, México a
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY
PRESENTE.-Por medio de la presente hago constar que soy autor y titular de la obra denominada"
, en los sucesivo LA OBRA, en virtud de lo cual autorizo a el Instituto Tecnológico y de Estudios Superiores de Monterrey (EL INSTITUTO) para que efectúe la divulgación, publicación, comunicación pública, distribución, distribución pública y reproducción, así como la digitalización de la misma, con fines académicos o propios al objeto de EL INSTITUTO, dentro del círculo de la comunidad del Tecnológico de Monterrey.
El Instituto se compromete a respetar en todo momento mi autoría y a otorgarme el crédito correspondiente en todas las actividades mencionadas anteriormente de la obra.
De la misma manera, manifiesto que el contenido académico, literario, la edición y en general cualquier parte de LA OBRA son de mi entera responsabilidad, por lo que deslindo a EL INSTITUTO por cualquier violación a los derechos de autor y/o propiedad intelectual y/o cualquier responsabilidad relacionada con la OBRA que cometa el suscrito frente a terceros.
Nombre y Firma AUTOR (A)
PGI-13.5-F-3 Formato Información y Carta Permiso. Tesis, Tesinas, Disertaciones Doctorales. Versión 5
Tendencias Tecnológicas en Compresión de Video-Edición
Única
Title Tendencias Tecnológicas en Compresión de Video-Edición Única
Authors Mauricio Javier Varguez Ramírez
Affiliation Tecnológico de Monterrey, Campus Monterrey Issue Date 2009-11-01
Item type Tesis
Rights Open Access
Downloaded 18-Jan-2017 23:46:50
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
CAMPUS MONTERREY
PROGRAMA DE GRADUADOS DE MECATRÓNICA Y
TECNOLOGÍAS DE LA INFORMACIÓN
TENDENCIAS TECNOLÓGICAS EN
COMPRESIÓN DE VIDEO
Por:
Mauricio Javier Varguez Ramírez
Tesis
Presentada como requisito parcial para obtener el grado académico de:
Maestro en Administración de las Telecomunicaciones
ii
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE MONTERREY
CAMPUS MONTERREY
DIVISIÓN DE MECATRÓNICA Y TECNOLOGÍAS DE INFORMACIÓN
PROGRAMA DE GRADUADOS EN
MECATRÓNICA Y TECNOLOGÍAS DE INFORMACIÓN
Los miembros del comité de tesis recomendamos que la presente tesis del Ing. Mauricio Javier Varguez Ramírez sea aceptada como requisito parcial para obtener el grado académico de Maestro en Administración de las Telecomunicaciones.
Comité de tesis:
Dr. Ramón Martín Rodríguez Dagnino Asesor
Dr. Gabriel Campuzano Treviño Sinodal
Mtro. Fernando Rodríguez Meza Sinodal
Dr. Ramón Felipe Brena Pinero
Director de Maestrías en Computación de la División de Mecatrónica y Tecnologías de Información
iii
TENDENCIAS TECNOLÓGICAS EN
COMPRESIÓN DE VIDEO
Por:
Mauricio Javier Varguez Ramírez
Tesis
Presentado por el Programa de Graduados de Mecatrónica y Tecnología de la Información
Este trabajo es requisito parcial para obtener el grado de Maestro en Administración de las Telecomunicaciones
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS SUPERIORES DE
MONTERREY
iv
v
Agradecimientos
A mis padres, Silvia y Manuel, gracias, por todo el apoyo sentimental, moral, psicológico y económico que me han dado, ya que gracias a ellos tengo los recursos suficientes para salir adelante y poder completar esta etapa académica.
A mi hermana Milagros y mi hermano Luis, gracias por todo su apoyo, comprensión, comentarios y esfuerzo, fueron un factor muy importante en la realización de mi tesis.
A mi asesor el Dr. Ramón Martín Rodríguez Dagnino, por la guía y conocimiento que me impartió durante la realización de mi tesis.
A mis Sinodales, el Dr. Gabriel Campuzano Treviño y al Mtro. Fernando Rodríguez Meza, por haber participado tan amablemente en la revisión de mi tesis enriqueciéndola con sus valiosos comentarios y aportaciones.
A mis amigos que nunca dejaron de creer en mí y que siempre me apoyaron y ayudaron para que pudiese seguir adelante.
Al Instituto Tecnológico y de Estudios Superiores de Monterrey (ITESM), por el apoyo por medio de la beca de excelencia, la cual fue un gran incentivo para realizar mi estudio de postgrado.
vi
TENDENCIAS TECNOLÓGICAS EN
COMPRESIÓN DE VIDEO
MTL Mauricio Javier Varguez Ramírez
INSTITUTO TECNOLÓGICO Y DE ESTUDIOS
SUPERIORES DE MONTERREY
2009
Asesor de Tesis: Ramón Martín Rodríguez Dagnino
Esta investigación define el por qué es importante realizar un estudio del estado del arte sobre la utilización de los codificadores y decodificadores de video en comunicación inalámbrica, qué impacto tienen en nuestras vidas diaria y cuáles son las áreas de oportunidad que éstos ofrecen para el desarrollo de la tecnología y procesos de video, teniendo como objetivo la identificación del estado del arte de los compresores de video para así poder distinguir el futuro tecnológico de éstos.
vii Contenido
Lista de Figuras ... ix
Capítulo 1 PLANTEAMIENTO DEL PROBLEMA ... 1
1.1 Problemática ... 1
1.2 Definición del Problema ... 3
1.3 Objetivo de Investigación ... 5
1.4 Limitación del proyecto de Investigación ... 6
1.5 Estructura de Tesis ... 6
1.6 Producto Final y Contribución Esperada ... 7
Capítulo 2 CODIFICADOR / DECODIFICADOR ... 9
2.1 Características y Limitación de la Comunicación Inalámbrica ... 9
2.2 ¿Qué es un CODEC? ... 10
2.3 Atributos del CODEC ... 11
2.3.1 Método Lossless ... 12
2.3.2 Método Lossy ... 15
2.4 Calidad de la Imagen ... 23
Capítulo 3HISTORIA DE ESTÁNDARES DE VIDEO ... 25
3.1 Administradores de los Estándares ... 25
3.2 Estándares ... 26
3.2.1 H.261 ... 26
3.2.2 MPEG-1 ... 26
3.2.3 MPEG-2/H.262 ... 27
3.2.4 H.263 ... 27
3.2.5 H.264/MPEG-4 AVC ... 27
Capítulo 4 ESTRUCTURA DEL CODEC ... 30
4.1 MPEG 1 ... 30
4.1.1 Fotogramas ... 30
4.1.2 Estructura de Secuencia de bits ... 33
4.2 MPEG 2 ... 39
4.2.1 Rebanadas ... 39
viii
4.2.3 Codificación Escalable ... 40
4.2.4 Capa de Sistemas ... 41
4.3 MPEG-4 ... 42
4.3.1 MPEG-4 Parte 2 ... 43
4.3.2 MPEG-4 parte 10 o H.264 ... 44
Capítulo 5 DVC ... 46
5.1 PRISM ... 48
5.1.1 Codificación ... 52
5.1.2 Decodificación... 56
5.1.3 Desventajas del PRISM ... 58
Capítulo 6 ACTUALIZACIONES AL PRISM ... 59
Capítulo 7 ACTUALIZACIONES DEL H.264 ... 61
CONCLUSIONES ... 62
Apéndice A ... 65
BIBLIOGRAFÍA ... 66
ix
Lista de Figuras
Figura 1. CODEC………...11
Figura 2. Ejemplo del RLE.……….13
Figura 3. Ejemplo de la coincidencia de patrones en Texto.………..14
Figura 4. Ejemplo de código Huffman de valor 3-bits..………...15
Figura 5. Reproducción de imagen para crear una escala de grises de dos colores.………17
Figura 6. Código Predictivo.……….19
Figura 7. DCT.………...21
Figura 8. Compensación por Movimiento...23
Figura 9. Progresión cronológica de los estándares ITU y MPEG.………...26
Figura 10. Fotogramas Clave.……….31
Figura 11. Fotograma de diferencias.……….31
Figura 12. Fotogramas Bidireccionales de Diferencias.………..33
Figura 13. Película dividida en secuencias………...34
Figura 14. Estructura de grupos de imágenes dentro de una secuencia.…………34
Figura 15. Una secuencia de grupo de imágenes cerrada.………35
Figura 16. Una secuencia de grupo de imágenes abierta………..…35
Imagen 17. Un grupo de imágenes sencillo.……….36
Figura 18. Secuencia de Transmisión de un grupo de imágenes.………36
Figura 19. Macrobloques.……….37
Figura 20. Macrobloque y rebanadas……….38
Figura 22. Conversión DCT.………39
Figura 22. Comparación de la distribución de rebanadas en 1 y MPEG-2.………..40
Figura 23. Secuencias anidadas.………...42
Figura 24. Arquitectura básica del CODEC DISCOVER.………47
Figura 25. Arquitectura del código de video Wyner Ziv de Stanford……….48
Figura 26. Implementación de información lateral………50
Figura 27. Diagrama a bloques del codificador PRISM.……….52
x
1
Capítulo 1
PLANTEAMIENTO DEL PROBLEMA
En esta investigación se definirá el por qué es importante realizar un estudio del estado del arte sobre la utilización de los codificadores y decodificadores de video, qué impacto tienen en nuestras vidas diaria y cuáles son las áreas de oportunidad que éstos ofrecen para el desarrollo de la tecnología y procesos de video. Lo anterior es a través de una demarcación del objetivo de la investigación, limitaciones del estudio, así como la contribución esperada por los hallazgos realizados por el presente estudio exploratorio, sobre la compresión del video actual que se encuentra en constante evolución y representa una ventana de oportunidad para las nuevas tecnologías de almacenamiento y transmisión.
