el
MSR
.
Procedimiento 1 de selecci´
on.
1. Seleccionar con la misma probabilidad, 1
/N
, un primer elemento de los
N
elementos
de la poblaci´on y no regresarlo;
2. Seleccionar con la misma probabilidad, 1
/
(
N
−
1), un segundo elemento de los
N
−
1
elementos restantes y no regresarlo;
...
Este procedimiento de selecci´on produce muestras
s
de tama˜
no
n
. Adem´as, la
probabili-dad de obtener cada muestra
s
es
P
(
{
s
}
) =
N1
n.
El conjunto de posibles muestras es
S
=
{
s
⊂
U
:
s
tiene
n
elementos distintos
}
. Otro
procedimiento de selecci´on en un MSR es el siguiente.
Procedimiento 2 de selecci´
on.
1. Para cada elemento de la poblaci´on generar un valor de una distribuci´on
unif orme
(0
,
1);
2. Ordenar en forma ascendente los elementos de acuerdo a los n´
umeros generados;
3. Seleccionar los primeros
n
elementos para integrar la muestra.
Observese que los dos procedimientos de selecci´on descritos anteriormente producen el
mismo dise˜
no de muestreo, ver (Sarndal
et al
.,
1992).
3.3.
Probabilidades de inclusi´
on
Por la estructura del espacio de probabilidad asociada a un dise˜
no, cualquier funci´on del
conjunto de muestras
S
a los n´
umeros reales
R
es una variable aleatoria. En especial las
funciones
λ
k(s
) =
α
si
k
∈
s
,
α
6
= 0
0 si
k /
∈
s
,
para todo
k
∈
U
y toda
s
∈
S
, son variables aleatorias.
La importancia de ´este conjunto de variables aleatorias en la teor´ıa de muestreo se muestra
con el siguiente ejemplo.
Ejemplo 1
Variables Indicadoras
. Sea
I
kla variable aleatoria que nos indica si la unidad
k
est´a en la muestra
s
. Esta variable se define como
I
k(s
) =
3.3. Probabilidades de inclusi´
on
Ahora tenemos las propiedades de las variables indicadoras. Notemos que cada variable
indicadora
I
kes una variable aleatoria Bernoulli con probabilidad de ´exito
P
(
I
k= 1) =
P
(
{
s
∈
S
:
s
∋
k
}
) =
X
s∋k
P
(
{
s
}
) :=
π
k.
A
π
kse le conoce como la
probabilidad de inclusi´
on de primer orden
del elemento
k
.
A 1
/π
kse le denomina
factor de expansi´
on
y se utiliza en la estimaci´on de par´ametros
poblacionales.
Dado que
I
kes una variable aleatoria Bernoulli, entonces
E
(
I
k) =π
k,y
V ar
(
I
k) =π
k(1−
π
k),k
= 1
, . . . , N
.
Ahora veamos como calcular la probabilidad de que la muestra contenga dos elementos,
es decir,
P
(
{
j, k
} ⊂
s
) =
P
(
I
jI
k= 1)
=
P
(
{
s
∈
S
:
s
⊃ {
j, k
}}
)
=
X
s⊃{j,k}
P
(
{
s
}
) :=
π
jk.
A
π
jkse le conoce como la
probabilidad de inclusi´
on de segundo orden
de los elementos
j
y
k
. Tambi´en es posible mostrar que
E
(
I
jI
k= 1) =
π
jk,
Cov
(
I
j, I
k) =π
jk−
π
jπ
k:= ∆jk
.
Veamos un ejemplo en donde apliquemos los conceptos de probabilidades de inclusi´on
dados anteriormente, cuando utilizamos MSR para la selecci´on de las muestras.
