Diseño de una herramienta basada en machine learning para toma de decisiones en los procesos de due diligence del derecho laboral
101
0
0
Texto completo
(2) Introducción. ii. El presente trabajo tiene como eje central a la inteligencia artificial que es una rama de las ciencias de la computación que poco a poco se ha formado como parte de nuestra vida cotidiana y está cambiando nuestro mundo con significativos avances. Está creando una revolución en conocimiento, formas de hacer las cosas y cambiando nuestra propia visión del mundo. Así como ahora no concebimos el mundo sin la web, en unos años no tardaremos en acostumbrarnos y asimilar la inteligencia artificial como parte de una vida normal. La inteligencia artificial tiene muchas ramas, pero en la que nos basamos para este proyecto fue machine learning o aprendizaje de máquina, la idea principal de esta disciplina es hacer que los procesos con el pasar del tiempo del tiempo se vuelvan más precisos y efectivos, esto se logra con la identificación de patrones en estos procesos y la aplicación de algoritmos que analizan un conjunto de datos para imitar el comportamiento humano deseado. En Colombia la inteligencia artificial está creciendo en las diferentes áreas de aplicación, pero a pesar de este crecimiento ha tenido poca aceptación de algunas personas y empresas que tienen la errada creencia de que se reemplazará el trabajo humano, siendo que esta ha servido más para reforzar los procesos y con la rama de la IA - machine learning disminuir el error humano. El interés de este documento además de dar una visión general de la inteligencia artificial es específicamente enfocarnos en el tema de aprendizaje de máquina, y en cómo se aplicó este conocimiento al análisis de proyectos legales. Nuestro punto de partida y eje para diseñar un modelo de aprendizaje está basado en un caso de estudio real; tomando la situación de una empresa y llevándola a una red neuronal..
(3) Tabla de Contenido. iii. PARTE I. CONTEXTUALIZACIÓN DE LA INVESTIGACIÓN ..................................................... ix 1. Capítulo I Descripción de la investigación .......................................................................................... 1 1.1 Planteamiento/Identificación del problema ................................................................................ 1 1.1.1 Planteamiento del problema ...................................................................................................... 1 1.1.2 Formulación del problema ......................................................................................................... 1 1.1.3 Sistematización del problema .................................................................................................... 2 1.2 Objetivos ........................................................................................................................................... 2 1.2.1 Objetivo general .......................................................................................................................... 2 1.2.2 Objetivos específicos .................................................................................................................. 2 1.3 Justificación de la investigación ..................................................................................................... 3 1.3.1 Justificación práctica ................................................................................................................... 3 1.4 Hipótesis ........................................................................................................................................... 3 1.5 Metodología de la investigación..................................................................................................... 3 1.5.1 Tipo de estudio ............................................................................................................................ 3 1.5.2 Método de investigación ............................................................................................................ 4 PARTE II. DESARROLLO DE LA INVESTIGACIÓN ........................................................................ 5 2. Capítulo II Análisis .................................................................................................................................. 6 2.1 Negocio ............................................................................................................................................. 6 2.1.1 Posse Herrera Ruiz ..................................................................................................................... 6 2.1.2 Proyectos Legales ........................................................................................................................ 6 2.1.3 Derecho Laboral.......................................................................................................................... 7 2.1.4 Due Dilegence ............................................................................................................................. 7 2.2 Inteligencia Artificial ....................................................................................................................... 8 2.2.1 Introducción ................................................................................................................................ 8 2.2.2 Definición y teoría de la inteligencia artificial ......................................................................... 9 2.2.3 Métodos de la inteligencia artificial convencional ................................................................11 2.3 Machine Learning ..........................................................................................................................16 2.3.1 Aprendizaje supervisado ..........................................................................................................16 2.3.2 Aprendizaje sin supervisión .....................................................................................................17 2.3.3 Función de costo .......................................................................................................................17 2.3.4 Sobreajuste .................................................................................................................................22 2.3.5 Tipos de redes neuronales........................................................................................................22 2.4 Tipos de datos ................................................................................................................................34 2.4.1 Datos nominales ........................................................................................................................35 2.4.2 Datos ordinales ..........................................................................................................................35 2.4.3 Datos de intervalo .....................................................................................................................36 2.4.4 Datos de relación.......................................................................................................................37 3. Capítulo III Desarrollo de la investigación .........................................................................................39 3.1 Análisis ............................................................................................................................................39 3.1.1 Organización ..............................................................................................................................39 3.1.2 Proceso .......................................................................................................................................40 3.1.3 Aplicación ...................................................................................................................................40 3.2 Requerimientos ..............................................................................................................................43 3.2.1 Requerimientos Funcionales....................................................................................................43 3.2.2 Requerimientos NO Funcionales ...........................................................................................43.
(4) 3.3 Desarrollo ................................................................................................................................... 44iv 3.3.1 Origen de los datos ...................................................................................................................44 3.3.2 Exploración de datos ................................................................................................................46 3.3.3 Redes de entrenamiento ...........................................................................................................57 3.3.4 Web Service................................................................................................................................74 3.3.5 Cliente -Web ..............................................................................................................................74 3.4 Validación del prototipo ...............................................................................................................77 PARTE III. CIERRE DE LA INVESTIGACIÓN ..................................................................................80 4. Conclusiones............................................................................................................................................81 5. Trabajos Futuros .....................................................................................................................................82 6. Bibliografía ...............................................................................................................................................83 ANEXOS ..........................................................................................................................................................85 ANEXO I. Fragmento del DataSet utilizado en el proyecto................................................................86 ANEXO II. Código del cliente de consumo del servicio......................................................................89 ANEXO III. Configuración Web Service ...............................................................................................90 Instalación de Jupyter Kernel Gateway ...............................................................................................90 Configuración de Notebook .................................................................................................................92.
(5) Lista de Imágenes. v. Imagen 1. Dendral primer sistema experto. Tomado de: https://expertossitemas.webcindario.com/dendral.html ........................................................ 12 Imagen 2. Grafo de síntomas y enfermedades. Tomado de: https://ccc.inaoep.mx/~esucar/Clasesmgp/caprb.pdf ....................................................................................................................... 14 Imagen 3. Dispositivos basados en la lógica difusa ...................................................................... 15 Imagen 4. Ejemplo de grafico de datos. Autores .......................................................................... 18 Imagen 5. Regresión lineal simple. Autores ................................................................................. 20 Imagen 6. Desviación de regresión lineal. Autores ...................................................................... 20 Imagen 7. Desviación mínima. Autores ........................................................................................ 21 Imagen 8. Comparación de sobreajuste. Autores.......................................................................... 22 Imagen 9. Perceptrón. Tomado de: https://es.wikipedia.org/wiki/Perceptr%C3%B3n#/media/File:Perceptr%C3%B3n_5_unidad es.svg..................................................................................................................................... 23 Imagen 10. Condición lógica AND. Tomado de: https://commons.wikimedia.org/wiki/File:Computer.Science.AI.Neuron.AND.svg ........... 24 Imagen 11. Condición lógica OR. Tomado de: https://commons.wikimedia.org/wiki/File:Computer.Science.AI.Neuron.OR.svg .............. 25 Imagen 12. Condición lógica XOR. Tomado de: https://commons.wikimedia.org/wiki/File:Computer.Science.AI.Neuron.XOR.svg ........... 25 Imagen 13. Función de paso. Tomado de: https://en.wikipedia.org/wiki/Step_function#/media/File:Dirac_distribution_CDF.svg ...... 27 Imagen 14. Función sigmoide. Tomado de: https://es.wikipedia.org/wiki/Funci%C3%B3n_sigmoide#/media/File:Funci%C3%B3n_sig moide_01.svg ........................................................................................................................ 27 Imagen 15. Función tangencial. Tomado de: https://es.wikipedia.org/wiki/Tangente_hiperb%C3%B3lica#/media/File:Hyperbolic_Tange nt.svg ..................................................................................................................................... 27 Imagen 16. Función rectificadora. Tomado de: https://es.wikipedia.org/wiki/Rectificador_(redes_neuronales)#/media/File:Rectifier_and_so ftplus_functions.svg .............................................................................................................. 28 Imagen 17. Redes recurrentes. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/ ...................................................... 29 Imagen 18. Autocodificadores. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/ ...................................................... 29 Imagen 19. Redes con aleatoriedad. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/ ...................................................... 30 Imagen 20. Red profunda. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/ 31 Imagen 21. Redes profundas compuestas. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/ ...................................................... 31 Imagen 22. Funcionamiento de red convolucional. Tomado de: https://stats.stackexchange.com/questions/146413/why-convolutional-neural-networksbelong-to-deep-learning ........................................................................................................ 32 Imagen 23. Redes especializadas. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/ ...................................................... 32.