1.1 Problemática
En años recientes el incremento en la demanda de productos de video digital a nivel mundial ha ido en aumento exponencial. Algunos ejemplos de aplicaciones populares son la comunicación por video, seguridad, vigilancia, automatización industrial y con una gran importancia: el entretenimiento, el cual incluye el formato DVD, televisión satelital, videojuegos y grabadora de video personal. La compresión de video es esencial para la realización de estos nuevos productos de video (Golston, 2006), ya que a partir de ello podemos obtener una optimización en el almacenamiento y la transmisión, así como el desarrollo de los lectores de dichos formatos de compresión.
2 o Periodismo móvil: Las operaciones de obtención de noticias solían requerir
de un grupo de individuos que trabajaban de manera móvil y en el sitio de los hechos noticiosos, con un equipo pesado y costoso. A medida que ha progresado la tecnología, las cámaras de video profesional se han hecho más pequeñas, livianas y fáciles de utilizar. En la actualidad es muy probable que la cámara la lleve el propio periodista y se pueda preparar para que funcione de forma automática, prescindiendo del recurso humano del camarógrafo. Las noticias que se emiten en la actualidad tienen su origen en videófonos, minicámaras y teléfonos móviles habilitados para la captura de video. La calidad de estas cámaras mejora con rapidez, sin embargo para mantener un tamaño y peso cómodo para su transporte la capacidad de almacenamiento, en lo que a hardware se refiere, se ve afectada dando como resultado un espacio limitado. La compresión de video aumenta la capacidad y por lo tanto, el tiempo de grabación disponible al condensar los datos antes de que se lleve a cabo la grabación, con un impacto directo también en la transmisión de la información hacia las oficinas centrales del periódico. Esto beneficia dicha industria periodística tanto en tiempo como en el uso de los recursos.
o Videoconferencias: Las grandes empresas multinacionales han utilizado la
3
comunicación audiovisual han permitido que una videoconferencia pueda ser realizada desde la computadora personal o teléfono móvil. Esto sólo es posible porque la compresión de video reduce la transferencia de datos y la memoria requerida para su almacenamiento. Esta opción también tiene un alto potencial de ser utilizada en los sistemas de educación a distancia y videoconferencia empresarial en nuestro país.
o Seguridad y vigilancia: La sociedad moderna requiere que una gran parte
de nuestras actividades se realicen bajo el escrutinio de captación de movimientos, para así dar un sentido de seguridad a nuestro actuar. Una persona que viaja en coche desde su casa a la estación del ferrocarril y que después toma el tren para llegar a su oficina, puede ser capturado aproximadamente por unas 200 cámaras de vigilancia entre su casa y su oficina, por lo que se trata de una cantidad cuantiosa de información en video. En la actualidad, se introducen sistemas más recientes que usan compresión de video para preservar la calidad, incrementar las velocidades de fotogramas y automatizar el almacenamiento de video en repositorios centralizados. Mediante el uso de video digital, los sistemas de búsqueda y reconocimiento facial podrán estar conectados al repositorio.
1.2 Definición
del
Problema
4
importante. Para un teléfono celular que depende de una batería pequeña se vuelve más importante la eficiencia con que un chip usa la energía (Markoff, J. 2008), la funcionalidad del aparato y la resolución de necesidades de conexión e interconexión de los usuarios.
El control de potencia es un mecanismo que juega un papel importante en muchos sistemas de comunicaciones y en especial en los de comunicaciones móviles. El control de potencia tiene como objetivo principal trasmitir señales con la calidad adecuada para su correcta recepción con la menor interferencia posible causada por otras señales. Contando con un control de potencia adecuado se intenta reducir la utilización de potencia al realizar una transmisión que repercute directamente en el consumo de batería de las terminales móviles usadas. (Gamero, 2003)
Los algoritmos de compresión – descompresión (CODEC) hacen posible agrupar y transmitir video digital. Suelen haber muchos métodos prácticos de medición de la potencia consumida por el algoritmo, entre los que destacan el tiempo de ejecución y la cantidad de memoria. Para ambos hay que determinar el tamaño del algoritmo basándose en el número de datos N a procesar.
Conocer el tiempo de ejecución de un programa en función de N se puede hacer de diferentes formas, las más aplicables son ejecutándose el programa y midiendo el tiempo en que tarde en ejecutarse o bien, calculando sobre el código contando el número de instrucciones a ejecutar y multiplicándolo por el tiempo requerido para cada instrucción, el cual será proporcionado por el tiempo que tarde el dispositivo electrónico en ejecutar una instrucción. (Gamero, 2003)
5
usuario. Sin embargo, la ejecución de los CODECs en tiempo real sigue siendo un reto debido principalmente a la gran cantidad de energía que consumen los dispositivos de compresión. La obtención de la eficiencia óptima de compresión con potencia limitada de trabajo es una ciencia difícil. (Golston, 2006).
Tomar las funciones de un televisor portátil, un reproductor de DVD, un PDA, funciones de una computadora y un teléfono móvil e integrarlas en un solo dispositivo nos permite prácticamente tener un dispositivo multimedia portátil definitivo. Wootton (2005/2006) indica que el CODEC H.264 se ha diseñado para que resulte útil para los dispositivos móviles y la reproducción de video de consumo, por lo que se puede presentar un menor consumo de la energía y la optimización de los recursos.
Wootton (2005/2006) menciona que existen problemas con el formato de un dispositivo portátil. Para crear una experiencia que resulte cómoda, es posible que necesiten dispositivos más pesados de lo que debe ser un teléfono móvil. Los teclados aumentan el tamaño de estos dispositivos móviles por lo que su uso futuro puede predecirse. En la actualidad resulta bastante costoso proporcionar suficiente capacidad de almacenamiento sin recurrir a un disco duro incrustado. Esto tiende a reducir la vida de la batería, por lo que ahí que conviene estudiar las nuevas tecnologías de almacenamiento que se encuentran en desarrollo, para poder ofrecer un dispositivo integrado, con un tamaño adecuado a la funcionalidad requerida por el usuario, pero ante todo con una optimización de su energía y un compresor de video que permita obtener una imagen nítida y de bajo peso.
1.3 Objetivo de Investigación
6
Identificar el estado del arte de los compresores de video para así poder distinguir el futuro tecnológico de los mismos.
1.4 Limitación del proyecto de Investigación
De acuerdo con las investigaciones realizadas por Baptista (2003) y tomando en cuenta el objetivo de la presente investigación, este estudio es catalogado de tipo exploratorio, ya que éste se realiza normalmente cuando el tema o el objetivo a examinar ha sido poco estudiado o no ha sido analizado anteriormente. He aquí la relevancia e innovación del tema, siendo un referente a futuro de la información científica que se genere y compile. Este tipo de estudio nos llevará a familiarizarnos más con los puntos desconocidos en esta investigación.