Ejemplo 2
El conjunto de posibles muestras para el
MSR
es de la forma
S
M SR=
{
s
⊂
U
:
s
tiene
n
elementos distintos
}
,
y la probabilidad de seleccionar cada muestra, es decir, el dise˜
no de muestreo, es
P
M SR({
s
}
) =
N1
n,
De esta forma la probabilidad de inclusi´on de primer orden para cada elemento
k
es
π
k=
X
s∋k
P
(
{
s
}
) =
X
s∋k1
N n=
N−1n−1
N n
=
n
N
,
ya que existen
Nn−−11muestras de tama˜
no
n
que contienen al elemento
k
.
De forma similar se obtiene que la probabilidad de inclusi´on de segundo orden de los
elementos
j
y
k
es
π
jk=
X
s⊃{j,k}
P
(
{
s
}
) =
X
s⊃{j,k}1
N n=
N−2n−2
N n
=
n
(
n
−
1)
N
(
N
−
1)
.
Cuando las muestras son de tama˜
no variable es ´
util tener la siguiente variable aleatoria,
que nos proporciona el tama˜
no de la muestra. Esta variable se expresa como
n
=
X
k∈UI
k.
Entonces para una muestra
s
seleccionada, su tama˜
no de muestra es
n(
s
) =
X
k∈U
I
k(s
) =
X
k∈s1
,
n(
s
) es el n´
umero de elementos diferentes en
s
. Tambi´en se tienen algunas propiedades
de
n,
E
(n) =
X
k∈UE
(
I
k) =X
k∈Uπ
k;es decir, la suma de las probabilidades de inclusi´on de primer orden proporciona el tama˜
no
de muestra esperado. La expresi´on de la varianza del tama˜
no de la muestra es
V ar
(
n
) =
X
k∈UV ar
(
I
k) +X X
k6=j∈UCov
(
I
j, I
k) =X
k∈U
π
k(1−
π
k) +X X
k6=j∈U(
π
jk−
π
jπ
k).
Si la muestra
s
es de tama˜
no fijo
n
, entonces
n
≡
n
con probabilidad 1 y
n
=
X
3.4. Par´
ametros poblacionales y sus estimadores
3.4.
Par´
ametros poblacionales y sus estimadores
En la primera secci´on denotamos a la caracter´ıstica de inter´es de cada elemento de la
poblaci´on por
y
U=
{
y
1, y
2, . . . , y
N}
. Cualquier funci´on de
y
Use le denomina
par´
ametro
poblacional
. Si la caracter´ıstica de inter´es se modela con las variables aleatorias
Y
U=
{
Y
1, Y
2, . . . , Y
N}
cuya funci´on de distribuci´on conjunta es
G
θ, entonces aθ
se le denomina
par´
ametro del modelo
.
Las siguientes cantidades son ejemplos de par´ametros poblacionales:
Total poblacional:
t
y=
X
k∈U
y
k,
Media poblacional:
µ
y=
1
N
X
k∈U
y
k,
Varianza poblacional:
σ
y2=
1
N
−
1
X
k∈U
(
y
k−
µ
y)
2.
Si para cada elemento de la poblaci´on se estudian dos caracter´ısticas, digamos
{
(
x
1, y
1)
,
(
x
2, y
2)
, . . . ,
(
x
N, y
N)
}
,
un par´ametro poblacional puede ser
θ
=
P
k∈U
y
kP
k∈U
x
k.
Sea
t
∈
R
. Otro par´ametro poblacional es la funci´on de distribuci´on poblacional evaluada
en
t
. Esta funci´on se define por:
G
U(t
) =
#(
y
k≤
t
)
N
.
El anterior par´ametro poblacional se puede interpretar como la fracci´on de individuos en
la poblaci´on cuyo valor de la caracter´ıstica de inter´es es menor o igual a
t
.