(6) Imagen 24. Red de turing. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/ vi ............................................................................................................................................... 34 Imagen 25. Ejemplo de datos nominales. Tomado de: https://medium.com/ai3-theory-practicebusiness/the-engineers-guide-to-machine-learning-data-processing-data-typesba40e6bf8765 ........................................................................................................................ 35 Imagen 26. Ejemplo de datos ordinales. Tomado de: https://medium.com/ai3-theory-practicebusiness/the-engineers-guide-to-machine-learning-data-processing-data-typesba40e6bf8765 ........................................................................................................................ 36 Imagen 27. Ejemplo de datos de intervalo. Tomado de: https://medium.com/ai3-theory-practicebusiness/the-engineers-guide-to-machine-learning-data-processing-data-typesba40e6bf8765 ........................................................................................................................ 37 Imagen 28. Ejemplo de datos de relación. Tomado de: https://medium.com/ai3-theory-practicebusiness/the-engineers-guide-to-machine-learning-data-processing-data-typesba40e6bf8765 ........................................................................................................................ 38 Imagen 29. Punto de vista de negocio. Autores ............................................................................ 39 Imagen 30. Punto de vista de proceso. Autores ............................................................................ 40 Imagen 31. Microservicios. Tomado de: https://docs.microsoft.com/eses/azure/architecture/guide/architecture-styles/images/microservices-logical.svg .............. 41 Imagen 32. Diseño básico de microservicio. Autores................................................................... 41 Imagen 33. Diseño general de arquitectura de microservicios. Tomado de: https://docs.microsoft.com/es-es/azure/architecture/guide/architecturestyles/images/microservices-acs.png .................................................................................... 42 Imagen 34. Diseño y herramientas del prototipo. Autores ........................................................... 42 Imagen 35. Diseño de base de datos. Autores. ............................................................................. 44 Imagen 36. Flujo de control de la ETL. Autores .......................................................................... 45 Imagen 37. Flujo de datos de la ETL. Autores. ............................................................................ 45 Imagen 38. Asignaciones de columnas. Autores. ......................................................................... 46 Imagen 39. Categorización de los datos ....................................................................................... 47 Imagen 40. Histograma de la frecuencia de los datos. Autores .................................................... 48 Imagen 41.Cantidad de casos de Due Diligence por tipo de empresa. Autores. .......................... 49 Imagen 42. Cantidad de casos Due Diligence por tipo de caso. Autores. .................................... 50 Imagen 43. Tiempo en días por tipo de caso y empresa. Autores. ............................................... 50 Imagen 44. Total de casos por país. Autores. ............................................................................... 51 Imagen 45. Comportamiento de los días. Autores ........................................................................ 51 Imagen 46. Ruta principal de árbol de decisiones. Autores. ......................................................... 53 Imagen 47. Ruta alterna de árbol de decisiones. Autores. ............................................................ 54 Imagen 48. Ruta corta en árbol de decisiones. Autores. ............................................................... 55 Imagen 49. Dataset de horas por categorías. Autores. .................................................................. 57 Imagen 50. Logotipo de Anaconda, Jupyter y Spider. Tomado de: https://www.youtube.com/watch?v=Q0jGAZAdZqM ......................................................... 58 Imagen 51. Primer modelo de regresión lineal. Autores. ............................................................. 59 Imagen 52. Procesamiento del primer modelo de regresión lineal. Autores. ............................... 61 Imagen 53. Prototipo de red neural. Autores. ............................................................................... 63 Imagen 54. Notebook del modelo. Autores. ................................................................................. 65 Imagen 55. Prototipo de red neural sin nodos de activación sigmoide. Autores. ......................... 66 Imagen 56. Prototipo de red neural. Autores. ............................................................................... 67.
(7) Imagen 57. Notebook del modelo.Autores. .............................................................................. 69vii Imagen 58. Prototipo de red neural final sigmoide. Autores. ....................................................... 70 Imagen 59. Características de la maquina donde se realiza el entrenamiento de la red. Autores. 72 Imagen 60. Uso de máquina. Autores. .......................................................................................... 72 Imagen 61. Notebook del modelo final. Autores. ......................................................................... 73 Imagen 62. Reporte del aplicativo. Autores.................................................................................. 75 Imagen 63. Formulario de predicción de datos. Autores. ............................................................. 76 Imagen 64. Componentes del aplicativo. Autores. ....................................................................... 77 Imagen 65. Calculo del error cuadrático. Autores. ....................................................................... 77.
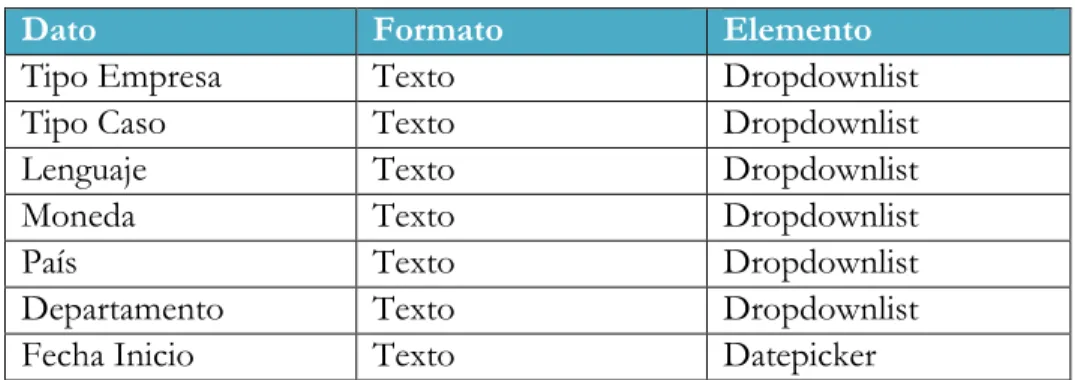
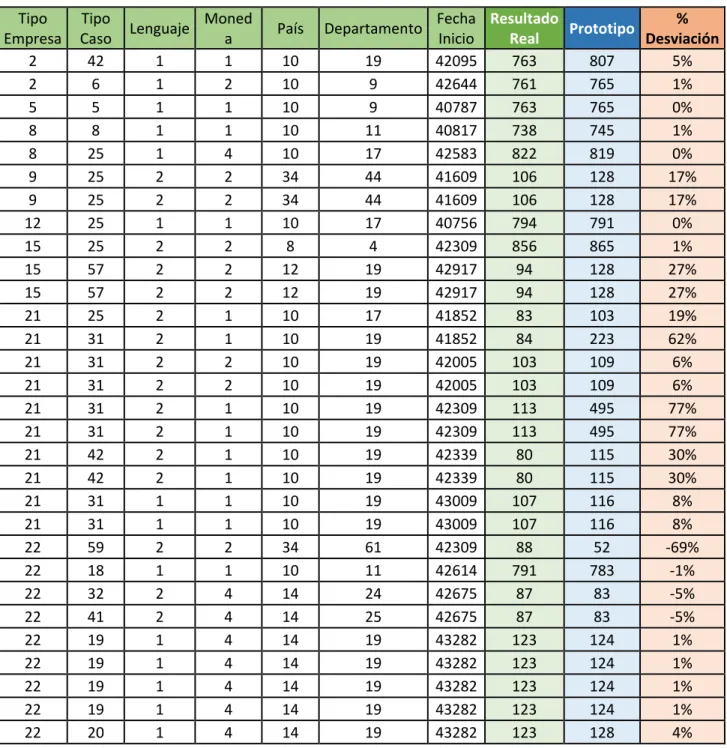
(8) Lista de tablas. viii. Tabla 1. Campos de interfaz. Autores. .......................................................................................... 43 Tabla 2. Validación del prototipo de regresión lineal. Autores. ................................................... 63 Tabla 3. Comparación de predicción del prototipo vs datos reales. ............................................. 78.