Durante esta investigación surgieron varias limitantes para su realización como: la poca información disponible de manera pública y la falta de información actualizada sobre el tema de la investigación, debido a que hay una carencia de publicación de artículos al respecto en los círculos especializados del tema, en los que se muestren avances o mejoras significantes.
1.5 Estructura de Tesis
La presente tesis esta desarrollada en 8 capítulos. El Capítulo 1 define la importancia de la realización de un estudio exploratorio del tema así como la demarcación del objetivo, limitaciones y contribuciones del estudio.
7
En el capítulo 3 se esboza el contexto histórico de los codificadores y decodificadores de video, así como el objetivo principal de su creación. De igual forma, se presentan sus principales ventajas y desventajas en el estándar de video más usado recientemente.
En el capítulo 4 se describe desde el CODEC más básico MPEG-1 para así poder comprender con mayor facilidad el funcionamiento y estructura del H.264. Después de describir el MPEG-1, se explican las mejoras así como las diferencias realizadas al MPEG-2, MPEG-4 y por último al H.264.
En el capítulo 5 se explica el nuevo paradigma de la codificación de video, el DVC, explicando las ventajas que ofrece y la base de su constitución, para luego dar paso a la explicación de los 3 DVC más importantes entre los investigadores.
En los capítulos 6 y 7 se examinan las actualizaciones realizadas al PRISM y al H.264, respectivamente, donde se mencionan las modificaciones mas recientes y los resultados obtenidos por ellas, para luego dar paso a las Conclusiones, en la cual se resumen los hallazgos de la investigación y se da una opinión sobre el futuro de los compresores para la transmisión de video.
1.6 Contribución
En el presente escrito se contempla que emanen los beneficios de implementar los compresores de video actuales, así como las áreas de oportunidad a desarrollar para lograr un mejor desempeño en el consumo de potencia.
8
9
Capítulo 2
CODIFICADOR / DECODIFICADOR
En este capítulo se definirá lo que es un codificador y decodificador. Una vez definido esto, se mencionarán y describirán los dos tipos de compresión y su clasificación con el fin de entender mejor las características básicas del codificador y decodificador.
2.1 Características y Limitación de la Comunicación Inalámbrica
La comunicación inalámbrica es aquella que no utiliza medios físicos cableados para realizar una transmisión. Los dispositivos terminales de usuario son celulares, PDA, computadoras portátiles para así dar movilidad y comunicación entre personas sin necesidad de estar conectado a un cable todo el tiempo. Callicó (2004) menciona que las comunicaciones multimedia, a través de canales inalámbricos, poseen tres características principales:
o Muy bajo ancho de banda: Esta característica determina que, cuando se
están manejando grandes cantidades de información, es absolutamente necesario contar con algoritmos eficientes de compresión y descompresión de información en los extremos emisor y receptor respectivamente para de esta forma, hacer más eficiente la transmisión.
o Alta tasa de errores de bit: Este hecho hace que la información digital que
se manda a través de un canal inalámbrico desde el emisor hacia el receptor llegue con errores a este último.
o Naturaleza móvil de los dispositivos: Las terminales con los que se suele
10
su implementación final, así como un bajo consumo de potencia cuando se encuentren transmitiendo o recibiendo información.
Sin embargo, toda transmisión puede verse limitada por diferentes características y funciones tanto generales como particulares de los dispositivos y el medio de transmisión. Por ello, Ishwar (2006) indica que una red de banda ancha inalámbrica de vídeo es sometida a tres principales limitaciones generales:
o Limitada capacidad de procesamiento y diversas resoluciones de pantalla
debido en parte a los diseños de dispositivos de bajo costo y la limitada energía de la batería, lo cual provoca la búsqueda constante de los algoritmos de procesamiento de señales y compresión de alta eficiencia que puedan adaptarse a las diferentes capacidades de procesamiento de los dispositivos electrónicos donde se implementan los CODEC´s.
o Limitada potencia o energía, requiere una cuidadosa gestión
para maximizar la vida útil de la batería, la calidad de los datos adquiridos, y la exactitud de las decisiones. La gestión de energía eficiente requiere algoritmos de compresión que permitan maximizar la utilización de energía por bit comunicado y controlado por ciclos de latencia.
o La pérdida de información puede provocar la pérdida de comunicación
inalámbrica, además de la afectación en la calidad de la información recibida. Por ello, se requieren algoritmos fiables de codificación, comunicación y protocolos de redes robustos a errores.
2.2 ¿Qué es un CODEC?
11
el proceso donde se condensa una secuencia de video digital en un número de bits menor. (Richardson, 2003)
[image:23.612.105.533.300.362.2]La compresión requiere de un par de sistemas, un compresor (encoder) y un descompresor (decoder) (ver Figura 1). El encoder convierte el archivo fuente de información en una forma comprimida para transmitirla o almacenarla, y el decoder convierte la información comprimida en una representación de la información del video original. (Richardson, 2003). El encoder/decoder es generalmente conocido como CODEC, la cual tiene como objetivo principal usar la menor cantidad de bits posible manteniendo una calidad adecuada. (Richardson, 2003)
Figura 1. CODEC (Richardson, 2003)
2.3 Atributos
del
CODEC
La descripción detallada de la técnica específica de la compresión es conocida como algoritmo, el cual usualmente es descrito de forma matemática, aunque también puede ser descrita usando diagrama a bloques o gráficas. Toda técnica de compresión requiere de cierta cantidad de procesos para realizar la compresión de información y a su vez de otra cierta cantidad de procesos para realizar la descompresión. Estos procesos son significativos en términos de cantidad de
12
tiempo real, pero la descompresión es realizada en tiempo real en un sistema pequeño y de bajo costo. (Luther, 1997)
Los atributos son propiedades o características que identifican al CODEC como tal. En la compresión existen dos métodos principales: lossless y lossy, el primero es también conocido como “codecs de producción” y es usado para transmitir información completa sin perdidas o errores donde la compresión dependerá de la interpretación cuantitativa de la información. La segunda, lossy, permite la compresión de información donde existe pérdida de información o modificaciones sin que la apariencia de la información transmitida se vea afectada significativamente. Este método también es conocido como “códec de distribución”. (Wootton, 2006)
2.3.1 Método Lossless
Este método es un algoritmo de compresión de información que permite que la información original sea reconstruida desde los datos comprimidos y se utilice cuando se necesite que la información descomprimida sea idéntica a la original ó cuando no se pueden asumir datos. Aunque este método no es recurrentemente usado para audio y video, este método puede ser utilizado como parte del algoritmo lossy. A continuación se expondrán los métodos de compresión más importantes.
2.3.1.1 Run-Length Encoding (RLE)
13
reconocimiento de la repetición de un valor y transmitida una sola vez, seguida de un código que represente el tiempo de representación del valor. (Luther, 1997)
Para realizar el RLE se debe tener un valor el cual sea reconocido por el descompresor. Dicho valor tiene como objetivo indicar la realización del RLE, este valor debe de ser peculiar y con poca o nula ocurrencia. Por ejemplo, el valor 25510 en un sistema de 8 bits puede ser reservado para este propósito, el cual se
conoce como código escape e indica que los dos siguientes valores representan el valor del pixel y el número de repeticiones para el valor del pixel (ver Figura 2) (Luther, 1997).
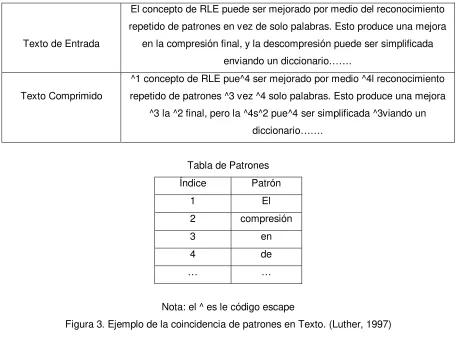
Figura 2. Ejemplo del RLE. (Luther, 1997)
2.3.1.2 Coincidencia de Patrones
14 Texto de Entrada
El concepto de RLE puede ser mejorado por medio del reconocimiento repetido de patrones en vez de solo palabras. Esto produce una mejora
en la compresión final, y la descompresión puede ser simplificada enviando un diccionario…….