En general un estimador del par´ametro poblacional
θ
es de la forma
b
En particular es funci´on de la forma
θ
b
(
y
1, y
2, . . . , y
N, I
1, I
2, . . . , I
N). Si el estimador del
par´ametro poblacional
θ
es de la forma
b
θ
(
y
1, y
2, . . . , y
N, λ
1, λ
2, . . . , λ
N)
,
la inferencia se dice basada en dise˜
nos, es decir, las propiedades estad´ısticas de
θ
b
se
calculan con base al dise˜
no de muestreo
P
. Si el estimador fuera de la forma
b
θ
(
Y
1, Y
2, . . . , Y
N, λ
1, λ
2, . . . , λ
N)
y sus propiedades estad´ısticas se calculan con base al modelo
G
θunicamente, entonces
´
la inferencia se dice basada en modelos. Adem´as si la caracter´ıstica de inter´es se modela
con las variables aleatorias
Y
U=
{
Y
1, Y
2, . . . , Y
N}
, entonces el par´ametro poblacional
θ
(
Y
1, Y
2, . . . , Y
N), antes visto como
θ
(
y
1, y
2, . . . , y
N)
,
es formalmente un estad´ıstico y
b
θ
(
Y
1, Y
2, . . . , Y
N, λ
1, λ
2, . . . , λ
N)
es formalmente un predictor de este estad´ıstico.
Ejemplo 3
Si utilizamos
MSR
, un posible estimador del total poblacional
t
yes
b
t
y=
N
n
X
k∈U
y
kI
k.
Para una muestra
s
seleccionada, la estimaci´on de
t
yes
b
t
y(
s
) =
N
n
X
k∈s
y
k=
N y
s.
Un par´ametro poblacional toma un s´olo valor y ´este puede ser desconocido. Por lo
tan-to, un estimador tendr´ıa que proporcionar este ´
unico elemento, el valor del par´ametro.
Pedir lo anterior ser´ıa equivalente a pedir que cualquier muestra y cualquier m´etodo de
estimaci´on nos proporcionaran el valor del par´ametro de inter´es. Lo cual es poco factible.
Aqu´ı un estimador nos proporcionar´a una variedad de valores para el par´ametro de
in-ter´es aunque este conjunto de valores no quede bien determinado. Lo deseable es que el
rango de valores que contenga al par´ametro poblacional fuera corto con una probabilidad
grande.
3.5.
Distribuci´
on aproximada de un estimador
3.6. Teor´ıa asint´
otica en muestreo de poblaciones finitas
Para cierto tipo de estimadores y dise˜
nos de muestreo es posible obtener que
ˆ
θ
−
θ
q
\
V ar
(ˆ
θ
)
tiene una distribuci´on
Normal est´
andar
, para m´as detalle ver el Cap´ıtulo 3 de (Thompson,
1997). Esto es, cuando el tama˜
no de la poblaci´on
N
→ ∞
y el tama˜
no de la muestra
n
→ ∞
, entonces la distribuci´on del cociente anterior tiende a una normal est´andar.
Con base a lo anterior, podemos construir intervalos de confianza para
θ
de la forma
ˆ
θ
±
z
1−α2
q
\
V ar
(ˆ
θ
)
,
donde
z
1−α2es el cuantil de orden 1
−
α2de una normal est´andar. En otras palabras, dado
el comportamiento de la distribuci´on de ˆ
θ
, se espera que aproximadamente 100(1
−
α
) %
de los intervalos as´ı construidos contengan al valor del par´ametro poblacional
θ
(tengan
una cobertura aproximada de 100(1
−
α
) %).
3.6.
Teor´ıa asint´
otica en muestreo de poblaciones
fini-tas
En esta secci´on se presentan definiciones y resultados que son de utilidad en el Cap´ıtulo
6.
En un contexto general de probabilidad y estad´ıstica, la notaci´on
o
p(1) (o peque˜na
p
-uno) es para una sucesi´on de vectores aleatorios que convergen a cero en probabilidad. La
expresi´on
O
p(1) (o grandep
-uno) denota una sucesi´on que es acotada en probabilidad.
En general, para una sucesi´on dada de variables aleatorias
R
n,X
n=
o
p(R
n)⇔
X
n=
Y
nR
n, Y
n p→
0
.