(9) ix. PARTE I. CONTEXTUALIZACIÓN DE LA INVESTIGACIÓN.
(10) 1 1. Capítulo I Descripción de la investigación 1.1. Planteamiento/Identificación del problema. 1.1.1. Planteamiento del problema. En todo tipo de proyecto se desea hacer un correcto planeamiento de recursos, gestión y costes. En este caso en particular se evaluó el proceso de tipo Due Diligence en el área de práctica del derecho laboral, este proceso y su metodología se detalla más adelante de manera puntual, pero consiste en una evaluación de los estados jurídicos de una empresa. Actualmente este análisis se hace por medio de comparación de experiencias con proyectos anteriores similares. Esta forma de análisis pone a prueba totalmente al experto que debe realizar esta labor, y muchas veces se prestan casos o situaciones particulares que hacen que se produzca costos diferentes que pueden causar una mala evaluación e incluso una pérdida de capital. Si esto no se trata, este problema va a seguir generando pérdidas de dinero y recursos, además de la valiosa información que se está perdiendo de cada uno de esos proyectos. Por esta razón se propone el diseño de un sistema basado en machine learning para analizar y aprender de los proyectos con los que se alimenta y así mitigar los posibles errores de análisis y poder usar los datos de cada proyecto cargado para hacer predicciones más contundentes. 1.1.2. Formulación del problema. Entonces, ¿Cómo se puede minimizar el riesgo de fallo en la evaluación? Esta pregunta es el eje de nuestra investigación y se quiere abordar por medio de tecnologías innovadoras y competitivas. En este ejercicio se optó por usar Machine Learning como motor y procesador, para generar un modelo que cumpla en responder a esta pregunta de investigación, y que solvente el problema planteado, además de generar una forma de seguir construyendo un sistema más sólido y eficaz..
(11) 2. 1.1.3. Sistematización del problema. Pero a raíz de esta selección surgen nuevos interrogantes. •. ¿Cómo trabaja y se implemente el Aprendizaje de máquina?. •. ¿Qué modelos neurales podemos usar para realizar el análisis de datos requeridos?. •. ¿Qué variables son relevantes, dentro de nuestro proceso de análisis?. •. ¿Qué modelo es el que más se ajusta a nuestro proyecto?. 1.2. Objetivos. 1.2.1. Objetivo general. Diseñar el prototipo de una aplicación que haga uso de los algoritmos de aprendizaje supervisado para realizar un análisis de los proyectos de tipo “Due Diligence” en el derecho laboral para que a través de las pasadas experiencias encuentre etiquetas de coincidencia y prediga estimaciones precisas, disminuyendo los actuales altos índices de error. 1.2.2 •. Objetivos específicos Obtener una definición de Machine Learning que sirva como herramienta y poderla llevar al campo práctico.. •. Realizar un análisis que prediga estimaciones de presupuesto, recursos y tiempo cada vez más asertivas; basándonos en la definición teórica y modelos identificados.. •. Validar la efectividad del modelo funcional propuesto, por medio de la simulación de procesamiento de datos para así mejorar o reestructurar el diseño..
(12) 3 1.3. Justificación de la investigación. 1.3.1. Justificación práctica. Machine Learning es una rama de la inteligencia artificial y se tomó como modelo para generar el proceso de aprendizaje aplicado al Due Diligence en el derecho laboral. Teniendo en cuenta esta premisa se realizó una investigación previa para recolectar la mayor cantidad de información que encamine a la solución, una vez recolectada esta información se inició con el diseño del modelo. Generando así una base de conocimiento (ya que no existe), y además un instrumento que se puede desarrollar, implementar y probar, o usar para futuras investigaciones. En pocas palabras, se generó un diseño para análisis de proyectos altamente estable y evolutivo, capaz de adaptarse y crecer a medida que se alimenta de datos de proyectos. El producto de esta investigación sirve como referencia y campo de prueba para el mejoramiento de los procesos de Due Diligence en otras áreas como tributario, litigios, inmobiliario, etc... Para la firma de abogados Posse Herrera Ruiz, y se espera que se pueda generar un modelo lo suficientemente complejo y estructurado para que pueda seguir aprendiendo y adaptarse a otro tipo de proyectos fuera del área legal. 1.4. Hipótesis. La herramienta que plantea este proyecto será capaz de evaluar correctamente la cantidad de recursos requeridos en los casos de Due Diligence, además con su uso se disminuirá la pérdida de tiempo, dinero y otros recursos, minimizando los riesgos en la gestión del proyecto legal. 1.5. Metodología de la investigación. 1.5.1. Tipo de estudio. El tipo de estudio es descriptivo ya que uno de los objetivos es identificar elementos y características del problema de investigación, ahondar de forma teórica y generar un modelo de análisis basado en las experiencias de una organización, además se espera que el resultado.
(13) 4 de esta investigación permita formular nuevas hipótesis y generar un modelo mucho más consistente y complejo que se adapte a nuevos escenarios. 1.5.2. Método de investigación. Se utilizó el método de investigación inductivo para plantear el marco teórico y así fundamentar y contextualizar la investigación. Posteriormente para generar el diseño se cambió al método deductivo, dando como resultado un método combinado de induccióndeducción..
(14) 5. PARTE II. DESARROLLO DE LA INVESTIGACIÓN.
(15) 6 2. Capítulo II Análisis 2.1. Negocio. 2.1.1. Posse Herrera Ruiz. Este proyecto fue un ejercicio que se realizó en la firma de abogados Posse Herrera Ruiz, la revista dinero define a esta firma como “una firma de abogados que actualmente cuenta con 16 socios y más de 120 abogados especializados en diferentes áreas de prácticas e industrias en Bogotá, Medellín y Barranquilla, siendo así una firma ‘full service’ con presencia en estas ciudades, que maneja temas como propiedad intelectual, derecho público y comercio exterior.” (Posse Herrera Ruiz, firma colombiana del año, 2015) La firma se especializa en las siguientes áreas: •. Fusiones y Adquisiciones. •. Derecho de la Competencia. •. Resolución de Conflictos. •. Derecho Corporativo. •. Propiedad Intelectual. •. Derecho Laboral y Migratorio. •. Impuestos, Aduanas y Comercio Exterior. •. Seguros. •. Mercado de Capitales y Derecho Financiero. •. Recursos Naturales y Energía. •. Infraestructura y Asociaciones Público-Privadas APP. •. Inmobiliario, Urbanismo y Agroindustria. •. Medio Ambiente. 2.1.2. Proyectos Legales. Legal Projects Management (LPM) es la aplicación de conceptos de gestión de proyectos al.
(16) 7 área jurídica, busca estimar un caso jurídico como un proyecto y poderle dar un manejo estratégico de planificación, ejecución y cierre. Por lo general se rigen bajo PMI aunque en los últimos años se han implementado proyectos con metodologías ágiles como SCRUM. Es importante controlar un caso jurídico desde antes que comience para poder llegar a culminarlo exitosamente para las partes interesadas. Como cliente se está interesado en conocer el costo del proyecto anticipadamente y como proveedor de servicios se desea saber la estimación de recursos para hacer una propuesta al cliente. 2.1.3. Derecho Laboral. El derecho laboral en Colombia surge cuando los trabajadores se manifiestan ante el desconocimiento de sus necesidades por parte de los grandes empresarios, a raíz de esto se crean las leyes que protegen sus horarios de trabajo, su derecho a la salud y las pensiones, etc... Y se vuelven necesarios como servicios mínimos a los cuales debe tener acceso un trabajador. El derecho laboral es la rama del derecho que regula las relaciones entre empleadores y empleados, con el objetivo de proteger el derecho fundamental al trabajo que tenemos los colombianos y el cual el estado debe garantizar. 2.1.4. Due Diligence. Cuando se planea realizar un proceso de compra (generalmente de empresas) es necesario realizar una investigación integral en todas las áreas (Laboral, tributario, fiscal, medio ambiental, litigios, etc.…) de los estados de la empresa objeto de la adquisición, esta investigación permite al cliente tener el máximo de información disponible en especial los riesgos existentes y se pueda tomar una decisión con respecto a la adquisición. En el área Laboral el proceso de Due Diligence debe identificar los aspectos donde haya incumplimientos legales y que tengan impacto en los estados financieros, los siguientes aspectos se consideran como los más importantes a tener en cuenta:.