Texto Comprimido
^1 concepto de RLE pue^4 ser mejorado por medio ^4l reconocimiento repetido de patrones ^3 vez ^4 solo palabras. Esto produce una mejora
^3 la ^2 final, pero la ^4s^2 pue^4 ser simplificada ^3viando un diccionario…….
Tabla de Patrones
Índice Patrón 1 El 2 compresión 3 en 4 de … …
[image:26.612.92.550.68.421.2]Nota: el ^ es le código escape
Figura 3. Ejemplo de la coincidencia de patrones en Texto. (Luther, 1997)
Un ejemplo de este método de compresión es el mostrado en la Figura 3. A diferencia de RLE este método puede empatar patrones ubicados en diferentes lugares de la información. (Luther, 1997)
La lectura excesiva del libro código debe de ser considerada para determinar el grado de compresión. Típicamente este método entrega una compresión de 2:1, por lo que resulta ineficiente en la compresión de señales de audio y video. (Luther, 1997)
2.3.1.3 Codificación Estática
15
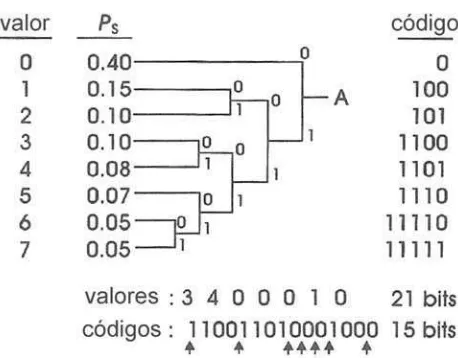
[image:27.612.194.423.245.424.2]serán más usados que otros. De acuerdo a esto, un sistema de código puede ser implementado para transmitir los valores de gran ocurrencia en un código pequeño, mientras que los códigos menos frecuentes pueden ser transmitidos en un código más largo, este sistema usa el principio del código Morse. En los sistemas digitales el método más común es el código Huffman, el cual es sumamente usado en los algoritmos de compresión de video, donde su efectividad dependerá del conocimiento que se tenga sobre la probabilidad de ocurrencia de cada valor. Un ejemplo de este código se muestra en la Figura 4. (Luther, 1997)
Figura 4. Ejemplo de código Huffman de valor 3-bits. (Luther, 1997)
El código Huffman es creado a partir de un árbol binario, el cual es hecho de un arreglo de valores descendente formado por orden de probabilidad de ocurrencia. El código es creado leyendo la salida del árbol binario (“A”) hacia la entrada, tomando el valor del bit de cada rama. (Luther, 1997)
2.3.2 Método
Lossy
16
es necesario para conocer las condiciones en las que el audio o video será reproducido por el receptor para así elegir el método de compresión necesario. A continuación se expondrán los métodos de compresión más importantes.
2.3.2.1 Truncamiento
Es la supresión de algunos bits menos significantes de las muestras. Este método es conocido como recuantizador y debe de realizarse de forma apropiada para así preservar la mayor información posible. (Luther, 1997). Bajo la condición ideal de visualización, el muestreo de la componente de video debe de tener al menos 8 bpp (bits por pixel), pero se puede reducir a 6 bpp sin que sea perceptible la degradación. Como la cuantización degrada 6 dB en la SNR por cada bit suprimido, el truncamiento no es la mejor opción a usar en termino de información reducida versus disminución del desempeño (Luther, 1997). Las muestras de alta calidad de audio deben de ser al menos de 16 bps (bits per sample), sin embargo una gran cantidad de sistemas pueden operar de manera exitosa con al menos 8 bps (Luther, 1997).
2.3.2.2 Sub-Muestreo
17 2.3.2.3 Tabla de Colores
Para algunos propósitos de video es posible reducir el número de Bits/Pixel haciendo que el valor del pixel se encuentre dentro de una tabla de valores de colores que son seleccionados de un amplio número de Bit/Pixel. Por ejemplo, el estándar PC VGA provee un modo de 8 bpp que selecciona 256 colores de una paleta de 18-bit. Otros sistemas usan diferentes números de bits. (Luther, 1997)
[image:29.612.200.441.471.613.2]Podría parecer que emitir 256 colores es una reproducción pobre de la imagen natural pero, bajo las condiciones adecuadas, la reproducción puede ser a una calidad superior a la esperada. Esto puede lograrse cuando la tabla de colores es realizada para cada imagen que será reproducida. Una mayor mejora es posible al usar la técnica de difuminado, que logra una mejor notoriedad de colores de los pixeles adyacentes. Un ejemplo de esta técnica se muestra en la Figura 5 para una imagen reproducida en solo dos valores de colores (blanco y negro). Si el observador está lo bastante lejos no podrá visualizar los pixeles de forma individual, los ojos mezclaran los pixeles adyacentes produciendo una combinación de colores (por ejemplo una escala de grises). (Luther, 1997)
18 2.3.2.4 Codificación Diferencial
En señales de audio y video el cambio de amplitud existente entre una muestra y la siguiente tiene una distribución de probabilidad con menor varianza que las muestras originales. Tomando esto en cuenta, se puede realizar una compresión codificando la diferencia entre muestras en vez de las propias muestras. Este proceso de código es llamado PCM diferencial (DPCM, Differential Pulse Code Modulation) y forma parte del grupo de Código Predictivo. (Luther, 1997). El DPCM ocurre cuando existe una diferencia grande de valores, el sistema se sobrecarga (también llamada slope overload) lo cual puede llegar a causar una distorsión severa por corto tiempo (Luther, 1997).
Varias formas avanzadas del DPCM han sido creadas para mejorar el desempeño sobre la variación de valores. Se hace un ajuste dinámico basado en qué tan grande es la diferencia en el instante considerado. Por ejemplo, un sistema típico tiene 4 bits para diferenciar valores el cual sólo puede realizar 16 pasos de reproducción diferentes. Sin embargo, si la diferencia de señales está siendo manejada en niveles bajos, los 16 pasos tendrán una diferencia pequeña, ya que al aumentar la diferencia de la señal, aumenta el tamaño del paso produciendo una mayor diferencia. A lo anterior se le conoce como ADPCM (Adaptive DPCM) el cual es frecuentemente usado para la compresión de audio pudiendo lograr una compresión de audio de 4:1. Aunque puede existir distorsión cuando el mecanismo que adapta los pasos cambie de tamaño aún así, tomando en cuenta el grado de compresión, es aceptable para varios propósitos. (Luther, 1997)
2.3.2.5 Código Predictivo
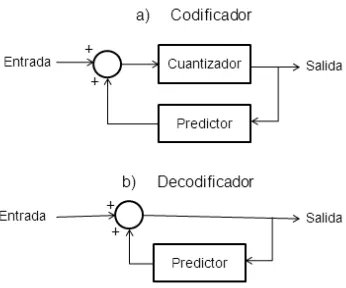
19
[image:31.612.238.411.201.345.2]muestra o muestras anteriores. Para ello, el resultado del bloque de predicción es comparado con la siguiente muestra y se transmite la diferencia de la comparación. El receptor puede reproducir la muestra usando la diferencia de valores y un módulo de predicción idéntico. El éxito dependerá del desarrollo y creación de un algoritmo de predicción que reconozca y acepte las propiedades de la información que será comprimida. (Luther, 1997)
Figura 6. Código Predictivo. (Luther, 1997)
2.3.2.6 Codificación por Medio de Transformadas
El tratar directamente con la señal original muestreada no es la mejor manera de exponer la redundancia de la señal, la cual puede ser eliminada en la compresión por medio de algunas transformadas. Éste es el caso particular de la señal de video, el cual debe de ser de 2 o 3 dimensiones (horizontal, vertical y temporal). Las transformadas son simples representaciones de información que pueden ser obtenidas por medio de procesos matemáticos. Cada transformada debe de tener su transformada inversa la cual es realizada durante la descompresión ya que la transformada es realizada durante la compresión. (Luther, 1997)
20
el cual es una parte pequeña de la imagen que no se pueda reconocer o asociar, pero al transformarlo al dominio de la frecuencia, los componentes puedes ser evaluados fácilmente por su importancia en la reproducción final. Esto es debido al hecho que la alta frecuencia espacial es menos visible que las frecuencias más bajas. (Luther, 1997)
La transformada más importante en usar y explotar esta idea es la transformada de coseno discreta (DCT, discrete cosine transform), la cual está relacionada con la transformada de Fourier, mayormente usada para extraer los componentes de frecuencia de una onda arbitraria. La transformada de Fourier opera en ondas continuas, pero la versión que opera en grupos de muestras de la onda continua es aceptable también. A esta transformada basada en muestras se le denomina discreta. La transformada de Fourier de forma Discreta o Continua entrega un conjunto de componentes de frecuencia de senos y cosenos, el cual puede ser visto como un conjunto de componentes de frecuencia con valores de amplitud y fase. La simplificación es posible cuando la transformada discreta de Fourier es realizada en un conjunto de muestras de información seguidas de su imagen espejo en el tiempo. Los componentes senos de la trasformada de Fourier se cancelarán dejando sólo las componentes cosenos. Lo anterior es la transformada discreta de coseno y tiene la propiedad que un bloque de 8x8 de 64 muestras es transformado en un bloque de 8x8 en términos de coseno, representando frecuencia espacial en dos dimensiones. Matemáticamente se expresa: (Luther, 1997).