X
n=
O
p(
R
n)
⇔
X
n=
Y
nR
n, Y
n=
O
p(1)
.
Para formalizar los t´erminos de orden estoc´astico mencionados anteriormente, sean
{
a
n}
∞n=1y
{
b
n}
∞n=1sucesiones de n´
umeros reales, sean
{
f
n}
∞n=1y
{
g
n}
∞n=1sucesiones de n´
umeros
reales positivos, y sean
{
X
n}
∞n=1,
{
Y
n}
∞n=1sucesiones de variables aleatorias.
Definici´
on
Decimos que
a
nes de orden m´as peque˜
no que
g
ny se escribe
a
n=
o
(
g
n) si
l´ım
n→∞
a
ng
nDefinici´
on
Decimos que
a
nes a lo m´as de orden
g
ny se escribe
a
n=
O
(
g
n) si existe un
n´
umero real
M
tal que
g
−n1|
a
n| ≤
M
∀
n.
Definici´
on
La sucesi´on de variables aleatorias
{
X
n}
converge en probabilidad a la v.a.
X
, denotado como plim
X
n=
X
, si para cualquier
ǫ >
0
l´ım
n→∞
P
{|
X
n−
X
|
> ǫ
}
= 0
.
Definici´
on
Decimos que
X
nes de orden m´as peque˜
no en probabilidad que
g
n, denotado
como
X
n=
o
p(
g
n) siplim
g
n−1X
n= 0
.
Definici´
on
Decimos que
X
nes a lo m´as de orden
g
nen probabilidad (o acotado en
probabilidad por
g
n), denotado comoX
n=
O
p(
g
n) si para cualquierǫ >
0 existe un
n´
umero real positivo
M
ǫtal que
P
[
|
X
n| ≥
M
ǫg
n]≤
ǫ,
∀
n.
Usando las definiciones anteriores y las propiedades de l´ımites, se puede probar:
1. Si
X
n=
o
p(f
n) yY
n=
o
p(g
n),X
nY
n=
o
p(f
ng
n),
X
n+
Y
n=
o
p(m´ax{
f
n, g
n}
)
,
|
X
n|
s=
o
p(f
ns)
, s >
0
.
2. Si
X
n=
O
p(
f
n) y
Y
n=
O
p(
g
n),
X
nY
n=
O
p(f
ng
n),
X
n+
Y
n=
O
p(m´ax{
f
n, g
n}
)
,
|
X
n|
s=
O
p(f
ns)
, s >
0
.
3. Si
X
n=
o
p(f
n) yY
n=
O
p(g
n),X
nY
n=
o
p(f
ng
n).
3.6. Teor´ıa asint´
otica en muestreo de poblaciones finitas
1980). En (Fuller,
2009) hay una excelente revisi´on de teor´ıa asint´otica en el contexto de
muestreo.
En la siguiente parte de esta Secci´on se explica y describe la consistencia e insesgadez
asint´otica en el contexto de muestreo de poblaciones finitas.
Supongamos que
b
θ
nes un estimador de
θ
basado en una muestra de tama˜
no
n
de una
poblaci´on finita dada de tama˜
no
N
, entonces no podemos decir que
n
→ ∞
, ya que
n
≤
N
, adem´as
N
es fijo y finito. En este contexto, los resultados asint´oticos requieren
una maquinar´ıa m´as compleja con una sucesi´on de poblaciones crecientes tal que
n
y
N
tiendan a infinito.
Empezamos con la idea de una sucesi´on infinita de elementos, etiquetado como
k
=
1
,
2
, ...
, y una sucesi´on infinita asociada de valores de
y
, denotada por
y
1, y
2, ...
, donde
y
kest´a ligada al
k
-´esimo elemento.
Consideremos una sucesi´on de poblaciones
U
1, U
2, U
3, ...