(17) 8 • • • • • • • •. Cumplimiento de la norma vigente Revisión del proceso de contratación Políticas de recursos humanos Política retributiva Seguros sociales Ausentismo en la compañía Incapacidades Otros... atrasos salariales, indemnizaciones de pago, riesgos laborales etc.. 2.2. Inteligencia Artificial. 2.2.1. Introducción. La palabra inteligencia aún no cuenta con una definición aceptada, sin embargos varios autores de diferentes ramas del conocimiento coinciden que la inteligencia es una capacidad o habilidad cognitiva de representar el mundo que nos rodea. Una de estas representaciones más básicas es el lenguaje y la escritura donde por medio de los símbolos se intenta representar la realidad. La Real Academia de la Lengua Española define la inteligencia como la facultad de conocer, entender o comprender, pero es una definición muy ambigua puesto que hasta un sistema de aire acondicionado podría considerarse un sistema inteligente de bajo nivel por eso es que hay muchas formas de definir un comportamiento inteligente y es necesario hacer énfasis en que para considerar un sistema inteligente, se deben considerar todos los aspectos y demostrar un alto nivel en las facultades que define la RAE. La inteligencia artificial se considera que tuvo sus orígenes con los silogismos propuestos por Aristóteles, esta forma de razonamiento es la base de la lógica y el pensamiento científico, consta de dos premisas y una conclusión. Después de esto vinieron muchos aportes de filósofos, matemáticos y científicos como (Boole, Gardner etc..) pero no fue hasta el año 1936 cuando Alan Turing desarrollo la famosa “máquina automática” que es un modelo computacional de un dispositivo autómata finito donde se pueden leer, escribir o borrar símbolos. Este concepto es la base del funcionamiento de los computadores que usamos hoy en día..
(18) 9. En 1950 Alan Turing creo el Test de Turing para determinar las habilidades de comportamiento inteligente en las maquinas, el fundamento de esta prueba era determinar si las personas lograban diferenciar cuando estaban comunicándose con una maquina o con otro ser humano. Con estos aportes de Turing y de otros grandes científicos a la lógica matemática y el razonamiento, en 1958 John McCarthy en el Instituto Tecnológico de Massachussets (MIT) consolida el termino de inteligencia artificial refiriéndose a las maquinas que realizan cálculos inteligentes y proponiendo utilizar el cálculo como un idioma para representar el conocimiento. Se pensaba que para los años 70 el mundo iba a estar rodeado de inteligencia artificial, pero no fue sino hasta los años 90 donde las empresas empezaron a realizar inversiones en el área de análisis y procesamiento de datos como foco principal en la inteligencia artificial. En 1997 se empodero el termino cuando IBM desarrollo Deep Blue un sistema informático que fue capaz de vencer al campeón mundial del ajedrez. 2.2.2. Definición y teoría de la inteligencia artificial. La inteligencia artificial es la rama de la ciencia que trata de entender la inteligencia o el comportamiento inteligente de los seres humanos y replicarlo en la construcción de un sistema que sea útil en algún área del conocimiento como la psicología, física, economía, etc. La IA aborda un complejo problema que es determinar “¿Cómo es posible que un diminuto cerebro (sea biológico o electrónico) tenga capacidad para percibir comprender, predecir y manipular un mundo que en tamaño y complejidad lo excede?” (Ponce Cruz, 2010) fue aquí donde se comprendido que la IA debía empezar a comprenderse desde lo más básico de la raciocinio, el razonamiento animal para luego guiar el enfoque hacia la naturaleza, a partir de esto surgieron tres grandes grupos en los que se centra la inteligencia artificial:.
(19) 10. •. Comunicación y percepción: Aquí se encuentra todo lo relacionado con el lenguaje natural y todo lo que se obtiene a través de los sentidos, consiste en intentar que la maquina pueda comprender el lenguaje y el contexto de las palabras en una conversación.. •. Pensamiento simbólico: La representación mental de las experiencias a través de los símbolos e imágenes, con esto se busca que la maquina sea capaz de “razonar” según su base de conocimiento y que no solamente siga una serie de instrucciones lógicas.. •. Ingeniería del conocimiento: Transmitir los conocimientos y metodologías de un experto a un sistema, es la base de los sistemas expertos.. A partir de los anteriores grupos de estudio la IA surgieron los siguientes campos fundamentales donde cada uno aborda uno o más grupos de estudio, estos campos son: •. Redes neuronales. •. Sistemas difusos. •. Sistemas expertos. •. Redes bayesianas. •. Basada en comportamiento. •. Robótica. •. Aprendizaje de máquina. Con los siguientes enfoques: •. Tecnológico. •. Ingenieril. •. Científica. Si bien aún estamos en el comienzo del desarrollo de la inteligencia artificial y los sistemas aún se encuentran muy limitados en su proceso aprendizaje, en la última década ha habido.
(20) 11 importantes evoluciones en la inteligencia artificial han mejorado procesos y los han hecho más efectivos con un porcentaje de acierto más alto porque cuentan con muchas ventajas frente al ser humano como, por ejemplo: •. Agentes externos: No están afectados por factores externos como el tiempo (no envejecen), Cansancio, Presión, Entorno etc.. •. Velocidad: Pueden resolver problemas en menor tiempo que un ser humano y mucho más eficientemente. •. Fortalecimiento de conocimientos. Sin embargo, también cuentan con muchas desventajas como, por ejemplo: •. Incapacidad de aprender de las equivocaciones, lo cual es un proceso de alta importancia en el conocimiento.. • 2.2.3. No cuentan con emociones, moralidad, sentido común, lenguaje natural etc. Métodos de la inteligencia artificial convencional. 2.2.3.1. Sistemas Expertos. Un experto es una persona enfocada en una disciplina especifica. Los sistemas expertos son una rama de la inteligencia artificial que consisten en un programa computacional que esta entrenado para el aprendizaje, memorización, razonamiento, comunicación y acción a partir de una base de conocimientos, que le permite tomar decisiones como lo haría un humano experto. Para las compañías de hoy en día puede ser llamativo obtener un sistema experto puesto que estos sistemas no están susceptibles a situaciones relacionadas con el ser humano como por ejemplo que el experto se marche o tenga deterioros en su salud mental, además de ser más rápidos y precisos..
(21) 12 Los sistemas expertos son usados en varias áreas como por ejemplo la medicina, donde los sistemas hacen un diagnostico (inclusive más acertado que el de un ser humano), interpretación de las imágenes médicas, monitoreo, detección de enfermedades etc. En la milicia donde cuentan con armamento inteligente, cobertura, protección etc. El primer sistema experto que se conoció fue Dendral un proyecto que tuvo una duración de 10 años iniciando su desarrollo en los años 60 por Edward Feigenbaum (programador), Bruce G. Buchanan, Joshua Lederberg (experto en química orgánica) y Carl Djerassi, este tenía como objetivo colaborar a los químicos orgánicos en la identificación de moléculas orgánicas desconocidas analizando sus espectros de masas. Dendral se desarrolló en el lenguaje de programación Lisp que es considerado como el lenguaje de la inteligencia artificial, desarrollado por John McCarthy y es conocido por ser uno de los lenguajes de alto nivel más antiguos después de Fortran. Ver Imagen 1.. Imagen 1. Dendral primer sistema experto. Tomado de: https://expertossitemas.webcindario.com/dendral.html.