(ec.1) Donde x y y son índices dentro del bloque de pixeles de 8x8.
Donde u y v con índices dentro del bloque de 8x8 de salidas de coeficientes.
para w = 0
21
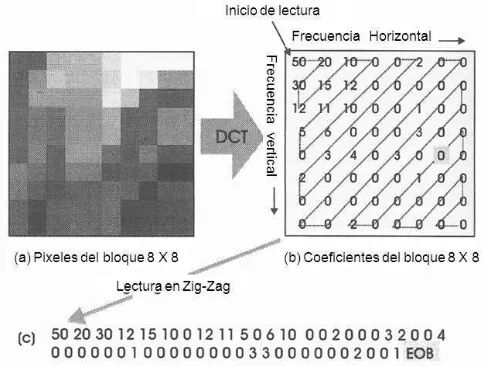
La ecuación 1 indica que cada coeficiente DCT es calculado asumiendo que todas las muestras de entrada tienen una función base de tipo coseno, esto depende de la posición del coeficiente en el arreglo de salida y de la posición de cada muestra en el arreglo de entrada. Algunas características de la DCT se muestran en la Figura 7. Se observa que la salida del procesador DCT es un arreglo de 8x8 de valores representando las amplitudes del componente de la frecuencia espacial (ver Figura 7 (b)) en un bloque 8x8 procesado. Hasta este punto el procesamiento DCT no ha producido compresión, sin embargo los coeficientes serán considerados compresos para después de aplicar futuros procesos de cuantización. (Luther, 1997)
Es recomendable poner los coeficientes en orden de frecuencia ascendente (ver Figura 7(c)) el cual es llamado orden zig-zag. Como se puede observar en la Figura 7(c), los componentes de frecuencia alta tienden a cero o a valores pequeños. Como estos valores no son muy importantes, pueden ser cuantizados sin que se pierda información en la imagen, por lo que es necesario transmitir los componentes que tengan un valor diferente de cero, con esto se logra una considerable reducción de información. Una marca de finalización de bloque (EOB
[image:33.612.193.437.508.691.2]end-to-block) es implementada para que no sean usados más valores que los adecuados. Los coeficientes restantes son usualmente codificados con RLE y codificación entrópica. (Luther, 1997)
22 2.3.2.7 Compensación por Movimiento
El video con movimiento tiene una redundancia considerable de un fotograma a otro. En un fotograma se almacena información contenida pudiendo no ser información nueva, y pueden ser simplemente parte del fotograma anterior. En principio, aquello que ya existe en el fotograma anterior no es necesario transmitirlo de nuevo. La tarea de revisar y discernir entre información nueva o ya existente en el fotograma se le conoce como compensación por movimiento. Este es una de las tareas más complejas en la compresión de video, de hecho la efectividad de la compensación por movimiento es siempre limitada por la velocidad y las limitaciones computacionales. (Luther, 1997)
La compensación por movimiento está basada en el procesamiento de imágenes en bloques. Dando un primer fotograma completo como punto inicial, se toma el siguiente (segundo) fotograma para así comparar el área con el primer fotograma para determinar si existen coincidencias en cualquier posición del primer fotograma. Si una coincidencia es encontrada, un vector en movimiento es creado por el receptor para predecir en el segundo fotograma, copiándolo del primer fotograma. Reconociendo que la cantidad de movimientos entre fotogramas no es muy buena, es necesario sólo buscar en un área pequeña del bloque que está siendo examinada. El bloque que no sea encontrado en el fotograma anterior deberá ser codificado y transmitido. (Luther, 1997)
23 Figura 8. Compensación por Movimiento. (Luther, 1997)
2.4 Calidad de la Imagen
Para poder especificar, evaluar y comparar los sistemas de comunicación de video es necesario determinar la calidad de las imágenes de video proyectadas. La medición de la calidad de la imagen es difícil y a menudo imprecisa ya que existen muchos factores que afectan los resultados. La calidad de la imagen es un valor subjetivo e influenciado por muchos factores que hacen imposible obtener una medición acertada. (Richardson, 2003)
La medición de la calidad de la imagen usando un criterio objetivo es acertada, cuando se obtienen resultados repetitivos, pero actualmente no existe una medición objetiva que iguale los resultados subjetivos de la calidad de la imagen. (Richardson, 2003)
24
cual repercute en gran proporción a la opinión que se tenga de la calidad de la imagen. (Richardson, 2003)
Existen diferentes procedimientos de prueba para evaluar la calidad de la imagen de forma subjetiva. La UIT (Unión Internacional de Telecomunicaciones) recomienda el examen BT.500/11. Este método presenta dos imágenes de manera alterna, por lo que una de las imágenes es la imagen original y la otra es aquella obtenida anterior al ser procesada por el CODEC. Para obtener un resultado se le pide al espectador que califique las imágenes en una escala de cinco barras, que comprende el rango de excelente a malo. Esta medición presenta problemas prácticos ya que depende en su totalidad de la evaluación otorgada por el espectador. (Richardson, 2003)
De igual manera, existen diferentes procedimientos de prueba para evaluar la calidad de la imagen de forma objetiva. La forma de medición más usada es por medio de la relación señal a ruido pico (PSNR – peak signal to noise ratio) la cual está dada en escala logarítmica y depende del error cuadrático medio (MSE – mean squared error) que existe entre la imagen original y la imagen recibida. (Richardson, 2003)
25
Capítulo 3
HISTORIA DE ESTÁNDARES DE VIDEO
En este capítulo se esboza el contexto histórico de los codificadores y decodificadores de video, así como el objetivo principal de su creación. De igual forma, se presentan sus principales ventajas y desventajas.
3.1 Administradores de los Estándares
Existen dos organizaciones que definen estándares de video:
• La Unión Internacional de Telecomunicaciones. De acuerdo a su página oficial, está enfocado en el desarrollo y aplicaciones de telecomunicaciones. La ITU ha creado el estándar H.26x para video teléfono con una baja tasa de bits, este estándar incluye el H.261, H.262, H.263 y H.264.
• La Organización Internacional de Estándares (ISO – International Standards Organization), como lo indica en la página oficial, está enfocada en promover el desarrollo de normas internacionales de fabricación, comercio y comunicación de las ramas industriales. Su función principal es buscar la estandarización de normas de productos y seguridad para las empresas u organizaciones a nivel internacional. ISO ha definido el estándar MPEG, el cual es el acrónimo de Moving Pictures Experts Group, para compresión de películas este estándar incluye MPEG-1, MPEG-2 y MPEG-4.
26 Figura 9. Progresión cronológica de los estándares ITU y MPEG. (Golston, 2006)
3.2 Estándares
A continuación se describirán brevemente los estándares de video más relevantes en forma cronológica, indicando el objetivo del diseño y su funcionalidad principal.