, donde
U
νconsiste de los primeros
N
νelementos de la sucesi´on infinita de elementos mencionados anteriormente, esto es,
U
ν=
{
1
,
2
, ..., N
ν}
. Se asume que
U
1⊂
U
2⊂
U
3⊂ · · ·
y por lo tanto
N
1< N
2< N
3<
· · ·
. Sea
θ
νlos valores de cierto par´ametro en la poblaci´on
U
ν, es decir,θ
νes una funci´on
de los valores
y
1, y
2, ..., y
Nν.
Para cada poblaci´on
U
ν, considere un dise˜
no de muestreo
p
ν(
·
) que asigna una cierta
probabilidad
p
ν(
s
ν) a cada muestra posible
s
νde elementos de
U
ν. Sean
π
νky
π
νkl(
k, l
= 1
,
2
, ..., N
ν) las probabilidades de inclusi´on determinadas por el dise˜
no
p
ν(
·
). Por
simplicidad, se asume que el tama˜
no de muestra es fijo y se denota por
n
ν. De igual forma,
se asume que
n
1< n
2< n
3<
· · ·
. Se puede observar,
ν
→ ∞
significa que
n
ν→ ∞
y
N
ν→ ∞
. Sea ˆ
θ
νun estimador de
θ
ν, basado en los valores observados
y
k, tales que
k
∈
s
ν.
Por ejemplo, el par´ametro
θ
νpuede ser la media poblacional
θ
ν=
y
Uν=
X
k∈Uν
y
kN
νy ˆ
θ
νpuede ser el estimador de Horvitz-Thompson (se revisa en la Secci´on siguiente)
ˆ
θ
ν=
X
k∈sν
y
kN
νπ
νk.
(3.1)
Definici´
on
Un estimador ˆ
θ
νes asint´oticamente insesgado para
θ
ν, si
l´ım
ν→∞
h
E
pνˆ
θ
ν−
θ
νi
= 0
.
Definici´
on
Un estimador ˆ
θ
νes consistente para
θ
ν, si para cualquier
ǫ >
0 fijo,
l´ım
ν→∞
P
h
θ
ˆ
ν−
θ
ν> ǫ
i
= 0
.
En el trabajo de (Isaki y Fuller,
1982) se dan condiciones para la consistencia del
esti-mador (3.1) y el estiesti-mador de regresi´on.
3.7.
Estimador de Horvitz-Thompson
Definici´
on
Sup´ongase que el par´ametro poblacional de inter´es es el total poblacional
t
y. El
estimador de Horvitz-Thompson
(HT) (Horvitz y Thompson,
1952)
b
t
yπdel total
poblacional
t
yes de la forma
b
t
yπ=
X
k∈U
y
kI
kπ
k,
siempre que
π
k>
0 para todo
k
∈
U
. Para una muestra
s
seleccionada, la estimaci´on del
total poblacional
t
yes
b
t
yπ(s
) =
X
k∈sy
kπ
k.
(3.2)
Tenemos las siguientes propiedades del estimador de Horvitz-Thompson descritas en la
siguiente:
Proposici´
on 1
a
. El estimador
b
t
yπes insesgado, es decir,
E
(
b
t
yπ) =
t
y.
b
. Su varianza (un par´ametro poblacional) es
V ar
(
b
t
yπ) =X
k∈Uy
2k
π
k+
X
j∈U
X
k6=j∈U
π
jkπ
jπ
k3.8. Muestreo para unidades poblacionales
c
. Un estimador insesgado de su varianza es
\
V ar
(
b
t
yπ) =
X
k∈U
1
π
k−
1
y
k2I
kπ
k+
X
j∈U
X
k6=j∈U
(
π
jk−
π
jπ
k)
y
jy
kπ
jπ
kI
jI
kπ
jk,
suponiendo que
π
jk>
0 para todo
k
6
=
j
∈
U
. Para una muestra
s
seleccionada, la
estimaci´on de
V ar
(
b
t
yπ) es\
V ar
(
b
t
yπ)(s
) =
X
k∈s1
π
k−
1
y
2k
π
k+
X
j∈s
X
k6=j∈s
1
π
jπ
k−
1
π
jky
jy
k.
d
. Si el tama˜
no de muestra es fijo, entonces la varianza en la Parte
b
se puede expresar
como
V ar
(
b
t
yπ) =X
i∈UX
i>j∈U
(
π
iπ
j−
π
ij)
y
iπ
i−
y
jπ
j 2.