(22) 13 Mycin es otro sistema experto desarrollado en los años 70 como tesis doctoral en la universidad de stanford por Edward Shortliffe (Mycin, s.f.) basado en Dendral, su principal función consistía en el diagnóstico de bacterias que causaban infecciones en la sangre, a partir de este diagnóstico generaba la recomendación de un tratamiento dependiendo de la persona. A pesar de la efectividad de diagnóstico de Mycin nunca pudo salir al mercado por inconvenientes en materia legal como por ejemplo la responsabilidad de las consecuencias de los diagnósticos y/o tratamientos equivocados. Este sistema experto al igual que Dendral estaba desarrollado sobre el lenguaje Lisp, opera sobre una base de conocimientos con una estructura de control simple: 1. Colección de hechos 2. Conjunto de reglas 3. Generador de inferencias. 2.2.3.2. Redes Bayesianas. Una red bayesiana es una técnica estadística muy usada en la rama de la inteligencia artificial ya que a partir de un conjunto de variables aleatorias y sus relaciones se puede generar un modelo de dependencia y obtener información interesante sobre cómo se relacionan las variables y predecir el comportamiento de variables no conocidas en base a las que ya se conocen, muchas veces este tipo de relación puede ser de causa efecto como por ejemplo enfermedad y síntoma, si establecemos este concepto un sistema fácilmente puede a partir de los síntomas predecir las enfermedades y gráficamente se podría ver en la Imagen 2:.
(23) 14. Imagen 2. Grafo de síntomas y enfermedades. Tomado de: https://ccc.inaoep.mx/~esucar/Clases-mgp/caprb.pdf. 2.2.3.3. Sistemas Difusos. Los sistemas fuzzy, borrosos o difusos son una extensión de la lógica, una forma matemática de representar lo impreciso, vago y ambiguo de los cuantificadores del lenguaje natural que usamos los seres humanos para compartir las experiencias con términos lingüísticos de bajo nivel como “muy”, “alto”, “medio”, “moderado”, “bajo” que para un ser humanos serían fáciles de comprender pero para una máquina que no tiene definidos estos conceptos es muy relativo y dependerá mucho del contexto que se le esté dando. Por ejemplo, tenemos la siguiente premisa “el nivel de la temperatura es moderada” un ser humano comprendería fácilmente esta afirmación, pero no sería tan sencillo para una máquina que no sabe lo que significa que la temperatura este moderada y dependerá totalmente del contexto que se le dé al por ejemplo indicarle que la temperatura es considerada como bajo si es menor a 0 grados centígrados y alta cuando supere los 30 grados centígrados, cuando se definen estos valores el sistema puede determinar que la temperatura que se está midiendo cuando esta entre los 0 y los 30 grados es “moderada”. Por lo tanto, es importante alimentar muy bien los elementos base del sistema y entre más precisos sean mejores serán los resultados del sistema, por ejemplo, podríamos indicarle el contexto de “muy caliente”, “hirviendo”, “tibio”, “congelado” y el sistema podría crecer aún más con la representación de estos intervalos..
(24) 15 La lógica difusa se fundamente en las reglas heurísticas “SI” y “ENTONCES” donde cada enunciado debe ser “borroso” como por ejemplo “Si la temperatura tiende a ser más alta ENTONCES está haciendo calor” a partir de estas premisas simples se construyen los sistemas basados en la lógica difusa. Actualmente muchos de los dispositivos que usamos están basados en la lógica difusa como lo podemos ver con la Imagen 3:. Imagen 3. Dispositivos basados en la lógica difusa.
(25) 16 2.3. Machine Learning. Machine learning (Aprendizaje de máquina o Aprendizaje automático) es una rama de la inteligencia artificial que nace de la necesidad que tienen las máquinas de simular un aprendizaje, para el análisis o clasificación de datos. Machine learning permite convertir los datos recolectados en información útil y aplicable, volviendo a la inteligencia artificial en algo reactivo y proactivo, que se puede adaptar y evolucionar. En este aspecto Machine learning toma un papel muy importante, ya que es el encargado de dar versatilidad, aprovechar los cambios y dar un valor agregado a la información recolectada, dándole al sistema una capa más de análisis y complejidad. Machine learning tiene dos corrientes de aprendizaje, a continuación, se describirá cada una de ellas y se introducirá un poco de historia para ver el desarrollo y evolución de estos conceptos, además de que permitirá explicar conceptos que se usaran más adelante en el desarrollo del modelo que se propone a solucionar esta investigación. 2.3.1. Aprendizaje supervisado. Con el aprendizaje supervisado se tiene un conjunto de datos y de antemano ya se conoce como debería ser la salida, teniendo en cuenta la relación existente entre la entrada y la salida. Es decir, se tiene un propósito claro y entendimiento de la relación entre variables. Dentro del aprendizaje supervisado tenemos dos soluciones posibles, a problemas de regresión y a problemas de clasificación. En un problema de regresión se trata de predecir un resultado dentro de un conjunto de resultados continuos, lo que significa que estamos tratando de asignar variables de entrada en una función lineal. Para comprender un poco mejor el concepto se plantea el siguiente ejemplo: Teniendo una cantidad de datos X, que se caracterizan por ser información referente a atributos de casas (Precio, Tamaño), se desea generar una función para predecir el valor, siendo.
(26) 17 conscientes que para el ejemplo se supone que la única variable que influye es el tamaño y de esta depende el precio, pero se podría agregar tantas variables de entrada como se necesitaran. Para plantear el problema de regresión se puede hacer con la pregunta, ¿Cómo se puede calcular el precio de un inmueble teniendo como principal dato el tamaño del mismo? Por el contrario, en un problema de clasificación se trata de predecir los resultados en un resultado discreto, en otras palabras, se desea asignar las variables de entrada a unas categorías discretas(conjuntos). Si usamos el ejemplo anterior el planteamiento de la pregunta puede ser, ¿Se vende el inmueble por más o menos del precio solicitado? 2.3.2. Aprendizaje sin supervisión. Este tipo de aprendizaje permite abordar problemas con poca o ninguna idea sobre cómo deberían definirse los resultados, se puede derivar una estructura de los datos de entrada donde no necesariamente se conoce el efecto de las variables, Se puede derivar esta estructura al agrupar los datos en función de las relaciones entre las variables, este modelo de aprendizaje se basa en un concepto de la neurociencia denominado Efecto cóctel, que consiste en la capacidad del cerebro de enfocar la atención auditiva en un estímulo particular mientras filtra otros estímulos(auditivos). Este algoritmo de cóctel permite encontrar la estructura en un entorno caótico, es decir poder identificar los atributos individualmente y un conjunto de variables. 2.3.3. Función de costo. El proceso de entrenamiento de una red neural es el siguiente. Se tiene un conjunto de datos que corresponde a las variables de entrada y los resultados deseados en un conjunto . Para dejarlo de una forma más clara, la red neuronal recibe para los datos de entrenamiento se usa una matriz m=(. para predecir. , de tal manera que. ), una porción de estos datos se. usará para el entrenamiento y la restante para evaluar la eficiencia de la red neuronal, en un porcentaje recomendado de 90, 10..
(27) 18 Cuando se cargan los datos de entrenamiento a la red neuronal, el objetivo de la misma es identificar y generar una función que dado X sea un buen predictor de Y. Expresado matemáticamente, es de la siguiente manera h( ). . Donde h es la hipótesis.. Se puede medir la precisión de la función de hipótesis utilizando una función de costo. Consiste en hacer un promedio (algo más sofisticado) de todos los resultados de la hipótesis con entradas X y salidas reales de Y, es decir la porción de 10% que se dejó del conjunto de entrenamiento, que es ahora el conjunto de validación. Suponiendo que se tiene un conjunto de datos de entrenamiento m, tal como se muestra en la Imagen 4, el objetivo es minimizar el error cuadrático de cada uno de los puntos (datos de entrenamiento).. Imagen 4. Ejemplo de grafico de datos. Autores. La línea que se muestra en el gráfico de la Imagen 4 no necesariamente es la más optima, y corresponde a la ecuación y = mx + b, en este caso m corresponde a la pendiente y b al punto de origen. El error cuadrático es la distancia entre un punto y línea que se trazó, en este caso esta línea se define como. . Cada uno de los puntos que se muestran en el plano cartesiano. se expresan de la siguiente manera. . Por lo que para calcular el error cuadrático de cada.