3.2.1 H.261
Definido por la UIT fue el primer estándar de compresión de video en sistema de videoconferencia en dos direcciones. Describe los métodos de codificación y decodificación del video de las imágenes en movimiento de los servicios audiovisuales a las velocidades de nx64 kbps, donde está comprendido entre 1 y 30. (Golston, 2006). Fue diseñado para comunicaciones en redes ISDN con ancho de banda entre 64 kbps y 2 Mbps, medidos en intervalos de 64 kbps. (Golston, 2006)
3.2.2 MPEG-1
27
digital como CDs. El MPEG-1 es similar al H.261, pero suelen lograr un mayor rendimiento para soportar el tamaño del video. (Golston, 2006)
3.2.3 MPEG-2/H.262
Fue desarrollado teniendo como objetivo la televisión digital y contiene dos estándares de televisión principales: el video progresivo y el video entrelazado, además, soporta los estándares de 720x489 y 720x576 pixeles. Es genérico y permite elegir el tipo de algoritmo a usar y los niveles de parámetros. Fue construido sobre el MPEG-1 en el cual se le añadió nuevos modos de compensación de movimiento, el inconveniente de MPEG-2 es que no está optimizado para bajas tasas de bits, sin embargo supera el desempeño del MPEG-1. (Golston, 2006)
3.2.4 H.263
Su objetivo principal era proporcionar mejor calidad de imagen que el H.261, enfocado en la disminución de la tasa de bits, proponiendo trasmitir video sobre modems telefónicos de 28.8 kbps, lo cual al final se logró pero de forma complicada. Emplea técnicas de codificación como la transformada discreta coseno y la compensación de movimiento. (Golston, 2006)
3.2.5 H.264/MPEG-4 AVC
28
Este CODEC representa un avance significativo en la codificación de videos ya que utiliza la misma técnica de codificación que los otros CODEC, pero combinándolo con el mejoramiento de la eficiencia de código y otras nuevas características que hacen de este nuevo estándar un CODEC más eficiente en compresión. (Golston, 2006)
Este estándar se encuentra bien posicionado en la industria de telecomunicaciones a nivel mundial. Es utilizado principalmente en:
o Celulares: El H.264 es usado para trasmitir video sobre la red del operador
celular. Es especialmente usado por su baja tasa de bits de video.
o Televisión sobre IP: probablemente éste sea el método más usual para
transportar video sobre la red IP porque fue creado en parte por la UIT y se ha visto una creciente utilización del ancho de banda de la red por este estándar.
o Transmisión vía satélite y vía redes de cable de televisión digital: este
estándar permite a los operadores de televisión de paga transmitir contenidos de televisión de alta definición dentro de su ancho de banda existente.
o Láser azul de los reproductores de DVD: estos reproductores son capaces
de decodificar el contenido de un disco bajo el estándar H.264.
La aplicación primaria del H.264 es en la red inalámbrica y ofrece una alta capacidad de compresión combinado con una baja resolución de video, lo que da un costo/beneficio aceptable para la transmisión de video entre aparatos móviles. Golston (2006) menciona que algunas de las ventajas de este estándar son:
o Eficiencia superior a la eficiencia del MPEG-2 en un ancho de banda para
usuarios que tengan la misma calidad de imagen.
o Reducción de la tasa de bits de 5 Mbps (MPEG-2) a 2.5 Mbps sin provocar
29 o Es mayormente utilizada en sistemas de comunicación inalámbrica, como
los celulares, ADSLs y WLANs para líneas telefónicas.
Asimismo, algunas de las desventajas más sobresalientes son:
o La gran cantidad de potencia requerida para el CODEC de video en tiempo
real.
o Requiere de más del doble de la potencia del sistema requerida para
procesar una imagen de la misma calidad que usando el MPEG-2.
o Limitación de implementación en dispositivos electrónicos debido al alto
30
Capítulo 4
ESTRUCTURA DEL CODEC
Para entender los formatos de compresión de video se describirá el CODEC más básico MPEG-1 para así poder comprender con mayor facilidad el funcionamiento y estructura del H.264. Después de describir el MPEG-1, se explicarán las mejoras así como las diferencias realizadas al MPEG-2, MPEG-4 y por último al H.264.
4.1 MPEG
1
Es el más sencillo de los formatos de compresión de video MPEG. El resto se basa en este modelo añadiendo mejoras al mismo. A continuación se explicarán las partes del cual está constituido el MPEG-1.
4.1.1 Fotogramas
Wootton (2006) nos indica que los fotogramas son una serie de instantáneas, donde las imágenes se organizan y se presentan como una serie de exploración sincronizada. El estándar MPEG-1 define básicamente tres tipos de fotogramas.
o Fotogramas Internos (I).
o Fotogramas Predichos de Diferencias (P).
o Fotogramas Bidireccionales de Diferencias (B).
4.1.1.1 Fotogramas Internos (I)
31
[image:43.612.221.415.117.224.2]tal como se aprecia en la Figura 10. El fotograma I se le denomina, también, fotograma clave.
Figura 10. Fotogramas Clave. (Wooton, 2006)
4.1.1.2 Fotograma predicho de diferencia (P)
El fotograma P se construye a partir de las diferencias que se añaden a un fotograma clave o un fotograma P más reciente, y no se distribuye necesariamente a partir del fotograma I a partir del cual se ha reconstruido. Los fotogramas P se encuentran en cascada, aquí cualquier error de codificación se propaga y, llegado el caso, la acumulación de errores se hace visible. (Wooton, 2006)
Figura 11. Fotograma de diferencias. (Wooton, 2006)
[image:43.612.215.419.457.559.2]32
reconstruir el fotograma B. El fotograma B no es posible verlo por sí solo, para ello es necesario sobreponer el Fotograma B en Fotograma A. (Wooton 2006)
El fotograma B es un fotograma delta o de diferencias. Al añadir dos fotogramas más, C y D. También pueden ser fotogramas de diferencias. La descripción de C es un conjunto de diferencias visibles entre las imágenes B y C. La descripción del fotograma D incluye la diferencia visible que se debe aplicar para crear el fotograma D a partir del fotograma C completamente reconstruido. (Wooton, 2006)
4.1.1.3 Fotograma Bidireccional (B)
Un fotograma B se codifica mediante las diferencias encontradas en el fotograma I precedente o un fotograma P siguiente. Retomando el modelo de fotogramas A,B,C y D, la descripción del fotograma C es una lista de diferencias que deben aplicarse al fotograma B y las diferencias que se aplican al fotograma C para crear el fotograma D no permiten crear un fotograma C si se aplica al fotograma B. (Wooton, 2006)
33 Figura 12. Fotogramas Bidireccionales de Diferencias. (Wooton 2006)
4.1.2 Estructura de Secuencia de bits
La salida del codificador es una secuencia de bits compatible con la sintaxis de los estándares. Cada una de las capas, aparte de la muestra individual, tiene un encabezado y un patrón de bits de alineación, de tal forma que se pueda distinguir dentro de una secuencia de bits. La organización sintáctica de una secuencia de bits está dada por:
o Secuencia de video.
o Grupo de imágenes
o Imagen.
o Rebanada.
o Macrobloque.
o Bloque.
o Muestra.
4.1.2.1 Estructura de la secuencia de Video
34 Figura 13. Película dividida en secuencias.
4.1.2.2 Grupo de Imágenes
La secuencia de imágenes contiene gran cantidad de información por lo que debe de subdividirse en componentes más pequeños. El estándar MPEG-1 describe una serie de fotogramas como un grupo de imágenes la cual consta de entre 10 y 30 imágenes. Esta estructura también se aplica a los CODEC MPEG-2, MPEG-4 y H.264. La estructura del grupo de imágenes se repite tantas veces como sea necesario para producir la secuencia. En la Figura 14 se ilustra este concepto. (Wooton, 2006)
Figura 14. Estructura de grupos de imágenes dentro de una secuencia. (Wooton 2006)
[image:46.612.179.462.407.461.2]35 4.1.2.2.1 Estructura de Grupo de imágenes cerrada
[image:47.612.211.433.222.280.2]Un grupo de imágenes cerradas contiene un fotograma I de inicio, algunos fotogramas P basados en el fotograma I y algunos fotogramas B codificados. En la Figura 15, las flechas indican el origen de los datos diferenciales sobre varios grupos de imágenes adyacentes.
Figura 15. Una secuencia de grupo de imágenes cerrada. (Wooton, 2006)
[image:47.612.218.426.385.445.2]4.1.2.2.2 Estructura de grupo de imágenes abierta
Figura 16. Una secuencia de grupo de imágenes abierta. (Wooton, 2006)
36
[image:48.612.188.450.239.340.2]Al mantener un grupo de imágenes pequeñas implica que la compresión no será tan eficaz. Al aumentar el número de fotogramas de diferencias, el grupo de imágenes aumenta y la relación de compresión mejora, pero también aumenta la acumulación de errores. Estos dos sistemas se conocen como “grupo de imágenes pequeña” y “grupo de imágenes grande” respectivamente (Wooton, 2006), en el que cada uno da ventajas y desventajas al uso del proceso. Ver la Figura 17.