(3.4)
Esta cantidad se conoce como
la expresi´
on de Sen-Yates-Grundy
de la varianza del
es-timador de
HT, para m´as detalle de esta varianza, ver (Sen,
1953) y (Yates y Grundy,
1953). Adem´as, un estimador insesgado de la anterior cantidad es
\
V ar
(
b
t
yπ) =X
i∈UX
i>j∈U
(
π
iπ
j−
π
ij)
y
iπ
i−
y
jπ
j 2I
iI
jπ
ij.
(3.5)
Para una muestra
s
seleccionada, la estimaci´on correspondiente es
\
V ar
(
b
t
yπ)(
s
) =
X
i∈s
X
i>j∈s
(
π
iπ
j−
π
ij)
y
iπ
i−
y
jπ
j 21
π
ij.
(3.6)
Demostraci´
on:
Ver (Sarndal
et al
.,
1992).
3.8.
Muestreo para unidades poblacionales
A continuaci´on se muestran algunos procedimientos de selecci´on de muestras. Estos
pro-cedimientos son com´
unmente utilizados en la pr´actica.
3.8.1.
Muestreo Bernoulli
Bernoulli
independientes y con probabilidad de ´exito
π
. Si el
i
−
´
esimo
experimento es
un ´exito, entonces el individuo
i
de la poblaci´on es seleccionado en la muestra.
Este dise˜
no tiene un valor did´actico y sirve para ilustrar un dise˜
no de muestreo que
produce muestras de tama˜
no variable. Tambi´en, este dise˜
no se puede utilizar para modelar
el n´
umero de individuos que s´ı responden a uno o varios objetos de un cuestionario.
Las muestras son desde tama˜
no cero hasta el tama˜
no de la poblaci´on. Si
π
es la
probabil-idad de ´exito de los experimentos Bernoulli con los cuales se seleccionan a los individuos
en la muestra, entonces el dise˜
no de muestreo es
P
(
{
s
}
) =
π
n(s)(1
−
π
)
N−n(s),
donde
n
representa a la variable aleatoria tama˜
no de la muestra. Es posible mostrar que
las variables indicadoras
I
1, . . . , I
Nson variables aleatorias independientes Bernoulli(
π
).
Entonces la variable aleatoria
n
se distribuye como una distribuci´on
Binomial
(
N, π
).
De acuerdo a lo comentado arriba tenemos que las probabilidades de inclusi´on de primer
y segundo orden son
π
j=
E
(
I
j) =
π
;
para todo
j
∈
U
, y
π
ij=
E
(
I
iI
j) =π
2;
para todos
i
6
=
j
∈
U
.
Por consiguiente, el estimador de
HT
del total poblacional
t
yes:
b
t
yπB=
1
π
X
j∈U
y
jI
j.
Para una muestra
s
seleccionada la estimaci´on resultante es:
b
t
yπB(
s
) =
1
π
X
j∈s
y
j.
Ahora, la varianza del estimador de
HT
del total poblacional
t
yes
V ar
(
b
t
yπB) =1
π
−
1
X
j∈U
y
j2,
ya que de la ecuaci´on (3.3), tenemos que
V ar
(
b
t
yπB) =X
k∈Uy
2k
π
+
X
j∈U
X
k6=j∈U
π
2ππ
y
jy
k−
X
k∈U
y
k!
2=
1
π
−
1
X
3.8. Muestreo para unidades poblacionales
Un estimador de la varianza es
\
V ar
(
b
t
yπB) =1
π
−
1
X
j∈U
y
j2I
jπ
.