(28) 19 uno de los puntos se emplea la ecuación. . Por lo tanto, para hallar el error. cuadrático total se utiliza la sumatoria de los errores al cuadrado.. Con esto se obtiene el error cuadrático con respecto a la línea, y una vez concluido este proceso se puede optimizar m y b para hallar los valores que disminuya el error cuadrático.. En la anterior ecuación se tiene en la primera parte de la igualdad la función de error cuadrático medio y en la segunda parte la media de la hipótesis. Esta es la función de costo, la cual valida si la línea descrita es la mejor opción para un conjunto de datos, esto con el gran objetivo de conseguir la mejor línea posible, tal que las distancias verticales promedio cuadradas de los puntos dispersos desde la línea sean mínimos. Así se garantiza que las predicciones que se realizará en base a la función hipótesis sean lo más acertadas posible. Para dejarlo más claro se hará un ejemplo con datos para poder visualizar cómo se hace el ajuste de con la función de costo. Suponiendo que se tiene un conjunto de datos de entrenamiento donde m=[(1,1), (2,2), (3,3)].
(29) 20. Imagen 5. Regresión lineal simple. Autores. plot([1,2,3],[1,2,3], '-o') En este momento, como se muestra en la Imagen 5, se tiene una línea en donde la pendiente es igual a 1 y la función de error cuadrático es igual a 0, ya que todos los puntos son atravesados por la línea, ahora se ingresan nuevos datos [(1,0.5), (2,1), (3,1.5)], ver Imagen 6.. Imagen 6. Desviación de regresión lineal. Autores. Plot ([3,2,1,0,1,2,3],[3,2,1,0,0.5,1,1.5], '-o').
(30) 21 Se calculará el valor de error cuadrático para los nuevos valores con respeto a la primera línea. Veamos cómo despejar el primer punto.. Si se continúa despejando más puntos, se obtiene una gráfica paraboloide 3D ya que hay que notar que la función. se construye a partir de los N datos que se tienen como variables A y. B. Aunque para poder observar mejor el punto de mínima desviación se visualiza en 2D, vea la Imagen 7.. Imagen 7. Desviación mínima. Autores. x=-2:0.1:4;Y=(x.^2)-2*x+1;plot(x,Y) Se debe tratar de minimizar la función de costo en este caso,. es el mínimo global. Con. esto logramos identificar cual es el mejor camino que debe seguir la línea, ya sea para un sistema de regresión lineal, como para un clasificador..
(31) 22. 2.3.4. Sobreajuste. El sobre ajuste es un problema que aparece cuando se intenta reducir el error cuadrático a 0, ya se obliga a la función a crear una línea que cruce por cada uno de los puntos, vea las gráficas en la Imagen 8 donde se ejemplifica esto.. Imagen 8. Comparación de sobreajuste. Autores. Se introduce una matriz de entrenamiento con 5 datos, con un sobre ajuste como se muestra en el gráfico de la izquierda., Al ingresar dos nuevos datos, representados en color verde se puede comparar con el gráfico de la derecha como el sobreajuste afecta el resultado. Por ende, el sobreajuste en un principio podría parecer el objetivo deseado, pero representa un gran peligro para la predicción de datos. 2.3.5. Tipos de redes neuronales. Las redes neuronales artificiales están basadas en el concepto de las redes neuronales biológicas, y como estas, se crean a partir de diferentes conexiones entre las neuronas que la componen. Las redes neuronales biológicas establecen sus conexiones por medio del aprendizaje y la repetición y se comunican entre sí por medio del proceso de sinapsis. En el.
(32) 23 caso de las redes neuronales artificiales, las neuronas están basadas en un concepto anterior, los árboles de decisiones, que se usan ampliamente en los sistemas expertos. Consiste en un algoritmo que toma decisiones en forma de cascada, pasando por diferentes condiciones y evaluaciones para deducir un resultado. Estos árboles se hacen en base a unas condiciones preestablecidas. En el caso del aprendizaje automático estas condiciones no son preestablecidas, y se generan a partir de funciones matemáticas, por lo que en una capa alta de abstracción no se puede saber qué hace cada neurona, para conocerlo se debe resolver cada una de las ecuaciones que genera ese árbol de decisiones, por este motivo se dice que cada uno de estos nodos(neuronas) está en una capa oculta, Se puede definir un mínimo y máximo de estos nodos y controlar su dirección de traspaso de información, en algo equivalente a una sinapsis artificial. En algunas aplicaciones se pueden hacer nodos de los cuales se conoce su funcionamiento para tareas específicas. El modelo matemático más simple de un nodo se denomina perceptrón. El perceptrón tiene varias unidades de análisis y a cada una se le asigna un peso sináptico, los datos entran y se procesan en estas unidades que luego generan una función común que genera el resultado, ver Imagen 9.. Imagen 9. Perceptrón. Tomado de: https://es.wikipedia.org/wiki/Perceptr%C3%B3n#/media/File:Perceptr%C3%B3n_5_unidades.svg.
(33) 24 Como se mencionó el perceptrón es la neurona artificial más básica, pero independiente de la complejidad todas las neuronas artificiales están compuestas por variables de entrada (estímulos), una o varias funciones matemáticas y una salida. Lo que cambia he identifica cada neurona son los pesos sinápticos y la función que realizan, es decir el peso sináptico es el ajuste que se hace para acercarse a la respuesta deseada y la función es la encargada de procesar los valores sinápticos para generar un resultado, hacer la regresión lineal. Como es lógico deducir, una simple neurona solo es capaz de trabajar con una recta, lo que traducido a programación es una compuerta lógica and u or, en el caso de una compuerta lógica xor o expresiones más complejas se requiere el trabajo de múltiples neuronas, así se pueden trazar múltiples líneas para clasificar los datos, vea las Imágenes 10, 11, y 12.. Imagen 10. Condición lógica AND. Tomado de: https://commons.wikimedia.org/wiki/File:Computer.Science.AI.Neuron.AND.svg.
(34) 25. Imagen 11. Condición lógica OR. Tomado de: https://commons.wikimedia.org/wiki/File:Computer.Science.AI.Neuron.OR.svg. Imagen 12. Condición lógica XOR. Tomado de: https://commons.wikimedia.org/wiki/File:Computer.Science.AI.Neuron.XOR.svg.
(35) 26 Las neuronas se organizan en la misma capa, es decir en un mismo vector que recibe los datos de entrada ya sea de la capa de entrada o de una capa oculta para así llegar a la capa de salida con el resultado deseado. Las neuronas artificiales se especializan en el manejo de datos específicos, es decir al entrenar una red neuronal, lo que se hace es especializar cada una de sus neuronas en el tratamiento de ciertos datos, lo que se mide en este entrenamiento es la correlación de las variables de entrada para así identificar los pesos sinápticos y generar la función de cálculo que dé como resultado los datos esperados. Entonces, entre más complejo sea el problema a solucionar, más capas ocultas se deben crear, esto introduce al concepto de aprendizaje profundo o deep learning, que se estudiará más adelante. En este punto se puede imaginar un problema real que surge en el entrenamiento de redes neuronales y es la relevancia de las variables de entrada. Es decir, la cantidad de información no determina la calidad de la misma. Por lo tanto, es obligación de quien entrena la red asegurar la relevancia de cada una de las variables de entrada. Retomando la idea de la capa oculta, se puede decir que la capa de salida es la sumatoria de cada una de las líneas que trazan las funciones que están en cada neurona de la capa oculta. Lo que da como resultado otra línea. Esto destruiría totalmente la red neuronal, ya que matemáticamente la sumatoria de varias líneas es otra línea. Por este motivo en las neuronas se incluye una función de activación. El objetivo de esta es distorsionar el valor de salida añadiendo deformaciones no lineales para así poder computar el resultado de varias neuronas encadenadas. Entre estas funciones se tiene la función escalonada (ver Imagen 13), sigmoidal (ver Imagen 14), tangente hiperbólica (ver Imagen 15), la unidad rectificada lineal (ver Imagen 16) y algunas estructuras alternativas que se conocen como funciones de base radial entre las que se encuentran las estructuras Gausiana, Multicuadraticas y Multicuadraticas inversas o las máquinas de soporte vectorial..