Imagen 17. Un grupo de imágenes sencillo. (Wooton, 2006)
37 Figura 18. Secuencia de Transmisión de un grupo de imágenes. (Wooton, 2006)
4.1.2.3 Macrobloques
El Macrobloque se realiza con el fin de reducir la dificultad de creación de fotogramas B e incrementar la probabilidad de encontrar áreas de las imágenes que sean idénticas, la imagen se fragmenta en cuadros de 16x16 denominados Macrobloques. En la Figura 19 se muestra la distribución simplificada de Macrobloques de un fotograma.
Figura 19. Macrobloques. (Wooton, 2006)
La matriz de la imagen que contiene los pixeles del fotograma que se comprime se convierte en una colección de rectángulos de menor tamaño con los que se trabajan de forma individual. (Wooton, 2006)
[image:49.612.186.454.432.552.2]38
trabaja. Los fotogramas P hacen referencia a otro tipo de fotograma, pero solo al fotograma I o P más reciente. El orden de estos deberá preservar la secuencia temporal de los fotogramas. Los fotogramas B de un Macrobloque, harán referencia al fotograma P anterior o posterior o bien, a un fotograma I anterior. (Wooton, 2006)
4.1.2.4 Rebanadas
Los Macrobloques se distribuyen en lo que se conoce como rebanadas, tiras o
[image:50.612.221.414.408.552.2]slices. Se trata de componentes estandarizados, donde el decodificador sabe que si pierde la sincronización a nivel Macrobloque, puede reconstruir la imagen a partir del limite de la rebanada siguiente (ver figura 20). (Wooton, 2006), por lo que la pérdida de información puede ser minimizada y reconstruida en base a su imagen antecesora.
Figura 20. Macrobloque y rebanadas. (Wooton, 2006)
39
[image:51.612.202.444.134.242.2]valores de frecuencia que se organiza en la misma forma rectangular como se aprecia en la Figura 21.
Figura 22. Conversión DCT. (Wooton 2006)
4.2 MPEG 2
Se basa en el MPEG-1 al que se le añade algunas funciones del proceso de codificación adicionales. Básicamente funciona de la misma forma, pero las mejoras introducidas permiten obtener una mayor calidad, un tamaño de imágenes más grandes y proporcionar funciones adicionales de entrelazado.
En el MPEG-2 la predicción de los fotogramas y los campos es diferente, en lugar de matrices de 16x16 pixeles, existen matrices de 16x8 y la predicción sólo se realiza en los campos correspondientes de otro fotograma. (Wooton 2006)
A continuación se mencionaran las distinciones y/o modificaciones hechas al MPEG-2 respecto al MPEG-1.
4.2.1 Rebanadas
40
[image:52.612.186.451.201.297.2]macrobloques, pero MPEG-2 sólo permite hacerlo en la única fila. Las rebanadas pueden ser de menor tamaño, pero no pueden ampliarse hacia la derecha y pasar a la línea siguiente como ocurre en el formato MPEG-1. La ventaja es que las interrupciones en la señal causan un daño mucho menor. Esto se aprecia en la Figura 22.
Figura 22. Comparación de la distribución de rebanadas en MPEG-1 y MPEG-2. (Wooton 2006)
4.2.2 Ocultación de Vector de Movimiento
Es una herramienta para proporcionar cierta redundancia en la codificación. Si se pierde el macrobloque, la ocultación de vectores en movimiento en un macrobloque adyacente proporciona una alternativa que es menos óptima pero que siempre es mejor que una interrupción total en la reproducción de la imagen. (Wooton 2006)
4.2.3 Codificación Escalable
41
Los datos de alta calidad se agregan a la versión de baja calidad sin repetir ninguna información. Solo proporciona datos adicionales de modo que el decodificador pueda reconstruir una imagen con resolución completa que incluya los datos adicionales. Existen dos métodos para realizar esta operación: (Wooton 2006)
o El Perfil SNR crea la señal de imagen con calidad moderada, junto con la
señal mejorada con una imagen con poco ruido.
o los perfiles espaciales y de altura generan una señal de imagen de baja
resolución y una señal de mejora de la imagen de alta resolución.
En ambos casos, combinar la señal base con la señal de mejora produce la información necesaria para recrear una interpretación de alta calidad.
4.2.4 Capa de Sistemas
42 Figura 23. Secuencias anidadas. (Wooton 2006)
4.3 MPEG-4
Es un estándar de CÓDEC de video multimedia para proporcionar una amplia gama de experiencias audiovisuales, además de soporte interactivo.
La codificación de video MPEG-4 introduce nueva terminología sobre la base de que cada elemento de la secuencia es un objeto.
o Secuencia Visual (VS, Visual Sequence), es el nivel de la representación
jerárquica basada en objetos.
o Objeto Visual (VO, Visual Object), se refiere a la secuencia de video o
fotogramas.
o Capa de objetos de Video (VOL, Video Object Layer), representa una capa
de la imagen que contiene algún video.
o Grupo de Planos de Objeto de Video (GOV, Group of VOP´s), el concepto
es similar al de grupo de imagen pero se trata de capas de estructura adicionales.
o Plano de Objeto de Video (VOP, Video Object Plane), es una secuencia de
43
El MPEG-4 incluye dos estándares de video, la parte 2 y la parte 10. Los cuales se explicaran en el siguiente apartado.
4.3.1 MPEG-4 Parte 2
Cuando se implementó el estándar MPEG-4 parte 2 se introdujeron algunas herramientas que afectan a la eficacia de la codificación. (Wooton 2006)
o La Compensación de Movimiento Global (GMC – Global Motion
Compensation) se aplica a un objeto en conjunto, se reduce los efectos de la compensación de movimiento en el nivel de macrobloque, reduciendo la complejidad de la codificación.
o La Compensación de Movimiento de Sub pixeles permite el cálculo del
movimiento con una resolución por debajo del nivel de los pixeles, los objetos que se mueven lentamente se codifican con mayor precisión y los fotogramas de predicción tienen menos errores y fallos residuales.
o El Video Escalado se implemento en el estándar MPEG-2, donde se
distribuía una señal de resolución y calidad básica con una señal diferente que se añade para ampliar la secuencia de bits con el fin de proporcionar suficientes datos para obtener una salida de calidad superior; el MPEG-4 es compatible con ella, pero a nivel de objetos individuales, permitiendo la existencia de mas de una capa de mejora.
o La Codificación DCT con Adaptación de Formas se utiliza al calcular
44
cantidad de datos que se debe considerar, con lo que se mejora la eficacia de compresión.
4.3.2 MPEG-4 parte 10 o H.264
Es el códec mas reciente de uso general y esta enfocado a aplicaciones que el MPEG-2 desempeñaba; mejora una gran cantidad de funciones y dota de una mayor flexibilidad y utilidad.
En este estándar, el algoritmo de codificación central se modifica a partir de una transformada discreta de coseno para admitir un esquema jerárquico. Al reducir el tamaño de los bloques, existen más posibilidades de encontrar Macrobloques similares o idénticos dentro de una misma imagen.
El algoritmo de transformación para el H.264 se ha modificado para emplear un área de pixeles de 4x4 como una subdivisión del Macrobloque de 16x16, a esto se le conoce como transformada de Hadamard, esto simplifica el algoritmo de compresión, permitiendo la implementación de la transformada como un par de operaciones matriciales básicas seguido de una operación de escalado.
El estándar H.264 admite dos métodos de codificación sin perdida que son admitidos en la fase de codificación proporcionada por la salida DCT.
o Codificación de Longitud Variable Adaptada al Contexto (CAVLC).
o Codificación Aritmética Binaria Adaptada al Contexto (CABAC).
45
para mejorar le eficacia. Ambos métodos se utilizan en casos con elevadas velocidades de bits.
46
Capítulo 5
DVC
Chein (2008) comenta que muchas aplicaciones tales como redes inalámbricas sensoriales y dispositivos móviles, requieren un CODEC de video de baja complejidad para así satisfacer las necesidades de costo, tamaño, potencia limitada y compresión en tiempo real.
Sabiendo que la compresión de los esquemas convencionales de codificación de video, como MPEG-4 y H.264 logra una gran tasa de compresión, sus decodificadores son altamente complejos.