Para una muestra
s
seleccionada la estimaci´on resultante es:
\
V ar
(
b
t
yπB)(
s
) =
1
π
−
1
1
π
X
j∈s
y
j2.
3.8.2.
Muestreo aleatorio simple sin reemplazo
El
muestreo aleatorio simple sin reemplazo
,
MSR
, es uno de los dise˜
nos de muestreo
m´as conocidos. Este dise˜
no produce muestras de tama˜
no
n
fijo. Tambi´en este dise˜
no
fu´e mencionado en la Secci´on
3.2
y se recomienda utilizarlo cuando la poblaci´on es
homog´enea con respecto a la caracter´ıstica que se desea estudiar o no conocemos nada
acerca de la poblaci´on con respecto a la caracter´ıstica de inter´es. Adem´as este dise˜
no
presupone que se tiene una lista de los individuos de la poblaci´on y la cual se utilizar´a en
la etapa de selecci´on de la muestra. En ocasiones
MSR
se utiliza por conveniencia, cuando
no se tiene informaci´on que permita la elecci´on de un dise˜
no alternativo.
La probabilidad de seleccionar una muestra por
MSR
es
P
(
{
s
}
) =
N1
n,
para toda muestra
s
de tama˜
no fijo
n
. Ya vimos en el ejemplo 2 de la Secci´on
3.3
que
las probabilidades de inclusi´on de primer y segundo orden son
π
j=
n
N
,
para todo
j
∈
U
y
π
jk=
n
(
n
−
1)
N
(
N
−
1)
,
para cualesquiera
{
j, k
} ⊂
U
.
Entonces el estimador de
HT
del total poblacional
t
yqueda de la siguiente manera
b
t
yπM SR=
N
n
X
Para una muestra
s
seleccionada, la estimaci´on resultante es:
b
t
yπM SR(s
) =
N
n
X
j∈s
y
j.
La varianza del estimador de
HT
es de la manera siguiente:
V ar
(
b
t
yπM SR) =N
21
n
−
1
N
σ
2y,
(3.7)
antes de desarrollar la deducci´on de (3.7), observese que en este caso tenemos muestras de
tama˜
no fijo
n
, por tanto la ecuaci´on (3.3) se reduce a la ecuaci´on (3.4). Por consiguiente
V ar
(
b
t
yπM SR) =X
i∈UX
i>j∈U
(
π
iπ
j−
π
ij)
y
iπ
i−
y
jπ
j 2=
N
−
n
n
(
N
−
1)
X
i∈U
X
i>j∈U
(
y
i−
y
j)2=
N
−
n
2
n
(
N
−
1)
{
X
i∈U
X
j∈U
(
y
i−
y
j)2−
X
i∈U
(
y
i−
y
i)2}
=
N
−
n
2
n
(
N
−
1)
{
2
X
i∈U
X
j∈U
y
i2−
2
X
i∈UX
j∈U
y
iy
j}
=
N
−
n
n
(
N
−
1)
{
X
i∈U
N y
2i−
N
2µ
2y}
=
N
(
N
−
n
)
n
(
N
−
1)
X
i∈U
(
y
i−
µ
y)
2=
N
(
N
−
n
)
n
σ
2
=
N
21
n
−
1
N
σ
y2.
Un estimador de la varianza anterior es:
\
V ar
(
b
t
yπM SR) =1
n
−
1
N
N
N
−
1
X
j∈U
X
j<k∈U
(
y
j−
y
k)2I
jI
kπ
jk,
observese que la ecuaci´on anterior es f´acil de obtener de la ecuaci´on (3.5). Para una
muestra
s
seleccionada, la estimaci´on resultante es:
\
V ar
(
b
t
yπM SR)(s
) =
N
21
n
−
1
N
3.8. Muestreo para unidades poblacionales
donde
σ
s2=
1
n
−
1
X
j∈s
(
y
j−
µ
s)2y
µ
s=
1
n
X
j∈s
y
j.