(36) 27. Imagen 13. Función de paso. Tomado de: https://en.wikipedia.org/wiki/Step_function#/media/File:Dirac_distribution_CDF.svg. Imagen 14. Función sigmoide. Tomado de: https://es.wikipedia.org/wiki/Funci%C3%B3n_sigmoide#/media/File:Funci%C3%B3n_sigmoide_01.svg. Imagen 15. Función tangencial. Tomado de: https://es.wikipedia.org/wiki/Tangente_hiperb%C3%B3lica#/media/File:Hyperbolic_Tangent.svg.
(37) 28. Imagen 16. Función rectificadora. Tomado de: https://es.wikipedia.org/wiki/Rectificador_(redes_neuronales)#/media/File:Rectifier_and_softplus_functions.svg. Las redes de retroalimentación son una evolución del perceptrón, añade una capa oculta, y cada una de las entradas se comunica con la capa oculta, siempre hacia adelante, es decir que no tiene bucles de retorno. Utiliza un sistema de entrenamiento llamado retropropagación, en inglés backpropagation. Este método consiste en el cálculo del gradiente del algoritmo(función) usado para hacer la predicción. En palabras más sencillas, los datos pasan mínimo dos veces por la red para calcular el error respecto a la salida. Una red neural de retroalimentación también puede usar funciones de base radial como función de activación, con el fin de dar valores más certeros en aproximaciones de funciones. Esta red de base radial se ajusta perfecto a sistemas que usan valores continuos. Las redes de retroalimentación pueden seguir creciendo también en capas ocultas, esto con el objetivo de minimizar los errores que se pasan de una capa a otra. Estas redes de retroalimentación con más de una capa se llaman redes de alimentación profunda. Con el uso de las redes de alimentación profunda (ver Imagen 17) y su evolución surge un nuevo concepto, las células recurrentes, su trabajo consiste en generar una salida y volver a procesarla. Lo que logra este reproceso es tener en cuenta un contexto. Por ejemplo, para el.
(38) 29 procesamiento de palabras que requiere de un contexto para comprender su significado y valor.. Imagen 17. Redes recurrentes. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/. Estas células recurrentes no pueden almacenar mucho del contexto. Por lo que para solventar esto se crean las células de memoria. Estas células de memoria pueden almacenar los últimos datos procesados, hasta datos con intervalos de tiempo, resultando en la creación de una nueva red. La red de memoria de corto y largo plazo, que tiene la capacidad de procesar fotogramas de video, voz y escritura. Las células de memoria de esta red tienen unos elementos denominados puertas recurrentes y son los encargados de controlar como se recuerda y olvida la información. Sin estas puertas se logra que sea más fácil repetir la misma salida para una entrada concreta varias veces, esto se hace en las redes de unidad de cerrado recurrente que consumen menos recursos y se utilizan ampliamente en síntesis de sonido.. Imagen 18. Autocodificadores. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/. Las redes que se comentaron anteriormente son para problemas de aprendizaje supervisado. Modificando la estructura para que el número de nodos de entrada sea mayor al número de nodos ocultos y el número de salidas es igual al número de nodos de entrada, se obliga a la red.
(39) 30 neuronal a generalizar los datos y buscar patrones comunes. A este tipo de redes se le conoce como autocodificadores (ver Imagen 18), y son usados en aprendizaje no supervisado. Esto se logra gracias a que se comprimen las características, pero otra manera de hacerlo es comprimiendo las probabilidades. En ese caso se conoce como un autocodificador variacional. Los autocodificadores presentan un problema, y es que al reducir los nodos ocultos se puede presentar un sobreajuste. Para solucionar esto se agrega un poco de ruido a las entradas, es decir se añaden unos bits aleatorios a cada entrada, para así obligar a construir una salida con ruido para así hacerla un poco más general y forzar a elegir características más comunes. A esta red se le conoce como un autocodificador de eliminación de ruido. Otra manera de construir un autocodificador es haciendo que la capa oculta tenga más nodos que la capa de entrada y salida. A esta configuración se le llama autocodificador de dispersión.. Imagen 19. Redes con aleatoriedad. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/. En la teoría de probabilidad existe el concepto de cadenas de Markov (ver Imagen 19), que indica la probabilidad de que ocurra un evento dependiendo de un evento inmediatamente anterior. Este concepto se puede aplicar a las redes neuronales de manera clásica, por ejemplo, para predecir la probabilidad de una palabra que viene a continuación de otra. El ejemplo más común sería el autocompletar de un teclado para dispositivos móviles, pero también pueden ser usados como filtros bayesianos y para clustering, como una máquina de estado finito. Una red Hopfield en su estructura es una red de Markov, pero están capacitadas con un conjunto limitado de muestras para que respondan a una muestra conocida con la misma muestra, por lo tanto, también se pueden usar para reconstruir y destruir las entradas, dado.
(40) 31 que al responder con la parte restante devolverá la muestra completa. Las máquinas de Boltzmann se distinguen de la red Hopfield porque en esta se definen unas entradas claras y los nodos ocultos pasan a ser salidas una vez termina de procesarse los datos.. Imagen 20. Red profunda. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/. Las redes de aprendizaje profundo (ver Imagen 20) son en realidad una pila de máquinas de Boltzmann (rodeadas de VAE). Básicamente una red entrena a la otra en secuencia, y se usan para generar datos por un patrón aprendido.. Imagen 21. Redes profundas compuestas. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/. La Red convolucional profunda (ver Imagen 21) en este momento representa uno de los grandes avances del machine learning con redes neuronales. Usa nodos de convolución, es decir que agrupa funciones y genera una única función por neurona cada una con un propósito diferente. Este tipo de redes se utiliza en el reconocimiento de imágenes, donde la red se entrena con un conjunto de imágenes con un proceso de comprensión de características al pasar por estas capas de convolución. A partir de los reconocimientos de imágenes, la primera.
(41) 32 capa detecta gradientes, la segunda líneas, la tercera formas y así sucesivamente hasta tener la escala de un objeto en particular, ver Imagen 22.. Imagen 22. Funcionamiento de red convolucional. Tomado de: https://stats.stackexchange.com/questions/146413/why-convolutionalneural-networks-belong-to-deep-learning. Se puede invertir una red convolucional para a partir de una imagen construida obtener sus características. Podemos unificar una red convolucional con una invertida para crear imágenes con las cuales nunca ha sido entrenada. Y para presentarlo más correctamente al unificarlas dejan de ser dos redes y se convierten en una red de tipo autocodificador.. Imagen 23. Redes especializadas. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/.
(42) 33 Por el contrario, como se puede ver en la Imagen 23 una red generativa adversaria, si está compuesta por dos redes neuronales, una es un generador y la otra es un discriminador o evaluador. Su trabajo consiste, uno por su parte generar datos y el otro al recibir los datos de muestra intenta evaluar los resultados generados contra las muestras, por lo que este tipo de redes puede estar en constante evolución, aunque deben estar en un equilibrio las dos redes. Una máquina de estado líquido es una red que no está totalmente conectada, y las funciones de activación se reemplazan por niveles de umbral. Donde los nodos acumulan valores de muestras secuenciales y emite la salida solo cuando se alcanza el umbral, y reinicia su contador interno a cero. Las máquinas de aprendizaje extremo intentan reducir la complejidad de las redes neurales, mediante la creación de capas ocultas dispersas con conexiones aleatorias, requieren menos potencia computacional, pero su eficiencia depende de la tarea que vaya a realizar y de los datos suministrados. Las máquinas de estado de repetición son redes recurrentes con otro enfoque. ya que se pueden activar nodos con características que son recurrentes. Por último, tenemos la máquina neural de Turing (ver Imagen 24), esta red intenta solucionar la visibilidad de las capas ocultas, ya que en las redes neuronales son como una caja negra, podemos entrenarlas, mejorarlas y obtener resultados, pero la ruta de decisión está mayormente oculto. Por este motivo esta red es de retroalimentación, pero con unos nodos de memoria extraídos que permite leer y escribir dependiendo del estado actual de la mismo..