La Codificación Distribuida de Video (DVC por sus siglas en ingles Distributed
Video Coding) es un enfoque que cambia la carga del fotograma interno para el decodificador, mientras preserva la eficiencia de compresión.
Rup (2009) menciona que los inicios de DVC son establecidos por los teoremas de Slepian-Wolf y Wyner-Ziv, en las cuales explican que dos señales estadísticamente dependientes son codificados por separado, pero pueden ser conjuntamente decodificadas, a una tasa igual a su entropía en conjunto. Dentro de los modelos de DVC, existen 3 modelos que han resaltado en importancia:
o El propuesto por Majumdar, Puri, y Ramchandran, de la Universidad de
Berkeley, el PRISM es una fuente de codificación distribuida enfocada a la operación de la transformación de dominio y compresión a alta frecuencia usando codificación entrópica y coeficientes de frecuencia media bajo la utilización de codificación síndrome.
o La codificación distribuida para servicios de video (DISCOVER –
47
fue un proyecto de 27 meses que empezó en el 2005 por parte de la Unión Europea por medio del programa de Tecnologías de la Sociedad de la Información dentro de la temática del Futuro y Tecnologías Emergentes.
El objetivo principal del DICOVER es explorar y proponer nuevos esquemas y herramientas de DVC que tengan potencial para realizar nuevas aplicaciones concentrándose en eficiencia, errores de transmisión y escalabilidad.
[image:59.612.150.527.470.613.2]El esquema de video DISCOVER esta dividido en 2 partes; la primera es una serie de fotogramas llamados “fotogramas clave” los cuales son codificados con el H.264/AVC; los fotogramas restantes son fotogramas Wyner-Ziv, a los cuales se les aplica un transformada base que los convierte en coeficientes y los cuantiza; se realiza una secuencia de los coeficientes de la misma frecuencia pero en diferentes bloques; entonces los coeficientes son ordenados e introducidos en un buffer para ser transmitidos al decodificador, el cual tiene la facultad de pedir mas bits para un mejor resultado. Ver la Figura 24.
Figura 24. Arquitectura básica del CODEC DISCOVER.
48
un codificador simple, sin dejar de ser competitivo cuando es comparado con un CODEC mas complejo como el H.264
o El propuesto por Ranc, Aaron y Girod en el 2002 en la Universidad de
Stanford, el cual esta basado en técnicas de codificación de canal. La idea principal es tratar la información lateral (Y) como una versión ruidosa de la señal principal (X). Entonces Y debe ser enviada usando un fotograma interno mientras que X es enviada a una tasa menor que su entropía. Ver la Figura 25. (Pereira, 2009)
Figura 25. Arquitectura del código de video Wyner-Ziv de Stanford.
5.1 PRISM
Majumdar (2007) indica que, la red sensorial de video inalámbrica es caracterizada por los dispositivos con una limitada capacidad de procesamiento y una limitada potencia de batería, gran pérdida de canales inalámbricos y un bajo ancho de banda. En consecuencia un CODEC de video diseñado para una red sensorial de video inalámbrico desea tener:
o Robustez inherente al error provocado por la pérdida de sincronización
entre el codificador y el decodificador o errores en el canal de transmisión.
o Flexibilidad en la distribución de la complejidad computacional entre el
[image:60.612.223.459.266.401.2]49 o Compresión de alta eficiencia debido al ancho de banda y a las limitaciones
de potencia de transmisión.
Convencionalmente los CODECs de video no cumplen con todos estos requerimientos de forma simultánea (Ishwar 2006), por estas razones se creó un paradigma sobre codificación de video basado en los principios de fuentes de codificación distribuida o en la fuente de codificación de información lateral, a este paradigma se le conoce como PRISM que proviene del acrónimo Power-efficient,
Robust, high-compression, Syndrome-based Multimedia coding, el PRISM es basado el la teoría de Slepien-Wolf para el caso lossless y en la teoría Wyner-Ziv para el caso lossy. (Majumdar 2007)
A continuación se mostraran dos escenarios de fuente de codificación con información lateral (ver Figura 26) que implementan la teoría de Wyner-Ziv:
Sea X y Y informaciones binarias de 3 bits que pueden tomar cualquiera de las ocho opciones posibles, sin embargo están correlacionadas ya que la distancia Hamming entre ellos es a lo mucho 1, eso es, dado que Y (e.g., [010]), X puede tener la misma secuencia que Y ([010]), o puede ser diferente al inicio ([110]), o puede ser diferente en el bit del centro ([000]), o puede ser diferente en el último bit ([011]); el objetivo es codificar eficientemente X en los siguientes dos escenarios a fin de que pueda ser reconstruido perfectamente en el decodificador. (Majumdar 2007)
Escenario 1:
50 Escenario 2:
[image:62.612.110.526.274.372.2]En este escenario, Y tiene acceso al decodificador pero no así al codificador X (Ver Figura 26 (b)), sin embargo se conoce la estructura correlacionada y que el decodificador tiene acceso a Y. Este escenario tiene un desempeño limitado en comparación con el escenario 1, pero se puede obtener el mismo desempeño. (Majumdar 2007)
Figura 26. Implementación de información lateral, a) tanto el decodificador como el decodificador usan la información lateral, b) el único que usa la información lateral es el decodificador. (Majumdar
2007)
Estos escenarios pueden ser realizados usando el siguiente enfoque: el espacio de palabras clave de X es particionado en cuatro conjuntos (sets) cada uno, conteniendo dos palabras claves llamados:
Coset 1 [000] y [111] Coset 2 [001] y [110] Coset 3 [010] y [101] Coset 4 [100] y [011]
51
El PRISM tiene tres principales objetivos:
o Desempeño de Compresión:
El código de información lateral puede tener menores pérdidas de compresión comparada con el código de predicción. Sin embargo, en algunas ocasiones interesantes, el desempeño del sistema de codificación de información lateral puede ser similar a la codificación predictiva. (Majumdar 2007)
o Robustez:
La meta principal del PRISM es el de lograr robustez que empaquete y realice frames drops. El PRISM llega al objetivo usando “universally robust”
side information-based coding framework. (Majumdar 2007)
En esencia, en la codificación predictiva, la codificación de la unidad actual dependerá de la información de un solo predictor, las perdidas que se produzcan se reflejaran como errores de codificación y errores de propagación. El paradigma basado en la codificación de información lateral codifica la unidad actual respecto a la correlación estadística entre la unidad actual y el predictor. En el decodificador, la habilidad del predictor de satisfacer la correlación estadística permitirá una correcta decodificación. (Majumdar 2007)
o Moving Motion-Search Complexity del decodificador:
52 5.1.1 Codificación
Figura 27. Diagrama a bloques del codificador PRISM.
En la Figura 27 se muestra un diagrama a bloques del codificador PRISM. A continuación se enlistan los aspectos principales del proceso de codificación del PRISM. El fotograma del video que será codificado, es dividido en bloques espaciales no traslapables.
5.1.1.1 DCT
Se aplica primeramente el DCT en el bloque fuente para aproximarse a la transformada KL de correlación de procesos de innovación de ruido entre el vector de la fuente y la información lateral. (Majumdar 2007)
53 5.1.1.2 Cuantizacion
Se aplica una cuantizacion escalar. Los coeficientes de la transformada son cuantizados con un tamaño de cuantizacion proporcional a la desviación estándar de la correlación de ruido para obtener una reconstrucción de calidad. (Majumdar 2007)
5.1.1.3 Clasificación
En este paso se diseña el libro clave Wyner-Ziv para explotar la correlación entre la fuente y la información lateral. Es conveniente observar los coeficientes individuales de cuantizacion en un bloque en términos de bits planos. Como se muestra en la figura 3, la correlación entre el coeficiente Xi (i ) y su
correspondiente Yi de información lateral, pueden ser interpretadas en términos
del número más significativo en el plano de bits (bit plane) de la representación cuantizada de Xi que puede ser inferida por la información lateral Yi. Los restantes
bits menos significativos (los mostrados en negro y gris de la Figura 28) no interfieren con el decodificador y necesitan ser decodificados. Estos bits constituyen el codificador Wyner-Ziv para una fuente de coeficiente Xi. (Majumdar
[image:65.612.192.449.527.678.2]2007)