La expresi´on (3.8) se obtiene de forma similar a como se obtuvo la ecuaci´on (3.7).
3.8.3.
Muestreo con probabilidad proporcional al tama˜
no
En ocasiones se conoce el valor de una variable auxiliar para cada uno de los individuos
de la poblaci´on, denotemos estos valores por
{
x
1, . . . , x
N}
. Tambi´en en ocasiones, estos
valores son tales que
x
k∝
y
k(aproximadamente) para todo
k
∈
U
. Si este es el caso, se
acostumbra a denotar a
x
kcomo el tama˜
no de la
k
−
´
esima
unidad poblacional.
Con lo anterior, el t´ermino
muestreo con probabilidad proporcional al tama˜
no
,
PPT
, sirve
para denotar a cualquier dise˜
no de muestreo donde las probabilidades de inclusi´on de
primer orden son proporcionales al tama˜
no de la unidad poblacional, donde
π
k∝
x
k.Observese que si se utiliza un dise˜
no que produce muestras de tama˜
no fijo y si se utiliza el
estimador de HT para estimar el total, entonces la varianza de dicho estimador se puede
expresar como (ver la ecuaci´on
3.4):
V ar
(
b
t
yπ) =X
i∈UX
i>j∈U
(
π
iπ
j−
π
ij)
y
iπ
i−
y
jπ
j 2.
De aqu´ı, si
π
kes aproximadamente proporcional a
x
k, y por tanto ay
k, entonces elestimador tendr´a una varianza peque˜
na. Es posible obtener esta propiedad sobre la
pre-cisi´on del estimador cuando se tienen muestras de tama˜
no variable, ver el Cap´ıtulo 13
de (Huskova
et al
.,
1998). De lo anterior se desprende, que la combinaci´on de un dise˜
no
con probabilidad proporcional al tama˜
no y el estimador de HT del total, producen
esti-maciones con una alta precisi´on.
Por lo tanto, es conveniente utilizar el muestreo PPT cuando se tiene la informaci´on
disponible sobre lo que se ha denominado tama˜
no de la unidad poblacional.
Dise˜
no de muestreo
Procedimiento de selecci´on:
1
.
Ordenar a los individuos de la poblaci´on en forma descendente con respecto a su valor
del tama˜
no de la unidad;
2
.
Para el elemento
k
= 1, generar un n´
umero aleatorio
ε
1de una distribuci´on
Uniforme
(0
,
1).
Si
ε
1≤
nx
1t
x,
entonces seleccionar al elemento
k
= 1 en la muestra, en caso contario no. Aqu´ı
t
x=
P
j∈U
x
j;3
.
Para
k
= 2
,
3
, . . . ,
generar un n´
umero aleatorio
ε
kde una
Uniforme
(0
,
1). Si
ε
k≤
(
n
−
n
k)x
kt
xk,
entonces seleccionar al elemento
k
en la muestra, en caso contrario no. Aqu´ı
n
kes el
n´
umero de elementos seleccionados en la muestra hasta el momento
k
−
1 y
t
xk=
x
k+
x
k+1+
· · ·
+
x
N.
4
.
El proceso descrito en los pasos 1 al 3 termina cuando
n
k=
n
o
k
=
k
∗, lo que ocurra
primero, donde
k
∗= m´ın
{
k
0
, N
−
n
+ 1
}
y
k
0es el m´ınimo
k
para el cual
nxtxkk>
1;
5
.
Si
n
k∗< n
, el proceso de selecci´on descrito en los pasos 1 al 3 no produjo una muestra
del tama˜
no deseado. Los
n
−
n
k∗elementos faltantes en la muestra son seleccionados de
los restantes
N
−
k
∗+ 1 de la poblaci´on por muestreo MSR.
Los detalles del anterior procedimiento de selecci´on se puede consultar en (Sunter,
1977).
Probabilidades de Inclusi´
on
Es posible mostrar que las probabilidades de inclusi´on de primer orden son:
π
k=
nxk tx,
nxk∗tx