(43) 34. Imagen 24. Red de turing. Tomado de: https://www.asimovinstitute.org/author/fjodorvanveen/. 2.4. Tipos de datos. Esta es una de las partes más importantes en la creación de redes neuronales, ya que la eficiencia de la red depende directamente de la calidad y forma en que se le administren los datos. Se deben tener en cuenta los siguientes objetivos: •. Entender el contenido y las relaciones entre los datos.. •. Hacer el mejor uso de la información.. •. Los datos se ajustan al modelo de Machine Learning.. El aprendizaje de máquina es un trabajo sin sentido si no se conoce y no se entienden los datos. Para poder hacer esta labor se debe identificar: •. Características de los datos (Tamaño, tipos de datos, etc).. •. Resumen estadístico del conjunto de datos (Escala y rango de las variables).. •. Errores y valores que no son típicos.. •. Distribución de los atributos y tags de identificación de los mismos.. •. Frecuencia de rasgos categóricos.. Poder identificar todos estos aspectos de los datos se logra gracias a un proceso iterativo de procesamiento de los datos, en donde se debe identificar los tipos de datos y al propósito y tipo de predicciones que se pueden trabajar con ellos. Se pueden identificar cuatro grandes grupos de tipos de datos..
(44) 35. 2.4.1. Datos nominales. Este tipo de datos no requiere de una organización previa, ya que todas las agrupaciones son excluyentes, ver Imagen 25.. Imagen 25. Ejemplo de datos nominales. Tomado de: https://medium.com/ai3-theory-practice-business/the-engineers-guide-tomachine-learning-data-processing-data-types-ba40e6bf8765. 2.4.2. Datos ordinales. Este tipo de datos requiere de un orden para poderse procesar, aunque no se conozca las diferencias entre estas. Por ejemplo, en la figura que se presenta a continuación podemos ver como se clasifica un grupo de datos, agrupándolo en perfiles comunes, en donde el orden es totalmente importante para comprender el significado total de los datos, ver Imagen 26..
(45) 36. Imagen 26. Ejemplo de datos ordinales. Tomado de: https://medium.com/ai3-theory-practice-business/the-engineers-guide-tomachine-learning-data-processing-data-types-ba40e6bf8765. 2.4.3. Datos de intervalo. En este tipo de datos se requiere ordenar y reconocer las diferencias exactas entre los datos, ver Imagen 27. Este tipo de datos se presta fácilmente para su uso en la estadística, con su procesamiento con herramientas como moda, media, mediana, desviación estándar entre otros. Al crear escalas(intervalos) podemos generar diversas caracterizaciones y designar valores para cada elemento..
(46) 37. Imagen 27. Ejemplo de datos de intervalo. Tomado de: https://medium.com/ai3-theory-practice-business/the-engineers-guide-tomachine-learning-data-processing-data-types-ba40e6bf8765. 2.4.4. Datos de relación. Estos datos nos proporcionan en general la mayor cantidad de información posible y exacta de los mismos (orden, valor, medición y atributos). Ya que podemos relacionar e identificar los datos se pueden generar tanto medidas cualitativas como cuantitativas, y todo tipo de operaciones matemáticas y estadísticas, ver Imagen 28..
(47) 38. Imagen 28. Ejemplo de datos de relación. Tomado de: https://medium.com/ai3-theory-practice-business/the-engineers-guide-tomachine-learning-data-processing-data-types-ba40e6bf8765. Ya se adquirieron los conceptos y de destacaron los aspectos más importantes relacionados con los tipos de datos, ahora se procede a realizar la tabulación de estos, para el posterior diseño de la red neuronal..
(48) 39 3. Capítulo III Desarrollo de la investigación 3.1. Análisis. Con ayuda del estándar de modelador de arquitectura empresarial archimate (The Open Group, 2016) se utilizarán algunos puntos de vista que permitirán comprender acerca de la organización sus procesos, la aplicación en infraestructura de estos. 3.1.1. Organización. Para entender un poco cómo funcionan las interacciones entre los actores involucrados en la aplicación, se mostrará el punto de vista de función del negocio:. Imagen 29. Punto de vista de negocio. Autores. Con la imagen 29 podemos inferir que el proceso inicia cuando un socio encuentra una oportunidad de negocio y realiza una estimación sobre el mismo, cuando se da inicio al proyecto legal diferentes abogados y asistentes empiezan a registrar información de sus tiempos, gastos etc... en el ERP de la compañía a su vez con esta información los facturadores.
(49) 40 se encargan de emitir facturas a los clientes. Con esta información ya centralizada en un ERP se logra determinar más fácilmente los requisitos de datos que alimentaran la red neural. 3.1.2. Proceso. El proceso como tal de due diligence inicia con el levantamiento de la información necesaria, la realización de un análisis con esta información y la entrega de un informe final. La Imagen 30 representa el proceso de due diligence:. Imagen 30. Punto de vista de proceso. Autores. 3.1.3 3.1.3.1. Aplicación Microservicios. Este estilo de arquitectura está enfocada a proveer una colección de pequeños servicios autónomos, algunas de sus características son: •. Unidades pequeñas de despliegue. •. Reducción en tiempo de desarrollo. •. Los servicios pueden tener arquitecturas diferente y se acoplan independiente de esto. •. Fácil escalado horizontal. Los microservicios son una evolución de la arquitectura enfocada a servicios,.
(50) 41 pero integra nuevos conceptos enfocados a la gestión, orquestamiento y mantenimiento de todos los servicios que componen la solución, ver Imagen 31.. Imagen 31. Microservicios. Tomado de: https://docs.microsoft.com/es-es/azure/architecture/guide/architecturestyles/images/microservices-logical.svg. 3.1.3.2. ¿Por qué esta arquitectura?. Puede parecer que se está siendo muy ambicioso, y poco impráctico, ya que este tipo de arquitectura requiere de un gran mantenimiento y gestión. Pero también no podemos olvidar los beneficios. Principalmente se opta por esta arquitectura por su escalabilidad, ya que permite ir actualizando la solución a medida que se necesite.. Permitiendo la integración y. mejoramiento de servicios. El prototipo se limita a generar un único microservicio, que corresponde al proceso de Due Diligencie, que se revisó en capítulos anteriores. Recibiendo un vector con datos del proyecto que se desea analizar y generando como salida otro vector con los resultados(predicción), ver la Imagen 32.. Imagen 32. Diseño básico de microservicio. Autores.
(51) 42 Aunque este tipo de arquitectura no se limita solo a crear un contenedor de microservicios, tiene en cuenta aspectos como la seguridad y gestión de los microservicios por lo tanto para tener una visión general del diseño y de las herramientas a usar, vea la Imagen 33 y la imagen 34.. Imagen 33. Diseño general de arquitectura de microservicios. Tomado de: https://docs.microsoft.com/eses/azure/architecture/guide/architecture-styles/images/microservices-acs.png. Imagen 34. Diseño y herramientas del prototipo. Autores.
Figure

Documento similar
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
En estos últimos años, he tenido el privilegio, durante varias prolongadas visitas al extranjero, de hacer investigaciones sobre el teatro, y muchas veces he tenido la ocasión
que hasta que llegue el tiempo en que su regia planta ; | pise el hispano suelo... que hasta que el
Sanz (Universidad Carlos III-IUNE): "El papel de las fuentes de datos en los ranking nacionales de universidades".. Reuniones científicas 75 Los días 12 y 13 de noviembre
(Banco de España) Mancebo, Pascual (U. de Alicante) Marco, Mariluz (U. de València) Marhuenda, Francisco (U. de Alicante) Marhuenda, Joaquín (U. de Alicante) Marquerie,
d) que haya «identidad de órgano» (con identidad de Sala y Sección); e) que haya alteridad, es decir, que las sentencias aportadas sean de persona distinta a la recurrente, e) que
La siguiente y última ampliación en la Sala de Millones fue a finales de los años sesenta cuando Carlos III habilitó la sexta plaza para las ciudades con voto en Cortes de
En la parte central de la línea, entre los planes de gobierno o dirección política, en el extremo izquierdo, y los planes reguladores del uso del suelo (urbanísticos y
